

Demisifying CXL.mem with Back invalication snoop.
Recently I've been to FMS and notice that a lot of vendor has looked into the Type3 + Back invalication + software solutions for far memory.
Current MESIF in LLC of Intel is designed to be SNoopy Filter, when I was reverse engineering the PerfMon CHA Box filter, I found in the previous version of Intel will explicitly mark the request H, E, S for directory. Which is DCOH way of managing SF. I think that the device invalidate cacheline can let the host go directly to the device to fetch
But the cacheline is still maintained by the directory, and there may be conflicts
The current Intel in core MEISF SF is maintained in this way, and now only CXL CHA has no computing function, but the memory part is equivalent to a core
DCOH is the Snoopy filter cache tested on the device
For faster cacheline metadata maintenance
I remembered someone asked me earlier that they wanted to test DCOH
Where is the DCOH, indicating where the metadata is frequently updated
That is the role of bias
Intel's own Snoopy filter is maintained by directory

CXL RSS Limit Kernel Design
Because of CXL.Mem is not currently available in the market; we based our system approach on two NUMA SPR sockets. We built an eBPF approach because of uncontrollable performance noise, which is deprecated, and a production-ready system. The former [3] utilizes eBPF to hook the allocation of memory for the workload across different memory tiers with 20% overhead on Broadwell and 1% overhead on SPR, while the BedeKernel interacts with the kernel's memory cgroup to determine the placement of pages. Specifically, the simulator ensures that the workload's allocation from the local memory doesn't exceed a certain bound. Subsequent sections of this document provide justification for the simulator's reliance on NUMA, an explanation of its eBPF-based design, and a description of the workloads that were evaluated.
We also provide a kernel implementation with cgroup integration in [1] and [2], which at the kernel level get the dynamic capacity for CXL.mem done compared with Anjo University's auto tiering NVM approach. Current simulators for CXL.mem often yield imprecise outcomes when modeling the impact of assigning a segment of a workload's memory to a CXL.mem shared memory pool. Pond, a specific instance, delivers inconsistent simulation results. It operates through a user-level program that allocates and mlocks memory, constraining the quantity of local memory an application can utilize. Regrettably, variations in memory consumption from ongoing background tasks in the system cause inconsistencies in the amount of local memory accessible for each workload. An alternative to Pond, SMDK, habitually allocates insufficient local memory. By altering the kernel's mmap to steer allocations into various memory zones, SMDK intervenes in each memory allocation. This technique determines the memory placement during virtual memory allocation (i.e., at the time of mmap), but due to demand paging, many virtual memory allocations never translate into physical memory and shouldn't be factored into the workload's local memory consumption. To address the shortcomings in earlier simulators, our specific CXL.mem workload simulator for data collection leverages namespace. As the workload executes, the simulator monitors the resident set size, hooking the policy_node and policy_nodemask with namespace isolation. invoked during each page allocation. This guides page allocations to ensure that the total memory designated to local memory remains within the specified local memory bound.
There are some known limitations of BedeKernel:
- TODO: DSA Migration impl, currently just migrate page async.
- On cgroup start, starting bede struct. On cgroup init procfs, init the policy_node instrumentation. Locally-bind specially dealt with. Let k8s change the cgroup procfs variable to change the migration target. The full approach has a 5% overhead and a 10% deviation from the target RSS because of numastat metrics staleness in reason [5].
- On clone3 syscall, the cloned process may double the RSS limitation. Python is not working since it calls clone and detach child at the very beginning.
- On file-backed mmap syscall, on page fault, the decision does not go through the policy_node path, thus invalid.
- Kernel 6.4.0 removes atomic irq https://lore.kernel.org/all/[email protected]/, which makes numastat in hot path crash irq.
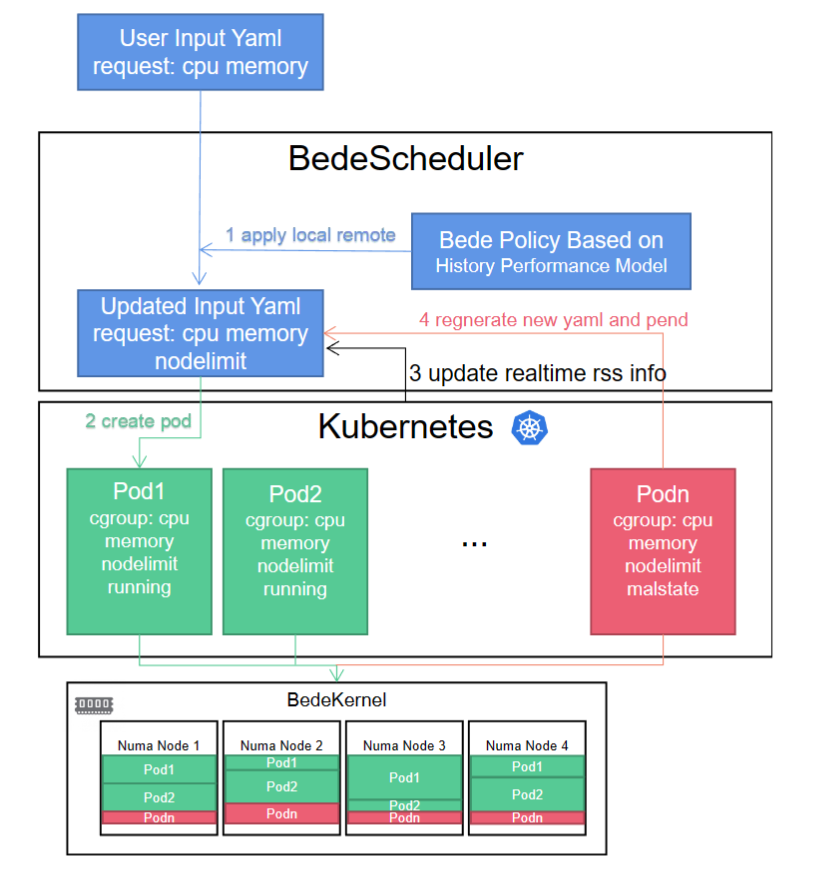
We also integrate the BedeKernel into k8s without a policy written yet because the performance gap of two socket memory in the NUMA machine is low. So, if you have the machine to evaluate my kernel, please feel free to help me. k8s utilizes cgroup as its interface for container management and oversees containers through the associated cgroup procfs directory files. As a result, we only need to make our node_limit visible to the Kubernetes scheduler. When a job's total memory size is defined through a user-input yaml file, the scheduler formulates a yaml as outlined in step 1 and applies the calculated node_limit to the corresponding pod's cgroup directory. The BedeKernel will then restrict page allocation at the hook points policy_node and policy_nodemask. In step 3, Kubernetes refreshes the real-time Resident Set Size (RSS) information to modify the node_limit for pending jobs. If a Pod is found to be in a compromised state, the scheduler will reconstruct the yaml file utilizing the historical performance model and apply it to the Kubernetes pending queue.
We think the above operation can also be codesigned with the fabric manager to make colocation work and avoid congestion in the channel, which the full discussion is here [4]; this will be done once the fabric manager is done. Because the hardware always has these or those bugs. Quote a guy from Alibaba Cloud: RDT's semantic and performance bugs make it not possible to provide a good workload history model in the k8s layer. I buy it. We should wait until a company integrates my implementation and see if the CXL fabric can be safely integrated without too much performance noise.
Reference
- https://github.com/SlugLab/Kubernetes
- https://github.com/SlugLab/Bede-linux
- https://github.com/victoryang00/node-limit-ebpf
- https://www.youtube.com/watch?v=sncOmRnO1O4
How to create rootfs for kernel debugging
Compulsory kernel options
CONFIG_E1000=ycreate rootfs
readonly BASEDIR=$(readlink -f $(dirname $0))/
QEMU_PATH=${BASEDIR}/
QEMU_BUILD_PATH=${QEMU_PATH}/build/
IMAGE_NAME=qemu-image.img
qemu-img create ${QEMU_PATH}/${IMAGE_NAME} 100g
mkfs.ext4 ${QEMU_PATH}/${IMAGE_NAME}
mkdir -p ${QEMU_PATH}/mount-point.dir
sudo mount -o loop ${QEMU_PATH}/${IMAGE_NAME} ${QEMU_PATH}/mount-point.dir/
sudo apt install debootstrap debian-keyring debian-archive-keyring
# When debootstrap install if wget error occurs,
# add proxy configuration to /etc/wgetrc (http_proxy, https_proxy, ftp_proxy)
sudo debootstrap --no-check-certificate --arch amd64 lunar ${QEMU_PATH}/mount-point.dir/
# mkdir - ${QEMU_PATH}/mnt
sudo mount ${IMAGE_NAME} ${QEMU_PATH}/mnt
cd ${QEMU_PATH}/mnt
sudo chroot .
# After creating rootfs,
# 1) Change root password
# $ passwd
# 2) (Optional) Add proxy configuration
# Open /etc/profile, and add proxy configuration
# export HTTP_PROXY="http://:/"
# export HTTPS_PROXY="http://:/"
# $ sh /etc/profile
# 3) (Optional) Add local Ubuntu repository mirrors
# Open /etc/apt/sources.list, and add repository mirrors
# 4) Package update
# $ apt update
# $ apt upgrade
# $ apt install nano pciutils debian-keyring debian-archive-keyring openssh-server net-tools ifupdown
# 5) Modify sshd config
# $ vi /etc/ssh/sshd_config
# ...
# PermitRootLogin yes
# ...
# 6) Modify network config
# $ vi /etc/network/interfaces
# # add below lines
# auto ens3
# iface ens3 inet dhcp
# # for q35 machine
# auto enp0s2
# iface enp0s2 inet dhcp
# alternative network config
# $ vi /etc/netplan/00-installer-config.yaml
# # add below lines
# network:
# ethernets:
# ens3:
# dhcp4: true
# enp0s2:
# dhcp4: true
# version: 2
# 7) Quit
# $ exit After create the rootfs and compiler the kernel
SMDK_KERNEL_PATH=${BASEDIR}/Bede-linux/
ROOTFS_PATH=${BASEDIR}
MONITOR_PORT=45454
QEMU_SYSTEM_BINARY=`which qemu-system-x86_64`
BZIMAGE_PATH=${SMDK_KERNEL_PATH}/arch/x86_64/boot/bzImage
INITRD_PATH=/boot/initrd.img-6.4.0+
IMAGE_PATH=${ROOTFS_PATH}/qemu-image.img
function print_usage(){
echo ""
echo "Usage:"
echo " $0 [-x vm_index(0-9)]"
echo ""
}
while getopts "x:" opt; do
case "$opt" in
x)
if [ $OPTARG -lt 0 ] || [ $OPTARG -gt 9 ]; then
echo "Error: VM count should be 0-9"
exit 2
fi
VMIDX=$OPTARG
;;
*)
print_usage
exit 2
;;
esac
done
if [ -z ${VMIDX} ]; then
NET_OPTION="-net user,hostfwd=tcp::2242-:22,hostfwd=tcp::6379-:6379,hostfwd=tcp::11211-:11211, -net nic"
else
echo "Info: Running VM #${VMIDX}..."
MONITOR_PORT="4545${VMIDX}"
IMAGE_PATH=$(echo ${IMAGE_PATH} | sed 's/.img/-'"${VMIDX}"'.img/')
MACADDR="52:54:00:12:34:${VMIDX}${VMIDX}"
TAPNAME="tap${VMIDX}"
NET_OPTION="-net nic,macaddr=${MACADDR} -net tap,ifname=${TAPNAME},script=no"
IFCONFIG_TAPINFO=`ifconfig | grep ${TAPNAME}`
if [ -z "${IFCONFIG_TAPINFO}" ]; then
log_error "${TAPNAME} SHOULD be up for using network in VM. Run 'setup_bridge.sh' in /path/to/SMDK/lib/qemu/"
exit 2
fi
fi
if [ ! -f "${QEMU_SYSTEM_BINARY}" ]; then
log_error "qemu-system-x86_64 binary does not exist. Run 'build_lib.sh qemu' in /path/to/SMDK/lib/"
exit 2
fi
if [ ! -f "${BZIMAGE_PATH}" ]; then
log_error "SMDK kernel image does not exist. Run 'build_lib.sh kernel' in /path/to/SMDK/lib/"
exit 2
fi
if [ ! -f "${IMAGE_PATH}" ]; then
log_error "QEMU rootfs ${IMAGE_PATH} does not exist. Run 'create_rootfs.sh' in /path/to/SMDK/lib/qemu/"
exit 2
fi
# echo sudo ${QEMU_SYSTEM_BINARY} \
# -smp 3 \
# -numa node,cpus=0-2,memdev=mem0,nodeid=0 \
# -object memory-backend-ram,id=mem0,size=8G \
# -kernel ${BZIMAGE_PATH} \
# -initrd ${INITRD_PATH} \
# -drive file=${IMAGE_PATH},index=0,media=disk,format=raw \
# -drive file=${IMAGE1_PATH},index=1,media=disk,format=raw \
# -enable-kvm \
# -monitor telnet::${MONITOR_PORT},server,nowait \
# -serial mon:stdio \
# -nographic \
# -append "root=/dev/sda rw console=ttyS0 nokaslr memblock=debug loglevel=7" \
# -m 8G,slots=4,maxmem=32G \
# -device virtio-crypto-pci,id=crypto0,cryptodev=cryptodev0 \
# -object cryptodev-backend-builtin,id=cryptodev0 \
# -object secret,id=sec0,file=./Drywall/passwd.txt \
# ${NET_OPTION}
${QEMU_SYSTEM_BINARY} \
-S -s -smp 4 \
-numa node,cpus=0,memdev=mem0,nodeid=0 \
-object memory-backend-ram,id=mem0,size=8G \
-numa node,cpus=1,memdev=mem1,nodeid=1 \
-object memory-backend-ram,id=mem1,size=8G \
-numa node,cpus=2,memdev=mem2,nodeid=2 \
-object memory-backend-ram,id=mem2,size=8G \
-numa node,cpus=3,memdev=mem3,nodeid=3 \
-object memory-backend-ram,id=mem3,size=8G \
-kernel ${BZIMAGE_PATH} \
-initrd ${INITRD_PATH} \
-drive file=${IMAGE_PATH},index=0,media=disk,format=raw \
-serial mon:stdio \
-nographic \
-append "root=/dev/sda rw console=ttyS0 memblock=debug loglevel=7 cgroup_no_v1=1" \
-m 32G,slots=4,maxmem=36G \
-nic bridge,br=virbr0,model=virtio-net-pci,mac=02:76:7d:d7:1e:3fOSDI23 Attendency

