这次投了一篇workshop,但是签证问题,所以这次前半段又得是一个线上会议,说实话我只关注CXL和codesign,本来可以见见刘神和jovan大师还有yan大师的,最后还是见到了,加上各种大师。机票是25号去西雅图的,也退不了,我现在改了护照hold on,在3.27号礼拜一飞LA取护照,被告知还没来,后来邮件来了,被告知第二天早上能到,然后见了大学同学,和WDY。3.28到LA领馆的时候,一开始没到,10.37分收到,10.45分拿到护照,12.35的飞机,uber去,11.28到,线上checkin过了15分钟安检,还好出境去canada比较快,安检前根本没有check合法证件,领登机牌的时候被check了入境加拿大的合法证件。晚点了半个小时。到温哥华下飞机,入境全部电子化,我被签证官问干什么,我说I‘m a Ph.D. student and attend conference. 然后就放我过了。到的时候是最后一个session,拿了badge,听完就poster session了,到第二天3点结束其实正好就听了一天。晚上的aqurium的award不错,social 认识了美本CMU博美女。(Trans 完全没有被歧视。)感觉加拿大完全是富人的天堂,能干活的人去只能做做底层工作,不划算,我觉得,这个国家,经济上政治上科技上完全被美帝压制和吸血。最前沿的东西也没有美国牛逼。由于asplos paper 太多,下面只放最重要的。
Firesim
主要是介绍他们的firesim的,就问他们什么时候更新f1 vu9p。tutorial讲很多怎么在f1上用firesim和chipyard敏捷开发riscv,ucb的252已经用chipyard当他们的体系结构作业了,仿真一个BOOM的TAGE很正常。
Integrating a high performance instruction set simulator with FireSim to cosimulate operating system boots By tesorrent
主要讲了怎么在firesim上敏捷开发

LATTE
workshop都是企业级别的对RTL/hw/sw的优化。
Exploring Performance of Cache-Aware Tiling Strategies in MLIR Infrastructure
Intel OneDNN在MLIR上approach
PyAIE: A Python-based Programming Framework for Versal ACAP AI Engines
Versal ACAP HLS
A Scalable Formal Approach for Correctness-Assured Hardware Design
Jin Yang 大师的,之前在AHA讲过了,
Yarch
Formal Characterization of Hardware Transmitters for Secure Software and Hardware Repair
和作者聊了一下,是个台湾中研院->stanford的女生,和Cristopher合作,(他要来UCB了)大概就是model hw state,用symbolic execution resolve branch 然后看有没有timing difference。在RTL上做。
Detecting Microarchitectural Vulnerabilities via Fuzz Testing of White-box CPUs
用fuzzing地手段找Store Bypass。

SMAD: Efficiently Defending Against Transient Execution Attacks
这次被分配的mentor的学生的,这个mentor在GPU side channel很著名。
Session 1B: Shared Memory/Mem Consistency
这个chair是admit,辣个VMWare最会排列组合Intel ext的男人

Cohort: Software-Oriented Acceleration for Heterogeneous SoCs
这篇是在fpga上自己定义L1/L2 cache和crypto accelerator。然后怎么弄在一起,在CXL.cache就不是一个问题。
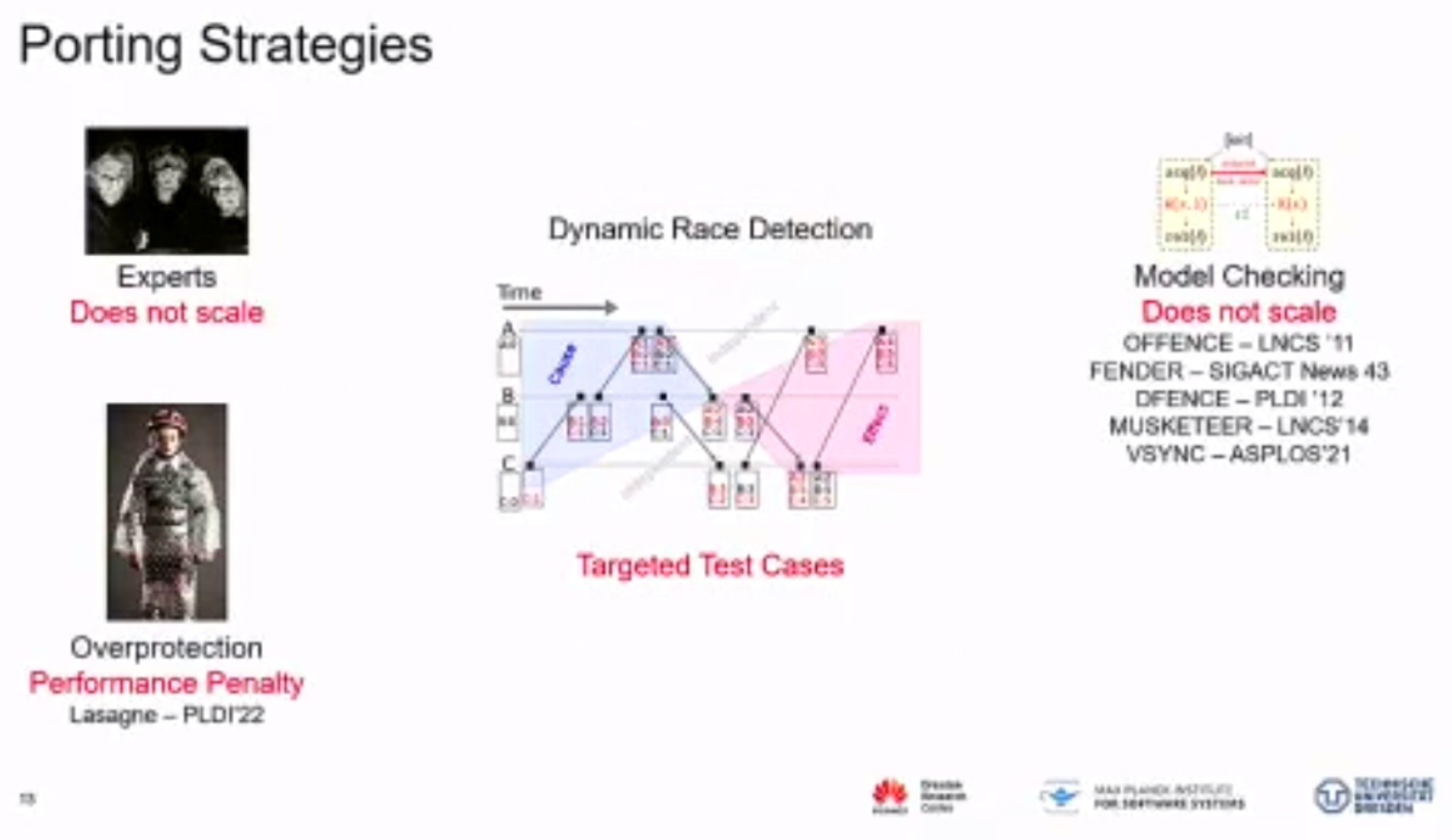
Probabilistic Concurrency Testing for Weak Memory Programs
一个PCT Frameware,用SC的规范来assert,找bug。
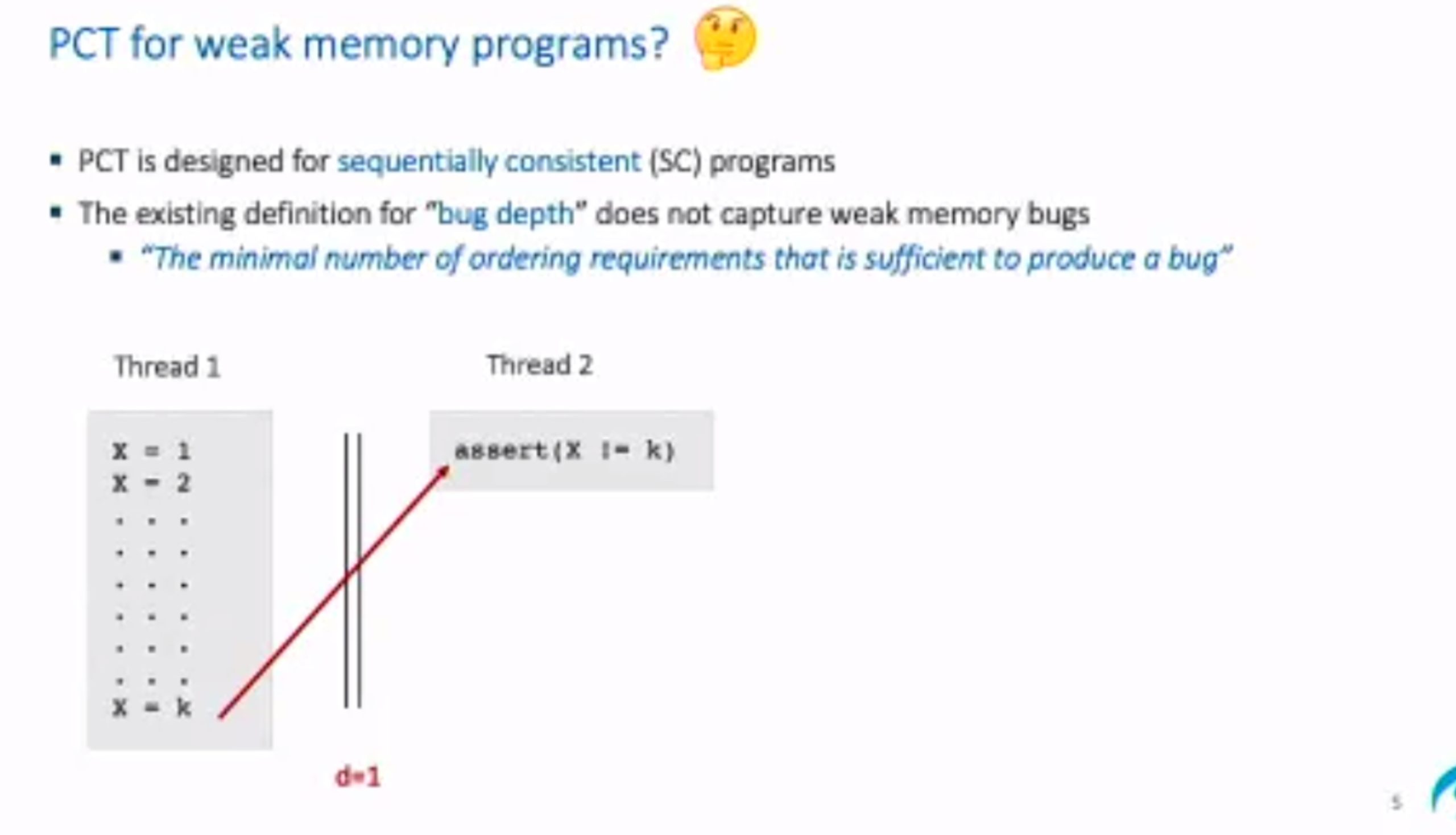

