How to resolve big chunk over 2GB


A Tech Nerd with a finance mind.
Nadav has been enumerating the Intel extensions providing support for virtualization for VMware and providing security mitigation or debugging applying for the Intel extensions. And provides things like userspace memory remote paging [2] for providing VMware a better service disaggregation technology. They've been investigating the vulnerability of IOMMU with the DMA [1] and remote TLB shootdown performance bugs(updating the page table will incur TLB shootdown) by introducing con-current flushing, early acknowledgment, cacheline consolidation, and in-context TLB flushes.
This paper examines the interaction between COW and pinned pages, which are pages that cannot be moved or paged out to allow the OS or I/O devices to access them directly.
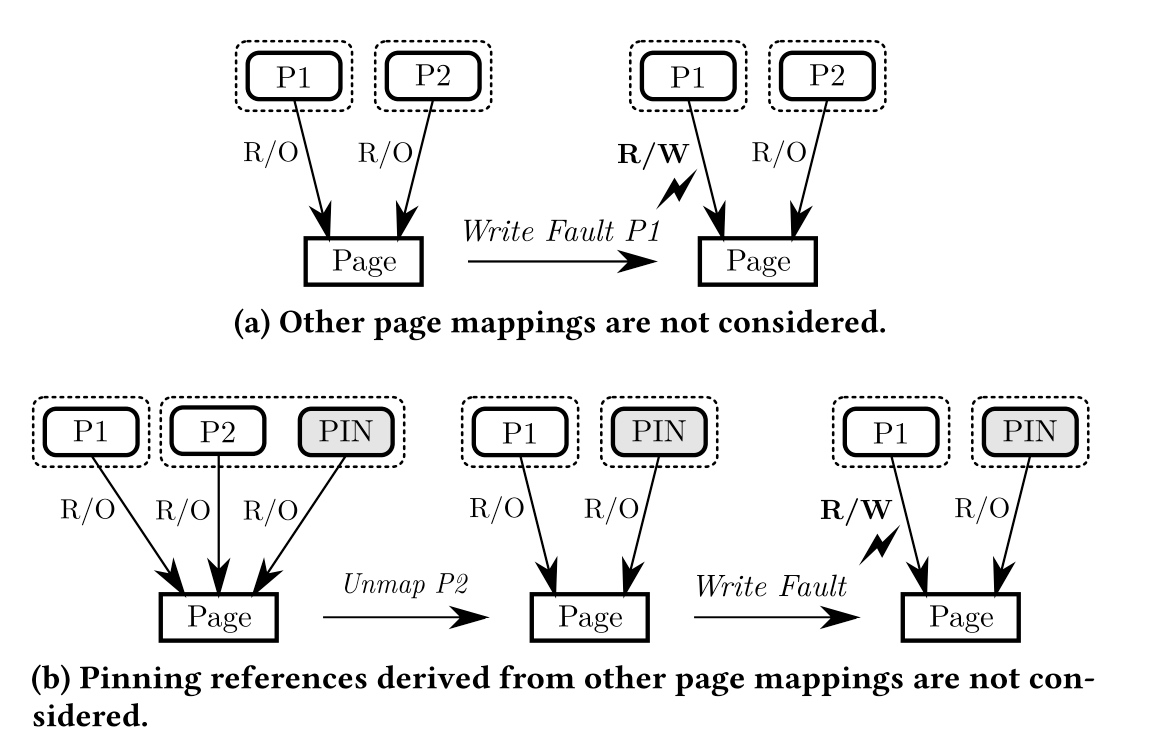
Basically, we need a COW-share prevention on the pinned page. The Missing Piece for Correct Copy-on-Write which considers how COW interacts with other prevalent OS mechanisms such as POSIX shared mapp1ings, caching references, and page pinning. It defines an invariant that indicates if there is any private writable mapping it must be a single exclusive mapping and provides test cases to evaluate COW and page pinning via O_DIRECT read()/write() in combination with fork() and write accesses.
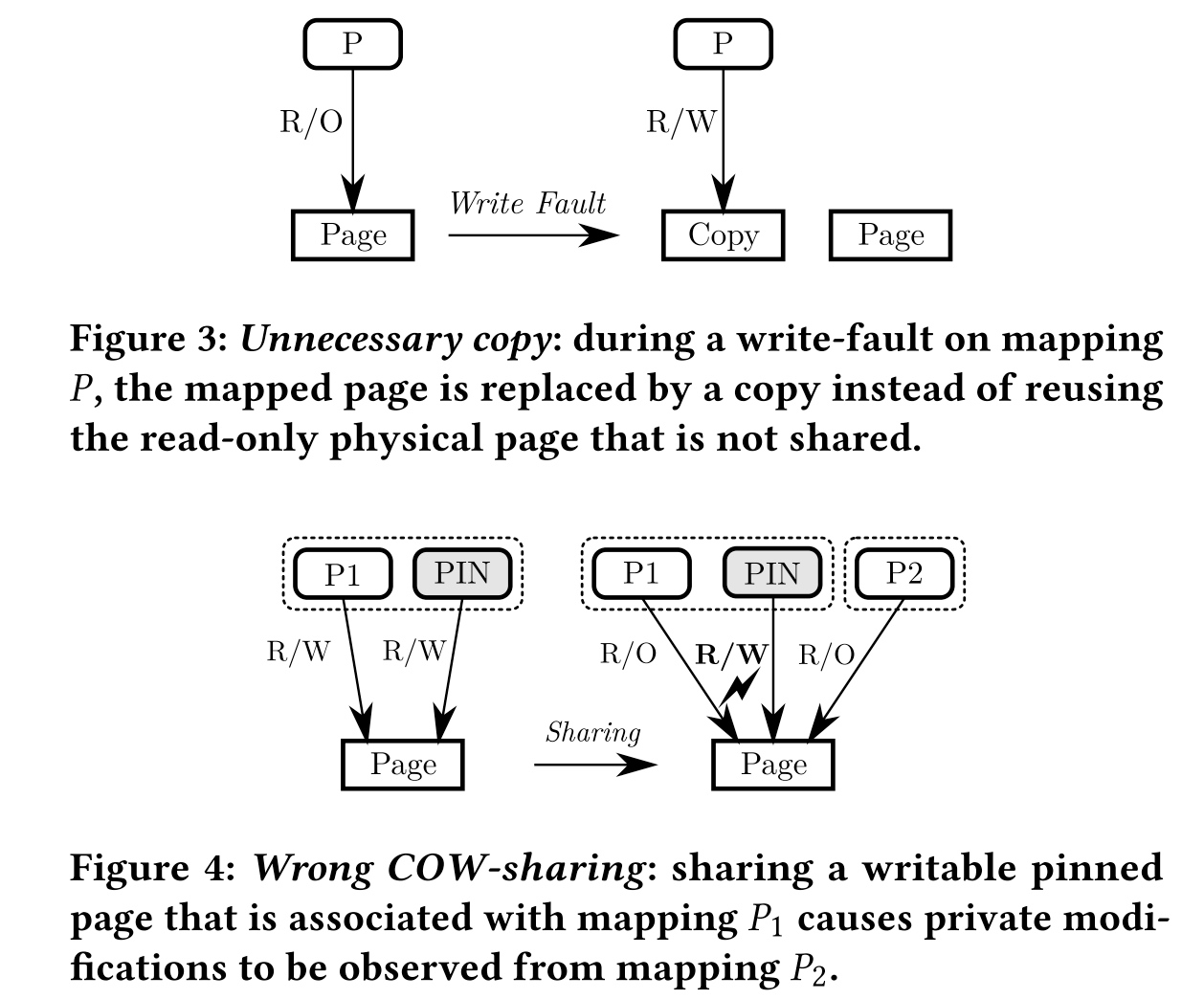
For implementation, they made a tool similarly to dynamic taint analysis that mark an exclusive flag for page(possibly of CXL to make a hardware software codesign of this, but in a cacheline or page granularity). This flag also introduces refinements to avoid unnecessary copies and handles swapping, migration and read-only pinning correctly. An evaluation of the performance of RelCOP compared to two prior COW handling schemes shows that it does not introduce noticeable overheads. An implementation of this design was integrated into upstream Linux 5.19 with 747 added and 340 removed lines of code. Evaluation results show that RelCOP performs better than PreCOP by up to 23% in the sequential access benchmark and 6% in the random access benchmark without introducing noticeable overheads.
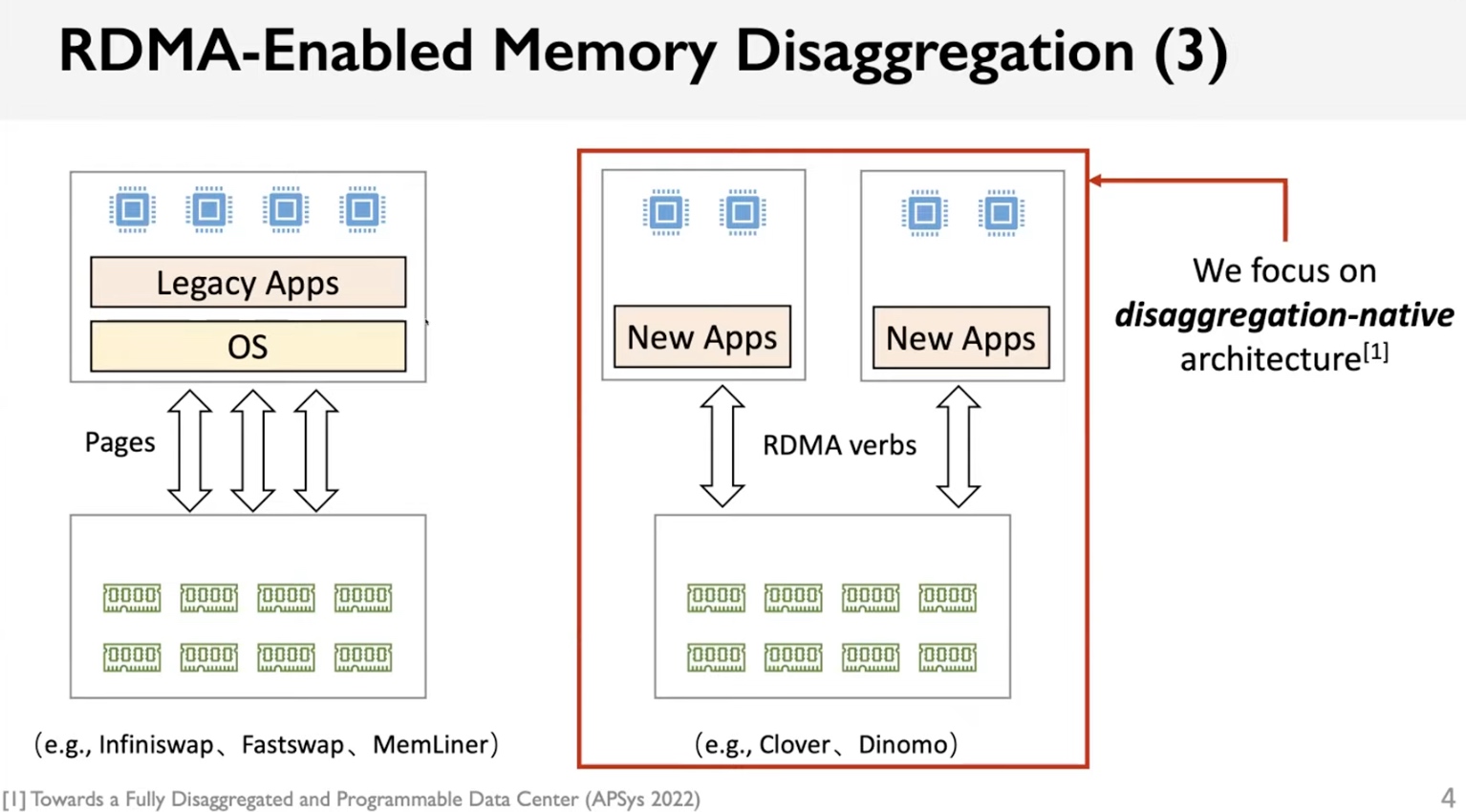

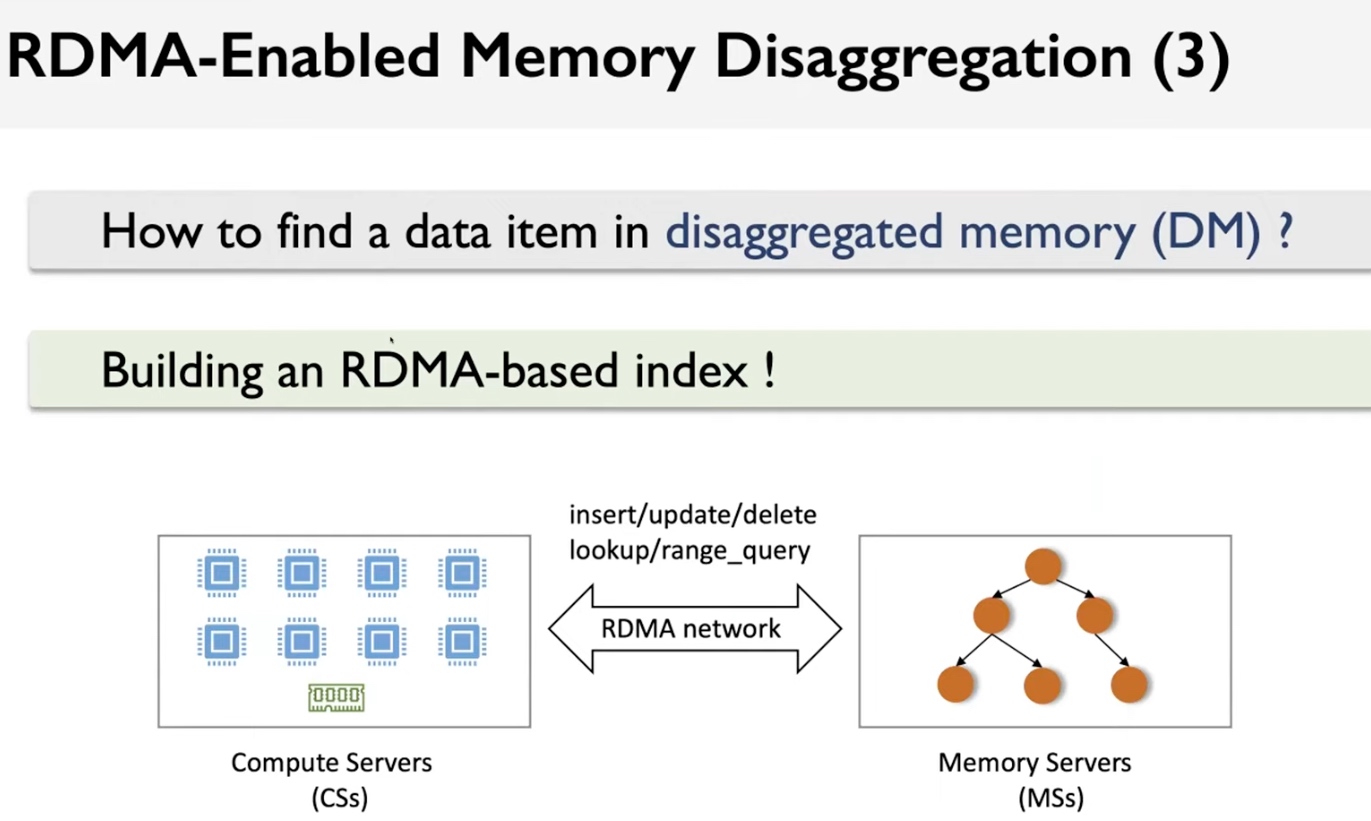
Today, after listening to the latest pre-CXL work of RDMA like carbink, AIFM, compucache, infiniswap, fastswap, memliner/ clover, dinomo/ RACE Hashing, sherman, fusee. I'm wondering much disaggregated memory has been deployed on the RNIC manner.
We will be weighing implementation ideas from research papers versus 3 critical requirements of Remoteable Pointers
Is Phantom address a good solution?
Is wasm a good solution?
A short answer is no.
Thus we still need SMDK such management layer to make jemalloc+libnuma+CXLSwap for CXL.mem. For interface with CXL.cache devices, I think defer allocation and managing everything through virtual memory would be fine. Thus we don't need programming models like CUDA; rather, we can static analysis through MLIR to do good data movement hint to every CXL controller's MMU and TLB. We could leverage CXL.cache cacheline state to treat as streaming buffer so that every possible endpoints read for and then do updates by next write.
学习是一种广泛的获取知识的过程,如果是为了高考或者是大学的期末考试的学习,其目的还是让学生掌握老师想让学生掌握的部分,是本专业所必需的基础理论和基本技能,但是老师并不负责知识的有效性和时效性.没了外力约束的学习,即一个人不需要获得GPA而获得荣誉或者去更好的地方学习,本科毕业的最低要求是各个课程及格,从而使得大量的废物产生在世界上.高等教育的学习,在我看来是在获得基本的求生技能的基础上培养一个人独立思考的能力,需要从社会的进步浪潮中发掘自己的擅长,如何与世界的进步发展同进步.就计算机专业而言,实践是获得此种能力的最好方式,培养实践能力比学习理论知识重要,因为工科的学习一切都有例外,没有办法用一个思辨的角度来发掘别的公司或者独立开发者为什么这么写,容易陷入过于苛求完美的循环中.工科的学习是循序渐进的,实践能力会随着眼界的拓宽而日益增长,直到自己也能造火车的那一天.PhD阶段的学习是从科研中来到科研中去的,我们无需关注无关自己课题的一切知识,其只能阻碍自己的钻研时间,而拓宽视野的过程应该流于与其他研究者的讨论,实践比赛或复现别人的artifacts,参与工作的实习,而不是单纯的从书本上寻找自己课题的答案.对于未来想要做的课题,可以提前参阅书籍和工业界的best practice,在潜意识中思考工业界没有想到过的部分,体现自己的价值.从学习到科研的转变,是一个人的学习热情从外驱力到内驱力,我认为什么东西工业界没有想到,或者没有提供全工业界的价值,而流于一些头部公司的东西,怎么更好的服务工业界.
从与已经失去科研兴趣的人交流过后,他们大多都在无尽的尝试中失去寻找自己可以作为PhD可以提供的价值,而放弃了探索,将PhD作为一种逃避经济衰退的手段,而苟活于柴米油盐,骗funding谋生.即便他们来自四大,即便他们认为这个世界已经被那些有规模效应的公司所占据了.什么是学术界的探索?究竞是所谓的peer review规则带来的劣币驱逐良币,还是PhD及其导师所想到的可以变革工业界思考的良币驱逐劣币?spark是一个很好的例子,Matai调研Facebook使用Hadoop却烦于其过慢的OLAP性能,即在伯克利创造了In memory Hadoop.我惊叹于伯克利的大力出奇迹,在peer review下并没有任何novelty却能在三次拒稿后用Facebook的广泛应用拿到了最佳paper.需求和解决方案是驱动计算机科学进步的源泉,没有思考的idea,如果它work,真正的peer也会告诉你,I buy it.伯克利不是一个适合做科研的地方,sky computing、alpa、foundation model、ORAM、UCB哪一个不是已经有别人的paper的基础上,封装一个伯克利defined layer,重新实现一遍,然后鼓吹这个东西made in UC Berkeley?但是这是一种创新吗?是.因为这就是共产主义.所谓的老人,告诉你一个怎么走捷径进入四大,top20,但是他们难道就能发SOSP吗,还是他们就是劣币,一个听从老板的left over的idea,让你实现,从而发顶会 ?PhD的位置是可以guide工业界行为的工作,这种美好的探索性的阶段绝不能浪费.
什么东西guide我的日常科研进度,我觉得老板只是提供方向上和日常怎么填满生活的建议,从而达到能发出paper的目标,真正的决定权在我,我希望在武力攻台之前拿到eb1a绿卡,我希望在毕业的时候能拿800k的工作.在做到这个之前,我理解工业界的需求是什么,我期望在他们着眼于此之前就提供我能提供的建议,同时获得价值.OpenAI说这是AI的黄金时代,David Patterson说这是体系结构的黄金时代,Chris Lattner说这是编译器的黄金时代,我说这是软硬件协同设计的黄金时代!
上了节Applied Cryptology的课。这老板和一切体系结构老师一样,非常push你做他想做的东西。大概密码学的研究,要不是一个全过程定义like CryptDB这样,或者弱化一个密码学的property优化性能,或者优化加密复杂度。一般都是找一个dummy implementation然后慢慢优化。