TCLocks
pyy是四作
lock中transfer ctx而非data。因为shared data 同步是多线程lock unlock的最大开销。
所以用delayed OoO lock主动interrupts拿到epherical stack(会被prefetch)。
用ip+stack capture locks不sound?
明煜问了个如果解锁顺序不一样可能会死锁。回答说无关。
RON
因为CPU的topology,single threadripper上的topology planning。在thread ripper CCX的topology下用TSP来scheduler lock的unlock顺序。多个锁的情况把同一个锁放到一个ccx里。
UB
所有syscall profiling guided都被userspace binary recompile到jit把所有东西弄到kernel里面做。syscall 变成kernel 态的jump,保护用SFI。
~992 cycle
Indirect cost
- L1 TLB pollution
- OoO stall
- KPTI
compared with iouring. Should compared with iouring + codegen to bpf
由于SFI 有online 开销,我觉得最好做法还是codegen BPF。
Relational Debugging
用good run run到的地方比对bad run到的地方的trace,发现炸的地方和root cause的关系。(逻辑关系一多又不行了。
Larch
extension to MPC with 椭圆曲线, make honest client enrollment for precomputation. $f_1(r)(m+kf_2(r))$, and save them in the client side for future authentication.
k9db
expose data ownership(multigraph) graph soundly to the third party and mark annotations for developers to reason the dependency
during storage operations like group by, it will also cast on the ownership multigraph efficiently.
HeDB
using fork with privacy preserving record &replay+ concolic construction of fake control flow input of secured DB for maintenance to fix smuggle attacks from database administrator. exp query rewriting and concurrent write workload.
LVMT
Proof Sharding: Merkle Tree operator of data chunks.
Honeycomb GPU TEE
static analysis of gpu binary rather than increasing the TCB size and decrease the IPC and runtime monitor, 一个在SEV-SNP里面,一个在sandbox VM里,两个在deployment可以解耦. 有kernel 部分的driver和user space的driver。 lauch kernel的时候hook 所有memory 加密,bus的传输假定可靠,会leak也没用。
Core Slicing
这篇是shanyizhou的,用rv pmp来控制对slice的生命周期,对intel来说,如果不能改micro code,是需要对硬件的model (尤其是ACPI)有假设的。
Duvisor
听limingyu说这玩意的第一性原理是Gu Ronghui的把kernel里无法验证的bounded loop提到上层,然后每一层都是容易被验证的。这篇吹的故事把kvm和driver code解耦,硬件的地址的取得都放rv里面。其实这东西在intel上uipi+driver的context软件实现就没问题,rocetchip PC也不喜欢,容易被喷。osdi22被拒的原因是“xilinx板子上夸张的强于kvm 2倍,qemu模拟的设备会放大duvisor在mmio上对kvm的优势”,现在才中。
听作者说在firesim里拿到的结果和xilinx的差的很多,主要原因是Xilinx板子没有给出网络性能的cycle accurate保证, 最后只交了firesim的结果,按理说rtl生成的一样怎么会性能差很多,虽然firesim那玩意坑很多,但听说网络性能输出稳定。最后的实验是非常让kvm的,二级页表优势关掉了,而且kvm加了直通中断。
这个工作让来自host-attacking的漏洞给弥补了,以后不再会有类似问题。
eZNS
动态分配zone space
PM RDMA replication
lyy组的,利用了PCIe硬件的queue和memory control和Pmem的write combining,insight就说在kv大小可控的情况下,daemon走pcie应该分多少size的对pm的写。
SEPH
在同时写PM和DRAM的场景下想个办法把对PMEM的写放前面。
Remote Fork
remote docker cold start的问题,不如先remote fork。naive的做法是CRIU(传diff 怎么样?)所以就直接上RDMA codesign, 让remote aware,先one sided read page table in the page fault migration。
cxl似乎就是用来解决cross memory migration without serialization的。
Johnny cache
太神了


CXL-ANNS
两边都做实验,他们的rv设备和gem5,主要就是offload一些operator到cxl controller。
CXL-flash
写了个mqsim的trace based 模拟器,trace是用vagrid收的。用于design cxl flash,一半内存一半flash。讲了如何设计flahs的prefetch和mshr算法来fill ld/st与nvme访问的gap。两者甚至会打架(cache pollution)。
STYP
这工作本质上是把CPU的compssion的cycle放到smartnic的CPU上。cgroup,kernel same-page merging, like page deduplication。zswap
kthread page statistics。ccnuma?smartNIC?zswap take cycle?
BWOS
fuming的文章。用block based split operation that only verify every blocks' workstealing来 proof parallel computing using task based schduling.问题是每次block 都要同步来prove,不知道这样的speed gain会不会影响正确性
SPOQ
No Loop or intrinsics allowed for verification
formalize LLVM IR, loop finetune gen proof from spec。Some how a good thing to gen a small set of data to speed up verify systemC.
Sharding the state machine
分而治之steate machine,两个例子是page cache in SplinterDB和node replication in NrOS
Exact Once DAG
failure 会检查有没有执行过。
SMartNIC Characterization
blueflied2 上arm core 和host cpu对Switch的data path的讨论,有PCIe的congestion也有CPU的DMA controller的throttle。
ServiceRouter
一个service区域调度器
Ensō
用streaming的抽象替换descripter,ringbuffer和packets抽象。而且如果还是用原来的抽象对比dpdk在几乎所有packets大小对比的bandwidth大小比较上都最优,可以说对大部分应用是free lunch.
这里在NIC里需要维护ip forward和prefetch,实际用到了on chip 计算资源。对延时敏感,packets size aware的用户会感觉到这个没有用。
Design of per cgroup memory disaggregation
This post will be integrate with yyw's knowledge base
For an orchestration system, resource management needs to consider at least the following aspects:
- An abstraction of the resource model; including,
- What kinds of resources are there, for example, CPU, memory (local vs remote that can be transparent to the user), etc.;
- How to represent these resources with data structures;
1. resource scheduling
- How to describe a resource application (spec) of a workload, for example, "This container requires 4 cores and 12GB~16GB(4GB local/ 8GB-12GB remote) of memory";
- How to describe the current resource allocation status of a node, such as the amount of allocated/unallocated resources, whether it supports over-segmentation, etc.;
- Scheduling algorithm: how to select the most suitable node for it according to the workload spec;
2.Resource quota
- How to ensure that the amount of resources used by the workload does not exceed the preset range (so as not to affect other workloads);
- How to ensure the quota of workload and system/basic service so that the two do not affect each other.
k8s is currently the most popular container orchestration system, so how does it solve these problems?
k8s resource model
Compared with the above questions, let's see how k8s is designed:
- Resource model :
- Abstract resource types such as cpu/memory/device/hugepage;
- Abstract the concept of node;
- Resource Scheduling :
requestThe two concepts of and are abstractedlimit, respectively representing the minimum (request) and maximum (limit) resources required by a container;AllocatableThe scheduling algorithm selects the appropriate node for the container according to the amount of resources currently available for allocation ( ) of each node ; Note that k8s scheduling only looks at requests, not limits .
- Resource enforcement :
- Use cgroups to ensure that the maximum amount of resources used by a workload does not exceed the specified limits at multiple levels.
An example of a resource application (container):
apiVersion: v2
kind: Pod
spec:
containers:
- name: busybox
image: busybox
resources:
limits:
cpu: 500m
memory: "400Mi"
requests:
cpu: 250m
memory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
Here requestsand limits represent the minimum and maximum values of required resources, respectively.
- The unit of CPU resources
mismillicoresthe abbreviation, which means one-thousandth of a core, socpu: 500mmeans that0.5a core is required; - The unit of memory is well understood, that is, common units such as MB and GB.
Node resource abstraction
$ k describe node <node>
...
Capacity:
cpu: 48
mem-hard-eviction-threshold: 500Mi
mem-soft-eviction-threshold: 1536Mi
memory: 263192560Ki
pods: 256
Allocatable:
cpu: 46
memory: 258486256Ki
pods: 256
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 800m (1%) 7200m (15%)
memory 1000Mi (0%) 7324Mi (2%)
hugepages-1Gi 0 (0%) 0 (0%)
...
Let's look at these parts separately.
Capacity
The total resources of this node (which can be simply understood as physical configuration ), for example, the above output shows that this node has 48CPU, 256GB memory, and so on.
Allocatable
The total amount of resources that can be allocated by k8s , obviously, Allocatable will not exceed Capacity, for example, there are 2 less CPUs as seen above, and only 46 are left.
Allocated
The amount of resources that this node has allocated so far, note that the message also said that the node may be oversubscribed , so the sum may exceed Allocatable, but it will not exceed Capacity.
Allocatable does not exceed Capacity, and this concept is also well understood; but which resources are allocated specifically , causing Allocatable < Capacityit?
Node resource segmentation (reserved)
Because k8s-related basic services such as kubelet/docker/containerd and other operating system processes such as systemd/journald run on each node, not all resources of a node can be used to create pods for k8s. Therefore, when k8s manages and schedules resources, it needs to separate out the resource usage and enforcement of these basic services.
To this end, k8s proposed the Node Allocatable Resources[1] proposal, from which the above terms such as Capacity and Allocatable come from. A few notes:
- If Allocatable is available, the scheduler will use Allocatable, otherwise it will use Capacity;
- Using Allocatable is not overcommit, using Capacity is overcommit;
Calculation formula: [Allocatable] = [NodeCapacity] - [KubeReserved] - [SystemReserved] - [HardEvictionThreshold]
Let’s look at these types separately.
System Reserved
Basic services of the operating system, such as systemd, journald, etc., are outside k8s management . k8s cannot manage the allocation of these resources, but it can manage the enforcement of these resources, as we will see later.
Kube Reserved
k8s infrastructure services, including kubelet/docker/containerd, etc. Similar to the system services above, k8s cannot manage the allocation of these resources, but it can manage the enforcement of these resources, as we will see later.
EvictionThreshold (eviction threshold)
When resources such as node memory/disk are about to be exhausted, kubelet starts to expel pods according to the QoS priority (best effort/burstable/guaranteed) , and eviction resources are reserved for this purpose.
Allocatable
Resources available for k8s to create pods.
The above is the basic resource model of k8s. Let's look at a few related configuration parameters.
Kubelet related configuration parameters
kubelet command parameters related to resource reservation (segmentation):
--system-reserved=""--kube-reserved=""--qos-reserved=""--reserved-cpus=""
It can also be configured via the kubelet, for example,
$ cat /etc/kubernetes/kubelet/config
...
systemReserved:
cpu: "2"
memory: "4Gi"
Do you need to use a dedicated cgroup for resource quotas for these reserved resources to ensure that they do not affect each other:
--kube-reserved-cgroup=""--system-reserved-cgroup=""
The default is not enabled. In fact, it is difficult to achieve complete isolation. The consequence is that the system process and the pod process may affect each other. For example, as of v1.26, k8s does not support IO isolation, so the IO of the host process (such as log rotate) soars, or when a pod process executes java dump, It will affect all pods on this node.
The k8s resource model will be introduced here first, and then enter the focus of this article, how k8s uses cgroups to limit the resource usage of workloads such as containers, pods, and basic services (enforcement).
k8s cgroup design
cgroup base
groups are Linux kernel infrastructures that can limit, record and isolate the amount of resources (CPU, memory, IO, etc.) used by process groups.
There are two versions of cgroup, v1 and v2. For the difference between the two, please refer to Control Group v2. Since it's already 2023, we focus on v2. The cgroup v1 exposes more memory stats like swapiness, and all the control is flat control, v2 exposes only cpuset and memory and exposes the hierarchy view.
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
$ root@banana:~/CXLMemSim/microbench# ls /sys/fs/cgroup
cgroup.controllers cpuset.mems.effective memory.reclaim
cgroup.max.depth dev-hugepages.mount memory.stat
cgroup.max.descendants dev-mqueue.mount misc.capacity
cgroup.pressure init.scope misc.current
cgroup.procs io.cost.model sys-fs-fuse-connections.mount
cgroup.stat io.cost.qos sys-kernel-config.mount
cgroup.subtree_control io.pressure sys-kernel-debug.mount
cgroup.threads io.prio.class sys-kernel-tracing.mount
cpu.pressure io.stat system.slice
cpu.stat memory.numa_stat user.slice
cpuset.cpus.effective memory.pressure yyw
$ root@banana:~/CXLMemSim/microbench# ls /sys/fs/cgroup/yyw
cgroup.controllers cpu.uclamp.max memory.oom.group
cgroup.events cpu.uclamp.min memory.peak
cgroup.freeze cpu.weight memory.pressure
cgroup.kill cpu.weight.nice memory.reclaim
cgroup.max.depth io.pressure memory.stat
cgroup.max.descendants memory.current memory.swap.current
cgroup.pressure memory.events memory.swap.events
cgroup.procs memory.events.local memory.swap.high
cgroup.stat memory.high memory.swap.max
cgroup.subtree_control memory.low memory.swap.peak
cgroup.threads memory.max memory.zswap.current
cgroup.type memory.min memory.zswap.max
cpu.idle memory.node_limit1 pids.current
cpu.max memory.node_limit2 pids.events
cpu.max.burst memory.node_limit3 pids.max
cpu.pressure memory.node_limit4 pids.peak
cpu.stat memory.numa_statThe procfs is registered in
ASPLOS23 attendency
这次投了一篇workshop,但是签证问题,所以这次前半段又得是一个线上会议,说实话我只关注CXL和codesign,本来可以见见刘神和jovan大师还有yan大师的,最后还是见到了,加上各种大师。机票是25号去西雅图的,也退不了,我现在改了护照hold on,在3.27号礼拜一飞LA取护照,被告知还没来,后来邮件来了,被告知第二天早上能到,然后见了大学同学,和WDY。3.28到LA领馆的时候,一开始没到,10.37分收到,10.45分拿到护照,12.35的飞机,uber去,11.28到,线上checkin过了15分钟安检,还好出境去canada比较快,安检前根本没有check合法证件,领登机牌的时候被check了入境加拿大的合法证件。晚点了半个小时。到温哥华下飞机,入境全部电子化,我被签证官问干什么,我说I‘m a Ph.D. student and attend conference. 然后就放我过了。到的时候是最后一个session,拿了badge,听完就poster session了,到第二天3点结束其实正好就听了一天。晚上的aqurium的award不错,social 认识了美本CMU博美女。(Trans 完全没有被歧视。)感觉加拿大完全是富人的天堂,能干活的人去只能做做底层工作,不划算,我觉得,这个国家,经济上政治上科技上完全被美帝压制和吸血。最前沿的东西也没有美国牛逼。由于asplos paper 太多,下面只放最重要的。
Firesim
主要是介绍他们的firesim的,就问他们什么时候更新f1 vu9p。tutorial讲很多怎么在f1上用firesim和chipyard敏捷开发riscv,ucb的252已经用chipyard当他们的体系结构作业了,仿真一个BOOM的TAGE很正常。
Integrating a high performance instruction set simulator with FireSim to cosimulate operating system boots By tesorrent
主要讲了怎么在firesim上敏捷开发

LATTE
workshop都是企业级别的对RTL/hw/sw的优化。
Exploring Performance of Cache-Aware Tiling Strategies in MLIR Infrastructure
Intel OneDNN在MLIR上approach
PyAIE: A Python-based Programming Framework for Versal ACAP AI Engines
Versal ACAP HLS
A Scalable Formal Approach for Correctness-Assured Hardware Design
Jin Yang 大师的,之前在AHA讲过了,
Yarch
Formal Characterization of Hardware Transmitters for Secure Software and Hardware Repair
和作者聊了一下,是个台湾中研院->stanford的女生,和Cristopher合作,(他要来UCB了)大概就是model hw state,用symbolic execution resolve branch 然后看有没有timing difference。在RTL上做。
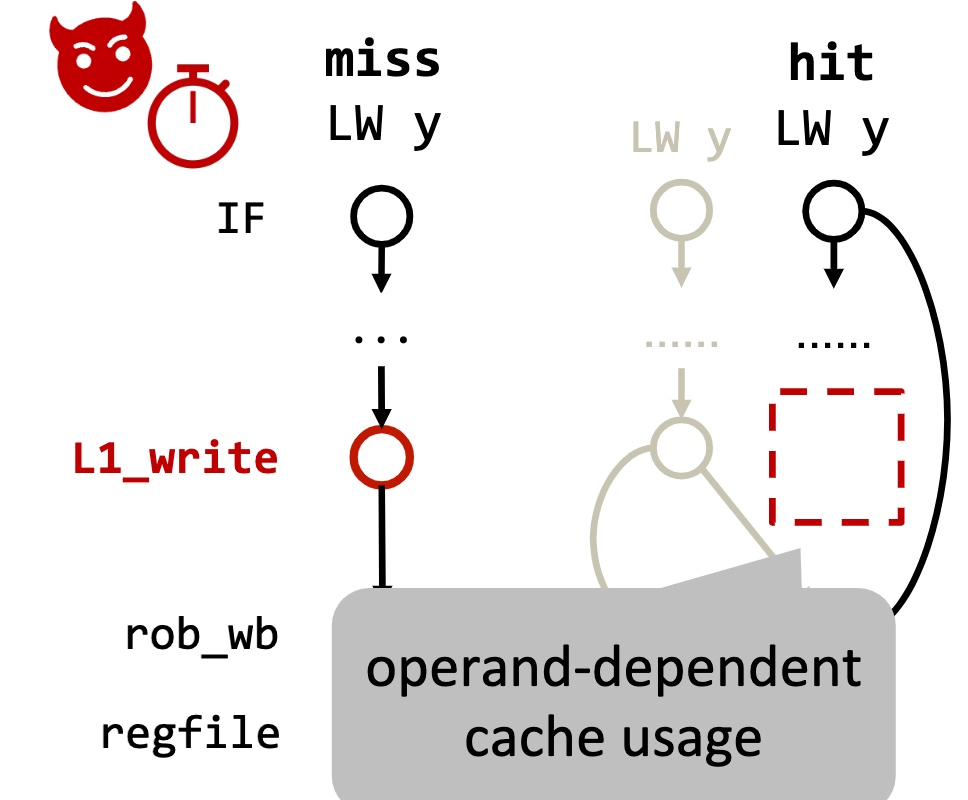
Detecting Microarchitectural Vulnerabilities via Fuzz Testing of White-box CPUs
用fuzzing地手段找Store Bypass。

