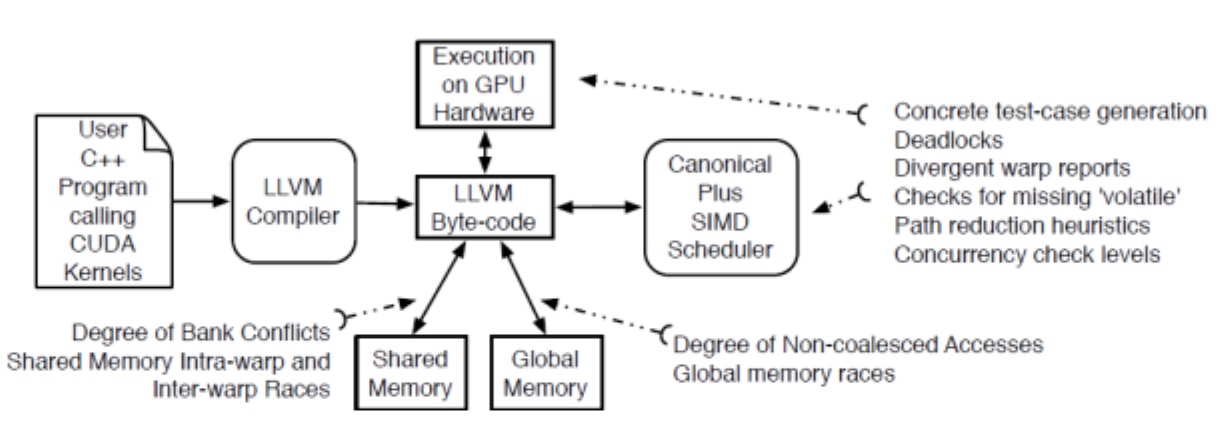
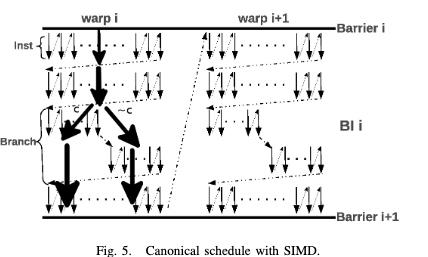
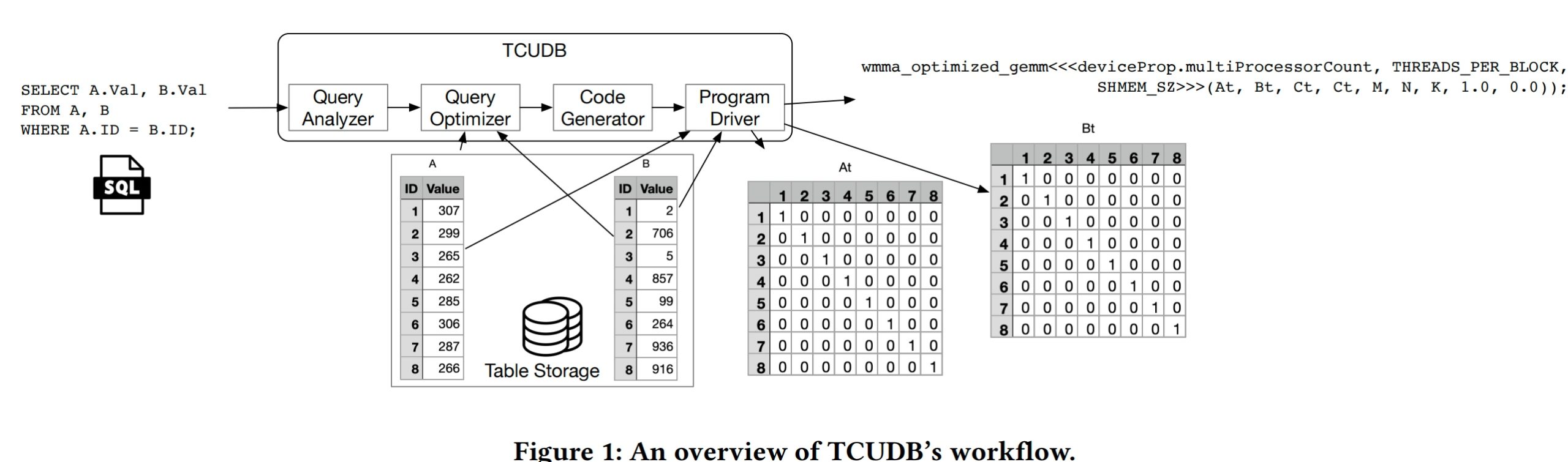
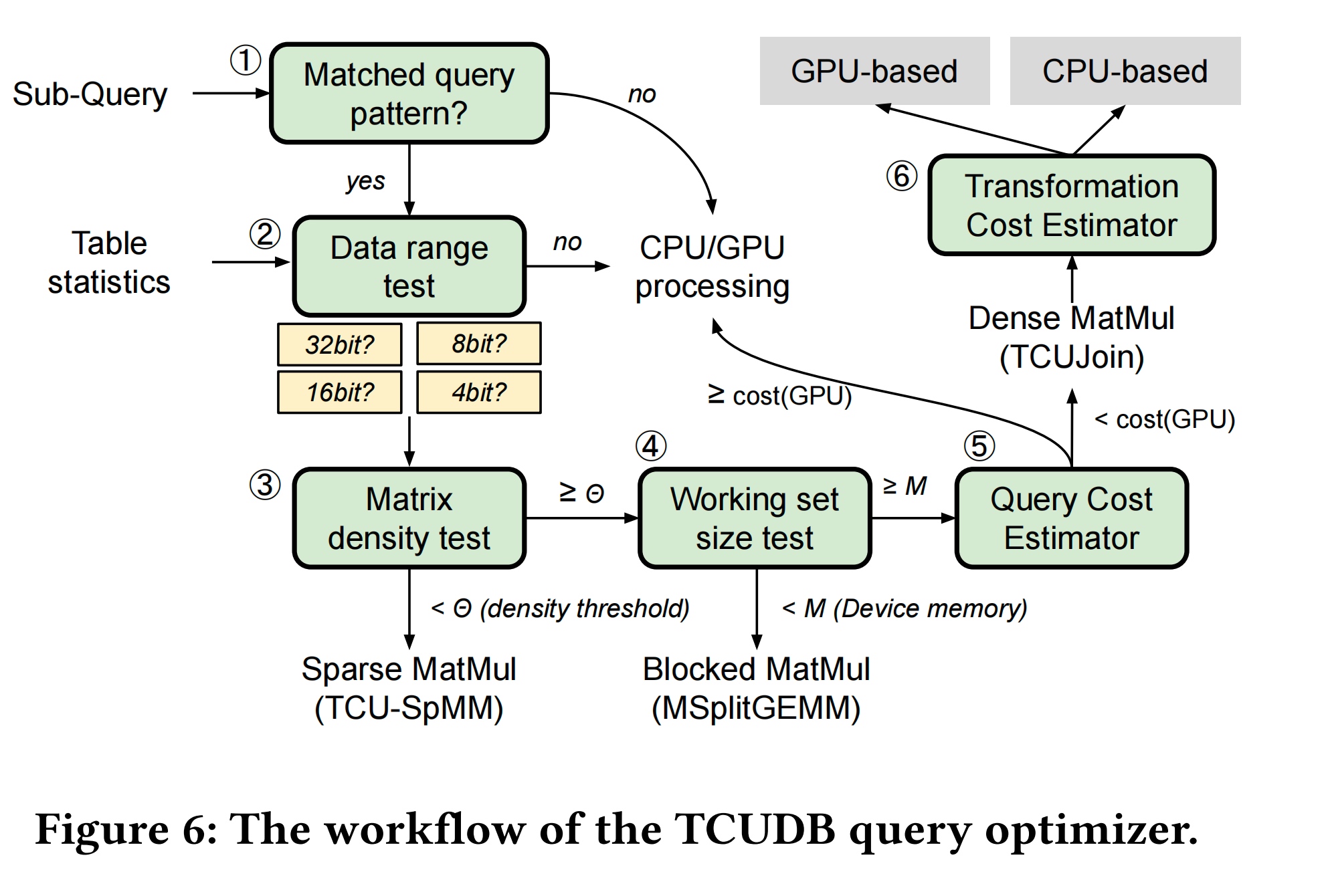
To understand the OLAP's runtime PMU metrics, how should it be a paper that's published on PVLDB. And also a PM evaluation also by Bytedance.
The in-memory OLTP has greatly studied a lot for Cache misses, especially hitm; my previous blog gives my experiment on TPCH over MonetDB, and Postgresql is not DRAM Bandwidth bound. It amazed me that a reference to remote NUMA memory should cause such a bound. The paper discusses only the scan-intensive queries with multiple cores that can hit the memory bound. join-intensive queries suffer from latency-bounded data cache stalls.
The OLAP differs from the transaction-based database; most of them have vectorized-based query planer and online analysis codegen. We may look at the velox and arrowdb.

