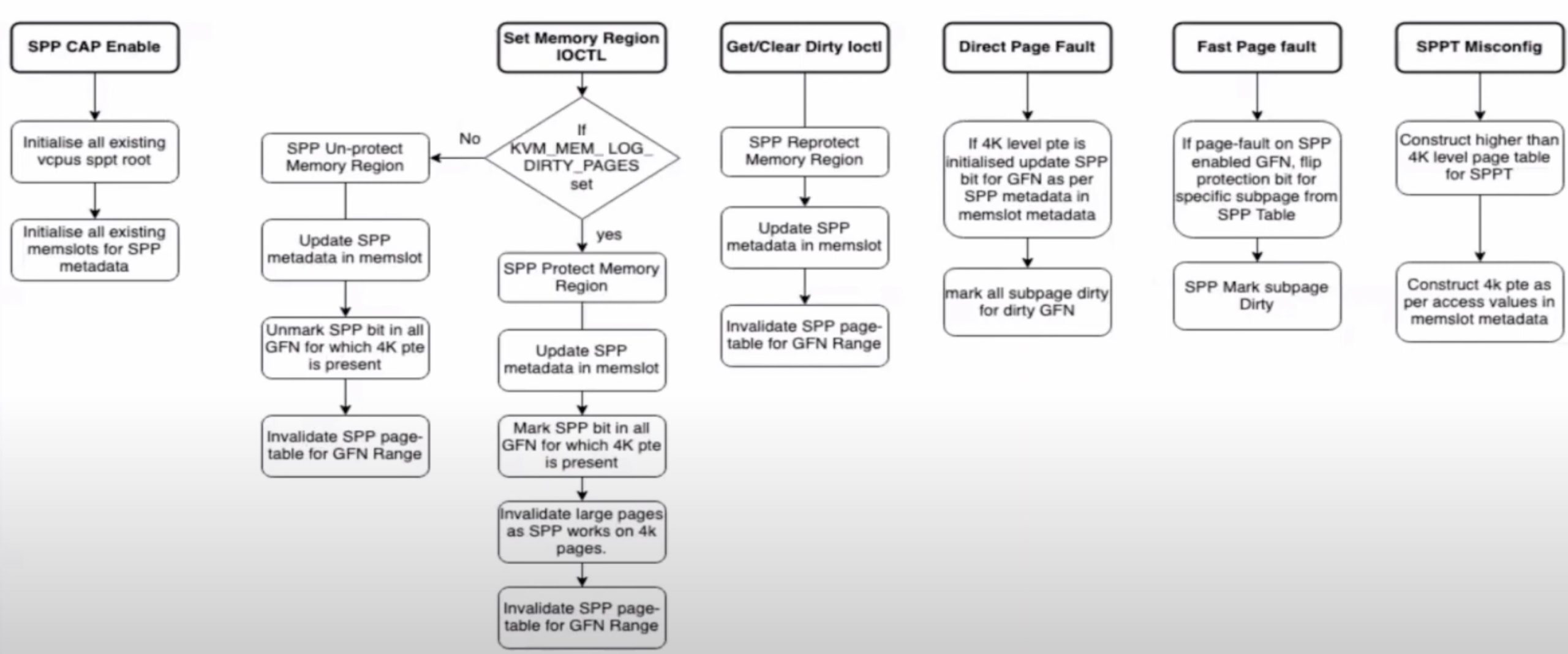
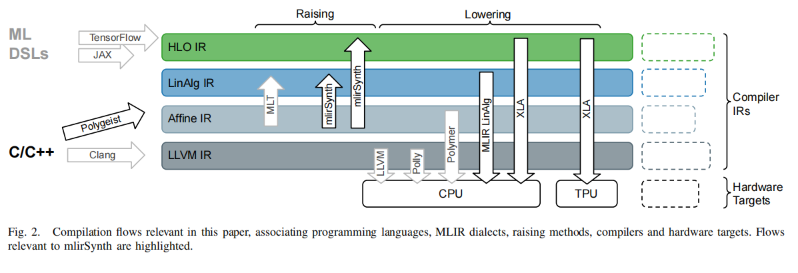
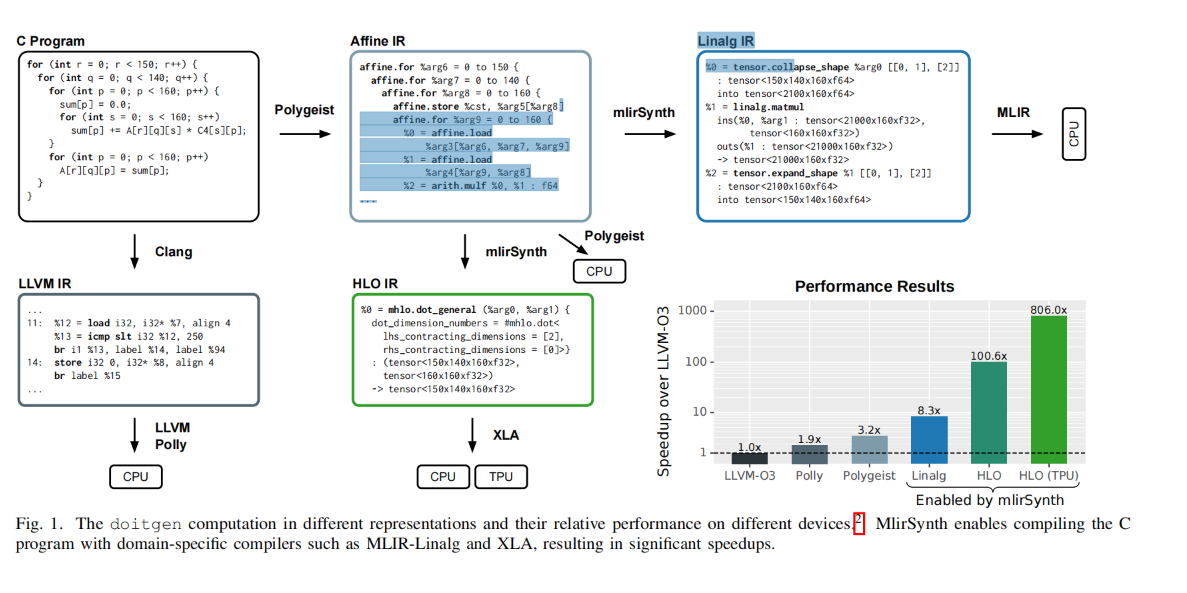
The current compilation phase for heterogeneous devices like CPU GPU or TPU is too divergent and not high performance because of the lack of semantic translation when lowering the IR.
MLIR is an infrastructure for developing domain-specific compilers. To aid this, MLIR provides reusable building blocks, especially the abstraction of dialects with a bunch of operators that have knowledge of cross-device memory communication and predefined and shared tools that allow us to define domain-specific languages and their compilation pipelines.
SoTA
Polygest has already filled what's done for multi-dimensional dialects like Affine IR, where we normally do auto-CGRA/GPU/TPU code generation.
Google's HLO can do XLA just like Jax or Chris Latner's Mojo is doing
LLVM Polly can do backend compilation with very good performance insight for a single machine.
Linalg IR (By the way Linear Algebra extensions have been accepted from the C++26 community that maps the header to this primitive IR) has the insight from the mathematical view to transform the matmul and transpose to be only one-time transpose. (together with many other mathematical optimizations) and has the best insight to clear away the linear algebra residual dead primitive.
Motivation
LLVM IR/Affine IR/Linalg IR are too heterogeneous in different ways. Sa HLO is a better way of raising from C++ to ML DSLs that is super useful for TPUs. Taking from the uniformed IR to a divergent but idompediency in terms of dataflow (especially IO) and semantic to easily codegen to different dialects are super useful for current development for the compiler to TPU/GPU/CPU extensions.
For raising and lowering, it is actually impossible to embed the same logic with no information loss. Say, I'm writing the predefined functions for an application, For cross-platform optimization in MLIR is good for memory translation and compliance to different targets' views from a data movement perspective if you are lowering to XLA.
For the impossible dimensions for compatibility, debug information and performance insight, Say, a library that's been optimized may be nonsense from a lowered IR perspective. If you don't have the knowledge of both IR, it's stupid abstraction.
DataFlow may be completely wrong, so we need a residual IO spec generator to maintain the idompediency.
Compared with HAILE and Fortran MLIR, we require a lot of functionality wise upgrades.
