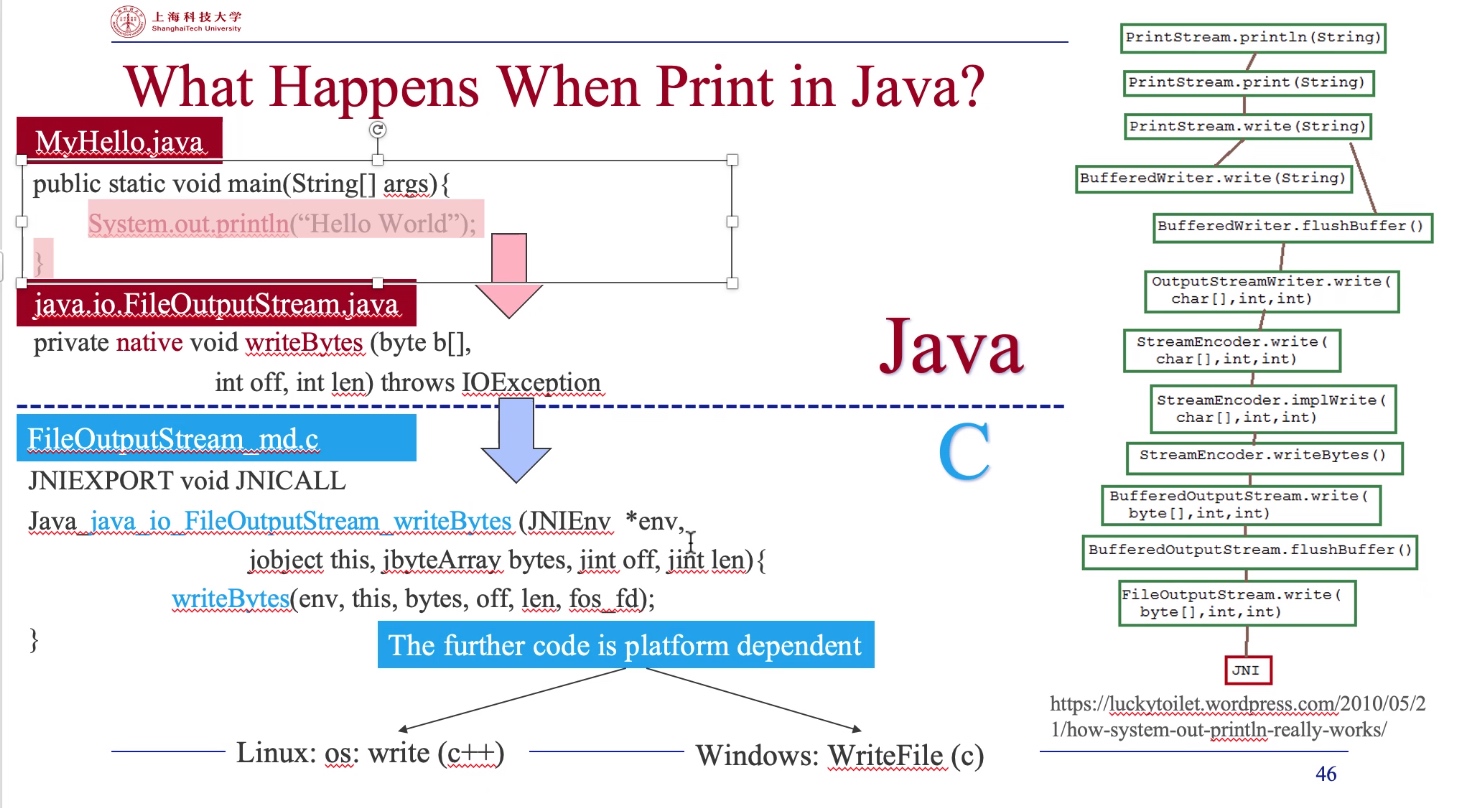
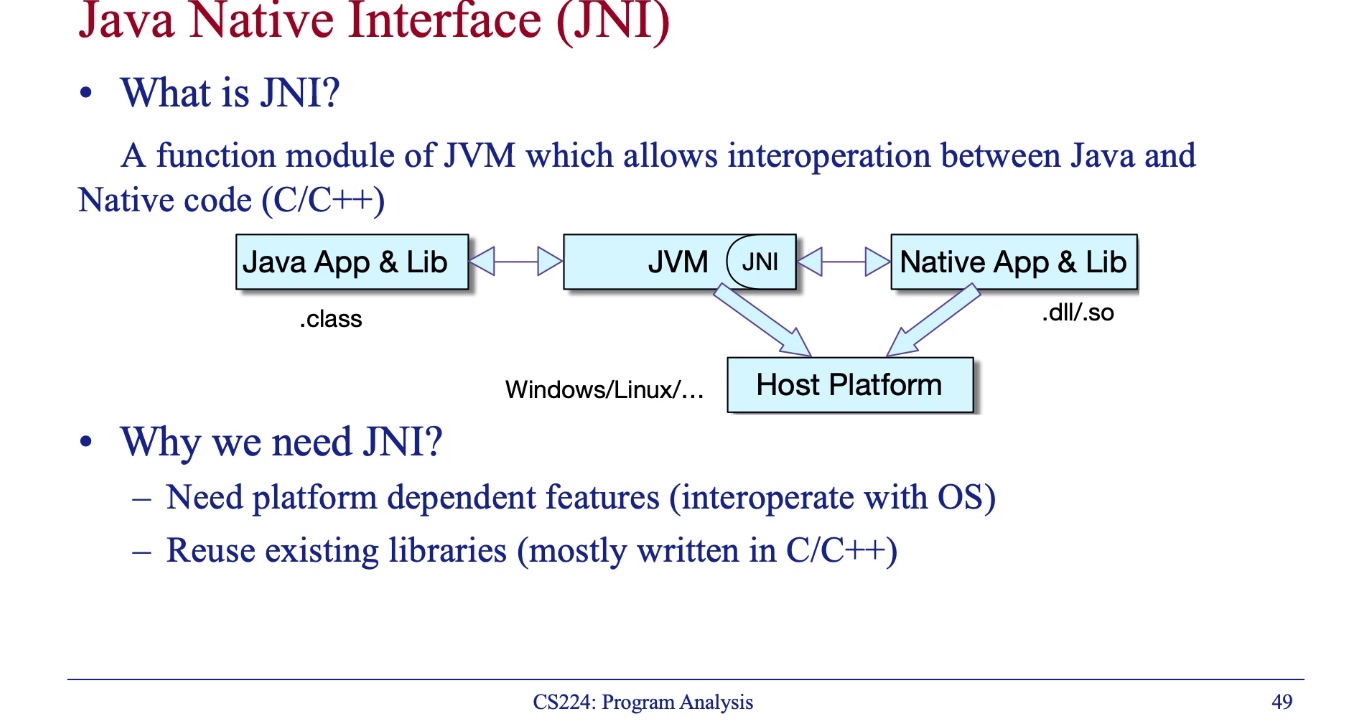
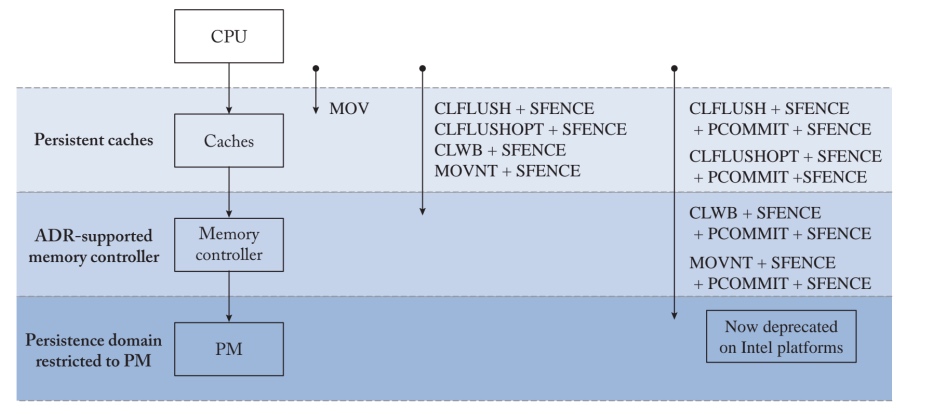
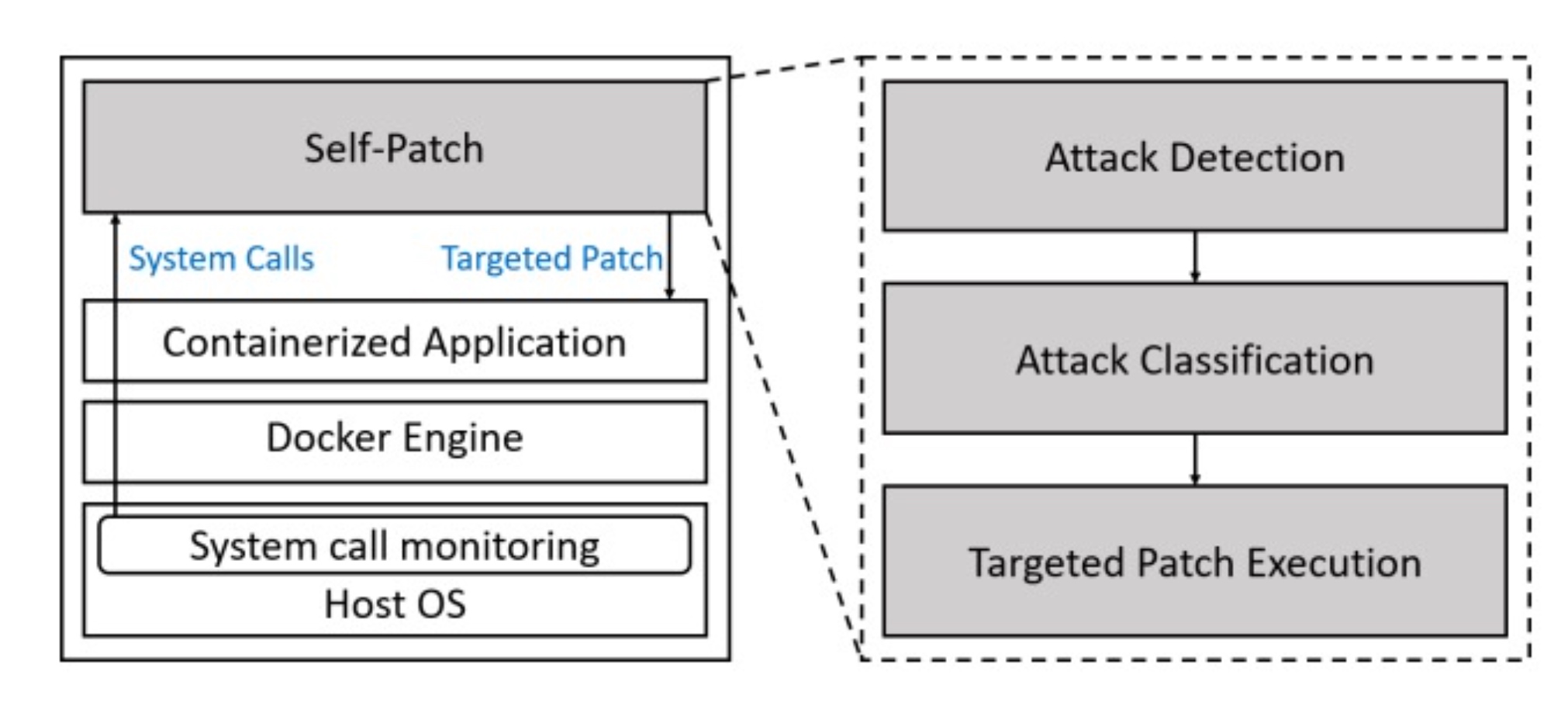
In defense to a situation where no program analysis in the program is soundness, so given term soundness for that program claims that they can cover most cases.
