

文章目录[隐藏]
Reference: Cuda dev blog
why we introduce intrinsics
-
Race condition: Different outcomes depending on execution order.
-
Race conditions can occur in any concurrent system, including GPUs.
- Code should print a =1,000,000.
- But actually printed a = 88.
-
GPUs have atomic intrinsics for simple atomic operations.
-
Hard to implement general mutex in CUDA.
- Codes using critical sections don’t perform well on GPUs anyway.
The atomic thread in critical section is not good in performance. The example is identified for variable d_a
cuda atomics
Can perform atomics on global or shared memory variables.
- int atomicInc(int *addr)
- Reads value at addr, increments it, returns old value.
- Hardware ensures all 3 instructions happen without interruption from any other thread.
- int atomicAdd(int *addr, int val)
- Reads value at addr, adds val to it, returns old value.
- int atomicMax(int *addr, int val)
- Reads value at addr, sets it to max of current value and val, returns old value.
- int atomicExch(int *addr1, int val)
- Sets val at addr to val, returns old value at val.
- int atomicCAS(int *addr, old, new)
- “Compare and swap”, a conditional atomic.
- Reads value at addr. If value equals old, sets value to new. Else does nothing.
- Indicates whether state changed, i.e. if your view is up to date.
- Universal operation, i.e. can be used to perform any other kind of synchronization
examples
Finding max of array

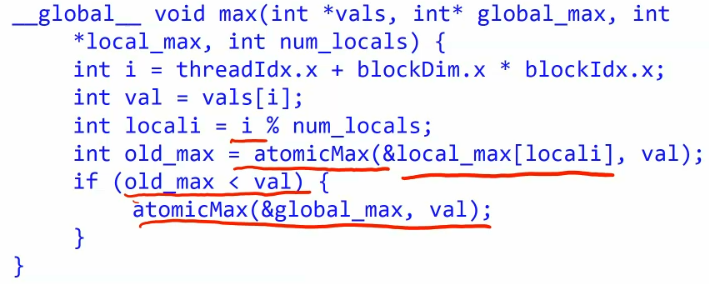
improve it
we can improve it bu split the single global max into num_locals number of local max value.
Thread i atomically maxes with its local max. can max the local_max[locali],

