


文章目录[隐藏]
- LLVM HPC workshop
- OpenMP 5.2
- Codesign
- ML at scale
- Parallel I/O in practice
- Advanced MPI Programming
- Exascle MPI
- Introduction to Networking Technologies for High-Performance Computing
- ROSS
- Accelerating Portable HPC Applications with Standard C++
- Best Practices for HPC in Cloud
- RSDHA
- Scientific Research Poster
- Galary
- ETHz talk about the future of computation
- Hardware-Efficient Machine Learning
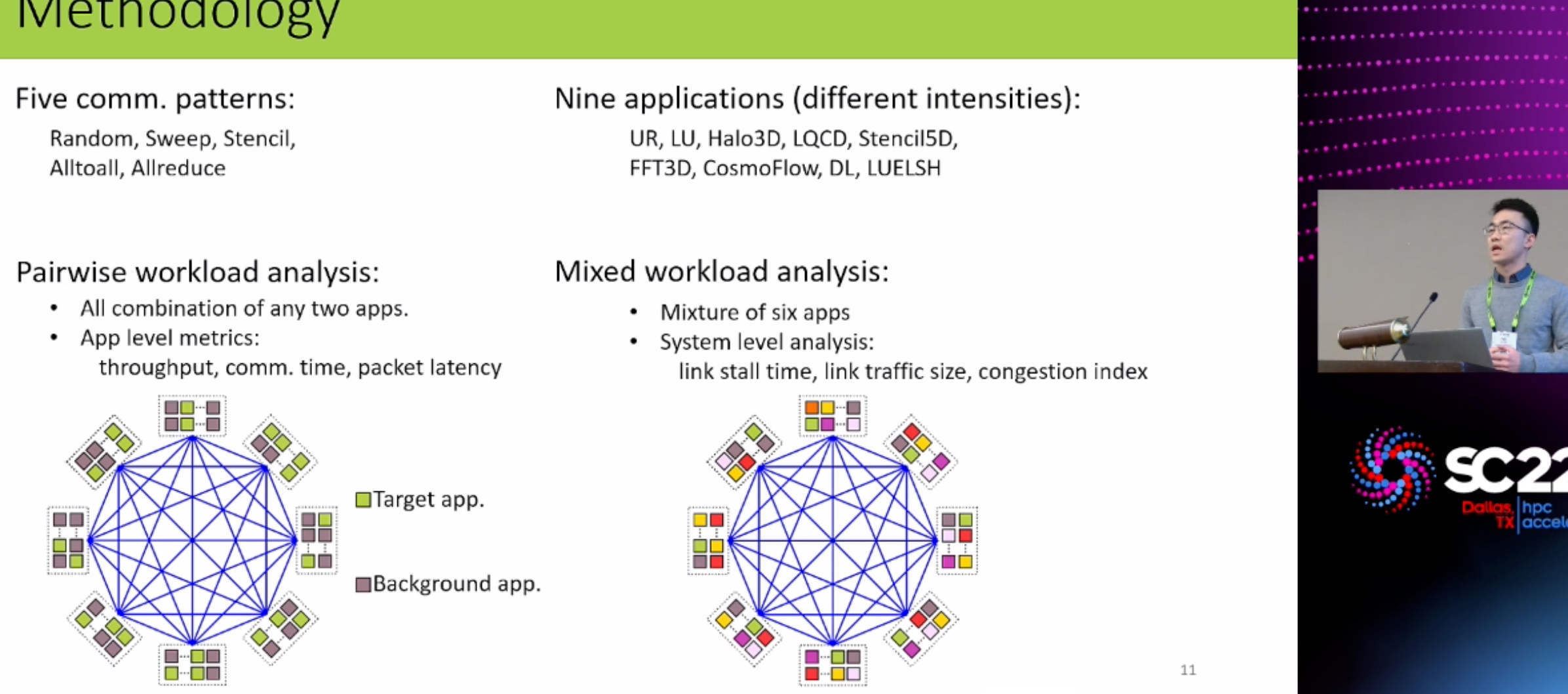
- Performance Modeling, Scaling, and Characterization
- CXL 3.0 Demo
- UniQ
- Octoml TVM
- SmartNIC
- Storage
- SMartNIC
- SCC见闻
- AMD SC22 Booth
- RESDIS
人生第一个in person的会.
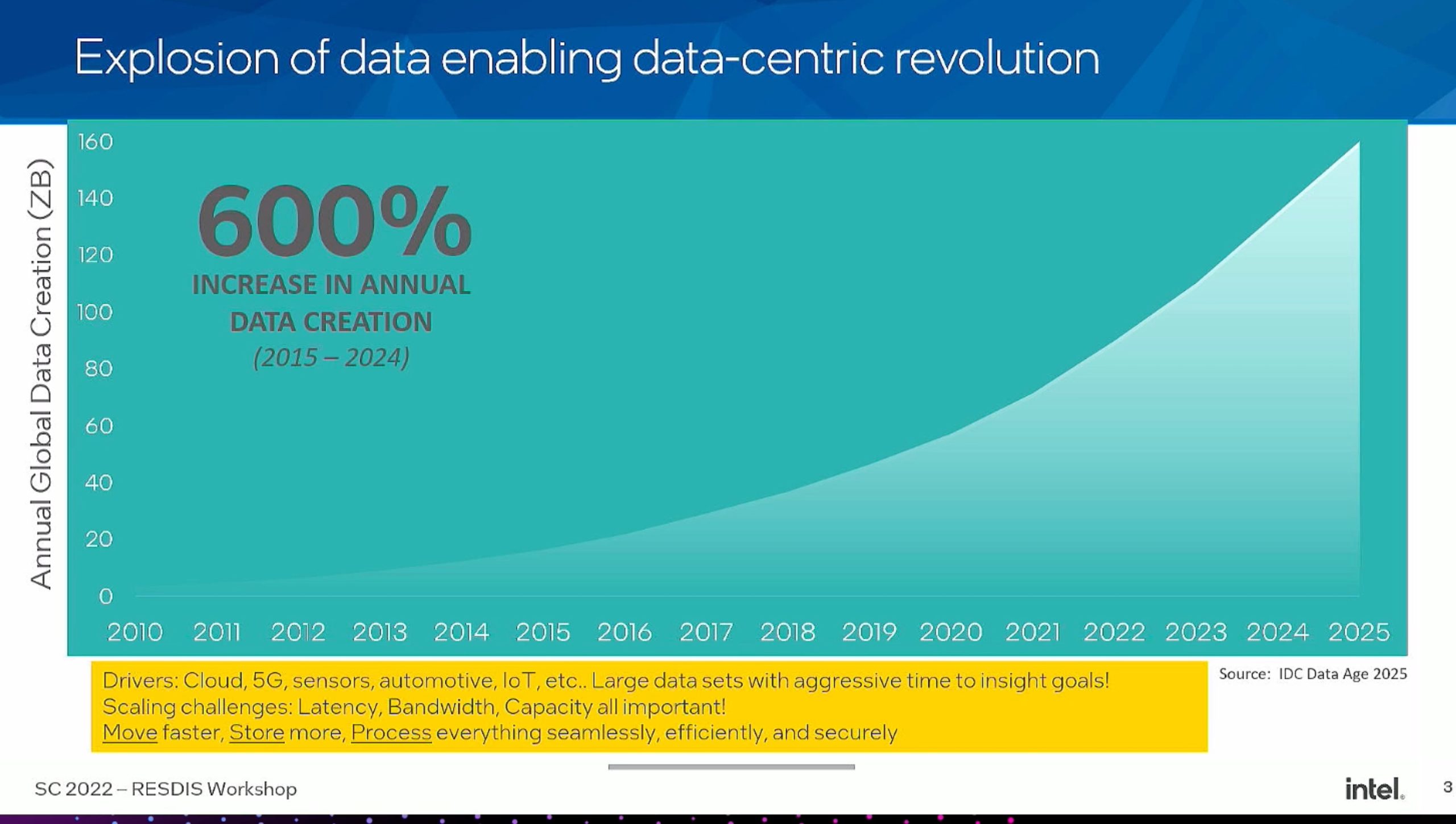
先放一张Intel的吹牛PPT,苹果之后大家都喜欢这么做CPU广告

LLVM HPC workshop
MLIR


The size is not incremented that is not aware by calling the size.

Stream Dialect





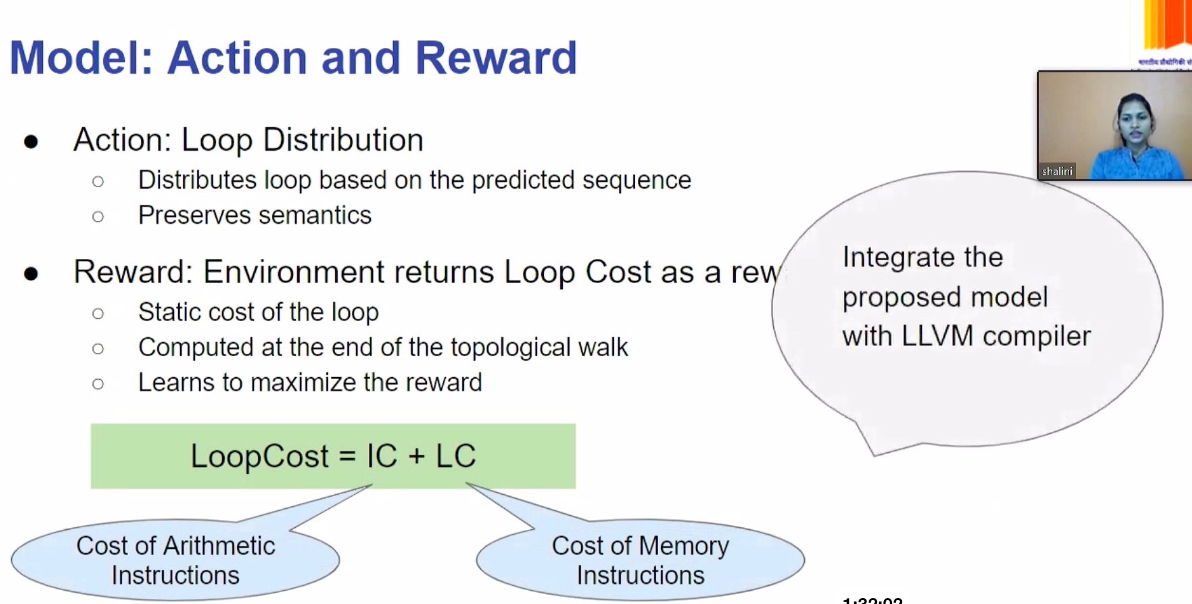



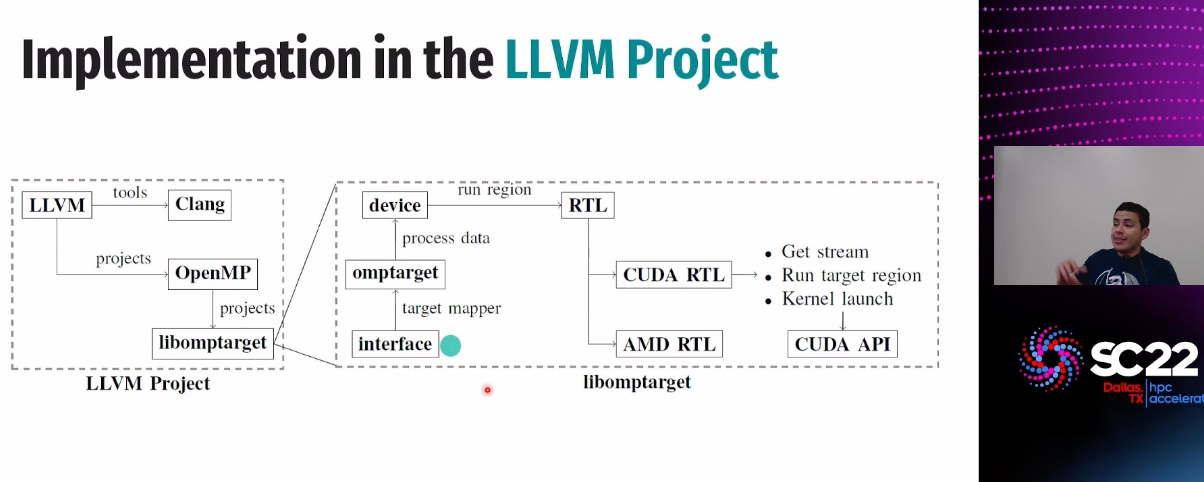
LLVM Memory movement for heterogenous device




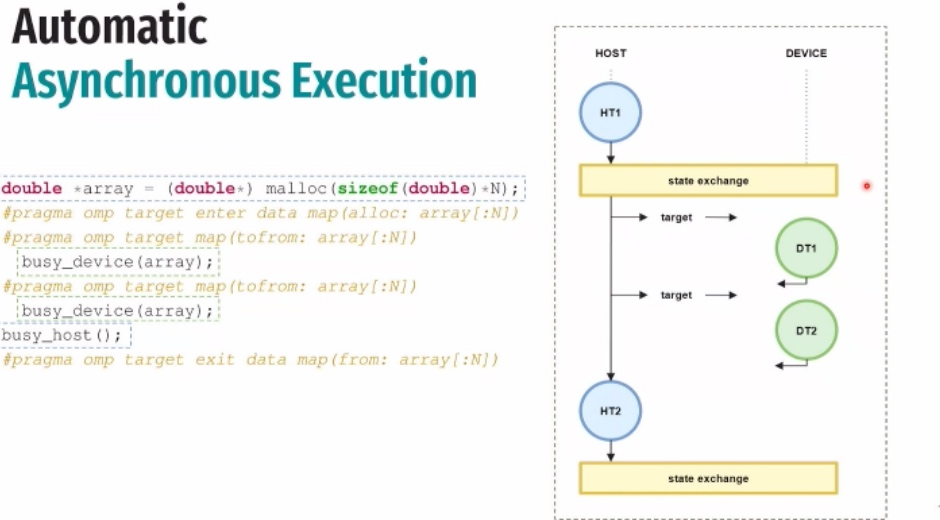
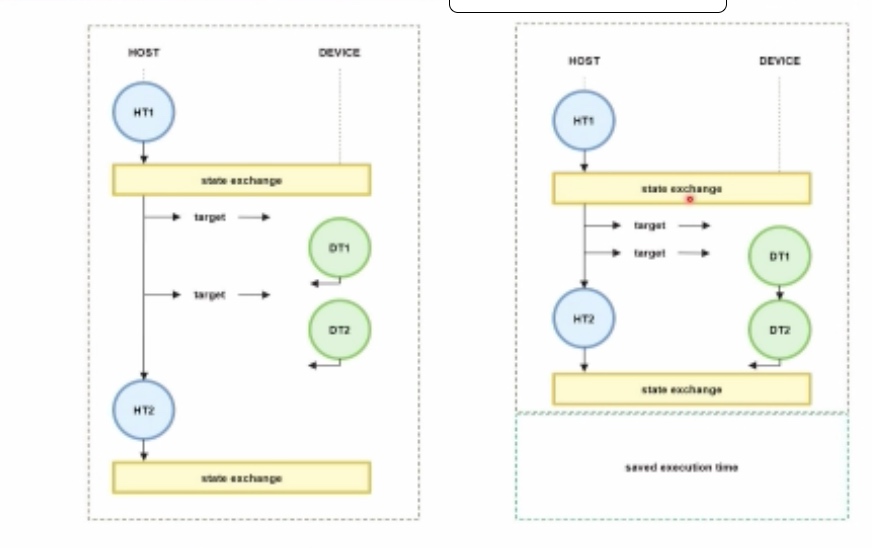

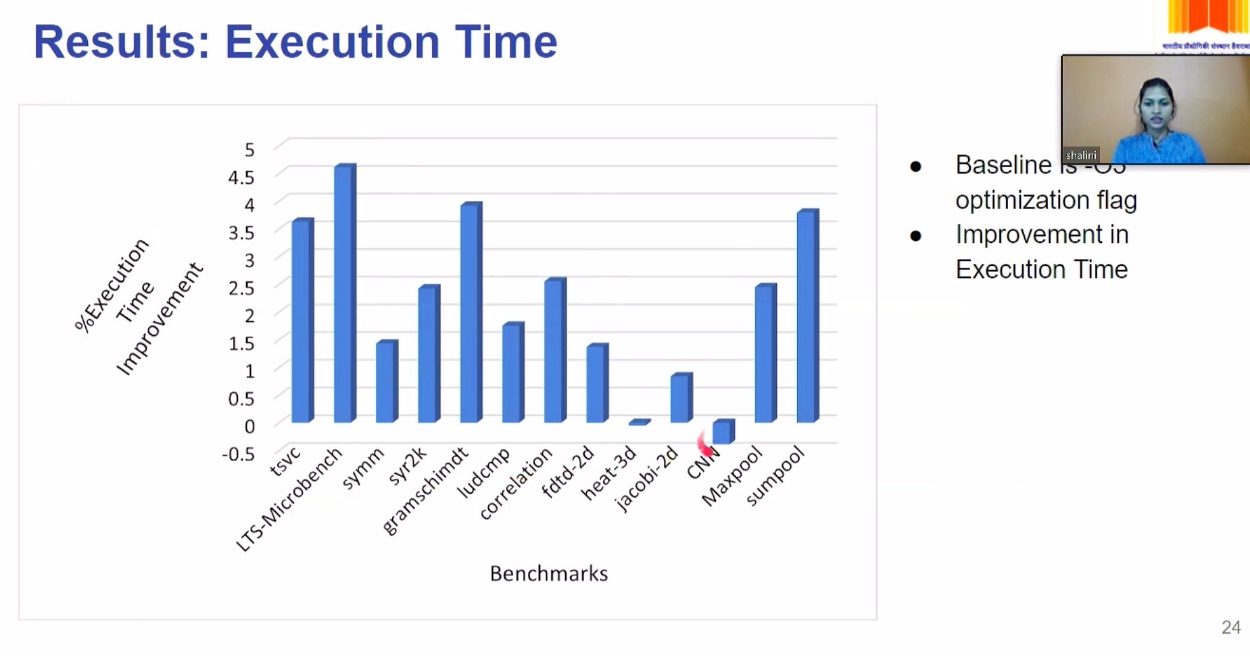
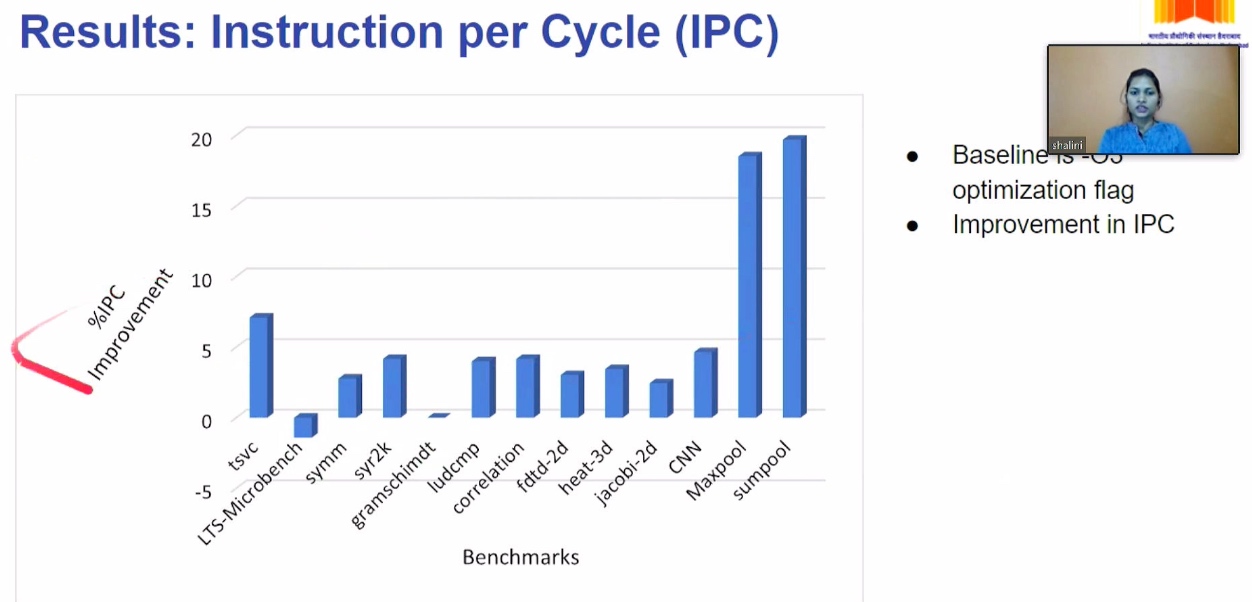
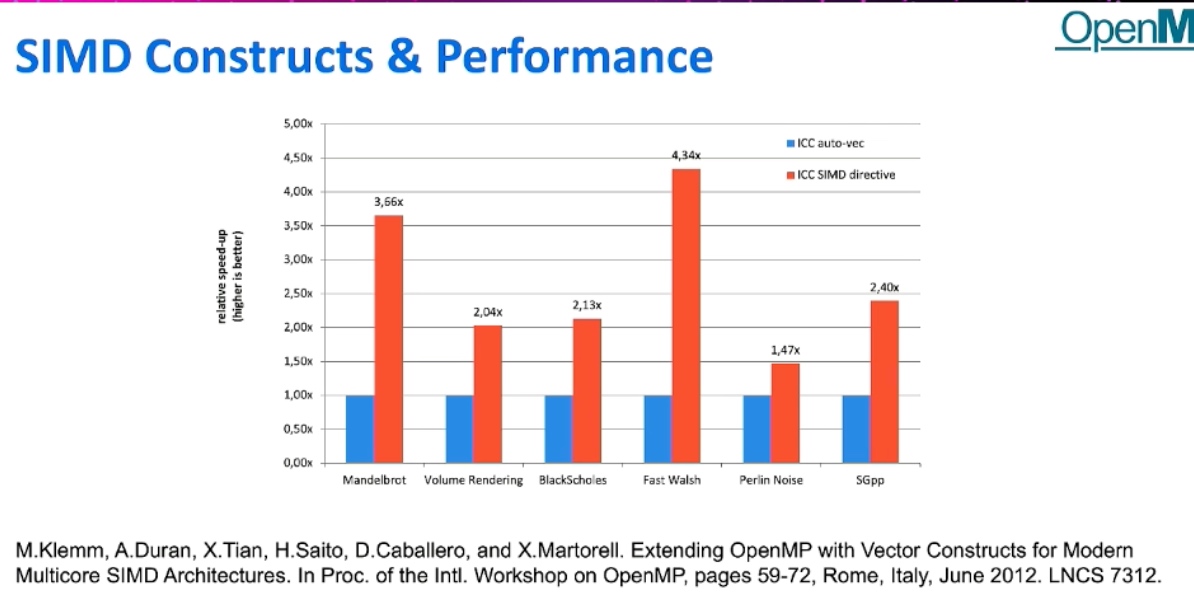
OpenMP 5.2

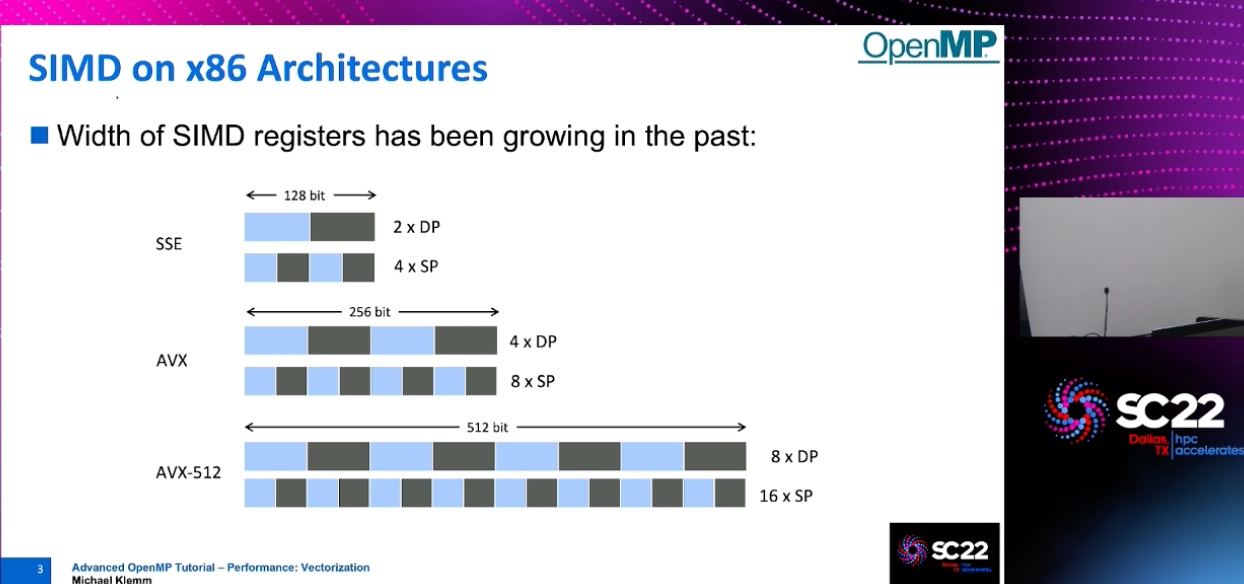

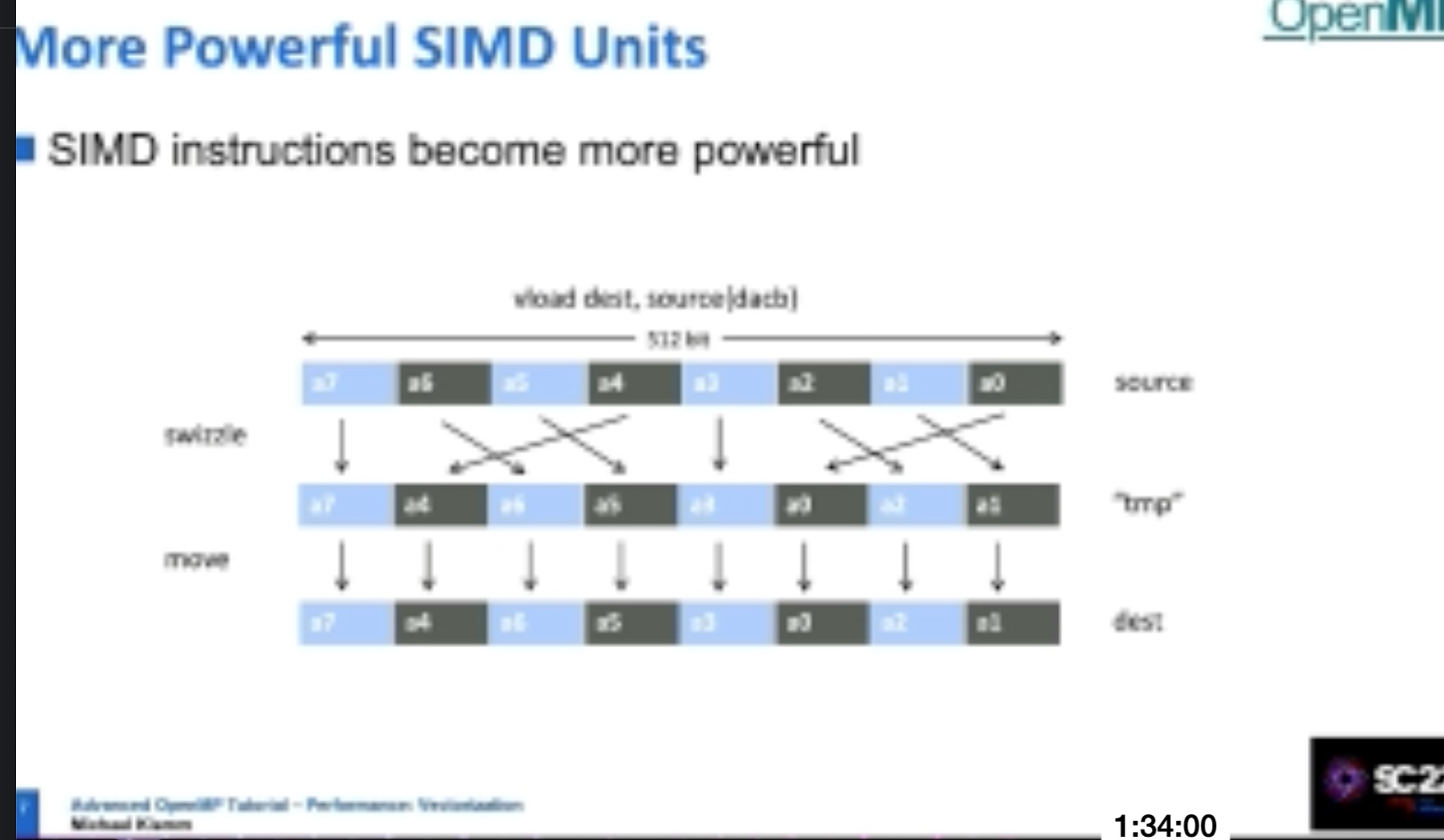





The thread division is not correct
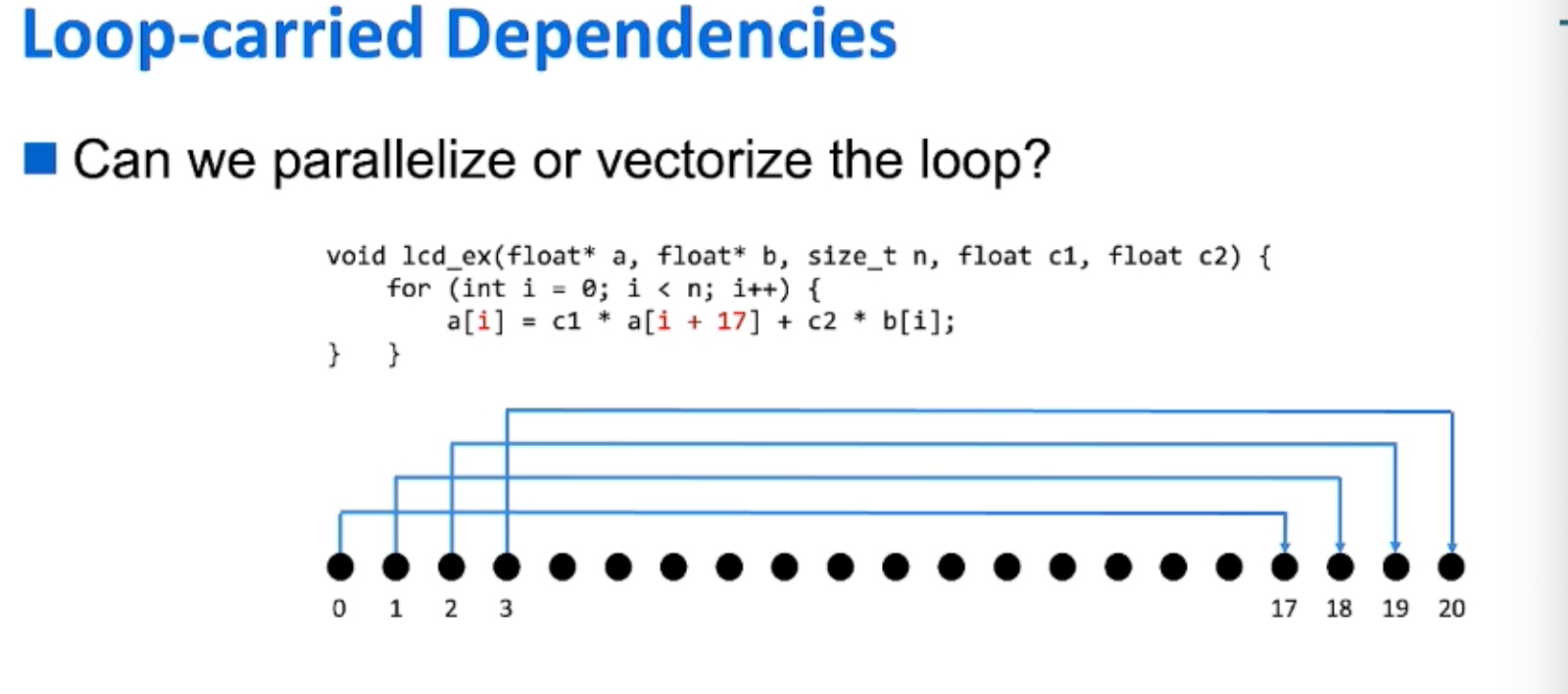
Thus No Parallelization was persumed. But Vectorization can be implemented because of Vectorization can store the distance of dependency.
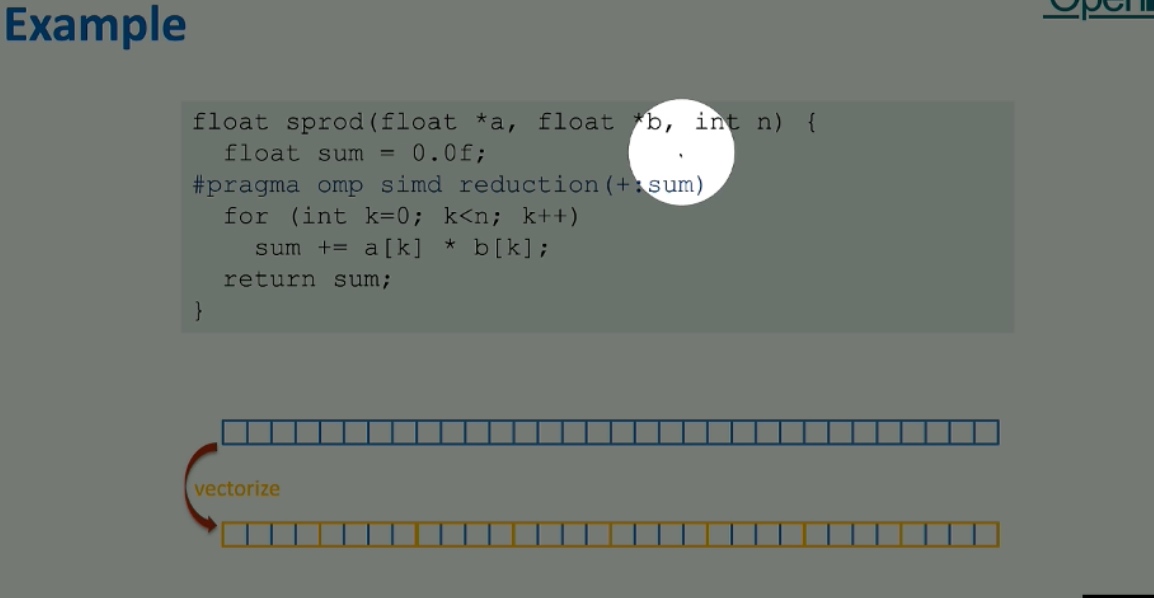



