实名羡慕过往的同学能去德国🇩🇪,我已经long long time 没有行万里路了,可影响我们在线上给予对宝座一定的冲击。
The HPC competition is all about hacking. Just like Neo (The hacker) dodging the bullets.

对于国内,德国,以及美国的比赛,我大致了解了三个区域对科研的态度。国内的情况之前已经描述过了,鉴于最近参加的ASSIST上科大选角大赛储存分场,我觉得中国真正做事的科研人员是承包国家项目的,其实强如陆游游也是如此,不过没有工业界做上层建筑,真的做出来的 filesys 都是玩具。德国这20天左右的调试和report,code challenge的代码质量简直💩。由此我觉得科研实习及学习还是得去万物之源——美国。年底的SC21进决赛了,我也在培养下一任队长了。(ASC22加油。

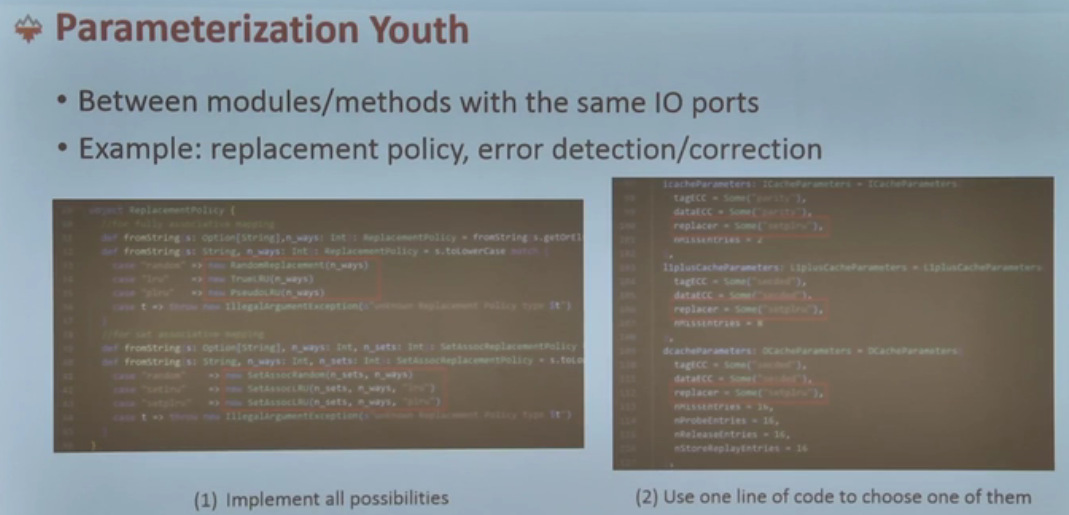
- 性能测试
- HPCC (10 pts)移植GPU
- HPCG (10 pts)
- HPL (10 pts,单独评奖)
- 传统 HPC 题
- gpaw (分子模拟,10pts)
- MetaHipMer 2 (宏基因组测序,10pts)
- WRF(气象推断,10pts)
- lammps(蛋白质模拟,10pts)
- Code Challenge (10pts)
- 对 wrf 和 gpaw 的 mpi_alltoallv 推断前端、以及(,10pts)
现场面试(10pts)
超算介绍