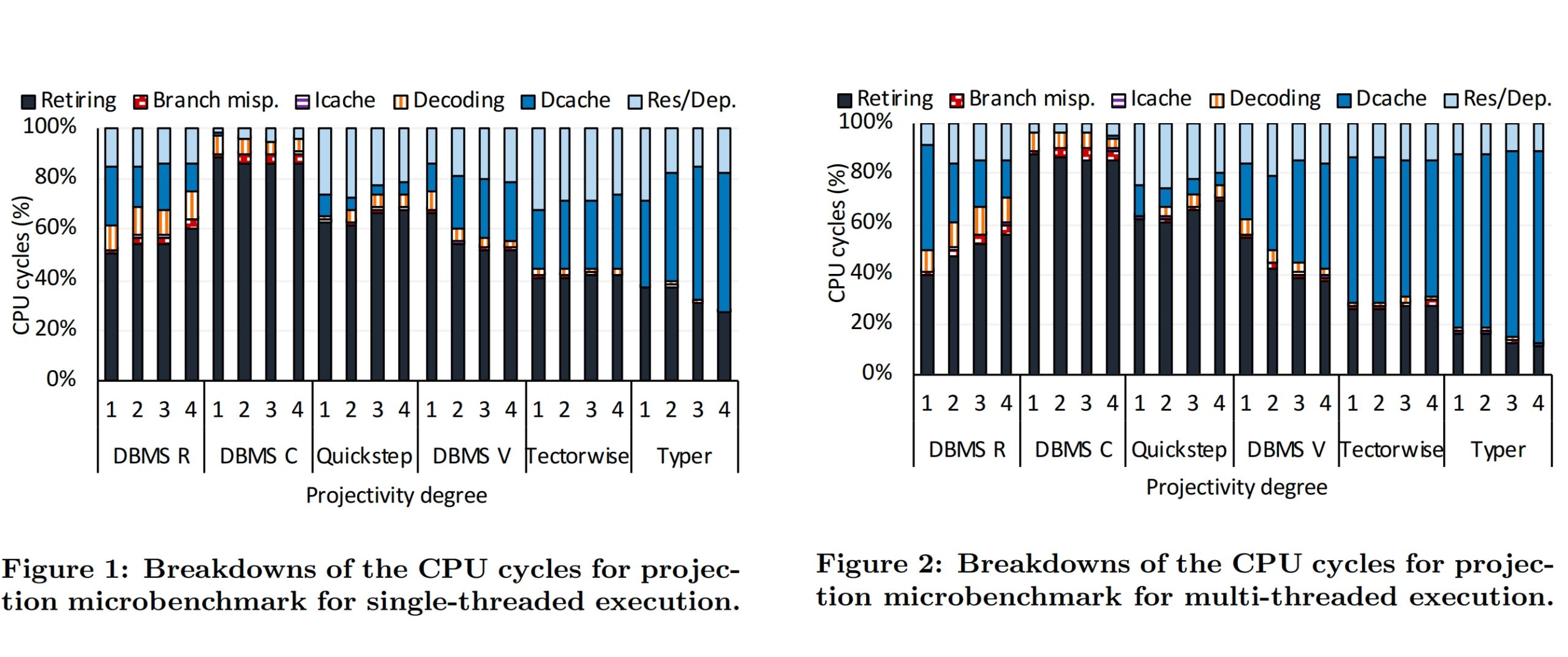
The breakdowns of CPU cycles in both single-thread execution and multi-thread execution. They affine the memory only on one NUMA socket and fully disable the prefetcher. We see that the scalability of DMBS C is good enough, while other DB has deterioration for multithread.
