

文章目录[隐藏]
implicit parallelism - pipelinig
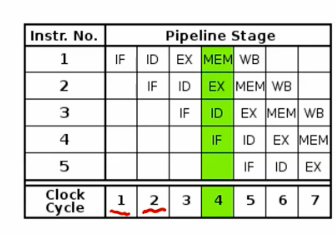
break up one instruction and execute pieces
different unit of cpu utilization
instruction fetch -> decode -> exec -> mem read -> write back
at most 5x with 5 stage pipeline
modern processors has 10-20 stages
if code branches, must guess how to full pipelines.
- branch misprediction requires flushing pipline.
- Typical code every 5 instructions.
so prediction is important
implicit parallelism - Superscalar
- we can have 2 fetch unit each clock

((i)has fewer data dependencies (iii)should be rescheduled.)
e.g.
1000 1004 1008 100C
--o---o---o---o
-- |---/ ---|---/
---R1 ----- R2
----|-----/ - execution must respect data dependencies.
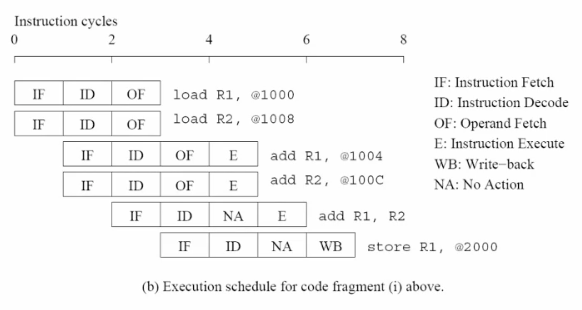
To deal with data race, Use DAG to label them.
Look ahead using CA to reorder the instruction set.
## implicit parallelism - VLIW(compile time)

memory performance
latency & bandwidth
speed & lanes
memory hierarchy
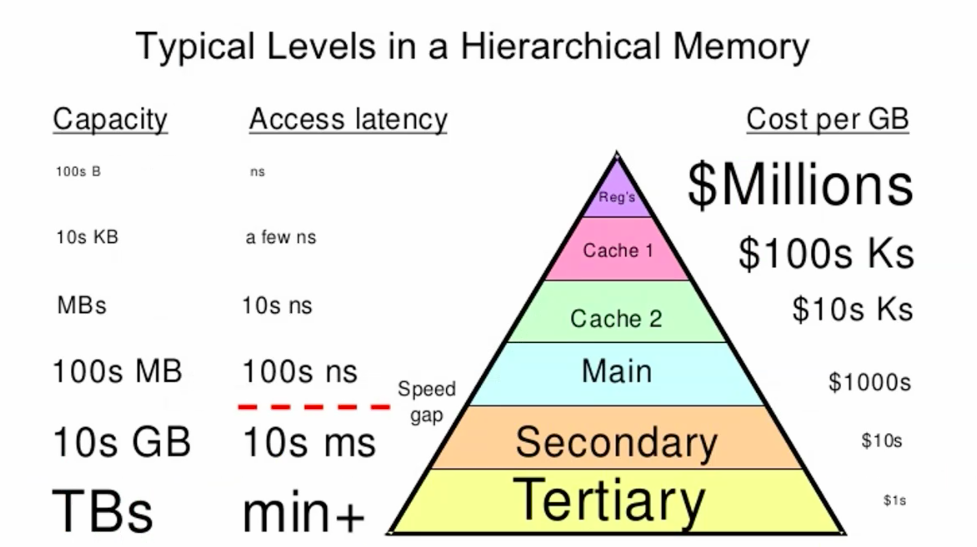
caching
locality
Temporal locality - small set of data accessed repeatedly
spacial locality - nearby pieces of data accessed together
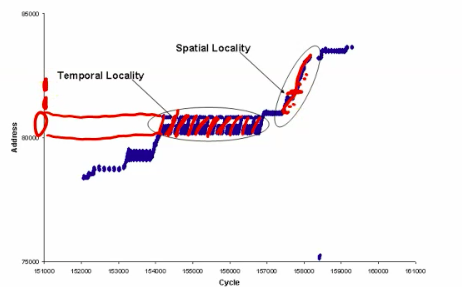
e.g.
