Introduction to Slug Wiki
Local storage for some of SlugLab's extremely small notes, including but not limited to:
- Kernel mm subsystem
- Kernel observability
- LLVM and MLIR
- RISCV in Chisel
PCIeCXL- RL for Sys
- rust
- c艹
- WASM
- Quantitative Approach: A Yiwei's perspective
You can join the discord for discussing anything above.
I've learned a lot from my ex-coworker Barry's blog, it's time for me to enlarge the wiki from my perspective.
Lazy Evaluation in C艹
pmr
analysis the lifetime for SWMR struct.
Static Replex Expression
Reference
- Lightning Talk: Static Reflection on the Budget in C++23 - Kris Jusiak - CppNow 2023
- Killing C++ Serialization Overhead and Complexity
- A Faster Serialization Library Based on Compile-time Reflection and C++ 20 - Yu Qi
This project will store the reading report of subsystem for linux kernel 6.4.0. I'm a newbie developer in kernel, so there's some fallacy in the explaination, please make issue in the repo
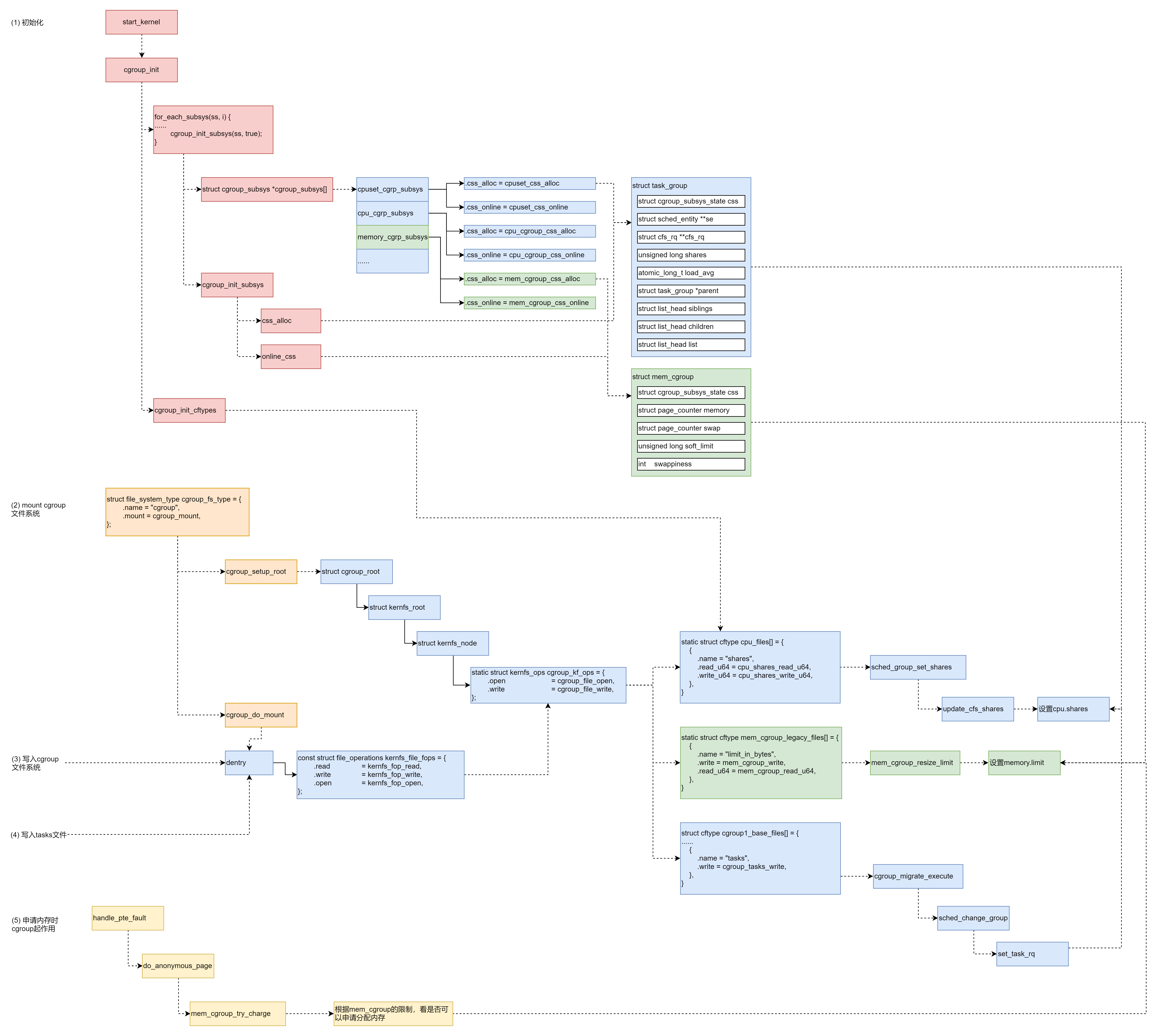
CGroup
First it leverage the procfs to gain update and stats from the kernel. It leverage the hooks in the namespace, which, for example, if you don't want the current cgroup not exceeds the memory.max, root_memcg and your current hierarchy of memcg both have memcg, and the container_of operations will get you to the offset of which memcg and read the corresponding memory.max value to limit the memory. Then, RDMA CGroup has abstraction of internal resource pool like hca_object and hca_handle, while IO CGroup chas limits of rbytes
V1 vs V2
- The procfs read write api are different.
{
.name = "swappiness",
.read_u64 = mem_cgroup_swappiness_read,
.write_u64 = mem_cgroup_swappiness_write,
},
static u64 mem_cgroup_swappiness_read(struct cgroup_subsys_state *css,
struct cftype *cft)
{
struct mem_cgroup *memcg = mem_cgroup_from_css(css);
return mem_cgroup_swappiness(memcg);
}
static int mem_cgroup_swappiness_write(struct cgroup_subsys_state *css,
struct cftype *cft, u64 val)
{
struct mem_cgroup *memcg = mem_cgroup_from_css(css);
if (val > 200)
return -EINVAL;
if (!mem_cgroup_is_root(memcg))
WRITE_ONCE(memcg->swappiness, val);
else
WRITE_ONCE(vm_swappiness, val);
return 0;
}
{
.name = "oom.group",
.flags = CFTYPE_NOT_ON_ROOT | CFTYPE_NS_DELEGATABLE,
.seq_show = memory_oom_group_show,
.write = memory_oom_group_write,
},
static int memory_oom_group_show(struct seq_file *m, void *v)
{
struct mem_cgroup *memcg = mem_cgroup_from_seq(m);
seq_printf(m, "%d\n", READ_ONCE(memcg->oom_group));
return 0;
}
static ssize_t memory_oom_group_write(struct kernfs_open_file *of,
char *buf, size_t nbytes, loff_t off)
{
struct mem_cgroup *memcg = mem_cgroup_from_css(of_css(of));
int ret, oom_group;
buf = strstrip(buf);
if (!buf)
return -EINVAL;
ret = kstrtoint(buf, 0, &oom_group);
if (ret)
return ret;
if (oom_group != 0 && oom_group != 1)
return -EINVAL;
WRITE_ONCE(memcg->oom_group, oom_group);
return nbytes;
}
- multiple hierchy definination vs. single hierarchical tree management.
- memory ownership and memory swap events
- eBPF and rootless containers
Lifetime of a cgroup
Migration on demand
https://lwn.net/Articles/916583/
How to get the struct what you want memcg etc. in kernel
I have to get memcg from the current pid.
- If it's located in the task struct scope, simply use the
currentfor getting the structget_mem_cgroup_from_mm(current->mm). - If you are in the
work_struct, you are possibly get struct by argument passing orcontainer_ofor back pointer.
It's hard to get something in the critical path because it always acquires locks or rcu for getting some struct to be multithread safe. But there's always performance work around hacks.
Read! Copy! Update!
When it comes to multithreaded programming, everyone can think of locking, such as user-state pthread_mutex_lock/unlock and kernel-state mutex_lock/spin_lock locking mechanisms. The common feature of these mechanisms is that they treat any party that adds a lock fairly. The variable decorated by RCU can hold the reader biased lock primitive for the variable.

- Read the variable with read-side critical section.
- The grace period is started by the writer until the CPU reports the CPU quiescent state. The writer protected critical section should be serializable.
void read(void)
{
rcu_read_lock();
// read the variable
rcu_read_unlock();
}
void write(void)
{
struct user *new = malloc(struct user);
struct uer *old = user_table[i];
memcpy(new, old, sizeof(struct user));
user_table[i] = new;
// don't care reads the new or old, grace point
synchronize_rcu();
free(old);
}
Drawbacks
- RCU has starvation problem.
- Although RCU readers and writers are always allowed to access a shared data, writers are not allowed to free dynamically allocated data that was modified before the end of the grace-period. The end of a grace period ensures that no readers are accessing the old version of dynamically allocated shared data, allowing writers to return the memory to the system safely. Hence, a drawback of RCU is that a long wait for the end of a grace period can lead the system to run out-of-memory.
Pitfalls
[ +6.019620] ------------[ cut here ]------------
[ +0.000004] Voluntary context switch within RCU read-side critical section!
