

文章目录[隐藏]
For the HPC system, prefetching both hw/sw requires sophisticated simulation and measurement to perform better.
The purpose of the author is because first, there is not much explanation of how best to insert prefetch intrinsic. Second, not a good understanding of the complex interactions between hardware prefetching and software prefetching.
The target of soft prefetching is found to be short array streams, irregular memory address patterns, L1 cache miss reduction. There is a positive effect, however, since software prefetching trains hardware prefetching, a further part of the situation is a bad effect. Since stream and stride prefetchers are the only two currently implemented commercially, our hardware prefetching strategies are restricted to those.
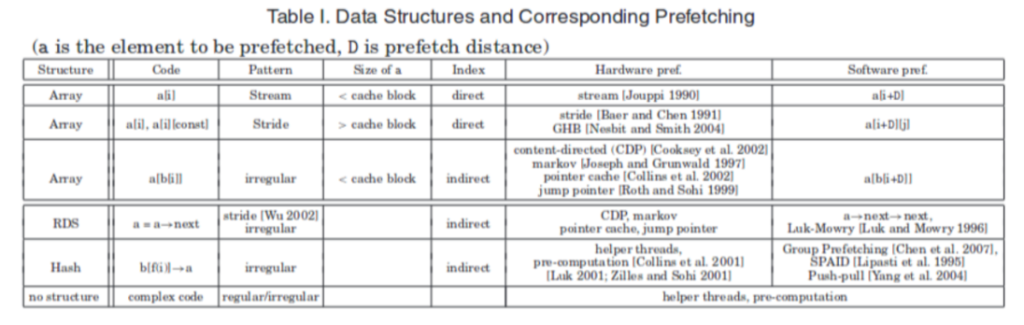
As the picture depicted above, the software can easily anticipate array accesses and prefetch data in advance. Stream means accessing data across a single cache line while stride means accessing across more than two cache lines.
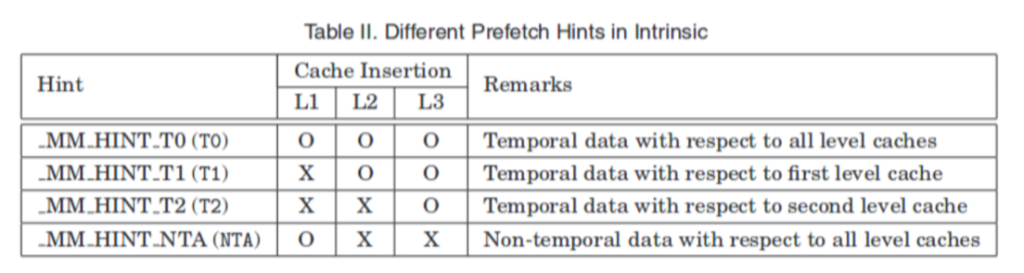
For Software Prefetch Intrinsics, temporal for the use of the data to be used again, so the next layer still have to put, such as L1 have to put L2, L3 are put, so that when the data is kicked out of the L1 cache can still be loaded from L2, L3 and None - temporal for the use of the data no longer used, so L1 put on the good, was kicked out will not be loaded from L2, L3.

In the software prefetch distance graph, prefetching data too early will make the data stay in the cache for too long, and the data will be kicked out of the cache before it is really used, while prefetching data too late causes cache miss latency to occur. The equation $D \geq \left. \ \left\lceil \frac{l}{s} \right.\ \right\rceil$ shows, where l is prefetch latency, and s is the length of the shortest path through the loop body. When D (D is a[i+D] of table) is large enough to cover the cache miss latency but when D is too large it may cause the prefetch to kick out useful data from the cache and the beginning of the array may not prefetch which may cause more cache misses
Indirect memory indexing is dependent on software calculation, so we expect software prefetch will be more effective than hardware prefetch.
Hardware-baselined prefetch mechanism has a stream, GHB, and contend-based algorithm.
The good point of soft prefetch that outweighs hardware prefetch is a large number of streams
short streams, irregular Memory Access, Cache Locality Hint, and possible Loop Bounds. However, the negative impacts of software prefetching lie in increased instruction count because, it actually requires more instruction to calculate the memory offset, static insertion without adaptivity, and code structure change. For antagonistic effects, both of them have negative training and may be harmful to the original program.
In the evaluation part, the author first introduced the prefetch intrinsic insertion algorithm which first quantitatively measured the distance by IPCs and memory latency. The method has been used in C++ static prefetcher. Second, the author implemented different hardware prefetchers by MacSim and use the different programs in SPEC 2006 and compilers icc/gcc etc. to test the effectiveness of those prefetchers. They found one of the restrictions is typically thought to be the requirement to choose a static prefetch distance, The primary metric for selecting a prefetching scheme should be coverage. By using this metric, we can see that data structures with weak stream behavior or regular stride patterns are poor candidates for software prefetching and may even perform worse than hardware prefetching. In contrast, data structures with strong stream behavior or regular stride patterns are good candidates for software prefetching.