

They've not been open-sourced! They may have to deploy on Huawei Qunpeng chassis or embed it into the Linux kernel. If I have time, I may reimplement this idea.
Both MCA lock and is not that applicable for heterogeneous cores in asymmetric multicore processors(big/little in Arm, Efficiency/Performance core in Alder Lake).
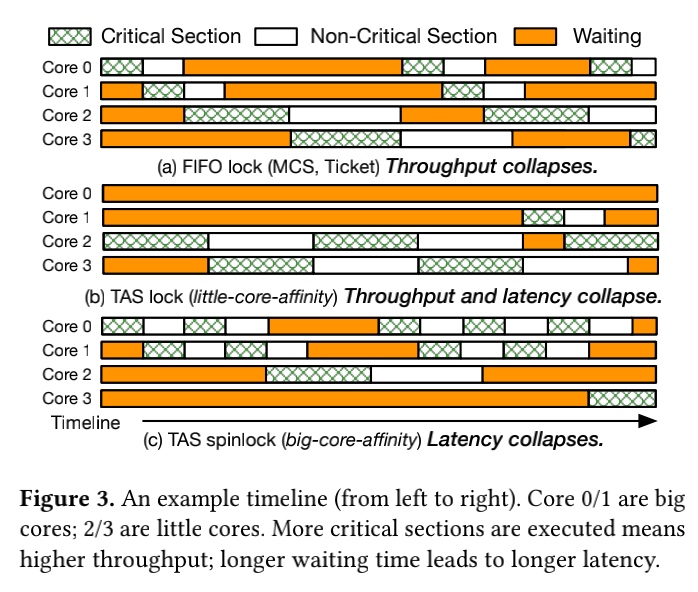
LibASL exposes the reorder capability as a configurable time window. Big cores can only reorder with little cores during that time window. Atop the reorderable lock, LibASL automatically chooses a suitable fine-grained reorder window according to applications' coarse-grained latency requirements through a feedback mechanism.