a better solution is to make it into the tree DS+CA
Compute the histogram
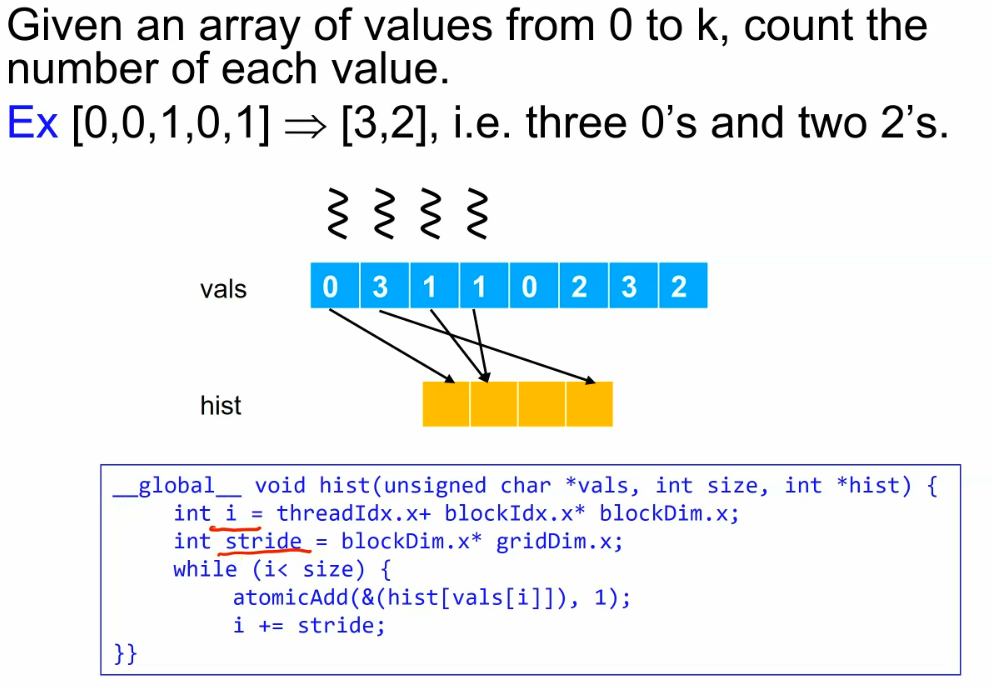
! whether the data is stored on shared or global memory is depend on programmers
Shuffle intrinsics
! this intrinsic is not limited to cuda but all SIMD architecture
from avx256 vector elements we have
__m256 load_rotr(float *src)
{
#ifdef __AVX2__
__m256 orig = _mm256_loadu_ps(src);
__m256 rotated_right = _mm256_permutevar8x32_ps(orig, _mm256_set_epi32(0,7,6,5,4,3,2,1));
return rotated_right;
#else
__m256 shifted = _mm256_loadu_ps(src + 1);
__m256 bcast = _mm256_set1_ps(*src);
return _mm256_blend_ps(shifted, bcast, 0b10000000);
#endif
}
For Kepler architecture, we have 4 intrisics.
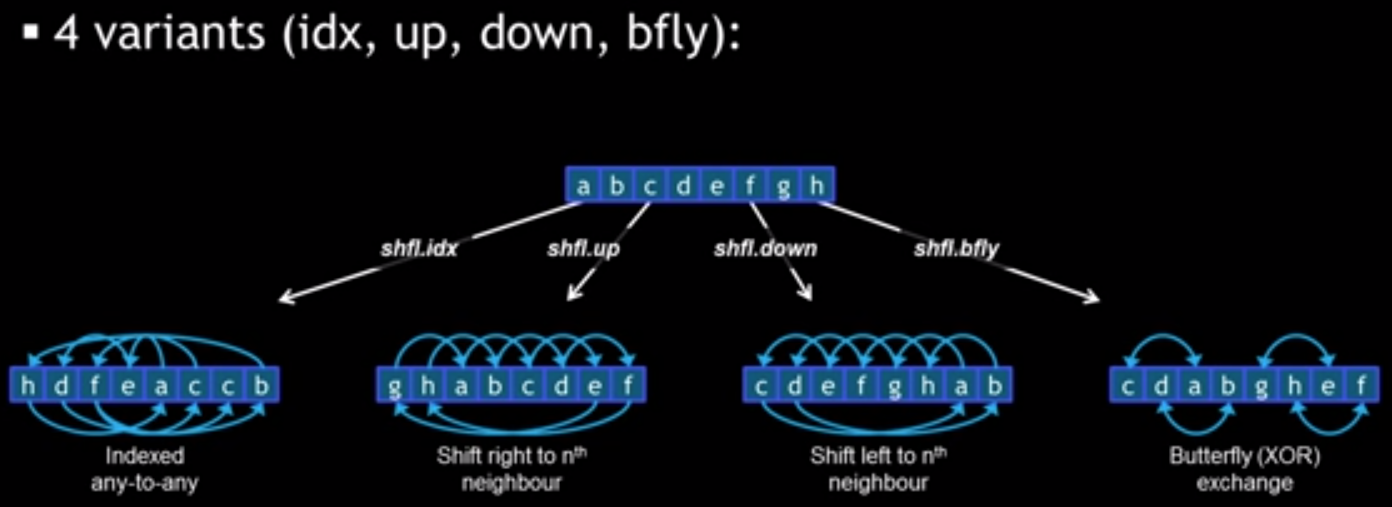
The goal of the shuffle intrinsics is actually for optimizing Memory-Fetch Model
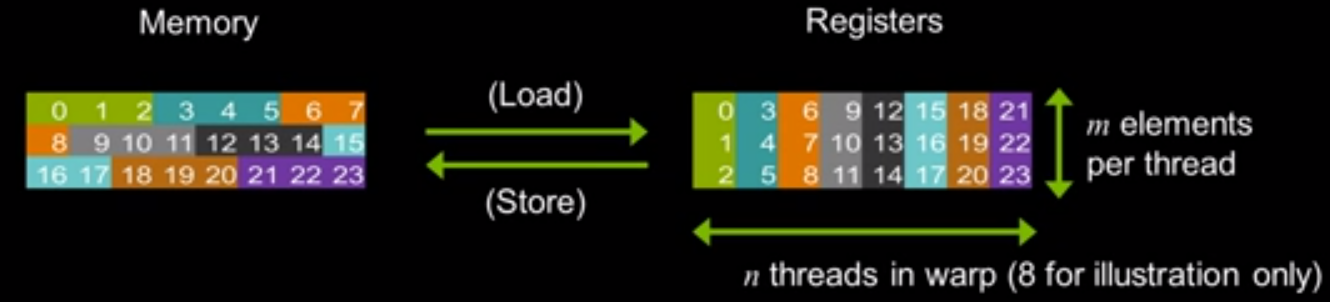
butterfly operations


Assume we have at most shuffle instead of shared memory