在刚开始拿到机器的时候我想笑,因为Niagara(在加拿大🇨🇦多伦多大学,意思是那个落差最大的瀑布)的配置和我在jump面试维护的几乎一样,从文件系统到scheduler。大概大前年我们ASC拿第二名是因为对两倍数据集的使用。还有当时志强对那个训练模型的熟悉,这次运气大致也到了我们上面。Niagara 登陆节点7个skx, CentOS7, Intel(R) Xeon(R) Gold 5115 CPU @ 2.40GHz,全是100GBps的IB卡,debug节点可以申1小时,和登陆节点配置是Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz,compute节点在nia1000左右可能可以申请到cascade lake。(所谓无痛提升性能。) 文件系统是gpfs和module放的用户态cvmfs。NSCC(National SuperComputing Centre)是新加坡大学联盟+ASTAR研究所的超算集群,就比较寒酸了,4个被很多人拷文件的登陆节点broadwell 2690-v3,CentOS6,IB卡是100Bps,主要是为了文件系统。但由于我我有NUS的好朋友(前同事)拿到了他的回校工具,这样我们就无痛多了4个登陆节点,但是交的队列是一样的。normal队列和登陆节点一样,而dgx是假的dgx,是16G的显存不说,nvlink也无。不过CPU稍稍好一点点,v3变v4。内卷之坡县尽如此,都不如我校校内的机器,终于知道我前老板为什么要回上海了。
还有说一下pbs和slurm,讲真,前者一点也不安全,其实就是一个后台程序在维护一套bash脚本,勉强维护住了,不过后者有商业版可以买,也做了很多cgroup的隔离,可sg机器上并没有,所以稍稍hack一下可以运行的时间还是可以的。同时也可以qsub -I一个交互干任何你想干的东西,(注意ip地址是ib卡的,qsub控制都是板载千兆口。)而在Niagara所有的openrun 和资源都是被控制住的。在进入的时候,ib卡就不能用于mpirun的host,这一点非常坑。