- SDa
- High-level idea: Organize Nupdates in a collection of at most $log_2N$ independent encrypted indexes
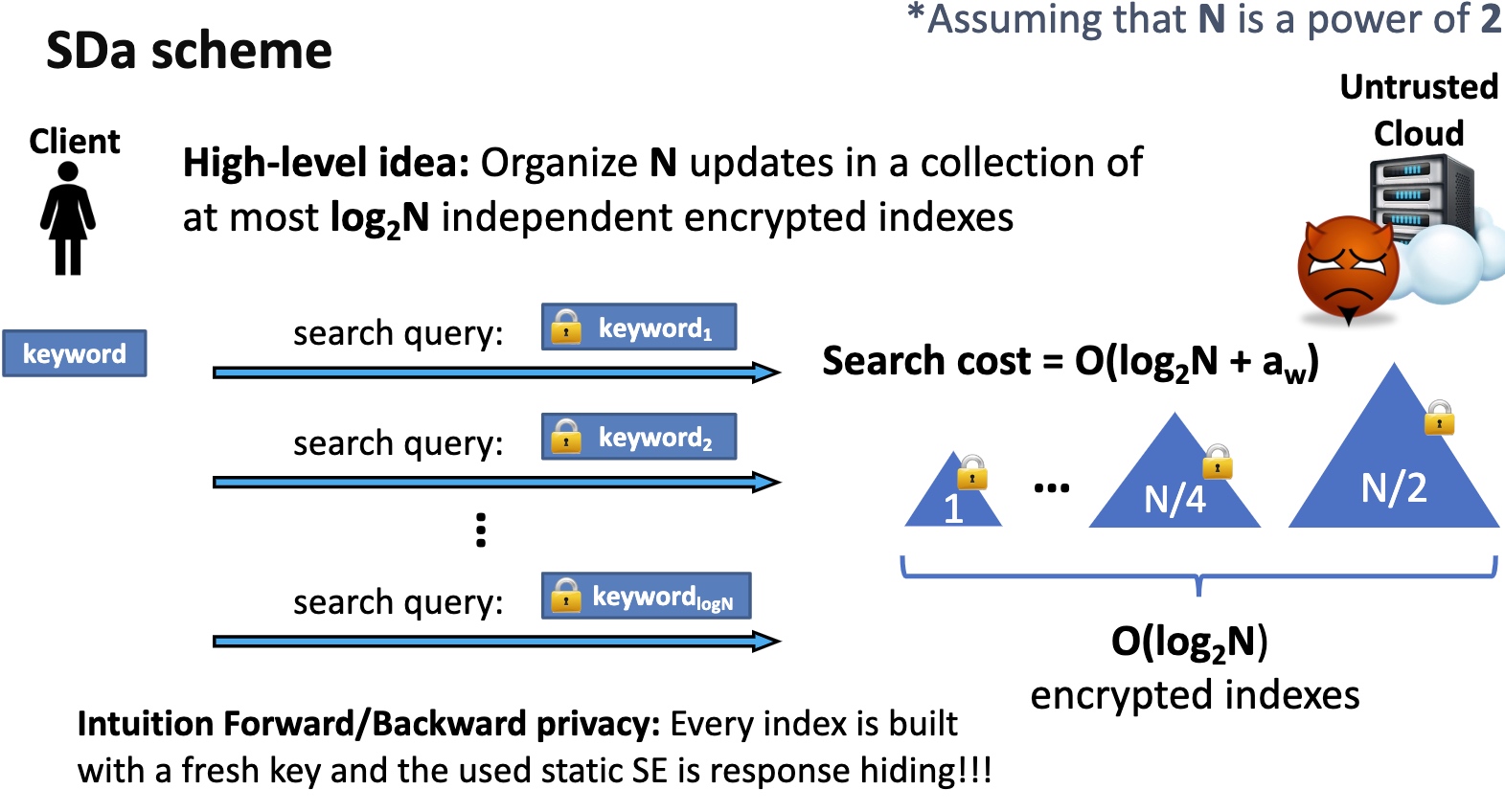
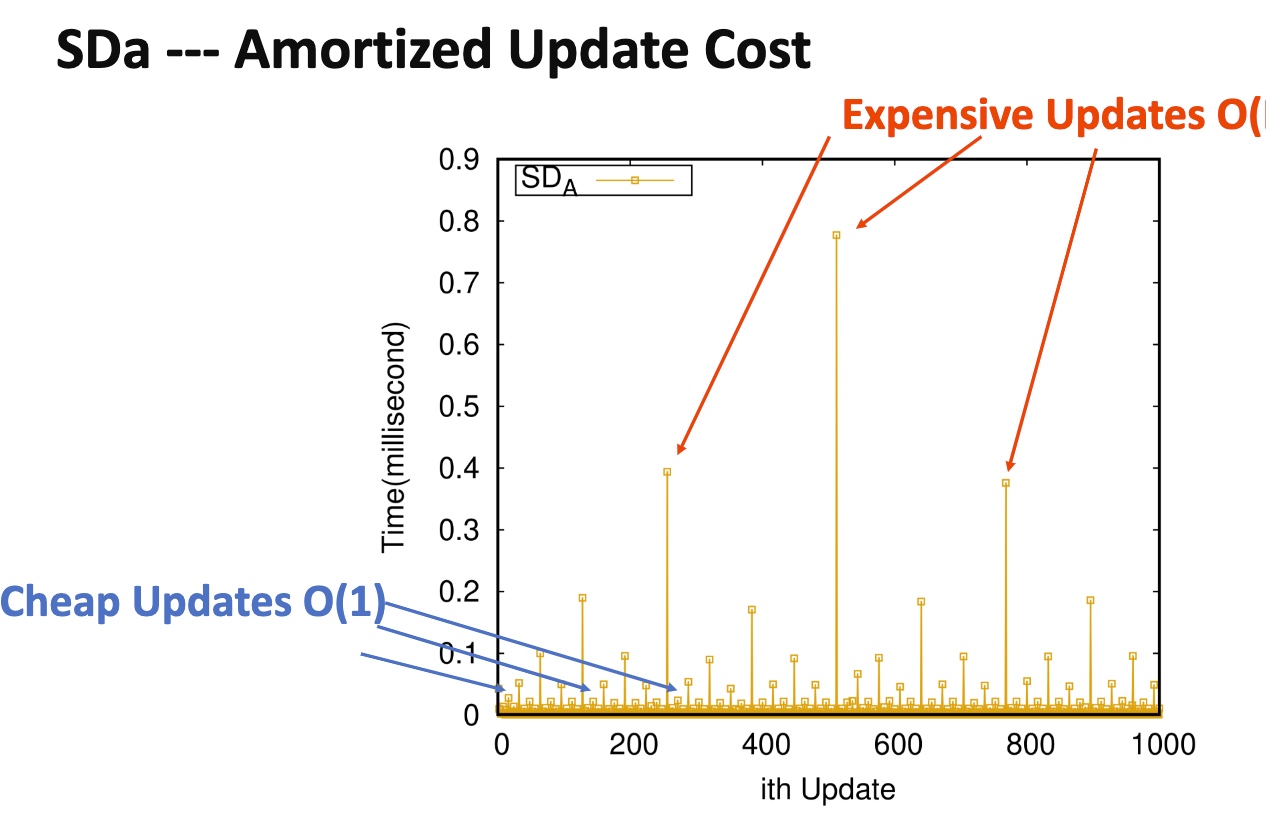
Can Reduce from amortized to de-amortized by constructing dummy code and sorting and obliviously make it work.
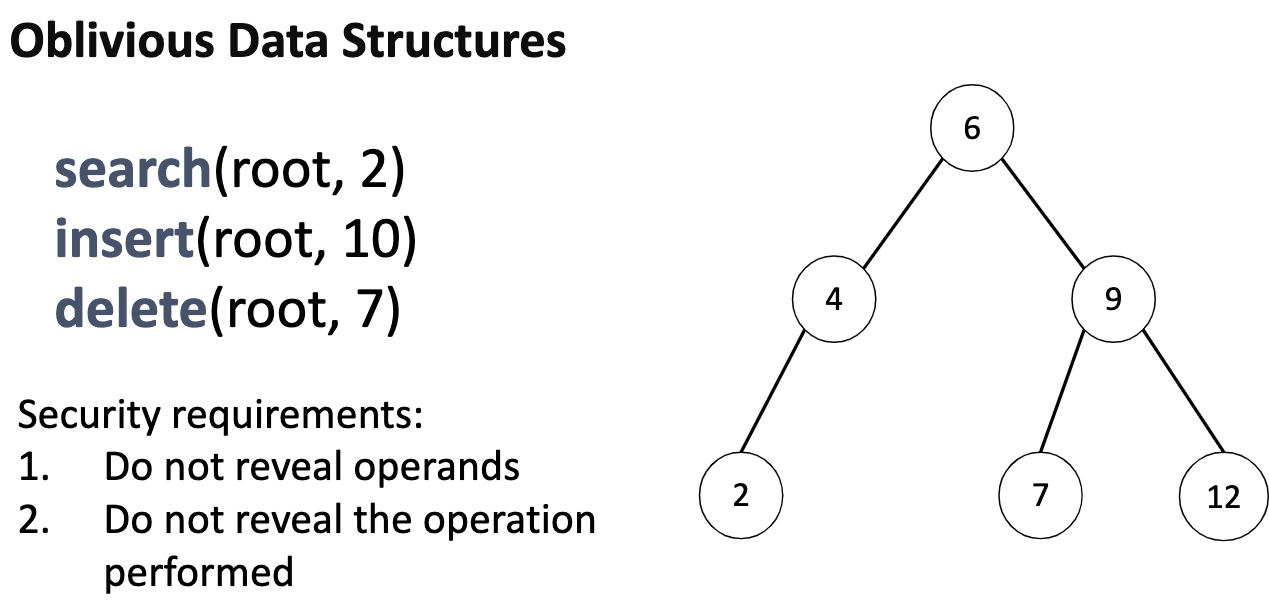
Oblivious algorithm
MPC

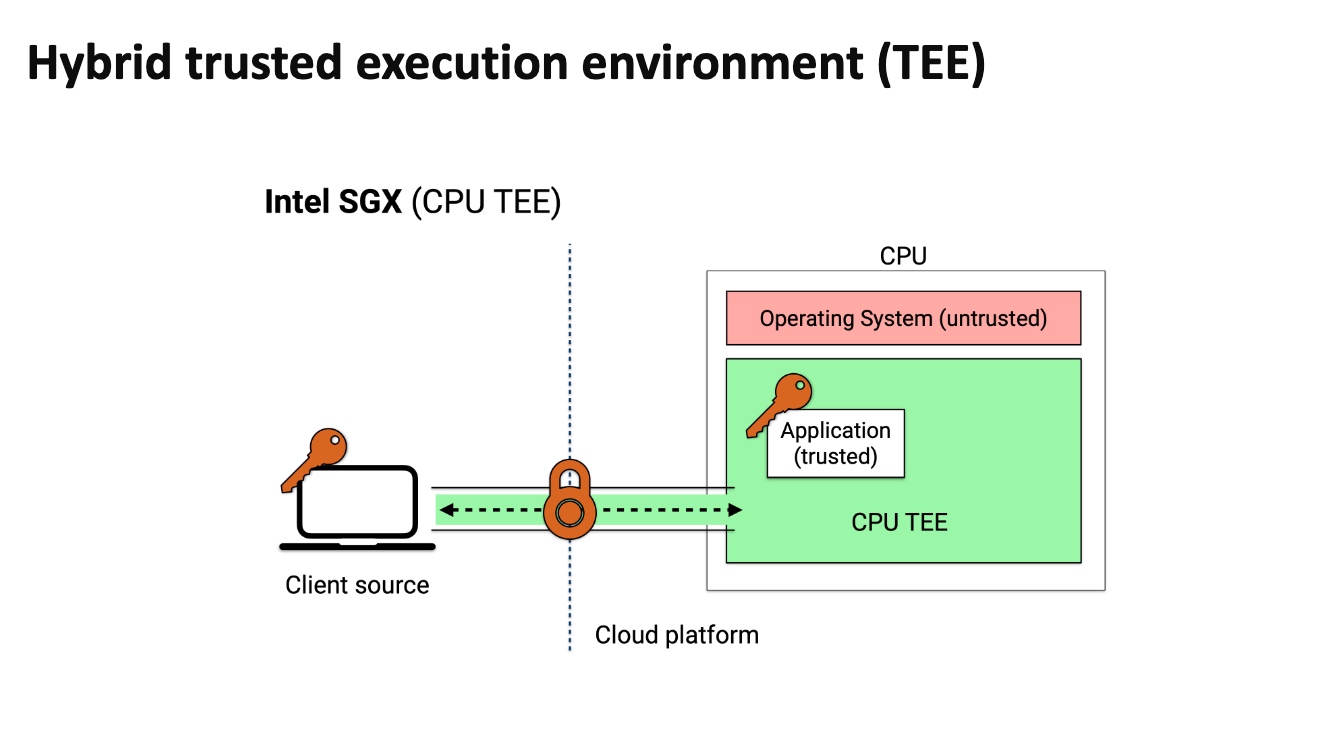
TEE doesn't need every time download everything, but makes client inside the enclave and exchange data with outer devices. It can save transmission time.
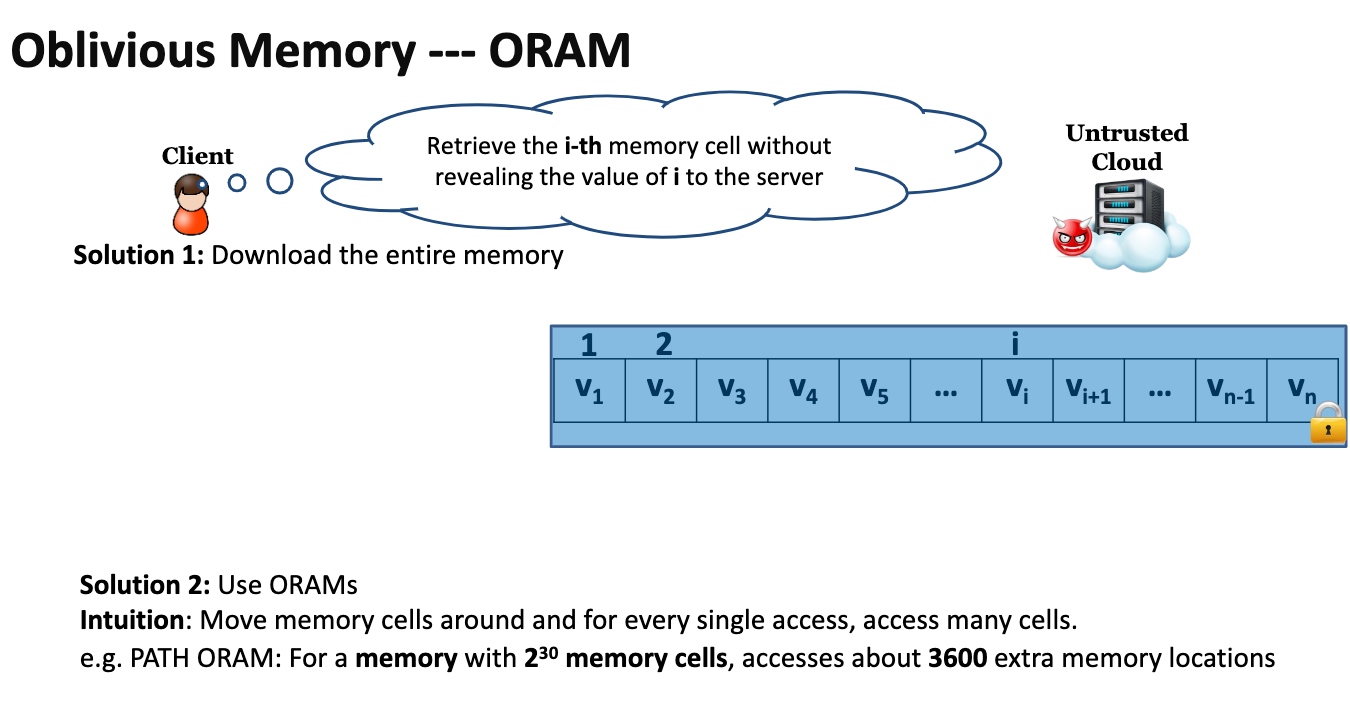
ORAM makes the access pattern to the RAM not leaked by the attacker
Backward Privacy


用cyphertext对search scheme的(de)encrypt,可以想像就是死慢。有很多rebalance/重排操作优化
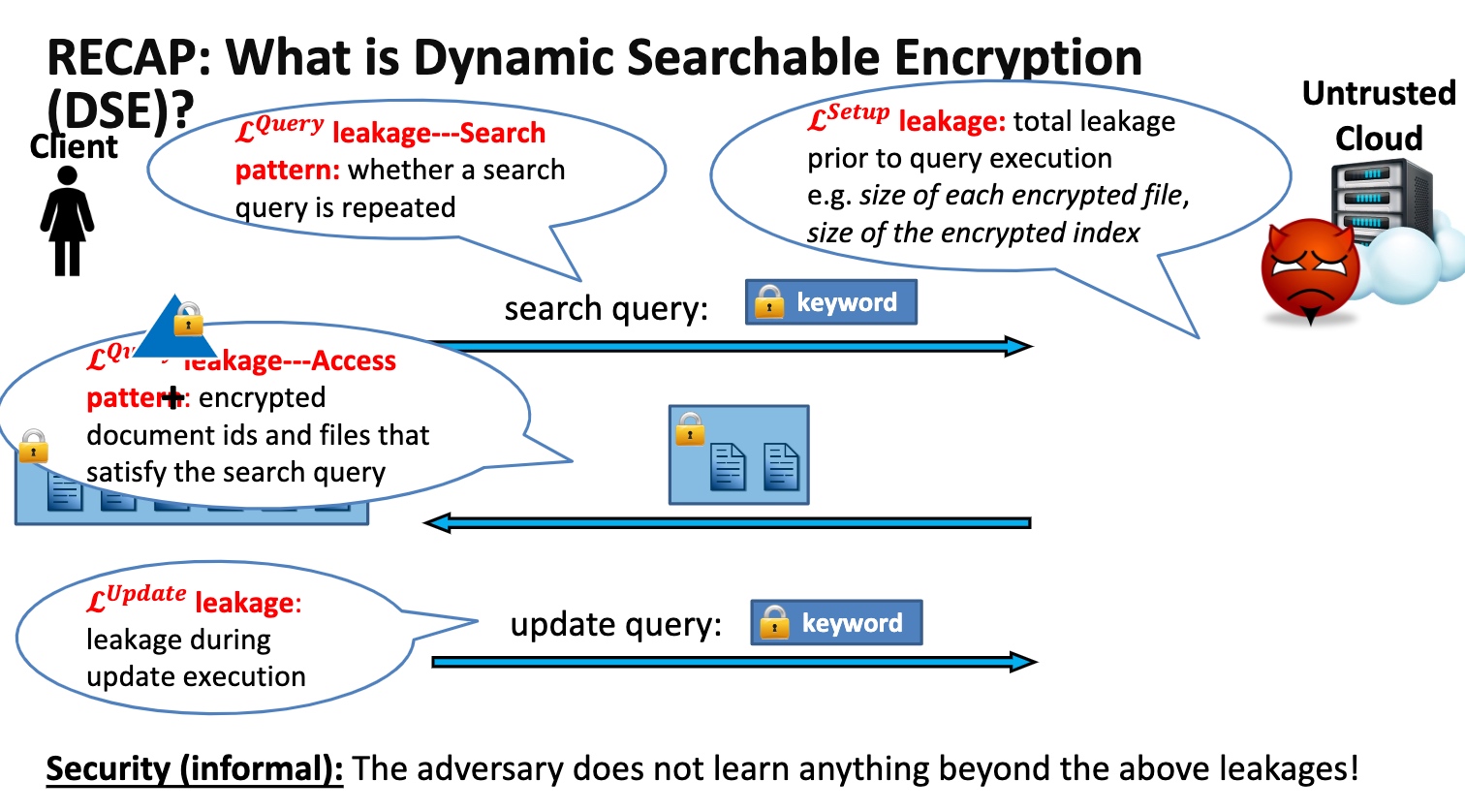
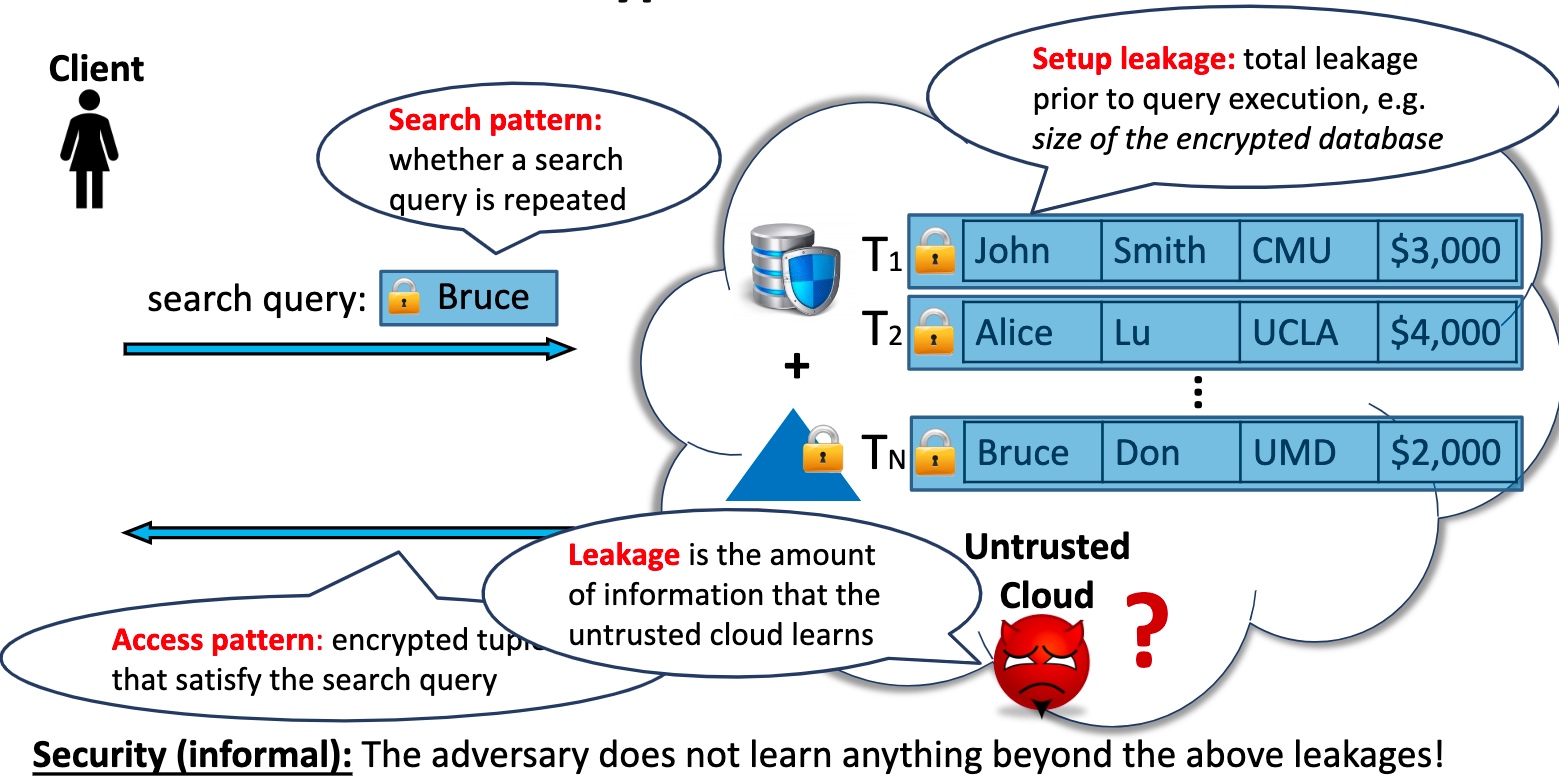
怎么保证在search的过程中没有任何信息被leak,尤其是access pattern
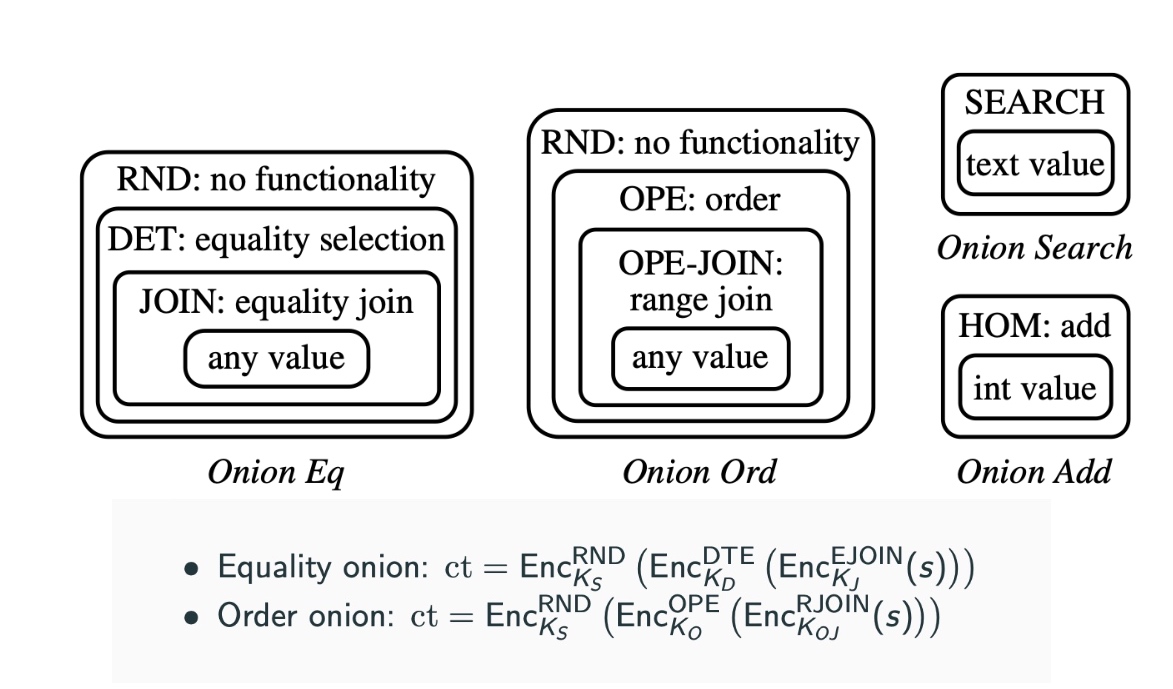
我们可以对一个db操作的任何一个步骤都encrypt

