

[A Turing Award level idea] Slug Architecture: Break the Von Neumann Great Memory Wall in performance, debuggability, and security
I'm exposing this because I'm as weak as only one Ph.D. student in terms of making connections to people with resources for getting CXL machines or from any big company. So, I open-sourced all my ideas, waiting for everybody to contribute despite the NDA. I'm not making this prediction for today's machine because I think the room-temperature superconductor may come true someday. The core speed can be 300 GHz, and possibly the memory infrastructure for that vision is wrong. I think CXL.mem is a little backward, but CXL.cache plus CXL.mem are guiding future computation. I want to formalize the definition of slug architecture, which could possibly break the Von Neumann Architecture Wall.
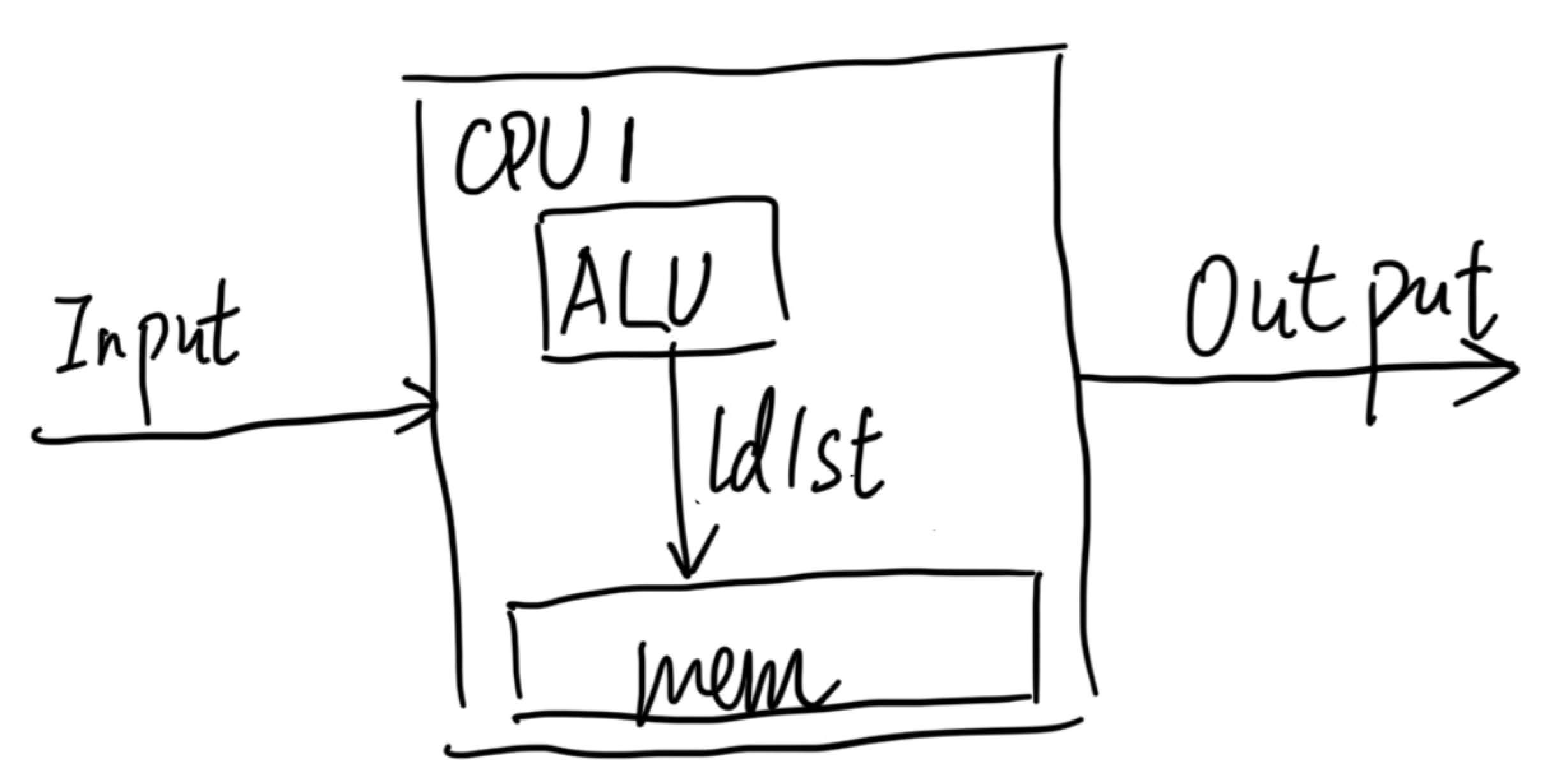
Von Neumann is the god of computer systems. That CPU gets an arbitrary input; it will go into an arbitrary output. The abstraction of Von Neumann is that it gets all the control flow, and data flow happens within the CPU, which uses memory itself for load and storage. So, if we snapshot all the states within the CPU, we can replay them elsewhere.
