花了半个月,11月23号早上就到货了,本来是一个月才到货,这也是一个小惊喜吧。买这个本的初步想法就是学习arm汇编,同时尝试反编译一下metal api到苹果的asic的过程。总之就是想花钱买开心。
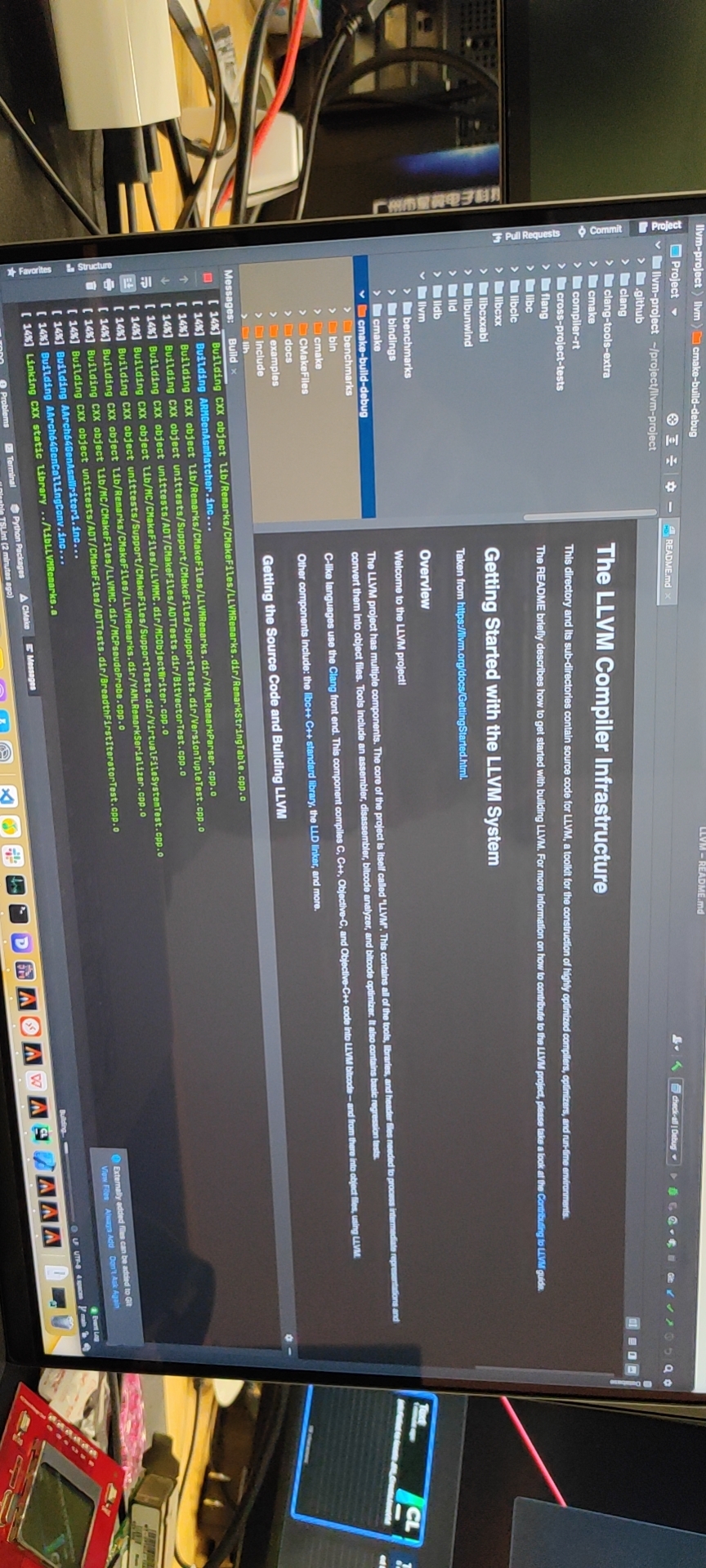
LLVM all 14分钟就编译完了。几乎是我9700k的2倍。我终于实现了rust电量自由。


A Tech Nerd with a finance mind.