Security 喜欢干的也是写模拟器。

需要保证的是一次search对ideal的访问操作的概率差在一个相关$\lambda$的可控范围内,有点像$\epsilon-N$定义。最naive的定义是PiBas模拟器来模拟SE。然后有个证明是用模拟器模拟和实际情况哦差别不大。



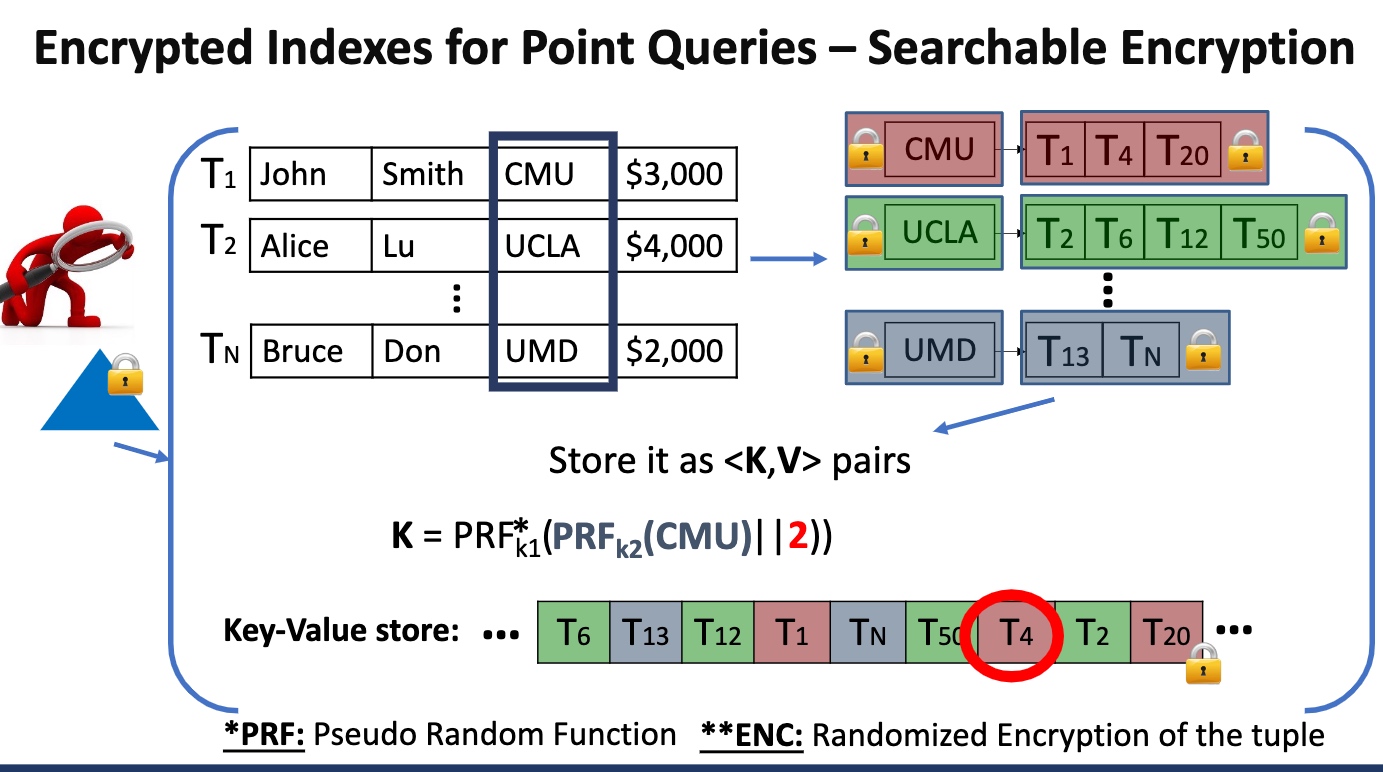
算法层面的定义key的encryption如上。

在模拟器里比较好测试算法的有效性。证明property like adaptive indistinguishability.

Whether construct all the key and pad to size of power of 2 will reduce the database result-size leakage?

What about adding random (key, value) pairs to $T$, so that the total number of elements is 2*N,

Use ORAM Map + Backward privacy
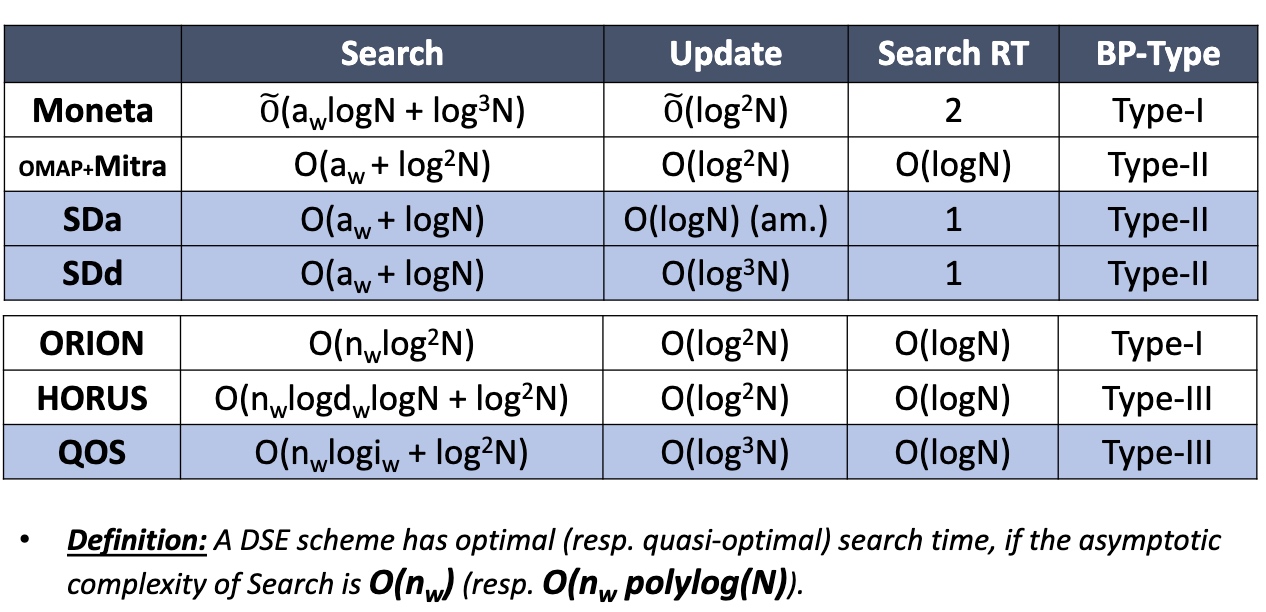
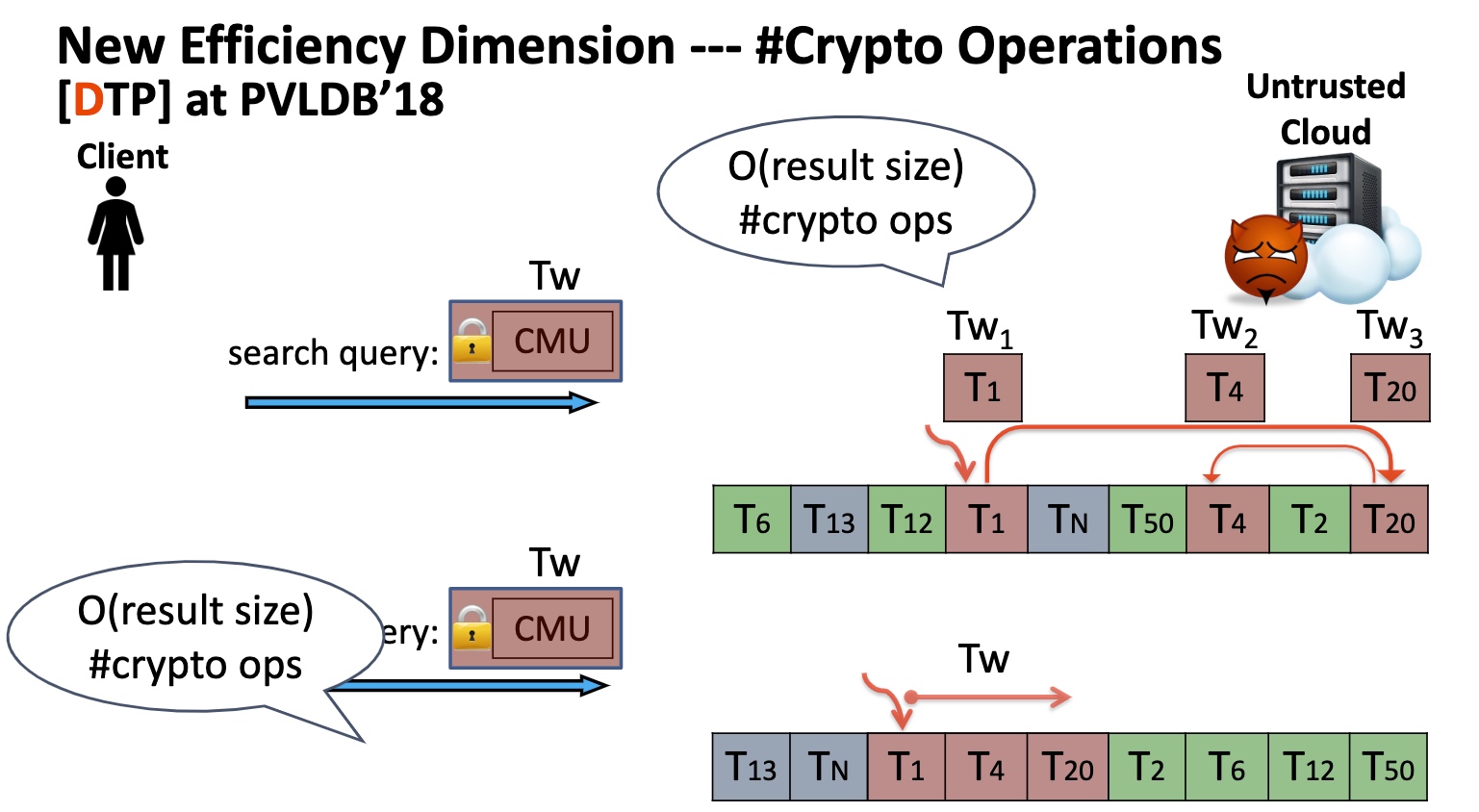
Define Locality and Read Efficiency
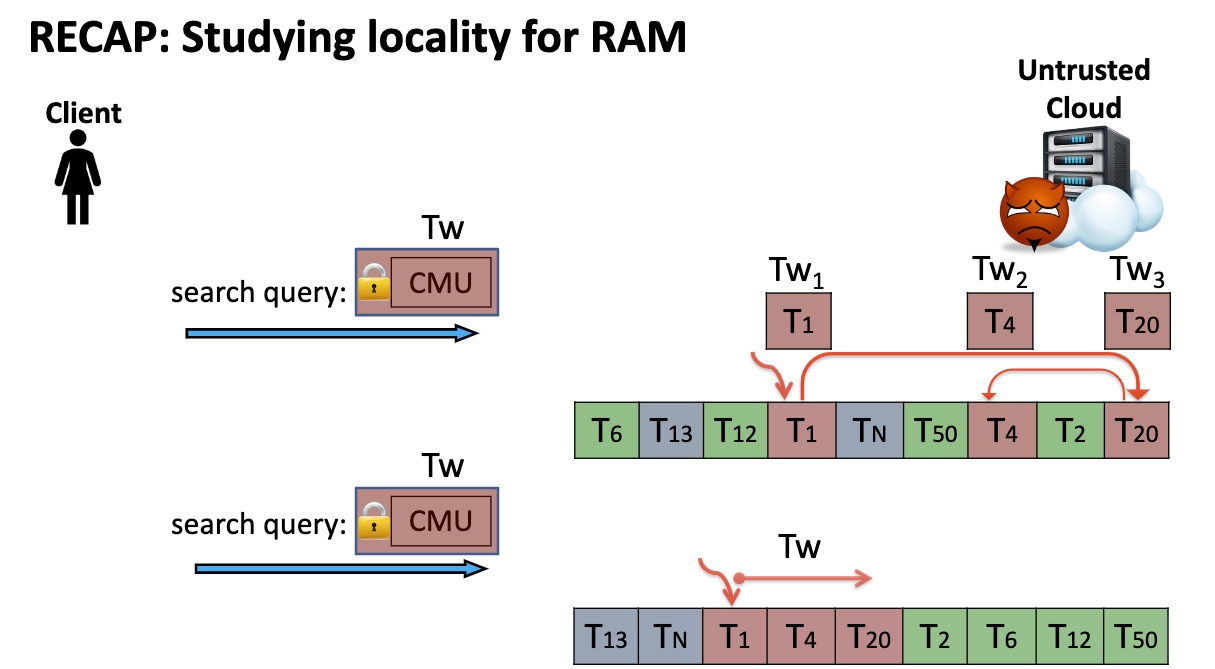
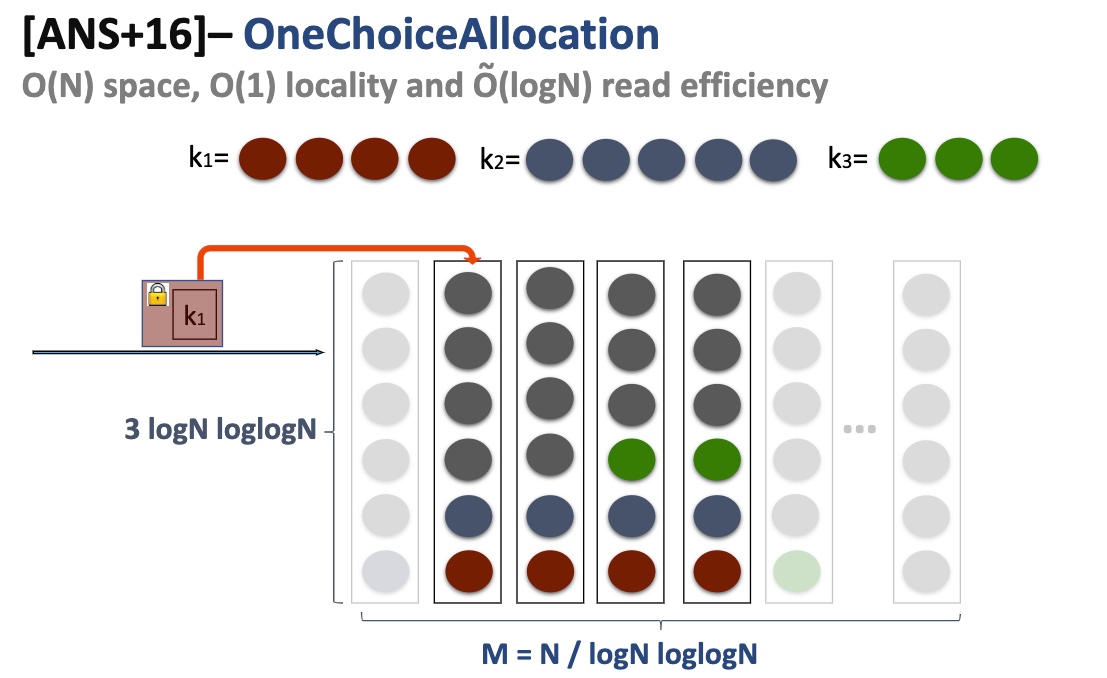
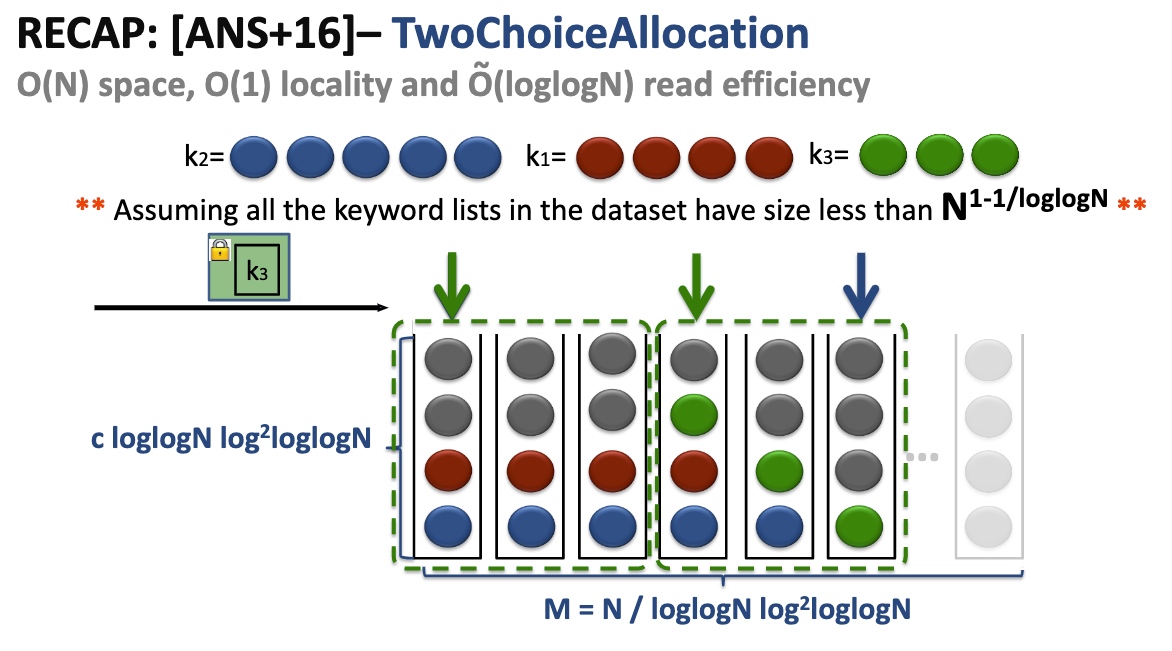
Lower the Property that has a minor possibility of leaking the access pattern - Page Efficient SSE.

