感觉这次的code challenge 必然会很卷,因为有GaTech/ETHz这种HPC强校,感觉就是NV想从我们学生这榨干点优化,正如罡兴投资激发的大家对网卡simd优化产生了兴趣。这篇就稍微记录下可优化的点。
ISC22 code challenge


A Tech Nerd with a finance mind.
感觉这次的code challenge 必然会很卷,因为有GaTech/ETHz这种HPC强校,感觉就是NV想从我们学生这榨干点优化,正如罡兴投资激发的大家对网卡simd优化产生了兴趣。这篇就稍微记录下可优化的点。
# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other
# Spack Project Developers. See the top-level COPYRIGHT file for details.
#
# SPDX-License-Identifier: (Apache-2.0 OR MIT)
# ----------------------------------------------------------------------------
# If you submit this package back to Spack as a pull request,
# please first remove this boilerplate and all FIXME comments.
#
# This is a template package file for Spack. We've put "FIXME"
# next to all the things you'll want to change. Once you've handled
# them, you can save this file and test your package like this:
#
# spack install icon
#
# You can edit this file again by typing:
#
# spack edit icon
#
# See the Spack documentation for more information on packaging.
# ----------------------------------------------------------------------------
from spack import *
import os
class Icon(AutotoolsPackage):
"""ISC22 ICON package."""
homepage = "https://hpcadvisorycouncil.atlassian.net/wiki/spaces/HPCWORKS/pages/2792161313/Getting+started+with+ICON+for+ISC22+SCC"
url = "http://localhost:31415/icon-2.6.4.tar.gz"
maintainers = ['spedoske','victoryang00']
version('2.6.4', sha256='1860028836d0894224ce301c3d0cb27a899548823267b08bf5c97ae696c3758d')
depends_on('libxml2')
depends_on('eccodes')
depends_on('intel-oneapi-mkl')
#if self.compiler.name == 'nvhpc':
#depends_on('intel-oneapi-mpi')
depends_on('netcdf-fortran')
depends_on('netcdf-c')
depends_on('hdf5+mpi+fortran+hl+szip')
depends_on('zlib')
depends_on('libszip')
depends_on('mpi')
depends_on('cuda')
#depends_on('nvhpc')
depends_on('serialbox')
def configure_args(self):
args = [#'--enable-art',
'--enable-coupling',
'--enable-serialization',
'--enable-emvorado',
'--enable-grib2',
'--disable-yaxt',
'--enable-sct',
'--enable-ecrad',
'--enable-rte-rrtmgp',
'--enable-mpi',
'--enable-gpu',
'--disable-explicit-fpp'
]
# if self.compiler.name == 'nvhpc':
# args.append('--enable-gpu')
# else:
# args.append('--disable-gpu')
#from print import pprint
#pprint(vars(self.spec['nvhpc']),depth=4)
#print(os.environ)
os.environ['CC'] = os.environ['MPICC']
os.environ['CXX'] = os.environ['MPICXX']
os.environ['F77'] = os.environ['MPIF77']
os.environ['F90'] = os.environ['MPIF90']
os.environ['FC'] = os.environ['MPIF90']
os.environ['MPICH_CC'] = os.environ['MPICC']
os.environ['MPICH_CXX'] = os.environ['MPICXX']
os.environ['MPICH_F77'] = os.environ['MPIF77']
os.environ['MPICH_F90'] = os.environ['MPIF90']
os.environ['MPICH_FC'] = os.environ['MPIF90']
#nvhpc_bin = '/home/coffee/spack/opt/spack/linux-ubuntu20.04-zen2/oneapi-2021.4.0/nvhpc-21.9-ymnvxvr4e2q7475djr4lig7cbucg54uv/Linux_x86_64/21.9/compilers/bin'
#os.environ['OMPI_CC'] = os.path.join(nvhpc_bin,'nvc')
#os.environ['OMPI_CXX'] = os.path.join(nvhpc_bin,'nvc++')
#os.environ['OMPI_F77'] = os.path.join(nvhpc_bin,'nvfortran')
#os.environ['OMPI_FC'] = os.path.join(nvhpc_bin,'nvfortran')
CPPFLAGS=["CPPFLAGS="]
FCFLAGS=["FCFLAGS="]
LDFLAGS=["LDFLAGS="]
LIBS=["LIBS="]
# zlib
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['zlib'].prefix,'lib')))
LIBS.append('-lz')
# hdf5
CPPFLAGS.append('-I{}'.format(os.path.join(self.spec['hdf5'].prefix,'include')))
FCFLAGS.append('-I{}'.format(os.path.join(self.spec['hdf5'].prefix,'include')))
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['hdf5'].prefix,'lib')))
LIBS.append('-lhdf5hl_fortran -lhdf5_fortran -lhdf5')
# netcdf-fortran
FCFLAGS.append('-I{}'.format(os.path.join(self.spec['netcdf-fortran'].prefix,'include')))
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['netcdf-fortran'].prefix,'lib')))
LIBS.append('-lnetcdff')
# netcdf-c
CPPFLAGS.append('-I{}'.format(os.path.join(self.spec['netcdf-c'].prefix,'include')))
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['netcdf-c'].prefix,'lib')))
LIBS.append('-lnetcdf')
# blas and lapack
CPPFLAGS.append('-I{}'.format(os.path.join(self.spec['intel-oneapi-mkl'].prefix,'include')))
LIBS.append('-lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5 -lpthread -lm -ldl -lmpi -lxml2')
# xml2
CPPFLAGS.append('-I{}'.format(os.path.join(self.spec['libxml2'].prefix,'include/libxml2/')))
# eccodes c/fc
CPPFLAGS.append('-I{}'.format(os.path.join(self.spec['eccodes'].prefix,'include')))
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['eccodes'].prefix,'lib')))
FCFLAGS.append('-I{}'.format(os.path.join(self.spec['eccodes'].prefix,'include')))
LIBS.append('-leccodes -leccodes_f90')
# serialbox
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['serialbox'].prefix,'lib')))
FCFLAGS.append('-I{}'.format(os.path.join(self.spec['serialbox'].prefix,'include')))
LIBS.append('-lSerialboxFortran')
# LDFLAGS.append('-L{}'.format(os.path.join(self.spec['cuda'].prefix,'lib64')))
# LIBS.append('-lcudart')
# gpu
#LDFLAGS.append('-L/usr/lib')
#LIBS.append('-lstdc++ -lstdc++ -L/usr/lib')
# gpu
if self.compiler.name == 'nvhpc':
LDFLAGS.append('-L{}'.format(os.path.join(self.spec['cuda'].prefix,'lib64')))
LDFLAGS.append('-L/lib/x86_64-linux-gnu/ -lstdc++')
LDFLAGS.append('-I{}'.format(os.path.join(self.spec['openmpi'].prefix,'lib')))
FCFLAGS.append('-I{}'.format(os.path.join(self.spec['openmpi'].prefix,'lib')))
LIBS.append('-lcudart')
args.append(' '.join(CPPFLAGS))
args.append(' '.join(FCFLAGS))
args.append(' '.join(LDFLAGS))
args.append(' '.join(LIBS))
args.append('SB2PP='+self.spec['serialbox'].prefix+'/python/pp_ser/pp_ser.py')
if self.compiler.name == 'nvhpc':
depends_on('nvhpc')
#args.append('MPI_LAUNCH='+self.spec['openmpi'].prefix+'/bin/mpirun')
args.append("MPI_LAUNCH=/usr/bin/mpirun")
args.append('NVCC=nvcc -std=c++11 -ccbin {} -allow-unsupported-compiler'.format(self.compiler.cxx))
else:
depends_on('intel-oneapi-mpi')
args.append('MPI_LAUNCH='+self.spec['intel-oneapi-mpi'].prefix+'/mpi/2021.4.0/bin/mpirun')
args.append('NVCC=nvcc -std=c++11 -ccbin {} -allow-unsupported-compiler'.format(self.compiler.cc))
return args
def setup_run_environment(self, env):
env.set('PYTHONPATH', join_path(self.spec['serialbox'].prefix,'python'))
cmake 通过修改开关,只让GPU使用 ptx 及 fortran intrinsic ABI 直接编译,替代 OpenACC的 kernel 实现。MPI 库实现替换为 ucx gpr_copy. AUARF32 时间从 4m59s 提升至 1m51s。 但在多卡上仍就有很大的通讯开销。由于 cuda_ipc 在 x86 架构上只能通过 PCIe 传输,4卡高达1小时左右。即便是开了-nk 2的情况下。 issue
针对 AUARF112 测试案例,在针对 core.F90 中的 scf 场进行 cache 调优

实名羡慕过往的同学能去德国🇩🇪,我已经long long time 没有行万里路了,可影响我们在线上给予对宝座一定的冲击。
The HPC competition is all about hacking. Just like Neo (The hacker) dodging the bullets.

