

文章目录[隐藏]
A Distributed NVM modeled OS runtime for the arrangement of NVM data structure that
- Does not require explicit (un)loading
- Less serialization (Context available persistent ptr to reduce memcpy).
- Has basic support for security/ share/ crash atomicity
For a DBOS design, it has a prototype of communicating between OSes using
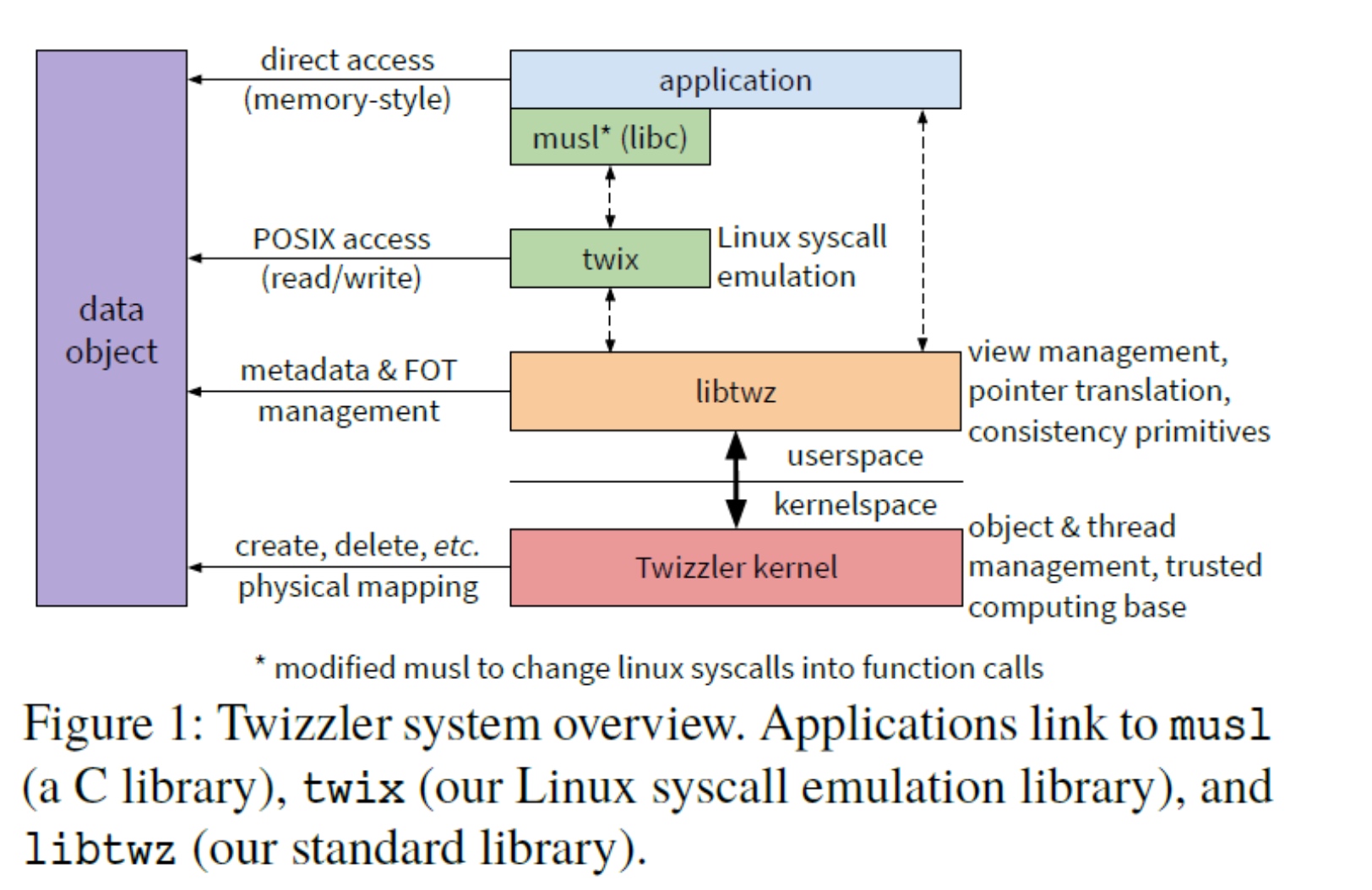
Implementation
Object Management
Twizzler organizes data into objects, which may be persistent. Each object is identified by a unique 128-bit object ID. Objects provide contiguous areas of memory that organize semantically related data with similar lifecycles. Applications access objects through a mapping service by mapping each object to a contiguous range in the address space.