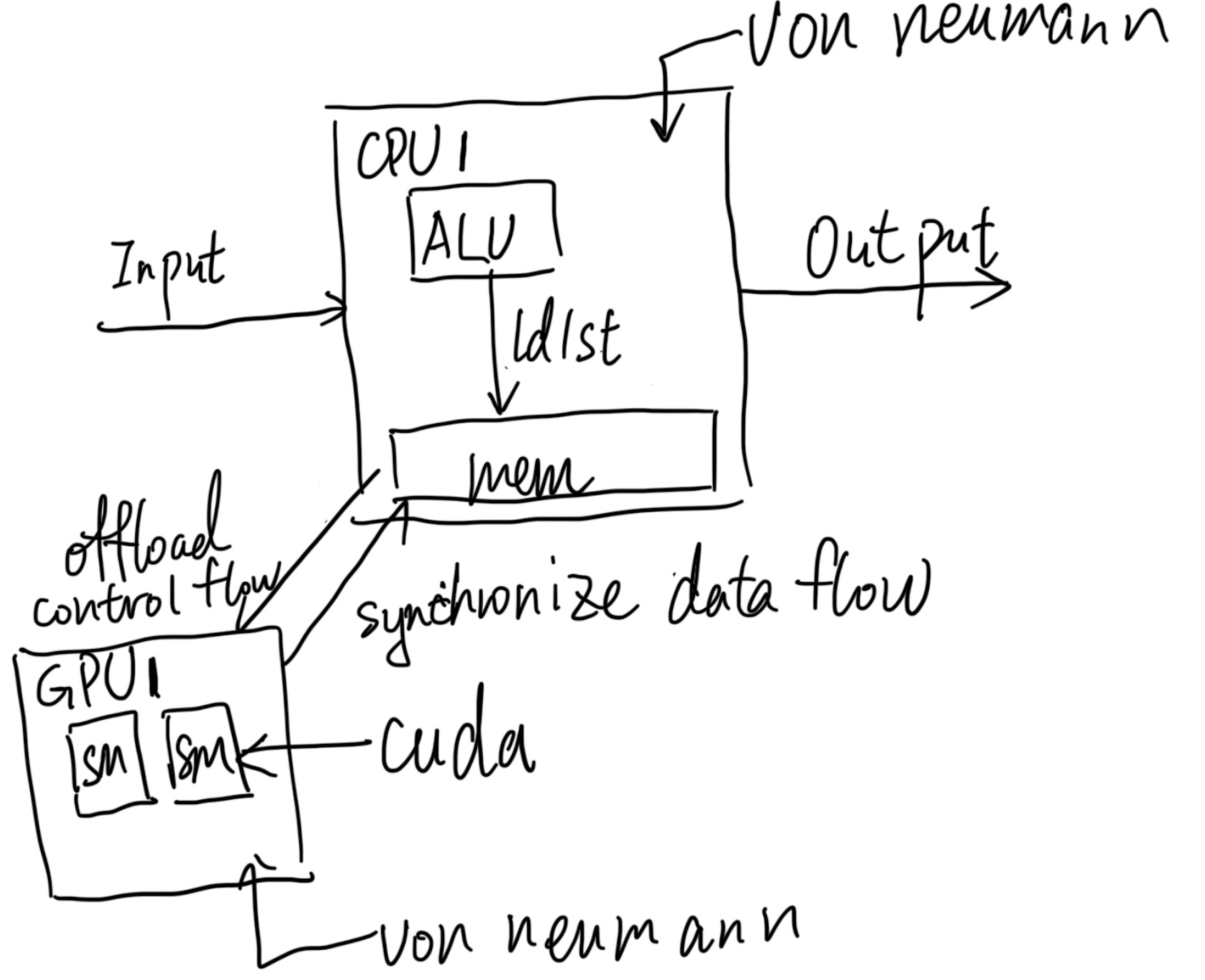
Now, we come to the scenario of heterogeneous systems. The endpoint could happen in the PCIe attachment or within the SoC that adds the ISA extension to a certain CPU, like Intel DSA, IAA, AVX, or AMX. The former is a standalone Von Neumann Architecture that does the same as above; the latter is just integrated into the CPU, which adds the register state for those extensions. If the GPU wants to access the memory inside the CPU, the CPU needs to offload the control flow and synchronize all the data flow if you want to record and replay things inside the GPU. The control flow is what we are familiar with, which is CUDA. It will rely on the UVM driver in the CPU to get the offloading control flow done and transmit the memory. When everything is done, UVM will put the data the right way inside the CPU, like by leveraging DMA or DSA in a recent CPU. Then we need to ask a question: Is that enough? We see solutions like Ray that use the above method of data movement to virtualize certain GPU operations, like epoch-wise snapshots of AI workloads, but it's way too much overhead.
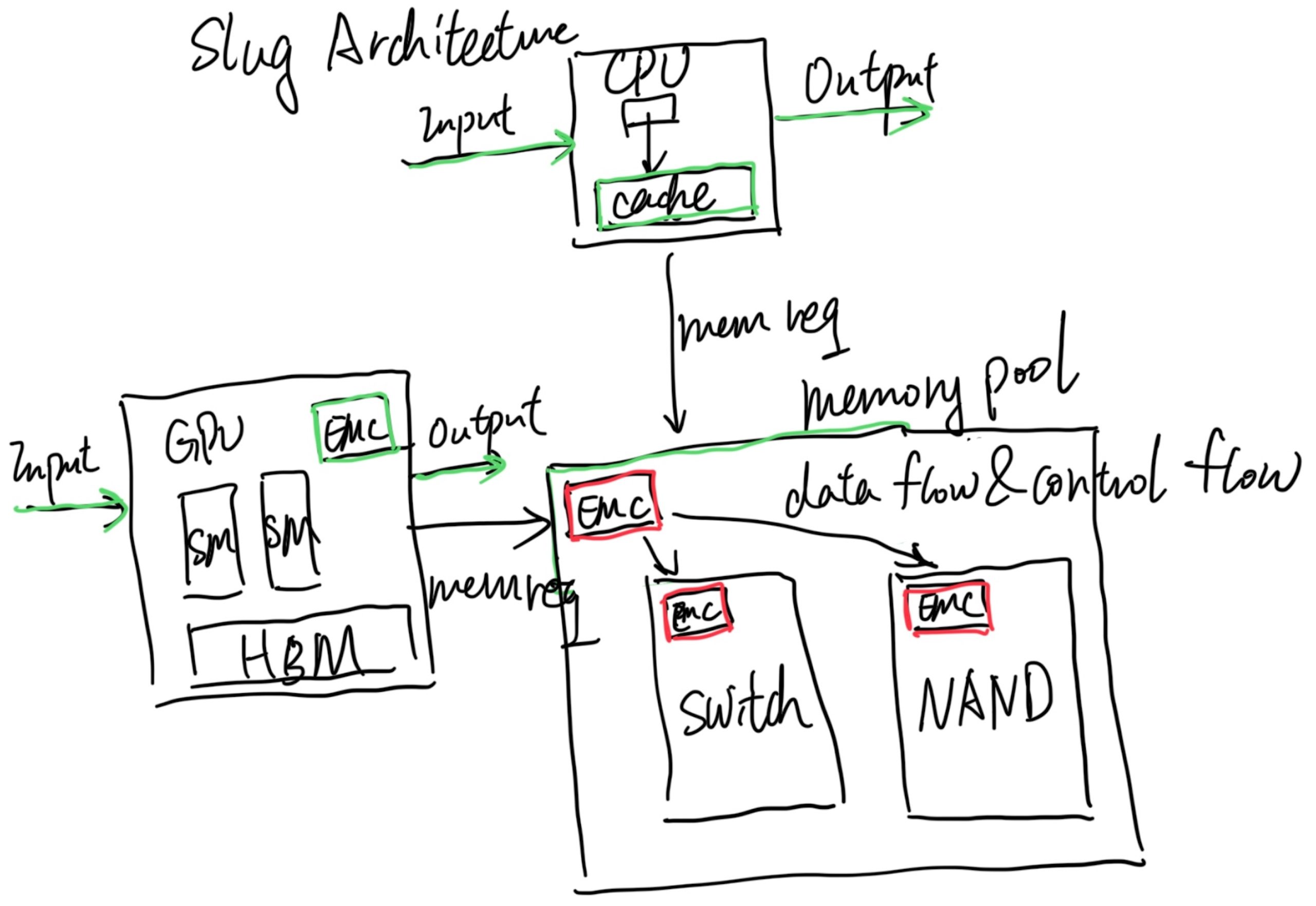
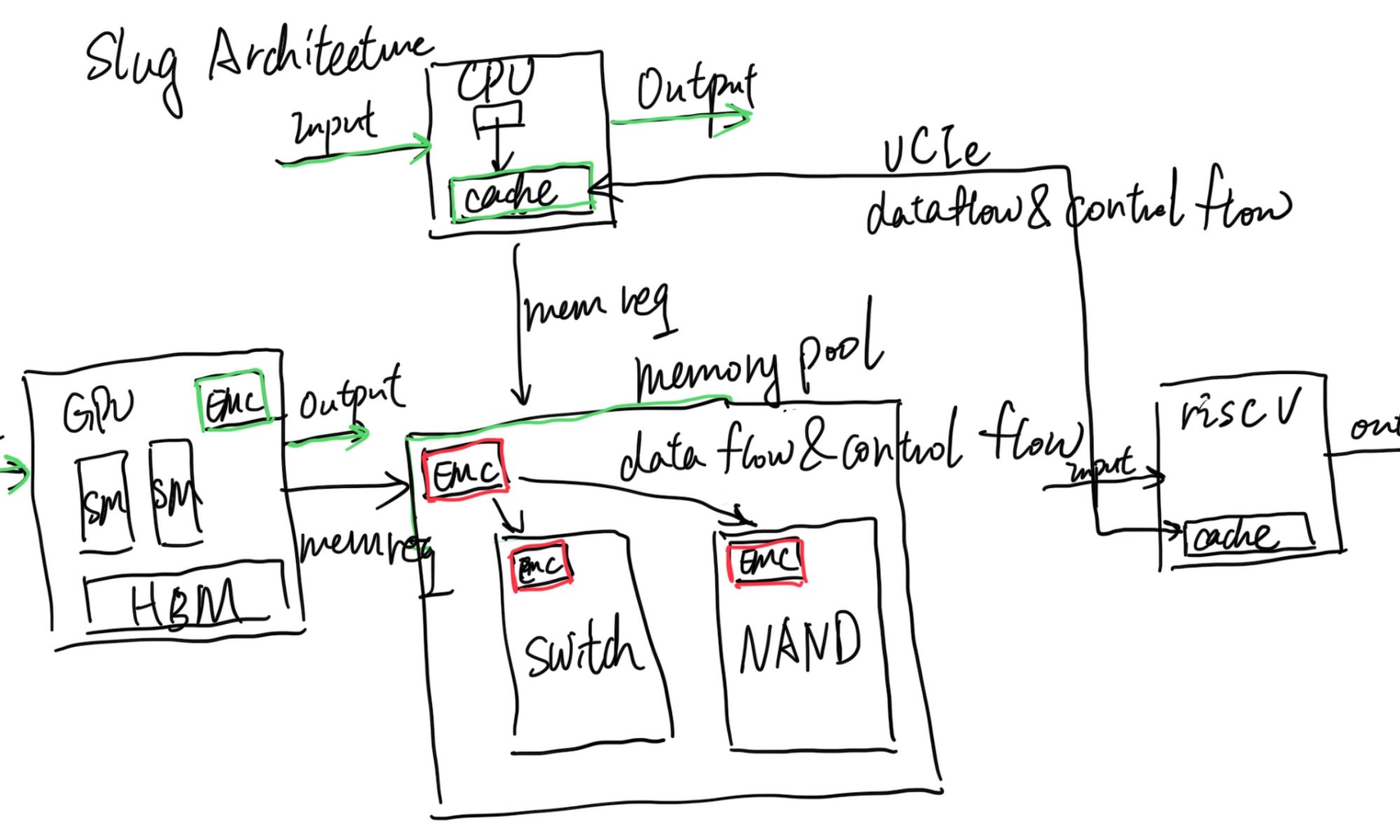
That's where Slug Architecture takes place. Every endpoint that has a cache agent (CHA), which in the above graph is the CPU and GPU, is Von Neumann. The difference is we add green stuff inside the CPU; we already have implementations like Intel PT or Arm Core Sight to record the CPU Von Neumann operations, and the GPU has nsys with private protocols inside their profiler to do the hack to record the GPU Von Neumann operations, which is just fine in side Slug Architecture. The difference is that the Slug Architecture requires every endpoint to have an External Memory Controller that does more than memory load and store instructions; it does memory offload (data flow and control flow that is not only ld/st) requests and can monitor every request to or from this Von Neumann Architecture's memory requests just like pebs do. It could be software manageable for switching on or off. Also, inside every EMC of traditional memory components, like CXL 3.0 switches, DRAM, and NAND, we have the same thing for recording those. Then the problem is, if we decouple all the components that have their own state, can we only add EMC's CXL fabric state to record and replay? I think it's yes. The current offloading of the code and code monitoring for getting which cycle to do what is event-driven is doable by leveraging the J Extension that has memory operations bubbles for compiling; you can stall the world of the CPU and let it wait until the next event!