Normalized response time breakdowns for Quickstep when it runs the large join micro-benchmark query, as single-threaded, w/wo using Filter Join
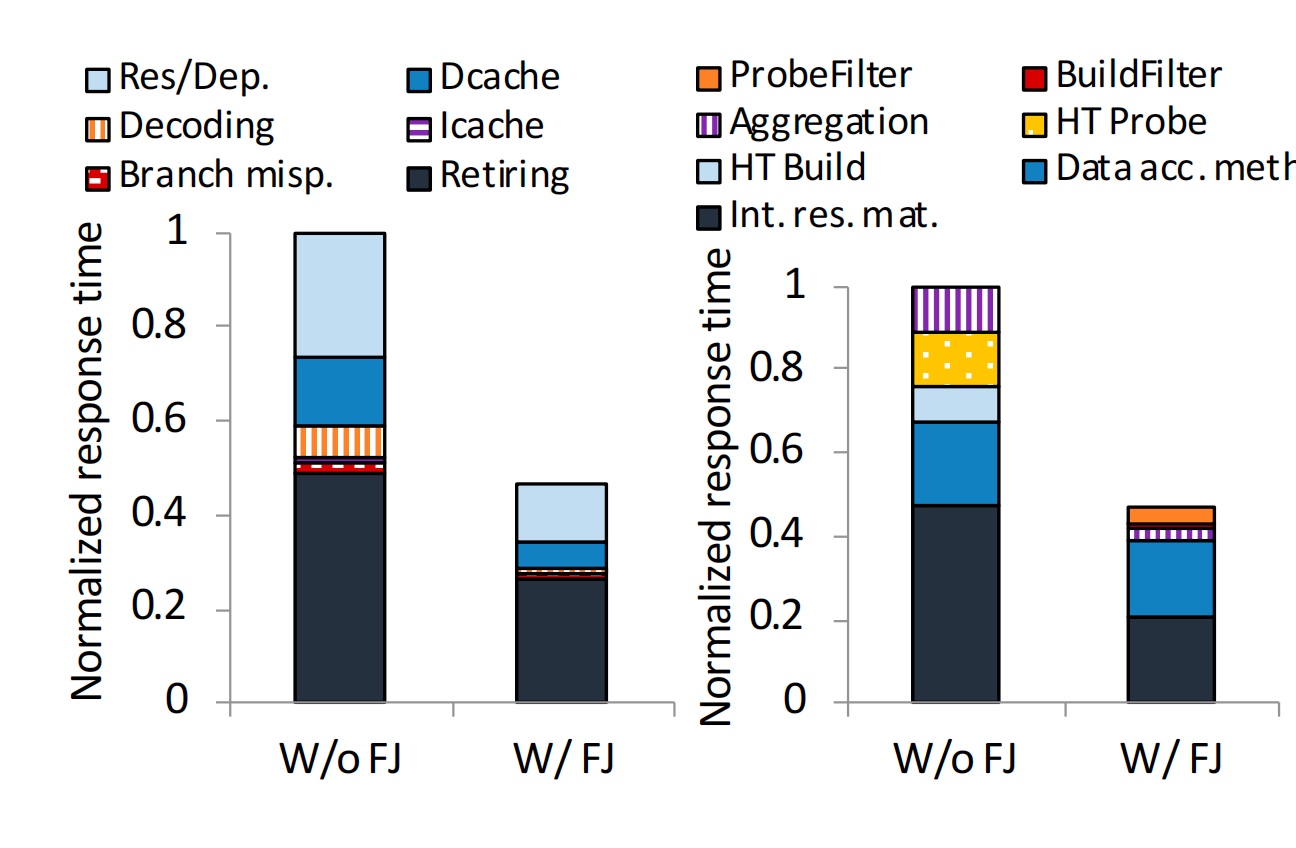
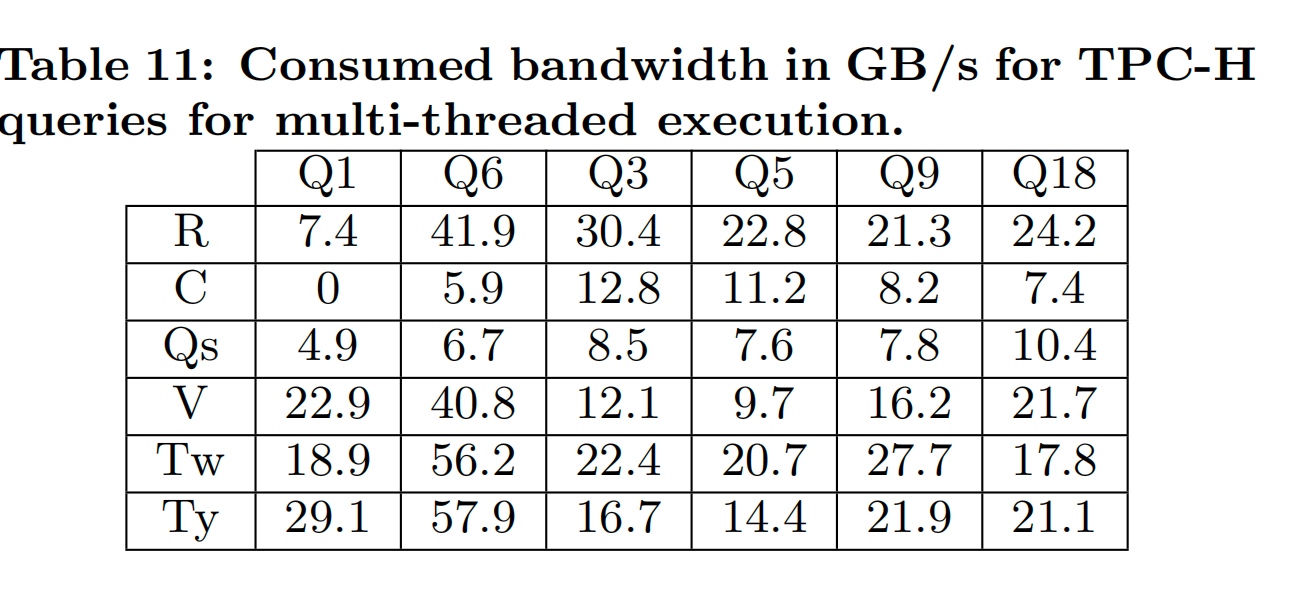
Only the Multi-thread will hit the bandwidth bound.
 g)
g)