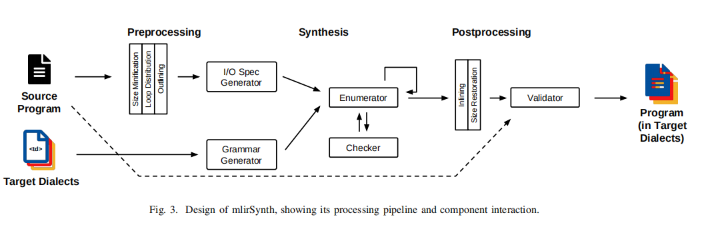
Compiler Solution: The MLIRSynth Framework - A virtual Compilation Phase abstraction:
Heuristics: candidate set for getting the phi instruction out to match the set between target dialect and source dialect.
Soundiness: CBMC Z3 for determining the correctness statically.
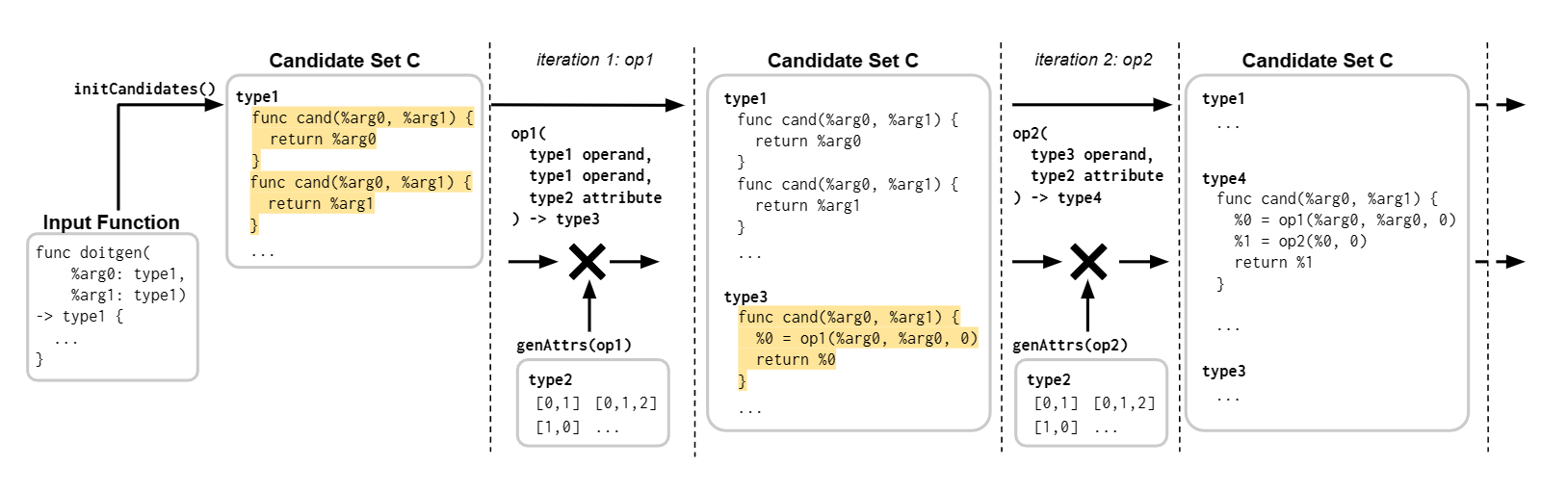
To extract φ (phi) with the candidate set, the algorithm follows a bottom-up synthesis approach. Here is a summary of the process:
Initialization: The algorithm starts by creating a candidate set (C) with valid candidates that produce distinct values from each other. This set includes candidates that return the arguments of the reference function (f) and simple constants.
Enumeration: The algorithm iterates through the set of operations in the grammar. For each operation, it identifies sets of possible operands, attributes, and regions based on the operation signature.
Candidate Generation: The algorithm generates possible candidates by taking the Cartesian product of sets of operands, attributes, and regions.
Candidate Checking: Each candidate in the set is validated using a series of static checks, ordered by complexity. These checks include type correctness and additional checks via dialects verification interface.
Equivalence Pruning and Validation: If the static checks succeed, the algorithm uses MLIR's execution engine to compile the candidate. It then checks φobsn by executing the candidate program (f') on a set of inputs and comparing the output value with the output value produced by the reference function (f).