[ +0.000004] WARNING: CPU: 12 PID: 1010 at kernel/rcu/tree_plugin.h:320 rcu_note_context_switch+0x43d/0x560
[ +0.000009] Modules linked in: xt_CHECKSUM ipt_REJECT nf_reject_ipv4 xt_tcpudp nft_chain_nat rpcsec_gss_krb5 auth_rpcgss xt_MASQUERADE nf_nat nf_conntrack_netlink xfrm_user xfrm_algo xt_addrtype br_netfilter bridge stp llc nfsv4 nfs lockd grace fscache netfs xt_conntrack nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_comment nft_compat nf_tables nfnetlink binfmt_misc sunrpc intel_rapl_msr intel_rapl_common intel_uncore_frequency intel_uncore_frequency_common i10nm_edac nfit x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel nls_iso8859_1 pmt_telemetry kvm pmt_class intel_sdsi irqbypass cmdlinepart rapl intel_cstate spi_nor idxd input_leds mei_me isst_if_mbox_pci isst_if_mmio mtd intel_vsec isst_if_common idxd_bus mei ipmi_ssif acpi_ipmi ipmi_si ipmi_devintf ipmi_msghandler acpi_power_meter acpi_pad mac_hid pfr_update pfr_telemetry sch_fq_codel dm_multipath scsi_dh_rdac scsi_dh_emc scsi_dh_alua msr pstore_blk ramoops reed_solomon pstore_zone efi_pstore ip_tables x_tables autofs4 btrfs blake2b_generic raid10
[ +0.000065] raid456 async_raid6_recov async_memcpy async_pq async_xor async_tx xor raid6_pq libcrc32c raid1 raid0 multipath linear hid_generic usbhid rndis_host hid cdc_ether usbnet igb crct10dif_pclmul nvme crc32_pclmul drm_shmem_helper polyval_clmulni polyval_generic drm_kms_helper nvme_core ghash_clmulni_intel sha512_ssse3 aesni_intel dax_hmem cxl_acpi ahci drm cxl_core crypto_simd cryptd dca spi_intel_pci nvme_common libahci i2c_i801 xhci_pci i2c_algo_bit spi_intel i2c_ismt i2c_smbus xhci_pci_renesas wmi pinctrl_emmitsburg
[ +0.000038] CPU: 12 PID: 1010 Comm: kworker/u193:11 Tainted: G S 6.4.0+ #39
[ +0.000003] Hardware name: Supermicro SYS-621C-TN12R/X13DDW-A, BIOS 1.1 02/02/2023
[ +0.000002] Workqueue: writeback wb_workfn (flush-259:0)
[ +0.000008] RIP: 0010:rcu_note_context_switch+0x43d/0x560
[ +0.000004] Code: 00 48 89 be 40 08 00 00 48 89 86 48 08 00 00 48 89 10 e9 63 fe ff ff 48 c7 c7 d0 cd 94 82 c6 05 a6 ac 41 02 01 e8 73 1b f3 ff <0f> 0b e9 27 fc ff ff a9 ff ff ff 7f 0f 84 cf fc ff ff 65 48 8b 3c
[ +0.000002] RSP: 0018:ffa00000203674a8 EFLAGS: 00010046
[ +0.000003] RAX: 0000000000000000 RBX: ff11001fff733640 RCX: 0000000000000000
[ +0.000003] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
[ +0.000001] RBP: ffa00000203674c8 R08: 0000000000000000 R09: 0000000000000000
[ +0.000001] R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000000
[ +0.000001] R13: 0000000000000000 R14: ff110001ce730000 R15: ff110001ce730000
[ +0.000001] FS: 0000000000000000(0000) GS:ff11001fff700000(0000) knlGS:0000000000000000
[ +0.000002] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ +0.000002] CR2: 000000c0007da000 CR3: 0000000007a3a004 CR4: 0000000000771ee0
[ +0.000002] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ +0.000001] DR3: 0000000000000000 DR6: 00000000fffe07f0 DR7: 0000000000000400
[ +0.000001] PKRU: 55555554
[ +0.000002] Call Trace:
[ +0.000002] <TASK>
[ +0.000003] ? show_regs+0x72/0x90
[ +0.000008] ? rcu_note_context_switch+0x43d/0x560
[ +0.000002] ? __warn+0x8d/0x160
[ +0.000007] ? rcu_note_context_switch+0x43d/0x560
[ +0.000002] ? report_bug+0x1bb/0x1d0
[ +0.000008] ? handle_bug+0x46/0x90
[ +0.000006] ? exc_invalid_op+0x19/0x80
[ +0.000003] ? asm_exc_invalid_op+0x1b/0x20
[ +0.000006] ? rcu_note_context_switch+0x43d/0x560
[ +0.000002] ? rcu_note_context_switch+0x43d/0x560
[ +0.000002] __schedule+0xb9/0x15f0
[ +0.000006] ? blk_mq_flush_plug_list+0x19d/0x5e0
[ +0.000007] ? __blk_flush_plug+0xe9/0x130
[ +0.000005] schedule+0x68/0x110
[ +0.000004] io_schedule+0x46/0x80
[ +0.000004] ? __pfx_wbt_inflight_cb+0x10/0x10
[ +0.000005] rq_qos_wait+0xd0/0x170
[ +0.000006] ? __pfx_wbt_cleanup_cb+0x10/0x10
[ +0.000003] ? __pfx_rq_qos_wake_function+0x10/0x10
[ +0.000003] ? __pfx_wbt_inflight_cb+0x10/0x10
[ +0.000004] wbt_wait+0xa8/0x100
[ +0.000003] __rq_qos_throttle+0x25/0x40
[ +0.000003] blk_mq_submit_bio+0x291/0x660
[ +0.000004] __submit_bio+0xb3/0x1c0
[ +0.000004] submit_bio_noacct_nocheck+0x2ce/0x390
[ +0.000004] submit_bio_noacct+0x20a/0x560
[ +0.000003] submit_bio+0x6c/0x80
[ +0.000003] ext4_bio_write_folio+0x2d9/0x6a0
[ +0.000006] ? folio_clear_dirty_for_io+0x148/0x1e0
[ +0.000005] mpage_submit_folio+0x91/0xc0
[ +0.000008] mpage_process_page_bufs+0x181/0x1b0
[ +0.000004] mpage_prepare_extent_to_map+0x1fb/0x570
[ +0.000004] ext4_do_writepages+0x4bd/0xd80
[ +0.000005] ext4_writepages+0xb8/0x1a0
[ +0.000003] do_writepages+0xd0/0x1b0
[ +0.000004] ? __wb_calc_thresh+0x3e/0x130
[ +0.000003] __writeback_single_inode+0x44/0x360
[ +0.000002] writeback_sb_inodes+0x22f/0x500
[ +0.000004] __writeback_inodes_wb+0x56/0xf0
[ +0.000003] wb_writeback+0x12b/0x2c0
[ +0.000002] wb_workfn+0x2dc/0x4e0
[ +0.000003] ? __schedule+0x3dd/0x15f0
[ +0.000003] ? add_timer+0x20/0x40
[ +0.000006] process_one_work+0x229/0x450
[ +0.000006] worker_thread+0x50/0x3f0
[ +0.000003] ? __pfx_worker_thread+0x10/0x10
[ +0.000002] kthread+0xf4/0x130
[ +0.000006] ? __pfx_kthread+0x10/0x10
[ +0.000003] ret_from_fork+0x29/0x50
[ +0.000007] </TASK>
[ +0.000001] ---[ end trace 0000000000000000 ]---
dmesg -wH[ +4.088043] audit: type=1400 audit(1690245681.539:137): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1608723/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
^A[ +10.108572] audit: type=1400 audit(1690245691.647:138): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1617988/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.125741] audit: type=1400 audit(1690245701.775:139): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618033/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.107064] audit: type=1400 audit(1690245711.879:140): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618070/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[Jul25 00:42] audit: type=1400 audit(1690245721.998:141): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618107/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.109829] audit: type=1400 audit(1690245732.106:142): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618136/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +5.361027] rcu: INFO: rcu_preempt detected stalls on CPUs/tasks:
[ +0.000005] rcu: Tasks blocked on level-1 rcu_node (CPUs 0-15): P1010/3:b..l
[ +0.000009] rcu: (detected by 95, t=15002 jiffies, g=122497, q=1257526 ncpus=96)
[ +0.000006] task:kworker/u193:11 state:I stack:0 pid:1010 ppid:2 flags:0x00004000
[ +0.000004] Workqueue: 0x0 (events_power_efficient)
[ +0.000006] Call Trace:
[ +0.000002] <TASK>
[ +0.000003] __schedule+0x3d5/0x15f0
[ +0.000008] ? add_timer+0x20/0x40
[ +0.000006] ? queue_delayed_work_on+0x6e/0x80
[ +0.000004] ? fb_flashcursor+0x159/0x1d0
[ +0.000004] ? __pfx_bit_cursor+0x10/0x10
[ +0.000002] schedule+0x68/0x110
[ +0.000003] worker_thread+0xbd/0x3f0
[ +0.000002] ? __pfx_worker_thread+0x10/0x10
[ +0.000002] kthread+0xf4/0x130
[ +0.000003] ? __pfx_kthread+0x10/0x10
[ +0.000003] ret_from_fork+0x29/0x50
[ +0.000005] </TASK>
[ +4.746203] audit: type=1400 audit(1690245742.213:143): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618184/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.110853] audit: type=1400 audit(1690245752.329:144): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618273/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.104983] audit: type=1400 audit(1690245762.433:145): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618325/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.106410] audit: type=1400 audit(1690245772.536:146): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618353/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[Jul25 00:43] audit: type=1400 audit(1690245782.648:147): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618381/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +3.181659] bash: page allocation failure: order:0, mode:0x400dc0(GFP_KERNEL_ACCOUNT|__GFP_ZERO), nodemask=0,cpuset=user.slice,mems_allowed=0-1
[ +0.000011] CPU: 78 PID: 1618437 Comm: bash Tainted: G S W 6.4.0+ #39
[ +0.000003] Hardware name: Supermicro SYS-621C-TN12R/X13DDW-A, BIOS 1.1 02/02/2023
[ +0.000001] Call Trace:
[ +0.000003] <TASK>
[ +0.000003] dump_stack_lvl+0x48/0x70
[ +0.000007] dump_stack+0x10/0x20
[ +0.000001] warn_alloc+0x14b/0x1c0
[ +0.000006] __alloc_pages+0x117f/0x1210
[ +0.000004] ? __mod_lruvec_page_state+0xa0/0x160
[ +0.000004] ? bede_flush_node_rss+0x77/0x150
[ +0.000004] alloc_pages+0x95/0x1a0
[ +0.000002] pte_alloc_one+0x18/0x50
[ +0.000005] do_fault+0x20a/0x3e0
[ +0.000003] __handle_mm_fault+0x6ca/0xc70
[ +0.000004] handle_mm_fault+0xe9/0x350
[ +0.000002] do_user_addr_fault+0x225/0x6c0
[ +0.000002] exc_page_fault+0x84/0x1b0
[ +0.000004] asm_exc_page_fault+0x27/0x30
[ +0.000004] RIP: 0033:0x560e5fcc8d29
