

文章目录[隐藏]
I'm exposing this because I'm as weak as only one Ph.D. student in terms of making connections to people with resources for getting CXL machines or from any big company. So, I open-sourced all my ideas, waiting for everybody to contribute despite the NDA. I'm not making this prediction for today's machine because I think the room-temperature superconductor may come true someday. The core speed can be 300 GHz, and possibly the memory infrastructure for that vision is wrong. I think CXL.mem is a little backward, but CXL.cache plus CXL.mem are guiding future computation. I want to formalize the definition of slug architecture, which could possibly break the Von Neumann Architecture Wall.
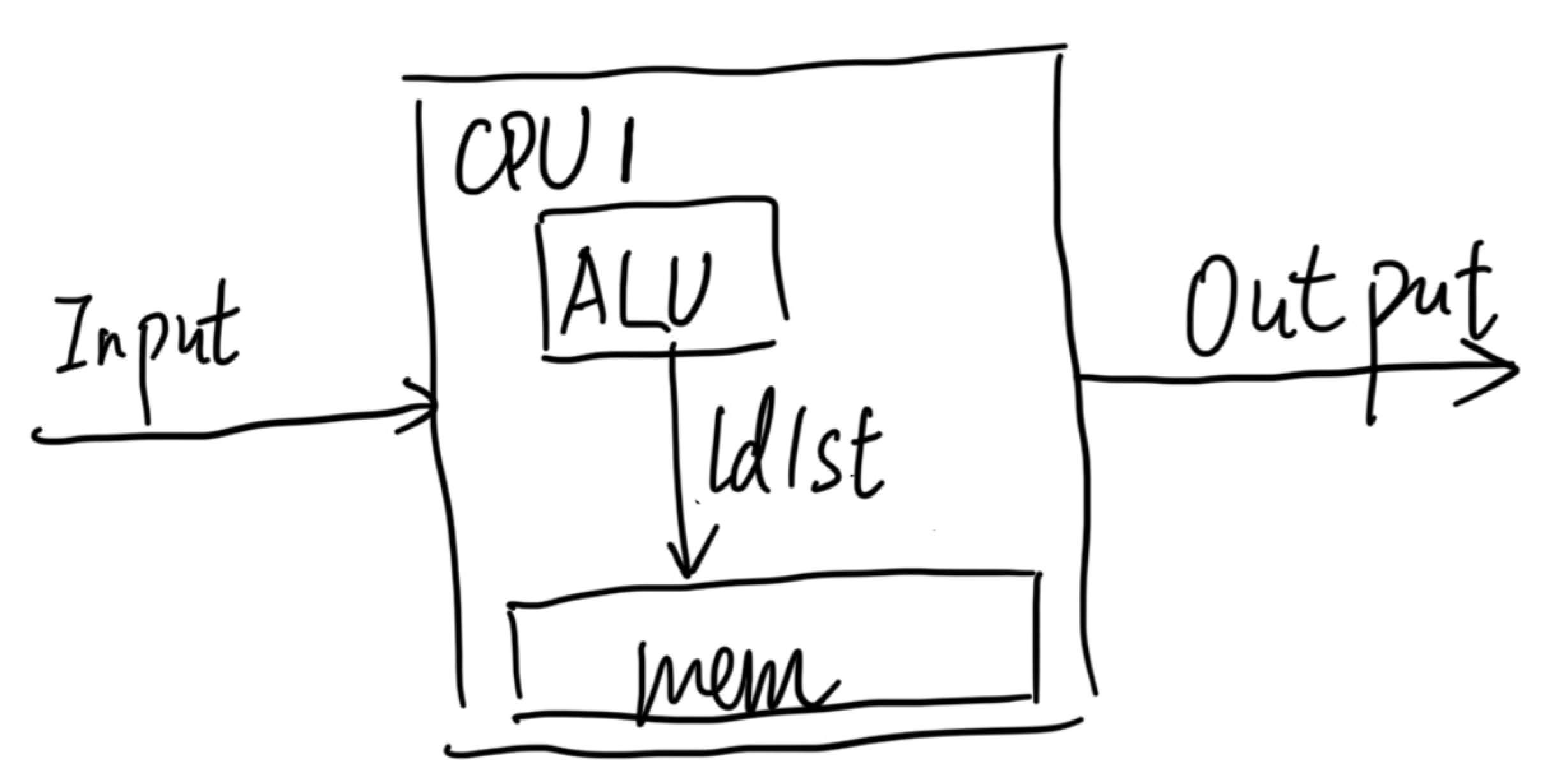
Von Neumann is the god of computer systems. That CPU gets an arbitrary input; it will go into an arbitrary output. The abstraction of Von Neumann is that it gets all the control flow, and data flow happens within the CPU, which uses memory itself for load and storage. So, if we snapshot all the states within the CPU, we can replay them elsewhere.