对于国内,德国,以及美国的比赛,我大致了解了三个区域对科研的态度。国内的情况之前已经描述过了,鉴于最近参加的ASSIST上科大选角大赛储存分场,我觉得中国真正做事的科研人员是承包国家项目的,其实强如陆游游也是如此,不过没有工业界做上层建筑,真的做出来的 filesys 都是玩具。德国这20天左右的调试和report,code challenge的代码质量简直💩。由此我觉得科研实习及学习还是得去万物之源——美国。年底的SC21进决赛了,我也在培养下一任队长了。(ASC22加油。

现场面试(10pts)
在刚开始拿到机器的时候我想笑,因为Niagara(在加拿大🇨🇦多伦多大学,意思是那个落差最大的瀑布)的配置和我在jump面试维护的几乎一样,从文件系统到scheduler。大概大前年我们ASC拿第二名是因为对两倍数据集的使用。还有当时志强对那个训练模型的熟悉,这次运气大致也到了我们上面。Niagara 登陆节点7个skx, CentOS7, Intel(R) Xeon(R) Gold 5115 CPU @ 2.40GHz,全是100GBps的IB卡,debug节点可以申1小时,和登陆节点配置是Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz,compute节点在nia1000左右可能可以申请到cascade lake。(所谓无痛提升性能。) 文件系统是gpfs和module放的用户态cvmfs。NSCC(National SuperComputing Centre)是新加坡大学联盟+ASTAR研究所的超算集群,就比较寒酸了,4个被很多人拷文件的登陆节点broadwell 2690-v3,CentOS6,IB卡是100Bps,主要是为了文件系统。但由于我我有NUS的好朋友(前同事)拿到了他的回校工具,这样我们就无痛多了4个登陆节点,但是交的队列是一样的。normal队列和登陆节点一样,而dgx是假的dgx,是16G的显存不说,nvlink也无。不过CPU稍稍好一点点,v3变v4。内卷之坡县尽如此,都不如我校校内的机器,终于知道我前老板为什么要回上海了。
还有说一下pbs和slurm,讲真,前者一点也不安全,其实就是一个后台程序在维护一套bash脚本,勉强维护住了,不过后者有商业版可以买,也做了很多cgroup的隔离,可sg机器上并没有,所以稍稍hack一下可以运行的时间还是可以的。同时也可以qsub -I一个交互干任何你想干的东西,(注意ip地址是ib卡的,qsub控制都是板载千兆口。)而在Niagara所有的openrun 和资源都是被控制住的。在进入的时候,ib卡就不能用于mpirun的host,这一点非常坑。
两个超算集群都有很好的GPFS,但是NSCC的scratch没有flock,导致不能用spack.总之POSIX是个对读写都需要加🔒的协议,GPFS并没有做到这一点。
虽然每次都觉着这是跑分,可这次真不一样。我们本来以为这是dgx就可以靠nvlink 这个topology搞点事情。可惜只能搞CPU的affinity了,我们用taskset 搞了这个😄。
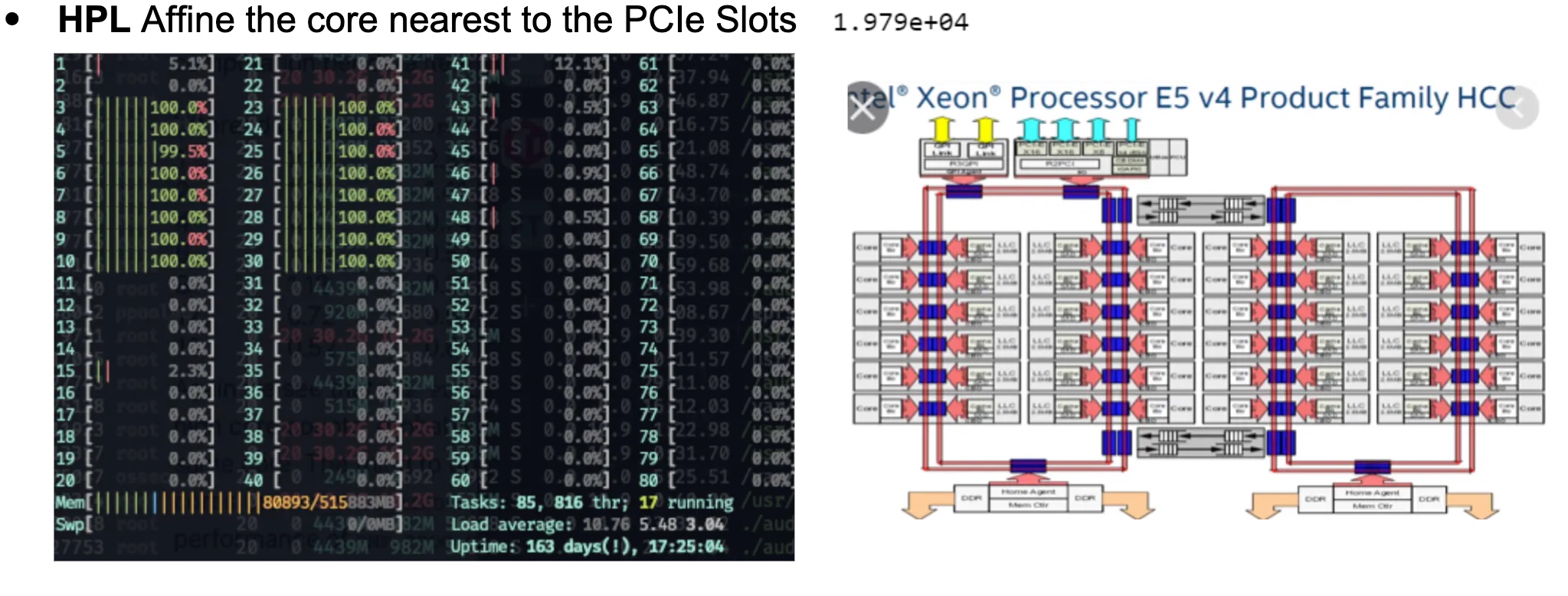
虽然性能提升是个玄学,不过有总比没好。
这次还需要在cpu上跑,从官网上搞了个xhpcg_skx,没想到在tuning的时候到了cascadelake,后来我们每次跑都指定那个节点。
以前比赛从来没有过这么老的东西去跑benchmark,这是一个最后commit 13年的东西,有HPL,FFT等7个小case,主流benchmark都不用这玩意了,可能欧洲人比较念旧吧。我们调了一版本CuBLAS编译的HPL和CuFFT变异的FFTW。性能是直线上升。
我们拿到这个题目的时候,觉得这个赛题我们可以改很多,我还为此分配了两个同学去研读代码,不过松辉和候补同学拿这个项目直接成了他们的并行计算project可还行。可我忘了作者,LBLL,berkeley 和能源部的大神写的,怎么可能会需要我们去魔改他的代码。失策失策。论文里的种种,cuckoo hashing,k-mer,DHT,都是貌似可以改的东西。可惜他们已经survive了TB级别ACGT的测试,工程师已经写的够充分了。不过upcxx(一个并行编程范式)有挺多小问题的。当时并行计算并没有涉及到GASNET并行模型,其实就是global_ptr和local_ptr的那些东西,这个并行模型比较适合DHT,特别是TB级别的数据。
我们最先发现的是RPC他写的很慢,profiling完以后的结果告诉我中间传输过程太多,可没啥可以改代码的,都是libverbs点对点通信。

作为尝试,我们尝试了upcxx 的后端,可以是libverbs 也可是Intel MPI,Niagara上面装的rdma-core是rpm装的而非mellanoax下下来编译的,这弄坏了挺多东西。所以我们关于libverbs都是在singularity里弄的。在configure正常的情况下,MPI和libverbs 性能差不多。在NSCC上,GasNet对内存有异常多的需求。这程序几乎有线性的scability。
