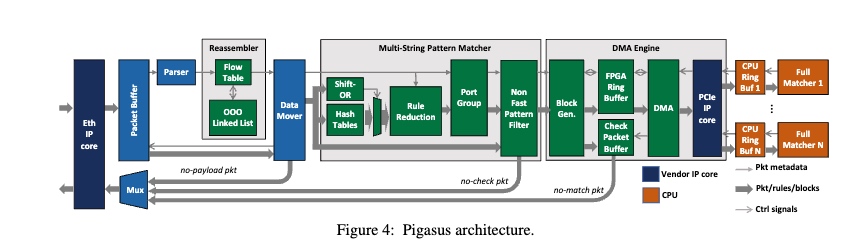
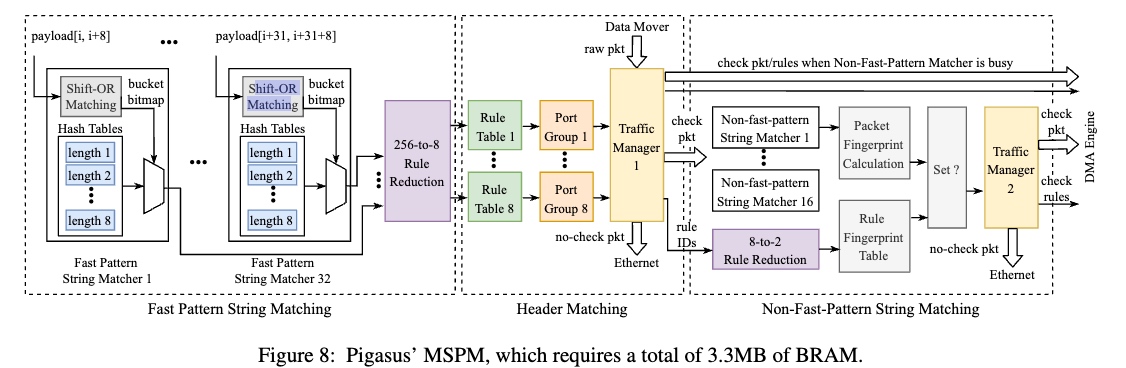
Summary
-
Motivation: To reduce the overhead of guest overcommitting memory and exploiting content-based page sharing and hot I/O page remapping, VMWare proposed EXSi. When a client accesses a large block of I/O through DMA (Direct Memory Access), the QEMU emulator will not put the result into the shared page, but write the result directly to the client's memory through memory mapping. The advantage of this approach is that it can simulate a wide variety of hardware devices; the disadvantage is that the path of each I/O operation is long, requiring multiple context switches and multiple data copies, so the performance is poor. The ESXi comes with various mechanisms and policies that manage proportional sharing for memory and upcoming research for GPU devices.
- Ballooning is a method for ESXi server to reclaim memory from the guest OS. To do this, pinned pages are created in the physical memory by using the guest OS's memory management algorithms. The ESX server then takes back these pinned pages. This concept is based on the idea that the guest operating system has the best knowledge of the page that has to be removed.
- Content-Based Transparent Page Sharing – Contrary to disco, which required particular interfaces for shared page creation The ESX server efficiently compares comparable pages between VMs by scanning them and using a hash map. An inactive background process actively scans and generates hash values, which are then utilized to locate related pages using a hash map. If a match is discovered, the object is tagged as COW, and the duplicate memory is freed.
- The unresolved issue in share-based resource management is resolved by the idle memory penalty. The basic concept is to charge a VM extra for idle pages compared to those that are being actively used. To recapture the idle pages, utilize the ballooning technique described above.
- I/O Page remapping is also used in large-memory systems to lower I/O copying overheads.
-
Solution: a thin software layer that effectively multiplexes different hardware resources among several virtual machines. What makes this unique? Traditional virtual machine platforms used a hypervisor, which runs on top of a standard operating system, to intercept I/O device requests coming from VMs and handle them as host OS system calls. Because ESX Server operates directly on top of the system hardware, it offers faster I/O performance and greater resource management flexibility. With any necessary OS modifications, can run several operating systems. When allocating a virtual machine hypervisor creates a contiguous addressable memory space for the virtual machine. They designed a hypervisor called
pmapthat mapped the shadow page from guest virtual to guest physical fast, and it also manages the oversubscription. To inflate the memory balloon in the VM, the virtual machine balloon driver will pin the page to prevent the page out to disk, and unmap the two pages from the guest OS to the host OS. -
The numerous strategies discussed in the study are precisely evaluated in this paper. The performance boost over Disco is contrasted at numerous places. The overall throughput is improved by idle memory stressing, among other significant findings. Memory is made available that increases linearly with the number of VMs thanks to content-based memory sharing. While the performance of inflated VMs was nearly identical to that of unballooned VMs with the same amount of memory, ballooning adds a very tiny overhead (1.4 - 4.4%). This indicates the performance reduced compared to the Disco.
Critique
- At least one example from each unique technique is used to clearly evaluate them all. In terms of ballooning, a Linux virtual machine running Dbench with 40 clients displayed nearly identical performance when compared to a server without ballooning. Three real-world guest Oss instances were launched to evaluate content-based sharing, and the page-sharing method was able to recoup more than one-third of the virtual machine. By adjusting the tax rate, the percentage share on 2 VMs was tracked to evaluate the effectiveness of the idle memory tax.
- This is definitely the start of scientific research but EXSi is pure engineering work and took a great amount of time. The idea of utilizing the idle page is widely used today. The disaggregation stuff happens to start from the boom of Memory Resource Management. The ballooning technique is all architecture that wants to gain memory virtualization performance, they will implement one, like GPU virt like "XenGT" and "gScale" or "CXL" based virtualization.
- This approach can be applied to the latest MemTrade. But I think the latest work for an idle page or cold page identification is not that efficient. For virtualization, we can simply be done in the page level, but we didn't make everything work smoothly before the bottleneck of the memory. like if the memory pool of the host device is 80% fulfilled, we need to design a mechanism to swap/zswap/disaggregate instead of waiting till the end of the memory then to these.