

文章目录[隐藏]
感觉这次的code challenge 必然会很卷,因为有GaTech/ETHz这种HPC强校,感觉就是NV想从我们学生这榨干点优化,正如罡兴投资激发的大家对网卡simd优化产生了兴趣。这篇就稍微记录下可优化的点。
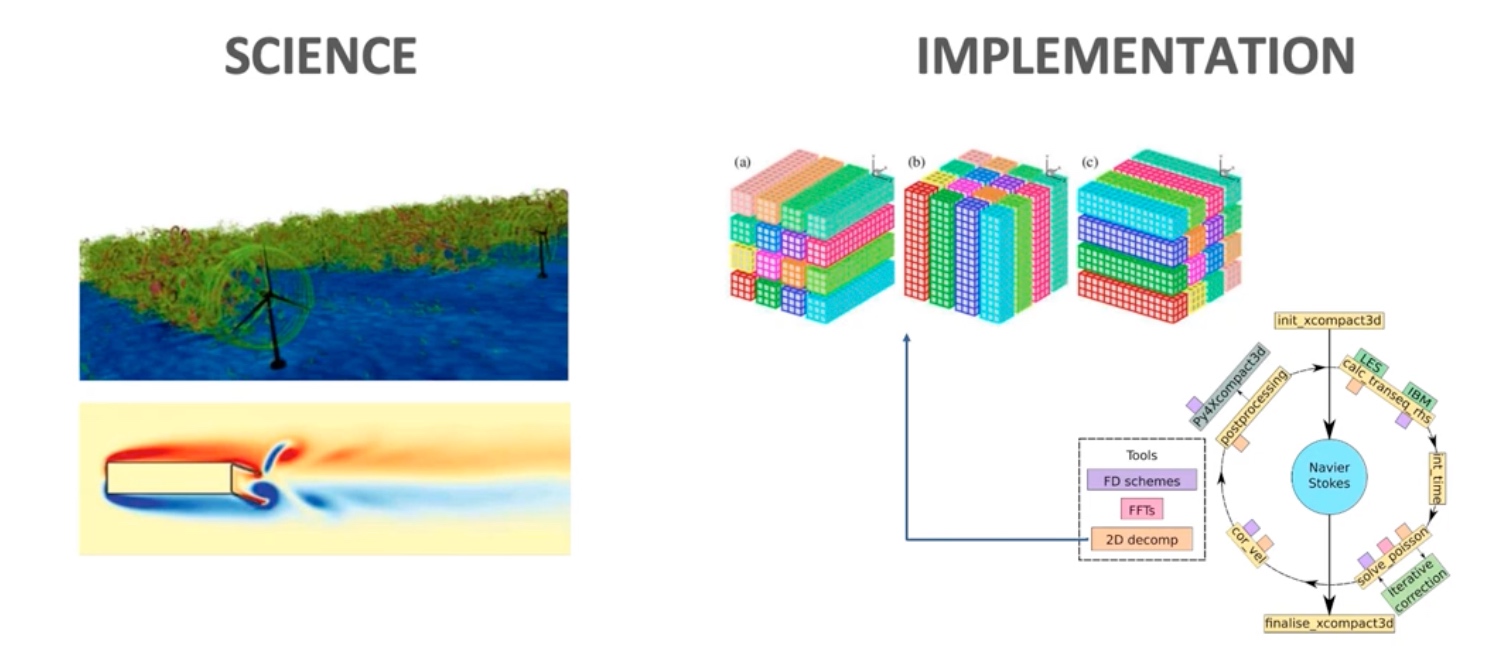
Compact 3D是做流体力学仿真的。要做的是mpi alltoall 到 DPU 上的移植+调优。
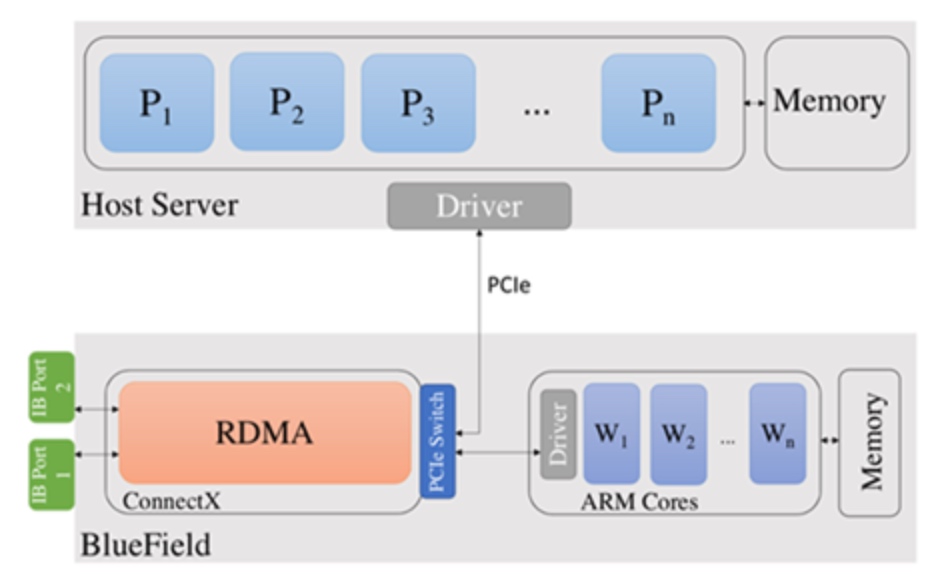
- ConnectX-6 network adapter with 200Gbps InfiniBand
- System-on-chip containing eight 64-bit ARMv8 A72 cores with 2.75 GHz each
- 16 GB of memory for the ARM cores
bluefield+DPU MPI 做的一件事就是自动的把nonblocking collective数据offload到Arm core的memory上,处理完再发包。(但如果对包精巧设计的话,应该是没FPGA可以做的更快)或者能自动生成FPGA code。 当然arm core上的所有代码都是可开发的,需要配合sdk使用。
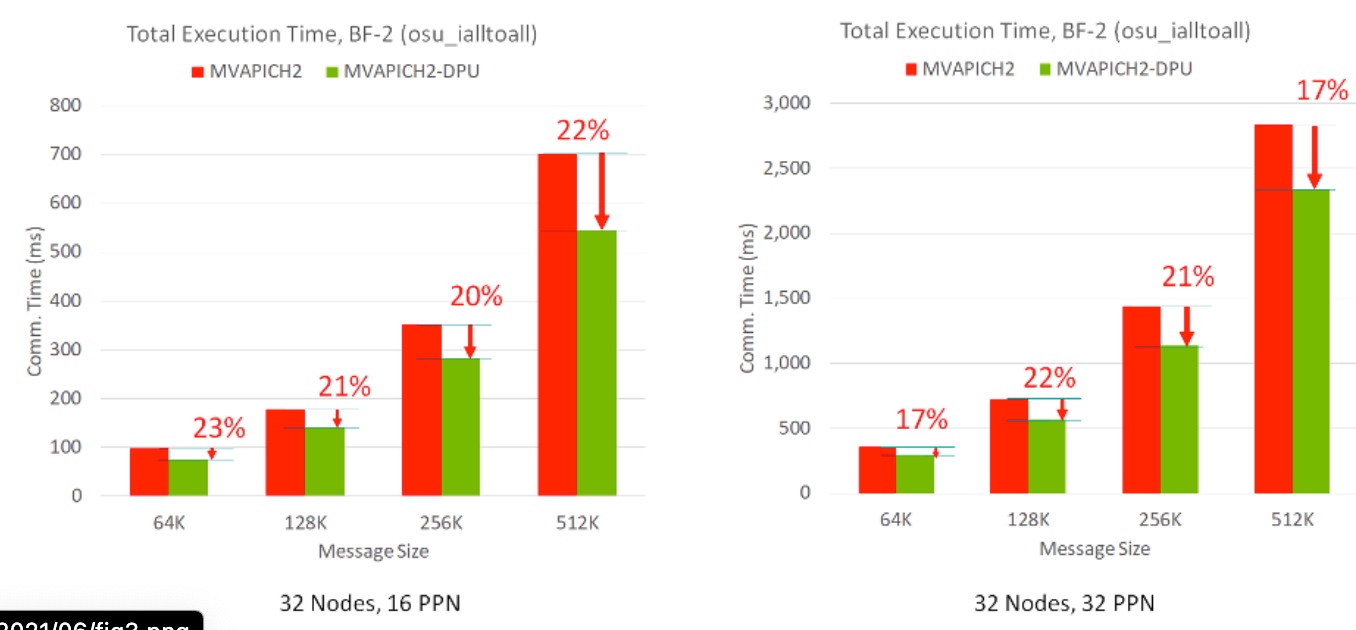
在默认库在没有offloading的机器上MPI nonblocking collective 重叠很少,这样Host CPU可以做更多的计算从而不需要等all to all的结果。
Requirements for Next-Generation MPI Libraries
- Message Passing Interface (MPI) libraries are used for HPC and AI applications