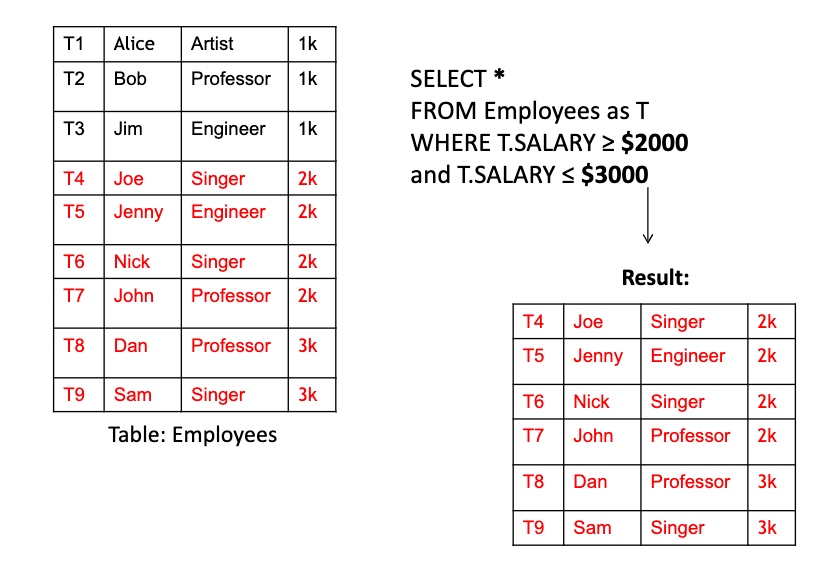
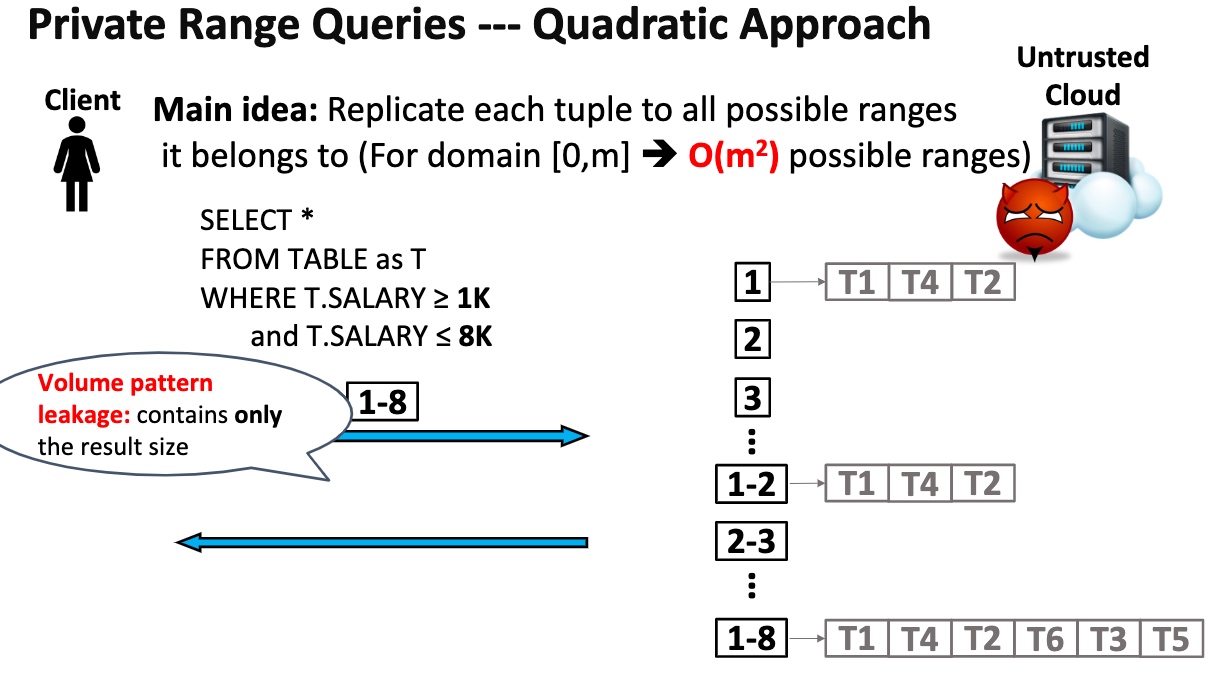
Key Idea is to transform the range queries into point queries.
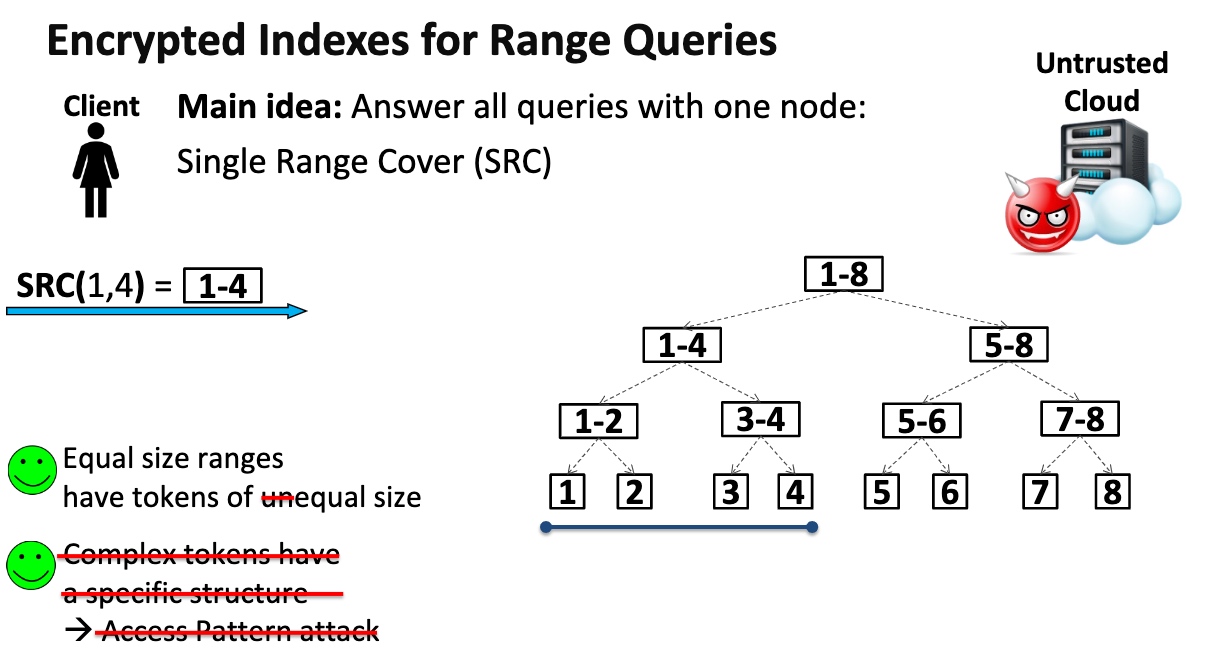
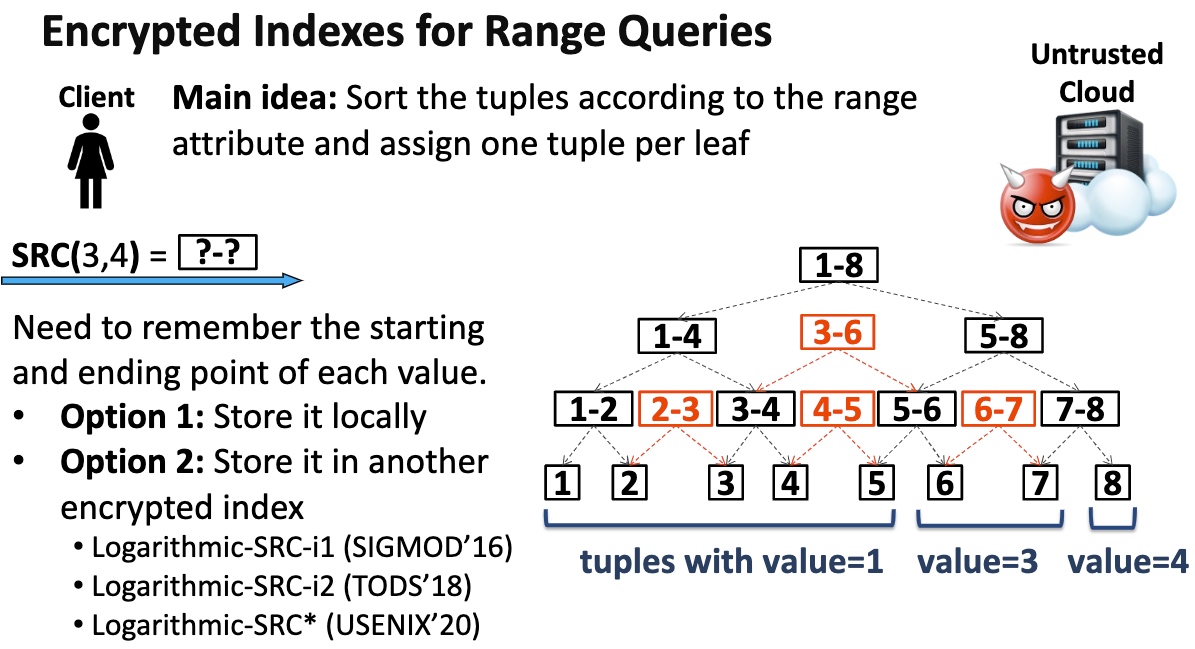
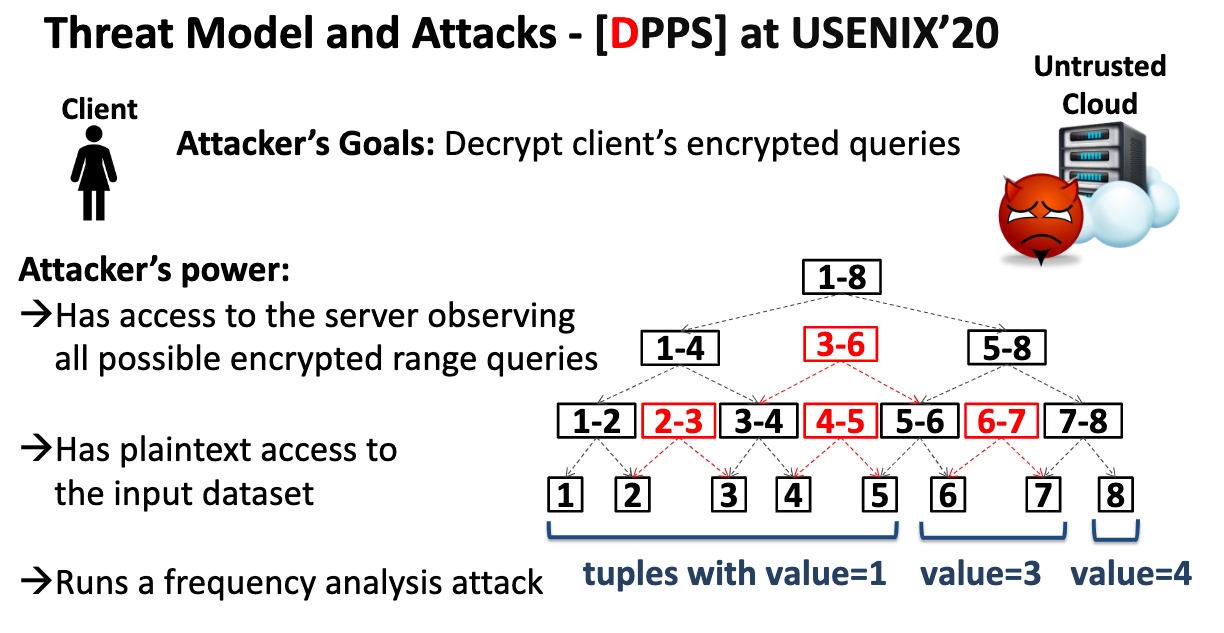
这部分就是看清哪里可以abuse的。
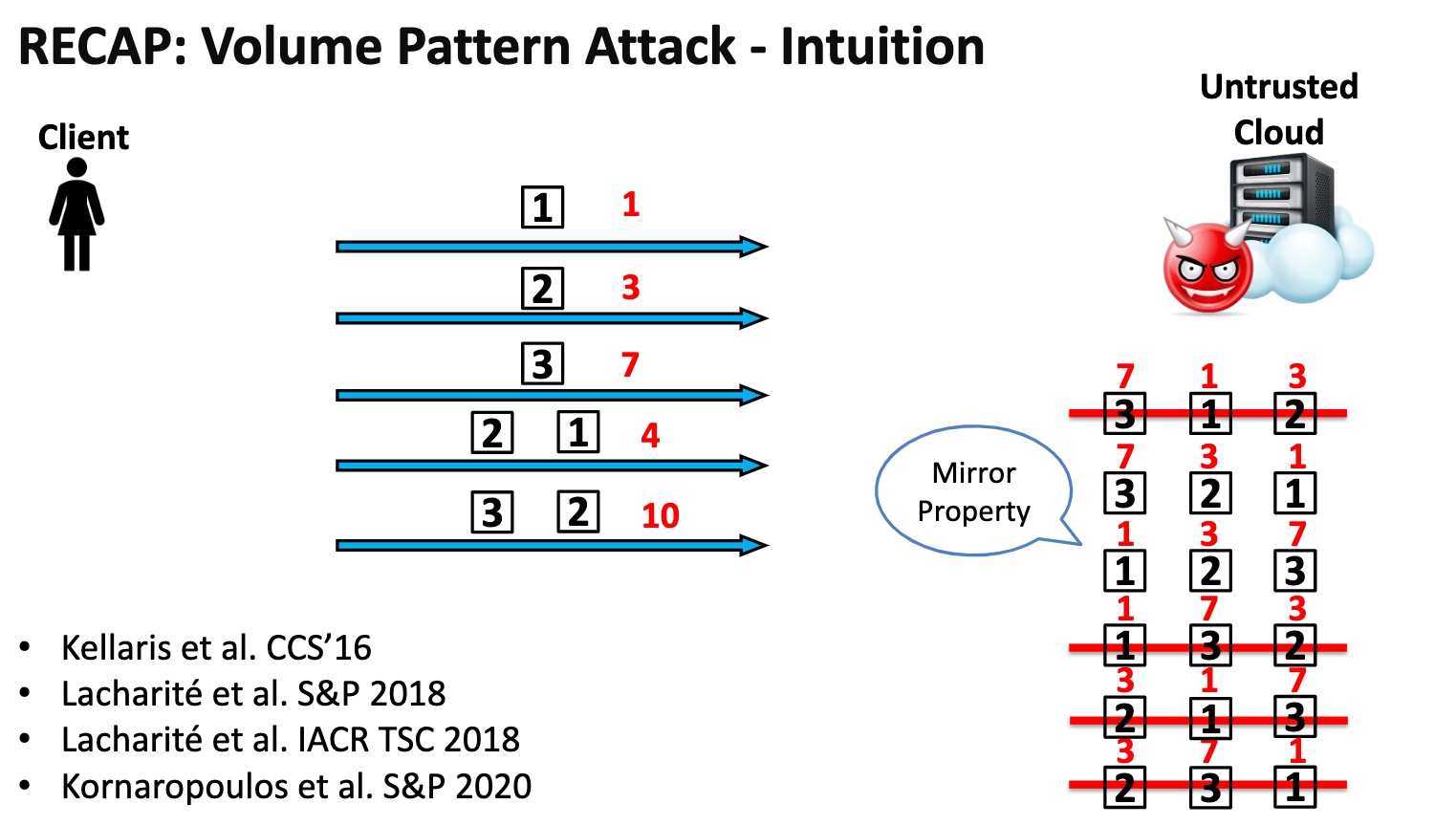



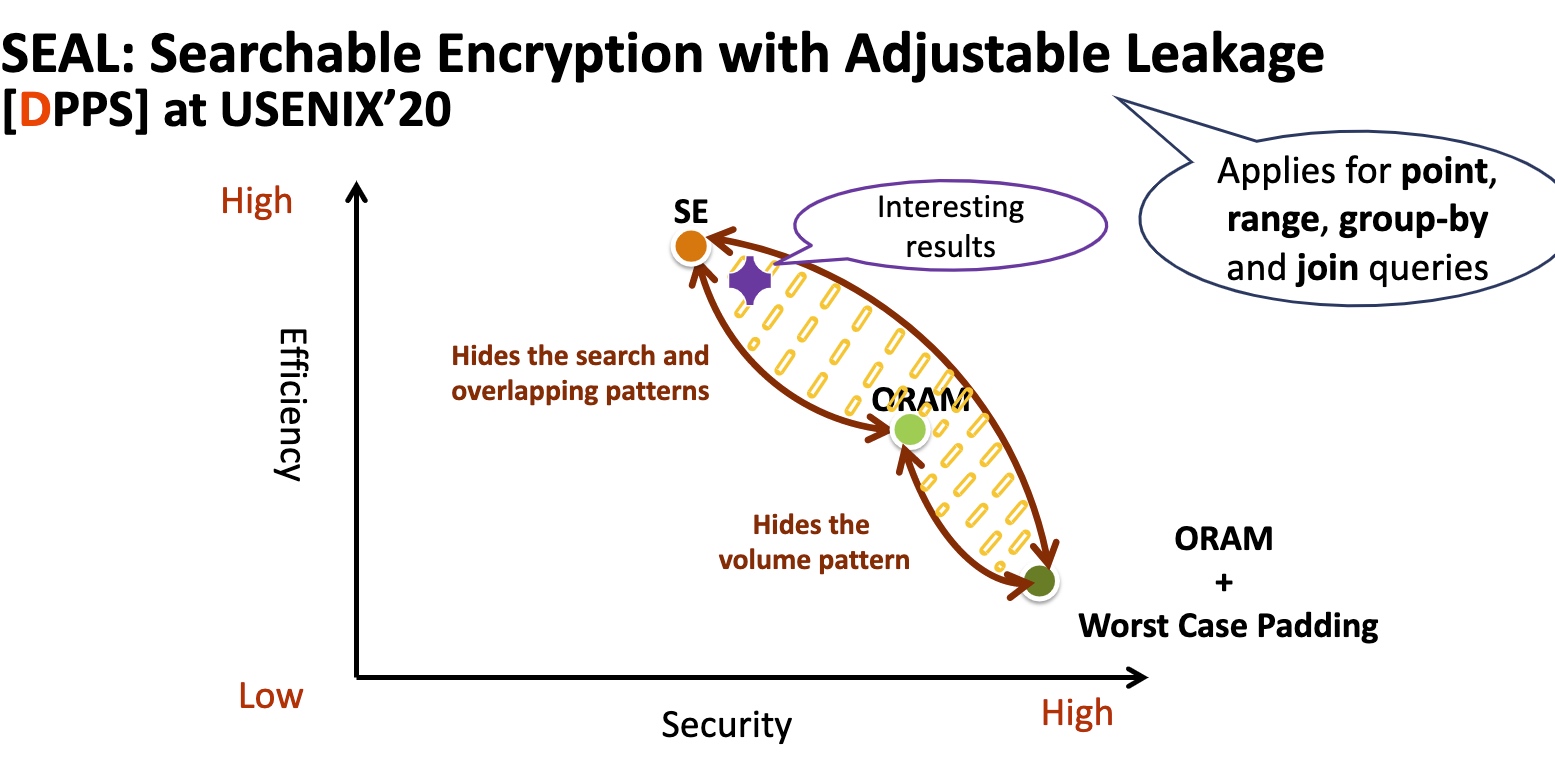

基本思想是在你的ORAM放一个aside ORAM,用一个散列函数分成俩$^n$倍。






Can leak the private join operation

This Oblivious Shuffling basically tell use the mapping will cost O(log N) for storage O(1), O(N) for storage O(log N) and O(N log N) for storage(N1)

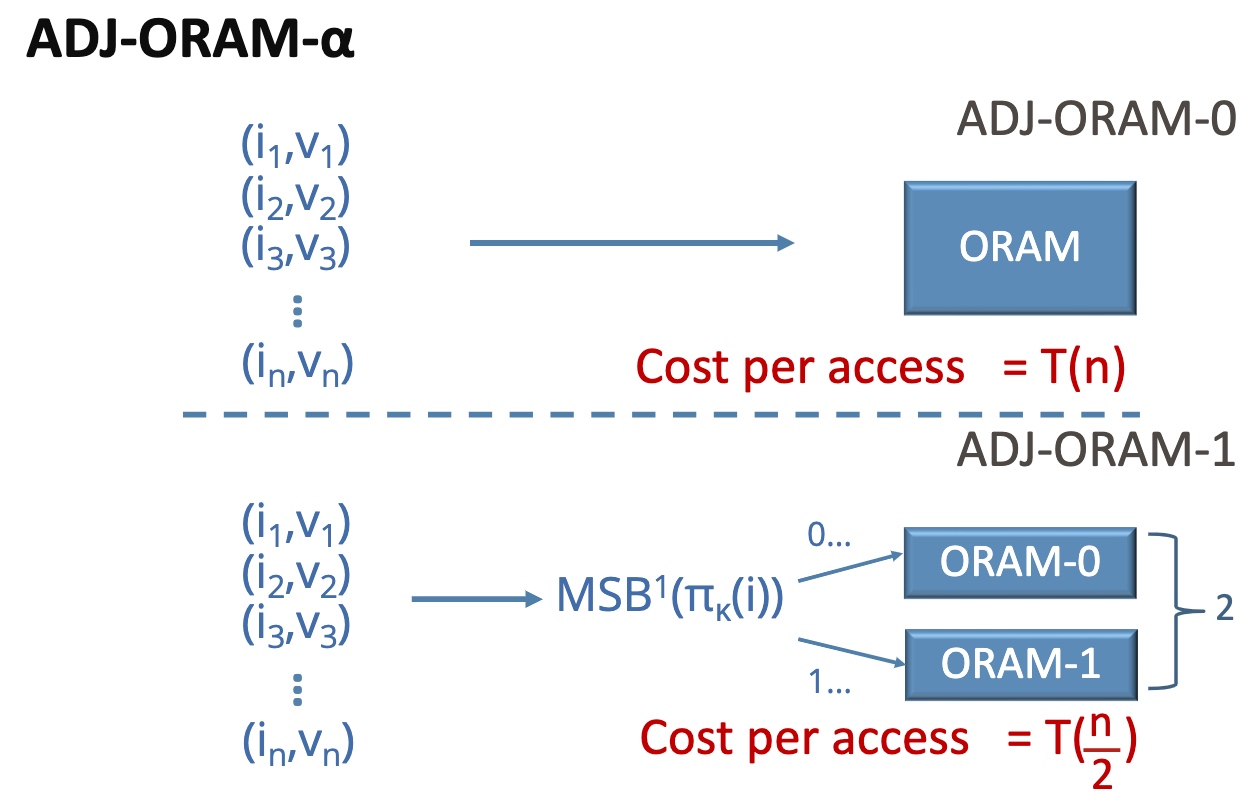
1

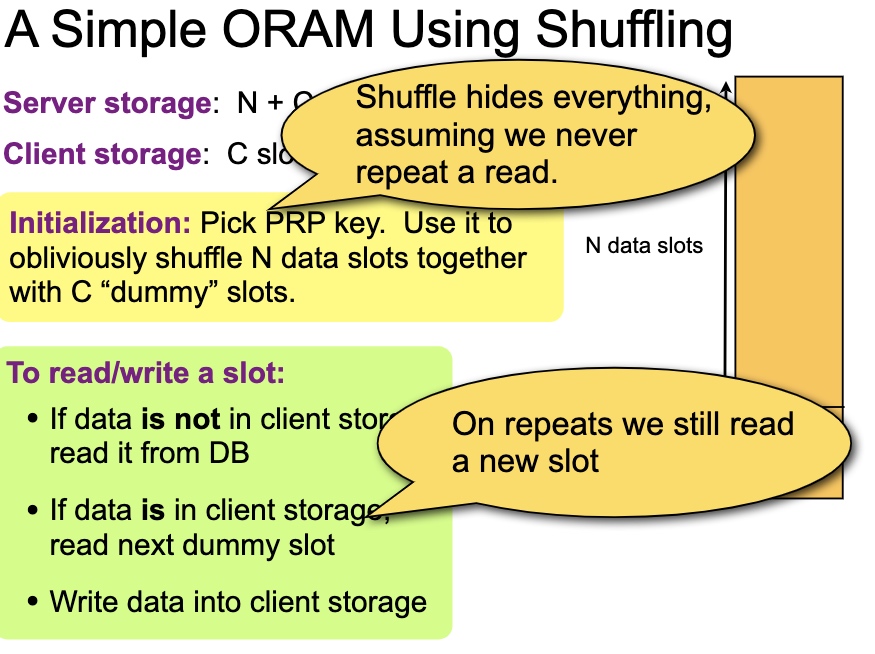
shuffle有很多variant, double buffer amortized square root shuffle and cubic。安全证明是对$\sqrt N$的操作寻找整个data slot的期望是正好的。所以buffer可以到$\sqrt N$。

