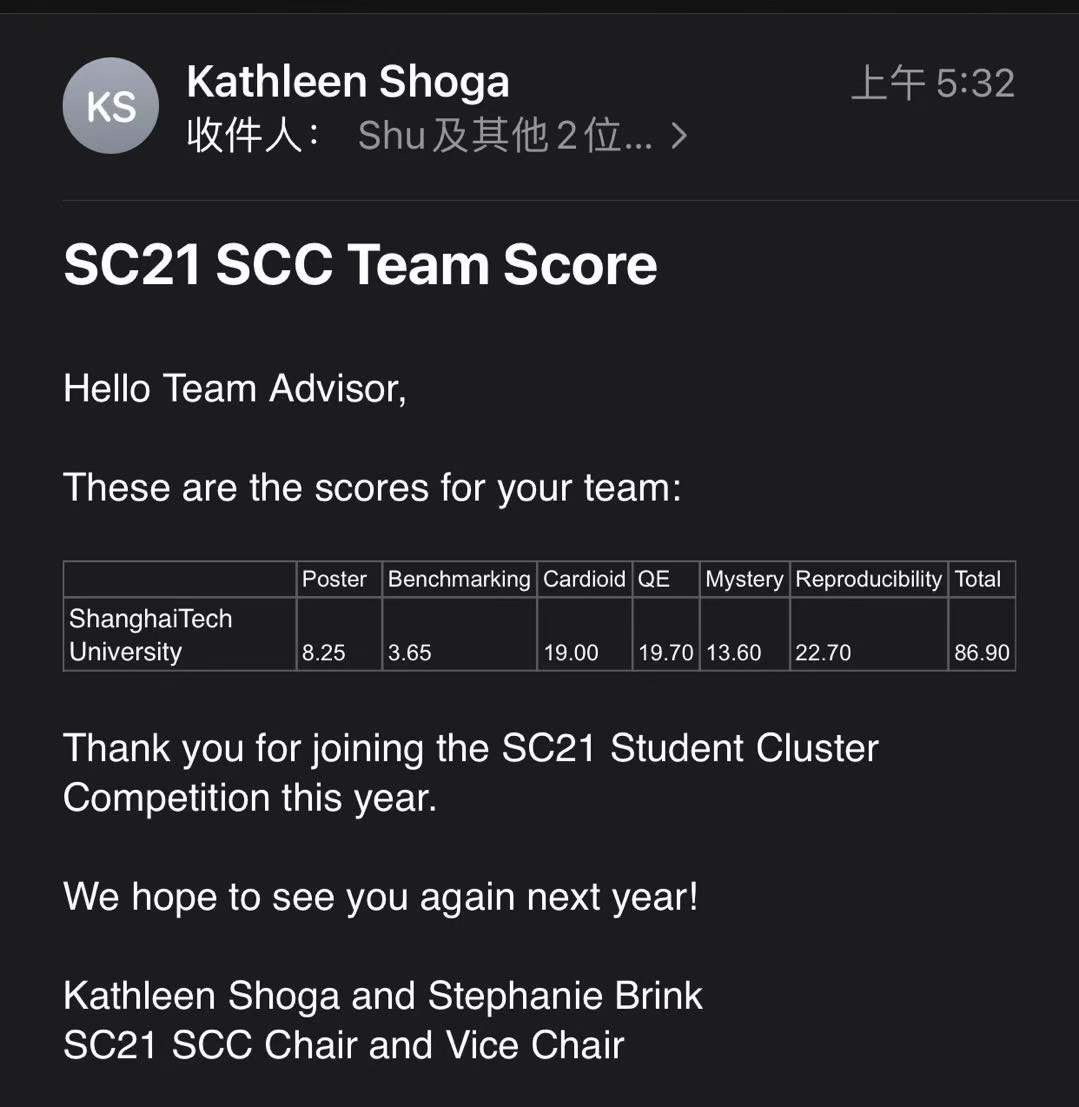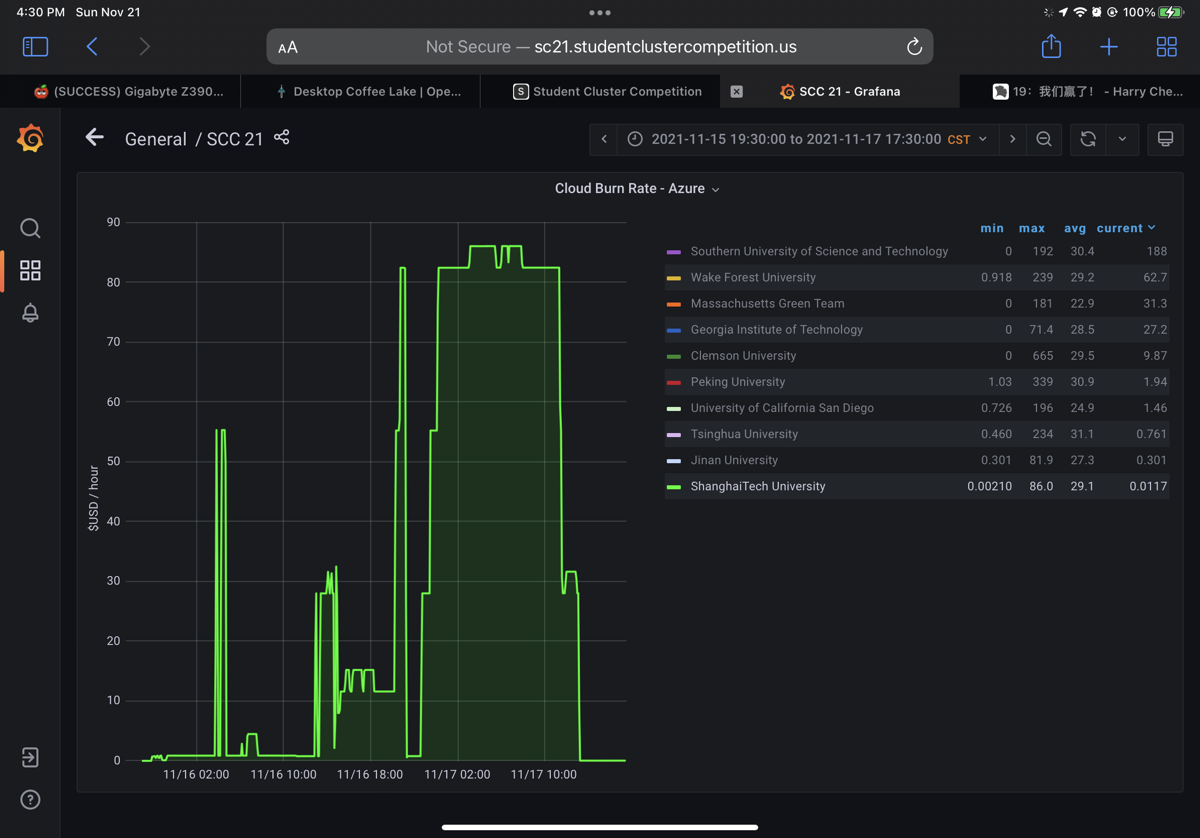
我不是一个爱回忆的人,但是总觉得过去22年是我作为男生部分的时间,总应该有点什么东西留下来,正如鲁迅的《朝花夕拾》是对旧文化,养育他的之乎者也中汲取新世界白话的力量。我所认为的新时代,一个没有强权,网络绝对自由,有能力者自食其力的世界也会在我所创立的公司中体现。Anyway,show time。
四年的时间,我其实只是想做更有趣的事情,没想到把吉他、摄影、无人机甚至女友义无反顾的丢掉,在一个PUA国度里面,我活的好压抑。我觉得整个大学的失败是我一手造就的,没有找到最需要发力的主要矛盾。每次想的太快做的太慢。
我从一开始就是想make GeekPie_HPC great again,其他所有的都是为了学更多的东西。博士是Jump Trading实习结束以后决定的,因为赚钱全是engineer effort,对我没什么挑战。大致真正发现这个学校的丑恶也是每一次面对这个学校的老师的时候,我觉得我太天真、太傻了。
试错与探寻兴趣所在
约莫着大一的时候,发现《数学分析》时间和精力上都比不过卷王,第一学期就拿了B+,貌似 Competitive Programming 也不是我的菜,张龙文在 ICPC和智能体已经拿了银牌和第四了,由于反编译助教发的标程(连debuginfo都没去),直接交了 