



A Tech Nerd with a finance mind.
export SCALA_HOME=/root/Downloads/spark-2.4.3-bin-hadoop2.7/
export HADOOP_HOME=/root/Downloads/hadoop-2.7.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=Master
SPARK_LOCAL_DIRS=/root/Downloads/spark-2.4.3-bin-hadoop2.7
SPARK_DRIVER_MEMORY=512M
different unit of cpu utilization
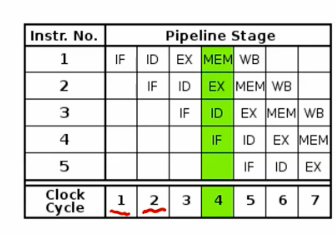
instruction fetch -> decode -> exec -> mem read -> write back
at most 5x with 5 stage pipeline

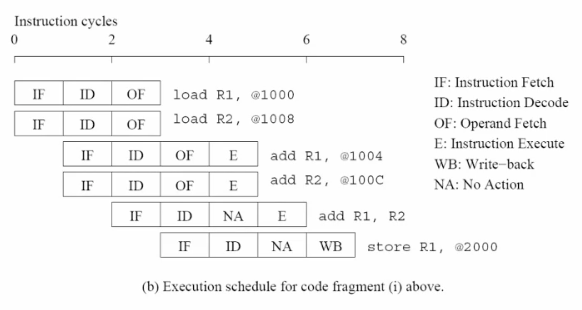

latency & bandwidth
speed & lanes
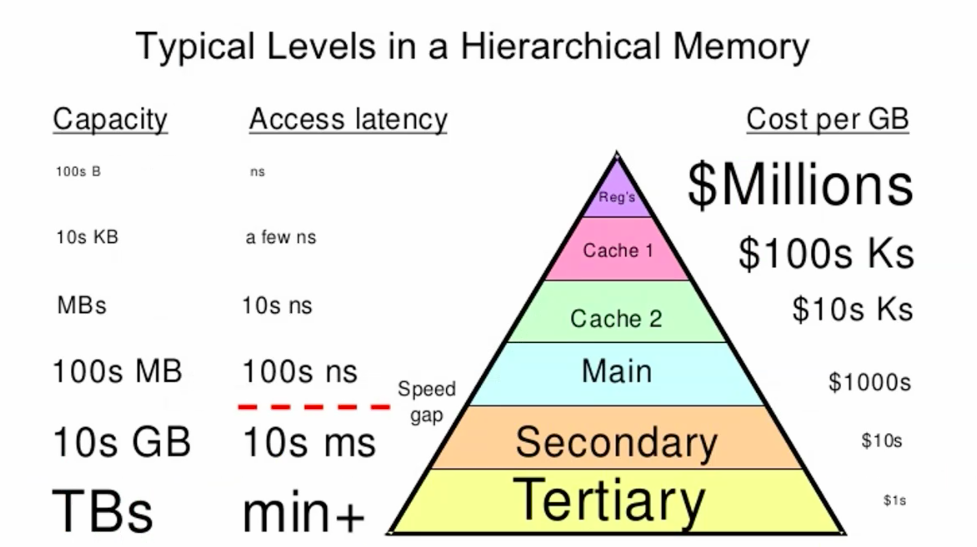
Temporal locality - small set of data accessed repeatedly
spacial locality - nearby pieces of data accessed together
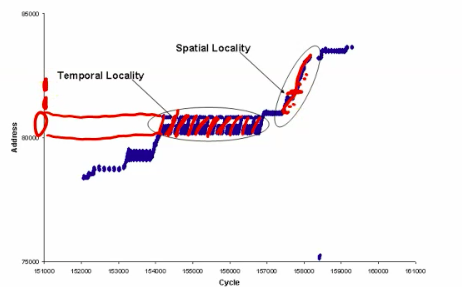
Matrix Multiplications have both temporal locality and spatial locality.

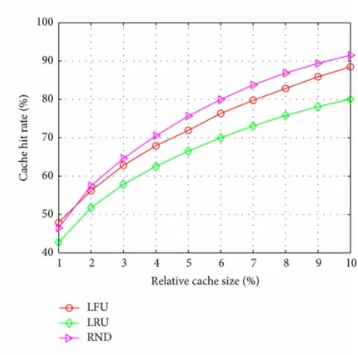
cache hit rate is the proportion of data accesses serviced from the cache.
e.g.