\[
\begin{array}{l}
\begin{array}{l}
\text { Comm} & \text{Build } & \text { System CPU } & \text { User CPU } &\text{nodes}
\end{array}\\
\begin{array}{llrlll}
\hline \text { mpi } & \text { Release } & 37.36 & 02: 54.9 & 1: 35: 15 & 4 \\
\hline \text { mpi } & \text { Release } & 60.74 & 01: 37.4 & 1: 19: 27 & 2 \\
\hline \text { ibv } & \text { Release } & 37.27 & 02: 57.3 & 1: 36: 37 & 4 \\
\hline \text { ibv } & \text { Release } & 61.69 & 01: 36.6 & 1: 19: 33 & 2 \\
\text { ibv } & \text { Debug } & 112.3 & 03: 44.6 & 4: 54: 57 & 4 \\
\text { mpi } & \text { Debug } & 134.4 & 06: 11.6 & 5: 57: 13 & 4 \\
\text { mpi } & \text { Release } & 37.79 & 07: 31.1 & 1: 39: 17 & 4 \\
\text { mpi } & \text { Release } & 545.35 & 1: 18: 27 & 18: 15: 26 & 4 \\
\text { mpi } & \text { Release } & 104.88 & 02: 54.6 & 1: 08: 33 & 1
\end{array}
\end{array}
\]
接下来就是调k-mer中的k了,这个非常有用,但是会减少精度。添加一个k就是增加他计算队列的长度,大致比原来的慢\(\frac17\).所以我们干的一件事就是分析精度缺失和k的关系。让其保持在一个合理的范围内。
DHT是并行计算课上讲过的那种,过一段时间会对在圈上的下一个节点加一次update。更新数据的过程是先write only(write barrier),在同时读和写,最后是read only(read barrier)。其bottleneck在于能否利用这个特性让其更快。(然而提出锅的人并咩有解决这个问题。DHT 的优化就是把那个圈变成其他结构,可似乎networkIO已经是bound了,逃。File System 上他们想用raid 去做这件事。
我们在这题上失利了,因为code challenge部分有这块的alltoallv的优化,可是只有一个case真正调用了gpaw,做这个的宇昊由于我的编译原理作业没有花太多时间,导致没有发现问题。
这应用换个elpa库就能很快很快。
对lammp s这么成熟的蛋白质应用来说,我觉得其应该很稳定,可事实并不是这样。我们在当中找到了各种segfault,尤其是intel package,一个intel 架构师写的加速lammps性能的库。
这么一个类,几乎所有的half neighbor 的计算都要用到
同时在跑ipm学到一个奇怪的LD_PRELOAD顺序问题。
又是一个天气应用,当时我们SC20的失利很大程度上就是那个 fortran 的 segfault 11,之前的解决方案是unlimit -s。据Harry说就是我们踩坑不够多,不停的换小版本编译,如果都不行才说明不是编译器的问题。我们这次在Niagara上是所有小版本都加了,结果还是不行。在比赛结束没几天的时候,在翻阅了WRF的官方部署ppt后,我们发现是一个KMP_STACKSIZE=20480000000的问题(由于intelifort维护的main程序需要对所有进程的状态进行描述,超过4KB就烫烫烫烫了);在Niagara上还有个奇怪的坑,mpi是完全由slurm的srun控制的,你写的mpirun -np 160在集群上也会被换成srun -ntask $SLURM_NTASK -cpus-per-rank $SLURM_CPUS_PER_TASK -bind-by core导致每个node的core并不是你mpirun写的核心,而是你predefined的,这需要你ssh上去,而你也不能开交互spawn mpi task,因为mpirun走不了ib卡。所以在slurm脚本最前面定义一下就好了。这些坑真的只能在文档中体现,后人才不需要重新踩。现在fortran都要出2021了,时代变了,我的jump trading前老板最喜欢的还是F77,泪目。