SMAD: Efficiently Defending Against Transient Execution Attacks
这次被分配的mentor的学生的,这个mentor在GPU side channel很著名。
Session 1B: Shared Memory/Mem Consistency
这个chair是admit,辣个VMWare最会排列组合Intel ext的男人

Cohort: Software-Oriented Acceleration for Heterogeneous SoCs
这篇是在fpga上自己定义L1/L2 cache和crypto accelerator。然后怎么弄在一起,在CXL.cache就不是一个问题。
Probabilistic Concurrency Testing for Weak Memory Programs
一个PCT Frameware,用SC的规范来assert,找bug。
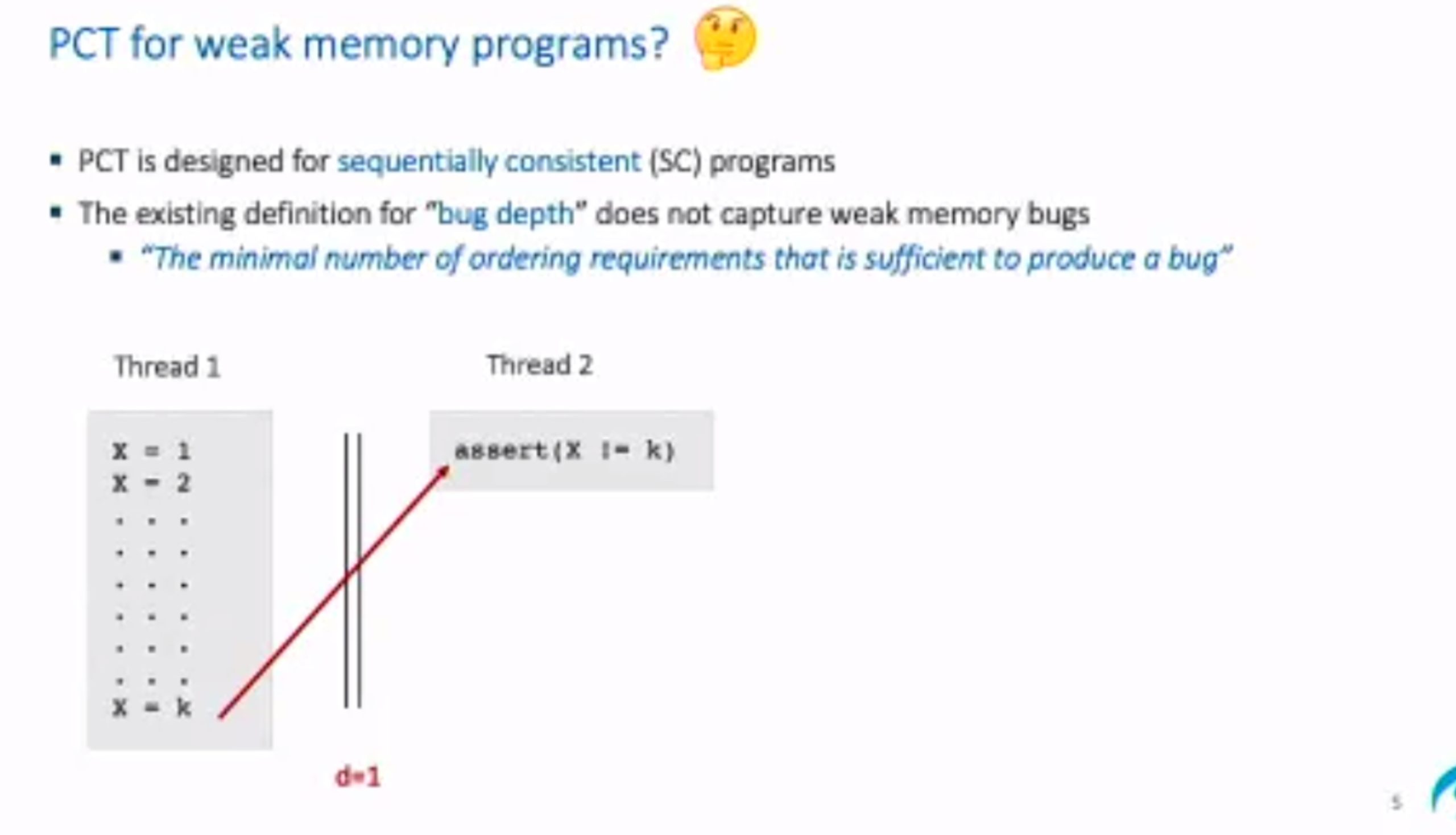

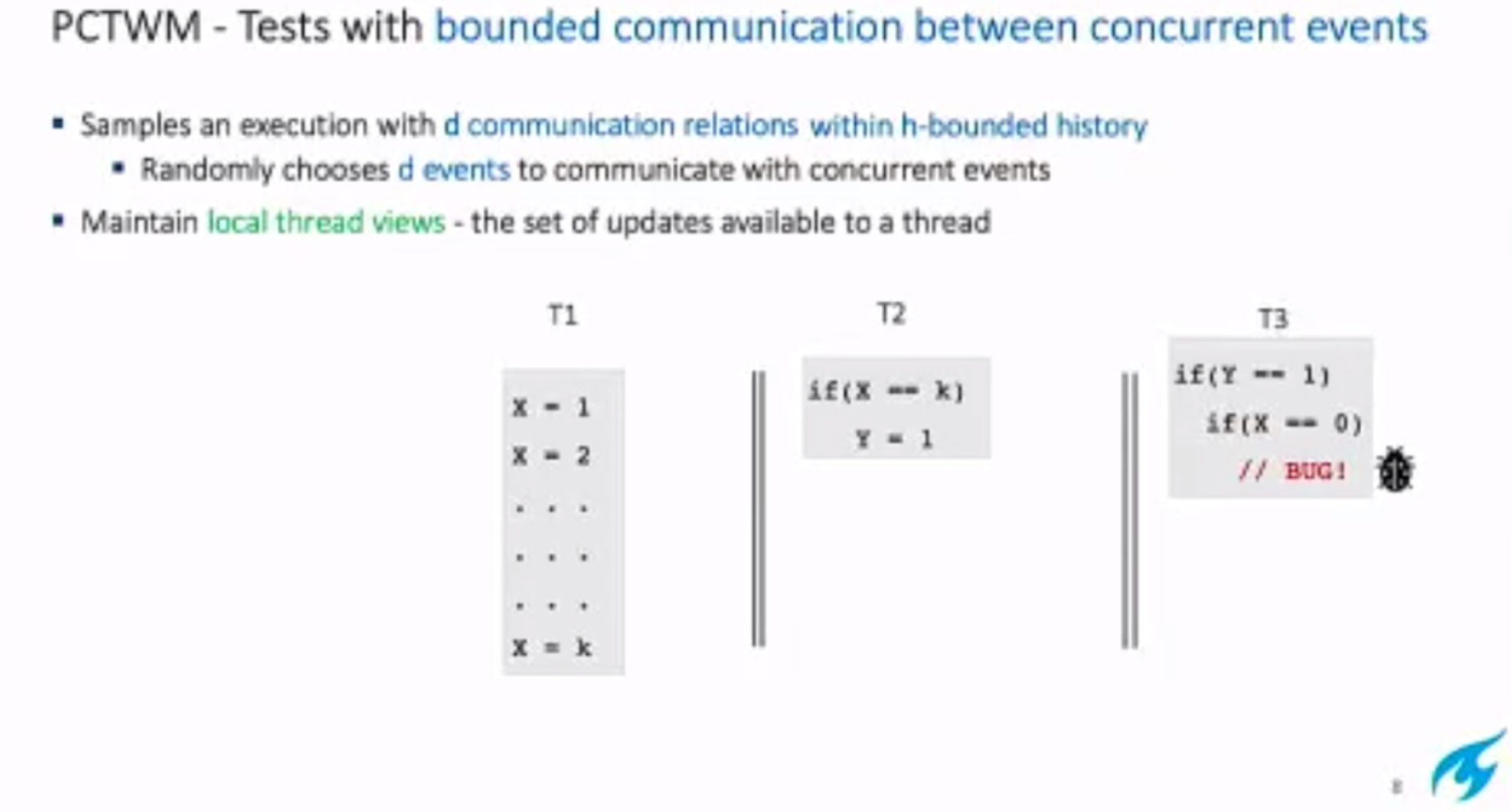

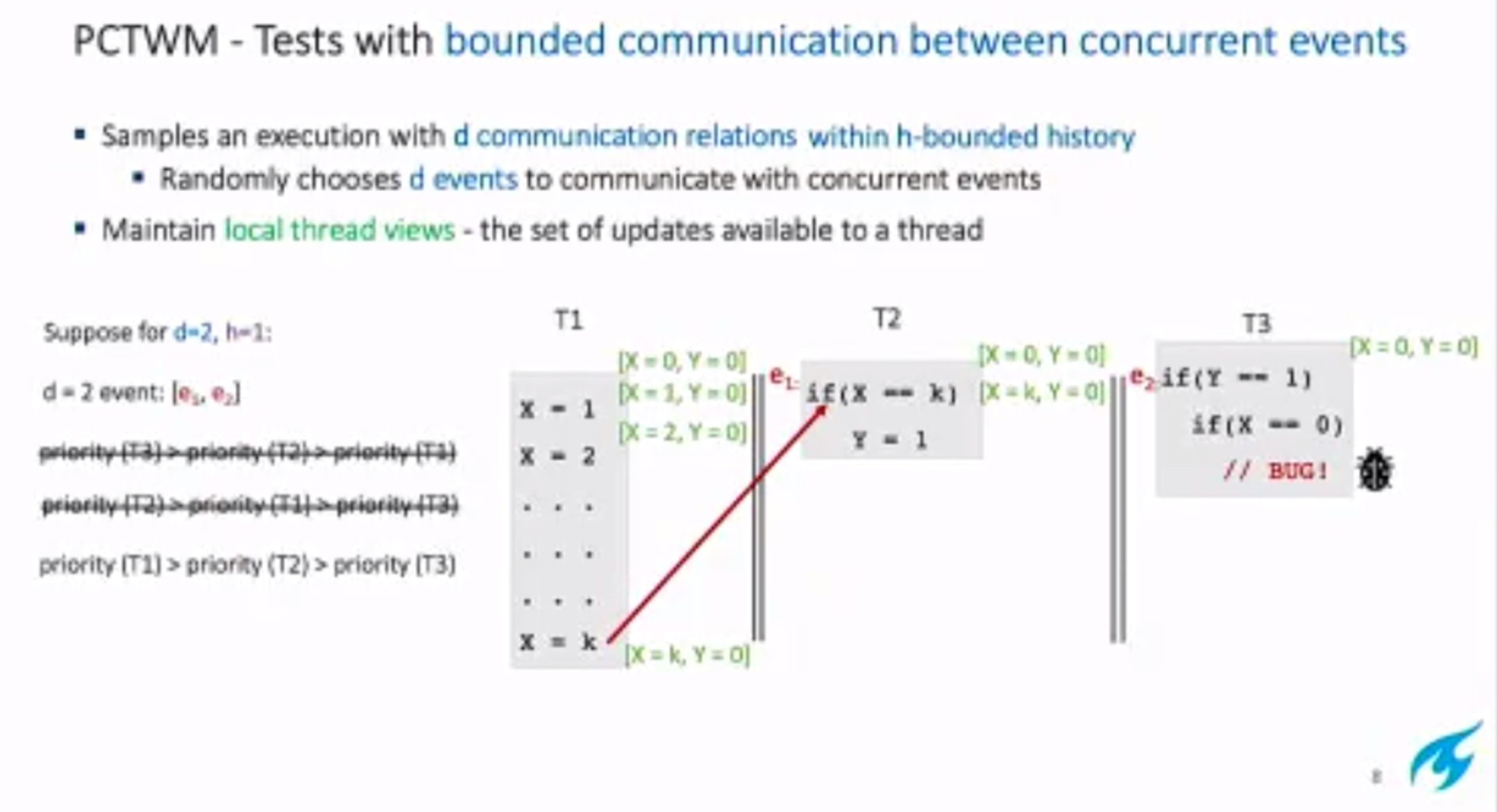

hit bug 更快
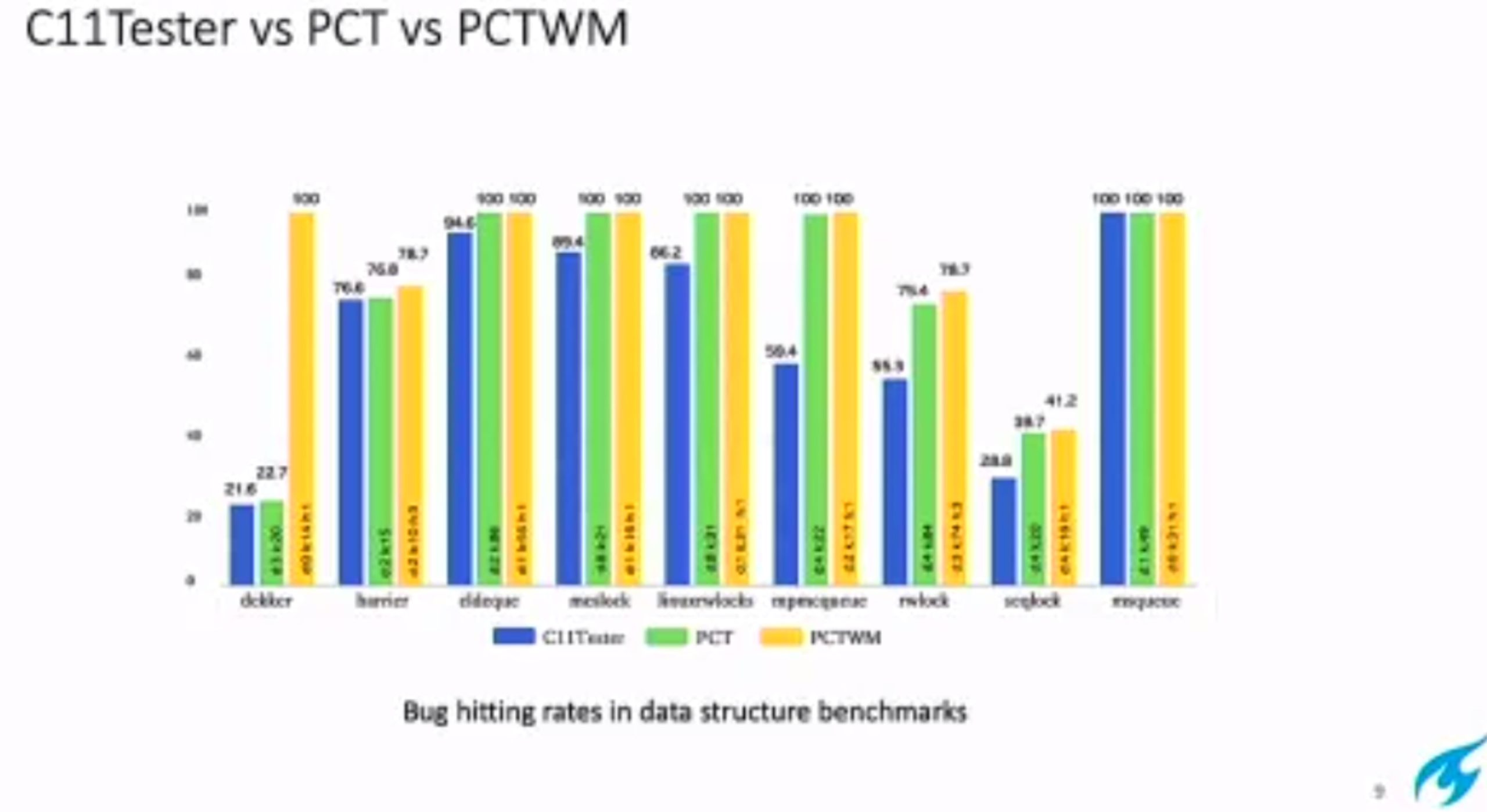

Hieristic for h is good enough for data structure test. assertion tests looks great, When I was in shanghaitech, there’s people using the same tool on PM.







