

本篇是《A Primer on Memory Persistency》这本书的中文阅读笔记,会整理出我认为重要的部分。当年看《A Primer on Memory Consistency and Cache Coherence》的时候,被其对内存的描述惊艳到了,也是我对内存提起兴趣的最重要的原因。上CA2的时候对这几本书翻了又翻。
Persistent Memories Intro
现有的PM存储的hierachy。Jishen Zhao发的一篇LENS/VANS把每个PM的组件的延时和硬件的处理方式(尤其是XPBuffer的语义)用模拟器的形式写出来,才让大家对于PM有更深刻的理解。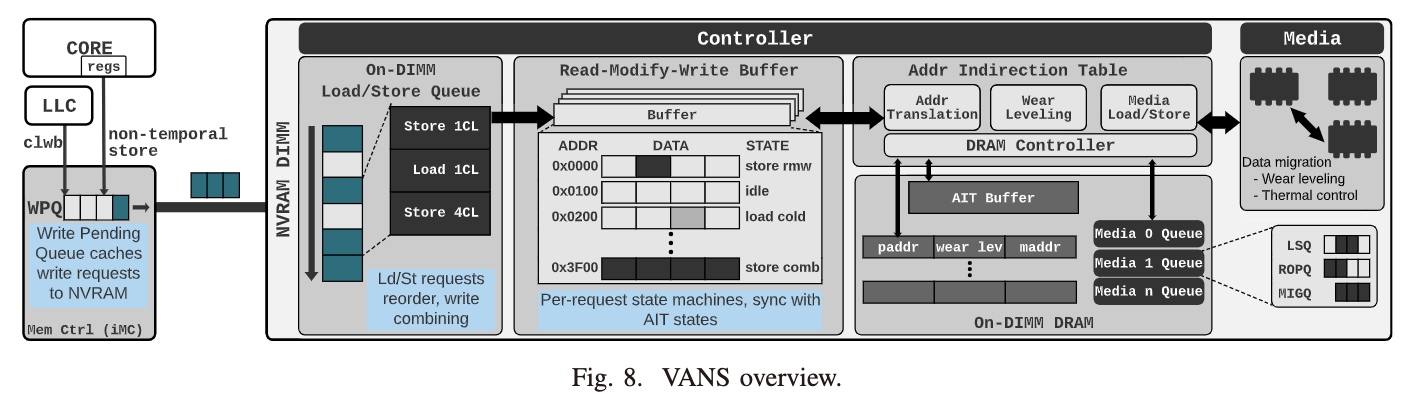
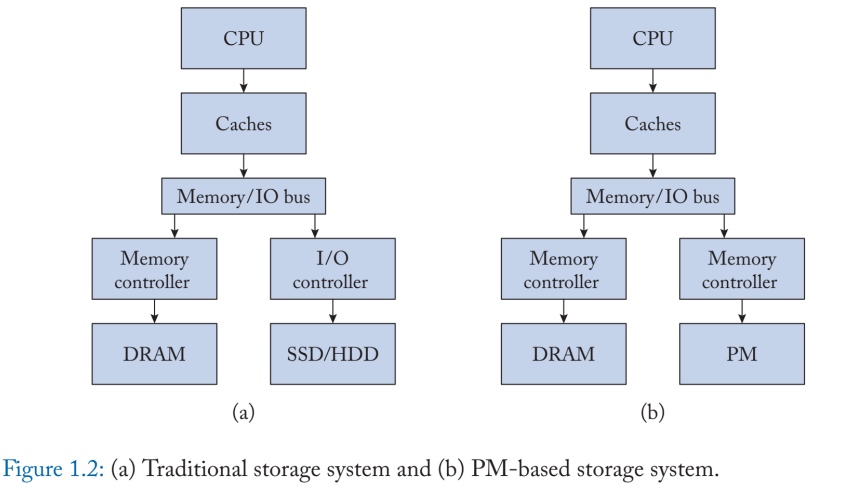
对于传统的一个文件的读取,要不是EXT4-DAX,通过pmem_clflush的方式持久化在PM上,但是有4K atomicity的问题。现有的文件系统的方向大多是在硬件性能提升的状态下,软件的开销占据了主导地位,以前的bdi的模式、VFS的层数开销,已经影响到PM性能的释放,同时前人对于DRAM以large footprint,page cache etc的访问形式也不适用于时延相对高的PM。
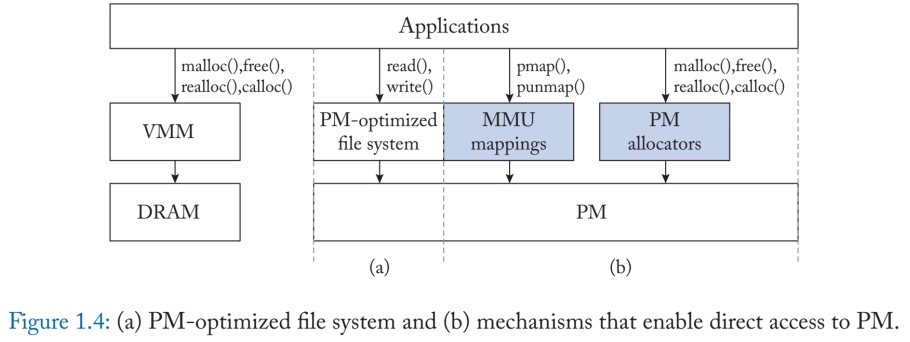
传统的文件系统是以块为单位进行访问的。例如,对于每个写操作,他们从存储设备中获取一个块到DRAM中,执行更新,然后将数据块冲回存储。另外,PM优化的文件系统可以执行就地的数据操作,没有不必要的内存拷贝,粒度也很细。NOVA就是这样一个为PM优化的文件系统的例子。它的性能比Linux ext4文件系统好10倍。另外还有些利用PM特性的 工作,如NV-Heaps、Mnemosyne和PMTest。
Data Persistence
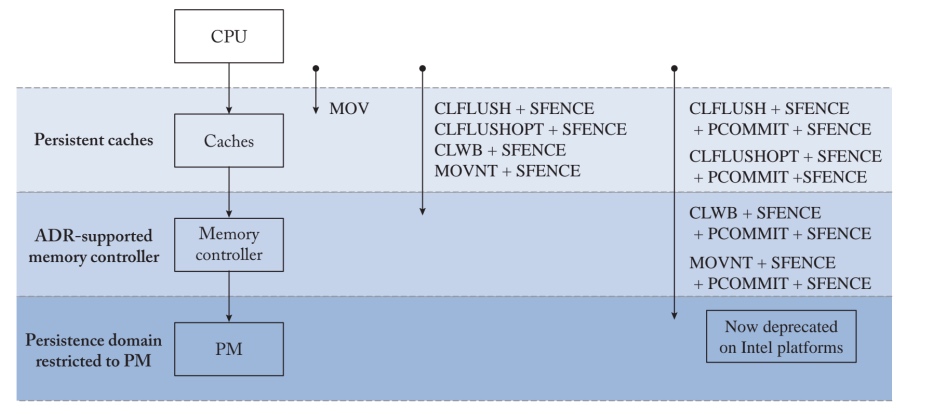
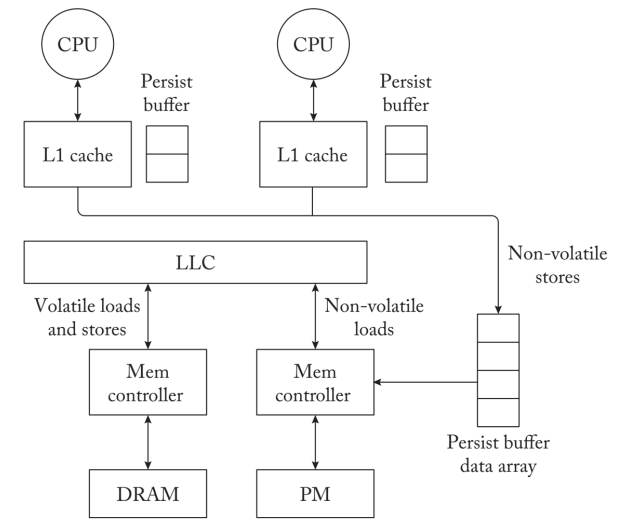
ADR(Asynchronous DRAM Refresh) supported controller 已经被Intel删掉了,因为第一版的实现问题,和第二版的eADR。Controller为了保证crash atomicity,intel 把已经到达iMC的操作都可以保证断电一致性。而不是对CPU可观测的ADR。对于其他内存上的操作,Intel x86平台上的MOV操作在其更新被写入L1缓存时就完成了,并保证了数据的持久性。Intel提供了几条指令,可以一起使用来Fluash到PM控制器。在最近的Intel x86平台上,CPU可以使用CLWB、CLFLUSHOPT或CLFLUSH指令将易失性回写缓存中的更新冲到PM控制器上。缓存线回写(CLWB)指令冲刷更新,同时在回写缓存中保留缓存线的干净副本。优化的缓存刷新(CLFLUSHOPT)指令与CLWB类似,只是它在向PM控制器刷新缓存行的时候会使其失效。尽管CLWB和CLFLUSHOPT都可以用于数据的持久性,但CLWB指令通过在高速缓存中保留数据的副本来实现更好的性能。因此,CLWB指令保留了应用程序访问的时间定位,因为对同一位置的任何后续内存操作都会导致高速缓存命中。CLWB和CLFLUSHOPT本身并不能保证数据的持久性。例如,如果冲洗操作没有到达ADR支持的PM控制器,任何正在进行的CLWB操作在断电时可能会丢失。如图2.1所示,需要一个后续的SFENCE指令来保证前面的CLWB操作的完成。因此,执行CLWB+SFENCE(或CLFLUSHOPT(在cascadelake以前此操作与CLWB一致)+SFENCE)序列可以保证更新被持久地写入PM控制器。与CLFLUSHOPT类似,CLFLUSH将脏的缓存行冲到PM控制器中,并使缓存行失效。对同一内存位置的后续访问会导致一个强制性的高速缓存缺失。然而,与CLFLUSHOPT不同的是,CLFLUSH实现了一个隐含的barrier操作,保证在发出任何后续的内存操作之前完成冲刷操作。另外,MOVNT也可以被用来持久地执行更新。非时序存储完全绕过了易失性缓存,直接对PM控制器进行更新。由于更新没有被缓存,非时间性存储未能利用内存访问的时间定位性。随后的内存访问在缓存中错过,需要从PM中获取数据。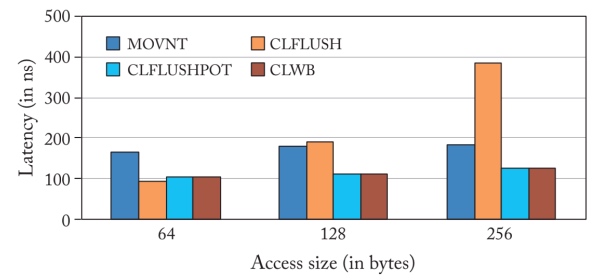
对于ARMv8.2的拓展
ARMv8.2有 DC CVAP 指令,相当于Intel x86的CLFLUSH。但是完全没有aware ADR。
持久化数据结构书写
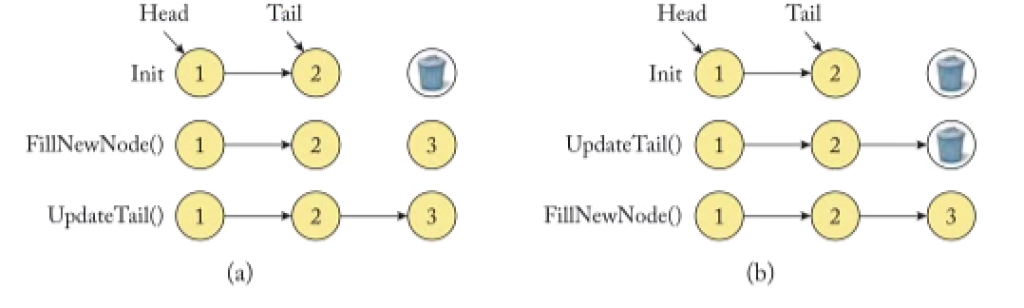
对链表进行append操作的例子,显示了为什么内存操作需要对PM进行排序以实现正确恢复。(a)对链表的追加涉及到创建一个新的节点,然后更新指向新创建的节点的尾指针;(b)两种操作重新排序的情况;尾部指针的更新发生在用有效值填充新创建节点之前。
书写持久化数据结构需要考虑内存持久化顺序和观测顺序。假设链接列表的操作在映射下来到PM位置的两个存储操作。为了正确的恢复,存储到内存位置A的操作必须发生在存储到内存位置B的操作之前。假设,内存位置A和B位于回写缓冲区的不同缓冲线上。1, 2 CPU对回写缓冲区执行两个操作。这两个操作在缓存线被更新时完成。脏的高速缓存线可能会在未来的某个时候懒洋洋地把它们的内容写回给PM,这可能是由于高速缓存线冲突。(3) 由于冲突,缓存将位置B的更新写回给了PM。位置A的更新仍然停留在易失性回写缓存中。4 失败发生了,擦除了高速缓存中的易失性内容,包括位置A的更新。失败后,位置B的更新在PM中,而对A的更新则丢失了。因此,由回写缓存引入的内存重新排序破坏了链表。