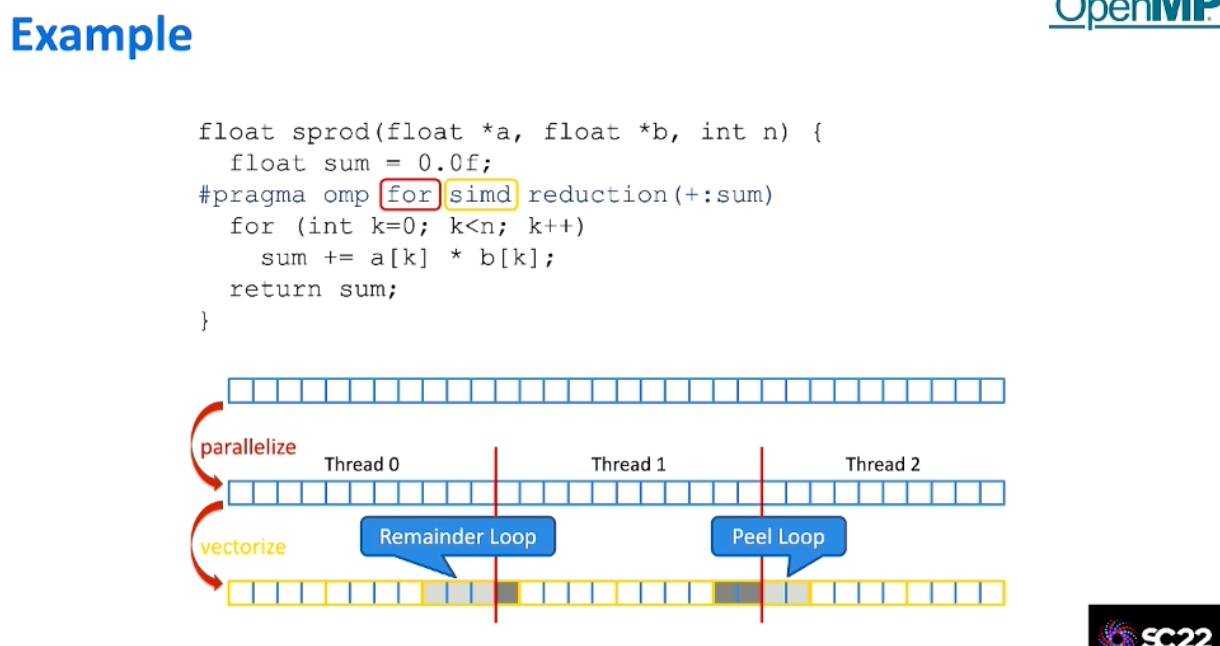






Codesign


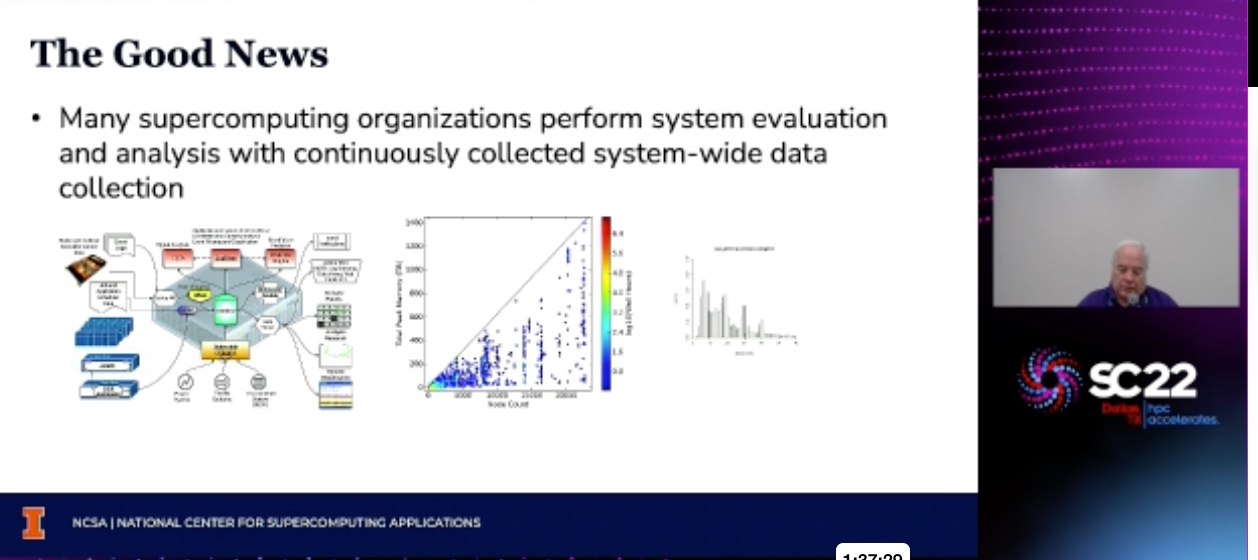

ML at scale



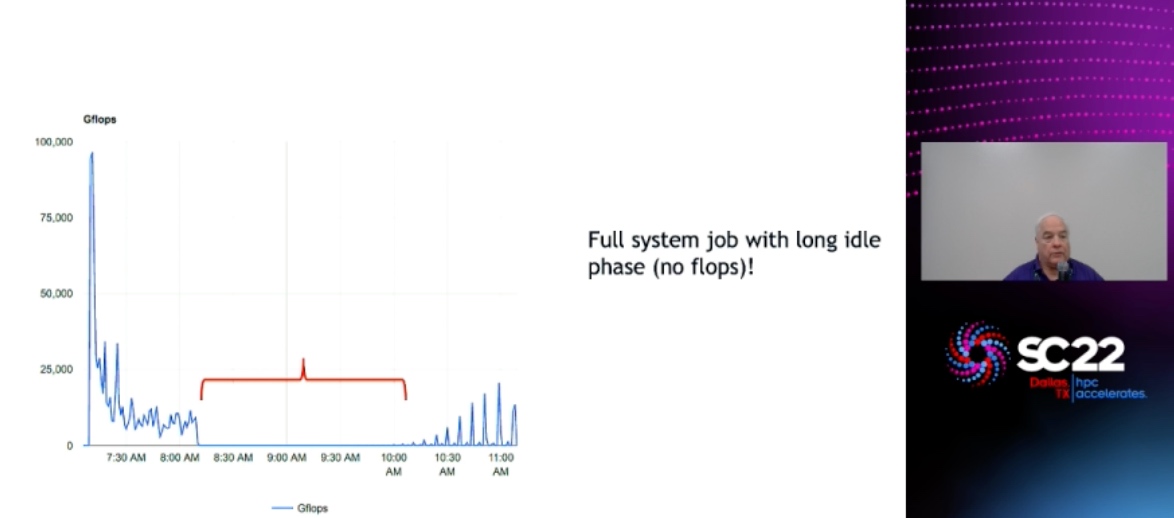
Parallel I/O in practice
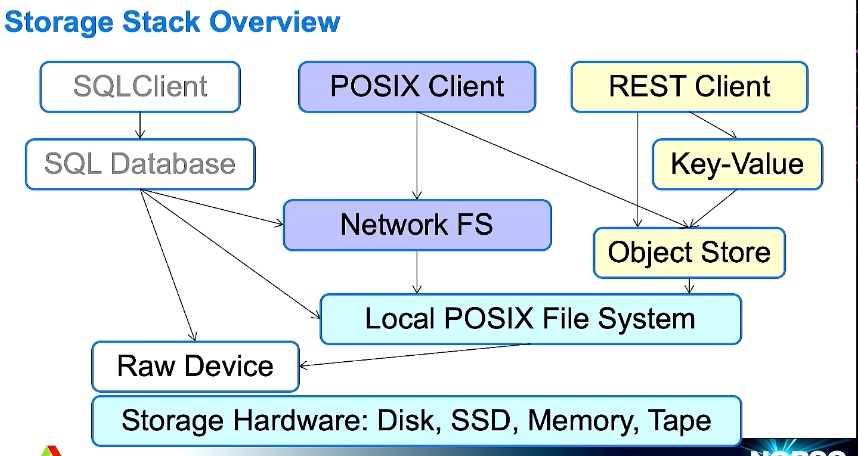

Advanced MPI Programming
Exascle MPI

Introduction to Networking Technologies for High-Performance Computing
ROSS
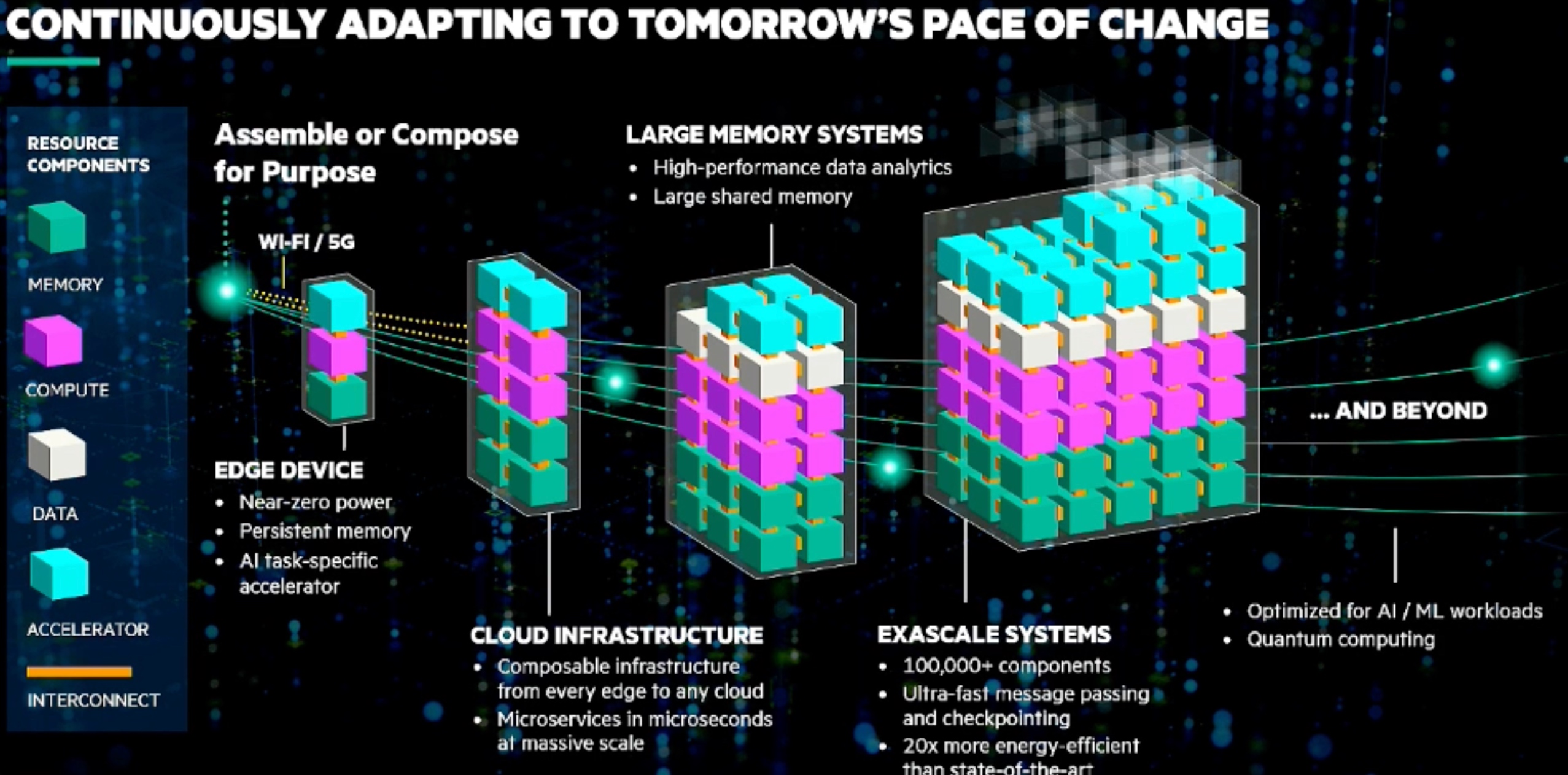

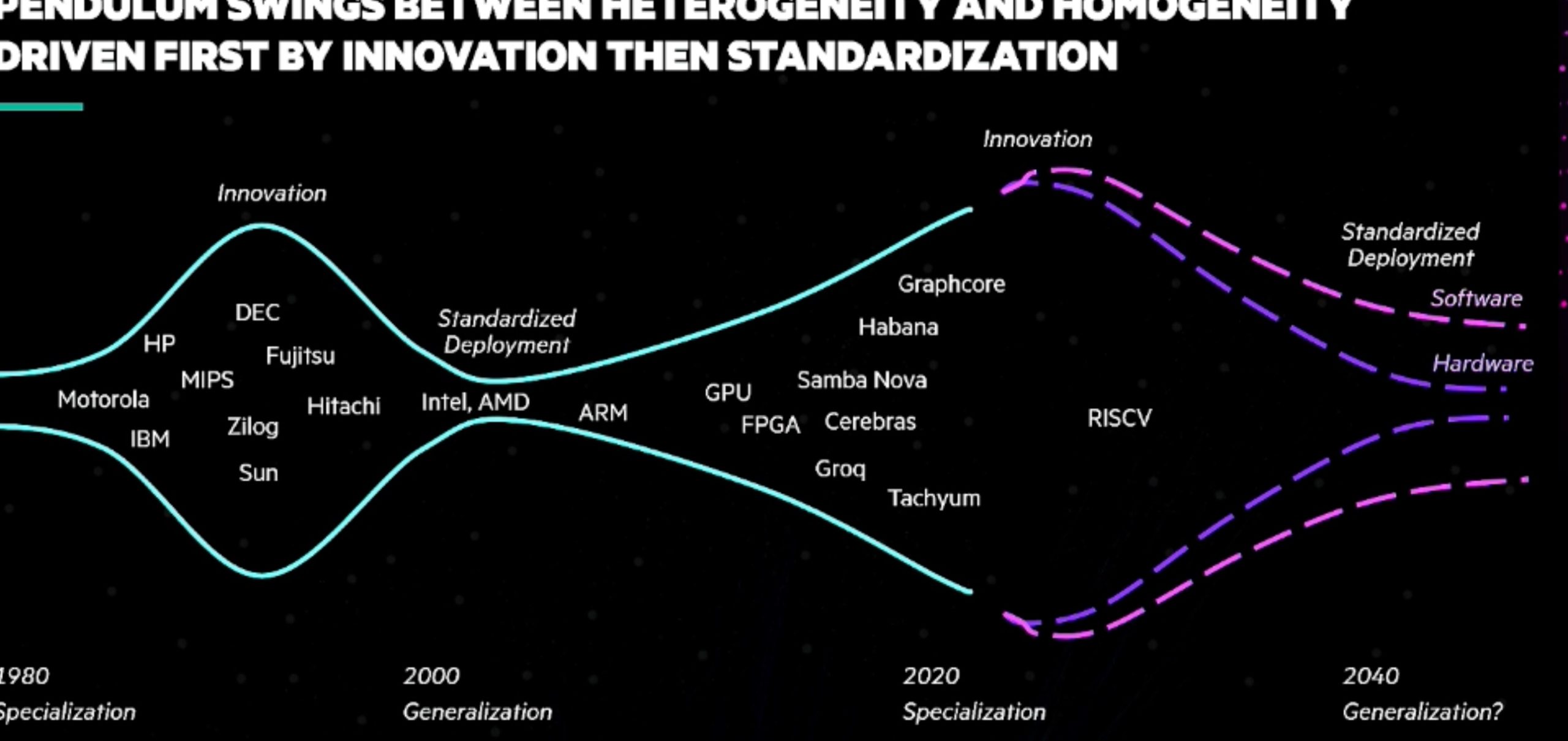
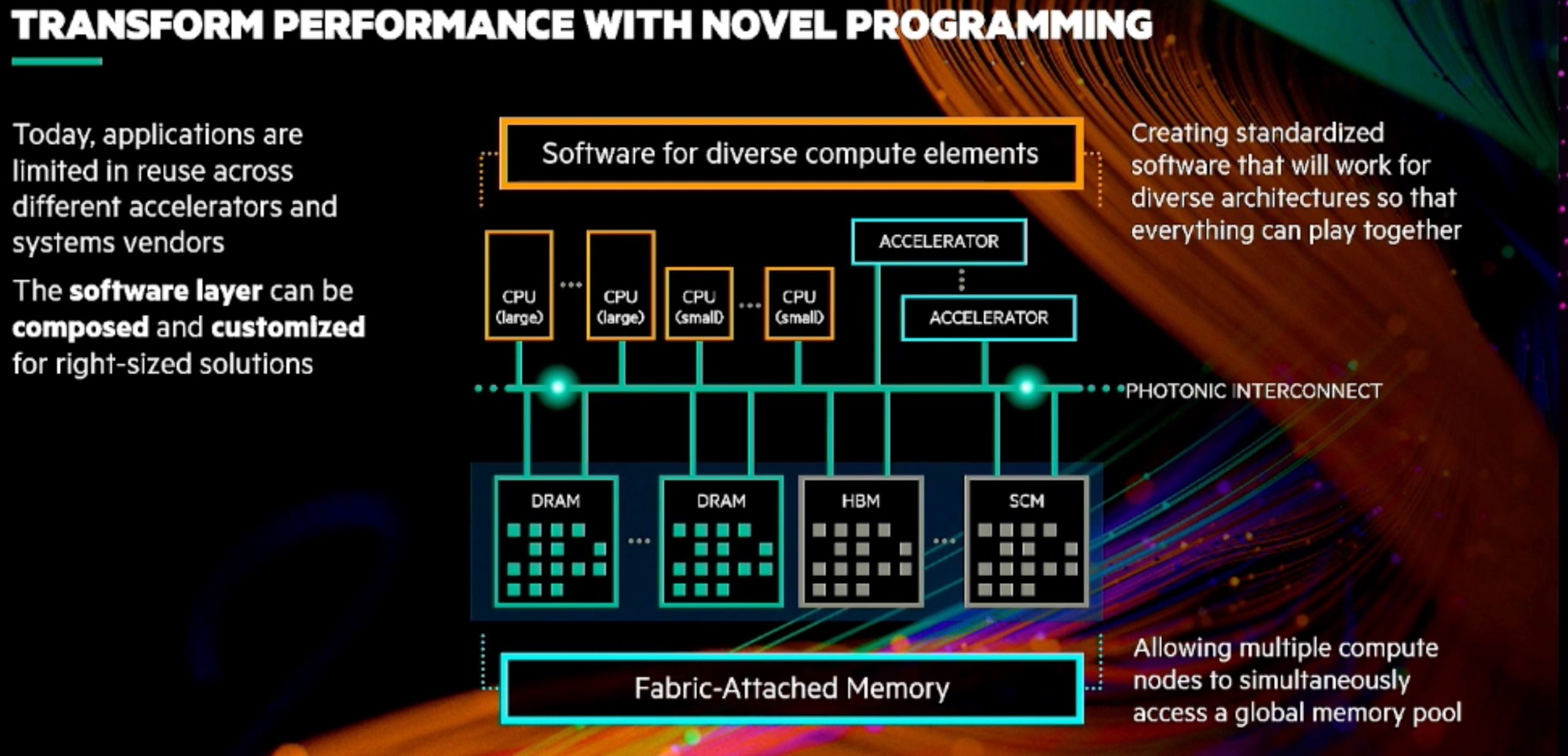
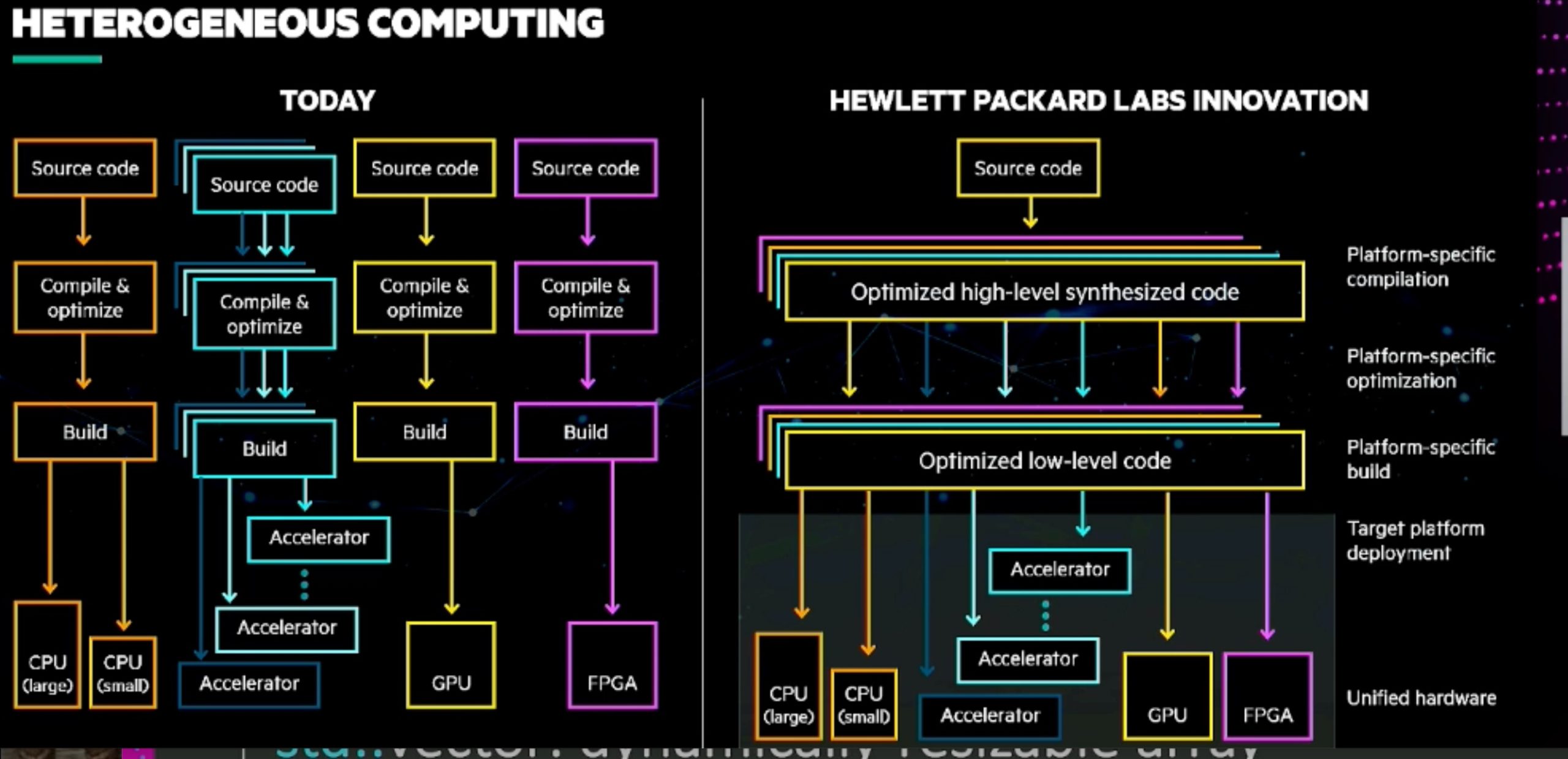
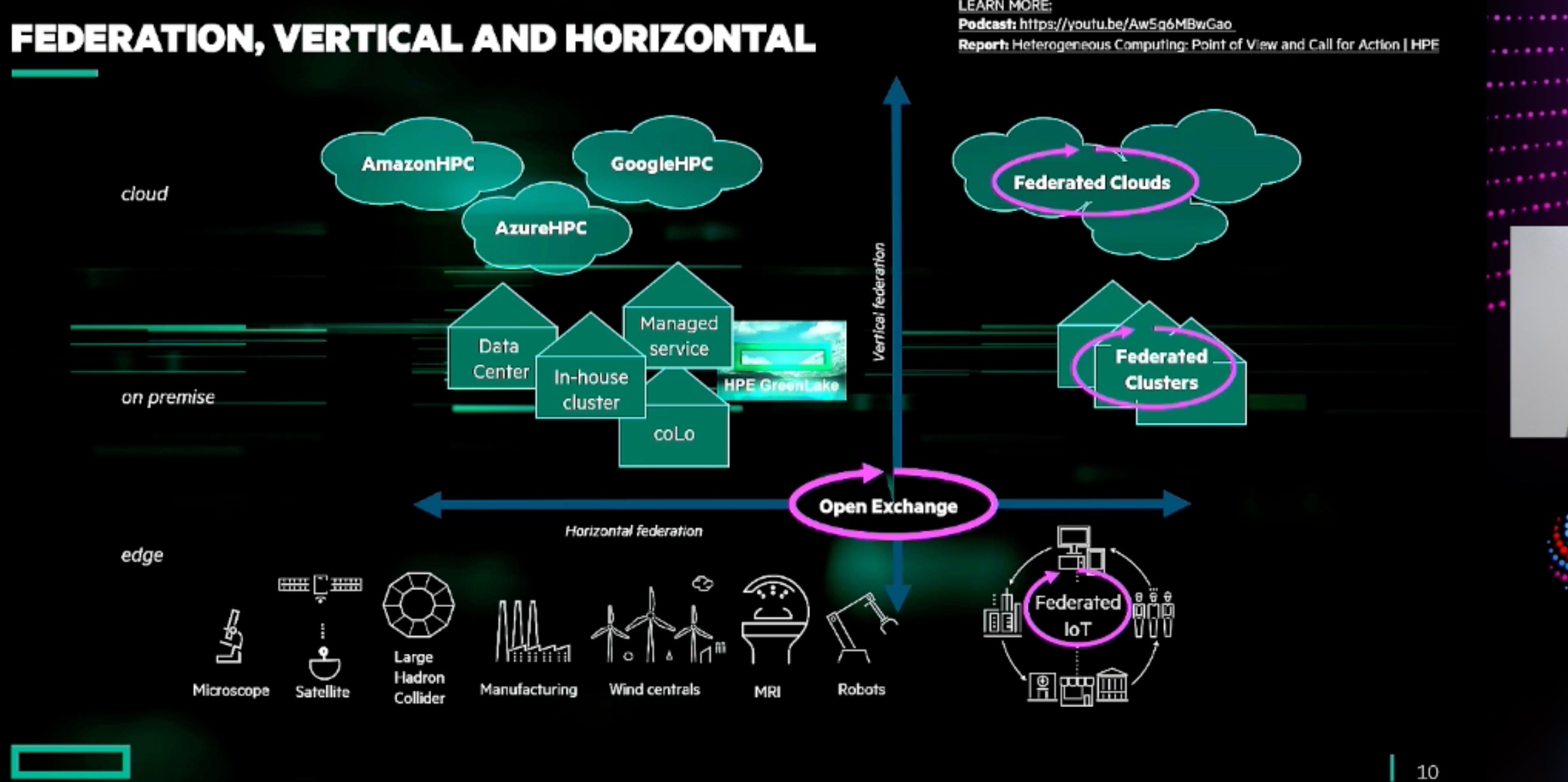
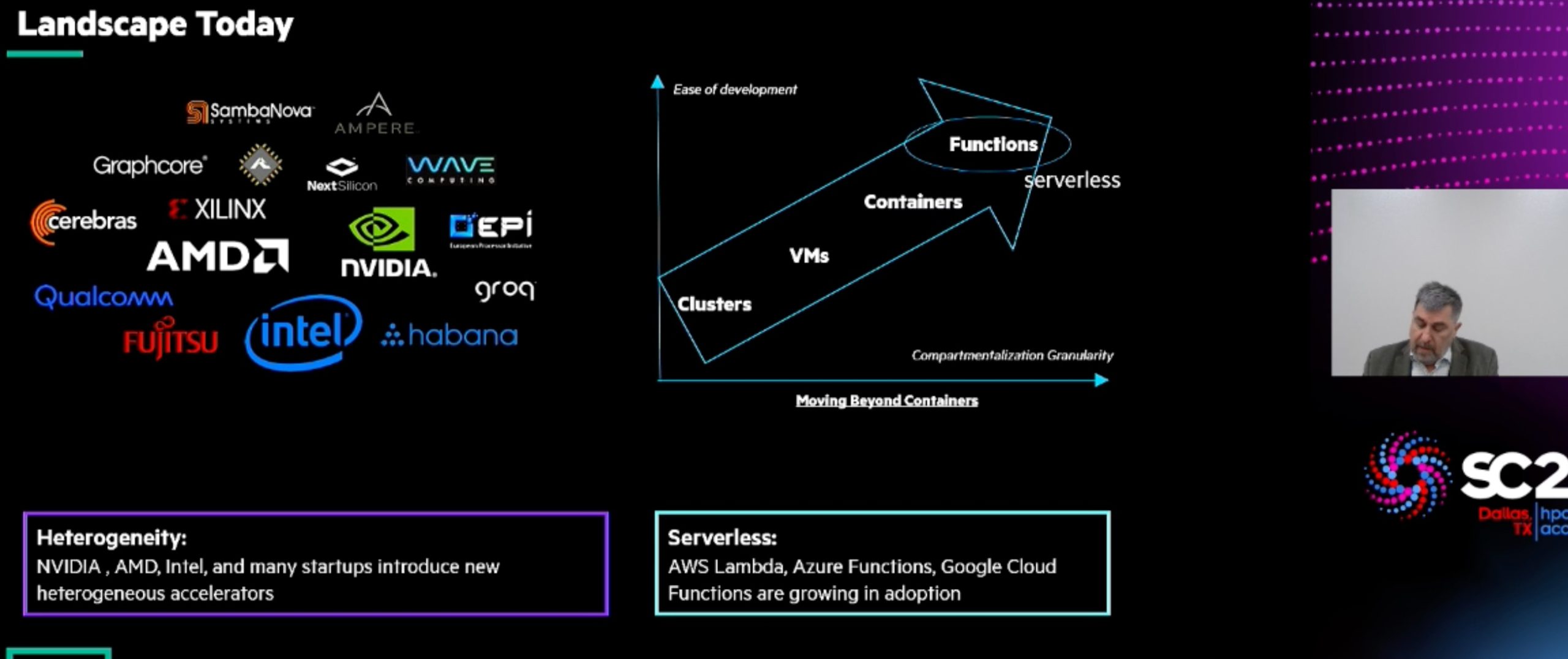
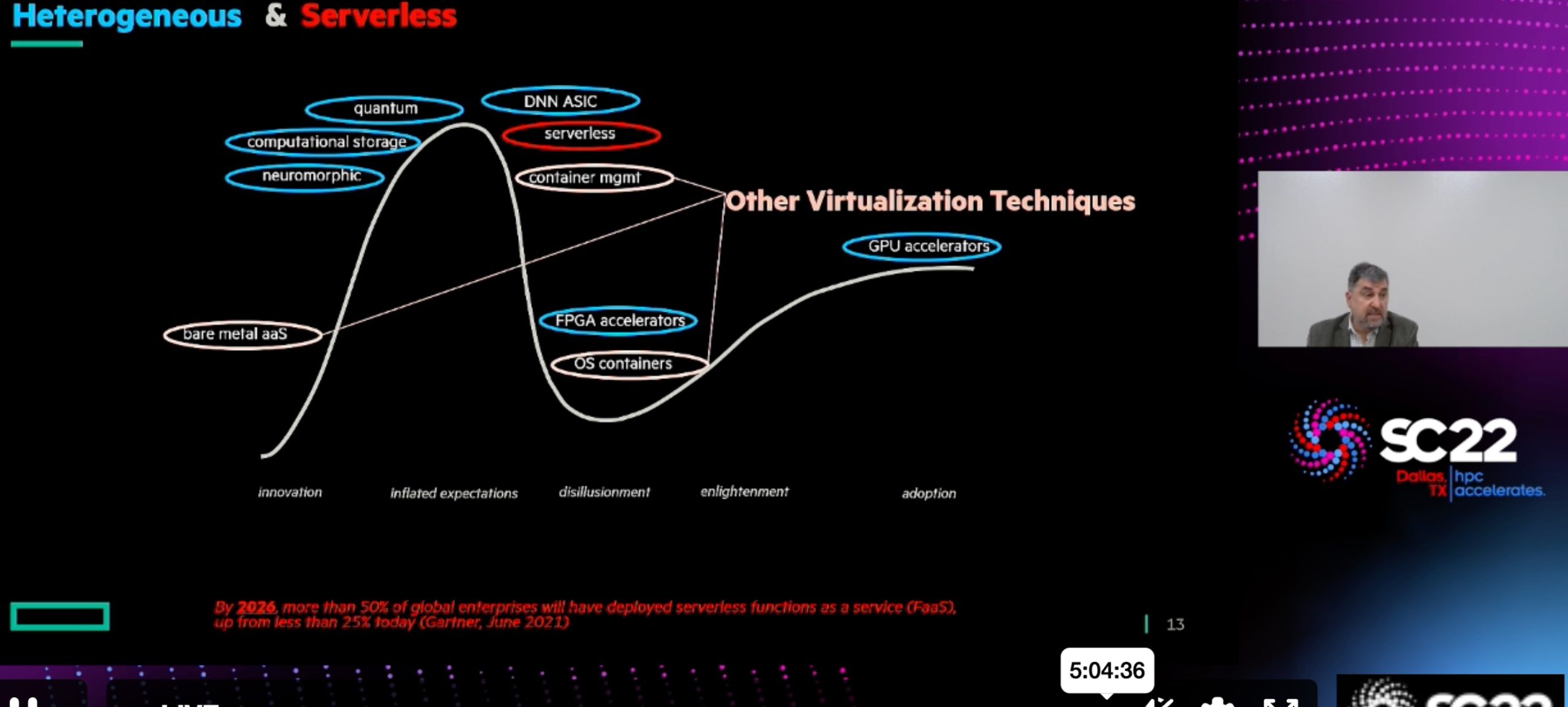
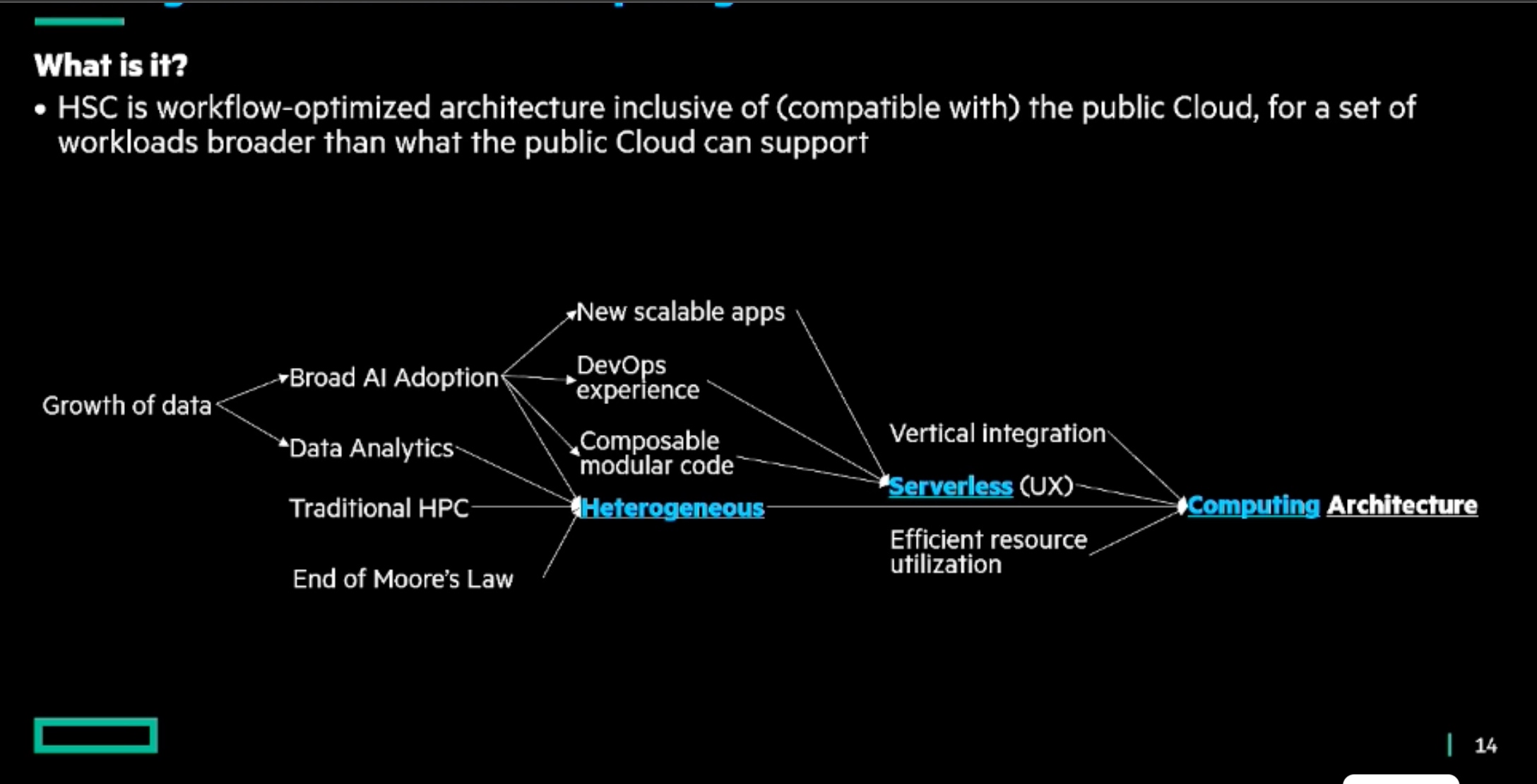


