

文章目录[隐藏]
The paper is joined work between my upperclassman Jian Zhang who's currently taking Ph.D. at Rutgers.
Current Hw-Sw co-design
- Hardware Trend
- Design a fast path to reduce latency.
- Software Trend
- Do kernel bypass/zero-copy
Good
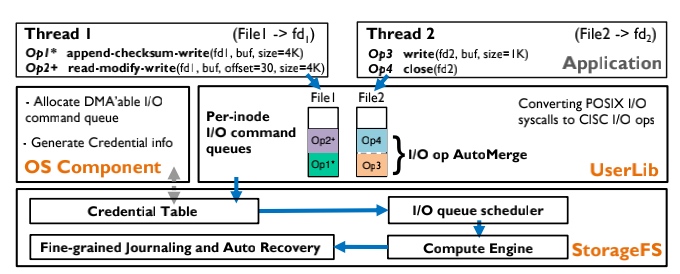
FusionFS comes up with aggregated I/O ops into $CISC_{Ops}$, the fuses and offloads data ops are carried out on the co-processor on storage. These higher throughputs are gained with assurance to the resource management fairness, crash consistency, and fast recovery.
-
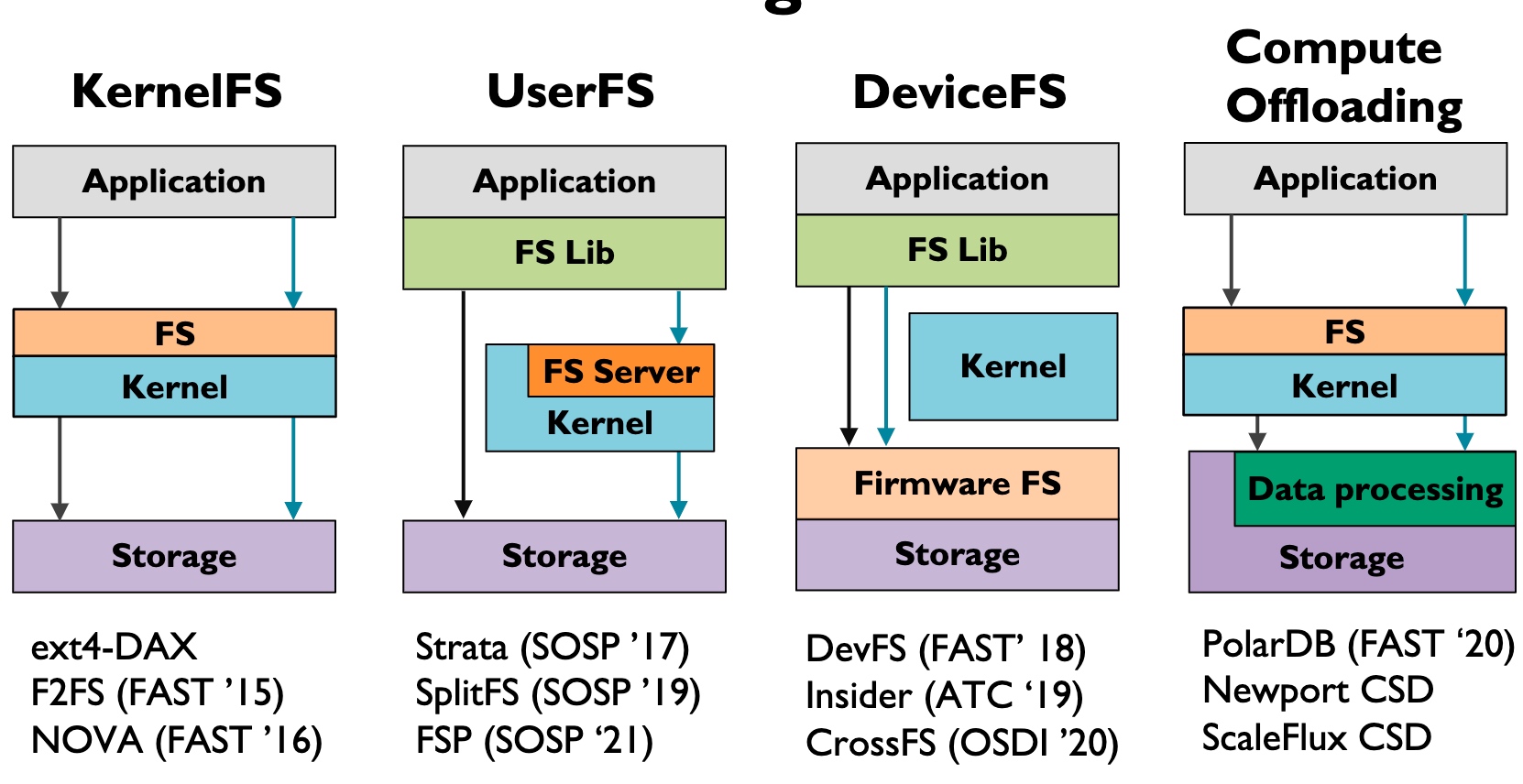
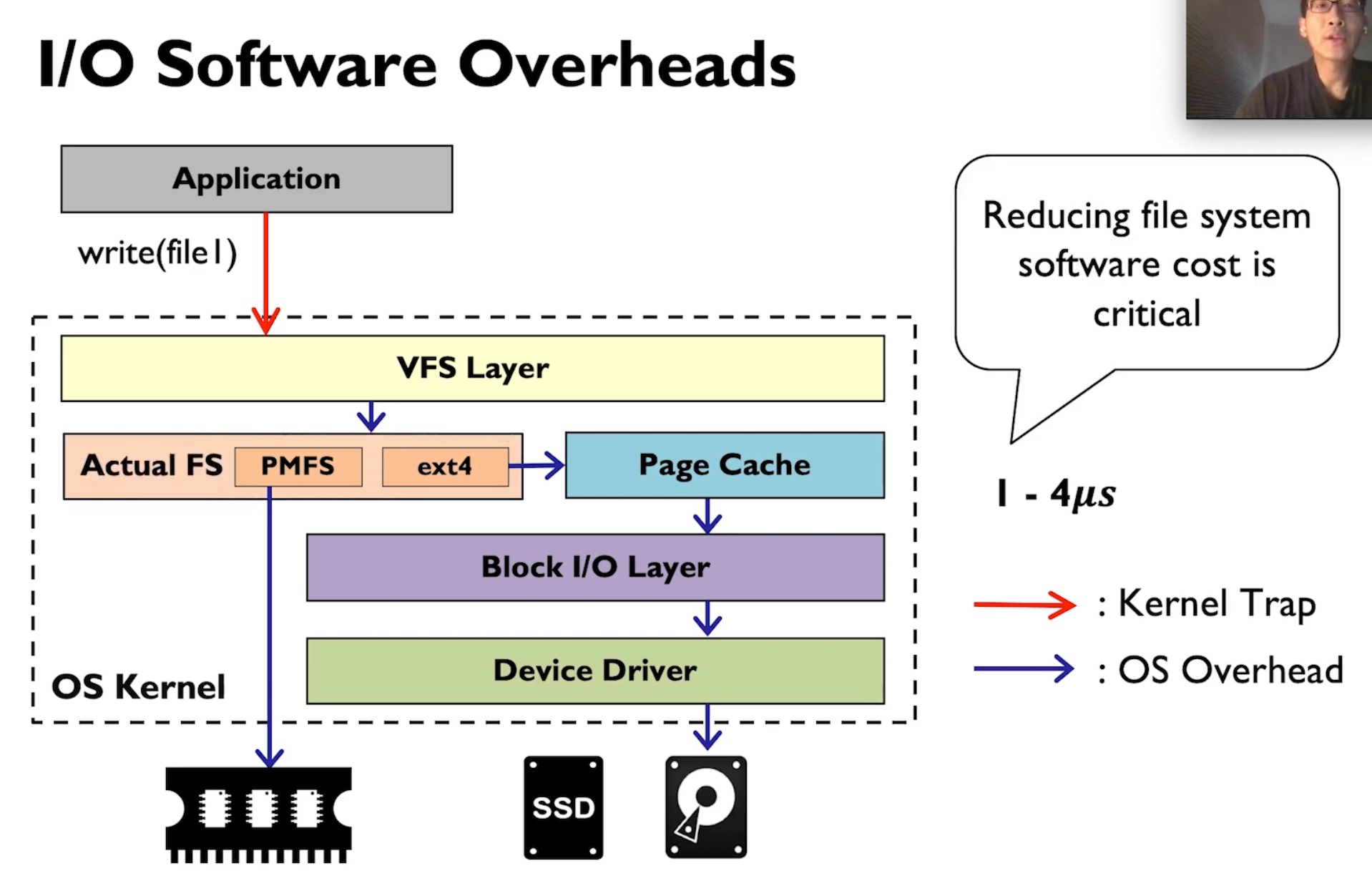
Kernel FS pushes all the W/R to the VFS Layer, this does not necessarily mean it's slow, often the time waiting for heavy-weighted Writeback, page cache is not hit, I/O queue locks waiting for the device ready, or deep VFS calls.
