文章目录[隐藏]
The auto-flushing-persistently from GPU to PMEM without serializing the GPU memory makes it the greatest in snapshotting or swapping. When I was rewriting QuEST in ASC 21-22, we found that Tsinghua University Zhangcheng and NUDT is doing swapping memory back and forth to make it possible to emulate more QuBits. This arch will be a best fit for that.
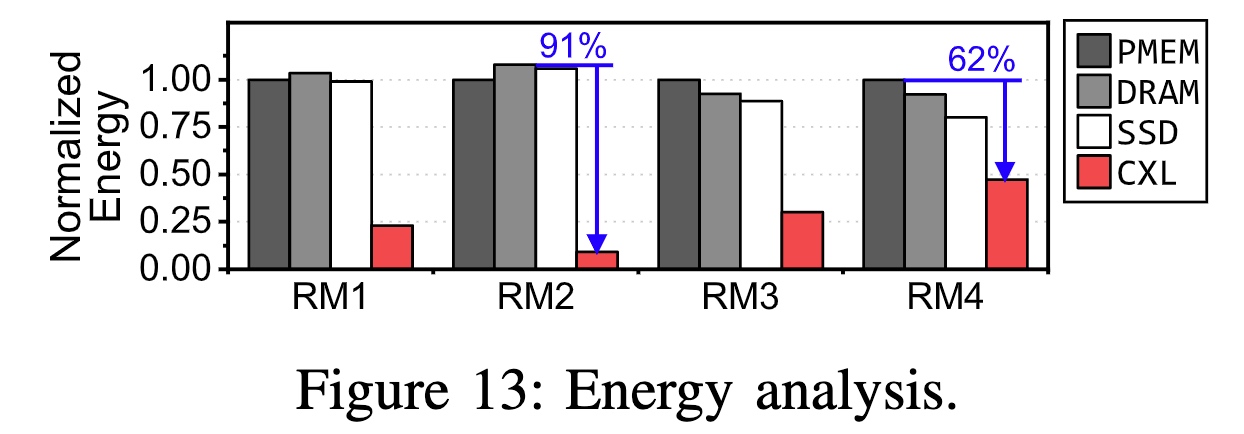
Their story is a recommendation system that the embedding table could not fit in a single card and disaggregate the GPU memory illustration of the embedding table to other CXL2.0 devices.
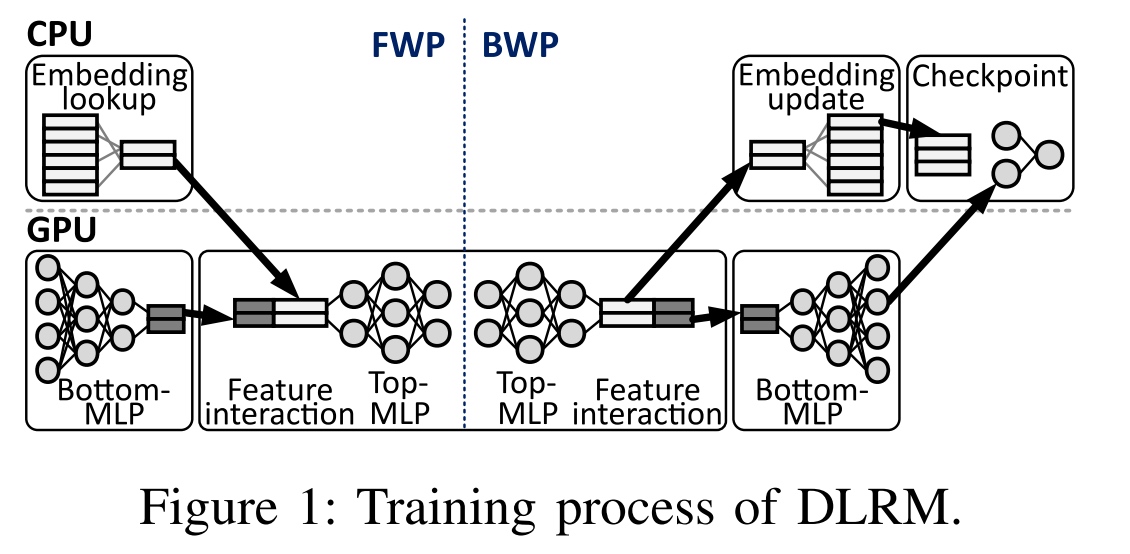
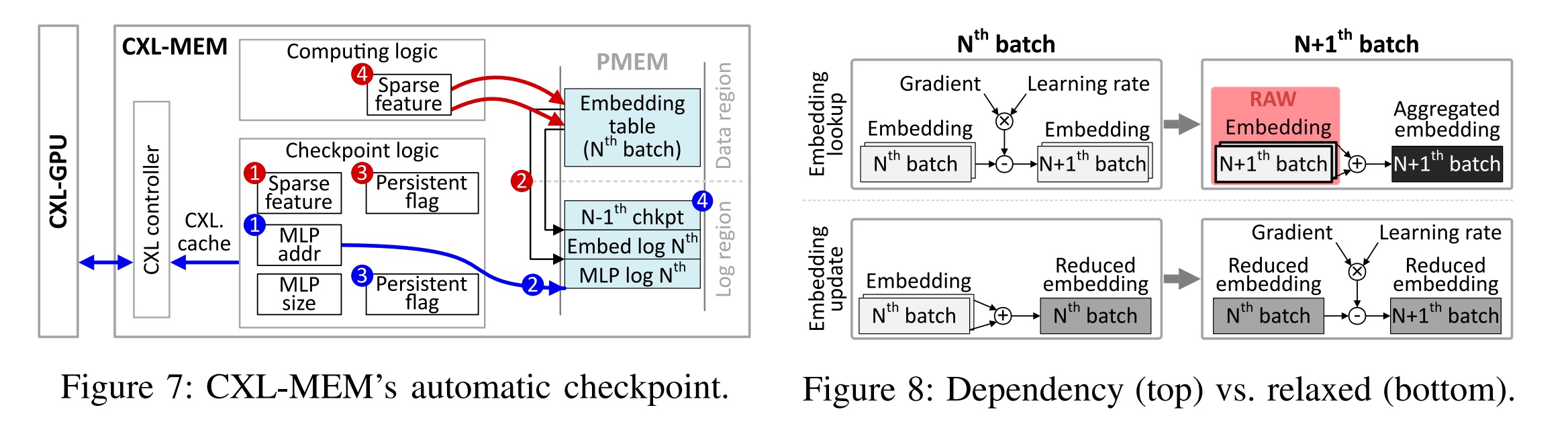