说下我们做的task和优化:(给我们的testcase居然是上海。)第一个是题目要求的分析MPI和omp的比例对WRF的影响, 其次是AVX512和AVX2的比较。最后是我们加的一个N-N file write middleware。

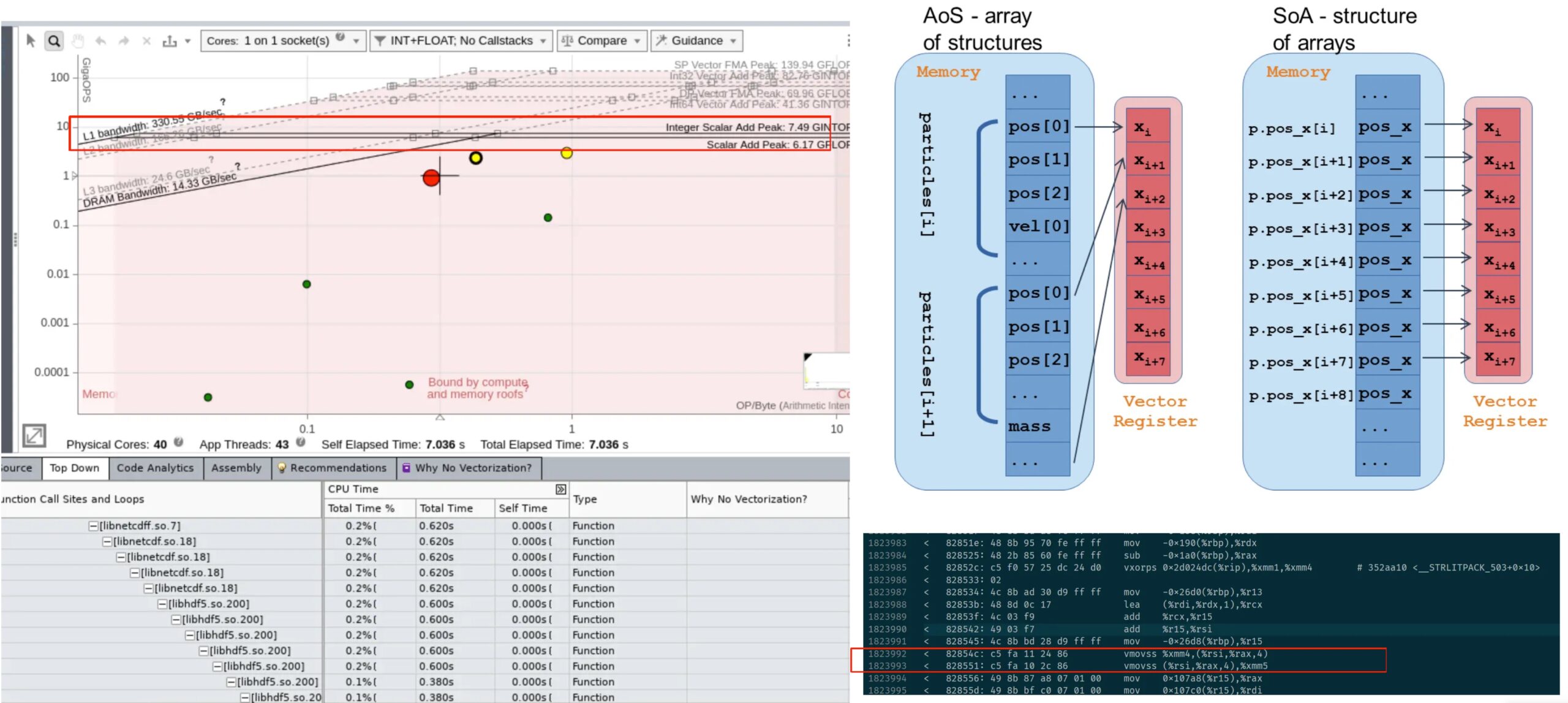
首先是profiling结果,由于加上vtune以后更容易seg11,就算加了那几个环境变量也一样,那我们就骂intel ifort傻逼好吧。之后虽然有几个小testcase我们成功跑完了一次advisor 和hotspots。这里只放nvsight(闷骚绿)的结果。
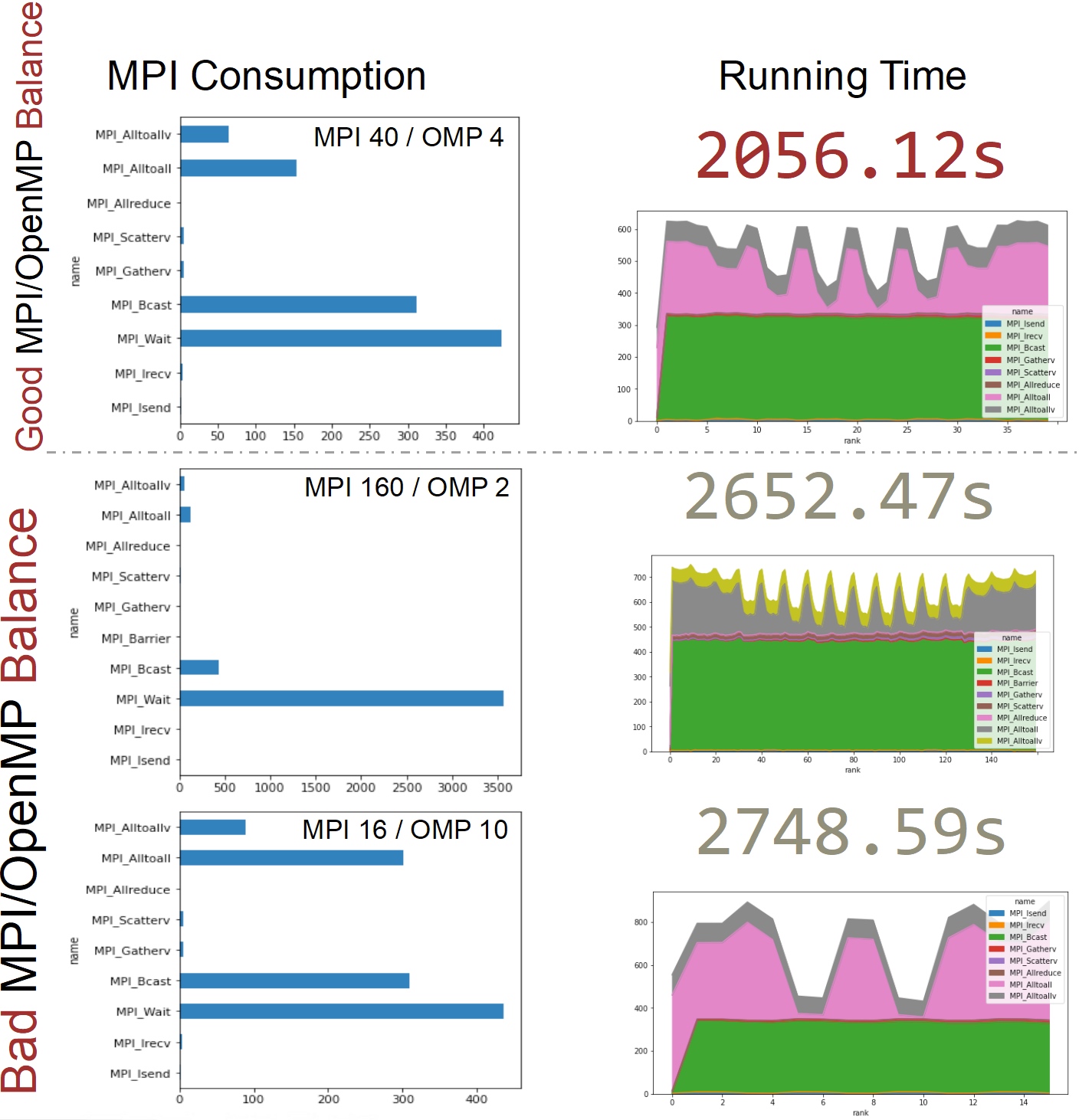
大概解释下就是他会把数据向这样切
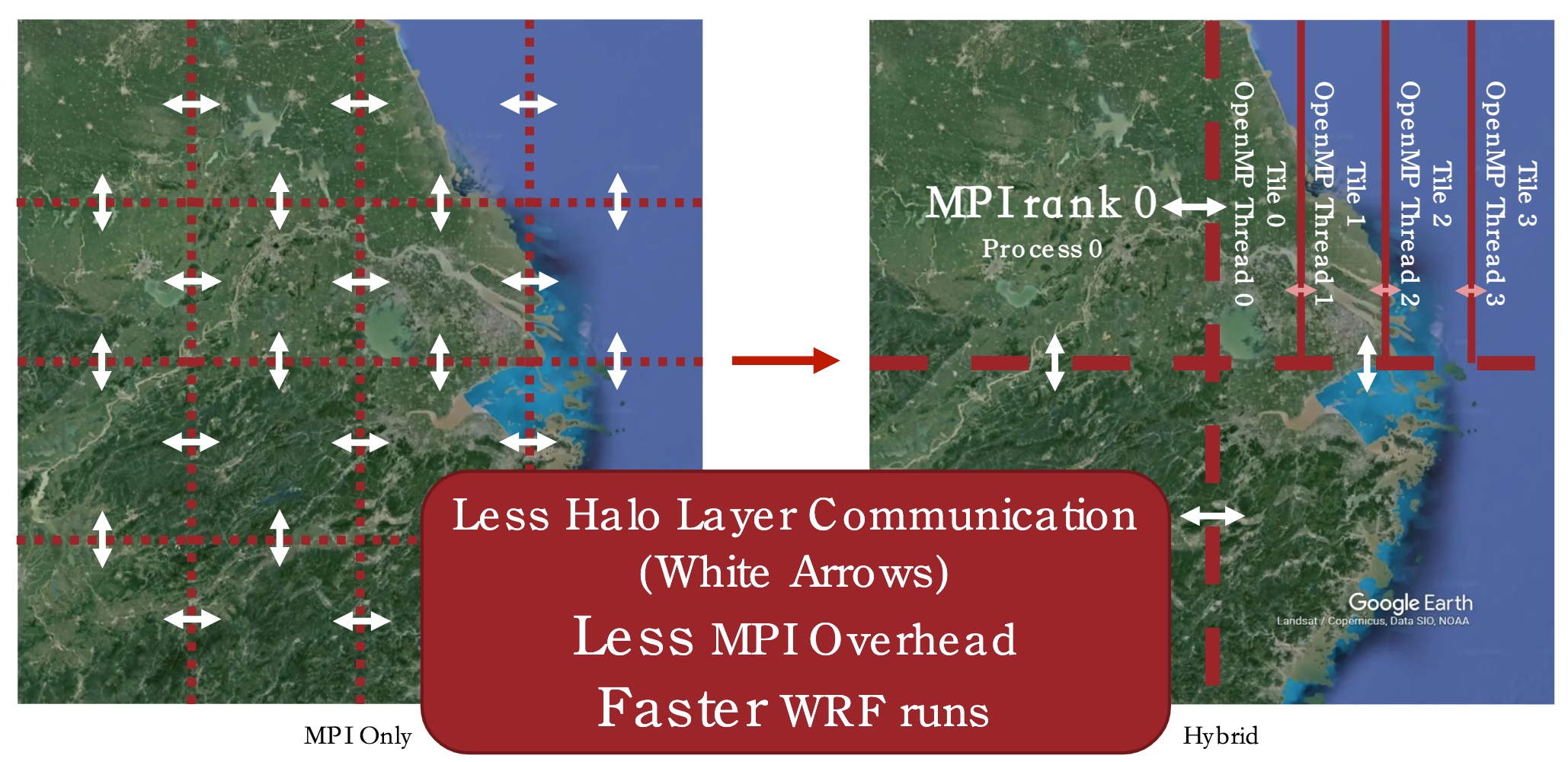
更少的MPI overhead就会得到最好的性能,所以我们写了一个bayesian 调参机。非常简单,但效果也不错。
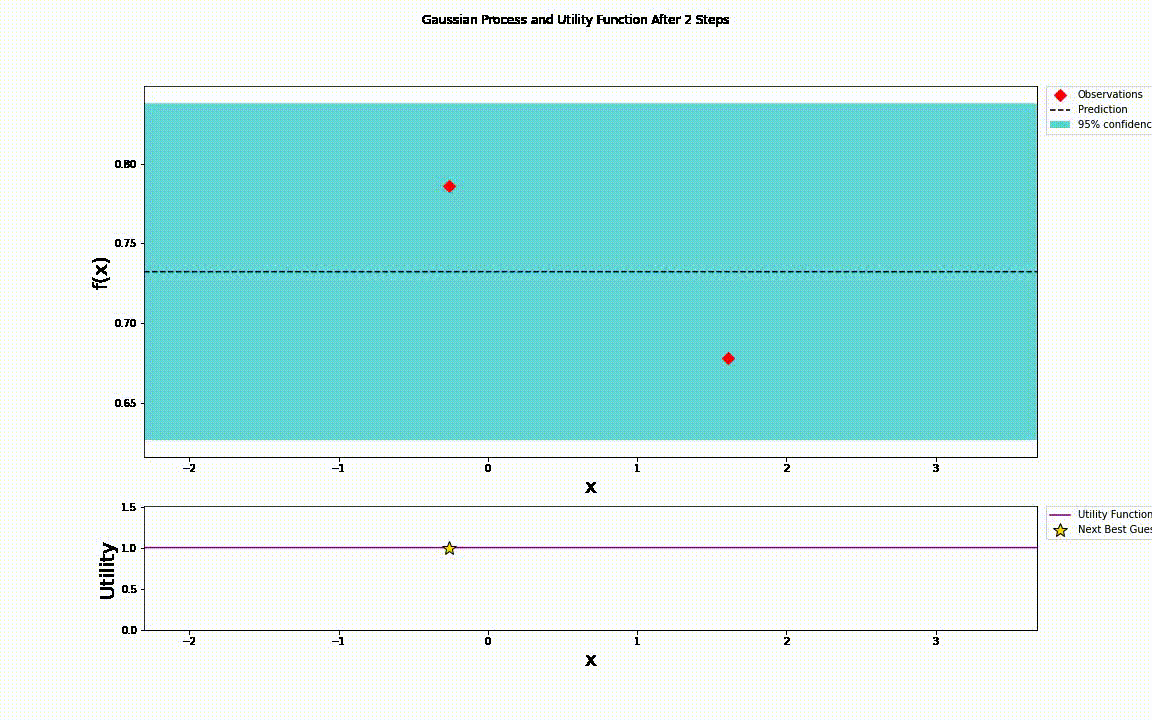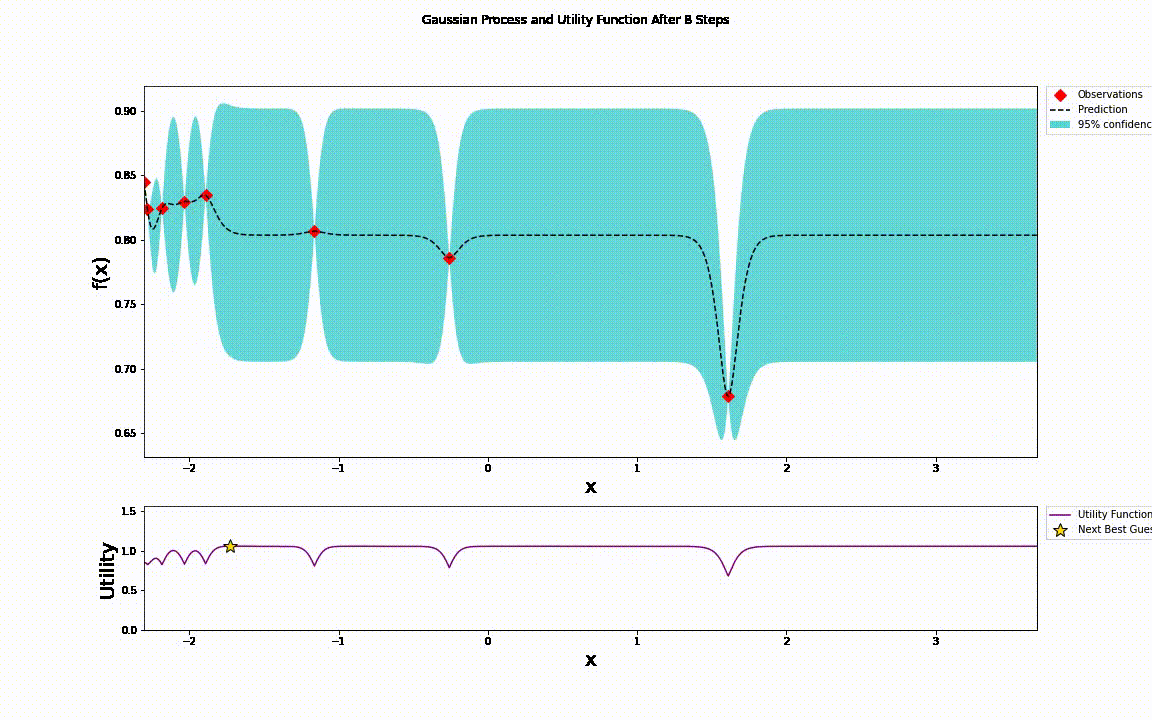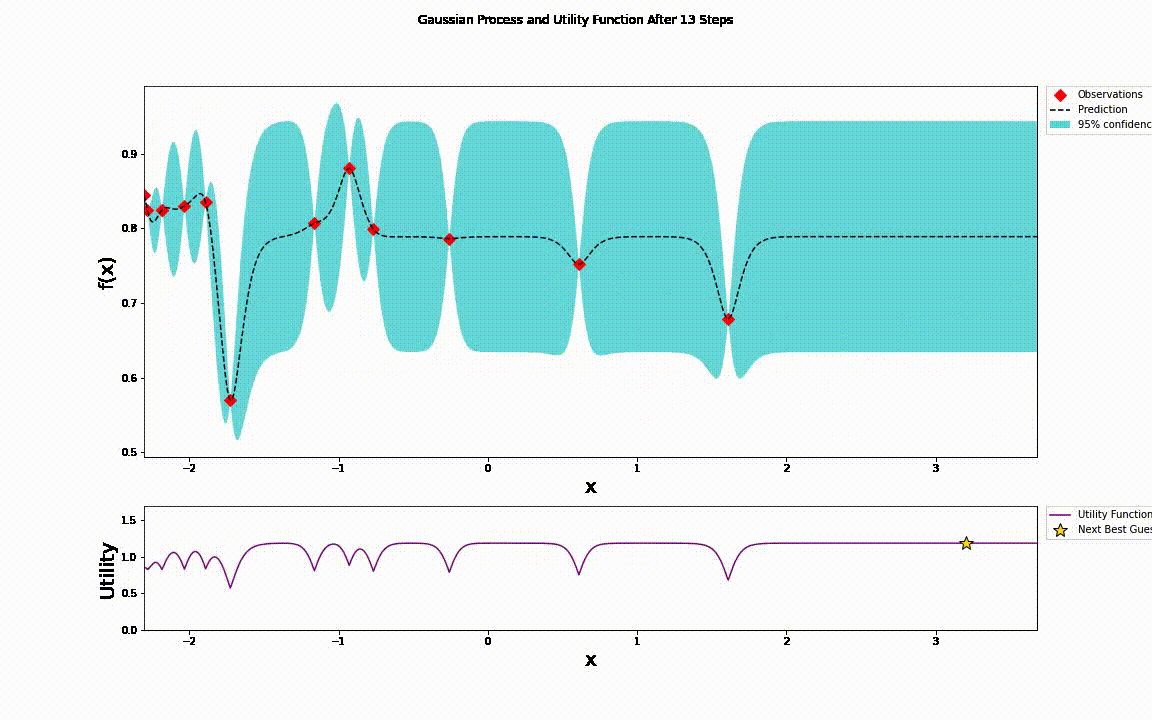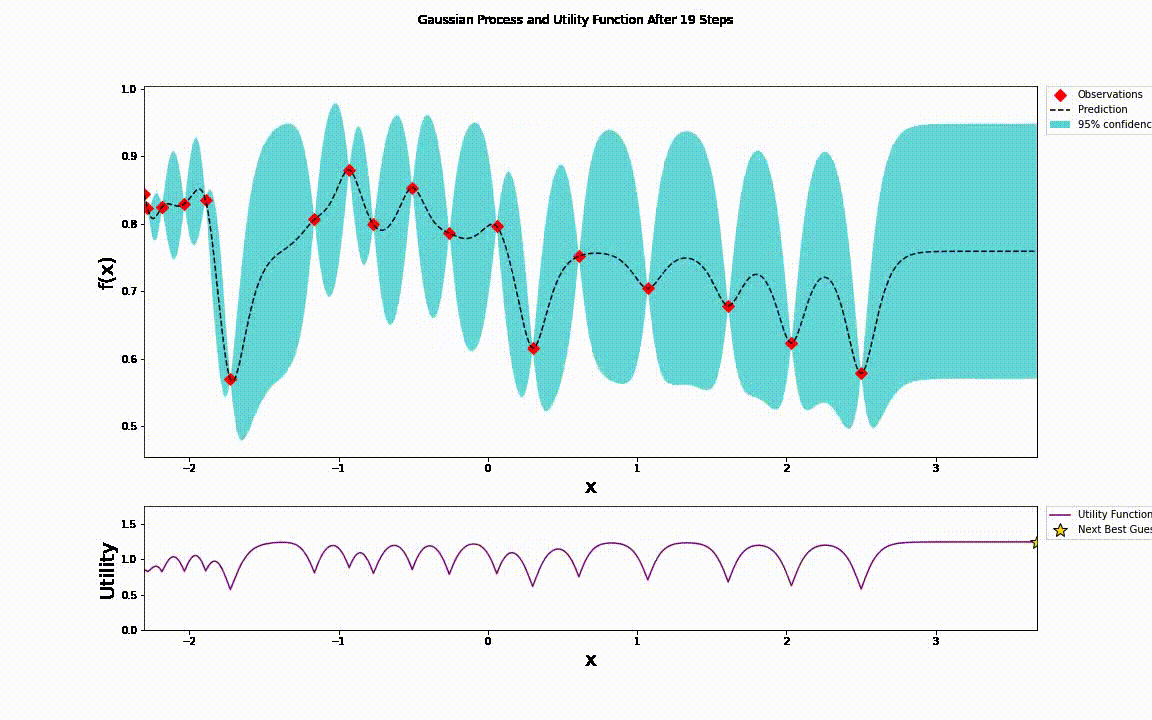
在AVX512和AVX2方面,我们发现AVX512有严重的降频。
之后我们加了个殷老师特技FileSys middleware,我也终于搞懂了fuse到底干了啥。so-called. transform N-1 I/O pattern to N-N
while maintaining the file abstraction

简要来说就是英伟达工程师写了个垃圾go程序,用于前端显示他们内部调benchmark 的过程,尤其是mellanoax的hpcx提供的openmpi的osu,这是一个很吃alltoallv的东西。以及夹带gpr_copy的ompi的性能。总之,在和shenghao和jiajie讨论了一下后,我们一致认为这是坨💩。所以我的策略就是➕zlib和COO sparse matrix,后来他们upstream了。
前端我们改成json的api传输了,这样压力给了前端,不过我们用了蚂蚁的一个前端库,已经用wasm优化的很好了,我们只需要把他的md转成序列化的json。
给你们说一个笑话。




感觉这次时间拉的过长,我和做WRF的厶元几乎为此付出了RA工作和后面的几场考试,没事,能work就行。时间长就导致最后大家其实差不多,不知道评奖的机制是什么,至少我从和THU 暨南 NTU SYSU pk的过程中学了很多很多。清华好像最后两天才开始做,我只能说他们可能对评奖并没有什么兴趣了,反正就是第一了,反正年底我们去不了美国了。就面不了基了。
然后又是一年奇怪的陪跑。感觉就是自己太菜了。
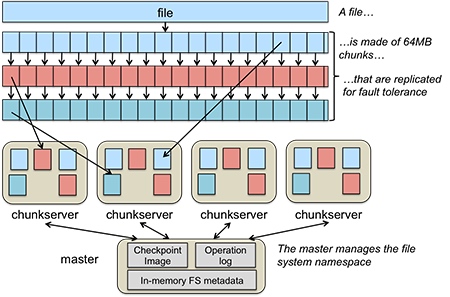
In the resource allocation problem in the Distributed Systems under the High Performance Computer, we don't really know which device like disk, NIC (network interface) is more likely to be worn, or not currently on duty which may trigger delaying a while to get the data ready. The current solution is random or round robin scheduling algorithm in avoidance of wearing and dynamic routing for fastest speed. We can utilize the data collected to make it automatic.
Matured system administrator may know the pattern of the parameter to tweak like stride on the distributed File Systems, network MTUs for Infiniband card and the route to fetch the data. Currently, eBPF(extended Berkeley Packets Filter) can store those information like the IO latency on the storage node, network latency over the topology into the time series data. We can use these data to predict which topology and stride and other parameter may be the best way to seek data.