asm(""); 导致在 MOSS 里控制流和别人一样(没学编译原理,完全不会AST,这题Foo 出的,一半人被抄袭。),后来confess 拿了 CS100 的 B,物理花了很多时间,拿了个A。前几个学期做 pre 的课都很好,没项目就考试的我就不想花时间去砸时间刷题。
第二学期的失败在没有朋友和没有有效获得老师和助教的信息。电路和离散都没拿到好分,重要问题是离散在某一次作业之后助教在 piazza 的很隐蔽的地方发了下一次不能再在 gradescope 上不 assign page,然后那一个月的作业都零分。个人感觉我离散学的还挺好的,后来曼哈顿距离、博弈树实习的时候还给别人做pre。电路作业挺难的,但每次解微分方程的时候都敲错计算器,高中的遗留问题吧,考的不好,作业也没对答案。其他几门课还不错,《数学分析2》拿了 A-,期末考试就考了格林定理的特殊情况,也是当时看的stein的《傅立叶分析》、《复分析》、《实分析》。哦,思修提示重教作业在我在印度旅游手机丢的情况下,微信收不到消息,因为被清空了,后来argue的时候,说我违反规定在暑假初出去玩,如果继续argue失败会被勒令“社死”(通报批评+退学)。后来还是选择了挂科重修。说来也有意思,思修的影片还是我剪的,我队友也没其他途径提醒我。第二学期成功的地方是结识了张龙文、叶者、张弛斌。三个很厉害的人,至少比我当时厉害多了。当然也结识了诸如csh之流。出去打了hackathon和ctf,成绩还不错,全靠被带。
