老师上课开始讲运行时环境了,这也导致后半部分一节课一个话题的开始。知识点杂乱,但是每一个步骤都很爽,感觉自己学到了挺多东西的。
整个llvm 有足足8个多g,看了下大多数都是优化部分,集中在llvm pass当中
(未完待续)


A Tech Nerd with a finance mind.
老师上课开始讲运行时环境了,这也导致后半部分一节课一个话题的开始。知识点杂乱,但是每一个步骤都很爽,感觉自己学到了挺多东西的。
整个llvm 有足足8个多g,看了下大多数都是优化部分,集中在llvm pass当中
(未完待续)
Reference:
Device:
https://gist.github.com/victoryang00/cd6324acffc5ac79464d8409f768656a
outher good reference:
https://cas-pra.sugon.com/detail.html?tournament_id=6
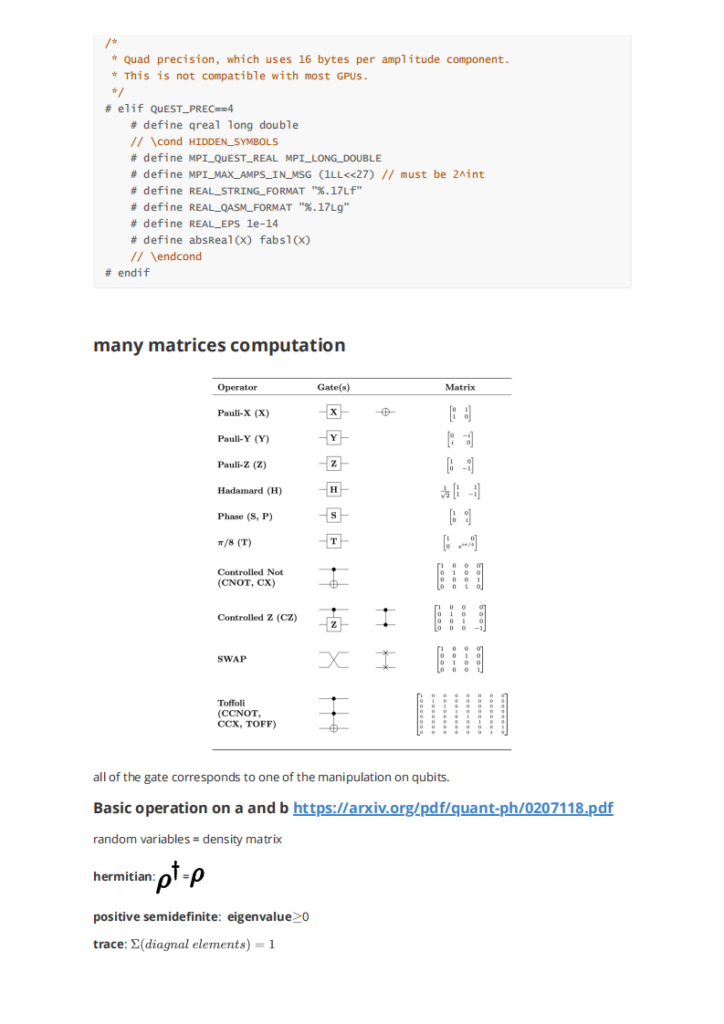
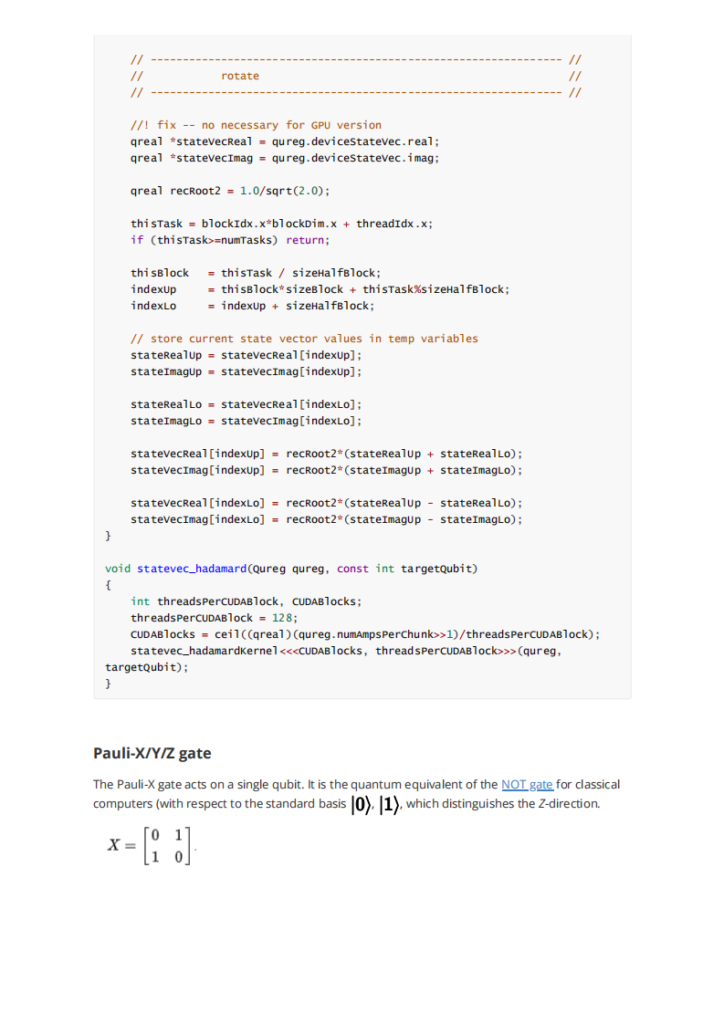
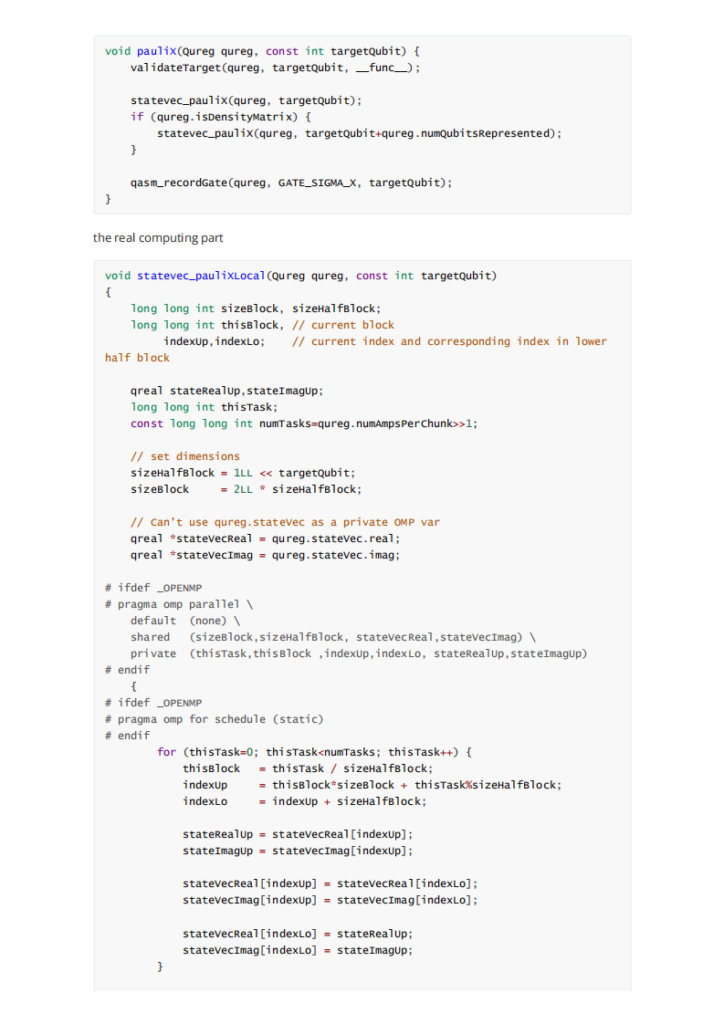
rocblas自身的实现为架构通用的tensile 机器码,很少会顾及isa架构相关的优化如内存读入,寄存器分配,block size大小等。在对rocblas_sgemm_strided_batch 和自己写的naive版本的batch进行profiling和extractkernel后,着重发现和了解了几个重难点。首先是块与线程部分。第一最高线程速率,硬件生成Threads的速率将直接影响最终程序的效率, 例如GPU显存的读写速度,测试发现gfx906获得64 threads/Cycles的极限性能;第二是1D形状的线程速率曲线。