The data is online, and the prediction function can be online reinforce learning. Just like k-arm bandit, the reward can be the function of latency gains and device wearing parameter. The update data can be the real time latency for disks and networks. The information that gives to the RL bots can be where the data locate on disks, which data sought more frequently (DBMS query or random small files) and what frequency the disk make fail.
Benchmarks and evaluation can be the statistical gain of our systems latency and the overall disk wearing after the stress tests.

不太理解asc评审人脑回路,同时看尽了一些国内的学术风气,同时联想到自己的GPA,觉得自己快没书读了。
总之用rpmbuild最快。想改就改改 slurm.spec 就行
rpmbuild -ta slurm*.tar.bz2
大概有几个小坑,
tar -jxvf *, 把configure 部分改成 --with-hdf5=no。
create 个 munged key 放 /etc/munge/munge.key
compute control 节点的 /etc/slurm/slurm.conf 得一样。
ClusterName=epyc
ControlMachine=epyc.node1
ControlAddr=192.168.100.5
SlurmUser=slurm1
MailProg=/bin/mail
SlurmctldPort=6817
SlurmdPort=6818
AuthType=auth/munge
StateSaveLocation=/var/spool/slurmctld
SlurmdSpoolDir=/var/spool/slurmd
SwitchType=switch/none
MpiDefault=none
SlurmctldPidFile=/var/run/slurmctld.pid
SlurmdPidFile=/var/run/slurmd.pid
ProctrackType=proctrack/linuxproc
#PluginDir=
#FirstJobId=
ReturnToService=0
# TIMERS
SlurmctldTimeout=300
SlurmdTimeout=300
InactiveLimit=0
MinJobAge=300
KillWait=30
Waittime=0
#
# SCHEDULING
SchedulerType=sched/backfill
#SchedulerAuth=
SelectType=select/cons_tres
SelectTypeParameters=CR_Core
#
# LOGGING
SlurmctldDebug=3
SlurmctldLogFile=/var/log/slurmctld.log
SlurmdDebug=3
SlurmdLogFile=/var/log/slurmd.log
JobCompType=jobcomp/none
#JobCompLoc=
#
# ACCOUNTING
#JobAcctGatherType=jobacct_gather/linux
#JobAcctGatherFrequency=30
#
#AccountingStorageType=accounting_storage/slurmdbd
#AccountingStorageHost=
#AccountingStorageLoc=
#AccountingStoragePass=
#AccountingStorageUser=
#
# COMPUTE NODES
NodeName=epyc.node1 NodeAddr=192.168.100.5 CPUs=256 RealMemory=1024 Sockets=2 CoresPerSocket=64 ThreadsPerCore=2 State=IDLE