暑假先去了新马泰印尼。暑学期搞了个fintech课,完善了hackathon的东西拿了第一。那次用奖金吃饭的感觉就很好,同时我学到了如何和女同事合作。

社会实践没啥好玩的,别人都脱单了。


暑假后面学校里还有个讲precedure decison的课。
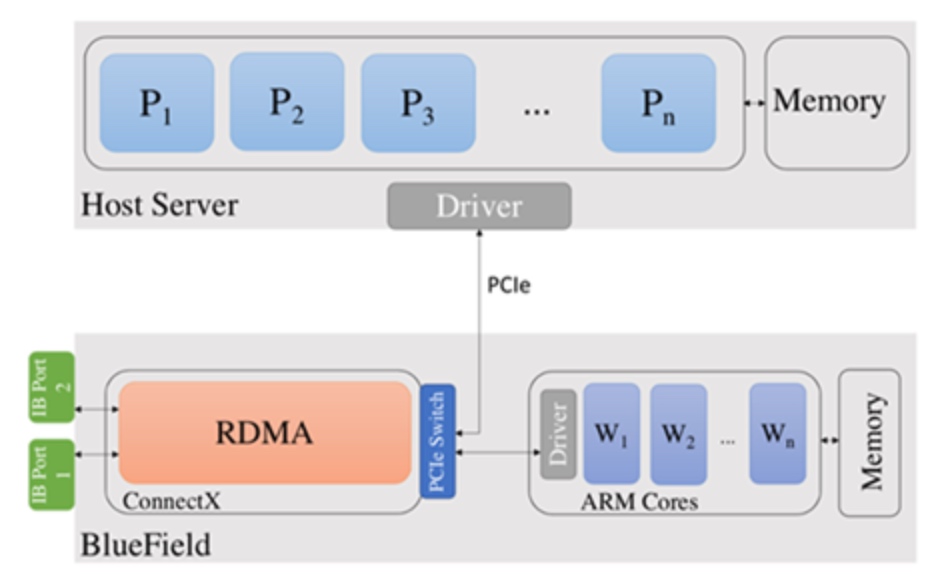
暑假的后半部分就在帮zhaozhe学长跑实验,是一个AI Adv的活儿,缺很多实验。主要我做的部分实验都在那个暑假搞定了,后来Foo又给了个和叶者一起合作的锅,那我也接了,只是第二学期的Compiler和OS太花时间了。所以很多事情暂时搁置了,但是我在Foo组每周听到的组会上的内容真的对我的提升很大,当时讲SGX和Side-Channel的很多,我也有了个在谢学长对面的座位,这让我更好的向学长请教。对AI Sec上基本就是调包,改一个类似fuzzer的mutator生成器,让数据的AUROC比baseline好。叶者的锅就一直gu一直gu,主要他写的太杂了。Z3 SMT-based验证一个stackful的语言不是那么难,问题是,很多内部的东西,比如spec,文档都不全。而且1.2一直在更新,每一个小版本都会改动很多。
第三学期,Compiler被龙哥带了!

