

David Patterson's Computer Architecture
I think TPU is wrong, RVV is wrong, Google WSC price calculation is deprecated, and X86 is not as bad as RISCV, so I guess we need to revisit Computer Architecture: A Quantitative Approach. The main fallacy is that most of the work added is David's own work, neither guiding anything in the arch space nor having a profound impact that endures the testimony of time. I think Arch should have codesign, but not VLIW, and should not redo the things that have been discussed a long time ago. The ideology of the whole book misled the architect into having new ideas to thrive in this golden age. I'm saying this because I found Thead's fallacy in RVV and many other fallacies, and programmers' view of this is based on those misleading books.
MOJO
Implemented in GO and codegen to MLIR with a standard library implemented in C++. I would say it is currently just a frontend of Python that codegen to MLIR with cohesion to Python FFI and CFFI, like what I did for ChocoPy-LLVM [6]. I think Chris' idea is to map the Python semantics, especially the memory model, to Rust or C++ so that every memory can be managed as RAII with shared ptr plus some workarounds without GC. Suddenly, I feel that the transition from LLVM to MLIR is a very natural thing. Instead of defining a set for AMX, AVX512, and NVVM separately, it's better to integrate them.
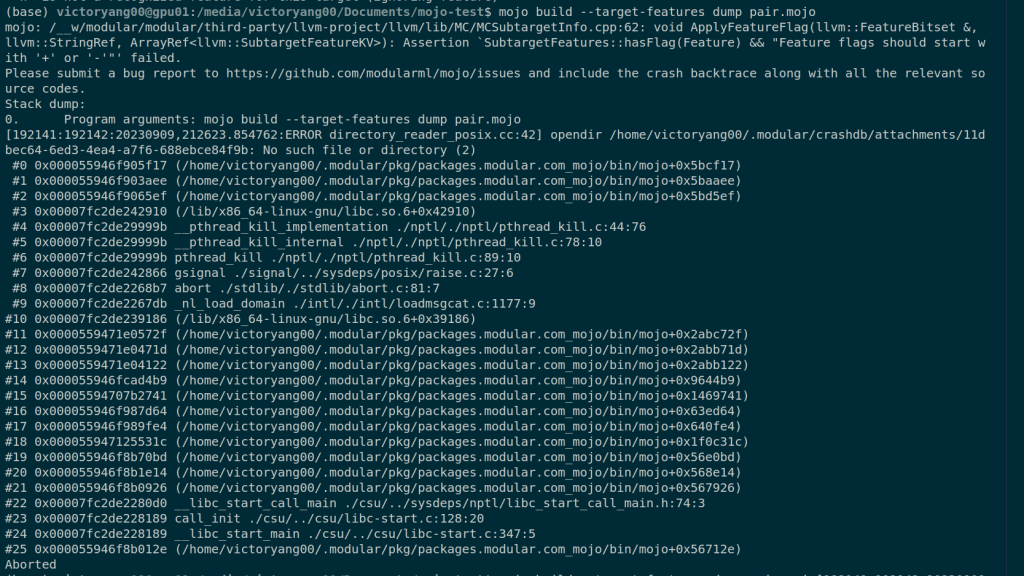
Static Analysis
- Class is not implemented yet; no multi-inheritance
- "Try" is needed for mapping to the C++ exception model.
- To increase speed, use the grammar sugar for calling the vector MLIR in [4], and parallel call primitives. It's seamlessly connected and has easily been called to WASM/WebGPU.
Implementation of LLDB and MLIR
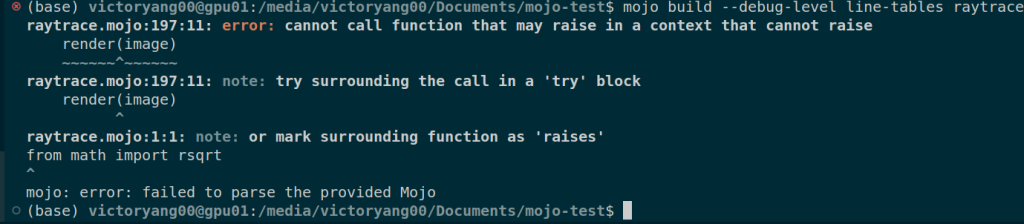
Debug with Location info
- Basically, C++ with MLIR and mapping back DWARF to mojo.
- C++ ABI
- The current mapping to the debugger of LLDB is not ready.
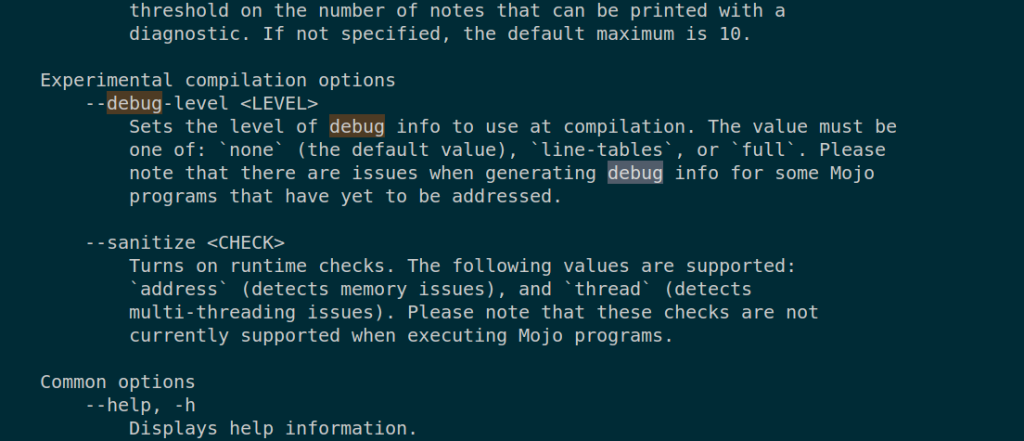
MLIR lowering to GPU/CPU heterogeneous code
var y : __mlir_type.i1
if x:
y = __mlir_op.`index.bool.constant`[value : __mlir_attr.`true`]()
else:
y = __mlir_op.`index.bool.constant`[value : __mlir_attr.`false`]()- -mcpu=sapphirerapids with avx512
- -mcpu=amdgpu call from cpu to gpu
Currently, there's no MLIR code generated, and I don't want to do RE to dump that. You can write some MLIR implementation in amdgpu to force heterogeneous code.
Reference
- https://github.com/victoryang00/CS131-discussion/blob/main/11-discussion.tex
- https://github.com/modularml/mojo/issues/3
- https://mlir.llvm.org/docs/Dialects/AMDGPU/
- https://mlir.llvm.org/docs/Dialects/MathOps/
- https://mlir.llvm.org/docs/Dialects/IndexOps/
- https://github.com/Chocopy-LLVM/chocopy-llvm