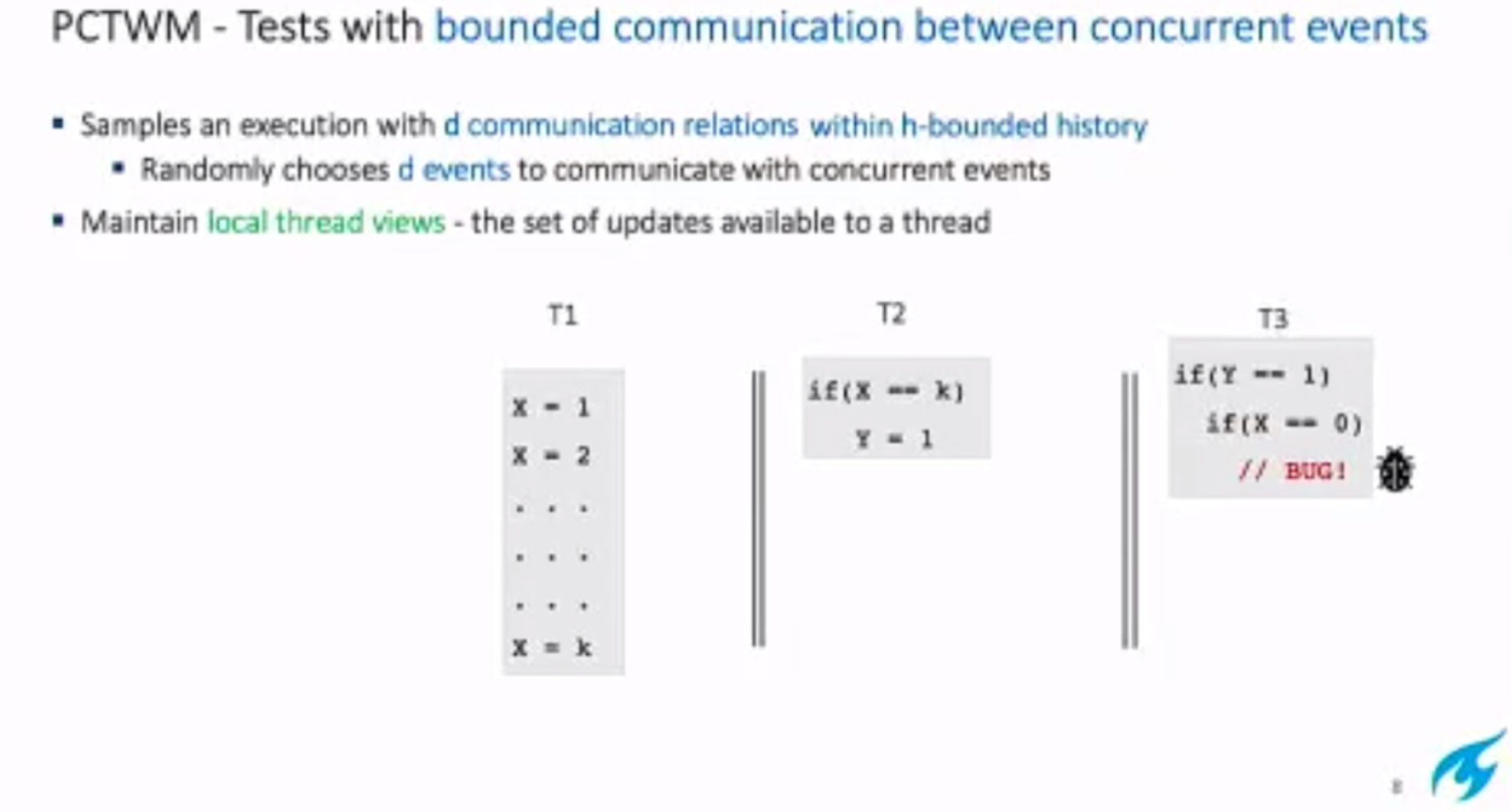

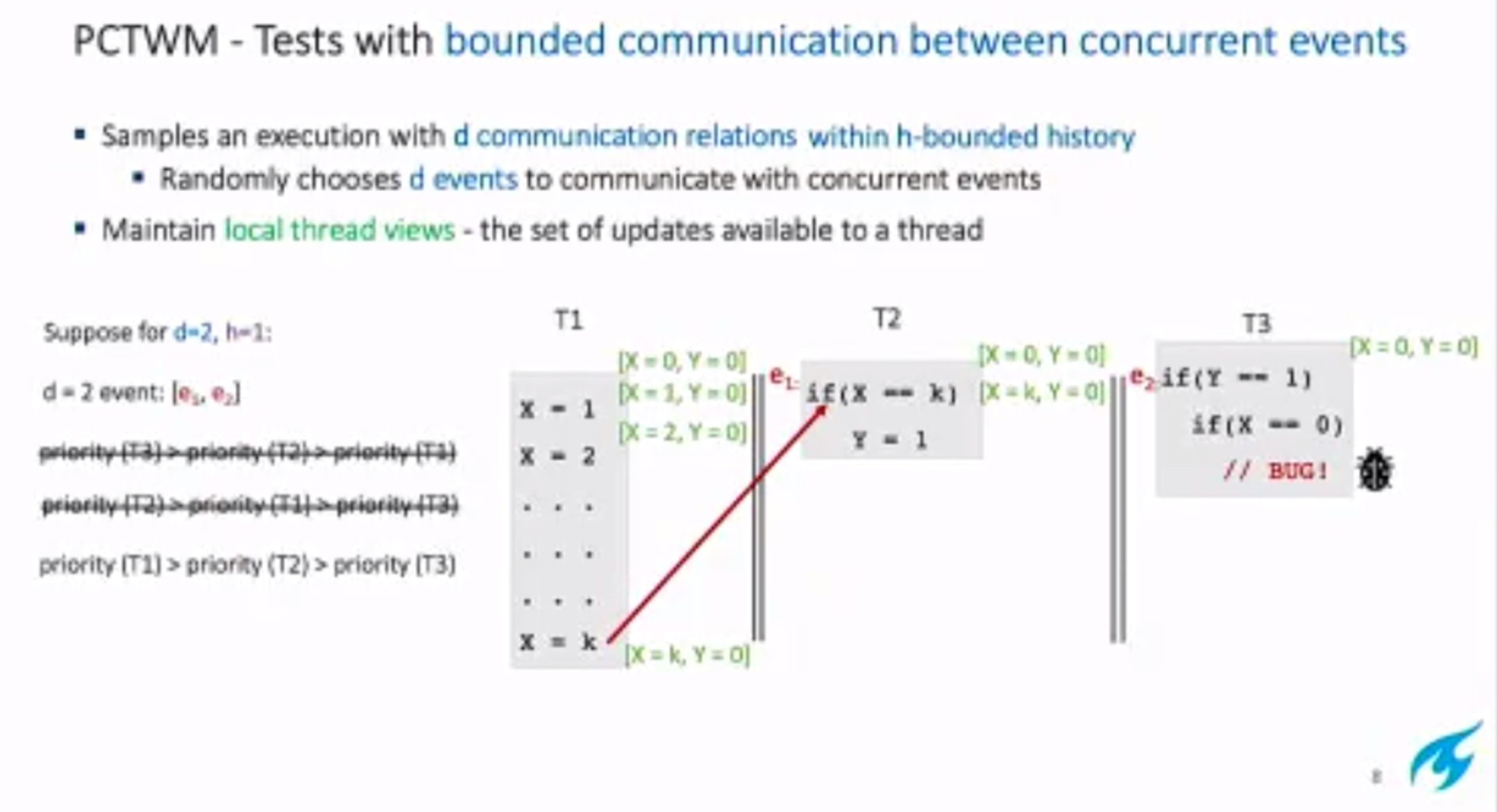

hit bug 更快
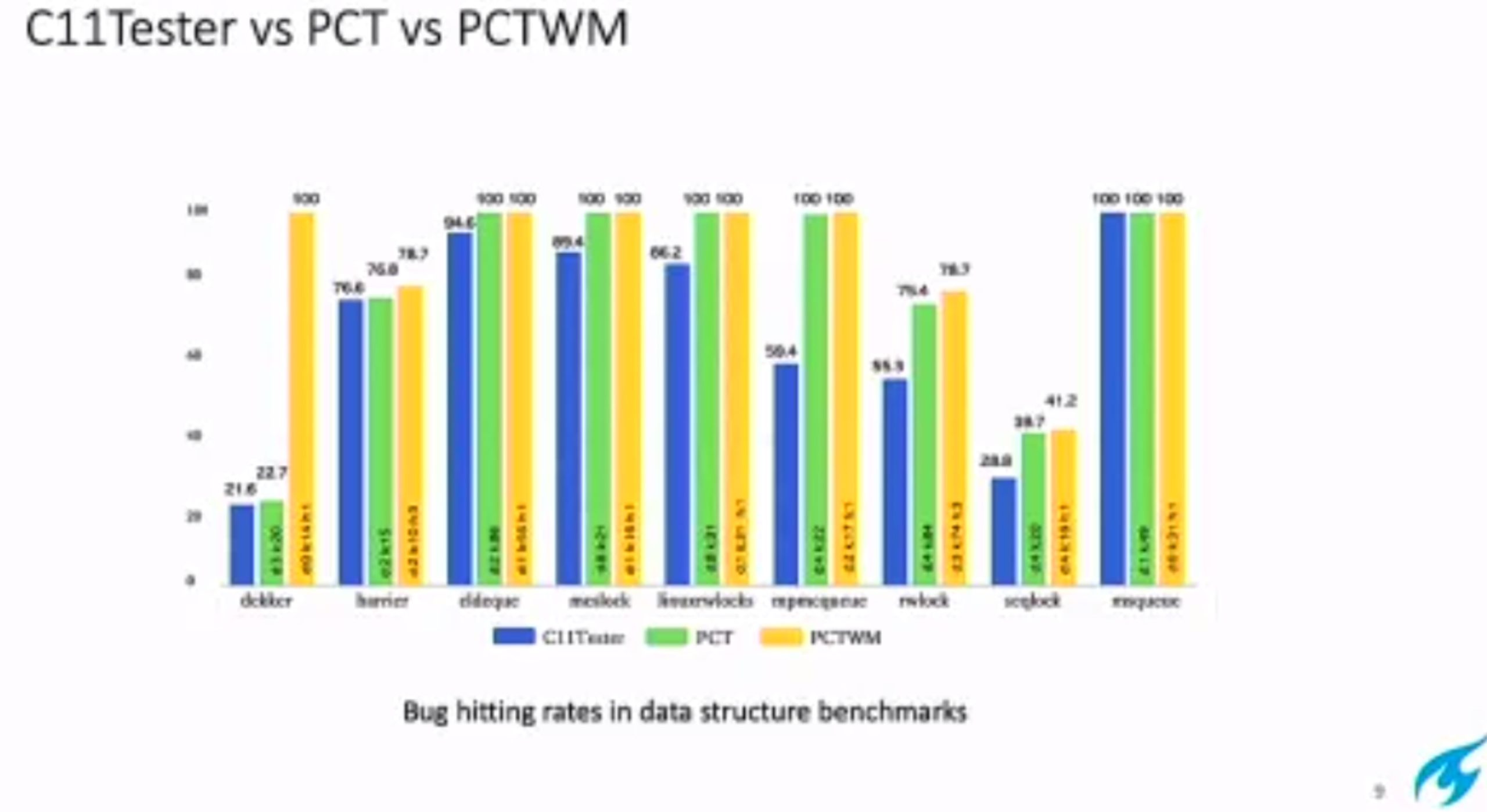
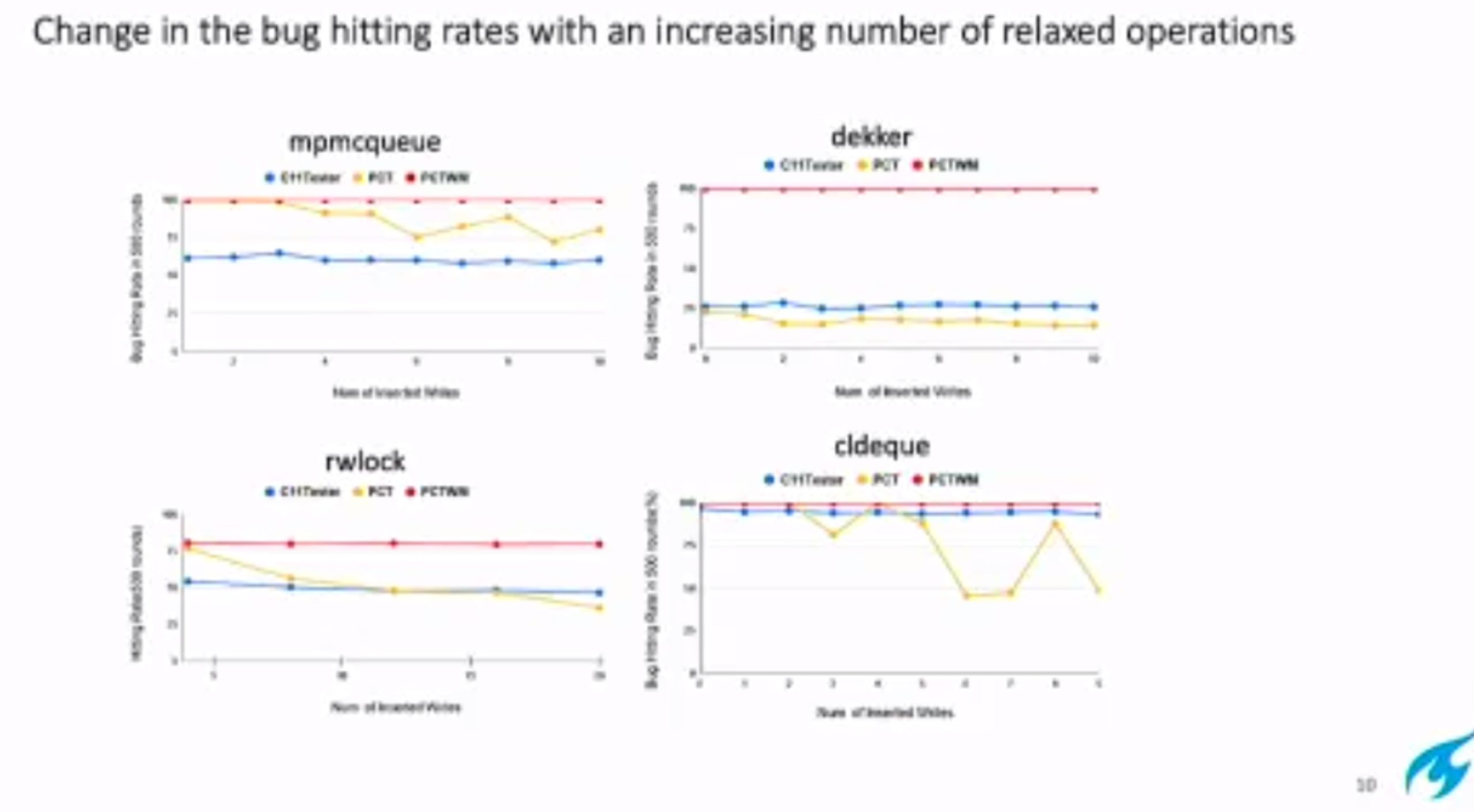

Hieristic for h is good enough for data structure test. assertion tests looks great, When I was in shanghaitech, there’s people using the same tool on PM.







