

文章目录[隐藏]
Because of CXL.Mem is not currently available in the market; we based our system approach on two NUMA SPR sockets. We built an eBPF approach because of uncontrollable performance noise, which is deprecated, and a production-ready system. The former [3] utilizes eBPF to hook the allocation of memory for the workload across different memory tiers with 20% overhead on Broadwell and 1% overhead on SPR, while the BedeKernel interacts with the kernel's memory cgroup to determine the placement of pages. Specifically, the simulator ensures that the workload's allocation from the local memory doesn't exceed a certain bound. Subsequent sections of this document provide justification for the simulator's reliance on NUMA, an explanation of its eBPF-based design, and a description of the workloads that were evaluated.
We also provide a kernel implementation with cgroup integration in [1] and [2], which at the kernel level get the dynamic capacity for CXL.mem done compared with Anjo University's auto tiering NVM approach. Current simulators for CXL.mem often yield imprecise outcomes when modeling the impact of assigning a segment of a workload's memory to a CXL.mem shared memory pool. Pond, a specific instance, delivers inconsistent simulation results. It operates through a user-level program that allocates and mlocks memory, constraining the quantity of local memory an application can utilize. Regrettably, variations in memory consumption from ongoing background tasks in the system cause inconsistencies in the amount of local memory accessible for each workload. An alternative to Pond, SMDK, habitually allocates insufficient local memory. By altering the kernel's mmap to steer allocations into various memory zones, SMDK intervenes in each memory allocation. This technique determines the memory placement during virtual memory allocation (i.e., at the time of mmap), but due to demand paging, many virtual memory allocations never translate into physical memory and shouldn't be factored into the workload's local memory consumption. To address the shortcomings in earlier simulators, our specific CXL.mem workload simulator for data collection leverages namespace. As the workload executes, the simulator monitors the resident set size, hooking the policy_node and policy_nodemask with namespace isolation. invoked during each page allocation. This guides page allocations to ensure that the total memory designated to local memory remains within the specified local memory bound.
There are some known limitations of BedeKernel:
- TODO: DSA Migration impl, currently just migrate page async.
