http://bbs.5imx.com/forum.php?mod=viewthread&tid=1054297&page=1&authorid=268833



A Tech Nerd with a finance mind.
http://sist.shanghaitech.edu.cn/faculty/songfu/Projects/SCInfer/ScInfer.zip
没想到宋富老师也是有青春的。
口口声声说不让我们做工程的东西,自己年轻的时候也深受其害呀。

主要思想就是如何实现,架子用solidworks ,PWM ( Width Modulation )脉冲宽度调制是一种模拟控制方式,根据相应载荷的变化来调制晶体管基极或MOS管栅极的偏置,来实现晶体管或MOS管导通时间的改变,从而实现开关稳压电源输出的改变。 (摘自百度百科)用于算法实现用IMU( inertial measurement unit ) 惯性测量单元 ,它由三个单轴的加速度计和三个单轴的陀螺仪组成,加速度计检测物体在载体坐标系统独立三轴的加速度信号,而陀螺仪检测载体相对于导航坐标系的角速度信号,对这些信号进行处理之后,便可解算出物体的姿态,这点弥补了GPS定位的不足。 算法用于实现机体稳定,主要思想是负反馈。
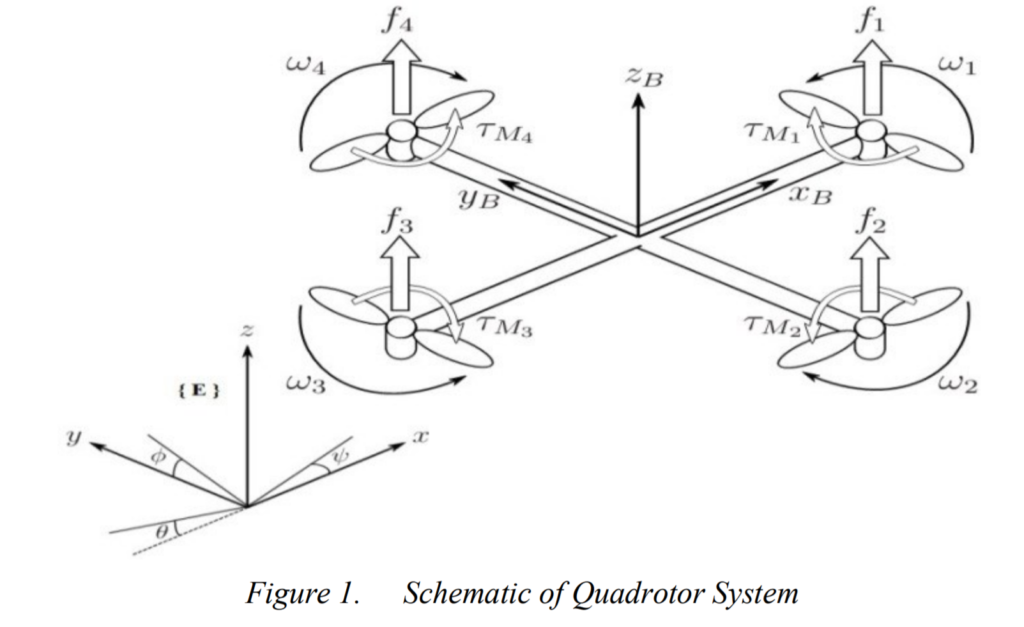
Quadrotor (四旋翼)系统的动力轴
动力学公式
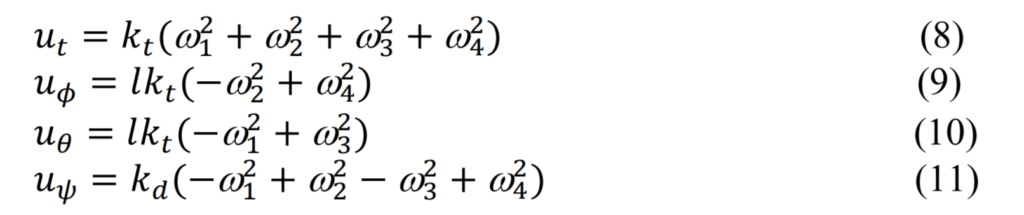
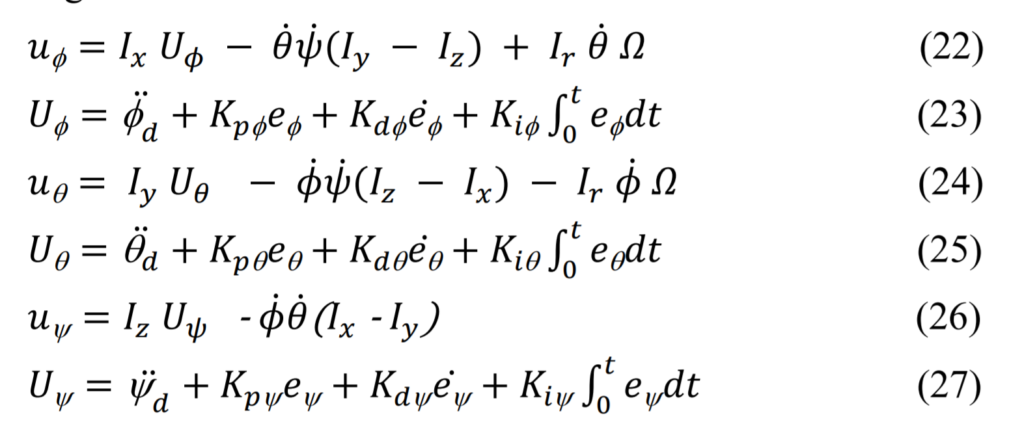
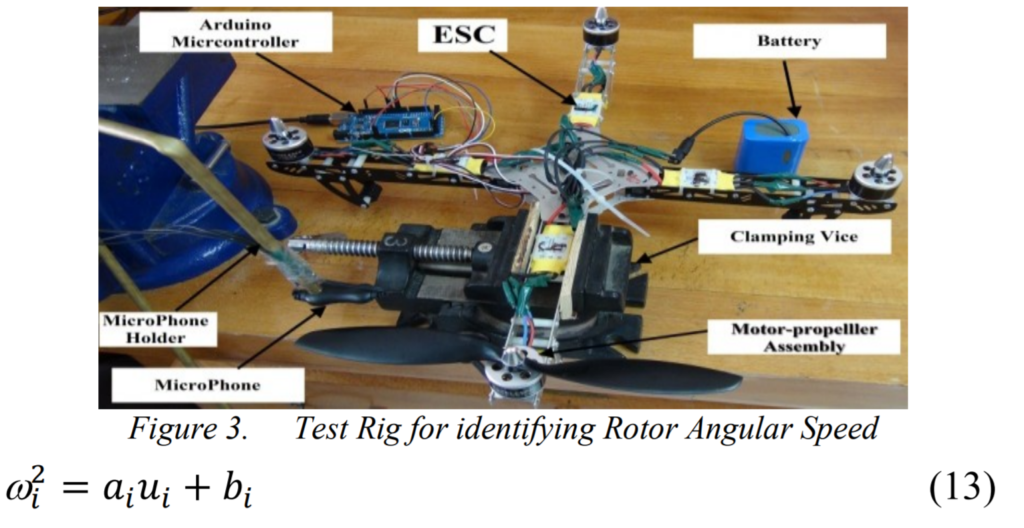
调试与调控


成果

