

文章目录[隐藏]
NVOverlay is a fast technique to make fast snapshot from the DRAM or Cache to make them persistent. Meantime, it utilized tracking technique, which is common to the commercially available VMWare or Virtual Box on storage. Plus, it used NVM mapping to reduce the write amplification compared with the sota logged based snapshot.(by undo(write to NVM before they are updated) or redo may add the write amplification. To specify not the XPBuffer write amplification, but the log may adds more writing data)
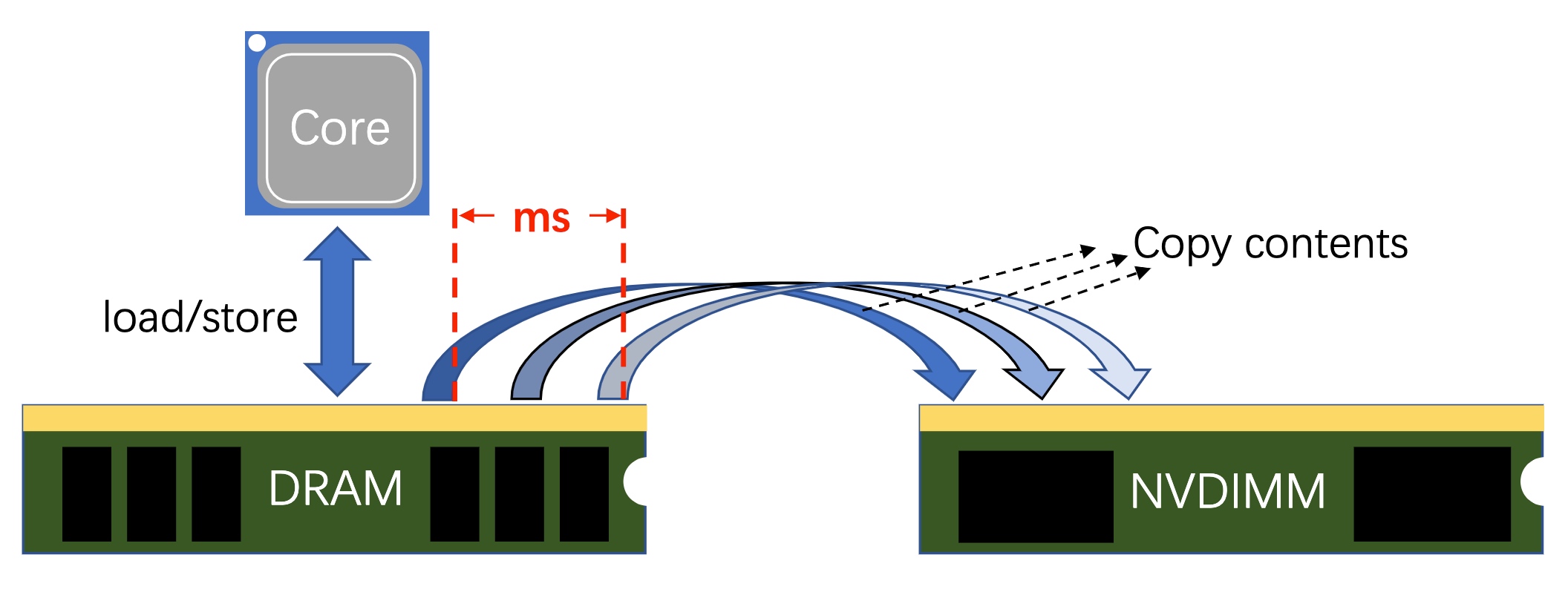
So-called High-frequency snapshotting is to copy all the possible data in a millisecs interval when CPU load/store to DRAM. Microservice thread may require multiple random access to MVCC of data, especially for time series ones. To better debug the thread of these load/store, the copy contents process should be fast and scalable.