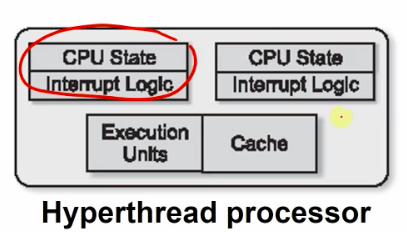
1000+ core stream simultaneously.
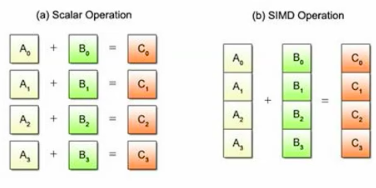
SIMD processors can perform different instructions.
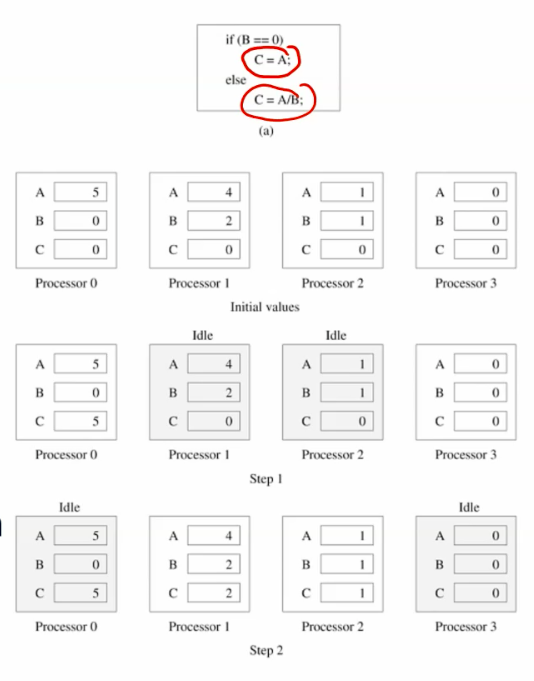
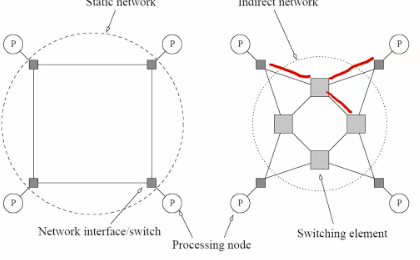
all processors shared the same mems-pace.
Pros: easy to write program
Cons: limited scalability.
UMA vs. NUMA
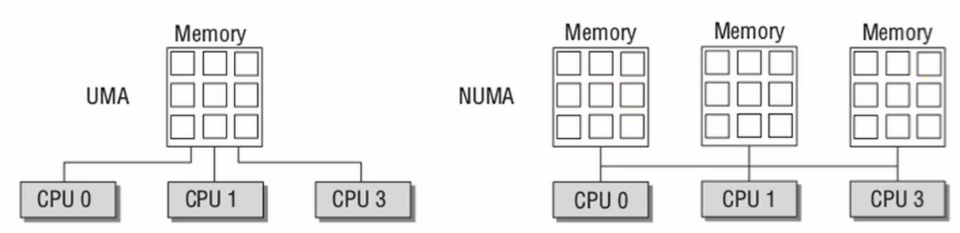
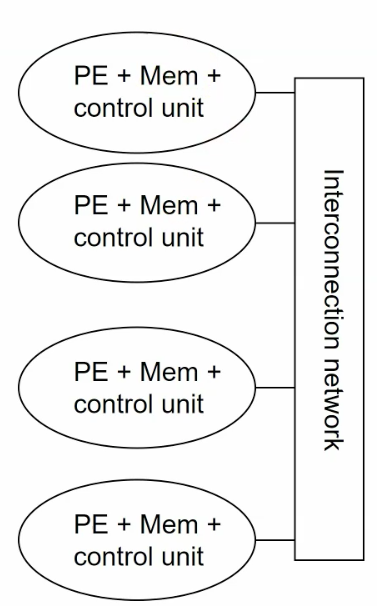
combination of shared memory and non-shared memory.
connect workstations with networking.
e.g. Beowulf
all processors use mem on the same bus.
the bandwidth is the bottlenech.
switched network for higher end shared memory system.
allow all processors to communicate with all mem modules simultaneously. -nonblocking
Higher bandwidth
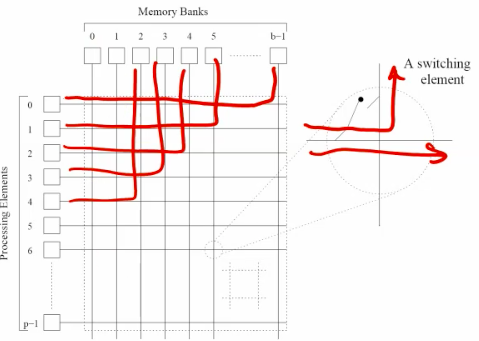
multihop networks.
The combination of the bus and cross bar. flexibility between bandwidth and scalability.
feature:

OpenHPC是一个Linux Foundation合作项目,其任务是集成以HPC为中心的组件,以提供功能全面的参考HPC软件堆栈。


老样子,代码开源在 http://victoryang00.xyz:5012/victoryang/pintos-team-20 .
这次的实现非常难,如果是课程要拿学分的话,一定要提早开始设计,一个良好的设计思维导图,在实现的时候非常有用,大概需要的是什么时候同步锁,三个 table 之间的关系是什么?在debug的时候一定要围绕着这张思维导图来,这样至少不会全不过。
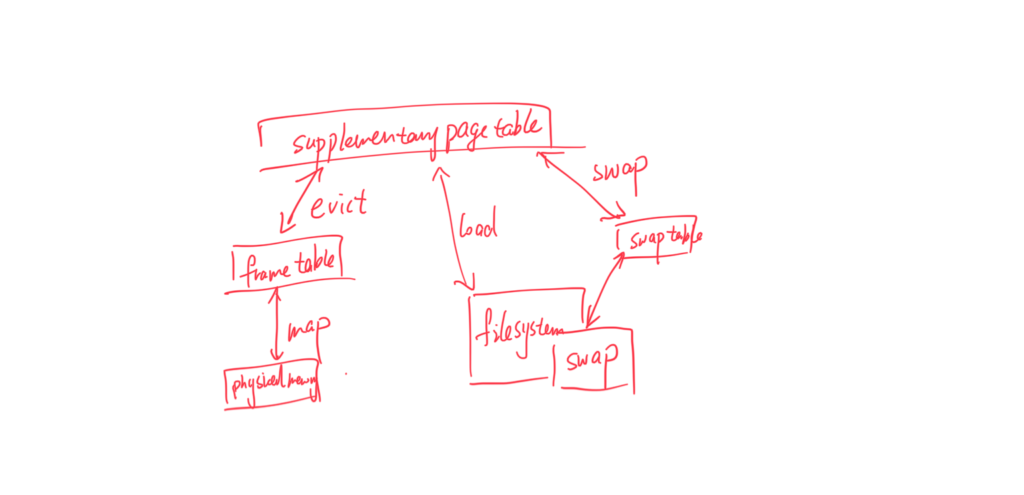
总之,本次作业要实现的功能是 disk-backed virtual memory. 进入本次的文件可以发现vm 文件夹里什么都没有,那就需要自己创建。我建了这些文件。
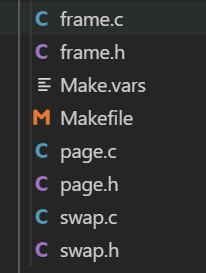
需要在 Makefile 里添加:
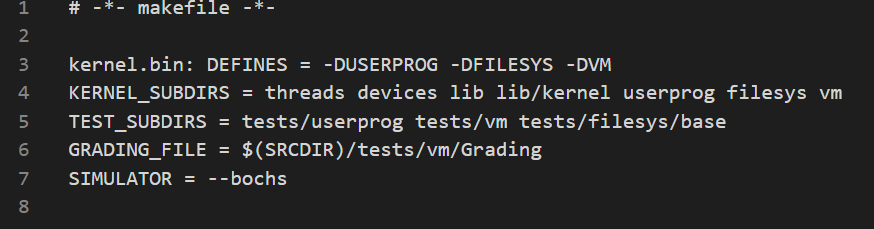
以及在 makefile.kernel 里面加入你新加的文件。
一开始 pintos 几乎没有任何对虚存的支持。 有的只是 process 地址和空间分离和userprog 的load。再看一看工具:
1.为了load & save 虚存分页的 swap partition
2.bitmap, 一种有点像两位哈希的数据结构,用于寻找在 swap partition 里面是否有剩余空间。
3. hashtable, 由于实现 page-frame frame-memoryLocation 之间的 O(1) 查找,极大优化性能。(此步可用linked list 代替,只不过查找变成 O(n) )
4.已经实现好的 lock acquire & lock release, 也就是说你不用管 syncronization ,只需要当黑盒api 调用就行。
5.已经全pass 的proj2. (syscall)
6. debug 工具。pintos-gdb,网上有一个更好用的 Docker-for-pintos,不过好像只支持macOS。这次大概的 debug 模式就是,先运行,看报错,如果找不到报错,就一步一步 gdb 来,看看输出某一个输出的时候会先调用什么,确定位置,一般是在 kernel mode 下锁不对的问题。然后确定程序在这个特定的位置应该运行什么,改一下先后顺序。一般调通一个就能过一片。如果你在 debug 用了过多时间,不如重新来一遍思维导图。
P.S. 这些一定要好好看懂。
为 load program binaries 实现 demand-paging,(纯 demand-paging)
为 stack pages 实现 demand-paging, (需要先分配一个frame 给第一个 stack page, 也就是上一个的特例)(写完这个就能拿到除24个testcase以外的所有分数)
stack
self learnt from https://www.csie.nuk.edu.tw/~wuch/course/csd511/csd511-08.pdf