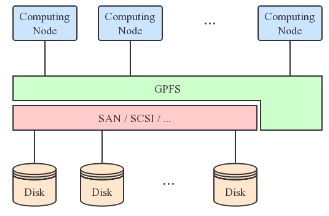
两个超算集群都有很好的GPFS,但是NSCC的scratch没有flock,导致不能用spack.总之POSIX是个对读写都需要加🔒的协议,GPFS并没有做到这一点。
Benchmark
HPL
虽然每次都觉着这是跑分,可这次真不一样。我们本来以为这是dgx就可以靠nvlink 这个topology搞点事情。可惜只能搞CPU的affinity了,我们用taskset 搞了这个😄。
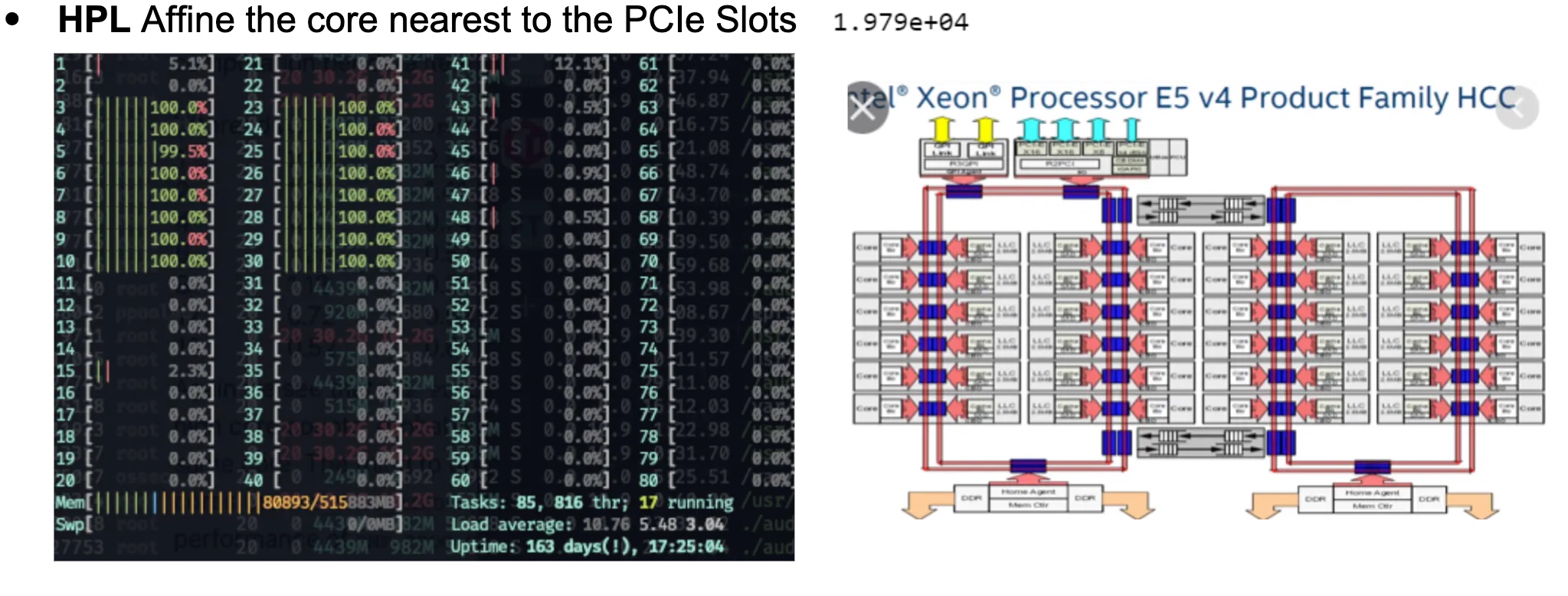
虽然性能提升是个玄学,不过有总比没好。
HPCG
这次还需要在cpu上跑,从官网上搞了个xhpcg_skx,没想到在tuning的时候到了cascadelake,后来我们每次跑都指定那个节点。
HPCC
以前比赛从来没有过这么老的东西去跑benchmark,这是一个最后commit 13年的东西,有HPL,FFT等7个小case,主流benchmark都不用这玩意了,可能欧洲人比较念旧吧。我们调了一版本CuBLAS编译的HPL和CuFFT变异的FFTW。性能是直线上升。
MHM2
我们拿到这个题目的时候,觉得这个赛题我们可以改很多,我还为此分配了两个同学去研读代码,不过松辉和候补同学拿这个项目直接成了他们的并行计算project可还行。可我忘了作者,LBLL,berkeley 和能源部的大神写的,怎么可能会需要我们去魔改他的代码。失策失策。论文里的种种,cuckoo hashing,k-mer,DHT,都是貌似可以改的东西。可惜他们已经survive了TB级别ACGT的测试,工程师已经写的够充分了。不过upcxx(一个并行编程范式)有挺多小问题的。当时并行计算并没有涉及到GASNET并行模型,其实就是global_ptr和local_ptr的那些东西,这个并行模型比较适合DHT,特别是TB级别的数据。