花了半个月,11月23号早上就到货了,本来是一个月才到货,这也是一个小惊喜吧。买这个本的初步想法就是学习arm汇编,同时尝试反编译一下metal api到苹果的asic的过程。总之就是想花钱买开心。
LLVM all 14分钟就编译完了。几乎是我9700k的2倍。我终于实现了rust电量自由。
在北京时间11/16日早上9点半至11/18日早上7点半超算队线上参加了SC21-SCC,这是本年的最后一战,我是按照我的最后一次比赛的标准来准备的,毕竟有申请和科研,之后也不会这么好玩的参与比赛了,以后可能为了智商保持参加一下ctf。在准备和规划上和比赛进行时有挺多出入的,所以只能说我带领的同学很好的各司其职,失败的原因我更愿意归咎于我的Timing的能力。不过我也明智在多找了几个运维高手。
预算是开始时给出的,在Azure上只有1500USD,在另一个今年新加的Oracle机器上不限,下面标*的是在oracle上跑的题目。 SC21的题目很早就放在网上了,大概有
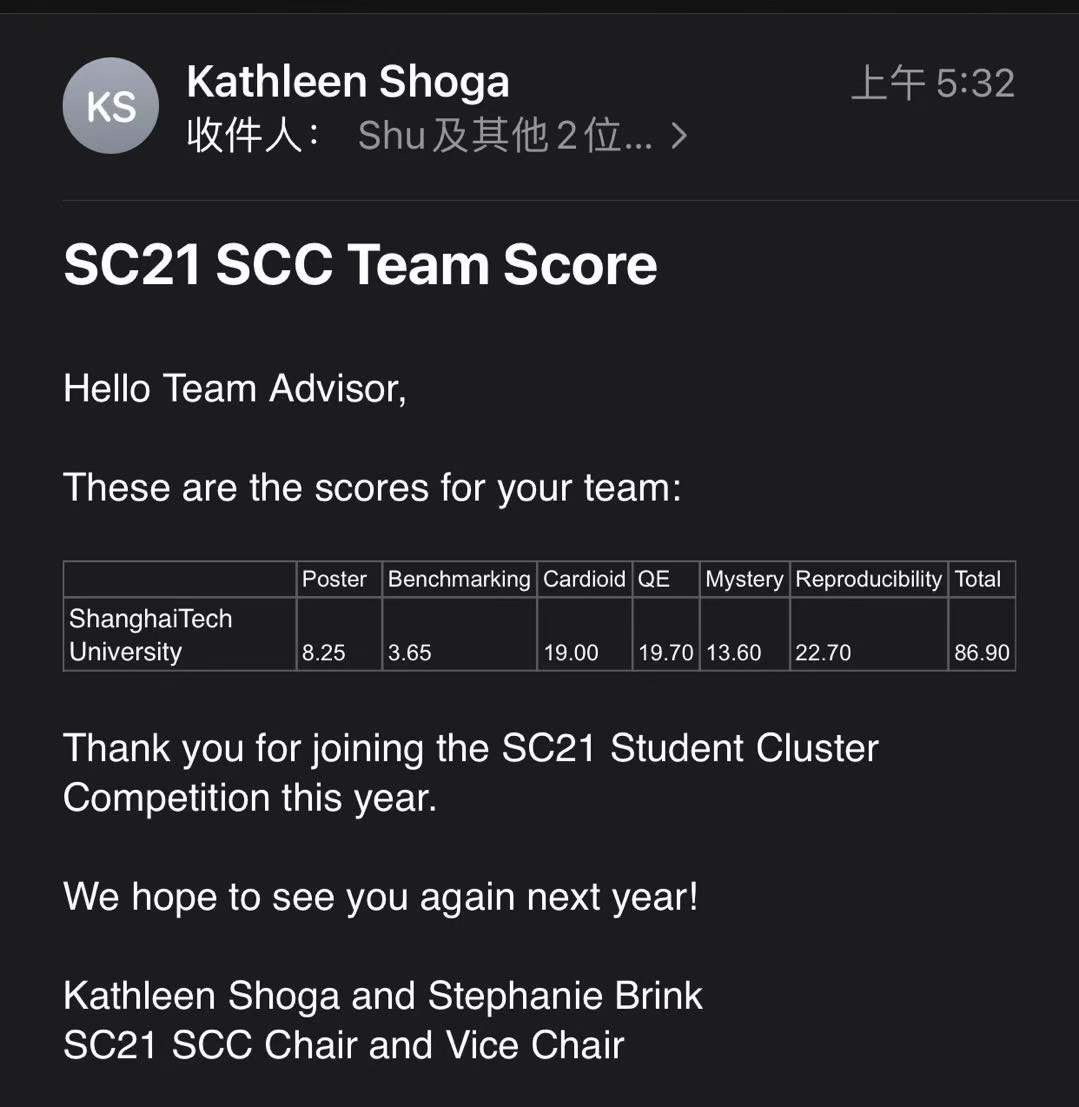
poster比清华低1.*分,benchmark低4分,QE高2分,mystery低2分,最后低了5分左右。而benchmark和mystery都是卡的竞争导致的差距,也可以说是我们学生临场发挥的能力略逊于清华。
