最近在做编译原理课程设计的设计,看了很多到 LLVM 的编译器的想法,同时发现 Rust 类型体操作为黑魔法合集也能带给社区很多新鲜玩意,就把之前设计 Chocopy LLVM 层的一些小想法放在这,上科大的同学想玩可以加个piazza,invite code: CHOCOPY。有一部分参考 High Level Constructs to LLVM_IR, 范型的设计更多参考 rust 和 c。
高级语言 to LLVM 的解释层



A Tech Nerd with a finance mind.
最近在做编译原理课程设计的设计,看了很多到 LLVM 的编译器的想法,同时发现 Rust 类型体操作为黑魔法合集也能带给社区很多新鲜玩意,就把之前设计 Chocopy LLVM 层的一些小想法放在这,上科大的同学想玩可以加个piazza,invite code: CHOCOPY。有一部分参考 High Level Constructs to LLVM_IR, 范型的设计更多参考 rust 和 c。

I'm trying to do some log stuff in a Compiler project. When I'm trying to use the fmt::format library.

It was safe and sound to run with apple-clang 13, but when it comes to gcc-11 for the following line:
if ((x.second)->is_list_type()) {
LOG(INFO) << fmt::format("{} : [{}]", x.first,
((ClassValueType *)((ListValueType *)x.second)->elementType)->className);
}
LogStream is something like:
class LogStream {
public:
LogStream() { sstream_ = new std::stringstream(); }
~LogStream() = default;
template <typename T> LogStream &operator<<(const T &val) noexcept {
(*sstream_) << val;
return *this;
}
friend class LogWriter;
private:
std::stringstream *sstream_;
};
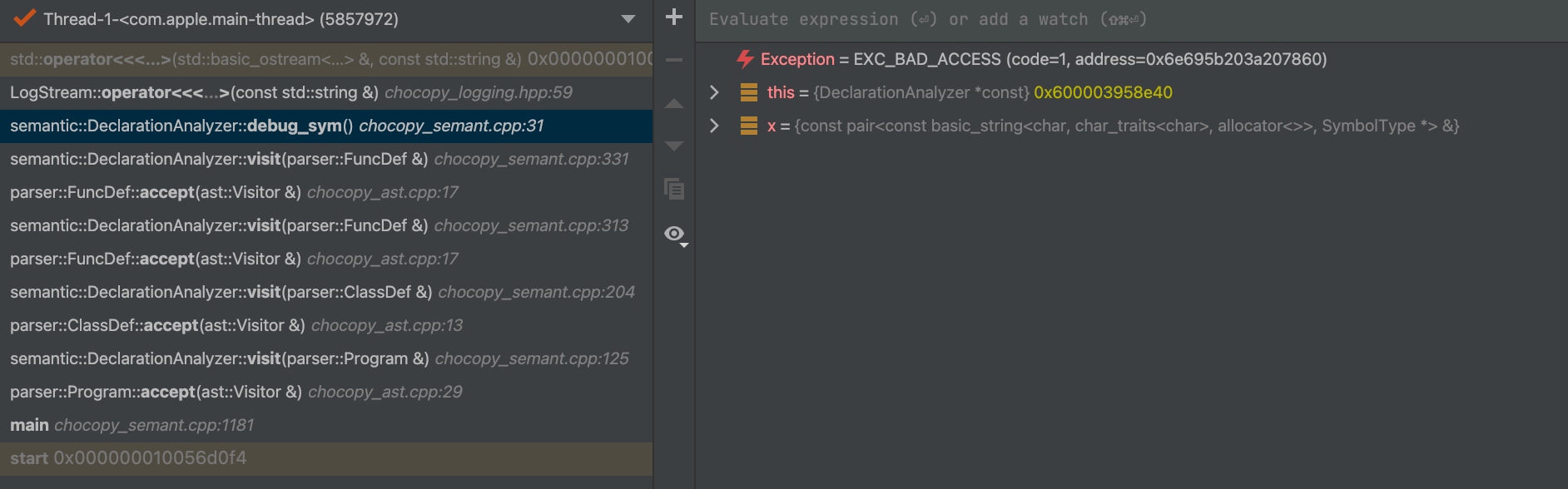
The operator << gets error reading the memory byte from the fmt byte, possibly because the author of GCC is not aware the pointer passed do not fit in the following ldur style of stream out. On x86 OSX machine, the GCC have some _M_is_leaked() check in the same line and on Windows MSVC, the line has reported the memory leakage for doubly linked pointer.
The compiled code is:
There's trick to maintain a compiler that have a universal error code output.
老师上课开始讲运行时环境了,这也导致后半部分一节课一个话题的开始。知识点杂乱,但是每一个步骤都很爽,感觉自己学到了挺多东西的。
