FPGA offload 入侵检测, performance/power efficiency balance。这篇的insight就是要做above 100Gbps TCP的on chip计算,比如负载均衡、能量负载、安全等如果放在CPU或者PIM上算都太慢了,所以搞了这个near NIC的computation。在交易所网络包发送的过程中也有类似的需要更改简单逻辑的场景,运用smartNIC在保证volatility的条件下可以大大减少延时。这篇的第二个insight是用到了intel hyperscan尽可能software 提速匹配IDS/IPSA。

第三个insight是硬件调度优化三个操作Regex matching rules/TCP reassemble/other task。
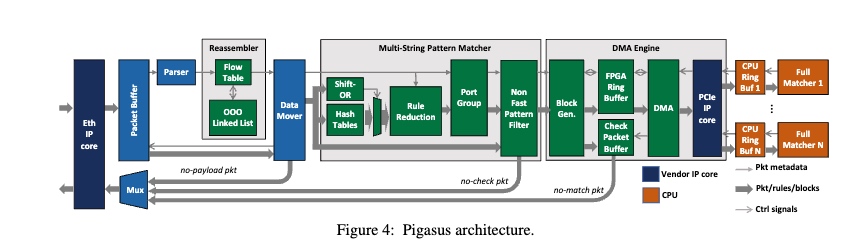
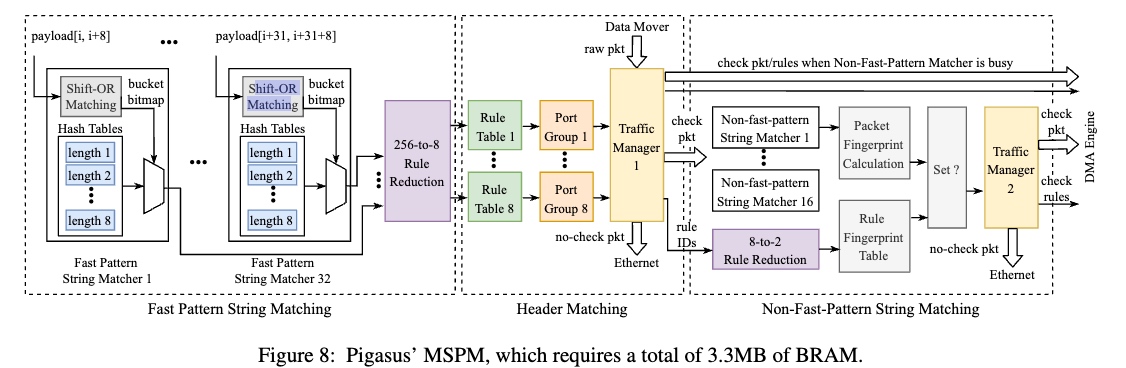
其中full matcher轮询一个由DMA engine填充的环形缓冲器。每个数据包都携带元数据,包括MSPM确定为部分匹配的规则ID(hyper scan的后半部分)。对于每个规则ID,完全匹配器检索完整的规则(包括正则表达式)并检查是否完全匹配。
TCP resembler 是一个ooo的设计。packets会先渠道fast path, 再到一个bram的cuckoo hashing table(flow table), insertion table 会弥补不同执行时间的ooo engine。
为了减少在FPSM的hash table lookup,其还写进去了一个SIMD shift or matching(显然应该不会比商用的intel的fpu写的快。(不过在FPGA上塞这么多逻辑.