- Requirements for a high-performance and scalable MPI library:
- Low latency communication
- High bandwidth communication
- Minimum contention for host CPU resources tr progress non-blocking collectives
- High overlap of computation with communication
- CPU based non-blocking communication progress can lead to sub-par performance as the main application has less CPU resources for useful application-level computation
Network offload mechanisms are gaining attraction as they have the potential to completely offload the communication of MPI primitives into the network
Current release
- Supports offloads of the following non-bıocking collectives
- Alltoall (MPI_lalltoall)
- Allgather (MPI_lallgather)
- Broadcast (MPI_Ibcast)
Task 1 Modifying the given apps to leverage NV GPU
需要使用DPU offload mode 跑通 https://github.com/xcompact3d/incompact3d,改改parameters。
Task 2 Performance assessment of original versus modified graph
就是跑一个8node strong scaling 的图,PPN 4-32.
Task 3 Summarize all the findings and results
讲分工和improvement的,比如对FFT的优化。(PDE都需要)
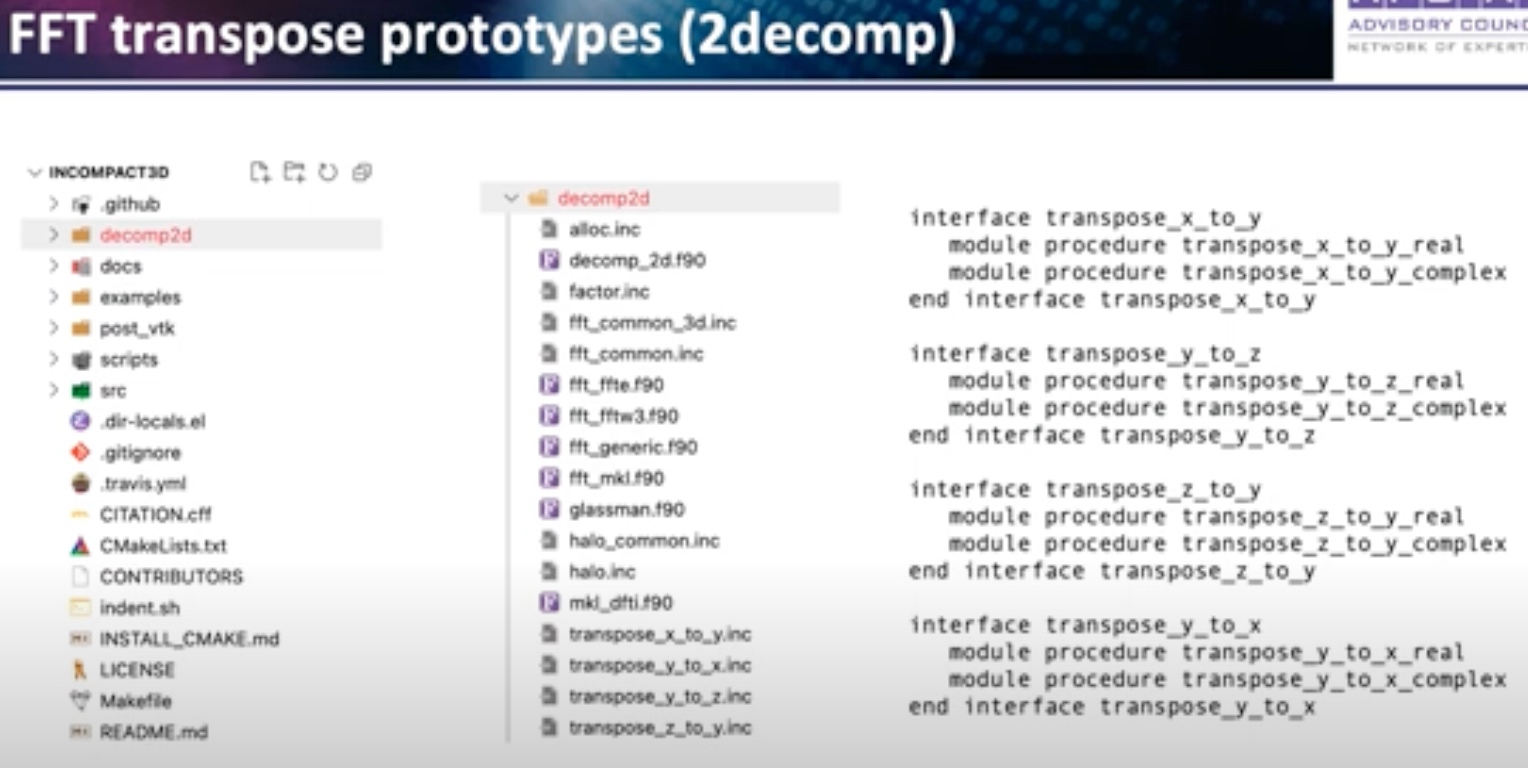
subroutine transpose_x_to_y_real(src, dst, opt_decomp)
implicit none
real (mytype), dimension $(:,:,:)$, intent(IN) : : src
real (mytype), dimension $(:,:,$, , intent(OUT) : : dst
TYPE (DECOMP_INFO), intent(IN), optional :: opt_decomp
TYPE(DECOMP_INFO) : : decomp
! rearrange source array as send buffer
call mem_split_xy_real(src, s1, s2, s3, work1_r, dims(1), &
decomp% 1dist, decomp)
! transpose using MPI_ALLTOALL (V)
call MPI_ALLTOALLV (work 1_r, decomp% 1 cnts, decomp% 1 disp, &
real_type, work2_r, decomp\%y 1cnts, decomp%y 1disp, &
real_type, DECOMP_2D_COMM_COL, ierror)
call mem_merge_xy_real(work2_r, d1, d2, d3, dst, dims(1), &
decomp%y 1 dist, decomp)
return
end subroutine transpose_x_to_y_real
change to non-blocking transpose prototype. 就是先post 一个MPI communication,主进程还是继续,子进程还是blocking
interface transpose_x_to_y_start
module procedure transpose_x_to_y_real_start
module procedure transpose_x_to_y_complex_start
end interface transpose_x_to_y_start
interface transpose_x_to_y_wait
module procedure transpose_x_to_y_real_wait
module procedure transpose_x_to_y_complex_wait
end interface transpose_x_to_y_wait
除此之外,他们还做了shared memory的优化。
#ifdef SHM
if (decomp%COL_INFO%CORE_ME==1) THEN
call MPI_ALLTOALLV(work1, decomp%x1cnts_s, decomp%x1disp_s, &
complex_type, work2, decomp%y1cnts_s, decomp%y1disp_s, &
complex_type, decomp%COL_INFO%SMP_COMM, ierror)
end if
#endif
Sync point 会在wait的时候,start到wait之间是overlap compute and communication的时间。

启动的时候需要加参数-dpufile。