整个llvm 有足足8个多g,看了下大多数都是优化部分,集中在llvm pass当中
(未完待续)
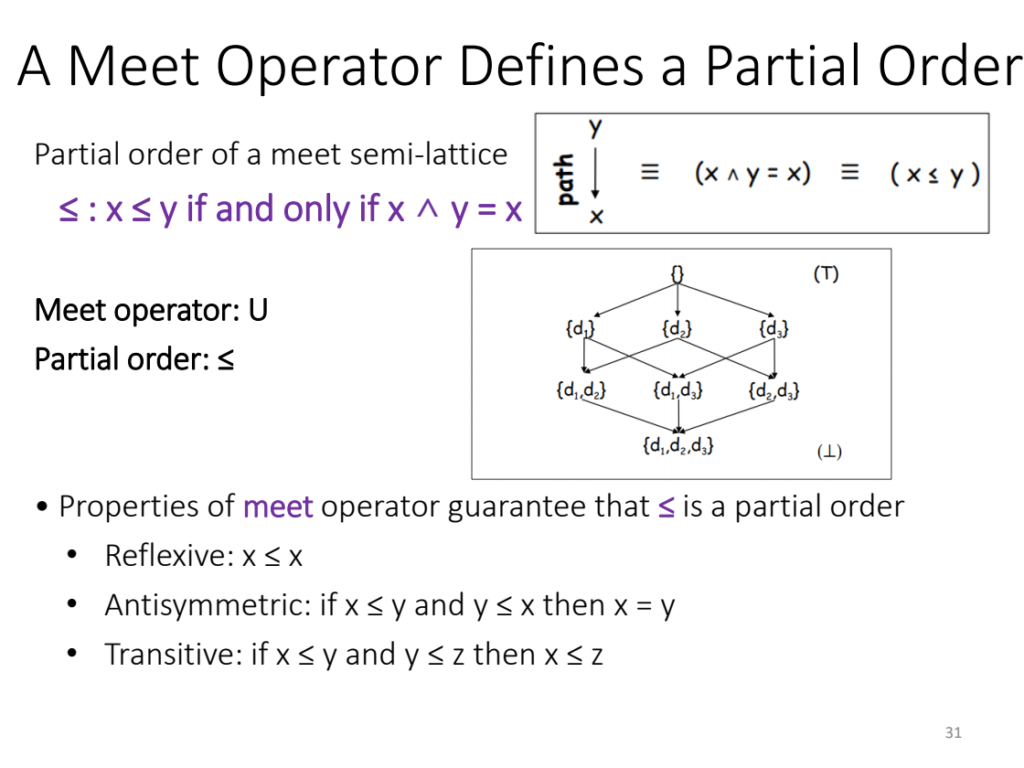
summary: 只要理解其中的意思,即forward 传递函数是reaching, backward 传递函数是liveness。
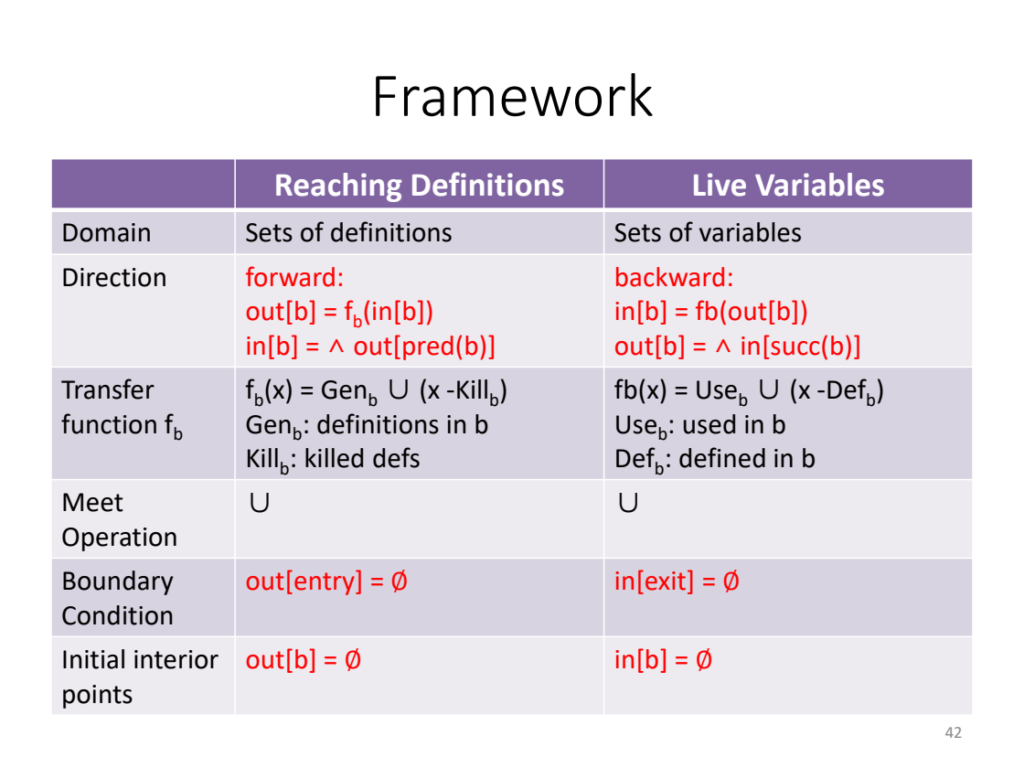
Must reach 是指必须要达到的特定的位置,那么只是meet operation 变成了 交。
Flex (fast lexical analyzer generator) is a lexical analyzer generator that usually works with GNU bison. Flex uses regular expressions to describe each Token. For the usage of regular expressions, see Wikipedia.
其中有两点值得注意:
Source Code已给,bug一堆。
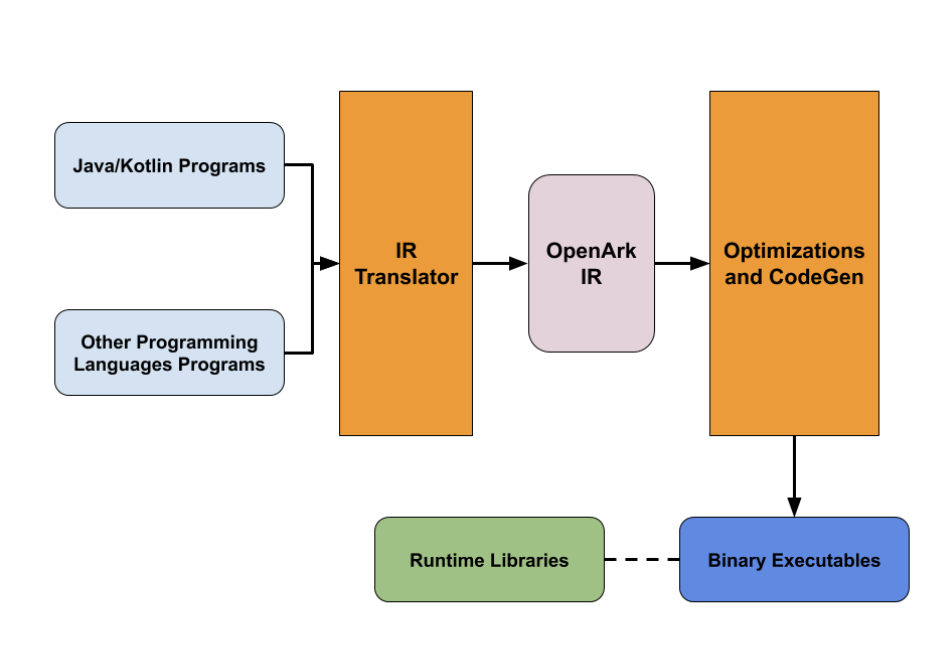
从这张图当中,我们发现华为创新性地加入了M2M作为mid-end。
语言特定降低,VTable生成,异常处理和类级分析。
SS SA构造,参考计数(RC)插入,别名分析,“mplt处理” , RC优化,部分冗余消除(PRE),内联,副作用分析,去虚拟化,空指针消除,死代码消除(DCE), 边界检查消除,逃逸分析,复制传播,“跨语言优化”。等。
堆栈分配,控制流优化,“EBO”优化,窥视孔,寄存器分配(RA)。等。
对于大多数中端优化,我认为是阶段化,而另一个IR(他们只是称之为Me)。现在让我们深入了解它们。
正如我们提到的,有两层IR:MAPLE和Me。他们在MAPLE上有相当不错的文档和规范,但基本上没有我的文档。
