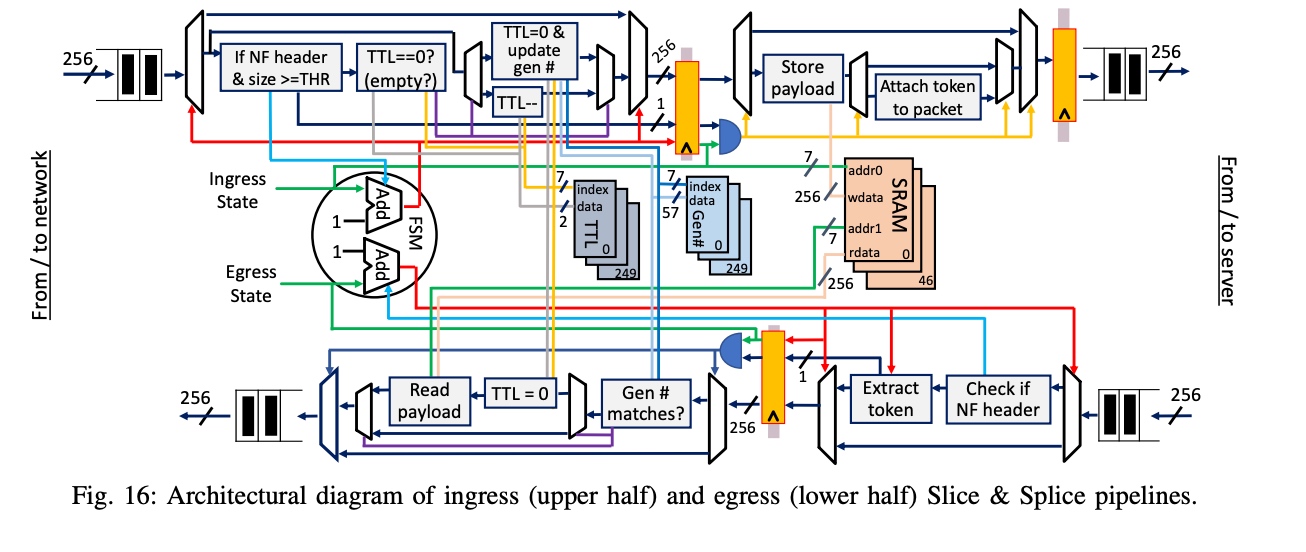
This paper is an implementation of near-data processing data placement for recommendation inference. Normally, the operation by embedding table operation is ~10 GB of storage, irregular Access and Low compute intensity.
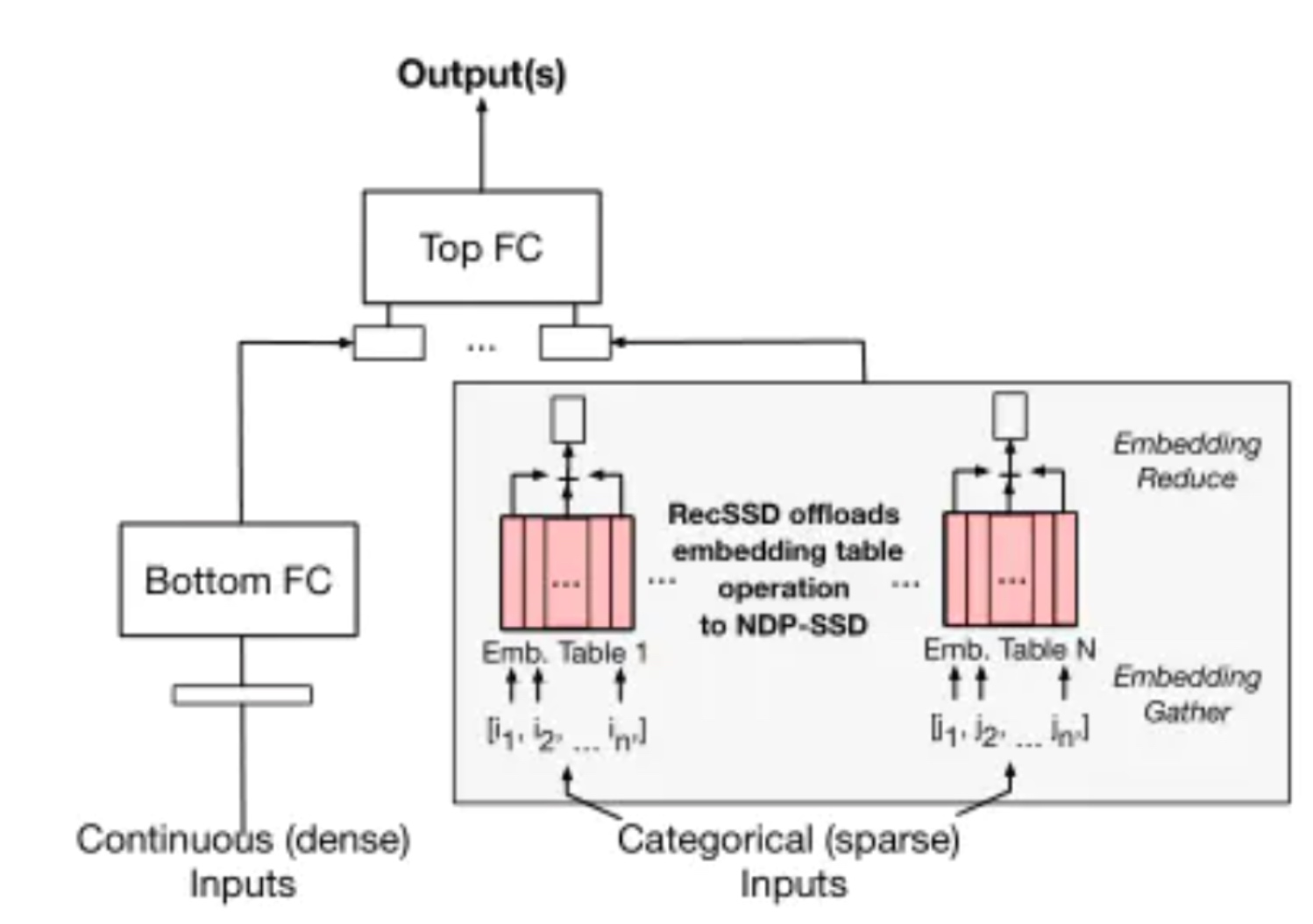
2 Fully connected layer with non-conformed-sized embedding table. The embedding table is organized such that each row is a unique embedding vector, typically including 16, 32, or 64 learned features (i.e., the number of columns in the table). For each inference, a set of embedding vectors, specified by a set of identifiers (e.g. multi-hot coded classification inputs), are aggregated together. Common operations for aggregating embedding vectors together include summation, averaging, concatenation, and