-
User FS may have some of the W/R intercepted and bypass the kernel. Some of the userspace semantic fusion is implemented using FUSE.
-
Device FS(Before CrossFS is Firmware FS) makes FS Lib directly call the firmware to wait until it can make DMA to memory.
- Good for Disaggregation & Concurrency throughput
- Mainly for NVM when speed is high, not applicable to SSDs
-
This paper used Compute Offloading, which is greatly applied in the SMartNIC. Storage plus the data processing makes transparent to the kernel, the kernel only needs to know some of the results is fused.
- write fusion
- read fusion
- data replacement for locality
- PolarDB - PCIe layer compute offloading. I think it could be replaced by CXL.
-
crc-append interpreted into CISCops
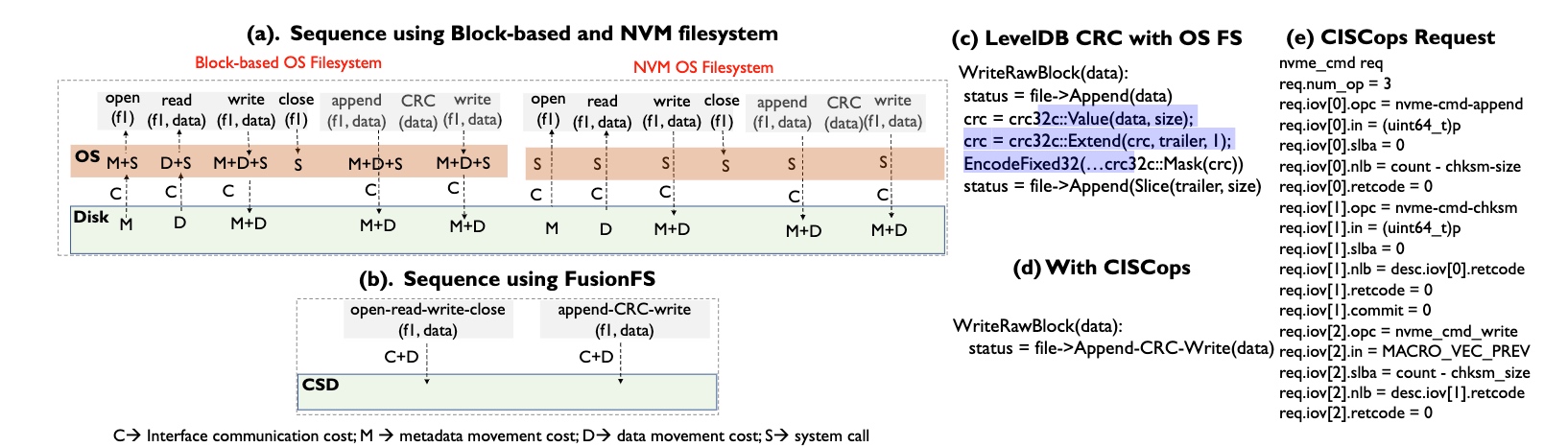 Basically, based on the predefined rules, the co-processor is able to fuse most of the data operations like LevelDB CRC, open read-write close.