[ +0.000003] Code: 8b 3c 24 4c 8b 54 24 08 0f b6 54 24 28 48 8b 30 31 c0 8d 4f 02 48 63 c9 66 0f 1f 84 00 00 00 00 00 41 89 c0 0f b6 c2 8d 79 ff <0f> b7 04 46 66 c1 e8 03 83 e0 01 80 fa 5f 0f 94 c2 08 d0 0f 84 8e
[ +0.000001] RSP: 002b:00007ffea31bac80 EFLAGS: 00010246
[ +0.000002] RAX: 0000000000000073 RBX: 00007ffea31badbc RCX: 0000000000000002
[ +0.000002] RDX: 0000000000000073 RSI: 00007f61b221982c RDI: 0000000000000001
[ +0.000000] RBP: 0000560e60f3d360 R08: 0000000000000000 R09: 0000560e5fd72a3c
[ +0.000001] R10: 0000560e60f3d361 R11: 00007ffea31badb4 R12: 0000000000000001
[ +0.000001] R13: 0000560e60f3d360 R14: 0000000000000000 R15: 0000000000000001
[ +0.000002] </TASK>
[ +0.000001] Mem-Info:
[ +0.000010] active_anon:716 inactive_anon:214225 isolated_anon:0
active_file:2383940 inactive_file:3365237 isolated_file:0
unevictable:6921 dirty:4 writeback:0
slab_reclaimable:218619 slab_unreclaimable:225558
mapped:135395 shmem:720 pagetables:6282
sec_pagetables:0 bounce:0
kernel_misc_reclaimable:0
free:59304993 free_pcp:43676 free_cma:0
[ +0.000004] Node 0 active_anon:1836kB inactive_anon:541260kB active_file:4060952kB inactive_file:7522280kB unevictable:4944kB isolated(anon):0kB isolated(file):0kB mapped:353180kB dirty:12kB writeback:0kB shmem:1852kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB kernel_stack:14472kB pagetables:17076kB sec_pagetables:0kB all_unreclaimable? no
[ +0.000005] Node 0 DMA free:11304kB boost:0kB min:4kB low:16kB high:28kB reserved_highatomic:0KB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15400kB mlocked:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB
[ +0.000004] lowmem_reserve[]: 0 1611 128577 128577 128577
[ +0.000005] Node 0 DMA32 free:1644984kB boost:0kB min:564kB low:2212kB high:3860kB reserved_highatomic:0KB active_anon:0kB inactive_anon:28kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:1779904kB managed:1658912kB mlocked:0kB bounce:0kB free_pcp:9184kB local_pcp:0kB free_cma:0kB
[ +0.000003] lowmem_reserve[]: 0 0 126966 126966 126966
[ +0.000005] Node 0 Normal free:116203888kB boost:0kB min:44556kB low:174568kB high:304580kB reserved_highatomic:0KB active_anon:1836kB inactive_anon:541232kB active_file:4060952kB inactive_file:7522280kB unevictable:4944kB writepending:12kB present:132120576kB managed:130013316kB mlocked:4944kB bounce:0kB free_pcp:165500kB local_pcp:1048kB free_cma:0kB
[ +0.000004] lowmem_reserve[]: 0 0 0 0 0
[ +0.000003] Node 0 DMA: 2*4kB (U) 2*8kB (U) 1*16kB (U) 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 1*1024kB (U) 1*2048kB (M) 2*4096kB (M) = 11304kB
[ +0.000009] Node 0 DMA32: 6*4kB (UM) 7*8kB (UM) 4*16kB (UM) 9*32kB (UM) 4*64kB (UM) 6*128kB (UM) 6*256kB (UM) 10*512kB (UM) 9*1024kB (M) 9*2048kB (UM) 393*4096kB (M) = 1645488kB
[ +0.000010] Node 0 Normal: 515*4kB (UME) 5*8kB (UME) 31*16kB (ME) 13*32kB (ME) 29*64kB (UME) 33*128kB (ME) 25*256kB (ME) 10*512kB (M) 3*1024kB (UME) 0*2048kB 28364*4096kB (UM) = 116202628kB
[ +0.000011] Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=1048576kB
[ +0.000001] Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB
[ +0.000001] 5750183 total pagecache pages
[ +0.000001] 0 pages in swap cache
[ +0.000001] Free swap = 0kB
[ +0.000000] Total swap = 0kB
[ +0.000001] 67033550 pages RAM
[ +0.000000] 0 pages HighMem/MovableOnly
[ +0.000001] 1086155 pages reserved
[ +0.000001] 0 pages hwpoisoned
[ +0.000001] Huh VM_FAULT_OOM leaked out to the #PF handler. Retrying PF
[ +6.926681] audit: type=1400 audit(1690245792.756:148): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618513/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.107864] audit: type=1400 audit(1690245802.860:149): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618587/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.105275] audit: type=1400 audit(1690245812.967:150): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618650/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.109661] audit: type=1400 audit(1690245823.075:151): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618680/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +8.500616] audit: type=1400 audit(1690245831.575:152): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618740/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +1.607178] audit: type=1400 audit(1690245833.183:153): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618752/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[Jul25 00:44] audit: type=1400 audit(1690245843.287:154): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618812/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.121376] audit: type=1400 audit(1690245853.411:155): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618883/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.109163] audit: type=1400 audit(1690245863.519:156): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1618986/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +3.110811] INFO: task systemd:1 blocked for more than 120 seconds.
[ +0.000004] Tainted: G S W 6.4.0+ #39
[ +0.000001] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ +0.000001] task:systemd state:D stack:0 pid:1 ppid:0 flags:0x00000002
[ +0.000003] Call Trace:
[ +0.000002] <TASK>
[ +0.000003] __schedule+0x3d5/0x15f0
[ +0.000008] schedule+0x68/0x110
[ +0.000002] schedule_timeout+0x151/0x160
[ +0.000004] ? get_page_from_freelist+0x6a4/0x1450
[ +0.000005] __wait_for_common+0x8f/0x190
[ +0.000003] ? __pfx_schedule_timeout+0x10/0x10
[ +0.000002] wait_for_completion+0x24/0x40
[ +0.000003] __wait_rcu_gp+0x137/0x140
[ +0.000004] synchronize_rcu+0x10b/0x120
[ +0.000002] ? __pfx_call_rcu_hurry+0x10/0x10
[ +0.000002] ? __pfx_wakeme_after_rcu+0x10/0x10
[ +0.000002] rcu_sync_enter+0x58/0xf0
[ +0.000002] ? _kstrtoull+0x3b/0xa0
[ +0.000004] percpu_down_write+0x2b/0x1d0
[ +0.000002] cgroup_procs_write_start+0x105/0x180
[ +0.000003] __cgroup_procs_write+0x5d/0x180
[ +0.000002] cgroup_procs_write+0x17/0x30
[ +0.000002] cgroup_file_write+0x8c/0x190
[ +0.000003] ? __check_object_size+0x2a3/0x310
[ +0.000005] kernfs_fop_write_iter+0x153/0x1e0
[ +0.000004] vfs_write+0x2cf/0x400
[ +0.000004] ksys_write+0x67/0xf0
[ +0.000001] __x64_sys_write+0x19/0x30
[ +0.000001] do_syscall_64+0x59/0x90
[ +0.000004] ? count_memcg_events.constprop.0+0x2a/0x50
[ +0.000004] ? handle_mm_fault+0x1e7/0x350
[ +0.000002] ? exit_to_user_mode_prepare+0x39/0x190
[ +0.000005] ? irqentry_exit_to_user_mode+0x9/0x20
[ +0.000002] ? irqentry_exit+0x43/0x50
[ +0.000001] ? exc_page_fault+0x95/0x1b0
[ +0.000002] entry_SYSCALL_64_after_hwframe+0x6e/0xd8
[ +0.000002] RIP: 0033:0x7f9a68314a6f
[ +0.000002] RSP: 002b:00007fffd0e52350 EFLAGS: 00000293 ORIG_RAX: 0000000000000001
[ +0.000002] RAX: ffffffffffffffda RBX: 0000000000000008 RCX: 00007f9a68314a6f
[ +0.000001] RDX: 0000000000000008 RSI: 00007fffd0e5250a RDI: 0000000000000019
[ +0.000001] RBP: 00007fffd0e5250a R08: 0000000000000000 R09: 00007fffd0e52390
[ +0.000001] R10: 0000000000000000 R11: 0000000000000293 R12: 0000000000000008
[ +0.000001] R13: 00005644ec569cb0 R14: 00007f9a68415a00 R15: 0000000000000008
[ +0.000002] </TASK>
[ +0.000095] INFO: task systemd-journal:1199 blocked for more than 120 seconds.
[ +0.000002] Tainted: G S W 6.4.0+ #39
[ +0.000000] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ +0.000001] task:systemd-journal state:D stack:0 pid:1199 ppid:1 flags:0x00000002
[ +0.000002] Call Trace:
[ +0.000001] <TASK>
[ +0.000001] __schedule+0x3d5/0x15f0
[ +0.000003] ? __mod_memcg_lruvec_state+0x8f/0x130
[ +0.000003] schedule+0x68/0x110
[ +0.000003] schedule_preempt_disabled+0x15/0x30
[ +0.000002] __mutex_lock.constprop.0+0x3d8/0x770
[ +0.000002] __mutex_lock_slowpath+0x13/0x20
[ +0.000002] mutex_lock+0x3e/0x50
[ +0.000001] proc_cgroup_show+0x4c/0x450
[ +0.000002] proc_single_show+0x53/0xe0
[ +0.000004] seq_read_iter+0x132/0x4e0
[ +0.000004] seq_read+0xa5/0xe0
[ +0.000003] vfs_read+0xb1/0x320
[ +0.000002] ? __seccomp_filter+0x3df/0x5e0
[ +0.000003] ksys_read+0x67/0xf0
[ +0.000002] __x64_sys_read+0x19/0x30
[ +0.000001] do_syscall_64+0x59/0x90
[ +0.000003] ? exit_to_user_mode_prepare+0x39/0x190
[ +0.000003] ? syscall_exit_to_user_mode+0x2a/0x50
[ +0.000002] ? do_syscall_64+0x69/0x90
[ +0.000002] ? do_syscall_64+0x69/0x90
[ +0.000002] ? syscall_exit_to_user_mode+0x2a/0x50
[ +0.000002] ? do_syscall_64+0x69/0x90
[ +0.000002] ? do_syscall_64+0x69/0x90
[ +0.000002] entry_SYSCALL_64_after_hwframe+0x6e/0xd8
[ +0.000001] RIP: 0033:0x7f5106d149cc
[ +0.000001] RSP: 002b:00007ffe61c321c0 EFLAGS: 00000246 ORIG_RAX: 0000000000000000
[ +0.000002] RAX: ffffffffffffffda RBX: 0000564ccf0b8210 RCX: 00007f5106d149cc
[ +0.000001] RDX: 0000000000000400 RSI: 0000564ccf0b7b10 RDI: 0000000000000024
[ +0.000001] RBP: 00007f5106e16600 R08: 0000000000000000 R09: 0000000000000001
[ +0.000000] R10: 0000000000001000 R11: 0000000000000246 R12: 00007f51072cf6c8
[ +0.000001] R13: 0000000000000d68 R14: 00007f5106e15a00 R15: 0000000000000d68
[ +0.000002] </TASK>
[ +0.000128] INFO: task (piserver):1607062 blocked for more than 120 seconds.
