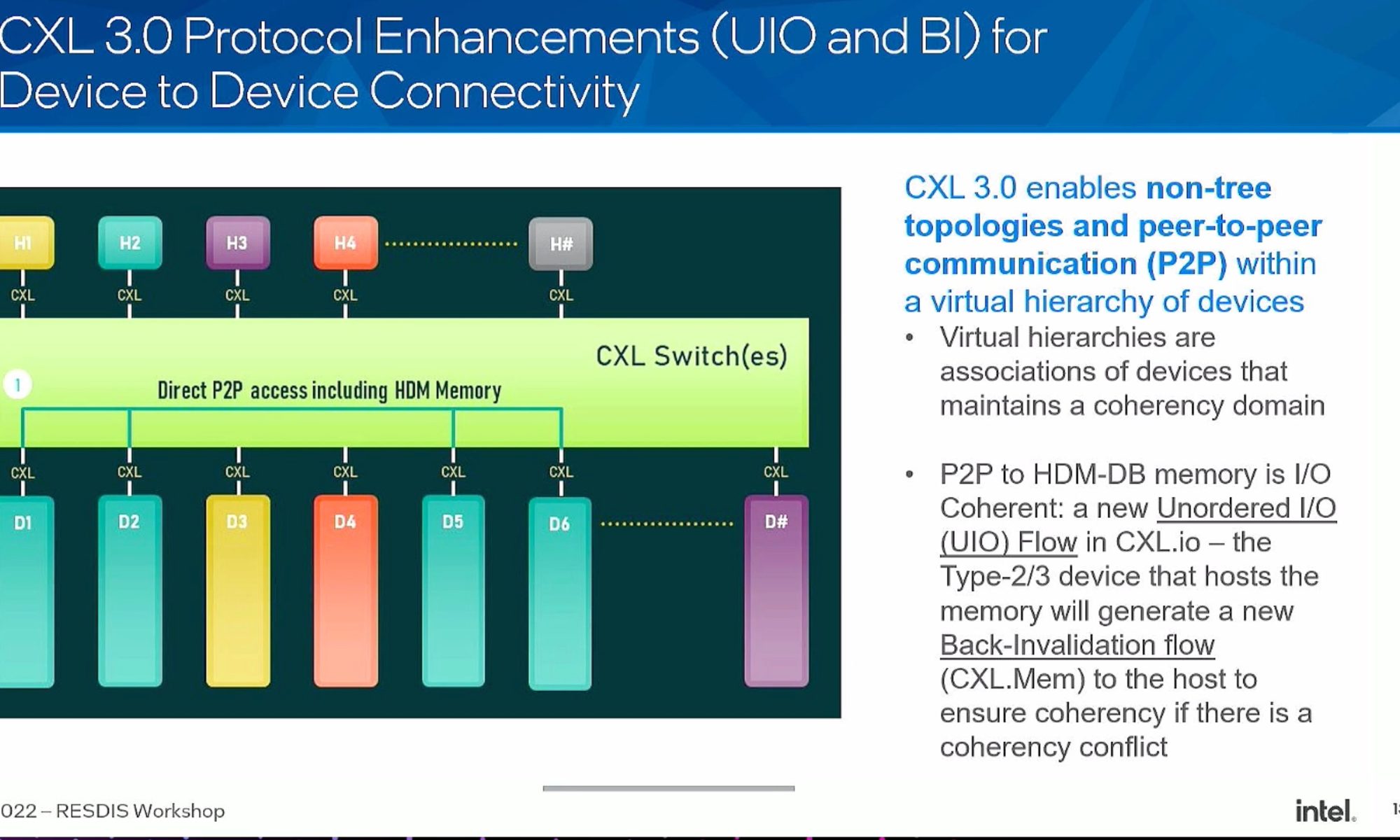
Overview of PTX vs SASS State
Live-migrating a running GPU computation requires capturing the execution state – including each thread’s registers, relevant memory regions, and program counters. NVIDIA GPUs execute SASS (Streaming Assembler) machine code, whereas PTX is a higher-level virtual ISA used at compile-time. There is not a one-to-one correspondence between PTX instructions and SASS instructions in optimized code. A single PTX instruction may be compiled into multiple SASS instructions or even eliminated or fused with others during optimization. This gap makes it challenging to directly derive PTX-level state (e.g. PTX register values and the exact PTX program counter) from the low-level SASS state. In other words, the GPU’s actual state exists in terms of SASS (hardware registers, SASS PC, etc.), and recovering the abstract PTX state requires careful mapping and tooling.