'
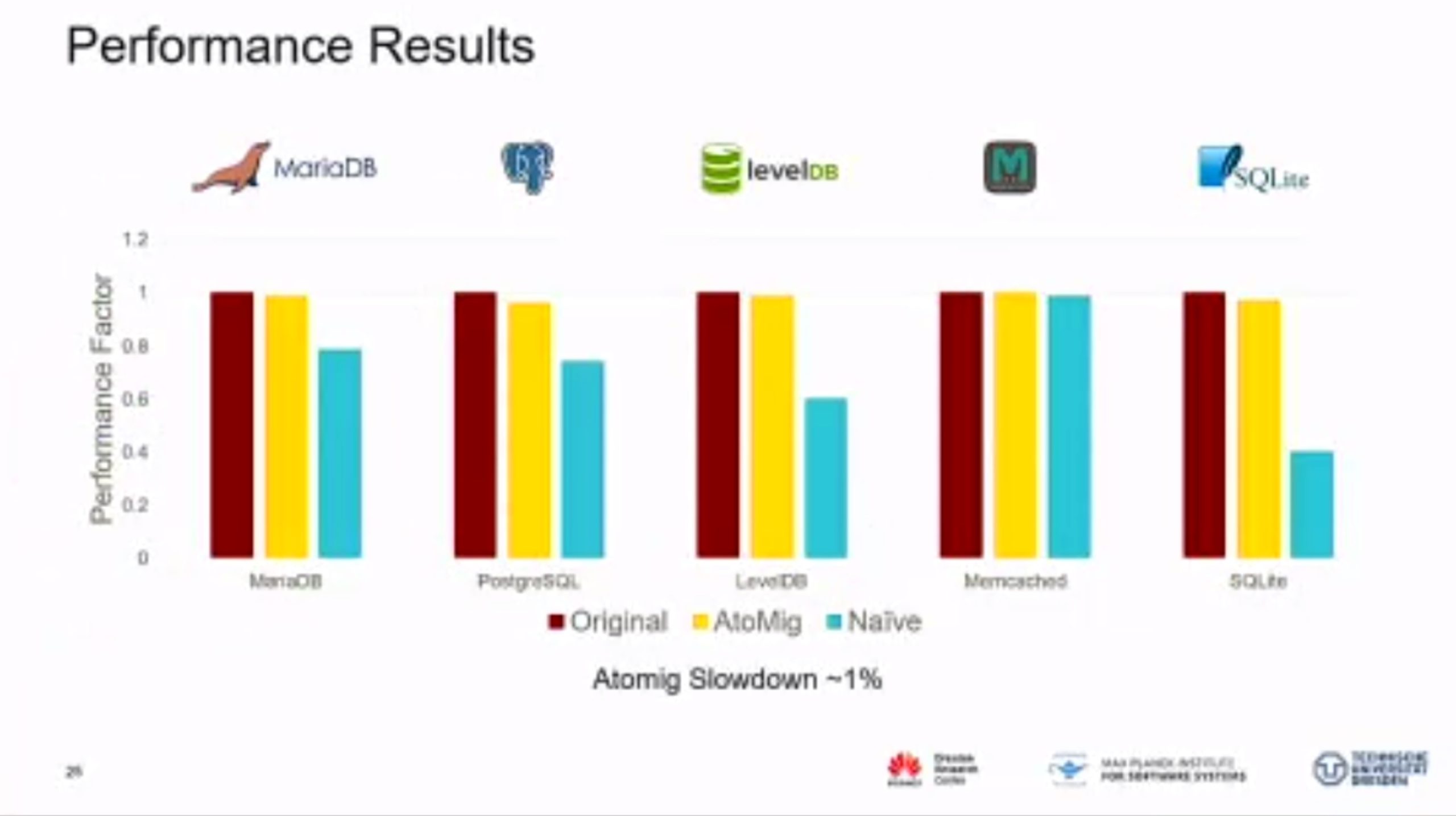
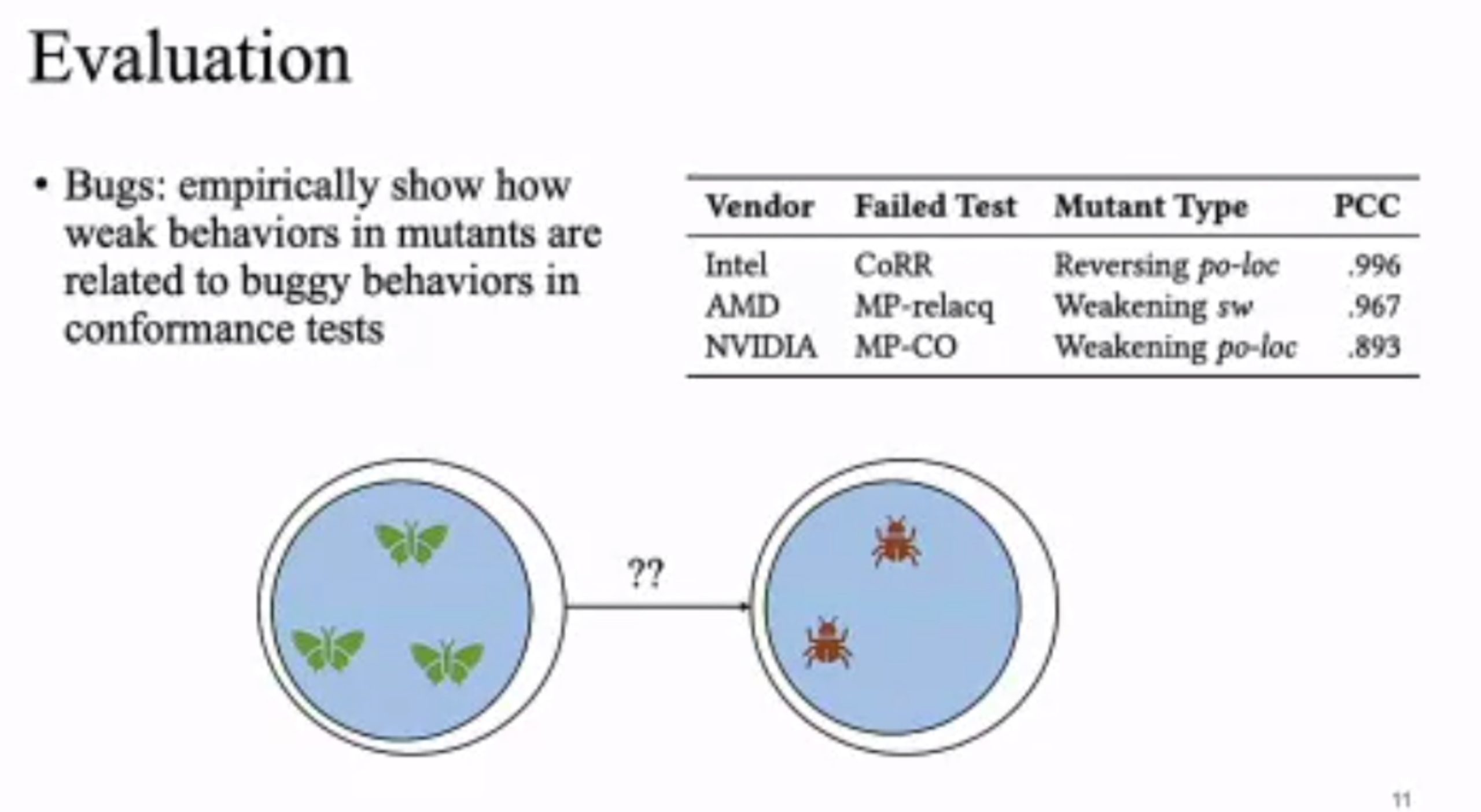
MC Mutants: Evaluating and Improving Testing for Memory Consistency Specifications

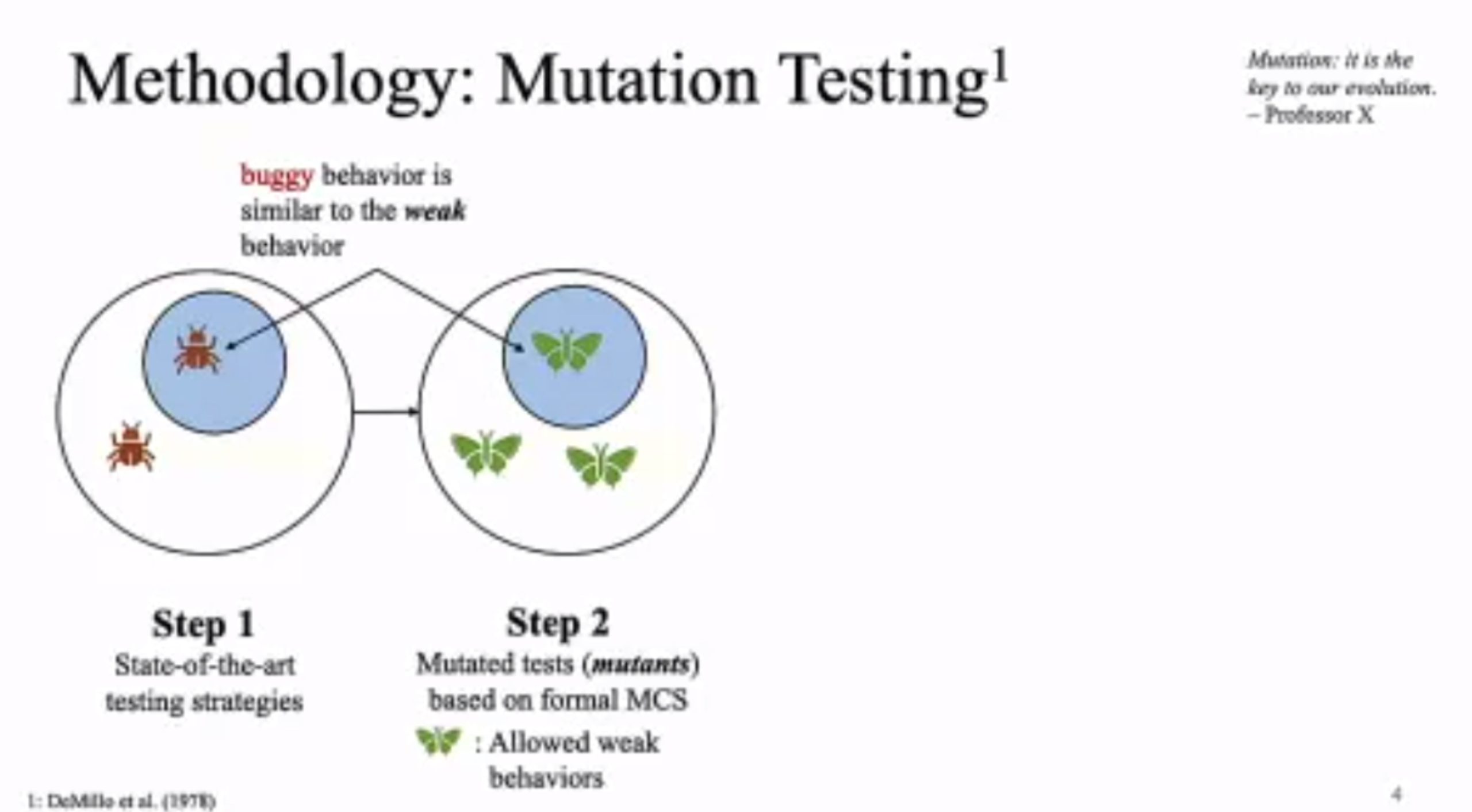
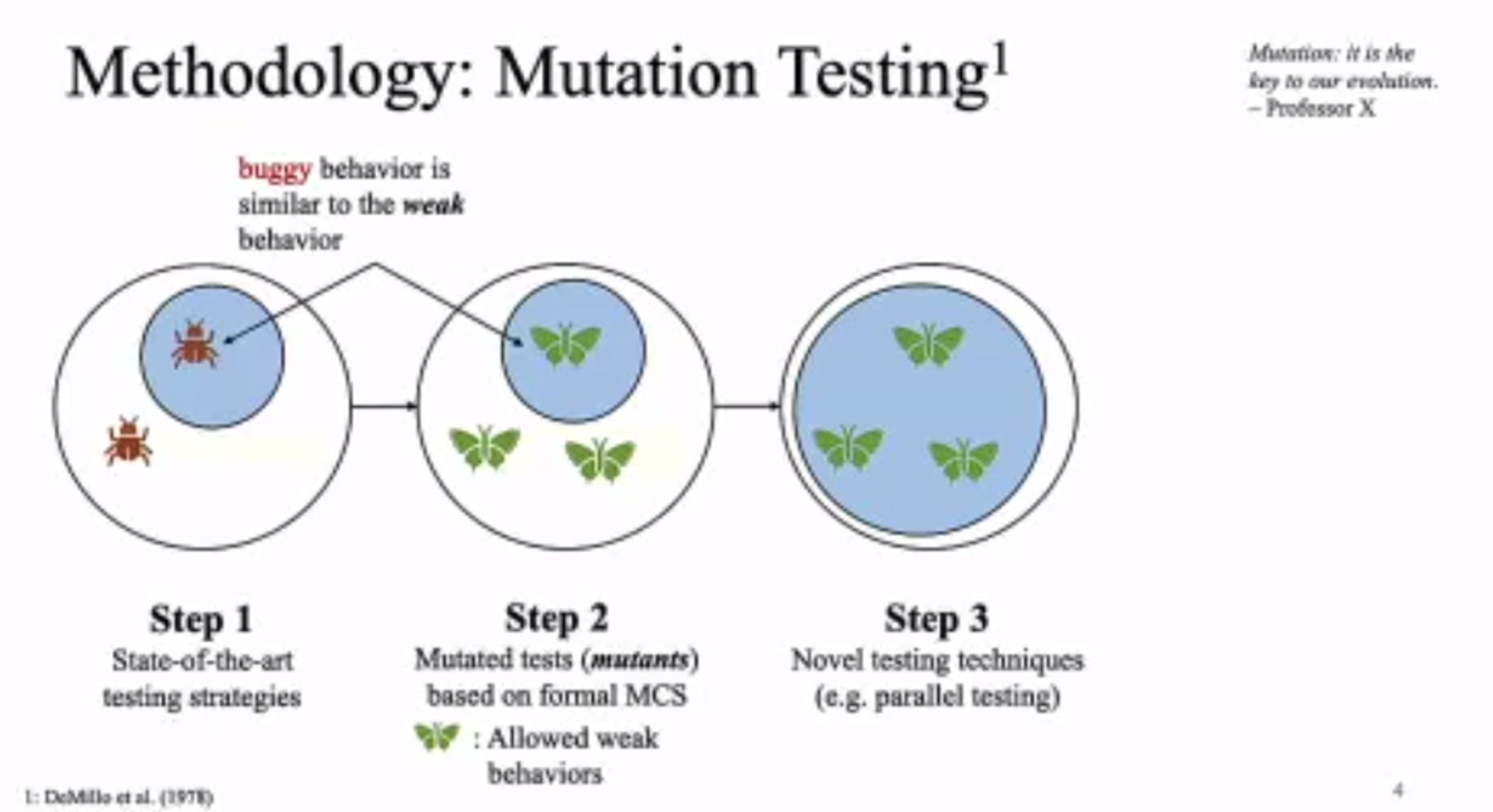
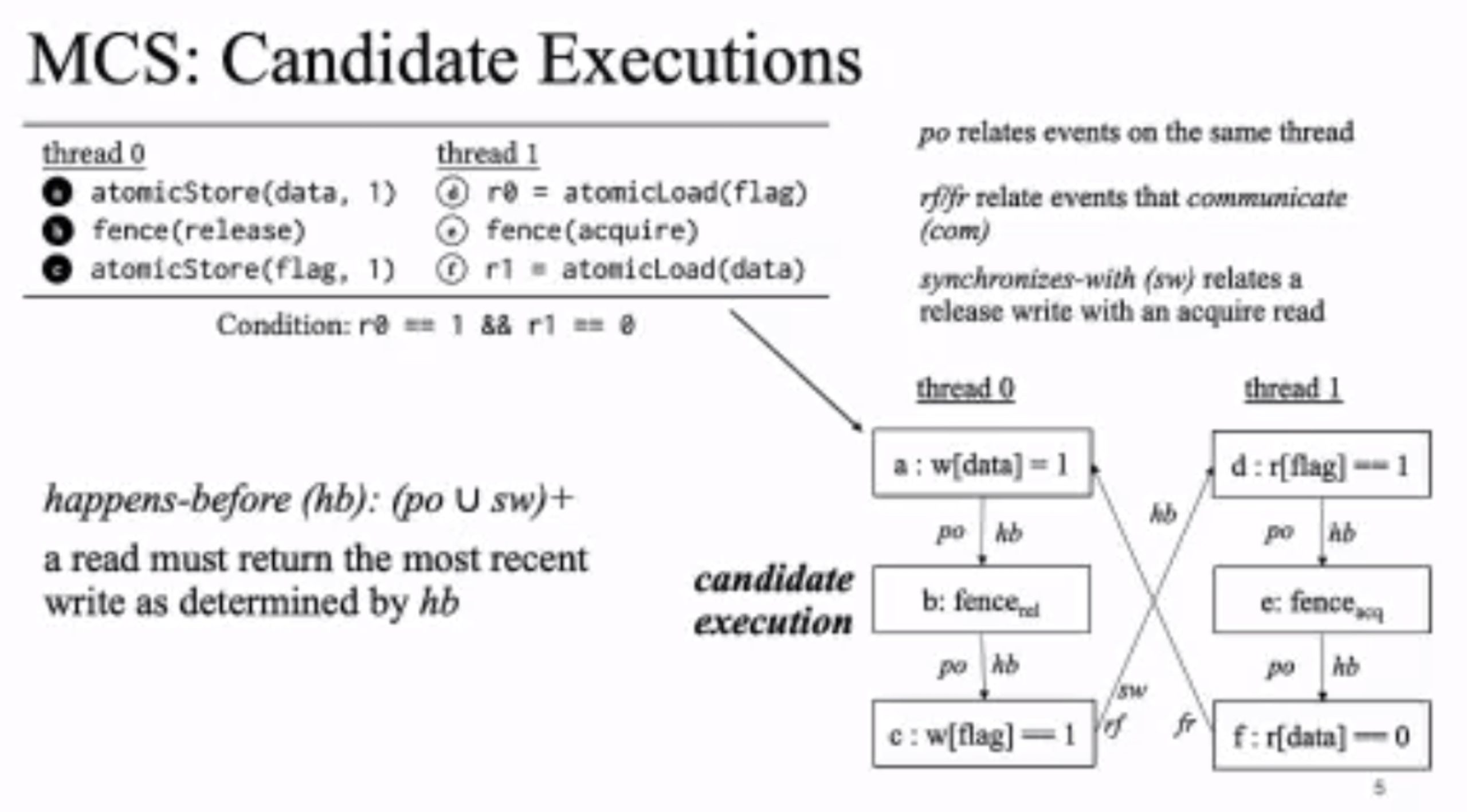
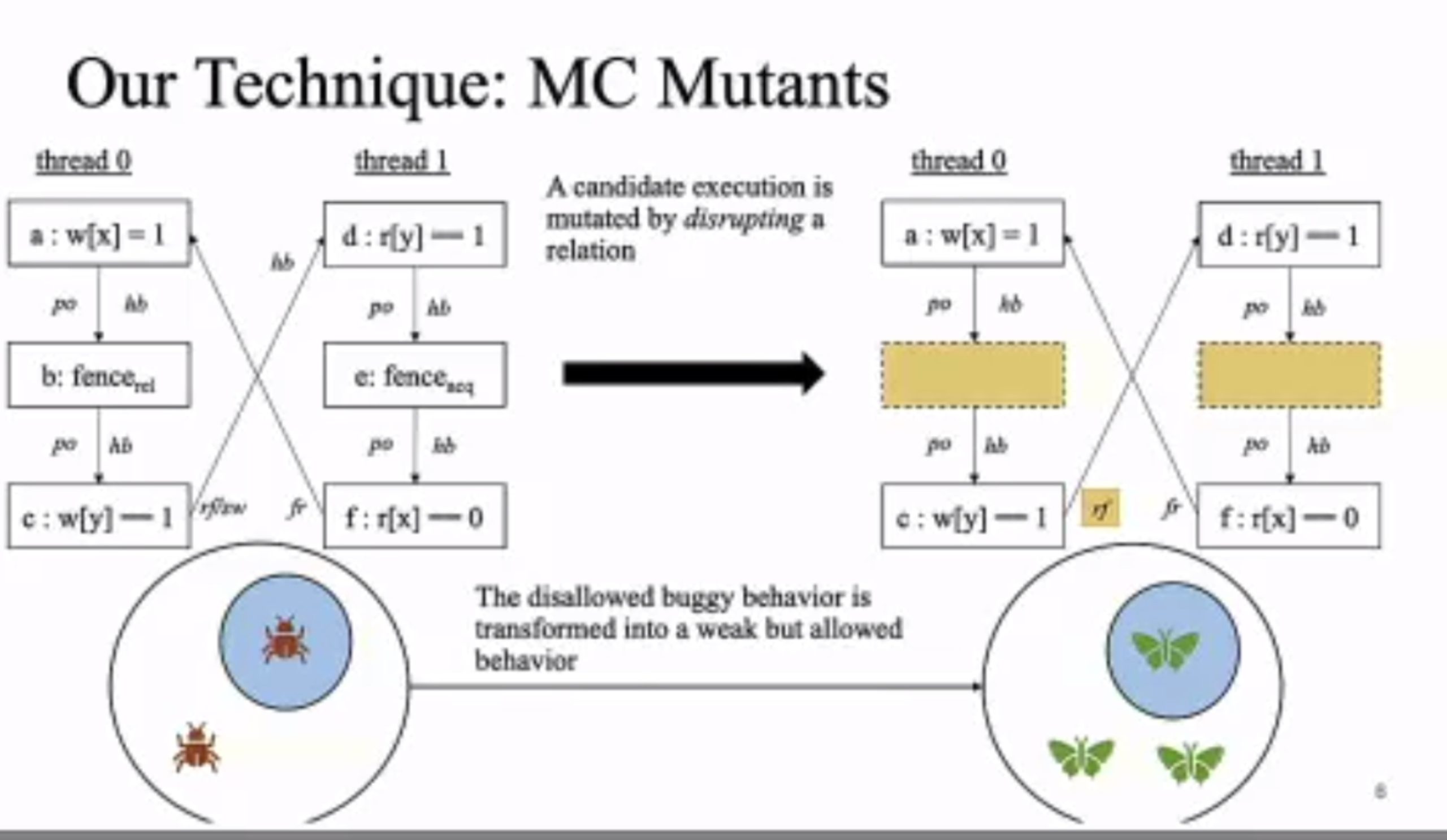
Transform disallowed memory to weak memory label.