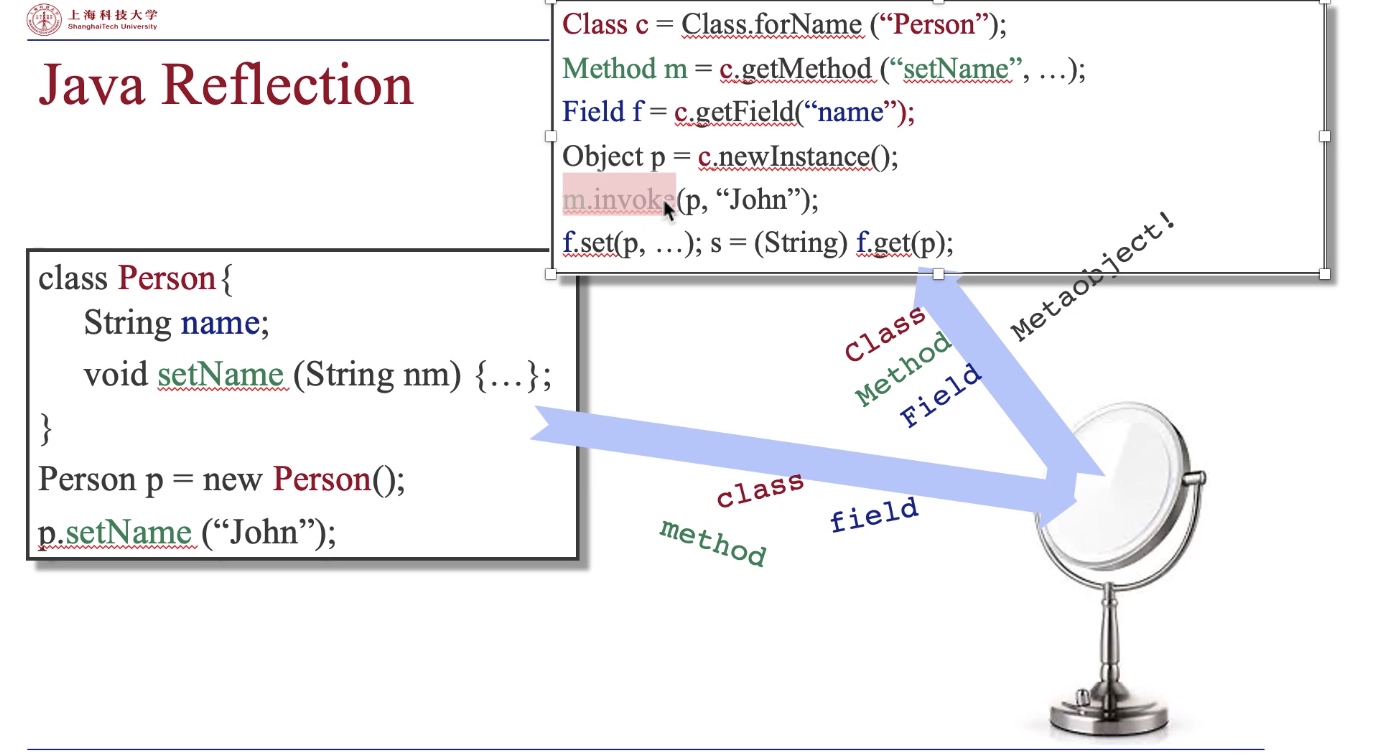
Reflection in Java
First on Java reflection: Class + Method + Field Metaobject
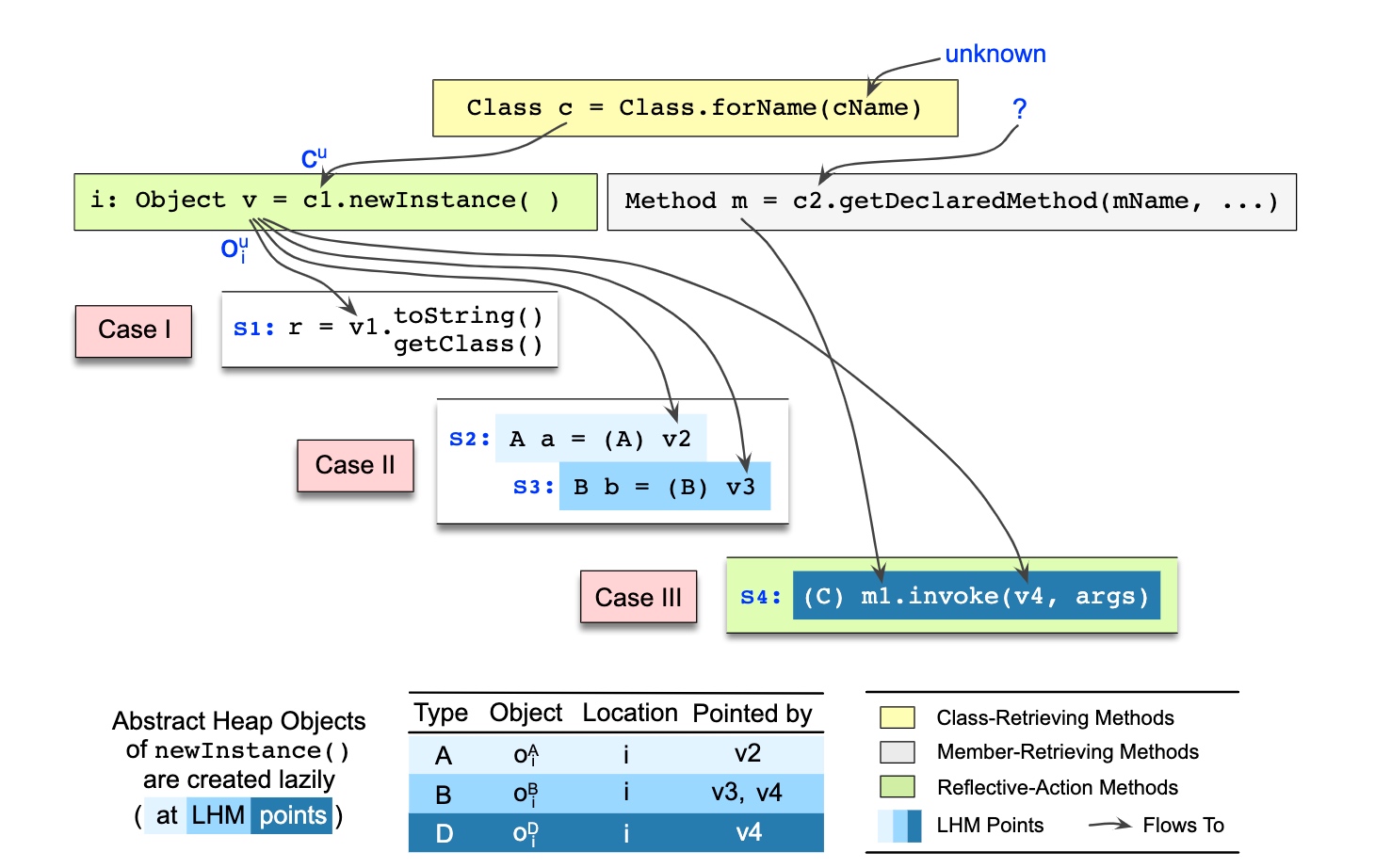
One solution: String Constant analysis + Pointer Analysis
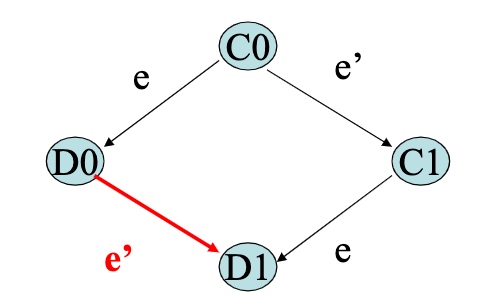
a ->b ==> TS(a) < TS(b) The reverse does not hold.
vector lock
Use vector to store the lock with every cores. Follows the reverse of the property.
