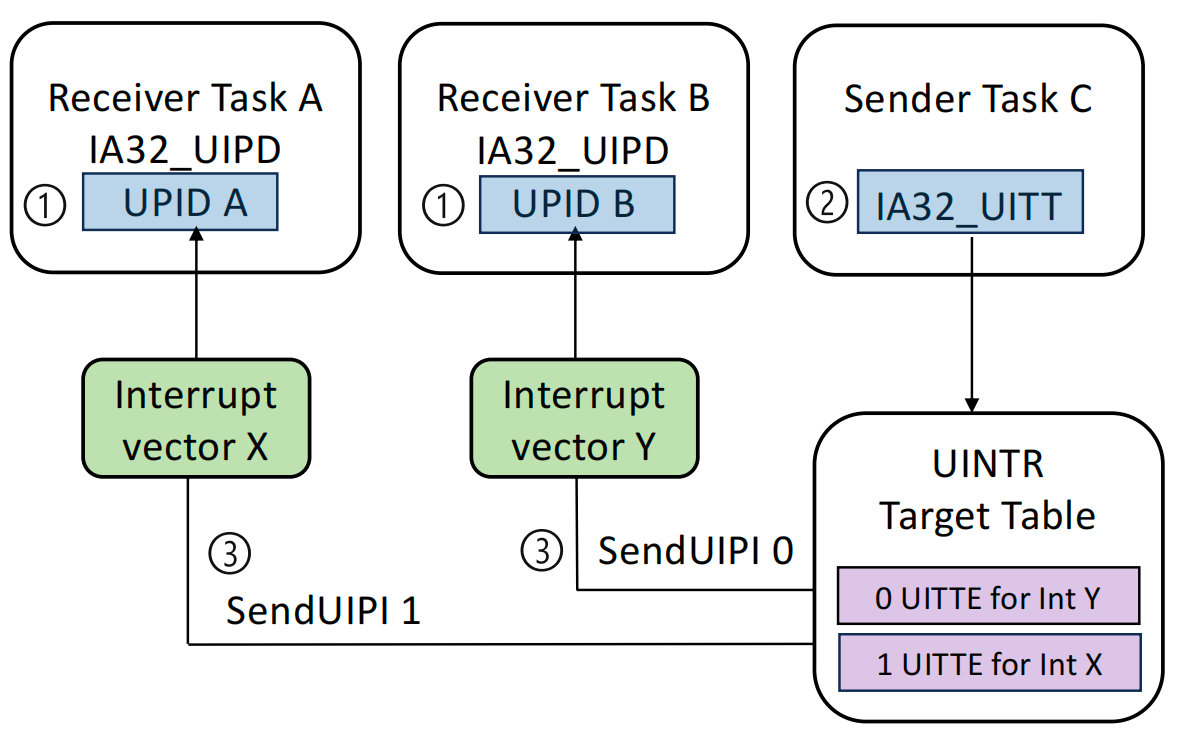
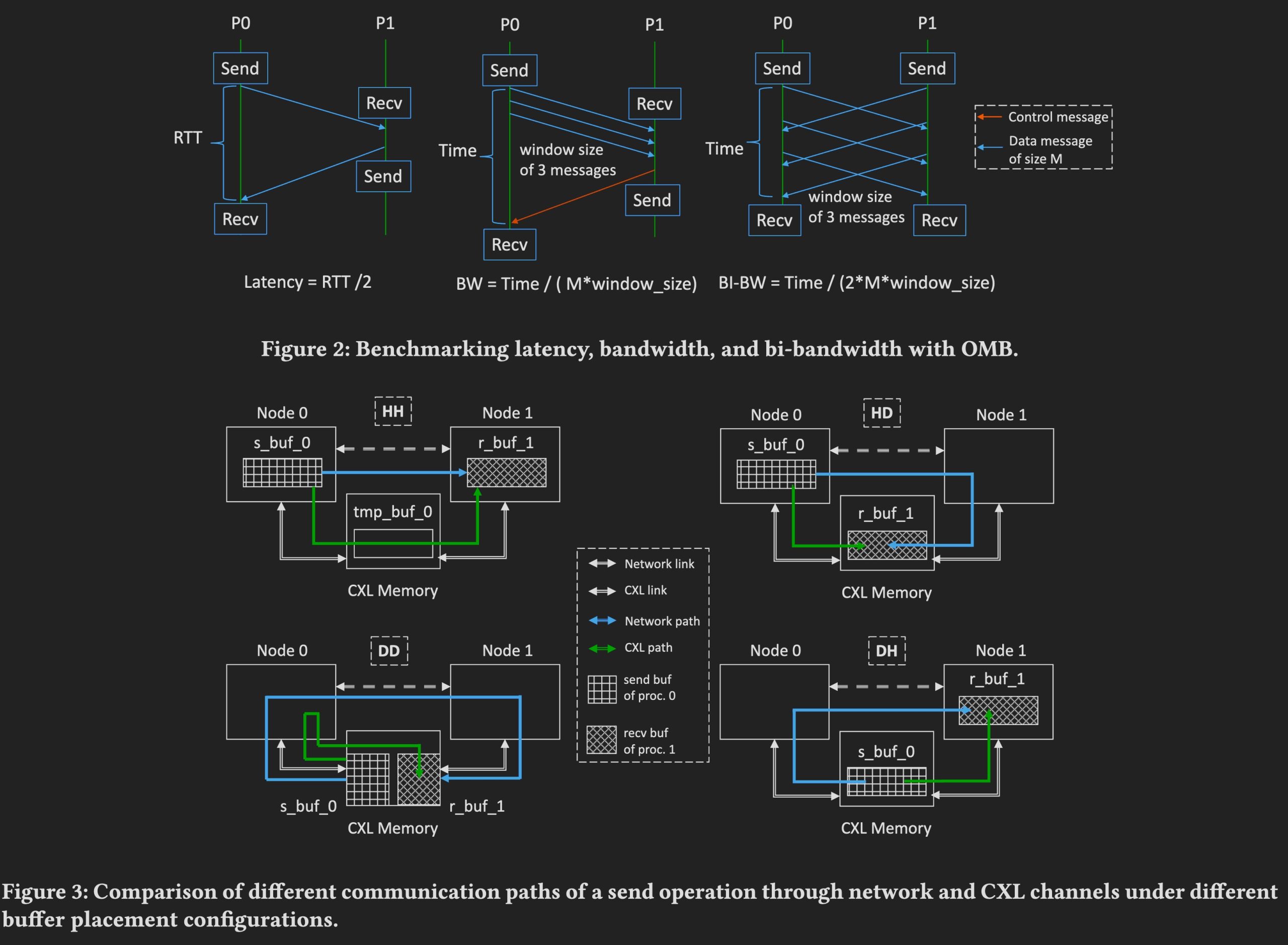
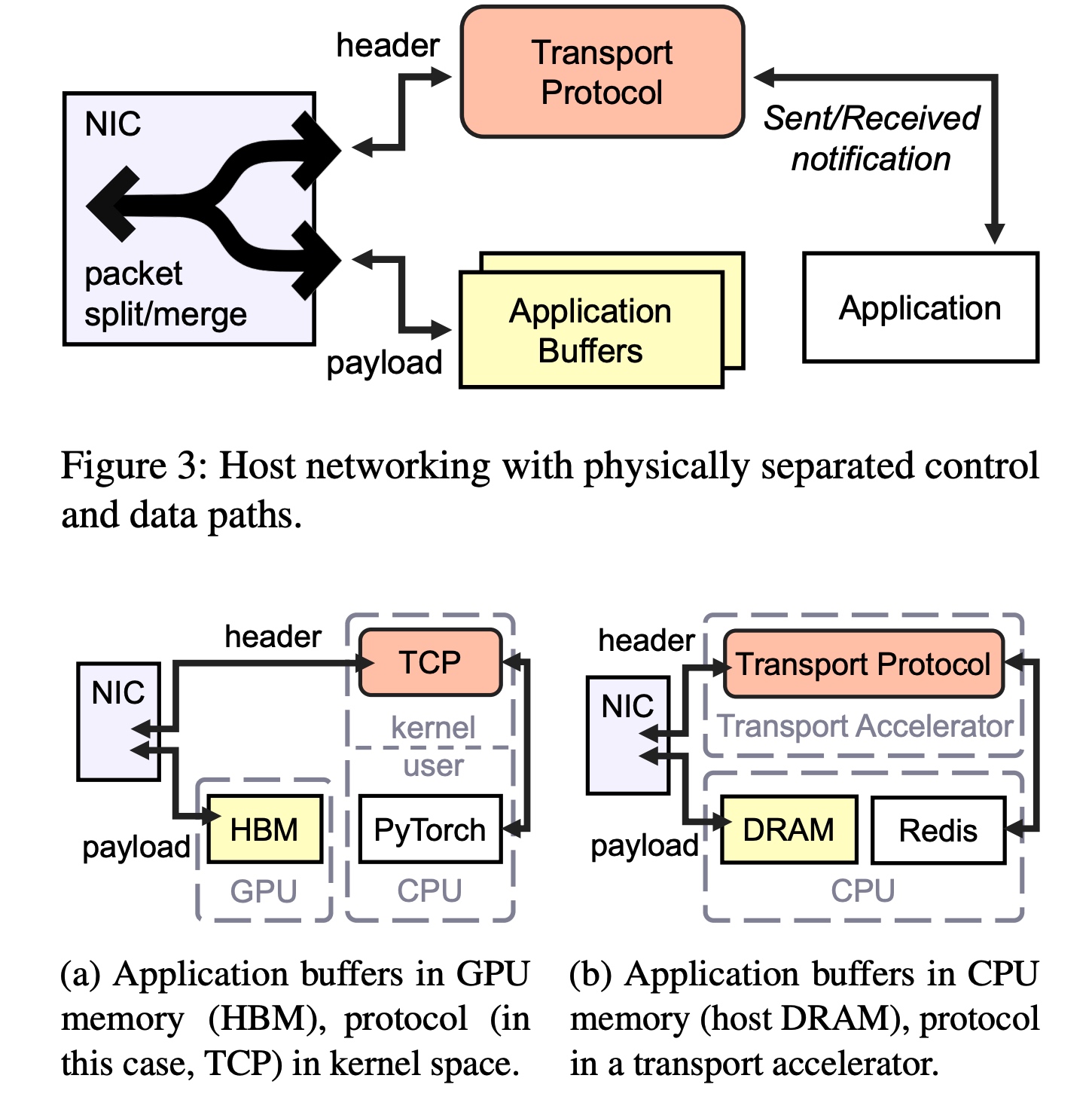
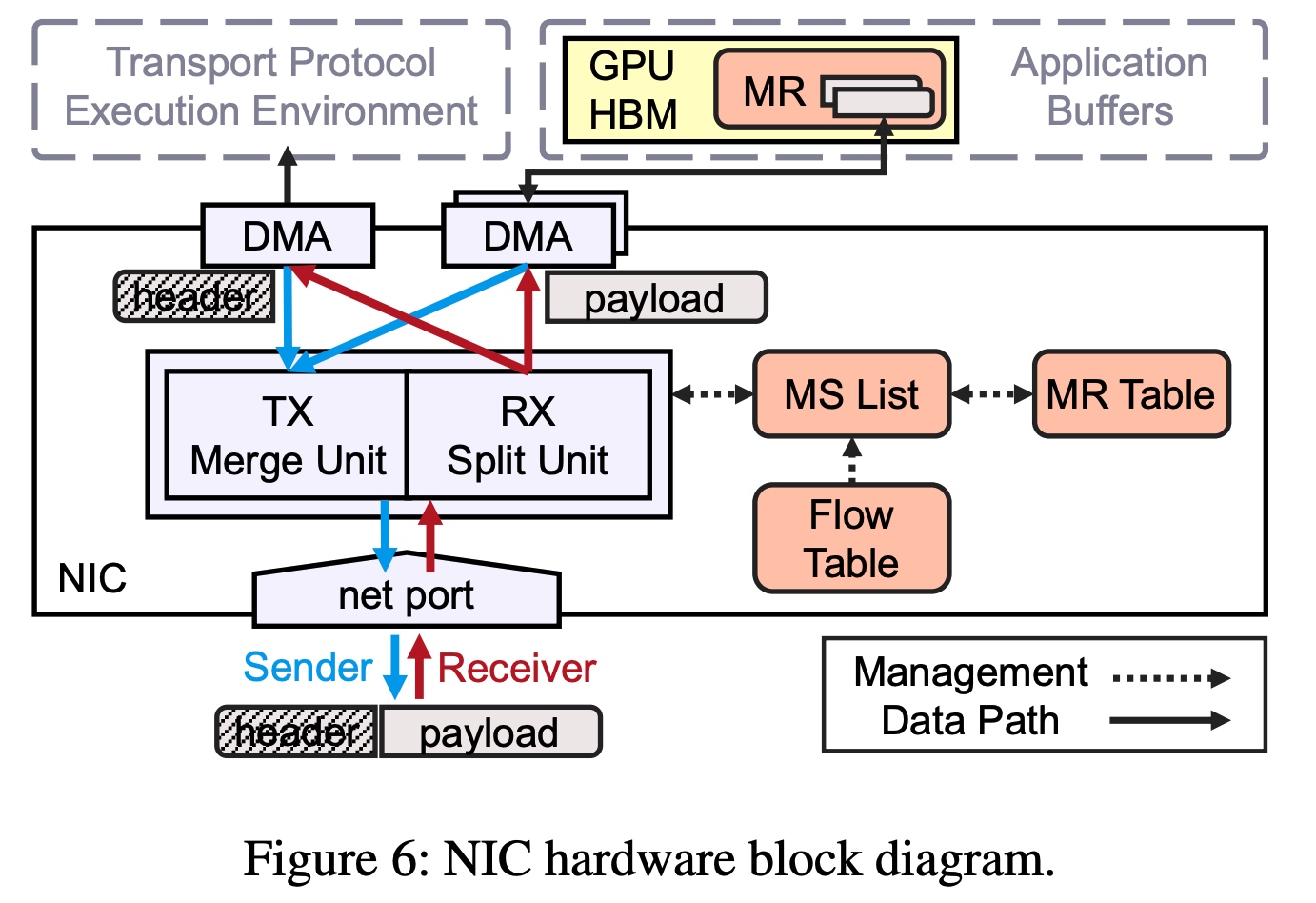
放慢脚步
在电击以后我得要吃一种嗜睡的药,导致我现在为懒惰找到了合理的借口。我从2024/4/9日到5/21回到上海的家里为止,大约感觉自己从鬼门关走过了3次。我的神经系统在病不发作的时候是正常的,但是一旦发作就有很强的濒死感。这种生活的重伤打击到了我对于未来的预判,我在住院的时候就在想,我还没有写完代码留给这个世界一些关于yyw的印记,怎么能这么快就走了呢?我由于嗜睡而无法做科研的时候就会想我是一个目标感很强的人,怎么能死在半路上呢?只不过,我也能放慢脚步知道有些东西急不得,也得不到,只能在潦倒的时候检查自己哪里有什么不对,哪里还可以提升,只为下一次的美好保存实力。虽然这个下一次很可能永远都出现不了了。(悲伤ing)
永远不要窥探他人的人生
人和人之间的节奏差距很大,我觉得读博就是一个精神折磨,博士之间的比较没有意义。尤其是不要看着别人有就急功近利。