一个binary translator



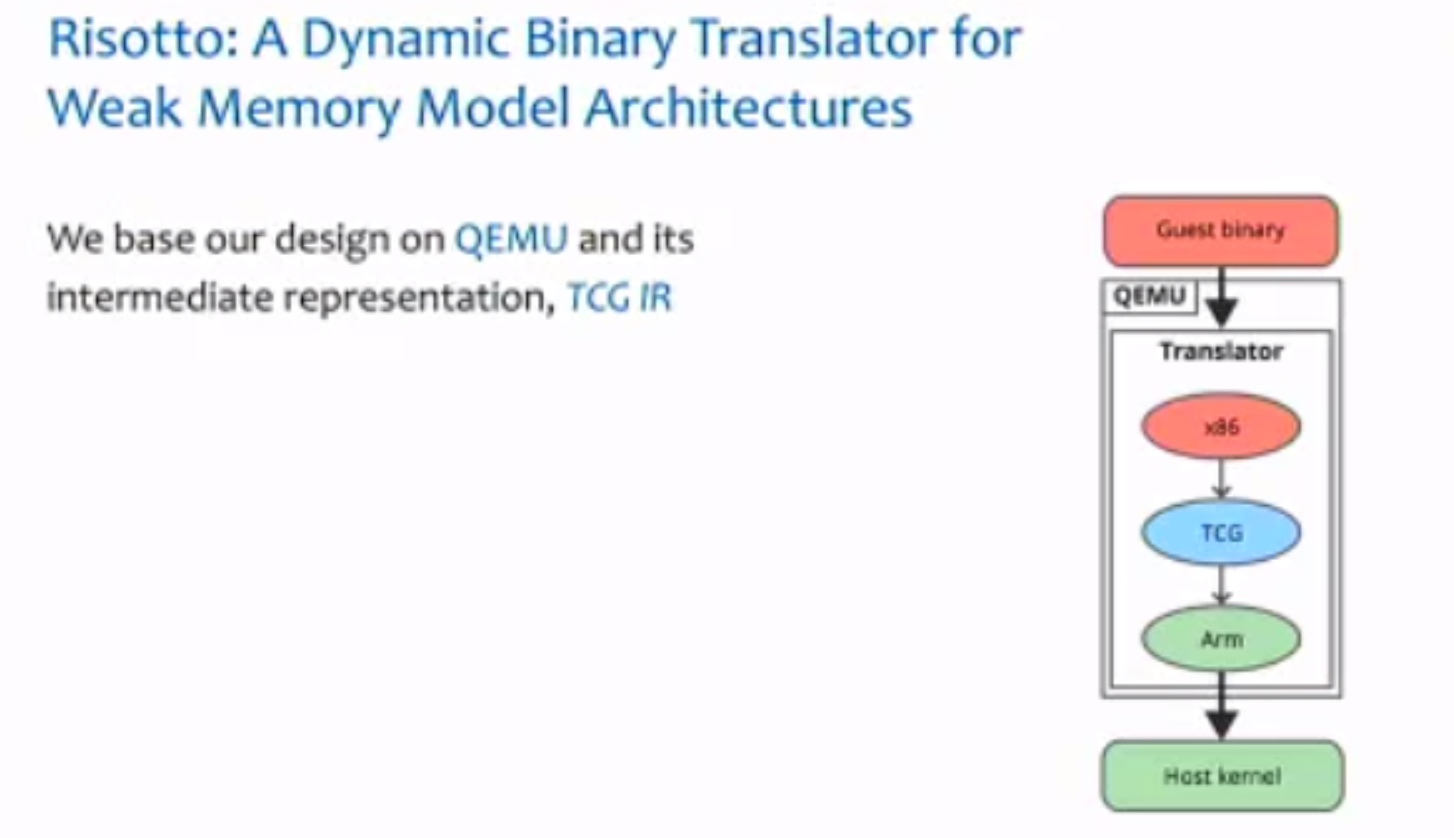
Session 2A: Compiler Techniques & Optimization
SPLENDID: Supporting Parallel LLVM-IR Enhanced Natural Decompilation for Interactive Development
让Decompilation更丝滑。
Beyond Static Parallel Loops: Supporting Dynamic Task Parallelism on Manycore Architectures with Software-Managed Scratchpad Memories
Graphene: An IR for Optimized Tensor Computations on GPUs
Coyote: A Compiler for Vectorizing Encrypted Arithmetic Circuits
这怎么喝
NNSmith: Generating Diverse and Valid Test Cases for Deep Learning Compilers
刘神的,写几个z3规则用来生成fuzzer,就是csmith in NN。
Session 3B: Accelerators A
Mapping Very Large Scale Spiking Neuron Network to Neuromorphic Hardware



1d locality is 3d locality
CRLA mapping like traditional DNN? NO.
HuffDuff: Stealing Pruned DNNs from Sparse Accelerators
观测到了HW的boundary effect可以搞。


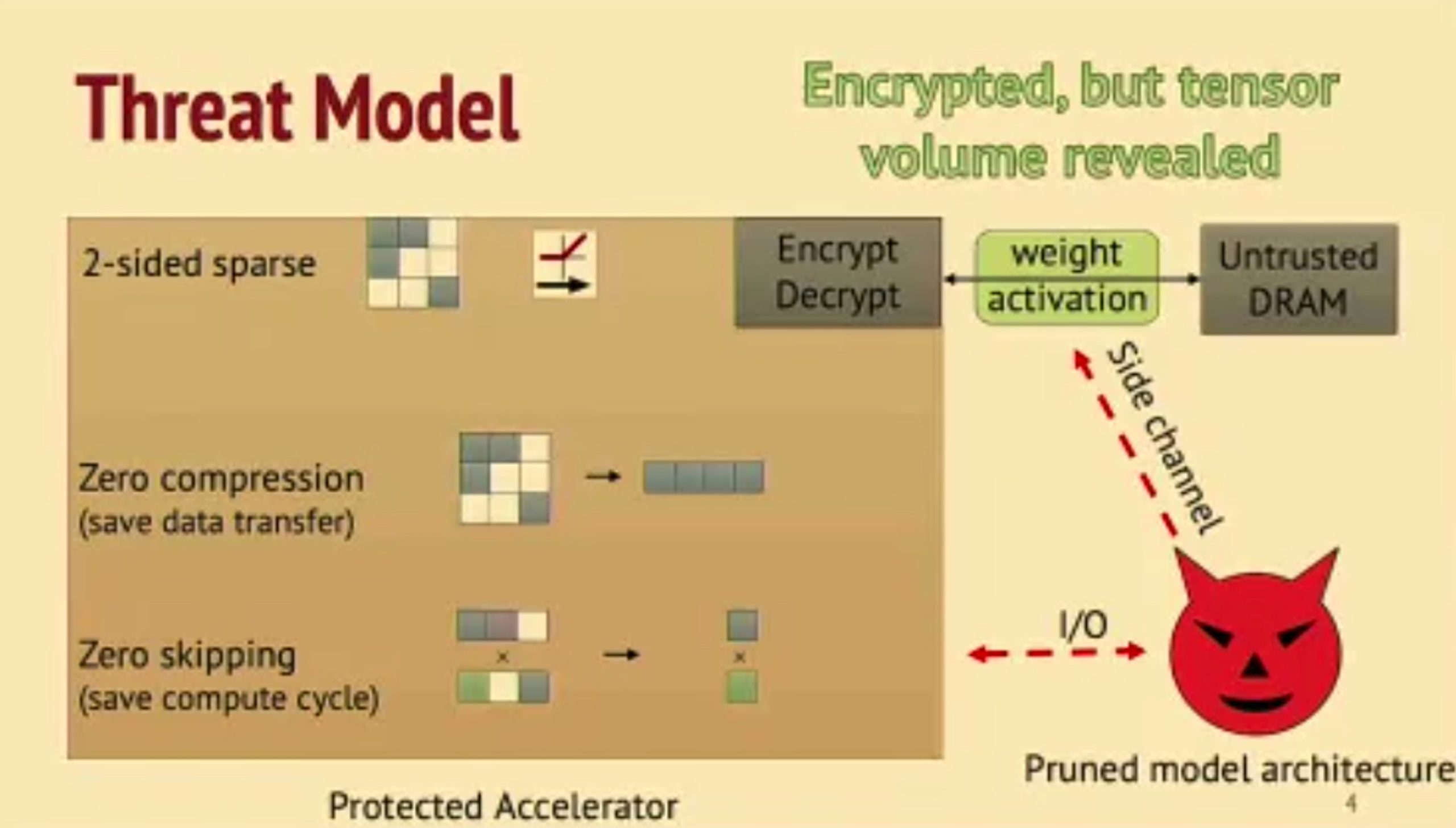
- Can snoop the weights update.
- dense data are more easliy being observed.