Challenges in Mapping SASS Back to PTX
NVIDIA’s PTX is an virtual assembly that gets translated by the ptxas compiler into SASS (target-specific machine code). During this translation, numerous optimizations and transformations occur. For example, an arithmetic operation in PTX might be strength-reduced or combined with another, so it no longer appears as a distinct instruction in SASS. Some PTX instructions expand into an emulation sequence of several SASS instructions (e.g. 64-bit operations might become multiple 32-bit SASS ops). Conversely, some SASS instructions (like address calculations or predicate moves) have no direct PTX source equivalent – they might be introduced by the compiler. As a result, the correspondence between a PTX instruction and the runtime SASS state is often many-to-many or non-existent in complex optimized code. This means we cannot naively take a SASS program counter or register and assume it maps to a single PTX line or variable. In general, reliably reconstructing PTX-level program state from an arbitrary optimized SASS state is difficult. It may only be feasible in limited scenarios – for example, code compiled with minimal optimization or with debug information that preserves a closer mapping between PTX and SASS.
Tools for Disassembly and Code Mapping
To bridge the gap between SASS and PTX, several tools can help inspect binaries and provide mapping information:
cuobjdump: NVIDIA’s CUDA Binary Utility for examining compiled binaries. It can extract and disassemble SASS, and also dump embedded PTX if the binary contains it (e.g. fatbins often include PTX as JIT fallback). This is useful for static analysis: you can see the machine code instructions and resource usage per kernel. However,cuobjdumpdoes not align SASS with source or PTX lines – it simply lists instructions. (In fact, an attempt to get interleaved CUDA C++ source with SASS usingcuobjdumpis not possible via command-line.)nvdisasm: A more advanced disassembler that operates on cubin files. Unlike cuobjdump,nvdisasmhas richer output options. Critically, if the binary was compiled with debug symbols or line info (using-Gor-lineinfoflags),nvdisasmcan report the source line correspondence for each SASS instruction. Usingnvdisasm -gwill annotate the disassembly with references to source lines. If the source was CUDA C++, those will be C++ lines; if the source was PTX (e.g. compiled from a.ptxfile with line info), those can be PTX line numbers. This feature helps map a SASS program counter (address) to the nearest PTX instruction. Note: the output shows line references (file and line number) rather than the actual source text, but it provides the needed correlation. By compiling the code with-lineinfo(and ensuring PTX is embedded for the target architecture), one can later usenvdisasmto find which PTX instruction corresponds to a given SASS address.- Nsight Compute (GUI): NVIDIA’s profiling tool can display source, PTX, and SASS side-by-side in its Source page. This requires the binary to include PTX (for the target or as intermediate) and line mapping info. While this is a GUI tool (not automated via CLI), it confirms that the compiler can produce the mapping when requested. In practice, for our purposes, we would use the underlying mechanisms (DWARF debug info in the cubin) via
nvdisasmor other CLI parsing rather than the GUI. Nsight Compute essentially leverages the same line info to link SASS to PTX or high-level source. - CUDA Compiler Flags: To facilitate mapping, it is recommended to compile kernels with debug or line information. Using
-G(device debug) or-lineinfowill embed debug symbols that map PTX or source lines to SASS. There is also-src-in-ptx, which interleaves source code as comments in the PTX output for human reference (helpful for debugging). In some cases, one might compile the CUDA C++ to PTX (-keep) and then useptxaswith-gto get a cubin where the PTX file’s line numbers are referenced in SASS. This way, the PTX itself is treated as “source” for debugging purposes. In summary, ensuring your binary carries PTX and line mappings is crucial for any PTX↔SASS correlation.