[ +0.000001] Tainted: G S W 6.4.0+ #39
[ +0.000001] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ +0.000000] task:(piserver) state:D stack:0 pid:1607062 ppid:1 flags:0x00000002
[ +0.000002] Call Trace:
[ +0.000001] <TASK>
[ +0.000001] __schedule+0x3d5/0x15f0
[ +0.000002] ? __kmem_cache_alloc_node+0x1b1/0x320
[ +0.000003] schedule+0x68/0x110
[ +0.000003] schedule_preempt_disabled+0x15/0x30
[ +0.000002] __mutex_lock.constprop.0+0x3d8/0x770
[ +0.000002] __mutex_lock_slowpath+0x13/0x20
[ +0.000001] mutex_lock+0x3e/0x50
[ +0.000002] cgroup_kn_lock_live+0x47/0xf0
[ +0.000002] __cgroup_procs_write+0x3e/0x180
[ +0.000002] cgroup_procs_write+0x17/0x30
[ +0.000002] cgroup_file_write+0x8c/0x190
[ +0.000001] ? __check_object_size+0x2a3/0x310
[ +0.000003] kernfs_fop_write_iter+0x153/0x1e0
[ +0.000002] vfs_write+0x2cf/0x400
[ +0.000003] ksys_write+0x67/0xf0
[ +0.000002] __x64_sys_write+0x19/0x30
[ +0.000001] do_syscall_64+0x59/0x90
[ +0.000002] ? exit_to_user_mode_prepare+0x39/0x190
[ +0.000003] ? irqentry_exit_to_user_mode+0x9/0x20
[ +0.000002] ? irqentry_exit+0x43/0x50
[ +0.000001] ? exc_page_fault+0x95/0x1b0
[ +0.000001] entry_SYSCALL_64_after_hwframe+0x6e/0xd8
[ +0.000002] RIP: 0033:0x7f9a68314a6f
[ +0.000000] RSP: 002b:00007fffd0e51fd0 EFLAGS: 00000293 ORIG_RAX: 0000000000000001
[ +0.000002] RAX: ffffffffffffffda RBX: 0000000000000008 RCX: 00007f9a68314a6f
[ +0.000000] RDX: 0000000000000008 RSI: 00007fffd0e5218a RDI: 0000000000000003
[ +0.000001] RBP: 00007fffd0e5218a R08: 0000000000000000 R09: 00007fffd0e52010
[ +0.000001] R10: 0000000000000000 R11: 0000000000000293 R12: 0000000000000008
[ +0.000001] R13: 00005644ec569cb0 R14: 00007f9a68415a00 R15: 0000000000000008
[ +0.000001] </TASK>
[ +6.996450] audit: type=1400 audit(1690245873.626:157): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619065/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +7.175238] audit: type=1400 audit(1690245880.798:158): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619108/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +2.931534] audit: type=1400 audit(1690245883.730:159): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619127/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.105076] audit: type=1400 audit(1690245893.838:160): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619155/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[Jul25 00:45] audit: type=1400 audit(1690245903.942:161): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619200/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.106562] audit: type=1400 audit(1690245914.050:162): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619272/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +3.439124] rcu: INFO: rcu_preempt detected stalls on CPUs/tasks:
[ +0.000003] rcu: Tasks blocked on level-1 rcu_node (CPUs 0-15): P1010/5:b..l
[ +0.000009] rcu: (detected by 11, t=60007 jiffies, g=122497, q=1502891 ncpus=96)
[ +0.000006] task:kworker/u193:11 state:I stack:0 pid:1010 ppid:2 flags:0x00004000
[ +0.000004] Workqueue: 0x0 (events_power_efficient)
[ +0.000005] Call Trace:
[ +0.000002] <TASK>
[ +0.000002] __schedule+0x3d5/0x15f0
[ +0.000006] ? add_timer+0x20/0x40
[ +0.000005] ? queue_delayed_work_on+0x6e/0x80
[ +0.000004] ? _raw_write_unlock_bh+0x1a/0x30
[ +0.000003] schedule+0x68/0x110
[ +0.000003] worker_thread+0xbd/0x3f0
[ +0.000002] ? __pfx_worker_thread+0x10/0x10
[ +0.000002] kthread+0xf4/0x130
[ +0.000004] ? __pfx_kthread+0x10/0x10
[ +0.000002] ret_from_fork+0x29/0x50
[ +0.000006] </TASK>
[ +6.666093] audit: type=1400 audit(1690245924.154:163): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619338/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.107491] audit: type=1400 audit(1690245934.262:164): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619459/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.106095] audit: type=1400 audit(1690245944.366:165): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619506/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[ +10.107349] audit: type=1400 audit(1690245954.474:166): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619537/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
[Jul25 00:46] audit: type=1400 audit(1690245964.582:167): apparmor="ALLOWED" operation="open" class="file" profile="/usr/sbin/sssd" name="/proc/1619565/cmdline" pid=1942 comm="sssd_nss" requested_mask="r" denied_mask="r" fsuid=0 ouid=0
The syndrome above is first get rcu read-side critical section been violated cuased by following code. Then jiffies will be wrong and core dump process caused by increasing jiffies and died because of VM_FAULT_OOM leaked out to the #PF handler. Retrying PF.
bool bede_flush_node_rss(struct mem_cgroup *memcg) { // work around for every time call policy_node for delayed
int nid;
if (mem_cgroup_disabled()){
return false;
}
mem_cgroup_flush_stats();
for_each_node_state(nid, N_MEMORY) {
u64 size;
struct lruvec *lruvec;
pg_data_t *pgdat = NODE_DATA(nid);
if (!pgdat)
return false;
lruvec = mem_cgroup_lruvec(memcg, pgdat);
if (!lruvec)
return false;
size = lruvec_page_state_local(lruvec, NR_ANON_MAPPED) >> PAGE_SHIFT;
memcg->node_rss[nid] = size >> 20;
}
return true;
}
...
int policy_node(gfp_t gfp, struct mempolicy *policy, int nd)
{
if (policy->mode != MPOL_BIND && bede_should_policy) {
struct mem_cgroup *memcg = get_mem_cgroup_from_mm(current->mm);
if (memcg && root_mem_cgroup && memcg != root_mem_cgroup) {
if (bede_flush_node_rss(memcg)) {
// bede_append_page_walk_and_migration(current->cgroups->dfl_cgrp->bede);
nd = bede_get_node(memcg, nd);
return nd;
}
}
}
I tried https://lwn.net/Articles/916583/ and https://lwn.net/Articles/916583/. And I thought the race is possibly interrupt that caused into __mod_node_page_state, or memcg may encounter TOUTOC bug. I decided not to put un-preemptable job into hot path.
Current Status in 6.6.0-4c4
Debug Interface
Motivation
For an orchestration system, resource management needs to consider at least the following aspects:
-
An abstraction of the resource model; including,
- What kinds of resources are there, for example, CPU, memory (local vs remote that can be transparent to the user), etc.;
- How to represent these resources with data structures;
- resource scheduling
- How to describe a resource application (spec) of a workload, for example, "This container requires 4 cores and 12GB~16GB(4GB local/ 8GB-12GB remote) of memory";
- How to describe the current resource allocation status of a node, such as the amount of allocated/unallocated resources, whether it supports over-segmentation, etc.;
- Scheduling algorithm: how to select the most suitable node for it according to the workload spec;
-
Resource quota
- How to ensure that the amount of resources used by the workload does not exceed the preset range (so as not to affect other workloads);
- How to ensure the quota of workload and system/basic service so that the two do not affect each other.
-
What if add the CXL 3.0 and fabric manager?
- CXL 2.0 introduces switching functionality similar to PCIe switching, but because CXL supports LD-ST memory access by the CPU, you'll not only be able to deploy memory at a distance for far-memory capacity scaling, but enable multiple systems to take advantage of it in what's called memory pooling. The significant difference between SLDs and MLDs appears in memory pooling
- The 3.0 spec also provides means for direct peer-to-peer communications over switches and fabrics. This means peripherals — say two GPUs or a GPU and memory-expansion module — could theoretically talk to one another without the host CPU's involvement, which eliminates the CPU as a potential checkpoint.
k8s resource model
Compared with the above questions, let's see how k8s is designed:
- Resource model
- Abstract resource types such as cpu/memory/device/hugepage;
- Abstract the concept of node;
- Resource Scheduling
requestThe two concepts of and are abstractedlimit, respectively representing the minimum (request) and maximum (limit) resources required by a container;AllocatableThe scheduling algorithm selects the appropriate node for the container according to the amount of resources currently available for allocation ( ) of each node ; Note that k8s scheduling only looks at requests, not limits .
- Resource enforcement
- Use cgroups to ensure that the maximum amount of resources used by a workload does not exceed the specified limits at multiple levels.
An example of a resource application (container):
apiVersion: v2
kind: Pod
spec:
containers:
- name: busybox
image: busybox
resources:
limits:
cpu: 500m
memory: "400Mi"
requests:
cpu: 250m
memory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
Here, requests and limits represent the minimum and maximum values of required resources.
- The unit of CPU resources
mismillicoresthe abbreviation, which means one-thousandth of a core, socpu: 500mmeans that0.5a core is required; - The unit of memory is well understood, that is, common units such as MB and GB.
Node resource abstraction
$ k describe node <node>
...
Capacity:
cpu: 48
mem-hard-eviction-threshold: 500Mi
mem-soft-eviction-threshold: 1536Mi
memory: 263192560Ki
pods: 256
Allocatable:
cpu: 46
memory: 258486256Ki
pods: 256
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 800m (1%) 7200m (15%)
memory 1000Mi (0%) 7324Mi (2%)
hugepages-1Gi 0 (0%) 0 (0%)
...
Let's look at these parts separately.
Capacity
The total resources of this node (which can be simply understood as physical configuration ), for example, the above output shows that this node has 48CPU, 256GB memory, and so on.
Allocatable
The total amount of resources that can be allocated by k8s , obviously, Allocatable will not exceed Capacity, for example, there are 2 less CPUs as seen above, and only 46 are left.
Allocated
The amount of resources that this node has allocated so far, note that the message also said that the node may be oversubscribed , so the sum may exceed Allocatable, but it will not exceed Capacity.
Allocatable does not exceed Capacity, and this concept is also well understood; but which resources are allocated specifically , causing Allocatable < Capacityit?
Node resource segmentation (reserved)
Because k8s-related basic services such as kubelet/docker/containerd and other operating system processes such as systemd/journald run on each node, not all resources of a node can be used to create pods for k8s. Therefore, when k8s manages and schedules resources, it needs to separate out the resource usage and enforcement of these basic services.
To this end, k8s proposed the Node Allocatable Resources[1] proposal, from which the above terms such as Capacity and Allocatable come from. A few notes:
- If Allocatable is available, the scheduler will use Allocatable, otherwise it will use Capacity;
- Using Allocatable is not overcommit, using Capacity is overcommit;
Calculation formula: [Allocatable] = [NodeCapacity] - [KubeReserved] - [SystemReserved] - [HardEvictionThreshold]
Let’s look at these types separately.
System Reserved
Basic services of the operating system, such as systemd, journald, etc., are outside k8s management . k8s cannot manage the allocation of these resources, but it can manage the enforcement of these resources, as we will see later.
Kube Reserved
k8s infrastructure services, including kubelet/docker/containerd, etc. Similar to the system services above, k8s cannot manage the allocation of these resources, but it can manage the enforcement of these resources, as we will see later.
EvictionThreshold (eviction threshold)
When resources such as node memory/disk are about to be exhausted, kubelet starts to expel pods according to the QoS priority (best effort/burstable/guaranteed) , and eviction resources are reserved for this purpose.
Allocatable
Resources available for k8s to create pods.
The above is the basic resource model of k8s. Let's look at a few related configuration parameters.