并不transferable to other model,但是可以通过观测有没有bound effect来看是不是convolution。
NV eng问:Gemm/FC也可以reverse engineering。
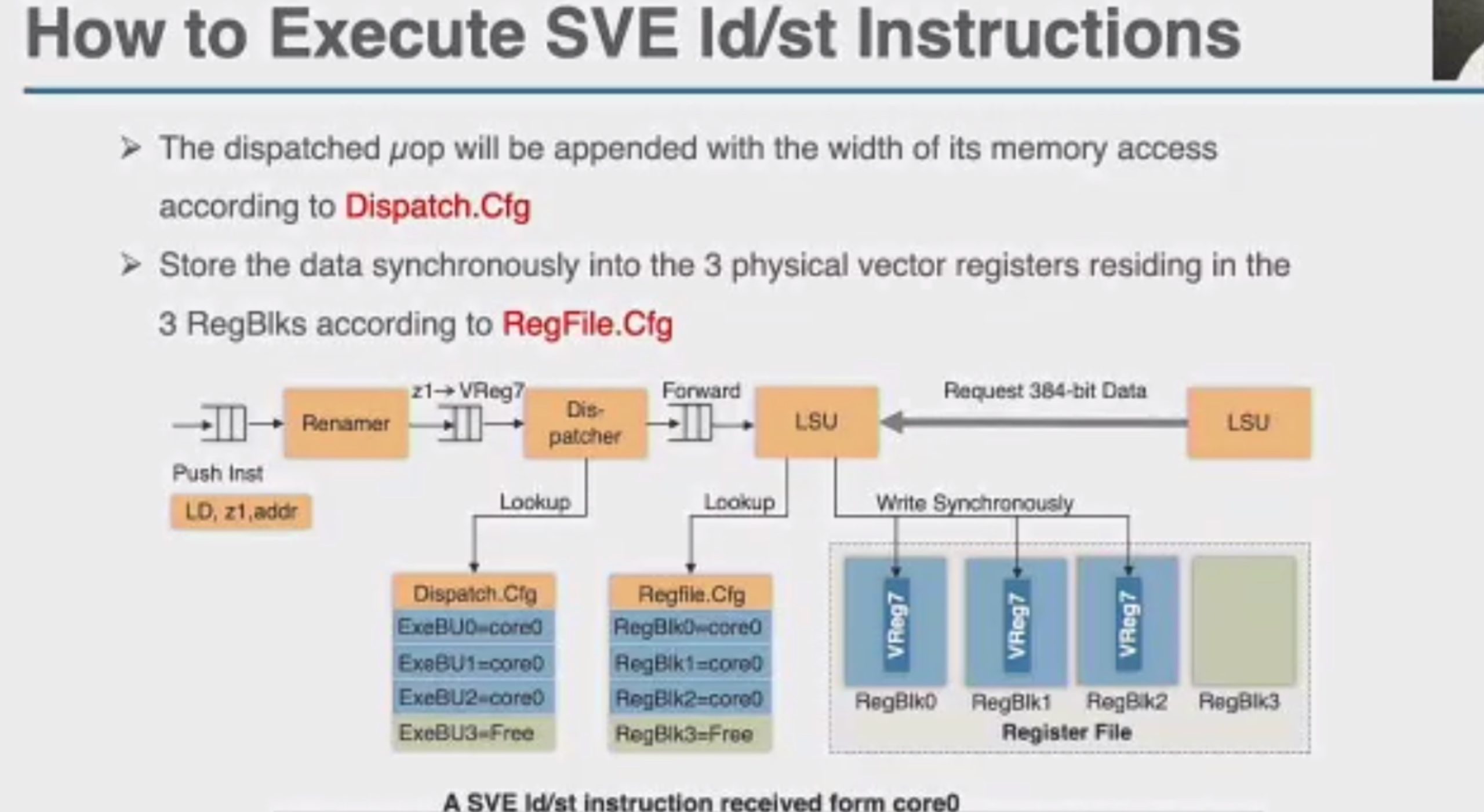
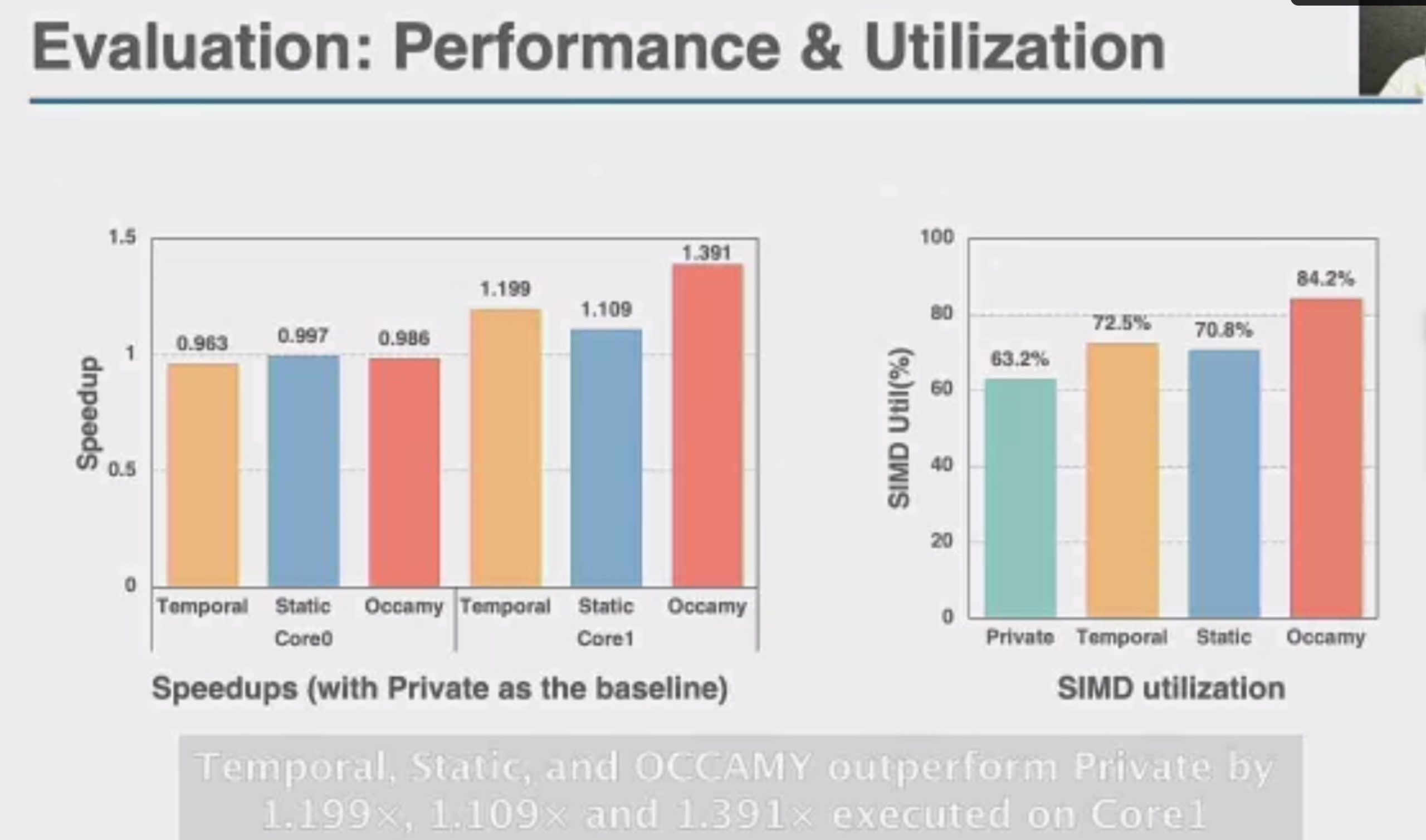
OCCAMY: Elastically Sharing a SIMD Cc processor across Multiple CPU Cores