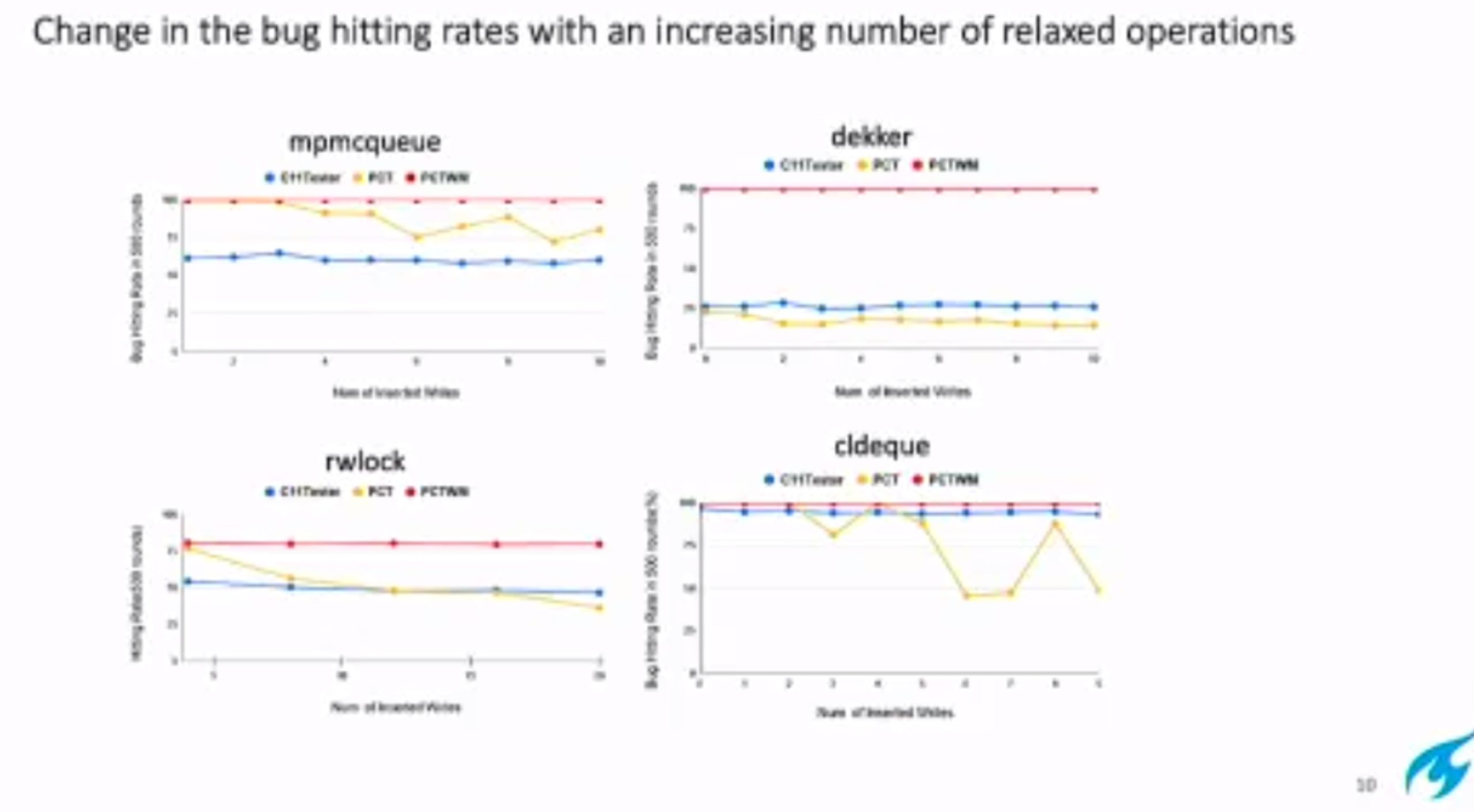
'
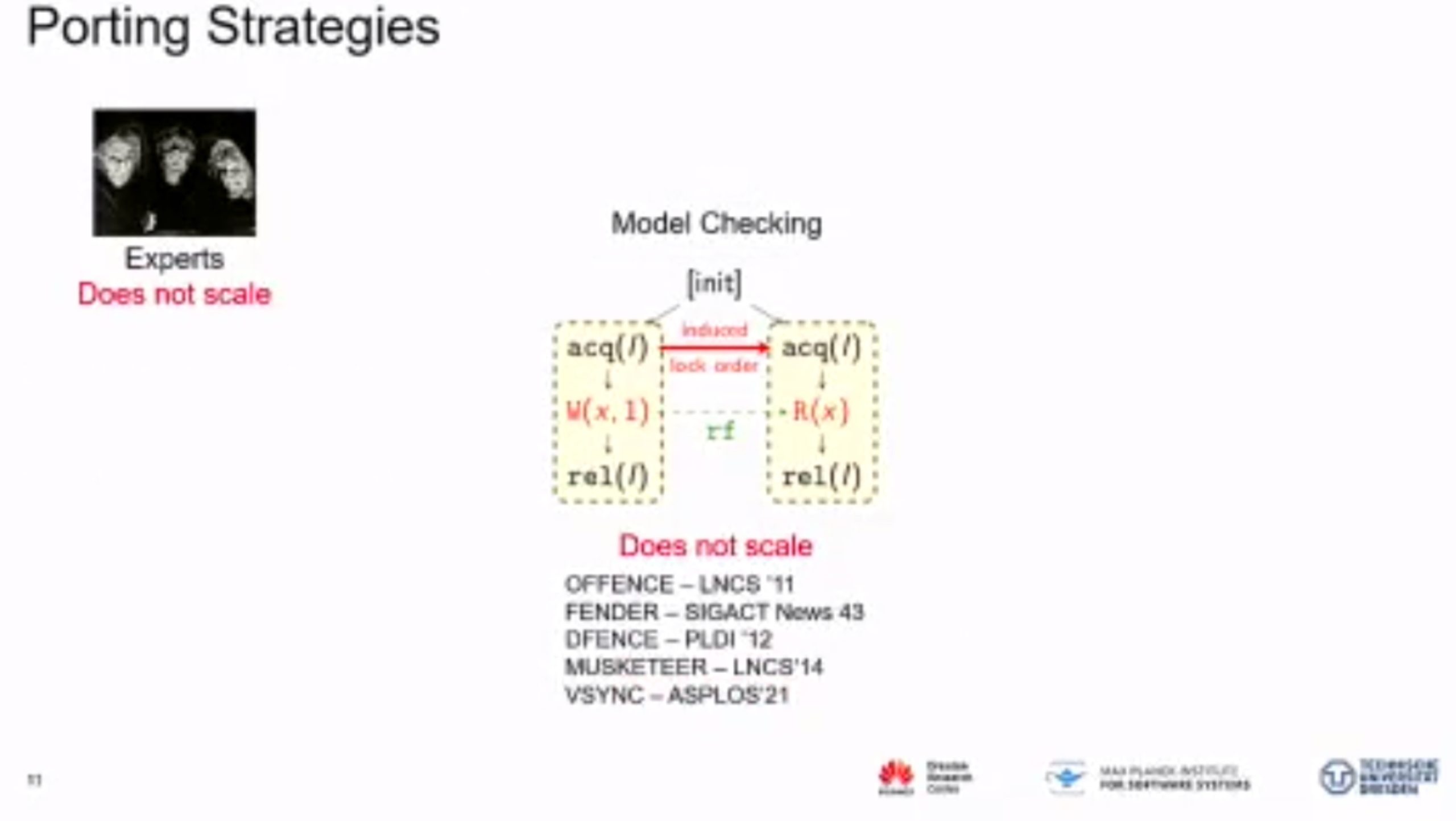
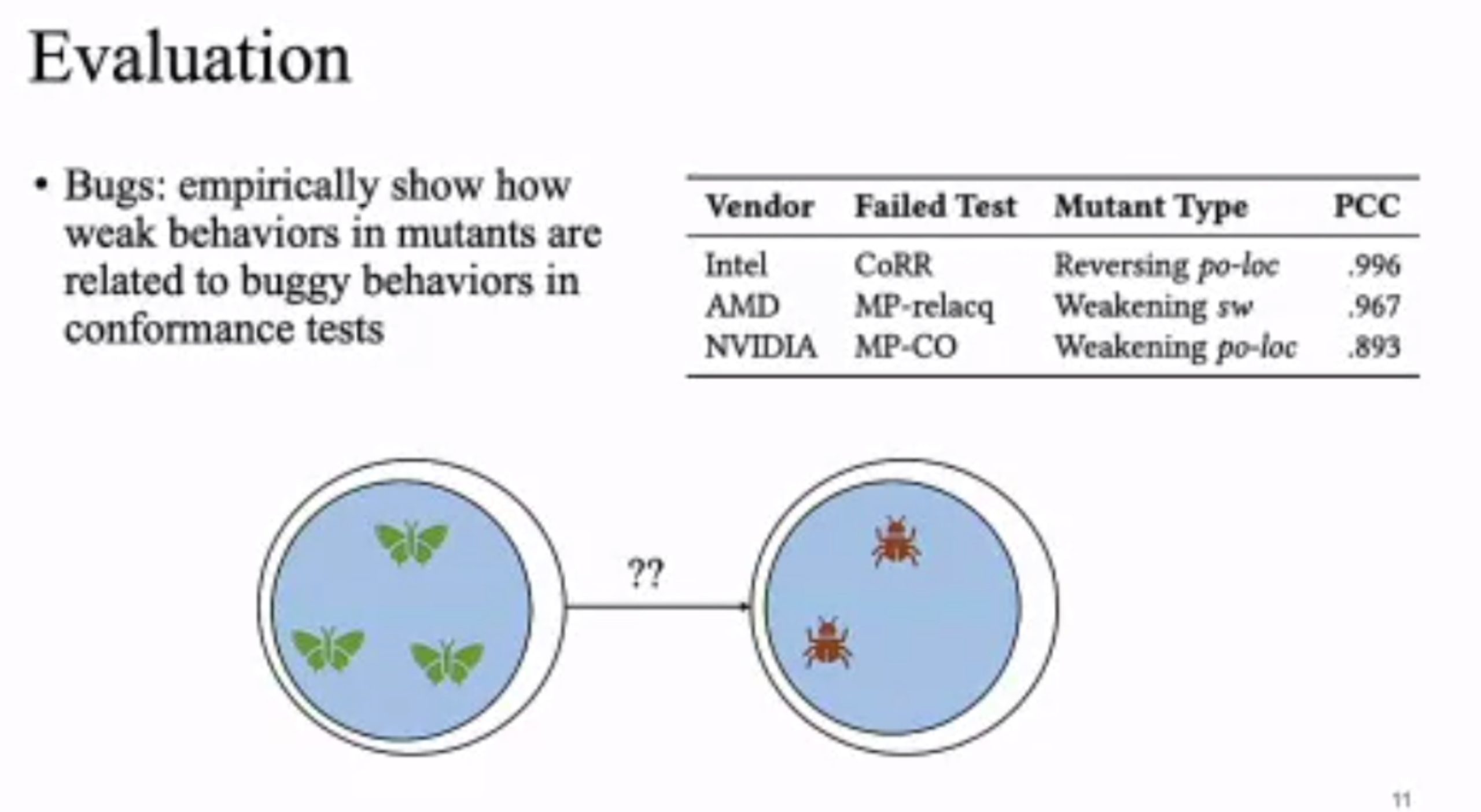
MC Mutants: Evaluating and Improving Testing for Memory Consistency Specifications

