其中双缓存的概念在asc20 hpl优化的时候得到了验证,4*teslav100=32g =128g,内存占用也是128g。实际上host 到device 的带宽太小,不适合做大规模的内存迁移,所以双缓存还是十分必要的。

gpu的延时是数百个时钟周期。


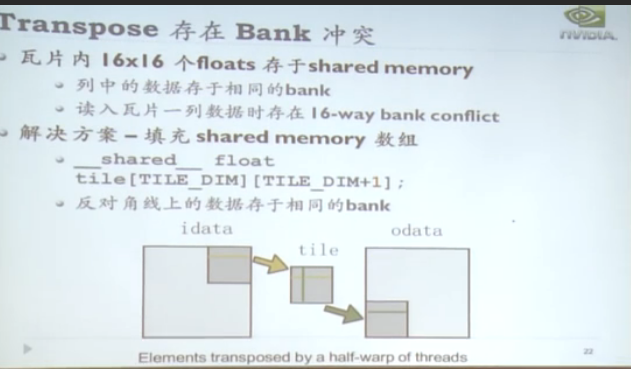
sm资源调度模型用于解决访存冲突。有texture 纹理寻址。
基本操作:

另外几种优化的方向。
single转double

Data Prefetching 数据预读

引入预读操作

编译器bb优化



A Tech Nerd with a finance mind.
其中双缓存的概念在asc20 hpl优化的时候得到了验证,4*teslav100=32g =128g,内存占用也是128g。实际上host 到device 的带宽太小,不适合做大规模的内存迁移,所以双缓存还是十分必要的。
gpu的延时是数百个时钟周期。
sm资源调度模型用于解决访存冲突。有texture 纹理寻址。
基本操作:
另外几种优化的方向。
single转double
Data Prefetching 数据预读
引入预读操作
编译器bb优化

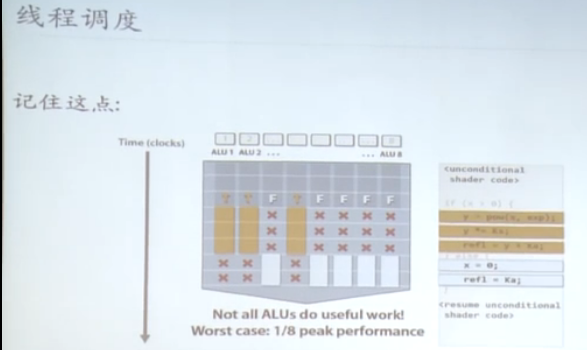
类似SIMT中的线程,被serialized。很多特性和线程几乎一致。在host中经常被用到的概念,也是区别block的基本单位。
一个block 不是最小单元,最好的优化是在warp上调度,warp的步调是一致的。
P.S. 尽量不要写过多的深层的递归,因为在gpu上实现这个是需要开指数级别的线程数,没开一个线程就意味着特定的内存开销,显存很容易被撑满。

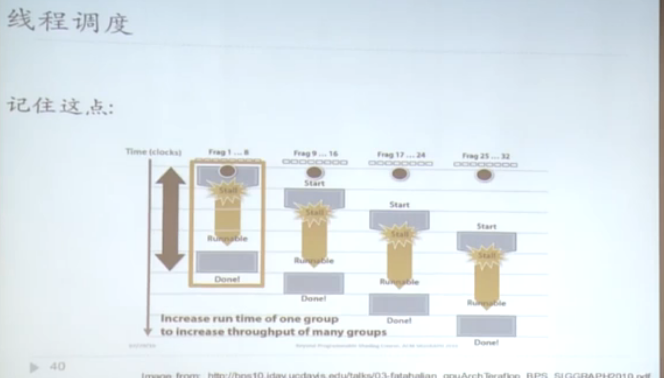
用线程调度的方法来达到延时隐藏的效果,对于gpu的warp来说,context switch 的开销几乎为零。在特定的时间点只可能一个warp在执行。
如果warp内部线程沿不同的