现代的处理器、编译器和软件系统引入了许多对程序员来说是透明的这种内存重排的来源。ROB、Write Buffer和Write Back Cache可能会重新排序PM操作。在易失性片上缓冲器中的任何in-flight operation也可能将内存操作重新排序为PM。编译器包括许多优化,以提高重新排序指令的生成代码的性能,包括通过重新排序的内存操作。几个常用的编译器优化,如常数传播、循环不变的代码传播和常见的子表达式消除,对程序员来说是透明的,可以重新排序内存操作。
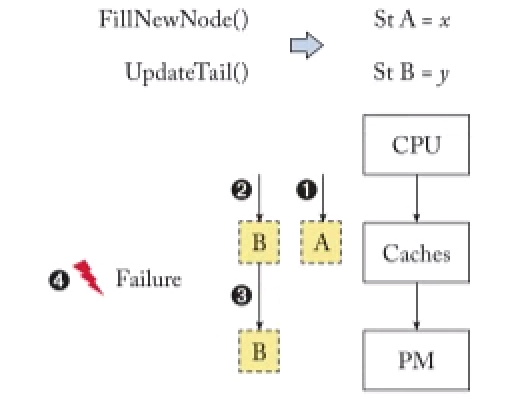
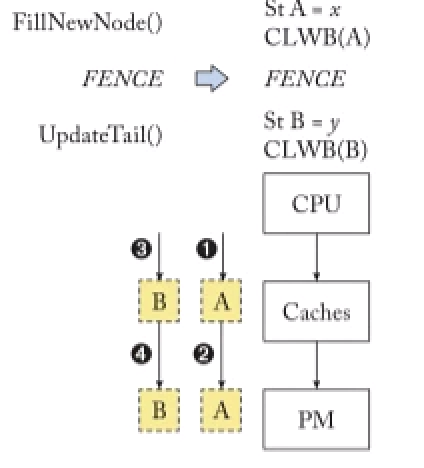
对于这个的修复,Ian的HIPPOCRATES及最新的ASPLOS22的华科的自动修复工作都有涉及。本质上就是在两次CLWB中加fence,修复的工作比较偏软工。前两天看的rvwmo的一个talk,里面提到了Operational(事务性) VS. Axiomatic(公理性)。前者就是通过定义一个类似MESI CC的自动机,所有的状态转移都被定义在这个状态机内,如果包含了所有可能就说这是一个对内存model的验证与证明,如后面提到的证明以及TM的x86语义证明,而后者是给出类似rvwmo的13条规则,如果满足公理条件就是满足内存序定义,CPU实现和C++程序(atomic/memory_order)实现都需要参照此手册。
Memory Persistency Model
之前定义的memory persistency model没有考虑体系结构的ROB、Write Buffer和Write Back Cache。其persistency consistency model,尤其是不同核心对同一个cacheline的观测序是不一样的,这就需要一套完整的model来定义。持久性模型规定了内存操作如何持久化到PM的顺序要求,类似于内存一致性模型定义内存操作在共享内存中的可见顺序。Pelley将持久性模型分为三类:strict persistency, epoch persistency, and strand persistency。这些持久性模型在其可编程性、复杂性和它们所能实现的性能方面有所不同。严格持久性更简单,更容易编程,允许在PM中进行直观的内存排序,但有很高的排序开销。相比之下,epoch和strand persistency放宽了PM操作的顺序,消除了冗余的排序开销,并实现了更高的性能,但却很复杂,不直观,并带来了很高的可编程性负担。epoch和strand持久性模型类似于宽松的一致性模型,它对共享内存中的内存操作施加最小的排序约束,但需要复杂的编程注释。持久性模型为硬件和底层软件提供了一个框架,以便对PM操作进行排序。我们在本章中讨论了这些模型,将其形式化,并定义了其硬件实现。
数据恢复的观测者问题
恢复机制要求对PM的持久化操作是有序的。如果没有对持久化的排序约束,持久化数据结构在故障后很容易出现数据损坏。持久性模型规定了对PM的内存操作的顺序。具体来说,持久性模型定义持久性内存顺序,以指定正确恢复所需的排序约束。这类似于内存一致性模型,它引入了对易失性内存顺序所定义的内存操作的可见性的约束。一致性和持久性模型并存,以指定PM操作的可见性顺序和持久性顺序的不同关系集。这两种模型可能会对内存操作施加一套不同的顺序约束;在持久性模型下,持久性可能是并发的,但相应的存储操作的可见性可能受到一致性模型的约束。同样地,更严格的持久性模型可能会将内存操作的顺序序列化为PM,但如果系统的一致性模型允许,它们可能会不按顺序发生在易失性共享内存上。
一致性模型定义了多个内核访问共享内存位置时允许的内存行为。与一致性模型(只适用于多处理器系统)不同,持久性模型必须定义单核和多核系统的PM状态:故障可能发生在单核系统中,并将任何内存重新排序暴露给recovery。
为了推理故障后的PM状态,引入了恢复观察者的概念,它在故障后原子化地观察PM的全部内容。恢复观察者可以被概念化为一个假想的执行线程,它与另一个处理器上的故障前执行同时进行,并可以观察到持久化的顺序。正确恢复所需的持久化器的排序约束意味着相对于恢复观察者的持久化顺序。这些持久者在PM中是由持久性模型来排序的。与此相反,在持久化模型下,没有相对于恢复观察者排序的持久化可以被同时发布。这些持久化器可以以任意的顺序排到 PM 中。
与只适用于多处理器系统的一致性模型不同,恢复观测器的概念可以扩展到单处理器和多处理器系统。任何核心执行的持久化都可能与恢复观察者的概念观察形成数据竞赛。在发生故障的情况下,恢复观察者可能观察到违反正确恢复所需的排序约束。在PM上运行的单核和多核系统必须遵循持久性模型所定义的排序约束。
持久性模型将正确恢复所需的持久性排序要求从其实际实现中抽象出来。它规定了一套高级程序可以依赖的排序保证;硬件实现可以实现优化(例如,持久性重新排序和凝聚),只要它们正确地履行持久性模型规定的排序要求。持久性模型可以分为严格的、时代的和链式的持久性模型。严格的持久性提供了一个直观的设计,但要付出很高的性能代价。像宽松的一致性模型一样,历时性和链式持久性模型以简单性为代价,以实现更大的持久性并发性(从而实现更高的性能)。接下来我们将详细描述这些模型中的每一个。
严格持久性
The persistent memory order is identical to the visibility order of memory operations.