主要由Honeywell公司组成的ZigBe Alliance制定,从1998年开始发展,于2001年向电机电子工程师学会(IEEE)提案纳入IEEE 802.15.4标准规范之中,自此将ZigBee技术渐渐成为各业界共同通用的低速短距无线通信技术之一。
在802.15.4标准中指定了两个物理频段和直接序列扩频(DSSS)物理层频段:868/915MHz和2.4GHz。2.4GHz的物理层支持空气中250kb/s的速率,而868/915MHz的物理层支持空气中20kb/s和40kb/s的传输速率。由于数据包开销和处理延迟,实际的数据吞吐量会小于规定的比特率。作为支持低速率、低功耗、短距离无线通信的协议标准,802.15.4在无线电频率和数据率、数据传输模型、设备类型、网络工作方式、安全等方面都做出了说明。并且将协议模型划分为物理层和媒体接入控制层两个子层进行实现。

自编译了一套威联通系统,参考老骥伏枥。
机器 4570 16GB 2T*4 1066 大概13年给家里买的台式(主要是给我打QQ三国和三国无双,结果我爸为了不让我玩后者就没给我买显卡。大学以后才购入的1066跑渲染、剪视频和炼丹,做了1年主力机后和15底年的macbook air一起退役。
编译好的文件在 https://www.asplos.dev/vQTS-Boot.img 和 https://www.asplos.dev/TS653B20180528.img
2022.1.29 update 那台机器后来弄成了我的gitlab CI,先后支撑了我的CG CI,春东课sniper CI,还有自娱自乐训练的一些东西,于2021.5.16 宕机 被前前后后拆了垃圾装又被Logan拿了盘去给他的nas,1066送给了murez。