Basically, based on the predefined rules, the co-processor is able to fuse most of the data operations like LevelDB CRC, open read-write close. -
CFS I/O scheduling.
-
Durability maintained by Micro Tx.
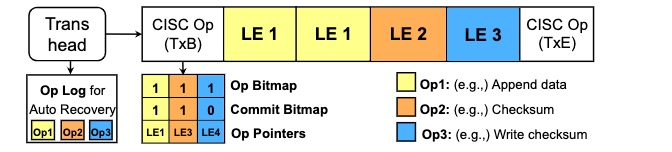
Bad
-
Large sequential data read/write will introduce preprocessor overhead, at least for data calculation and buffer store. Can pattern matching and make bypass the data processing.
-
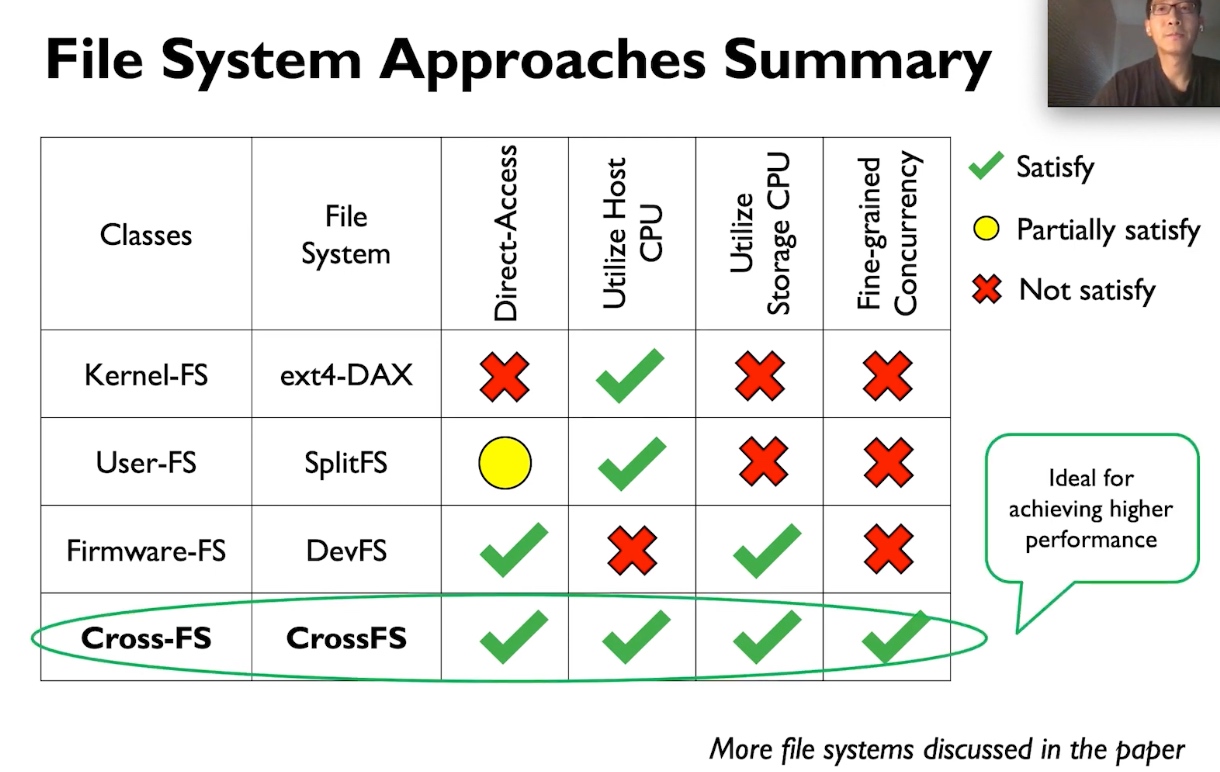
This paper shared a lot of similar designs with CrossFS for resource management, durability, and Permission checks.
-
 I'm curious why not implement the SSD main controller? It's meaningless to write on NVM because programmers must do handmade I/O fusion on such devices.