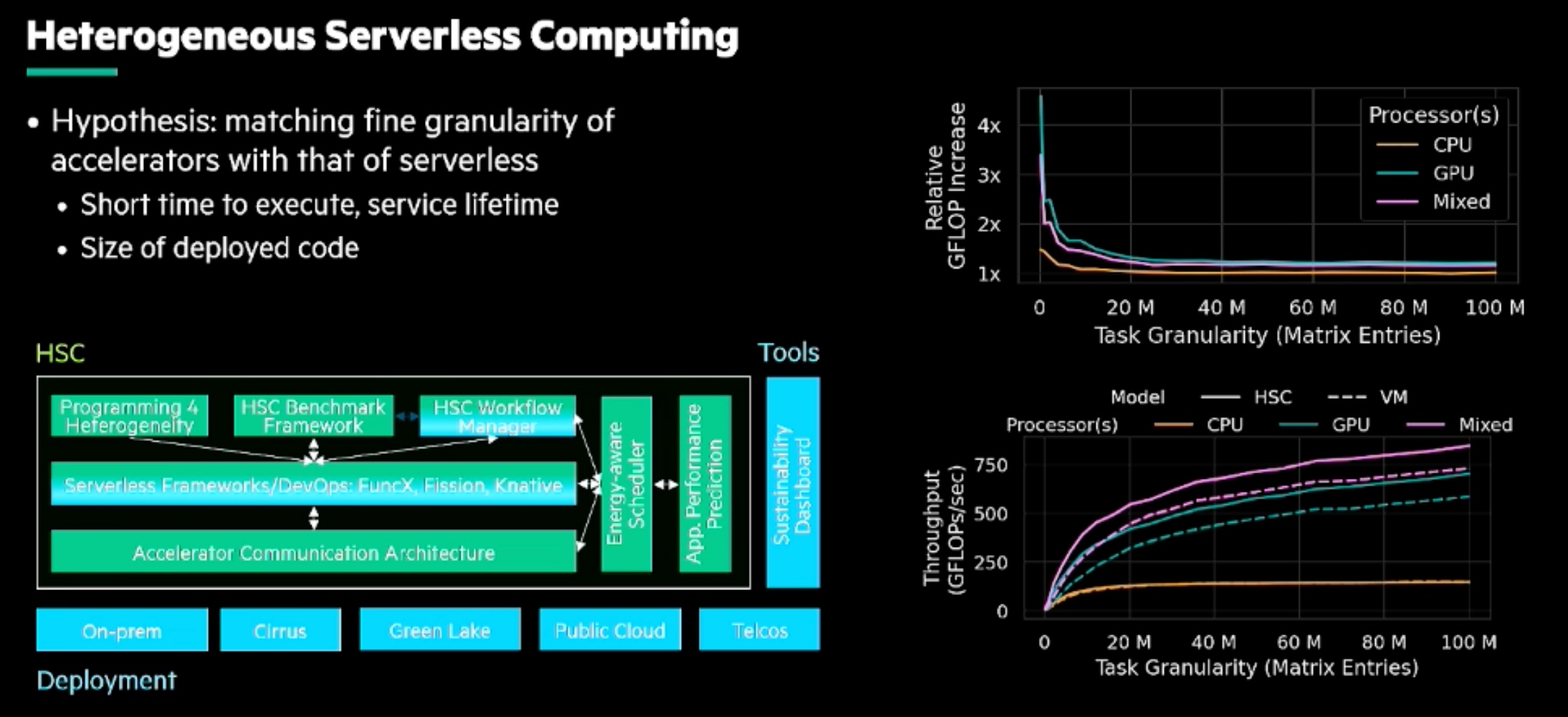
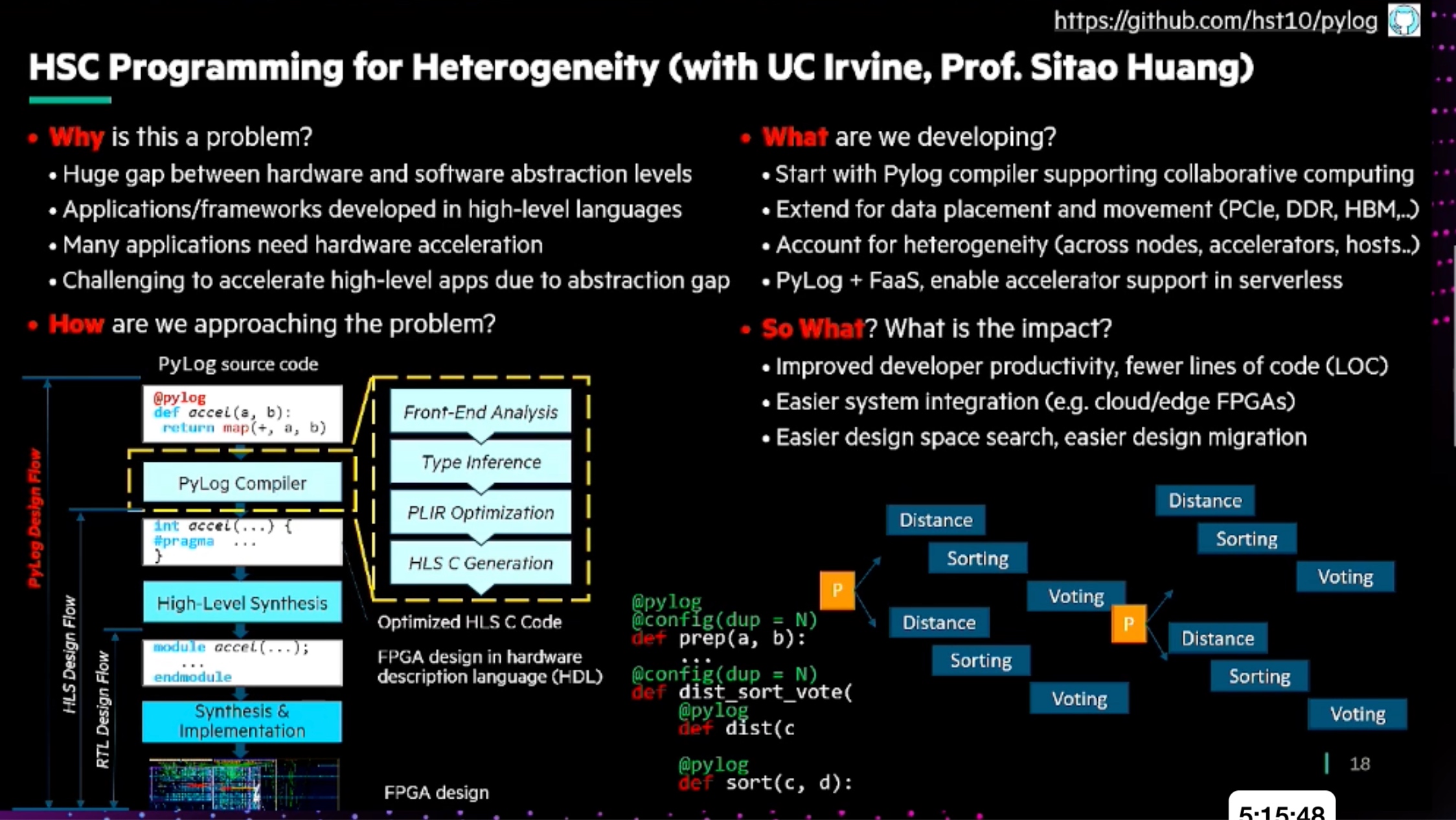
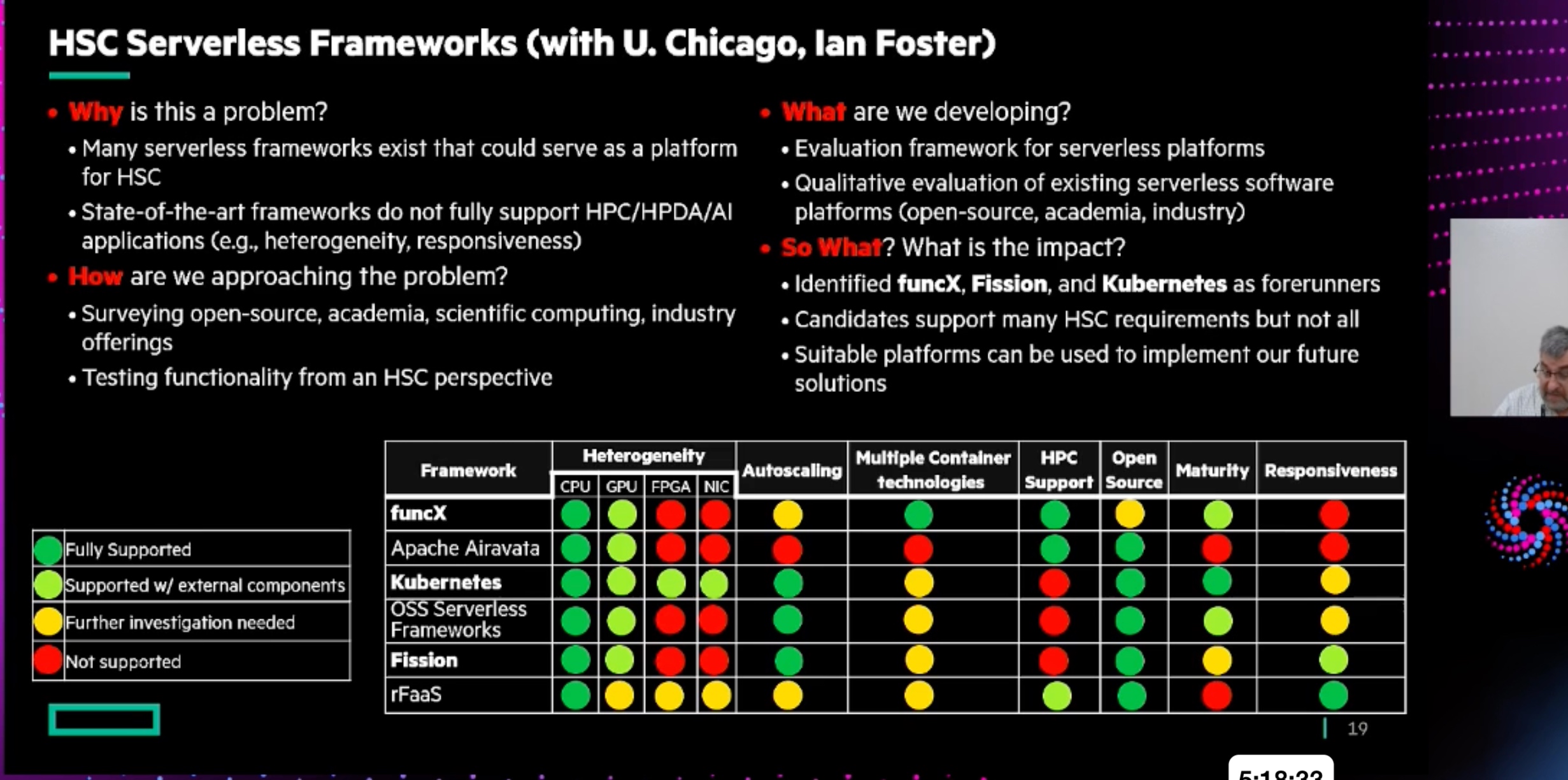

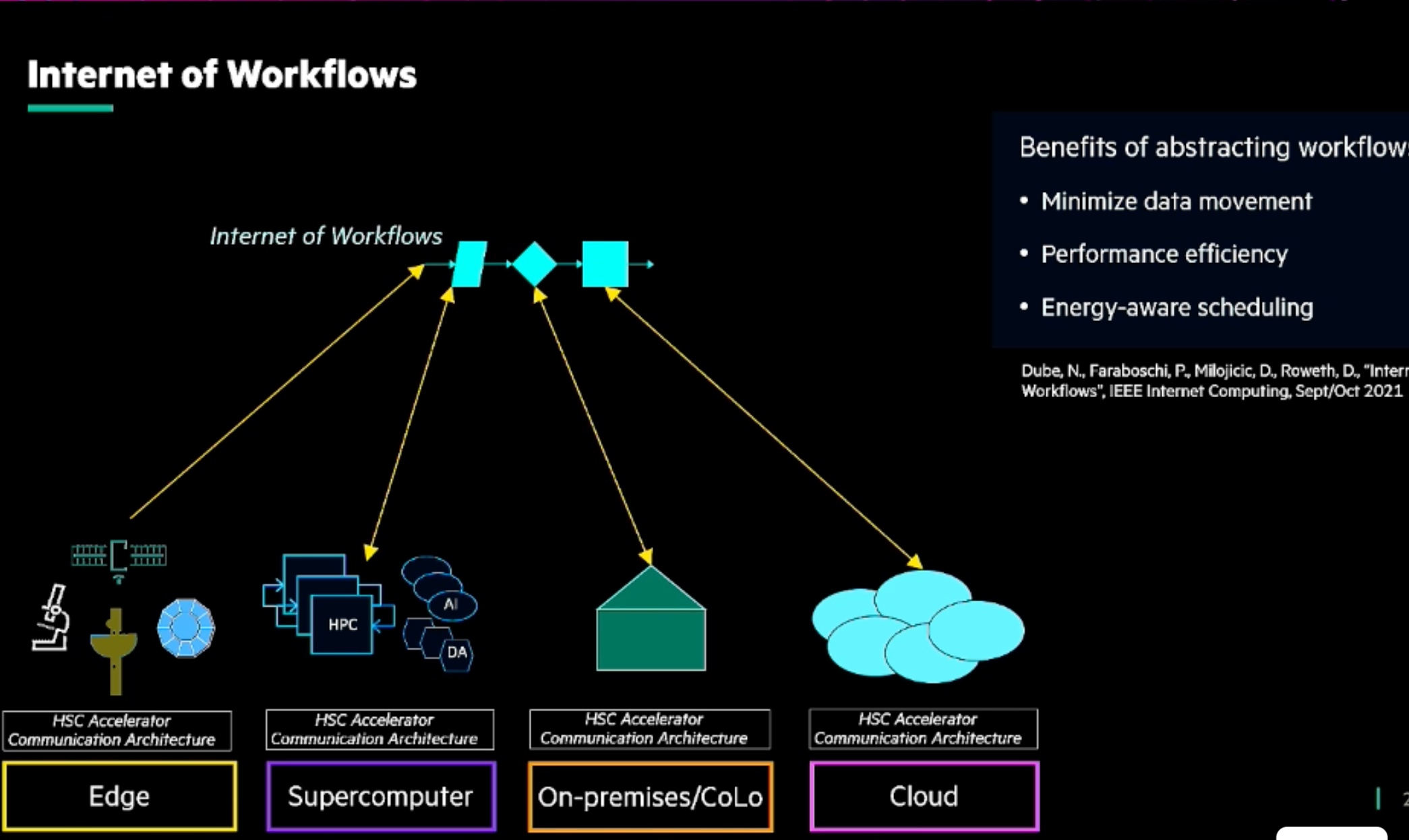
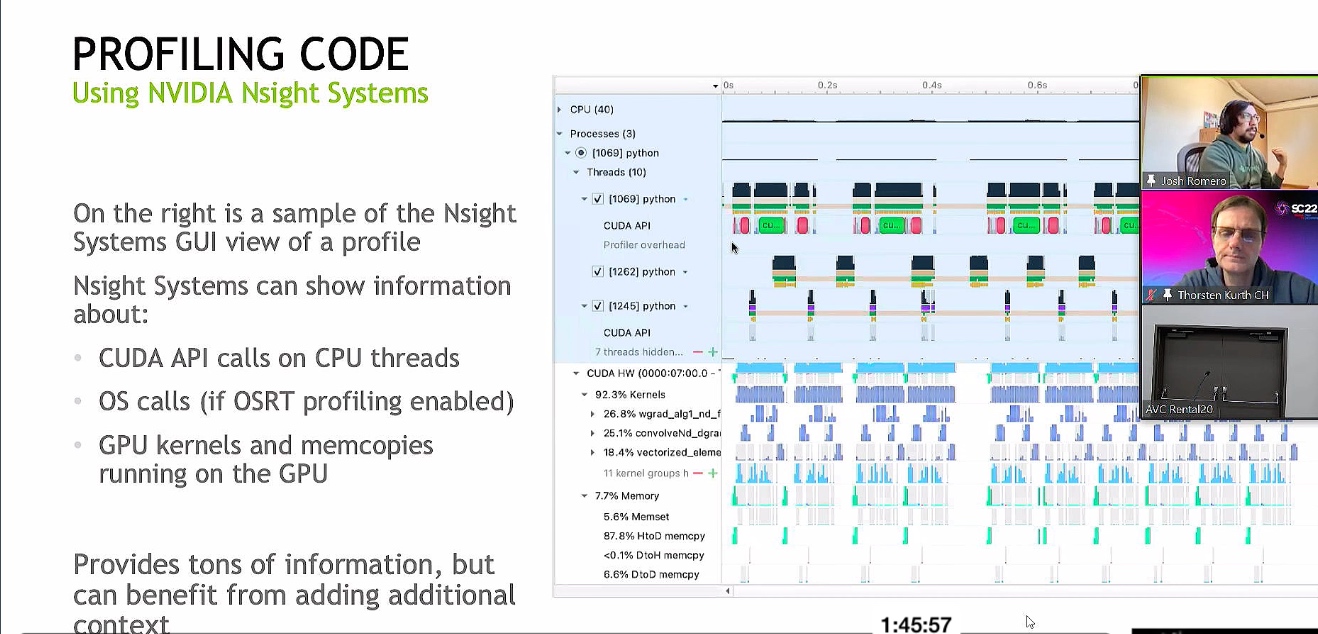
Accelerating Portable HPC Applications with Standard C++






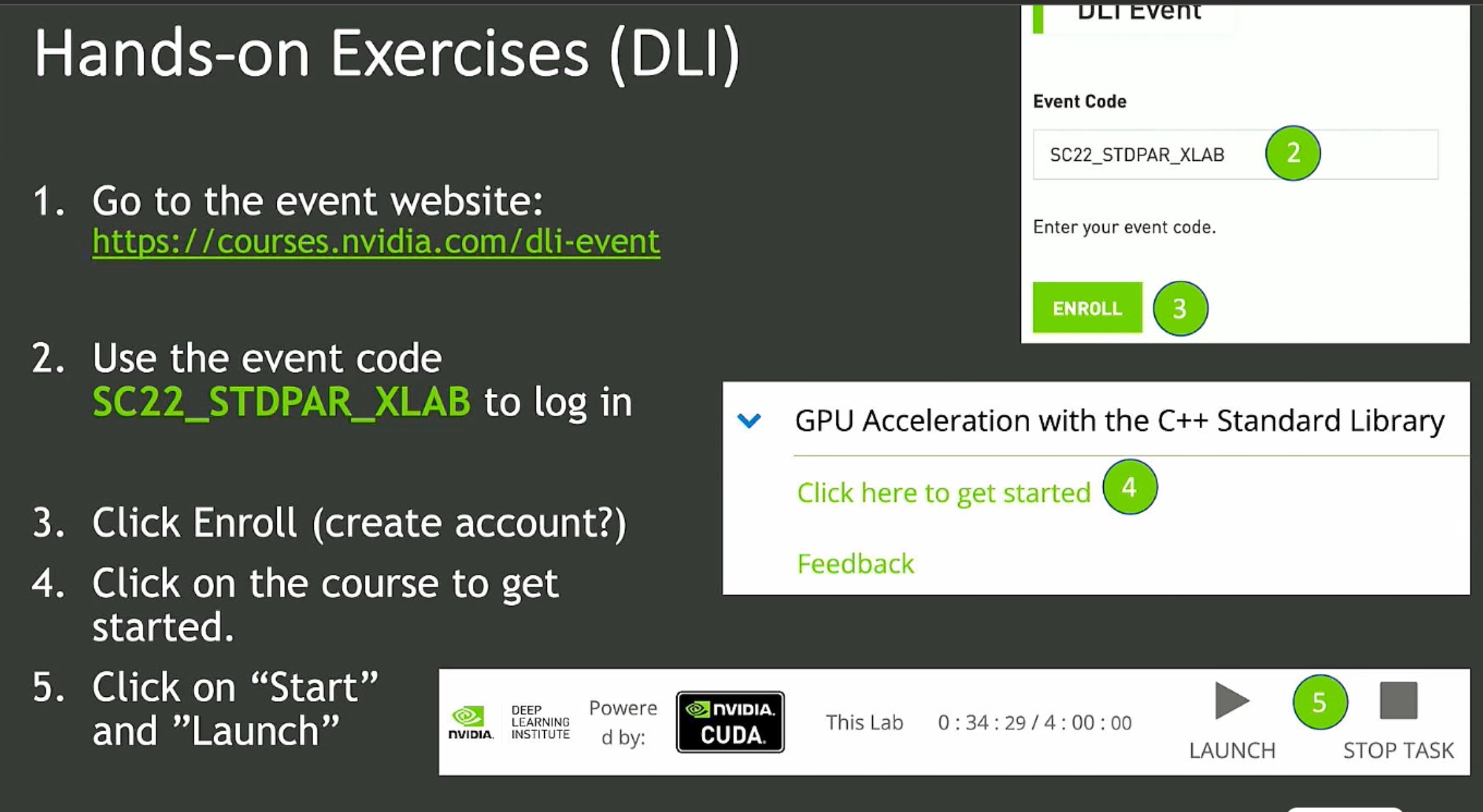










Best Practices for HPC in Cloud

RSDHA
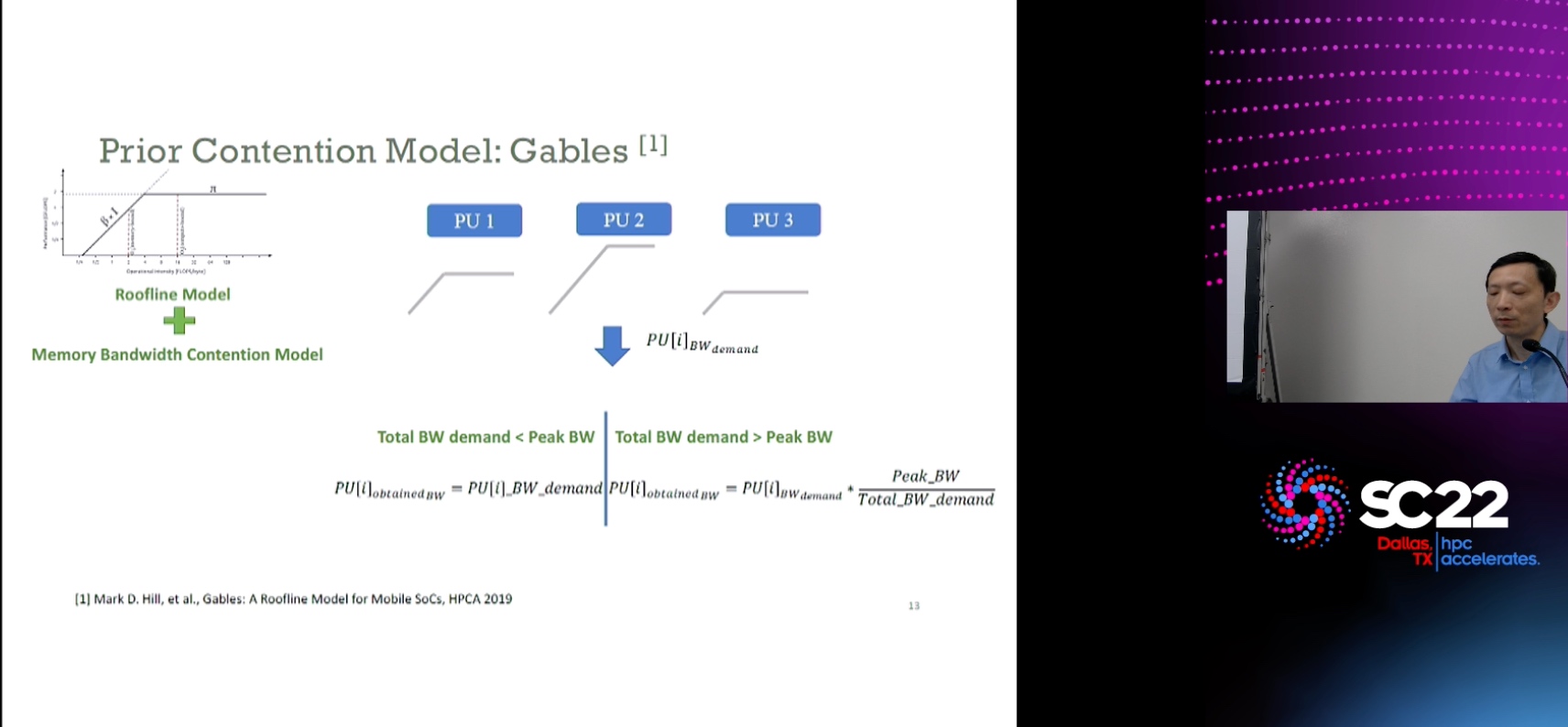
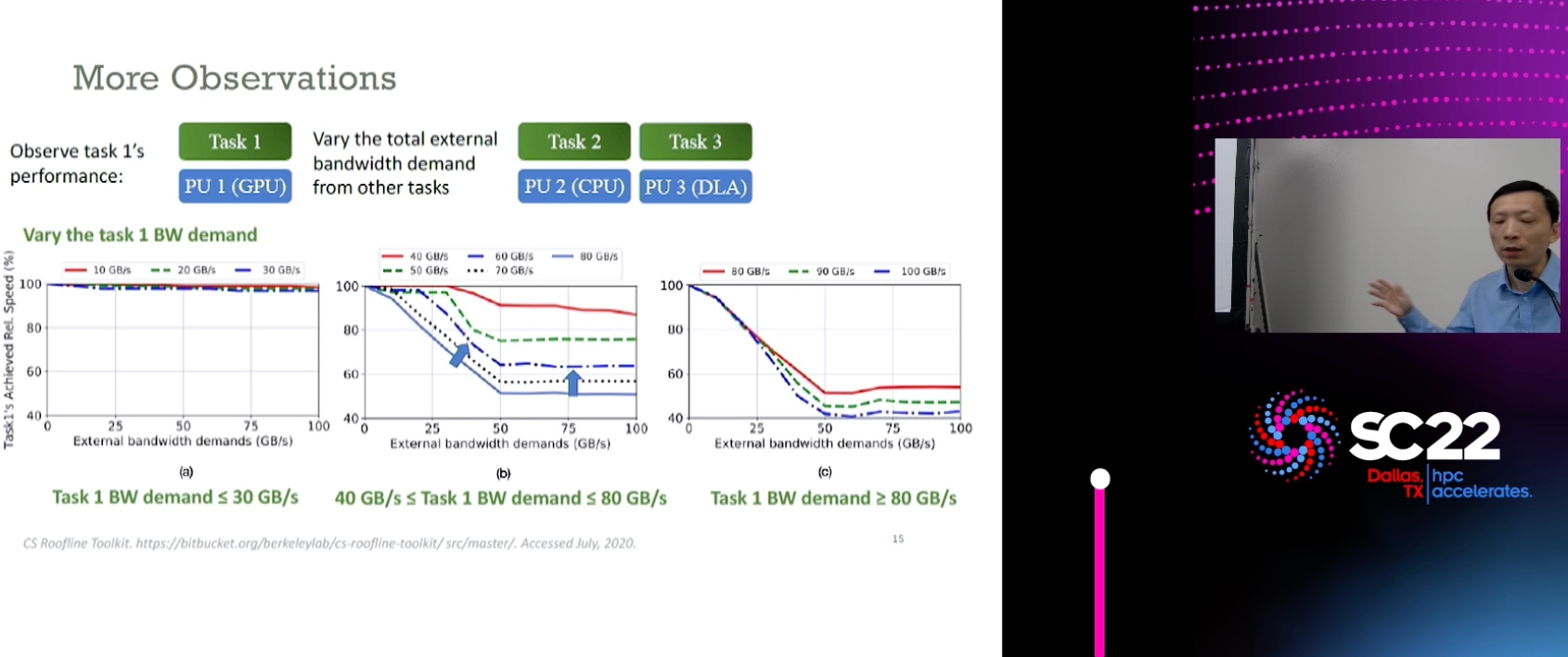
Scientific Research Poster
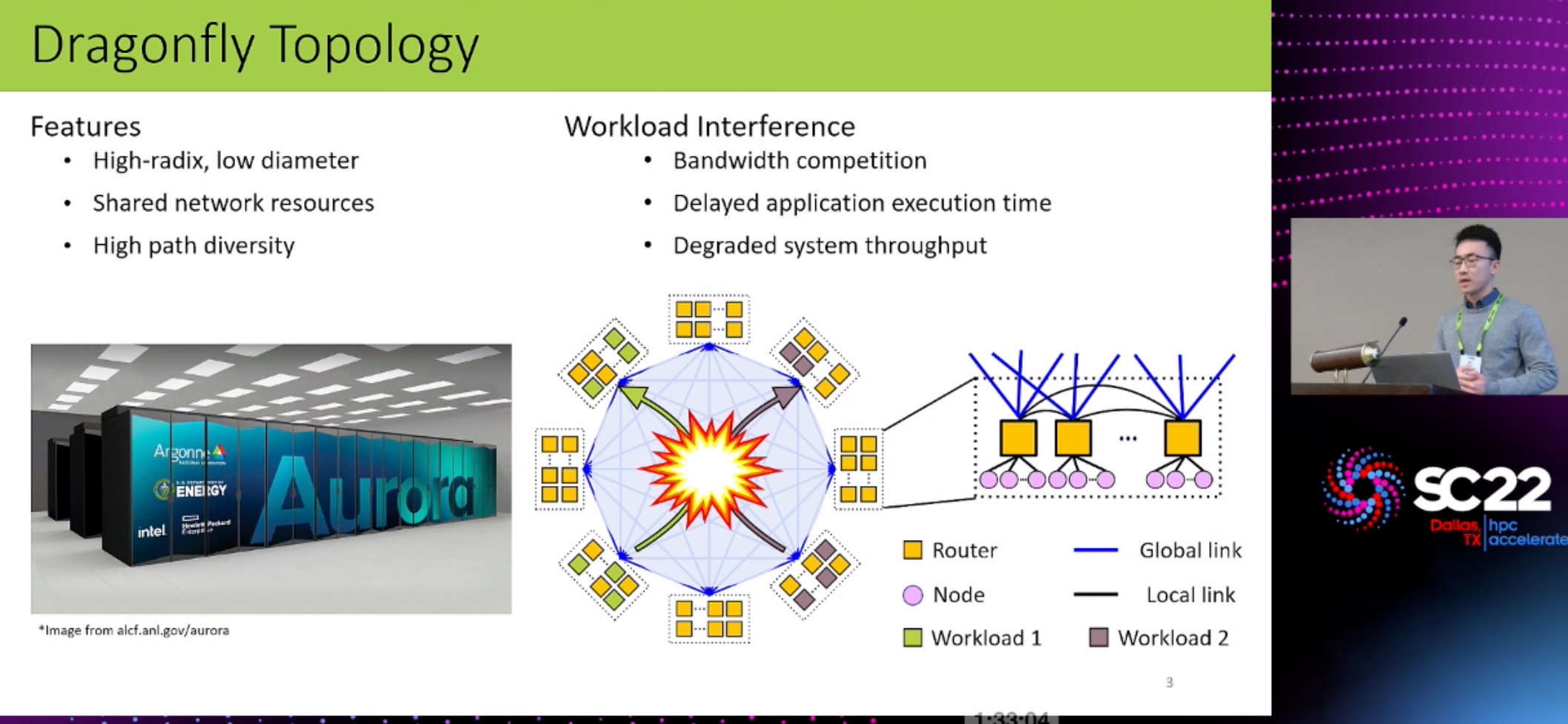
HPC Network Architecture
一个switch的链路优化.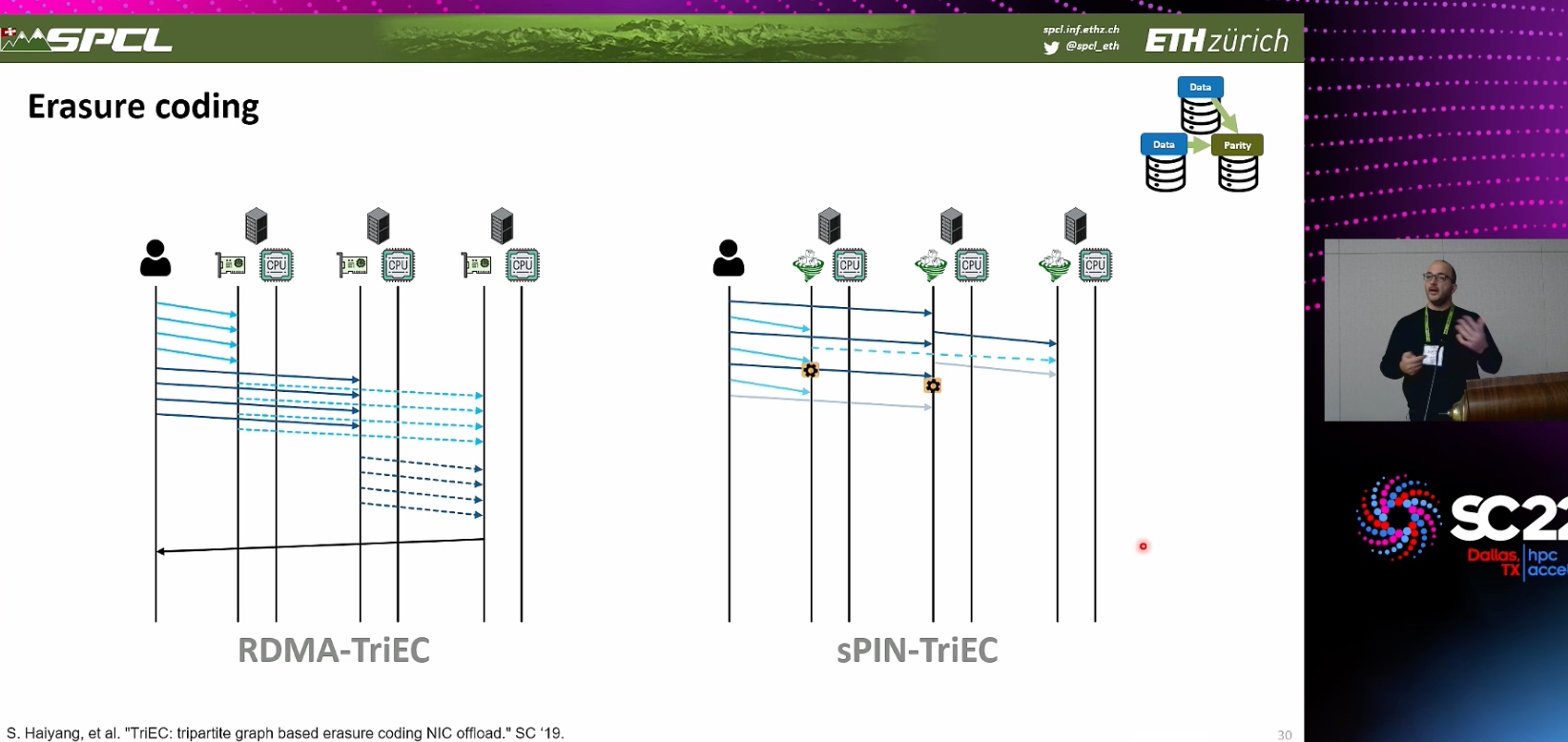
Galary
Samsung
和SMDK的developer聊天,他说1. CXL device 对OS的page cache可以不知道,这个是CPU管的事情,其实CXL device只要维护CXL的coherency layer就行,没有办法做device侧的offload. 2. 他们业务部做的比较分部,不会做CPU的hack,内存部只负责对Zen4和SPR的支持. 3. 他们在iterate SMDK,未来不一定是EXMEM和SMallocator(jemalloc+libnuma)的解决方案.但是这种方法是最好的. 4. 他们只有CXL2.0 type3 io+mem, 没有cache, CXLSSD cache是另一个部门负责的. SMDK是20人 PhD 团队写的. 回答问题的是tech lead,旁边有一个销售.
另一个部门有中文服务. 1. SmartSSD永远在路上. 2. CXLSSD 搞定PoC了,即插即用,对标Optane,上市2025 3. 他们都有Zen4和SPR.
They talked about the EXMEM
PCIe 6.0 has interleave in spec
So SMDK developer thinks Jemalloc is not going to upstream to Linux.
But EXMEM Zone configuration may be.
I asked about the kernel page allocator for EXMEM Zone
SMDK guy confesses it has a problem when putting pages onto the CXL EXMEM Zon
Micron
他们在PMDK/SMDK/TPP/Pond上在他们的机器上做了超多实验,跑了各种workloads,但是不公开,手慢了所以没发paper.但是可以合作.尤其是对workloads的allocator.
Intel
Kurt Lender这个人在现场科普CXL.cache,然后我问他tsx支不支持,他说只支持STM,另一个是GT的韩国人做数据库的phd在旁边问redis workloads CXL.cache有没有优化.他回答当然有,device claim cacheline,别的CPU直接aware,那么polling thread都不用干了,CC由CXL来维护.我又问了实现CXL.cache和CXL.mem有没有共通的地方,他说CXL.mem是CXL.cache的子集.主要是RoO需要走UPI(这里还是有datapath的congestion)和CXL switch 让其他所有node和device aware,他们实现的比AMD高速...(好吧随便你吹,你是dailao),然后谈了CXL.mem要实存转虚存需不需要DFS CXL complex. 他说实时cache到switch上,(因为IOMMU可能会更新他们的位置,也有可能多对一,像操蛋的PM Memory mode一样),然后就他设计的还挺好的...
AWS
他们在migrate很多的传统行业和Web3/Quantum这种新兴行业的数据到他们的数据存储和网络API上.有几个例子:一个提供quantum computing服务的trading API,他们部署运算到离他们实例最近的地方就行.(怎么这么trading firm.),一个FSx mount to LUSTRE/OpenZFS的例子,FS as a service,这个老哥我提了几个问题,1. 你们这个只适合需要跑应用拿结果的人,但是有些人想通过魔改内核和文件系统怎么办呢?他们的baremetal机器似乎很贵.他说他们只服务前者,后者找他们工程师改. 2. 如果有些公司想要数据private cloud怎么办?可不可以接S3到你们的机器,他说还没实现,只能整套解决方案卖. 还有一个做VDI的,似乎必须实例需要在数据旁边,不能我在Tokio,机器在Houston的情况,那只能wireguard,他们数据中心间不是很链路优化.
下面是他们新部署的Gravation Arm机器.超厉害.
Elastics.cloud
这个公司知道自己比Micron做的慢,想做CPU coprocessor(RV+X or UCIe)做PIM或者allocator. 他们现场的机器连开机都够呛,极其像我的12900k超频.
Meta
他们听说要搞BPF CPU scheduler.
ETHz talk about the future of computation
Data Movement should also be considered in the computation of complexity.
Hardware-Efficient Machine Learning

