
其中双缓存的概念在asc20 hpl优化的时候得到了验证,4*teslav100=32g =128g,内存占用也是128g。实际上host 到device 的带宽太小,不适合做大规模的内存迁移,所以双缓存还是十分必要的。

gpu的延时是数百个时钟周期。


sm资源调度模型用于解决访存冲突。有texture 纹理寻址。
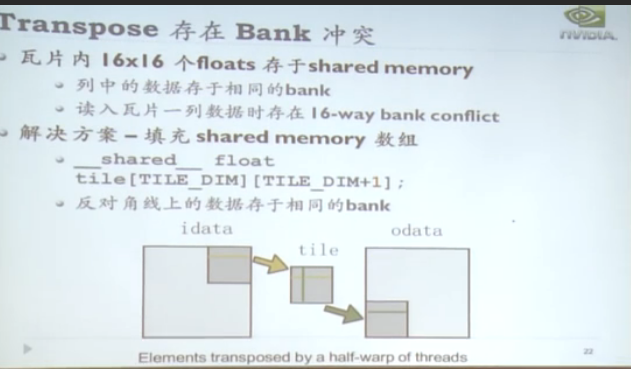
基本操作:

另外几种优化的方向。
single转double

Data Prefetching 数据预读

引入预读操作

编译器bb优化



A Tech Nerd with a finance mind.
其中双缓存的概念在asc20 hpl优化的时候得到了验证,4*teslav100=32g =128g,内存占用也是128g。实际上host 到device 的带宽太小,不适合做大规模的内存迁移,所以双缓存还是十分必要的。
gpu的延时是数百个时钟周期。
sm资源调度模型用于解决访存冲突。有texture 纹理寻址。
基本操作:
另外几种优化的方向。
single转double
Data Prefetching 数据预读
引入预读操作
编译器bb优化