测试得到仅仅当 BlockDim = 256, 512, 1024时, 线程产生速度达到峰值。也即是如果能够将原来4 threads的工作合并到一个thread,每个线程处理的事务随之提高到4倍,例如读写操作,将极大地提高理论极限。在测试了2D 和 3D 之后得出以 256倍的BlockDim性能最佳。其次,在Instruction cahceline的部分,结果表明增加越多的线程能更有效的增加SIMD的效率。在对dump后的VGPR寄存器分析后,发现:HIPCC大多数时候不使用s_load_dword,C ++ Statemetn不能将内联汇编的输出用作操作数,C ++的操作数必须来自C ++,64位地址或数据在内联汇编中很难调用,内联汇编是一个很难用C ++变量,if-esle,for-loop等控制的程序。HIPCC分配SGPR / VGPR的情况不太好GCN限制:s_load_DWORDx4,x8,X16 SGPR必须以x4地址开头内联汇编很难具有正确的VGPR / SGPR设置。由此引出了我们的解决方案:每个 WorkGroup 的 Macro-Tile和Micro-Tile 的分配问题,也即是VLP SGEMM 大小为128的WorkGroup的Macro使用 M=64,N=128,256 的Macro则为 M=64,N=256,每个线程为的Micro tile 大小为M=64, N=1,即每个线程运算Matrix A= 64xK, Matrix B = Kx64, 结果在 Matrix-C 64 x1。对于64个线程,每个M的Matrix-C地址是连续的。每个Wave 的 Matrix A 的Basic Offset 被设定为 N/64 *64 *lda;而B为M/64 *64 lda,取数据的指令为s_load_dwordx8 s[32:39], s[12:13], s18。