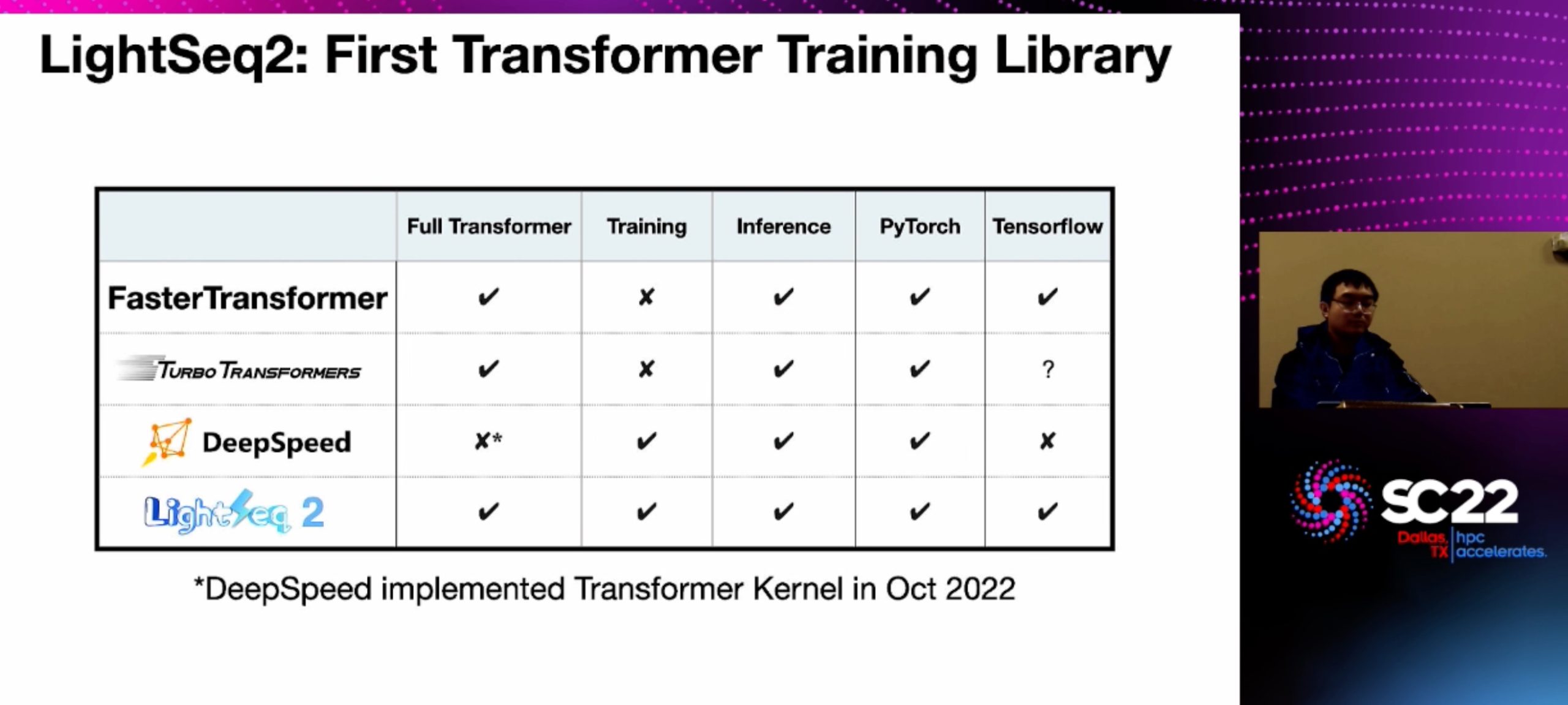
LightSeq2
Performance Modeling, Scaling, and Characterization


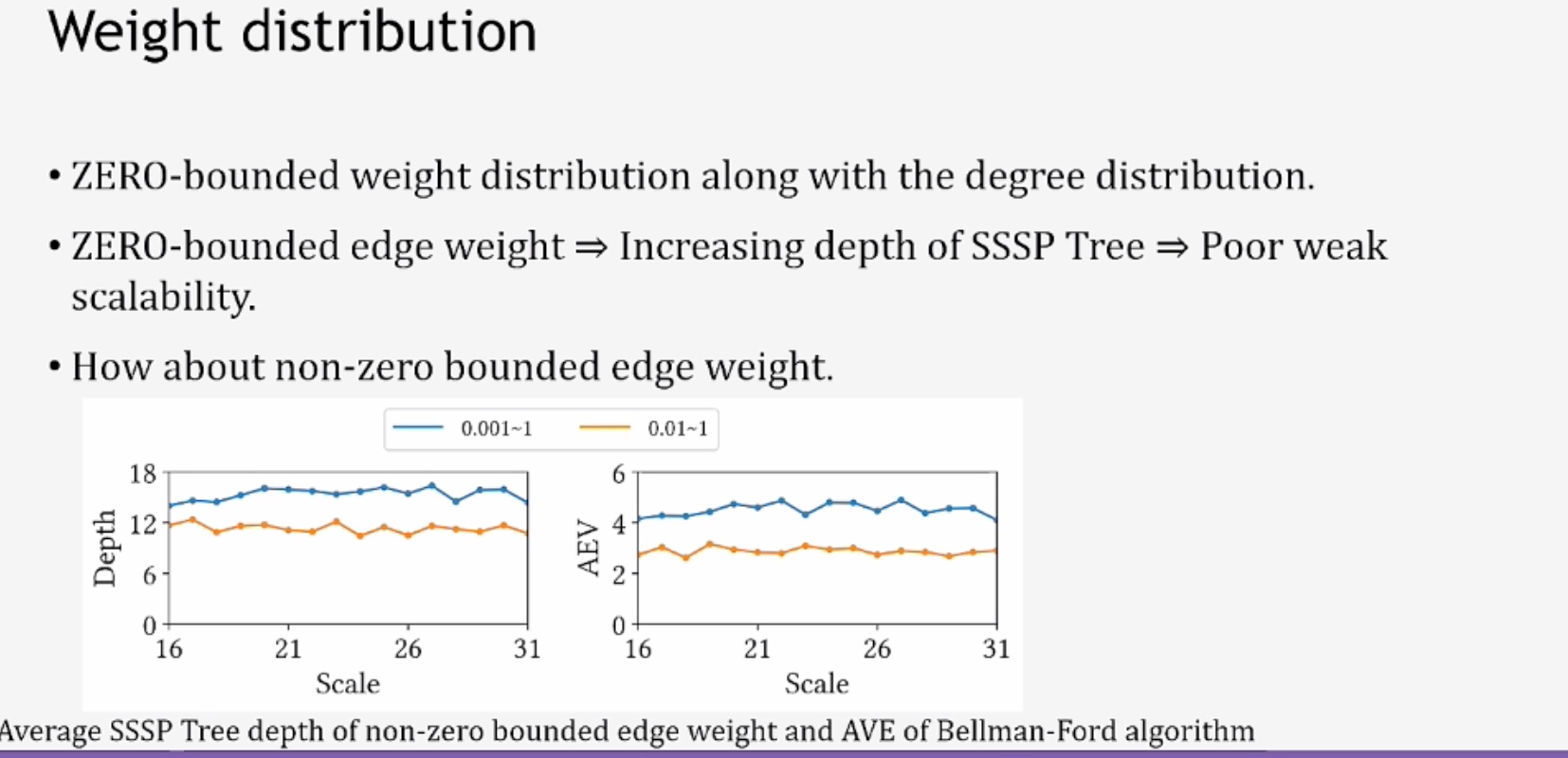
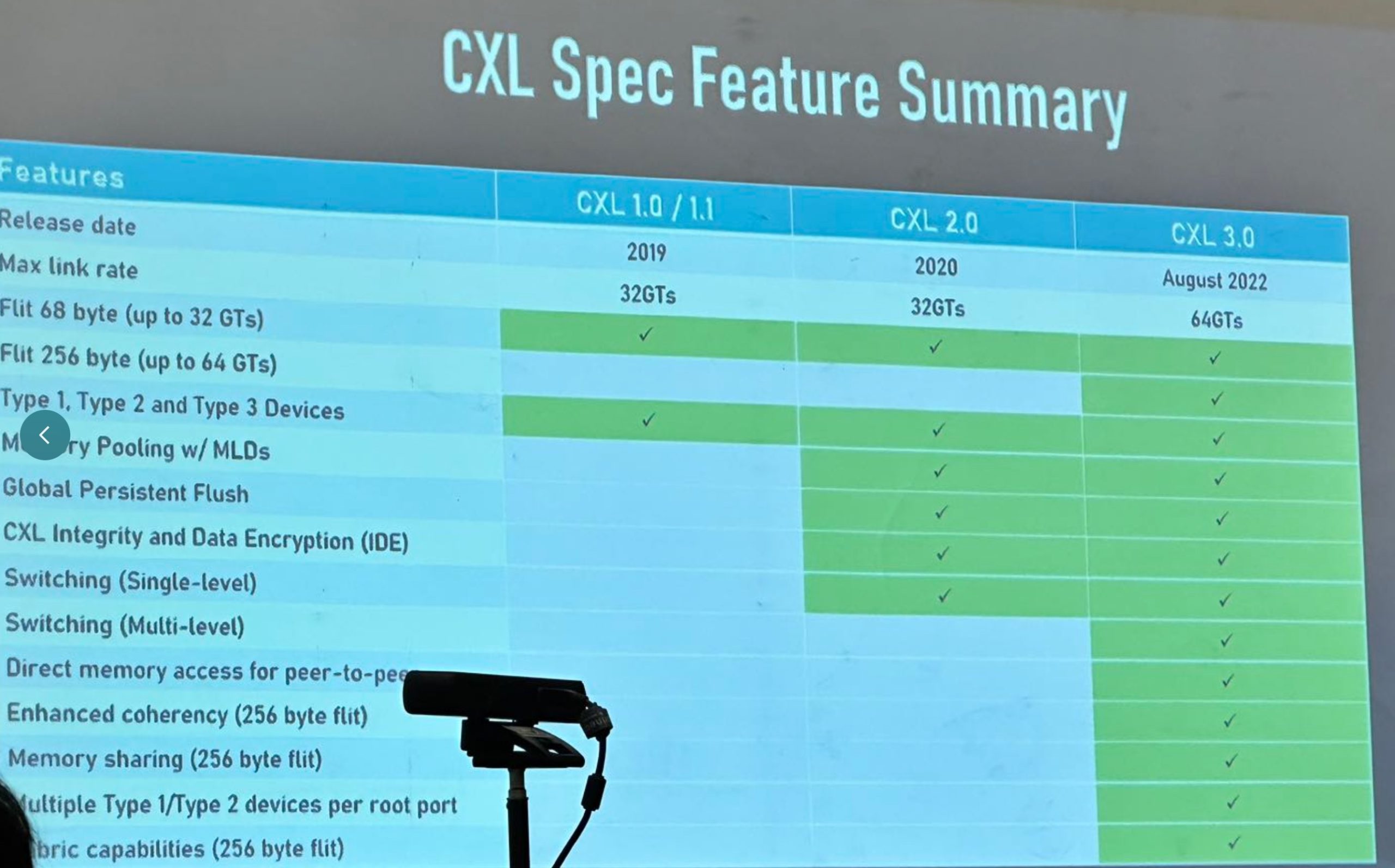
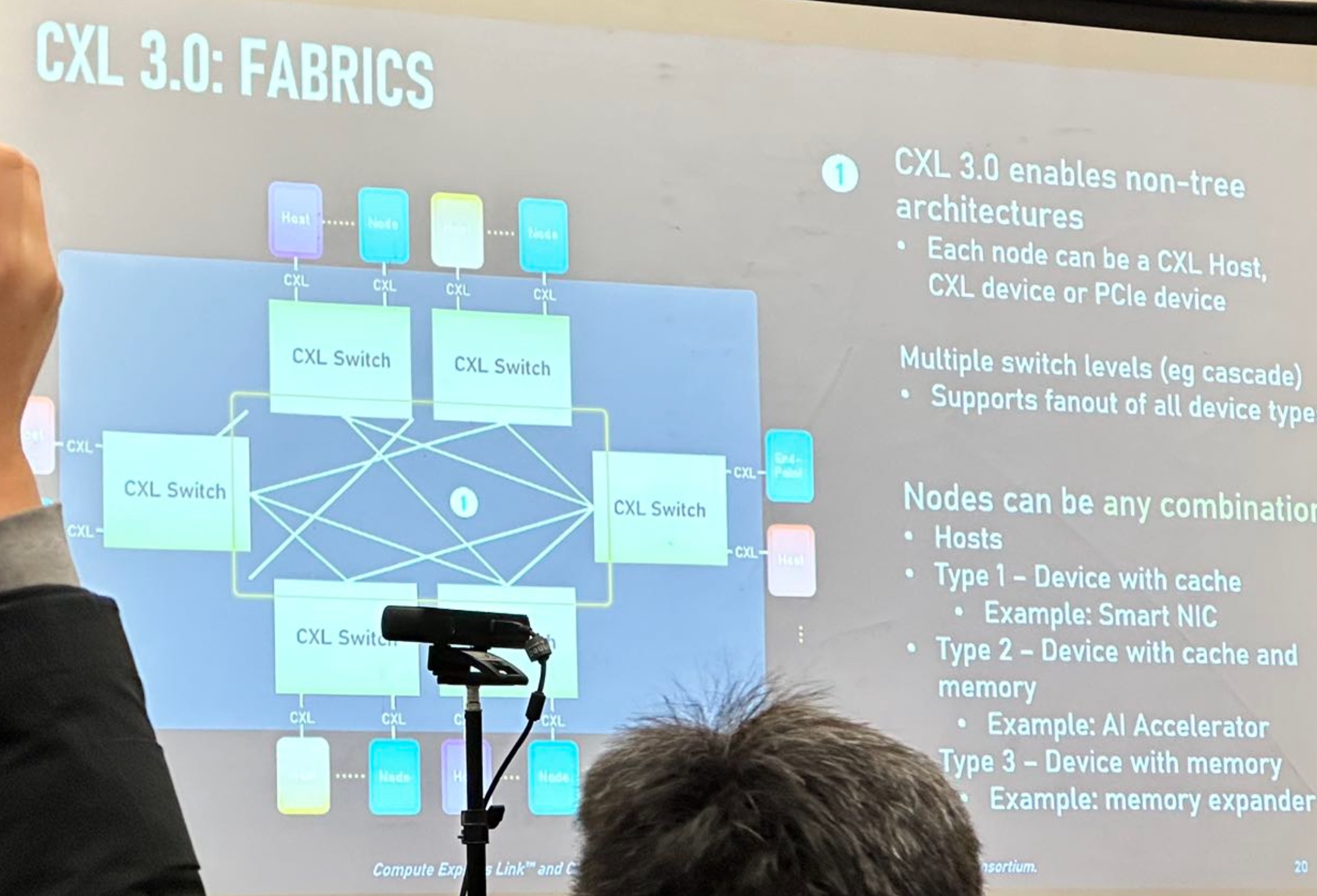
CXL 3.0 Demo








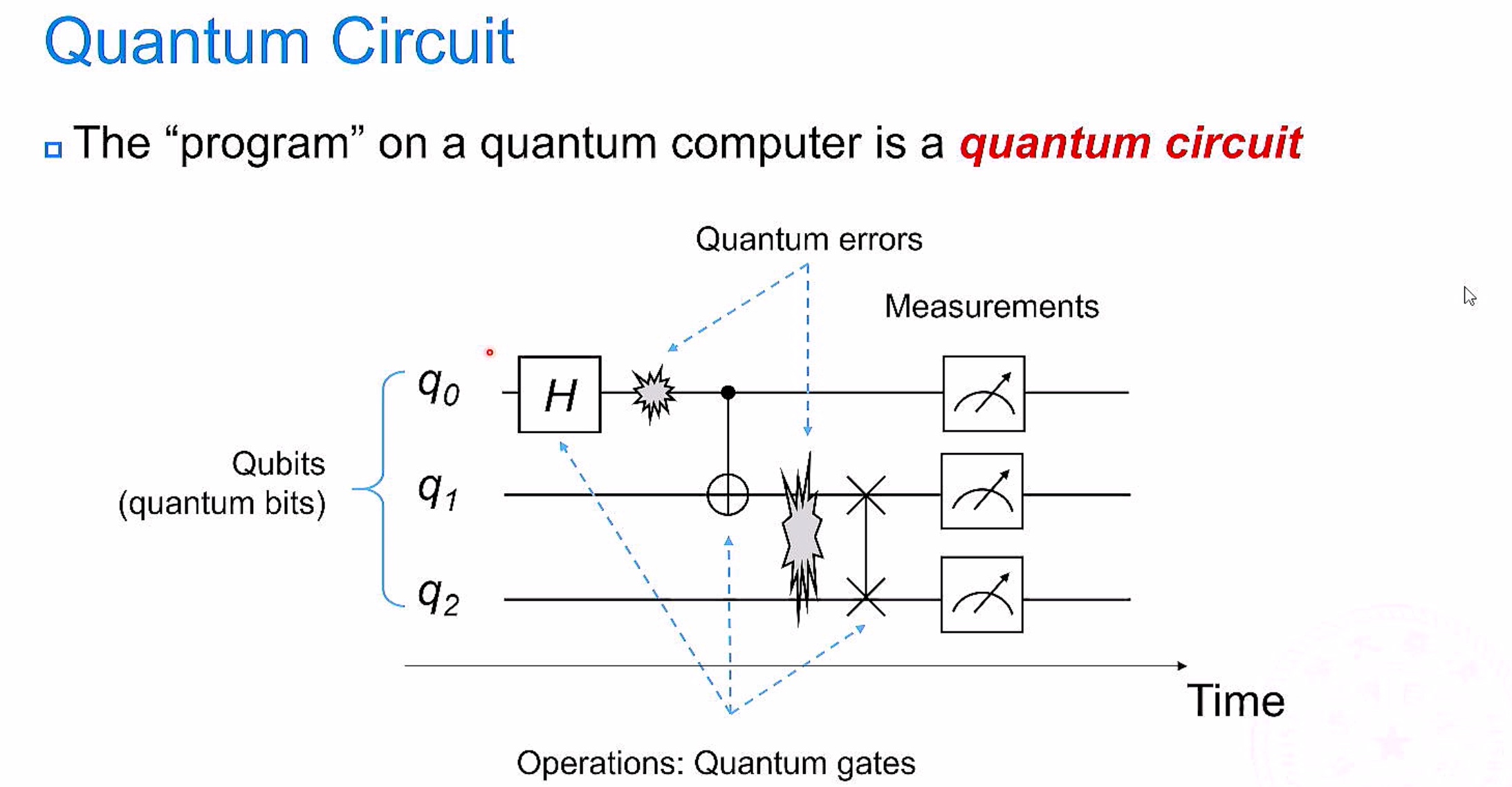
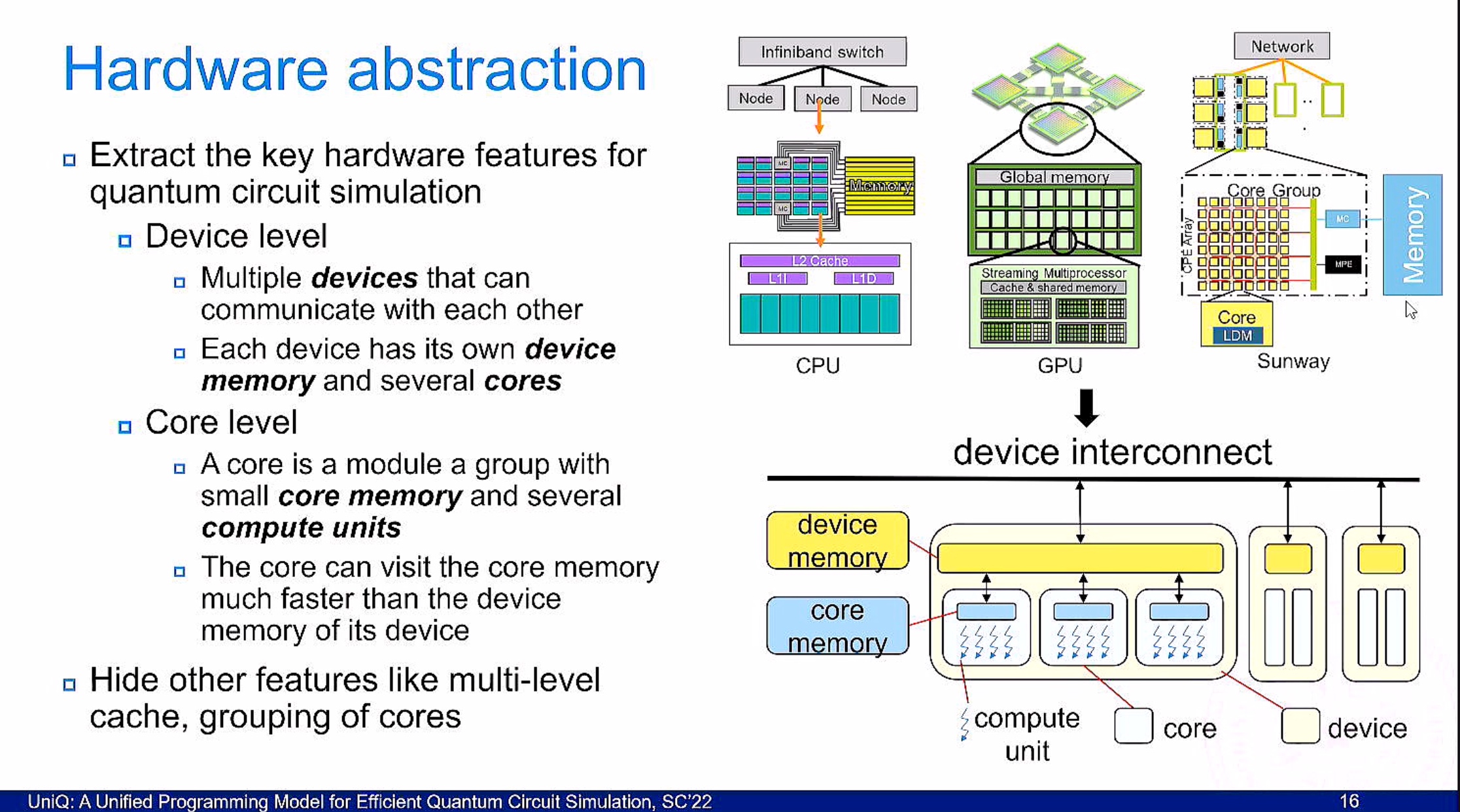
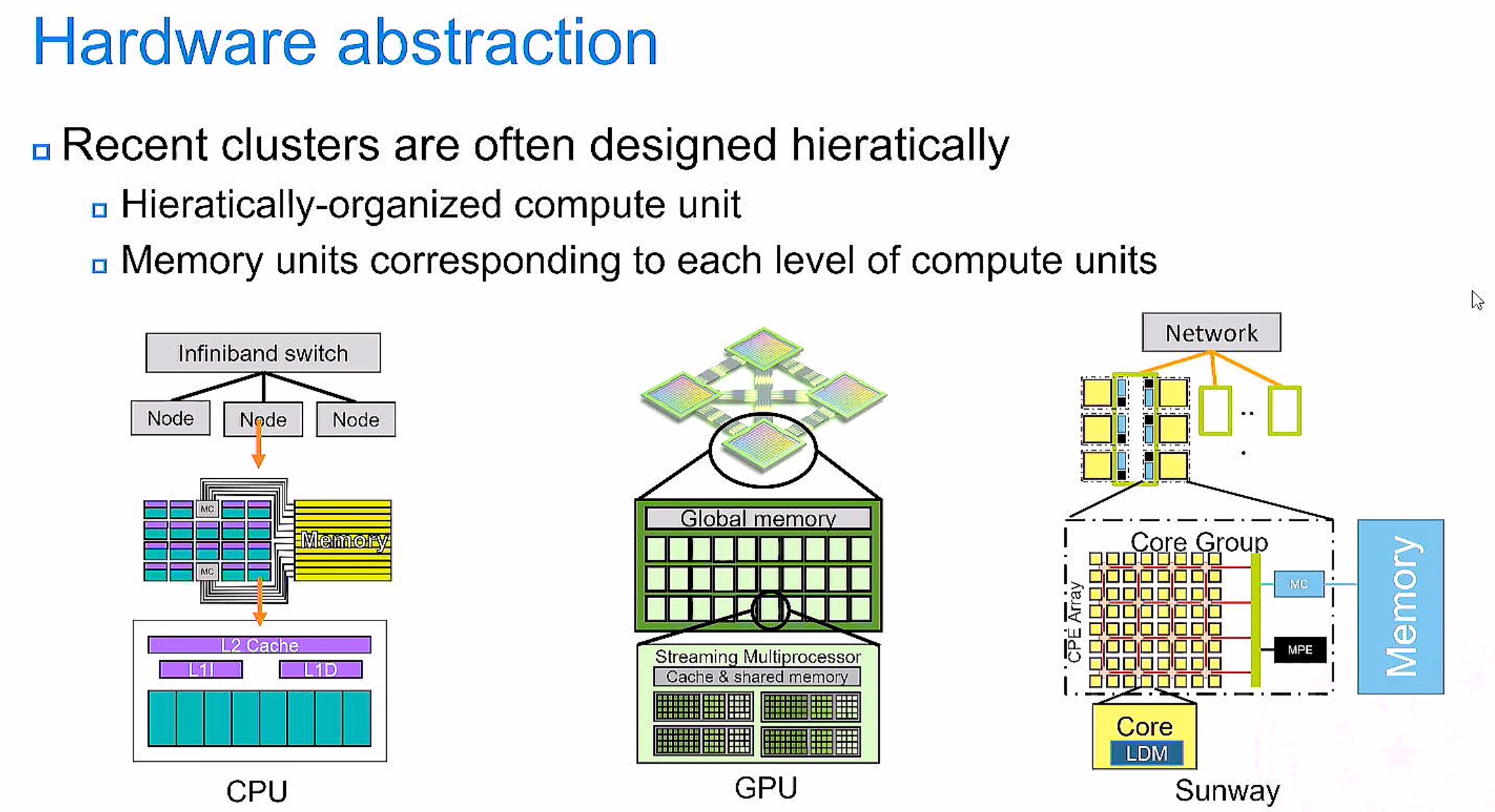
UniQ






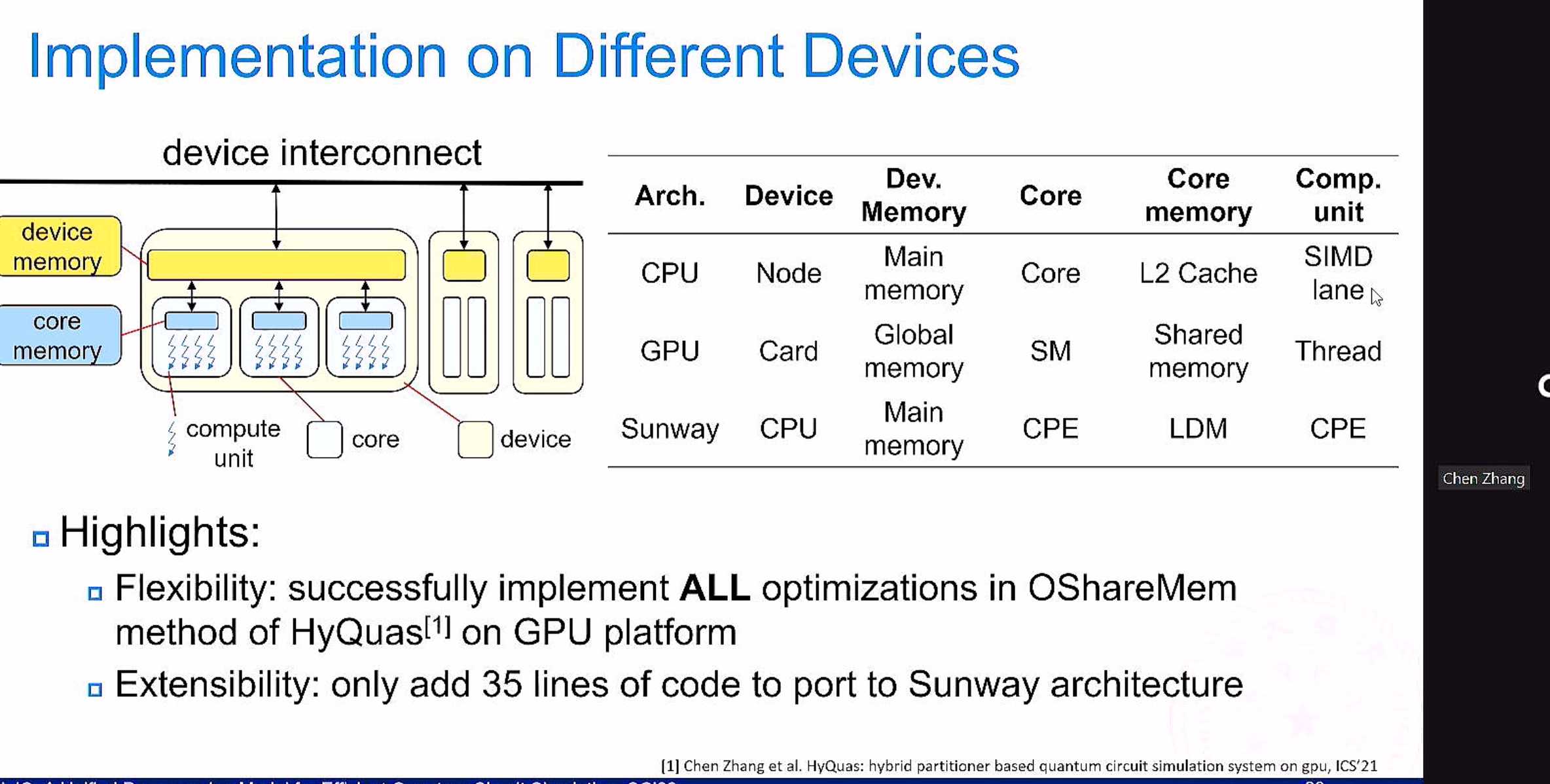

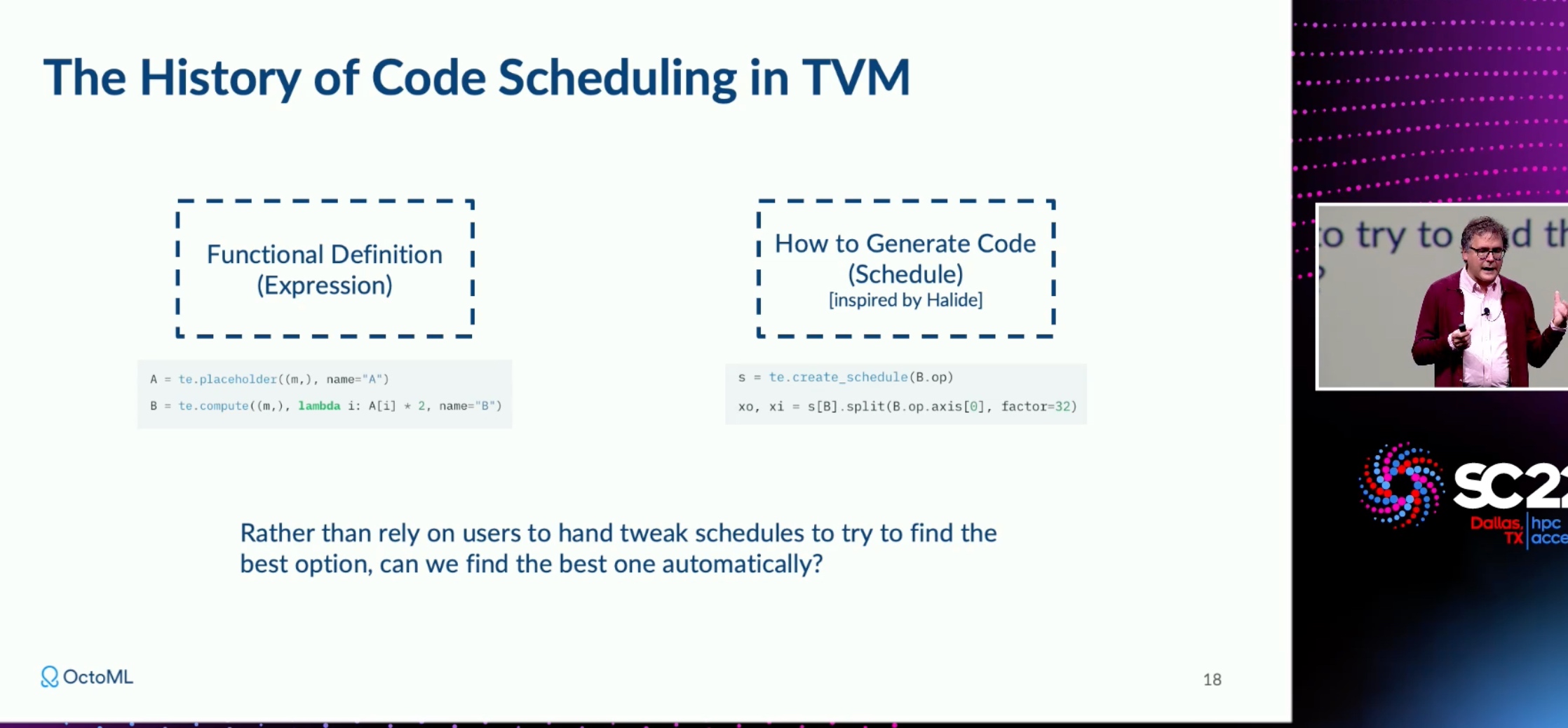
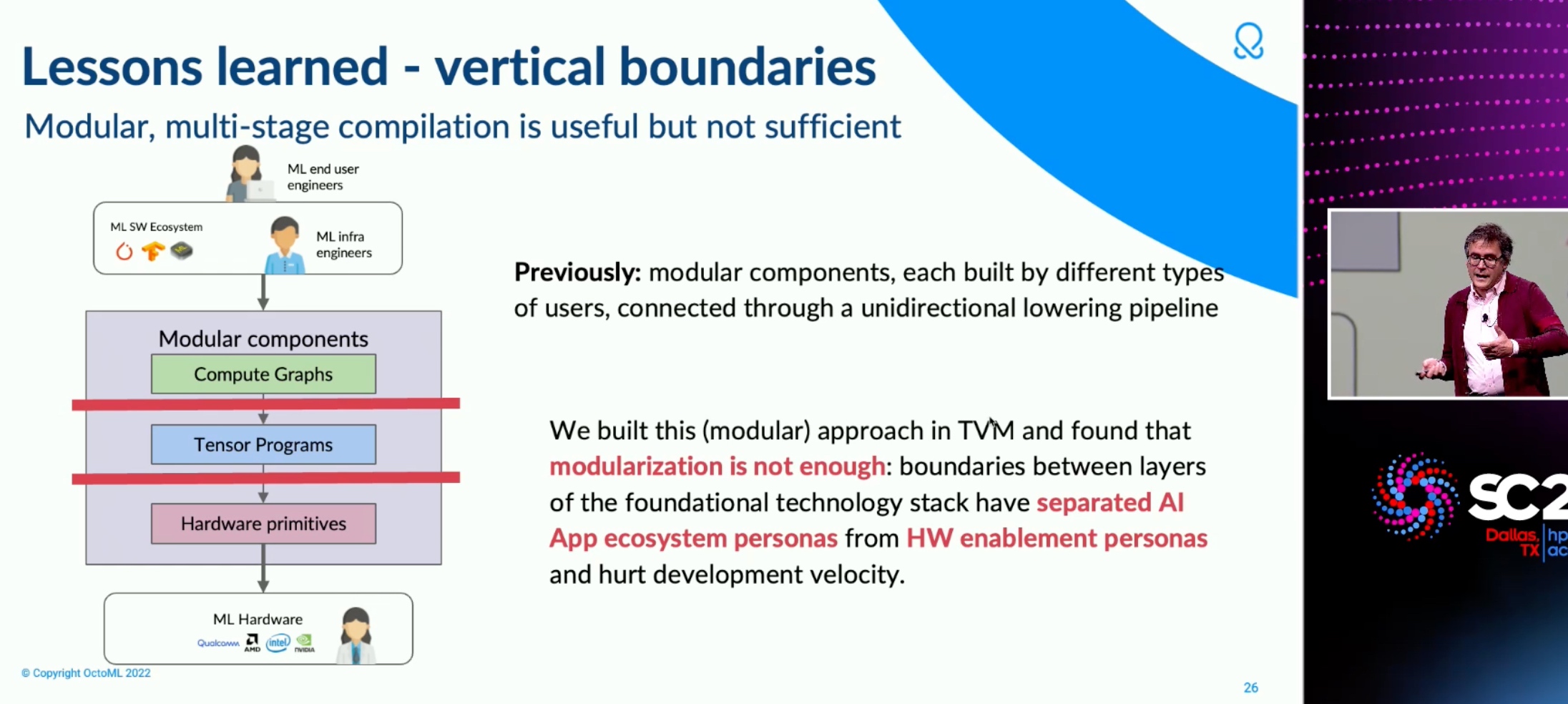
Octoml TVM