编译原理后半部分是他写的,101不会的题目都请教他,有道维护区间有序的题用list没用dynamic vector,查找O(n)没过一个点。不过这助教简直傻逼,洛谷原题不改。OS教的很差,OSPP写的很好,但是就是教的差,lock guard讲了3节课,CA上过的东西狂上,页表怎么切讲得不清楚,后面我去上课就复习Compiler了。Compiler我上的还行,Foo后期讲了IFDS一些数据流静态分析和他组会上经常会提到的污点分析是我那时候常干的事情,我们的编译原理project也是用了TaintART的DTA,在所有的syscall和敏感API调用上动态的给开发者返回possible emission信息,东西是在java maple IR上做的,其实就写了个描述层。到最后很多东西没解决,就糊了一个demo。(面向testcase编程。)其中国内考试的时候去了一趟深圳TSBI,是我唯一一次出去开会,见到了Petter Davison、中科院计算所的大佬们,还有jyy riscv nemu课设、杜东penglai、中国chisel之父刘jiuyan。总之就是去社交了一波。OS是没时间了交了个改了一点点的project3上去没混淆。就没了。概率论这学期必修是和别人错开的,因为和OS冲突。不过zcb也是这学期选的,他101上学年就学了。也是一个精致的利己主义。
第四学期开始的时候搞的GeekGame2020,用React糊了一个前端,比叶者这个专业的还是差了好多好多。第四学期被他带了一半。CA的前半部份上的贼差,后半部分上的很好,尤其是spectre、RAID那里,我也 CA的后半部分project主要是他写的,lab 除了 map reduce是我做的。选了RL、CG和Parallel Compuing。RL和CG靠带。Project是和他一起写的。PC全自己写的,尤其是cuda,主要原因是夏而下要打ASC、SC了。直接赶驴上马。本来想做一石二鸟的工作把QuEST优化很多的,改了个MPI版GPU,性能基本线性叠加,但问题是这没卵用。连决赛都没进,但是后继无人导致我还是成为了队长,搞了wiki开始训练的pipeline。龙哥gu了这超算比赛和之后的龙芯杯和Compiler比赛,去yu组赚钱去了。叶者也去那里赚钱去了,不过Mars给的确实有点多。我太菜了,没去。之后就去Jump Trading了。
这个暑假可以说是终身难忘。众所周知我的两个舍友在第一学期就被CS100劝退转专业了,又是天天在寝室吃麻辣烫、打游戏的人,我很受不了,但是不能换寝室,因为有人不愿意。但是Jump Trading 给我31楼的昌邑路海客滨江一套。以便开展我的🧍♀️活动。同时我感受到了被尊重的感觉,以及我饿技术可以被马上应用于production。比如刚学的parallel computing就用上了。以及"谈笑有清北",那时候身边交流的都是清北/CMU大佬,让我觉得,所有的技术问题,我都可以解决的感觉。
但事实是,出了Jump Trading就没那个机会了。没有人能记住一个垃圾学校的垃圾。第五学期干的事是上研究生课,尤其是CA2、CA3、OS重修、概率论、网络、数据库、计算理论还有个SC20一起搞的时候,我觉得我不care GPA了,因为我受够了这个学校的PUA、我只要知识、和锻炼我在压力下的水平。我感觉CA2太需要花没有意义的时间了,Sniper连多线程同步都没写好,及其浪费时间,考试的时候让你手推不同周期在干啥。
寒假做了6.824和看了6.888.
