

Both of the papers are from Dimitrios
Memory offloading
Because the memory occupation on a single node is huge, we are required to offload them into far memory.
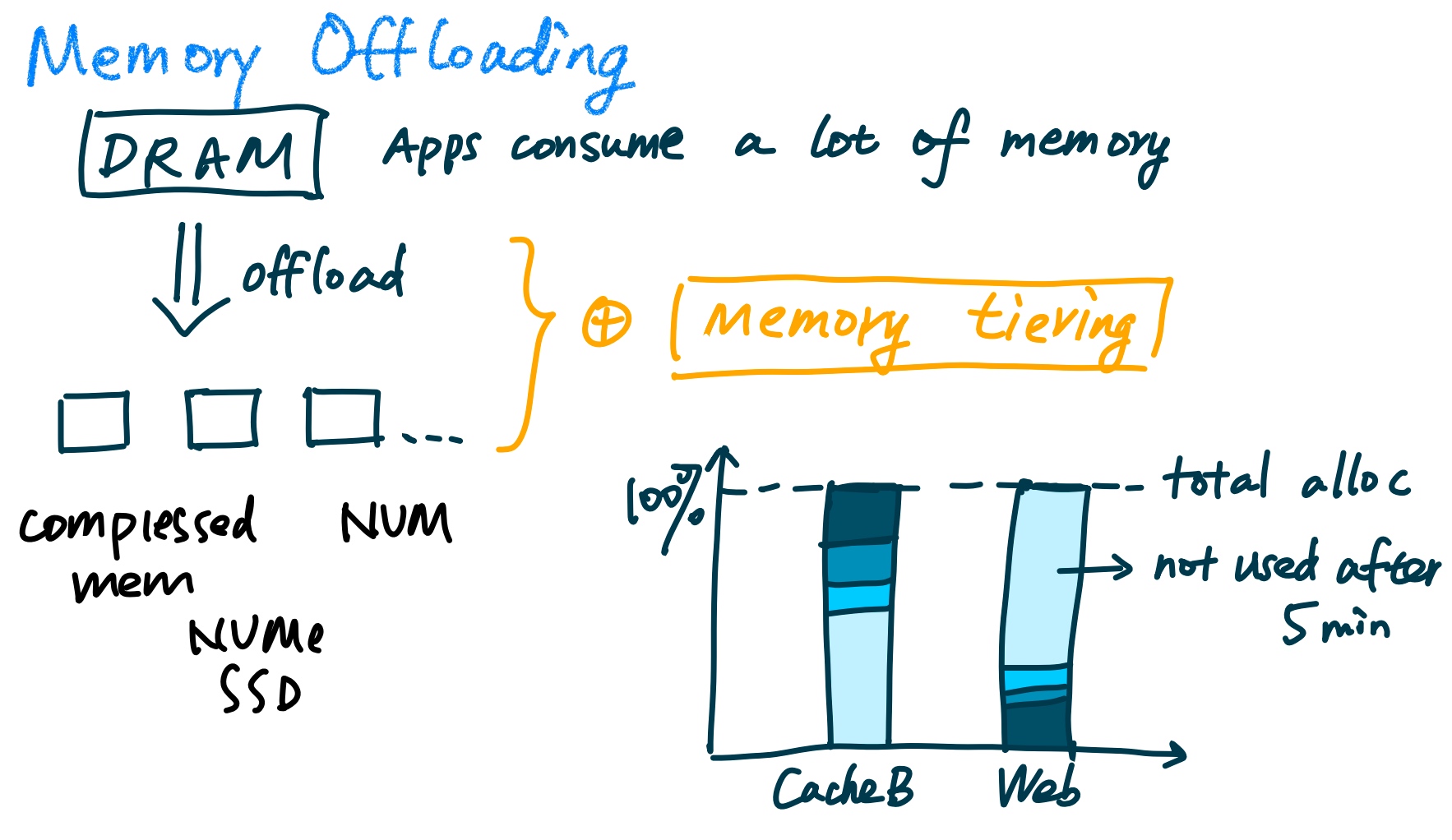
They have to model what the memory footprint is like. And what's shown in the previous work zswap, it only has a single slow memory tier with compressed memory and they only have offline application profiling, which the metric is merely page-promotion rate.
Transparent memory offloading
Memory Tax comes can be triggered by infrastructure-level functions like packaging, logging, and profiling and microservices like routing and proxy. The primary target of offloading is memory tax SLA.
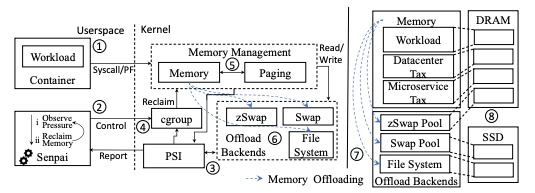
TMO basically sees through the resulting performance info like pressure stall info to predict how much memory to offload.