After viewing much of the ppt online, I grabbed that most of the US schools focus on practice. Maybe because the ppt is for Microsoft intern. Actually, the Sun and the Andrew has been the history.
First off, many kinds. and all of them is to make online repositories browsed just as offline. like ftp on linux r samba on windows.

The architecture is the webserver one that is response and response. I'd say it's more r less a application layer thing, all the mapping connects to other api. In ufid part, it's stateless and a server end fd.
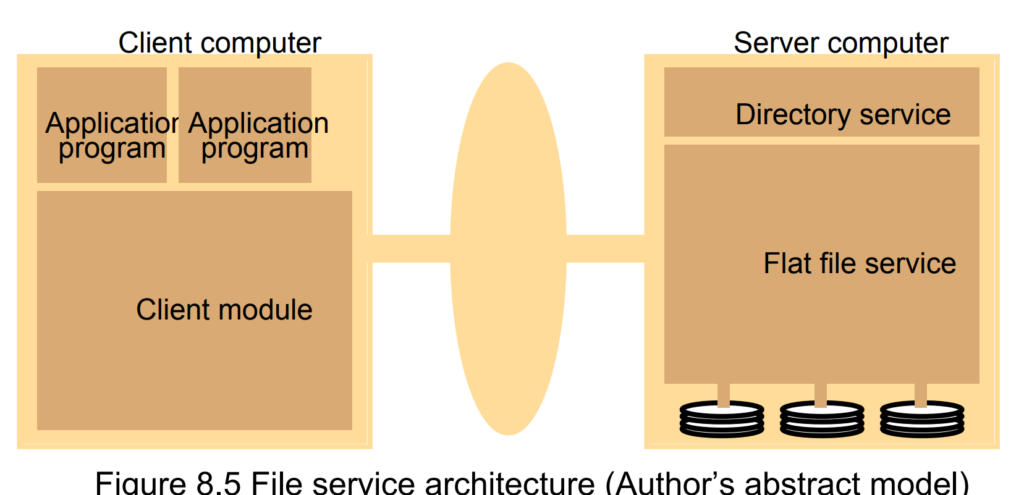
The connection contract is based on RPC which requires:

This is the remote procedure call interface to extend the local directory services to a distributed model.

Every operations would not be directly modified, all requires a tcp requiest, so the identifier requires a 32bits and 16bits date for time stamp. After being transfered, all operations are similar to local ones. Take Sun NFS systems as instance.
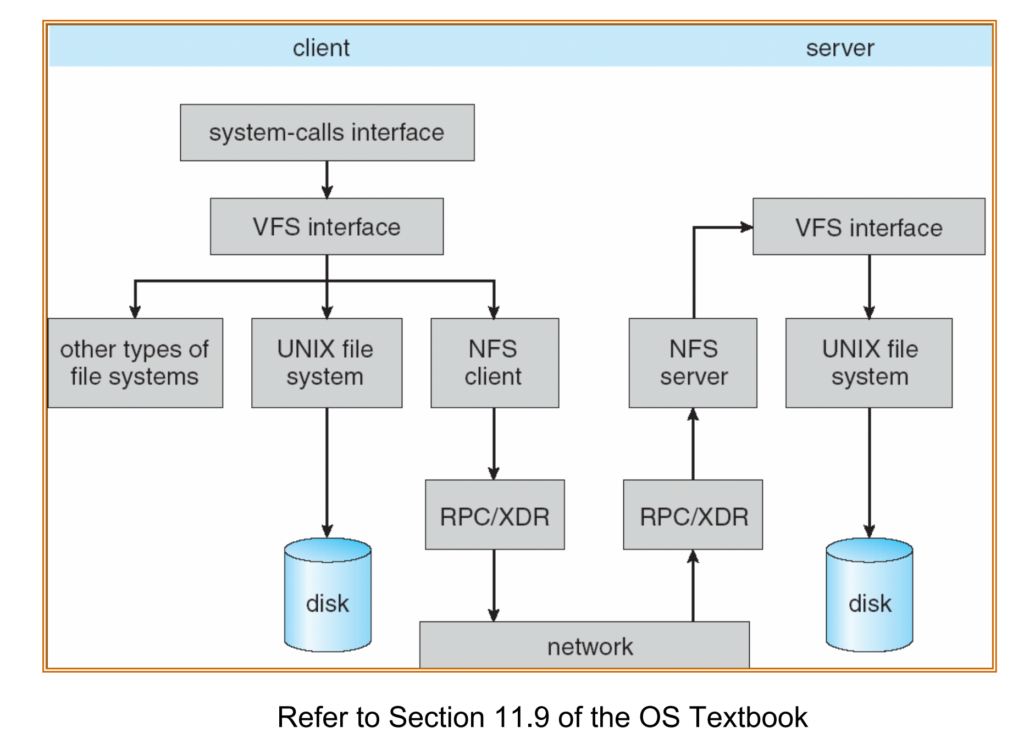
VFS do it more direct, I would say. It put the Hardware abstraction more abstract based on network architechture. Vnode rather than Inode( a file saving DS). In pintos is like:
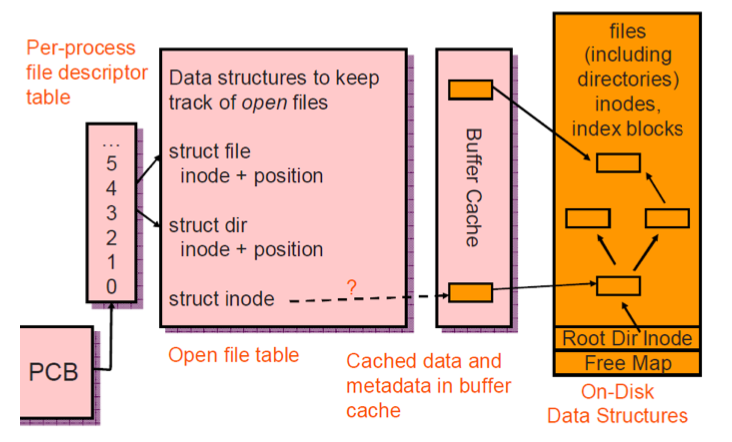
while VFS works this way

