

之前听过这个talk,但是由于作者本人的英语口语不太行,所以当时么认真看。这篇同样,在CXL.cache出来以后实现方法完全是另外一套,但是我们完全可以在其他device上实现相同逻辑,用CXL.cache做offload。但是TLB等硬件的hack加速还是必要的。
GPU side 的smartNIC是为了
- 使用GPU虚拟地址与本地GPU进行直接的PCIe P2P通信,并为远程GPU提供可靠的100Gb网络访问。(用DPA或者IOMMU都是相对比较慢的操作
- 有编程能力用C++ HLS做datapath优化。
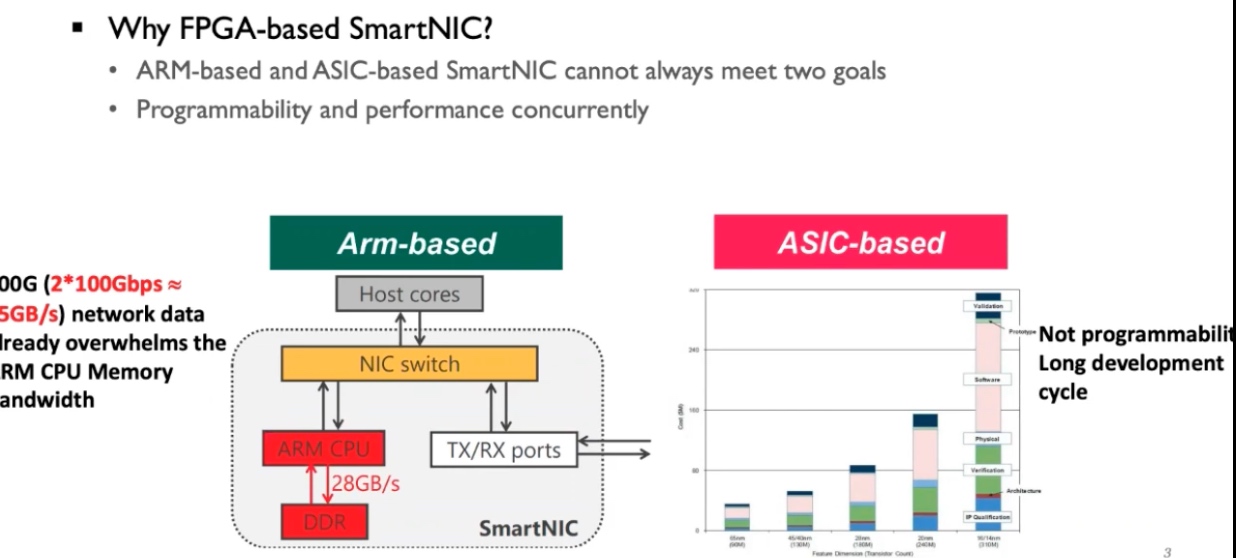