Objects are created by the create system call, which returns an object ID, and the application can optionally provide an existing object ID to the create call, indicating that the new object should be a copy of the existing object. copy-on-write is used by Twizzler for this purpose.
Deleting objects via the delete system call. Like Unix's unlink, objects are reference counted, where reference refers to a mapping in the address space. Once the reference count reaches zero, the object can be deleted.
Address Space Management
To support user space operation on the address space, the kernel and user space share an object that defines the address view. A view is a normal object that can apply the standard access control mechanism.
When applications map objects to their address space, they update the view to specify that a particular object should be addressable at a particular location. The kernel then reads the objects and determines the layout of the requested virtual address space. The view objects are laid out like a page table, where each entry in the table corresponds to a slot in the virtual address space. Each table entry contains the object ID and reads, writes, and (e.g., performs protection bits to further protect access to the object).
When a page error occurs, the error handler attempts to handle the error by performing a copy-on-write, checking permissions, or attempting to map the object to a slot. If it cannot handle the fault (due to a protection error or an empty entry in the view object), it raises the fault to the user space where libtwz handles it, possibly by terminating the thread, or possibly by mapping the object. When the kernel maps an object into a slot, it updates the page table of the address space accordingly.
When threads add entries to a view object, they do not need to notify the kernel, which reads the entries as needed when a fault occurs. However, when an entry is changed or deleted, the thread must notify the kernel so that it can update the existing page table entry.
Persistent Pointers
Twizzler provides a persistent pointer across objects, the pointer is not pointing to virtual address but the object-id, offset tuple can use encoding to point to the offset.
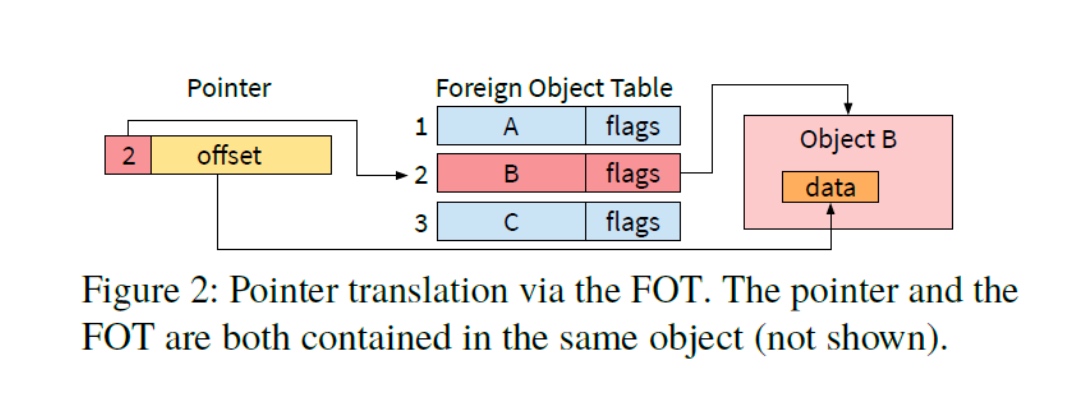
FOT is used to encode this tuple more efficiently, an index is used through each object's FOT, which is located at a known offset within each object.
- This allows pointers to refer to persistent data, but it also allows objects to have external pointers that refer to data in any object in the global object space.
- The FOT is an array of entries, each of which stores an object ID. cross-object pointers are stored as 64-bit FOT_idx:offset values, where FOT_idx is the index of the FOT. This provides a large offset and a large number of object IDs, since the IDs are not stored in the pointers themselves.
- When dereferenced, Twizzler uses the FOT_idx part of the pointer as an index to the FOT to retrieve the object ID. the combination of the FOT and the cross-object pointer logically forms an object-id:offset pair.
- To extend the namespace into multiple machines, Twizzler extends the namespace of data objects beyond a single machine, and machine-independent data references are a natural consequence of cross-object pointers.
Existing solutions are limited in this extensibility. They either limit the ID space (necessary to store IDs in pointers), requiring complex coordination or serialization when sharing, or require additional states (e.g., per-process or per-machine ID tables) that must be shared with the data, forcing the receiving machine to "repair" the reference. Worse, the repair is application-specific, since the object ID is located within any pointer, rather than in a location normally known.