Table 1: Key Tools and Methods for Inspecting GPU Code and State
| Tool / Method | Purpose | Notes and Usage |
|---|---|---|
| cuobjdump (binary utility) | Disassemble and extract contents of CUDA binaries (fatbins). Shows SASS, resource usage, embedded PTX. | Works on executables or cubin files. Does not auto-map SASS to PTX lines (manual correlation needed). |
| nvdisasm (disassembler) | Detailed disassembly of cubin with control-flow info and source line references. | Use -g/-gi with a cubin compiled with -lineinfo to get SASS with file:line annotations. Enables mapping PC addresses to PTX or source. |
| cuda-gdb (debugger) | Can attach to running kernels (in device debug mode) to inspect state at runtime. | Works at SASS level; allows querying registers and warps. No direct PTX source view (PTX must be mapped manually). Useful for concept of reading registers if kernel is halted. |
| NVBit (dynamic instrumentation) | Inject custom monitoring code into GPU binaries at runtime. Can intercept and modify SASS instructions on the fly. | Allows inspecting ISA-visible state (registers, predicates, etc.) and logging or modifying it during execution. Useful to capture register values or program counters by instrumenting the kernel binary. |
| CUPTI / Profiling | Profiling interface (PC sampling, counters). | Can sample the program counter over time to statistically map hotspots to source, but not designed for exact state dump. Does not provide direct register dumps. |
| CUDA Checkpoint API (CUDA 12) | Driver-level API to checkpoint GPU memory state for a process. | In CUDA 12, functions like cuCheckpointProcessLock/Unlock/Checkpoint/Restore can save all GPU memory to host. However, this excludes live registers/PC mid-kernel – kernels must complete or be preempted. Mainly handles memory and resets GPU context. |
Capturing GPU Memory State
Memory state is the easiest part of the GPU context to capture, and it’s largely independent of PTX vs SASS issues. A GPU program can use multiple memory spaces (global, shared, local, constant, etc.), all of which need saving:
- Global Memory (Device DRAM): All allocated global memory buffers (e.g. via
cudaMalloc) must be copied out. This can be done with standard API calls (cudaMemcpyDeviceToHostfor each buffer) if the kernel is paused or not actively writing. NVIDIA’s official checkpoint utility automates this: when you call the driver APIcuCheckpointProcessCheckpoint, “the GPU memory contents will be brought into host memory” (and GPU pointers are invalidated). Thus, the bulk of data (tensors, etc.) can be saved straightforwardly. Constant memory and texture memory (if used) are typically initialized from host and read-only during kernel execution, so they can be reinitialized on the target side rather than dynamically dumped. - Shared Memory (SMEM): Shared memory is on-chip and private to each thread block. If a kernel is mid-execution, each resident block has its own shared memory contents that are not directly accessible from the host. There is no built-in API to read shared memory of a running block. To capture it, one approach is to instrument the kernel: e.g., insert SASS instructions at a checkpoint to copy the shared memory region into global memory (so it can then be copied to host). Another approach is to rely on hardware preemption: on GPUs that support thread-block preemption, the scheduler could save the state of SMEM to DRAM as part of context save – but such mechanisms are internal and not exposed publicly. In practice, application-level checkpointing schemes avoid needing to snapshot arbitrary shared memory by ensuring kernels reach a synchronization point or end-of-kernel where shared memory is naturally either not in use or can be retrieved via normal means (since the kernel ended). For a truly live mid-kernel migration, one would have to emulate what the GPU does during a context switch: allocate a buffer for each block’s SMEM and copy it out. This likely requires custom SASS instrumentation (since no API gives SMEM content directly).
- Local Memory: Local memory is memory private to each thread, used for register spills or large local arrays. It is actually allocated in global memory space (per-thread heap) and automatically indexed by the GPU. If a thread has values in local memory (spill slots), those are part of the overall device memory and would be included in the global memory snapshot if the entire GPU memory is checkpointed. In an application-managed approach, one could include known local arrays, but spills are harder to identify externally. However, by capturing the entire device memory (or at least the CUDA context’s allocations), we cover local memory. The challenge is knowing which portions correspond to which thread’s locals – that mapping is inside the SASS code and ABI. If needed, one could parse the cubin for the kernel’s stack frame size to know how much local memory per thread is used. For PTX-level restart, it might be acceptable to simply restore all local memory contents as they were.
