

Running Database on GPU tensor computing unit(TCU).
Claim
- The partitioned hash join algorithm in a non-matrix-friendly manner is hard to rewrite on TCU
- The underlying data movement requires different data organization.
- TCU is mostly int8 or fp16, which are not accurate enough.
The key-value hash map data storage has cuckoo hashing in GPU; the data storage can refer to such Memory management; the insight is how to accelerate every operator with optimizer and codegen to matmul that can make use of GPU.
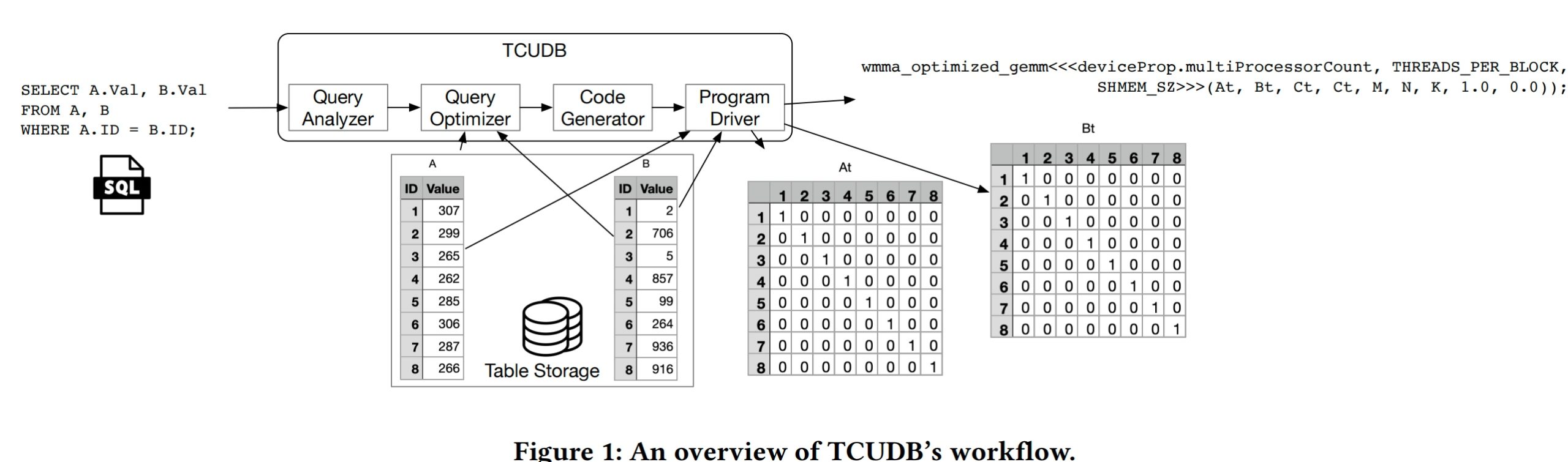
Also, because the single GPU's VRAM is typically smaller than CPU's private DRAM, we need the wss estimation for wh11ether the CPU or GPU plan. They use MSplitGEMM to test the working set size with is the upper bound of the VRAM occupation.
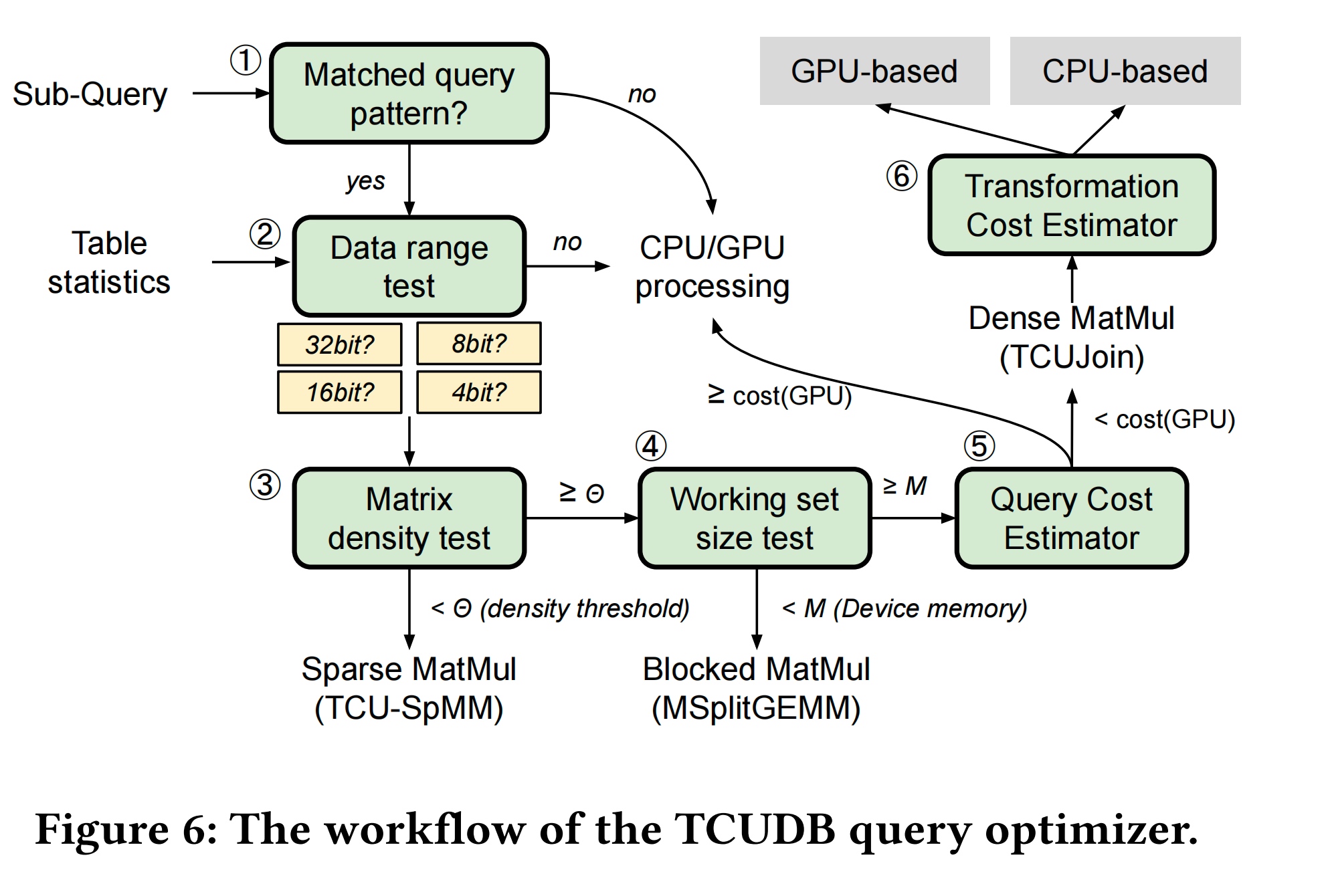
Supported query planner




The query planner has UNCOMPRESSED/COMPRESSED MEM/PINNED/MMAP and some movement assessment for whether compress or do the migration to CPU.
Their compressed data means the data is stored in a cuckoo hashing manner.
The Matrix Multiplication, Entity Matching, and PageRank have better performance because they leverage the online storage of GPU VRAM.
The fault tolerance of the GPU's data cannot be guaranteed; for more functionality, I think it still requires the DPU to store or disaggregate GPU VRAM to Memory Expander.