The per-object FOT results in easier sharing of self-contained objects, and thus better interaction with remote shared memory systems.
Pointer conversion occurs with the help of two libtwz functions: ptr_lea (load valid address) and ptr_store.
-
When a program dereferences a pointer, it first calls ptr_lea. by looking in the FOT, the pointer is resolved to an object_id:offset pair, after which libtwz determines whether the referenced object has been mapped by maintaining metadata for each view. If not, it selects an empty slot in the view and maps the object there, cuz an inexpensive operation that does not call the kernel. After mapping, libtwz combines the object's temporary virtual base address with an offset and returns the new pointer. The ptr_store function described does this relative to ptr_lea , which converts virtual pointers to persistent pointers.
-
FOT management is handled by libtwz. Although a lookup in the FOT is a simple array indexing operation, storage may need to be added to the FOT. to avoid duplicate entries, libtwz will traverse the FOT looking for compatible entries. If none is found, it automatically keeps a new entry and fills it before storing the pointer (refreshing the cache line to keep it).
-
Twizzler improves performance by caching each object previously translated.
Security
Twizzler's focus on memory-based objects requires us to design a security model around hardware-based execution, where the MMU checks every access. This design is unavoidable in a data-centric operating system because the kernel is not involved in every memory access. The kernel only specifies access rights when mapping objects, and then relies on hardware to enforce those rights with low overhead.
One of the key design choices Twizzler makes is to bind security later.
Applications request access to objects with the required permissions. If they access the object only in the allowed way (e.g., read-only objects), no error occurs. This is because when mapping an object (via a view), the kernel is not immediately involved and therefore cannot check the access rights for a particular access at the time of mapping. For example, if a program reads object A, and the program is allowed to read A, it should be allowed to perform the read even if it requests read/write access to the object. This late binding supports simpler programs that do not need to worry about elevating access rights by remapping data objects. Programs can progress without prior knowledge of the permissions of the objects they may access, allowing the OS's access control mechanisms to be reused in applications.
The security context abstraction in Unix-like OSes requires maintaining access to a fundamentally different set of things (such as paths, virtual memory locations, and system calls). In contrast, Twizzler's security contexts specify access to objects by ID rather than by virtual address. This also makes security contexts persistent, allowing them to be used as the primary way for threads to assign security roles.
Crash Consistency
- Twizzler provides a primitive language for building crash-consistent data structures. At a low level, it provides a write mechanism to return cacheline. Applications use these primitives outside of Twizzler to build larger, more complex support for crash-consistent data structures.
- Twizzler also provides a transaction persistence logging mechanism. Programmers can write TXSTART
- TXEND blocks to represent transactions and TXRECORD statements to log pre-changed values. This is similar to the mechanism provided by PMDK. If applications need more complex transactions that use different logging mechanisms, they can use libraries.
Evaluation
Twizzler aims to make all current memory-intensive applications easy to migrate with minimum overhead.
Writing New Software
Three new pieces of software were built for evaluation: a hash table-based key-value store (KVS), a red-black tree data structure, and a logging daemon. Each has different features and goals, and together they demonstrate Twizzler's flexibility in allowing simple implementations, virtually free access control, and the ability to directly express complex relationships between objects. Using our KVS and red-black tree code, porting SQLite to Twizzler along with the YCSB driver allowed us to explore Twizzler's model on a larger scale, and the existing program allowed us to study Twizzler's performance in a complex system that can store and process data.
Key-Value Storage
We implemented a multi-threaded hash table-based key-value store (KVS), called twzkv, to study late binding across object pointers and our access control. twzkv supports keystroke (arbitrary size) insertion, lookup, and deletion of values, and distributes direct pointers to persistent data during lookup. During insertion, it copies the data to the data area before indexing the inserted keys and values.
Implementing access control in twzkv involves having the index reference data in multiple data objects, assigning different access rights to those objects, and distributing from those objects according to the desired access rights. Because of Twizzler's cross-object pointer transparency, we are able to do this while preserving the original code. At insertion time, the application instructs the data object to which the data is to be copied, as shown in the figure below.