对于这种持久性要求,PM的顺序继承可见的store order,即如果系统是SC/TSO,那么对持久化内存也是SC/TSO。一些显然的WB cache WC/Reorder优化也是不可取的。对于RMO来说,persistency不用被barrier间隔,保证了memory concurrency,但是barrier stall until prior persists drain to the PM还是很耗时间。主要是为了保证visibility和persistency order一致。
Buffered 严格持久性
在内存持久化到PM上间有一个buffer,可以抹平严格持久化顺序带来的直接停顿。持久状态仍然按照严格的顺序(由它们的可见性定义)排到PM,但是在前面的持久状态排到PM之前,执行不需要停顿。例如,具有SC或TSO一致性模型的缓冲严格持久性模型仍然要求持久性按程序顺序流向PM。然而,根据一致性模型,在其他内存访问变得可见之后,持久性可能会被buffered或drained。在发生故障的情况下,恢复可能会观察到比处理器观察到的最新状态更早的程序状态。
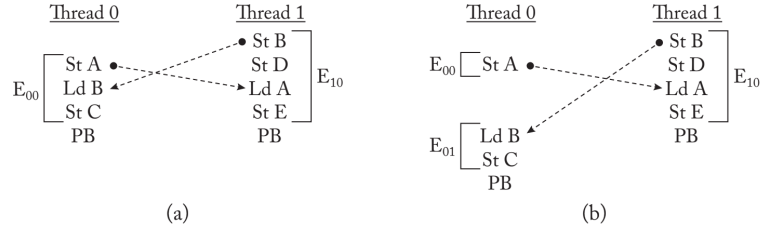
严格持久性的formal model
- $M_{x}^{i}:$ 线程i 对 $x$ 地址读写
- $L_{x}^{i}:$ 线程i 对 $x$ 地址读
- $S_{x}^{i}$ : 线程i 对 $x$ 地址写
- $P B^{i}:$ 线程i 发起的persistent barrier.
为了保证Volatile(可见性) memory order和persistent memory order的关系
$M_{x}^{i} \leq_{v} M_{y}^{j} \rightarrow M_{x}^{i} \leq p M_{y}^{j}$
可持久化的例子
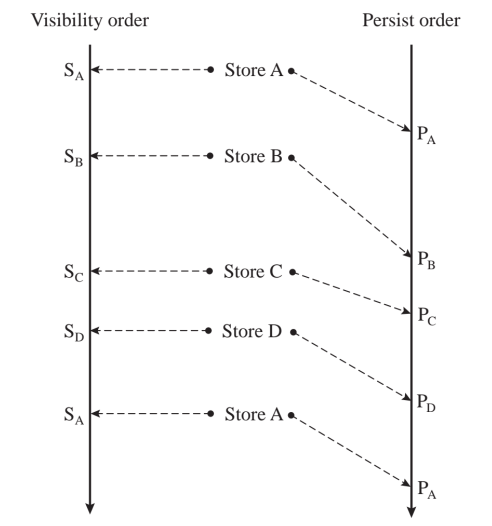
在SC严格持久性例子中,ABCD的store不会重排且visibility order保证persist order一致。对于bufferd 严格持久性例子,$P_B/P_C/P_D$可能会couple在一起persist。
硬件实现
- Naive: 维护一个顺序队列,如果不是队列首就stall到等到顺序队列的时候。
- Joshi: 具有顺序一致性的缓冲严格持久性模型;该设计将更新序列化到PM,但更新是批量发生的,以最小化持久性的关键路径。
- Armv7 RMO: Decoupled persist order实现了一个缓冲严格持久性模型,它提供了跟踪ARMv7一致性模型所强制执行的线程内和线程间排序依赖的硬件结构,并使用它们以正确的顺序持久drain。
Bulk Persistency
Bulk取自数据库的bulk loading,即自左向右,自上向下的load,用日志以保证执行顺序的正确性,这里也类似,用batched 请求,在batch里面做logging以保证atomicity。
Armv7实现
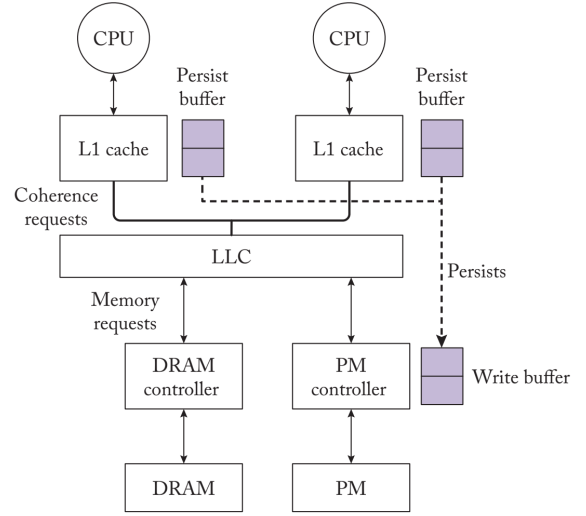
L1 cache 和PM controller 都有对应的buffer,DPO buffer监控数据和一致性请求例如一个核心发出的FENCE请求,需要在这个时间戳以后的内存脏数据同步,以保证线性依赖。在Armv7中,对不同线程的相同内存位置的存储是有顺序的。DPO规定,两个持久化程序以其一致性顺序发生在PM上。持久化缓冲区检测传入的独占读请求,这些请求可能在正在进行时steal缓存块的所有权。
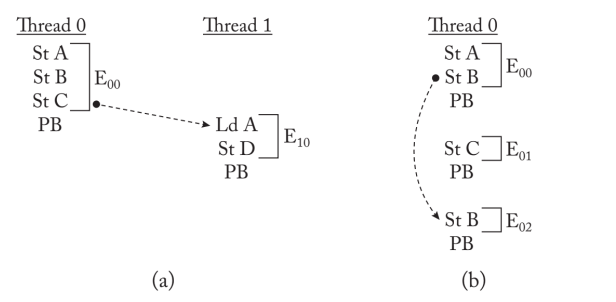
例如,当CPU 1试图从CPU 0窃取一个脏缓存块的所有权时,就会检测到冲突。CPU 0的持久化缓冲器对CPU 1的一致性响应进行注释,以记录这种持久化依赖。该注释阻止了CPU 1的持久化在CPU 0的持久化之前耗尽。CPU 1解决了持久化依赖,并在观察到$mathrm{CPU} 0$耗尽其持久化时清除了注释。0$通过窥探网络将其持久化数据耗尽到$mathrm{PM}$。因此,当线程内和线程间的依赖关系得到解决时,持久化缓冲区会将持久化数据排到PM。
严格持久性的缺点
严格的持久性和严格的一致性模型,一起将内存操作序列化到PM。由于持久化序列化到PM,内存延迟位于程序执行的关键路径中。串行化也不允许任何重新排序和coalesce PM操作的优化。严格的持久化模型与宽松的一致性模型,如ARMv8的RMO,可以实现更高的持久化并发性。被内存障碍物隔开的持久性是有序的,但是那些没有被barrier排序的持久性可以并发commit到PM。然而,这些模型也会在每个内存屏障处停滞程序的执行,直到之前的持久化完成。
缓冲的严格持久性模型允许异步放出持久性数据到PM。然而,只有当CPU发布持久化数据的速度低于向PM的速度时,缓冲模型才会有效。如果缓冲区被填满,缓冲模型就会出现与严格持久性模型类似的性能瓶颈。到现在为止PM的延时还是堪忧。
Epoch 持久模型
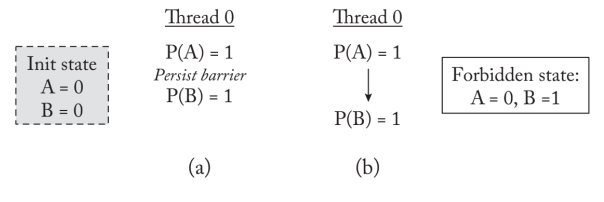
epoch持久化模型提出了一个宽松的模型,它允许更高的持久化并发性,而不是由系统的一致性模型对相应的内存操作的可见性限制所允许的那样。因此,历时持久性将持久性的顺序与内存操作的可见性解耦。内存操作的可见性继续遵循一致性模型所定义的顺序。与此相反,持久化的内存顺序对持久化操作实施排序约束,这可能与内存操作的可见性顺序不同。为了使持久化顺序与可见性脱钩,程序员必须对程序进行注释,以表明操作可以持久化到PM的顺序。
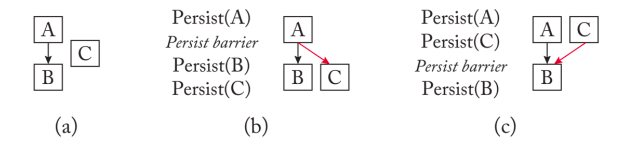
epoch持久性模型使用持久性障碍对持久性进行排序。持久性障碍将执行划分为历时;持久性顺序是以历时为单位进行管理的。位于同一epoch持久化可以重新排序或平行发生。那些被持久化障碍分开的持久化必须按照它们的程序顺序发生。失败时,恢复不会观察到来自不同epoch持久化程序失序。也就是说,如果先前的历时中的任何持久化不可见,那么恢复观察者就不会看到后续历时的持久化。
在历时性下,持久化障碍对内存操作的可见性没有影响。只要内存一致性模型允许,位于不同历时中的内存操作可以不按顺序可见。持久性模型只限制了持久性的顺序,而持久性的顺序可以排到PM中。图3.4a显示了使用持久化屏障将持久化数据发送到PM位置$\mathrm{A}$和$\mathrm{B}$的示例代码。到$\mathrm{A}$和$\mathrm{B}$位置的持久化被一个持久化屏障分开。
强持久化原子性
epoch可以保证强持久化性,但同时是一个宽松的模型,允许更高的持久化并发。因此,历时持久性将持久性的顺序与内存操作的可见性解耦。内存操作的可见性继续遵循一致性模型所定义的顺序。与此相反,持久化的内存顺序对持久化操作实施排序约束,这可能与内存操作的可见性顺序不同。为了使持久化顺序与可见性脱钩,程序员必须对程序进行注释,以表明操作可以持久化到PM的顺序。
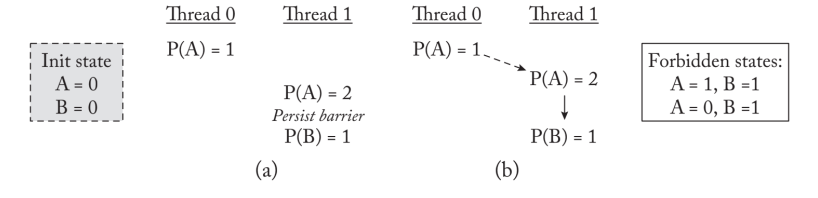
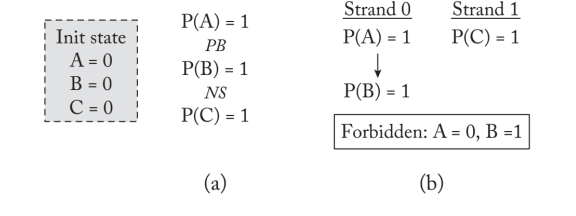