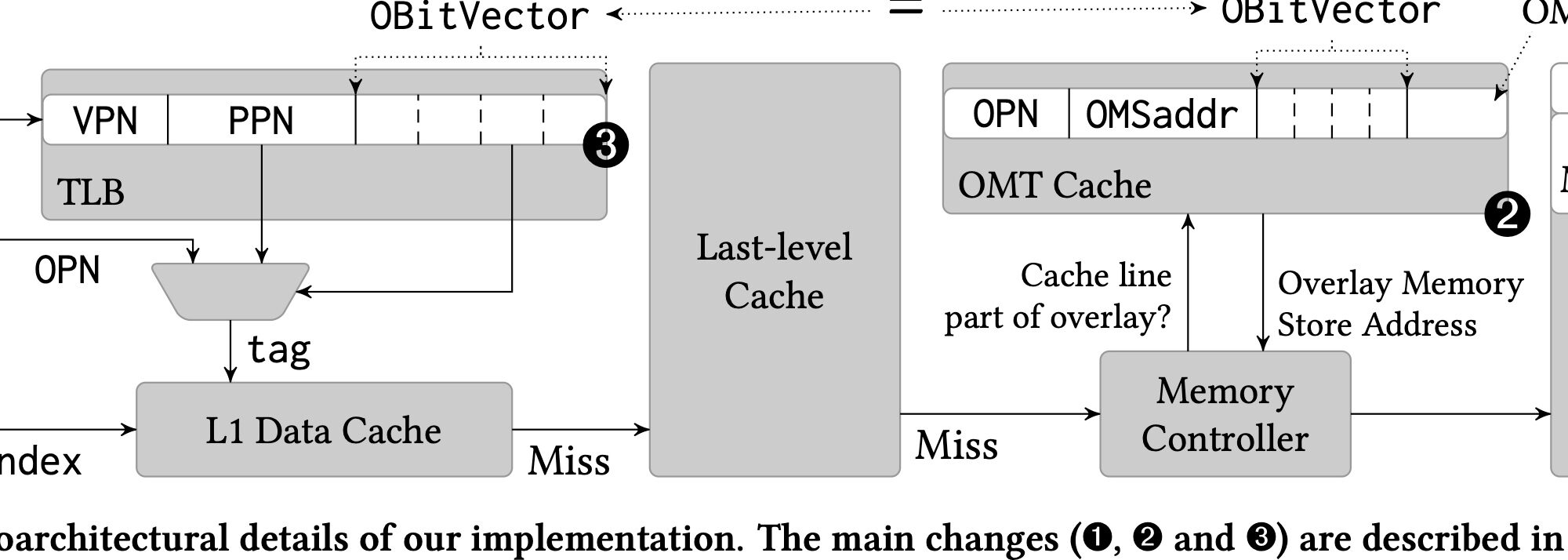
here OMC means overlay memory controller
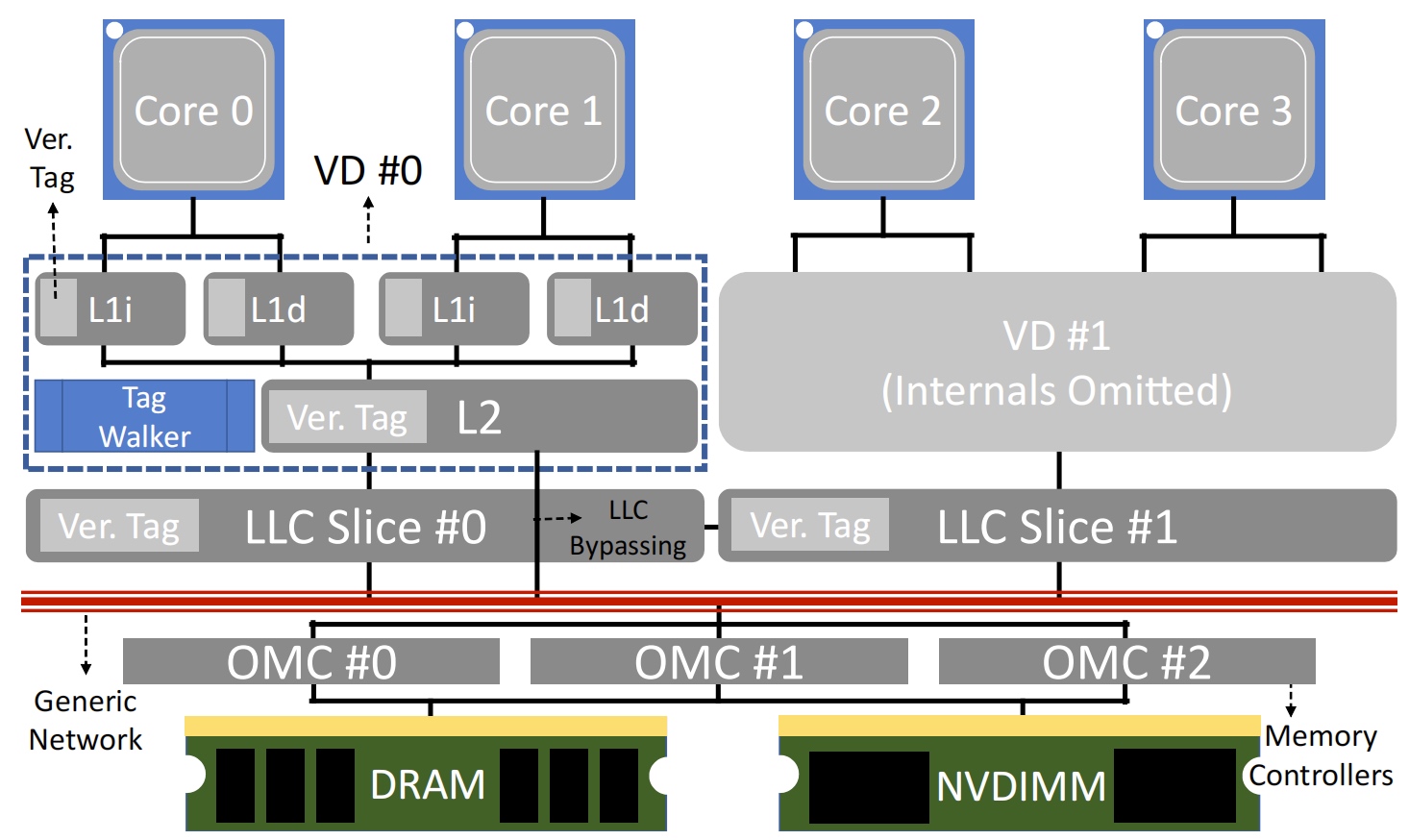
The cache coherency is considered deeply. For scalability to 4U or 8U chassis, they add a tag walk to store the local LLC tag. We know that all the LLC slice is VIPT because they are shared. For the same reason, the tag can be shared but unique to one shared space.
For a distributed system-wide problem that have to sync epoch counters bettween VDs, they used a Lamport clock to maintain the dirty cache's integrity.
The problem solved:
- The difficulty to track the diffs between data from different physical space in memory. They propose Coherent Snapshot Tracking - when a versioned domain, say epoch=E is calling an eviction to LLC/memory, the eviction will be evicted to the NVM.