Other OS operations works just do as the file system based on network.

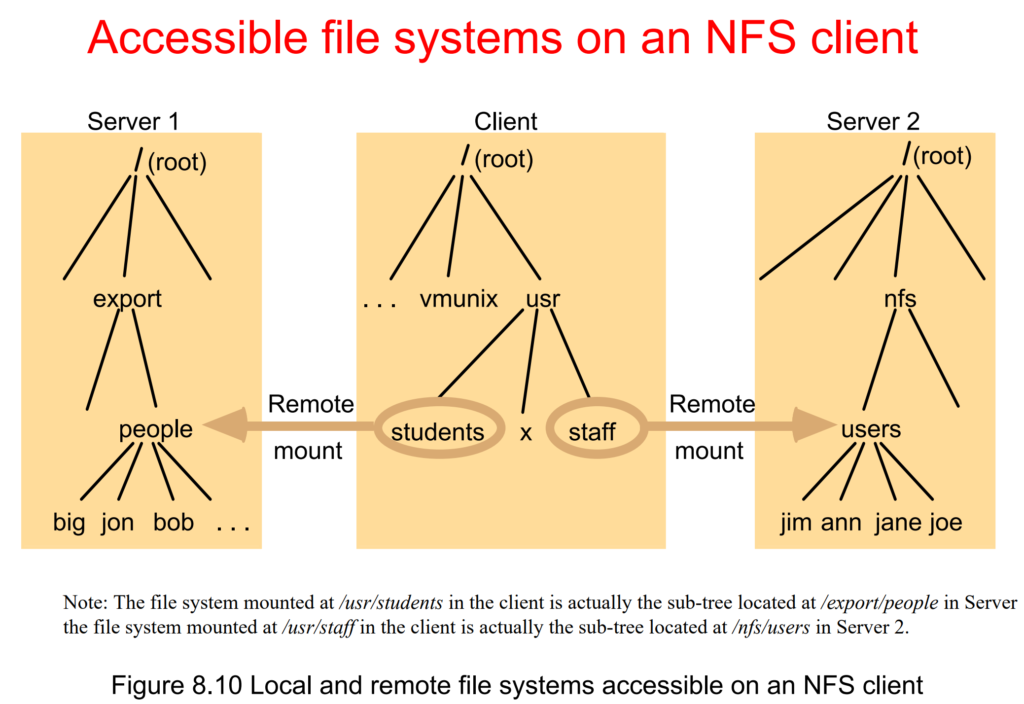



optimization: UDP packet is extended to 9KB to containing entire file block (8KB for UNIX BSD FFS) and RPC message in a single packet – Clients and servers of NFSv3 can negotiate sizes larger than 8 KB.

The Andrew File System (AFS)[1] is a distributed file system which uses a set of trusted servers to present a homogeneous, location-transparent file name space to all the client workstations. It was developed by Carnegie Mellon University as part of the Andrew Project.
Goal: provide transparent access to remote shared files
Two unusual design characteristics