只要内存一致性模型允许,位于不同历时中的内存操作可以不按顺序可见。持久性模型只限制了持久性的顺序,而持久性的顺序可以排到PM中。上图P(A)=2与P(B)=1间有barrier,保证了thread2的A=1,B=1/A=0,B=1的两个状态被拒绝。
Buffered epoch 持久化顺序
同样适用于抹平由于persist barrier导致的stall而设计的,尤其在小epoch下,严重程度和严格持久性模型一致。在加了一个bufer 和write back buffer后,仍然需要保证epoch的drain到PM的顺序。epoch允许持久性状态滞后其执行。程序的执行在持久化障碍之后继续进行,以便在随后的epoch中执行内存操作。后续的更新可以在易失性共享内存系统中进行。在失败时,在缓冲区的epoch持久性下,恢复被允许观察程序在PM中的早期状态,但它可能永远不会观察跨epoch持久性重新排序。也就是说,如果先前的历时的持久性对恢复来说是不可见的,那么随后的历时的持久性可能是不可见的。缓冲模型消除了每个持久化障碍的长延迟停顿,只要硬件有足够的缓冲来提升正在进行的不完整持久化。基于我之前的实验,Intel Optane DC 一代是这种持久化顺序。
epoch持久性的formal model
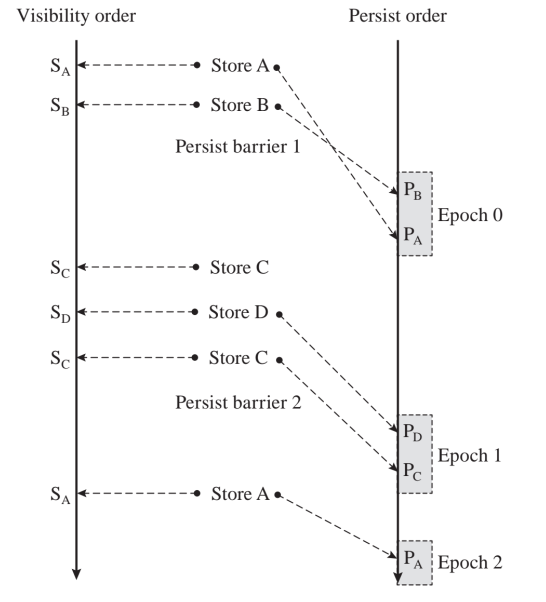
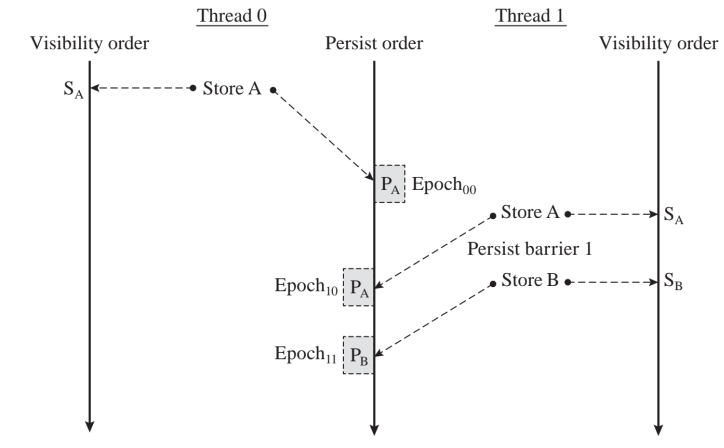
线程对内存读写定义与上文一致。在VMO下的顺序为 $M_{x}^{i} \leq_{v} M_{y}^{i}: M_{x}^{i}$,在PMO下的顺序为$M_{x}^{i} \leq_{p} M_{y}^{i}: M_{x}^{i}$这里需要添加三个axiom:
- Intra-thread persist order: $M_{x}^{i} \leq_{v} M_{y}^{i}: M_{x}^{i}$, 在epoch内的持久化的顺序可能在VMO上并行。
- Strong persist Atomicity:
$M_{x}^{i} \leq_{v} S_{x}^{j} \rightarrow M_{x}^{i} \leq_{p} S_{x}^{j}$
$S_{x}^{i} \leq_{v} M_{x}^{j} \rightarrow S_{x}^{i} \leq_{p} M_{x}^{j}$
用于拒绝掉不可能的states。
- Transitivity: $\left(M_{x}^{i} \leq_{p} M_{y}^{j}\right) \wedge\left(M_{y}^{j} \leq_{p} M_{z}^{k}\right) \rightarrow M_{x}^{i} \leq_{p} M_{z}^{k}$
epoch持久性的硬件实现
- Naive inplementation: 下一次epoch开始必须在上一次epoch完成之后。需要考虑几件事1.直接的CLFLUSH 2.Cache Replace Policy的Write back 同时要防止在write buffer里的OoO执行,naive的实现是每一个epoch后面都加SFENCE。同时epoch可以在iMC中被记录内存位置,同时做intra epoch的Write Combining。另外sw需要aware这个内存的改变,如Intel的CLWB。
- Buffered epoch 持久化硬件实现: BPFS是一个软工+数据库硬件化的实现,需要利用Intra-thread dependency的追踪来保证离线(BPFS导致的Lazy persistency)的冲突,在硬件实现的数据库里。
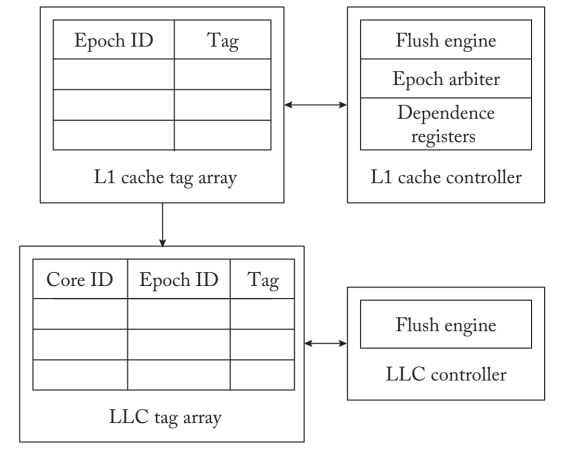
BPFS元数据来跟踪周期内和周期间的依赖关系。处理器为每个硬件上下文管理一个epoch计数器,以记录一个正在进行的epoch。当一个持久性barrier提交时,纪元计数器会增加。当每个$\mathrm{PM}$存储被传送到缓冲区时,处理器为其分配一个正在进行的epoch $\mathrm{ID}$。在相应的存储坚持到PM之前,该epoch $\mathrm{ID}$会通过缓存子系统传播。为了存储与每个更新相关的epoch ID,BPFS用一个epoch ID和与缓存行相关的持久性位来扩展每个缓存块。如果缓存行属于PM位置,则持久性位被设置。缓存控制器通过确保属于较年轻epoch的缓存行不从缓存中流失来执行epoch排序约束。当所有的缓存线从最老的epoch drain到$\mathrm{PM}$时,随后的epoch被允许drain。整个过程,BPFS不会主动找epoch的脏cacheline,但有冲突时,才会用intra-thread dependency resolve 原子性。保证顺序。
3. 把ordering和duribility barrier分开的方法: HOPS实现了持久缓冲区跟踪正在进行的更新。当处理器对L1高速缓存进行PM更新时,一个包含更新的高速缓存行的条目也被插入到持久化缓冲区。其他对epoch的管理类似BPFS。那些offence barrier 会在L1 cache中添加一个epoch ID。这是一个低延迟的操作,因为它不强制执行先前更新的persistency。任何后续的更新都会在持久化缓冲区中用更新的epoch ID来注释,因为它们属于后续的epoch。每个持久化缓冲区都会主动并发的刷新那些属于同一个epoch 到PM。
epoch持久性的缺点
它只将位于一个epoch内的连续持久化标记为并发。它并没有放松对位于不同epoch的持久化的约束。
Strand 持久模型
strand持久化模型允许程序员在持久化上指定任意的顺序。与历时持久性类似,它将内存操作的可见性顺序与持久化内存顺序解耦;内存操作的可见性由一致性模型管理,而持久性模型则将持久化发生在PM上的顺序编入其中。strand持久性模型管理strand内的持久性顺序。它将逻辑线程上的程序执行分为strand;持久化在strand内是有序的,但位于不同strand上的持久化是并发的。一个strand提供了一个独立的持久化流的抽象,这些持久化流碰巧位于同一个logical thread上,但可能会并发地发布给PM。strand 持久性添加了三个privmitive
- persist barrier: 在一个strand中是会排序持久化操作的,这与epoch类似。
- new strand: 一个新strand primitive会初始化一个strand,现在位于一个单独的strand上的后续持久化可以重新排序或与先前strand上的持久化同时被commit。持久性障碍并不对位于不同strand上的持久性进行排序。因此,就持久化内存的顺序而言,strand的行为是独立的逻辑线程。
- join thread: 一个连接strand primitive合并了先前的strand。任何被一个连接strand primitive分开的持久体都是有序的,即使它们位于不同的strand上。就持久化顺序而言,连接strand primitive的概念类似于合并先前逻辑线程的线程连接操作。连接strand primitive确保在发出任何后续持久化之前,先前的持久化已经完成。
强持久化原子性