我们最先发现的是RPC他写的很慢,profiling完以后的结果告诉我中间传输过程太多,可没啥可以改代码的,都是libverbs点对点通信。

作为尝试,我们尝试了upcxx 的后端,可以是libverbs 也可是Intel MPI,Niagara上面装的rdma-core是rpm装的而非mellanoax下下来编译的,这弄坏了挺多东西。所以我们关于libverbs都是在singularity里弄的。在configure正常的情况下,MPI和libverbs 性能差不多。在NSCC上,GasNet对内存有异常多的需求。这程序几乎有线性的scability。
\[
\begin{array}{l}
\begin{array}{l}
\text { Comm} & \text{Build } & \text { System CPU } & \text { User CPU } &\text{nodes}
\end{array}\\
\begin{array}{llrlll}
\hline \text { mpi } & \text { Release } & 37.36 & 02: 54.9 & 1: 35: 15 & 4 \\
\hline \text { mpi } & \text { Release } & 60.74 & 01: 37.4 & 1: 19: 27 & 2 \\
\hline \text { ibv } & \text { Release } & 37.27 & 02: 57.3 & 1: 36: 37 & 4 \\
\hline \text { ibv } & \text { Release } & 61.69 & 01: 36.6 & 1: 19: 33 & 2 \\
\text { ibv } & \text { Debug } & 112.3 & 03: 44.6 & 4: 54: 57 & 4 \\
\text { mpi } & \text { Debug } & 134.4 & 06: 11.6 & 5: 57: 13 & 4 \\
\text { mpi } & \text { Release } & 37.79 & 07: 31.1 & 1: 39: 17 & 4 \\
\text { mpi } & \text { Release } & 545.35 & 1: 18: 27 & 18: 15: 26 & 4 \\
\text { mpi } & \text { Release } & 104.88 & 02: 54.6 & 1: 08: 33 & 1
\end{array}
\end{array}
\]
接下来就是调k-mer中的k了,这个非常有用,但是会减少精度。添加一个k就是增加他计算队列的长度,大致比原来的慢\(\frac17\).所以我们干的一件事就是分析精度缺失和k的关系。让其保持在一个合理的范围内。
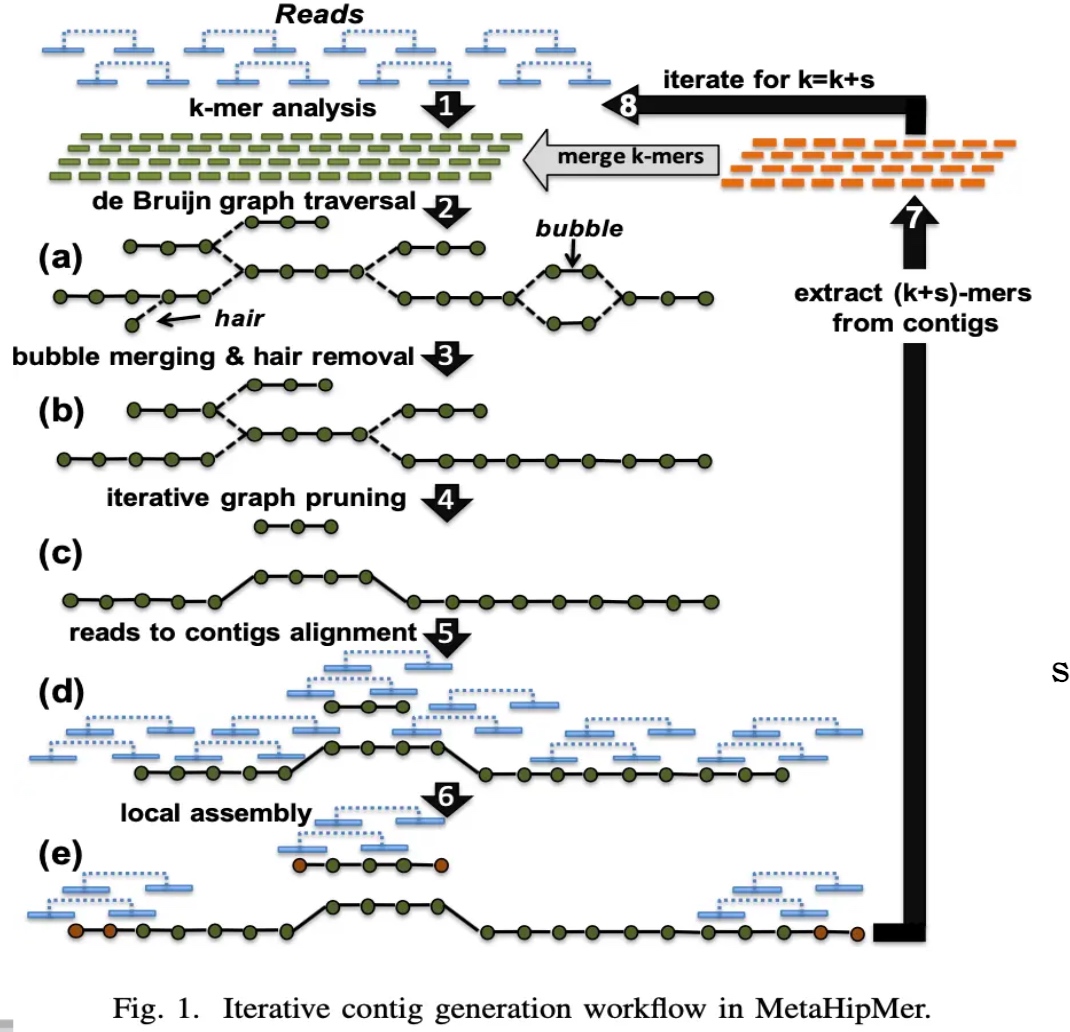
DHT是并行计算课上讲过的那种,过一段时间会对在圈上的下一个节点加一次update。更新数据的过程是先write only(write barrier),在同时读和写,最后是read only(read barrier)。其bottleneck在于能否利用这个特性让其更快。(然而提出锅的人并咩有解决这个问题。DHT 的优化就是把那个圈变成其他结构,可似乎networkIO已经是bound了,逃。File System 上他们想用raid 去做这件事。
GPAW