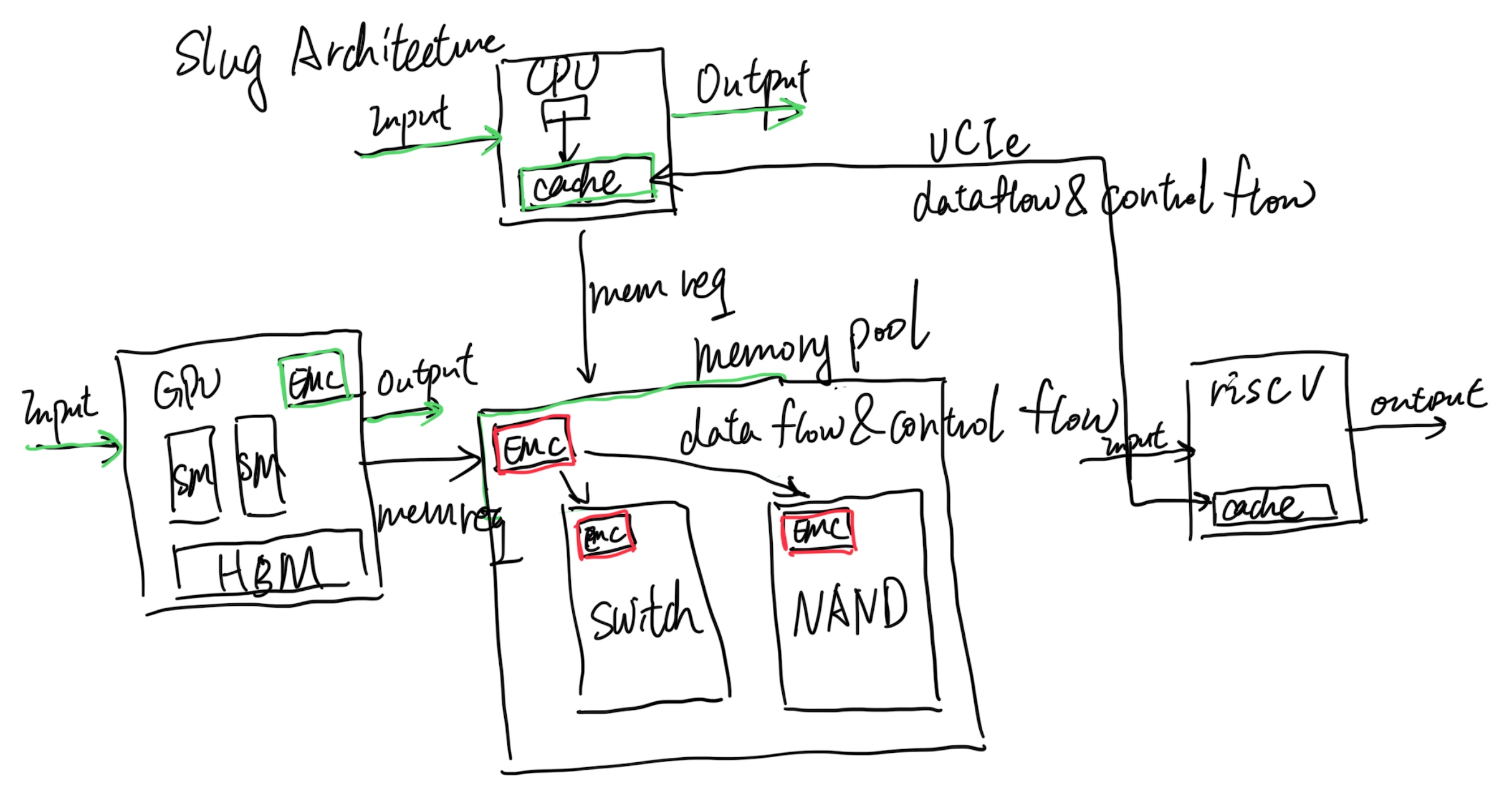
It should also be without the Memory to share the state; the CPU is not necessarily embracing all the technology that it requires, like it can decouple DSA to another UCIe packaged RiscV core for better fetching the data, or a UCIe packaged AMX vector machine, they don't necessarily go through the memory request, but they can be decoupled for record and replay leveraging the internal Von Neumann and EMC monitoring the link state.
In a nutshell, Slug Architecture is defined as targeting less residual data flow and control flow offloading like CUDA or Ray. It has first-priority support for virtualization and record & replay. It's super lightweight, without the need for big changes to the kernel.
Compare with the network view? There must be similar SDN solutions to the same vision, but they are not well-scaled in terms of metadata saving and Switch fabric limitation. CXL will resolve this problem across commercial electronics, data centers, and HPC. Our metadata can be serialized to distributed storage or CXL memory pools for persistence and recorded and replayed on another new GPU, for instance, in an LLM workflow with only Intel PT, or component of GPU, overhead, which is 10% at most.
Reference
- https://www.servethehome.com/sk-hynix-ai-memory-at-hot-chips-2023/
Rearchitecting streaming NIC with CXL.cache
A lot of people are questioning the usage of CXL.cache because of the complexity of introducing such hardware to arch design space. I totally agree that the traditional architecturist way of thinking shouldn't be good at getting a revolution of how things will work better. From the first principle view from the software development perspective, anything that saves latency with the latest fabric is always better than taking those in mind with software patches. If the latency gain from CXL.cache is much better than the architecture redesign efforts, the market will buy it. I'm proposing a new type of NIC with CXL.cache.
What's NIC? If we think of everything in the TCP/IP way, then there seems to be no need to integrate CXL.cache into the NIC because everything just went well, from IP translation to data packets. Things are getting weird when it comes to the low latency world in the HFT scenario; people will dive into the low latency fields of how packets can be dealt faster to the CPU. Alexandros Daglis from Georgia Tech has explored low-latency RPCs for ten years. Plus, mapping the semantics of streaming RPC like Enso from Intel and Microsoft rearchitecting the design of the packet for streaming data is just fine. I'm not rearchitecting the underlying hardware, but is there a way that makes the streaming data stream inside the CPU with the support of CXL.cache? The answer is totally YES. We just need to integrate CXL.cache with NIC semantics a little bit; the streaming data latency access will go from PCIe access to LLC access. The current hack, like DDIO, ICE or DSA, way of doing things will be completely tedious.
Then, let's think about why RDMA doesn't fit in the iWARP global protocol but only fits within the data center. This is because, in the former, routing takes most of the time. It is the same for NIC with CXL.cache. I regard this as translating from an IP unique identifier to an ATS identifier! The only meaning for getting NIC in the space of CXL.cache is translating from outer gRPC requests to CXL.cache requests inside the data center, which is full functional routing with the unique identifier of ATS src/target cacheline requests inside CXL pools. We can definitely map a gRPC semantic to the CXL.cache with CXl.mem plus ATS support; since the protocol is agile for making exclusive write/read and .cache enabled or not, then everything within the CXL.mem pool will be super low latency compared to the RDMA way of moving data!
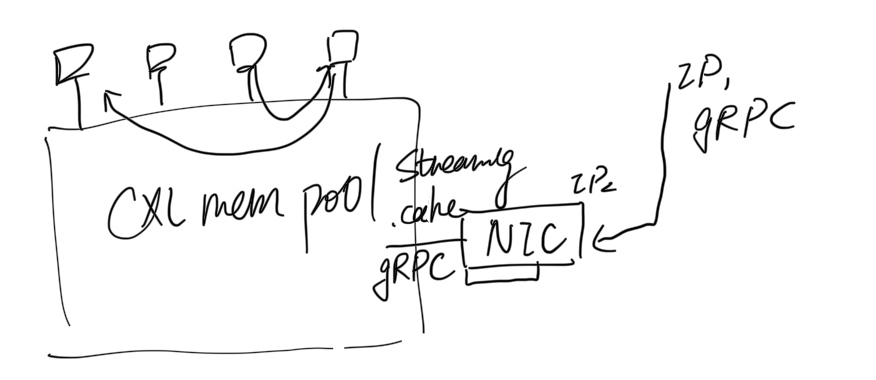
How to PoC the design? Using my simulator, you will need to map the thrift to CXL.cache requests; how to make it viable for the CPU's view‘s abstraction and how the application responds to the requests are the most important. Despite the fact that nothing has been ratified, neither industry nor vendors are starting to think through this way, but we can use the simulator to guide the design to guide the future industry.
Diving through the world of performance record and replay in Slug Architecture.
This doc will be maintained in wiki.