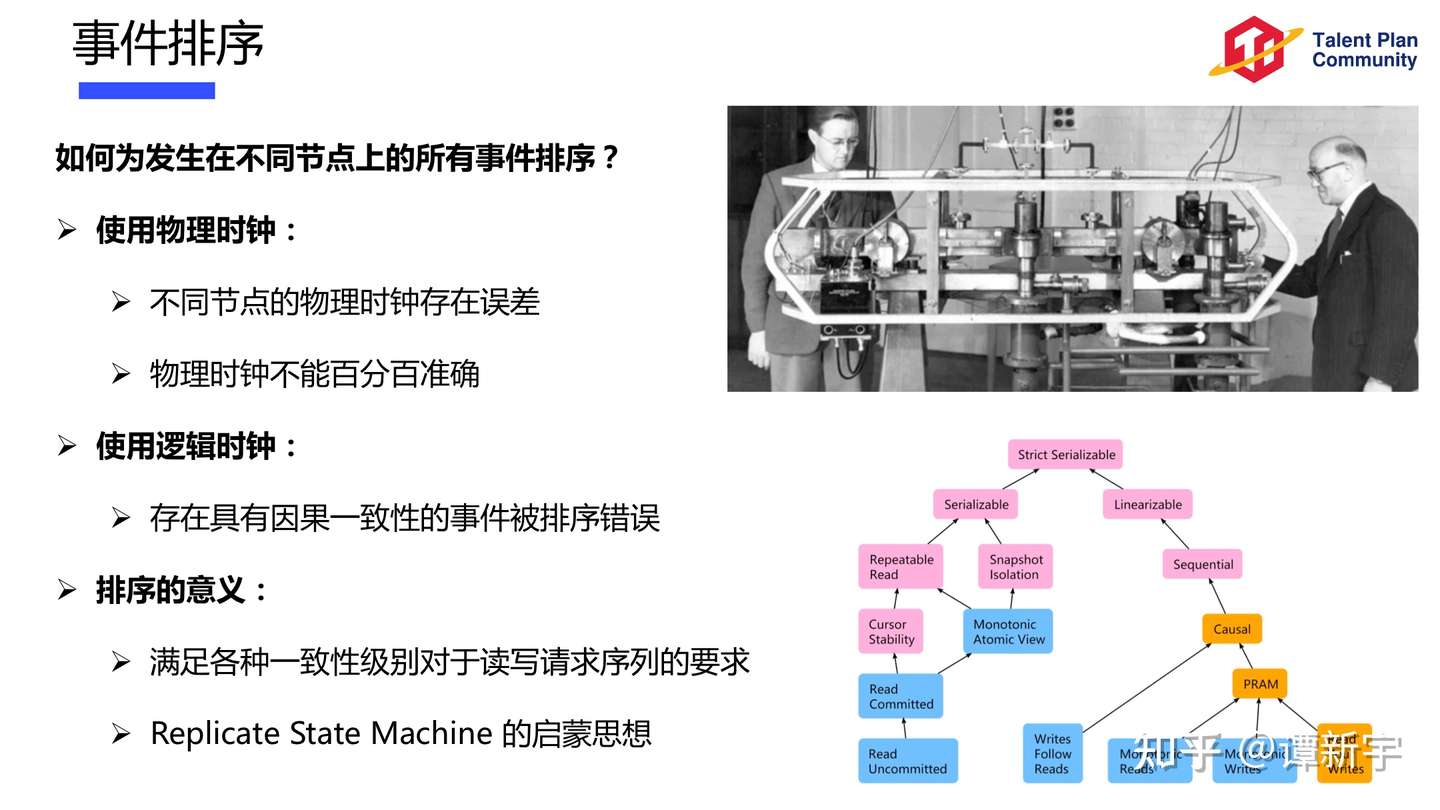
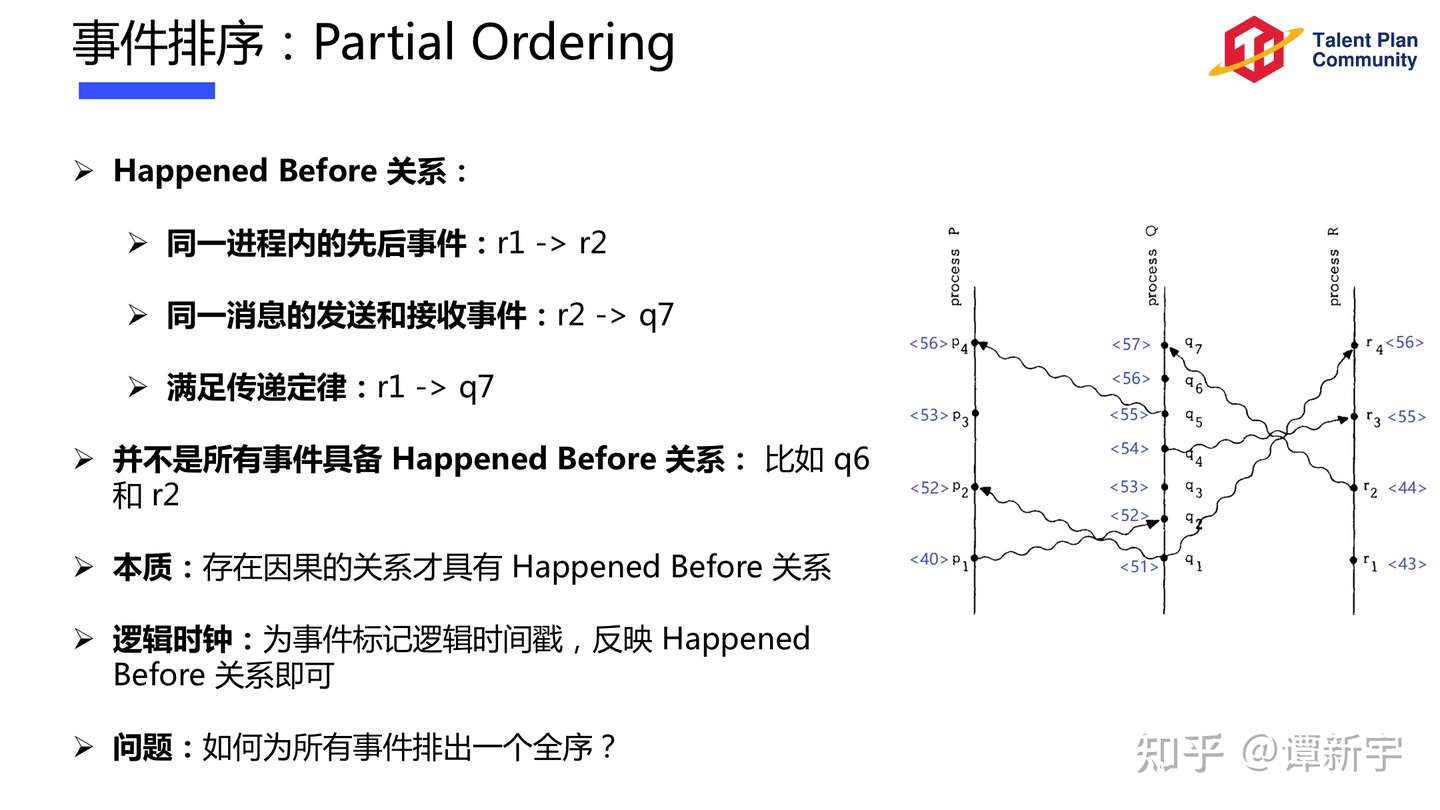
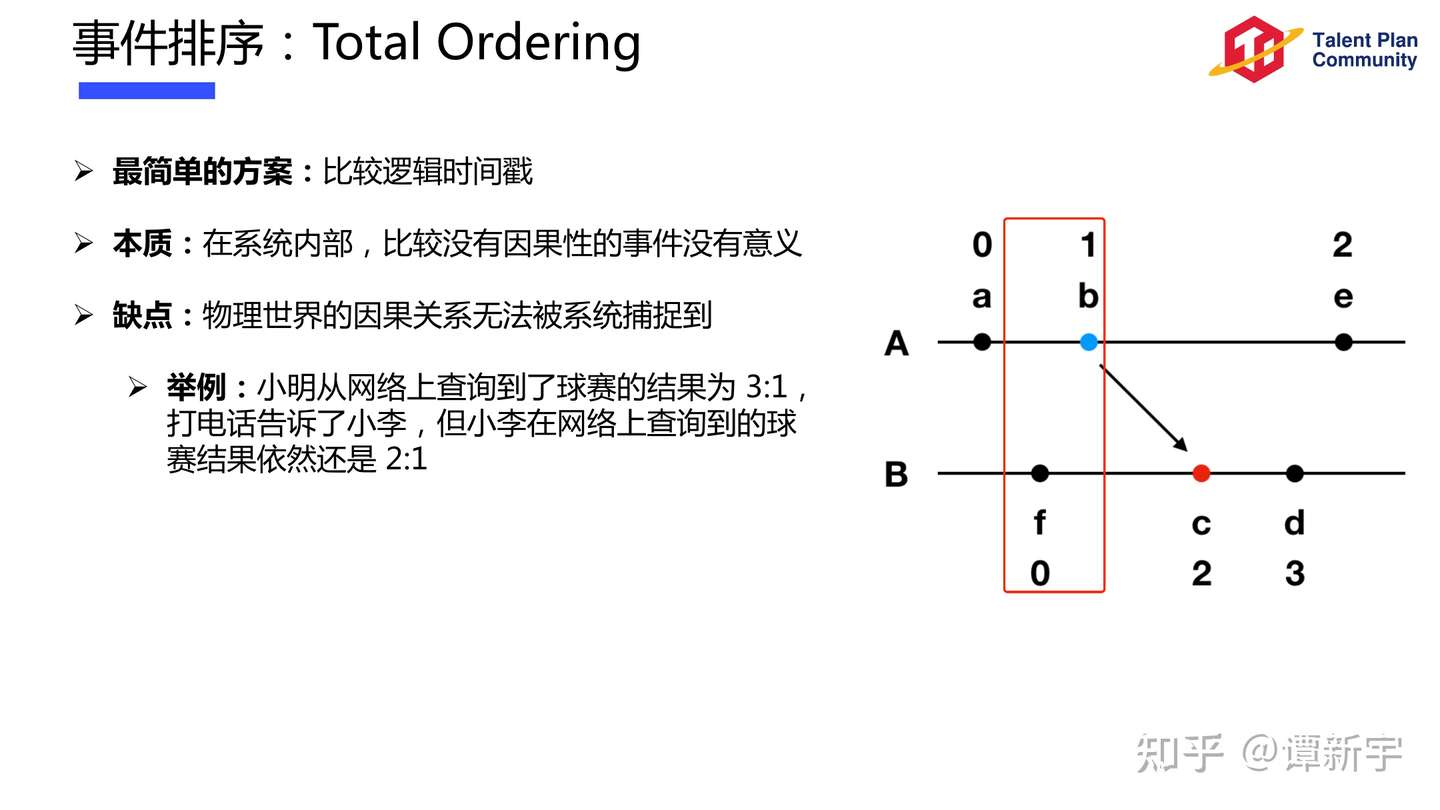
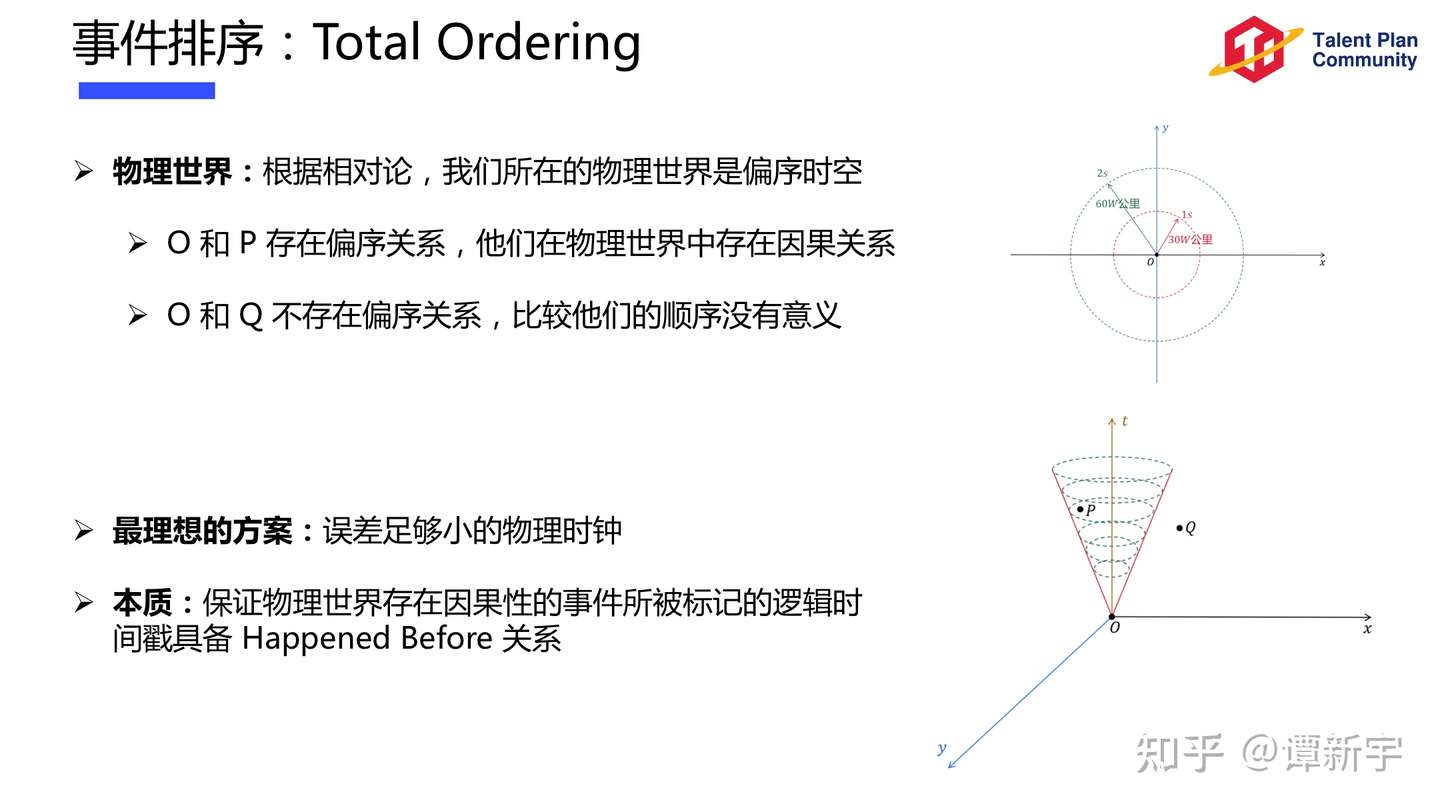
Ordering
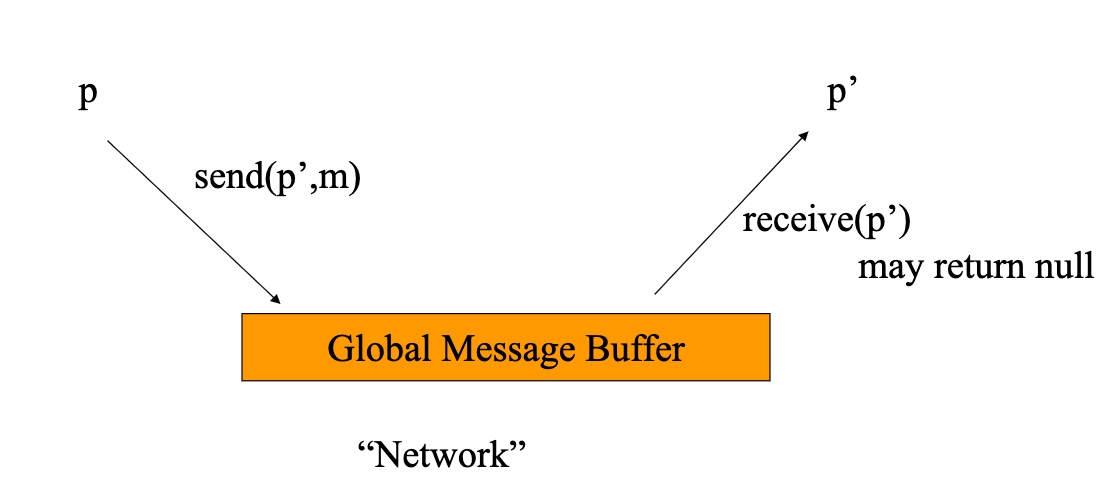
FLP
To prove that random timeouts can avoid live locking.
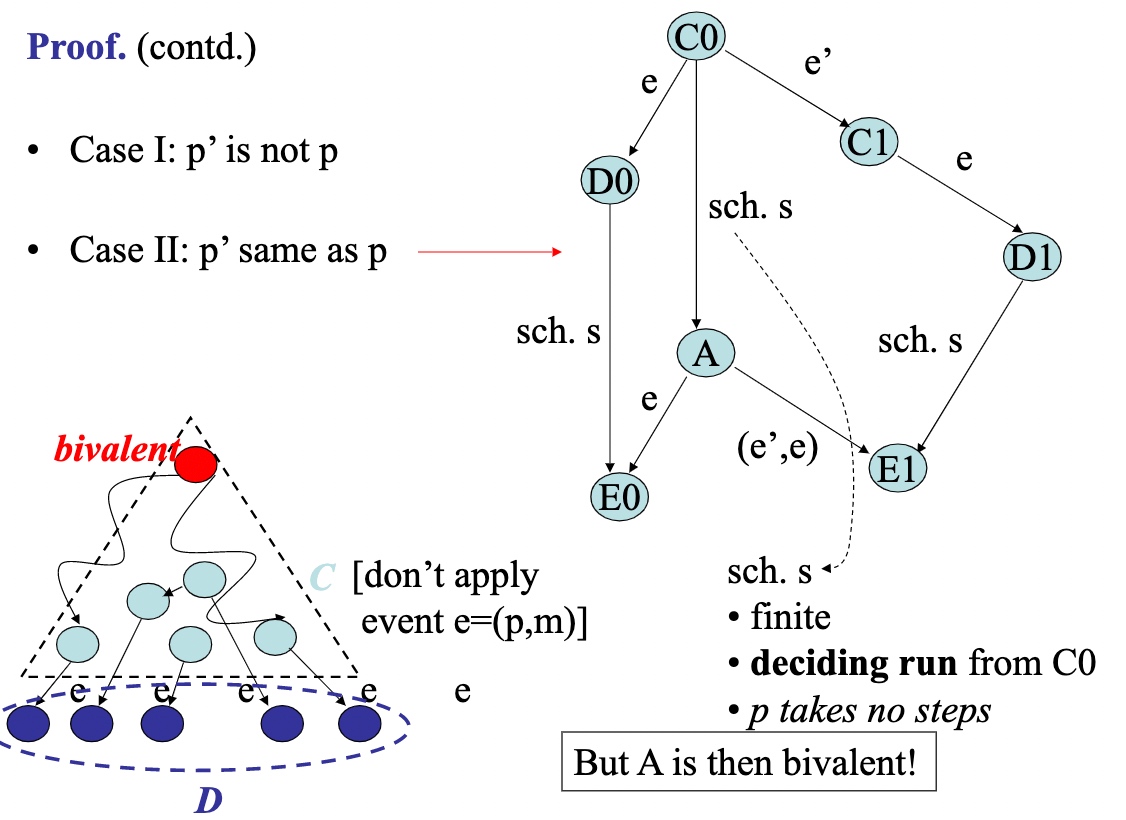
Lemma 1: Disjoint schedules are commutative
Lemma 2: There exists an initial configuration that is bivalent
Lemma 3: Starting from a bivalent config., there is always another bivalent config. that is reachable
Theorem (Impossibility of Consensus): There is always a run of events in an asynchronous distributed system such that the group of processes never reach consensus (i.e., stays bivalent all the time)
RPC
RPC = Remote Procedure Call
Proposed by Birrell and Nelson in 1984
Important abstraction for processes to call functions in other processes
Allows code reuse
Implemented and used in most distributed systems, including cloud computing systems
Counterpart in Object-based settings is called RMI (Remote Method Invocation)
What’s the No. 1 design choice for RPC?