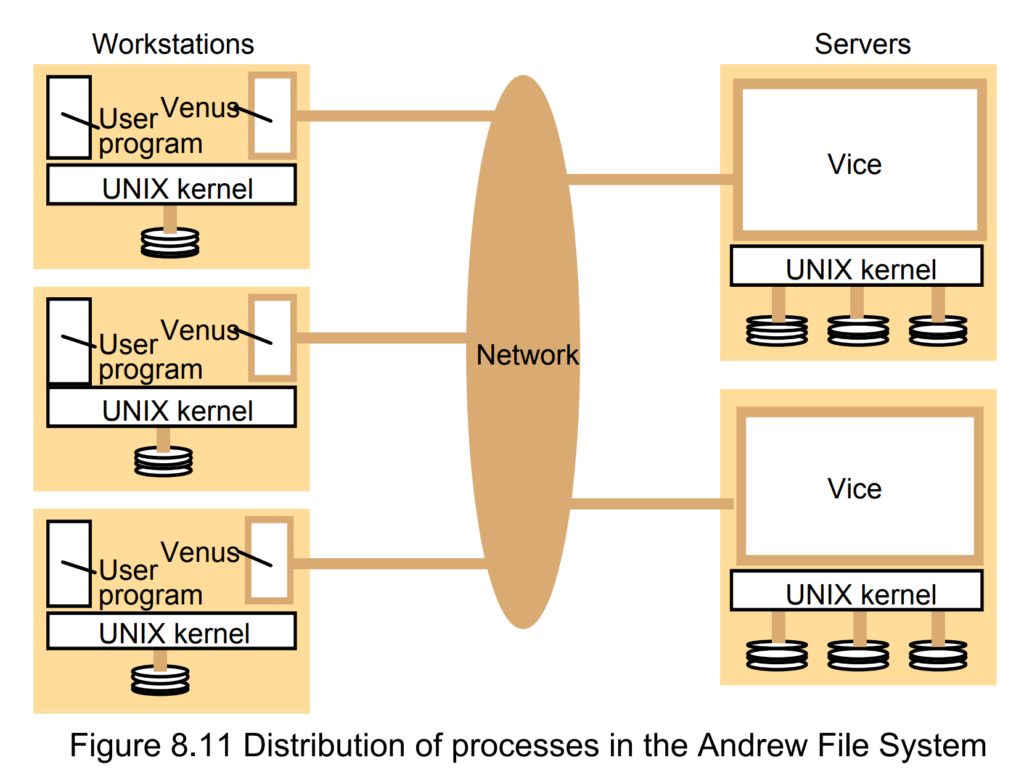


在上个月的紧赶慢赶,连续一周持续4点睡觉以后,终于完成了斯坦福OS的pintos2 project。网上中文资源太少,也没有所谓的详解,我就大概出来献一下丑。
我们的代码开源在 http://victoryang00.xyz:5012/victoryang/pintos-team-20
credit:https://static1.squarespace.com/static/5b18aa0955b02c1de94e4412/t/5b85fad2f950b7b16b7a2ed6/1535507195196/Pintos+Guide
需要改动的文件集中在userprog 文件夹下,官方给出的需要改动的行数:
threads/thread.c | 13 threads/thread.h | 26 + userprog/exception.c | 8 userprog/process.c | 247 ++++++++++++++-- userprog/syscall.c | 468 ++++++++++++++++++++++++++++++- userprog/syscall.h | 1 6 files changed, 725 insertions(+), 38 deletions(-)
为了通过测试,你需要做五件事:
•传递可执行文件名称,而不是线程_create和文件sys_open的原始文件名。 •正确设置堆栈
•实现简单形式的process_wait
•使用putbuf为STDOUT_FILENO实现write syscall
•实施出口syscall。
这将使您开始通过userprog的前几个测试。
这个测试集要求把值传入到 esp 中,非常像OS实现的脚本程序,比普通的python 中的 args.append() 多加一个地址处理来翻译。
pintos -v -k -T 60 --filesys-size=2 -p tests/userprog/args-none -a args-none -- -q -f run args-none
pintos -v -k -T 60 --filesys-size=2 -p tests/userprog/args-single -a args-single -- -q -f run 'args-single onearg'
pintos -v -k -T 60 --filesys-size=2 -p tests/userprog/args-multiple -a args-multiple -- -q -f run 'args-multiple some arguments for you!'
pintos -v -k -T 60 --filesys-size=2 -p tests/userprog/args-many -a args-many -- -q -f run 'args-many a b c d e f g h i j k l m n o p q r s t u v'
pintos -v -k -T 60 --filesys-size=2 -p tests/userprog/args-dbl-space -a args-dbl-space -- -q -f run 'args-dbl-space two spaces!'大概解释一下脚本的含义,贵校用的测试机上只有bochs,makefile.vars 中不用修改。 之前遇到启动 makefile 参数的问题,改这个文件就行。 pintos 命令是一个 perl 脚本,-v -k -T 60 是启动参数, --filesys-size=2 定义文件系统大小。名字不超过14,最大16个文件。 -p 载入文件, -a 载入测试名。 -q -f 为 format 以后 run, 最后是在系统中运行的命令。所有的源代码可以在 .c 文件中看到,如果有某个 testcase 没过就去看。
学长做 check 的时候问过这样一个问题,proj1 和 2 最大的 testcase 区别是什么?proj1 是直接调用写好的程序,而 proj2 传入参数。可以清楚的看到传入参数的格式:
user_program arg1 arg2 arg3 arg4
稍稍看看 args 最大的数量,最多 50 个参数,那直接开一个数组实现,这样的好处是直接通过空格看多少 args ,读的时候看位数就好。
(args) argv[20] = 't'
(args) argv[21] = 'u'
(args) argv[22] = 'v'
(args) argv[23] = null
(args) end
当用户程序开始被执行的时候是先调用process.c 再调用 thread_create() 。注意到该线程被命名为原始文件名:
tid = thread_create(file_name, PRI_DEFAULT, start_process, fn_copy);
你不希望线程具有原始文件名。相反,你希望线程的名称为可执行文件的名称。您将需要从file_name中提取可执行文件名称,然后将其传递。fd(file descriptor就上线了,好处是直接读取数组位置)
tid = thread_create {exec_name,PRI_DEFAULT,start_process,fn_copy;
另请注意fn_copy。这是原始文件名的副本,并作为辅助参数传递。这将派上用场。该线程将运行的函数是start_process,该函数接受参数void * file_name_。 fn_copy作为此参数传递,使您可以在此函数中访问完整的原始文件名的副本。这将派上用场。
如果您查看start_process函数,将看到一个load函数;此功能是在用户程序中加载所有数据的位置。在此加载功能中,Pintos将尝试加载描述。从参数中的指定文件执行用户程序,等待带有指定tid的子进程在继续执行之前完成。
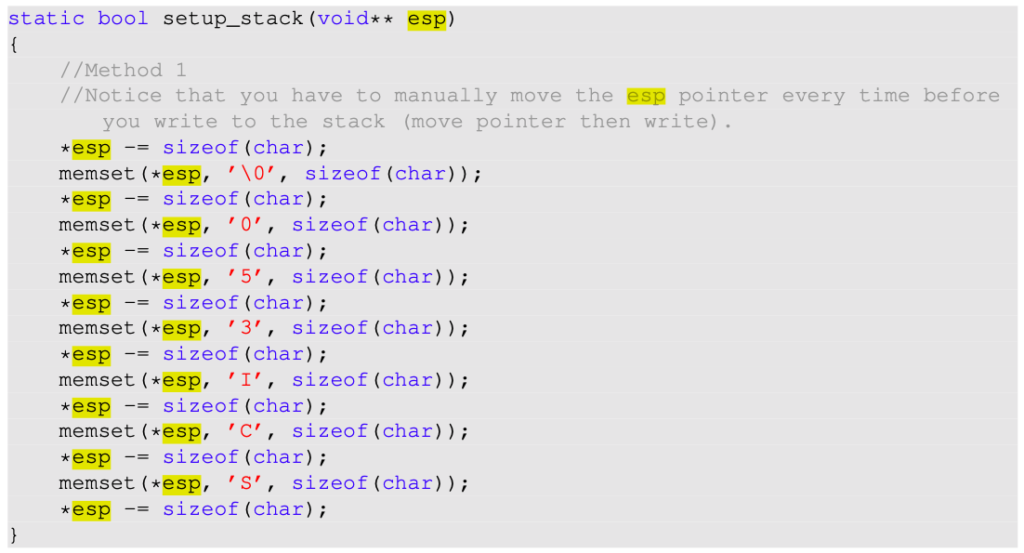
在装入函数中,您还将找到一个名为setup_stack的函数。在此功能中,您将为每个用户程序设置堆栈。
接下来看pintos guide 上的对 stack pointer 的描述,一开始需要先初始化 esp 来存值。首先要说的就是如何debug 因为你一上来一个testcase 都过不了。先介绍两个关于内存读入的函数和一个工具。
假设要将一条信息写入指针的目标,就用memset。例如,假设我们要编写字符a,执行以下操作:
#include <stdio.h>
int main(void)
{
char my_string[] = "XSCI350";
printf("Original: %s\n", my_string);
//ptr points to the start of the string
char* ptr = my_string;
//memset(void pointer to data to modify, write data, size of data in bytes)
memset(static_cast<void*>(ptr), ’C’, sizeof(char)); printf("After: %s\n", my_string);
return 0;
}输出是:
Original: XSCI350 After: CSCI350
这不是要写单个数据,而是要写一个数据字符串。 这时就要使用 memcpy。 例如,假设我们要编写字符串CSCI350,将执行以下操作:
#include <stdio.h>
int main(void)
{
char my_string[] = "ABCD123";
printf("Original: %s\n", my_string); //ptr points to the start of the string
char* ptr = my_string;
//memcpy(void pointer to data to modify, write data, size of data in bytes)
memset(static_cast<void*>(ptr), ’CSCI350’, sizeof(char) * 7);
printf("After: %s\n", my_string);
return 0;
}输出是:
Original: ABCD123 After: CSCI350
它允许你打印出指定堆栈的地址和地址内容。 使用十六进制转储的原型是:
static void hex_dump((uintptr_t)**, void**, int, bool)
这里有一个 hexdump 的案例

