


文章目录[隐藏]
- Debugger
- Yet another PyPy
- Persistent Memory - Nap: A Black-Box Approach to NUMA-Aware Persistent Memory Indexes
- Persistent Memory - XFUSE: An Infrastructure for Running Filesystem Services in User Space
- Persistent Memory - Ayudante: A Deep Reinforcement Learning Approach to Assist Persistent Memory Programming
- GoJournal
- PIM (DRAM Processing DPU, not NV's DPU)
最近参加了软工顶会和操作系统相关顶会,由于之前没有学生申请,这次被完美坑了200🔪。不过总的来说收获颇多,大概知道了一个博士毕业生需要的水平和付出。
Debugger
The debbugger dealt locally。
Good at first sight, but not that fancy,
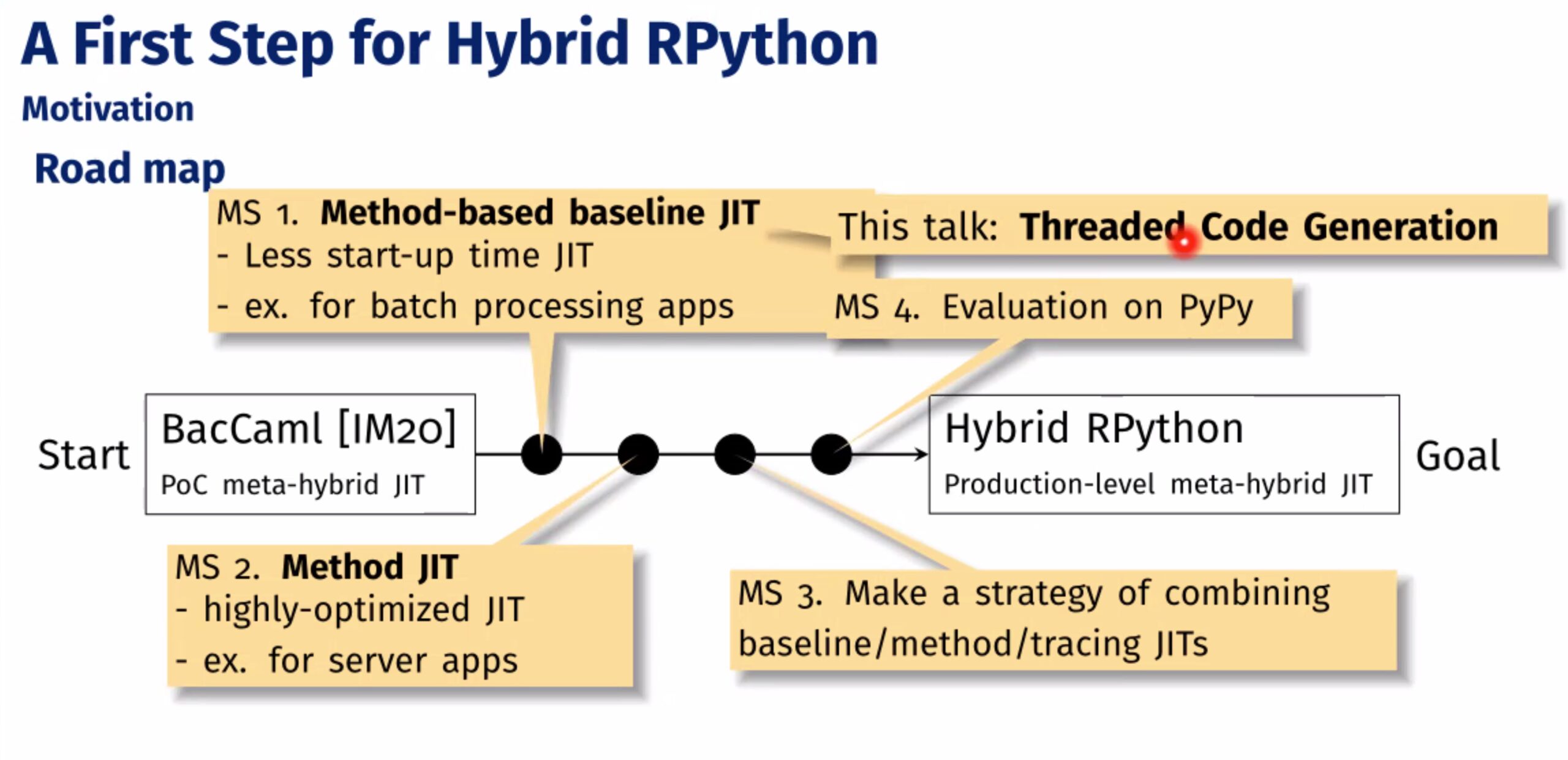
Yet another PyPy

Persistent Memory - Nap: A Black-Box Approach to NUMA-Aware Persistent Memory Indexes
看到youyou 又又又发了一篇 2000行代码的 PMEM+NUMA的,就是把PMEM 的fs index kv hash 到 DRAM上。这样就不会对UPI contention。(软件层面很有意义吧。
然后,又看了两片测NVM时间和bandwidth的文章
Maximizing persistent memory bandwidth utilization for olap workloads@SIGMOD‘21“ and "System Evaluation of the Intel Optane Byte-Addressable NVM@MEMSYS'19。然后了解了如何保证持久化顺序,CLWB+SFENCE老生常谈了,in-cache line ordering是一个常用的技巧,为了减少fence,可以看一下fast-fair或者Fine-Grain Checkpointing with In-Cache-Line Logging。感觉做的好可以攻击,这也是前老板的强项😄。
不是很懂App Direct。今年atc facebook的“Improving Performance of Flash Based Key-Value Stores Using Storage Class Memory as a Volatile Memory Extension”里面测的,感觉memory mode不如针对应用定制化的DRAM+PM的混合机制,但是在HPC领域MM还是很有用的。
fsdax的metadata是惊人的大,为了低延时可以在DRAM上(ndctl可以设),不过缺失了failure atomicity。
Persistent Memory - XFUSE: An Infrastructure for Running Filesystem Services in User Space
主要是fuse在remote 等ack的时候有个忙等的问题。10ms 超时做重request。
Persistent Memory - Ayudante: A Deep Reinforcement Learning Approach to Assist Persistent Memory Programming
用RL 生成pmem代码。让其过pmemcheck和PMTest。
GoJournal
MIT貌似特别喜欢在Go上面做文章,但chan context用的也不多,这里就是侧重并发写log。
PIM (DRAM Processing DPU, not NV's DPU)
考虑DRAM间数据通信的PIM。能捕获本来会fetch 到核内计算的数据交换,大大提升throughput。问题是同步问题和compiller这类基础设施了。far from 可用。