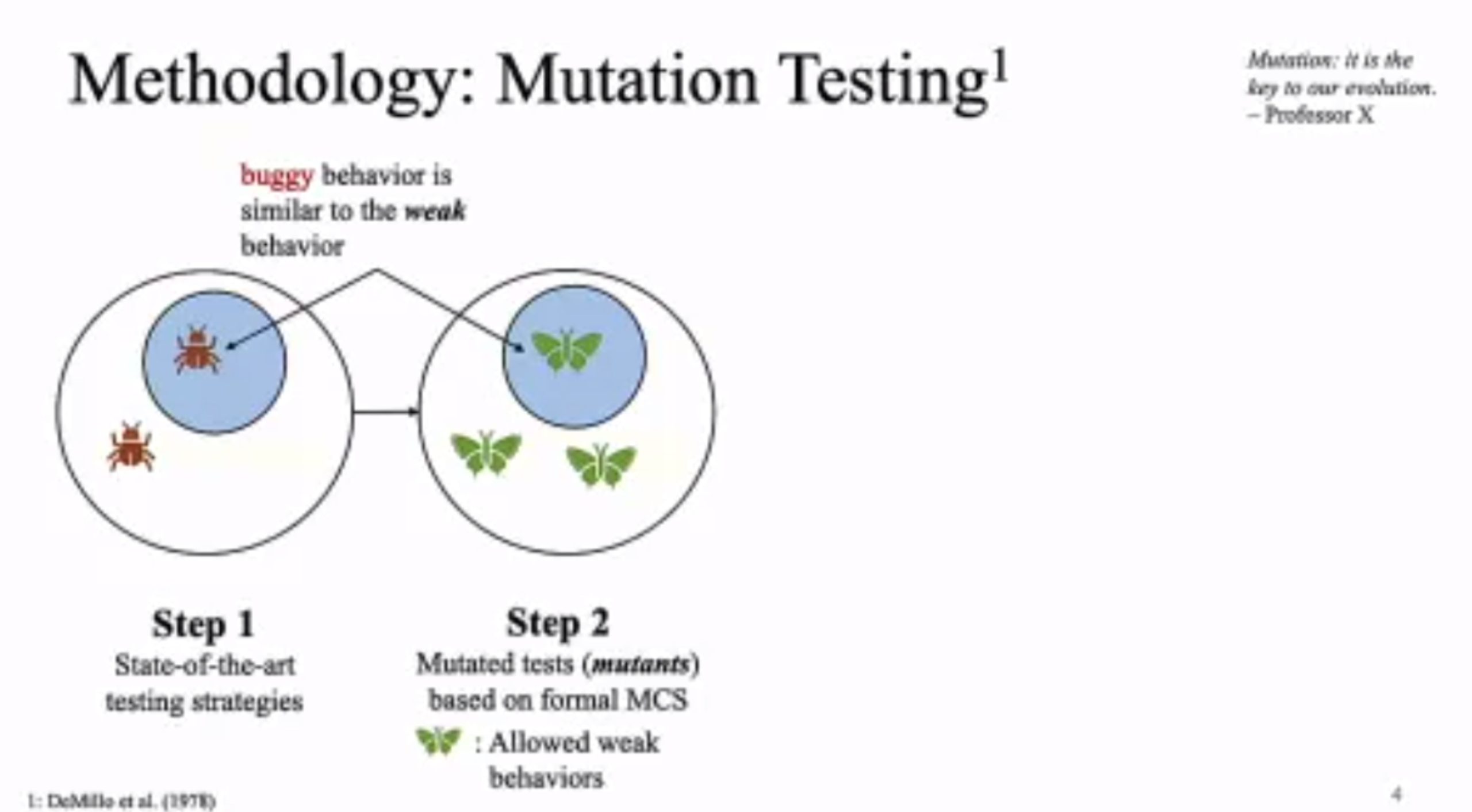
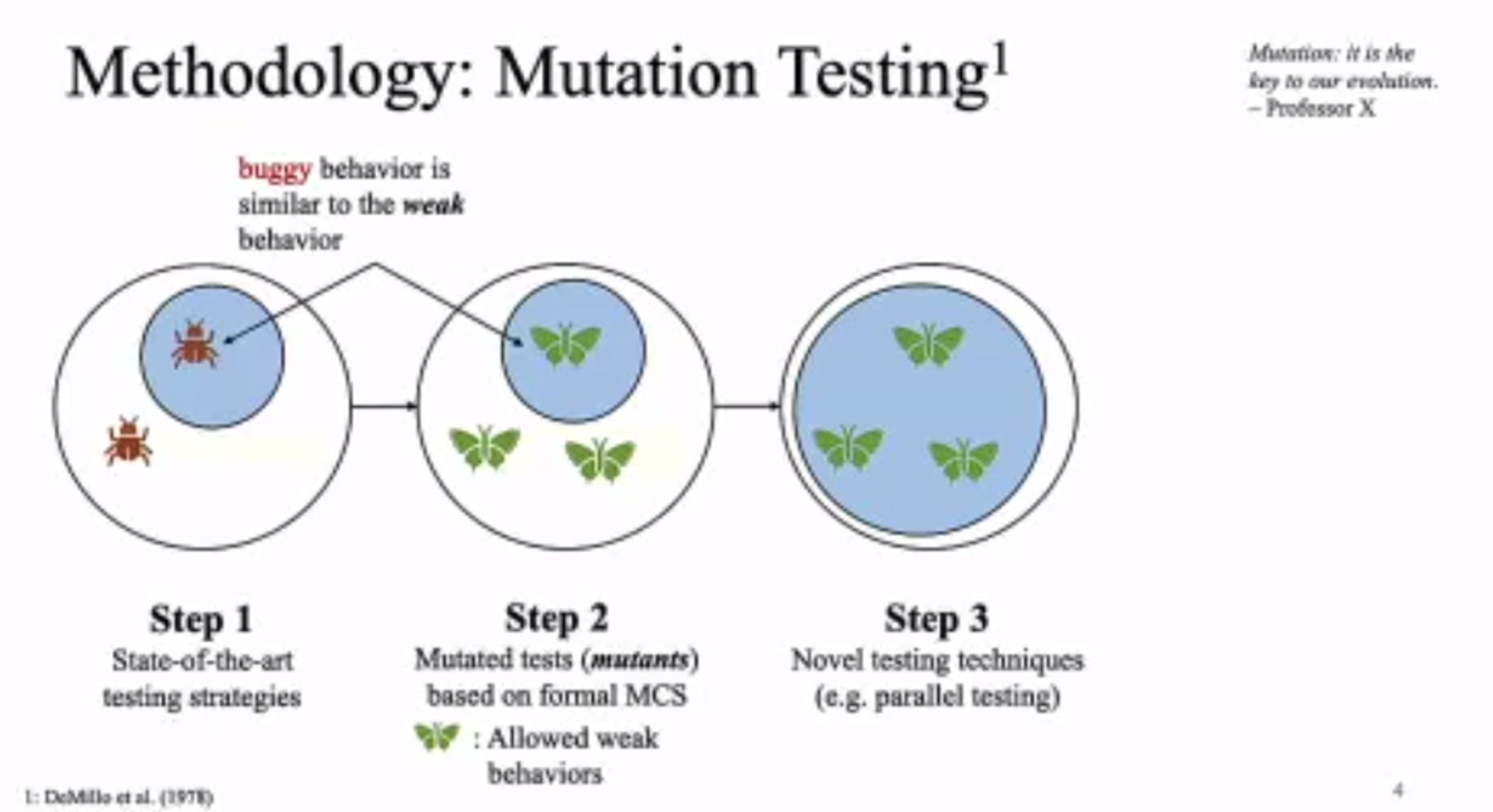
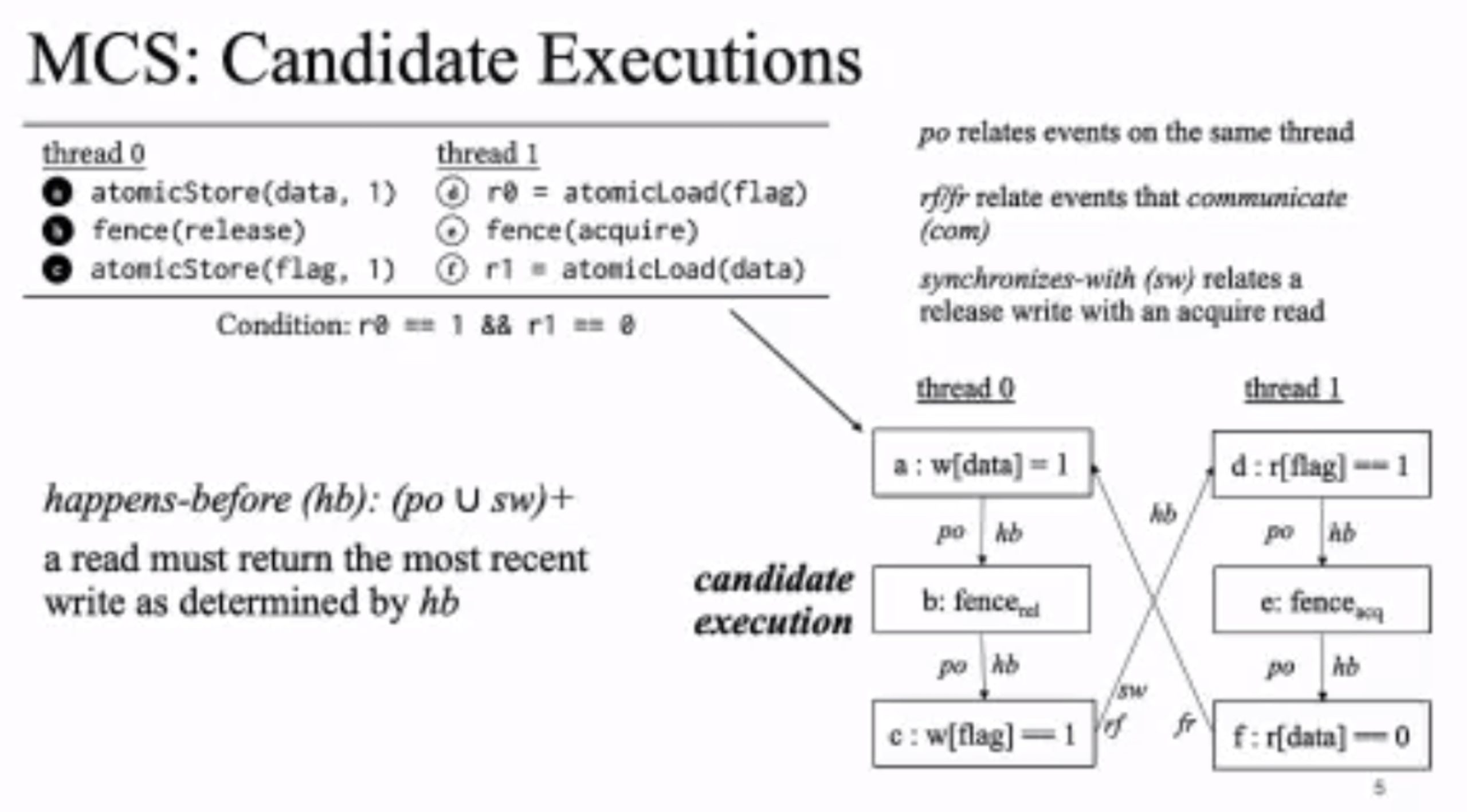
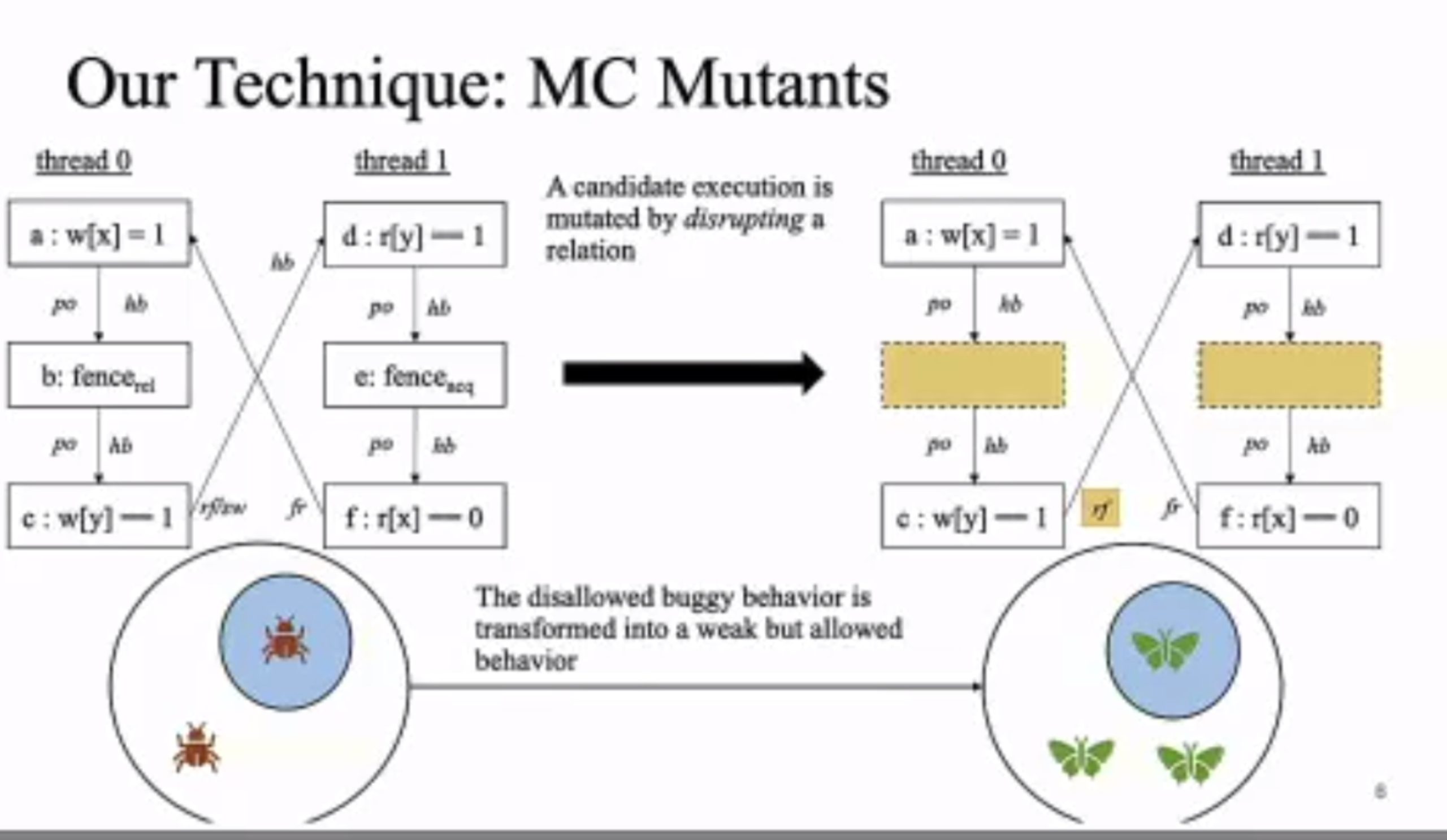
Transform disallowed memory to weak memory label.



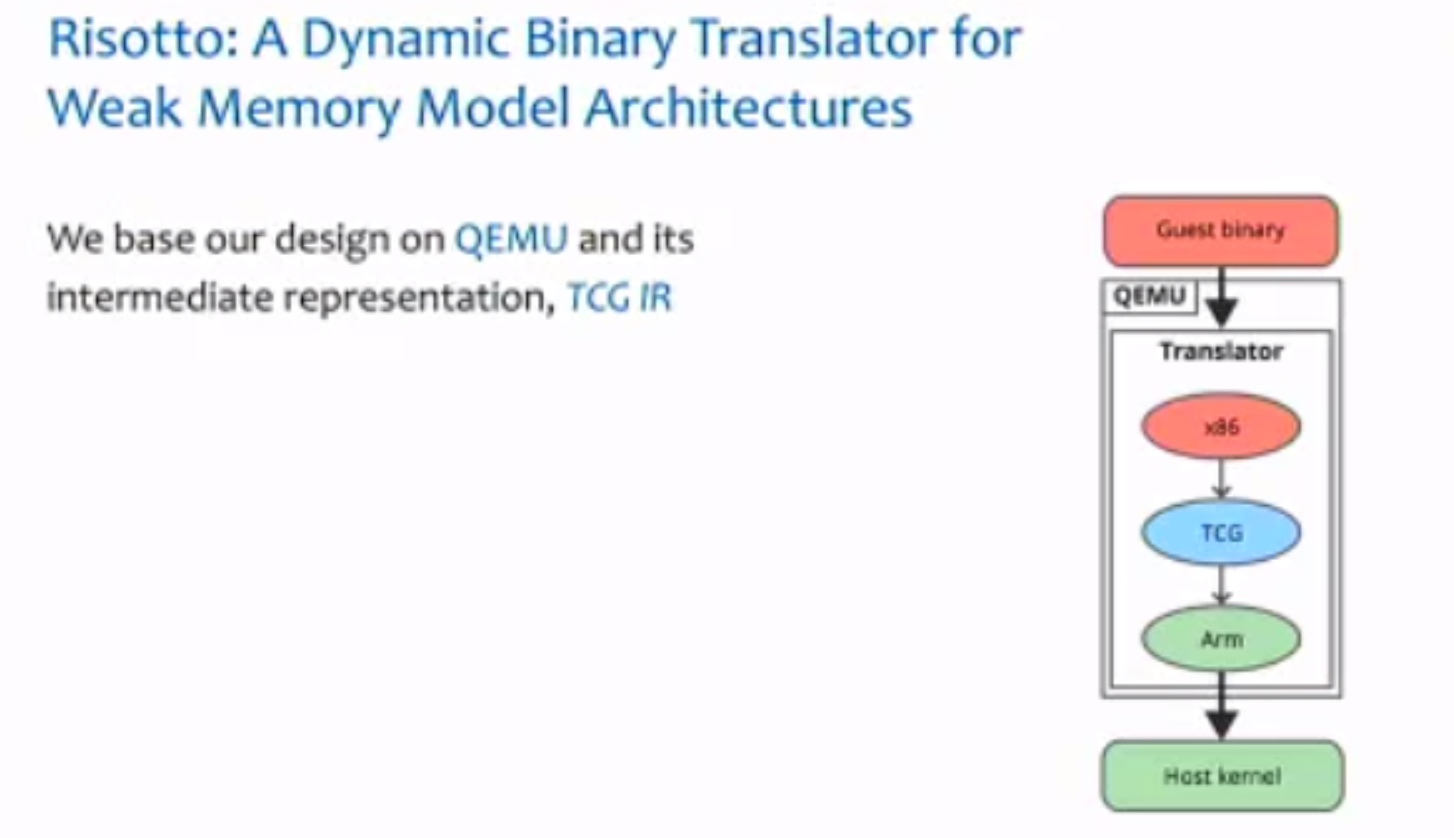
一个binary translator



Session 2A: Compiler Techniques & Optimization
SPLENDID: Supporting Parallel LLVM-IR Enhanced Natural Decompilation for Interactive Development
让Decompilation更丝滑。
Beyond Static Parallel Loops: Supporting Dynamic Task Parallelism on Manycore Architectures with Software-Managed Scratchpad Memories
Graphene: An IR for Optimized Tensor Computations on GPUs
Coyote: A Compiler for Vectorizing Encrypted Arithmetic Circuits
这怎么喝
NNSmith: Generating Diverse and Valid Test Cases for Deep Learning Compilers
刘神的,写几个z3规则用来生成fuzzer,就是csmith in NN。
Session 3B: Accelerators A
Mapping Very Large Scale Spiking Neuron Network to Neuromorphic Hardware