When I was in OSDI this year, I talked with the Lead of KAIST OS lab Youngjin Kwon talking about bringing record and replay into the first-tier support. I challenged him about not using OS layer abstraction, but we should bring up a brand new architecture to view this problem from the bottom up. Especially, we don't actually need to implement OS because you will endure another implementation complexity explosion of what Linux is tailoring to. The best strategy is implemented in the library with the support of eBPF or other stuff for talking into the kernel and we leverage hardware extensxion like J extension. And we build a library upon all these.
We live in a world of tons of NoC whose CPU count increases and from one farthest core to local req can live up to 20ns, the total access range of SRAM, and out of CPU accelerators like GPU or crypto ASIC. The demand for recording and replay in a performance-preserving way is very important. Remember debugging the performance bug inside any distributed system is painful. We maintained software epochs to hunt the bug or even live to migrate the whole spot to another cluster of computing devices. People try to make things stateless but get into the problem of metadata explosion. The demand to accelerate the record and replay using hardware acceleration is high.
- What's the virtualization of the CPU?
- General Register State.
- C State, P State, and machine state registers like performance counter.
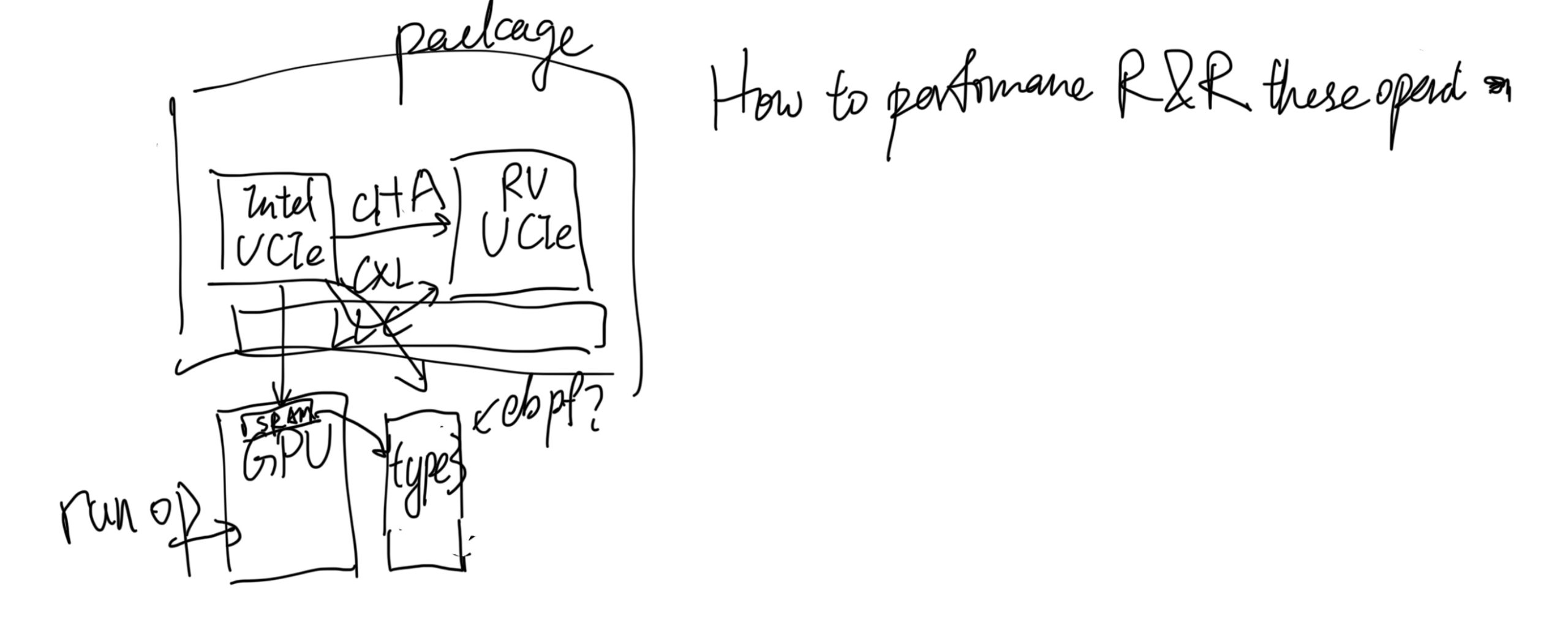
- CPU Extensions abstraction by record and replay. You normally interact with Intel extensions with drivers that map a certain address to it and get the results after the callback. Or even you are doing MPX-like style VMEXIT VMENTER. They are actually the same as CXL devices because, in the scenario of UCIe, every extension is a device and talks to others through the CXL link. The difference is only the cost model of latency and bandwidth.
- What's the virtualization of memory?
- MMU - process abstraction
- boundary check
- What's the virtualization of CXL devices in terms of CPU?
- Requests in the CXL link
- What's the virtualization of CXL devices in terms of outer devices?
- VFIO
- SRIOV
- DDA
Now we sit in the intersection of CXL, where NoC talk to each other the same as what GPU is talking to NIC or NIC talking to either core. I will regard them as Slug Architecture in the name of our lab. Remember the Von Noeman Architecture saying every IO/NIC/Outer device sending requests to CPU and CPU handler will record the state internally inside the memory. Harvard Architecture says every IO/NIC/Outer device is independent and stateless of each other. If you snapshot the CPU with memory, you don't necessarily get all the states of other stuff. I will take the record and replay of each component plus the link - CXL fabric as all the hacks take place. Say we have SmartNICs and SmartSSDs with growing computing power, we have NPUs and CPUs, The previous way of computing in the world of Von Noeman is CPU dominated everything, but in my view, which is Slug Architecture that is based upon Harvard Architecture, CPU fetches the results of outer devices results and continue, NPU fetches SmartSSDs results to continue. And for vector lock like timing recording, we need bus or fabric monitoring.
- Bus monitor
- CXL Address Translation Service
- Possible Implementation
- MVVM, we can actually leverage the virtualized env of WASM for core or endpoint abstraction
- J Extension with mmap memory for stall cycles until the observed signal
Why Ray is a dummy idea in terms of this? Ray just leverages Von Neumann Architecture but jumps its brain with the Architecture Wall. It requires every epoch of the GPU and sends everything back to the memory. We should reduce the data flow transmission and put control flow offloads.
Why LegoOS is a dummy idea in terms of this? LegoOS abstracts out the metadata server which is a centralized metadata server, which couldn't scale up. If you offload all the operations to the remote and add up the metadata of MDS this is also Von Neumann Bound. The programming model and OS abstraction of this is meaningless then, and our work can completely be a Linux userspace application.
CXL RSS Limit Kernel Design
Because of CXL.Mem is not currently available in the market; we based our system approach on two NUMA SPR sockets. We built an eBPF approach because of uncontrollable performance noise, which is deprecated, and a production-ready system. The former [3] utilizes eBPF to hook the allocation of memory for the workload across different memory tiers with 20% overhead on Broadwell and 1% overhead on SPR, while the BedeKernel interacts with the kernel's memory cgroup to determine the placement of pages. Specifically, the simulator ensures that the workload's allocation from the local memory doesn't exceed a certain bound. Subsequent sections of this document provide justification for the simulator's reliance on NUMA, an explanation of its eBPF-based design, and a description of the workloads that were evaluated.