我们在这题上失利了,因为code challenge部分有这块的alltoallv的优化,可是只有一个case真正调用了gpaw,做这个的宇昊由于我的编译原理作业没有花太多时间,导致没有发现问题。
这应用换个elpa库就能很快很快。
LAMMPS
对lammp s这么成熟的蛋白质应用来说,我觉得其应该很稳定,可事实并不是这样。我们在当中找到了各种segfault,尤其是intel package,一个intel 架构师写的加速lammps性能的库。
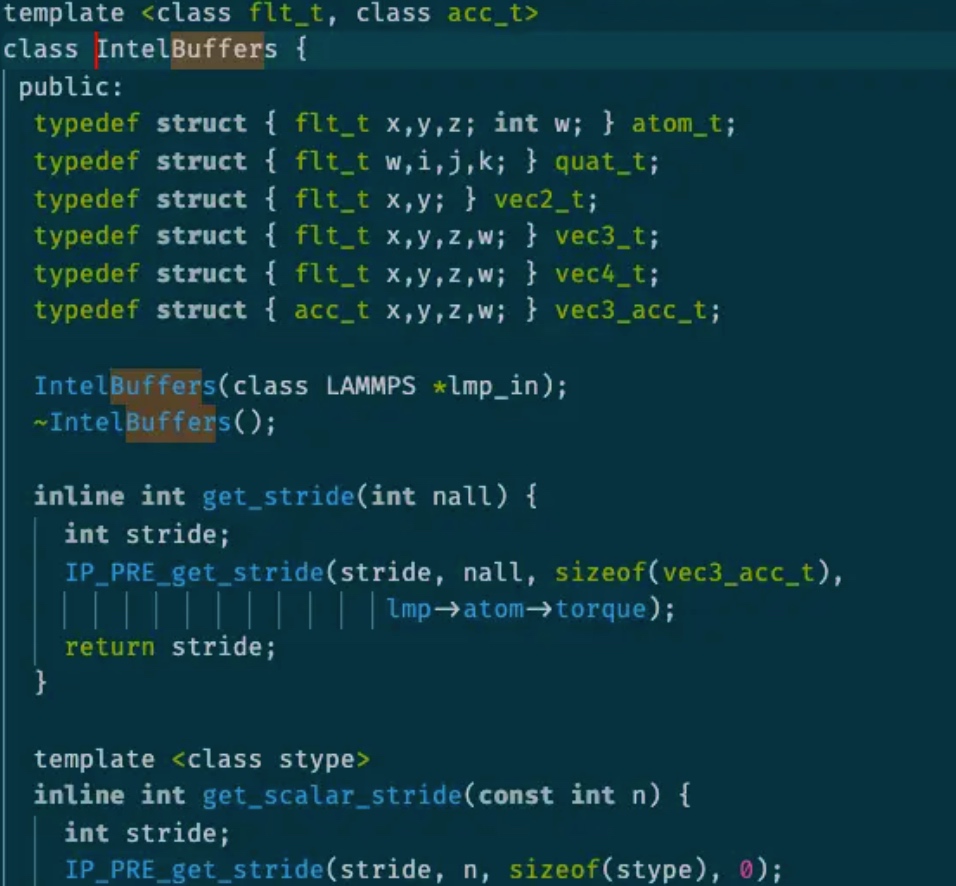
这么一个类,几乎所有的half neighbor 的计算都要用到
同时在跑ipm学到一个奇怪的LD_PRELOAD顺序问题。
WRF(Wolf)
又是一个天气应用,当时我们SC20的失利很大程度上就是那个 fortran 的 segfault 11,之前的解决方案是unlimit -s。据Harry说就是我们踩坑不够多,不停的换小版本编译,如果都不行才说明不是编译器的问题。我们这次在Niagara上是所有小版本都加了,结果还是不行。在比赛结束没几天的时候,在翻阅了WRF的官方部署ppt后,我们发现是一个KMP_STACKSIZE=20480000000的问题(由于intelifort维护的main程序需要对所有进程的状态进行描述,超过4KB就烫烫烫烫了);在Niagara上还有个奇怪的坑,mpi是完全由slurm的srun控制的,你写的mpirun -np 160在集群上也会被换成srun -ntask $SLURM_NTASK -cpus-per-rank $SLURM_CPUS_PER_TASK -bind-by core导致每个node的core并不是你mpirun写的核心,而是你predefined的,这需要你ssh上去,而你也不能开交互spawn mpi task,因为mpirun走不了ib卡。所以在slurm脚本最前面定义一下就好了。这些坑真的只能在文档中体现,后人才不需要重新踩。现在fortran都要出2021了,时代变了,我的jump trading前老板最喜欢的还是F77,泪目。