与epoch类似,strand持久性模型也确保对相同或重叠的内存位置的持久性被序列化为PM。这些指向冲突的内存地址的持久化可以位于一个线程内的相同或不同的strand上,也可以位于不同的线程上。持久化内存顺序假定了强持久化原子性下的内存操作的可见性顺序。三个primitive的组合将强制执行持久化顺序。失败后的恢复可能永远不会观察到任何持久化的错误顺序;对于恢复来说,由一个strand内的持久化屏障排序的持久化,或者由一个连接strand分开的持久化,总是有序的。此外,在同一strand、不同strand或不同逻辑线程上的冲突持久化,通过强大的持久化原子性排序,被恢复观察到的顺序。
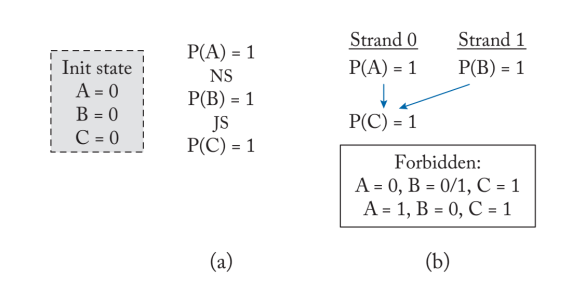


strand持久性的formal model
线程对内存读写定义需要添加
$N S^{i}:$ A new strand issued by thread $i$.
$J S^{i}:$ A join strand issued by thread $i$
在VMO下的顺序为 $M_{x}^{i} \leq_{v} M_{y}^{i}: M_{x}^{i}$,在PMO下的顺序为$M_{x}^{i} \leq_{p} M_{y}^{i}: M_{x}^{i}$这里需要添加三个axiom:
- Intra-strand persist order: $\left(M_{x}^{i} \leq_{v} P B^{i} \leq_{v} M_{y}^{i}\right) \wedge\left(\nexists N S^{i}: M_{x}^{i} \leq_{v} N S^{i} \leq_{v} M_{y}^{i}\right) \rightarrow M_{x}^{i} \leq_{p} M_{y}^{i}$, 在strand内的持久化的顺序可能在VMO上并行。$M_{x}^{i} \leq_{v} J S^{i} \leq_{v} M_{y}^{i} \rightarrow M_{x}^{i} \leq_{p} M_{y}^{i}$,在join thread primitive上需要排序在不同strand不同逻辑线程上的memory
- Strong persist Atomicity:
$M_{x}^{i} \leq_{v} S_{x}^{j} \rightarrow M_{x}^{i} \leq_{p} S_{x}^{j}$
$S_{x}^{i} \leq_{v} M_{x}^{j} \rightarrow S_{x}^{i} \leq_{p} M_{x}^{j}$
用于拒绝掉不可能的states。
- Transitivity: $\left(M_{x}^{i} \leq_{p} M_{y}^{j}\right) \wedge\left(M_{y}^{j} \leq_{p} M_{z}^{k}\right) \rightarrow M_{x}^{i} \leq_{p} M_{z}^{k}$
strand持久性的硬件实现
- Strand Waiver:
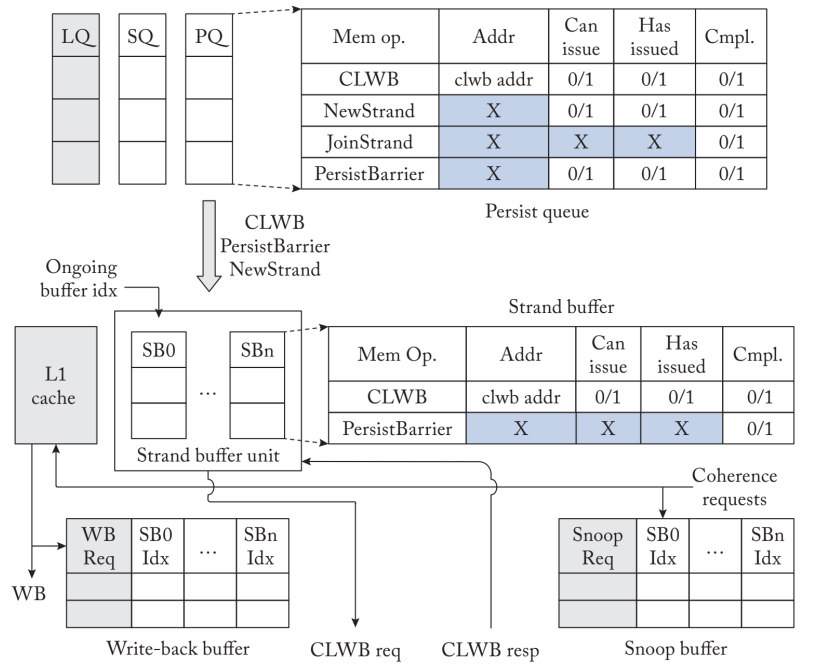
StrandWeaver在硬件中建立了strand持久性模型,将持久性约束到最小。它将易失性和持久性内存顺序解耦,即使系统建立在英特尔TSO这样的保守一致性模型上,也能放松持久性顺序。StrandWeaver实现了strand原语、persist barrier、NewStrand和JoinStrand作为硬件ISA扩展。它使用CLWB操作,将脏的缓存行冲到PM。当CPU收到PM控制器的确认时,CLWB操作完成。
图3.19$显示了StrandWeaver的高层结构。它的特点是持久化队列和strand buffer unit,共同执行持久化排序。持久队列与load-store 队列一起实现。它确保CLWB和存储操作按顺序发布到L1缓存中,并且由JoinStrand操作分开的CLWB按顺序完成。strand缓冲单元是在L1高速缓存旁边实现的,它管理持久化流向PM的顺序。它包括一个串联缓冲器阵列;每个串联缓冲器负责对串联内的持久化数据进行排序,并确保串联内被持久化障碍分开的持久化数据按顺序完成。它还监控一致性消息以保持线程间的持久化顺序。
持久化队列记录正在进行的CLWBs、持久化障碍、NewStrand和JoinStrand操作,并在它们的任何顺序限制解决后,将它们发布到strand缓冲单元。它与存储队列协调,以排序任何存储和CLWB,由一个strand内的持久性障碍分开。它也命令被JoinStrand操作分开的CLWB。JoinStrand使后续的CLWBs延迟发布,直到之前的CLWBs完成。当持久化队列收到来自链式缓冲单元的完成确认时,CLWBs、持久化屏障和NewStrand操作就完成了。
strand持久性的缺点
strand持久性明显好于intel x86 with PM的实现,所以我们有理由相信Optane DC第二代采用的就是这种方式。
原子持续性的硬件机制
PM编程要求在发生故障时,数据在PM中是一致的,以便能够恢复和恢复执行。恢复软件检查PM数据,确保数据一致性,并恢复系统。通过为一组PM的更新提供故障原子性,可以大大简化故障后的恢复。失败原子性确保在发生故障的情况下,所有的或没有的更新对恢复是可见的。它减少了故障时恢复可能观察到的状态空间。英特尔x86提供了对PM的8字节对齐更新的故障原子性。也就是说,在故障时,要么整个持续操作发生在PM中,要么PM位置保留其先前状态。恢复将永远不会观察到部分更新。
Failure Atomicity
为了保证写PM的大于8字节的操作不是故障原子性的问题,PM采用了文件Write Ahead Log/Shadow Paging/HTM等方法来保证这个问题。在eADR出现后,这个过程是硬件保证的,在硬件中提供故障原子性的机制主要集中在写前记录上,因为它更适合于缓存线粒度的随机更新。这些建议的主要目的是绕过软件的开销,在硬件中建立撤销和/或重做日志机制,同时暴露出了软件接口和编译器协同的机制。
Write-Ahead Log
在读写数据前先完成对log得读写,这样在一个读写周期中的所有操作都可以保证Failure Atomicity。这部分可以参考PVFS和Nova文件系统。
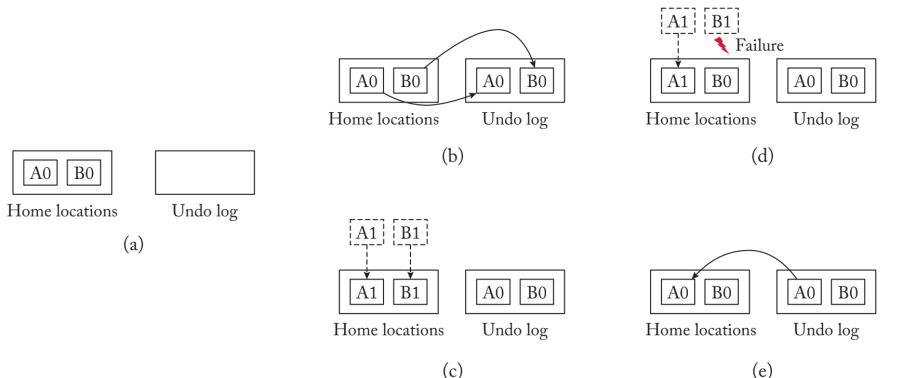
硬件实现的Undo Log
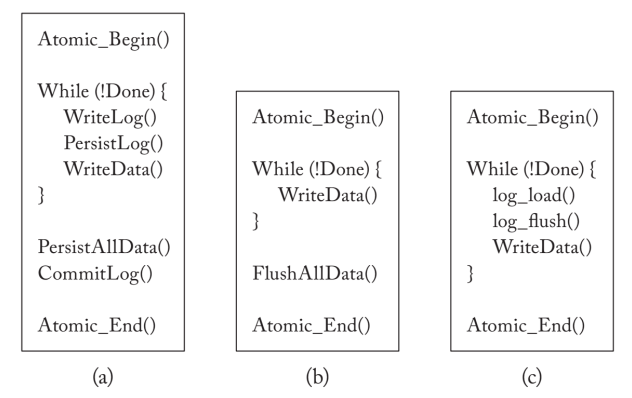
在ATOM中。Atomic_Begin 原语在硬件中启动了对故障原子区域中的更新的日志记录。Atomic_End会终止该区域并提交日志。ATOM仍然要求程序员在故障原子区域终止之前将原地更新冲到PM。这些基元提供了耐久性,但不是隔离性。ATOM依靠程序员对共享内存位置进行同步操作,避免数据竞赛。
下图显示了ATOM的硬件结构。ATOM在L1高速缓存旁边维护一个日志管理器,管理日志操作。操作系统在PM中初始化$log$空间,日志条目被写入其中。当处理器向L1高速缓存发出PM更新时,假设高速缓存中出现了命中,日志管理器会创建一个日志条目,记录PM位置的旧值和内存地址。它向PM发出日志条目并拖延原地更新的完成,直到它从PM控制器收到$log/$完成的确认。当日志条目持续存在于PM中时,就地更新会修改L1缓存。