Matrix Multiplications have both temporal locality and spatial locality.

performance
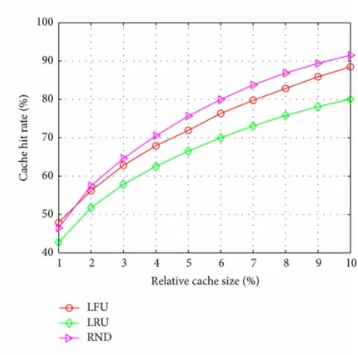
cache hit rate is the proportion of data accesses serviced from the cache.
e.g.

processor architectures
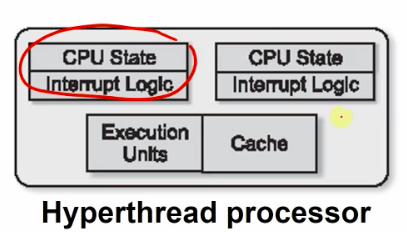
- a multiprocessor contains several cores communicating through memory.
- a multicore has several cores on a single die.
- each core is a complete processor, but runs simultaneously.
- they share L2/L3 cache.
- cheap to replicate CPU state.(registers, program counter, stack) (SMT)
GPGPU
1000+ core stream simultaneously.
Flynn's taxonomy
- SISD conventional sequential processor.
- SIMD single control unit for multiple processing unit
- MISD uncommon
- MIMD Distributed systems
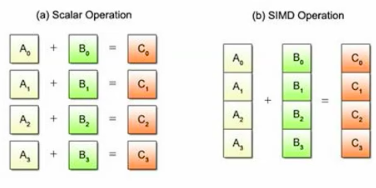
SIMD
- control unit fetches single instruction and broadcast it to processing units.
- PEs each apply instruction to its own data item in synchrony.
- e.g. adding two arrays.
- very popular today.
- dgemm, graphics and video, ML
- cheap to implement, don't duplicate hardware for fetch.
- Used in GPU(SIMT), avx, phi
- 100s bits lanes -> 4-32 lanes
- e.g. adding two arrays.
Instruction divergence
SIMD processors can perform different instructions.
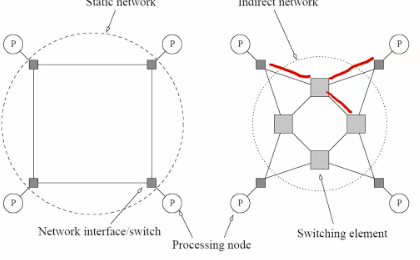
Interconnection networks
- built using links and switches
- links are fixed connection between 2 processors.
- switch connect set of processors on input ports with processors on output ports
- static vs. dynamic
- quadratic needed
shared memory architecture
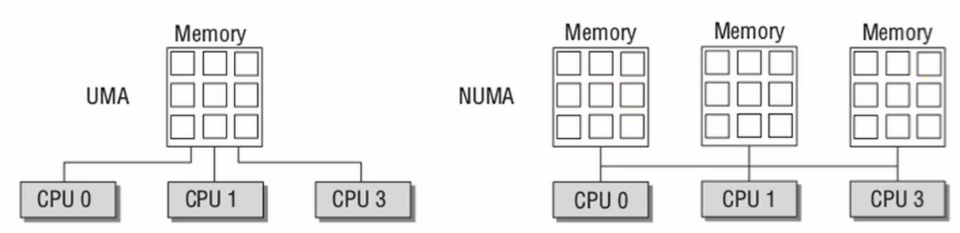
all processors shared the same mems-pace.
Pros: easy to write program
Cons: limited scalability.
UMA vs. NUMA
Distributed memory architecture
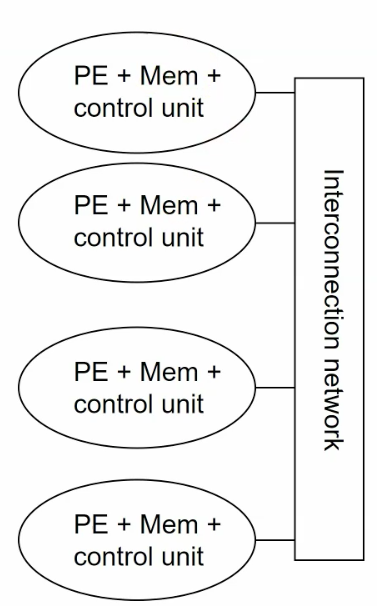
combination of shared memory and non-shared memory.