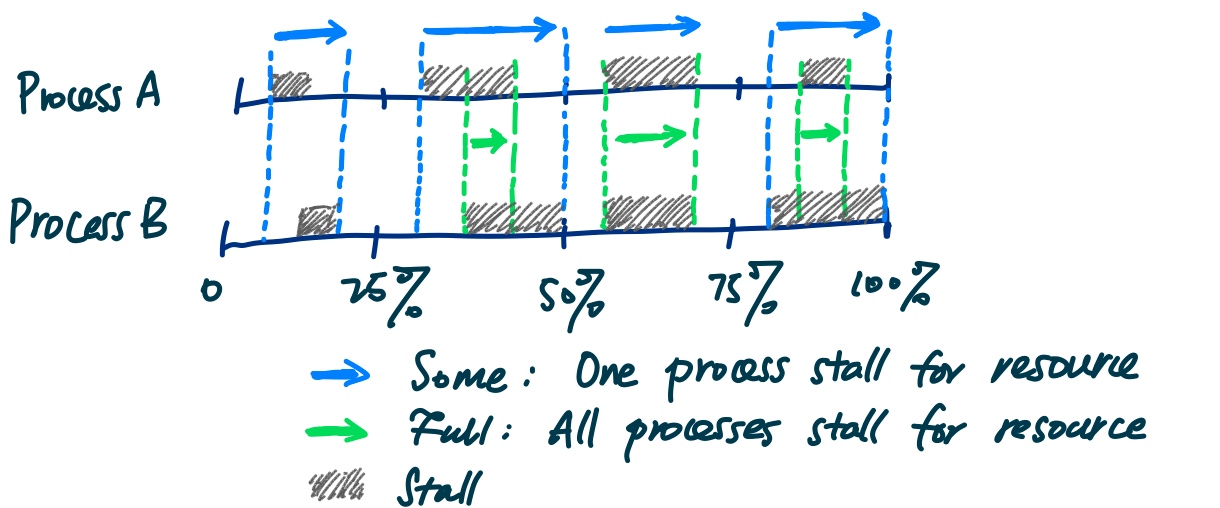
Then they use the PSI tracking to limit the memory/IO/CPU using cgroup, which they called Senpai.
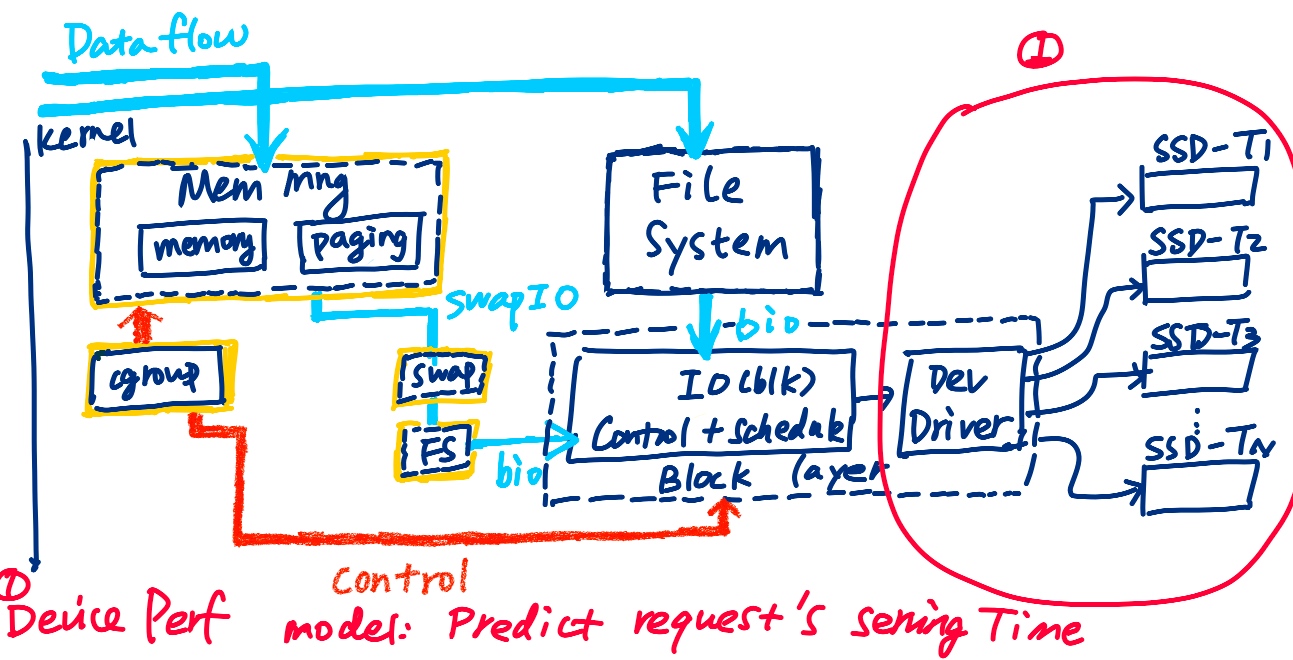
IOCost reclaims not frequently used pages to SSD.
Reference
- Jing Liu's blog
- Software-Defined Far Memory in Warehouse-Scale Computers
- Cerebros: Evading the RPC Tax in Datacenters
- Beyond malloc efficiency to fleet efficiency: a hugepage-aware memory allocator