So still taking the memory as an outer device but not integrating the fault tolerance into the protocol level to make sure the single node fault tolerance. Still, it's a pure hardware stack implemented software check-pointing idea. Way brute forcing and nontransferable to other workloads. The flag and MLP unique features augmented is the basic idea of write log we were researching on the persistent memory file systems.
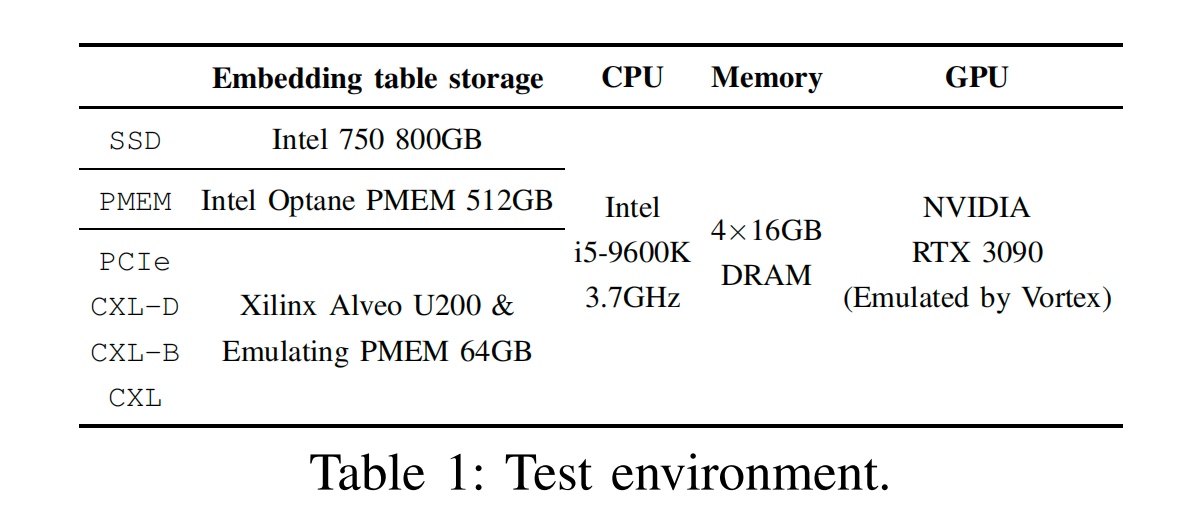
Their emulation platform is ... I'm shocked... The GPU emulation is Vortex. They don't actually need both the GPU and CPU to support the CXL controller interface. They just want to make cacheline shared in the CXl pool between Intel Optane and GPU. However, I think this kind of emulation is not accurate enough for CPU internal cacheline mechanism.