#!/bin/bash
# Copied and modified from https://github.com/Technica-Corporation/Tegra-Docker
# Copyright (c) 2017, Technica Corporation. All rights reserved.
NV_LIBS="/usr/lib/aarch64-linux-gnu \
/usr/local/cuda/lib64 \
/usr/local/cuda \
/usr/src/tensorrt \
/usr/local/cuda-10.0 \
/usr/include \
/usr/src "
LD_PATH="/usr/lib/aarch64-linux-gnu \
/usr/lib/aarch64-linux-gnu/tegra \
/usr/local/cuda/lib64 \
/usr/src/tensorrt \
/usr/local/cuda \
/usr/local/cuda-10.0 \
/usr/include"
GPU_DEVICES="/dev/nvhost-ctrl \
/dev/nvhost-ctrl-gpu \
/dev/nvhost-prof-gpu \
/dev/nvmap \
/dev/nvhost-gpu \
/dev/nvhost-as-gpu"
NV_DOCKER_ARGS="--net=host"
build_docker_args() {
#set the required libraries as volumes on the docker container
LIB_ARGS=""
for lib in $NV_LIBS; do
LIB_ARGS="$LIB_ARGS -v $lib:$lib"
done
#set the required devices to be passed through to the container
DEV_ARGS=""
for dev in $GPU_DEVICES; do
