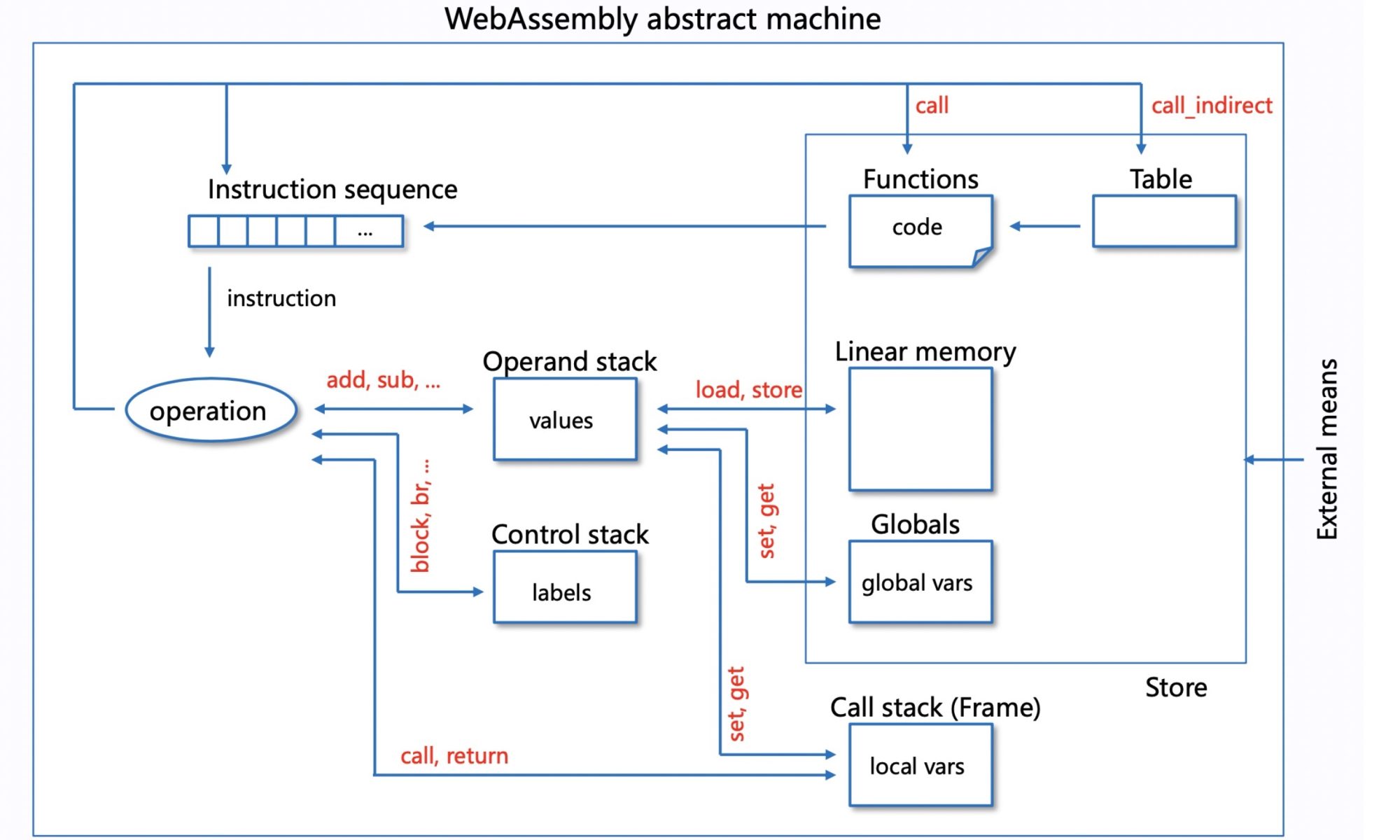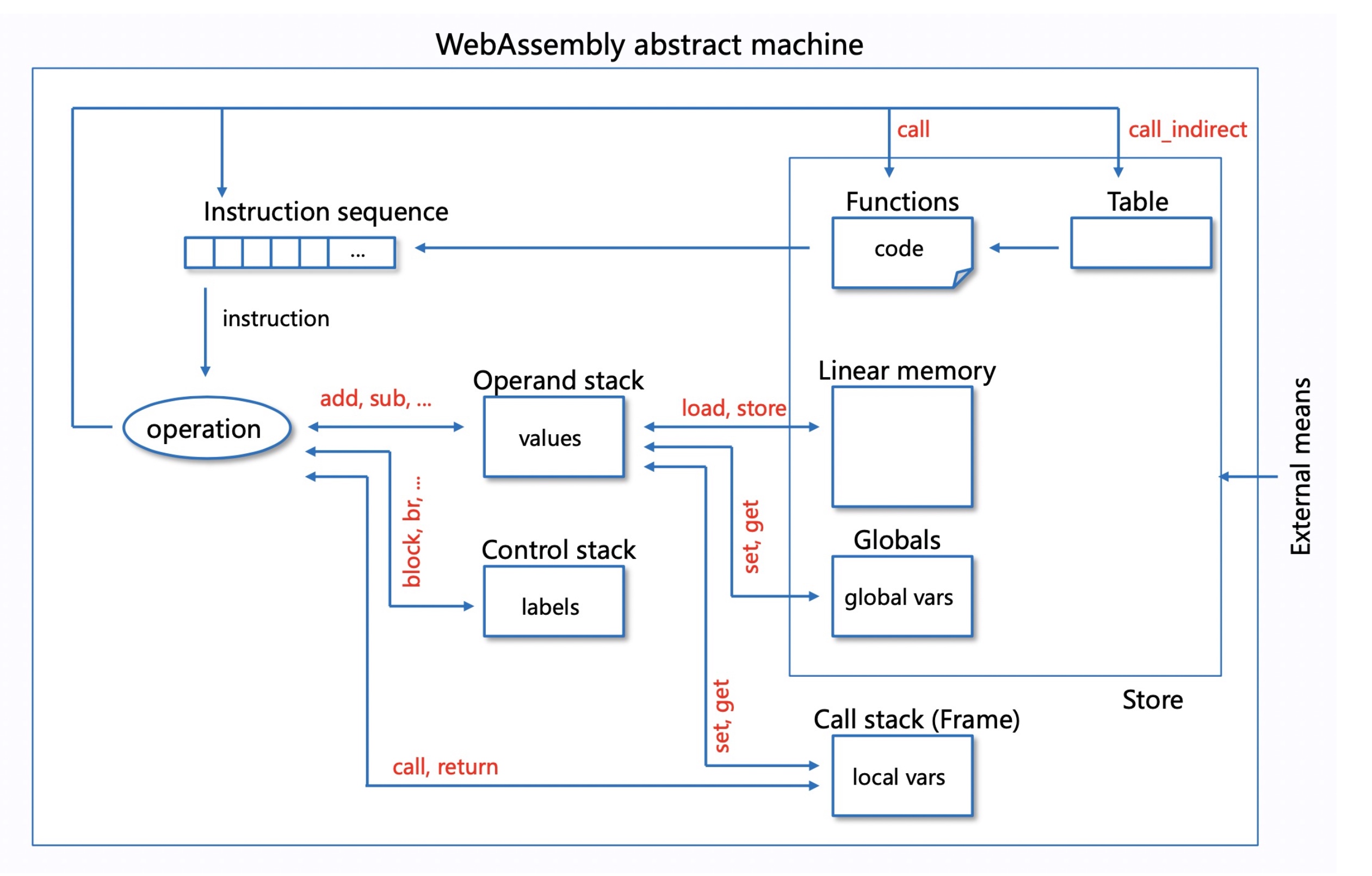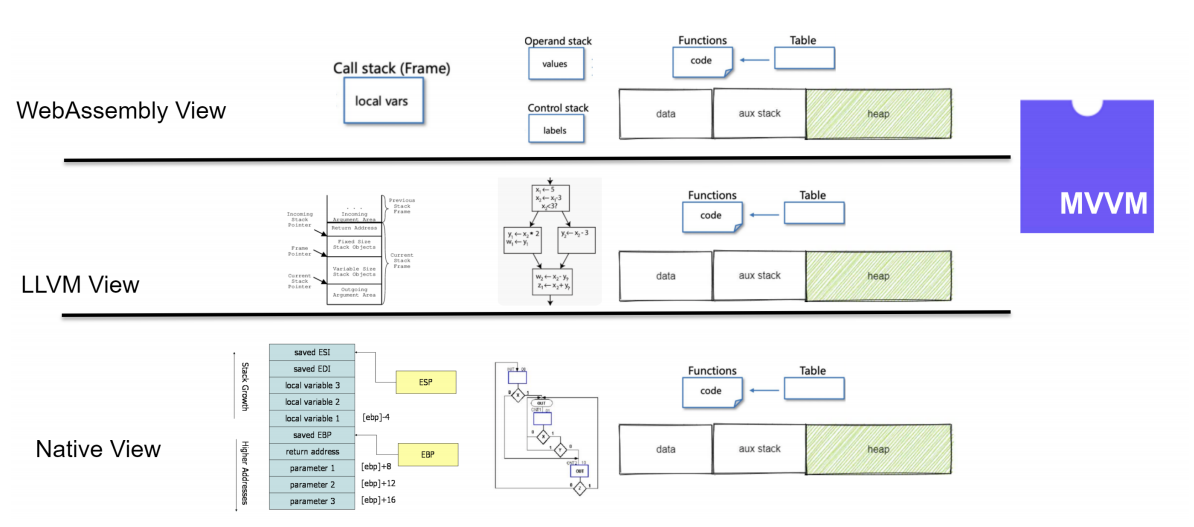
We focus on the Classic Interpreter for function PoC and AOT for performance PoC. In the above picture, We think the LLVM view before machine-related optimization together with the wasm view is cross-platform. For the latter, we need to find a stable point like function calls, branch operations, and jump for not architecturally reordering the instruction or semantically hazardous. For turning back the view to the wasm, we originally thought DWARF would help, but the WAMR team did not implement the mapping of the wasm and native stack mapping. But they implemented AOT GC that on those stable points periodically commits the native stack to the wasm view.
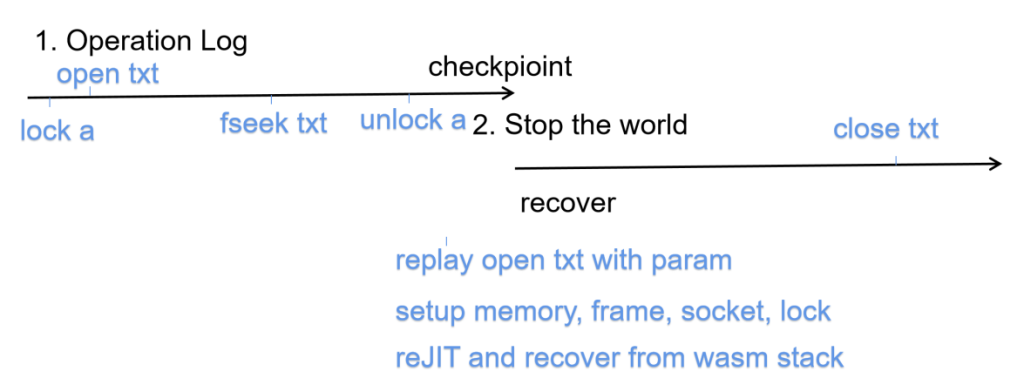