千万不要以为proposal就是全部,毕竟当时还不知道多少预算,我们就大概糊了一个什么时候跑啥的tactic。我们预想着是第二天凌晨的时候开始benchmark,这对我的指挥失误有些影响,那时候根本抢不到A100. 同时我们在比赛开始前就注意到标*的是接近免费的机器,只是到比赛的时候才知道才0.0021USD每小时,主办方确认能用,我们一早就把所有这种以v5结尾的测试机器先拿了,quota到限制了,别人就完全拿不到了。
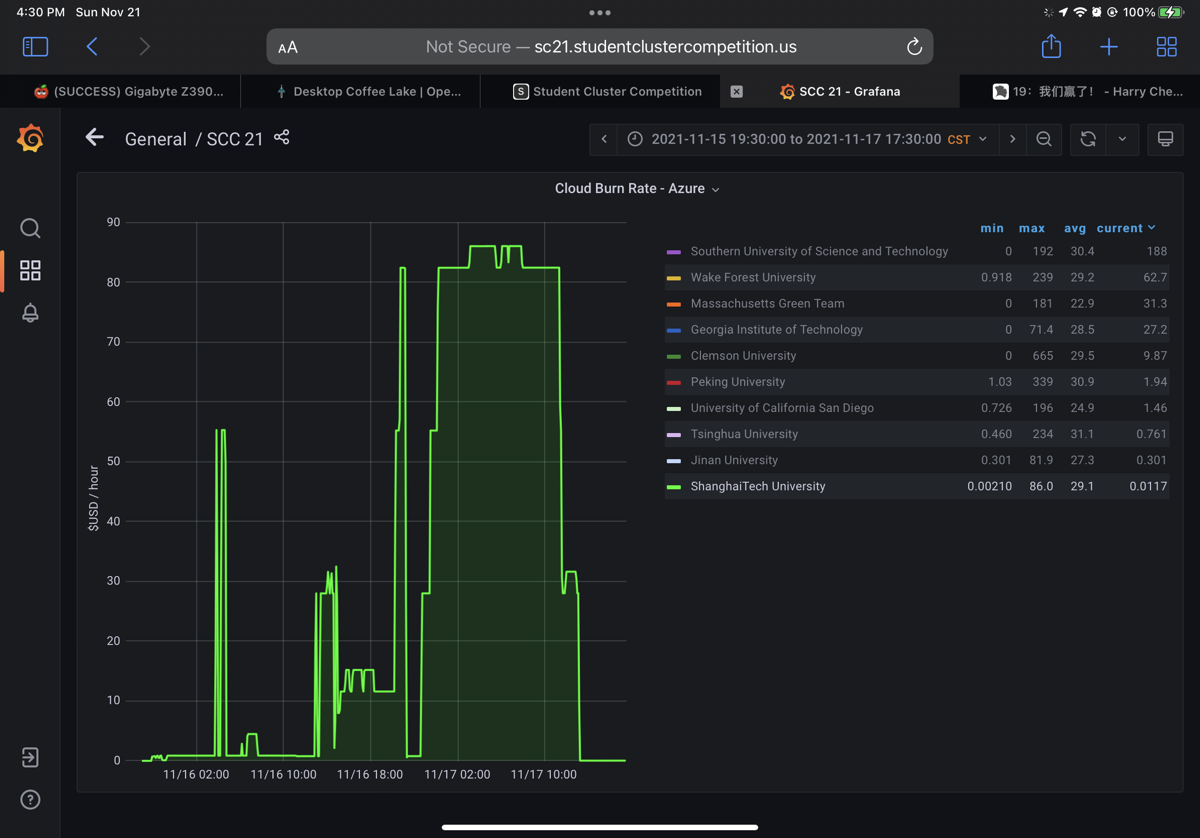
我们claim说我们能完成spack integration,比赛前也确实完成了,我们给所有azure机器加了一个启动脚本用于给我们自己的slack发脚本,这最终导致我们免费slack消息超出10K条(以后得找学校赞助了。)
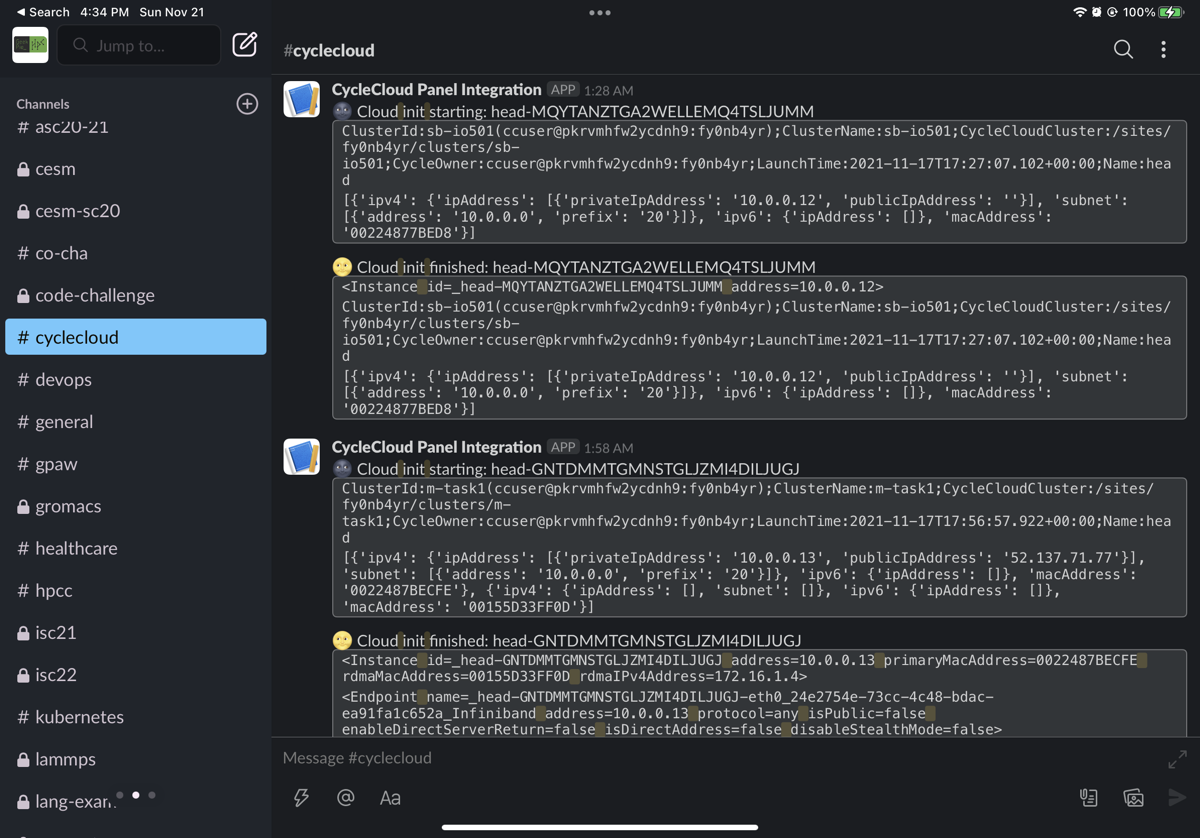
cycle cloud 之所以别人玩不来是因为有很多坑,而我们有王凯留(运维最省钱了)。他精通powershell,ruby。普通的image只能得到chef error等问题,大概只有北大和暨南使用的centos7可以过,但进去还是会有坑。在确定使用microsoft-dsvm:ubuntu-hpc:2004:latest这个能自动装好所有我们想要的东西(spack,go,rust)的基础上,他用cloud-init干了自动配置他自己编译的slurm,把他的--noswtich=0以及--shutdown=none还有cyclecloud.so编译进去。后来通过反编译他的那个.so只干了指定参数的作用。主要的流程,比如更新slurm机器状态都是jetpack做的。BeeGFS他后来编译了一个5.x内核可用的template,最后也上production了。最最重要的是,他在处理chef问题的过程中找到了cyclecloud如何确定整个区域谁拿走了什么机器的API,他之后用此写了很多脚本。还有更令人搞笑的事情,为什么azure cyclecloud 会用chef?因为巨硬收购了一家cyclecomputing的公司先一步踏入云超算市场,可是infra都还是之前那个公司的legacy开发。总之oracle现在上来了,巨硬现在要重新用ansible写一遍了吧,如果微软日本员工看到了,一定要招王凯留帮你们写infra筽,一个启动时两个apt相互抢锁PR如下,一个chef安装时只用rpm的so覆盖deb的脏做法PR如下!