对比NV出的DPU确实有很大的优势,也许那些人做硬件的时候也没考虑为什么放一个Arm core 而不是放一个FPGA更好的software define。(年初打ISC的时候用过DPU,真的只能调用他们的OPENMPI优化少数几个primitive,如alltoallv.
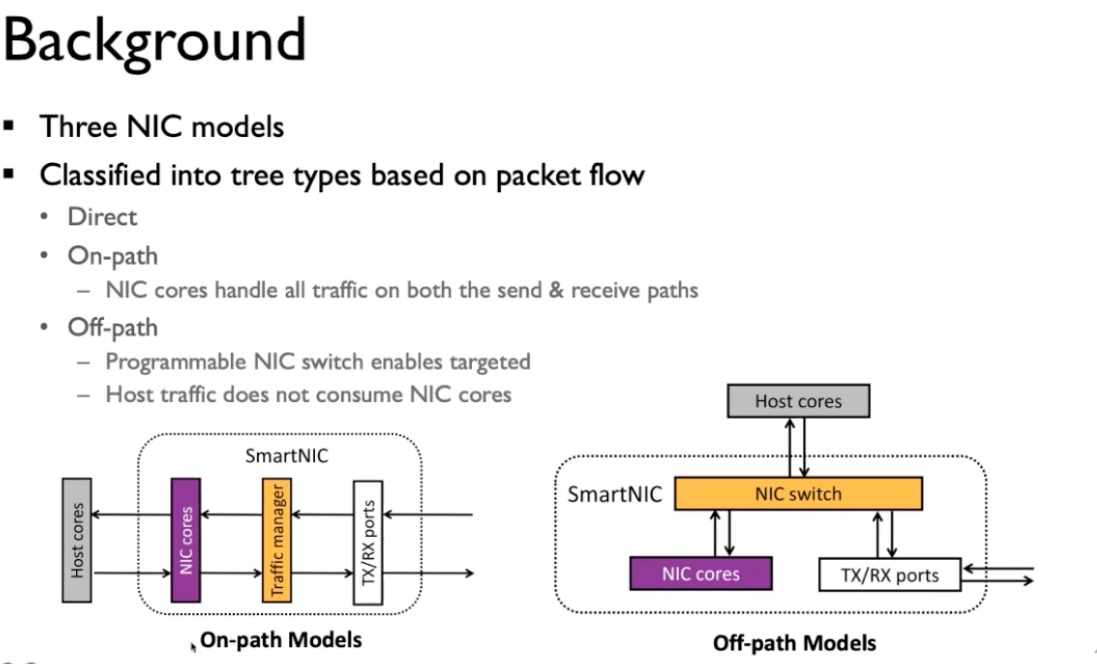
做法是hook GPU的send/recv请求,现在变成GPU到NIC的p2p通讯。这个操作需要offload control plane onto GPUs/offload data plane onto FPGA。