Kubelet related configuration parameters

kubelet command parameters related to resource reservation (segmentation):
--system-reserved=""--kube-reserved=""--qos-reserved=""--reserved-cpus=""
It can also be configured via the kubelet, for example,
$ cat /etc/kubernetes/kubelet/config
...
systemReserved:
cpu: "2"
memory: "4Gi"
Do you need to use a dedicated cgroup for resource quotas for these reserved resources to ensure that they do not affect each other:
--kube-reserved-cgroup=""--system-reserved-cgroup=""
The default is not enabled. In fact, it is difficult to achieve complete isolation. The consequence is that the system process and the pod process may affect each other. For example, as of v1.26, k8s does not support IO isolation, so the IO of the host process (such as log rotate) soars, or when a pod process executes java dump, It will affect all pods on this node.
The k8s resource model will be introduced here first, and then enter the focus of this article, how k8s uses cgroups to limit the resource usage of workloads such as containers, pods, and basic services (enforcement).
k8s cgroup design
cgroup base
groups are Linux kernel infrastructures that can limit, record and isolate the amount of resources (CPU, memory, IO, etc.) used by process groups.
There are two versions of cgroup, v1 and v2. For the difference between the two, please refer to Control Group v2. Since it's already 2023, we focus on v2. The cgroup v1 exposes more memory stats like swapiness, and all the control is flat control, v2 exposes only cpuset and memory and exposes the hierarchy view.
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
$ root@banana:~/CXLMemSim/microbench# ls /sys/fs/cgroup
cgroup.controllers cpuset.mems.effective memory.reclaim
cgroup.max.depth dev-hugepages.mount memory.stat
cgroup.max.descendants dev-mqueue.mount misc.capacity
cgroup.pressure init.scope misc.current
cgroup.procs io.cost.model sys-fs-fuse-connections.mount
cgroup.stat io.cost.qos sys-kernel-config.mount
cgroup.subtree_control io.pressure sys-kernel-debug.mount
cgroup.threads io.prio.class sys-kernel-tracing.mount
cpu.pressure io.stat system.slice
cpu.stat memory.numa_stat user.slice
cpuset.cpus.effective memory.pressure yyw
$ root@banana:~/CXLMemSim/microbench# ls /sys/fs/cgroup/yyw
cgroup.controllers cpu.uclamp.max memory.oom.group
cgroup.events cpu.uclamp.min memory.peak
cgroup.freeze cpu.weight memory.pressure
cgroup.kill cpu.weight.nice memory.reclaim
cgroup.max.depth io.pressure memory.stat
cgroup.max.descendants memory.current memory.swap.current
cgroup.pressure memory.events memory.swap.events
cgroup.procs memory.events.local memory.swap.high
cgroup.stat memory.high memory.swap.max
cgroup.subtree_control memory.low memory.swap.peak
cgroup.threads memory.max memory.zswap.current
cgroup.type memory.min memory.zswap.max
cpu.idle memory.node_limit1 pids.current
cpu.max memory.node_limit2 pids.events
cpu.max.burst memory.node_limit3 pids.max
cpu.pressure memory.node_limit4 pids.peak
cpu.stat memory.numa_stat
The procfs is registered using the API cftype that updates on every access the memroy.numa_stat
anon N0=0 N1=0
file N0=4211032064 N1=13505200128
kernel_stack N0=0 N1=0
pagetables N0=0 N1=0
sec_pagetables N0=0 N1=0
shmem N0=0 N1=0
file_mapped N0=0 N1=0
file_dirty N0=0 N1=0
file_writeback N0=0 N1=0
swapcached N0=0 N1=0
anon_thp N0=0 N1=0
file_thp N0=0 N1=0
shmem_thp N0=0 N1=0
inactive_anon N0=0 N1=0
active_anon N0=0 N1=0
inactive_file N0=4176166912 N1=11106676736
active_file N0=34865152 N1=2398523392
unevictable N0=0 N1=0
slab_reclaimable N0=21441072 N1=19589888
slab_unreclaimable N0=136 N1=0
workingset_refault_anon N0=0 N1=0
workingset_refault_file N0=0 N1=0
workingset_activate_anon N0=0 N1=0
workingset_activate_file N0=0 N1=0
workingset_restore_anon N0=0 N1=0
workingset_restore_file N0=0 N1=0
workingset_nodereclaim N0=0 N1=0
Cgroup manager is an interface to support
In pkg/kubelet/cm/qos_container_manager_linux.go:90 will initialize 2 sub directory in /sys/fs/cgroup/kubepods/ to control burstable and besteffort qos.
// Top level for Qos containers are created only for Burstable
// and Best Effort classes
qosClasses := map[v1.PodQOSClass]CgroupName{
v1.PodQOSBurstable: NewCgroupName(rootContainer, strings.ToLower(string(v1.PodQOSBurstable))),
v1.PodQOSBestEffort: NewCgroupName(rootContainer, strings.ToLower(string(v1.PodQOSBestEffort))),
}
For cgroup container manager, the api are described in kubelet as below. every once in a while, even if the cgroup scheduler does nothing, it will 1. periodically check the cgroup memory pod and check whether need to reserve more memory or from one qos group to the other. On calling setMemoryReserve, it will updates memory.max in the corresponding pod cgroup path. Other checking stats of cgroup path is defined in vendor/github.com/google/cadvisor/manager/container.go
type qosContainerManagerImpl struct {
sync.Mutex
qosContainersInfo QOSContainersInfo
subsystems *CgroupSubsystems
cgroupManager CgroupManager
activePods ActivePodsFunc
getNodeAllocatable func() v1.ResourceList
cgroupRoot CgroupName
qosReserved map[v1.ResourceName]int64
}
// CgroupManager allows for cgroup management.
// Supports Cgroup Creation ,Deletion and Updates.
type CgroupManager interface {
// Create creates and applies the cgroup configurations on the cgroup.
// It just creates the leaf cgroups.
// It expects the parent cgroup to already exist.
Create(*CgroupConfig) error
// Destroy the cgroup.
Destroy(*CgroupConfig) error
// Update cgroup configuration.
Update(*CgroupConfig) error
// Validate checks if the cgroup is valid
Validate(name CgroupName) error
// Exists checks if the cgroup already exists
Exists(name CgroupName) bool
// Name returns the literal cgroupfs name on the host after any driver specific conversions.
// We would expect systemd implementation to make appropriate name conversion.
// For example, if we pass {"foo", "bar"}
// then systemd should convert the name to something like
// foo.slice/foo-bar.slice
Name(name CgroupName) string
// CgroupName converts the literal cgroupfs name on the host to an internal identifier.
CgroupName(name string) CgroupName
// Pids scans through all subsystems to find pids associated with specified cgroup.
Pids(name CgroupName) []int
// ReduceCPULimits reduces the CPU CFS values to the minimum amount of shares.
ReduceCPULimits(cgroupName CgroupName) error
// MemoryUsage returns current memory usage of the specified cgroup, as read from the cgroupfs.
MemoryUsage(name CgroupName) (int64, error)
// Get the resource config values applied to the cgroup for specified resource type
GetCgroupConfig(name CgroupName, resource v1.ResourceName) (*ResourceConfig, error)
// Set resource config for the specified resource type on the cgroup
SetCgroupConfig(name CgroupName, resource v1.ResourceName, resourceConfig *ResourceConfig) error
}
For memory scheduler in the scheduler, k8s defined:
// Manager interface provides methods for Kubelet to manage pod memory.
type Manager interface {
// Start is called during Kubelet initialization.
Start(activePods ActivePodsFunc, sourcesReady config.SourcesReady, podStatusProvider status.PodStatusProvider, containerRuntime runtimeService, initialContainers containermap.ContainerMap) error
// AddContainer adds the mapping between container ID to pod UID and the container name
// The mapping used to remove the memory allocation during the container removal
AddContainer(p *v1.Pod, c *v1.Container, containerID string)
// Allocate is called to pre-allocate memory resources during Pod admission.
// This must be called at some point prior to the AddContainer() call for a container, e.g. at pod admission time.
Allocate(pod *v1.Pod, container *v1.Container) error
// RemoveContainer is called after Kubelet decides to kill or delete a
// container. After this call, any memory allocated to the container is freed.
RemoveContainer(containerID string) error
// State returns a read-only interface to the internal memory manager state.
State() state.Reader
// GetTopologyHints implements the topologymanager.HintProvider Interface
// and is consulted to achieve NUMA aware resource alignment among this
// and other resource controllers.
GetTopologyHints(*v1.Pod, *v1.Container) map[string][]topologymanager.TopologyHint
// GetPodTopologyHints implements the topologymanager.HintProvider Interface
// and is consulted to achieve NUMA aware resource alignment among this
// and other resource controllers.
GetPodTopologyHints(*v1.Pod) map[string][]topologymanager.TopologyHint
// GetMemoryNUMANodes provides NUMA nodes that are used to allocate the container memory
GetMemoryNUMANodes(pod *v1.Pod, container *v1.Container) sets.Int
// GetAllocatableMemory returns the amount of allocatable memory for each NUMA node
GetAllocatableMemory() []state.Block
// GetMemory returns the memory allocated by a container from NUMA nodes
GetMemory(podUID, containerName string) []state.Block
}
Record and Replay
We have an idea of bringing "performance record and replay" onto the table in the CXL world and been supported in the first place inside Arch.
Assumption
- What's the virtualization of CPU?
- General Register State.
- C State, P State and machine state registers like performance counter.
- CPU Extensions abstraction by record and replay. You normally interact with Intel extensions with drivers that maps certain address to it and get the results after callback. Or even you are doing MPX-like style VMEXIT VMENTER. They are actually the same as CXL devices because in the scenario of UCIe, every extension is a device and talk to others through CXL link. the difference is only the cost model of latency and bandwidth.
- What's the virtualization of memory?
- MMU - process abstraction
- boundary check
- What's the virtualization of CXL devices in terms of CPU?
- Requests in the CXL link
- What's the virtualization of CXL devices in terms of outer devices?
- VFIO
- SRIOV
- DDA
Implementation
- Bus monitor
- CXL Address Translation Service
- CXL Address Translation Service
- Possible Implementation
- MVVM, we can actually leverage the
- J Extension with mmap memory for stall cycles until observed signal
Dynamic Program Instrumentation
We currently have such instrumentation techniques:
- ptrace
- int 3
- syscall intercept sound disassembler between int 0x80
- kprobe
- kretprobe
- LD_PRELOAD
- zpoline use a zero page for trampoline.
Dynamic GPU ABI Instrumentation
Based upon the GPU call ABI, you can generate a trampoline to intercept the call just like CPU.
AMD CPU has multiple GPU context in the same SMs, while Nvidia need to have persistent kernel to hack the mps. And it's easier to do Dynamic GPU ABI Instrumentation on AMD GPU. The ABI translation can be found in the CuPBoP-AMD.
- NVIDIA Nsight Systems which leverage CUPTI.