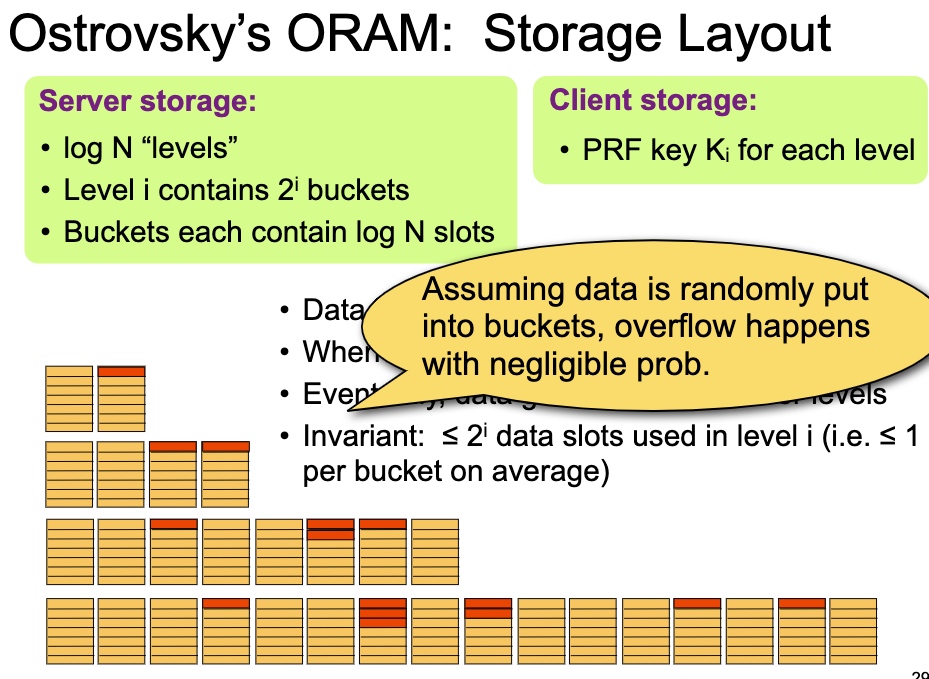

每次读,除了第一层都用PRF $K_i$ 拿到结果,然后put to first。第i层每$2^i$次操作reshuffle一次。
一个标准的TEE保护数据。
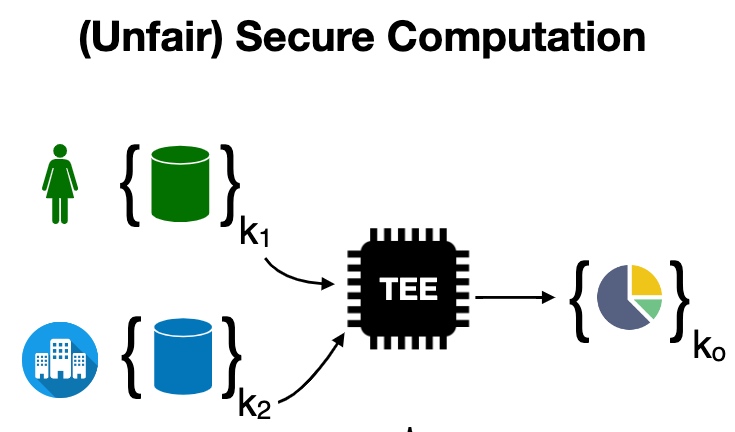
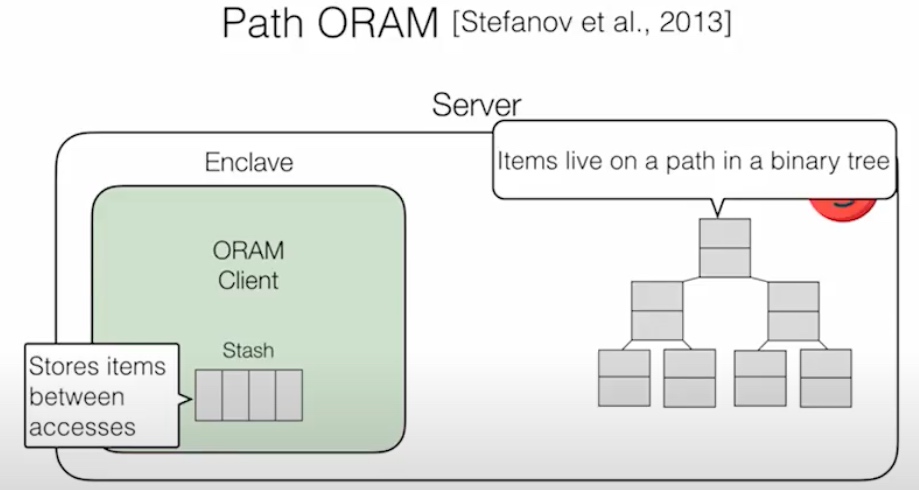
这个DB是Rust写的。想法是把client 放在SGX里面,做到双向Olivious,即ORAM clients make data-independent accesses to client memory (within enclave),让server和client相互看不到access pattern。PATH ORAM的方法是把stash data的position map放在enclave client里,item放在不安全的binary tree上,通过trace拿到结果,这个操作是singly ORAM。
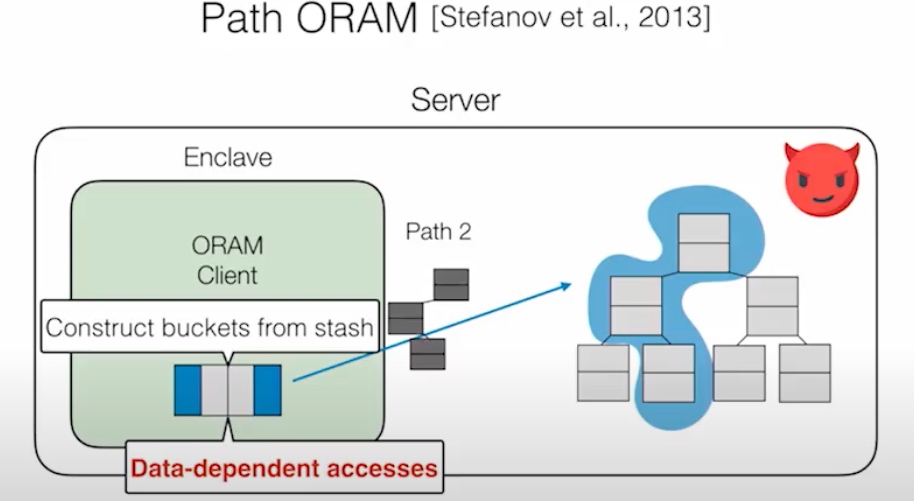
DORAM 说的是通过Block和fetched Block分离的方式读在server端的trace,
Read:get一次path替换dummy,添加block,添加dummy path到buckets里。
Write Back:
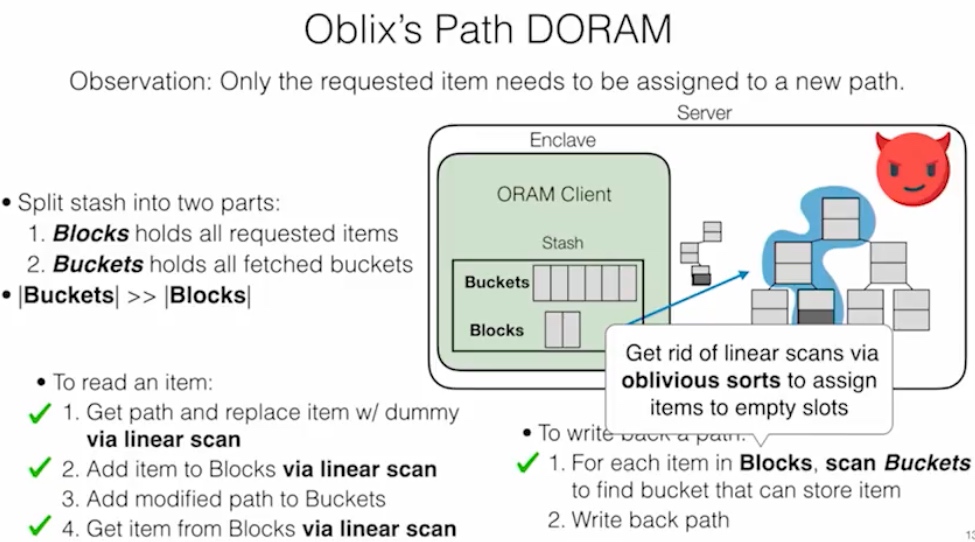
这部分还是一个性能和安全的tradeoff
The comparison between RMA based memory disaggregation and CXL.mem based memory disaggregation.
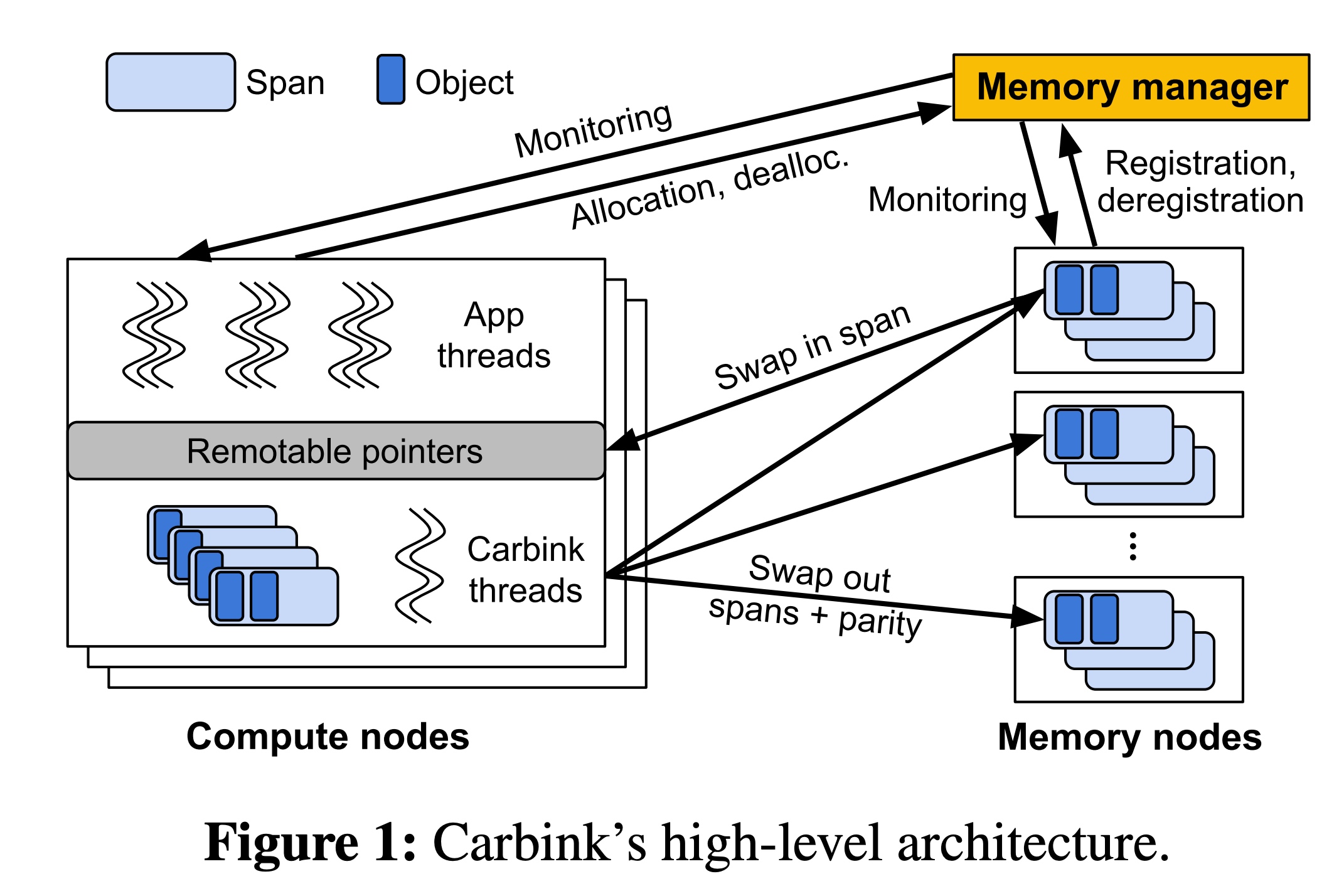
The span+coherency state in Carbink is just like cacheline coherency in CXL.mem but except that if two threads contention on one span it will go back and forth, that's the charm of cachable that CXL don't need the cacheline be transmitted but they are registered in the window of local LLC.
A lot of the software optimization is based on the panelty of small chunks transmission of RDMA is too huge that if we replace with CXL, we don't need to care ptr serialization and relinking because they are in the same memory space. maintaining a metadata of pages is still a huge overhead. The local page map is a two-level radix tree. The lookup process is similar to a page table walk: the first 20 bits of the object's virtual address are indexed to the first level radix tree table, and the next 15 bits are indexed to the second level table. The same mapping method allows Carbink to map the virtual address of a locally-resident span to its metadata. Thus this paper in era of CXL is useless, nothing to refer.
The difference of EC-Split(their implementation of Hydra) and EC-Batch is the critical path of the memory transaction. To reconstruct a single span, a compute node must contact multiple memory nodes to pull in all the required fragments. This requirement to contact multiple memory nodes makes the swap operation vulnerable to deviators, thus increasing the tail latency. And their compaction and de-fragmentation approach is to save the remote data usage but has no upgain for performance actually for their local vs remote upper than 50%. They only gain 10% for more on local side by the hiding of the span swap operations.
今年Fast在家门口开,那当人就请个假去玩玩咯.paper现在已经可以access了.两个Best paper都是中国的,一个是zuopengfei的ROLEX,一个是Fail-Slow的时序预测模型。
VAST Data's approach? LDC: workloads matters.
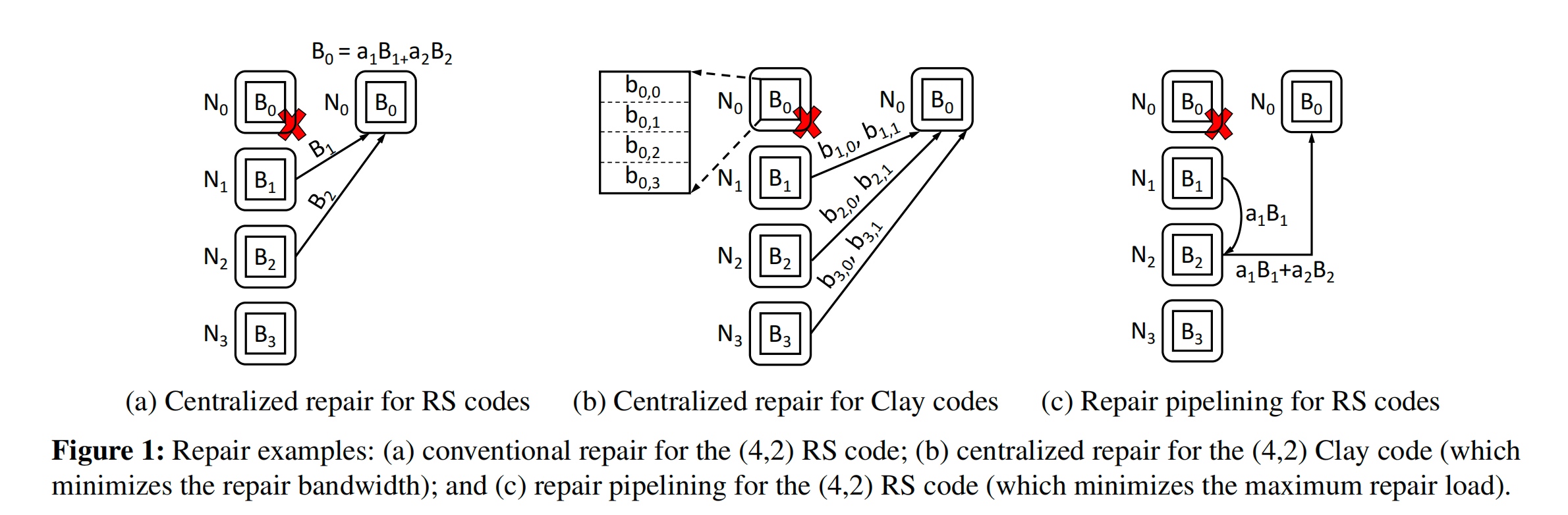
Repair penalty of RS Code
For SoTA (4,2)Clay code, the blocks size is 256MB while bandwidth and MRL are both 384MB.
Repair can be pipelining while the block can be chunk into blocks, (bw ,MRL)=>(512,256), drawback is additive associative. But we can subpackerize the block.
pECDAG to parallel GC for Clay codes.
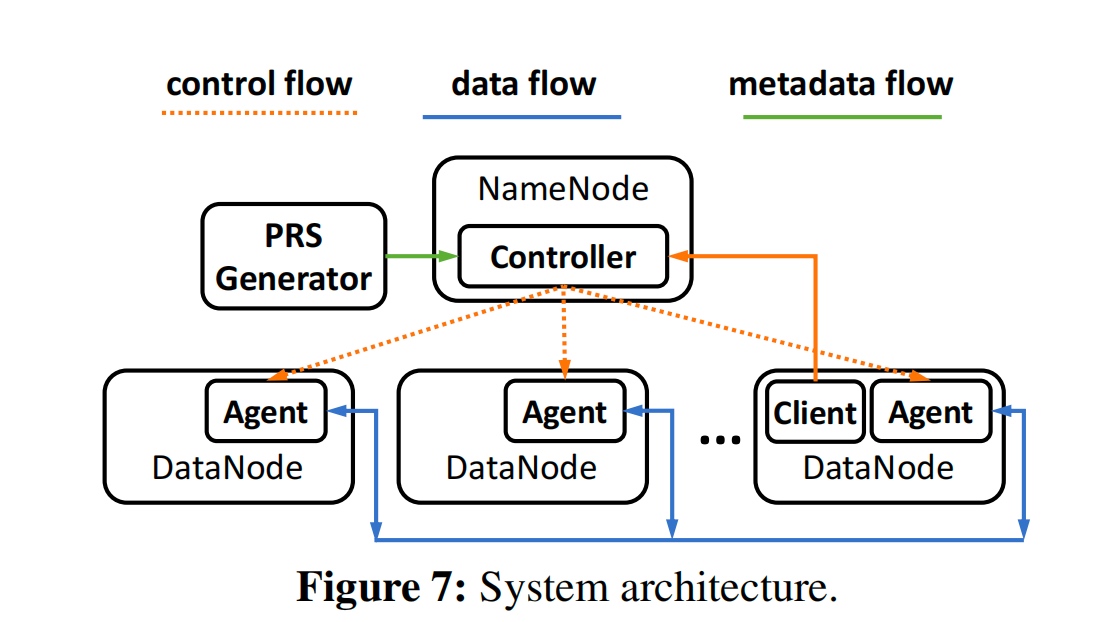
Cloud Tiering and backup data requires Deduplication in the cloud hypervisor level. They get teh fingerprint and semantic from the cloud tier and send the request to the local tier.
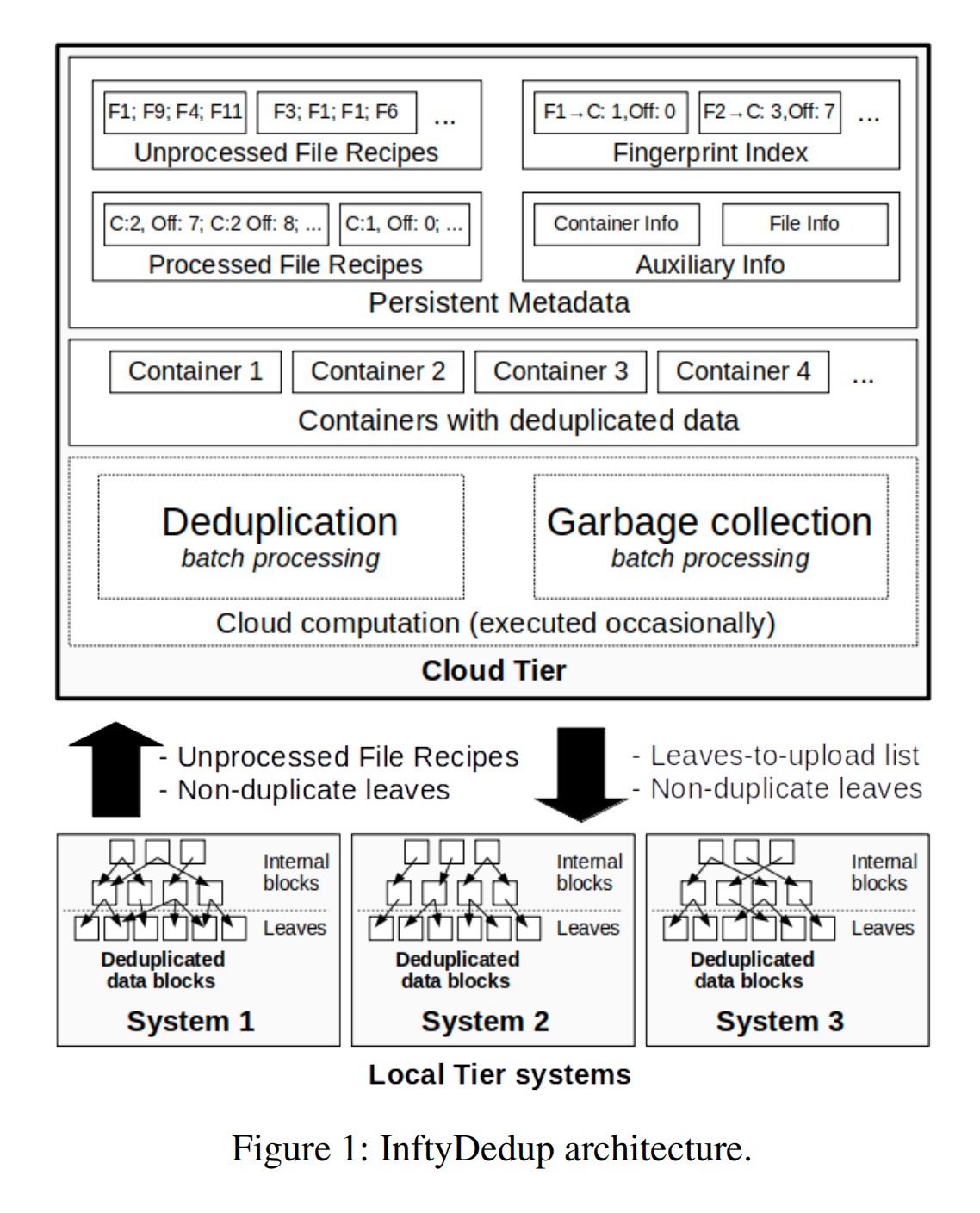
The GC algortihm is basically BatchDedup.
fingerprint Indexing in SSD.
用sliding window 做peer evaluation。
用时序模型预测Fail-Slow的出现时间 Latency vs Throuput+Linear regression。
用历史数据学不同SSD的RocksDB的L0-L1 compaction,data overflow.
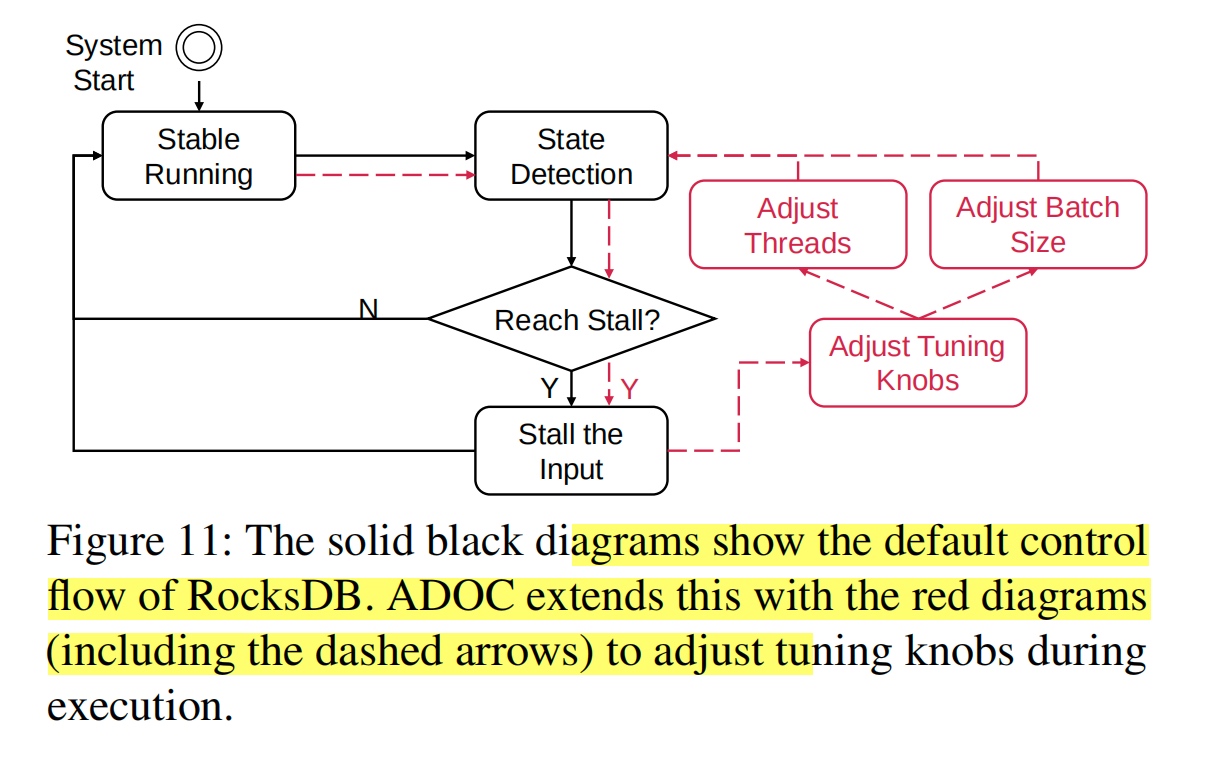
感觉做的没Kill Two Birds with One Stone: Auto-tuningRocksDB for High Bandwidth and Low Latency好。
RocksDB会自己increase memtable?
Does RDO control compaction? All layer compaction
RDO MMO encoder Transformer?Future work。
这篇和Ceph的想法基本一样。只不过放到了disagregated memory。