Network of workstation(NOW)
connect workstations with networking.
e.g. Beowulf
Bus architecture.
all processors use mem on the same bus.
the bandwidth is the bottlenech.
Crossbar architecture.
switched network for higher end shared memory system.
allow all processors to communicate with all mem modules simultaneously. -nonblocking
Higher bandwidth
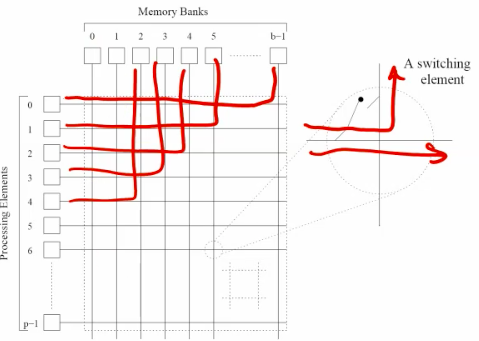
topology
multihop networks.
The combination of the bus and cross bar. flexibility between bandwidth and scalability.
feature:
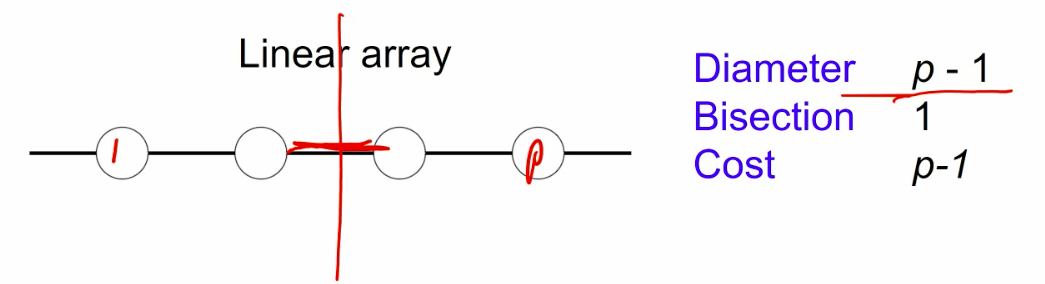
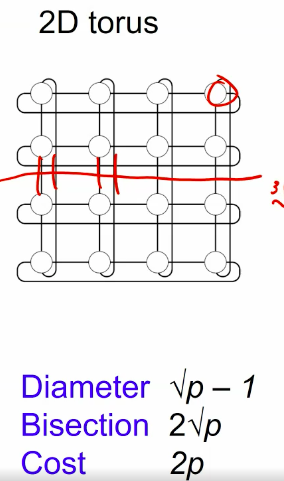
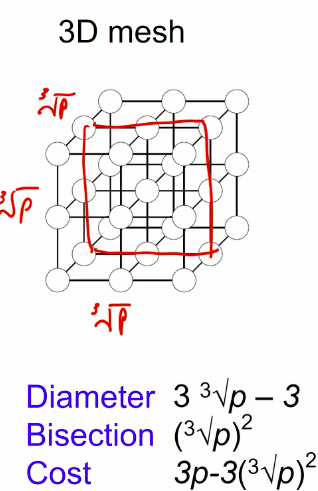
- Diameter
- Distance between farthest pair of processors.
- Gives worst case latency.
- Bisection width. - fault tolerence
- Minimum number of links to cut to partition the network into 3 equal halves.
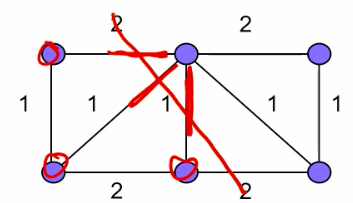
- Indicates bottlenecks.
- links out bandwidth.
- Minimum number of links to cut to partition the network into 3 equal halves.
- cost
- the number of links.