MAPLE是一个高级IR,表示与原始源代码关闭的概念。有三个重要的构建块:
Maple IR 首先把不同语言lower成一个中间语言,再进行语言有关的优化。 它还将来自不同语言的共同特征组合成单个表示,这样编译器也可以执行与语言无关的优化。
除此之外,OpenArk基本上在同一组优化和分析中使用Me IR,您可以在其他编译器框架中找到:Alias Analysis,Dominator Tree,Dead Code Eliminations ...
OpenArk是一个编译器框架,它尝试将不同的语言编译为公共中间层并生成本机二进制文件。 它采用多层IR设计,可以在不同的抽象级别进行优化和分析。更多源代码和(英文)文档即将发布。
https://github.com/oracle/graal/tree/master/truffle https://doc.ecoscentric.com/gnutools/doc/gccint/GENERIC.html#GENERIC
Source: https://www.youtube.com/watch?v=pMNsedoGoa4
主要是实践部分。
有几个注意点:
1.如果需要加入在输入的时候上下左右cursor 需要lex include y.tab.h,这个文件是由yacc生成的。
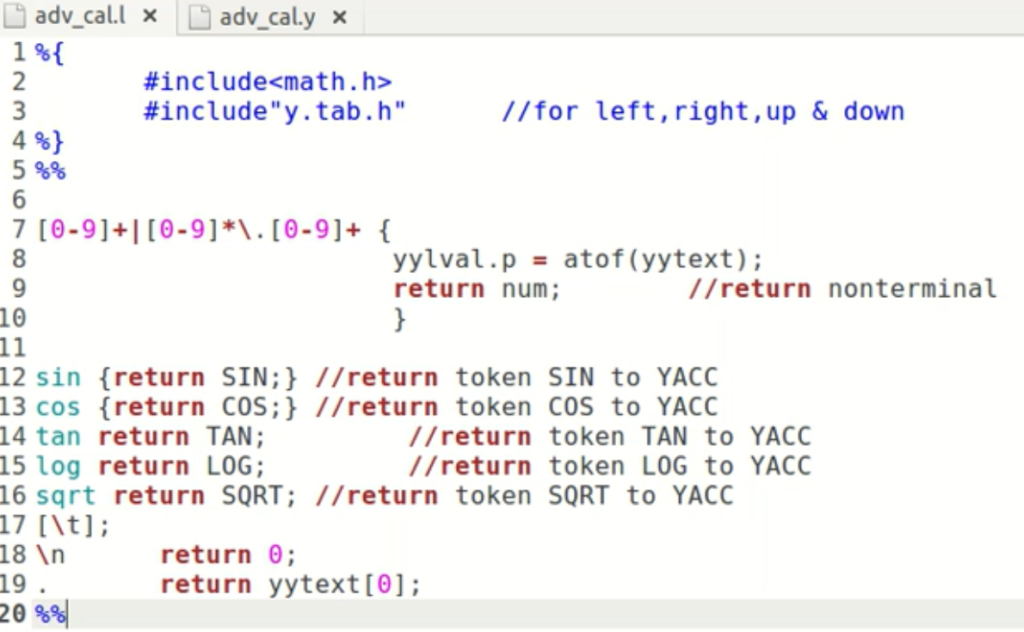
2. 在yacc中 seporater 用 %%。在%%(C declaration)中 yacc main 函数语法类c。着重说一下yacc的语法。
FIRST PART
%%
production action......
%%
THIRD PART
above is the Input, First part contains the declaration, the third part is the implementation in c.