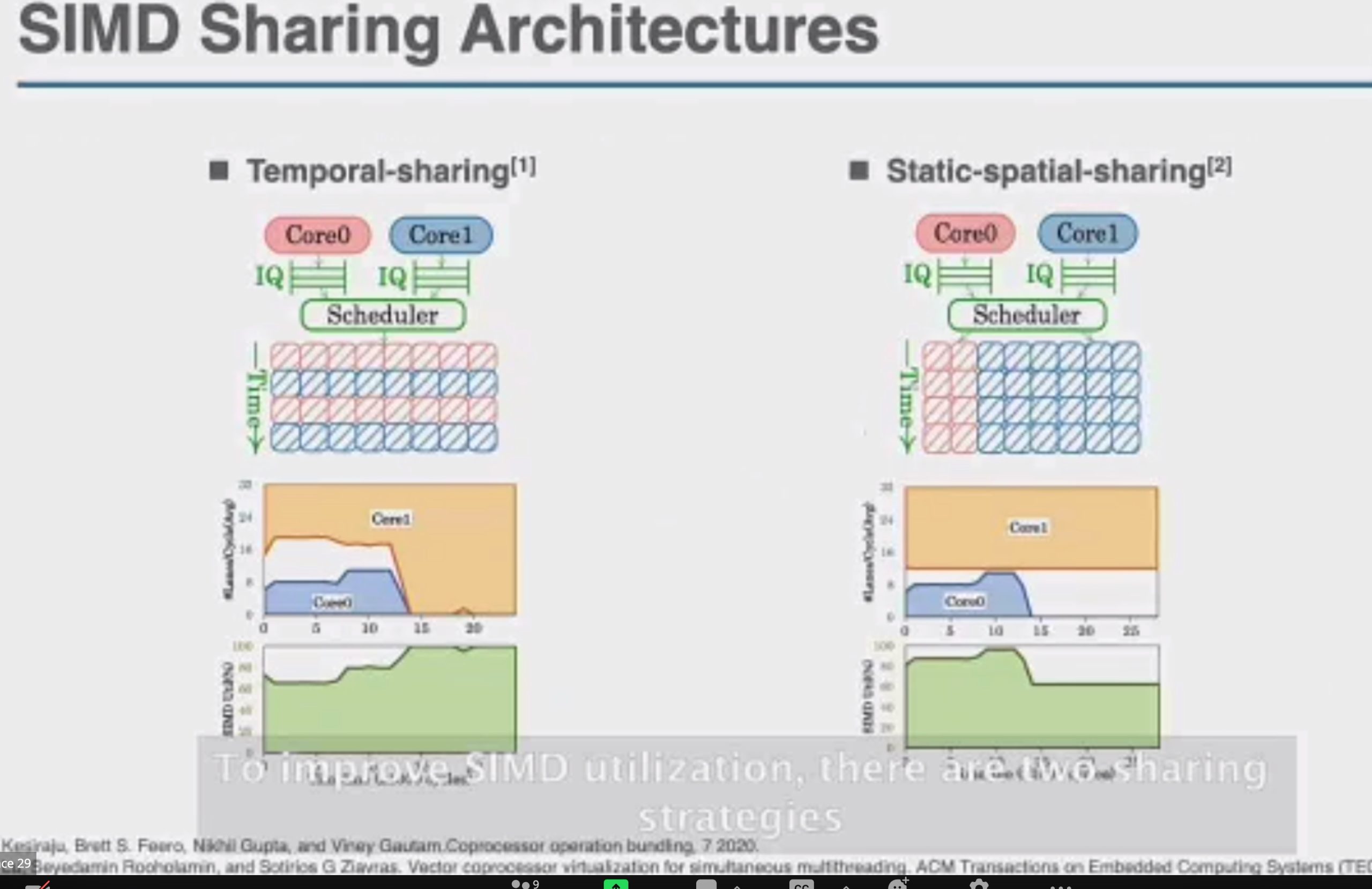
SIMD有两种sharing
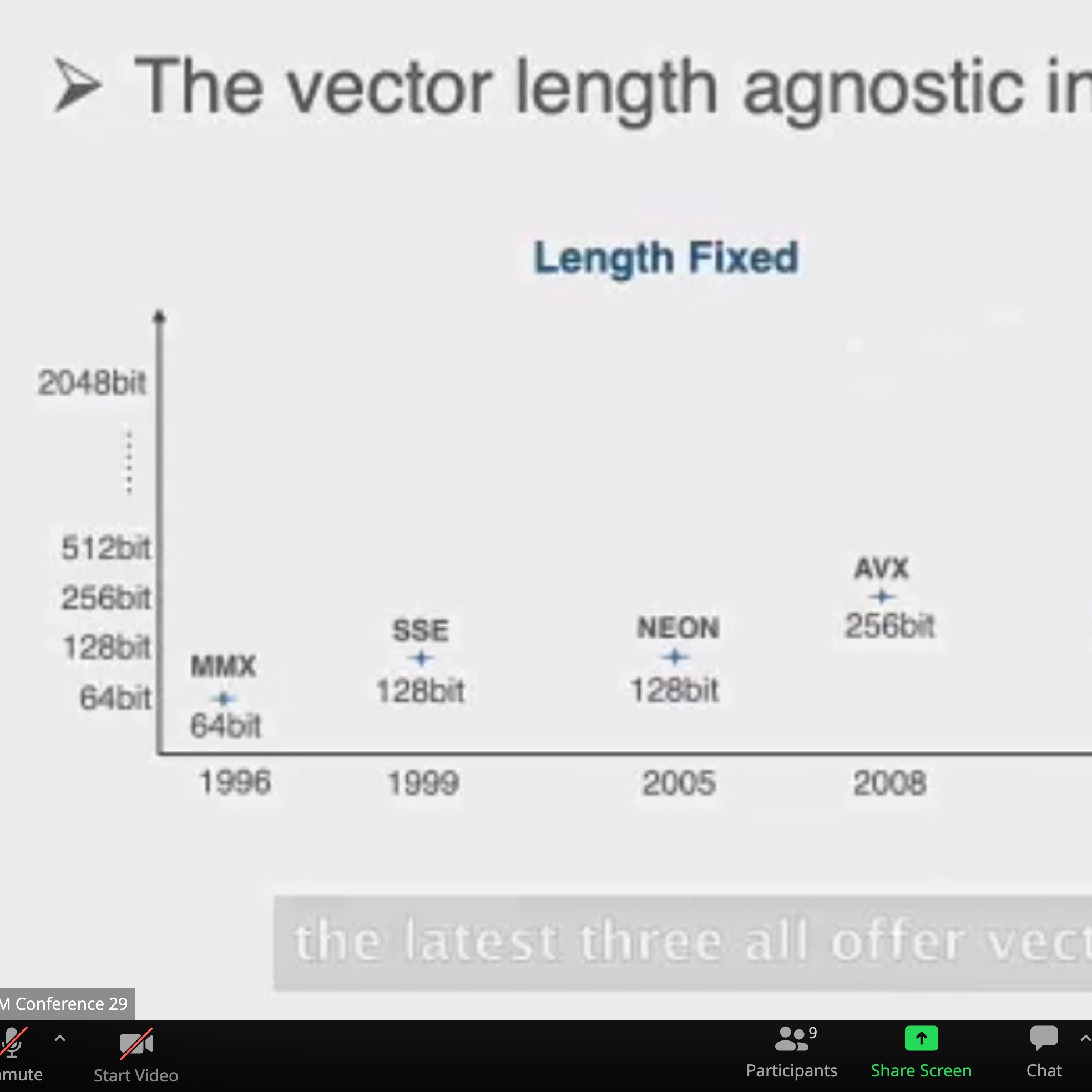
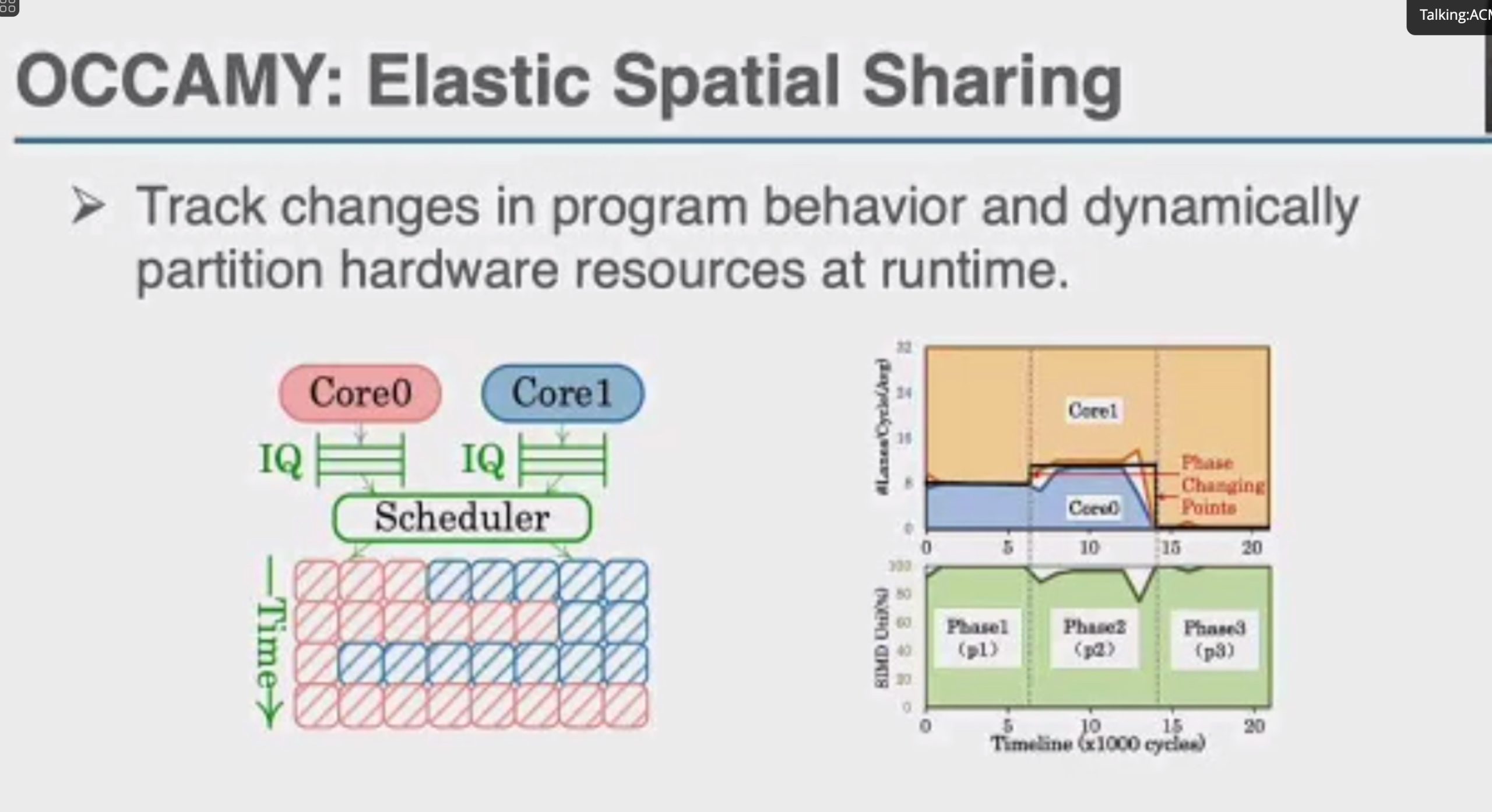

加两个hint length和load时间predicate,用类似rob的方法dispatch指令。


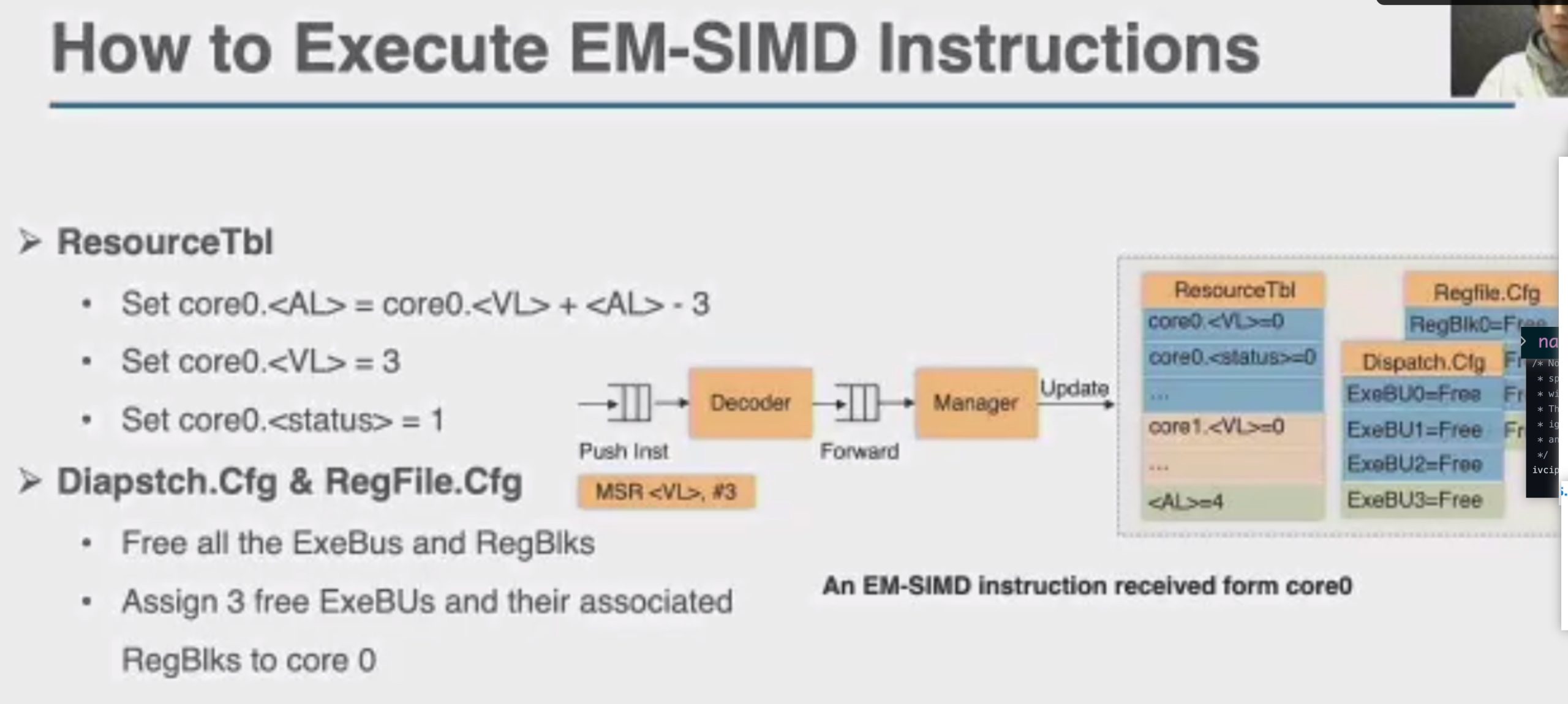
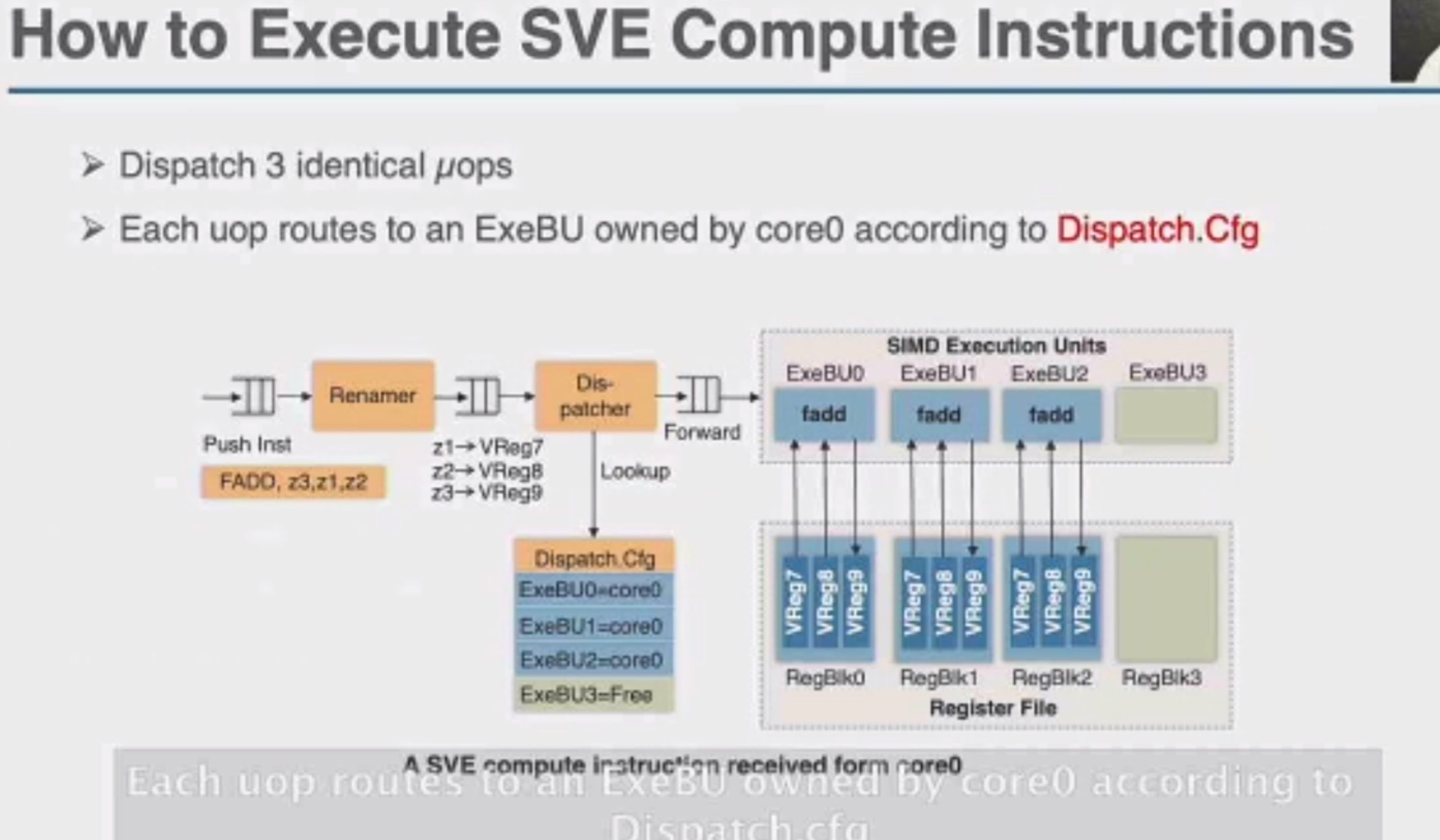

这直接上roofline就行

Motivation why arm unmodified? but with compiler inserted MSR and MRS.
Session 4B: Memory Mgmt. / Near Data Processing
Session 4C: Tensor Computation
Keynote 3: Language Models - The Most Important Computational Challenge of Our Time
NV吹逼大会