1d topologies
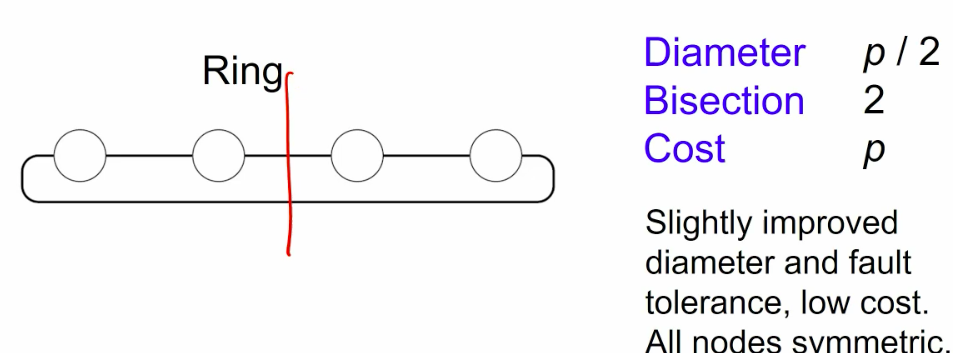
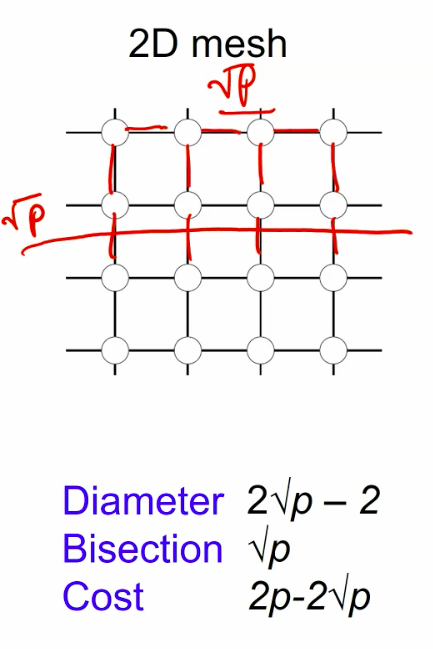
meshes and tori
hypercube
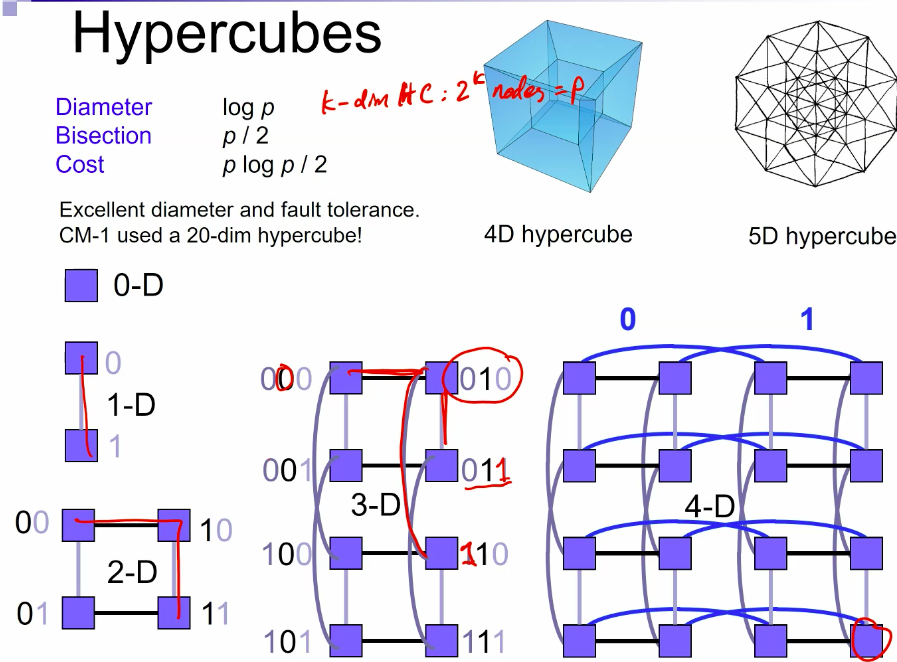
advantage
- good algorithm to calculate the path(only change the number of different bit)
- Bisection can always be \(\frac{P}{2}\) so there's little bottleneck
- nodes do not have hierarchy (v.s. fat tree)