SmartNIC
Storage
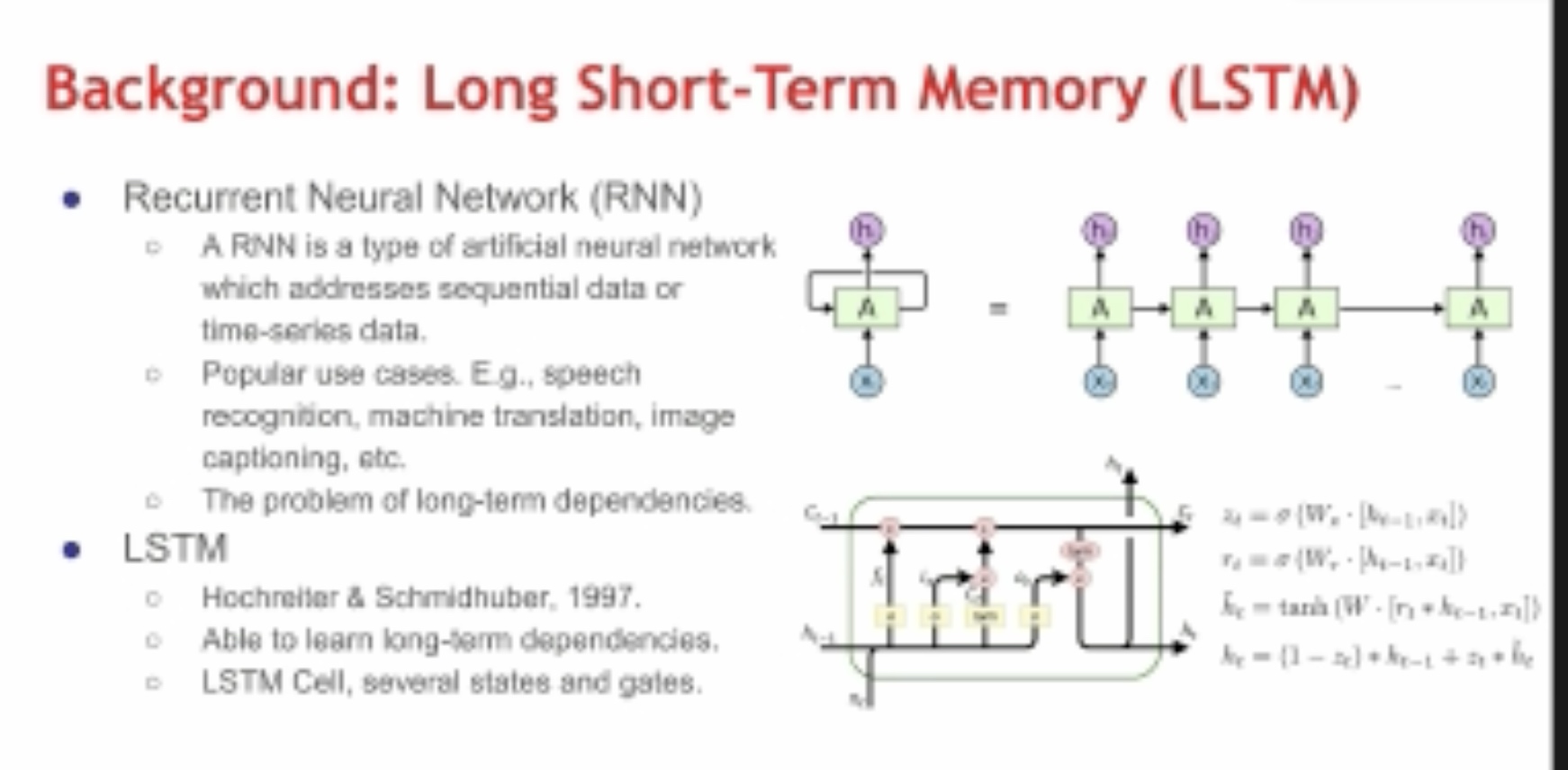
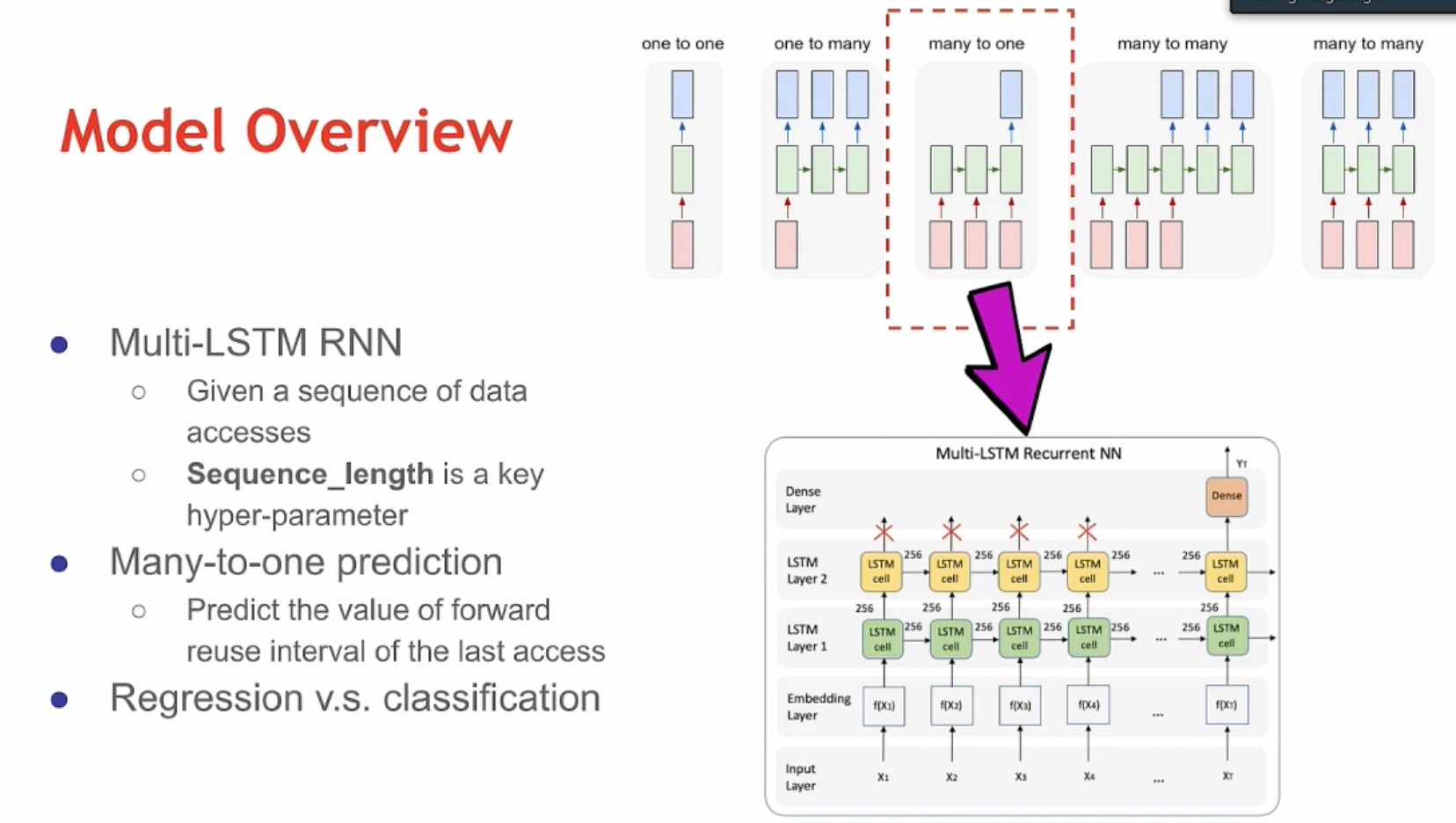
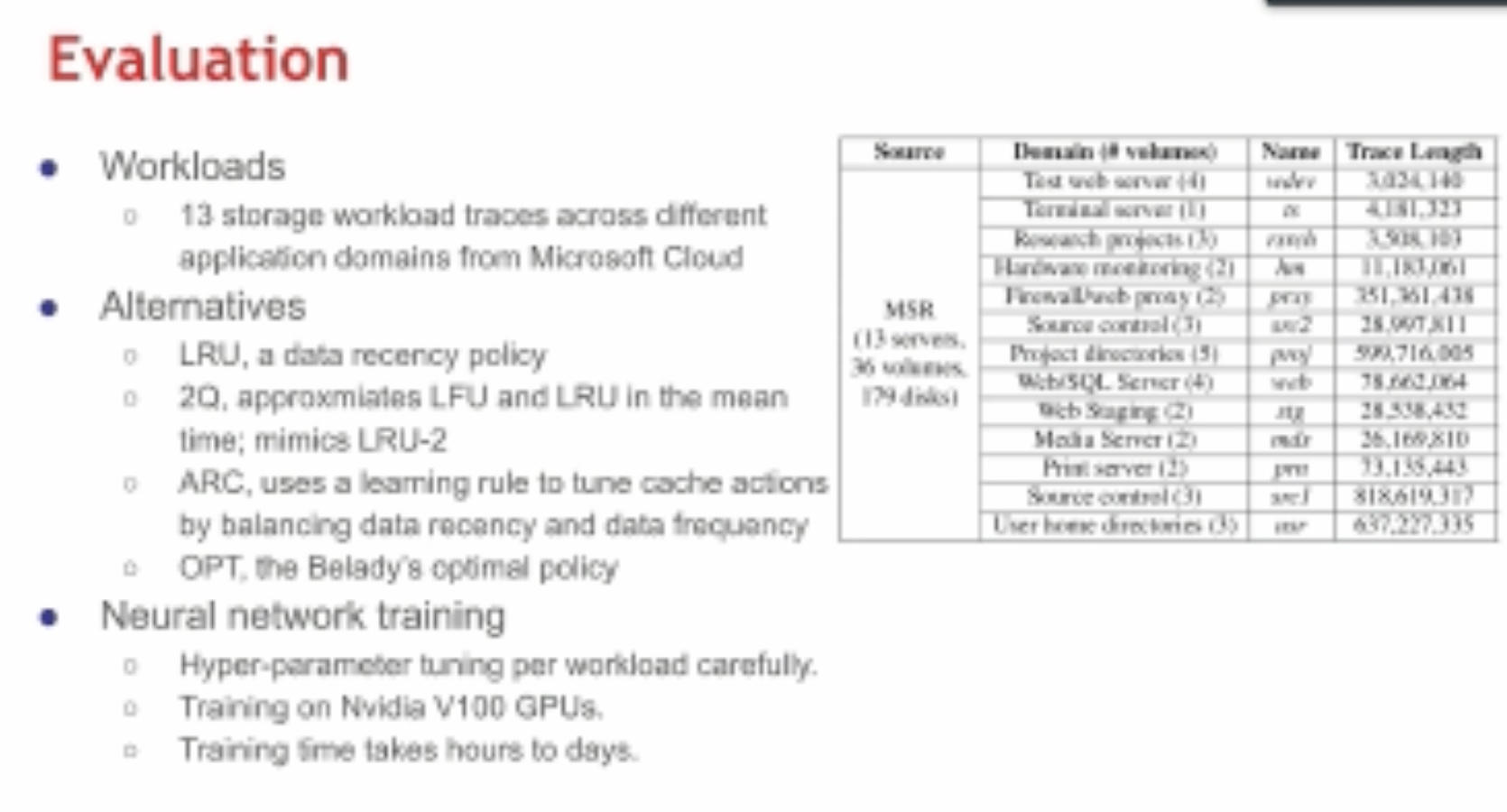
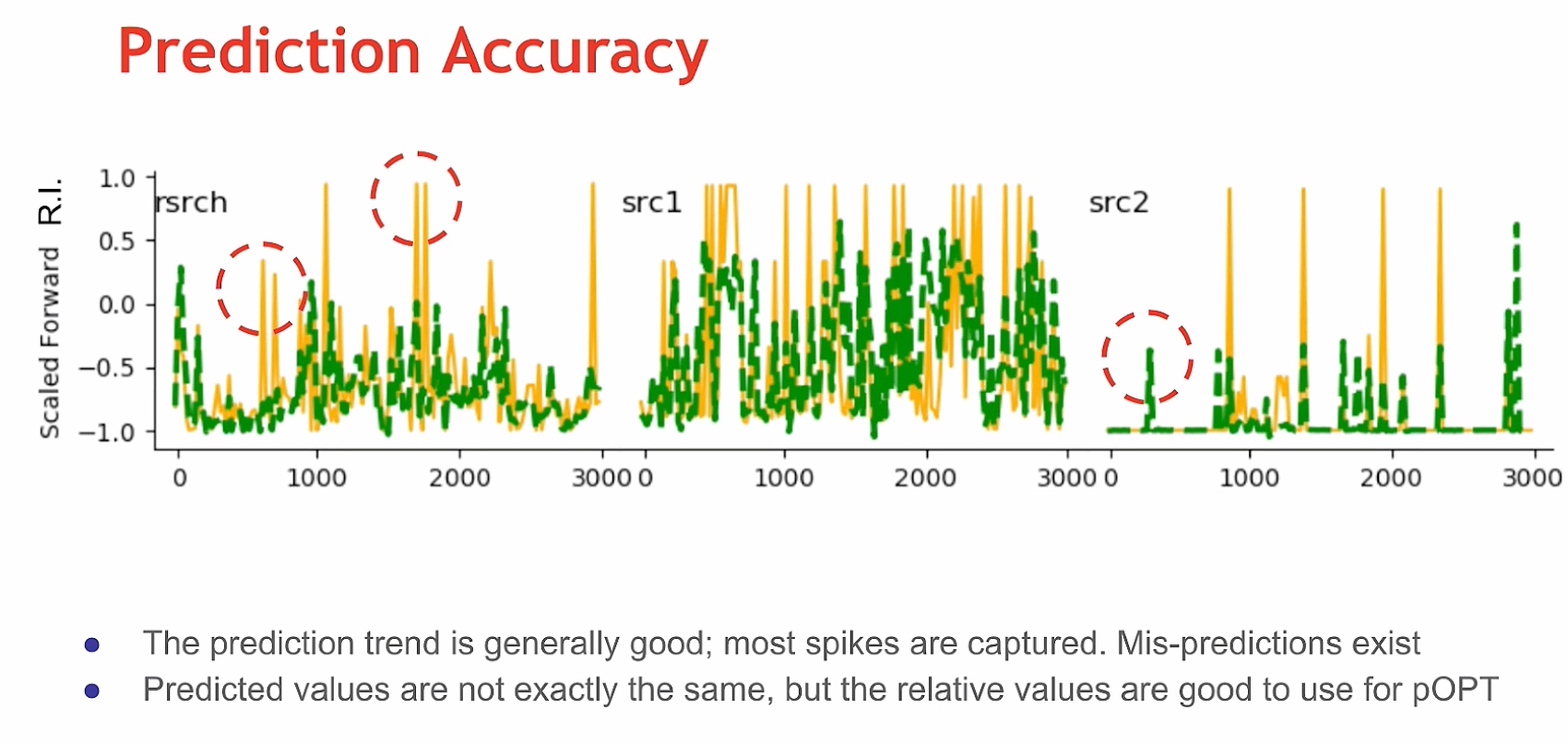
cace reuse, 王老师之前做的,但是是深度学习based的,LSTM-Based Machine Learning Approach,感觉听了几个talk,用LSTM的预测能很好的知道时序数据
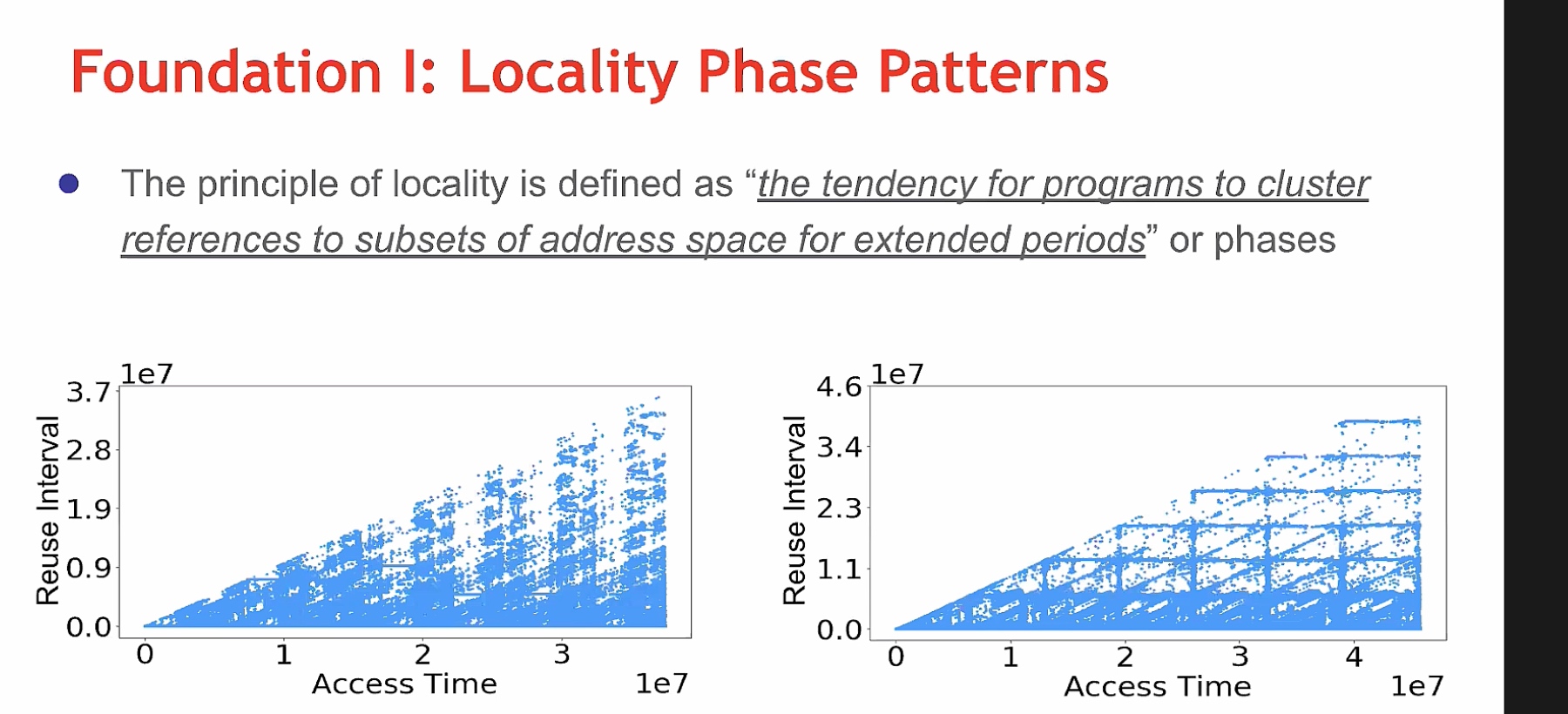

Hardware support Hypervisor on HPC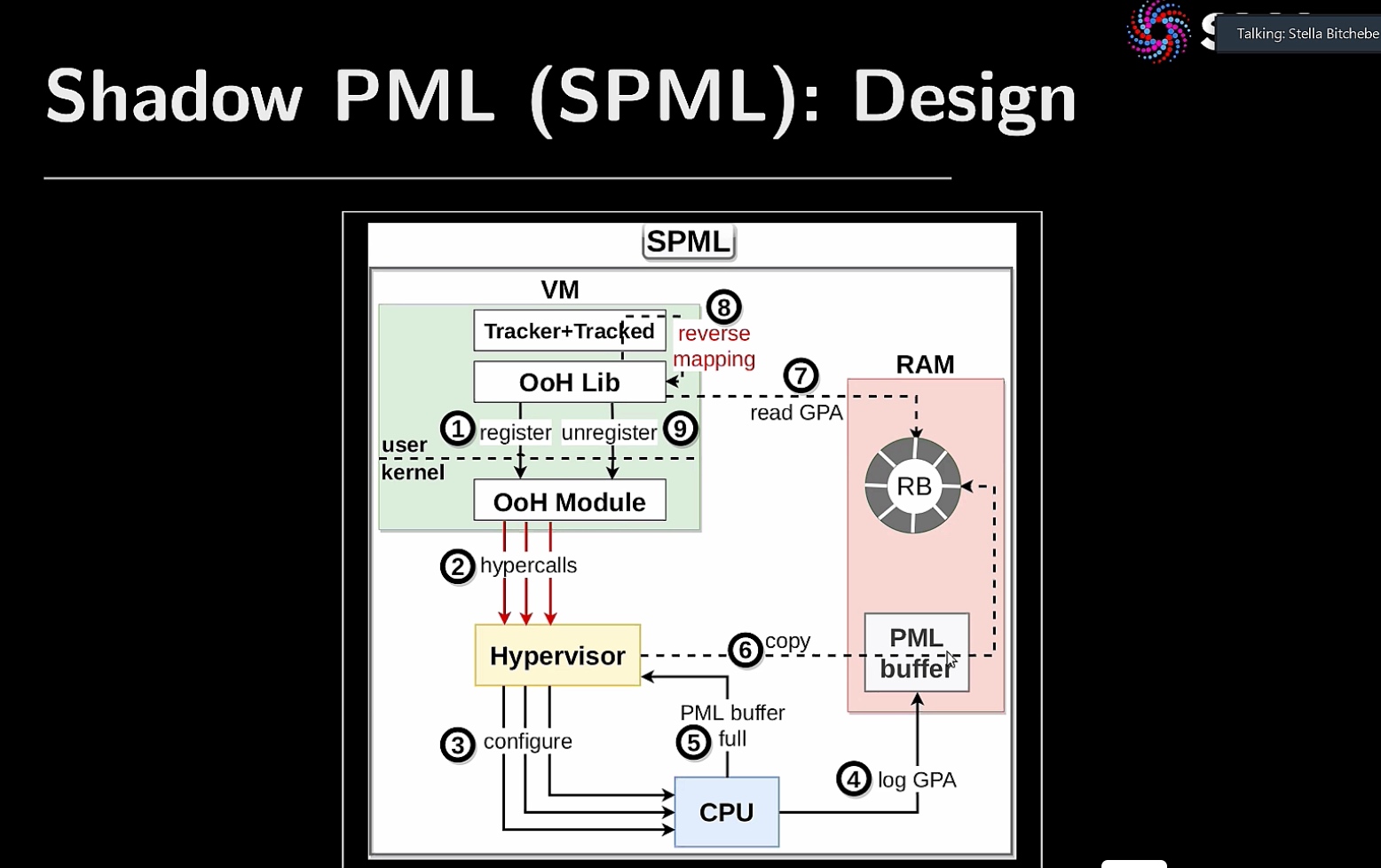
SMartNIC
small message+ specialized synchronization will solve the peek+idle interleaving problem. >= shared memory
SCC见闻
NTU的人有一位福州一中的认识我...然后MIT/UCSD带AMD Instinct,而且还直接移植Kokkos,感觉NTU/NTHU完全没了,他们两个都是带了3个节点8卡A100,但是NTU有俩 最后还是NTHU赢了,repro似乎是类CESM的应用,编译出来就很牛逼了.
AMD SC22 Booth
Fujistu compiler requires a pipeline with a limited register model to fit the Core.
RESDIS
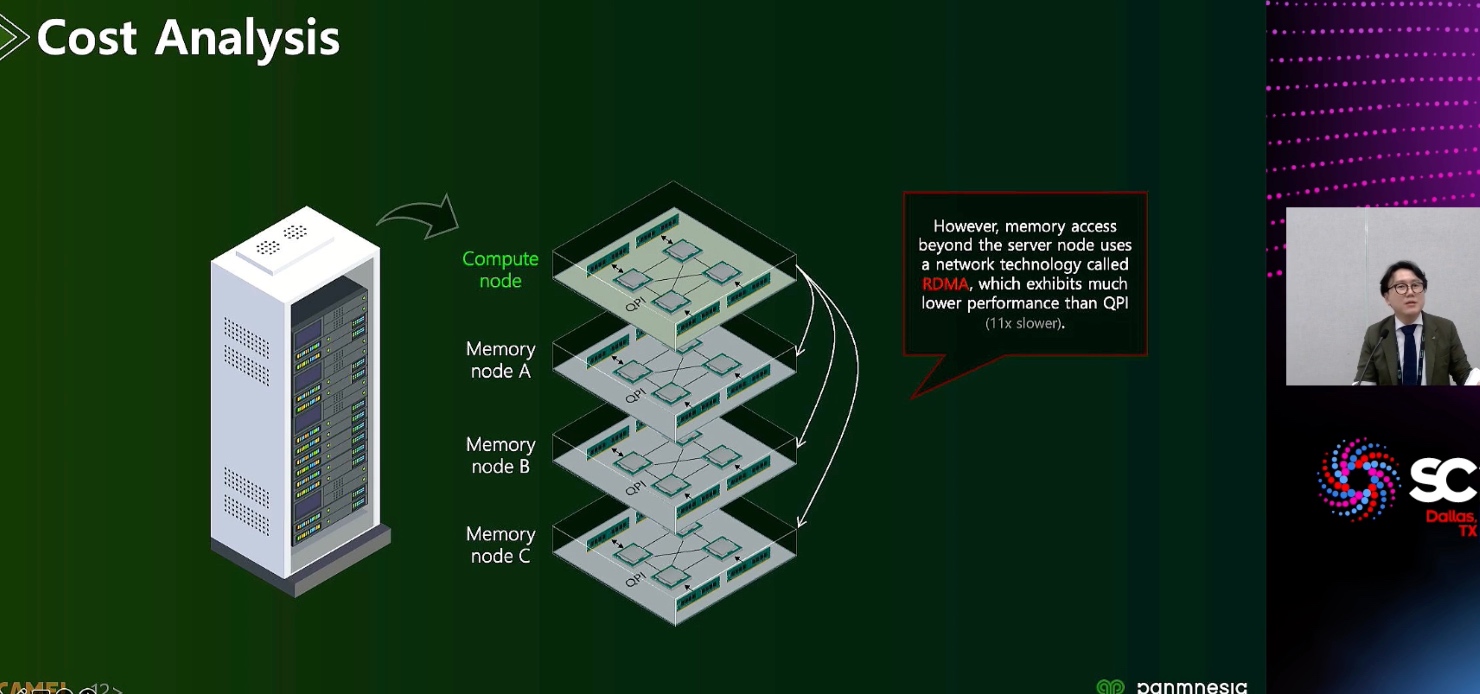
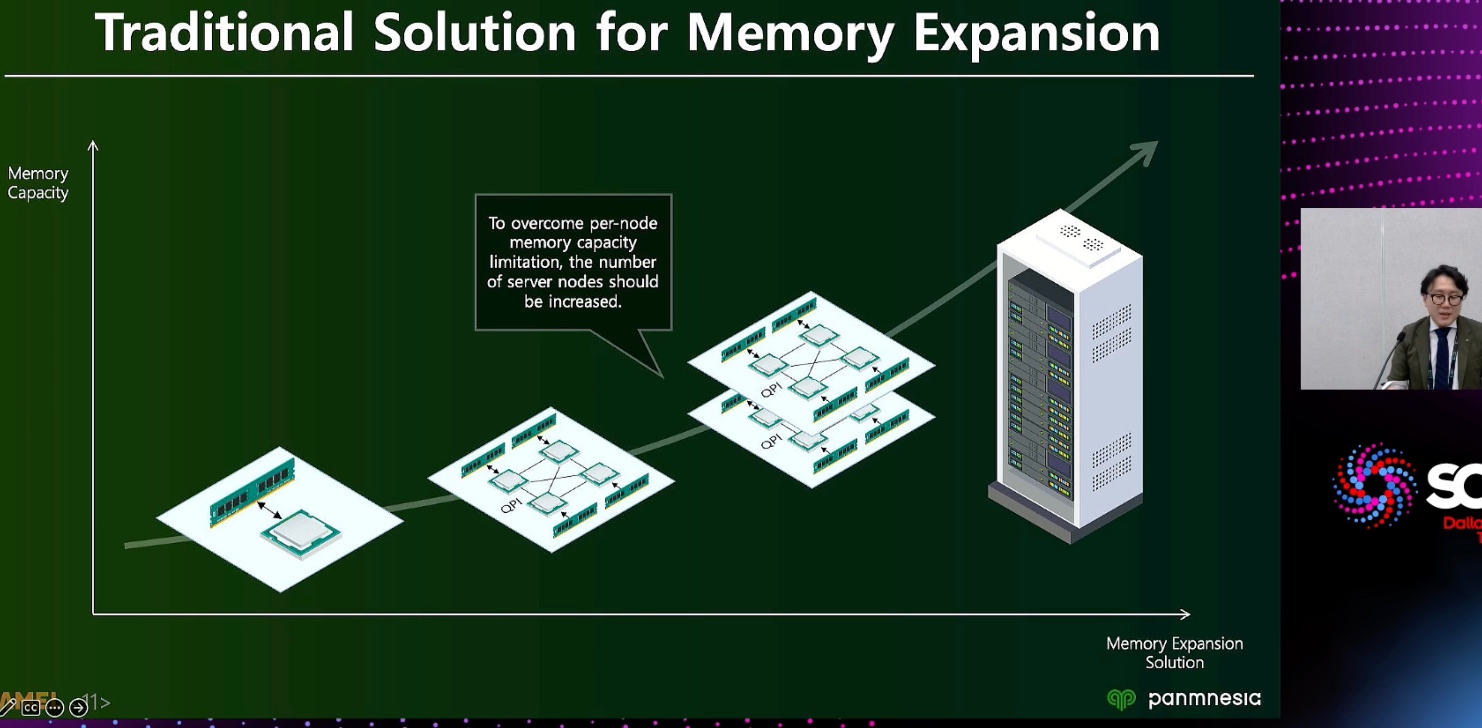
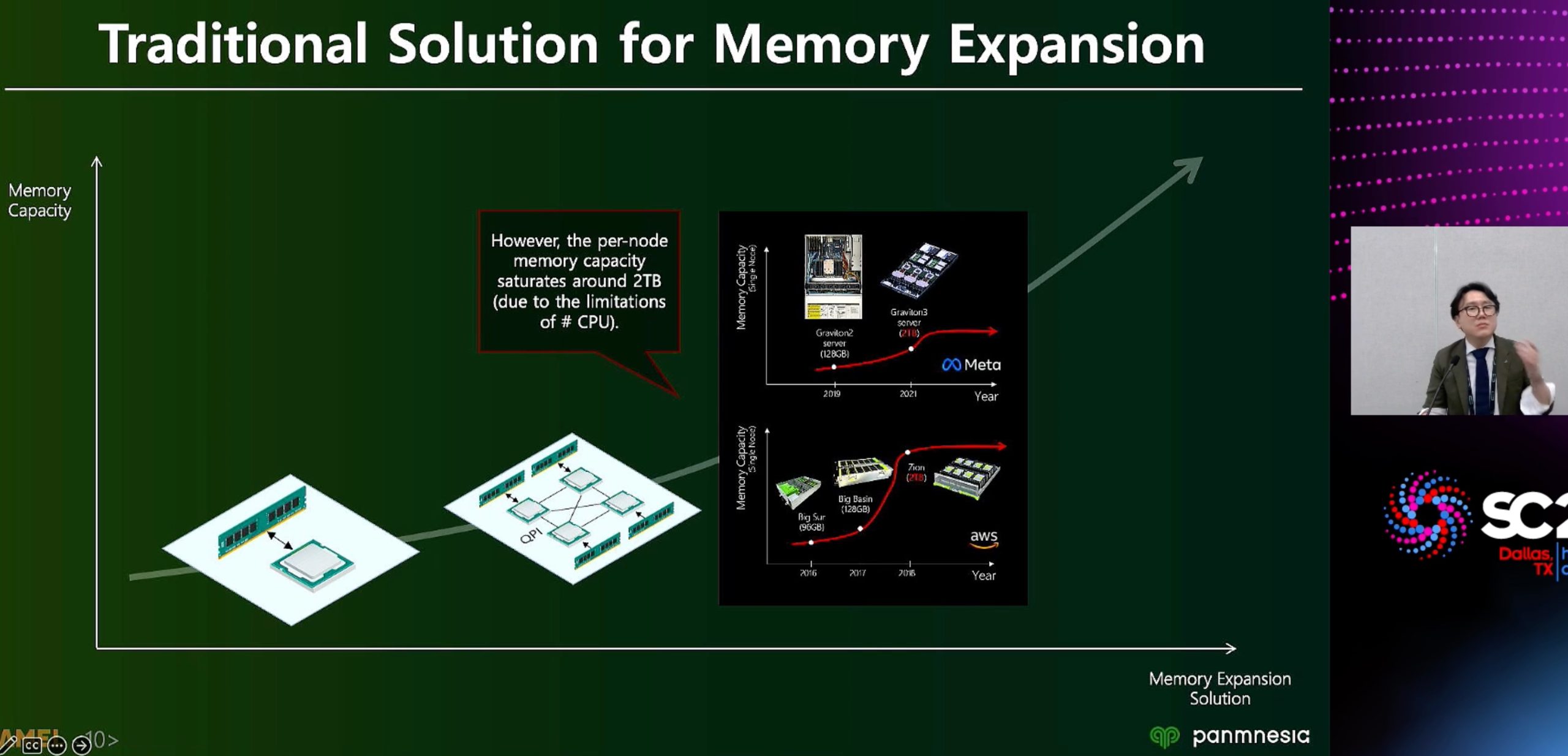