matrix multiplication [30, 445]; Figure 1 shows an example of using summation. Inference requests are often processed in batches to share the control overhead and make better use of computational resources. In addition, the model usually contains many embedding tables. Currently, production-scale data centers store embedding tables in dynamic random access memory, while the central processor performs embedding table operations and optimizations, such as vectorization instructions and software prefetching.
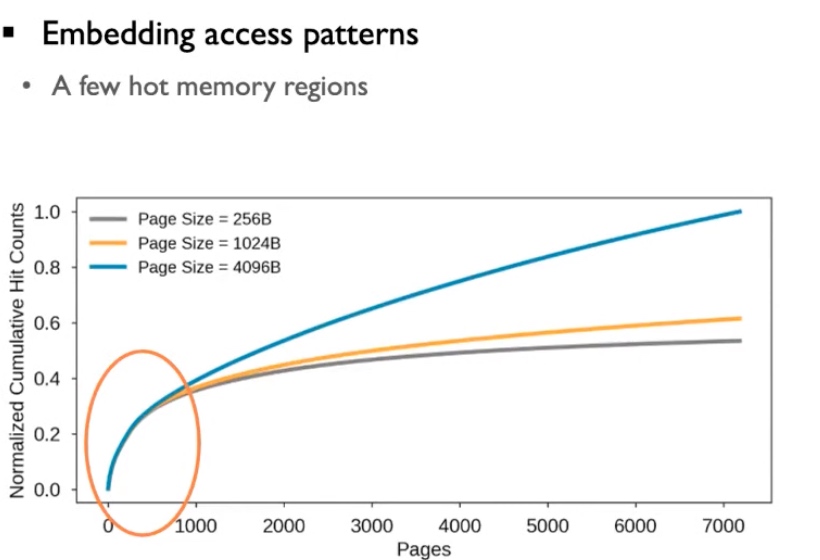
Embedding-Domain models include DLRM-RMC1,2,3, their observation is the hot memory hit gets up drastically for several pages. This requires a real-world computation to have a software-defined allocation and prefetching technique and vectorization.