GCN架构总共有96个可用的SGPR 这个算法使用s32到95,只有64个读取A,而88的并行读入设计使得效率提升。对B来说,每个线程使用微区块大小M = 64,N = 1。每个线程需要8个VGPR来加载1个N的8xK数据。该算法使用global_load_dwordx4来获得最佳的缓存行命中率。下一条存储器读取指令读取同一高速缓存行的下4个DWORD。关于VGPR分配,每个线程需要V [2:3]作为矩阵B的每个线程偏移量。矩阵B的双缓冲区加载需要16倍VGPR。这样总共83个剩下的VGPR负责每个SIMD 3个Waves 得到了很好的性能表现。还有,这种先由先分配变量至寄存器再反编译到机器码(相当于inline 静态库)的方式使得完全没有调度器带来的barrier 和LDS(LDS访存慢于L1 和VGPR)。最终,完成这些操作能使gdx906最高达到77%的性能释放。
make
./lib/sgemm_strided_batch_final -m 512 -n 512 -k 256 --batch_count 10
make compile_co
深入研读gpu,也即是gcn架构的体系结构相关知识。用汇编和反编译代码的方式优化。主要为优化代码,尤其是gpu代码提供一种优化思路,即先编译分配好VGPR的inline函数和其他一些工具到机器码,再反编译到.co文件,被需要的cpp文件当作外部库来使用,可以极大地利用体系机构地优势从而加速sgemm。
SgemmBatchedStrided 的应用领域非常多。但是我认为最能体现本答卷价值的是CNN的Convolution,即用体系架构的优化代码方式优化现有CNN代码,用profile 和dump工具对现有的CNN Convolution 汇编分析,比如可以看的点主要有一/二级缓存命中延时、缓存行长度,接下来就可以用简单的汇编代码inlin 再反汇编进行优化。
Just Download here on Google.