We also provide a kernel implementation with cgroup integration in [1] and [2], which at the kernel level get the dynamic capacity for CXL.mem done compared with Anjo University's auto tiering NVM approach. Current simulators for CXL.mem often yield imprecise outcomes when modeling the impact of assigning a segment of a workload's memory to a CXL.mem shared memory pool. Pond, a specific instance, delivers inconsistent simulation results. It operates through a user-level program that allocates and mlocks memory, constraining the quantity of local memory an application can utilize. Regrettably, variations in memory consumption from ongoing background tasks in the system cause inconsistencies in the amount of local memory accessible for each workload. An alternative to Pond, SMDK, habitually allocates insufficient local memory. By altering the kernel's mmap to steer allocations into various memory zones, SMDK intervenes in each memory allocation. This technique determines the memory placement during virtual memory allocation (i.e., at the time of mmap), but due to demand paging, many virtual memory allocations never translate into physical memory and shouldn't be factored into the workload's local memory consumption. To address the shortcomings in earlier simulators, our specific CXL.mem workload simulator for data collection leverages namespace. As the workload executes, the simulator monitors the resident set size, hooking the policy_node and policy_nodemask with namespace isolation. invoked during each page allocation. This guides page allocations to ensure that the total memory designated to local memory remains within the specified local memory bound.
There are some known limitations of BedeKernel:
- TODO: DSA Migration impl, currently just migrate page async.
- On cgroup start, starting bede struct. On cgroup init procfs, init the policy_node instrumentation. Locally-bind specially dealt with. Let k8s change the cgroup procfs variable to change the migration target. The full approach has a 5% overhead and a 10% deviation from the target RSS because of numastat metrics staleness in reason [5].
- On clone3 syscall, the cloned process may double the RSS limitation. Python is not working since it calls clone and detach child at the very beginning.
- On file-backed mmap syscall, on page fault, the decision does not go through the policy_node path, thus invalid.
- Kernel 6.4.0 removes atomic irq https://lore.kernel.org/all/[email protected]/, which makes numastat in hot path crash irq.
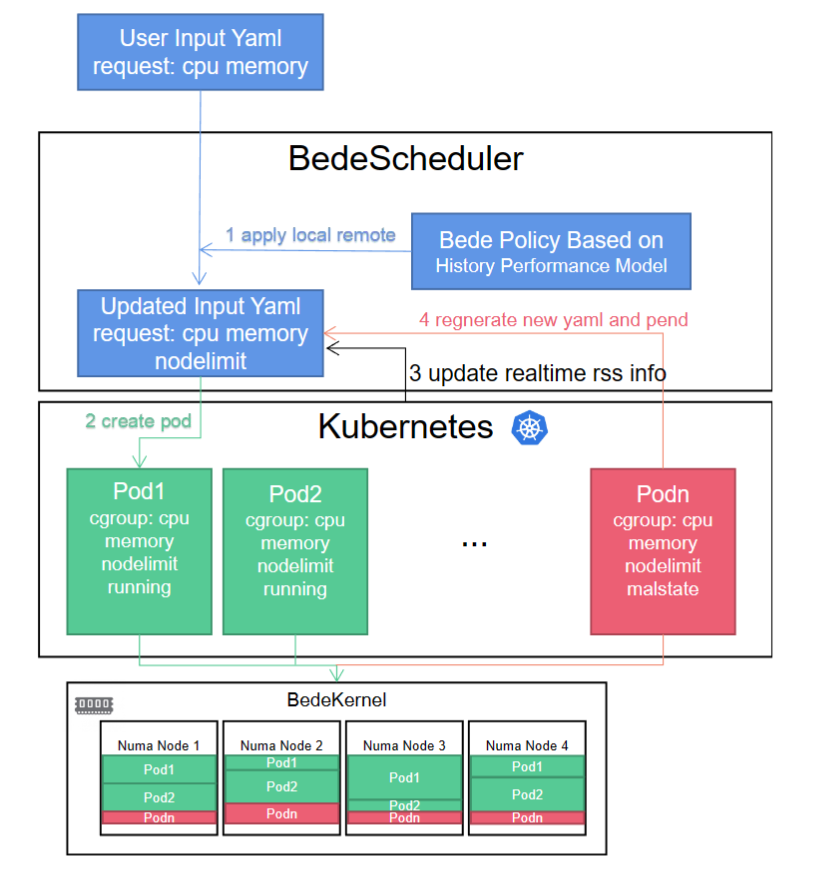
We also integrate the BedeKernel into k8s without a policy written yet because the performance gap of two socket memory in the NUMA machine is low. So, if you have the machine to evaluate my kernel, please feel free to help me. k8s utilizes cgroup as its interface for container management and oversees containers through the associated cgroup procfs directory files. As a result, we only need to make our node_limit visible to the Kubernetes scheduler. When a job's total memory size is defined through a user-input yaml file, the scheduler formulates a yaml as outlined in step 1 and applies the calculated node_limit to the corresponding pod's cgroup directory. The BedeKernel will then restrict page allocation at the hook points policy_node and policy_nodemask. In step 3, Kubernetes refreshes the real-time Resident Set Size (RSS) information to modify the node_limit for pending jobs. If a Pod is found to be in a compromised state, the scheduler will reconstruct the yaml file utilizing the historical performance model and apply it to the Kubernetes pending queue.
We think the above operation can also be codesigned with the fabric manager to make colocation work and avoid congestion in the channel, which the full discussion is here [4]; this will be done once the fabric manager is done. Because the hardware always has these or those bugs. Quote a guy from Alibaba Cloud: RDT's semantic and performance bugs make it not possible to provide a good workload history model in the k8s layer. I buy it. We should wait until a company integrates my implementation and see if the CXL fabric can be safely integrated without too much performance noise.
Reference
- https://github.com/SlugLab/Kubernetes
- https://github.com/SlugLab/Bede-linux
- https://github.com/victoryang00/node-limit-ebpf
- https://www.youtube.com/watch?v=sncOmRnO1O4
CXLMemUring: A Hardware Software Co-design Paradigm for Asynchronous and Flexible Parallel CXL Memory Pool Access
Address Generation Unit operation offloading.
CXL.mem does not have ATS required since the coherency may be too crowded maintain, the type 3 devices will be only within the DCOH of endpoint.
ATS info is recorded in the firmware level as PMU. Sounds need other logic to get these metrics.

Reference
TMTS Talk @CXL SIG

Scheduling asynchronous page migration based on the access pattern.