NodeName=epyc.node2 NodeAddr=192.168.100.6 CPUs=256 RealMemory=1024 Sockets=2 CoresPerSocket=64 ThreadsPerCore=2 State=IDLE
PartitionName=control Nodes=epyc.node1 Default=YES MaxTime=INFINITE State=UP
PartitionName=compute Nodes=epyc.node2 Default=NO MaxTime=INFINITE State=UP
动态关注 /var/log/slurm* 会有各种新发现。
建议不要开 slurmdbd, 因为很难配成功。
sacct 不需要这个功能。
slurm 里面有基于负载均衡的QoS控制,而 RDMA traffic 的时序数据很好拿到,那就很好动态调QoS了。
$ sudo opensm -g 0x98039b03009fcfd6 -F /etc/opensm/opensm.conf -B
-------------------------------------------------
OpenSM 5.4.0.MLNX20190422.ed81811
Config file is `/etc/opensm/opensm.conf`:
Reading Cached Option File: /etc/opensm/opensm.conf
Loading Cached Option:qos = TRUE
Loading Changed QoS Cached Option:qos_max_vls = 2
Loading Changed QoS Cached Option:qos_high_limit = 255
Loading Changed QoS Cached Option:qos_vlarb_low = 0:64
Loading Changed QoS Cached Option:qos_vlarb_high = 1:192
Loading Changed QoS Cached Option:qos_sl2vl = 0,1
Warning: Cached Option qos_sl2vl: < 16 VLs listed
Command Line Arguments:
Guid <0x98039b03009fcfd6>
Daemon mode
Log File: /var/log/opensm.log
message table affinity
$ numactl --cpunodebind=0 ib_write_bw -d mlx5_0 -i 1 --report_gbits -F --sl=0 -D 10
---------------------------------------------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
CQ Moderation : 100
Mtu : 4096[B]
Link type : IB
Max inline data : 0[B]
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0x8f QPN 0xdd16 PSN 0x25f4a4 RKey 0x0e1848 VAddr 0x002b65b2130000
remote address: LID 0x8d QPN 0x02c6 PSN 0xdb2c00 RKey 0x17d997 VAddr 0x002b8263ed0000
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]
65536 0 0.000000 0.000000 0.000000
---------------------------------------------------------------------------------------
```
改affinity
$ numactl --cpunodebind=1 ib_write_bw -d mlx5_0 -i 1 --report_gbits -F --sl=1 -D 10
集成到slurm QoS 控制API中。
### 最后弄个playbook
```yml
---
slurm_upgrade: no
slurm_roles: []
slurm_partitions: []
slurm_nodes: []
slurm_config_dir: "{{ '/etc/slurm' }}"
slurm_configure_munge: yes
slurmd_service_name: slurmd
slurmctld_service_name: slurmctld
slurmdbd_service_name: slurmdbd