In summary, memory state capture is well-supported: NVIDIA’s checkpoint tools lock the GPU, wait for work to quiesce, and then snapshot all memory to host. For live migration, you’d transfer these memory dumps to the destination GPU and restore them (e.g. via cuCheckpointProcessRestore which reverses the process, or manually cudaMemcpy them to the new context). The hardest part is ensuring consistency if a kernel is mid-run – hence a need to pause the kernel.
Capturing Registers and Program Counter State
Capturing the register state and program counters of threads on the GPU is the most challenging aspect. Unlike memory, there is no public API to dump the registers of all threads in a running kernel. GPU registers are distributed across streaming multiprocessors and are heavily optimized by the hardware. Key considerations:
- Per-Thread vs Per-Warp Execution State: On pre-Volta architectures, threads in a warp share an execution PC (program counter) – they execute in lock-step (with divergence managed by predication and reconvergence). Starting with Volta (Compute Capability 7.0), NVIDIA introduced independent thread scheduling, which gives each thread its own PC and enables finer-grained scheduling. Internally, Volta GPUs assign two hardware register slots per thread to store the thread’s program counter. This means the PC has become part of the thread’s architectural state (just like registers) rather than an implicit warp-level pointer. For checkpointing, this is good news: it is possible to capture each thread’s PC value if we can read those special registers. The bad news is that user-level code cannot directly read these PC registers under normal operation.
- No Direct Register Access: GPU kernels cannot read or write arbitrary registers directly; they only manipulate registers through instructions the compiler emits. NVIDIA does not expose a mechanism like x86’s context save/restore to user programs. Even the CUDA driver’s checkpointing API avoids dealing with registers explicitly – it requires that the process be locked (i.e. no active kernel running) before checkpoint, thus sidestepping the issue of mid-kernel register capture. Essentially, NVIDIA’s official approach is to finish or pause the kernel, then save memory, assuming you’ll restart the kernel from the beginning on restore. Truly capturing a snapshot in the middle of kernel execution requires either special hardware support or clever software instrumentation.
- Hardware Preemption: Newer GPUs (Pascal and Volta onward) introduced limited preemption ability. In Volta, thread blocks can be suspended and resumed, which implies the GPU hardware/driver can save the register state of all threads and reload it later. However, this functionality is used internally by the scheduler and not exposed through CUDA APIs for general checkpointing. For example, on time-out or higher-priority preemption, the GPU context switch mechanism will spill out registers to memory. As developers, we don’t have direct hooks into this pipeline. If one were implementing a hypervisor or low-level driver for virtualization (e.g. NVIDIA’s SR-IOV vGPU for data center), there are driver-level methods to snapshot a virtual GPU’s state (which includes registers, engines, etc.). Those are not accessible from user space. Therefore, our options at user-level reduce to either using the CUDA debugger or modifying the code.
- Using a Debugger (CUDA-GDB): In a debugging session (with
cuda-gdband a kernel compiled for debug), one can break execution of a kernel. This effectively pauses the SMs, and the debugger can read registers, shared memory, etc., for the current point.cuda-gdbworks at the SASS level and provides commands likeinfo registersfor the current warp. It is conceivable to leverage this in a custom way – e.g., attach to the process, programmatically interrupt the kernel, and scrape the register values and PCs. However, this approach would be quite complex and is not an intended use of the API. As NVIDIA’s experts note, the debugger is “always working at the SASS level” and doesn’t present a PTX-source view, so one would still need to correlate back to PTX manually. This could be a last-resort method to get a one-time snapshot of registers for a few warps, but it’s not a general solution for live migration (especially at scale, with potentially thousands of warps). - Dynamic Instrumentation (NVBit): A more promising approach is to use binary instrumentation to insert code that dumps register state at runtime. NVIDIA’s NVBit framework allows you to inject custom instructions into the GPU binary as it’s loaded, without needing driver source or special privileges. With NVBit, one can intercept each SASS instruction or each basic block and execute additional code. For instance, you could instrument the kernel to periodically check a “should checkpoint” flag in global memory and, if set, have each thread store its register values to a designated memory buffer. NVBit makes this easier by providing an API to query an instruction’s operands and to insert calls to user-defined device functions. The NVBit paper notes that it “allows inspection of all ISA-visible state” and even modification of register state at runtime. Practically, you might implement a tool that, at a particular PC (say a label in PTX or a known synchronization point), injects a sequence that writes out all general-purpose registers (and predicate registers, condition codes, etc. as needed) to global memory. The output could be structured per thread (e.g. an array indexed by thread ID). Then you would signal the kernel to execute this dump (perhaps by setting a flag via host). After the dump, you’d have a memory region on device containing a full register snapshot for each thread, which you can copy to host. This is complex but achievable with instrumentation – albeit with non-trivial overhead and engineering effort.