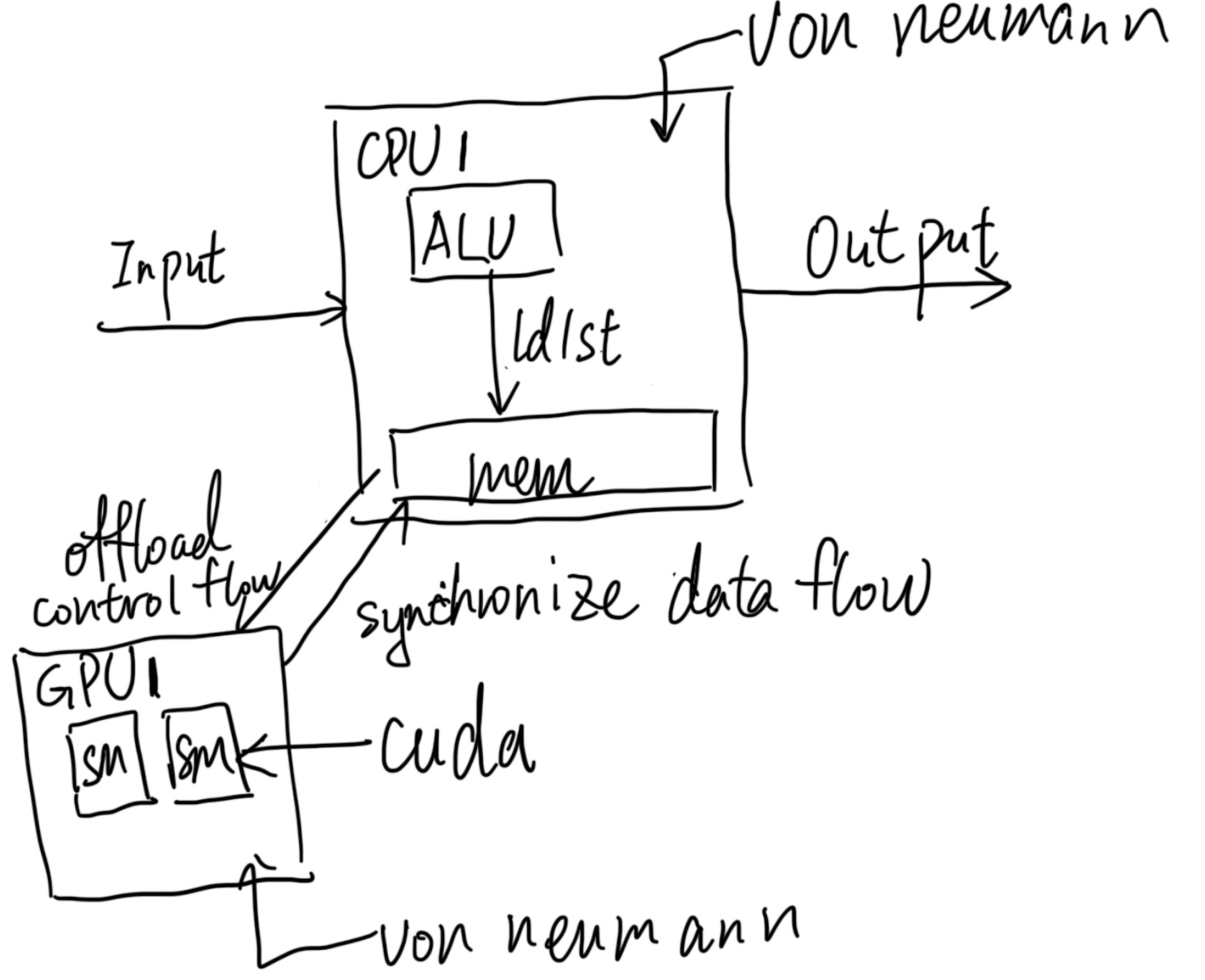
Now, we come to the scenario of heterogeneous systems. The endpoint could happen in the PCIe attachment or within the SoC that adds the ISA extension to a certain CPU, like Intel DSA, IAA, AVX, or AMX. The former is a standalone Von Neumann Architecture that does the same as above; the latter is just integrated into the CPU, which adds the register state for those extensions. If the GPU wants to access the memory inside the CPU, the CPU needs to offload the control flow and synchronize all the data flow if you want to record and replay things inside the GPU. The control flow is what we are familiar with, which is CUDA. It