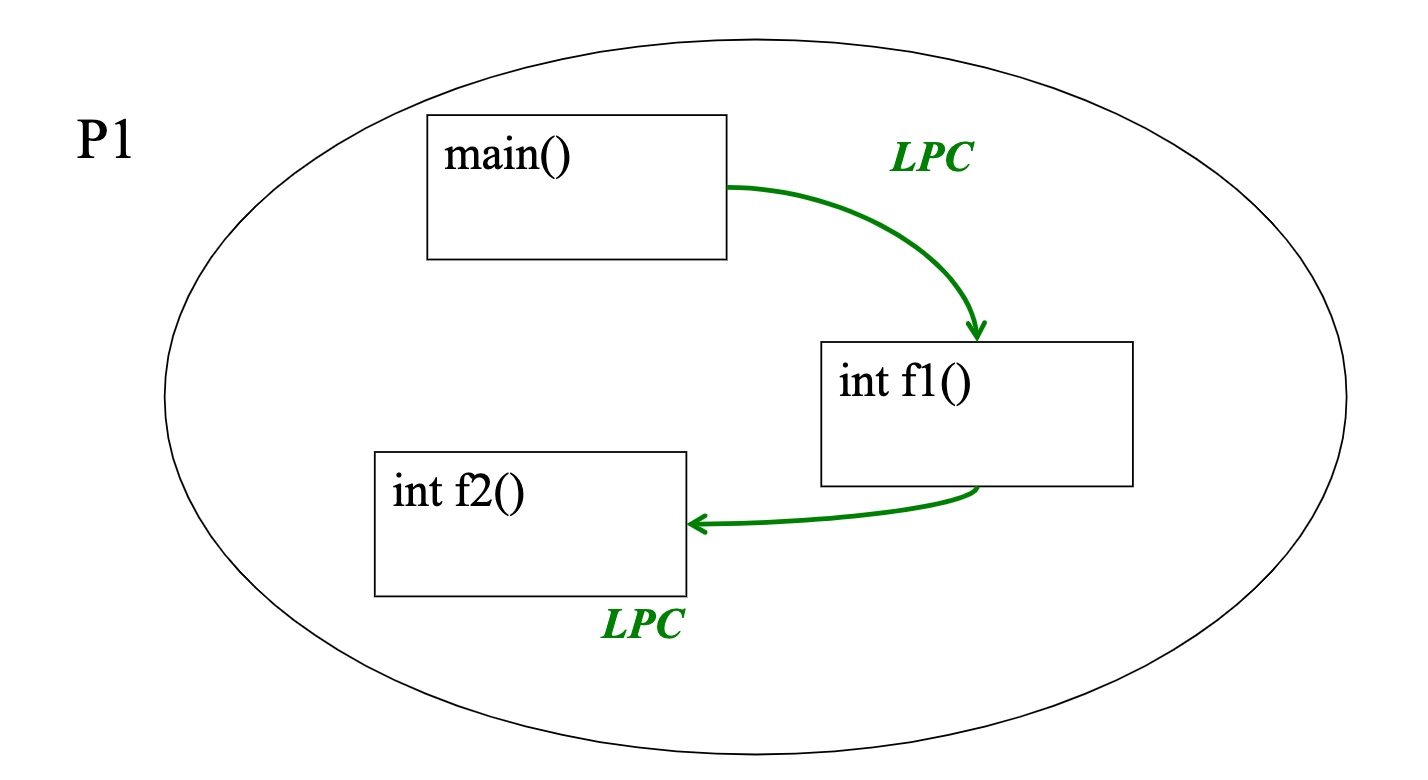
Local Procedure Call (LPC)
The call from one function to another function within the same process
Uses stack to pass arguments and return values
Accesses objects via pointers(e.g., C) or by reference(e.g., Java)
LPC has exactly-once semantics
Remote Procedure Call
Call from one function to another function, where caller and callee function reside in different processes
Function call crosses a process boundary
Accesses procedures via global references(e.g., Procedure address = IP + port + procedure number)
Cannot use pointers across processes since a reference address in process P1 may point to a different object in another process P2(We need serialization)
Similarly, RMI (Remote Method Invocation) in Object-based settings
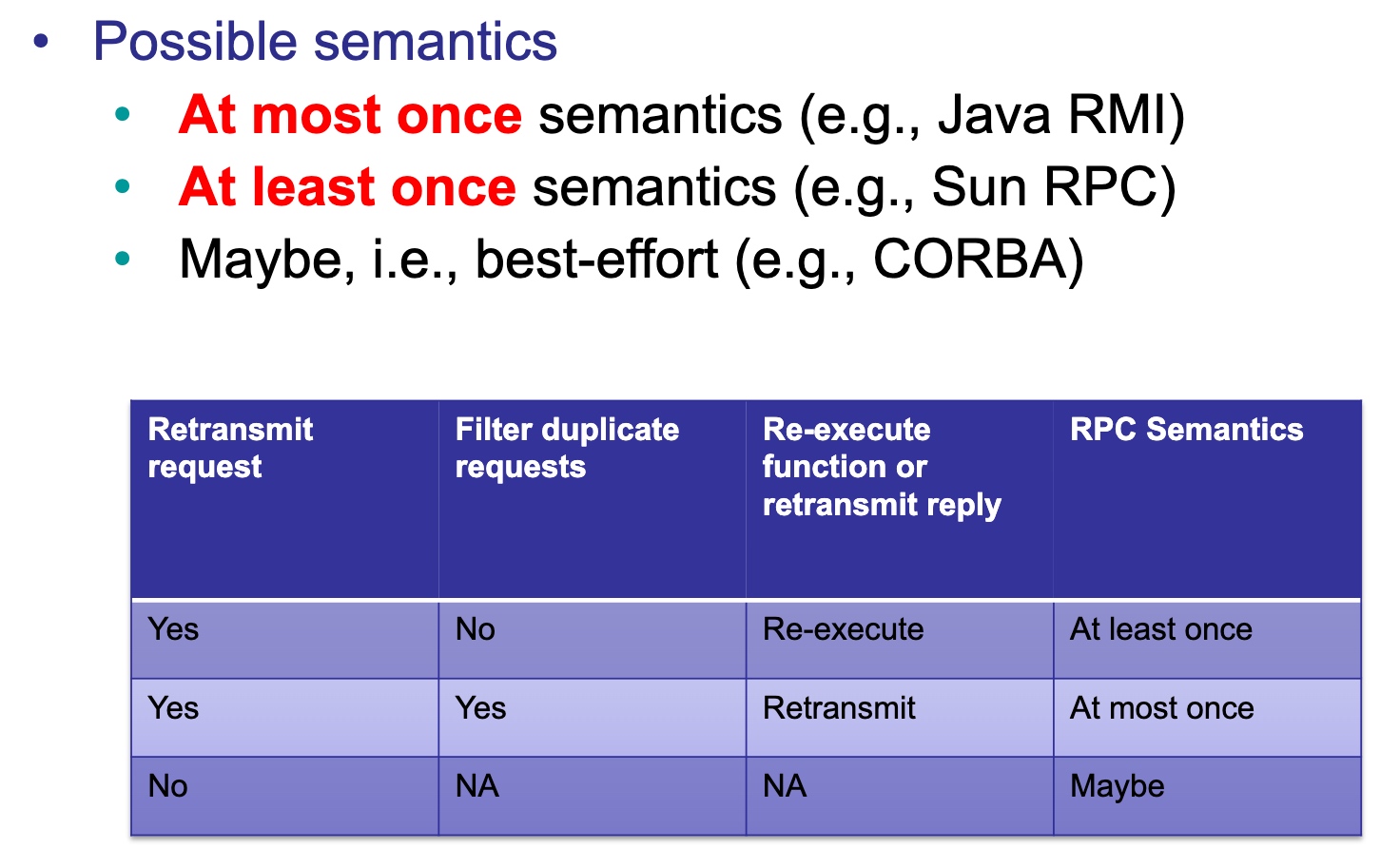
Semantics
Under failures, hard to guarantee exactly-once semantics
Function may not be executed if
Request (call) message is dropped
Reply (return) message is dropped
Called process fails before executing called function
Called process fails after executing called function
Hard for the caller to distinguish these cases