And you may meet the problem just as me
yiweiyang ~ Downloads > JEB.android.decompiler.3.0.0.201808031948Pro > sh ./jeb_macos.sh
2020-02-15 05:51:30.768 jeb[1807:69065] Failed to find library.:
2020-02-15 05:51:30.769 jeb[1807:69065] jeb:Failed to locate JNI_CreateJavaVM
2020-02-15 05:51:30.769 jeb[1807:69065] jeb:Failed to launch JVM
This may because the Jeb failed to locate the right JDK and on macOS or other unix-like system, java is determined through the /usr/libexec/java_home -V other than JAVA_HOME
First Download the JDK on Oracle.
Then
/usr/libexec/java_home -V
Matching Java Virtual Machines (3):
12.0.1, x86_64: "OpenJDK 12.0.1" /Library/Java/JavaVirtualMachines/openjdk-12.0.1.jdk/Contents/Home
1.8.0_241, x86_64: "Java SE 8" /Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home
1.8.0_222, x86_64: "AdoptOpenJDK 8" /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
Write
<key>JVMCapabilities</key>
<array>
<string>CommandLine</string>
<string>JNI</string>
<string>BundledApp</string>
</array>
to /Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Info.plist
sudo mkdir -p /Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home/bundle/Libraries
sudo ln -s /Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home/jre/lib/server/libjvm.dylib /Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home/bundle/Libraries/libserver.dylib
To check
/usr/libexec/java_home -t BundledAPP
/Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home
Done
sh ./jeb_macos.sh
Memory Usage: 61.5M allocated (20.5M used, 41.0M free) - max: 910.5M
JEB v3.0.0.201808031948 (release/full/individual/air-gap/any-client/core-api)
Current directory: /Users/yiweiyang/Downloads/JEB.android.decompiler.3.0.0.201808031948Pro/bin/jeb.app/Contents/Java
Base directory: /Users/yiweiyang/Downloads/JEB.android.decompiler.3.0.0.201808031948Pro
Program directory: /Users/yiweiyang/Downloads/JEB.android.decompiler.3.0.0.201808031948Pro/bin
System: Mac OS X 10.15.2 (x86_64) en_CN
Java: Oracle Corporation 1.8.0_241
Plugin loaded: com.pnf.plugin.oat.OATPlugin
Plugin loaded: com.pnf.androsig.gen.AndroidSigGenPlugin