总之同学们都写好脚本了,都开源了,大概就花了几天时间搞定的事情,比赛时就不用操心了,不过那几个队员做完题目也没能力再帮别人了,这也是人员上没清华有弹性的原因.不过我们这题做的好,和THU差不多吧。
这次我主要负责QE,QE总之我们是研究的非常透彻的,在自己机器上tune了多卡(发现了很多坑。这当然都是早就解决了的,测例我们一开始就选择的是AUSURF,后面也是原题,只是精度有点差别,需要更多的显存。我们尝试改了一版Vkfft,后来没cufft快就放弃了,还试图搞了异构,花了挺多时间的,不过这也给他们当并行计算final project了,至少没白花时间。Cardioid我和jyc好好优化了一下,其实就改了一个set和一个MPI_Reduce,就说最后运行的机器只有单机八卡,他之前的做法是要到500nodes才有效果。所以我们就为单node优化了。
在ISC结束的时候我拉了一位和我一起写和清华MadFS差不多思路的文件系统,但使用不同实现,不用UCX而用ibverbs,不用rocksdb写放大而用concurrent ART Tree。可是那个同学锅更多,就give up了(所以问题是我校人数太少,PUA太多)。
开始的时候我们莫名其妙开始跑了,原来是和BU他们名字搞反了,巨硬养老院的Andy是真靠不住。换回来后我们还莫名其妙多了30USD。貌似也退不了。比赛到1个小时的时候莫名我们nfs的home被删了,我们理解为是惊喜。我们重装了了一遍集群才搞定,幸好都是自动化的。Azure上面每台机器只有20G的本地磁盘,/tmp经常写爆,所以只能export TMP=/mnt/shared/tmp。只是注意什么启动阶段什么东西好了。
Q-E很快就用上了"免费机器",我们申请了650core的免费机器跑AUSURF,时间和cost都是全场第一。第二个测例和第三个测例我查了一下网站,算了一下,发现分别nk=4和ntg=2/npool=4最好,加上特调的binder.sh,以及1台8卡A100还有和Ye Luo的唠嗑,我们拿了接近满分。这是第一次拿到两台A100(ND96)的时间。
在第二次高峰的时候我们准备放benchmark,murez咕了去搞mystery app了,有很多坑,现在nfs上面配好。我就负责了HPL和HPCG。第一次拿到的时候发现就拿不到3台以上了,于是通过计算得到全场只有8台8卡A100,我们果断切了另一个集群用脚本抢。可是还是只有三台。总之,不如用于憋死别人吧。至少北大比我们晚一点就没了,导致他们和清华只能用V100.我在这里跑了1次HPCG和10次HPL后就被mystery app的自动调参机接管了,不过mystery app刚开始的时候就有问题,是mpi没配对,准确的说是mpi用了错误的libmpi.so.12,经验不足训练不足吧。这让murez很紧张,这大概浪费了1小时吧,后来我帮他编译成功了。他就任性的用满显存搞事情。全精度,半精度,混合精度的他把batch size调到正好24卡A100从而获得最好性能,不过遗憾是我们没用本地的机器,所以参数都是真的看到结果反哺去调的,清华可以在自己的机器上拿到不错的参数再继续,可是我们社连A100都没有啊,总之就只能这样了(他们用同样的A100机器也能做的比我们好一些,因为参数). IO test是放在tmpfs上跑的,跑了1400,(这里清华可以over madfs。)我们这个阶段也没钱拿HB120rs用于BeeGFS了,所以IO test是不行了。