第六学期,学习到了在一个组里面怎么活。我觉得王老师是一个严厉的老师,这很好,但是他严厉的地方不对。在他实验室三个月的时间里,每周我都有他拍脑袋的任务,现在看确实是新发的ASPLOS22 PM相关关注的问题。可是搞清楚又有什么用呢,让我做的东西,实现也拍脑袋,我反正是做不出来,Meltdown我都没怎么实现过。这学期又学到了怎么当一个助教,感觉在上科大当助教吃力不讨好。被陈濛骂我出题他觉得没定义清楚就在那里闹。然后他讨论课从来不来。我也不知道该怎么搞。我感觉,还是不要自己出题吧。让他能找到原题比较好,否则他就觉得难了。哎,上科大不是北大。
暑假去暑研了。这是个15个人暑研的地方,我和北大的一位同学选了investigate order dependent tests,这是个Darko和Wing顾不过来的方向,因为他们本身有3篇要在暑假投出去的工作,还有Ruixin的Python flaky test Workshop,感觉在周会上一直很活跃的是修Flaky Test的chen yang 同学(她去UIUC了),但是修bug真的挺好费时间的,她一定很痛苦。我的话就一直在用Pradet跑artifact,需要给她提供order dependent变量,然后Darko总能找到class 的flakiness的案例,我们总能找到Pradet的bug,但是跑的3000+个case(对,iDFlaky+Non-idempedent+poluter的总共这么多,不过有些重复,有些不是OD。有问题都会去找Pu Yi,他是北大的,之前在做JPF,后来也在做JPF。总之就很怪,我们选的也是探索性的项目,等ICSE截稿了以后,Wing度假了2周后找我们实现一个bramble上的brittle test 改 flaky order test准备投ICST。传播方程写好了。可是bramble 完全不会debug,加之投稿来不及了,就鸽了,真的不太会mvn插件啊,反正推荐信是够了,北大同学在熊英飞组跑试验投OOPSLA也溜了。相反chenyang和ruixin做了python flaky test发了个demo。(感觉虽然学会了很多理论、DTA怎么传播,怎么找OD,但是没有学到idea,做的事情也是很糙。(不过,软工确实好发啊)总之,两次科研经历,如果老板能多给点指导时间就好了,否则兴趣都转移了。也可能我在本科阶段做的事比较功利。
第七学期就上了门创管的课,只有后八周,这是学分要求的最后的课,投资学与金融市场。讲的很理论,也是金融专业必修,也就是和这个专业的人竞争GPA。project糊了很多,比如chisel3 简易riscv单发射5级流水,chocopy,一个rust版cmudb,被cjj带着写badfs。比赛拿了第二。毕业论文是hdf5语义下放,是小圆ATC22 under revision文章的中文版+若干没放上去的实验。
对于Ph.D.的面试我还是有些东西想讨论的。不同老师的风格真的不一样,GaTech有两位面我,一位是做meltdown的🇮🇱人Genkins,我大概先说了对MDS的兴趣来自jump的intel processor micro benchmark,后面说了之后的一些精力,他觉得我的尝试都很没有想好,和大佬说话就不是拍脑袋了,很有engineer implementation价值。 他就认为他的任务是crack widely used stuff down. 他对于防御也没有兴趣,同时他对我的用高级的工具去解决前人就能做的东西很不齿,比如eBPF侦测内核,估计是我的思考他觉得没有意义挂了我。第二位是kim,做rustra的。开始也是问项目,问了threadsantinizer的实现,false negative怎么出现。有没有更完美的解决方案。