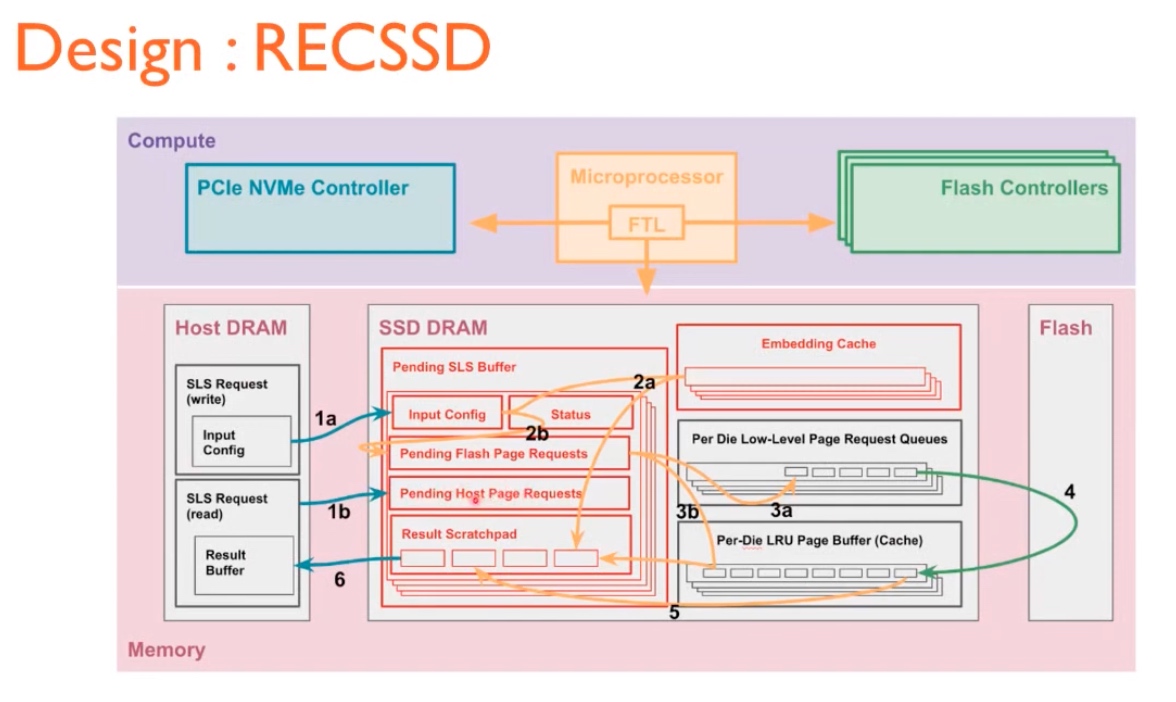
Implementation
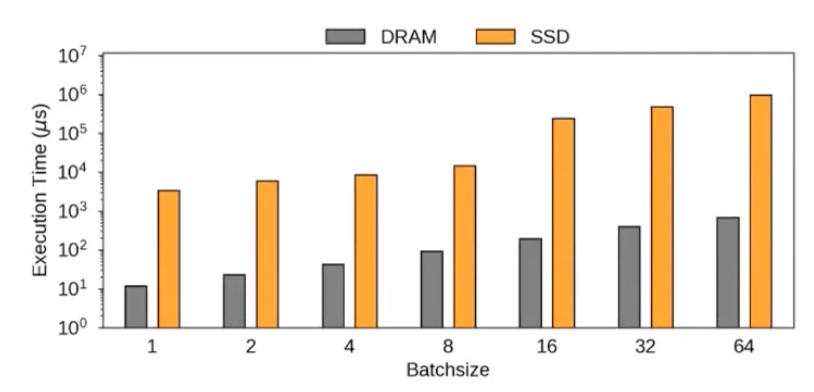
Their solution is on an OpenSSD over micro UNVMe stack (which can simply be replaced with SmartSSD.)