Hardware support is crucial
- Page access scans alone have high latency
- PMU address sampling drastically reduces promotion latency (access to promotion time)
- Earlier promotion improves performance
Per application policy is crucial
- The ufard they run in the userspace is per processs control flow
- Each application's policy of migration page should be separated and have conflict using PGO
Thoughts
- PGO rather than online PEBS? because PEBS's overhead is huge, even if you start in a seperate threads, or lower the sample period to 10k or 2m.
- The TLB should be hidden by CXL.cache atomic exchange cacheline and no need to update the page table. The page table reuse distance should be also considered, since either way of updating page table 1. mark page ro and migrate or atomic exchange requires timing next time use this page.
- will eBPF to control all the policies be a better choice? offloading policy to rc/ep
Reference
Contiguitas: The Pursuit of Physical Memory Contiguity in Datacenters @ISCA23
TLB in larger memory capacity era is not big enough and if the programmer want to resolve page fragmentation need to invalidate TLB for sure. The paper designed a transparent migration layer to accelerate contiguous page access.
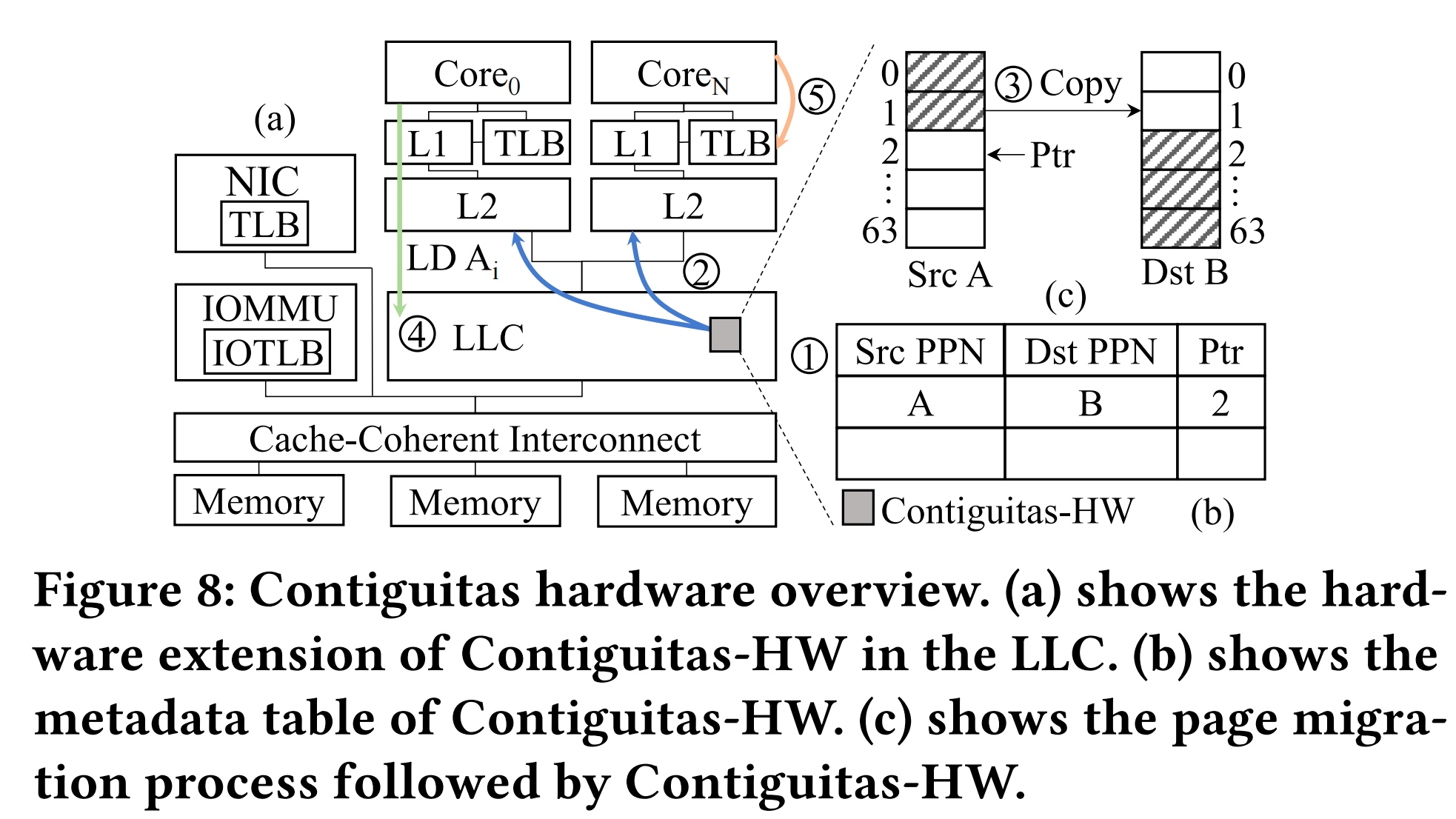