1d locality is 3d locality
CRLA mapping like traditional DNN? NO.
HuffDuff: Stealing Pruned DNNs from Sparse Accelerators
观测到了HW的boundary effect可以搞。


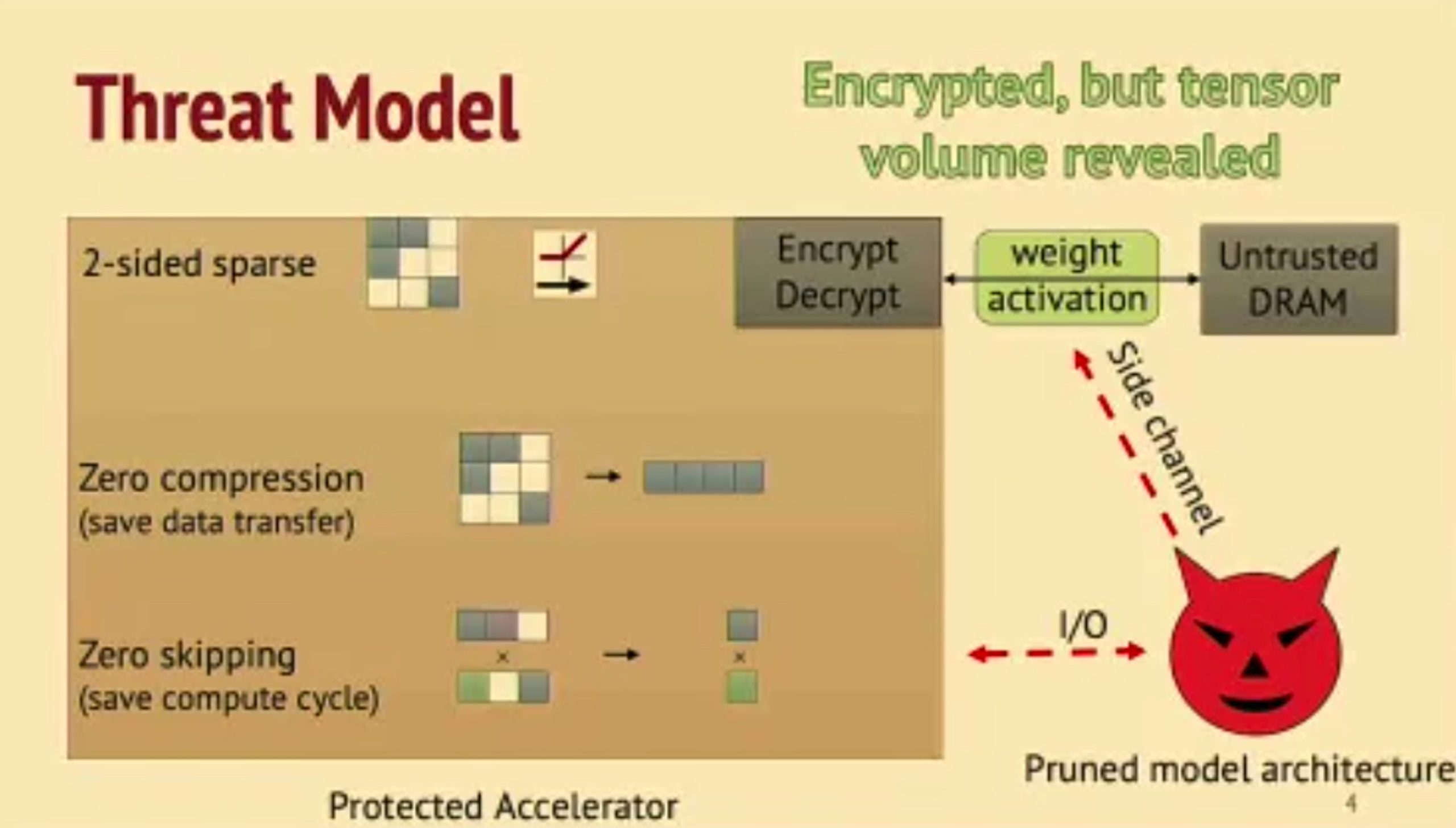
- Can snoop the weights update.
- dense data are more easliy being observed.


并不transferable to other model,但是可以通过观测有没有bound effect来看是不是convolution。
NV eng问:Gemm/FC也可以reverse engineering。
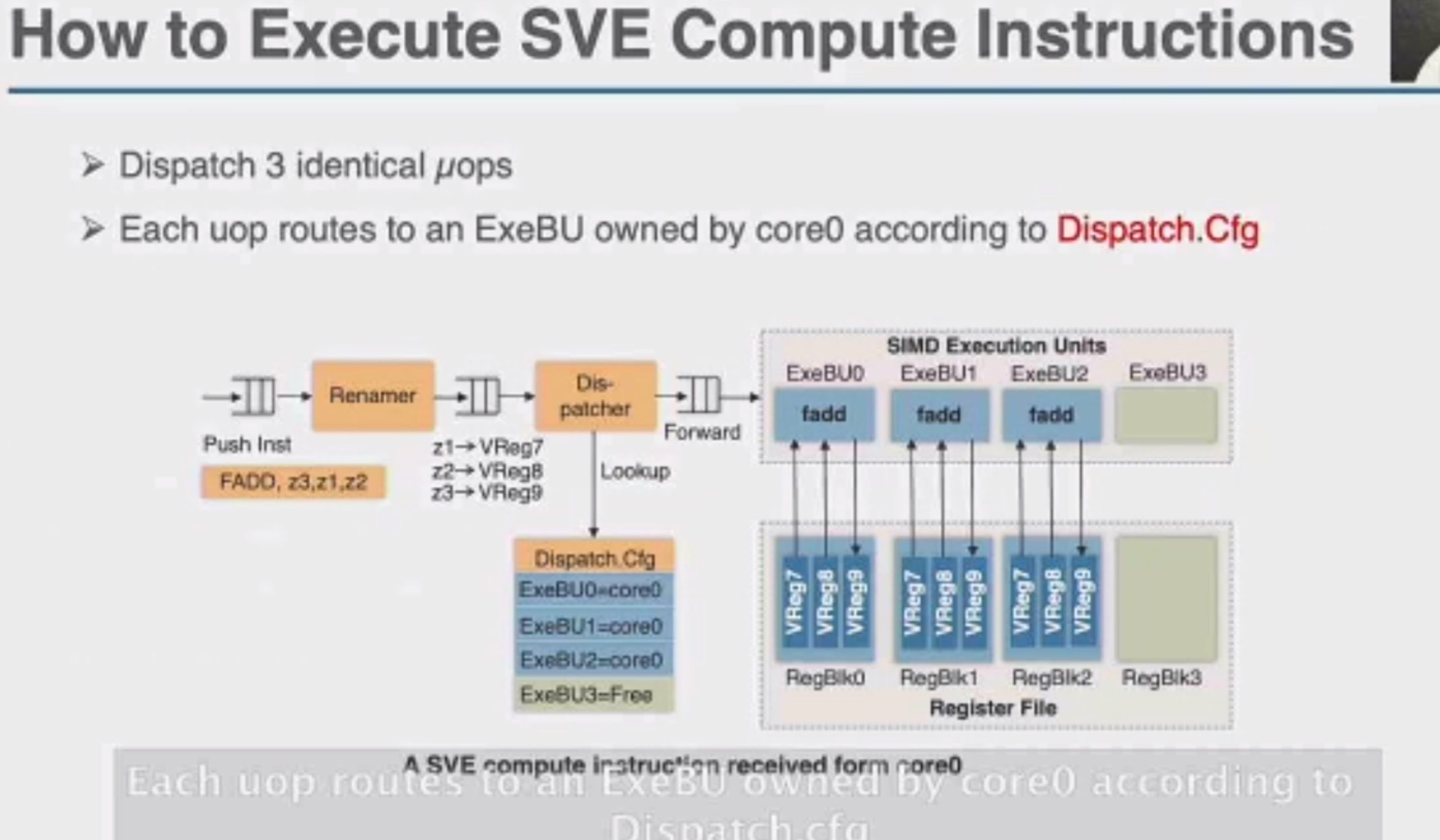
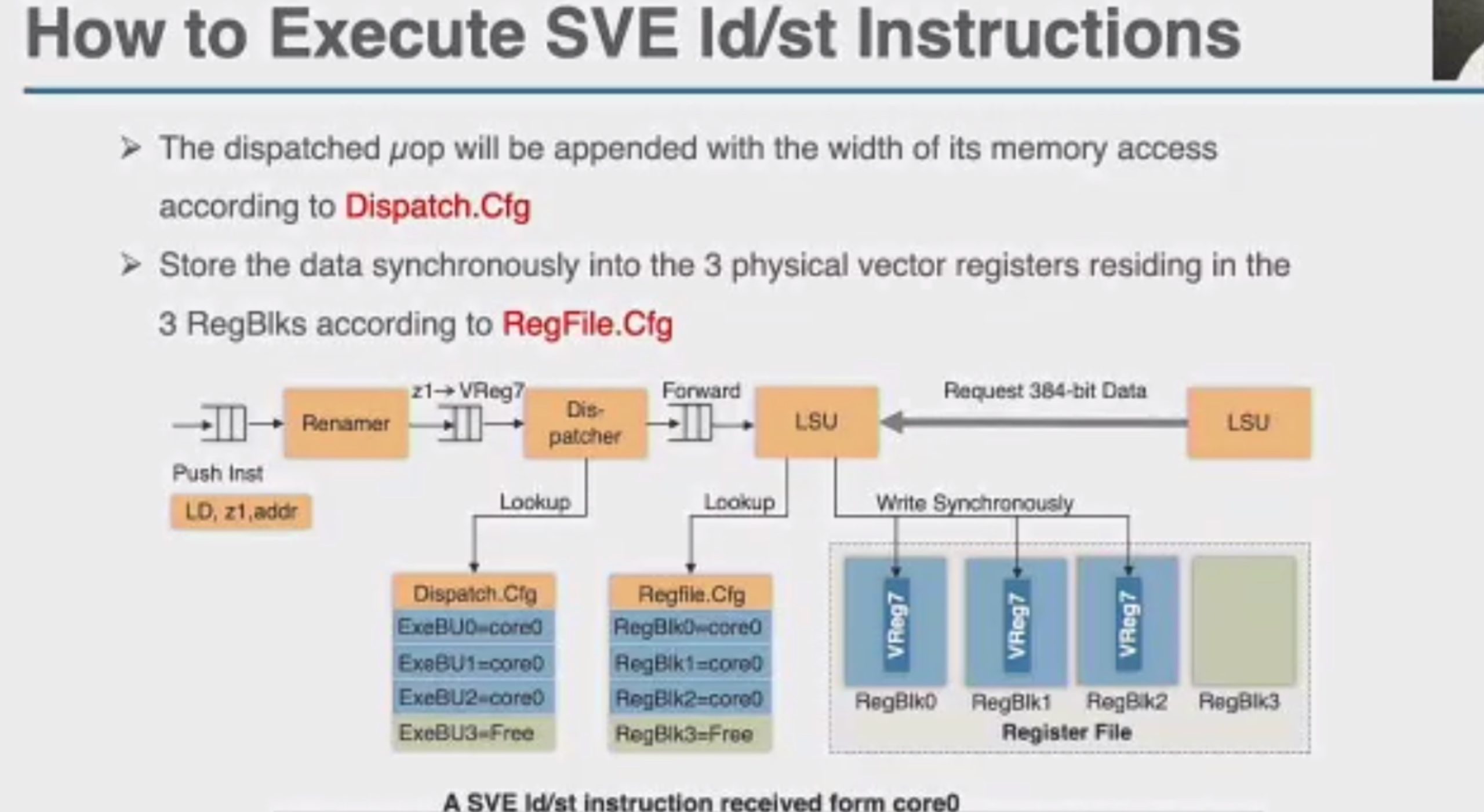
OCCAMY: Elastically Sharing a SIMD Cc processor across Multiple CPU Cores