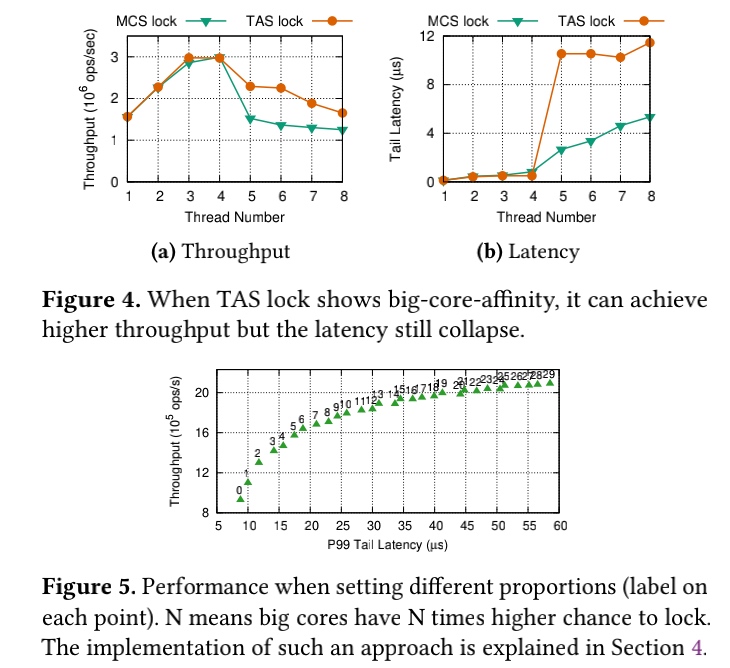
MCA lock

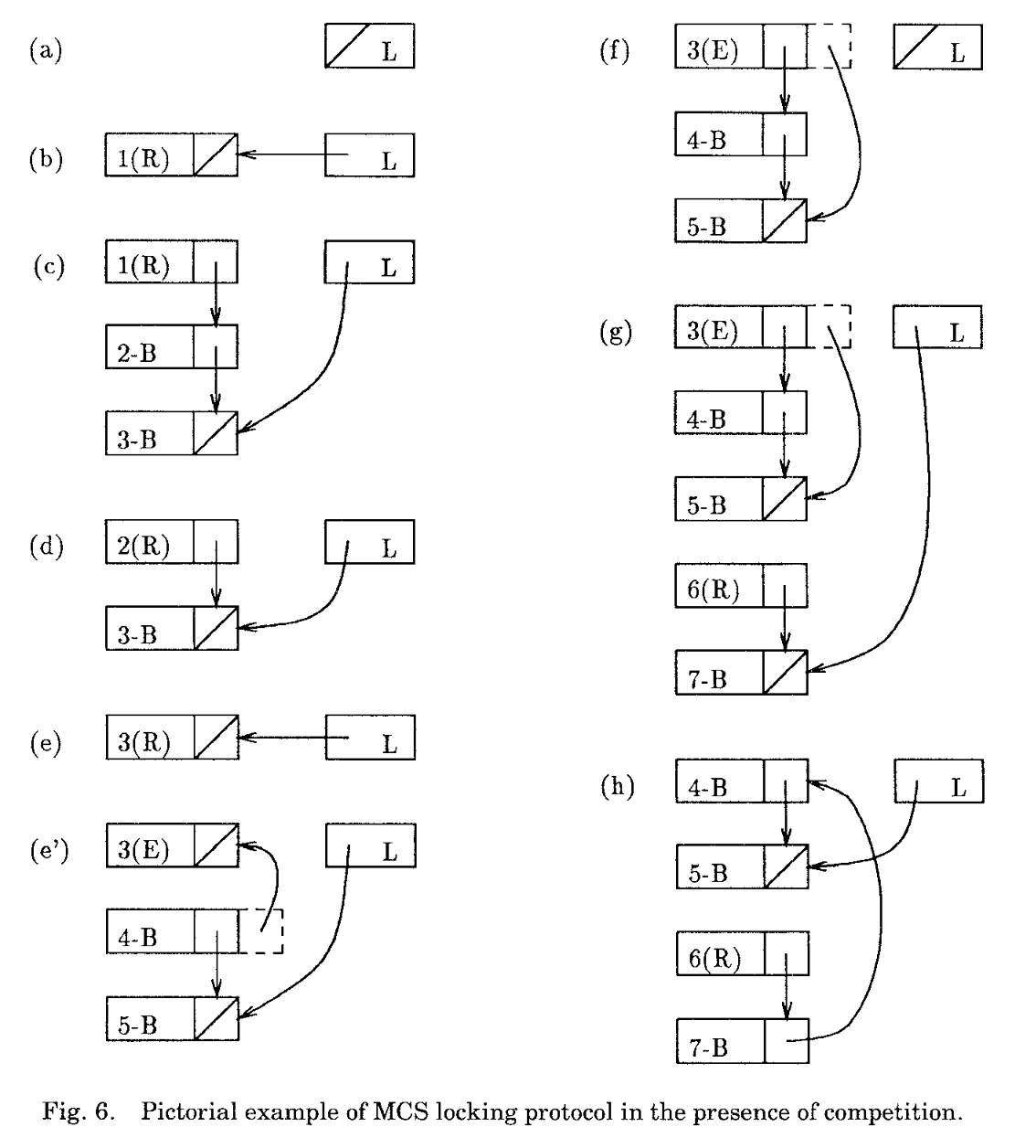
Basically a FIFO list on the lock bit, which combines the good of array-based queue lock and test_and_set ticket lock.
LibASL
The queue in MCS can be a reorder window aware of the big little cores' latency SLO. Big cores and little cores are not competing for the same lock in big cores. In little cores, LibASL behaves similarly to the backoff spinlock. When they are competing for the same lock with heavy content, little core can be reordered with big cores' lock once the latency SLO is still met. Or the sweet spot will be found to saturate the lock for better throughput.
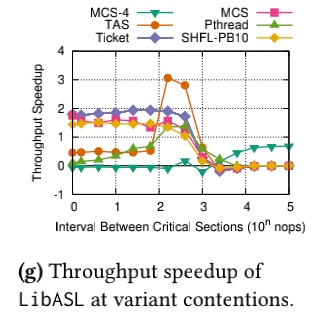
Refinement
The latency graph can be used to construct a reorder priority queue for the affinity of the big/little core transformation.