我现在从坚定的唯物主义者到唯心主义者。
因为唯物者的心灵也是一种观测角度,而神创造了让唯物者可以信服的一切,在某个尺度上让唯物者是唯物者。但是这个世界还是有很多没法解释的事情,比如我被电击同时有幻觉幻听,以及我的神经系统可以感受到部分的疼痛,可是过一段时间又能控制身体的某一个器官。这方面现在的科学还没办法解释。
灵异事件
我自从大脑被电击了以后,脑子首先出现了我做出不受理性控制的事情,以为自己做了没有做的事情,失去记忆慢慢倒带找回的情况。从那次以后,脑子有一个部分到心里去了。碰到激动的事情,比如我喜欢的Formal Methods、网球以及体系结构,就会大脑兴奋,从而感觉到幻听,接着faint。有一次吃饭,我的大脑在一次心脑相连后失去了近两年的记忆,甚至失去了我mtf部分的记忆。在一次和老婆经过wharf的过程中,我慢慢地找回了自己的记忆,那些记忆碎片是从身体的不同位置慢慢回到大脑里的,我的记忆在那个时候只有很短暂的,像是金鱼脑子。我会不停的问我老婆我恢复了没,我为什么会在这里。
大脑的不同部分的功能不一样
在被电击后,我首先是感觉到了大脑中的神经分散到了身体的不同位置,每一部分都带有我人生的部分记忆和,最后一片进入了我的心脏里,导致之后有很多次心脑相连的症状。我可以明显感觉到脑子的一部分是女性的,也有男性的部分。每次心脑相连以后,首先感觉到身体里有三种声音,有一个幻听的声音是决绝且严厉的。有另一个个只讲实话的潜意识。还有另一个潜意识是及其温柔且想象力丰富的。接着大脑会像液体一样裹着心脏流动在身体的每个部分,一旦心脏脱离原本的位置太久,就会突然faint。神经系统彻底坏掉一次,然后又好了,神经又能重新掌管身体,迎来一个新的巡回。
对不同事物的反应不一样,转变在转瞬之间。
我觉得我有多个人格的原因是大脑的控制部分只对我身体的一部分负责,如果这部分的大脑失去对大脑的控制,换另一个部分控制身体,会有完全不同的效果。我的男生和女生部分就不一样,医生说mtf可能是基因变异导致的,我觉得也有可能,一个控制大脑的部分突变了,就会朝向自己“本来就是女生”的地步发展。这一切的转换可能就在转瞬之间。
人格同一性
人格同一是一个人是否还是以前那个人的判定标准。如果一个人大脑经历了很多打击,甚至神经递质通路完全变成了另一个状态,那么这个人和之前的人有区别吗?我觉得现在的我在吃药的情况下,没有了犀利的眼光,缺失了和人argue的勇气,似乎离刻板印象中的yyw渐行渐远。