- SASS-Level Checkpoint Stubs: Prior research has attempted to modify SASS or use assembly stubs for checkpointing. For example, the Cricket GPU virtualization project directly injected SASS code to capture device execution state. They essentially reverse-engineered how to save and restore GPU state by manipulating the binary. Another project (Singularity) used
cuobjdumpto get information about kernel parameters and PTX, then intercepted the JIT compiler to extract signatures, in order to help reconstruct state. Both approaches were reported to be error-prone and high-overhead, due to the complexity of reverse-engineering and the differences across GPU generations. These attempts underscore how challenging manual state capture is – they worked, but at a significant complexity cost. Modern alternatives like NVBit provide a more structured way to inject code without fully manual binary editing. - Program Counter Mapping: To resume a kernel at the correct point, we need the program counter per thread (or per warp on older GPUs). If using instrumentation, one could capture the value of the PC at the moment of checkpoint. NVBit provides the address of each instruction being executed to the instrumentation callback, so you can record the last seen PC for each thread. Alternatively, you can insert an explicit marker in the code: for example, a dummy instruction or a particular unused register value that indicates a checkpoint location, then search for it. But the simpler way is to leverage the debug line mapping: given a SASS address we stopped at, use
nvdisasm -gor DWARF info to find which PTX line that corresponds to. That tells us the logical point in the PTX program. Essentially, we want to resume at that PTX instruction. One caveat: if the checkpoint is in the middle of what was originally one PTX instruction’s operation (e.g., between theIADD.CCandIADD.Xthat implement a 64-bit add), we might prefer to roll back to the start of the PTX instruction for a clean resume. This might mean the checkpoint routine should detect such cases or simply always resume at a known safe point (like just before a barrier or a particular label). - PTX Register Reconstruction: After dumping the SASS registers, we have their values but we need to translate them into PTX-level variables if we want an architecture-independent state. In a straightforward scenario (no compiler optimizations), each PTX virtual register maps to a physical SASS register. For example, PTX
%r5might have ended up as SASSR10. If we know that mapping, we can label the saved values accordingly. However, with optimization, the situation is murkier. Some SASS registers have no direct PTX equivalent (they might hold temporary results, loop counters, addresses, etc. introduced by optimization). Some PTX registers might not have any live SASS register if they were optimized out or stored in memory. The best case is if we compiled with-G(no optimization) – then ptxas tries to preserve a close correspondence. Under-G, the compiler also emits symbols for local variables and possibly PTX register names which could be accessible via DWARF info. In practice, to get a PTX-level view, one strategy is: (a) Compile the kernel with line info and minimal optimization. (b) Use the DWARF debugging information in the cubin to map each SASS register to a source variable or PTX value where possible. For example, the DWARF may tell us that at a given PC, a certain high-level variable or PTX register is located in SASS register Rn. This is analogous to how CPU debuggers map machine registers to variables. If such info is available, we can construct a mapping table. If not, a manual static analysis comparing PTX and SASS code might be needed.
In summary, capturing the live register and PC state is possible but requires stepping outside normal user APIs. Using a combination of debug modes and instrumentation is the practical approach. For instance, you might run the kernel in a special mode (with debug info, possibly launched under a tool like NVBit or cuda-gdb) to pause it and extract state. The state extraction would involve writing register values to memory (either via injected code or via the debugger’s queries). Once you have the SASS-level snapshot, you then translate it to PTX-level terms using the compilation metadata.