P.S.

看了眼youtube 上可以用的资源,全是阿三口音,那就看着吧。反正我觉得不错。

以上和编译原理上讲的kleebe 和其他正则表达式的写法一致。只是在C和pascal当中要注意\转义符。在自行加definition的时候一定要注意。

lex就是一个lexical analysis 的东西,现在流行的语言是flex。(作为一个语言的必须)
举个栗子

这是一个标准的lex文件,和之前的男阿三说过的一样,lex包含auxiliary definitions 和 translation rules。也就是一一对应关系。

生成lex 文件,我们轻易的发现头文件部分和变量定义被省略,之后放在预处理里面操作。token相关被置换。

比如exp的部分在写表达式时被置换成$$相当于this了。$3指代输入的词素。

Yacc处理的main function 主要用到了 yyparse 函数
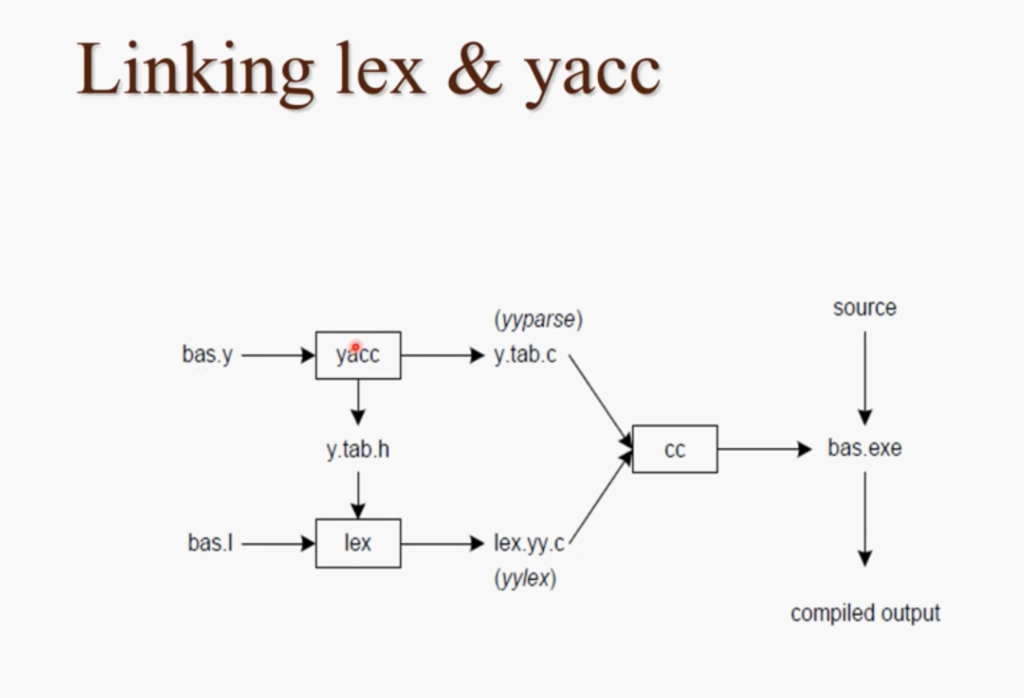
也就是
lex cal.l yacc -d cal.y cc lex.yy.c y.tab.c -ll -ly lm ./a.out