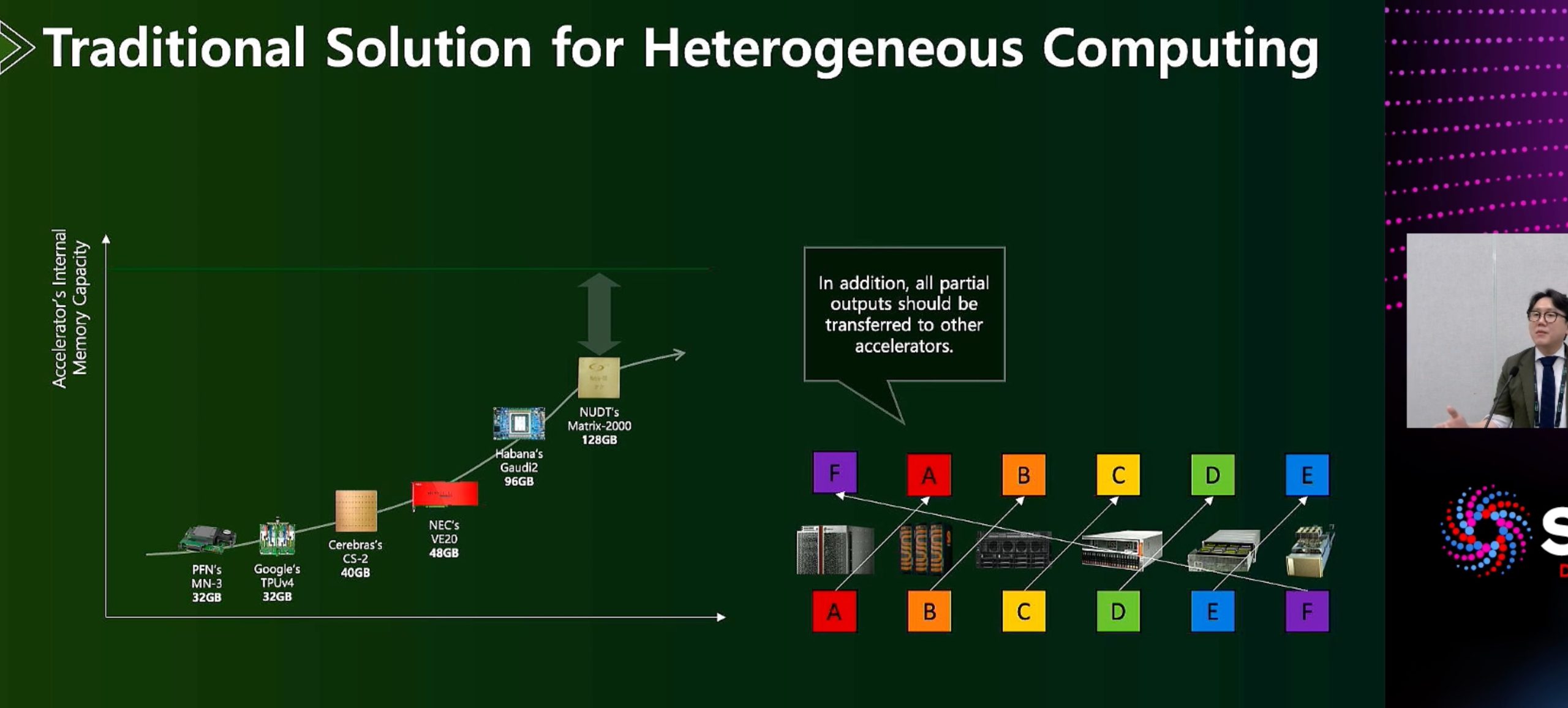
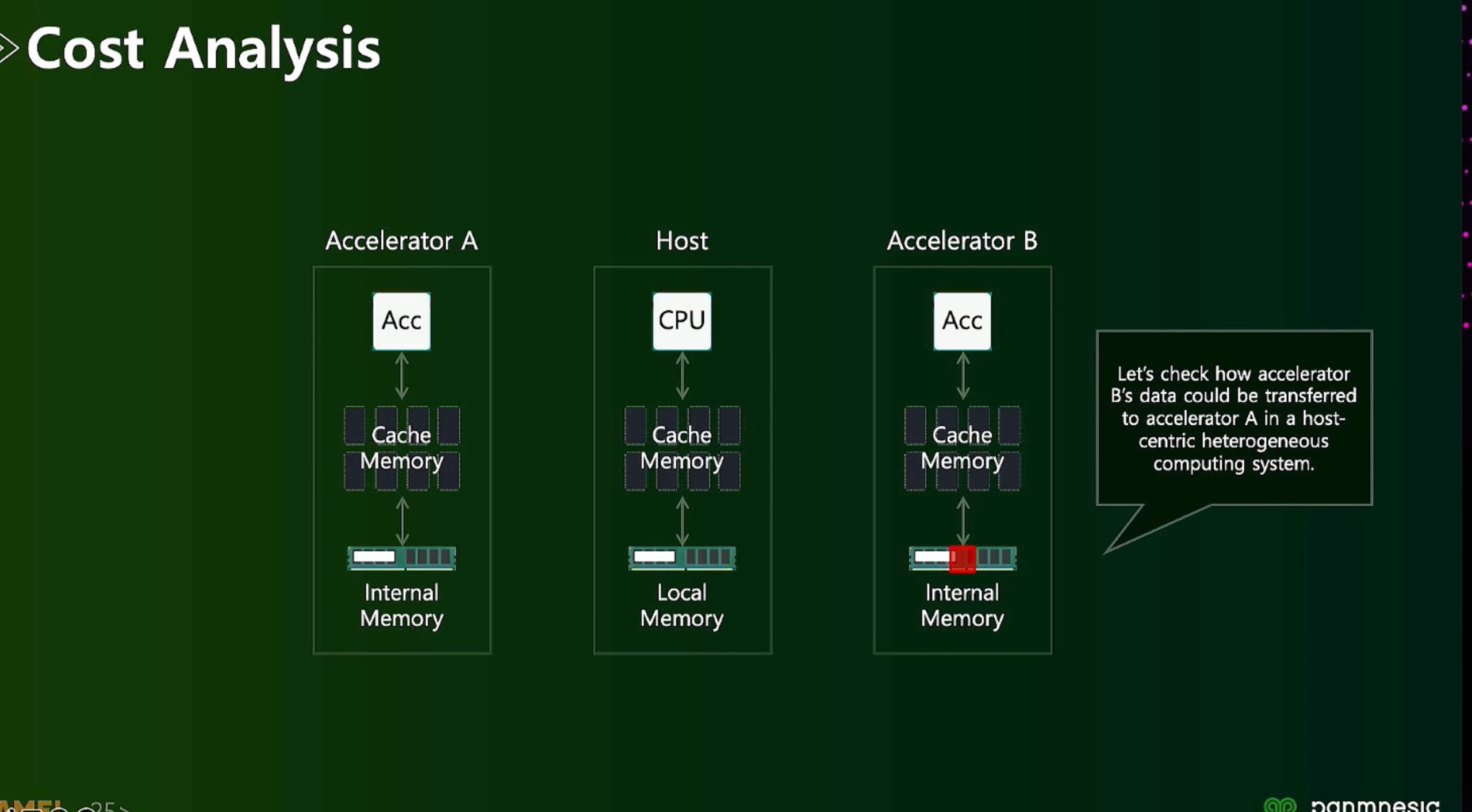
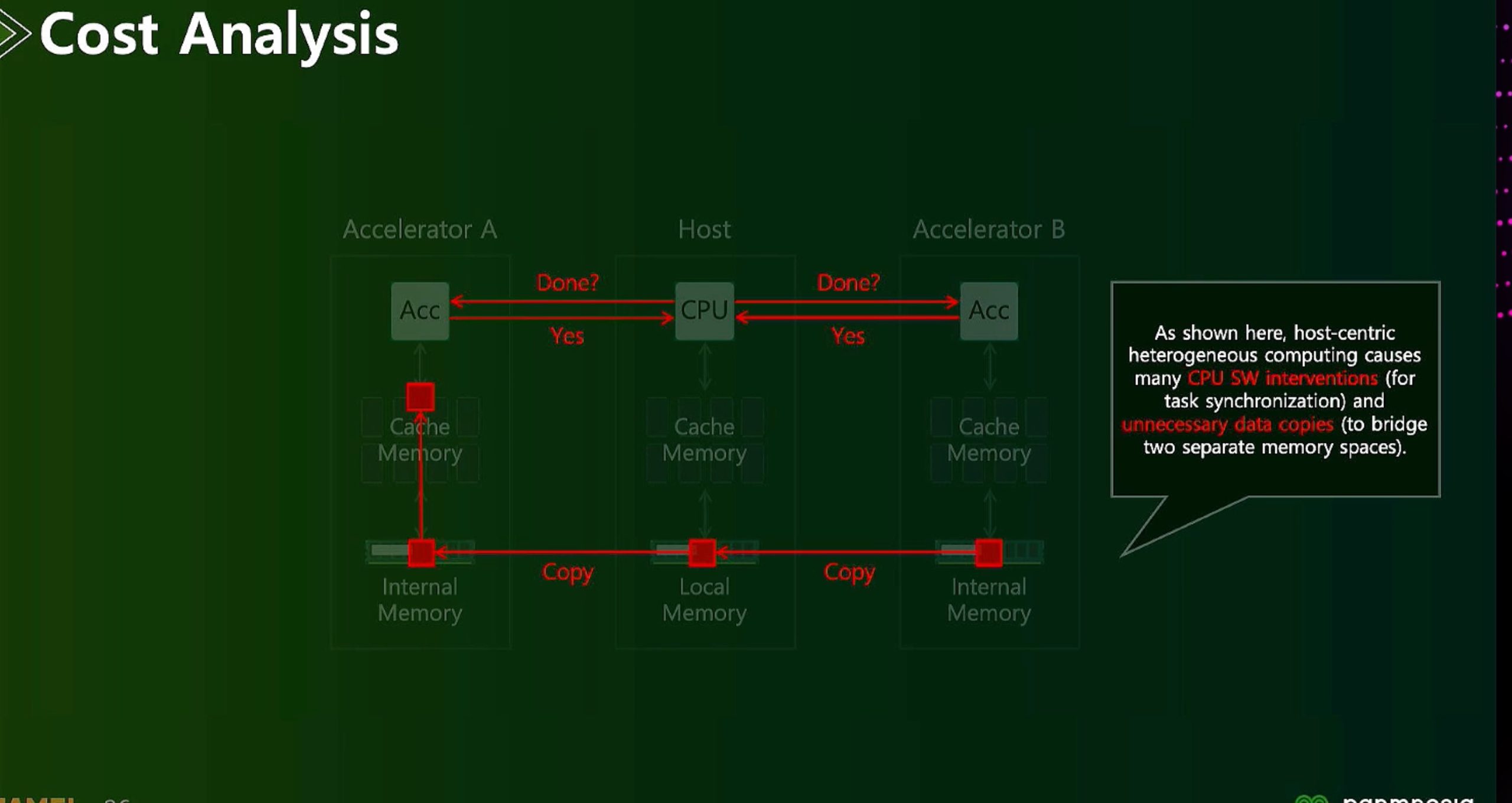
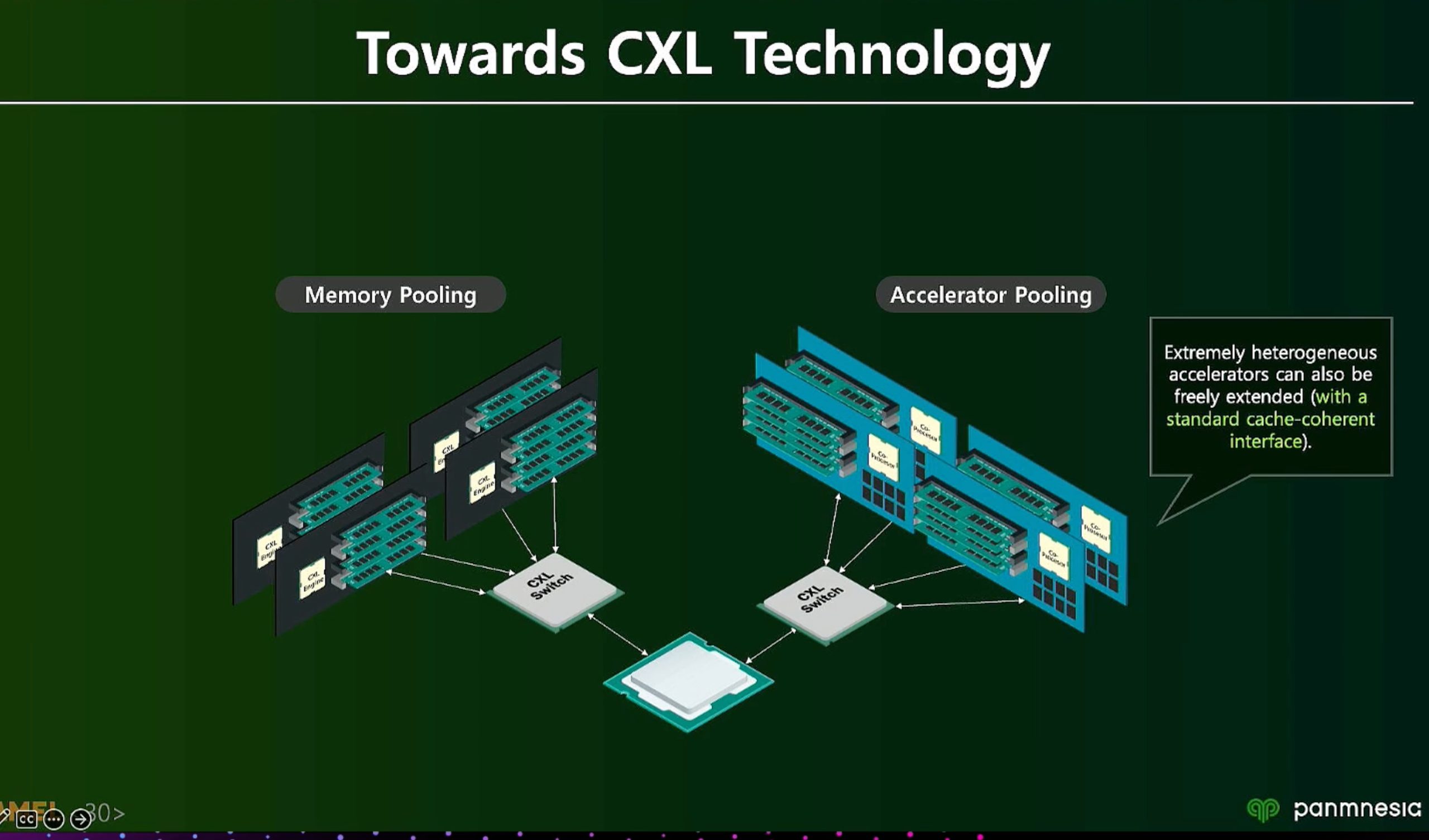

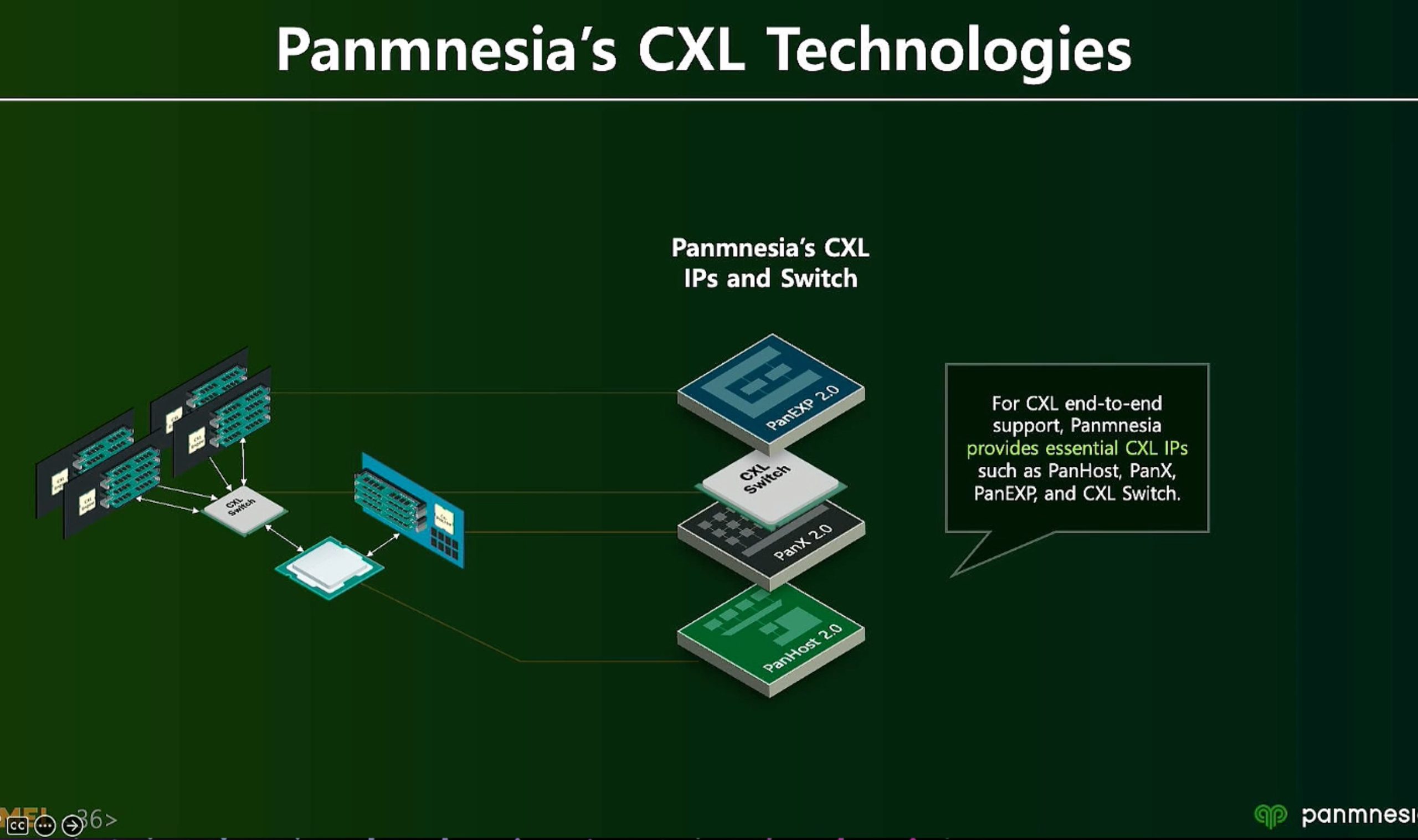

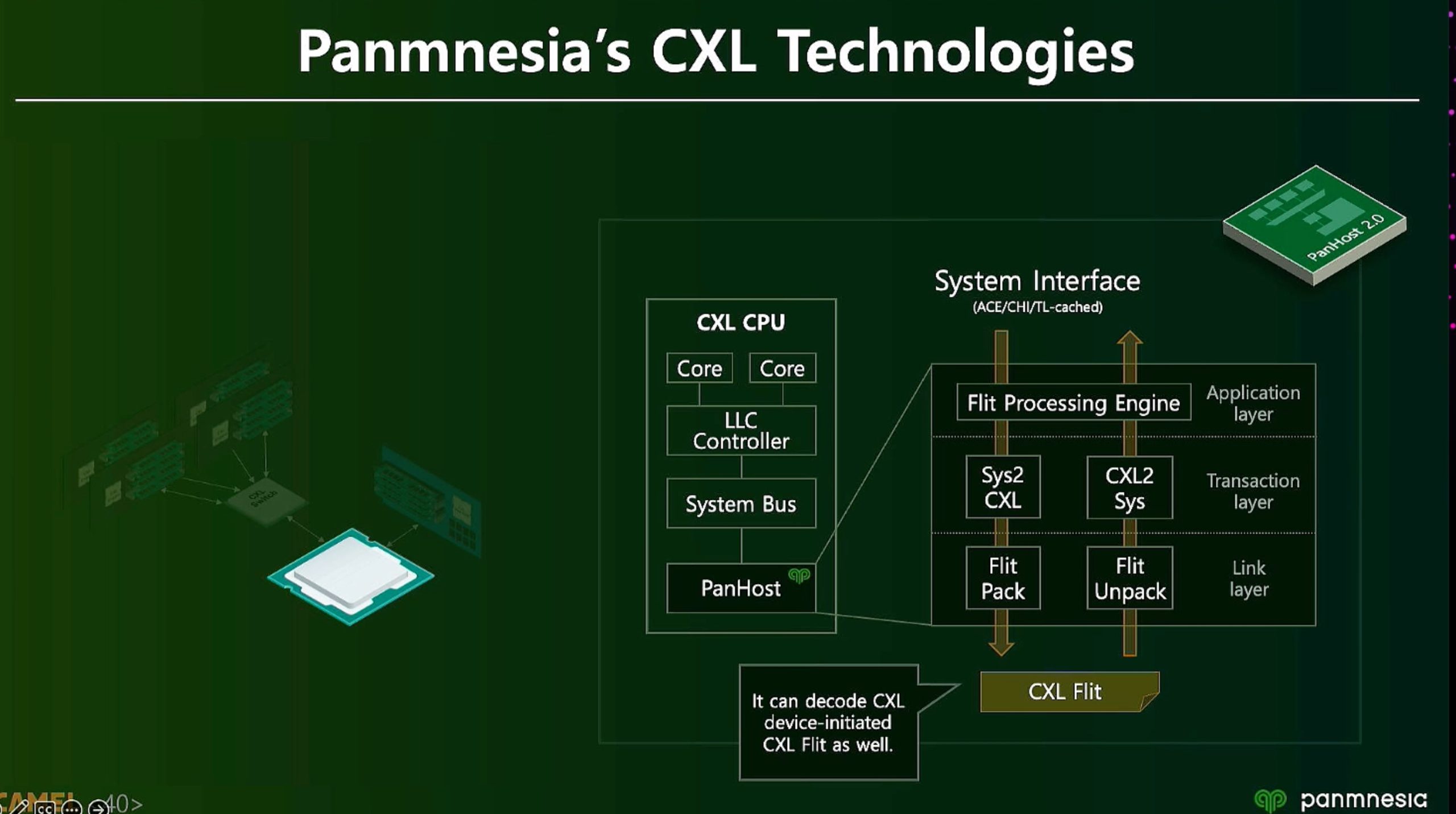
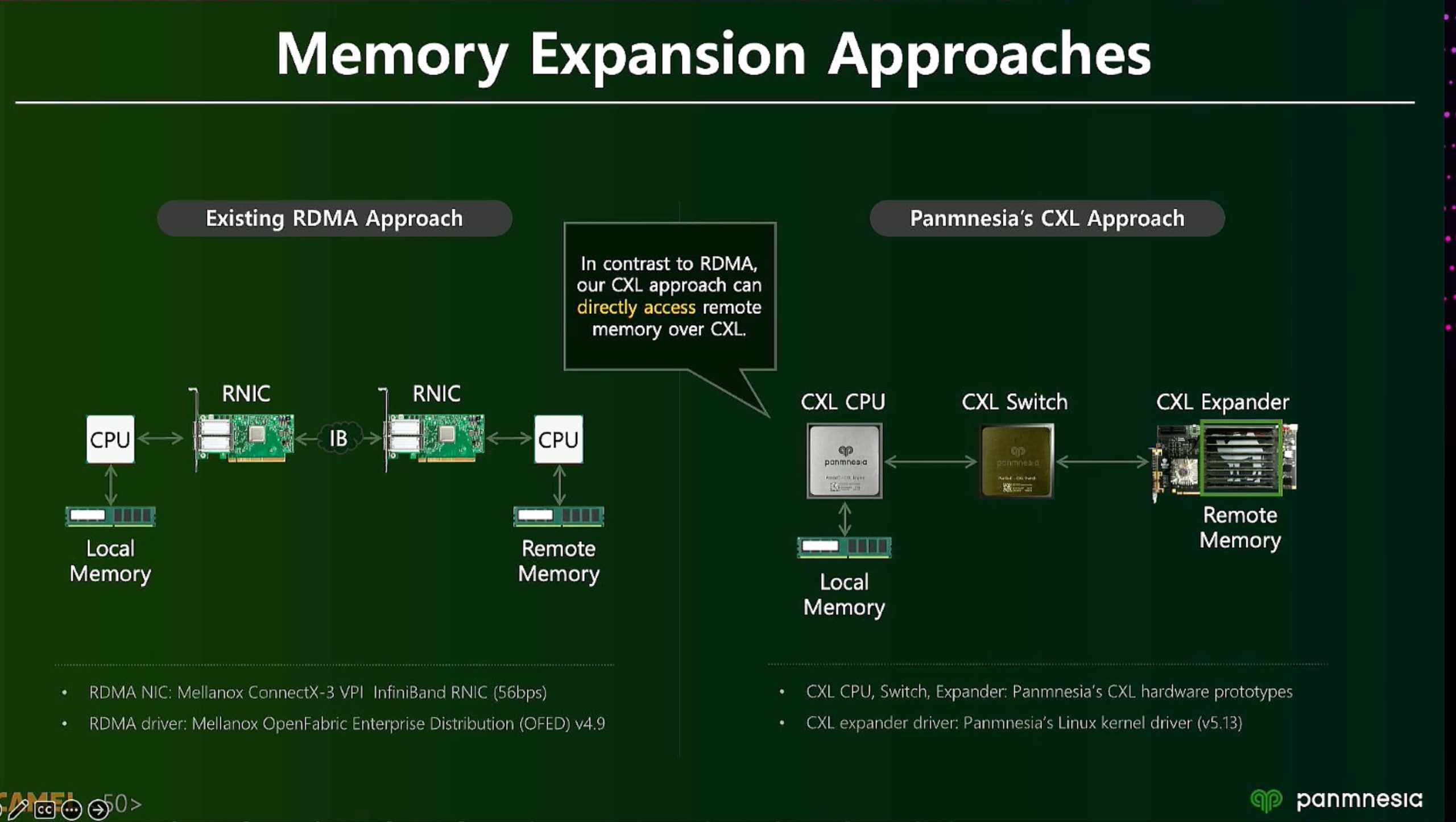
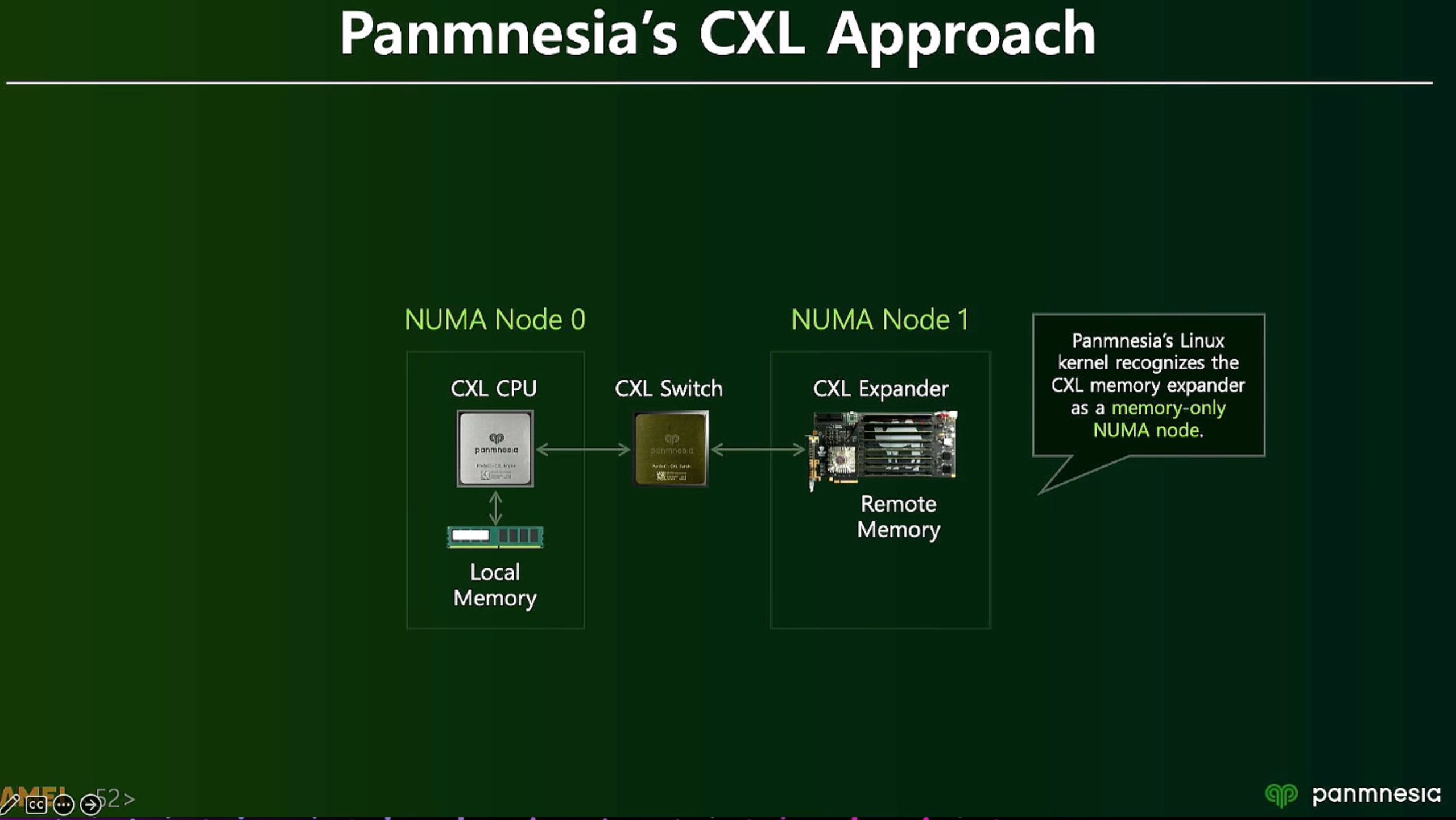
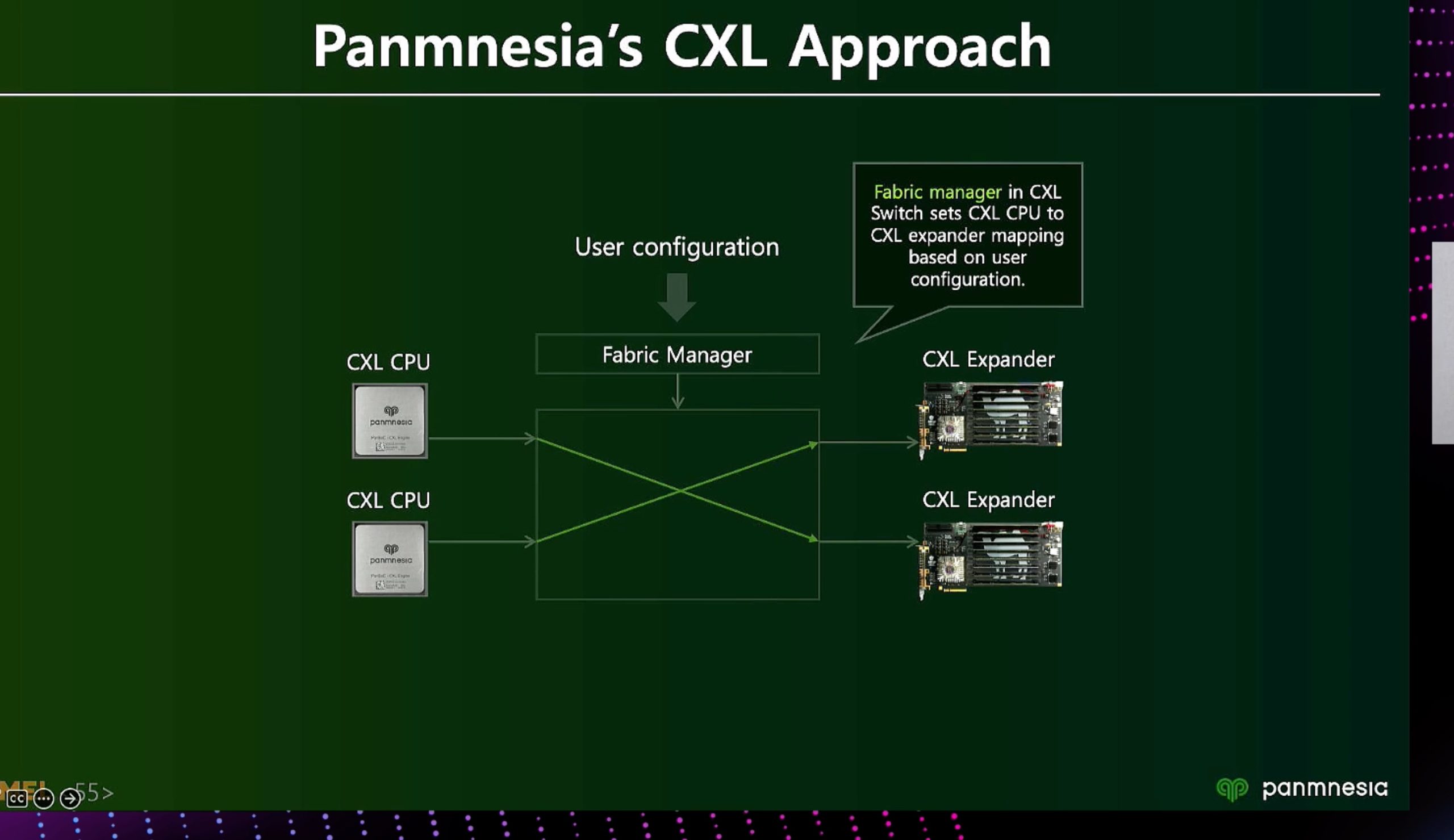


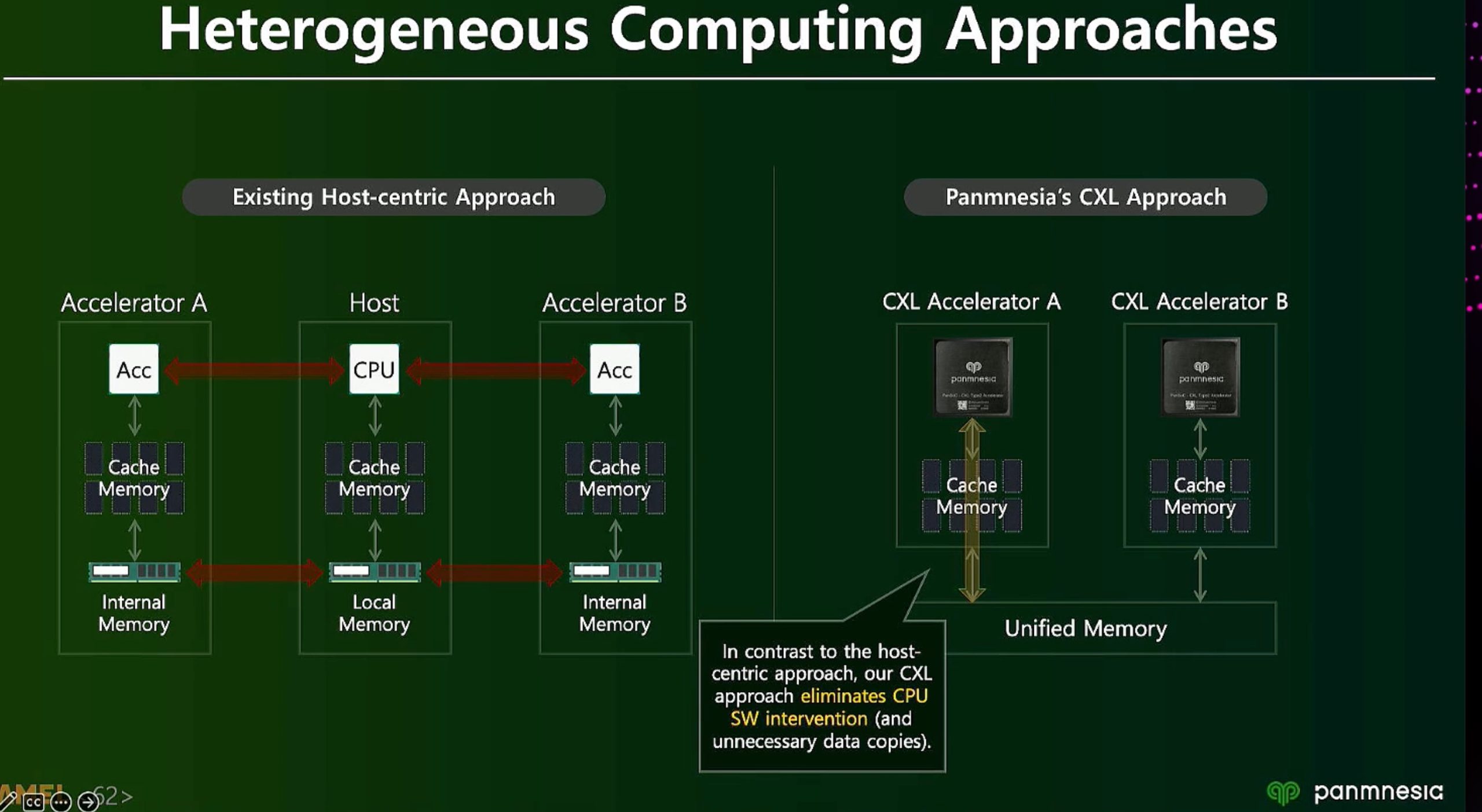
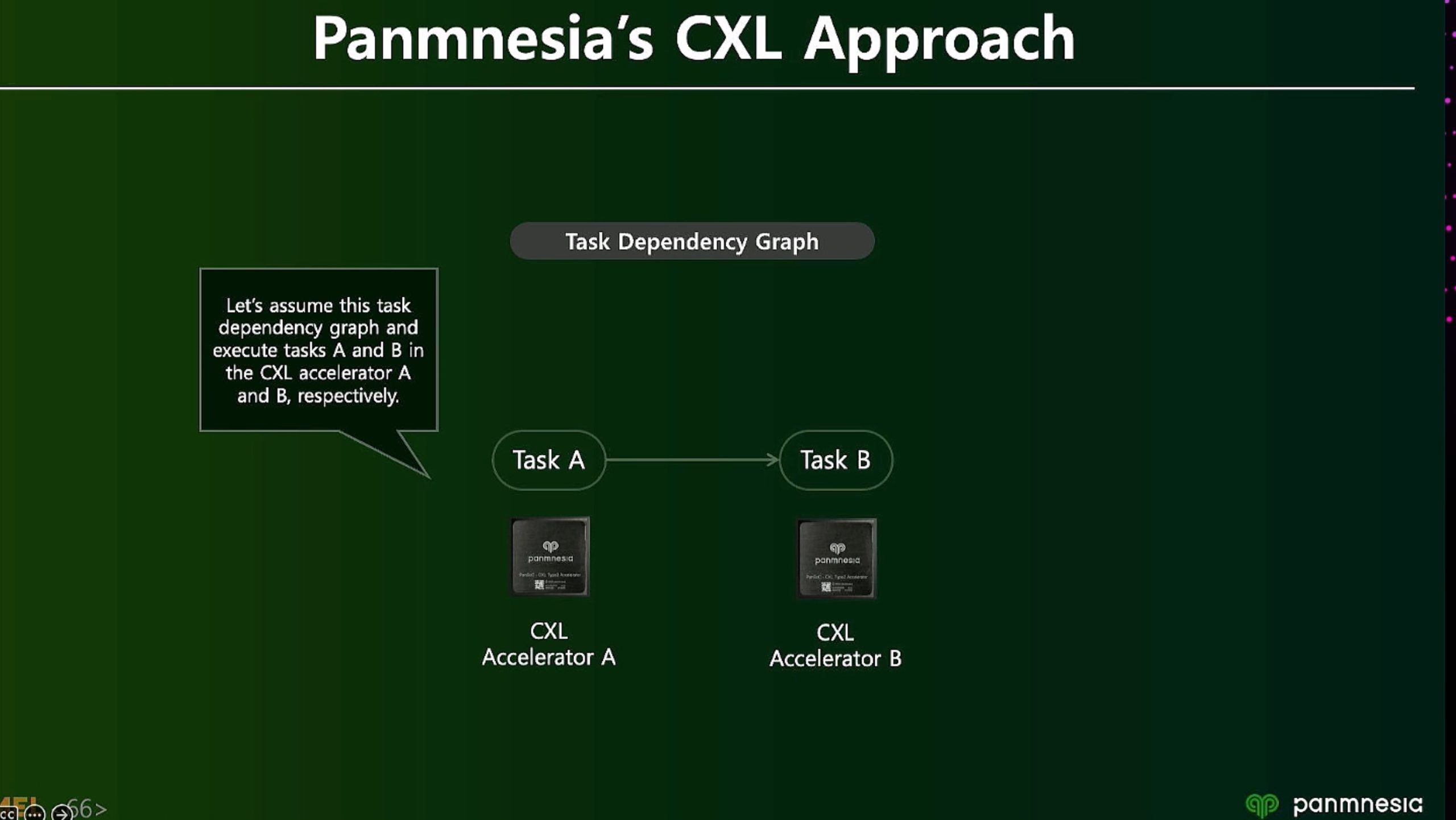
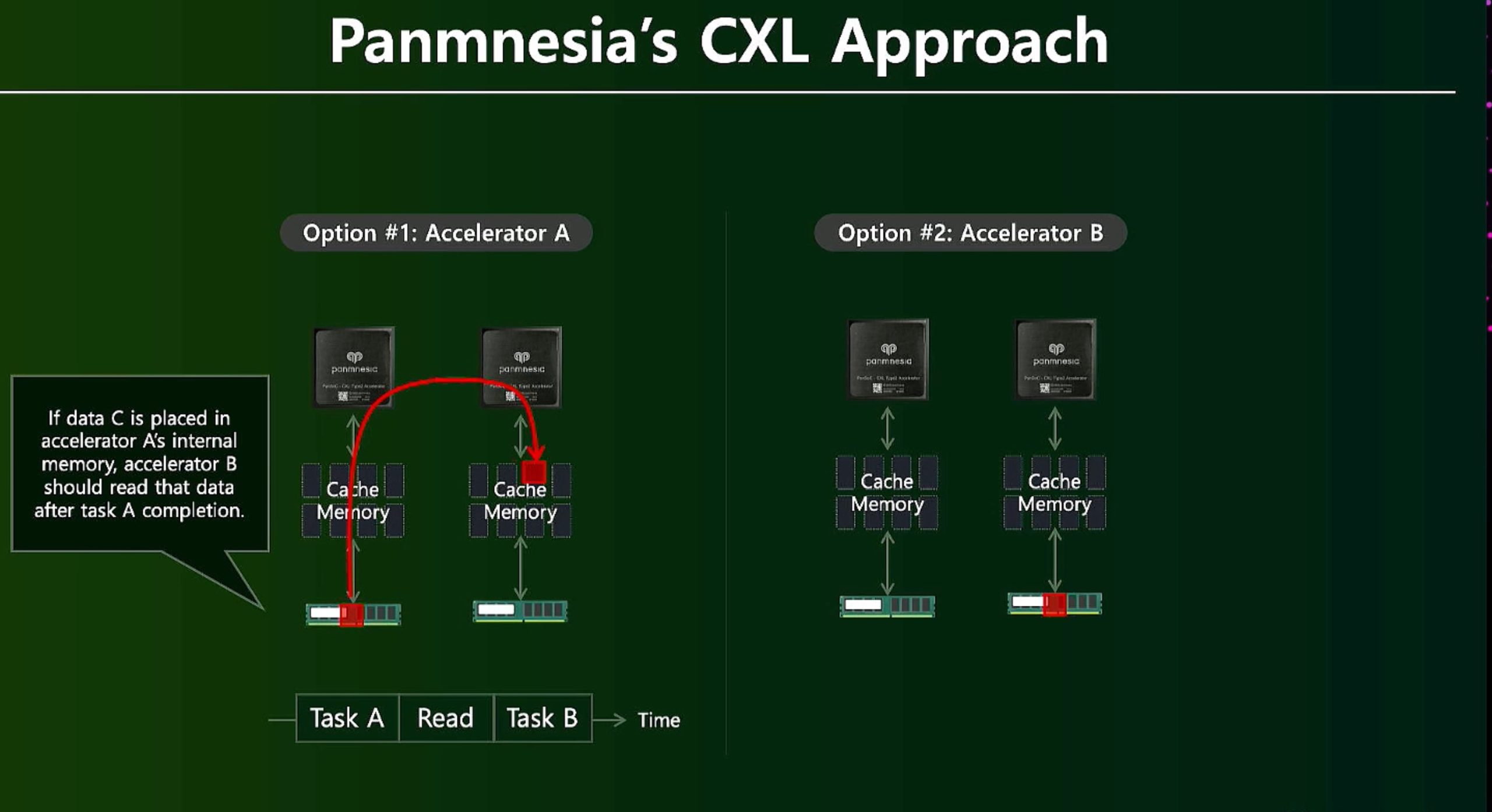