DEV_ARGS="$DEV_ARGS --device=$dev"
done
NV_DOCKER_ARGS="$NV_DOCKER_ARGS $LIB_ARGS $DEV_ARGS"
}
build_env() {
#build the LD_LIBRARY_PATH
LD_LIBRARY_PATH=""
for lib in $LD_PATH; do
LD_LIBRARY_PATH="$LD_LIBRARY_PATH:$lib"
done
}
if [[ $# -ge 2 && $1 == "run" ]]; then
echo "Running an nvidia docker image"
build_docker_args
build_env
DOCKER_OPTS="-e LD_LIBRARY_PATH=$LD_LIBRARY_PATH $NV_DOCKER_ARGS ${@:2}"
echo "docker run $DOCKER_OPTS"
docker run $DOCKER_OPTS
fi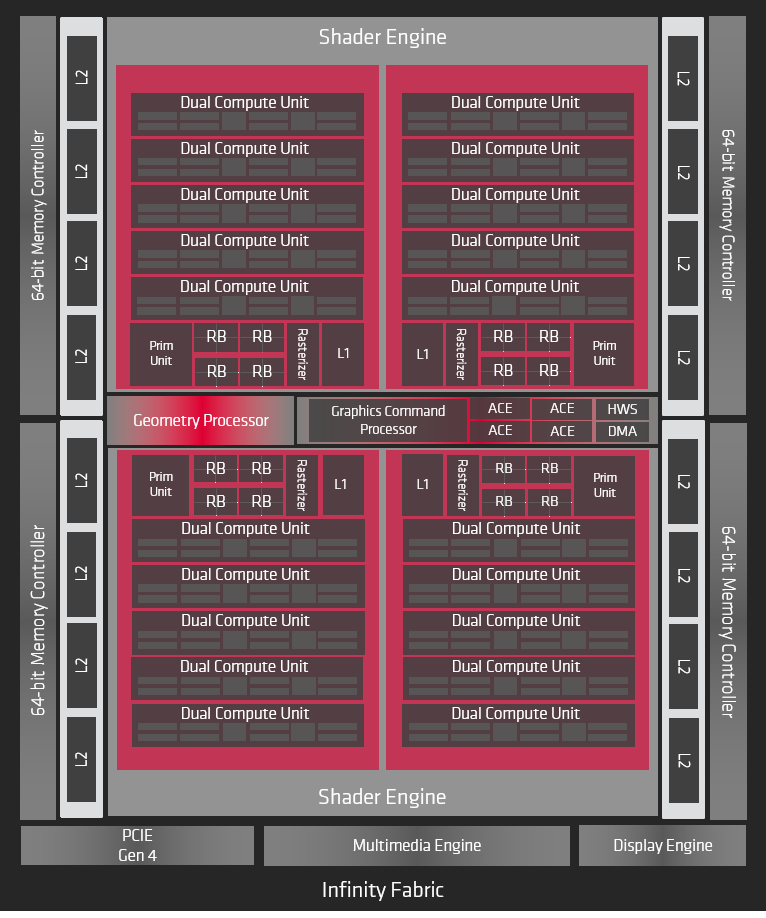
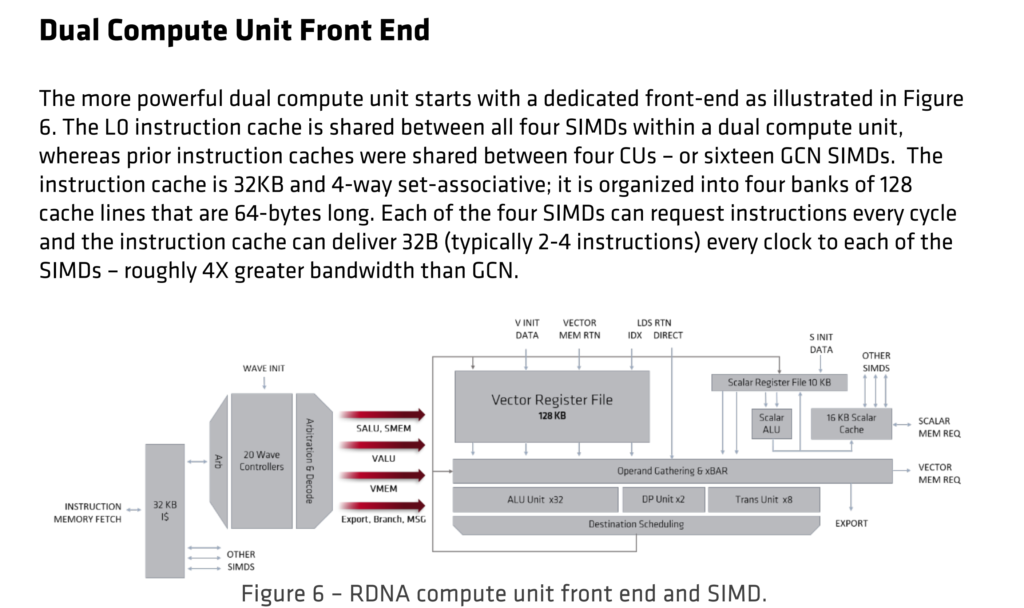
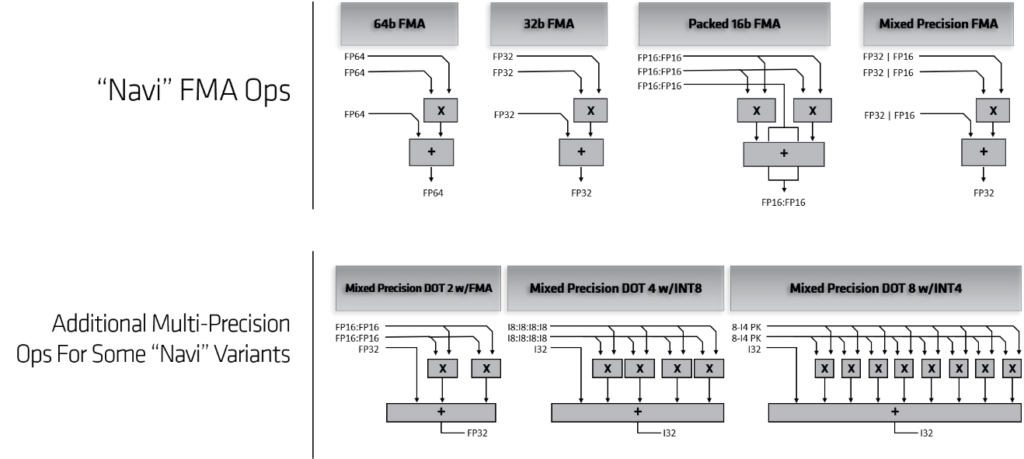
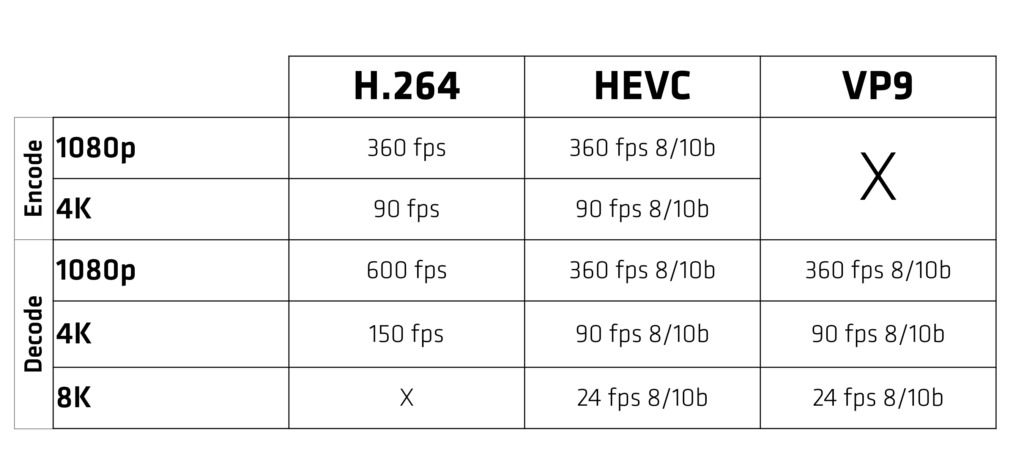
RX 5700 XT分为几个主要模块,使用AMD的Infinity Fabric连接在一起。 命令处理器和PCI Express接口将GPU连接到外部世界并控制各种功能。 两个着色器引擎包含所有可编程计算资源和一些专用图形硬件。 两个着色器引擎中的每一个包括两个着色器阵列,其包括新的双计算单元,共享图形L1高速缓存,基元单元,光栅化器和四个渲染后端(RB)。 此外,GPU包括用于多媒体和显示处理的专用逻辑。 对内存的访问通过分区的L2缓存和内存控制器进行路由。
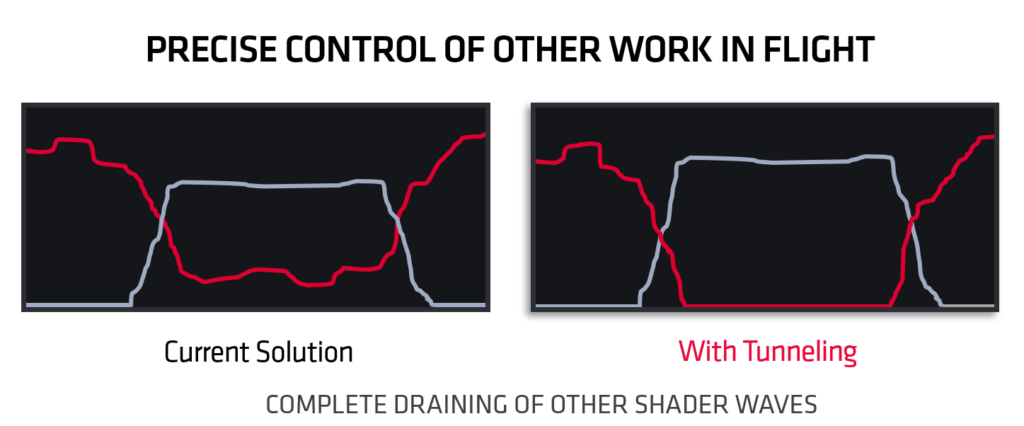