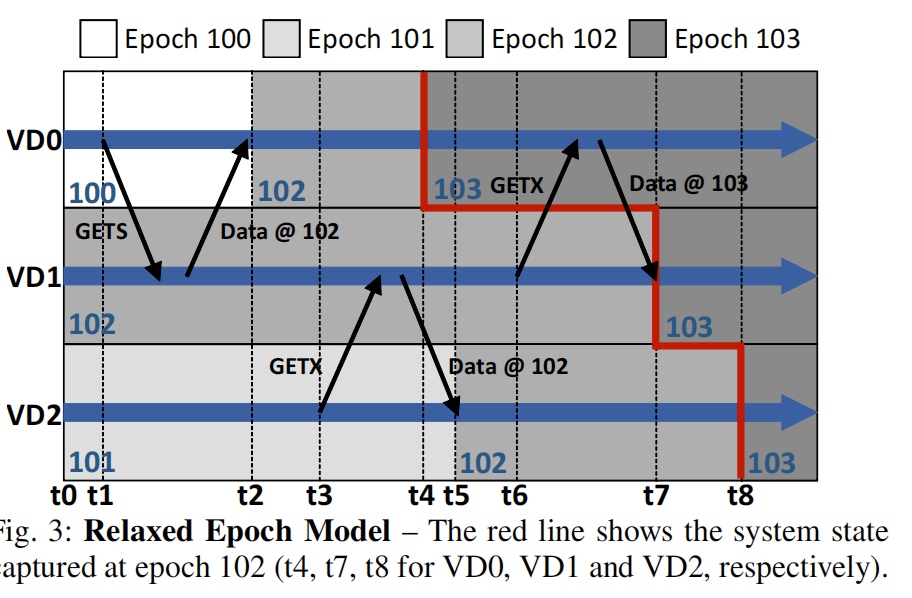
The epoch means the execution of the versioned domain stored as a 16 bit integer. The rpc betweeen VD is coherent message in cache coherence protocol's getX and getS.

multiple VD can interact via shared memory access. But once the synchronized epoch only when smaller than requested is safe to satisfy the data dependency issue.
The time VD get data from a higher epoch will it gain the updated epoch.
Page Overlay: Each cache line in the hierarchy is tagged with a Overlay ID (OID). A single address tagged with different OIDs could be mapped to different physical