Record and replay files, sockets, IPC, and locks. In the VM, there are 2 implementations of wasi, one is POSIX-based, but only uses the subset of POSIX since the definition, and the other is uvwasi which is a message-passing library that has an implementation on the Windows platform. Because we don’t really know which implementation is the target, we only record the operation log for files, sockets, IPC, and locks.
Specifically for open syscall, since it's not calling into WAMR's libwasi, while it's merely a bunch of function calls fopen->__wasilibc_open_nomode->find_relpath->__wasilibc_nocwd_openat_nomode->__fdopen. So we simply instrument the fopen and get the fdopen input to get the {fd, path, option} three-element tuple. Need instrument in AOT mode.
Snapshotting for WebAssmebly view of Memory and Frame. For the Interpreter, we defined a C++ struct for better snapshotting the memory and frame and put them in the C++ struct snapshots. The interpreter frame is just linearly set up for every function call. For JIT/AOT we need to rely on the call convention on the source machine and symbolically execute the call frame from the wasm stack on recovery. For big/little endian, you just transform if they are different, the JIT/AOT phase should take care of the memory.
Re-architecture of AOT for snapshot The current implementation of the native stack frame is incremental. which is not necessarily good for recovery, should do something like FastJIT in all the function calls and basic blocks are just jmp with auxiliary operations of stacks. (convenient for committing regs?) Then we need to on every function call commit the CPU state to the wasm stack that relies on LLVM infra for generating 1. labels that will not be optimized out by both sides. Research problem(the frequently accessed points.) 2. Register and native stack mapping to the wasm stack on stable point. (Or we need dwarf and stronger information if we only get one time on checkpoint). On recovery, we can just jmp to the label and just resume.