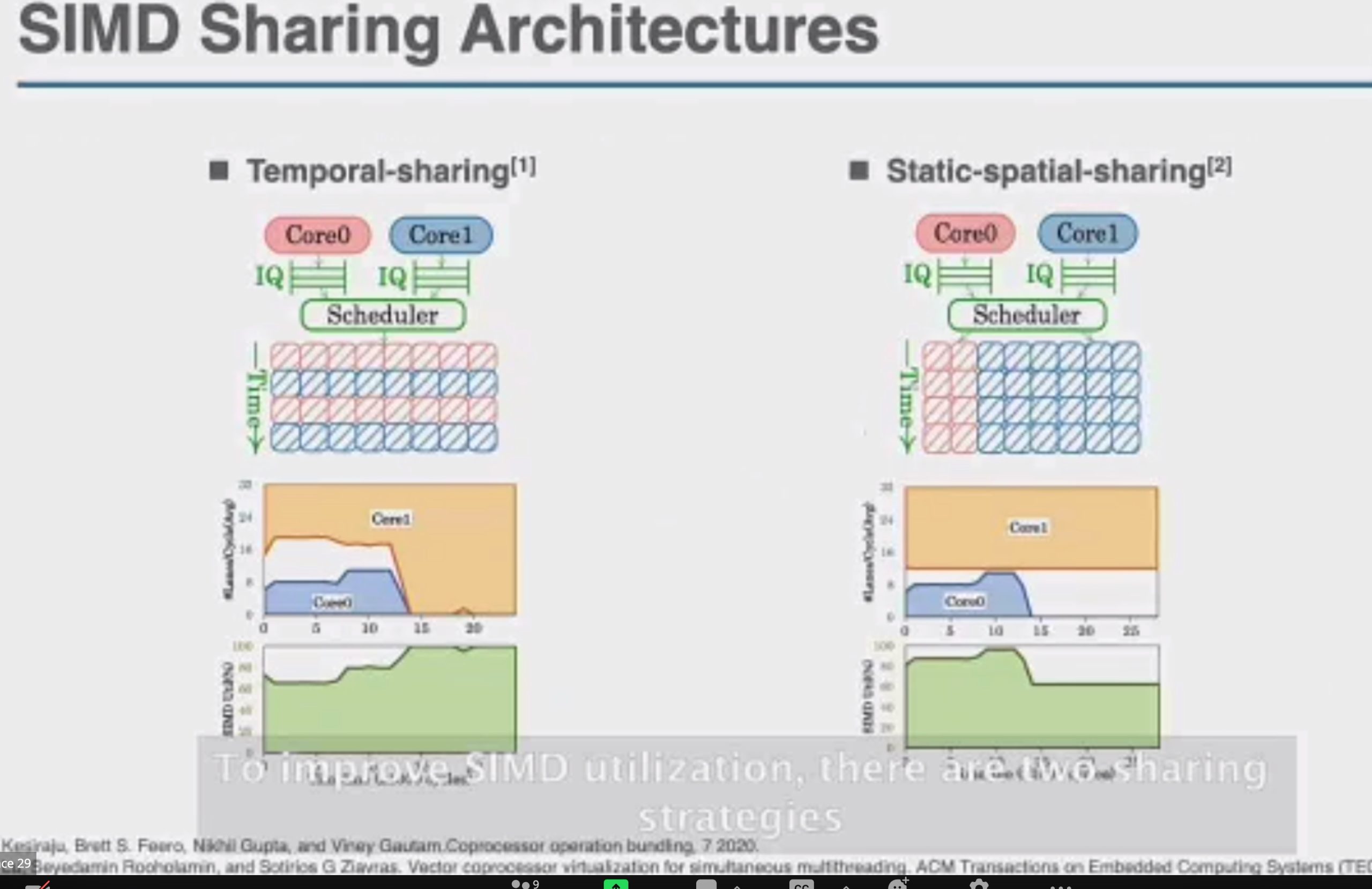
SIMD有两种sharing
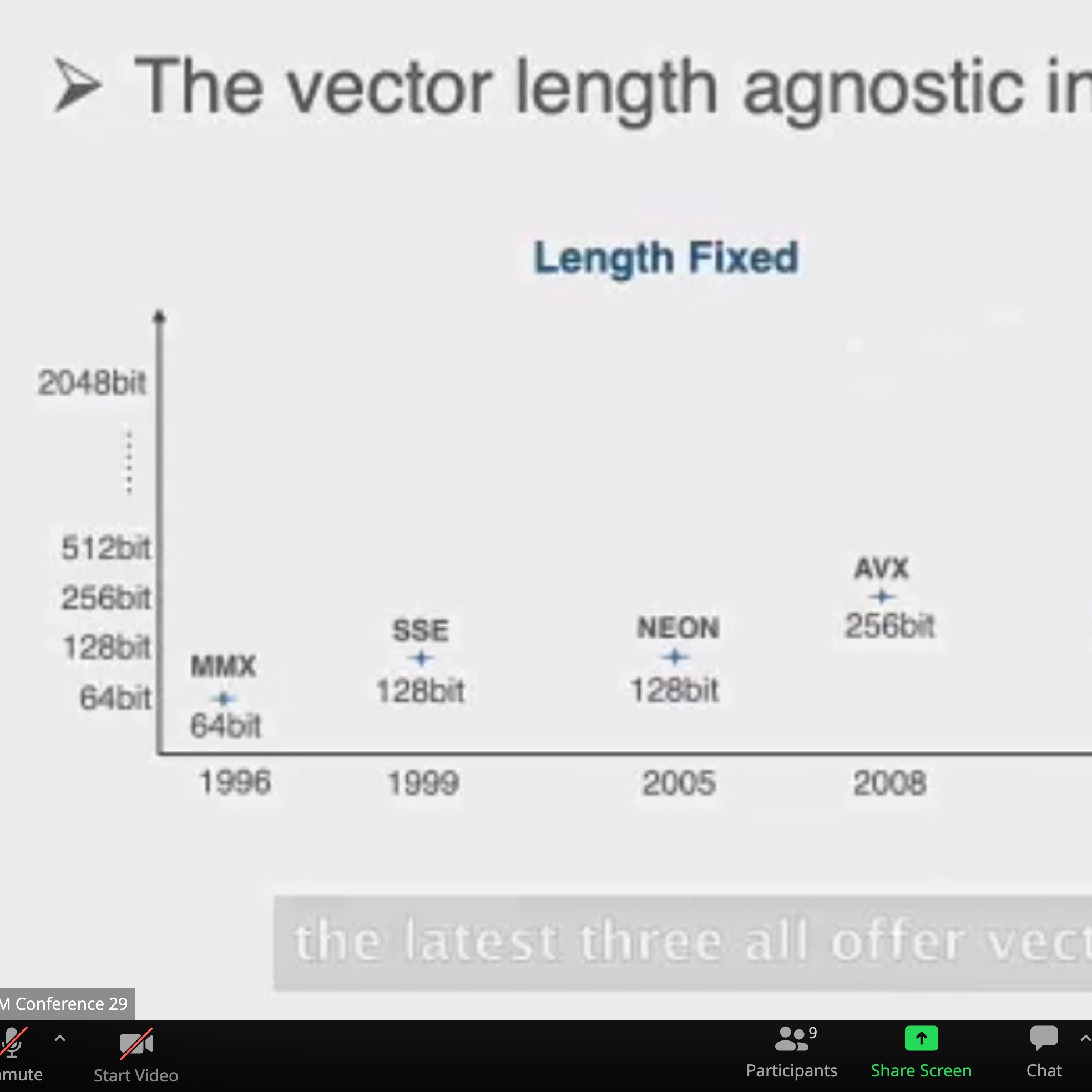
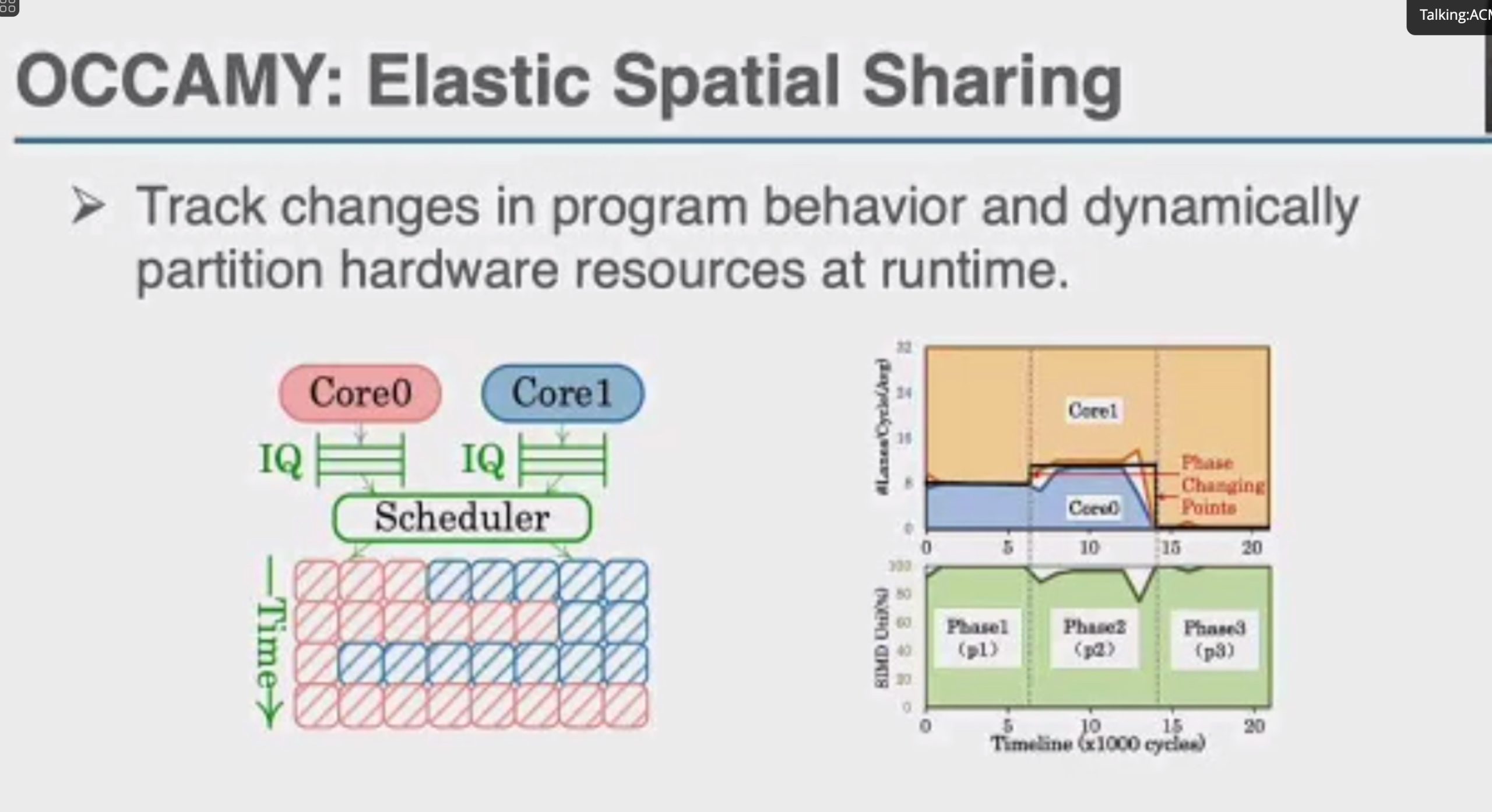

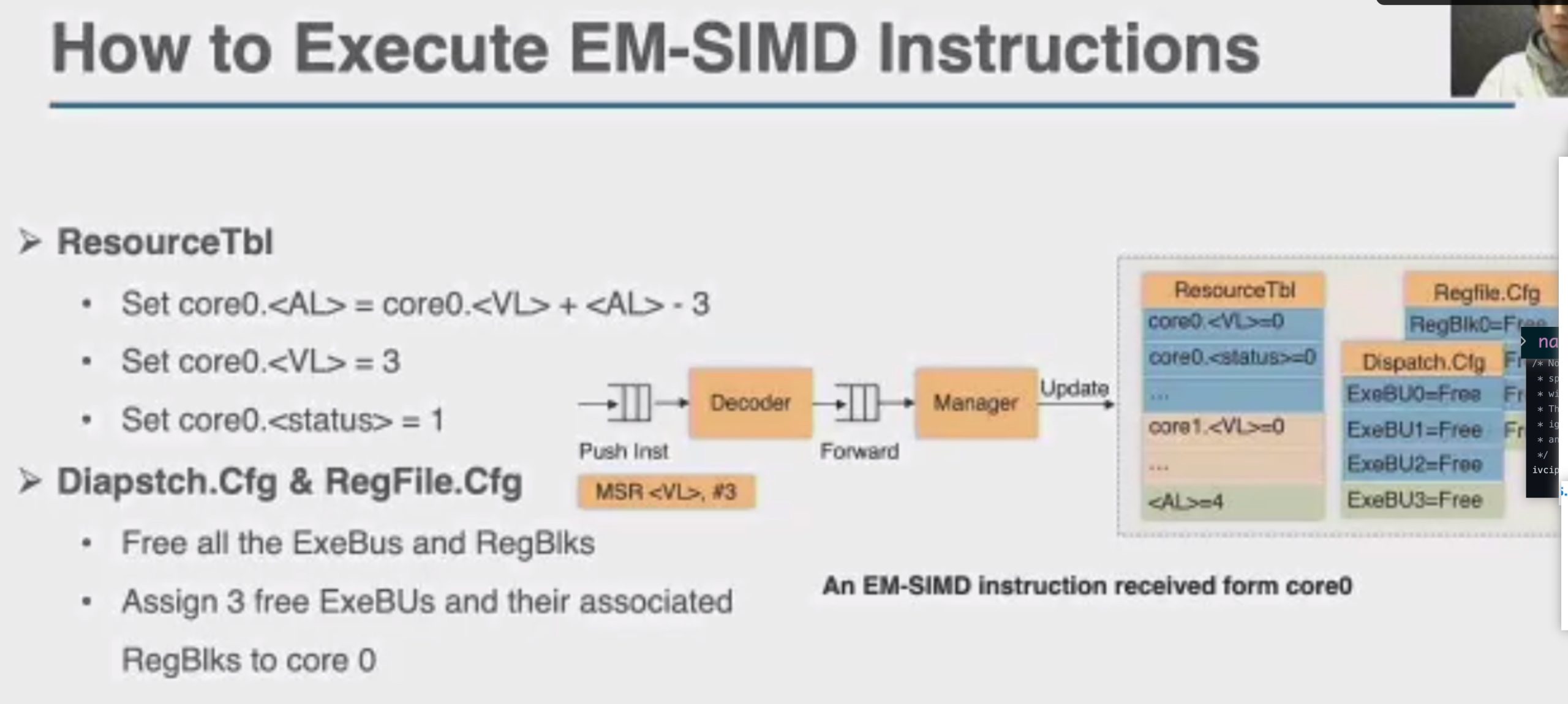
加两个hint length和load时间predicate,用类似rob的方法dispatch指令。



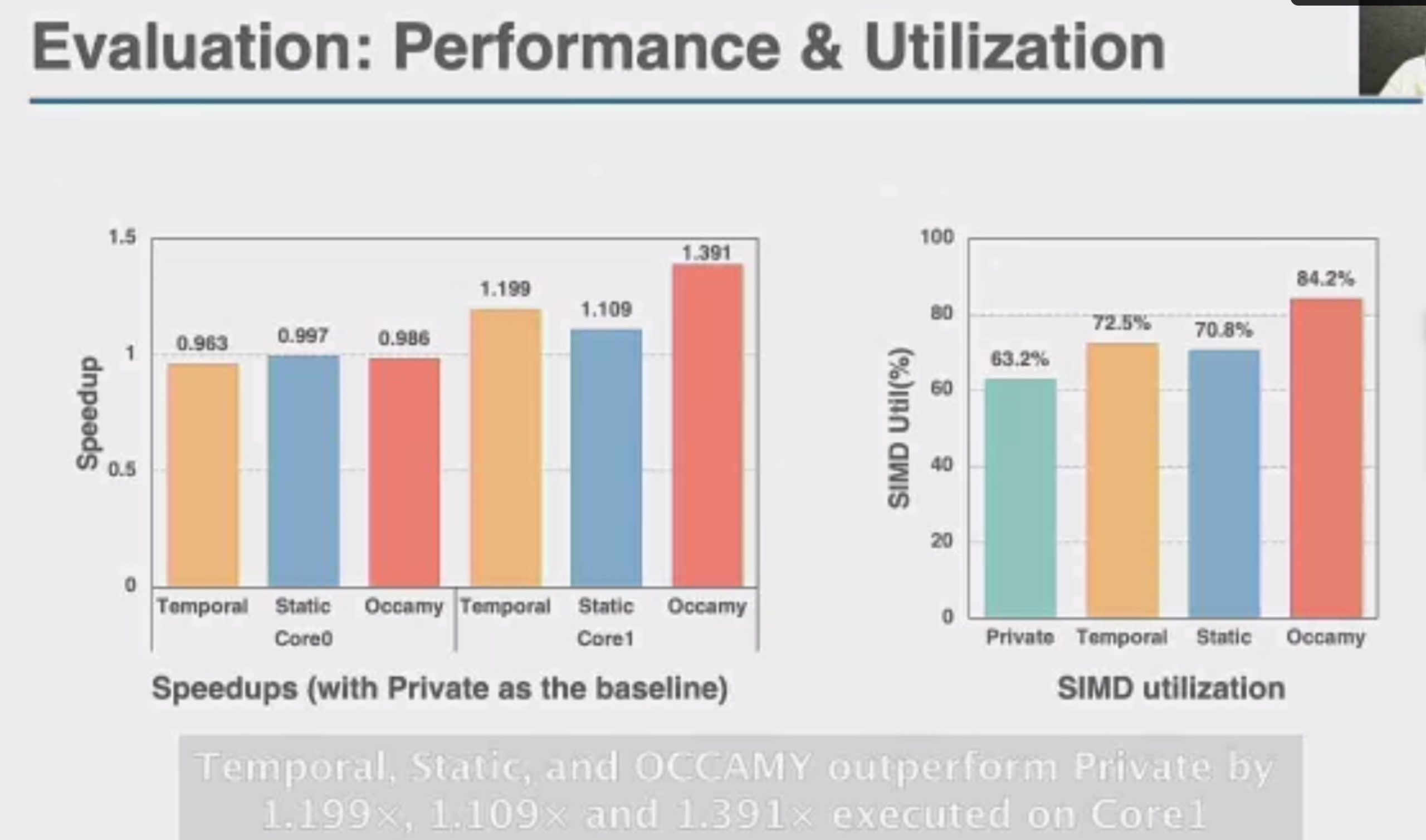
这直接上roofline就行

Motivation why arm unmodified? but with compiler inserted MSR and MRS.
Session 4B: Memory Mgmt. / Near Data Processing
Session 4C: Tensor Computation
Keynote 3: Language Models - The Most Important Computational Challenge of Our Time
NV吹逼大会