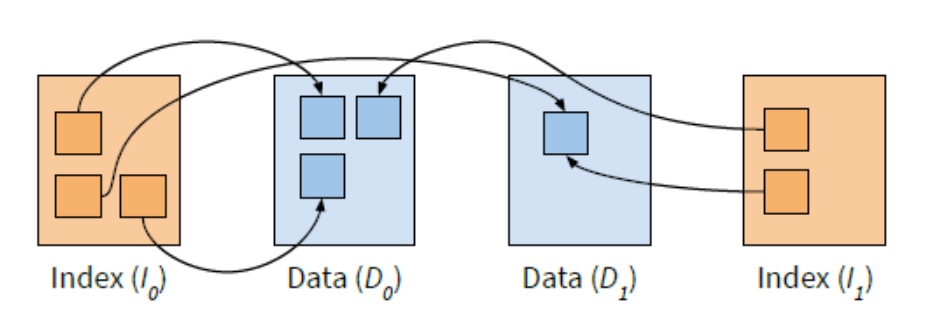
By supporting multiple data objects, twzkv can take advantage of the operating system's access control and avoid complexity. Since each object has different access controls, the user can set the object's access rights and then decide where to insert the data based on the policy. Regardless of the data object access restrictions, the index points to the correct location and twzkv still distribute direct pointers, but users with restricted access to data in D1 will not be able to dereference the pointer.
Comparison with Unix implementations. For comparison with existing technology, a similar KVS was built using only Unix functionality (called unixkv).
It also separates the index from the data, but it has to calculate and construct the pointer manually.
Supporting multiple data objects in unixkv is complicated because we have to store and process file paths in the index and store references to pointer paths, adding 36% overhead and code complexity. This is a lot for a relatively small number of implementations of pointers.
In unixkv just to reimplement Twizzler support, the additional complexity includes code to manually open, map, and grow files, much of which is handled internally by Twizzler in Twizzler.
Due to manual pointer handling, the development of unixkv with errors that did not exist when developing twzkv extended development time.
While twzkv gains transparent access control, unixkv does not because of the lack of on-demand object mapping and secure post-binding. Instead, unixkv requires object permissions to be known prior to mapping, a limitation that limits the ability to reuse OS access control, which twzkv can exploit through secure post-binding.
Red-black trees
unixrbt uses an application-specific solution to manage pointers; if other applications want to use the data structures created by unixrbt, they will have to know the implementation details of the pointer system (or share the implementation, thus reimplementing much of Twizzler's library). In addition, these conversions can be automated due to Twizzler's improved system-wide support for cross-object pointers.
Unlike twzrbt, unixrbt's tree is limited to a single persistent object; the restriction preventing arbitrary tree growth does not allow it to directly encode references to data outside the tree object, and does not gain the benefits of cross-object data references discussed above for twzkv. Adding support for this to unixrbt requires modifying the core data structure to include paths and significantly changing the code to increase its length by at least a factor of 2, which twzrbt gets for free.
Another advantage of twzrbt is the reduction in support code compared to unixrbt; unixrbt requires code to manage and grow files and mappings, while we implement twzrbt as simple data structure code, and Twizzler manages this complexity. The additional error handling code and pointer validity checks in unixrbt (handled automatically in Twizzler) added development time and implementation complexity.
Porting SQLite
SQLite was ported to Twizzler to demonstrate Twizzler's support for existing software and to evaluate the performance of the SQLite backend designed for Twizzler.
The implementation of the LMDB interface confirms what we learned from the KVS case study: most of the complexity of the storage interface and implementation comes from the separation between storage and memory. But the advent of NVM has been a big game changer, allowing programmers to think directly through the data structures in memory. The result is that interfaces like cursors in KVS become redundant. We implemented this interface for LMDB, but the functions were mainly wrapped around storing pointers to B-tree nodes and traversing the tree directly without separate loading and copying. The result is a very simple implementation (500 LoC) that still satisfies the required interface. Future NVM software can use Twizzler's programming model to write software more efficiently, thus avoiding the need for the complexity imposed by a two-level storage hierarchy.
Performance Comparison
To measure the performance of KVS and RedBlackTree, microbenchmarks were performed and the Twizzler port of SQLite was evaluated against SQLite, a Linux (Ubuntu 19.10) instance of SQLightning, and our SQLite to PMDK port. The tests were run on an Intel Xeon Gold 5218 CPU running at 2.30 GHz, 192 GB DRAM and 128 GB Intel Persistent DIMM. We compiled all tests against the musl C library instead of glibc, because Twizzler uses musl to support Unix programs.
Benchmark: This is used to measure the maximum real-world performance of the machine's hardware, as well as the performance gains from software optimizations.
The table above shows the latency of common Twizzler functions, including pointer conversions. The overhead shown for parsing pointers does not include dereferencing the final result, which is required regardless of how the pointer is parsed.