我知道实现,create thread的时候把所有variable record 一下,每个path都DTA一下。fn就受ipc污染过的变量修改后检测不出来,函数order检测不出来。修补嘛,就说rust里send sync的方法。其他检查unsafe里变量有没有data race。(糊了一遍他的论文,幸好看过)不过似乎他觉得我回答不满意,也没要我。purdue最奇怪,poi陶瓷的时候很热情给了个面试过了下cv,之后王建国和我说poi招满了,艹。王建国老海王pua了,在邮件里面说他已经有USTC的优秀同学,还发了篇十四五计划 db规划,想着一定是北大/复旦没写过db的文科研究生翻译的,我寻思着什么垃圾dber,5年才3篇vldb,算了👋🏻。西北xingxinyu的面试极其不formal,说是代表committee,微信电话,全问的私活,想着也是看我有jt的经历,追着问我thread interleaving怎么debug,我就说了thread里差sleep,用script卡thread时间,停在thread里就好。他觉得不是one for all 的解决方案。cmu ece的面试也是走个过场,很不尊重我。
最后这一年我的想法是给Ph.D.做一个缓冲的一年,代码在学,因为博士还是新硬件体系结构、LLVM、kernel。所以还是把之前的几个项目都完善下。又做了助教/家教好累啊,出题还要想。
减法、加法
摄影的数据流向
由于NAS被肢解了,我前几年拍的照片都已经被删除了,我归因于在学校里根本没有好的数据解决方案,放个nas太容易断电断网,出了学校,由于学校出口教育网/电信网的分流问题,网络延时又特别高。自从全心全意只写代码以后,就再也没摄影了,不过最近有在捡起来。之前录的一些吉他曲也整理出来了,以后可以放博客上。现在博客在psychz tokyo上。
接管无人机社
我当时拉了5个人,一个西南工业大学的学姐,家琪是 SLAM 大师,还有物理学马大师,和贺贯奇,买了一堆飞机,飞了几乎所有类型的飞机,CADC去玩过一次。现在是陈大师管理了。
女装与MtF
我从印度回来以后对自己进行非常深刻的思考,我觉得我需要一个时机来让我有理由干这件事,我在Jump Trading实习的时候由于有自己的地方,我天天在晚上穿女装,感觉很爽。发现自己真的喜欢以女性的方式去社交。其实我早就知道HRT。但是付诸实践真的是因为我觉得这个世界对男人过于残酷,我很害怕。我只是个喜欢和强者交朋友的xyn,请多指教。反思了一下,我每天观看twitter的时间有点过多了,得少关注美美的人,多关注自己的码力。但是这是xyn的后遗症吧,我的青春又还有多久呢?
YOLO

我很喜欢的一种精神,也是和NTU的shenghao聊天的时候知道的。我为了ISC21能有名次把抽代给挂了,其实我多学半周应该B不是问题,Daniel觉得我是态度问题。毕竟最后的OH也没找他。后来知道他学期末发了那篇PDE拿tenure了,恭喜🎉。所以挂了,不过凸优化我还是好好复习了一晚上混了个B+。yolo我认为是你可以为了自己想要的放弃掉世俗意义上的别人要你做的事情,这很重要。
可以托付终身的人与物
我的准老婆,从高三的时候就认识了。之前一直情绪不稳定,我也一度因为自己太忙的原因抛弃过她,但是我知道她很爱我,我也很爱她。希望我能把我的未来的一切喜怒哀乐、功过是非都托付给她。已见她父亲,已被透,已半同居。结婚还需要一年。回上海定居还有8年。
人生可解与不可解
我无法知道从进大学以来的一切发生的事情,我曾经认为,我能用自己的能力发很多paper、以满绩完成最难的课程。总有人卷没有意义的东西,也总有人用旁门左道过桥。但是我会选择一条我认为离改变世界最近的一条路。我选择UCSC,(当然也没得选)我想在搞paper的同时见识下什么是硅谷精神。人生是Undeciable 的,也同时是 Deciable的。