Plugin loaded: com.pnf.androsig.apply.andsig.AndroidSigApplyPlugin
Plugin loaded: com.pnf.plugin.pdf.PdfPlugin
optimize sgemm strided basic theory : https://ieeexplore.ieee.org/document/7839684







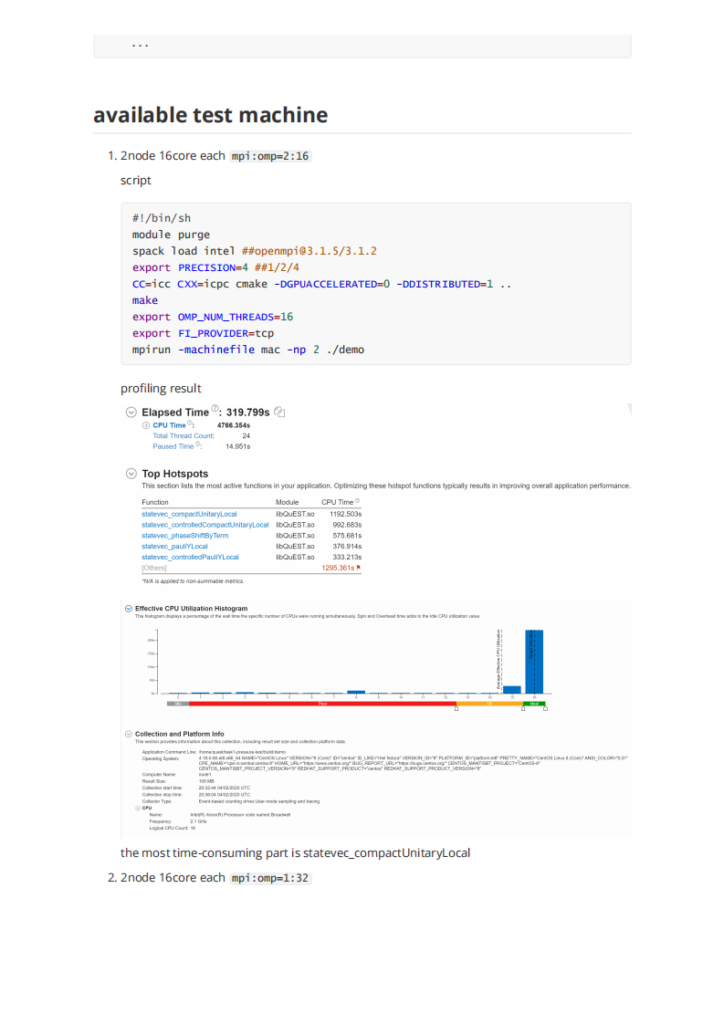

bios:顺序一定要让centos 先。超微主板的flexyboot 一定要disable 否则就会像这次一样卡死。
开机自启服务:
其他都可以再开机以后做,所以无所谓。
再看下ht开没开。nvidia-smi 在不在。内存有没有掉。
超微为了减少功耗是可以热插拔pcie 的,因为显卡插着就有25w功耗,热量积攒就算不用也会上升到平均30w左右。所以开机看看能不能热插拔。
最后总之能不重启就不重启。
我们在开科学计算的选项的时候总是会碰到这种问题:内存如何分配。尤其是用到gpu的计算的时候。很难有减少内存传输overhead 的办法。正如这次asc quest题目作者所说的:
Firstly, QuEST uses its hardware to accelerate the simulation of a single quantum register at a time. While I think there are good uses of multi-GPU to speedup simultaneous simulation of multiple registers, this would be a totally new pattern to QuEST's simulation style. So let's consider using multi-GPU to accelerate a single register.
There are a few ways you can have "multiple GPUs":
作者没有实现distributed gpu的主要原因是他觉得显存带宽复制的时间overhead比较大。不如就在单gpu上完成就行了。但是未来随着gpu显存的不断增加和计算的不断增加,这个放在多卡上的需求也与日俱增。
翻了很多关于gpu显卡的通讯,无论是单node 多卡还是多node多卡。最绕不开的就是mpi。但是当我找到一个更优秀的基于 infiniband 网卡的rdma的数据共享协议,让我眼前一亮,决定就用这个。如果你不是要写cuda 而是pytorch 请绕步pytorch distributed doc,如果是python 版本的nccl 可以选择
参考文档:
主要的步骤:先照着nccl文档安装nv_peer_memory, 再装nccl 最后装plugin。
安装后之后有两个test 一个是 gdrcopy 另一个是 nccl-tests。 跑的命令是 mpirun -N 1 --allow-run-as-root --hostfile host -x NCCL_IB_DISABLE=0 -x NCCL_IB_CUDA_SUPPORT=1 -x NCCL_IB_HCA=mlx4_0 -x NCCL_SOCKET_IFNAME=ib0 -x LD_LIBRARY_PATH=/usr/local/nccl/lib:/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH -x NCCL_DEBUG=INFO ./build/all_reduce_perf -b 16M -e 1024M -g 4
MPI 对于消息传递模型的设计
在开始教程之前,我会先解释一下 MPI 在消息传递模型设计上的一些经典概念。第一个概念是通讯器(communicator)。通讯器定义了一组能够互相发消息的进程。在这组进程中,每个进程会被分配一个序号,称作秩(rank),进程间显性地通过指定秩来进行通信。
通信的基础建立在不同进程间发送和接收操作。一个进程可以通过指定另一个进程的秩以及一个独一无二的消息标签(tag)来发送消息给另一个进程。接受者可以发送一个接收特定标签标记的消息的请求(或者也可以完全不管标签,接收任何消息),然后依次处理接收到的数据。类似这样的涉及一个发送者以及一个接受者的通信被称作点对点(point-to-point)通信。
当然在很多情况下,某个进程可能需要跟所有其他进程通信。比如主进程想发一个广播给所有的从进程。在这种情况下,手动去写一个个进程点对点的信息传递就显得很笨拙。而且事实上这样会导致网络利用率低下。MPI 有专门的接口来帮我们处理这类所有进程间的集体性(collective)通信。