caching requires both side DRAM caching, and the multithread I/O queue are fused with SSD



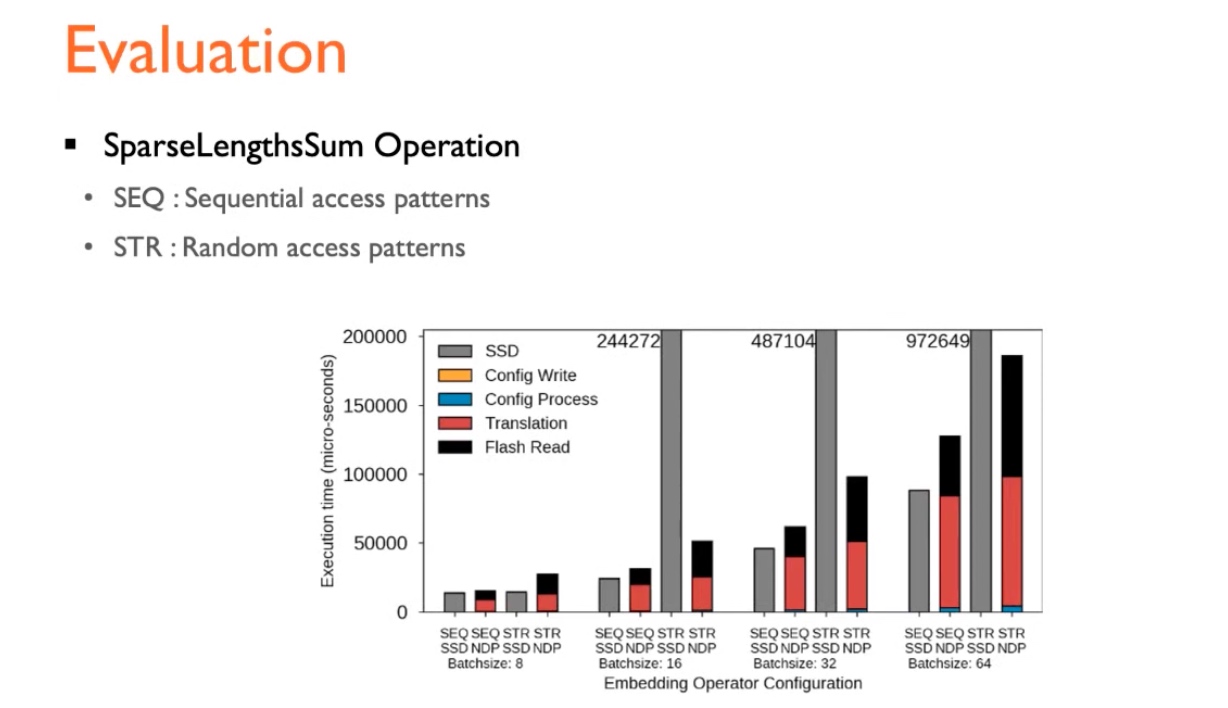
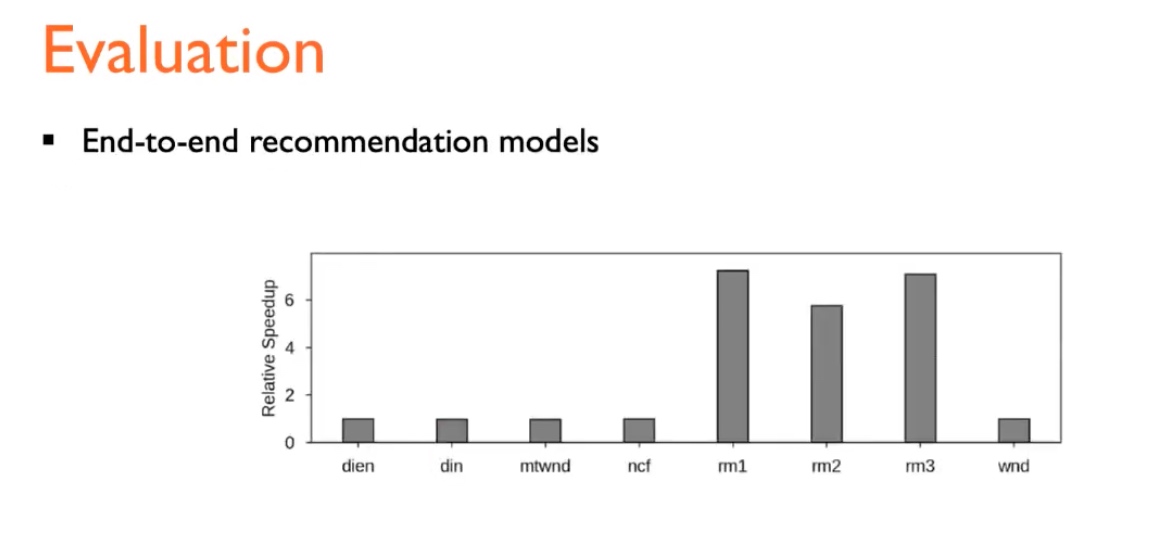
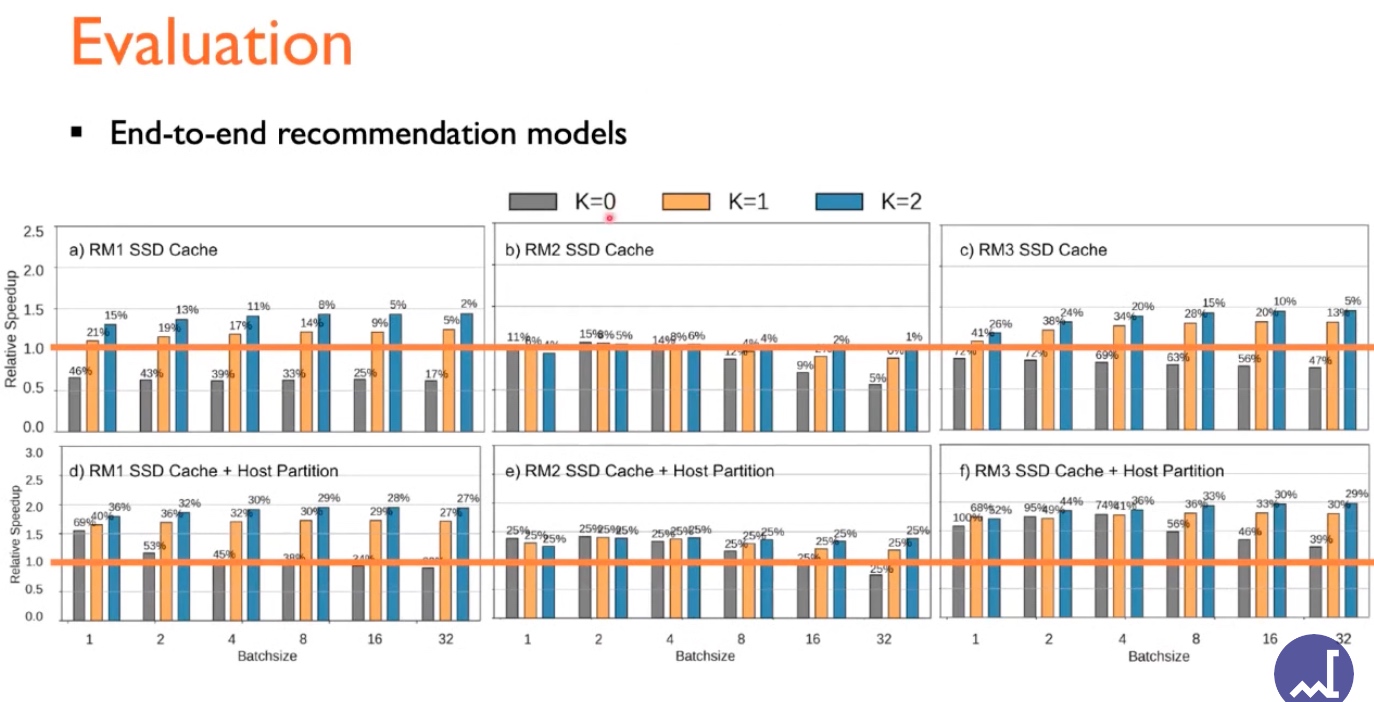
Performance