Function may be executed multiple times if
Request (call) message is duplicated
Idempotent OPerations
Idempotent operations are those that can be repeated multiple times, without any side effects
Idempotent operations can be used with at-least-once semantics
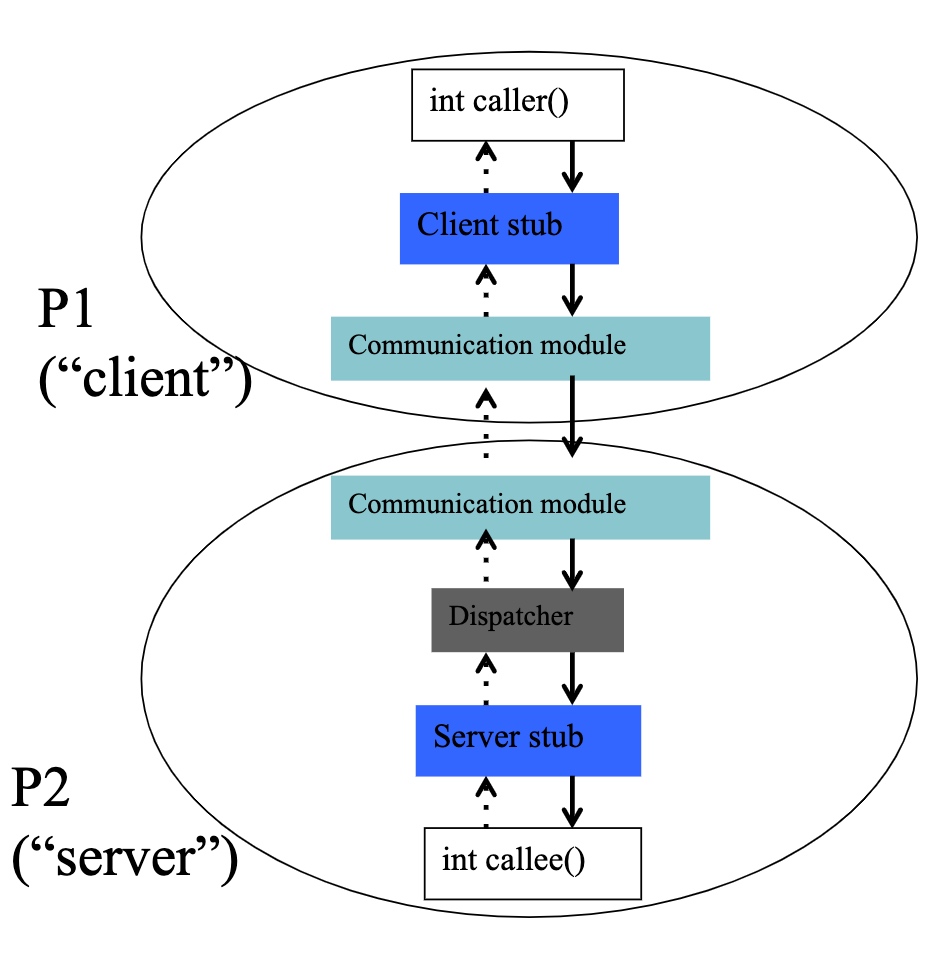
implementation
client stub: has same function signature as callee()
communication module: Forwards requests and replies to appropriate hosts
dispatcher: Selects which server stub to forward a request to
server stub: calls callee(), allows it to return a value
ACID
Atomicity: "all or nothing"
Consistency: "it looks correct to me"
Isolation: "as if alone"
Durability: "survive failures"
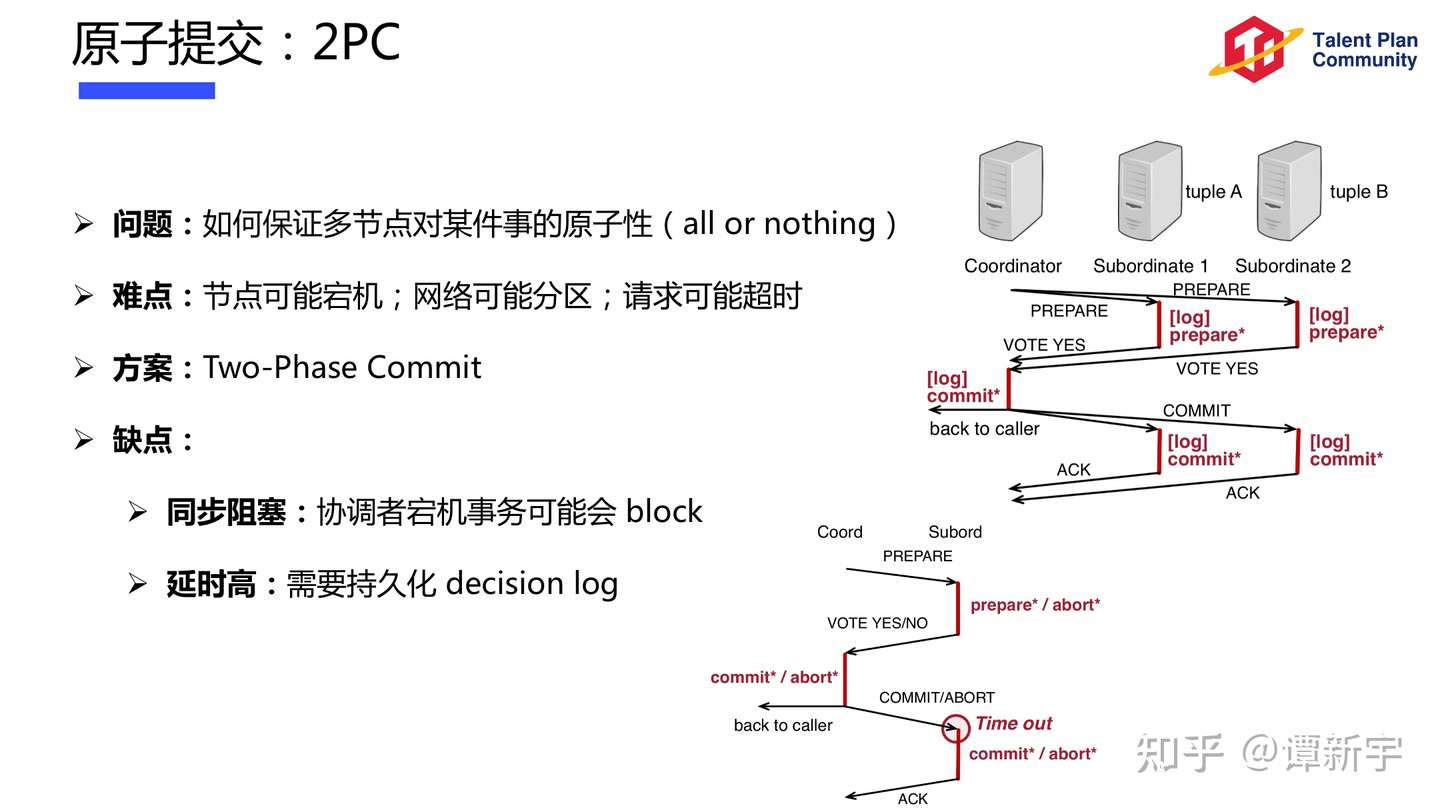
Fault in the Two-phase Commit
What if the database node crashes?
What if the coordinator crashes?
Coordinator writes its decision to disk
When it recovers, read the decision from the disk and send it to replicas (or abort if no decision was made before the crash)
If the coordinate crashes after preparation, but before broadcasting the decision, other nodes do not know how it has been decided.