说下我们做的task和优化:(给我们的testcase居然是上海。)第一个是题目要求的分析MPI和omp的比例对WRF的影响, 其次是AVX512和AVX2的比较。最后是我们加的一个N-N file write middleware。

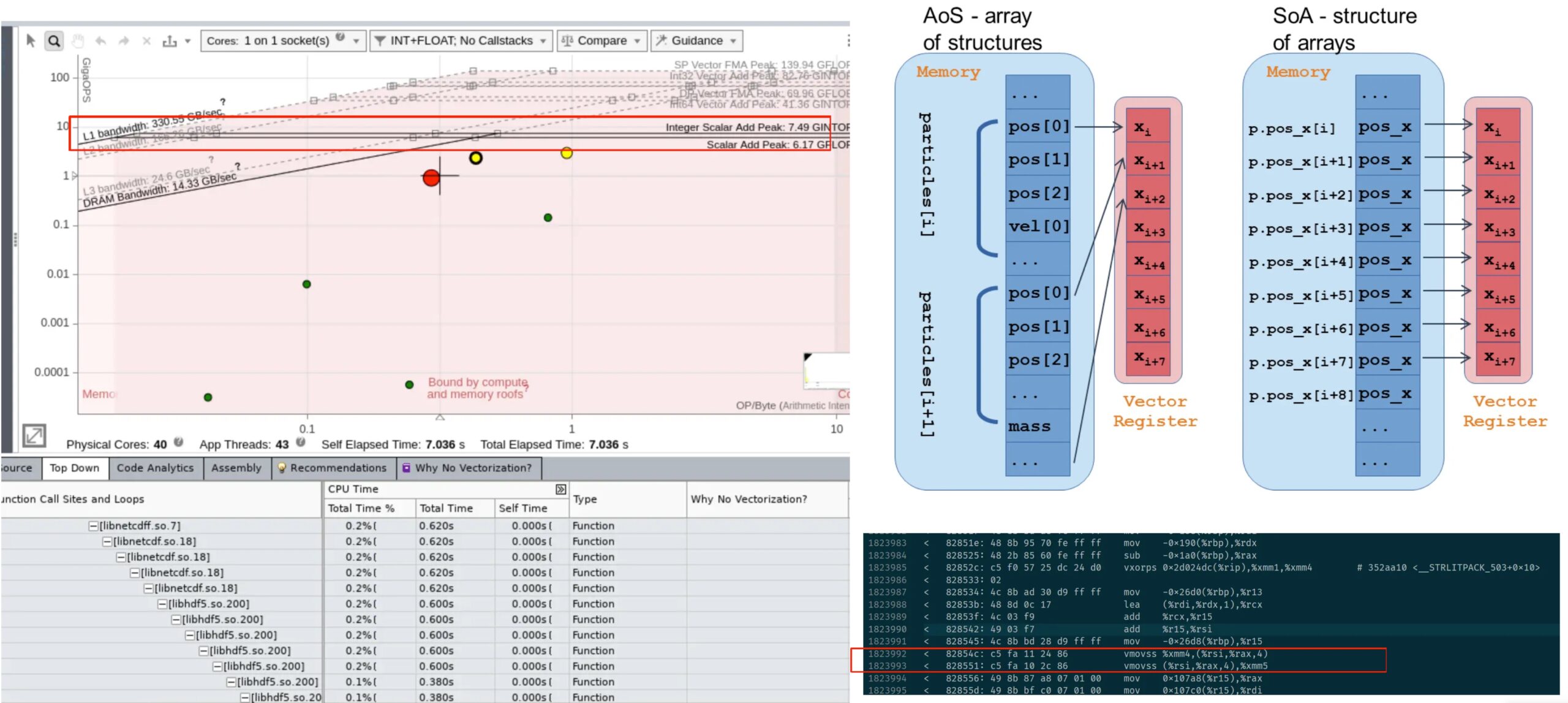
首先是profiling结果,由于加上vtune以后更容易seg11,就算加了那几个环境变量也一样,那我们就骂intel ifort傻逼好吧。之后虽然有几个小testcase我们成功跑完了一次advisor 和hotspots。这里只放nvsight(闷骚绿)的结果。
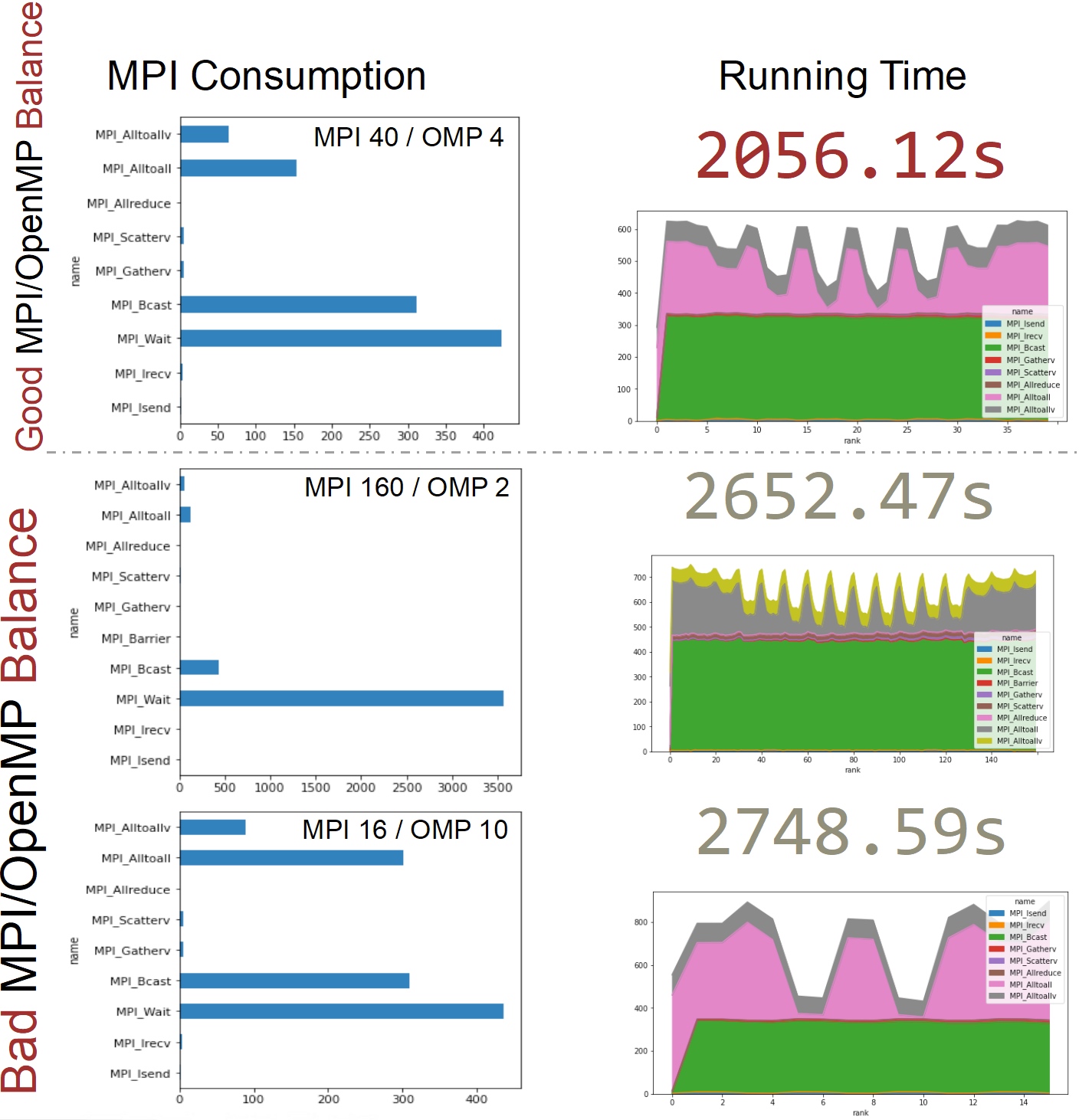
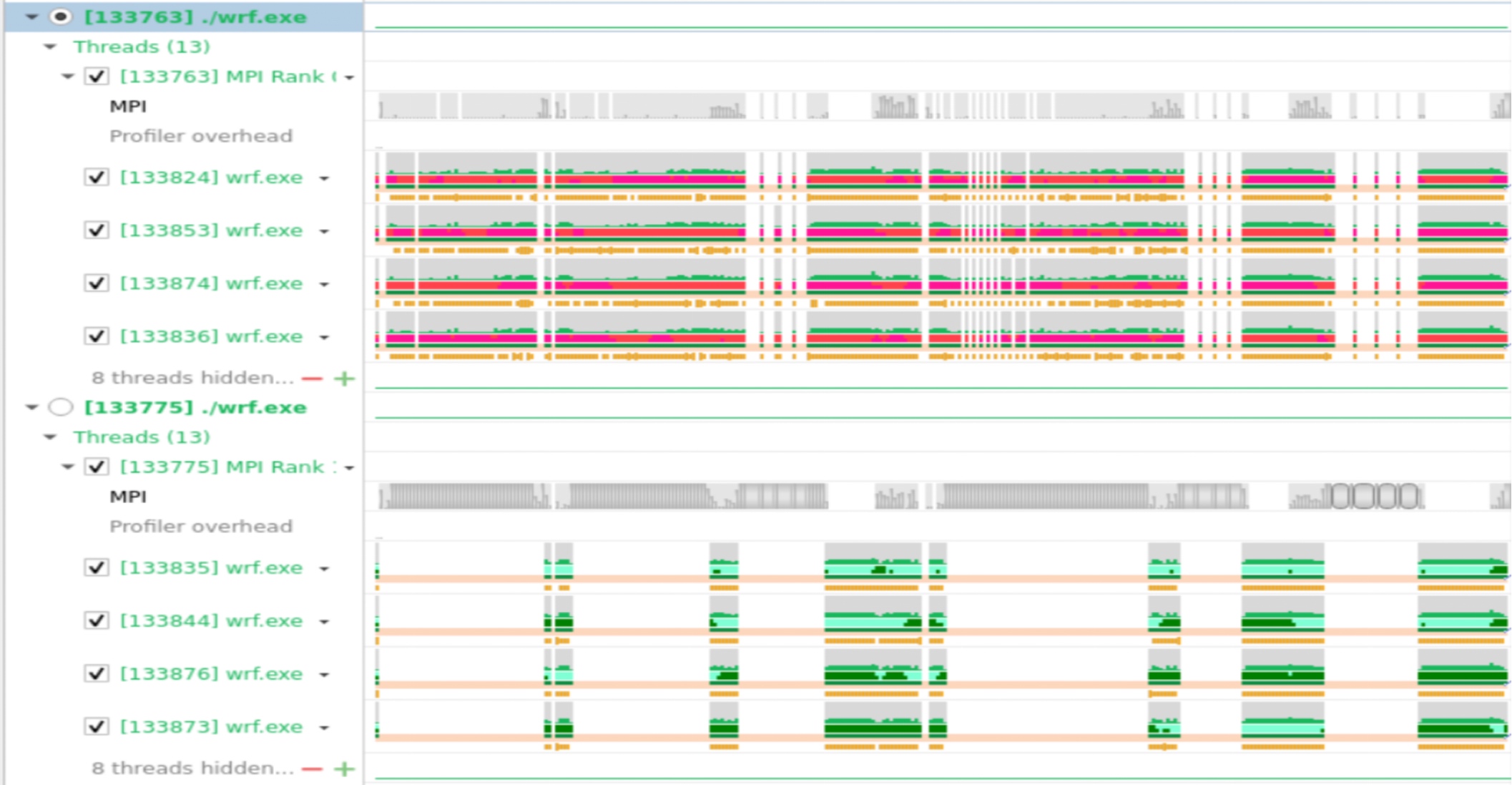
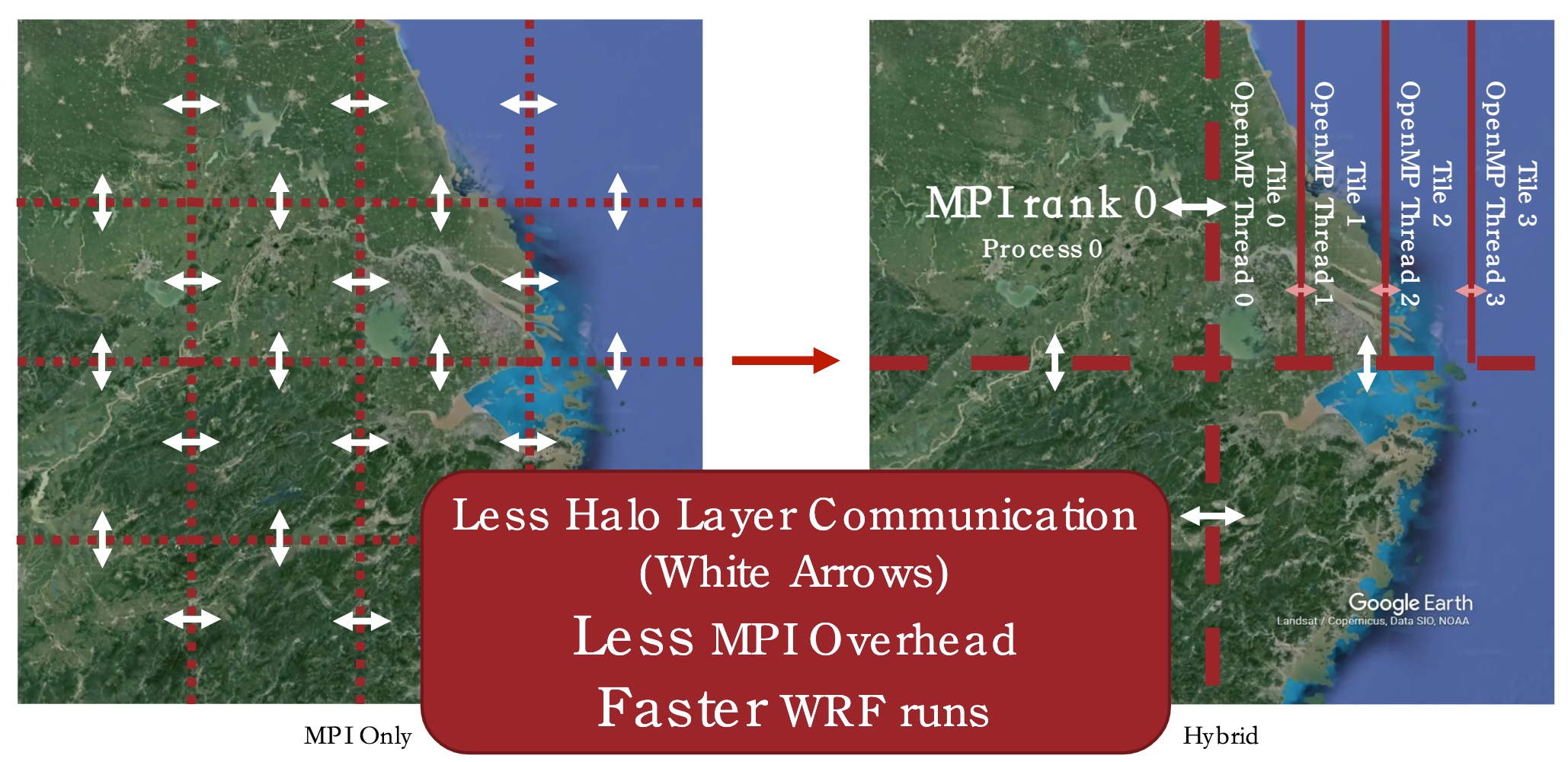
大概解释下就是他会把数据向这样切
更少的MPI overhead就会得到最好的性能,所以我们写了一个bayesian 调参机。非常简单,但效果也不错。
在AVX512和AVX2方面,我们发现AVX512有严重的降频。
之后我们加了个殷老师特技FileSys middleware,我也终于搞懂了fuse到底干了啥。so-called. transform N-1 I/O pattern to N-N
while maintaining the file abstraction

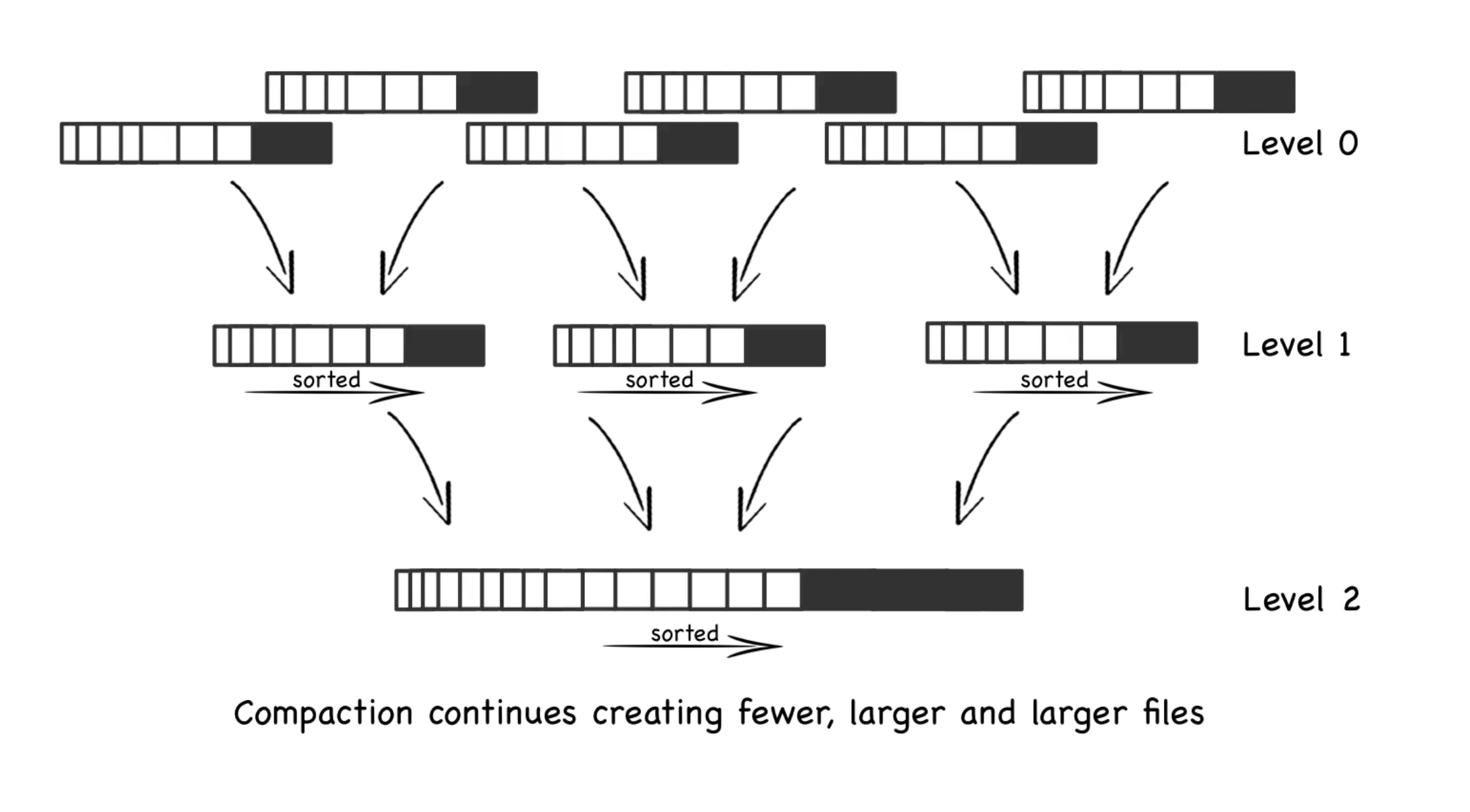
Code Challenge