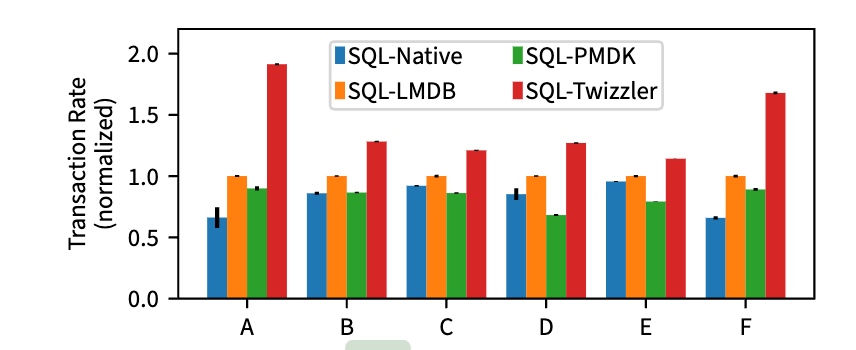
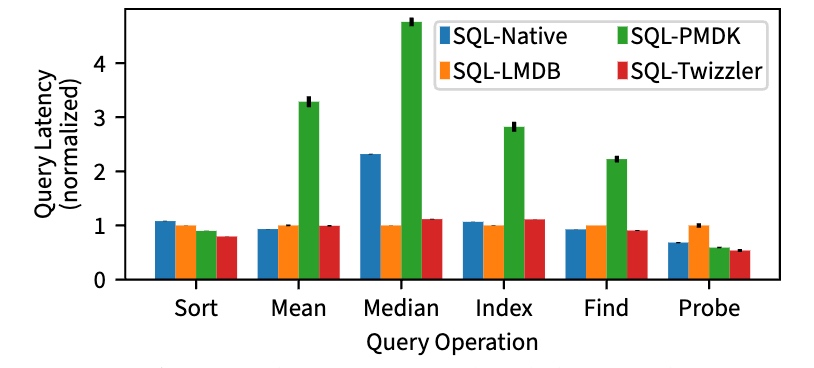
We ran four variants of SQLite, three on Linux and one on Twizzler, and compared their performance.
"SQL-Native" (unmodified SQLite)
"SQL-LMDB" (SQLite using LMDB as storage backend)
"SQL- PMDK" (SQLite uses our red-black tree on PMDK)
"SQL-Twizzler" (SQLite port that we run on Twizzler).
SQL-Native runs in mmap mode, so it and SQL-LMDB both use mmap to access data. We run each on the same hardware and normalize the results.
Throughput under standard YCSB workload.
Query latency on one million rows of tables, measuring performance of computing mean and median values, sorting rows, finding specific rows, building indexes, and probing indexes.
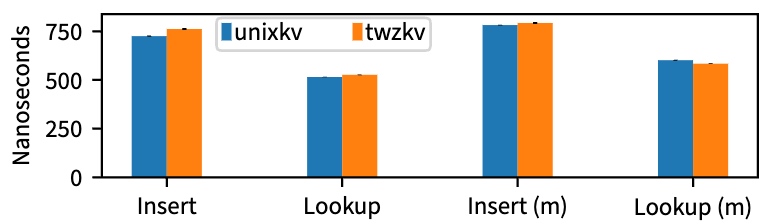
Twzkv was compared to unixkv by inserting one million different key-value pairs and then looking up each key-value pair sequentially.
The latency of inserting and looking up one million 32-bit integers was measured on unixrbt and twzrbt. twzrbt's insertion and lookup latencies were 528 ± 3 ns and 251.8 ± 0.5 ns while unixrbt's insertion and lookup latencies were 515 ± 2 ns and 213 ± 1 ns, respectively. the moderate overhead is accompanied by significantly higher flexibility because unixrbt does not support cross-object trees and supports less code (unixrbt implements mapping and pointer conversions manually).
Drawback
- The Centralized FOT is the bottleneck of the whole system. I'm wondering dOS can be resolved by managing resources like fd/memory/ptrs with the distributed protocol. Current Web3 solutions like Merkle tree-based IPFS are too slow to make this happen.
- The NVM idea currently can be offloaded to CXL.mem controller with persistent memory. I'm browsing the similar crash atomicity/HTM/Page table management design between CXL and persistent memory controller, the cancelation in Optane could give birth to more big memory thoughts.