RDNA架构是第一个使用PCIe®4.0与主机连接的GPU系列
处理器。

需求:在只有1G内存的搬瓦工VPS上弄的快点,基本盘就是都用源码编译,可是docker+alpine的极限小内存模式基本让我不用重新编译的,也专门有人做这种docker。
docker run -d -p 3306:3306 yobasystems/alpine-mariadb我们知道限制网速的因素有很多,内网有这么好和多的手法传输数据,却因为厂商之间的壁垒而打破,尤其是华为、苹果还有其他鬼。DJI的设备和安卓还有苹果还好。这个时候就需要一个nas。
树莓派3b+大家都知道是一个只有百兆网口和usb2.0的设备,而且它们占用同一根数据总线,操作数一多,或者两者同时占用,比如从usb2.0到百兆网口,极限速度大概只有4MB/s。
现在arm开发板的瓶颈大多在io和内存,cpu的性能可以比大多数入门级单核vps好。挂个docker不是什么问题。
有人说一定要x86架构,我不敢苟同,他威联通还能用marvell的armada8040做4k处理器,再加个gpu训练人脸识别就绝了。还能做gpu docker
https://community.arm.com/cn/b/blog/posts/marvell-armada-8040
Marvell ARMADA 8040超大规模vSoC的特性包括:
• 2.0GHz四核ARM Cortex-A72
• 1MB共享L2存储以及1MB专用L3存储
• 完整的ARMv8-A CPU虚拟化以及I/O虚拟化
• 高吞吐率低延迟的内存一致性子系统
• 拥有2x10GbE + 4x2.5GbE连接性的网络包处理器
• 可扩展到从1GbE到10GbE间的多端口
• SuitB兼容、10Gbp/s吞吐量安全引擎、IPSEC以及SSL协议卸载
• DDR3/3L/4 32b/64b+ECC扩展
• SATA3.0、USB3.0、PCIe3.0

有pcie就可以拓展显卡了,虽然它只有工控机的能力。拓展雷电三就完全不一样了。