Reconstructing or Resuming at PTX Level
The end goal of a PTX-level state dump is to enable resuming the computation on possibly a different GPU architecture by using PTX as a portable format. After obtaining the state (memory + registers + PC), how do we resume execution on the target GPU at the PTX level?
- Reloading Memory: All the saved memory regions (global, local, etc.) would be copied into the new GPU’s memory. This is straightforward with CUDA APIs (or using
cuCheckpointProcessRestorewhich does it in one go). We must ensure allocation of memory in the new context mirrors the original (same addresses for pointers if the code uses absolute addressing, though CUDA generally uses virtual addresses so that should be fine as long as we reload the module). - Reloading Registers (PTX level): There is no direct way to set GPU registers from host. The solution is to start a new kernel on the target GPU that will consume the saved state. One approach is to have modified PTX code for restart: for example, generate a version of the kernel PTX that begins with code to load the saved register values from memory into PTX virtual registers, then jump to the point in the code where it left off. Since PTX is an assembly-like language, we could imagine inserting a label in the PTX at the resume point and using a
bra(branch) or function call to enter at that point with the reconstructed values. The PTX JIT (at runtime) would compile this to the target SASS. This requires careful editing of PTX: essentially splicing the original PTX to create an entry at an arbitrary instruction. It’s tricky but conceptually similar to what a debugger does when it patches code to jump to a breakpoint handler and back. Another concept is to wrap the kernel in a bigif(resumeFlag) { goto ResumeLabel; } else { ... normal start ... }and use the saved state to set that flag and initial values. However, PTX and the GPU programming model don’t allow starting in the middle of a kernel easily – so more likely we’d launch a continuation kernel that is semantically equivalent. - Using PTX as an IR: Since PTX is portable, the saved PTX state (registers/variables and PC) should in theory be usable to resume on a different GPU architecture by re-running the PTX through the PTX-to-SASS JIT for that GPU. The question is whether the new architecture will execute it exactly the same way. PTX is designed to be forward-compatible, so a PTX program compiled for a newer SM should behave identically (barring some numeric edge cases). Thus, if we have the exact PTX instruction and the values of all its input registers as of checkpoint time, we can feed those into a new execution. The reliability comes down to whether we captured all relevant state. Besides general-purpose registers, we must consider predicate registers, condition codes (carry flags from add, etc.), and special registers (e.g.,
SR_TID,SR_CTAID– though those are deterministic from thread indices which we know). We would need to capture those as well. For example, if a warp was in the middle of a divergentifin PTX, the execution mask (which threads are active) is part of the state. On Volta+, per-thread PC implicitly handles this (threads that exited theifwill have a different PC than those in theif). On older GPUs, the reconvergence stack state would matter. Capturing that is extremely hard without hardware support. This is a limitation: certain control flow state (SIMT reconvergence information) may not be fully reconstructable from just registers and PC, unless the GPU provides it. The PTX model doesn’t explicitly expose the reconvergence stack. This suggests that our PTX-level state dump is more feasible on Volta and newer (with independent thread scheduling) than on older GPUs. - Reliability of PTX-State Reconstruction: In practice, achieving a fully reliable reconstruction is not guaranteed. If the code was compiled with optimizations that, say, split a PTX operation into several SASS operations, our checkpoint might catch the system in the middle of that operation. The PTX abstraction would consider that one instruction not yet completed. If we resume at the beginning of that PTX instruction, we must ensure the state is as it was before it started – which might mean rolling back a partial result. For instance, a 64-bit addition in PTX compiles to two 32-bit adds (with carry). If a checkpoint occurs after the first 32-bit add has executed (setting a carry flag), and we then resume at the PTX level, we would recompute the 64-bit add entirely. This might actually be fine (you’d just redo the first half), but we must be careful that no side-effects have occurred (memory writes, etc. – usually these complex instructions don’t have partial side-effects visible to memory, so PTX atomicity holds). Another example: PTX
bar.sync(barrier) might be implemented via multiple SASS instructions and some internal state in hardware. Checkpointing in the middle of a barrier is complex – better to only checkpoint when all threads have reached a safe point.