will rely on the UVM driver in the CPU to get the offloading control flow done and transmit the memory. When everything is done, UVM will put the data the right way inside the CPU, like by leveraging DMA or DSA in a recent CPU. Then we need to ask a question: Is that enough? We see solutions like Ray that use the above method of data movement to virtualize certain GPU operations, like epoch-wise snapshots of AI workloads, but it's way too much overhead.
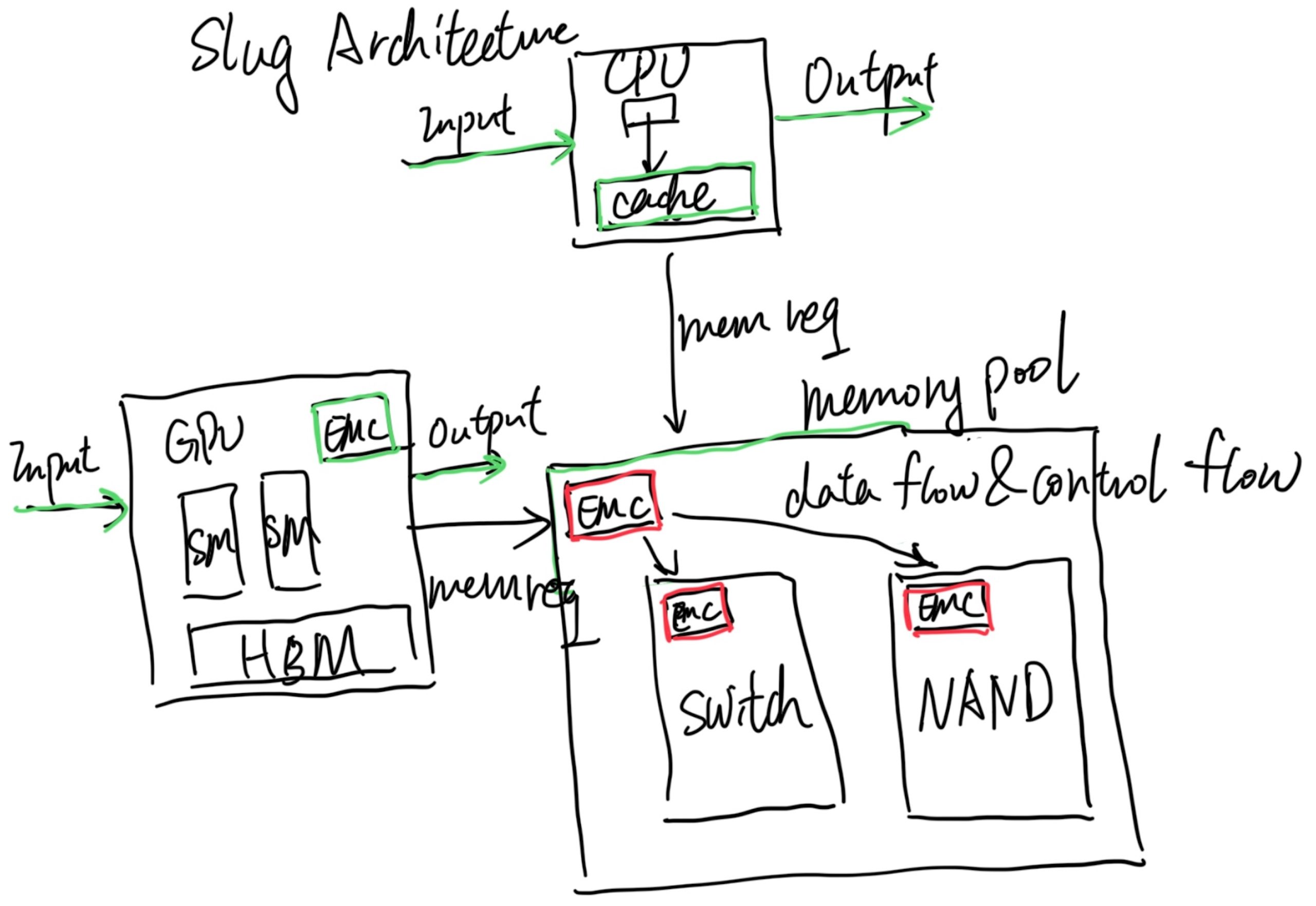
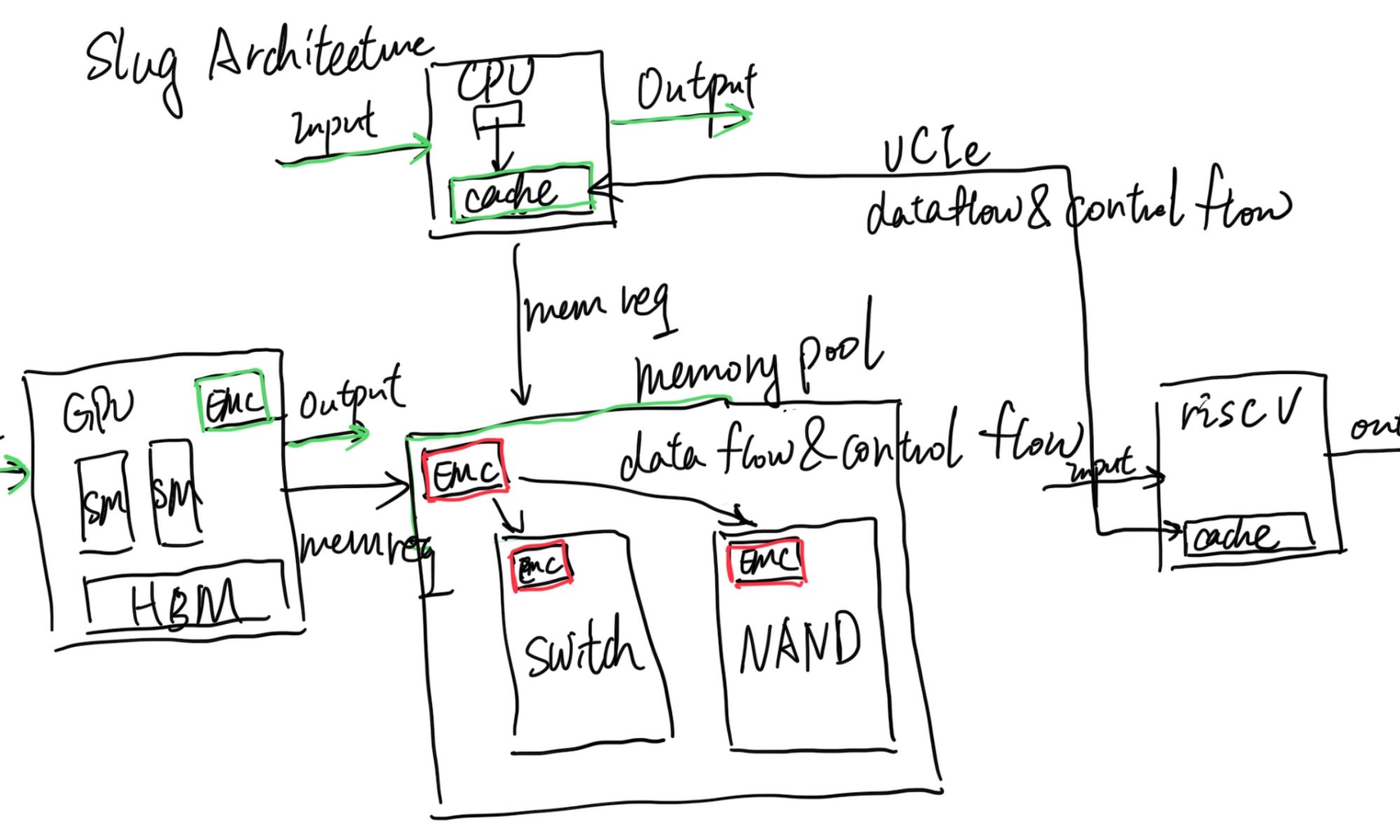
That's where Slug Architecture takes place. Every endpoint that has a cache agent (CHA), which in the above graph is the CPU and GPU, is Von Neumann. The difference is we add green stuff inside the CPU; we already have implementations like Intel PT or Arm Core Sight to record the CPU Von Neumann operations, and the GPU has nsys with private protocols inside their profiler to do the hack to record the GPU Von Neumann operations, which is just fine in side Slug Architecture. The difference is that the Slug Architecture requires every endpoint to have an External Memory Controller that does more than memory load and store instructions; it does memory offload (data flow and control flow that is not only ld/st) requests and can monitor every request to or from this Von Neumann Architecture's memory requests just like pebs do. It could be software manageable for switching on or off. Also, inside every EMC of traditional memory components, like CXL 3.0 switches, DRAM, and NAND, we have the same thing for recording those. Then the problem is, if we decouple all the components that have their own state, can we only add EMC's CXL fabric state to record and replay? I think it's yes. The current offloading of the code and code monitoring for getting which cycle to do what is event-driven is doable by leveraging the J Extension that has memory operations bubbles for compiling; you can stall the world of the CPU and let it wait until the next event!