Replicas participating in the transaction cannot commit or abort after responding “ok” to the prepared request
Algorithm is blocked until coordinator recovers
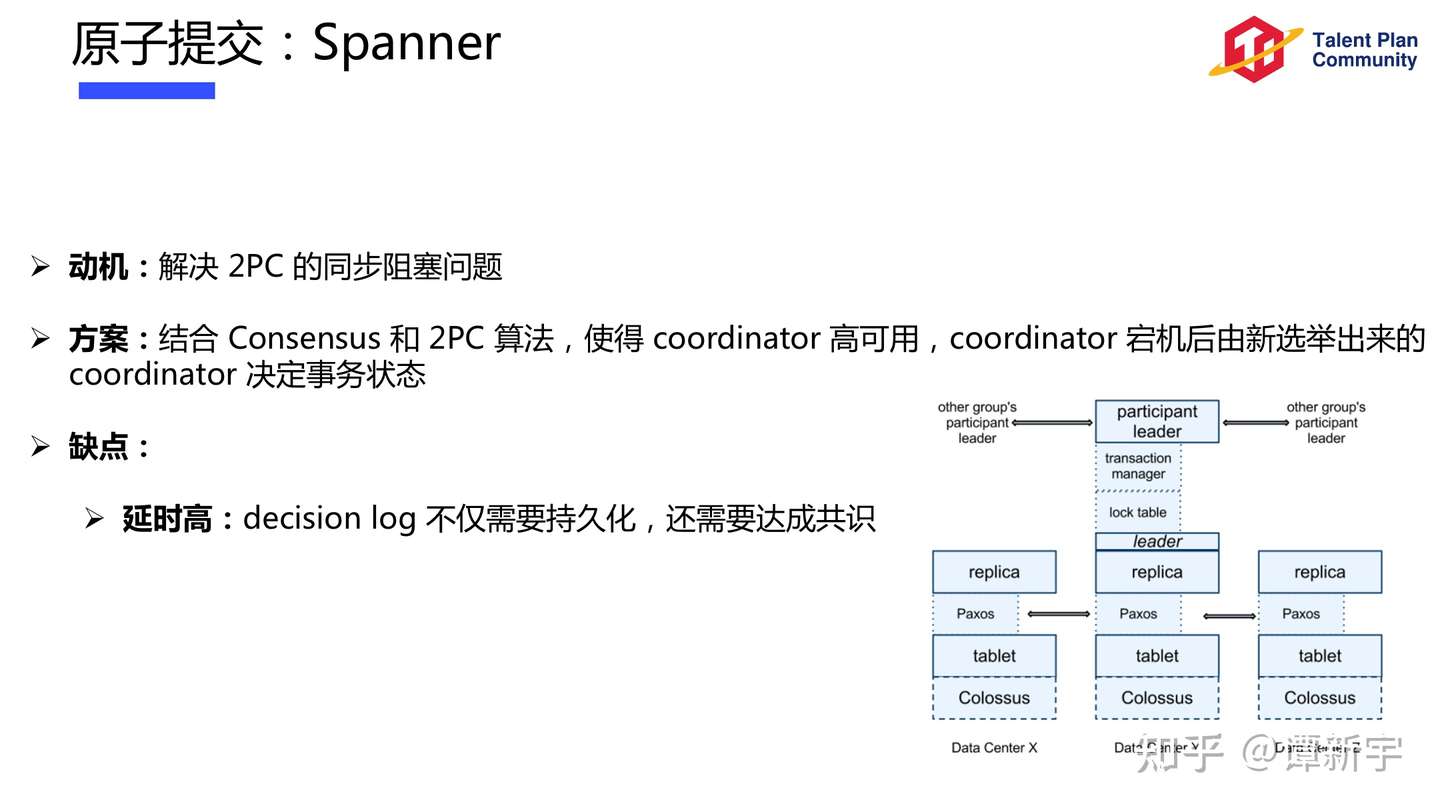
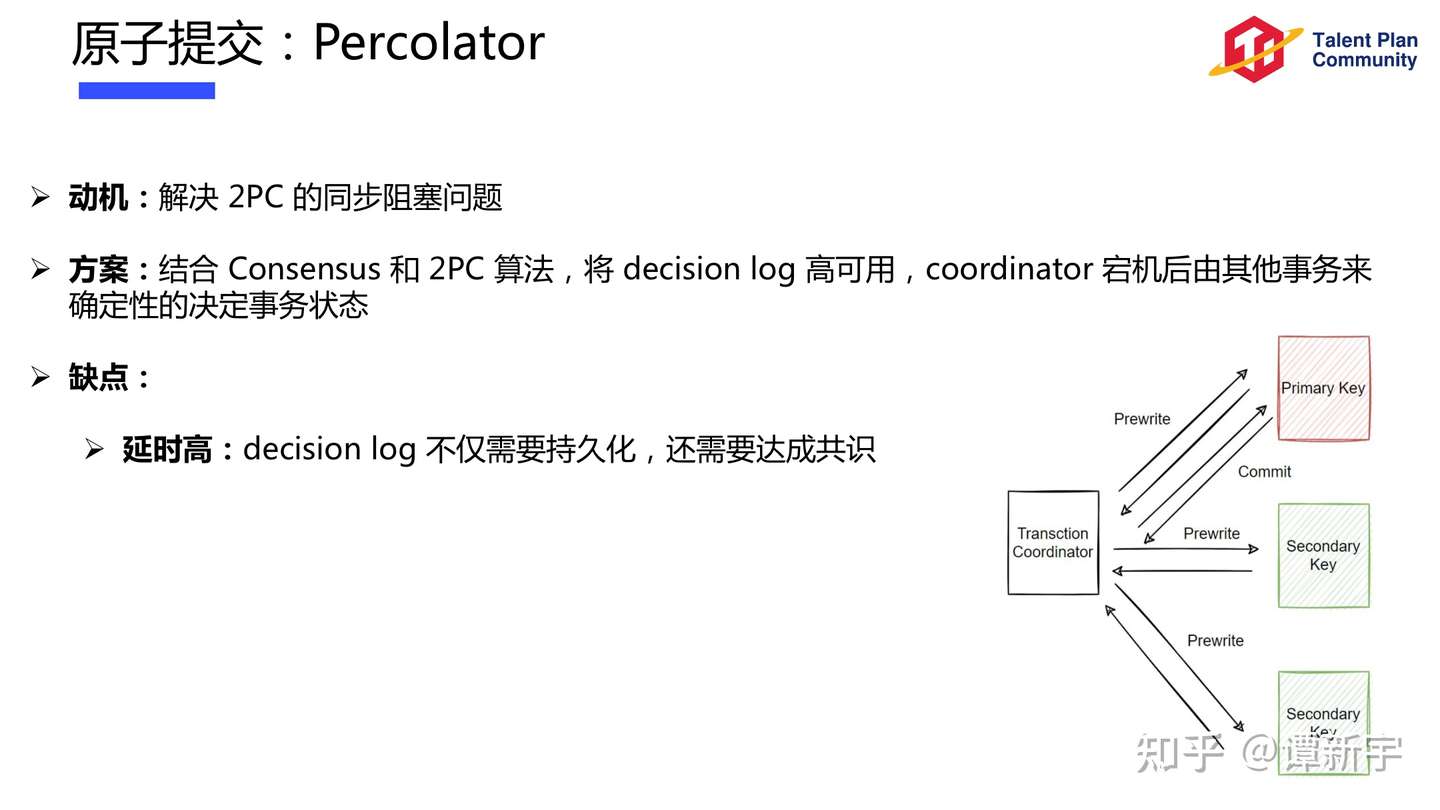
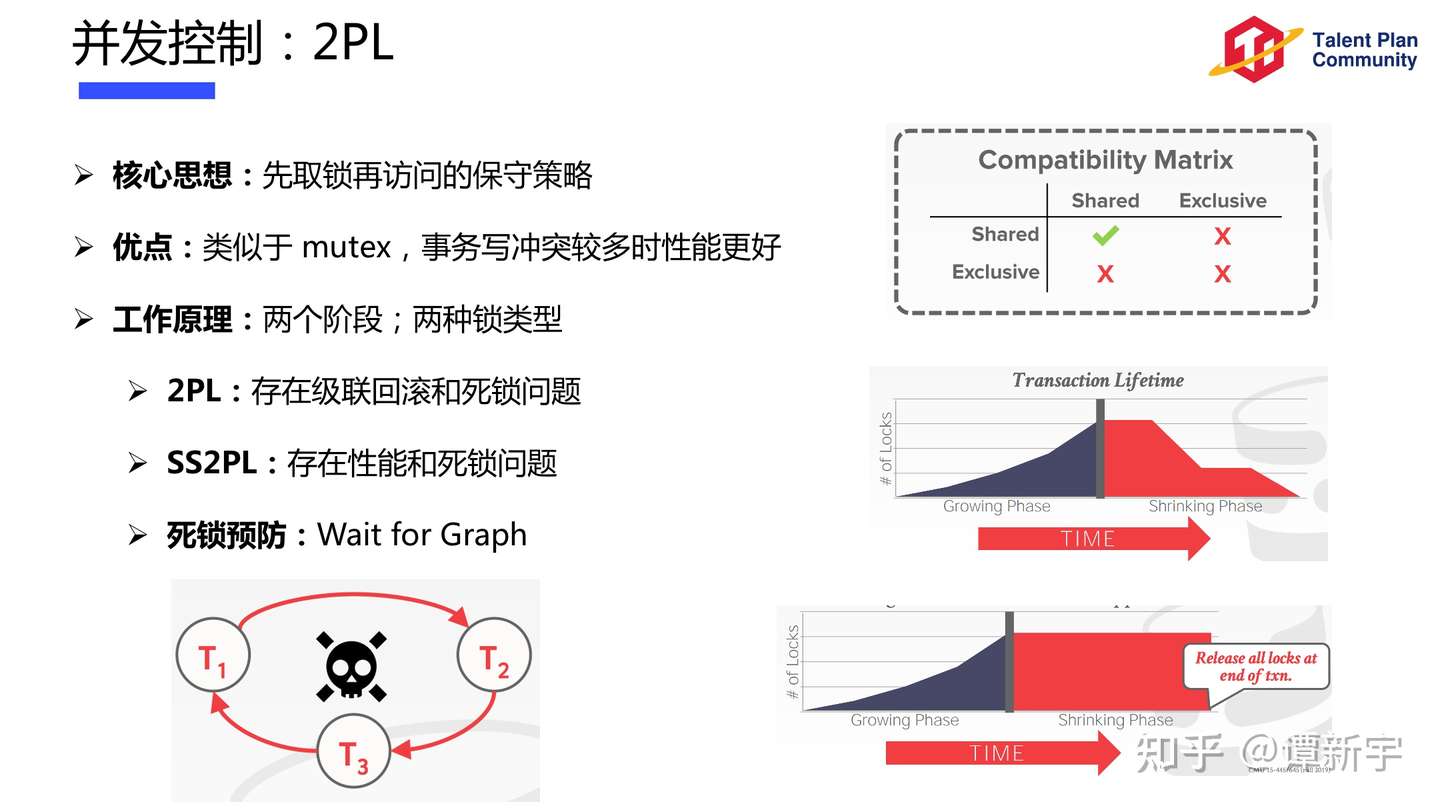
Consensus Protocol
Replication
Fault Tolerance and Reliable Multicast
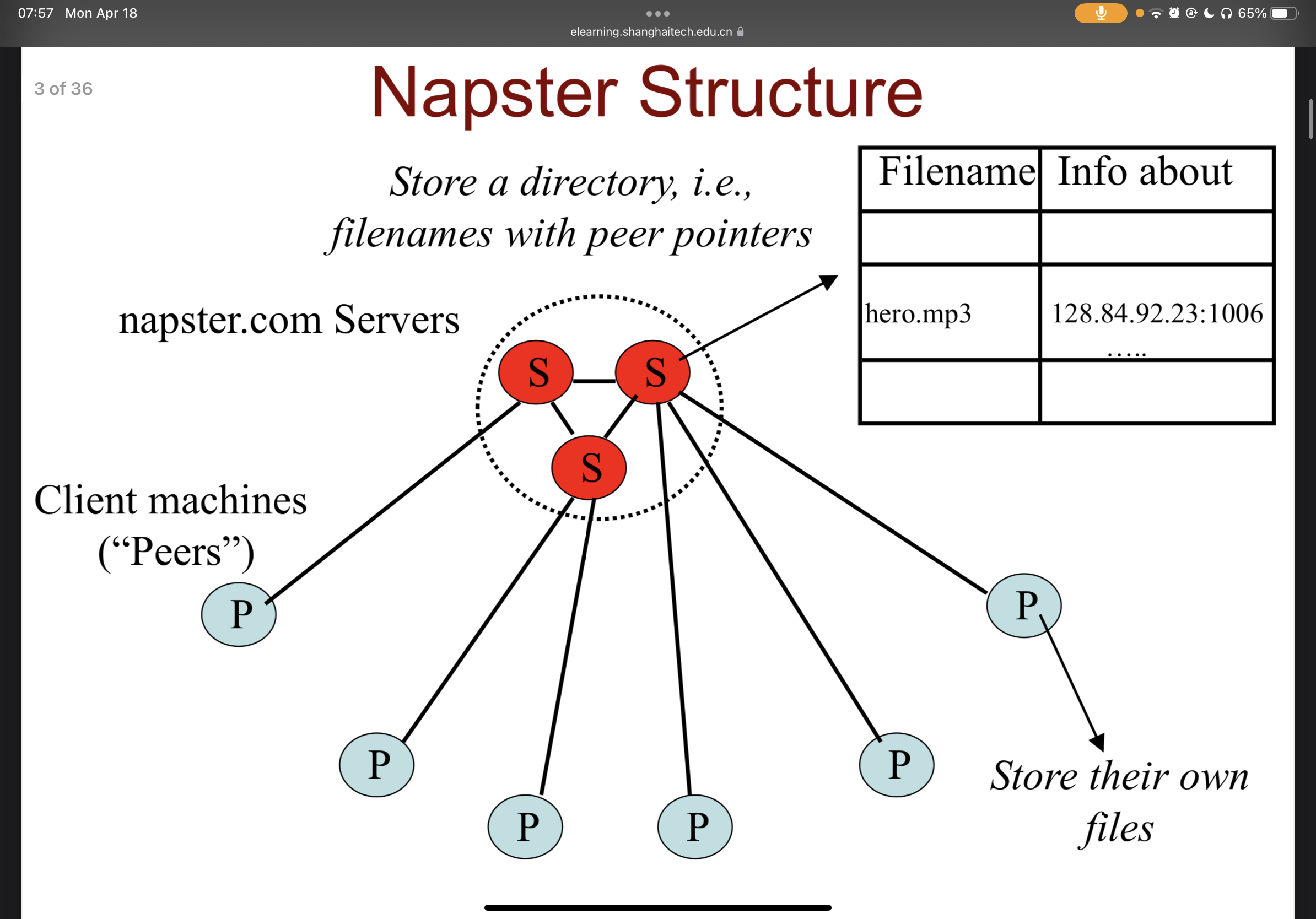
P2P System
Provenance:
Specialized
light-weight
easy-to-use software to enable Internet-scale file sharing
Data-intensive Computing: Massive
Some Examples
Google MapReduce
Yahoo Hadoop/PIG
Data parallel computing
IBM Research System S
InfosphereStream product
Continuous Data stream processing
Microsoft Dryad/ LINQ
DAG processing
SQL query support
Google Infra
Distributed file systems: GFS
Distributed storage: BigTable
Job scheduler: the work queue
Parallel computation: MapReduce
Distributed lock server: chubby
Map Reduce
A user-specified map the function processes a key/value pair to generate a set of intermediate key/value pairs.
A user-specified reduce function merges all intermediate values associated with the same intermediate key.
Cloud Computing
Cloud Compute
AI for systems
AI for IT operations. AIOps combines big data and ML to automate IT operations processes.
digital economy - increasing complexity of modern application arch.
no manual intervention
increased automation and faster remediation
The proliferation of monitoring tools makes analytics challenging
The use of disparate monitoring tools makes it extremely difficult to obtain end-to-end visibility across the entire business service or application
72% of IT organizations rely on up to nine different IT monitoring tools to support the modern application.
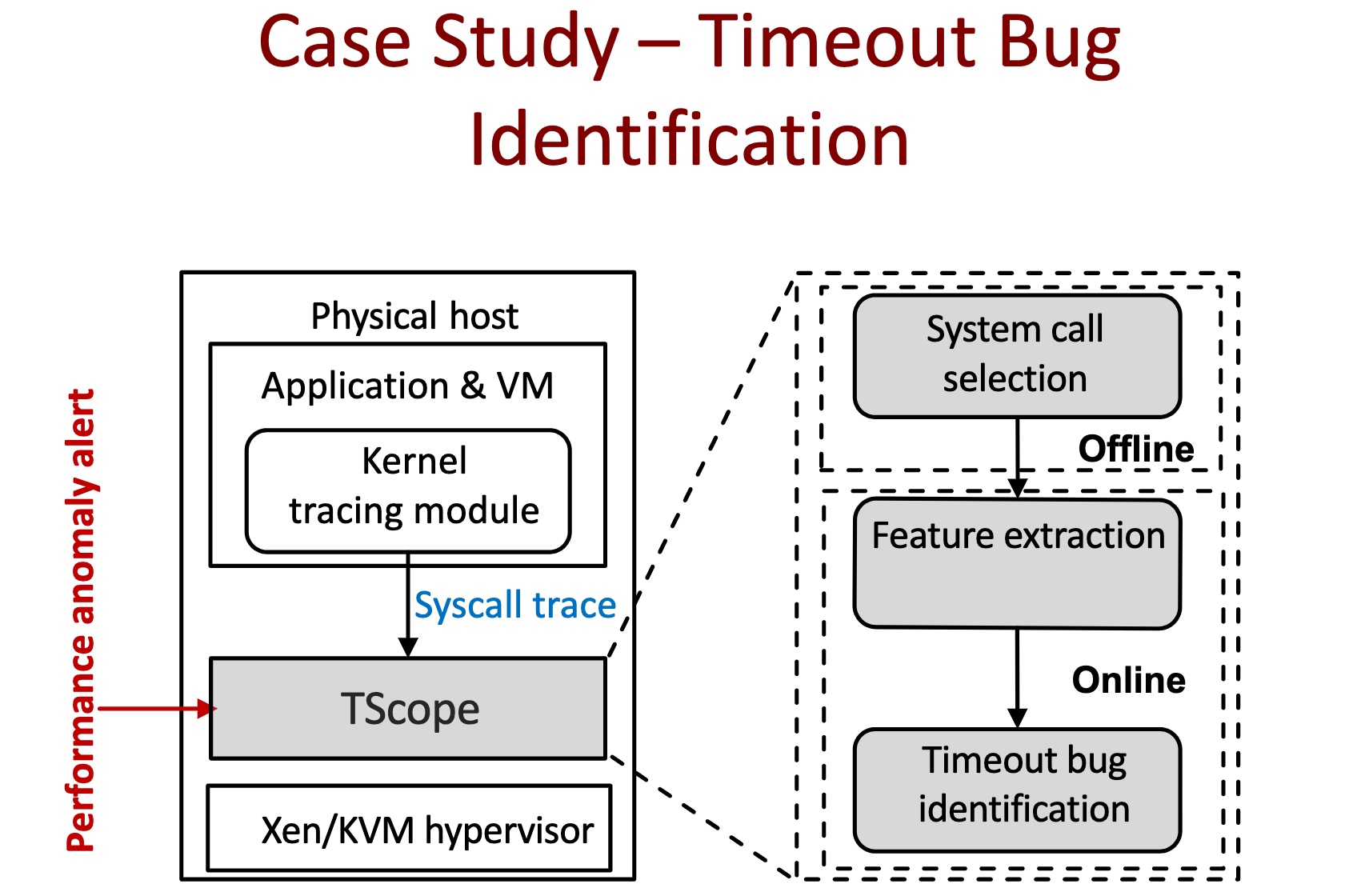
Case Study
Use un-supervised data to dig the vast majority of DevOps data.
runtime timeout bug identification tool.
Combines timeout-related feature selection and runtime anomaly detection to achieve higher precision.