Client centric index replications
Remote Memory Allocation: RACE hashing+SNAPSHOT
Metadata Corruption: Embeded operation log
RACE Hashing: onesided RDMA hashing
Primary and write-write conflict resolution by last-writer(majority writer) wins and update the other place thereby.
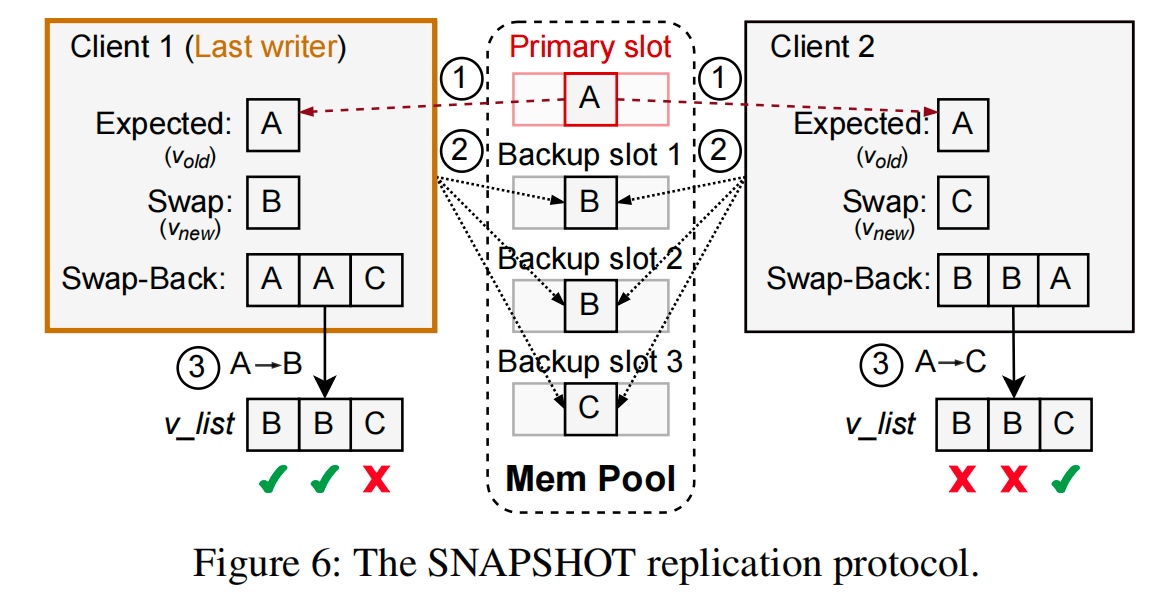
Compared with MDS that has key to hash for direct access to RDMA result. only 1 RTT for read.
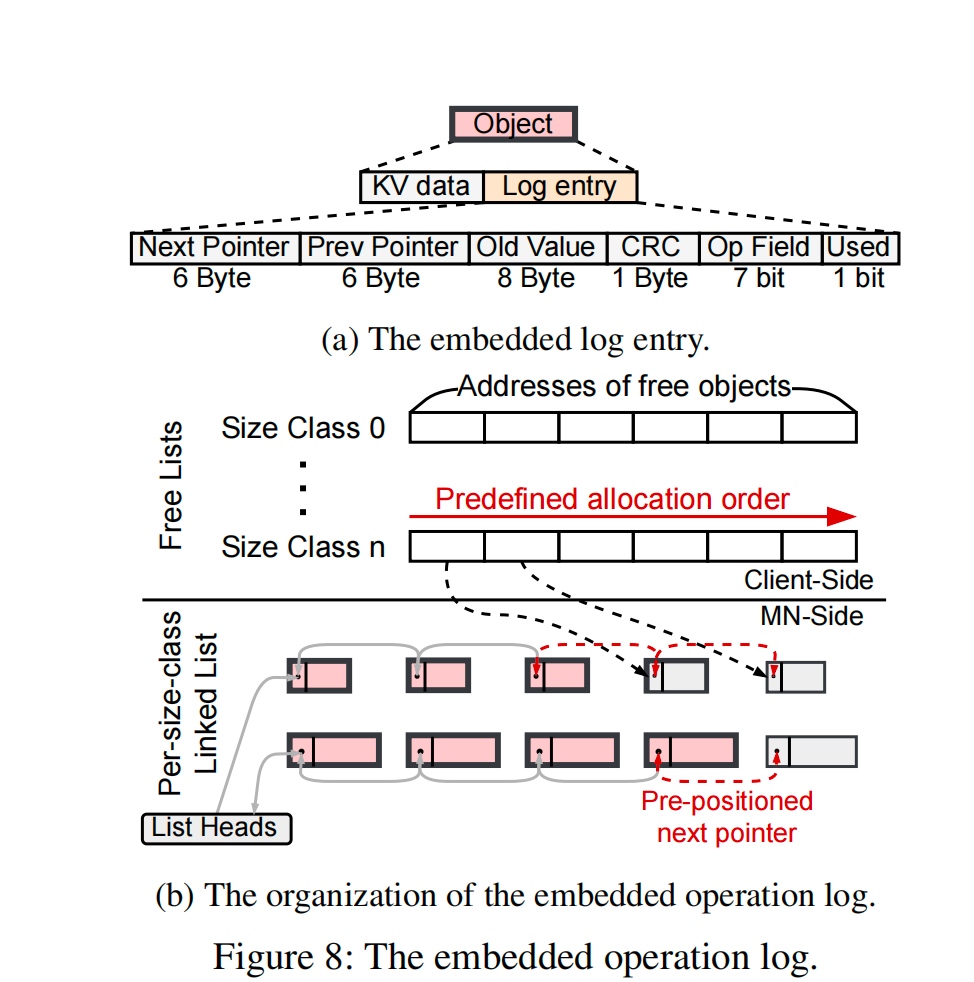
embedded operation log
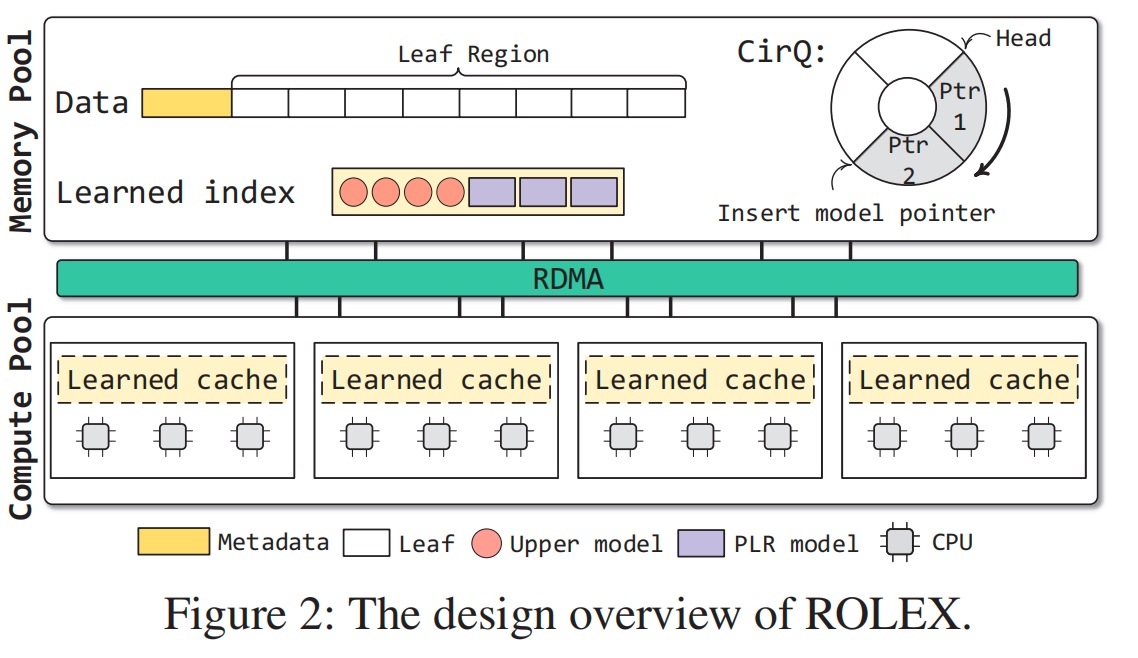
Learned key data movement and allocation requires recomputed decoupled learned indexes. The desired data leaves are fixed size bby the retraining decouple algorithm mathematically, which makes migration easier.
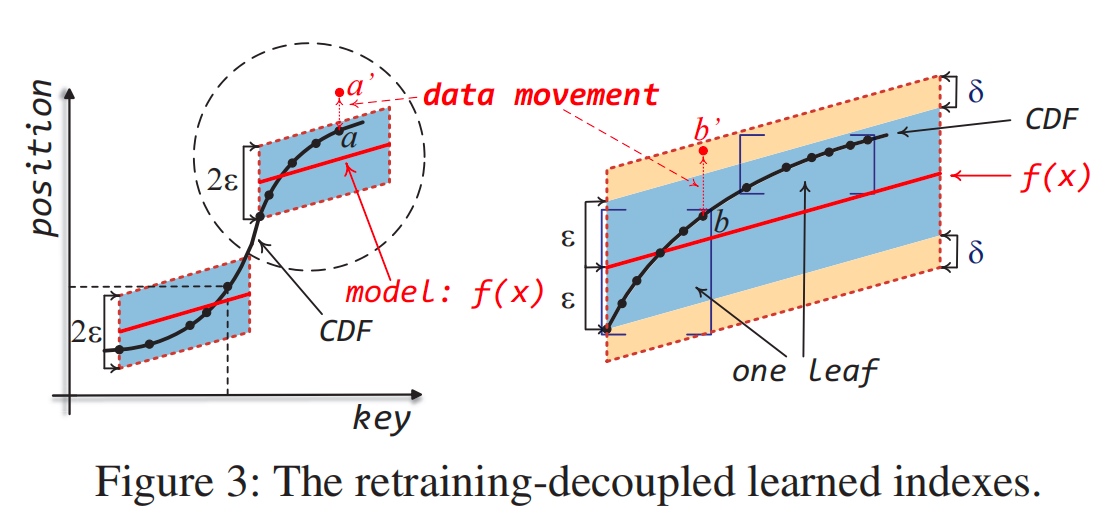
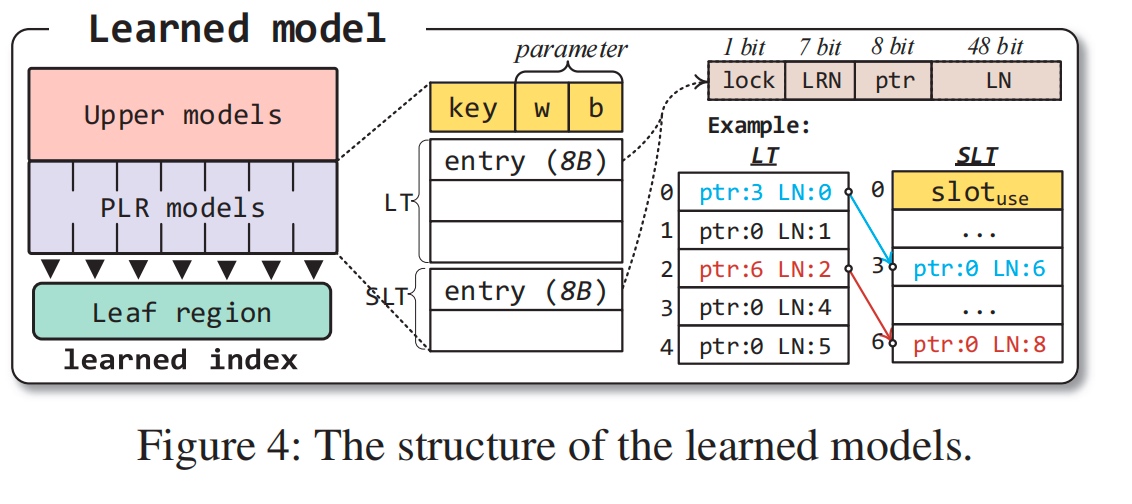
Consistency Guarantee, 感觉要同步的model的RDMA操作挺多的。
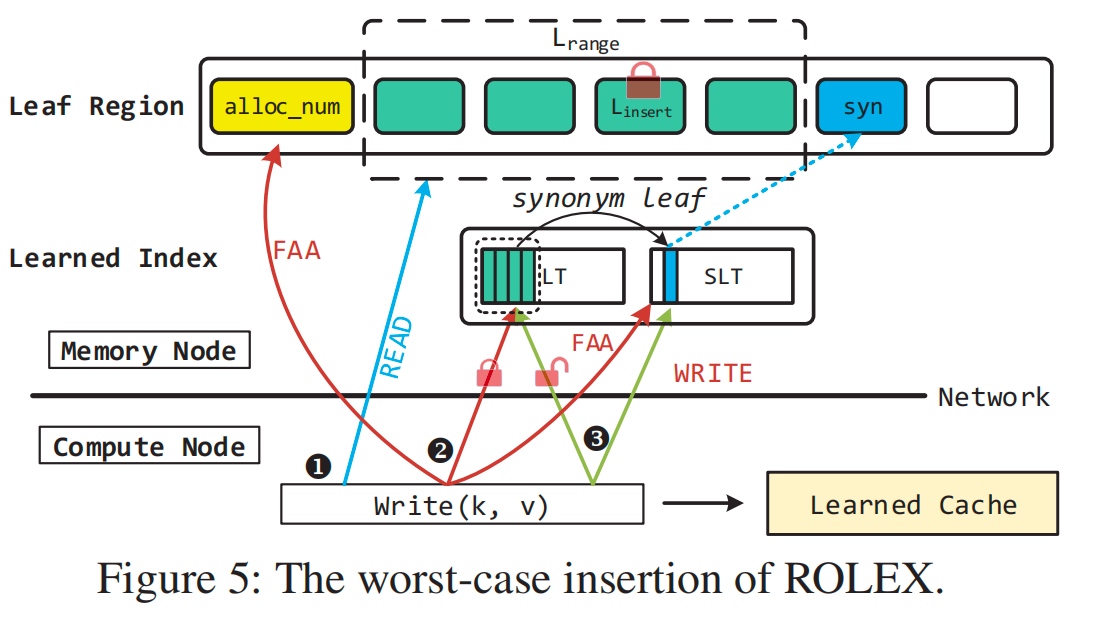
bit as lock? how to recover from the lock? future work.
Always update new model every read? first check the first entry of SLT. and update the model if changed.
xgboost学了utility time的metrics。然后按utility time evict。如果两个workloads公用cache就不行。以及如果cachesize很大我觉得预测的效率不如手动ttl的segcache。以及我觉得Transformer预测ttl更优秀,因为xgboost只是捕获信号,并没有预测能力。然后似乎这个metrics也是试出来的。
这篇是SC见到的同学的。
Multi version shadow paging
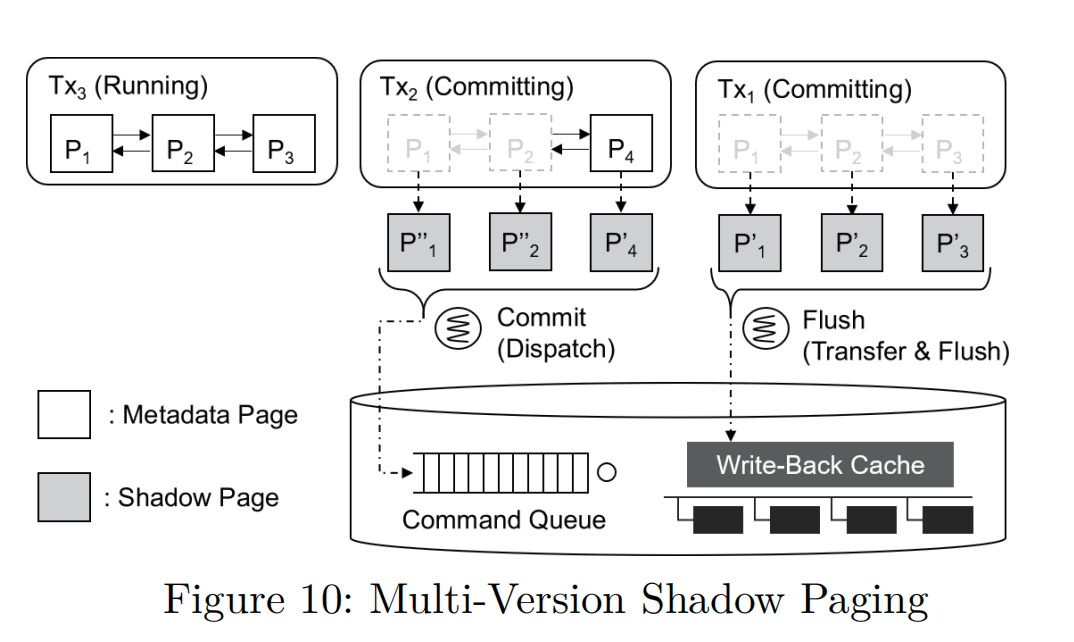
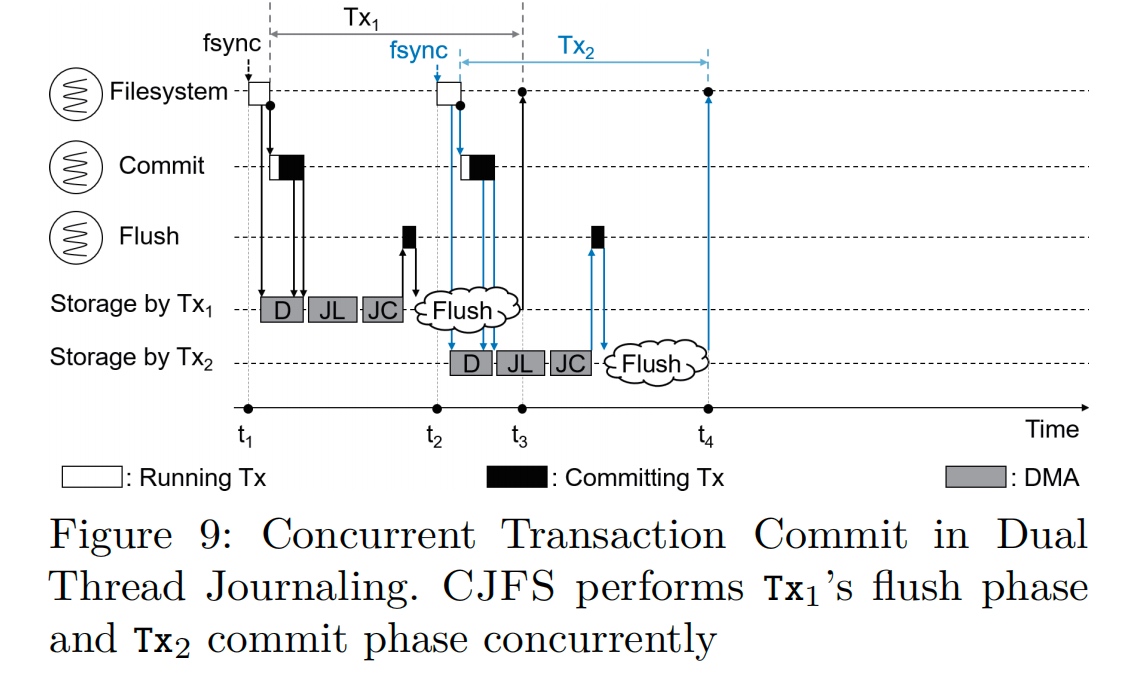
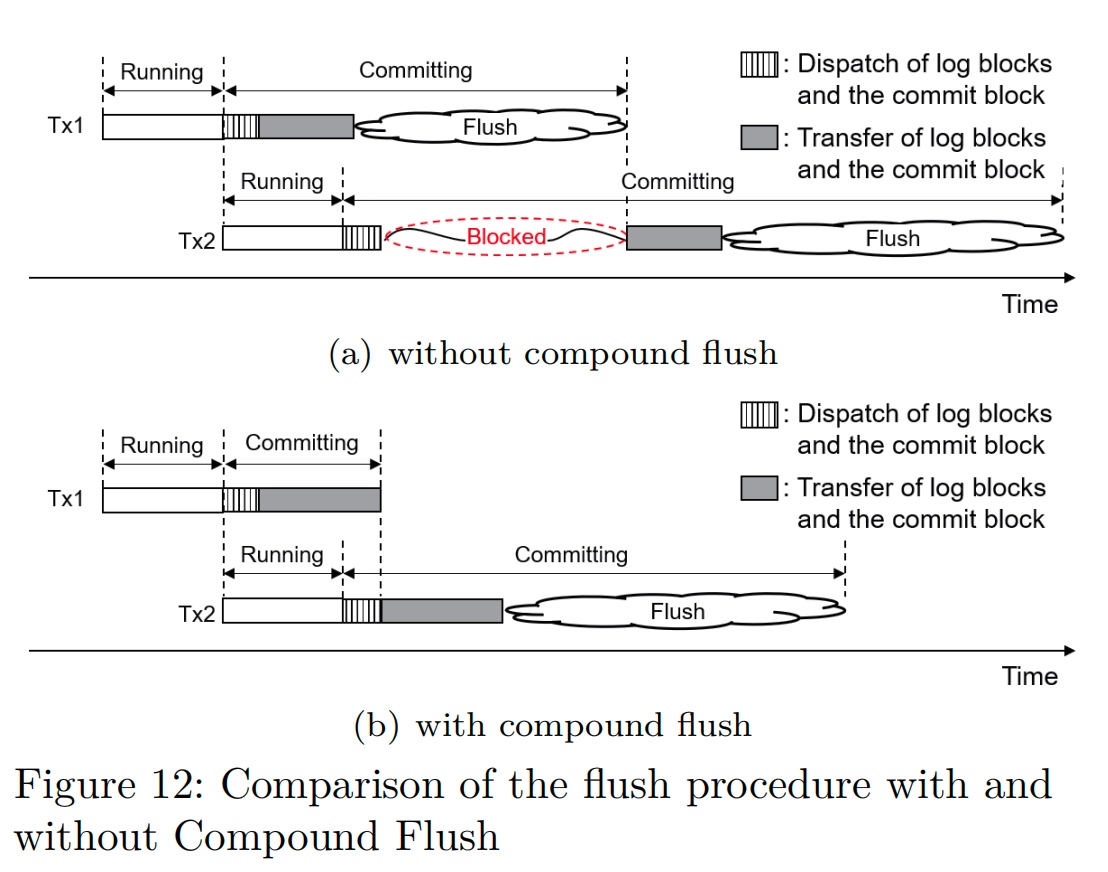
Compound flush: On Tx finish cache(DMA, which can be hack by CXL?) barrier send the interrupt to the storage.

