


文章目录[隐藏]
TCLocks
pyy是四作
lock中transfer ctx而非data。因为shared data 同步是多线程lock unlock的最大开销。
所以用delayed OoO lock主动interrupts拿到epherical stack(会被prefetch)。
用ip+stack capture locks不sound?
明煜问了个如果解锁顺序不一样可能会死锁。回答说无关。
RON
因为CPU的topology,single threadripper上的topology planning。在thread ripper CCX的topology下用TSP来scheduler lock的unlock顺序。多个锁的情况把同一个锁放到一个ccx里。
UB
所有syscall profiling guided都被userspace binary recompile到jit把所有东西弄到kernel里面做。syscall 变成kernel 态的jump,保护用SFI。
~992 cycle
Indirect cost
- L1 TLB pollution
- OoO stall
- KPTI
compared with iouring. Should compared with iouring + codegen to bpf
由于SFI 有online 开销,我觉得最好做法还是codegen BPF。
Relational Debugging
用good run run到的地方比对bad run到的地方的trace,发现炸的地方和root cause的关系。(逻辑关系一多又不行了。
Larch
extension to MPC with 椭圆曲线, make honest client enrollment for precomputation. $f_1(r)(m+kf_2(r))$, and save them in the client side for future authentication.
k9db
expose data ownership(multigraph) graph soundly to the third party and mark annotations for developers to reason the dependency
during storage operations like group by, it will also cast on the ownership multigraph efficiently.
HeDB
using fork with privacy preserving record &replay+ concolic construction of fake control flow input of secured DB for maintenance to fix smuggle attacks from database administrator. exp query rewriting and concurrent write workload.
LVMT
Proof Sharding: Merkle Tree operator of data chunks.
Honeycomb GPU TEE
static analysis of gpu binary rather than increasing the TCB size and decrease the IPC and runtime monitor, 一个在SEV-SNP里面,一个在sandbox VM里,两个在deployment可以解耦. 有kernel 部分的driver和user space的driver。 lauch kernel的时候hook 所有memory 加密,bus的传输假定可靠,会leak也没用。
Core Slicing
这篇是shanyizhou的,用rv pmp来控制对slice的生命周期,对intel来说,如果不能改micro code,是需要对硬件的model (尤其是ACPI)有假设的。
Duvisor
听limingyu说这玩意的第一性原理是Gu Ronghui的把kernel里无法验证的bounded loop提到上层,然后每一层都是容易被验证的。这篇吹的故事把kvm和driver code解耦,硬件的地址的取得都放rv里面。其实这东西在intel上uipi+driver的context软件实现就没问题,rocetchip PC也不喜欢,容易被喷。osdi22被拒的原因是“xilinx板子上夸张的强于kvm 2倍,qemu模拟的设备会放大duvisor在mmio上对kvm的优势”,现在才中。
听作者说在firesim里拿到的结果和xilinx的差的很多,主要原因是Xilinx板子没有给出网络性能的cycle accurate保证, 最后只交了firesim的结果,按理说rtl生成的一样怎么会性能差很多,虽然firesim那玩意坑很多,但听说网络性能输出稳定。最后的实验是非常让kvm的,二级页表优势关掉了,而且kvm加了直通中断。
这个工作让来自host-attacking的漏洞给弥补了,以后不再会有类似问题。
eZNS
动态分配zone space
PM RDMA replication
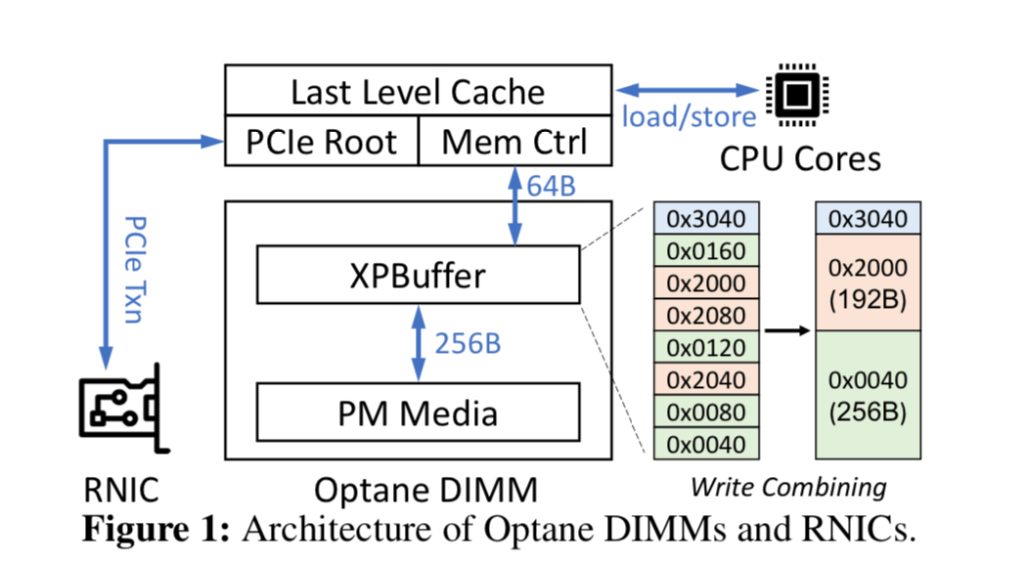
lyy组的,利用了PCIe硬件的queue和memory control和Pmem的write combining,insight就说在kv大小可控的情况下,daemon走pcie应该分多少size的对pm的写。
SEPH
在同时写PM和DRAM的场景下想个办法把对PMEM的写放前面。
Remote Fork
remote docker cold start的问题,不如先remote fork。naive的做法是CRIU(传diff 怎么样?)所以就直接上RDMA codesign, 让remote aware,先one sided read page table in the page fault migration。
cxl似乎就是用来解决cross memory migration without serialization的。
Johnny cache
太神了


CXL-ANNS
两边都做实验,他们的rv设备和gem5,主要就是offload一些operator到cxl controller。
CXL-flash
写了个mqsim的trace based 模拟器,trace是用vagrid收的。用于design cxl flash,一半内存一半flash。讲了如何设计flahs的prefetch和mshr算法来fill ld/st与nvme访问的gap。两者甚至会打架(cache pollution)。
STYP
这工作本质上是把CPU的compssion的cycle放到smartnic的CPU上。cgroup,kernel same-page merging, like page deduplication。zswap
kthread page statistics。ccnuma?smartNIC?zswap take cycle?
BWOS
fuming的文章。用block based split operation that only verify every blocks' workstealing来 proof parallel computing using task based schduling.问题是每次block 都要同步来prove,不知道这样的speed gain会不会影响正确性
SPOQ
No Loop or intrinsics allowed for verification
formalize LLVM IR, loop finetune gen proof from spec。Some how a good thing to gen a small set of data to speed up verify systemC.
Sharding the state machine
分而治之steate machine,两个例子是page cache in SplinterDB和node replication in NrOS
Exact Once DAG
failure 会检查有没有执行过。
SMartNIC Characterization
blueflied2 上arm core 和host cpu对Switch的data path的讨论,有PCIe的congestion也有CPU的DMA controller的throttle。
ServiceRouter
一个service区域调度器
Ensō
用streaming的抽象替换descripter,ringbuffer和packets抽象。而且如果还是用原来的抽象对比dpdk在几乎所有packets大小对比的bandwidth大小比较上都最优,可以说对大部分应用是free lunch.
这里在NIC里需要维护ip forward和prefetch,实际用到了on chip 计算资源。对延时敏感,packets size aware的用户会感觉到这个没有用。