Given these complexities, a conservative strategy is to only allow checkpoint at well-defined synchronization points in the kernel (or at least at PTX instruction boundaries which we can enforce by using the mapping info). By syncing all threads (e.g., at a block-wide barrier or after a certain loop iteration) and then checkpointing, we can treat the state as consistent at a higher level. The PTX dump would then be reliable. This is in line with how some application-level checkpointing works (inserting checkpoints in code at safe places). If truly arbitrary preemption is needed, one must account for these edge cases in the resume logic.
Conclusion and Practical Recommendations
Implementing a PTX-level state dump for NVIDIA GPUs during live migration is highly non-trivial, but with the right tools and constraints it can be approached. Key recommendations and findings:
- Leverage NVIDIA’s binary utilities and compiler flags to get insight into the PTX↔SASS mapping. Compile kernels with
-lineinfo(and include PTX in the fatbinary) so that tools likenvdisasmcan map SASS addresses to PTX source lines. This will help identify the PTX program counter corresponding to a given SASS PC during a snapshot. - Use dynamic instrumentation frameworks like NVBit to capture live state. NVBit can insert code to record register values and other architectural state at runtime. This is likely the most flexible method to dump register content and PC for all threads without needing driver modifications. Expect significant overhead during the dumping phase – essentially you momentarily stop useful work to copy out state – but for migration this is acceptable.
- Be mindful of optimizations: for more reliable mapping, consider compiling kernels with lower optimization (e.g.,
-O0or-Gfor debugging). This will sacrifice some performance but will simplify state capture by keeping PTX and SASS closer in structure and avoiding elusive compiler transformations. As an NVIDIA forum expert noted, correlating PTX to SASS in highly optimized code is very difficult. In a live migration scenario, one could even use a special migration build of the kernel that is optimized for state extractability. - Memory state should be captured using official or stable methods: either the new CUDA 12 checkpoint API (which will safely copy device memory to host), or manual
cudaMemcpyfor each allocation. Ensure to also save the contents of any GPU caches or buffers that might not be globally visible (in most cases, global memory and relevant states are coherent or can be rederived, so the main concern is shared memory and registers which we addressed separately). - Understand that complete PTX-level resume portability has limits. In theory, with a full snapshot of all threads’ registers and PC, one could relaunch the computation on a different GPU by feeding the state into a PTX re-execution. In practice, differences in GPU architectures and unseen state (e.g., warp-level execution masks on pre-Volta GPUs, or certain special registers) can make this complicated. If migrating between identical GPU architectures (say two Turing GPUs), it may be simpler to capture the SASS state and resume at SASS level (which NVIDIA’s driver likely does internally for virtualization). For cross-architecture migration, PTX-level recompile is the goal – but expect to handle the nuances discussed (control flow, partial instruction sequences, etc.).
- Prioritize official documentation and research: NVIDIA’s documentation on the new checkpoint features and developer blogs should be consulted to understand what the driver guarantees. Research papers like “Checkpoint/Restart for CUDA Kernels” and tools like Cricket and CRIUgpu provide insights into pitfalls others encountered (e.g., the need to intercept and replay CUDA API calls versus leveraging driver state save). These suggest that using the driver’s capabilities (when available) is far more robust than DIY hacks, if you can get access to them.
In conclusion, implementing a PTX-level state dump involves a hybrid of tool-assisted static analysis (to map between PTX and SASS and identify state variables) and dynamic instrumentation or debugging (to actually capture the live register/PC state). While it is possible to approximate PTX state from SASS, it is not fully reliable without careful control: you must account for compiler optimizations and hardware specifics. Whenever possible, force a correspondence (via debug mode or manual checkpoints in code) so that the PTX state is well-defined at the moment of capture. With these precautions, one can extract the needed information (registers, memory, program counters) and attempt a PTX-level resume on a target GPU. But one should remain aware that this is bleeding-edge – even NVIDIA’s own tooling only recently introduced basic checkpoint support (and that focuses on memory state). Thus, a PTX-centric migration strategy will require extensive validation. It’s wise to test on simple kernels (with known PTX-SASS mappings) and incrementally tackle more complex scenarios, using the aforementioned tools to verify that the state extracted and re-injected indeed reproduces the correct execution on the new device.