Specification Checking: The algorithm checks if the candidate satisfies the specifications φ_{obsn} and φ_{obsN} by comparing the outputs of the candidate and the reference function on a small finite set of inputs (In) and a large finite set of inputs (IN), respectively.
Illustrative Example:
The above is from one dialect to the other
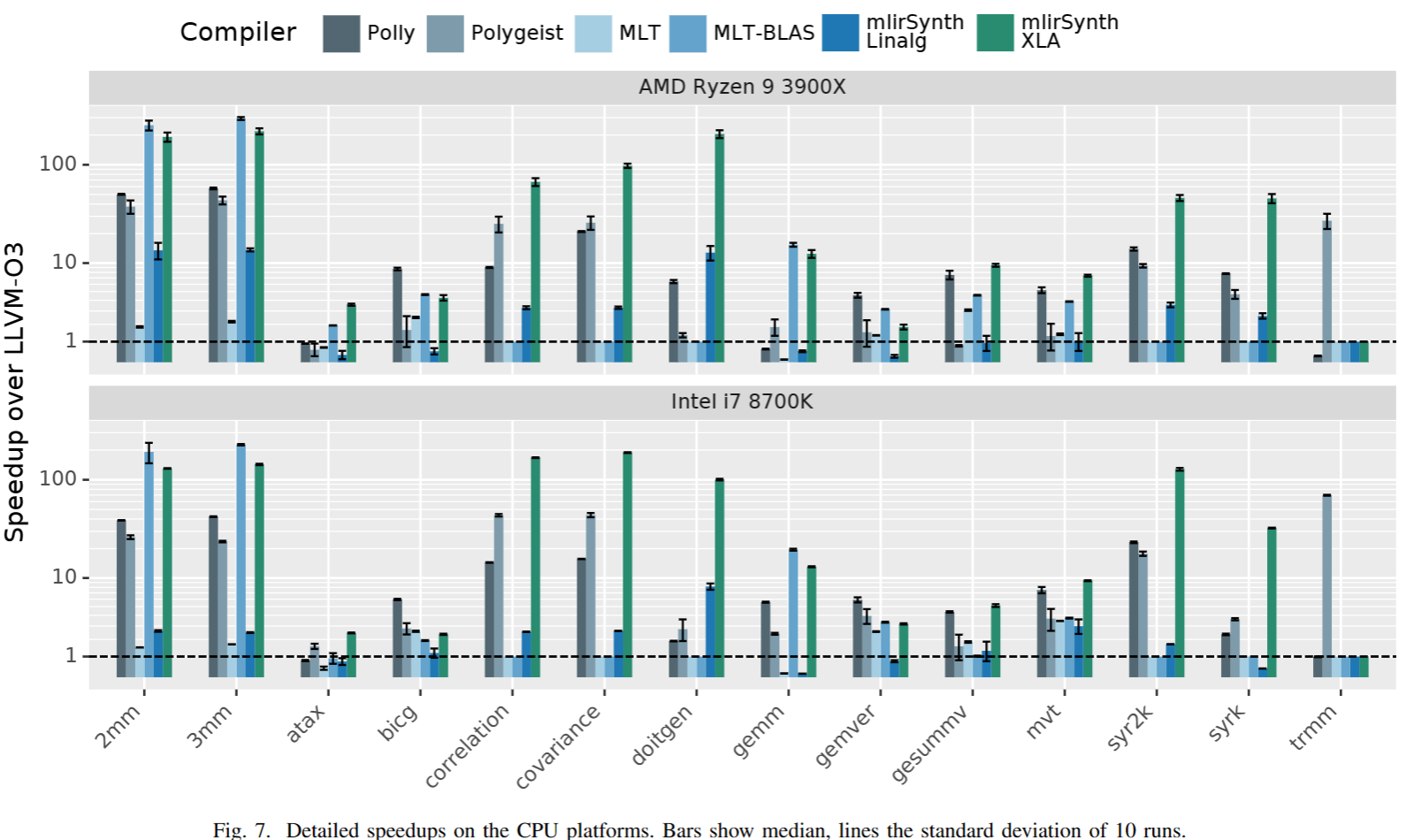
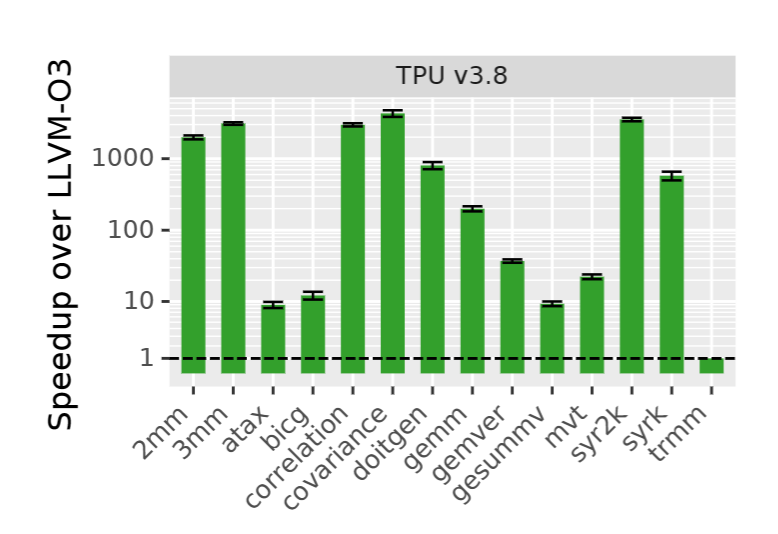
Key Results:
The evaluation over PollyBench on 8700k and 3990x summary tells us about the performance and effectiveness of the mlirSynth algorithm in raising programs to higher-level dialects within MLIR. The TPU performs well over LLVM for all(because LLVM is not a good IR for heterogenous accelerator) It provides information on the synthesis time, validity checks, and the impact of type information and candidate pruning on the synthesis process. The summary also mentions the performance improvement achieved by the raised programs compared to existing compilation flows, as well as the potential for further improvements and future work.
Discussion and Future Directions:
Benefits:
The bottom-up enumerative synthesis approach in MLIR allows for raising dialect levels within the MLIR framework.
The retargetable approach is applied to Affine IR, raising it to the Linalg and HLO IRs.
The raised IR code, when compiled to different platforms, outperforms existing compilation flows in terms of performance.
Implications:
The use of polyhedral analysis in the compilation community has been extensively explored, but MLIR-Synth offers a different approach by using polyhedral analysis to raise dialect levels instead of lowering code.