__slurm_user_name: "{{ (slurm_user | default({})).name | default('slurm') }}"
__slurm_group_name: "{{ (slurm_user | default({})).group | default(omit) }}"
__slurm_config_default:
AuthType: auth/munge
CryptoType: crypto/munge
SlurmUser: "{{ __slurm_user_name }}"
ClusterName: cluster
ProctrackType=proctrack/linuxproc
# slurmctld options
SlurmctldPort: 6817
SlurmctldLogFile: "{{ '/var/log/slurm/slurmctld.log' }}"
SlurmctldPidFile: >-
{{
'/var/run/slurm/slurmctld.pid'
}}
StateSaveLocation: >-
{{
'/var/lib/slurm/slurmctld'
}}
# slurmd options
SlurmdPort: 6818
SlurmdLogFile: "{{ '/var/log/slurm/slurmd.log' }}"
SlurmdPidFile: {{ '/var/run/slurm/slurmd.pid' }}
SlurmdSpoolDir: {{'/var/spool/slurm/slurmd' }}
__slurm_packages:
client: [slurm, munge]
slurmctld: [munge, slurm, slurm-slurmctld]
slurmd: [munge, slurm, slurm-slurmd]
slurmdbd: [munge, slurm-slurmdbd]
__slurmdbd_config_default:
AuthType: auth/munge
DbdPort: 6819
SlurmUser: "{{ __slurm_user_name }}"
LogFile: "{{ '/var/log/slurm/slurmdbd.log' }}"

我们输了,但也看到了差距

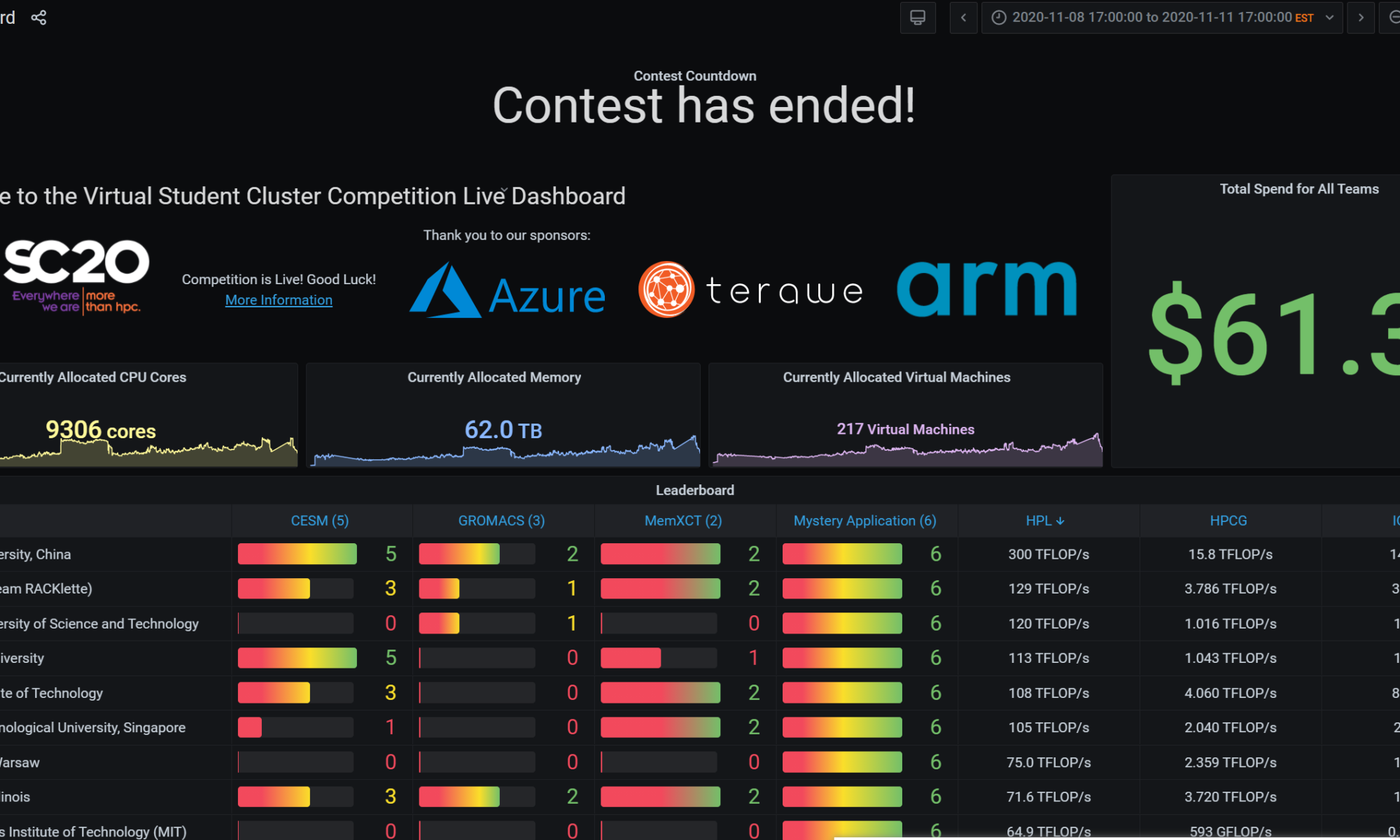
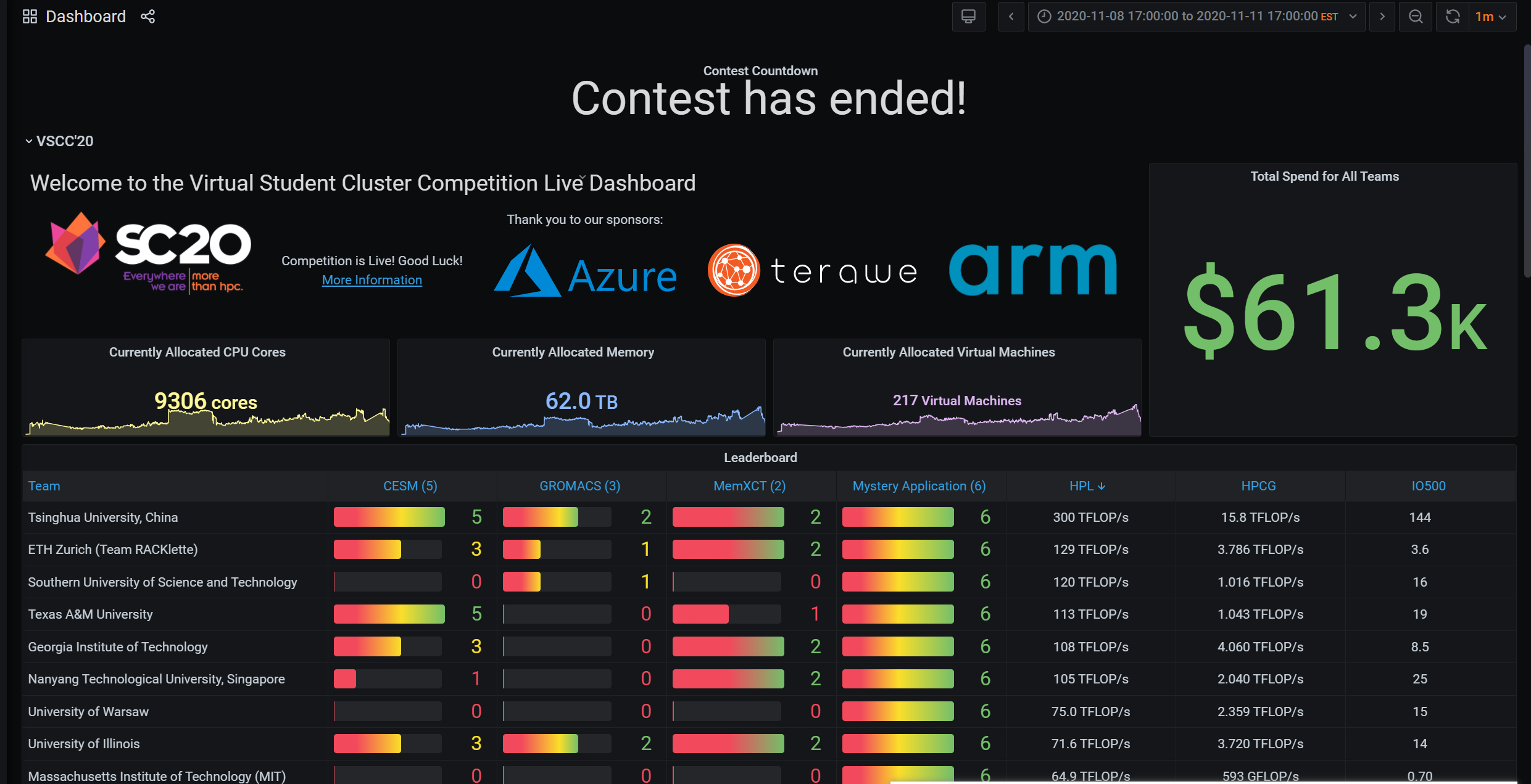
如果Harry Chen的后继者没能继续记录ISC ASC SC等比赛的比赛实况,这或许是一个好地方去报点"后Harry时代"比赛的流水账。、
TL;DR
Azure Cyclecloud 能很好的scale 你想干的任何计算,但我们在超过3000W的机器上没有很多经验,也许我在实习的时候有,但也只是对开着的集群运维,我并不那么善于精确的计算cost,在我们队里也似乎没有其他对弹性部署的机器有很好的理解。在写final arch的时候,我们带着以前的思路,由于预算限制导致的想着在任何时候用同样的价格。但云上比赛最好是用最好的机器跑最需要的应用。比如CESM需要HB120rs,那就新开一个机器。比赛之前我们只是把所有编译好的程序放到了一直开着的自带备份xfs的NFS上,pbs、grafana稍稍能用,后来开的机器懒就不配了,也没写脚本,吐槽下cyclecloud这个垃圾前端,还有HPC选项只有ubuntu18.04 和 rhel7。之后还配了个lustre template尝试跑IO500,可是性能不如单盘就放弃了。
如果说SC比赛是一个智商检测器,可以说是在中美贸易战的背景下,测试中国最高学府所能到达的最高点。也确实,三个应用其中两个:CESM、Gromacs都是需要学校背景支持的,清北作为一所能在短时间内集结所有题目的相关老师,并给出建设性建议,不愧为中国最高学府。IO500,RUNJI 宝宝在比赛前4个月左右开始写了一个为之量身定做的一个线性叠加IO性能的库MadFS。我们本来的研判是这只是一个burst cache 能减少memory最后flush cache的时间。但实际上RDMA可以做更好的scalability。据我猜测,他们用了8node L80s
几个比赛以后的反省:PBS scheduler 可以说一点卵用都没有。Azure上之前选用的机器是带SRIOV的,大概也只有之前玩过Exsi的人会吧,驱动安装走了点坑。最后安装的顺序只能是先编译网卡驱动,然后显卡驱动。显卡驱动会破坏ib的安装过程。这块之前写过脚本cloud-init就好了。作为队长,主控权由于我的状态原因,全权由殷老师管理。让我们丧失了一定的灵动性。
这次学校给我们提供了H1-306,可以说是图信的大本营,可以网络直出上海,而且没有限速。可以说很爽了,但比赛第二天下午开始还是各种不稳定,双十一剁手,跨洋剁手也不少。Azure的服务器在德州奥斯丁,而SC使用的zoom服务器在美国,我们的联络人是一个中东裔llbl实验室的computation physicist Axel Huebl,和HPC方向基本一致。