- On cgroup start, starting bede struct. On cgroup init procfs, init the policy_node instrumentation. Locally-bind specially dealt with. Let k8s change the cgroup procfs variable to change the migration target. The full approach has a 5% overhead and a 10% deviation from the target RSS because of numastat metrics staleness in reason [5].
- On clone3 syscall, the cloned process may double the RSS limitation. Python is not working since it calls clone and detach child at the very beginning.
- On file-backed mmap syscall, on page fault, the decision does not go through the policy_node path, thus invalid.
- Kernel 6.4.0 removes atomic irq https://lore.kernel.org/all/[email protected]/, which makes numastat in hot path crash irq.
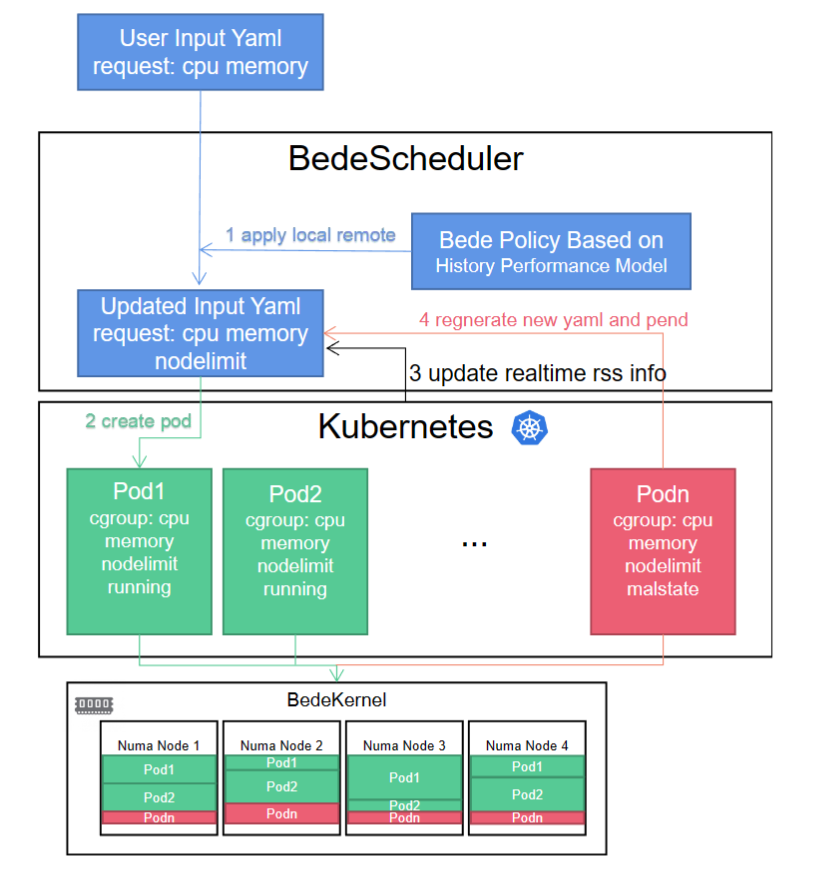
We also integrate the BedeKernel into k8s without a policy written yet because the performance gap of two socket memory in the NUMA machine is low. So, if you have the machine to evaluate my kernel, please feel free to help me. k8s utilizes cgroup as its interface for container management and oversees containers through the associated cgroup procfs directory files. As a result, we only need to make our node_limit visible to the Kubernetes scheduler. When a job's total memory size is defined through a user-input yaml file, the scheduler formulates a yaml as outlined in step 1 and applies the calculated node_limit to the corresponding pod's cgroup directory. The BedeKernel will then restrict page allocation at the hook points policy_node and policy_nodemask. In step 3, Kubernetes refreshes the real-time Resident Set Size (RSS) information to modify the node_limit for pending jobs. If a Pod is found to be in a compromised state, the scheduler will reconstruct the yaml file utilizing the historical performance model and apply it to the Kubernetes pending queue.
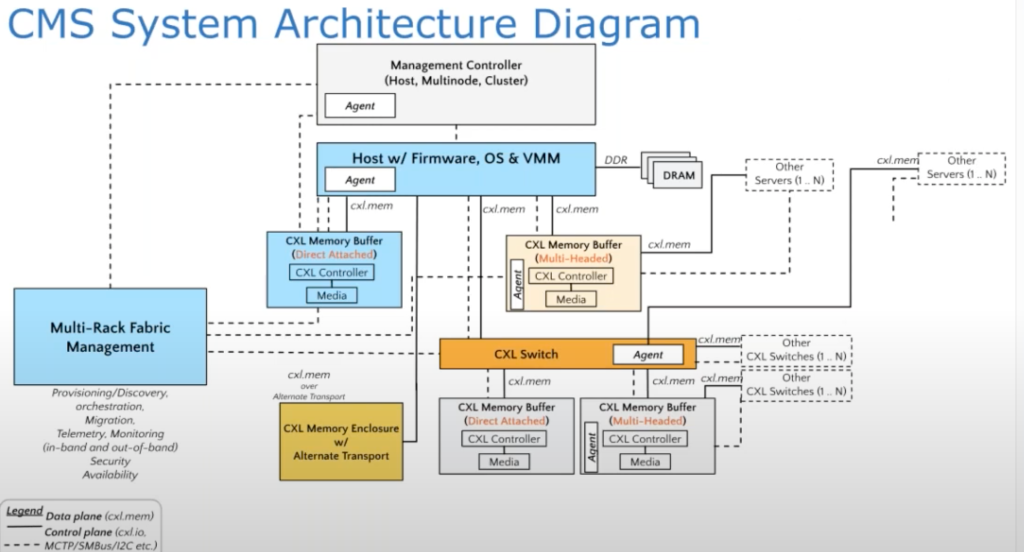
We think the above operation can also be codesigned with the fabric manager to make colocation work and avoid congestion in the channel, which the full discussion is here [4]; this will be done once the fabric manager is done. Because the hardware always has these or those bugs. Quote a guy from Alibaba Cloud: RDT's semantic and performance bugs make it not possible to provide a good workload history model in the k8s layer. I buy it. We should wait until a company integrates my implementation and see if the CXL fabric can be safely integrated without too much performance noise.
Reference
- https://github.com/SlugLab/Kubernetes
- https://github.com/SlugLab/Bede-linux
- https://github.com/victoryang00/node-limit-ebpf
- https://www.youtube.com/watch?v=sncOmRnO1O4