处理器可以在一个故障原子区域内多次对同一个PM位置进行就地更新。对于正确的恢复,撤销日志记录PM位置的最旧值(区域开始之前的值)就足够了。ATOM避免了为同一PM位置的每次更新创建单独的$log$条目。它为第一次更新创建日志条目。ATOM在L1缓存中维护一个$log$位,当第一次更新的日志条目持续存在时,该位被设置。只要PM中的日志位被设置,它就不会为同一位置的后续更新创建日志。当然,如果缓存行在两个后续更新之间被驱逐(例如,由于缓存冲突),ATOM也会对第二个更新执行日志记录。在失败时,撤销日志以其相反的创建顺序被重放,以将PM状态恢复到部分完成的失败原子区域的起点。
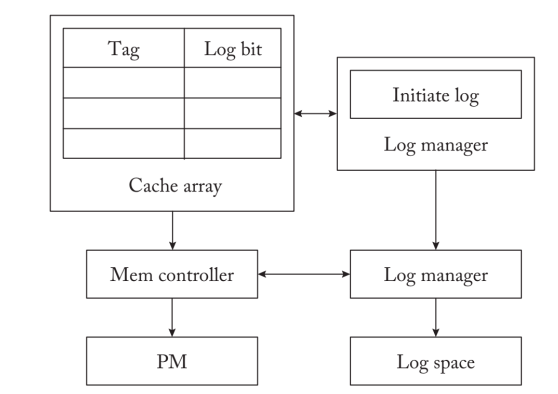
ATOM不需要PM Comptroller是ADR的,同时所有log 操作和读写操作不能reorder,这需要lock一条cacheline,如果有ADR的话这个操作不需要。在Cache miss时,ATOM会监控在log产生过程中的多余的数据迁移,并把它消除。
软件实现的Undo Logging
首先,需要建立了一个与L1高速缓存相邻的日志查询表,可能将日志操作凝聚到同一高速缓存行。日志查询表记录了正在进行的事务中最近发出的日志操作。如果之前对同一位置的操作存在于查找表中,Proteus就会丢弃该日志操作。这就防止了对时间上的本地PM访问的重复记录。
其次,Proteus做了一个有趣的观察,一旦写入,日志就不会在无故障的程序执行中使用。当一个正在进行的故障原子区域终止时,日志就会被废止。Proteus在支持ADR的PM控制器的$/log$待定队列中管理正在进行的$log$操作。当故障-原子区域终止时,它闪电般地清除了在该区域内创建的日志。Proteus优先考虑在日志之前对$P M$进行就地更新,这样日志等待队列就可以在PM控制器中被闪速清除,而不会被写入PM中。这保证了PM的写带宽主要被就地更新所利用。它还减少了对PM的写入流量,因为日志被丢弃在控制器中。减少对PM的写入可以减少其磨损,提高设备的使用寿命。
硬件实现的 Redo Logging
需要保证在redo log commits 之前没有inplace updates persist in PM。
redo logging日志机制在日志中记录PM位置的新值,在PM中保留旧值。当一个故障原子区域的所有更新的日志在PM中持续存在时,重做日志提交,新值从日志中复制到PM中的主位置。在失败时,PM中已提交的日志被用来重新应用更新到它们的原位置。未提交的重做日志在失败时被丢弃。
构建redo logging机制的硬件机制必须确保在重做日志提交之前,PM中没有原地更新持续存在。这些更新必须首先被记录在日志中。由于PM原点可能会记录陈旧的数据,硬件也必须将任何后续的加载重定向到日志空间,以找到最新的数据值。所有的加载操作必须探测日志条目,以检查更新是否存在于日志中。一旦错过,负载就会从PM中的原点读取最新值。硬件中额外的中介层增加了负载操作的延迟。随着需要探测的日志条目数量的增加,查找操作可能会越来越昂贵。
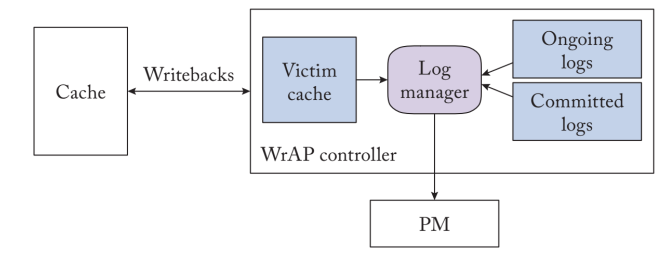
WrAP是一个硬件重做日志机制,确保重做日志在相应的就地更新之前持续存在,并消除了读取操作中昂贵的日志查询。图4.7$显示了WrAP的高级硬件架构。
WrAP为由atomic_begin和atomic_end原语限定的代码区域建立了故障原子性。它将PM中的日志空间作为重做日志条目的序列进行管理。每个原子区域的PM更新都会创建一个重做日志条目,并持有PM位置的新值和地址。在重做日志在PM中持续存在之前,WrAP不会停滞原地更新。它与重做日志同时执行对PM的更新,但将这些更新缓存在回写缓存中。它不允许就地更新从最后一级缓存中流出并更新PM中的原点。相反,它在受害者缓存中缓冲任何被LLC驱逐的缓存行。WrAP在LLC旁边建立了一个受害者缓存,用来保存任何被驱逐到PM的脏缓存行。受害者缓存是不稳定的,在失败时可能会丢失其内容。
WrAP使用绕过易失性缓存的非时间性流存储向PM发出日志操作。随着故障原子区域的终止,WrAP确保在该区域创建的日志记录持续到PM。一旦日志持久化,它就会提交重做日志。随着重做日志的提交,PM的原点仍然持有陈旧的数据,因为原地更新被缓存在LLC或victim缓存中。日志现在可以用来重新应用$PM$中的原点更新,以防随后发生故障。WrAP控制器异步地将已提交的重做$log$条目中记录的更新复制到PM中的主位置。一旦所有的更新被应用到PM的主位置,已提交的重做日志就会退役并被剪除。WrAP控制器通过不断地将更新应用到主位置和修剪退役的日志条目来限制日志大小。
随着重做日志的退出,WrAP也会删除victim缓存中的更新,这些更新是在相应的故障-原子区域中执行的。victim缓存中的这些更新不再需要了,因为PM原点记录了新的数据。在WrAP中,缓存的驱逐永远不会更新PM原点。
HTM
HTM+PM是一个很好的结合,DHTM就是一个durable的持久化
Shadow Paging
影子分页是一种写时复制机制,被一些文件系统和数据库或iMC所使用,用于做Checkpointing。它依赖于文件系统中的树状数据结构,以原子方式对文件页进行更新。它执行更新到存储中的空闲位置,保持旧的lata不被触动,并原子地更新树中的父节点以指向新创建的页面。这导致了在树上到根节点的级联更新,因为父节点也需要通过写时拷贝在树上进行合并。
DHTM
DHTM提出了一种redo logging的方法来提供硬件中的ACID事务。ACID事务确保所有或没有操作被执行(原子性),提供数据一致性,每个逻辑线程都有隔离的本地内存视图(隔离性),并保证更新是持久的(耐久性)。之前讨论的通过软件事务性内存或通过锁定提供原子性、一致性和故障原子区域的隔离。DHTM利用硬件事务性内存(HTM)(例如英特尔的限制性事务性内存)来提供原子性、一致性和隔离性,并在硬件中建立重做日志以确保事务的耐久性。
DHTM结合了商业HTM和硬件重做日志来提供故障原子性事务。DHTM确保交易的原子可见性,与HTM类似。它在L1高速缓存中为正在进行的事务维护读和写集。当L1高速缓存收到另一个核心对其读写集中的高速缓存行发出的相干性请求时,它就会检测到冲突。两个冲突的事务中的一个会中止,这是由冲突解决策略决定的。当一个事务提交时,read write set被清空。
DHTM建立在原子事务之上,以提供耐久性。与WrAP类似,DHTM在L1高速缓存中管理原地更新。当一个就地更新在L1高速缓存中执行时,L1高速缓存控制器会创建一个重做$log$条目。DHTM在L1高速缓存旁边建立了一个日志缓冲区,将为同一高速缓存行创建的任何重做日志条目凝聚在一起。这最大限度地减少了到PM的重做日志流量。DHTM通过持久化在该事务中创建的所有重做$log$条目来提交该事务。在这一点上,该事务是失败的,重做日志被用来在失败的情况下重放原地更新。一旦事务提交,L1高速缓存控制器就会将原地更新冲到PM中。这是因为为较小的L1缓存设计的冲突检测和元数据管理无法扩展到较大的共享LLC。DHTM维护PM中的溢出列表允许L1缓存溢出。溢出列表记录了在一个正在进行的事务中从L1缓存溢出到共享LLC的缓存行。在提交时,DHTM使用PM中的溢出列表来识别溢出的缓存行,并将它们冲到PM中。