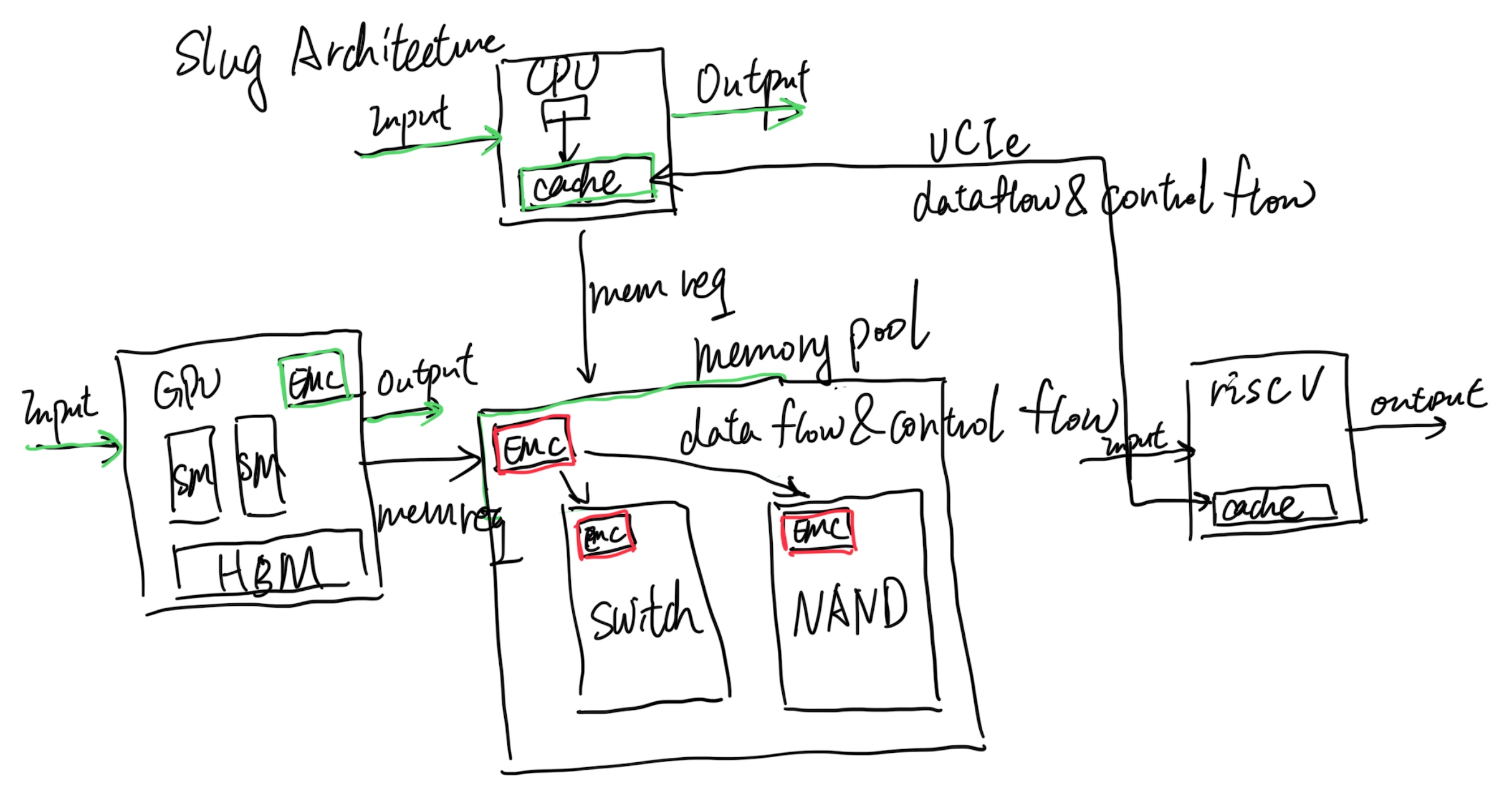
It should also be without the Memory to share the state; the CPU is not necessarily embracing all the technology that it requires, like it can decouple DSA to another UCIe packaged RiscV core for better fetching the data, or a UCIe packaged AMX vector machine, they don't necessarily go through the memory request, but they can be decoupled for record and replay leveraging the internal Von Neumann and EMC monitoring the link state.
In a nutshell, Slug Architecture is defined as targeting less residual data flow and control flow offloading like CUDA or Ray. It has first-priority support for virtualization and record & replay. It's super lightweight, without the need for big changes to the kernel.
Compare with the network view? There must be similar SDN solutions to the same vision, but they are not well-scaled in terms of metadata saving and Switch fabric limitation. CXL will resolve this problem across commercial electronics, data centers, and HPC. Our metadata can be serialized to distributed storage or CXL memory pools for persistence and recorded and replayed on another new GPU, for instance, in an LLM workflow with only Intel PT, or component of GPU, overhead, which is 10% at most.
Reference
- https://www.servethehome.com/sk-hynix-ai-memory-at-hot-chips-2023/