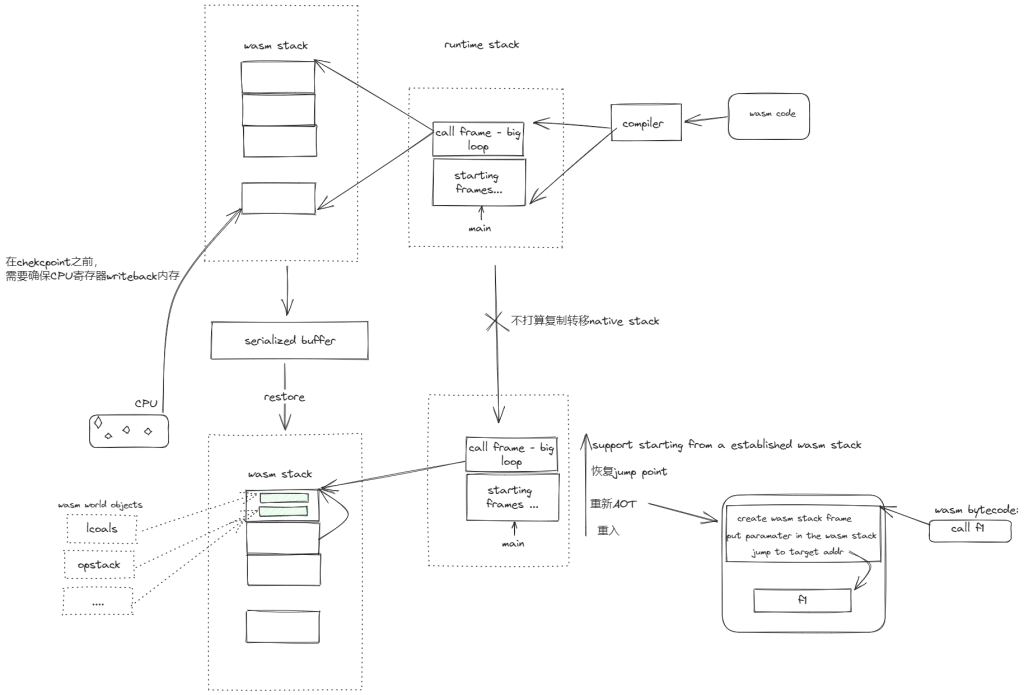
ReJIT or ReAOT on the target machine. We need to recover, first, ReJIT or ReAOT the wasm binary, and do a translation that only does the function call specific operation in the target machine of generated native code. Then the native call frame will be set up, and we just set the native PC to the last called function’s startup.
File Descriptor Recovery We will call the target machine’s implementation of the wasi for recovering the file descriptor and we need to make sure the order is the same.
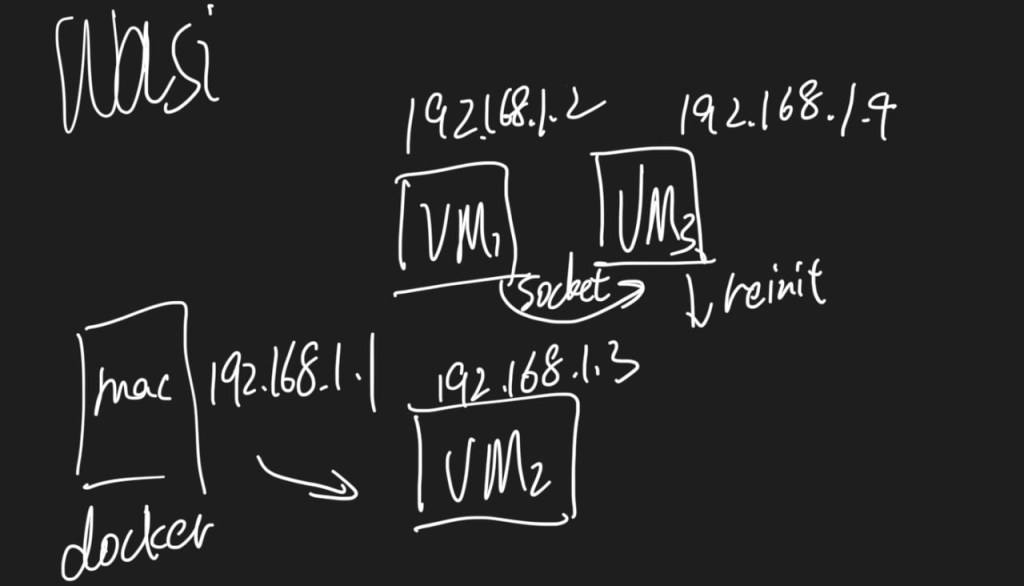
Socket recovery For the same IP, we can just refer to the CRIU's implementation that utilizes the kernel implementation of getsockopt(TCP_recover), but the problem is it will be platform-specific, so we set up a gateway for updating the NAT after migration and implemented a socket recovery our selves referring to this. In the MVP implementation, on migration, we should first notify the gateway in the below graph which is mac running docker with virtual IP 192.168.1.1, then, do socket migration, in the meantime the gateway sends keepalive ACK to the server VM2, after migration, VM3 first starts and reinits socket/bind/accept and notify the gateway to bypass all the request from VM2 to VM3.