Session 7A (Deep Learning Systems)
Session 7B: Security
Dekker
The instrumentation on control flow + linker + runtime 检测CFI, CPI,indirect pointer access
Finding Unstable Code via Compiler-driven Differential Testing
Use CompDiff-AFL++ to fuzz the UB
Going Beyond the Limits of SFI: Flexible Hardware-Assisted In-Process Isolation with HFI
WebAssembly for SFI + hardware assistance
Session 7C: Virtualization
Exit-less, Isolated, and Shared Access for Virtual Machines
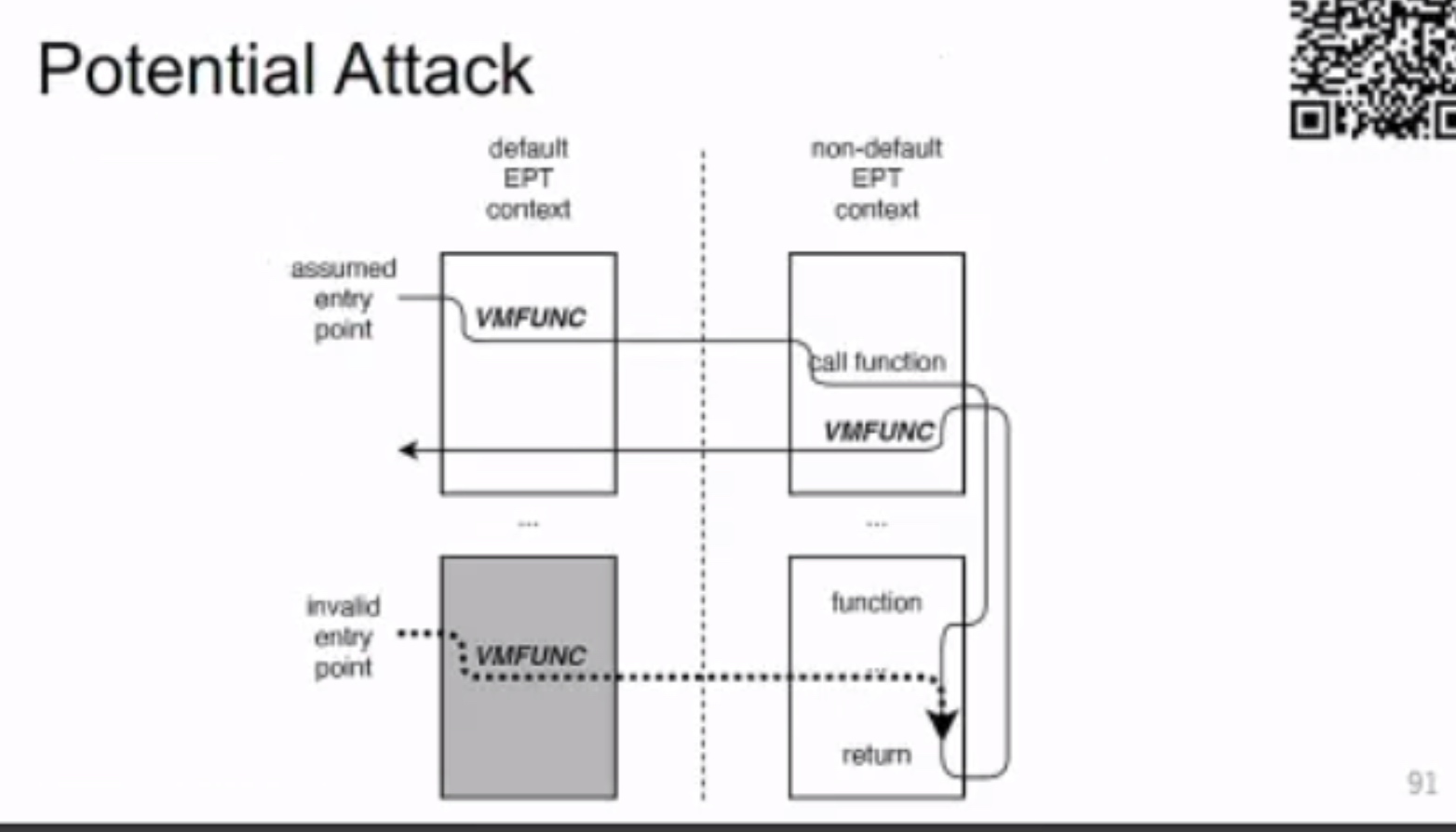
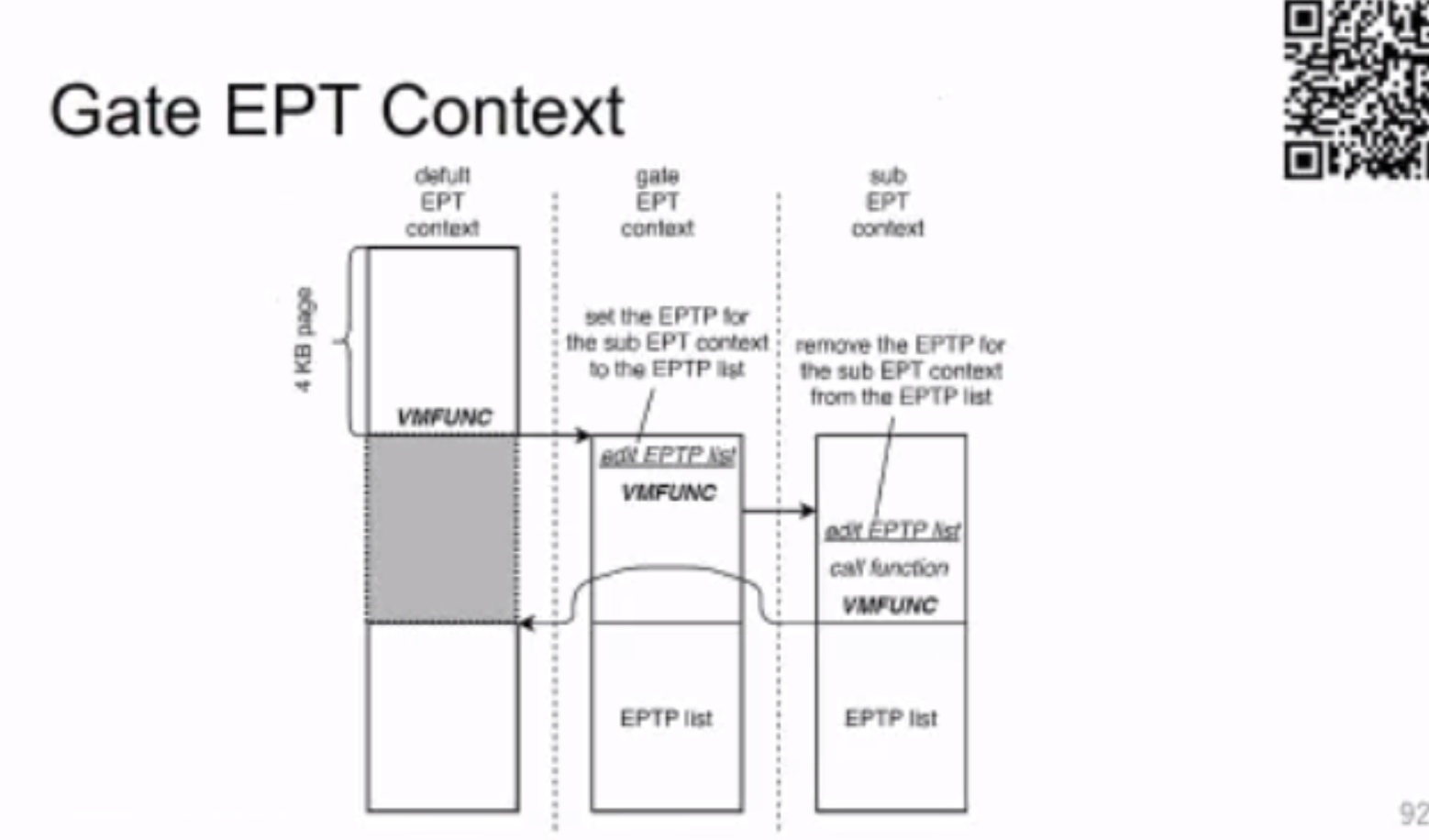
需要 gate &sub VM funciton


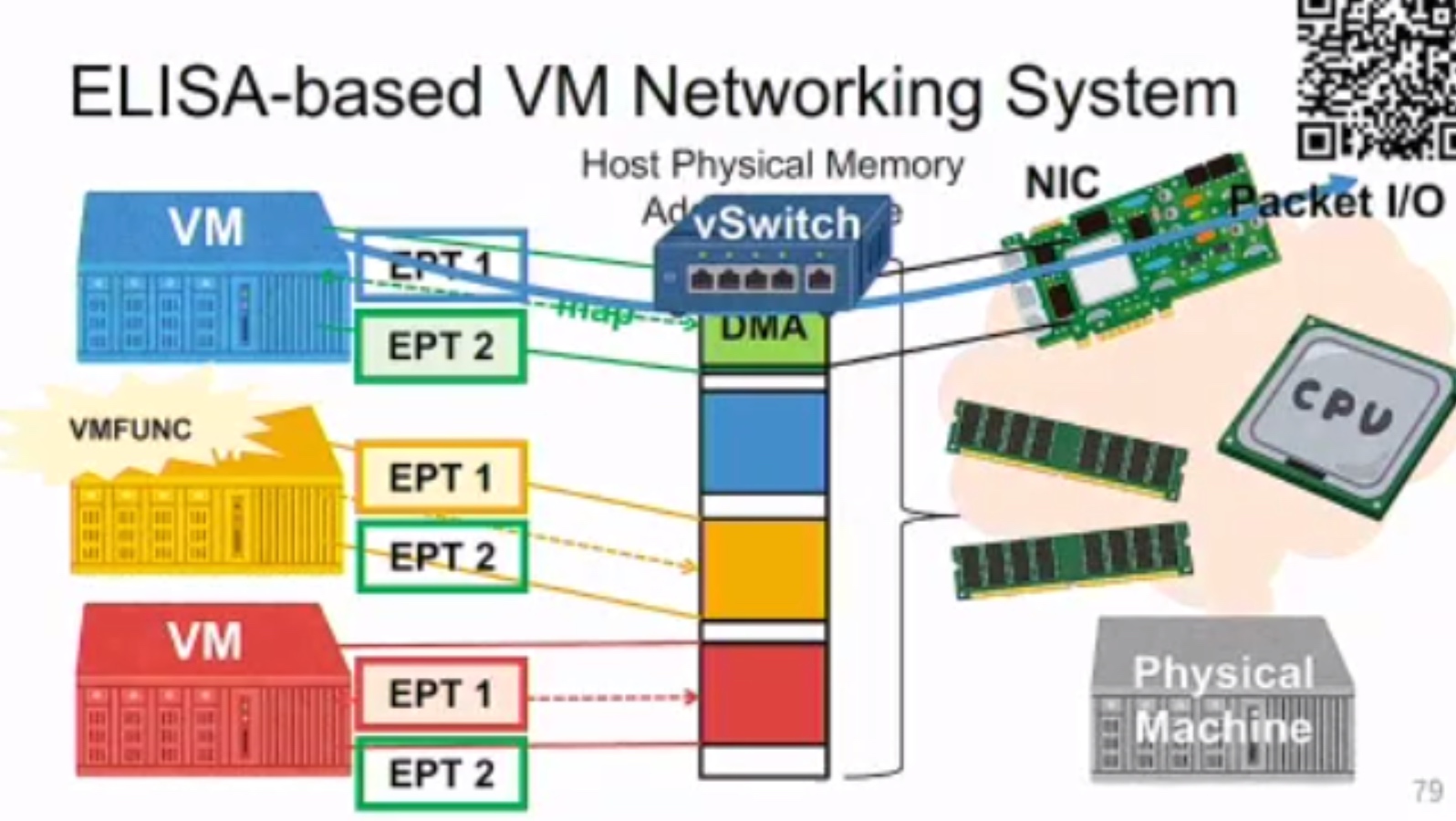
VDom: Fast and Unlimited Virtual Domains on Multiple Architectures


用PTE 隔离。
ghost descendent
想法是把schuduler从kernel 里抽象出来。
Session 8B: Accelerators C
TPP
transparent cacheline for TPP is another question.
和husan讲,一个toronto的教授问jvm怎么做更好的page placement,husan说这个在OS level最好
第二个人问用pebs和cpu pmu sampling waste cpu cycle。TPP sampling比较轻量
UBC的另一个人问,deref page的traffic怎么统计?
husan说这个page prefetch mechanism保证,也可以做multi hierarchy LRU,但是访问latency会变高
然后joseph问了个问题,will PMU in device side help investigate page warmth?
大概husan去AMD就做CXL hardware-software design for page promotion performance
hint 就是PMU,然后OS提供接口,不是madvice,而是一段内存granularity,device提供可以decide
这样最好
UBC那一些人和我做的一样。。
回去要加油了
不过他们绝对会cite我的simulator了😂,我宣传他们赶紧cite
Session 9C: Hardware Security
封笔,等21号ASPLOS ddl以后写。
Drywall updated progress report
How to resolve big chunk over 2GB
论学习到科研的转变与科研的探索与谋生
学习是一种广泛的获取知识的过程,如果是为了高考或者是大学的期末考试的学习,其目的还是让学生掌握老师想让学生掌握的部分,是本专业所必需的基础理论和基本技能,但是老师并不负责知识的有效性和时效性.没了外力约束的学习,即一个人不需要获得GPA而获得荣誉或者去更好的地方学习,本科毕业的最低要求是各个课程及格,从而使得大量的废物产生在世界上.高等教育的学习,在我看来是在获得基本的求生技能的基础上培养一个人独立思考的能力,需要从社会的进步浪潮中发掘自己的擅长,如何与世界的进步发展同进步.就计算机专业而言,实践是获得此种能力的最好方式,培养实践能力比学习理论知识重要,因为工科的学习一切都有例外,没有办法用一个思辨的角度来发掘别的公司或者独立开发者为什么这么写,容易陷入过于苛求完美的循环中.工科的学习是循序渐进的,实践能力会随着眼界的拓宽而日益增长,直到自己也能造火车的那一天.PhD阶段的学习是从科研中来到科研中去的,我们无需关注无关自己课题的一切知识,其只能阻碍自己的钻研时间,而拓宽视野的过程应该流于与其他研究者的讨论,实践比赛或复现别人的artifacts,参与工作的实习,而不是单纯的从书本上寻找自己课题的答案.对于未来想要做的课题,可以提前参阅书籍和工业界的best practice,在潜意识中思考工业界没有想到过的部分,体现自己的价值.从学习到科研的转变,是一个人的学习热情从外驱力到内驱力,我认为什么东西工业界没有想到,或者没有提供全工业界的价值,而流于一些头部公司的东西,怎么更好的服务工业界.
从与已经失去科研兴趣的人交流过后,他们大多都在无尽的尝试中失去寻找自己可以作为PhD可以提供的价值,而放弃了探索,将PhD作为一种逃避经济衰退的手段,而苟活于柴米油盐,骗funding谋生.即便他们来自四大,即便他们认为这个世界已经被那些有规模效应的公司所占据了.什么是学术界的探索?究竞是所谓的peer review规则带来的劣币驱逐良币,还是PhD及其导师所想到的可以变革工业界思考的良币驱逐劣币?spark是一个很好的例子,Matai调研Facebook使用Hadoop却烦于其过慢的OLAP性能,即在伯克利创造了In memory Hadoop.我惊叹于伯克利的大力出奇迹,在peer review下并没有任何novelty却能在三次拒稿后用Facebook的广泛应用拿到了最佳paper.需求和解决方案是驱动计算机科学进步的源泉,没有思考的idea,如果它work,真正的peer也会告诉你,I buy it.伯克利不是一个适合做科研的地方,sky computing、alpa、foundation model、ORAM、UCB哪一个不是已经有别人的paper的基础上,封装一个伯克利defined layer,重新实现一遍,然后鼓吹这个东西made in UC Berkeley?但是这是一种创新吗?是.因为这就是共产主义.所谓的老人,告诉你一个怎么走捷径进入四大,top20,但是他们难道就能发SOSP吗,还是他们就是劣币,一个听从老板的left over的idea,让你实现,从而发顶会 ?PhD的位置是可以guide工业界行为的工作,这种美好的探索性的阶段绝不能浪费.
什么东西guide我的日常科研进度,我觉得老板只是提供方向上和日常怎么填满生活的建议,从而达到能发出paper的目标,真正的决定权在我,我希望在武力攻台之前拿到eb1a绿卡,我希望在毕业的时候能拿800k的工作.在做到这个之前,我理解工业界的需求是什么,我期望在他们着眼于此之前就提供我能提供的建议,同时获得价值.OpenAI说这是AI的黄金时代,David Patterson说这是体系结构的黄金时代,Chris Lattner说这是编译器的黄金时代,我说这是软硬件协同设计的黄金时代!