主要让GPU能poll FPGA状态寄存器,FPGANIC可以直接访问GPU所有数据。
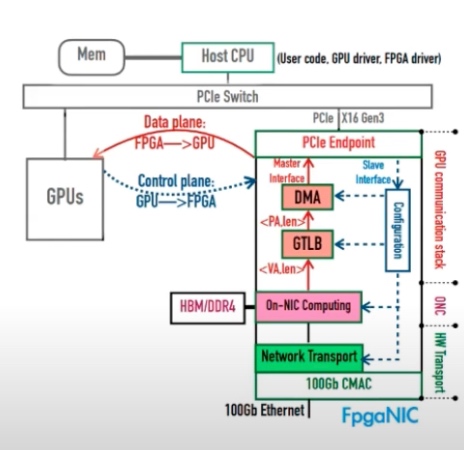
GTLB优化VA->PA转换,参数如下。

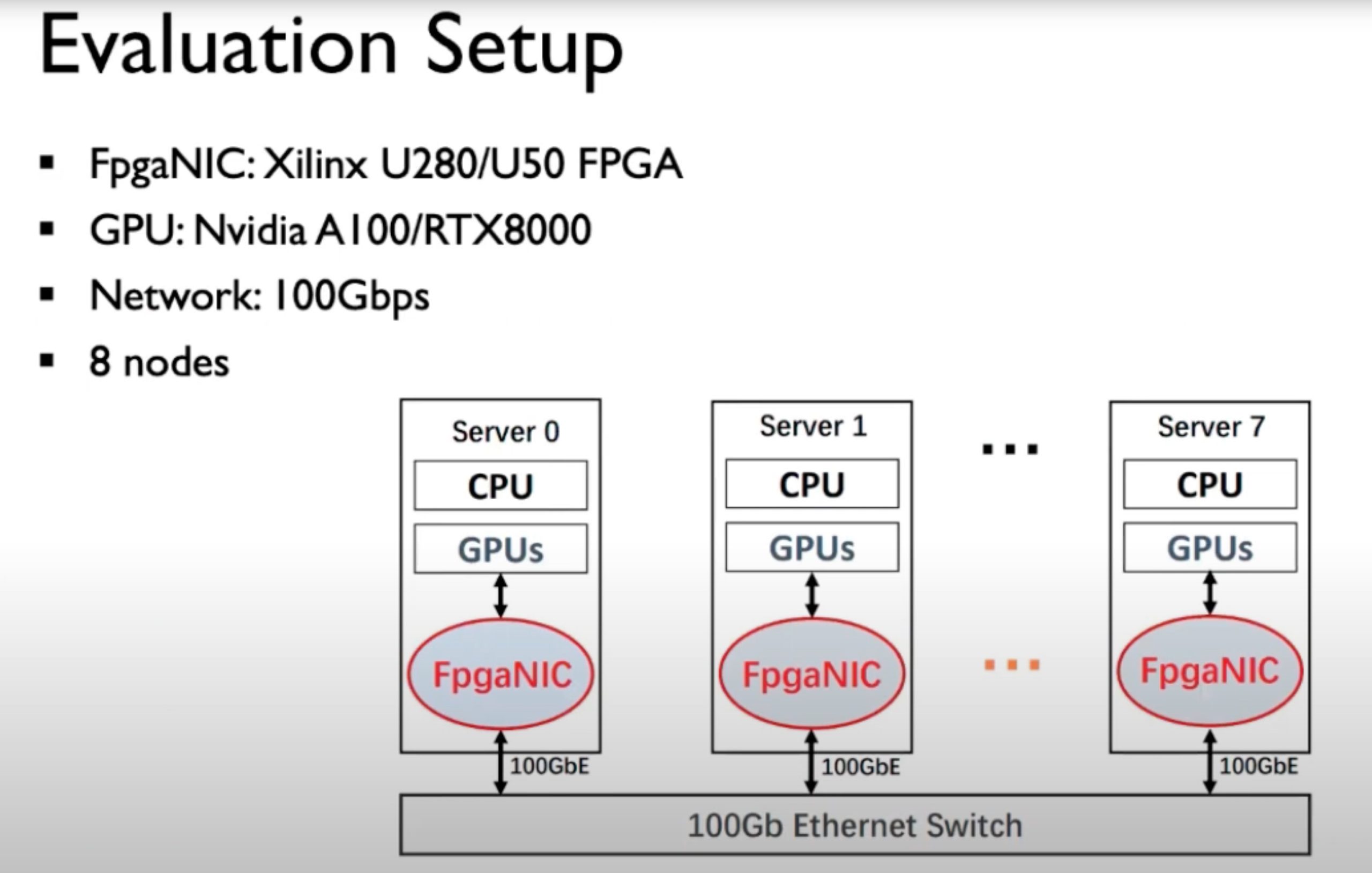
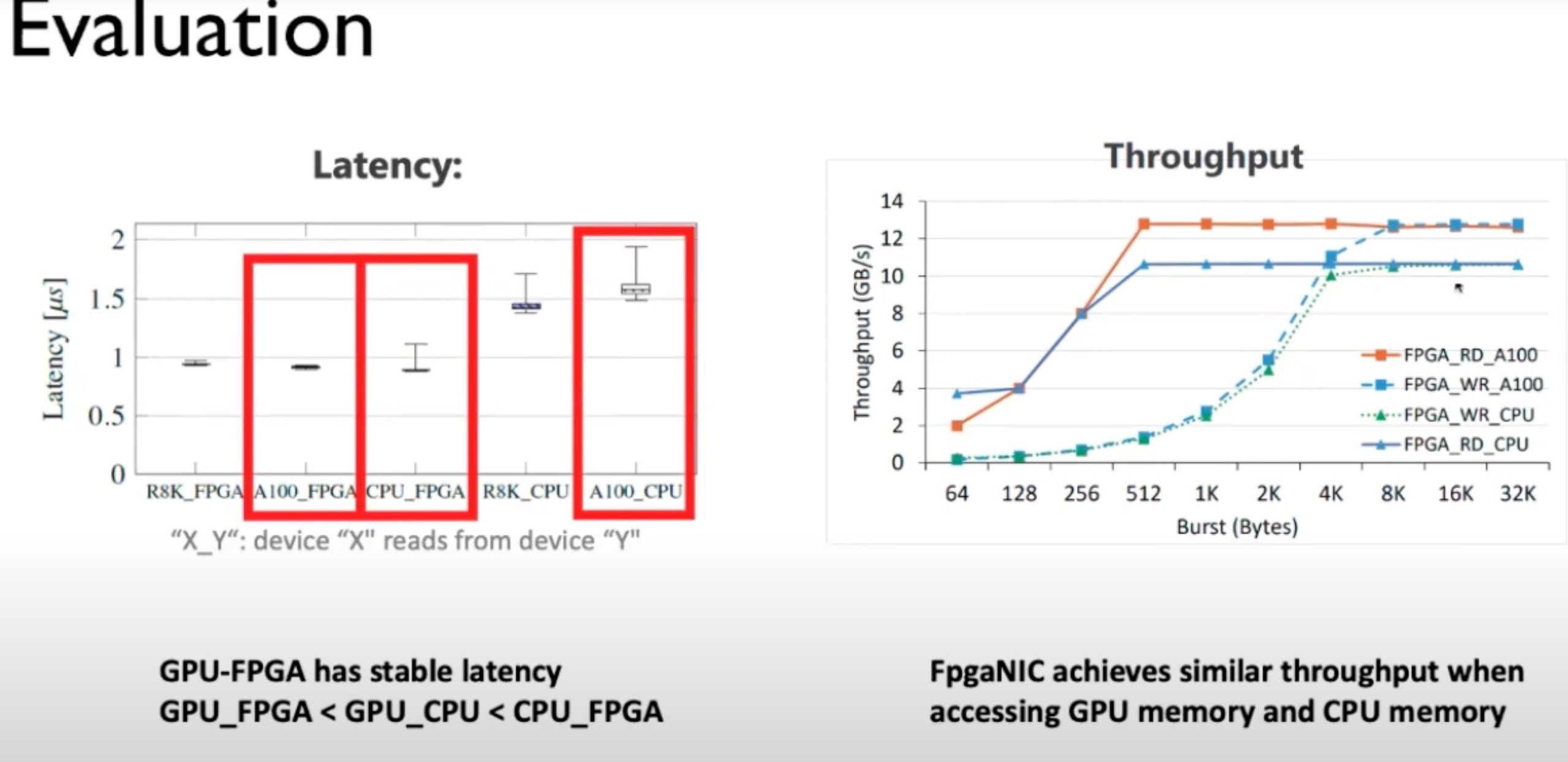

Evaluation 很成功。offloading和DPU所谓的overlap率有关,但是这个只适合高频公司特定需求,DPU已经很好的利用bandwidth了。