does not require any application instrumentation for bug detection.
Evaluates over 19 performance bugs and identifies 18 of them.
The final repo is stored at gitlab, added some hash function to the original algorithm.
Dear Professor, I’m Yiwei Victor Yang 2018533218 from your parallel computing class. My teammate and I are struggling in selecting the project. I proposed to set up a projects transplant of a CPU LSH-Deep learning (https://github.com/keroro824/HashingDeepLearning/tree/master/SLIDE), which is a technique newly proposed by Rice University and Intel co, ltd to utilize the avx512 instruction set and huge pages intrinsic in locality sensitive hashing which is the main overhead of the project. ( https://arxiv.org/pdf/1903.03129.pdf)
SLIDE is a project to reimplement BP on the CPU. After the LSH pre-processing, the paper proposed to utilize maximum inner product search (MIPS) which mainly do the Sparse matrix operations- Sparse Backpropagation or Gradient Update.
After the update of weight stored in CSR format Spmv, the paper do the Batch computing by OpenMP.
As research in the paper, we can see that the main overhead is pre-processing on CPU avx512 with huge pages cache-heap optimization on, which gained around 30% faster than the raw GPU Tesla V100. If we transplant that part(dynamic hashing) in GPU which is said not applicable by the author from intel, I think it may have a 50 percent chance to be faster than the current CPU version. As the paper’s reference paper puts it: it gains something like 2 times faster after porting to Cuda, which triggers conflicts. https://github.com/src-d/minhashcuda
Our proposal is to make a comparison amid the raw Tensorflow on GPU, SLIDE on avx512, and SLIDE on GPU using the dataset mentioned in the paper.
My question is whether the transplant of the CPU dynamic cuckoo in the SLIDE do you think can have real speed up than the original version and if we attempted to transplant the program and get little speed up, will we eventually get the score?