name collision, 之前有个git CVE。
软工找bug,实在太没意思了,改configuration(主要是allocator的内存格式/type信息/64bit?),然后污点分析,找这三个bug。

Compared with Hydra
MadFS 在无锡超算上跑的。
Consulidate the links from userspace.
是一个南大网络组的人去了盘古。阿里巴巴双十一现在完全基于这个了。
相当于implement了一个 lightweight file system client to improve the multiplexing of resources with a two-layer resource aggregation。每个computation storage vRPC agent proxy做负载均衡。
RPC serialization? 没有指针,docker/container的metadata都是flat的(只有offset),他们RPC几乎相当于RDMA over memcpy,很lightweight。 load balancer只做file-granularity based。如果DPU硬件fail了,直接RDMA migrate docker,其他请求fallback slow path,很快,用户无感。如果用户觉得IO慢了会提供全链路trace。
用tag+地址Btree连在一起的方式防止buffer overflow和dangling ptr。
file+dummy(2MB granularity)重排了文件写在DAX Pmem上,有写放大。concurrent control用的是CAS。metadata concurrent write好像没有处理,后来理解了因为open的寓意保证了write不会contension。
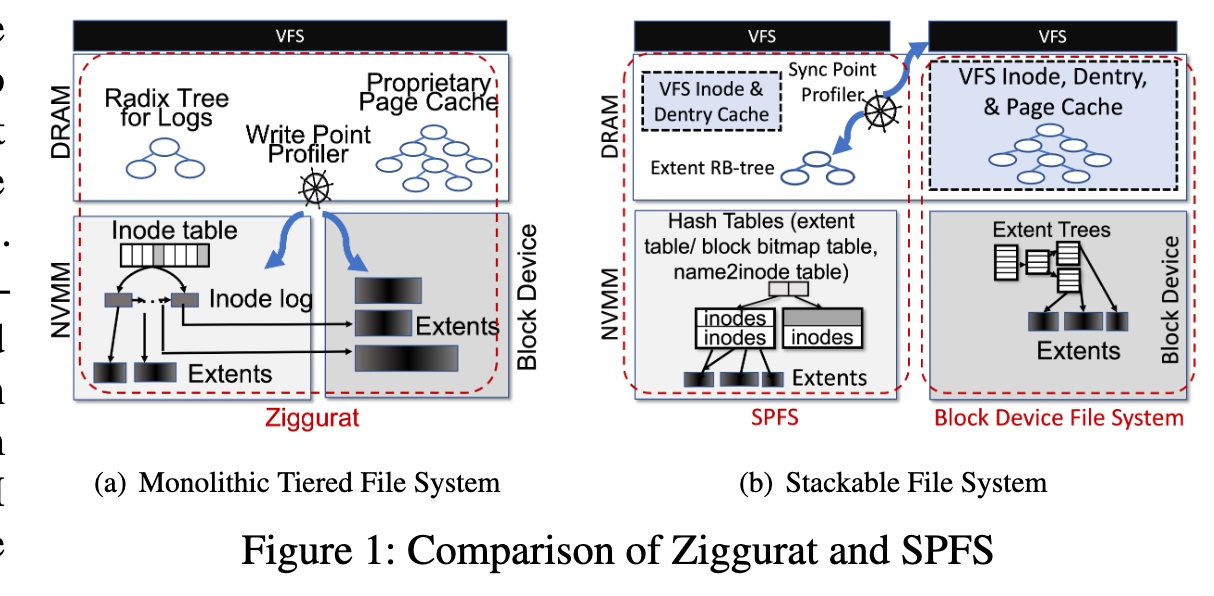
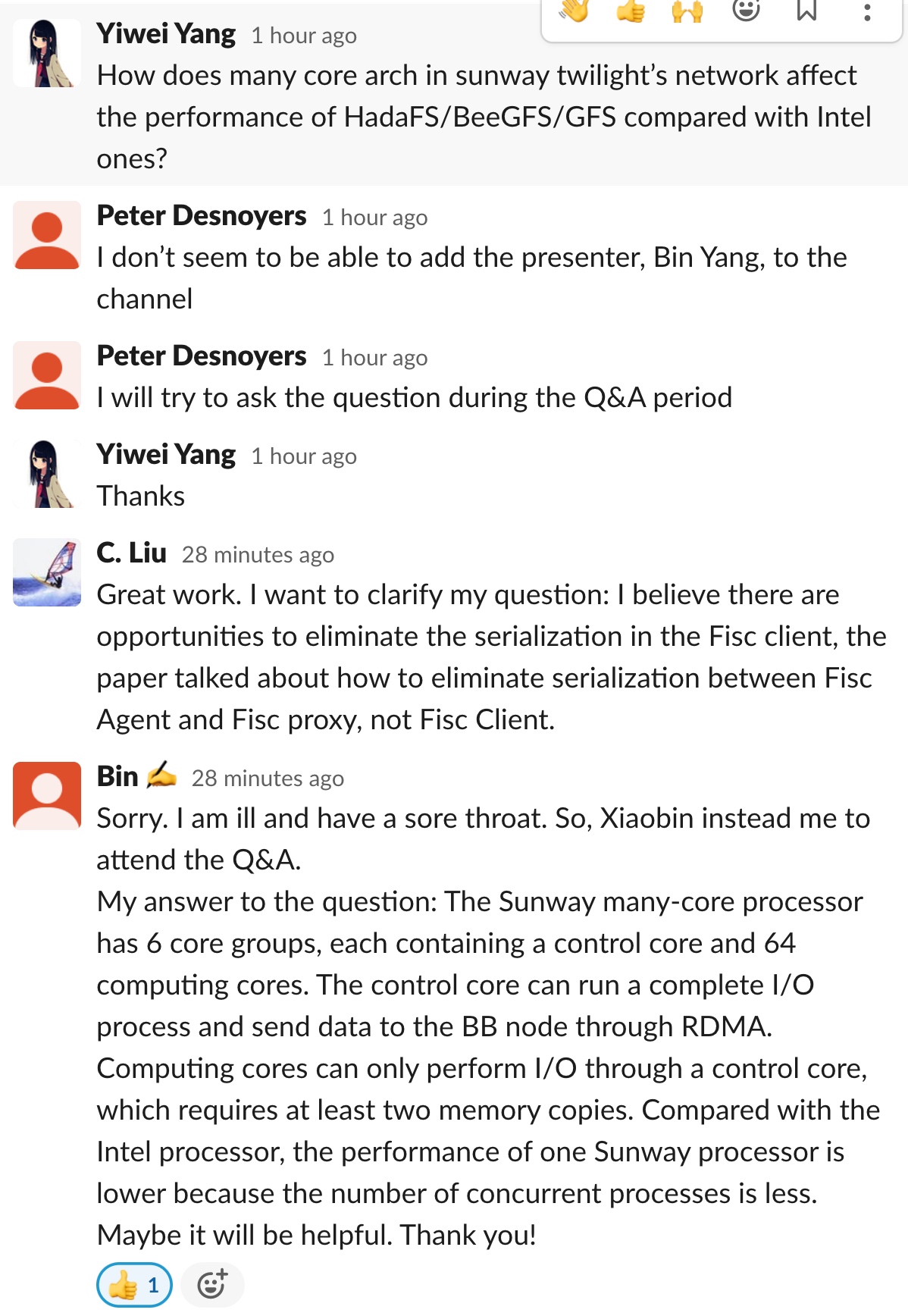
Stackable Memory Filesystem over normal filesystem.上面的内存文件系统比较轻量extent RB tree。Sync file system factor设计和dirty page wb有点像。
extent hashing和下面同步
线段树map ranges to tree ndoe。
Ext-CAS+Ext-TAA
用per memory window multiple qp and remote lease to protect the file,
盘古牛逼
陆老师和杨者的文章,想法是在kernel和SSD driver上跑统一的eBPF.
sBPF是对eBPF检查的减弱,想offload computation eBPF code没有语意上的限制。
通过page cache来观测是否在in memory database在kernel里可以被reuse,用这个metrics offload计算到设备。同时利用host CPU资源快,内存大,device计算资源少内存少但是离storage近,只用返回计算结果。
实验在SF=40 TPCH over Java上做,把syscall 分解为 read_λ(read, percentage, λ)的形式。λ本身就是sBPF的程序。
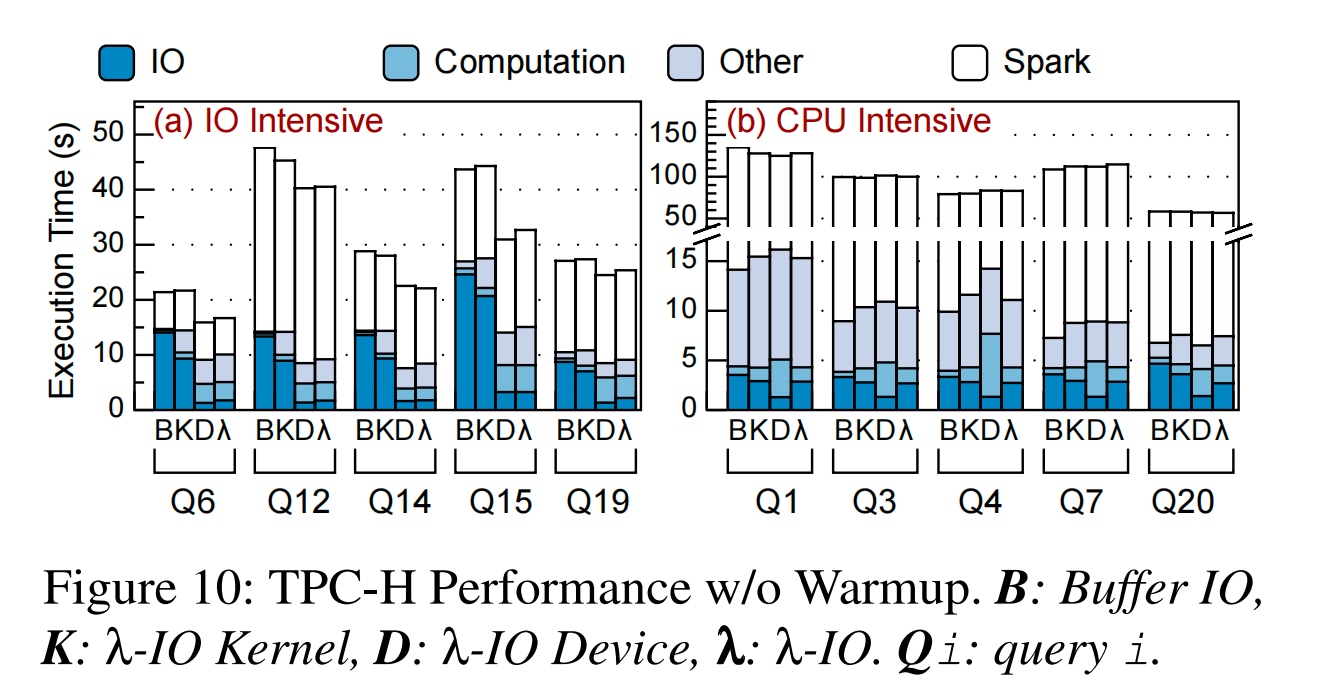
结果非常好,有2.16倍的加速
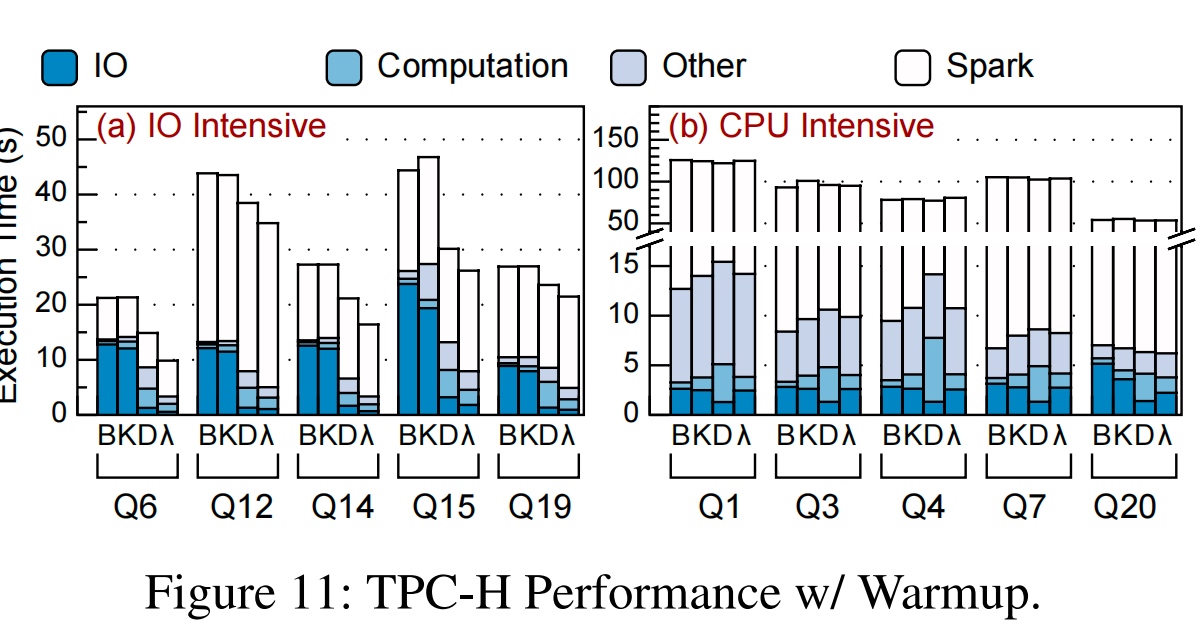
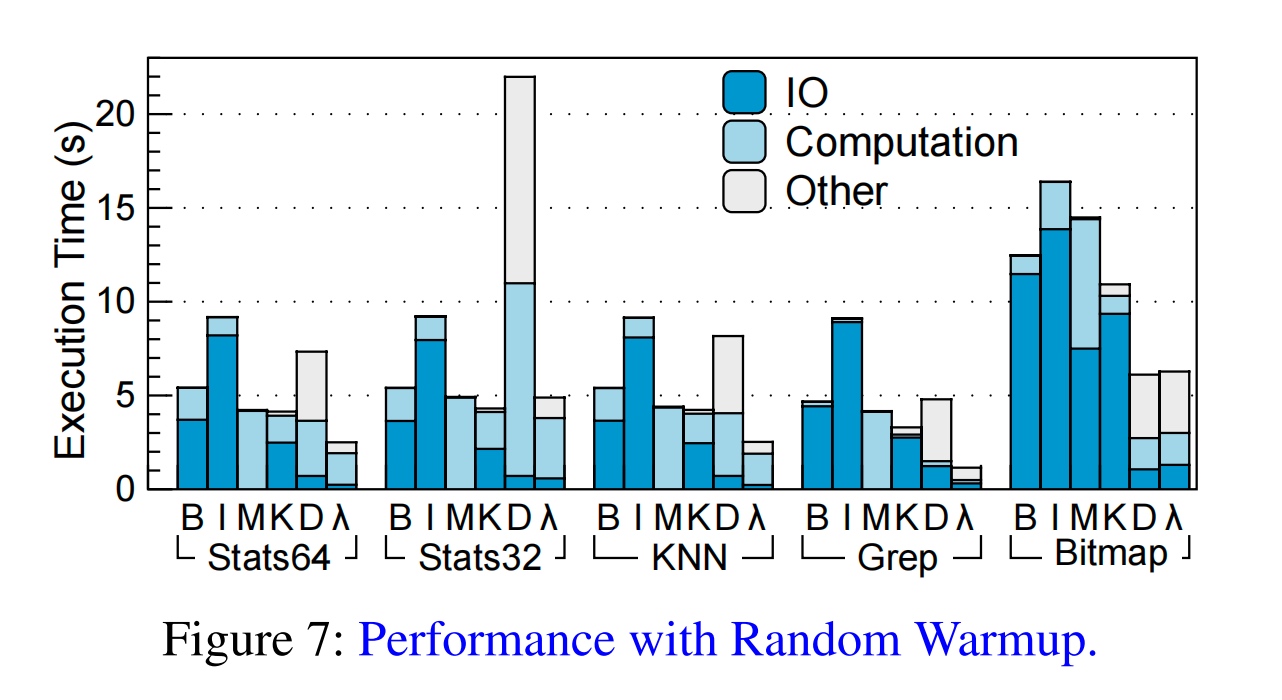
Why not Native?统一框架。 我们发现mmap的部分都是计算时间,于是,load from device mmap+page fault and trigger userspace WebAssembly computation? for mmap very fast。
CXL+eBPF,small pagetable for transaction?fast getting metrics from cacheline network,decide load or store and dma?
有一个concern是会占满PCIe Root Complex的带宽,仅仅观测page cache大小是会出问题。
更准的SSD模拟器,问了个为什么不模拟CXLSSD的问题。
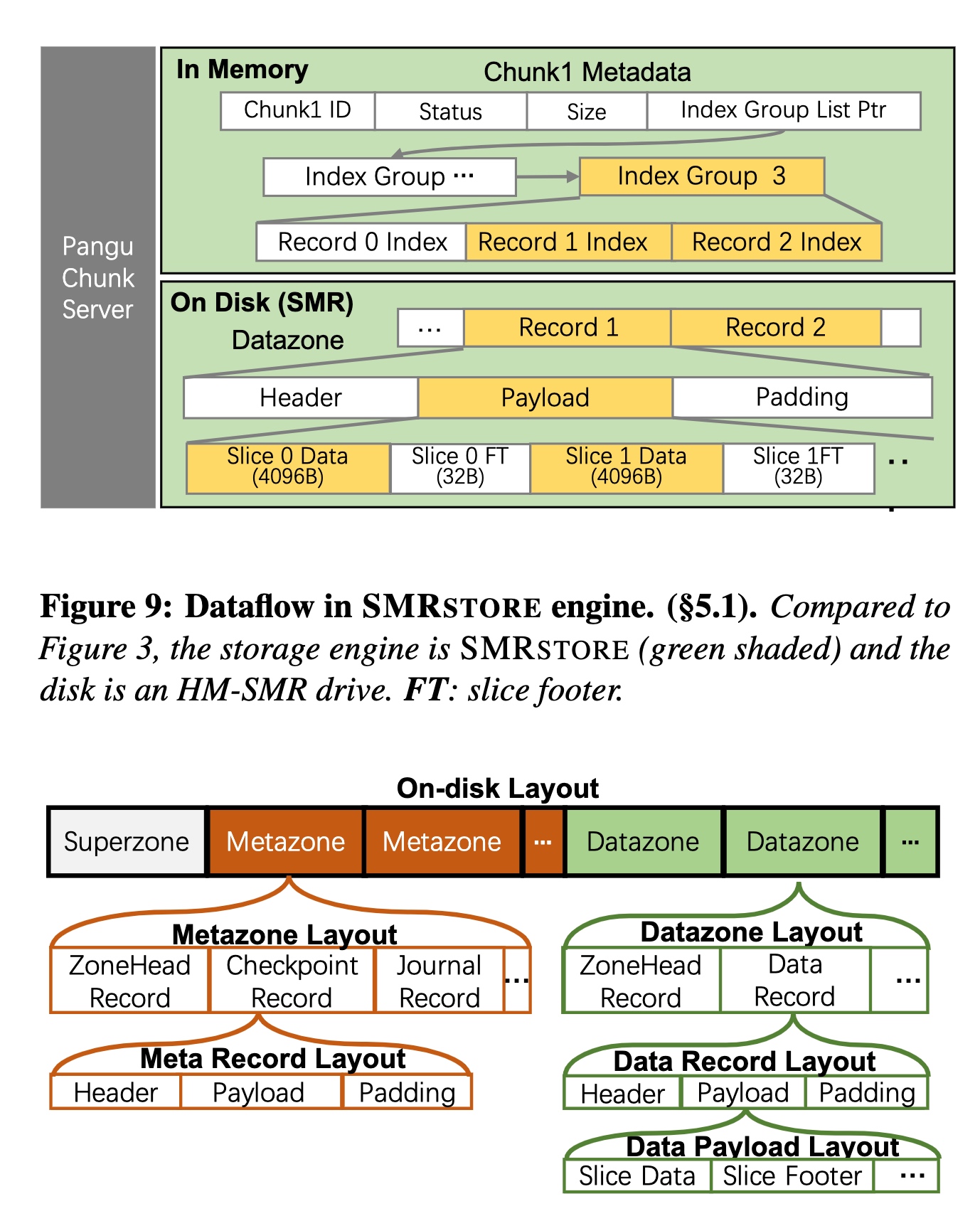
按zone分chunk在OSS更优,而且SMR问题determinist分配zone是一个比较优的策略。
15%reduction of time
用时序数据predict results
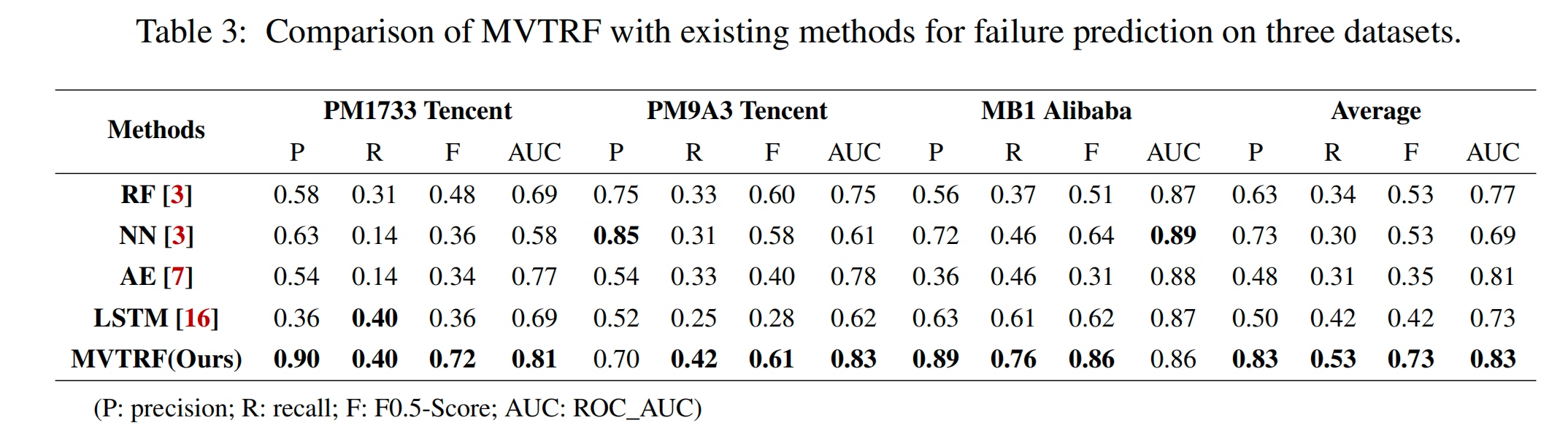
但是对异常数据不是很敏感。
不是很懂
拿L2P数据prefetch UFS的。在UFS上的数据结构比较deterministic。
This doc is frequently updated.
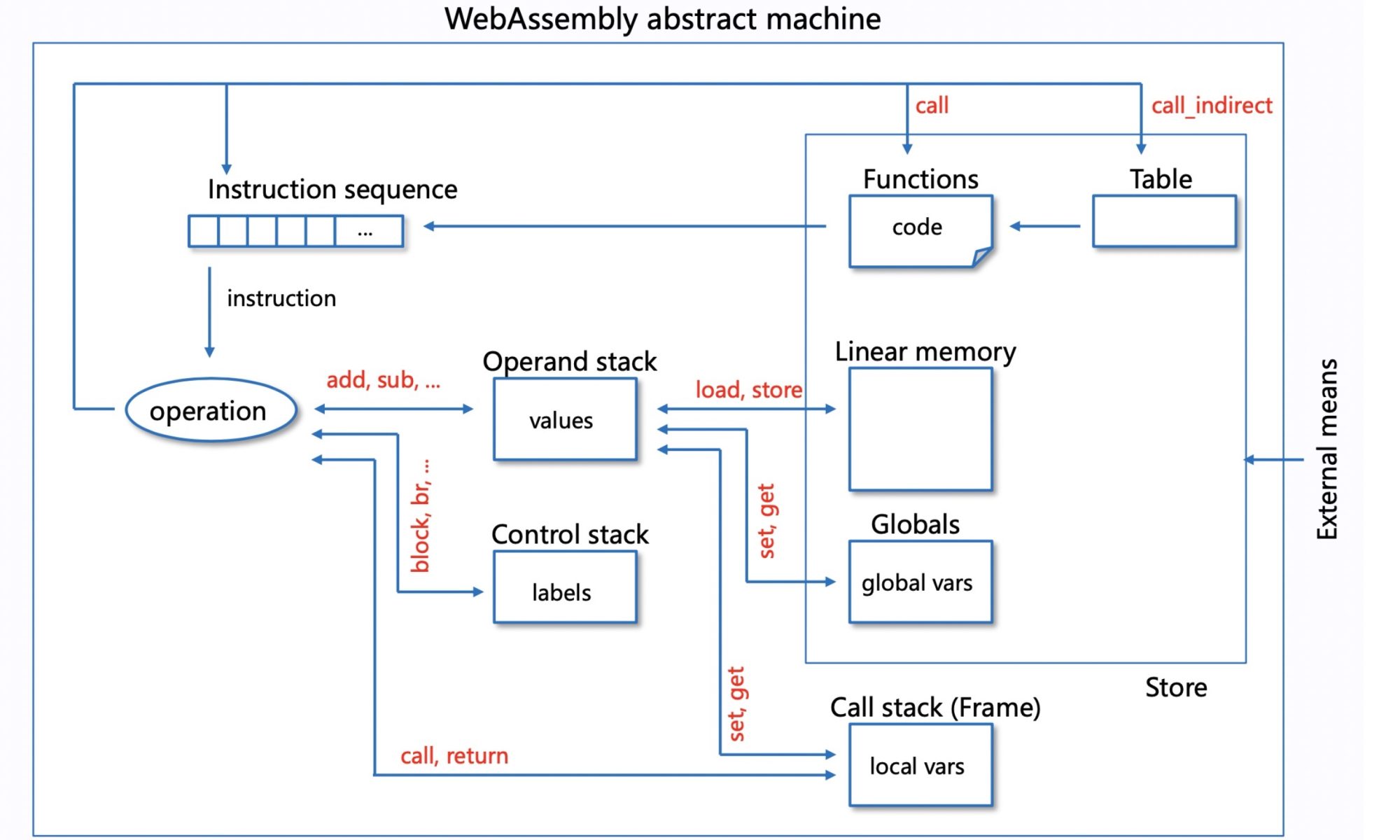
I'm looking into the design of WAMR because this fits the heterogeneous device migration.
The interpreter mode has two modes; the main difference between classic and fast is the handle table and indirect jump; they make it cache-friendly.
Fast JIT is a lightweight implementation that has the auxiliary stack for interp frame. But has 50%-80% performance of LLVM JIT.