DHTM使用LLC中的sticky一致性状态(类似于LogTM)来检测交易冲突。在一个正在进行的transaction set 中,如果一个核修改了L1缓存中的一个溢出到LLC的缓存行,LLC仍然记录该核为该缓存行的所有者。任何来自另一个核的后续一致性请求都会被引导到所有者那里,在那里会检测到交易冲突。
硬件checking point :ThyNVM
硬件中的写前日志机制提供了细粒度的PM状态的日志。它们为程序员定义的故障原子区域提供故障原子性,这些区域通常很小,从几十到几百个PM更新不等。细粒度的日志记录对日志和原地更新施加了频繁的排序限制。它还会导致在日志和PM的原点之间频繁地复制数据。
一些粗粒度的检查点机制已经出现了,它们消除了每次PM更新的数据拷贝。这些机制类似于早期为易失性内存的崩溃恢复系统提出的框架,这些框架经常通过检查点记录程序的执行。检查点机制包括在PM中持久地存储数据的当前工作副本的快照。这些机制以固定的时间间隔在PM中检查点程序状态。挥发性执行在数据的工作拷贝上操作,然后在每个间隔结束时将其复制到PM中的检查点。在故障时,恢复使用检查点来恢复系统。根据检查点的粒度,这些机制在故障时可能会失去大量的应用进展。
ThyNVM为PM系统在硬件中提供了一种软件无关的检查点机制。它以固定的时间间隔检查线程上下文(例如,CPU寄存器和脏的缓存块)和PM数据。在故障时,存储在PM中的检查点被恢复软件用来恢复系统并重新启动程序执行。
ThyNVM硬件将程序执行分为固定的时间间隔,每个间隔为10美元$\mathrm{~ms}$。每个时间间隔由两个阶段组成:执行阶段和检查点阶段。在执行阶段,ThyNVM对PM数据的工作副本进行操作(类似于重做日志),不触动PM中先前的检查点副本。在每个执行阶段结束时,ThyNVM对该间隔期间创建的PM数据的工作副本进行检查点。在一个琐碎的检查点框架中,硬件可能会在每个执行阶段结束时检查点程序状态,从而使程序执行停滞。
WSP
Whole system persistency: 一种debug的工具,用于dump所有内存/寄存器/Cache上的状态WSP使用一个可编程的微控制器,监测系统的供电情况。一旦检测到断电,它就会通过串行线触发一个中断到一个控制处理器。控制处理器是一个负责管理系统中冲洗操作的处理器。WSP估计,在AMD和英特尔平台上测量,完成对NVDIMM的冲洗操作的时间窗口在10美元/~ms到400美元/~ms之间。控制处理器通过处理器间中断通知其他处理器,并启动例行程序,将程序上下文冲到NVDIMM上。WSP评估了硬件缓存(大至12美元/MB大小)可能在5美元/~ms内完全刷新到NVDIMM,远在电源窗口之内。一旦上下文被刷新,控制处理器就会通知NVDIMM控制器即将发生的电源故障。然后,NVDIMM使用存储在其超级电容器中的备用电源,将DRAM内容冲刷到备份闪存
书写PM系统
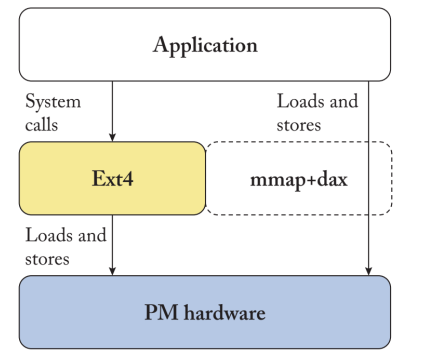
EXT4文件系统相比EXT3增加了inode连续预分配、使用修改过的B树Hash(Extent Tree)来存储内容索引,减少一部分非连续读写,并且操作系统对于文件的的元数据访问有上层的缓存,最大的文件系统的大小拓展到1EB。现在EXT4还在继续演进。在最新的5.10内核中对$\texttt{fsync}$系统调用进行了优化,增加了快速确认模式(fast commit),大大减少了多文件操作演示,正常情况下,$\texttt{fsync}$会同步一组元数据,快速确认模式仅将发生崩溃的元数据更新到inode表,加快了$\texttt{fsync}$调用同时提高主动操纵元数据的操作到性能。在持久内存出现后,EXT4 DAX模式应运而生。使用$\texttt{pmem_copy_from_iter()}$函数实现VFS的函数执行,最终调用glibc中$\texttt{__memcpy_flushcache()}$函数将数据持久化到傲腾内存上,与之对应的有direct I/O模式,此模式会经过通用块I/O块。在缓存数据同步和异步写以及读数据缓存命中在不同设备上时,都有不同的基于体系结构的优化。EXT4-DAX最大的问题是不支持4KB crash atomicity。
EXT4-DAX
NOVA
是比较流行的PM文件系统之一。NOVA最关注的是如何提供文件系统所期望的故障原子性保证。记录/日志是一种常见的方法,但是它至少会产生双倍的写入PM的数量(一个到日志,一个到实际位置)。影子日志是另一种方法,但是如果文件系统树中的多个叶子节点被原子化修改,它需要逐级写到文件系统树的顶端。因此,这两种方法都会产生显著的写入放大。
而NOVA建议使用日志结构化方法。日志结构文件系统的关键思想,最初是为磁盘提出的,是在DRAM中缓冲写更新,一旦有足够的更新被缓冲,就把它们凝聚起来,按顺序写到文件系统日志。所以,文件系统的数据只写一次,直接写到日志上。而且,对于硬盘和SSD来说,按顺序写入数据(即连续的位置)是非常重要的,可以大大节省成本。当一些文件系统数据要被读取时,就会搜索日志以找到数据并返回给用户。由于数据只驻留在日志中,日志结构化只需要向存储空间写入一次。为了尽量减少读取时搜索日志的成本,可以在DRAM中维护索引,将文件系统数据映射到日志中的确切位置。
NOVA将这种方法引入PM文件系统。传统上,日志结构的文件系统被认为是为SSD和硬盘优化的(由于它们产生的串行写入流量)。而NOVA则利用了这样一个事实:日志结构的文件系统比基于日志和影子日志的文件系统产生的写流量要少得多。然而,$log$结构化文件系统的一个重要限制是日志的顺序性。为了确保持续供应空的顺序区域,文件系统必须经常凝聚日志条目并压缩日志,从而增加开销。NOVA设计背后的一个关键想法是观察到,由于随机写入的速度几乎和PM上的顺序写入一样快,文件系统的日志不必是物理上连续的,只要是逻辑上连续的就够了。这个观察结果允许NOVA把日志设计成一个单链的链接列表,在DRAM中有一个索引。在每次写入时,数据被追加到日志中,DRAM中的索引被更新以指向日志中的新数据位置(一个PM页)。旧的数据页可以被回收供将来使用。
SplitFS
传统的文件系统在每个文件系统操作中都会增加大量的开销,尤其是在写入路径上。开销来自于在关键路径上执行昂贵的操作,包括分配、记录和更新多个复杂结构。系统界已经提出了不同的架构来减少开销。BPFS、PMFS和NOVA从头开始重新设计内核内文件系统以减少文件系统操作的开销。Aerie和Strata主张采用用户空间库文件系统,并试图通过不涉及内核的大多数文件系统操作来减少开销。尽管有这些努力,文件系统的数据操作,特别是写操作,会有很大的软件开销。
SplitFS,包括后来的Kuco FS是一个把某些操作offload到用户态的文件系统。例如,文件追加,mkdir())和一个处理数据操作的单独的用户空间库文件系统(常见的情况)。SplitFS的创新之处在于如何在用户空间和内核组件之间划分责任,以及为应用程序提供语义。与之前的工作不同,如Aerie,它只使用内核进行粗粒度的操作,或Strata,所有的操作都在用户空间,SplitFS将所有的元数据操作都路由到内核。在高层次上,SplitFS架构是基于这样的信念:如果我们能够加速常见的数据操作,就值得为相对稀少的元数据操作付出代价。这与NOVA这样的内核文件系统不同,后者广泛地修改文件系统以优化元数据操作。SplitFS的关键思想是透明地拦截应用程序进行的POSIX文件系统调用,对底层文件进行内存映射,并使用处理器的加载和存储指令进行文件读取和覆盖。SplitFS还通过引入一个新的文件系统基元 "relink "来优化文件追加操作,该基元在逻辑上和原子上将一个文件范围从一个文件移动到另一个文件,而不需要实际复制数据。重新链接操作可以被认为是一个文件内容的原子交换,可以用来实现写时复制机制。
