

A lot of people are questioning the usage of CXL.cache because of the complexity of introducing such hardware to arch design space. I totally agree that the traditional architecturist way of thinking shouldn't be good at getting a revolution of how things will work better. From the first principle view from the software development perspective, anything that saves latency with the latest fabric is always better than taking those in mind with software patches. If the latency gain from CXL.cache is much better than the architecture redesign efforts, the market will buy it. I'm proposing a new type of NIC with CXL.cache.
What's NIC? If we think of everything in the TCP/IP way, then there seems to be no need to integrate CXL.cache into the NIC because everything just went well, from IP translation to data packets. Things are getting weird when it comes to the low latency world in the HFT scenario; people will dive into the low latency fields of how packets can be dealt faster to the CPU. Alexandros Daglis from Georgia Tech has explored low-latency RPCs for ten years. Plus, mapping the semantics of streaming RPC like Enso from Intel and Microsoft rearchitecting the design of the packet for streaming data is just fine. I'm not rearchitecting the underlying hardware, but is there a way that makes the streaming data stream inside the CPU with the support of CXL.cache? The answer is totally YES. We just need to integrate CXL.cache with NIC semantics a little bit; the streaming data latency access will go from PCIe access to LLC access. The current hack, like DDIO, ICE or DSA, way of doing things will be completely tedious.
Then, let's think about why RDMA doesn't fit in the iWARP global protocol but only fits within the data center. This is because, in the former, routing takes most of the time. It is the same for NIC with CXL.cache. I regard this as translating from an IP unique identifier to an ATS identifier! The only meaning for getting NIC in the space of CXL.cache is translating from outer gRPC requests to CXL.cache requests inside the data center, which is full functional routing with the unique identifier of ATS src/target cacheline requests inside CXL pools. We can definitely map a gRPC semantic to the CXL.cache with CXl.mem plus ATS support; since the protocol is agile for making exclusive write/read and .cache enabled or not, then everything within the CXL.mem pool will be super low latency compared to the RDMA way of moving data!
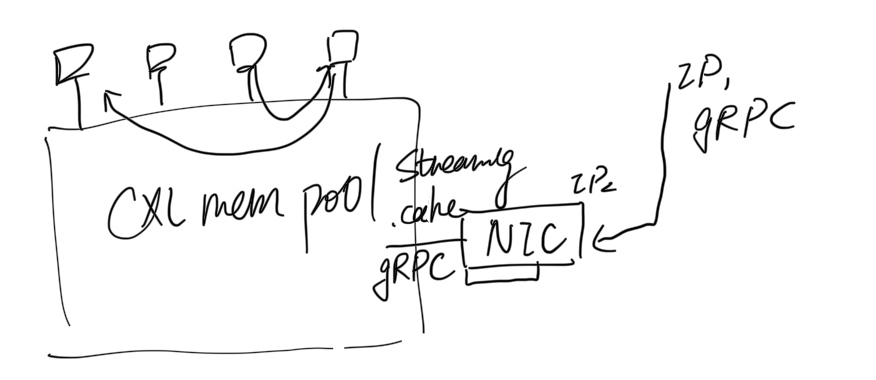
How to PoC the design? Using my simulator, you will need to map the thrift to CXL.cache requests; how to make it viable for the CPU's view‘s abstraction and how the application responds to the requests are the most important. Despite the fact that nothing has been ratified, neither industry nor vendors are starting to think through this way, but we can use the simulator to guide the design to guide the future industry.