接下来实现 process.c 的第一个函数 setup_stack 。
这是双指针,因为你将要进行指针操作,并且由于你希望这些修改是全局的,而不仅仅是在此功能的范围内,因此你将获得一个指向堆栈指针的指针(为指针传递一个指针)。 void** esp 将内容写到你要解引用的堆栈中
按照文档,一开始定义为 PHYS_BASE , 也就是 0xffffffff 。
这里是按 stack 的习惯写入。上面的CSCI350应该写为053ICSC。
上面是一个小测试,我们可以用 hexdump 来检查它输出的到底是什么。

剩下的就是反转了,没什么花样,不过除了我们实现的方法,还有更笨的直接取反。
这次的 multioom 是个很恶心的 testcase,相当于一个压力测试,先读入 args 到不能读,再继续不断地 syscall, 就是看你的程序会不会自己 halt 或者退出。
算是一个比较极端的例子,不过只要能跑其他的,这个只是看看你的上界对不对而已。
转载自 https://www.jianshu.com/p/397449cadc9a
前面大概提了一下在 network 中如何通过阻塞及同步异步还有多路复用来实现 I/O,现在终于可以讲到世纪linux中是如何使用API来实现I/O模型的. 这对比Operating书来说要实际和有意义.
blocking IO - 阻塞IO & nonblocking IO - 非阻塞IO & IO multiplexing - IO多路复用 & signal driven IO - 信号驱动IO 都可以归类为synchronous IO - 同步IO,而select、poll、epoll本质上也都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
在介绍select、poll、epoll之前,首先介绍一下Linux操作系统中基础的概念:
述符数量,返回0表示超时,返回-1表示出错;
epoll在Linux2.6内核正式提出,是基于事件驱动的I/O方式,相对于select来说,epoll没有描述符个数限制,使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
Linux中提供的epoll相关函数如下:
int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
1. epoll_create 函数创建一个epoll句柄,参数size表明内核要监听的描述符数量。调用成功时返回一个epoll句柄描述符,失败时返回-1。
2. epoll_ctl 函数注册要监听的事件类型。四个参数解释如下:
epfd 表示epoll句柄op 表示fd操作类型,有如下3种fd 是要监听的描述符event 表示要监听的事件epoll_event 结构体定义如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
3. epoll_wait 函数等待事件的就绪,成功时返回就绪的事件数目,调用失败时返回 -1,等待超时返回 0。
epfd 是epoll句柄events 表示从内核得到的就绪事件集合maxevents 告诉内核events的大小timeout 表示等待的超时事件epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
epoll除了提供select/poll那种IO事件的水平触发(Level Triggered)外,还提供了边缘触发(Edge Triggered),这就使得用户空间程序有可能缓存IO状态,减少epoll_wait/epoll_pwait的调用,提高应用程序效率。
LT和ET原本应该是用于脉冲信号的,可能用它来解释更加形象。Level和Edge指的就是触发点,Level为只要处于水平,那么就一直触发,而Edge则为上升沿和下降沿的时候触发。比如:0->1 就是Edge,1->1 就是Level。
ET模式很大程度上减少了epoll事件的触发次数,因此效率比LT模式下高。
一张图总结一下select,poll,epoll的区别:
| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 底层实现 | 数组 | 链表 | 哈希表 |
| IO效率 | 每次调用都进行线性遍历,时间复杂度为O(n) | 每次调用都进行线性遍历,时间复杂度为O(n) | 事件通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到readyList里面,时间复杂度O(1) |
| 最大连接数 | 1024(x86)或2048(x64) | 无上限 | 无上限 |
