


Currently, I'm busy writing emails for my Ph.D and taking TOEFL and taking care of the Quantum ESPRESSO library changing and MadFS Optimization, so it may waste some time. Till now, I have to apply the DTA tool of phosphor for the java order dependency project.
about surfire integration into normal tests.
- Maven extension
- Integration into Maven add the redirector
- Insert phosphor plugin one class by one into.
- Configuration to the phosphor
- Class Visitor, Method Visitor, Adaptor Mode Visitor
- Mutable field in the Dependency Tainter
- Start the taint for some place attach the tainted check after the test
- Assert the junit stuf in check=omparison.
- Brittle assertions in check(Taint
) recursively.
- Output the tainted version into the sufire executable folder
- Integration into Maven add the redirector
- Debug
mvn install -Dmaven.surefire.debug -f /Volumes/DataCorrupted/project/UIUC/bramble/integration-tests/pom.xmland attach the trace point.- Start from the maven compilation.
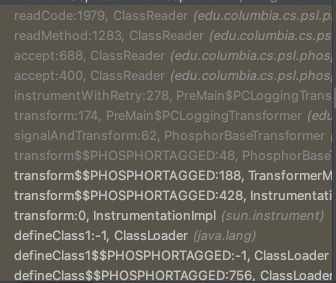
Brittle Assertion
This outputs only the dependency for one test introduced in Oracle Polish JPF. For dependenct between test1 and test2,
For NPE, get the pair by idflakies test first.
JVM Asm
Reference
- https://www.kingkk.com/2020/08/ASM%E5%8E%86%E9%99%A9%E8%AE%B0/