简要来说就是英伟达工程师写了个垃圾go程序,用于前端显示他们内部调benchmark 的过程,尤其是mellanoax的hpcx提供的openmpi的osu,这是一个很吃alltoallv的东西。以及夹带gpr_copy的ompi的性能。总之,在和shenghao和jiajie讨论了一下后,我们一致认为这是坨💩。所以我的策略就是➕zlib和COO sparse matrix,后来他们upstream了。
前端我们改成json的api传输了,这样压力给了前端,不过我们用了蚂蚁的一个前端库,已经用wasm优化的很好了,我们只需要把他的md转成序列化的json。
给你们说一个笑话。
ISC SCC Final




不太正常的总结
感觉这次时间拉的过长,我和做WRF的厶元几乎为此付出了RA工作和后面的几场考试,没事,能work就行。时间长就导致最后大家其实差不多,不知道评奖的机制是什么,至少我从和THU 暨南 NTU SYSU pk的过程中学了很多很多。清华好像最后两天才开始做,我只能说他们可能对评奖并没有什么兴趣了,反正就是第一了,反正年底我们去不了美国了。就面不了基了。
然后又是一年奇怪的陪跑。感觉就是自己太菜了。
Reference
- E. Georganas et al., "Extreme Scale De Novo Metagenome Assembly," SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 2018, pp. 122-13
- Hofmeyr, S., Egan, R., Georganas, E. et al. Terabase-scale metagenome coassembly with MetaHipMer. Sci Rep 10, 10689 (2020).