STRATA
是一个用户空间文件系统。Strata的建立是基于这样的设想:由于成本的原因,未来的计算系统可能会将PM、SSD、甚至HDD都组织成按性能降序和密度增序分层的存储设备。Strata的灵感还来自于现代应用的趋势,即绕过内核进行普通情况下的操作,减轻由于调用内核而产生的成本(上下文切换开销,内核有很长的复杂代码路径)。
Strata将文件系统组织成两个主要部分,一个是在PM中的快速用户空间日志,可以快速吸收应用程序的写入(并在可能的情况下提供读取服务),另一个是异步管理的长期存储,部分驻留在PM中,然后跨越SSD和HDD,或者基于系统的内存层次的PM、SSD和HDD的多层。在普通情况下,应用程序读取和写入PM日志,几乎不产生软件开销。如果日志不能为读取提供服务,那么就会访问长期存储。定期地,日志的内容被凝聚并应用到长期存储中,一旦变化被传播到长期存储中,$log$就被截断。将日志中的变化应用到长期存储中是与应用程序对日志的读写异步进行的。此外,日志对每个进程都是私有的,而长期存储在所有进程之间共享。Strata实现了适当的并发控制机制,以处理进程间通信和从私有日志到共享长期存储的冲突更新。
Strata将用户空间的日志组织成一个同步的数据结构,因此应用程序可以确信,当一个写调用返回时,他们的数据已经持久化。这种方法因PM的低延迟而成为可能,并减轻了开发人员不得不与异步系统调用作斗争的负担,这是高性能存储软件的一种复杂且易出错的方法。有了Strata,开发人员永远不必调用fsync操作。长期存储区域被组织成一棵LSM树,横跨PM、SSD和HDD等层,较热的数据被保持在树的上层,以便更快访问,较冷的数据被推到底部,以提高存储效率。
PMDK
比较好的例子是P-ART/P-CLHT,已经有比较成熟的检查工具。书写PMDK需要先通过PMDK申请看内存。剩下操作与管理内存差不多。值得注意的是需要知道简单访问pattern延时。多线程的性能drain的程度。
Deffered commit transactions
PM实现故障原子交易需要对PM的写入进行排序。例如,在写前日志下,正在进行的事务只有在该事务的日志记录在PM中持续存在后才可以提交。
虽然在一个事务中对PM的操作排序是正确的要求,但最小化这种排序依赖对于实现高性能的事务至关重要。特别是,他们把撤销日志作为一个例子,来说明一个直观的事务实现,他们称之为同步提交事务(SCT),是如何引入不必要的持久化依赖并过度约束持久化关键路径的。在SCT下,事务中的所有步骤--为隔离而获取锁、准备撤销日志条目并将其记录在PM中、在PM中就地突变数据、提交事务并释放锁--必须按顺序执行。虽然按顺序执行这些步骤是简单而直观的设计,但它也需要在锁下执行所有的日志操作,这就过度约束了持续的依赖图。延迟提交事务(DCT)旨在产生比SCT更短的持久性依赖图。
DCT通过在一个事务中就地突变数据后释放锁,并推迟提交,来减少持久性依赖关系。这确保了后续的独立事务可以在不等待先前事务提交的情况下进行。然而,推迟提交也导致了一个新的挑战,即在所有未完成的(可能是冲突的)事务中正确排序提交操作。也就是说,缺乏适当的同步可能会导致冲突的事务不按顺序提交,造成失败后的不正确恢复。提交顺序必须与事务最初获得锁的顺序一致,以确保事务的可序列化。DCT通过修改事务来保证事务的可序列化,以明确跟踪其前身的冲突事务,并在所有先前的confli $alpha_{2}$ ig事务提交之前暂停其提交。为了实现这一点,DCT在每个锁上扩展了一个指向最后一个获得该锁的事务的指针。当一个事务获得其锁集内的所有锁时,它就会记录所有与当前事务冲突的先前未决事务的指针。在该事务提交之前,它必须验证所有先前冲突的事务已经提交。因此,在提交当前事务之前,它对记录的指向先前事务的指针进行轮询,直到它们提交。这允许独立的事务以任何顺序进行和提交,但保证冲突的事务不会不按顺序提交。
SFR(synchronization-free region)
Failure atomicity for synchronization free region
耦合的SFR设计。这种设计将程序状态的持久性与它的可见性结合起来。也就是说,在故障时,保证恢复能够观察到每个线程上最新完成的同步操作的程序状态;持久化状态最多滞后执行一个(不完整和正在进行的)SFR。在这种设计中,PM的突变在每个SFR结束时被刷入PM,在该SFR中创建的撤销日志被立即提交。Coupled-SFR设计的关键优势在于,每个线程只需要跟踪其正在进行的SFR内执行的更新的日志条目。Coupled-SFR设计的线程私有性与ATLAS形成鲜明对比,ATLAS必须记录线程间的排序依赖关系,以确定必须以原子方式进行的日志条目。恢复后的PM状态很容易解释,因为它符合每个线程的最新同步操作。耦合-SFR设计的主要缺点是,它必须在每个SFR结束时刷新所有的PM更新并提交日志条目,从而在关键执行路径上暴露出大部分的PM持久化延迟。
解耦SFR设计。Decoupled-SFR设计以简单换取性能。它将PM更新的可见性与持久化状态的前沿解耦,并允许持久化状态在每个线程上滞后执行。故障恢复仍然需要与SFRs的更新是故障原子的,并且它们以SFRs执行的相同顺序成为持久化。如果没有这个保证,恢复可能会观察到与无故障程序执行的状态不一致的PM状态。为了确保正确的排序,Decoupled-SFR通过以下方式记录同步操作之间的先发生后排序关系。(1)在撤销日志中添加获取和释放注释,(2)按程序顺序创建和维护每线程日志以捕获线程内的排序,以及(3)通过在同步获取和释放对中维护单调的序列号来跟踪线程间的排序。
Atlas
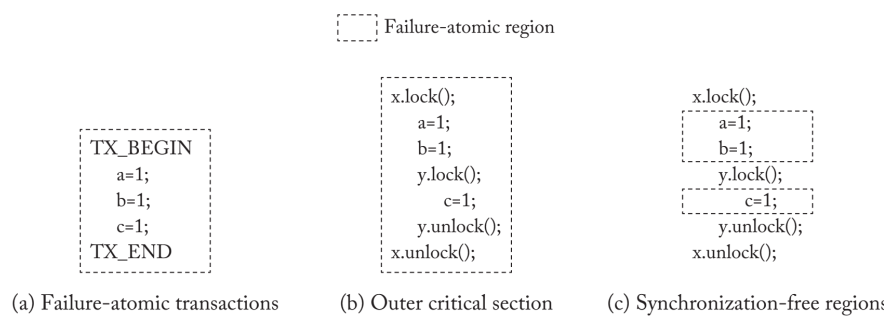
Failure atomicity for outer-critical section: locked based program can be transformed to Transactional program 因为结构仅在故障原子区域内是不一致的。ATLAS将持久性保证扩展到最外层的critical section,因此恢复时总是观察到一个一致的PM状态,就像程序中没有锁时一样。失败原子的最外层关键部分很有吸引力,因为它们确保恢复总是观察到一个顺序一致的PM状态。
与事务不同,锁可以嵌套,ATLAS必须确保最外层关键部分的持久性,以确保恢复时不会观察到部分完成的关键部分,因为它可能已经被故障打断了。它对最外层关键部分内的更新采用了撤销日志,以确保其故障的原子性。在故障时,它使用撤销日志将程序状态回滚到每个线程上最后完成的故障原子区域。ATLAS必须确保恢复永远不会观察到失败后回滚的更新的任何副作用。也就是说,如果内部关键部分(在部分完成的最外层关键部分内)所做的更新传播到其他线程,这些更新(以及它们的副作用)在失败后也需要回滚。ATLAS通过同步操作记录了线程之间的这些发生前排序关系。它使用这些发生在之前的排序关系,在失败时以相反的创建顺序回滚更新。