- ROCTracer
- OmniTrace
- NVBIT which leverages PTX JIT
Reference
- https://www.youtube.com/watch?v=aC_X0WU-tGM
- https://www.usenix.org/system/files/atc23_slides_yasukata.pdf
The general purpose usage of inserting bpf and modify state in kernel
I'm leveraging kretprobe_overwrite_return, an API was supposed to inject the fault to arbitrary kernel function. Latest Intel CPU has codesign for not flushing the ROB for these trampolines.
kprobe impl
instrument on any instruction to jmp to pre_handler->function
kretprobe impl
__kretprobe_trampoline_handler to hijack the pc to the trampoline code
uprobe impl
trap the user space instruction to pre_handler->function
bpftime impl
make a map in the userspace and use LLVM JIT to hook the function to write the map, no context switch, no ROB flush
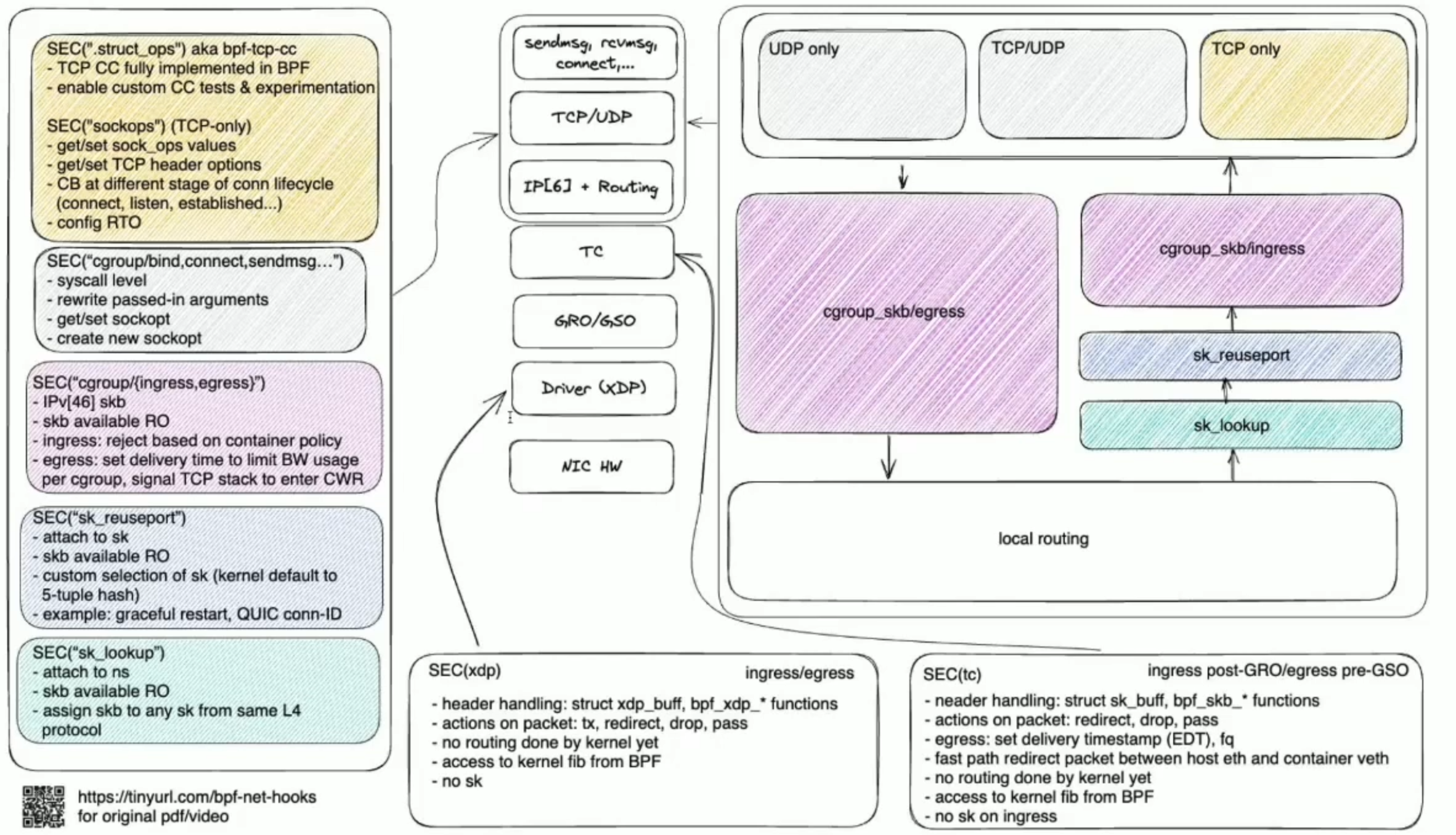
eBPF hardening tool
The Linux kernel has its eBPF verifier that achieves these guarantees by undertaking a strict static analysis across all eBPF programs, checking all paths for invalid memory accesses and disallowing loops to ensure termination.
- Spectre v1 Bound check bypass (mitigated by lfence or verifier)
- Spectre v2 Branch Target Injection (before loaded to the kernel mitigated by disabling interpreter)
- unprivileged BPF for SOCKET_FILTER and CGROUP_SKB only
Replace UserBypass
Compare with SFI way of protecting the boundary, the static compilation with security checks that do not introduce extra checking is always expensive.
Replace XRP
XRP's idea is syscall batching. We can take the mmaped buffer as a fast pass to User space programming offloading the file system operations to the firmware. io_uring or BPF FUSE has already gotten into the senario.
Need data plane in cross boundary communication. control plan in separate U/K.
Current userspace kernel space interaction
- Bpf Arena https://lwn.net/Articles/961594/
- Share user memory to BPF program through task storage map. https://lore.kernel.org/bpf/[email protected]
- bpf_probe_write_user_register https://lore.kernel.org/bpf/[email protected]/
Why eBPF for security is wrong
BPF_LSM on loading will enter a previledge mode, it will be hard to maintain the context whether the current thread's permission for memory is complicated, and with page fault or EL1->EL2(arm) change will be hard to maintain.
- can read arbitrary kernel data (can not be per cgroup)
- can deny operations
- can sleep
KFuncs explosion
We can see much more KFuncs is exported for helper function and verification. https://ebpf-docs.dylanreimerink.nl/linux/kfuncs/
Hot topics
- scheduler + bpf
- hid + bpf
- joystick
- oom + bpf
- cgroup + bpf
- rdma + bpf
- fuse + bpf
- userfaultfd + bpf
Reference
- https://lore.kernel.org/lkml/[email protected]/T/
- https://www.kernel.org/doc/html/latest/bpf/index.html
- https://www.youtube.com/watch?v=kvt4wdXEuRU
Perf is powerful
Perf can init bpf, performance counters, kprobes, uprobes, and tracepoints. basically observing the uncore and kernel metrics entry point, wraps all the initial procedure of init bpf jit, msr & set PMU Control register, redirect the PC and hijack the return of kretprobe and partially set ltrace point conditional one instruction. It also wraps the ending procedure of unmap the jit, recover the msr state, and clean the process. The essence of everything is a file manifests in the parameter can be either process-wise or system-wise, all CPU or single CPU. The problem is once you wrap everything into file abstraction, you still need to make sure they might be incorrect because of what. TOUTOC, register cfi, undocumented operations etc.
Kernel and CPU preparation of get solid results
flush_fs_caches()
{
echo 3 | sudo tee /proc/sys/vm/drop_caches >/dev/null 2>&1
sleep 10
}
disable_nmi_watchdog()
{
echo 0 | sudo tee /proc/sys/kernel/nmi_watchdog >/dev/null 2>&1
}
disable_turbo()
{
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo >/dev/null 2>&1
}
# 0: no randomization, everyting is static
# 1: conservative randomization, shared libraries, stack, mmap(), VDSO and heap
# are randomized
# 2: full randomization, the above points in 1 plus brk()
disable_va_aslr()
{
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space >/dev/null 2>&1
}
disable_swap()
{
sudo swapoff -a
}
disable_ksm()
{
echo 0 | sudo tee /sys/kernel/mm/ksm/run >/dev/null 2>&1
}
disable_numa_balancing()
{
echo 0 | sudo tee /proc/sys/kernel/numa_balancing >/dev/null 2>&1
}
# disable transparent hugepages
disable_thp()
{
echo "never" | sudo tee /sys/kernel/mm/transparent_hugepage/enabled >/dev/null 2>&1
}
enable_turbo()
{
echo 0 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo >/dev/null 2>&1
}
disable_ht()
{
echo off | sudo tee /sys/devices/system/cpu/smt/control >/dev/null 2>&1
}
disable_node1_cpus()
{
echo 0 | sudo tee /sys/devices/system/node/node1/cpu*/online >/dev/null 2>&1
}
set_performance_mode()
{
#echo " ===> Placing CPUs in performance mode ..."
for governor in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do
echo performance | sudo tee $governor >/dev/null 2>&1
done
}
disable_node1_mem()
{
echo 0 | sudo tee /sys/devices/system/node/node1/memory*/online >/dev/null 2>&1
}
# Keep all cores on Node 0 online while keeping all cores on Node 1 offline
disable_node1_core()
{
echo 0 | sudo tee /sys/devices/system/node/node1/cpu*/online >/dev/null 2>&1
}
# Can do it in bios https://www.supermicro.com/manuals/motherboard/X13/MNL-2470.pdf
disable_kti_prefetcher()
{
}
# Can do it in msr https://www.intel.com/content/www/us/en/developer/articles/technical/software-security-guidance/technical-documentation/cpuid-enumeration-and-architectural-msrs.html
disable_dmp_prefetcher()
{
wrmsr -a 0x48 0x8
}
The general initial process of perf
PerfInfo::PerfInfo(int group_fd, int cpu, pid_t pid, unsigned long flags, struct perf_event_attr attr)
: group_fd(group_fd), cpu(cpu), pid(pid), flags(flags), attr(attr) {
this->fd = perf_event_open(&this->attr, this->pid, this->cpu, this->group_fd, this->flags);
if (this->fd == -1) {
LOG(ERROR) << "perf_event_open";
throw;
}
ioctl(this->fd, PERF_EVENT_IOC_RESET, 0);
}
PerfInfo::PerfInfo(int fd, int group_fd, int cpu, pid_t pid, unsigned long flags, struct perf_event_attr attr)
: fd(fd), group_fd(group_fd), cpu(cpu), pid(pid), flags(flags), attr(attr) {
this->map = new ThreadSafeMap();
this->j = std::jthread{[&] { write_trace_to_map(map); }};
}
PerfInfo::~PerfInfo() {
this->j.join();
if (this->fd != -1) {
close(this->fd);
this->fd = -1;
}
}
ssize_t PerfInfo::read_pmu(uint64_t *value) {
ssize_t r = read(this->fd, value, sizeof(*value));
if (r < 0) {
LOG(ERROR) << "read";
}
return r;
}
int PerfInfo::start() {
if (ioctl(this->fd, PERF_EVENT_IOC_ENABLE, 0) < 0) {
LOG(ERROR) << "ioctl";
return -1;
}
return 0;
}
int PerfInfo::stop() {
if (ioctl(this->fd, PERF_EVENT_IOC_DISABLE, 0) < 0) {
LOG(ERROR) << "ioctl";
return -1;
}
return 0;
}
Limitation of attaching pmu
Limit to 4, because ctr only has 4 for each cha
Reference
- https://github.com/intel/pcm
Memory Tagging
- Linear Memory Masking
- Its usage Multi-Tag
- Sub-page granularity Sub-page Memory Write Protection
- Memory Tagging Extension
In this section, I'm proposing the reinforcement learning for system design. We made fundamental API and primitive for devops, scheduling and live migration decisions.