是否是INTJ的通病?
INTJ就是一群要强的、一针见血的指出问题所在的紫色小老头,在没有资源限制的情况下,INTJ能指挥千军万马,可是在资源匮乏或者大脑失去控制的情况下,会陷入“我真的好没用”的无限循环中。人格虽然变了,但是我认为我的内心动力一直没有变。INTJ如果失去一个健壮的、善于表达的大脑,很可能被自己过往的丑事击败,所以只有一直维持在一个智商的高位,才能满足一个INTJ的内心。所以大脑是INTJ最薄弱的环节。
哲学
我现在更加相信以前不太认可的哲学,诸如"人不可能同时踏入同一条河流","人的同一性",“人的大脑是人的一部分、心脏也是人的一部分,那么人失去了大脑以后还是之前的人吗?人嫁接了心脏起搏器还是原来的人吗?”我现在觉得人脑里面不同神经代表了对不同器官的控制,人脑细微的改变都可能改变其神经递质传输的过程,从而改变人的思想及其行为。
人是意识的总和
人的一切思考都基于神经递质的传播,而神经递质又依赖于当时这个人的激素水平,外部刺激。我认为人就是一个意识的总和。
人是解释性的动物,任何表达都是可解释的,只是理解困难程度
人总是擅长给一件事物做解释,人没有办法完全理解一件事物的时候,才会通过超灵的表达来诠释一个事物。我起初并不知道我的病的类型,
不同文化的人碰撞出来的东西、在同一个维度交流、才更有意义。人只不过是跑了一个foundational的解释性的model,dimm or not,strong opinion or not。
人的大脑的神经递质传输过程,和foundational model的产生perceptron加神经网络的过程很类似。而训练数据就是过往产生的一系列神经递质的强化能力,所以他们是类似的。若要能产生新的东西,得由不同的来自各方的观点碰撞出来,也就是训练数据的多元化。
女性真的通灵,但是可能她自己都不知道。
我的母亲非常能理解我在失去意识时作出的描述性言语。似乎这是女性的第六感感觉到的?我和母亲在微信电话中的没有
女性容易得阿尔兹海默症是不是过于通灵?
我和母亲的交流,发现她能察觉到文字以外我的情感,这些东西可能表现在细节的面容上。在我躯体化症状发病的时候,在电话另一头听到我受不了的时候,我母亲精确的提供了我的感觉的信息,而这些信息被我爸是过滤掉的。我不知道什么时候我妈也会随我外婆一样得阿尔兹海默症,但是能够察觉通灵,我感觉和阿尔兹海默症发病预兆很有关系。