Session 7A (Deep Learning Systems)
Session 7B: Security
Dekker
The instrumentation on control flow + linker + runtime 检测CFI, CPI,indirect pointer access
Finding Unstable Code via Compiler-driven Differential Testing
Use CompDiff-AFL++ to fuzz the UB
Going Beyond the Limits of SFI: Flexible Hardware-Assisted In-Process Isolation with HFI
WebAssembly for SFI + hardware assistance
Session 7C: Virtualization
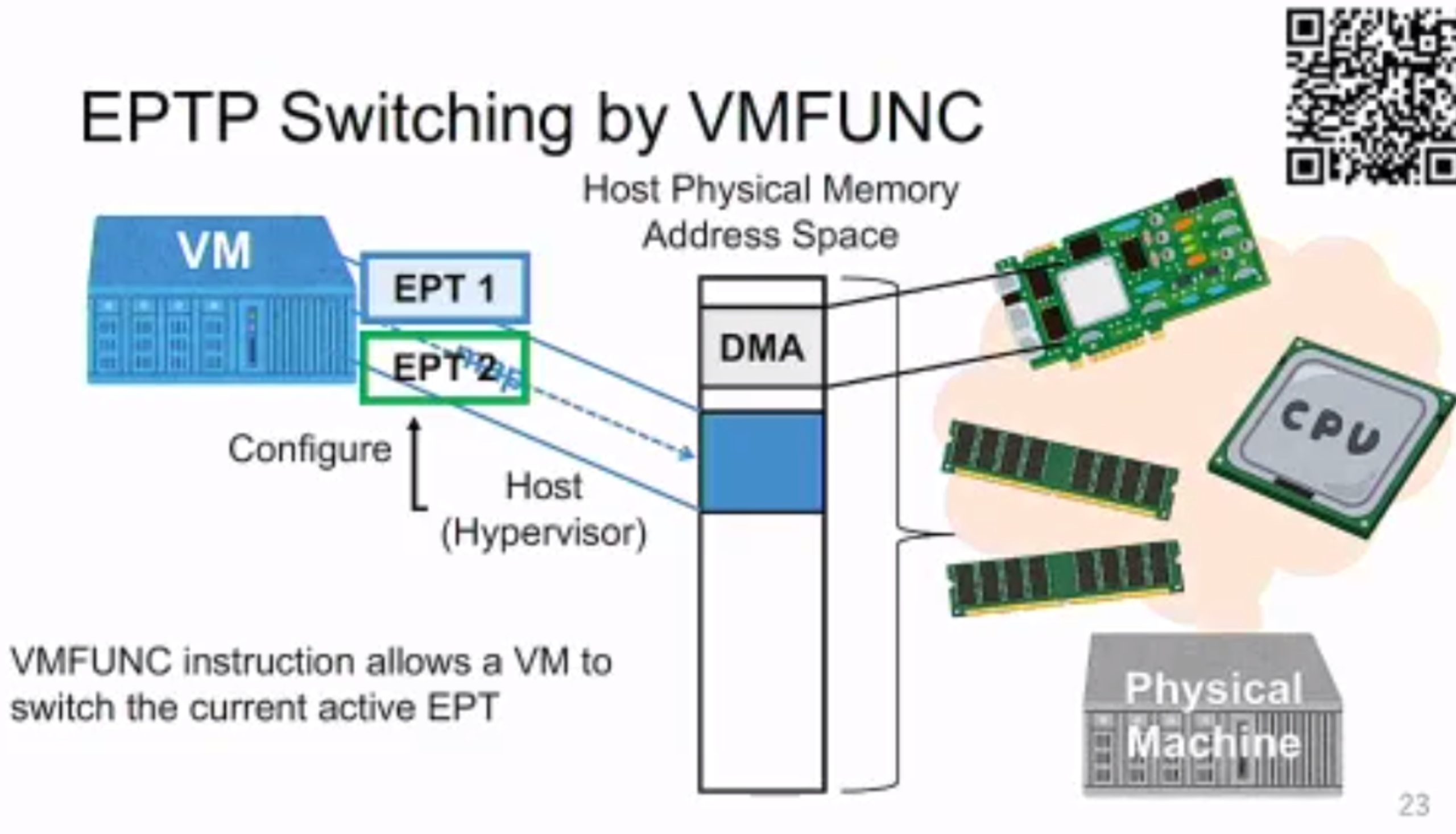
Exit-less, Isolated, and Shared Access for Virtual Machines
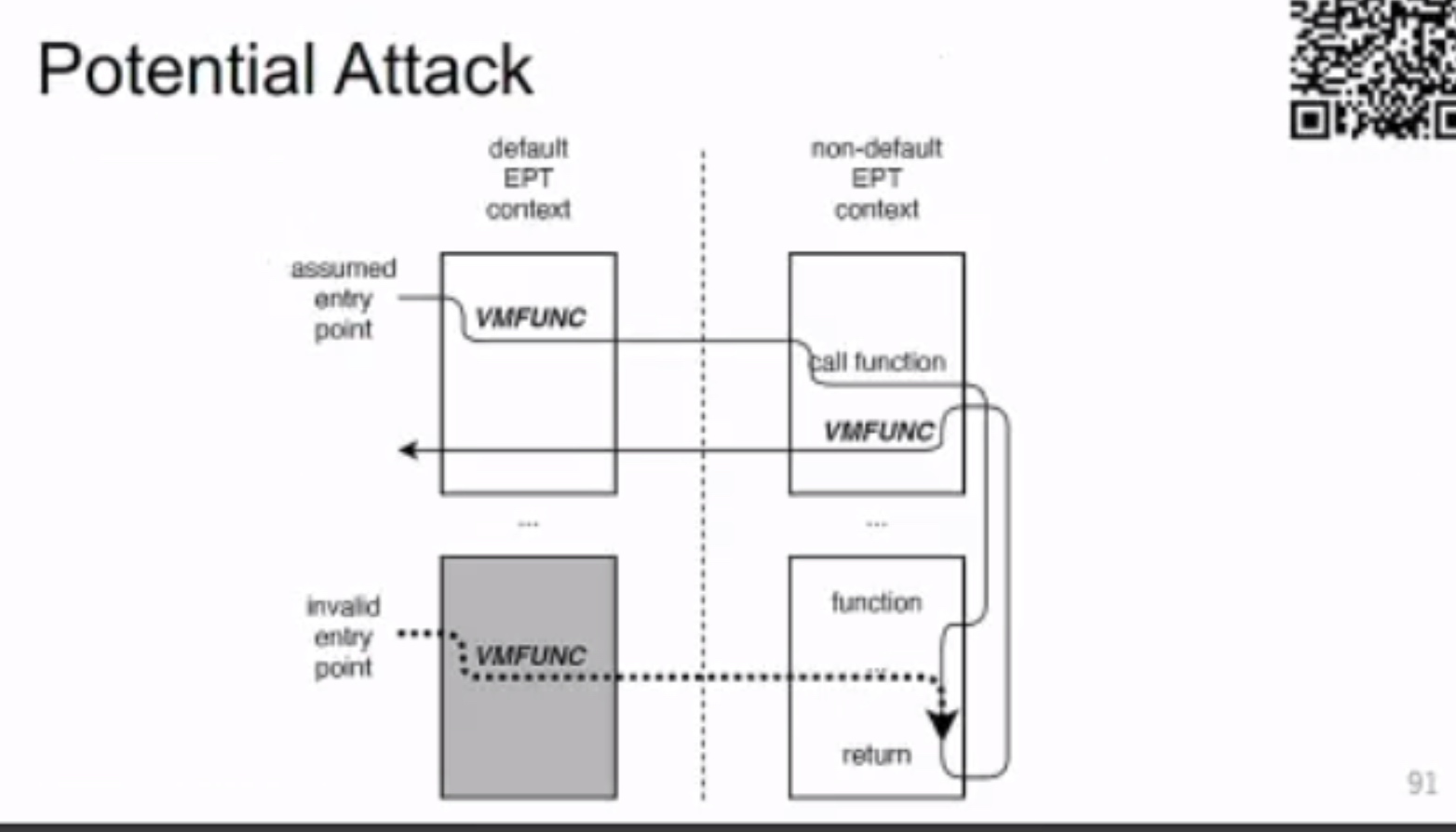
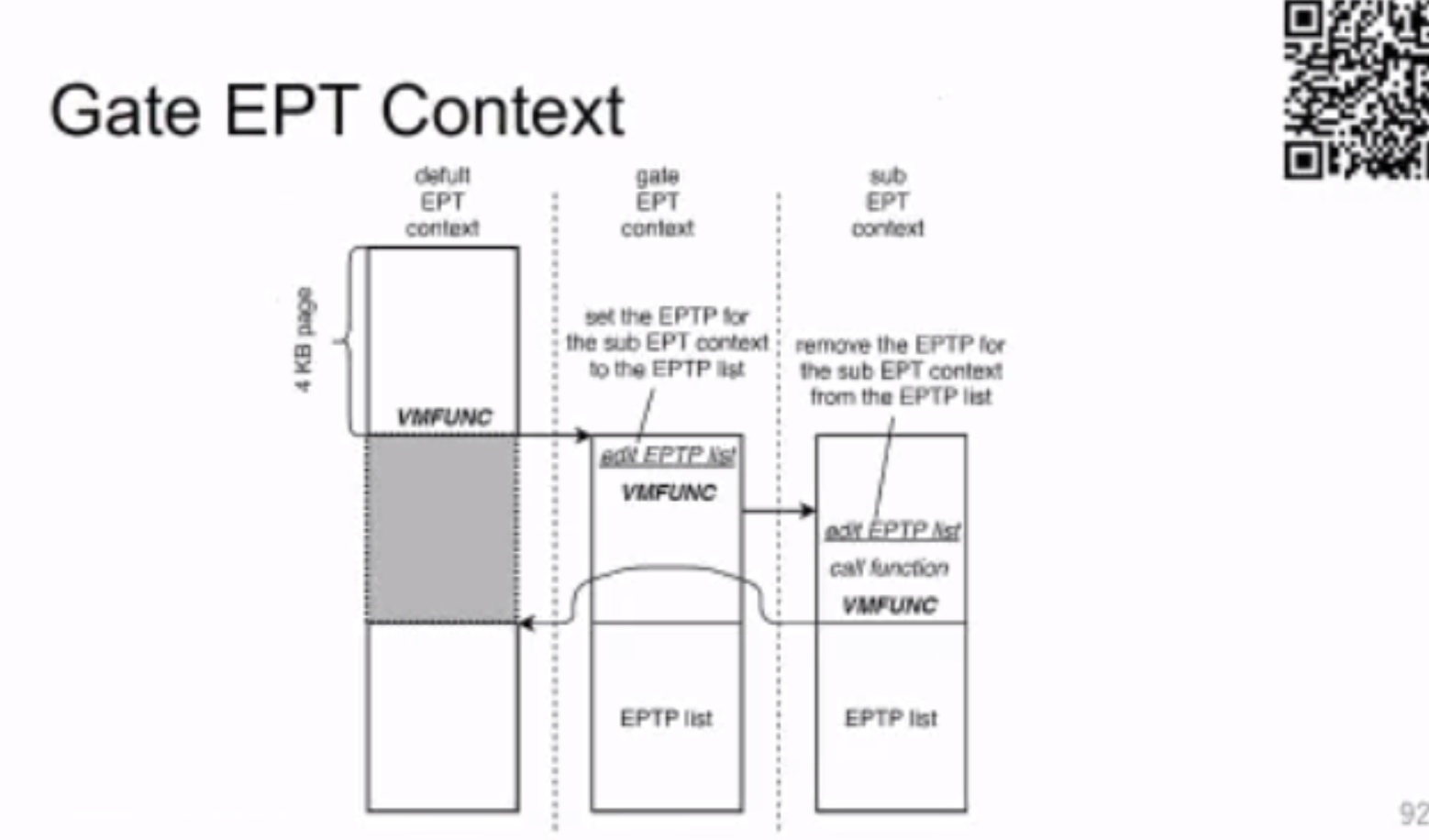
需要 gate &sub VM funciton