Fuzzing for kernel
LLM for Code Generation
Need logic guided learning for code generation. Recent LLM works have put more focus on ground truth-oriented code generation, which also helps the code repairing and debugging. LLMs have demonstrated state-of-the-art performance in code synthesis. Primary applications involve structured communication with computer systems, like creating programs from natural language descriptions, assisting with code completion, debugging, and producing documentation.
SoTA use of LLM
Normally, people fine-tune models either with a better dataset from Google Search and Youtube’s user browsing history that Google’s Gemini[21] trained with, the GitHub codebase that Github Copilot by Microsoft trained with, or Stack Overflow answers that OpenAI’s ChatGPT trained with, or a better transformer layer that memorizes more context, which for reaching the goal, researchers typically add more layer depths, speculative decoding or token compression. There are other ways, like RWKV, that reuse the neural network of RNN with inference memory hardened, which is easily deployed in edge endpoints but is still not production ready.
LLM for logic proof
LLM logic proof, like LogicGuide in is useful for getting correct semantics that is self-provable. It takes the underlying logic for every logic unit, which could be "if", "despite", or "because". The auto-generated logic, the evaluateable sequence, will be fed into the logic solver, and the final result complies with the logic's result. Or like Optimizer in uses LLM itself to instill the logic does not make the direction to the correction. Because it's unlike Alpha-Zero, the last self-competing training will converge to the true results anyway with the remaining exploration winning metrics. In the logic-proof space, there's no foundation for the reward function easily written. These approaches neither make a mapping to the code logic nor have an automatically re-prompting mechanism.
LLM for neural fuzzing
The LLM for neural fuzzing is a new type of code semantic understanding; we think the coverage-based method is legacy since the LLM should know the context if we optimize for this metric; it will be in trouble not getting the real work done because LLM can internally know the job and does not generate well-grounded-truth-guided code.
Z3 for Verification
I think the Z3 is a good tool for verification. LLM can know the stable mapping from natural language to z3 language for learning new things. However, the reasoning ability of LLM tools is an open problem. We still couldn’t say with no prior knowledge or similar questions before; it can provide a logical prompt. During the training, since the code generation maintains the logic preserving property, Code LLAMA will utilize every instruction logic point done by infilling, understanding the long context, and codegen the best choice based on Reinforcement learning from fine-tuned human feedback(RLHF), this feedback can be programmer’s alignment, not necessarily the general public’s alignment. Feedback based on this feedback will store the previous context to maintain the code’s correctness.The problem with this is the RLHF is only maintaining the correctness mapping for the function code generation but not the exact semantic mapping for each sentence and corresponding functions’ state, even with the best feedback. Thus, we need extra information with the kernel, and re-prompt the LLM for rethinking the context and codegen the corresponding functions’ state.
- good to map the compiler for LLM to understand
- Is there a way of Reinforcement Learning with compiler groud-truth guided.
- The compiling and verification leaks information that is sound for LLM to learn.
Z3 for Logic Proof
LLM for auto code logic proof has other implementations for C code applying CMBC or other formal verification during training and prompting. eBPF is a more domain-specific way of proving stable mapping from the underlying logic.
Reference
- KEN: Kernel Extensions using Natural Language
RTl
I'm getting to hands on RTL to make hardware part of my thinking, especially to fulfill the Slug Architecture.
What if I want to slow the memory down to 3us and what will happen in the modern CPU?
- The Demysifying paper does not give any information of the ROB and MSHR which says nothing, we need to answer this question to understand the workload better.
- If they were the first to make the delay buffer, I have some other things to ask and answer.
- For a serial linkage through CXL, how do we view delayed buffer? Is this remote ROB?
- If we have a remote ROB, how do we view the local ROB?
- How do we codesign the MSHR and ROB for less address translation like offloading AGU?
- I think in the latest CPU, the ROB and MSHR are not the same thing, and the ROB is not the same thing as the delay buffer. For the workload, the decision to learn is from those two latency model.
The partial traces collected
How do we codesign pebs to make it programmable?
The partial traces collected
Software management for the coherency
Dialect
MLIR is a modern compiler infrastructure built for flexibility and extensibility. Instead of offering a fixed set of instructions and types, MLIR operates through dialects, which are collections of user-defined operations, attributes, and types that can interoperate. These operations are a generalization of IR instructions and can be complex, potentially containing nested regions with more IR, resulting in a hierarchical representation. Operations in MLIR define and use values according to single static assignment (SSA) rules. For instance, MLIR dialects can represent entire instruction sets like NVVM (a virtual IR for NVIDIA GPUs), other IRs such as LLVM IR, control flow constructs like loops, parallel programming models such as OpenMP and OpenACC, machine learning graphs, and more.
scf
structured control flow
scf.for %i = 0 to 128 step %c1 {
%y = scf.execute_region -> i32 {
%x = load %A[%i] : memref<128xi32>
scf.yield %x : i32
}
}
scf.yield that passes the current values of all loop-carried variables to the next iteration.
memref
a multi dimentions array
parallel for
below can be lowered into NVVM dialect or OpenMP dialect.
func @launch(%h_out : memref<?xf32>, %h_in : memref<?xf32>, %n : i64) {
// Parallel for across all blocks in a grid.
parallel.for (%gx, %gy, %gz) = (0, 0, 0)
to (grid.x, grid.y, grid.z) {
// Shared memory = stack allocation in a block.
%shared_val = memref.alloca : memref<f32>
// Parallel for across all threads in a block.
parallel.for (%tx, %ty, %tz) = (0, 0, 0)
to (blk.x, blk.y, blk.z) {
// Control-flow is directly preserved.
if %tx == 0 {
%sum = func.call @sum(%d_in, %n)
memref.store %sum, %shared_val[] : memref<f32>
}
// Syncronization via explicit operation.
polygeist.barrier(%tx, %ty, %tz)
%tid = %gx + grid.x * %tx
if %tid < %n {
%res = ...
store %res, %d_out[%tid] : memref<?xf32>
}
}
}
}
MLIR JIT
mlir-cpu-runner
Write a pass that emit two dialect
Conversion
MLIR to MLIR rewrite.
Dialect Definition
Define Dialect Operation and Attributes. Attributes are embedded for static Dataflow computation.
Transform
Transform the dialect to target dialect.
Lowering
MLIR to LLVM IR rewrite.
Reference
Here's some thoughts for CXL outer devices with CPU support, since I think the problem in 2024 is not merely another computational storage or Near Data Computation. It's neither merely the CPU support because the Latency behind loading the data is un tolerable. To support the both side, we still need to expose the Mojo-like superset support compared to Python. CXL is also a transparent tiering, caching, remote memory or cache management problem. The most meaningful integration of CXL is rewrite the application and let the data sharing between multiple host to be minimized under 256MB and indexing huge amount of memory pool. Then we may come to kernel and driver integration that how we can transparently manage the remote cache. Workloads like VectorDB, MCF(A motor graph data workloads) or GAP can do address compression in the driver level. We also see radix tree management for paging or bloom filter in rMMU or rTLB support.
What's outcome of Network of chip
 The Cache Home Agent consists of Address Generation Unit(AGU), Address Translation Unit(ATU). The AGU is responsible for generating the physical address from the virtual address. The ATU is responsible for translating the physical address to the cache line address. The scheduling mechanism in the CPU includes:
The Cache Home Agent consists of Address Generation Unit(AGU), Address Translation Unit(ATU). The AGU is responsible for generating the physical address from the virtual address. The ATU is responsible for translating the physical address to the cache line address. The scheduling mechanism in the CPU includes:
- the fastest route from one CHA to the other.
- the scheduler for fetch exclusive/ fetch share/ invalidate before sharing or upgrade to directory based coherence protocol.
- CXL related: how to save message for remote fabric accesses?
- Is Intel HotChips' optics fabric good enough for in Rack communication?
Software hint using CXL.io to tell remote caching policy
The software hint is a hint to the remote caching policy. SDM's hint is a 4-bit vendor specific field in the CXL.io request to the mailbox to let the shared cacheline stuck there to save RTTs. But it's obviously an abuse to the mailbox since managing the cacheline level with control flow throttling the CXL bandwidth is not feasible. I think ZeroPoints' demo that utilzing mailbox for the compression memory is better use of mailbox. Programmably hinting the remote caching policy is a good idea. But I think it's a sophisticated timing problem requires observability tool for memory requests.
RoCC or MMIO for accelerator [4]
RoCC is useful for medium cohesive accelerator. If the accelerator is not cohesive, it's better to use MMIO. The strong cohesive part should be embedded into the pipeline of the processor. Most of UCB's work is using RoCC which is better for abstraction and generator using chisel, but it's not that high performance with the sacrifice of stall for communication.
Problem of using Distributed Shared Memory
Another Distributed System over the current infra. Fabric Manager will manage the fault tolerance, load balancing, and the data consistency. It still require remote software CPU efforts to decode the local host's shared memory primitives. CXL Fault Tolerance from SOSP23 provide a Memory RPC for Single Writer Single Reader and map the Ownership idea to the memory requests.
Reference
- SDM: Sharing-Enabled Disaggregated Memory System with Cache Coherent Compute Express Link
- Demystifying CXL with Genuine Devices
- Intel Optics Graph Processor PoC
- MMIO Peripherals
Hardware Part
SerDes
On chip decoding and encoding of the PCIe signal. The SERDES is a high speed serial transceiver that converts parallel data into serial data and vice versa. If for optics media, there's optics to electrical conversion. The performance number is worse than expected for pure CXL2.0 out of rack standalone switch. It's 90ns for accessing one hop of switch from Xconn [4]
CXL 1.1 is the current production ready version of CXL. It builds a new set of protocols and modernizes existing ones to run on top of PCI Express (PCIe) physical layer which in turn benefits from the evolution of serial links enabled by advances in Ethernet SerDes (serializer-deserializer) IPs as Ethernet continues its march from 100 gigabit to 200, 400 and 800 Gbps speeds using respectively 56 Gbps, 112 Gbps, and likely 224 Gbps SerDes.