The Unmovable Region like NIC/Storage/GPU is pinned to pages, this is not exactly true when we design new CXL devices. Other pages will be marked movable with IOMMU support. The transparent page movement contiguous will relax the TLB shootdown. The mapping will be migrate(ppn src,ppn dest). The difference of Non-cachable
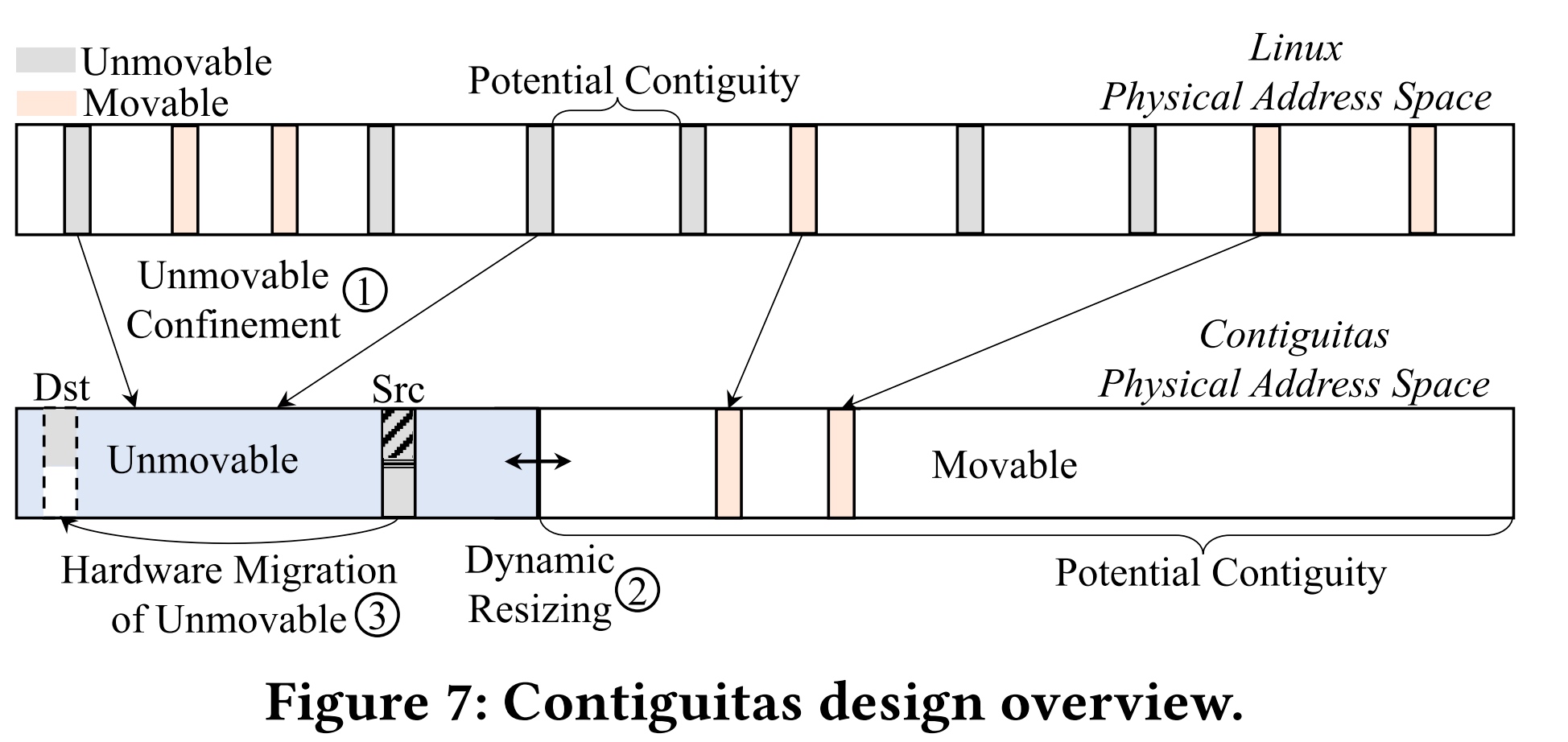
Region resize will go by the momentum of data movement to shrink or enlarge the unmovable region.

For a cycle simulator, as long as the warm-up will regard as resonable.
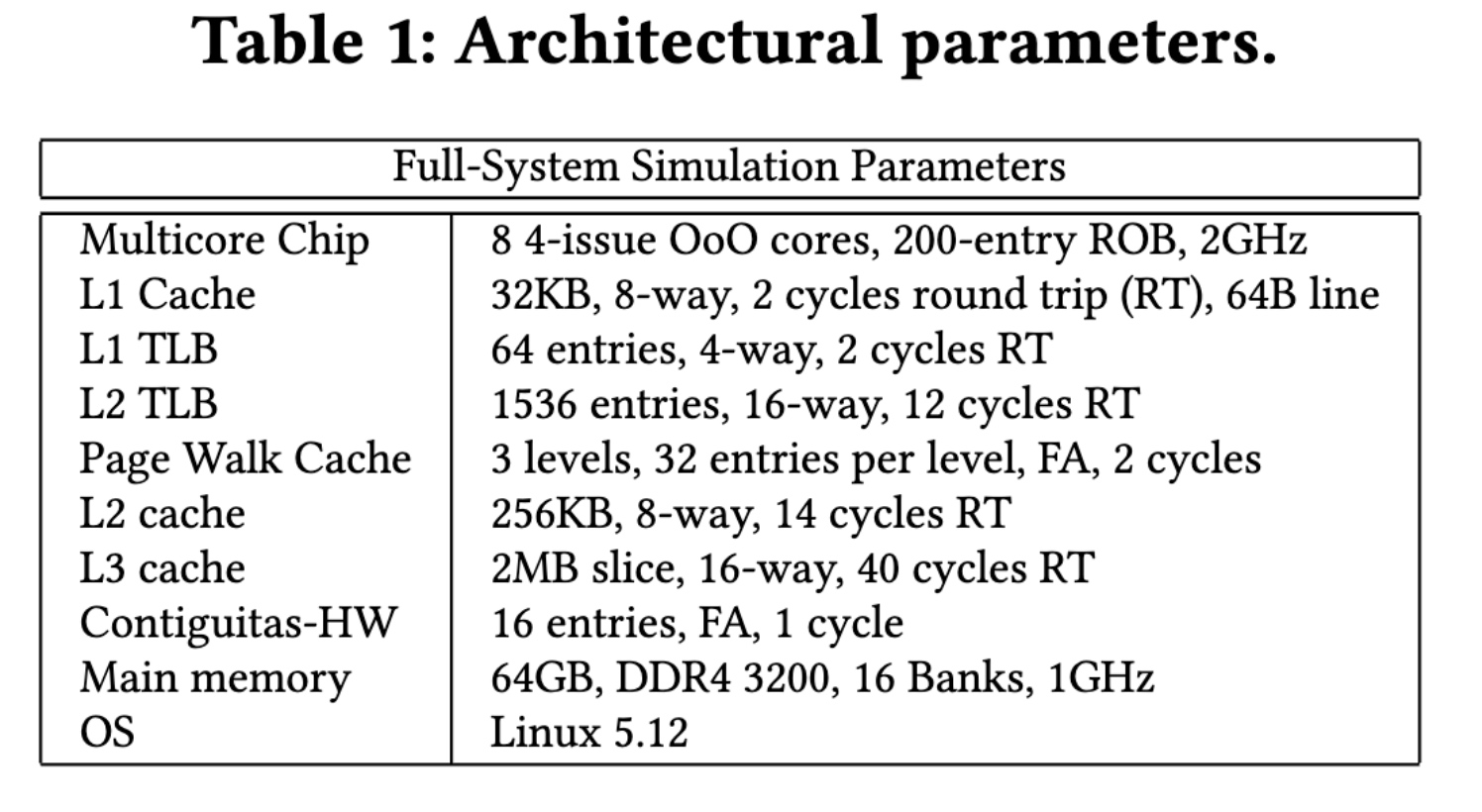
Reference
Rethinking the design of CXL Fault Tolerant Distributed System
- Ray-like software replication will introduce 20% overhead compared with MPI for distributed PyTorch training. Hardware-assisted replicas and erasure code should be implemented in the remote memory. The distributed kernel should be aware of the data's presence, how much time it takes for reconstruction, and the reliability rate for deciding where to put the data.
- Page table way of memory mapping seems tedious for local hardware resources of MSHR/TLB/ROB for hiding latency. The bound check could happen in the remote CXL pool ACL part. At the same time, the language runtime support should also comply with the check.