IO500 最后也没写完,所以最后我们拿了Optane SSD的单盘测试的,拿了个27.2
发现清华的学生不是状元就是金牌,这些令人仰望的人,我们学校培养的学生,是职业的,有学术训练的工程师和研究者,只能说有阶段性胜利,让我校进出口未来会好一点吧(多来点OI银牌。
总之还有有一点进步空间,只是对我来说没有下一次了,如果这次是最后一次,也许我请的那个人会和我一起写完。不过,真的能提升的也只有日常训练,对代码对系统对AI System的理解。
root@epyc:~# uname -a
Linux epyc.node2 4.19.0-18-amd64 #1 SMP Debian 4.19.208-1 (2021-09-29) x86_64 GNU/Linux
root@epyc:~# ldd --version
ldd (Debian GLIBC 2.28-10) 2.28
Copyright (C) 2018 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
In cases of quantum espresso
mpirun -hostfile ../AUSURF112/host --mca pml ucx --mca btl sm,rc,ud,self --mca btl_tcp_if_include 192.168.10.0/24 --bind-to core -x PATH -x LD_LIBRARY_PATH -x OMP_NUM_THREADS=1 -np 256 /home/qe/sb/bin/pw.x -nk 4 -nd 64 -i ./grir443.in > 11_7_out256 2> 11_7_out256err
It would dead for a while
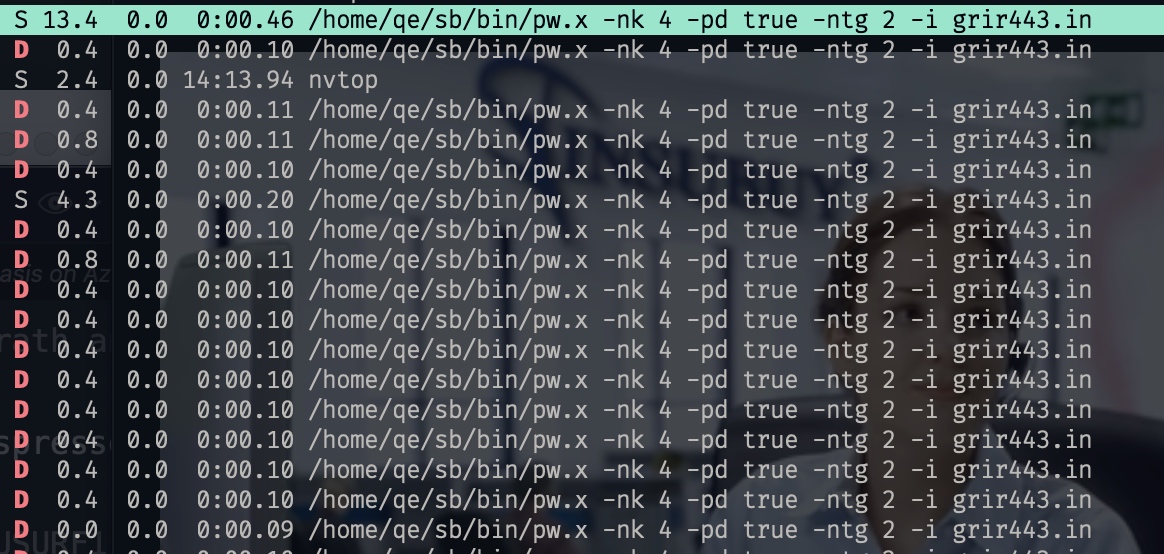
The bug is reported by pthread_rwlock.

diff --git 2.28/nptl/pthread_rwlock_common.c 2.29/nptl/pthread_rwlock_common.c
index a290d08332..81b162bbee 100644
--- 2.28/nptl/pthread_rwlock_common.c
+++ 2.29/nptl/pthread_rwlock_common.c
@@ -310,6 +310,7 @@ __pthread_rwlock_rdlock_full (pthread_rwlock_t *rwlock,
if (atomic_compare_exchange_weak_relaxed
(&rwlock->__data.__readers, &r, r | PTHREAD_RWLOCK_RWAITING))
{
+ r |= PTHREAD_RWLOCK_RWAITING;
/* Wait for as long as the flag is set. An ABA situation is
harmless because the flag is just about the state of
__readers, and all threads set the flag under the same