TLP
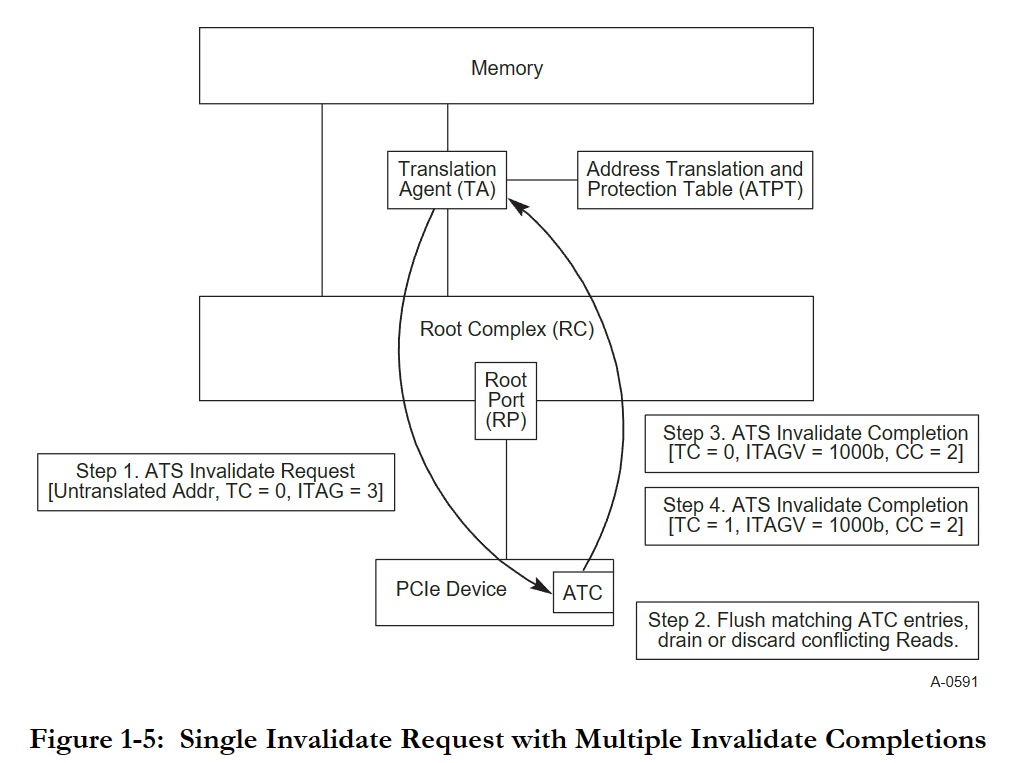
ATS
Address Translation Service,
Remote Memory Translation Idea
Utilizing remote memory and don't hurt the host CPU with flushing the TLB or irq the host CPU is a problem.
FLIT
Hardware hack for doubling the bandwidth with same latency. Squeezing the data into the same space slot.

Ordering
- PCIe
- CXL
Dynamic Capacity Devices
- Pooling implemented by 2GB segmentation, Pretty Production Ready.
- Sharing with a chip do labeling, Still PoC.
- Sk Hynix booth at SC23 has a online memory tracing for PNNL Super Cluster but not for CXL.
Reference
- PCIe Express book
- Rebooting Virtual Memory with Midgard
- Comparison of CXL1.1 and 2.0
- Xconn's Switch
- Liquid Full Stack
When I was designing the simulator I compared serveral back up solutions. I will tell why they are not working. So the problem is how to give ld/st interface desired delay from the application perspective.
Hardware implementation
The original implementation of CXL.mem is they have a window inside the LLC, and if you access that
Physical unplug Solution
lsmem to turn off memory for emulating the remote memory access using UPI.
PEMP dynamic region based Solution
Use a customed micro code for limiting the memory bandwidth to the region.
DAMON Solution from Amazon's
Fasttier and Memtis utilize DAMON, the histogram based calculation for memory access pattern. The problem is the future access is based on prediction rather than history. There might be more false positives. But it's currently
Reference
- https://airbus-seclab.github.io/qemu_blog/tcg_p3.html
- https://lists.gnu.org/archive/html/qemu-devel/2017-01/msg03522.html
- https://www.qemu.org/docs/master/devel/memory.html
IOURing for Windows
ntdll.dll is not fully exposed into the windows-rs. So we need C binding for getting the io_uring sqe and cqe.
pdbex.exe * ntkrnlmp.pdb -o ntkrnlmp.h
We found the cpp wrapped API with the following signature:
HRESULT win_ring_queue_init(_In_ uint32_t entries,
_Out_ struct win_ring *ring) {
NT_IORING_STRUCTV1 ioringStruct = {
.IoRingVersion = IORING_VERSION_3, // Requires Win11 22H2
.SubmissionQueueSize = entries,
.CompletionQueueSize = entries * 2,
.Flags = {
.Required = NT_IORING_CREATE_REQUIRED_FLAG_NONE,
.Advisory = NT_IORING_CREATE_ADVISORY_FLAG_NONE,
}};
NTSTATUS status =
NtCreateIoRing(&ring->handle, sizeof(ioringStruct), &ioringStruct,
sizeof(ring->info), &ring->info);
return HRESULT_FROM_NT(status);
};
Originally, we want to fully move this to rust with c pod definition, but cqe's return value from windows kernel is always wrong, if we wrap the unsafe. We thought is the ptr updates is stale and takes the wrong value. So we have to use the c binding for now.
GPU virt
Asahi KVM
Why MacOS did not adopt KVM and eBPF?
Reference
- https://www.reddit.com/r/AsahiLinux/comments/y7hplo/virtual_machines_on_asahi_linux/
Dynamic better than Static Instrumentation to hook syscall
- Syscall has semantic meaning, if you are writing a shim layer, only use static instrumentation may break the seccomp garentee for the syscall.
- range write after mmap etc. it will be hand made TOCTOU
- if you are using dynamic instrumentation, you can use the semantic meaning of syscall to do the right thing.
- libcapstone is a dynamic instrumentation tool, it can be used to hook arbritrary assembly. It's better than pin
- Essentially, syscall intercept discovered that a straightforward approach is sufficient for 0x80 operations within libc. While I've seen that this method isn't universally effective, it's interesting that it's adequate for its specific needs. They utilize 2-byte trampolines to ensure compatibility with syscall instructions.
Reference
- https://asplos.dev/wordpress/2022/05/03/cs225-distributed-kuco-fs-how-libcapstonelibrpmem-can-save-syscalls-for-distributed-fs/
- https://github.com/pmem/syscall_intercept
- https://github.com/victoryang00/distributed_kuco_fs/blob/main/badfs-pmem/badfs-intercept/src/lib.rs
- https://www.intel.com/content/www/us/en/developer/articles/tool/pin-a-dynamic-binary-instrumentation-tool.html
I'm using WAMR for MVVM development and wasmer fast jit for DoubleJIT development.
How AOT is implemented in LLVM
Compile everything with metadata structure and store in the struct comp_ctx.
Moduleis the basic unit of compilation- Optimization
- Passes
- Dynamic Linking(Von Neumann Architecture)
- Auxiliary data structure
- StandAlone Linker and Loader Relocation for function library
How JIT is implemented in LLVM
ORCJIT is not a standalone JIT engine and do not have dynamic compilation with program synthesis optimization.
- Concurrent/Speculative/Eager compilation, compilation on lookup with reexport/linking/indirection support
- low compilation overhead
- may be slow first time call
- Remote execution & debugging support [4]
- Good for live migration
- not good mapping accross platform
- Have standalone comp_ctx struct update during runtime. You can store the runtime information in the struct through runtime API.
- Runtime
- Try-Catch
- Static Var Init
- dlopen
- TLS
- C ABI
- Auto memory management for JITed code
- dwarf debug info(refer to julia) [3]
- codecache
What's the implementation of AOT in WAMR
aot_loader.cis the main entry point of AOTaot_runtime.cgives the runtime export function for AOT that can hook for specific logic exportsaot_compile.cyou can export the logic and output the corresponding calls the runtime function. etc.aot_alloc_frameandaot_free_framewithaot_call_indirectandaot_callto call the function with--aot-dump-frameon for wamrc option.aot_emit_*.cis the instruction emmitter for every instruction in wasm which literally the same as interpretor but to LLVM backend.- checkpoint happens with LLVM passes that insert the
INT3withfenceon top of the label. where the wasm stack is stateless of the LLVM state which we can snapshot all the corresponding state to wasm view. Restore happens to make the stateless wasm stack back to the LLVM state. which literally skip the logic that happens before the checkpoint.
References
- https://www.bilibili.com/video/BV13a41187NM/?spm_id_from=333.337.search-card.all.click
- https://dl.acm.org/doi/abs/10.1145/3603165.3607393
- https://ieeexplore.ieee.org/abstract/document/9912710
- https://link.springer.com/chapter/10.1007/978-3-319-39077-2_10
- https://github.com/llvm/llvm-project/trße/main/llvm/examples/OrcV2Examples
The WAMR memory is maintained in 1. Module Instance structure: WAMR maintains the module instance data using C struct “WASMModuleInstance”.
- function data: contain the function instances and a few pointer arrays that refer to the native function, function type and imported functions
-
- linear memory: the memory for the linear memory data space and associated information
- global data: the memory for the data of Wasm globals and associated information
- exports:
- tables:
- WASI context
- WASI-NN context
The impact of linear memory
Every memory ptr is the offset to the mmap address. __data_end global and __heap_base global is decided to indicate the memory size. It can dynamically enlarge memory through wasm_runtime_enlarge_memory(), update heap base realloc and add place new guard page. This only supports 32bit memory, for 64bit memory, it needs more codesign like MPK/MTE.

Other than linear memory, we have multiple memory regions for the global data, the table data, the function data, and the module instance data. The memory regions are either mmaped or malloced and mantained by linker and loader which is largely OS and libc specific.
InterpFrame, JITFrame & AOTFrame
The current WAMR frame model is implemented in a unified view after PR #2830. Whereas on each of WebAssembly branch, the native view will commit the register to the stack without going into the unified WASM Frame.
Reference
- https://github.com/bytecodealliance/wasm-micro-runtime/blob/main/doc/memory_tune.md
- Cage: Hardware-Accelerated Safe WebAssembly
computer-architecture-revisit-a-quantitative-approach
This repo stores a more profound view of Computer Architecture: A Quantitative Approach that tells multi-tenancy, virtualize, fine grained scheduling, map back to compiler, cross platform live migration and won't talk anything David Patterson's own work like RVV, RISC is better than CISC, TPU and deprecated X86
Is VLIW view of commiting the GPU good or bad?
Why RISC-V Vector Extension is VLIW? Let's see the operand. It requires we set some MSR register before we launch a bunch of kernel to the Vector Unit. The control flow is more like lunching cuda kernels with added GPU context like blocks and SM parameters. The Vector Unit implemented in the BOOMv3 is using a accelerator protocol called RoCC, which is a VLIW-like protocol. // shall use two
Tenstorrent way of dealing RISC-V Vector Extension
Reference
ROB in detail
m3-chip-explainer
A re pipeline referred to m1-chip-explainer