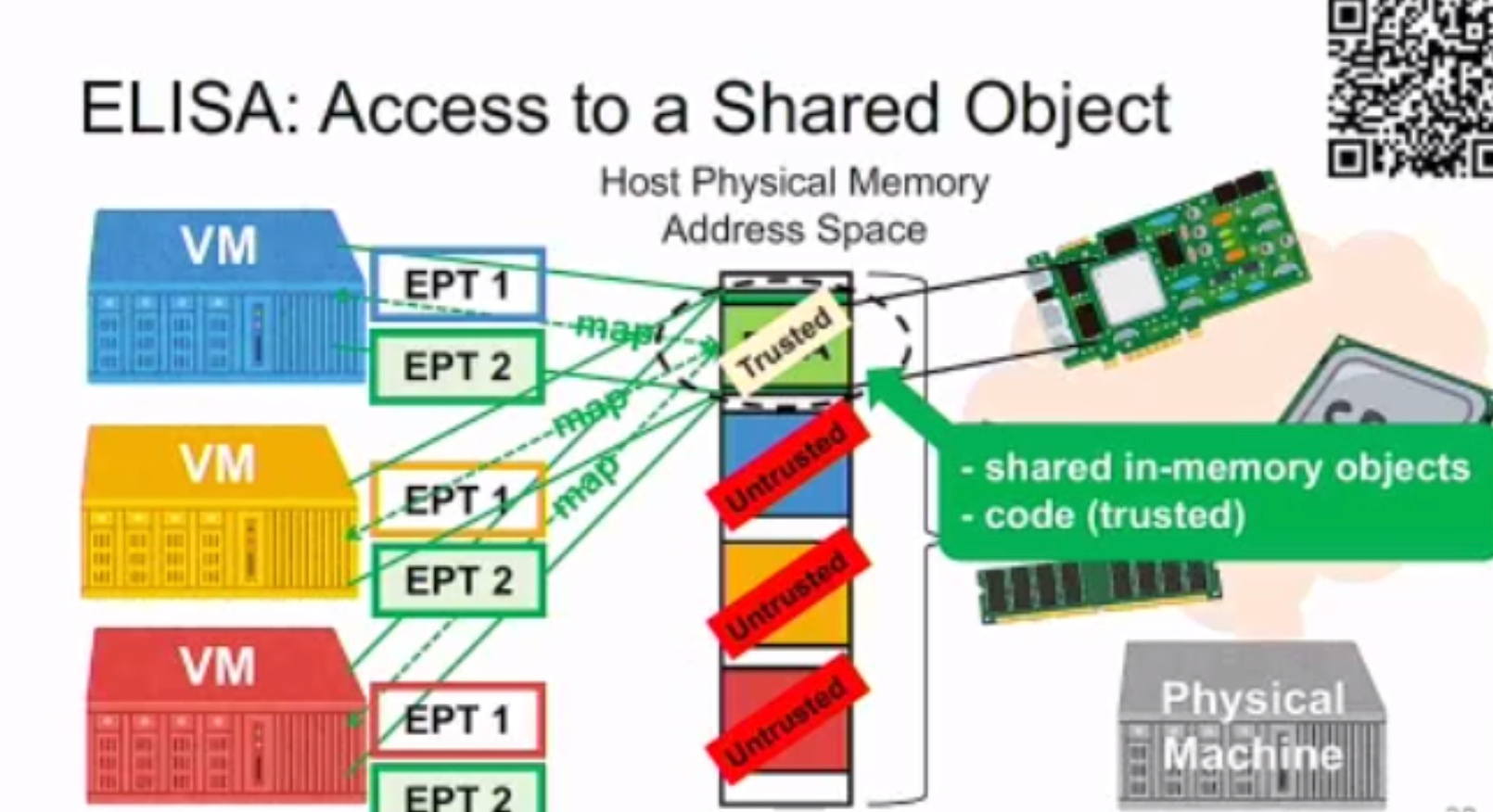

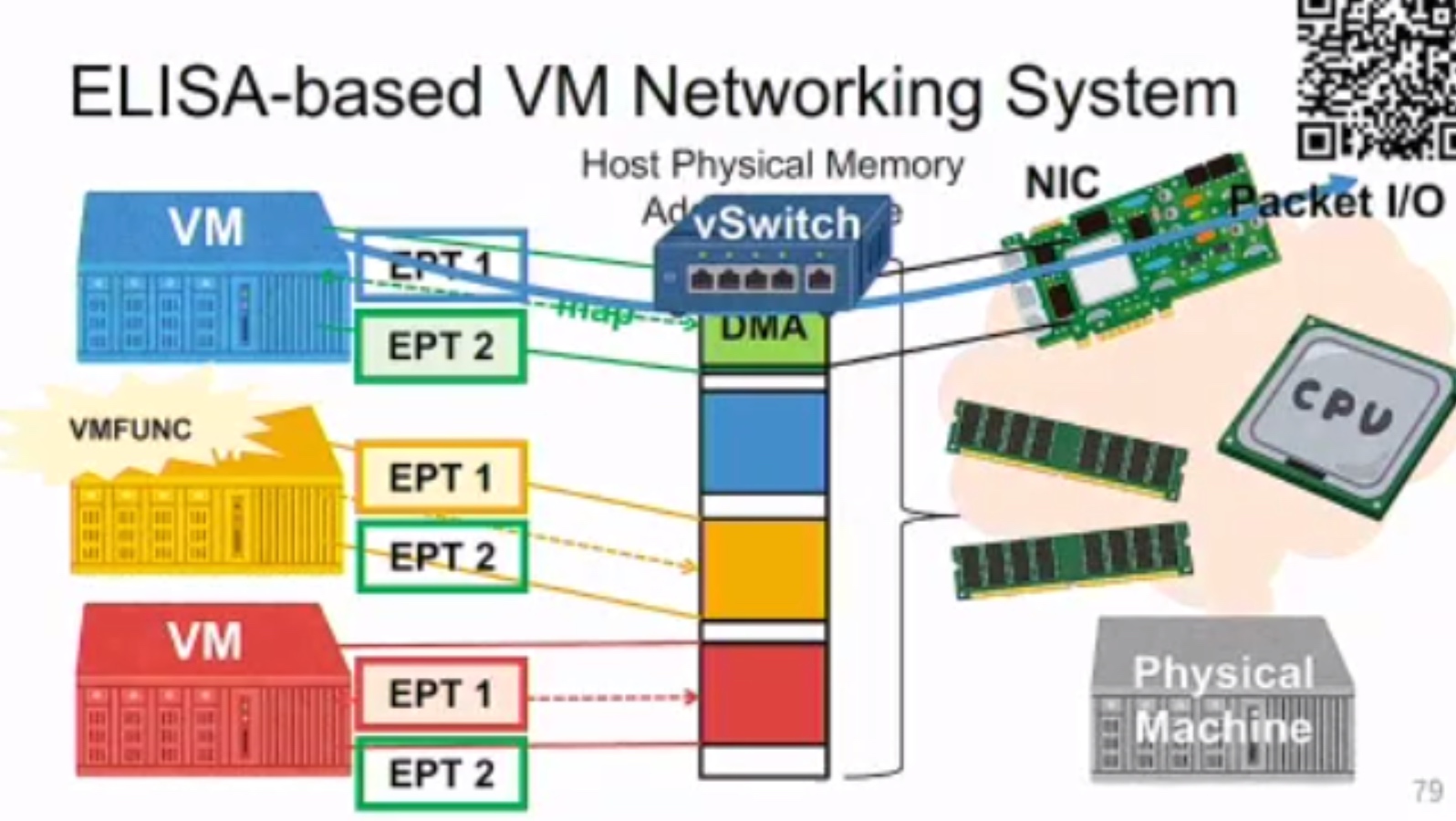
VDom: Fast and Unlimited Virtual Domains on Multiple Architectures

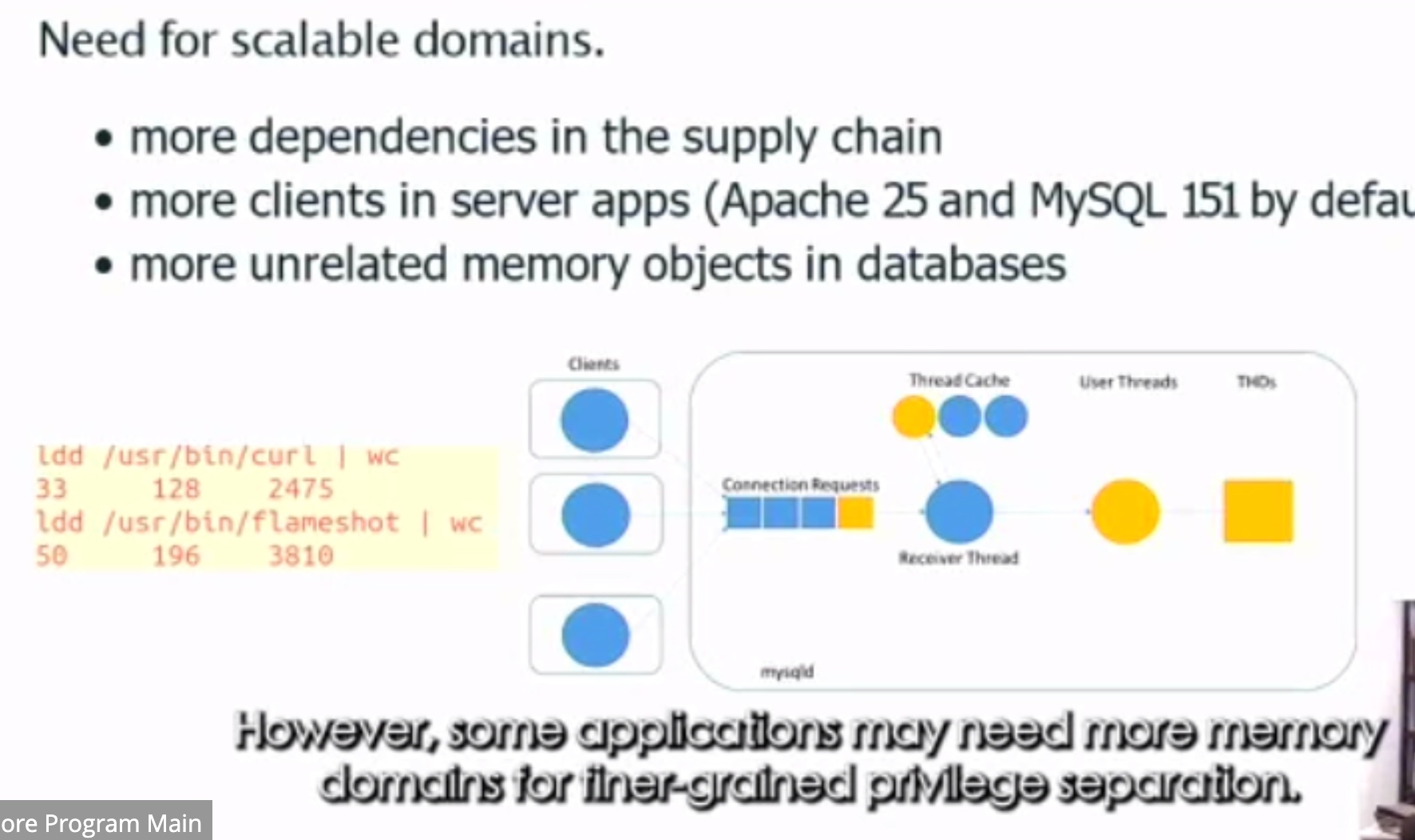

用PTE 隔离。
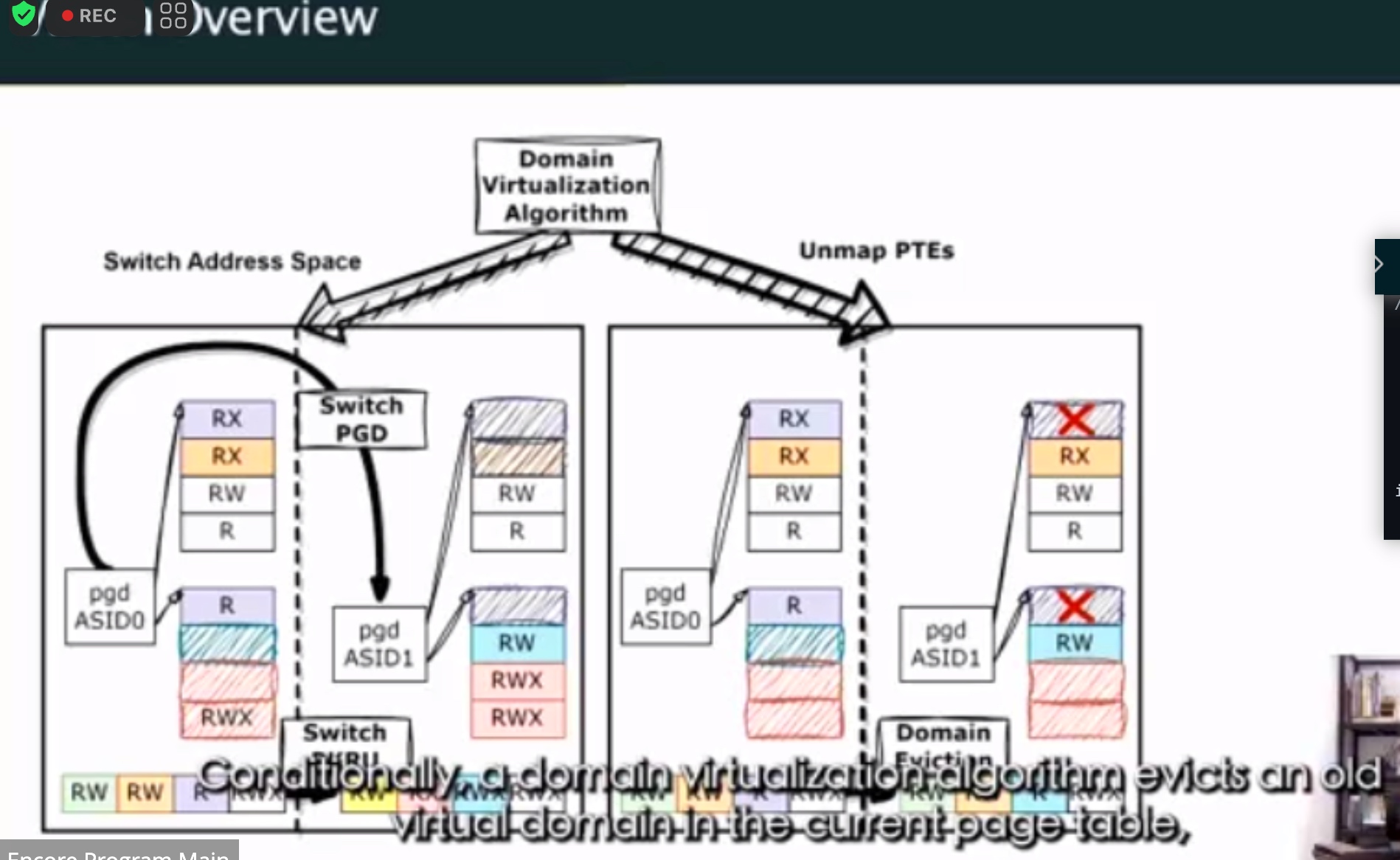
ghost descendent
想法是把schuduler从kernel 里抽象出来。
Session 8B: Accelerators C
TPP
transparent cacheline for TPP is another question.
和husan讲,一个toronto的教授问jvm怎么做更好的page placement,husan说这个在OS level最好
第二个人问用pebs和cpu pmu sampling waste cpu cycle。TPP sampling比较轻量
UBC的另一个人问,deref page的traffic怎么统计?
husan说这个page prefetch mechanism保证,也可以做multi hierarchy LRU,但是访问latency会变高
然后joseph问了个问题,will PMU in device side help investigate page warmth?
大概husan去AMD就做CXL hardware-software design for page promotion performance
hint 就是PMU,然后OS提供接口,不是madvice,而是一段内存granularity,device提供可以decide
这样最好
UBC那一些人和我做的一样。。
回去要加油了
不过他们绝对会cite我的simulator了😂,我宣传他们赶紧cite
Session 9C: Hardware Security
封笔,等21号ASPLOS ddl以后写。