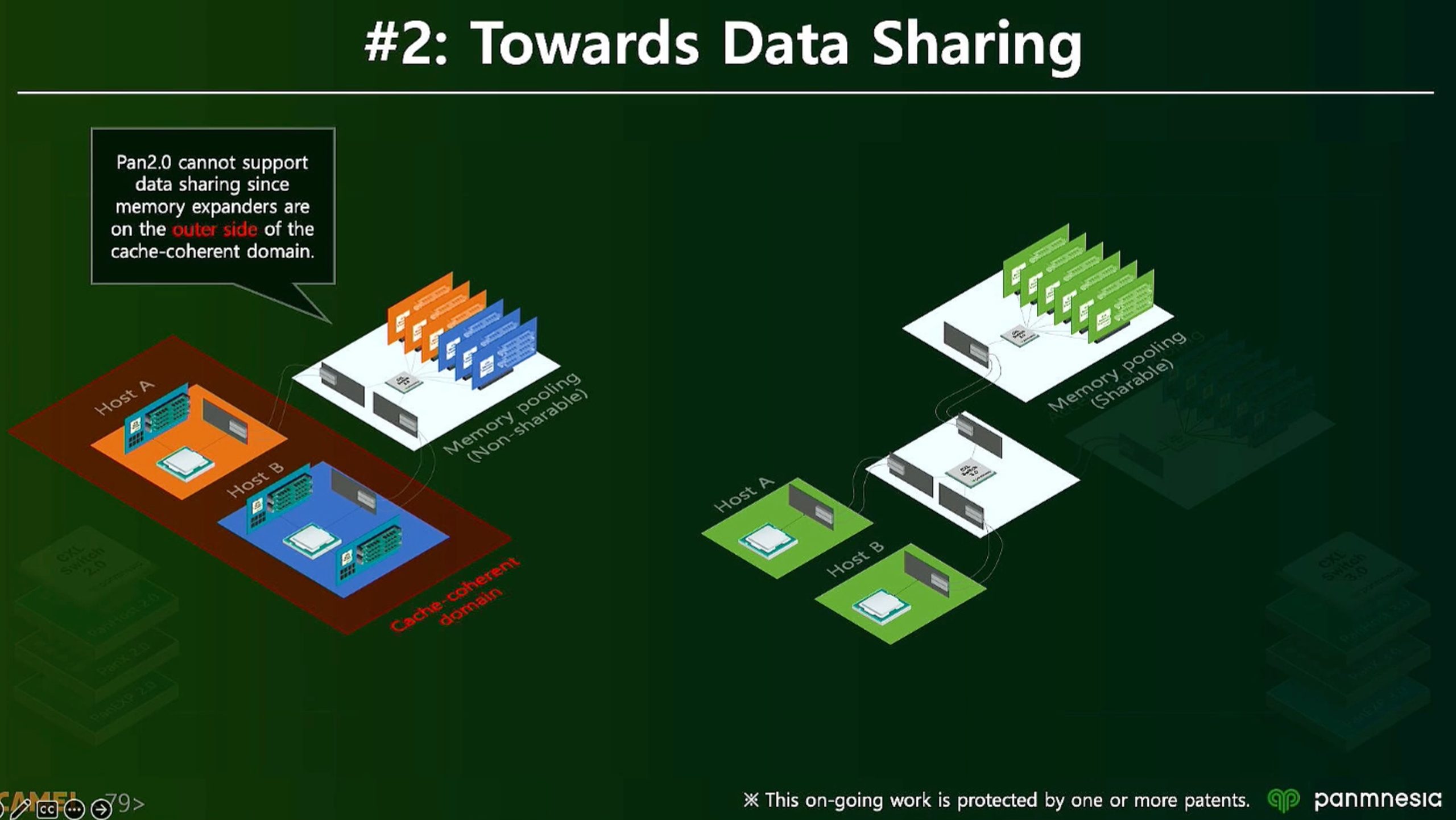
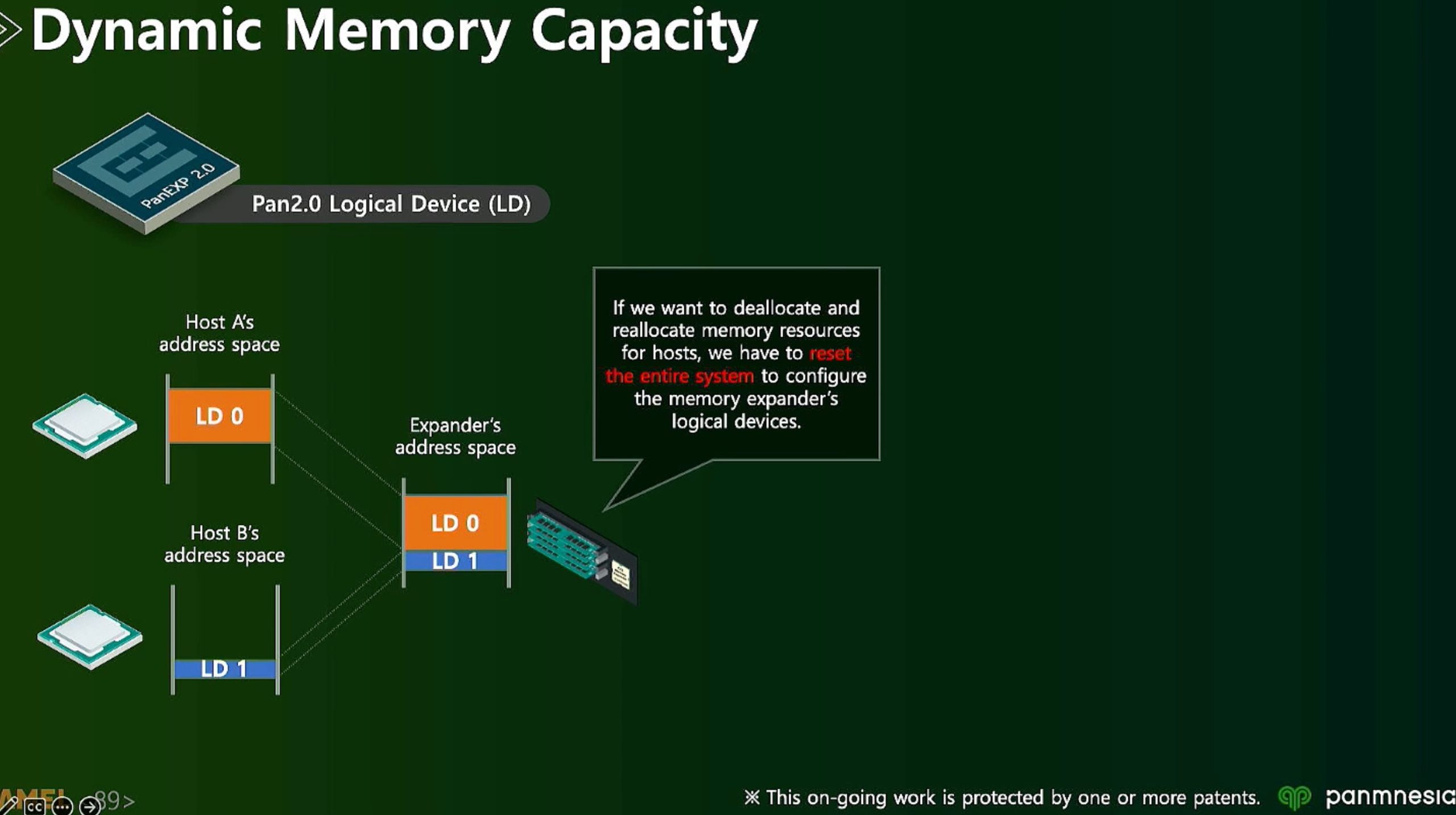
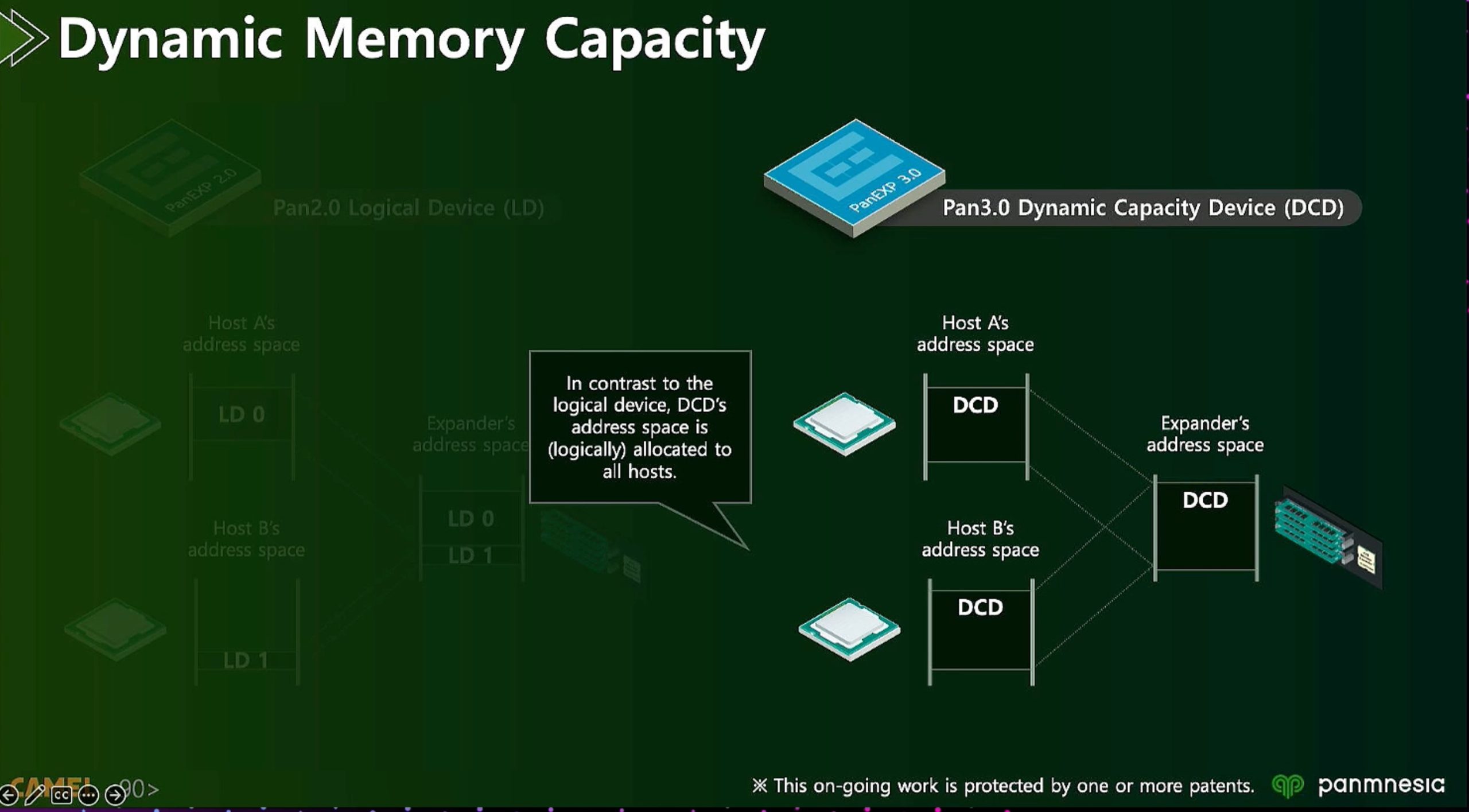
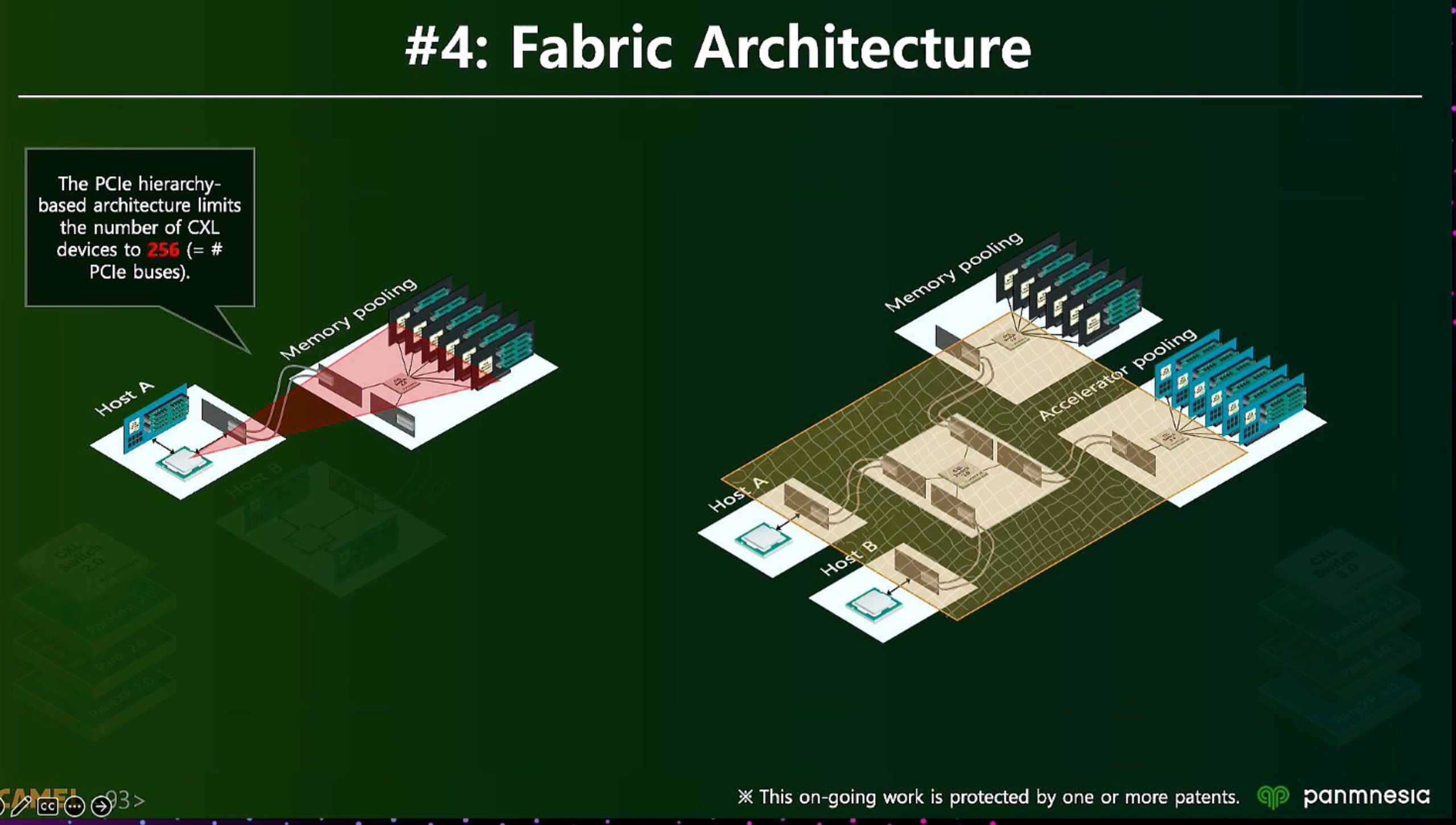



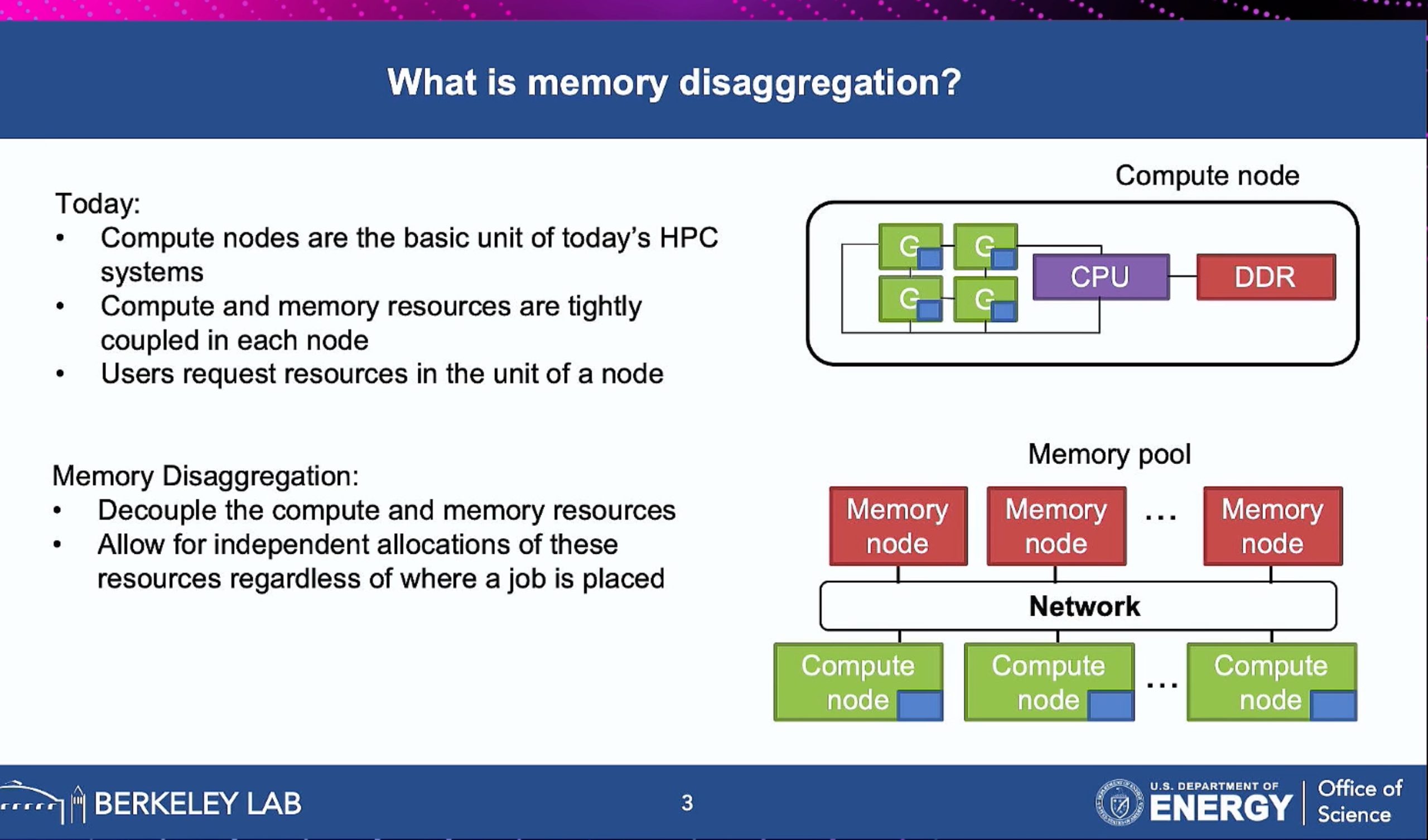


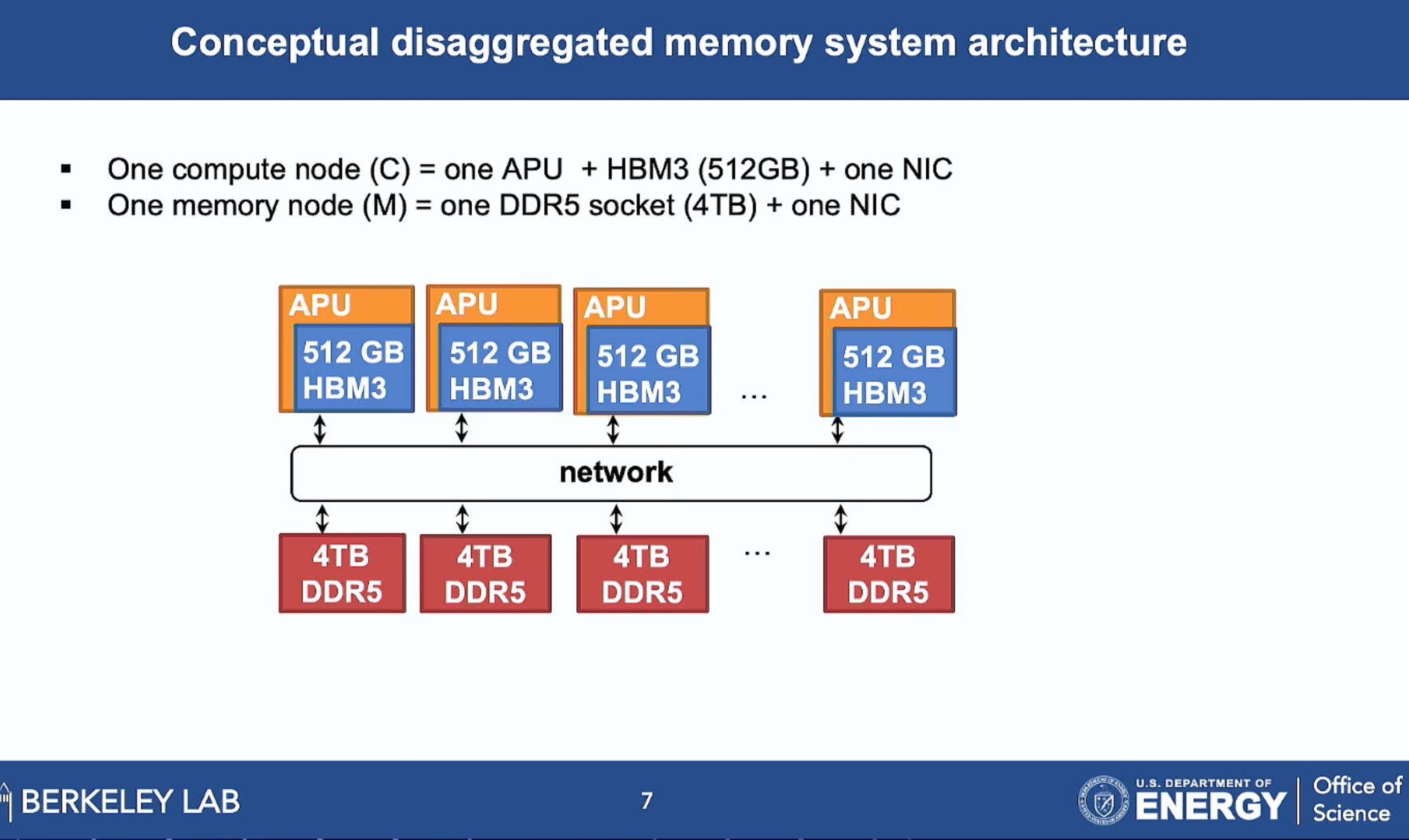

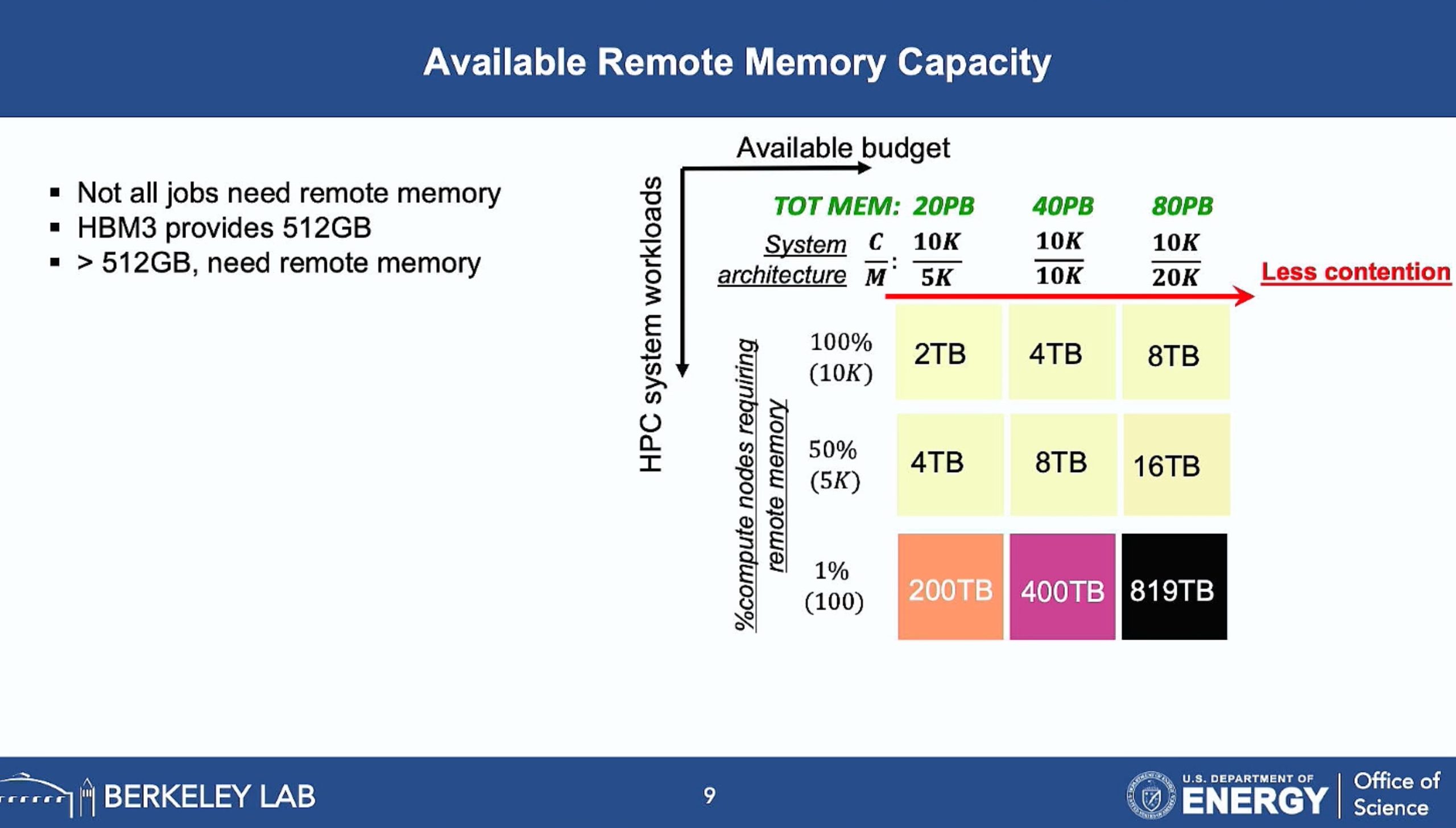


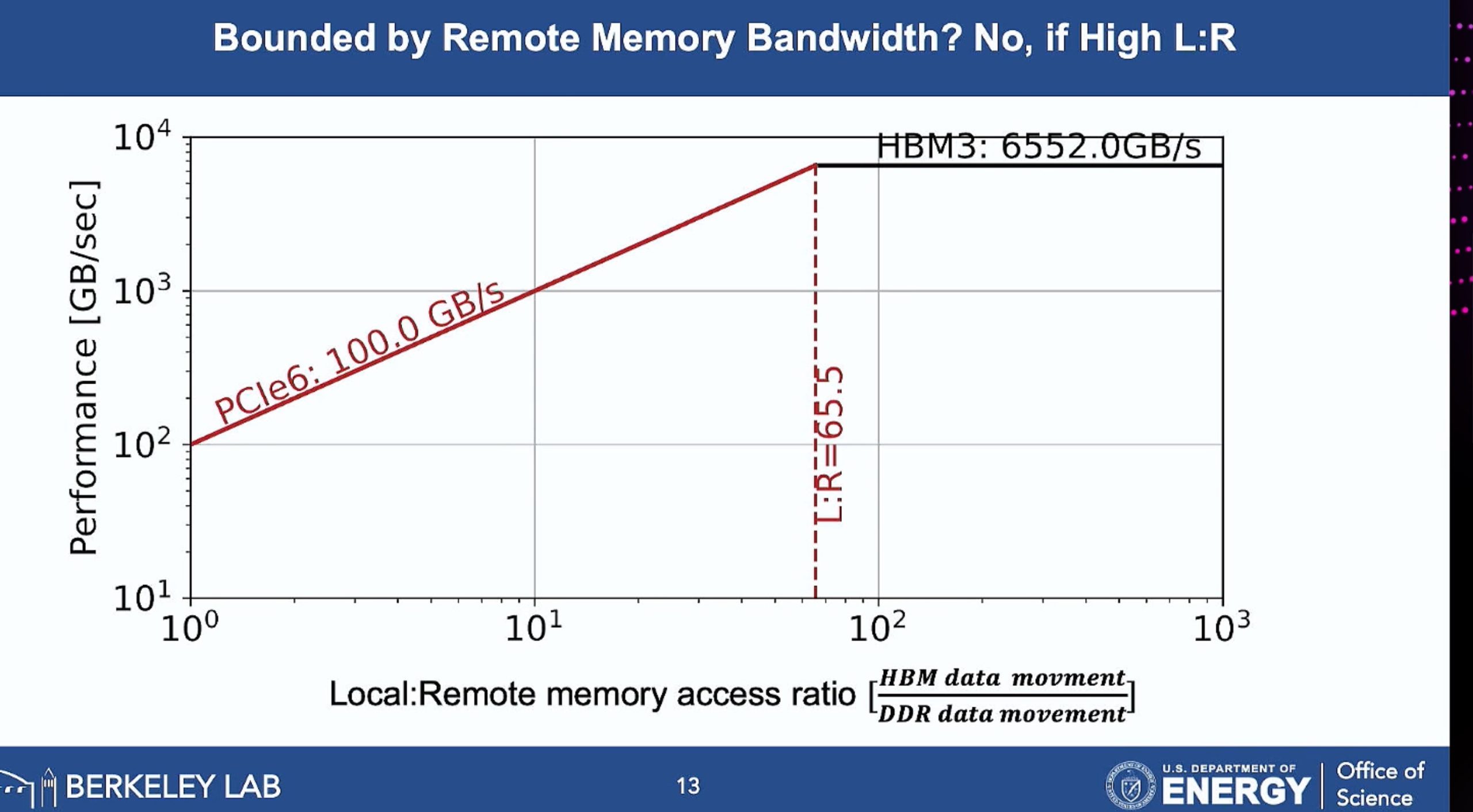
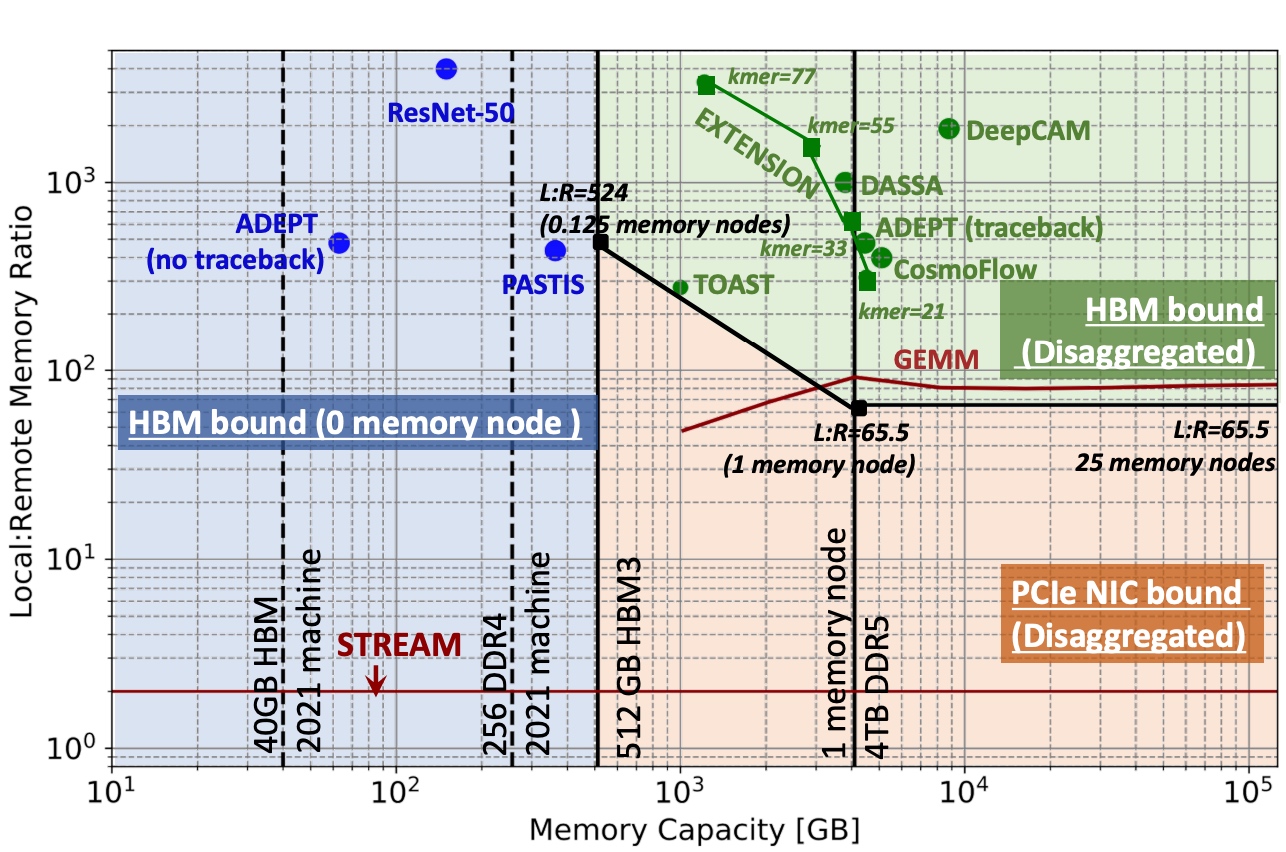