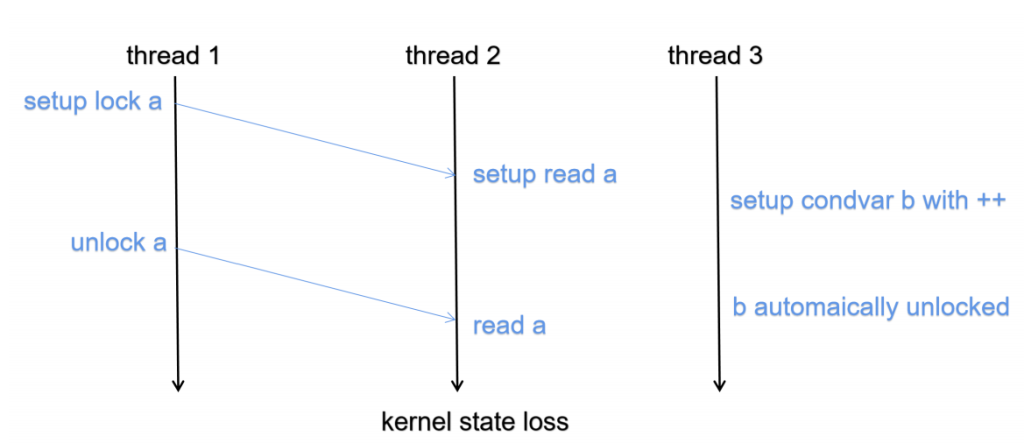
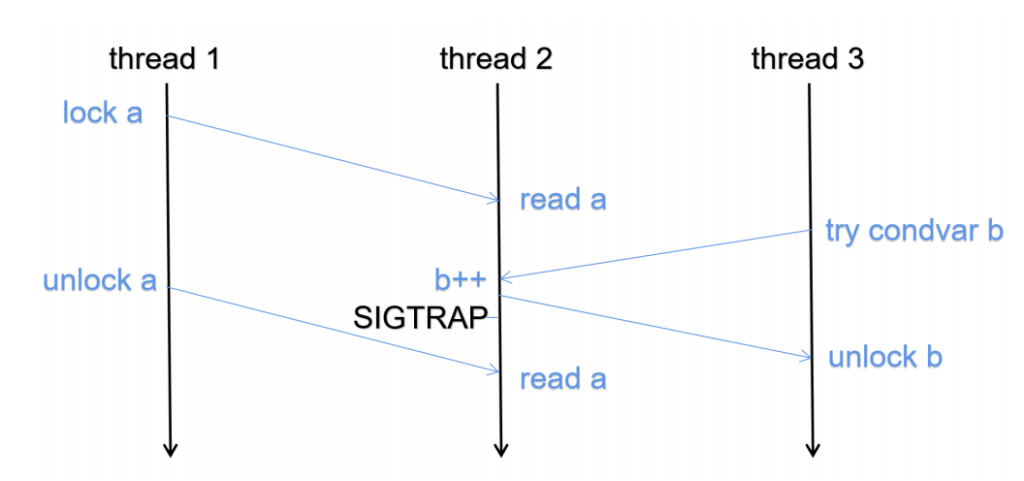
Locks recovery The order of the recovery to lock is very important since some of the states in the kernel will be canceled out if we only record and replay in the above graph. We need to track the order of setting the lock and who is blocking it because of what to semantically correct make the order right.