Basically, they share the same LLVM infrastructure, but AOT has more internal states that have been updated pretty well with a struct name starting with AOT*. AOT has a standalone compiler called wamrc for compiling the bytecode to AOT Module. On loading the program, AOT will load into the LLVM section and update the struct. JIT will not be called out, but they will call the same memory instance.
; ModuleID = 'WASM Module'
source_filename = "WASM Module"
define void @"aot_func#0"(i8** %e) {
f:
%a = getelementptr inbounds i8*, i8** %e, i32 2
%a1 = load i8*, i8** %a, align 8
%c = getelementptr inbounds i8, i8* %a1, i32 104
%f2 = getelementptr inbounds i8, i8* %a1, i32 40
%f3 = bitcast i8* %f2 to i8**
%f4 = load i8*, i8** %f3, align 8
%f5 = bitcast i8* %f4 to i8**
br label %f6
f6: ; preds = %f
ret void
}
define void @"aot_func#0_wrapper"() {
f:
ret void
}
We will lose the symbol for the function generation without the debug symbol. But they have a definition of dwarf for wasm specifically, which WAMR implemented on load.
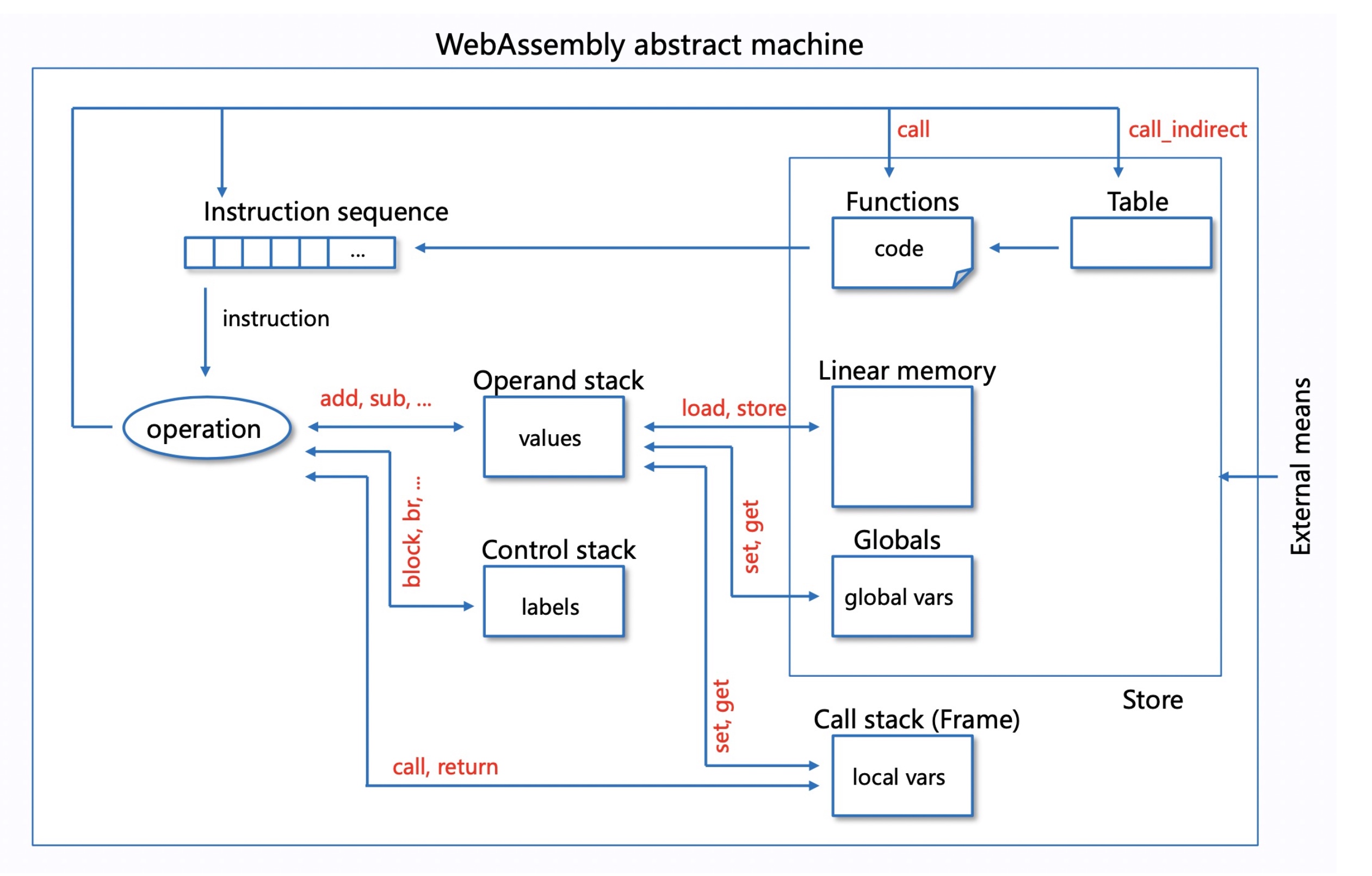
For Interpreter and AOT, every step has a state of every component stored at the C++ language level.
First, init with memory allocation on options.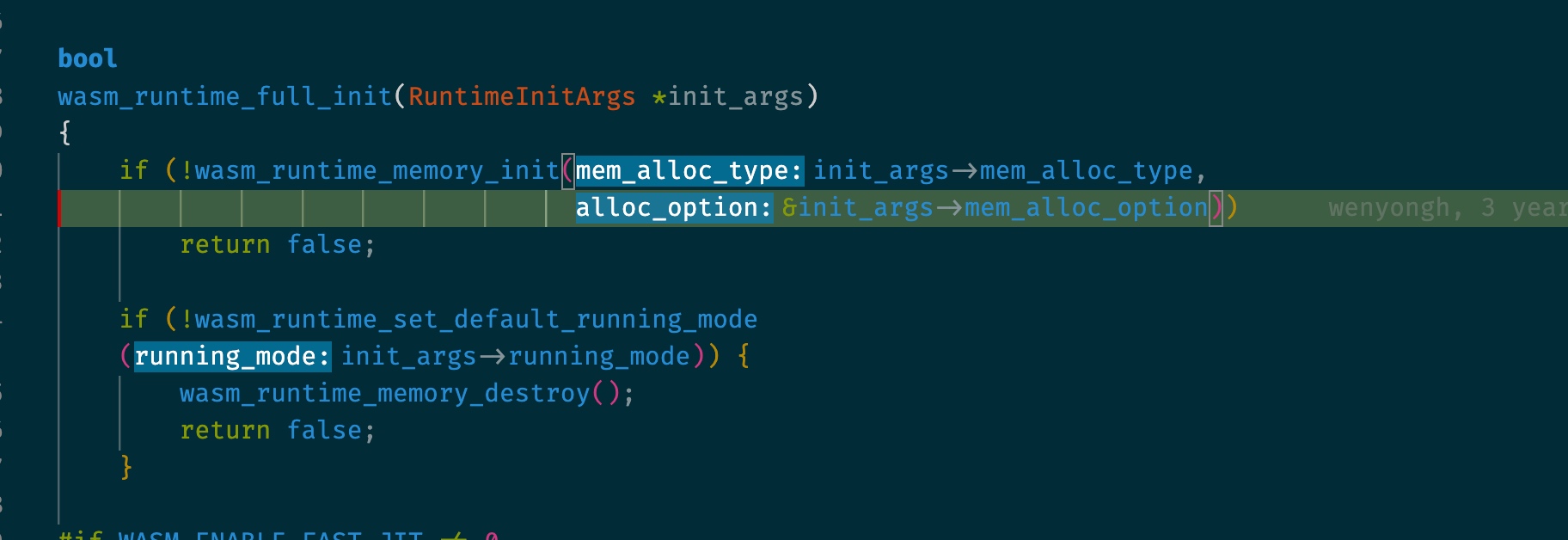
You can define the memory serialized data section in the same place and first initialize them into desired memory format.
RuntimeInitArgs wasm_args;
memset(&wasm_args, 0, sizeof(RuntimeInitArgs));
wasm_args.mem_alloc_type = Alloc_With_Allocator;
wasm_args.mem_alloc_option.allocator.malloc_func = ((void *)malloc);
wasm_args.mem_alloc_option.allocator.realloc_func = ((void *)realloc);
wasm_args.mem_alloc_option.allocator.free_func = ((void *)free);
wasm_args.max_thread_num = 16;
if(!is_jit)
wasm_args.running_mode = RunningMode::Mode_Interp;
else
wasm_args.running_mode = RunningMode::Mode_LLVM_JIT;
OS Bound Check does, from stack bottom to top, iterate to check whether is overflow every time access. as it was hardware accelerated by Flexible Hardware-Assisted In-Process Isolation with HFI
The wasm layer provides an interface for TensorFlow to call on, which is like a very lightweight abi for a better backend to codegen. As the tensor has different impl for CPU/NPU/GPU, it can easily be plugged and played for different platforms.
struct WAMRWASINNContext {
bool is_initialized;
graph_encoding current_encoding;
uint32_t current_models;
Model models[MAX_GRAPHS_PER_INST]; // From TFLite
uint32_t current_interpreters;
Interpreter interpreters[MAX_GRAPH_EXEC_CONTEXTS_PER_INST];
};
The specifi