locations by the Overlay Memory Controller (OMC), which serves as the memory controller sitting between the cache hierarchy and the main memory.
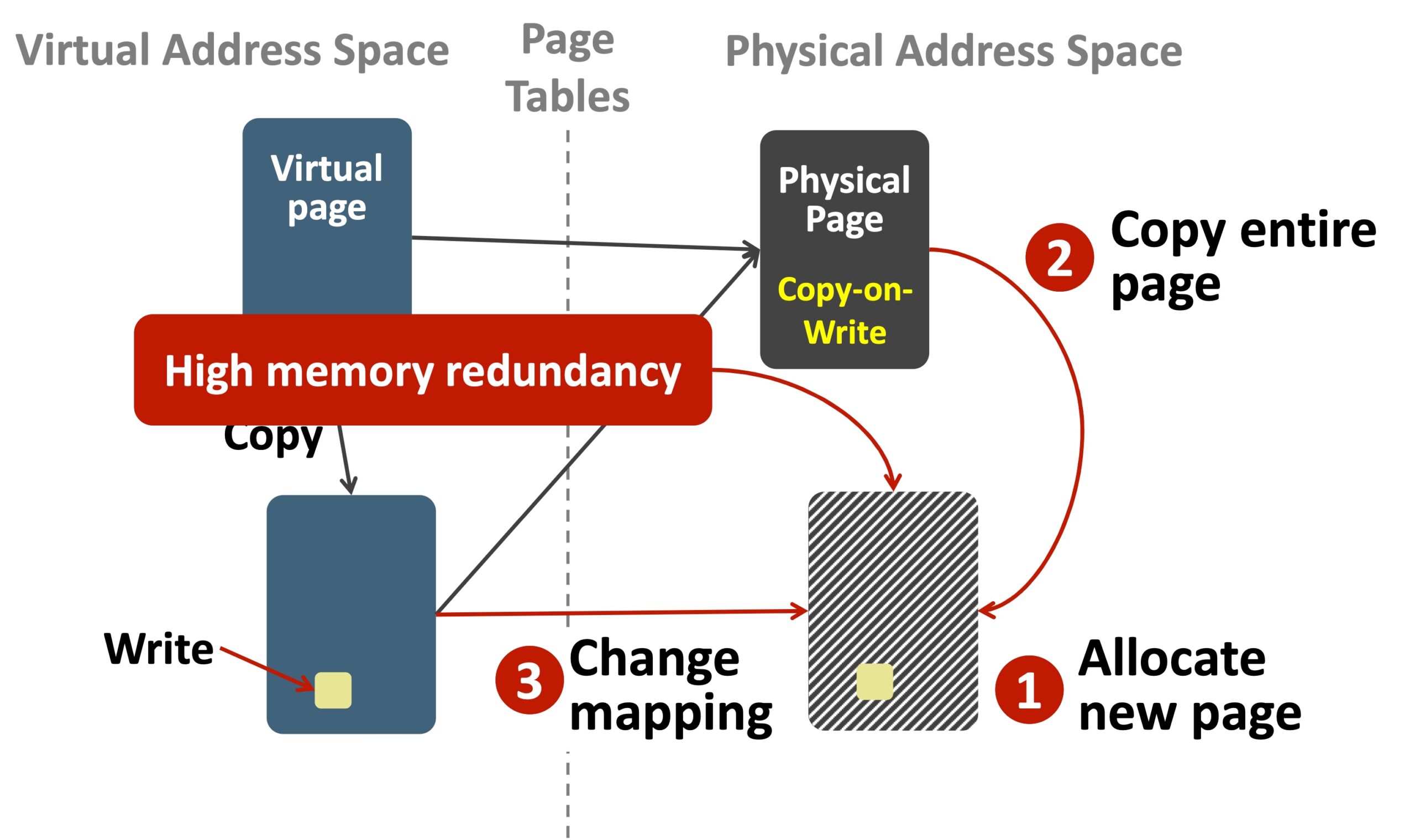
The copy on write to move a physical page to another one and remap.
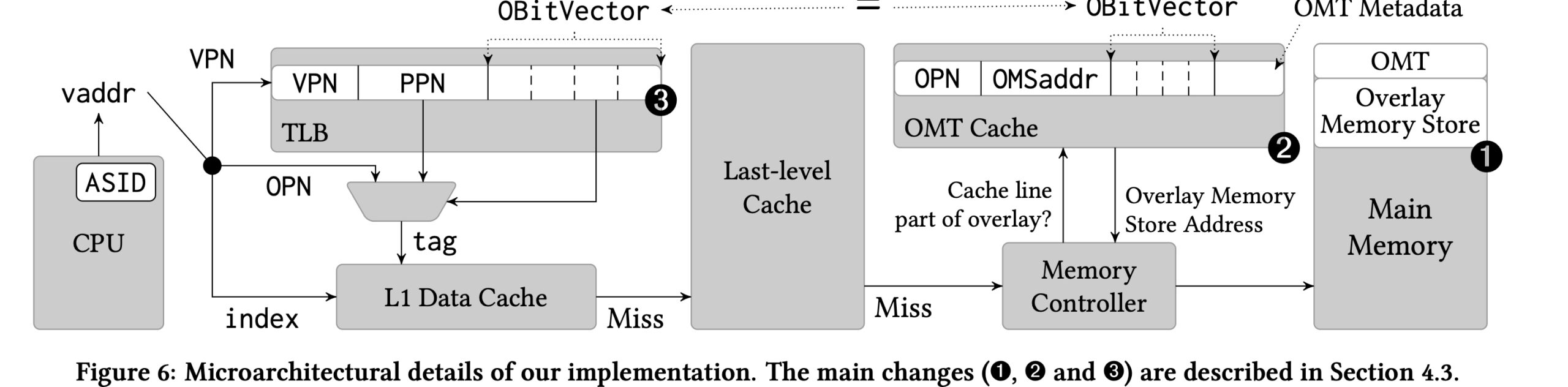
The graph from Page Overlay
-
COHERENT SNAPSHOT TRACKING (CST)

- incremental Version for L1. On receiving a load/store request, check whether is shared over L2, check whether have to modify OID on a miss. The eviction is a PUTX request to evict buffer which is not related?(really for clwb to other core?)