| fd拷贝 | 每次调用select,都需要把fd集合从用户态拷贝到内核态 | 每次调用poll,都需要把fd集合从用户态拷贝到内核态 | 调用epoll_ctl时拷贝进内核并保存,之后每次epoll_wait不拷贝 |
epoll是Linux目前大规模网络并发程序开发的首选模型。在绝大多数情况下性能远超select和poll。目前流行的高性能web服务器Nginx正式依赖于epoll提供的高效网络套接字轮询服务。但是,在并发连接不高的情况下,多线程+阻塞I/O方式可能性能更好。
既然select,poll,epoll都是I/O多路复用的具体的实现,之所以现在同时存在,其实他们也是不同历史时期的产物
第一步先理解 阻塞/非阻塞/同步/异步. 其实计算机当中的很多概念并不只是从操作系统中衍生出来,各个领域都会有大致相同,但实则定义不一致的概念.就比如网路和操作系统的概念区别.
这里讨论的主要是网络编程中的.同时signal driven主要是thread,直接处理IO的操作不多,所以这里不做讨论.
首先对于一个 network IO,就涉及到两个概念
那他们经历的两个交互过程是:
这大致和操作系统中的 thread_block 思路一致, 整个实现就是冲走了一遍 lock 机制. 不过就如同操作系统需要很多不同的机制来应对不同的问题,从而产生了Hoarne & Mesa Monitor Semaphore & Condition. 虽然四者可以互相实现,但是工程上需要做区分.
首先是Blocking IO, 又称阻塞IO. 在 linux 中,默认情况下所有的 socket 都是 blocking,一个典型的读操作流程大概如下图:
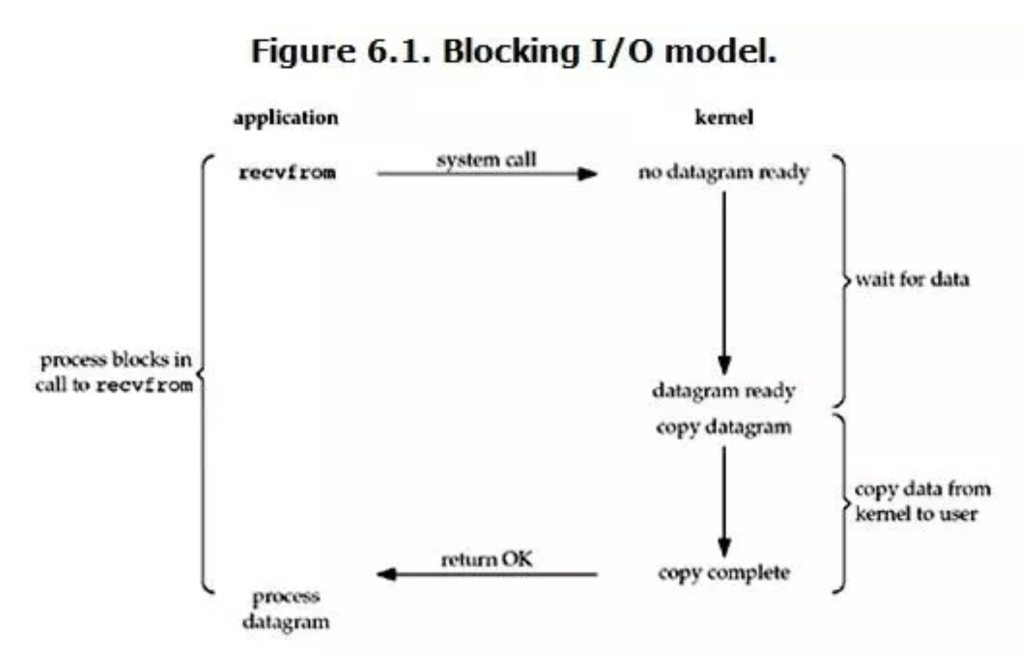
当用户进程调用了 recvfrom 这个 syscall, kernel 就开始了 IO 的第一个阶段,也就是收集数据, 对于network IO 来说,很多时候数据一开始还没有到达(比如,还没有收到一个完整的udp包),这个时候kernel 就要等待足够多的时间来.而在用户进程这里,整个进程都会被阻塞. 当kernel 一致等到数据准备好的时候,它就会从kernel中拷贝到用户内存.然后kernel 返回结果.用户进程才会接触block的状态,重新运行起来.
所以,blocking IO 的特点就是在IO执行的两个阶段就被block了.
这里与操作系统最大的区别就是network IO的延时通常比system 的数据流延时慢很多个时钟周期. 在操作系统中Blocking IO 一般是tick priority trigger 的.
其次是NoneBlockingIO,又称非阻塞IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
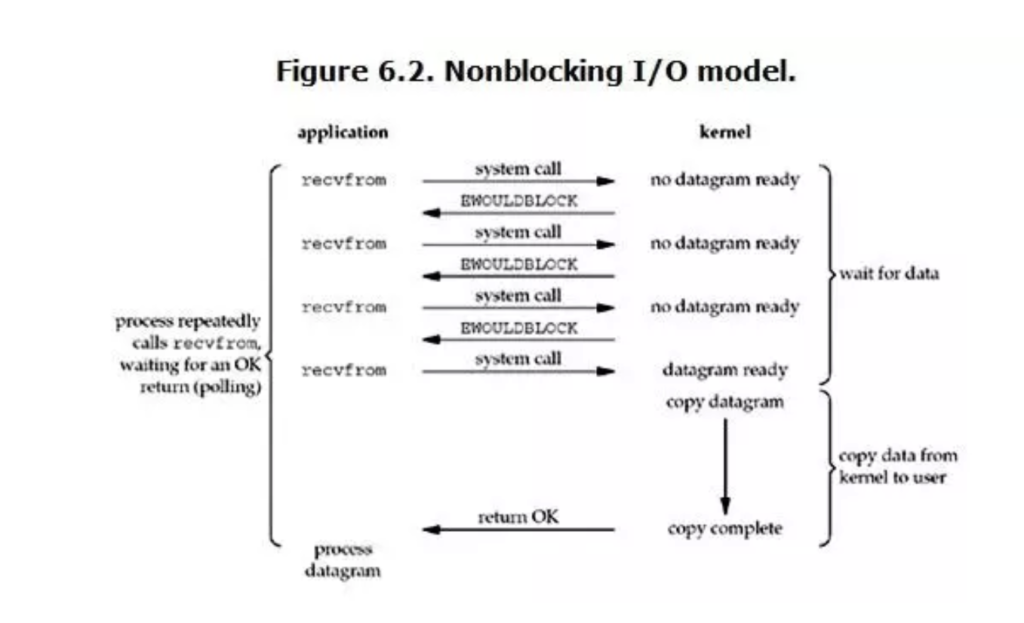
从图中可以看出,当用户进程发出recvfrom这个系统调用后,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个结果(no datagram ready)。从用户进程角度讲 ,它发起一个操作后,并没有等待,而是马上就得到了一个结果。用户进程得知数据还没有准备好后,它可以每隔一段时间再次发送recvfrom操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
I/O多路复用(multiplexing)是网络编程中最常用的模型,像我们最常用的select、epoll都属于这种模型。以select为例:
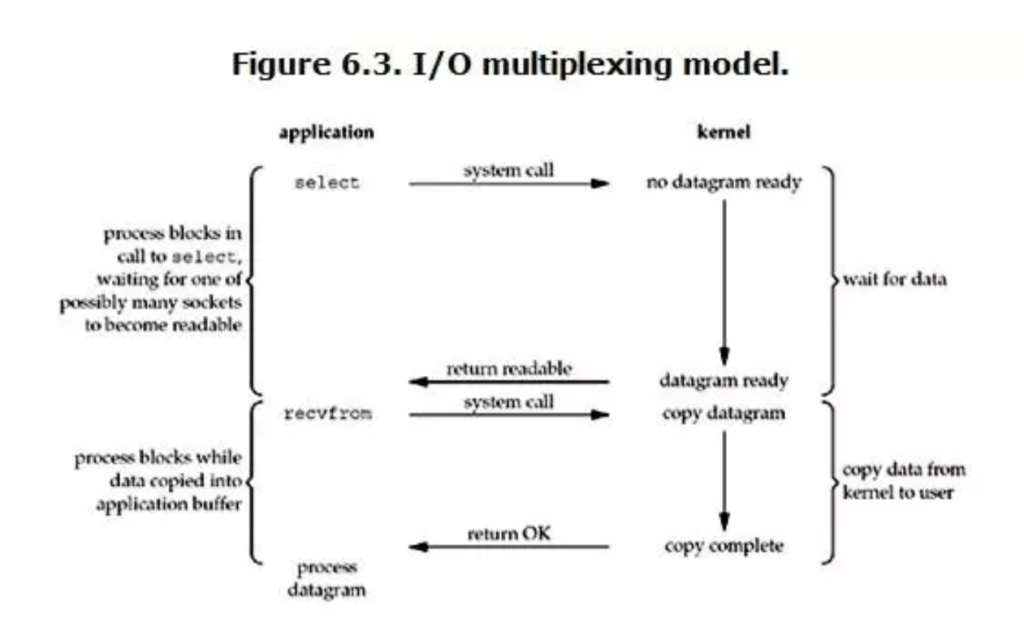
看起来它与blocking I/O很相似,两个阶段都阻塞。但它与blocking I/O的一个重要区别就是它可以等待多个数据报就绪(datagram ready),即可以处理多个连接。这里的select相当于一个“代理”,调用select以后进程会被select阻塞,这时候在内核空间内select会监听指定的多个datagram (如socket连接),如果其中任意一个数据就绪了就返回。此时程序再进行数据读取操作,将数据拷贝至当前进程内。由于select可以监听多个socket,我们可以用它来处理多个连接。
在select模型中每个socket一般都设置成non-blocking,虽然等待数据阶段仍然是阻塞状态,但是它是被select调用阻塞的,而不是直接被I/O阻塞的。select底层通过轮询机制来判断每个socket读写是否就绪。
当然select也有一些缺点,比如底层轮询机制会增加开销、支持的文件描述符数量过少等。为此,Linux引入了epoll作为select的改进版本。
异步I/O在网络编程中几乎用不到,在File I/O中可能会用到:

这里面的读取操作的语义与上面的几种模型都不同。这里的读取操作(aio_read)会通知内核进行读取操作并将数据拷贝至进程中,完事后通知进程整个操作全部完成(绑定一个回调函数处理数据)。读取操作会立刻返回,程序可以进行其它的操作,所有的读取、拷贝工作都由内核去做,做完以后通知进程,进程调用绑定的回调函数来处理数据。
我们来总结一下阻塞、非阻塞,同步和异步这两组概念。
先来说阻塞和非阻塞:
再说一说同步和异步:
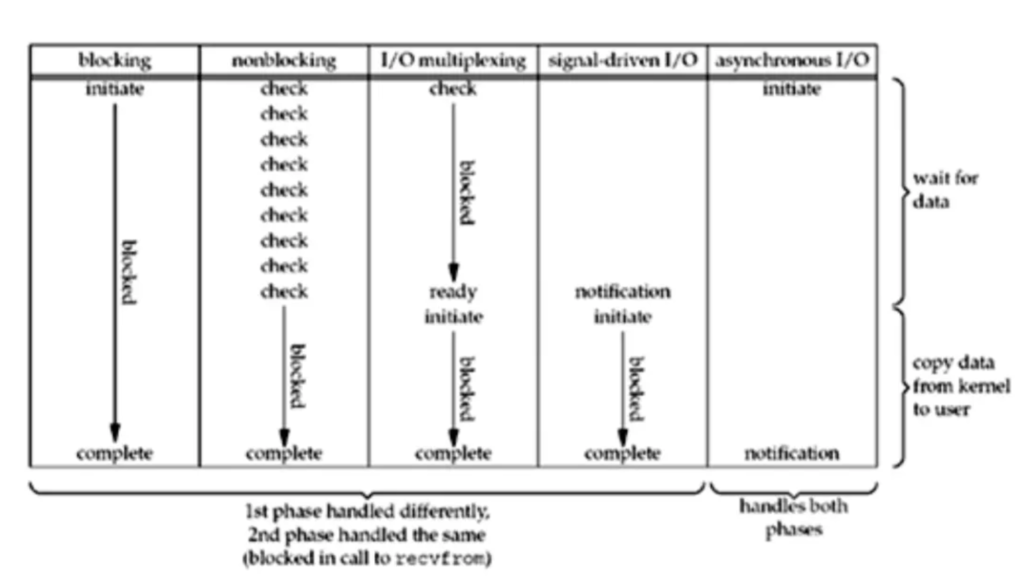
下面的这张图很好地总结了之前讲的这五种I/O模型(来自Unix Network Programming)
虽已不尽完美。但基本的cpuinfo得支持一下吧。tensorflow应该能跑,这玩意儿是alpine的i686架构的。
本质还是个chroot的container吧,只是调不到ios底层的东西,所以这些信息缺失,已实现的东西都是不平台依赖的包。
不过这玩意儿 import coreML能用?那岂不是可以破解ios游戏?