I'm curious why not implement the SSD main controller? It's meaningless to write on NVM because programmers must do handmade I/O fusion on such devices. -

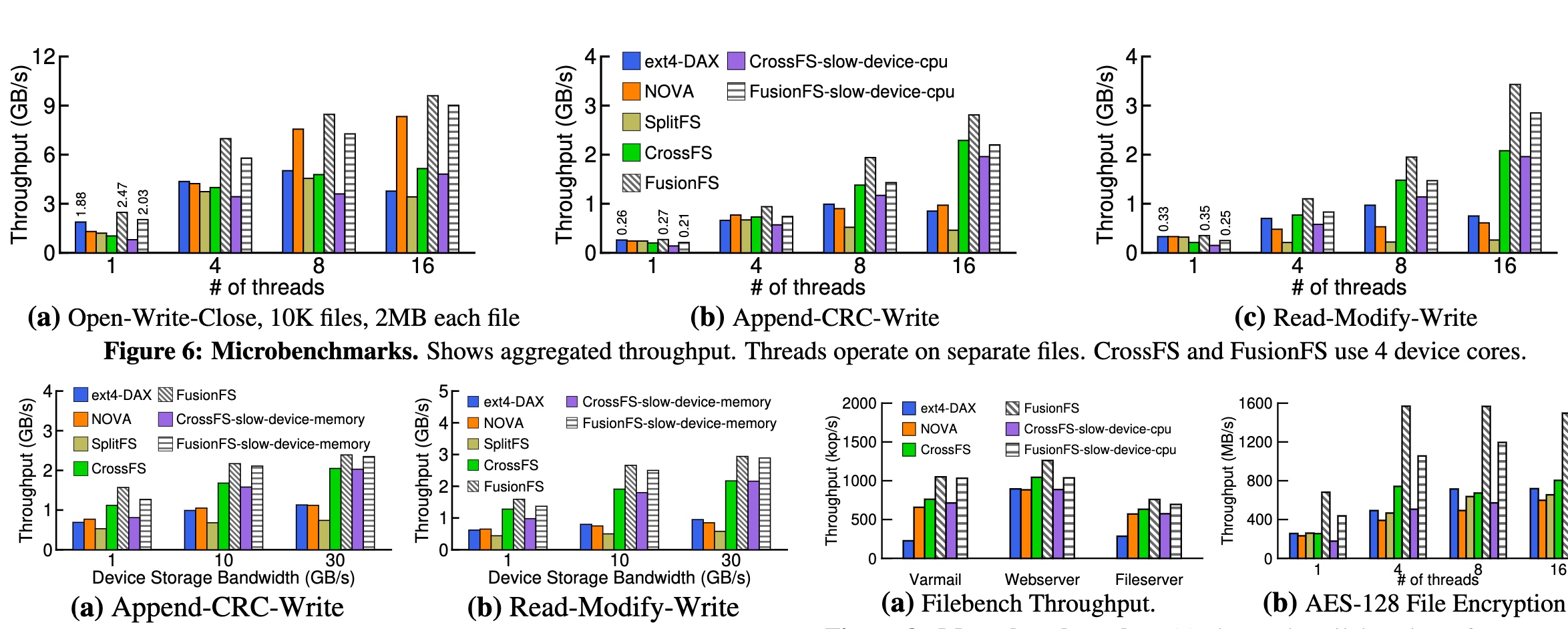 Performance is roughly the same with NOVA when with slow device CPU. I don't know if IO thread affinity and other kernel optimization are applied, the additional hardware has real benefits. However, the recovery speed is really quick because of MicroTx.
Performance is roughly the same with NOVA when with slow device CPU. I don't know if IO thread affinity and other kernel optimization are applied, the additional hardware has real benefits. However, the recovery speed is really quick because of MicroTx.
Refinement
- Still could apply kernel bypass over the FusionFS.
- SSD main controller/ Memory controller implementation is better than adding another CPU.
Reference
- POLARDB Meets Computational Storage: Efficiently Support AnalyticalWorkloads in Cloud-Native Relational Database
- CrossFS: A Cross-layered Direct-Access File System