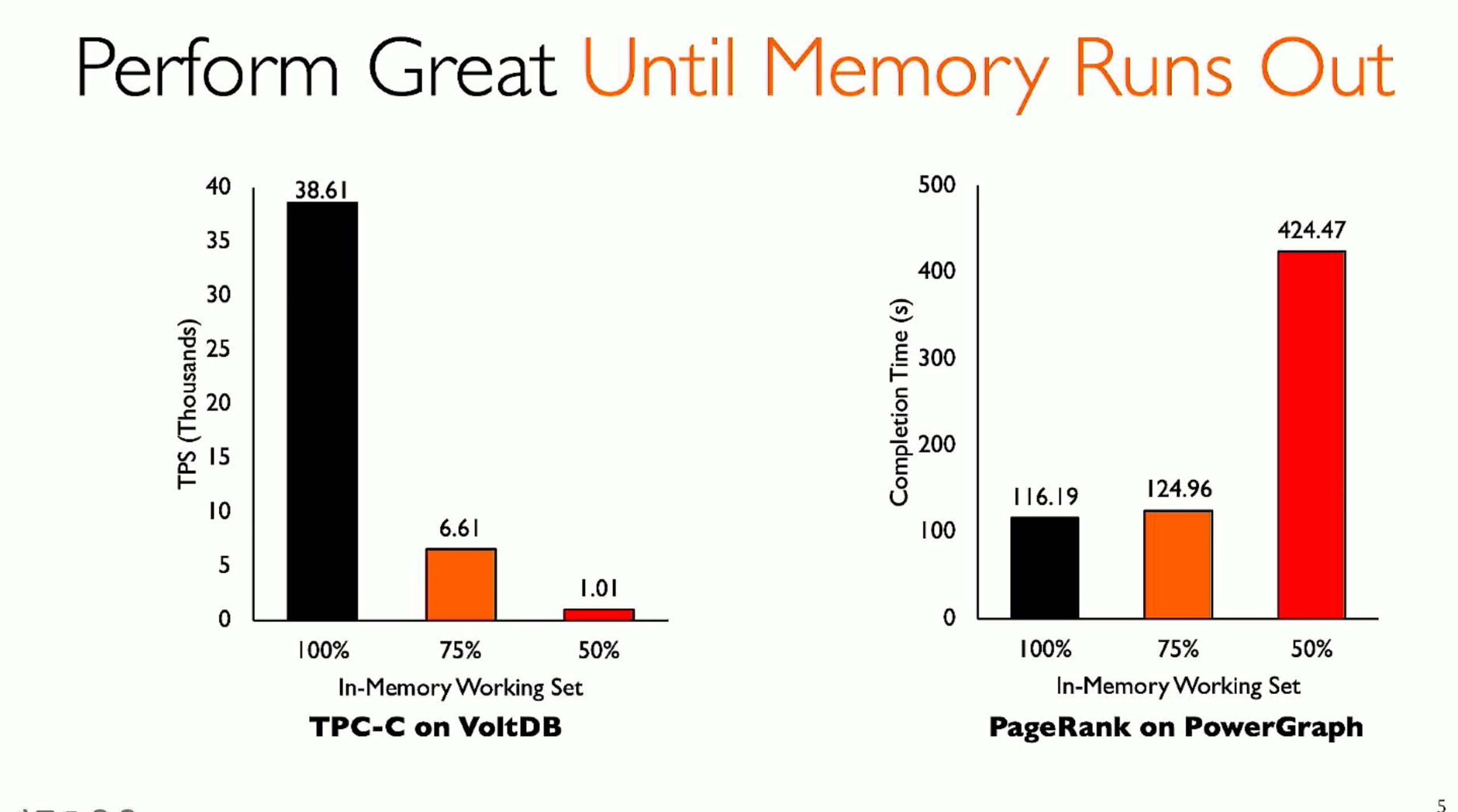


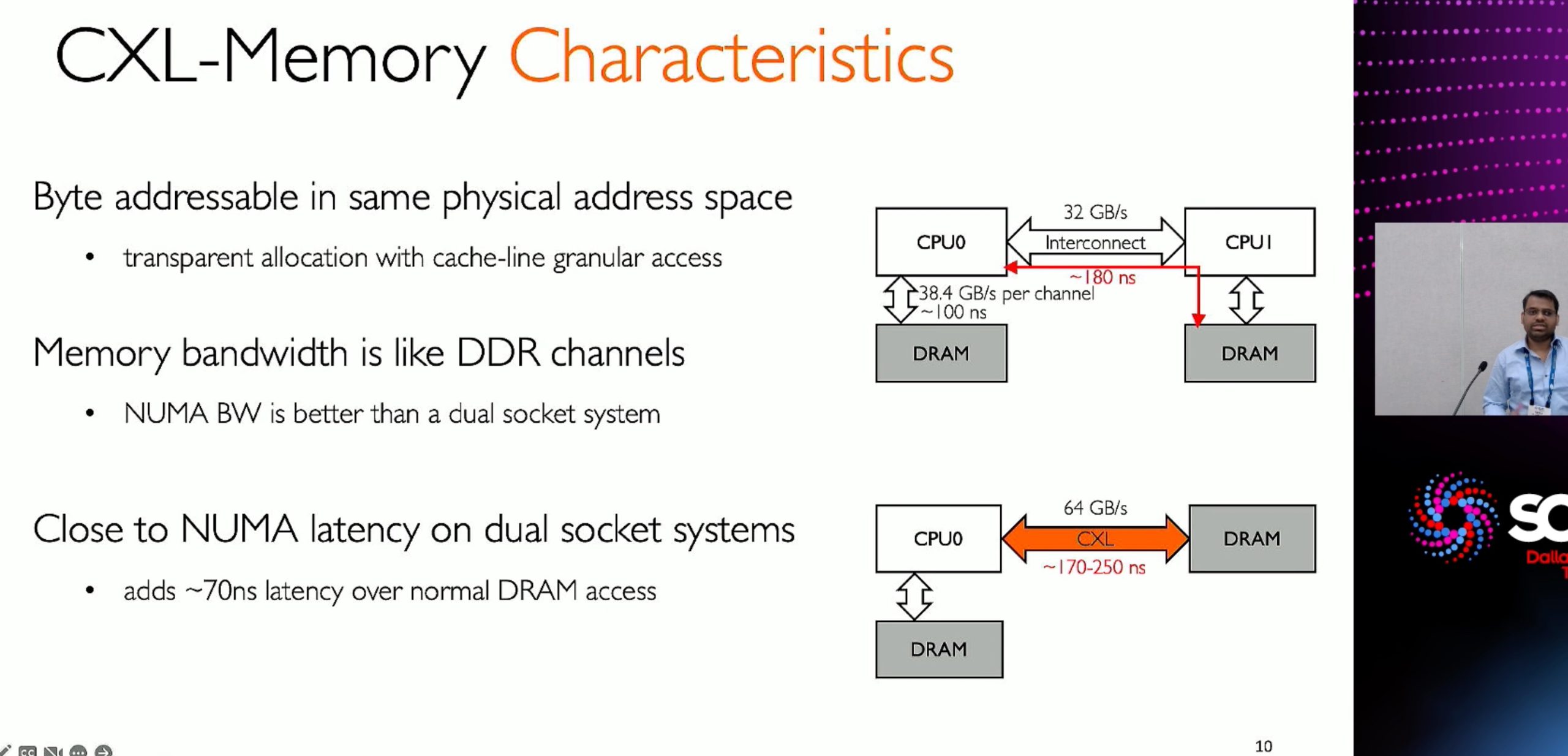



ML fine granularity extra overhead of
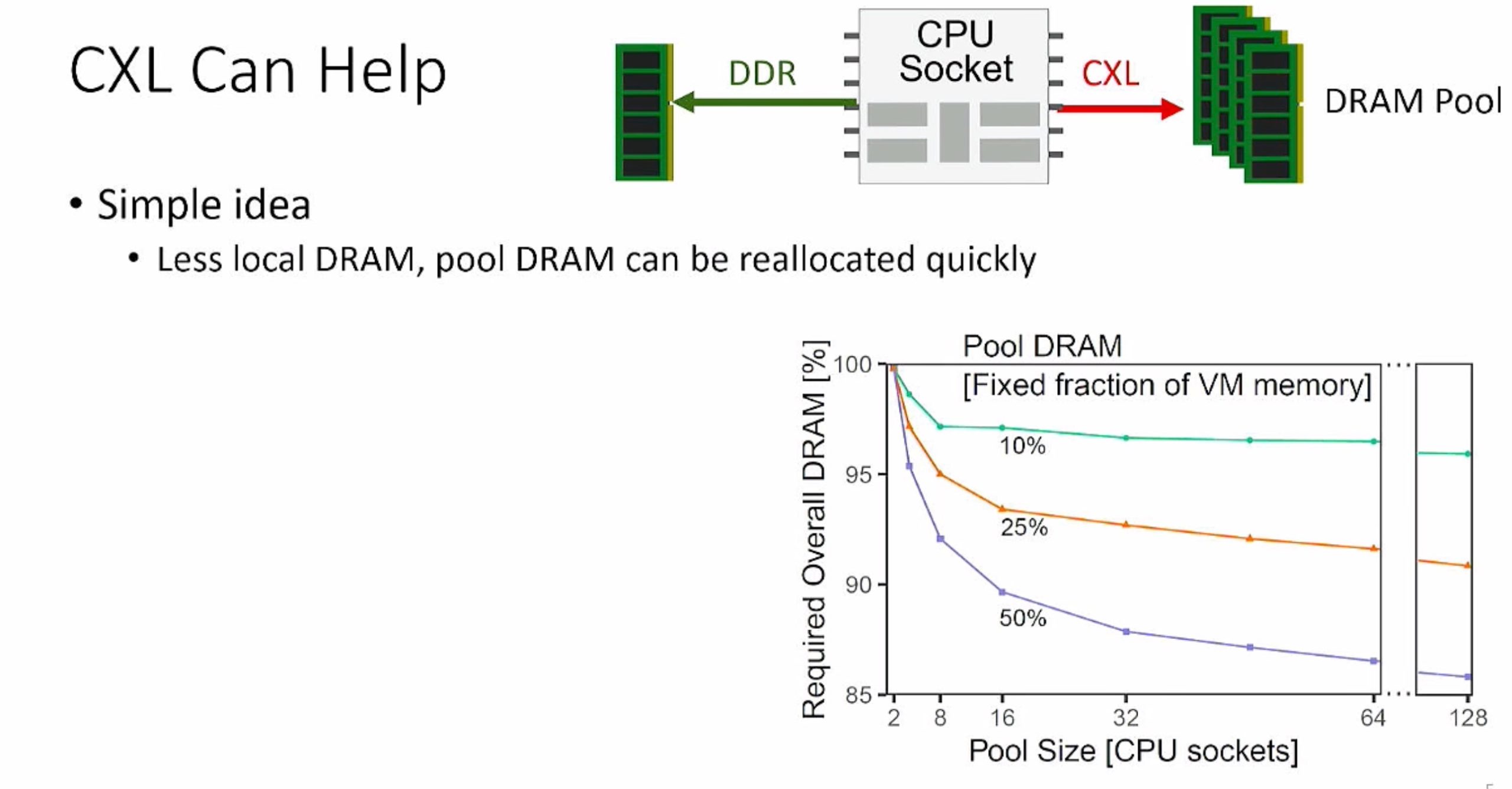
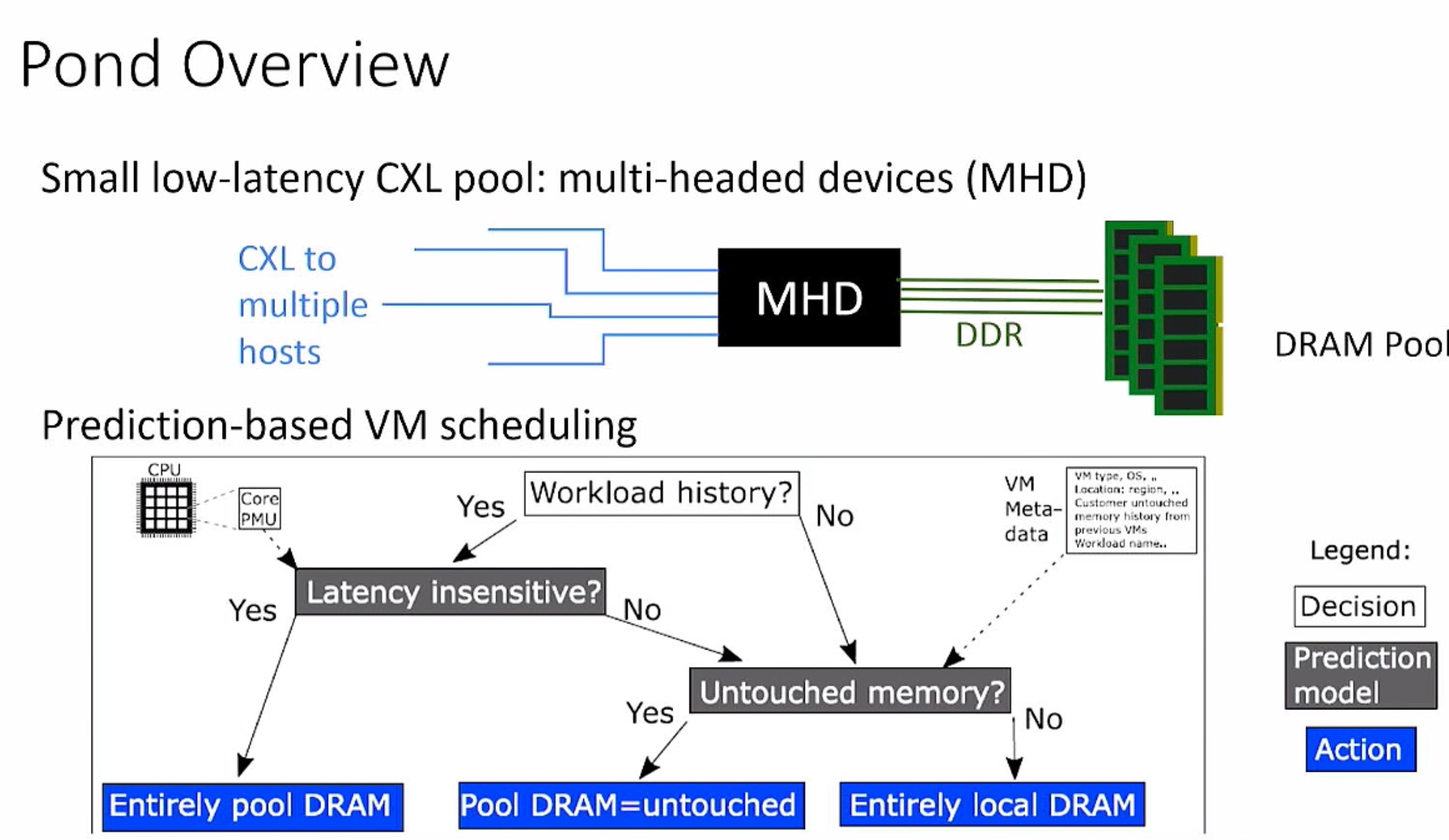
FaaS No OS/ OS page placement prediction
Hypervisor SMartNIC on Azure machine replace with CXL EMC
zero core NUMA
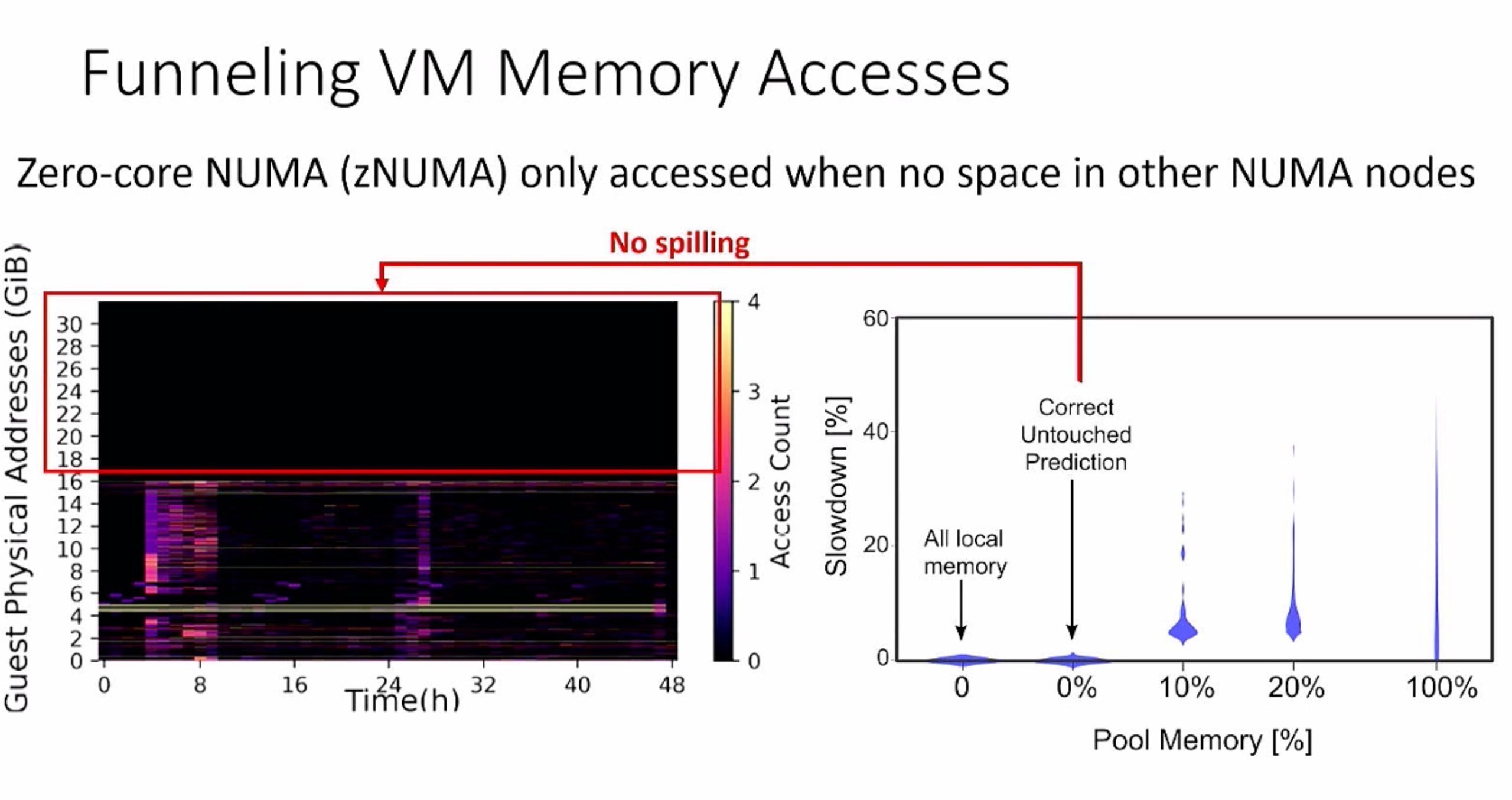
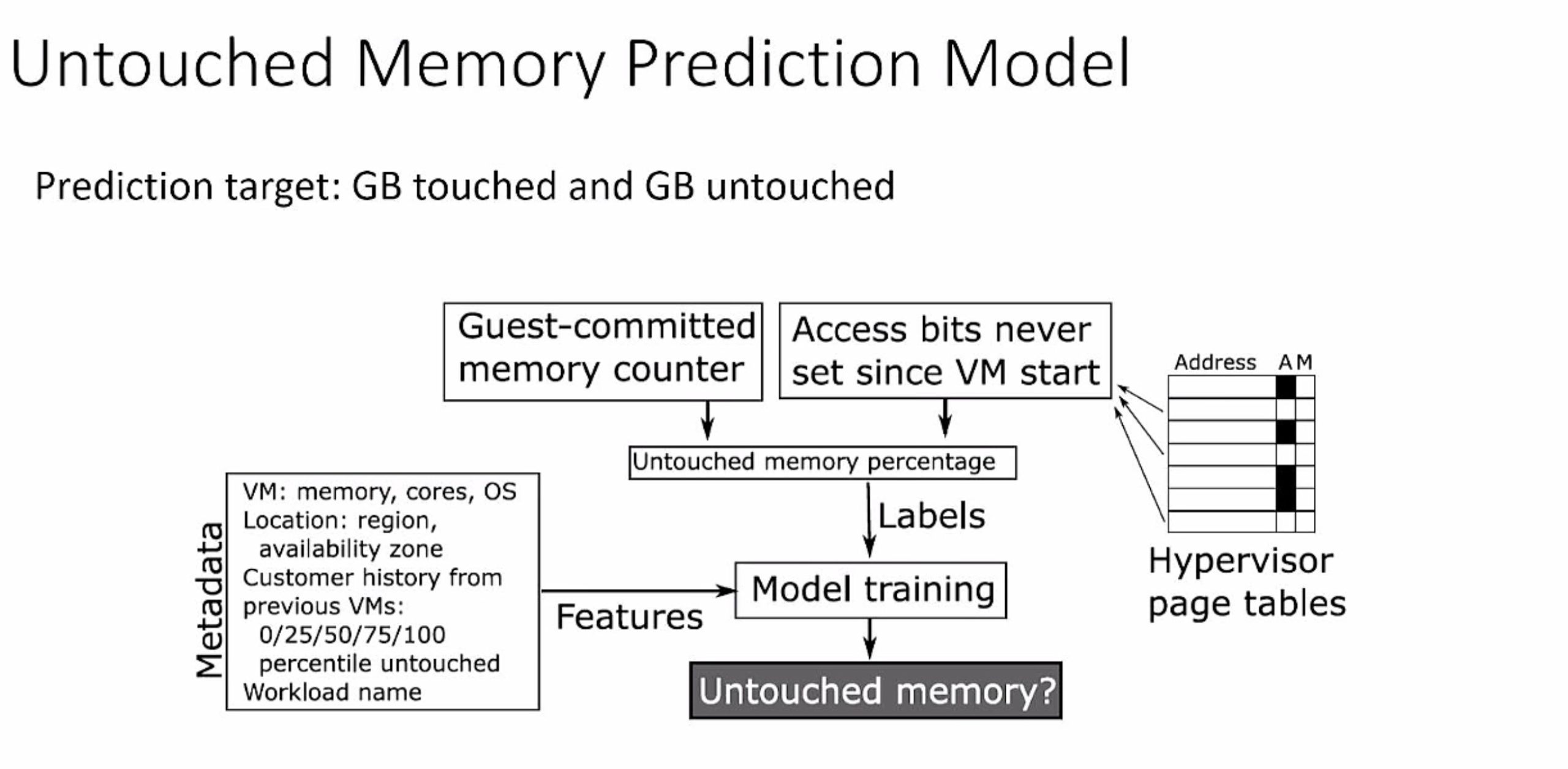
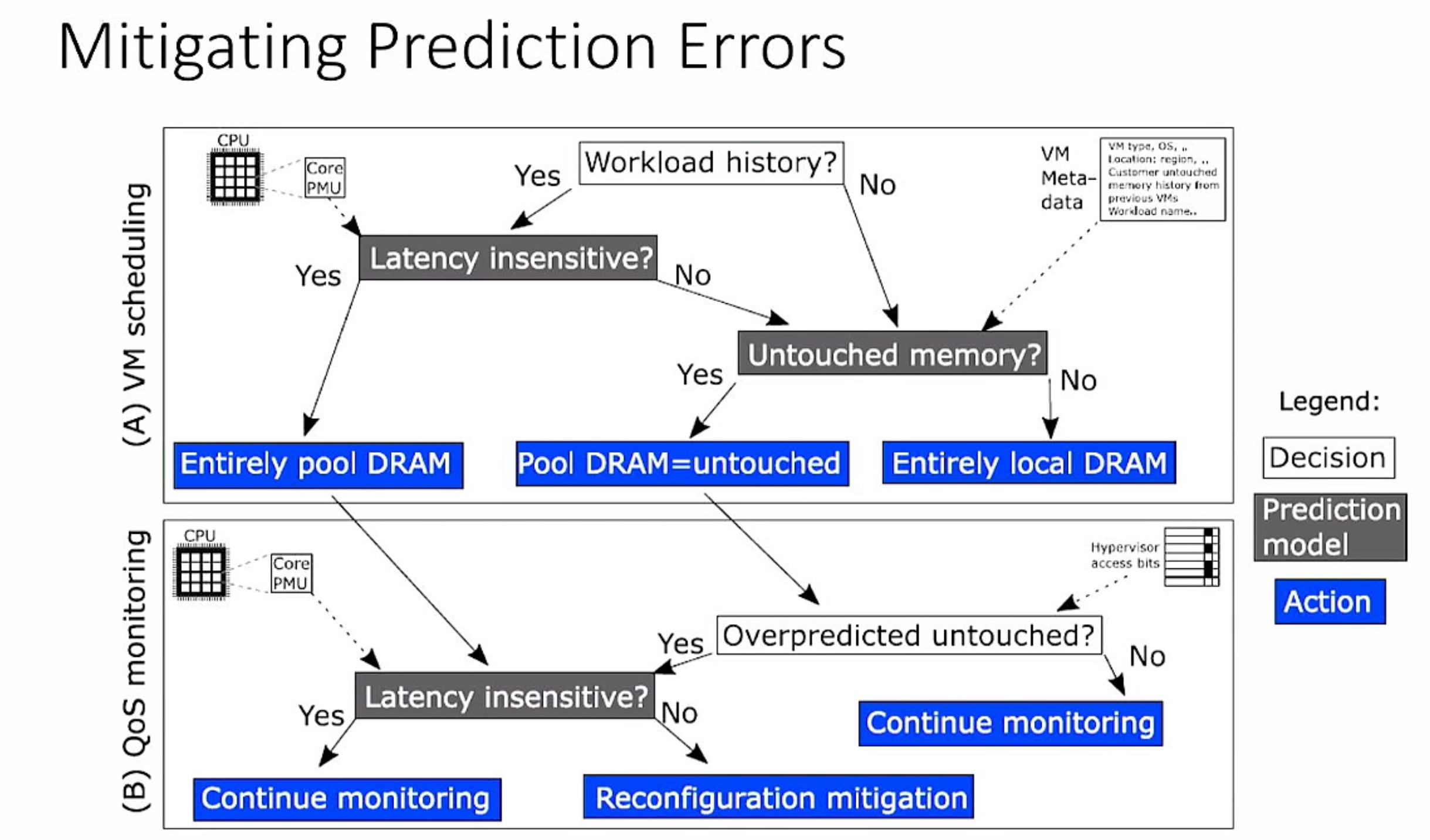







timing of awareness of other core/CXL endpoints and the memory ordering of ownership because every CXL endpoint has hw time/cxl time on fabric, is the ordering in terms of the CPU?
- Not being aware is enough.
- Vendor can configure the fabric to support
Some unhealthy persistent memory in one endpoint but on the fabric can know which specific device is unhealthy
- Different type has different crash state reporting.
Congestion pool upstream policies service the device back to control the cxl traffic.
- 3.0 multiple configuration P2P migrations
Heterogenous devices communicate, the cacheline state to see the data on the fly without inserting fences.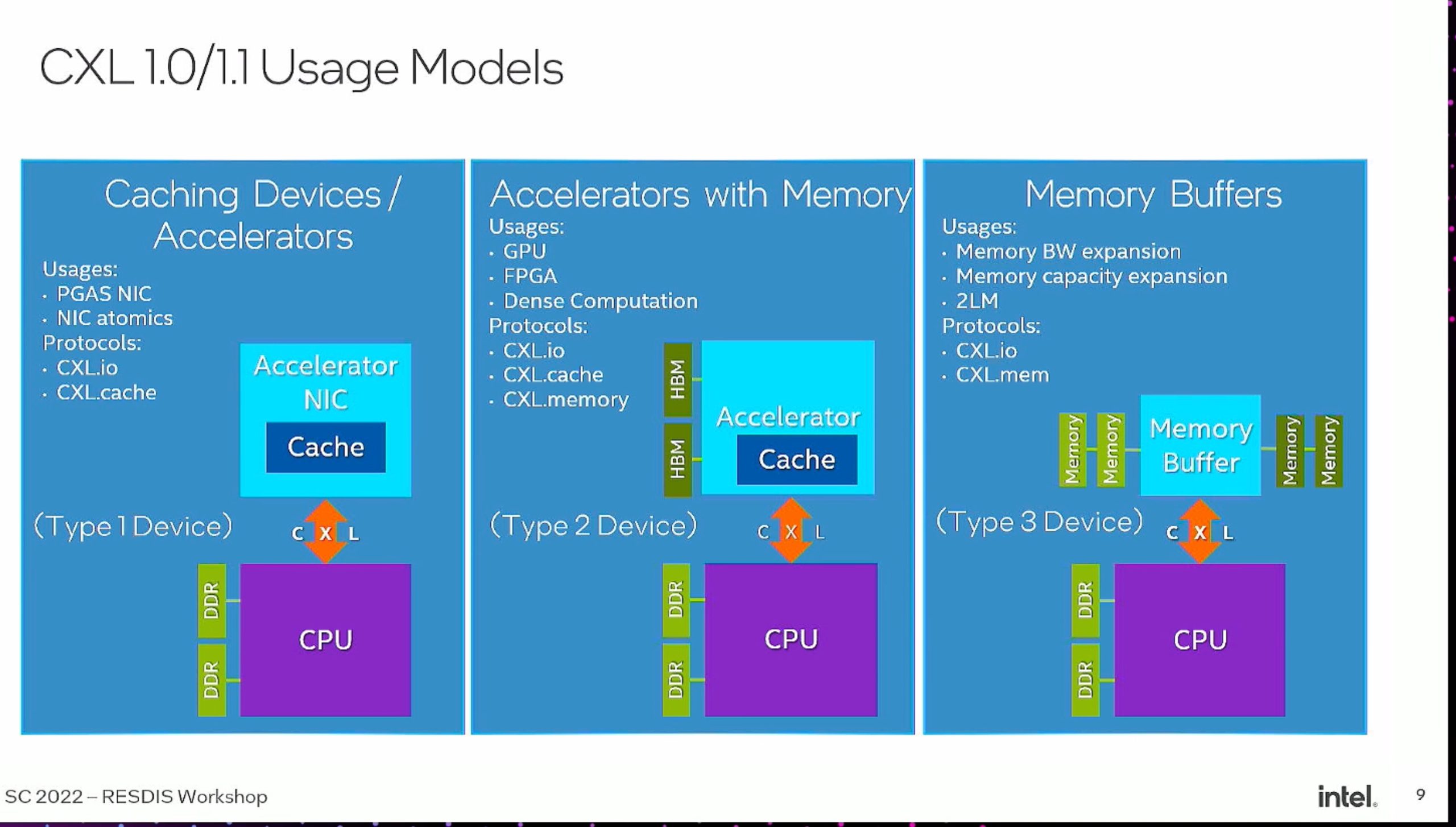




(1) Expanded use case showing memory sharing and pooling
(2) CXL Fabric Manager is available to setup, deploy, and modify the environment
(3) Shared Coherent Memory across hosts using hardware coherency (directory + BackInvalidate Flows). Allows one to build large clusters to solve large problems through shared memory constructs. Defines a Global Fabric Attached Memory (GFAM) which can provide access to up to 4095 entities
Implementation, check CRC without RTT.
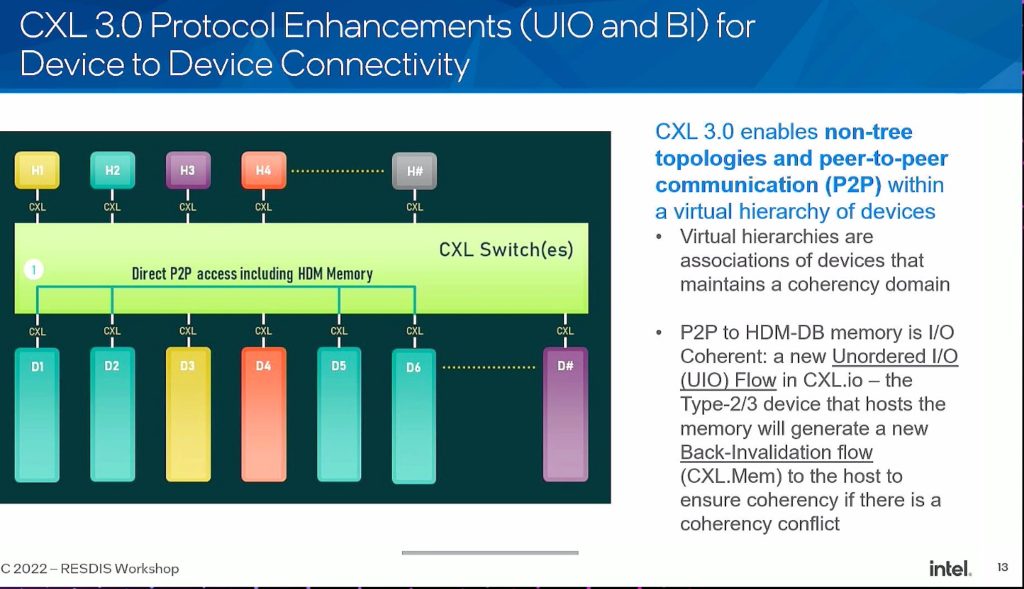
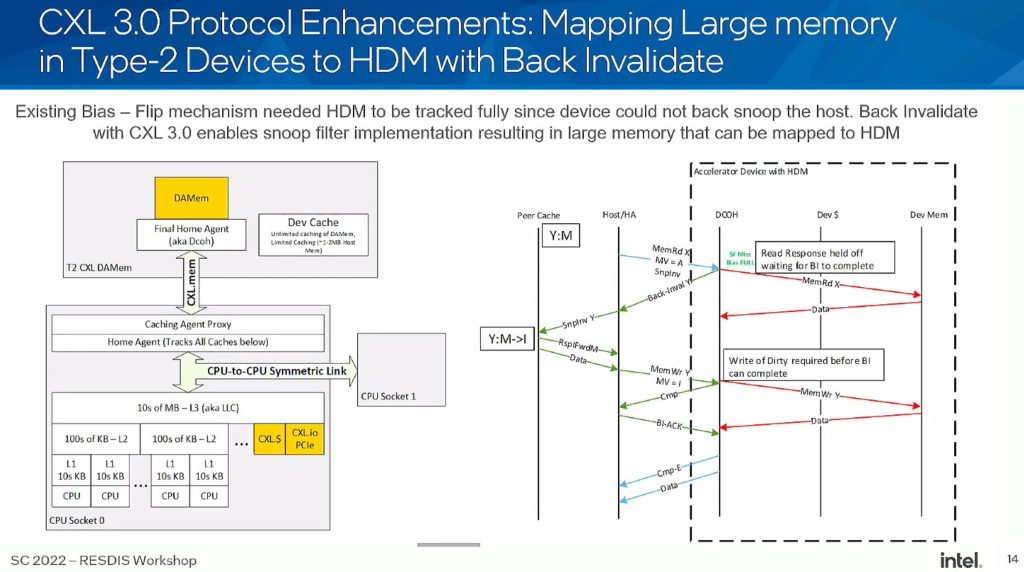
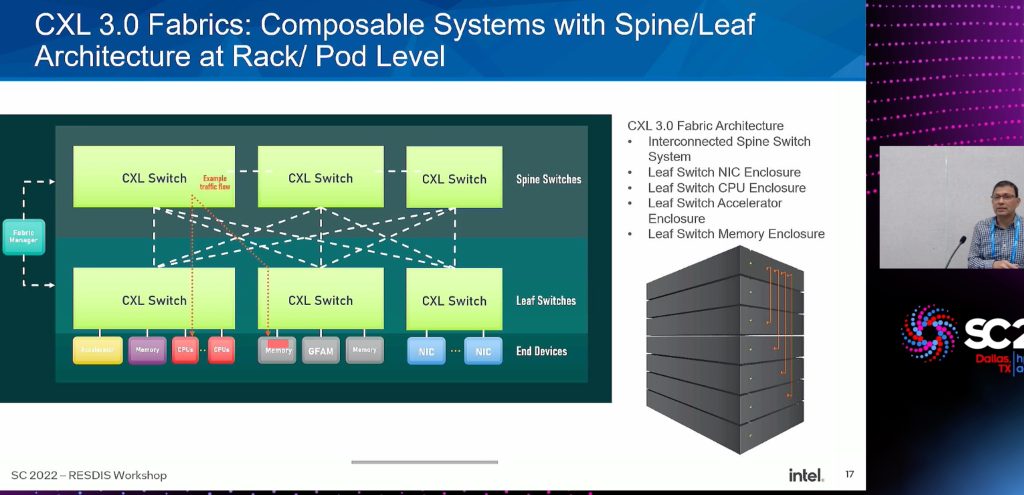
- Does not scale HDM/ back invalidate on demand
- how much of the parallel to hide the latency.
- MSR NVSHEM software solution latency > the first gen solution
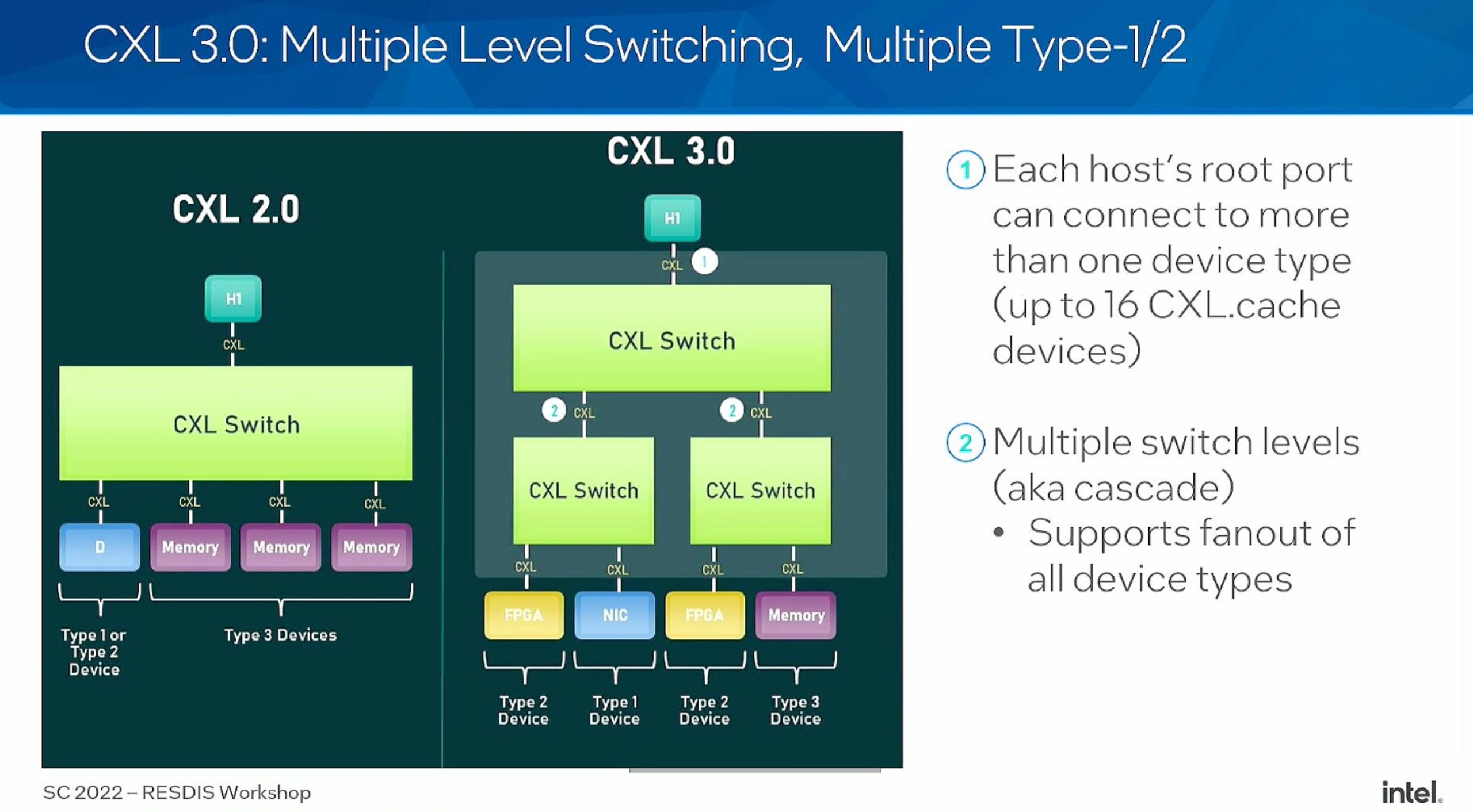

- Does not scale HDM/ back invalidate on demand
- how much of the parallel to hide the latency.
- MSR NVSHEM software solution latency > the first gen solution
- https://news.ycombinator.com/item?id=31270543