The synthesis process in MLIR-Synth involves type filtering, candidate evaluation, and equivalence checking, which significantly reduces synthesis time compared to a naive algorithm.
Future Work:
The authors plan to raise programs to multiple target dialects and improve the synthesis search by reusing previous program space explorations.
They also aim to integrate model checking into the synthesis process and evaluate raising to new and emerging dialects of MLIR.
The scalability of the synthesis algorithm will be improved to handle larger benchmark suites.
The middle IR is always there for sure that is easier been developed from different angle but it's not the killer app for giving a new tool. The speed up from the tool is basically the backend that already has.
众所周知,yyw眼中第一重要的是事业,第二重要的是老婆,第三重要的才是无尽的小裙子。但突然发现后两个好像并没有区别,把头发剃了和以前没啥区别,也可以戴假发穿小裙子,我也不是非常在意身体,以为我觉得对身体损伤最小的变性方式并没有出现,所以不会让自己过于陷于不受控制的境地。
Steve Jobs能在胰腺癌移植手术后继续苟活6年,yyw也能盼望这个世界能早日医疗进步,今天的每一天和昨天都不一样,尤其是在这个能最大限度释放yyw所想的加州。
所以我认为任何意义上的性别都不重要,重要的是唯心和以一种舒服的方式生活下去,如果我的皮肤能保持光滑的女性特质,这就足够装下yyw的灵魂了。我认为没有解决一个问题,纯粹是因为你没有站在更高的位面观测这个世界,并不是这个世界不存在,我尝试用激烈的测试手段来观测这个世界来让我达到一个更高的位面,但是同时又希望身边的人能获益。
所以老婆要yyw怎么样,都可以,只要她不离开yyw且同意给yyw生小孩。
The current GPU slicing by MIG is way to higher granularity.
The state of the art needs GPU on getting the service mesh requests letting you serve it, normally the launch time of the kernel and the data movement takes the most of the execution. Pre execution by MLIR JIT statically optimize out the launch but do GPU context coroutine.