-
incremental Version for L2. GETX& GETS is to check the permission and check the miss and then send to L1 as a response and set the OID to RV. PUTX(not invalidate the L1 copy) is to check the coherence state and do the put operation for different state and copy. data and OID into the cache slot. The eviction is to add a Overlay to OMC other then normal operation if it's dirty version(snapshot). If predicted dead, just do the LLC bypass. DIR-GETX and DIR-GETS is listed. The intra-VD is listed below.

A problem is that the intra-VD is the subset of advanced directory protocol discussed in the “Quantitative Methods”, I'm not sure the zepplin in AMD epyc rome is designed as this.
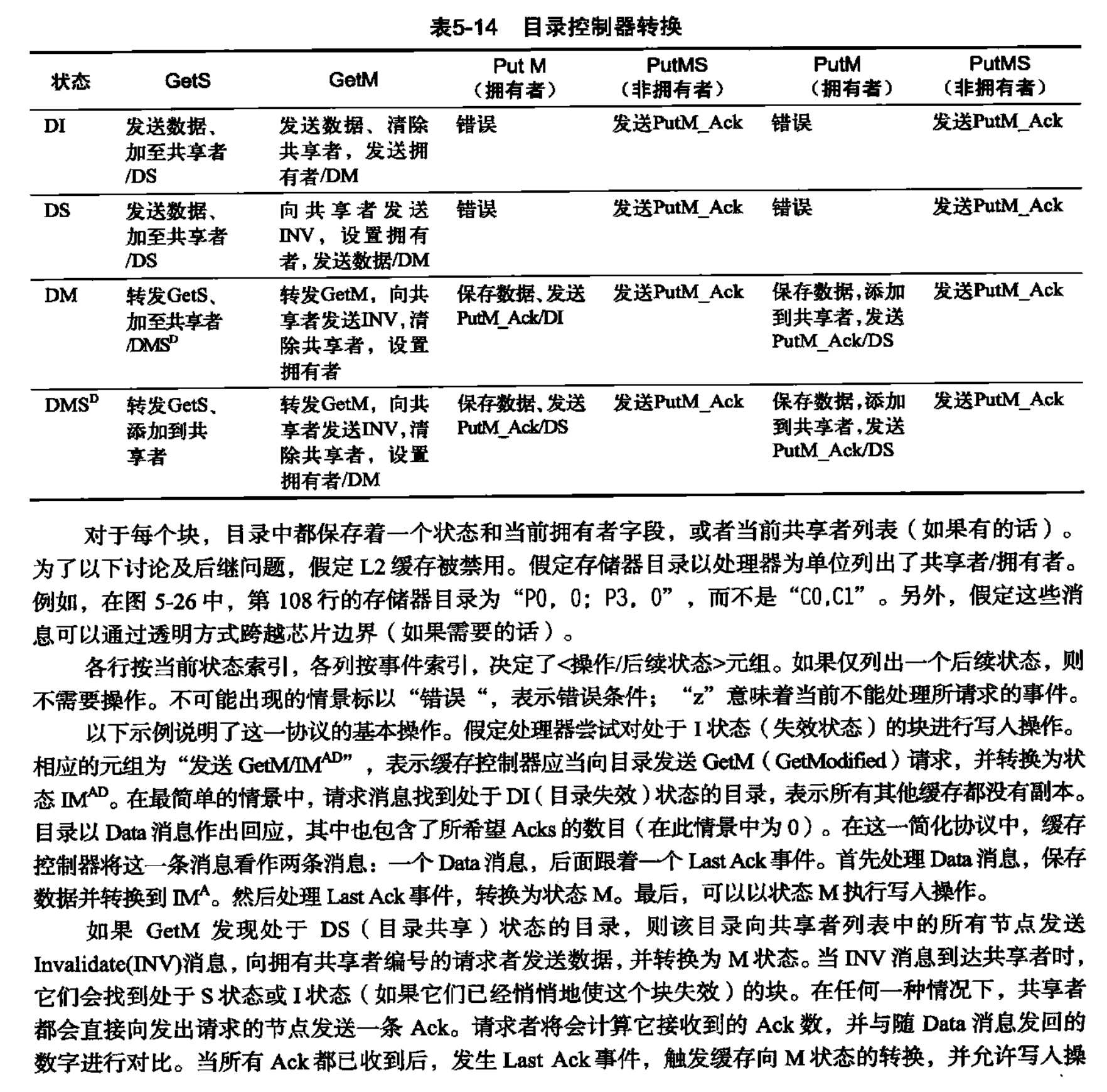
-