刚开始我们就跑了HPL和60s的HPCG以及IO500,用的英伟达[email protected][email protected]版本的binary,这里有个坑是HPL的binary一旦多于2node8卡就会segfault,而HPCG是不会的,这个坑知道多天以后我们才发现,由于我们从未在多于8卡的机器上跑过benchmark,这个坑算是踩中了。开始的结果不是很理想前者20左右后者800G,IO500随便组个raid0 就到了20,由于选择是8xP100,主办方又有后续不能改机型的规则。其他队都很鸡贼的不说具体时间选择的具体机型,我们老老实实列了我们仅需的机器,并没有为之考虑很多,同时也为预算考虑了很久,毕竟到比赛开始前我还一直以为比赛金额是2500USD。这时候看其他队HPL HPCG都爆70了,我们才知道之前设计时的信息不对称。于是考虑最后再尝试32台P100充分,这理论算力160TFLOPS和4TFLOPS,到这个时间点感觉稳了。指导老师殷老师叫我们稳一手,最后才交成绩。而HPCG需要跑3600s,所以这时候的成绩不合法。
第一天早上10点有个奇怪的考试,CA2.在那之前我也仅仅按照机器配好5台机器2xp100 2x hb60rs 1x d96as,跑完benchmark,刚看了看cesm的测试案例。由于我队友都不怎么会运维。到我们1点回来的时候居然所有机器都是空载的!空载的!啊这,不知道他们怎么想的,就是怕我回来之前他们配不完,应该关掉的。多烧了大约两三百🔪吧。不过这时候,本以为第二天才发的神秘应用minivive的所有脚本柳煜辰弄的都可以跑了,要花的时间也可控,不过可惜的是它只能开2的倍数的线程,而我们的机器是60核的,所以很长一段时间我们都是半载(不能改机器)。吴天元和徐开元负责的gromacs也大致能在GPU上跑了。可这个gromacs的testcase弄的挺恶心的,我们训练的时候发现及时用很大,几十兆大小的蛋白,都不需要很久。所以我们预计给gromacs的时间是不多的,可事实是gpu到第三天还在跑gromacs,是testcase 同一个蛋白要跑几百次,最后出一个趋势图。而且他还要求CPU也要有一半,gromacs是不支持多node的,所以一个算例往往要占一个node好几个小时。
回来以后,我的状态其实不是很好,由于之前一天刚check完通宵了2天写网络project,同时前一天还在负责场地啥的。CA考试就基本糊过去了。cesm是早有一份配置好编译器的环境,脚本提交了task2,和task3。3很快的能跑起来,同时也得到了结果,第一天晚上我也写了一个python轮询调度器,task3跑完跑2,2跑完跑1,1跑完跑4。早上起来的时候2和3都跑完了。可我队友起来的时候告诉我,他手动把一年的算例改成一个月了,跑的不作数,同时他用task脚本,把我跑出来一个月的结果给overwrite掉了,我人傻了。不过一个月还好。我看着有四个node还在跑1和5。后来发现1和5是个zombie程序。搞这些有的没的花了将近大半天时间,到下午4点左右我们才上正轨,跑完了3。这是我们发现之前能编译和跑的task1和5莫名出现了fortrl segfault 退出代码174。Harry的博客提到过这个报错,我们在尝试了ulimit、/etc/security/limit.conf、关selinux、换机器之后,还是没能解决这个问题。我欲哭无泪,第二天晚上就把该关的机器关了,让我队友重新编译了一份,剩下跑其他应用。这是柳煜辰已经整完了一份能自动配置新机器user的脚本。
第三天早上起来以后,队友还是用的intel编译器,不同版本编译的,我开始跑起来总是那个segfault。我尝试在google找遍了所有方法。调到4点钟左右,也就是还剩14小时,我们也没能找到办法,也就放弃了剩下的,这时北大已经交满了所有算例。可能唯一的方法就是换gnu编译器重新编译吧。这时,组委会发了条通知,多加500USD预算,THU杰哥 在下面评论了一句:“Thanks, it's very helpful.” az。
最后一晚,天元回去睡了,他们跑了一部分的task3的gromacs,可是最终算例太大,跑不完了,貌似钱也不太够,也相继放弃了。我是晚上才起来,起来时唯一还对cesm有点念想,最后还是放弃了。还有6小时的时候,我们4位开始了紧张刺激的冲benchmark行为。
NFS在装OMED驱动的时候挂过一次,stale handle detected。我们重启了一遍pbs集群,nfs集群。还好数据都在,我们相继在那个时候用azcopy上传了所有已有结果,发现了60sHPCG结果并不合法。殷老师脸色铁青。32个机器,用pipeline装机器的方法我们花了2个多小时才搞完。然后又花了1个小时弄openmpi的各种问题。最后没能在1小时之内再跑一次HPCG。预算也要抄了,我们只得关掉开的32台P100,回去睡觉了。本次比赛我们和清华的差距就是我们benchmark 没跑完。以及CESM没跑完。