LLC and DRAM Operations: Once a version leaves a VD, it is guaranteed to be persisted, even if the coherence state may still indicate dirty. The LLC and DRAM, therefore, do not implement the version coherence protocol, except that line OIDs are updated on write backs.
-
Reduce the NVM write amplification by frequently persistent snapshots and shadow paging(a memory interface for VMM to hypervise the VMs) simply because its write the data once. (The speed of it is not as fast as no log, pretty much the overhead) But plus XPBuffer, I don't think write amplification is a problem for UNDO Log is taking good advantage of it. However, the storage overhead of GC(1.5X) is not as high as UNDO Log(2X+).
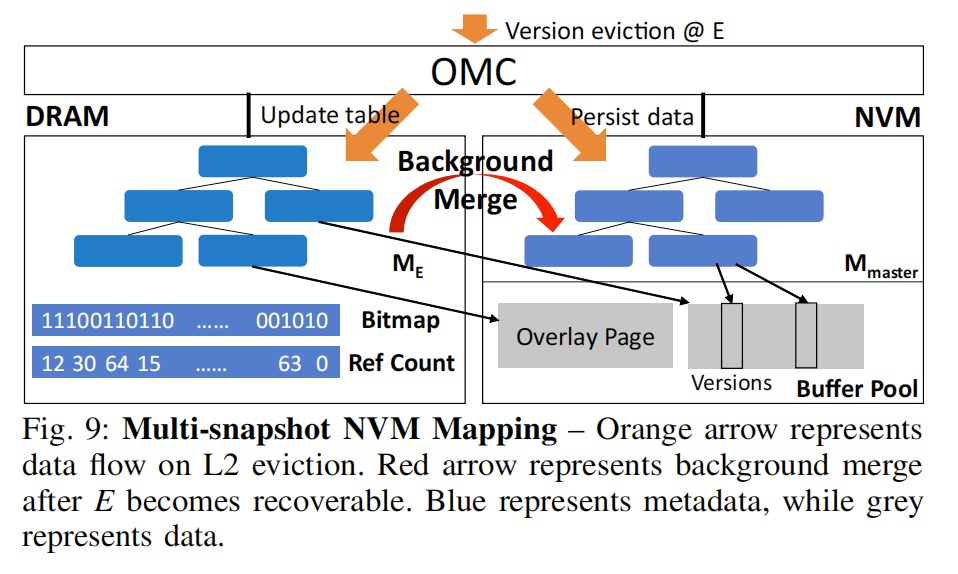
The persistent-data structure between DRAM and NVM.- MULTI-SNAPSHOT NVM MAPPING (MNM)
- 5-level radix Tree.
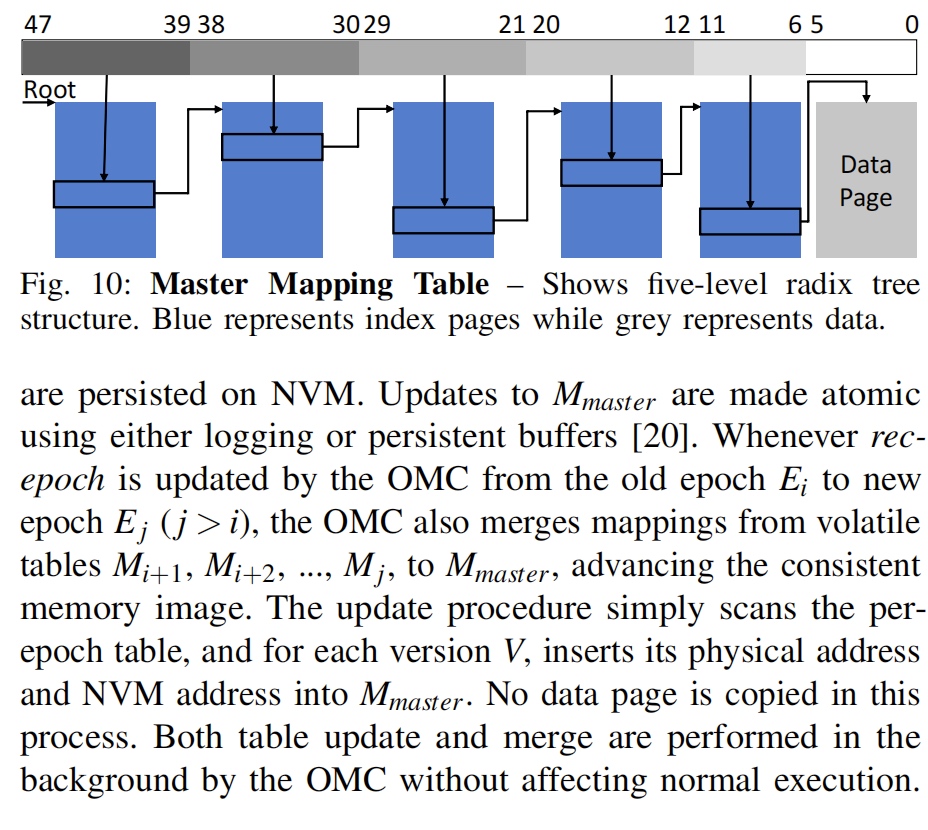
- 5-level radix Tree.
- MULTI-SNAPSHOT NVM MAPPING (MNM)
-
Experiment
- zSim
- Compared with hardware undo logging(hard code the algorithm in the RISC main memory controller) PiCL-L2 and PiCL. The latter have a tag walker periodically evicts the dirty lines from the previous epochs. The undo logging can be compressed using LWZ and don't need recovery after the log truncation to save the bandwidth of main fabric.
- SPEC2006 have some data is not suitable for data compression.
- OMC buffer can reduce the writes but also eliminates the write amplification of undo log.
Reflection for some simple case.
- clwb is a special isa. If a cacheline is located in other core, may lie in the other VD, it will go to LLC for the first place and be evicted afterwards. Then set the cacheline invalid. So it'll be GetX, (N)ACK, PutX and INV. For NVOverlay design, I'm not sure the tag tracker can make this path out.
- The computation intensive part of the logic should put in the backend, the RISC core in the OMC so that the bandwidth and frontend overhead could be saved.
- The Master Mapping Table is similar to the shadow page table in the XEN. They have many similarity in engineering implementation. So that IOMMU for NVM could be done by the way.
Reference
- https://www.cs.cmu.edu/~gpekhime/Papers/PageOverlays-isca15.pdf
- David Patterson "The Computer Architecture: A Quantitative Approach"
- https://people.inf.ethz.ch/omutlu/pub/page-overlays-for-fine-grained-memory-management_isca15-talk-nobackup.pdf