I see the nvdimm can be emulated through the kernel, so I'm wondering about the boots process.
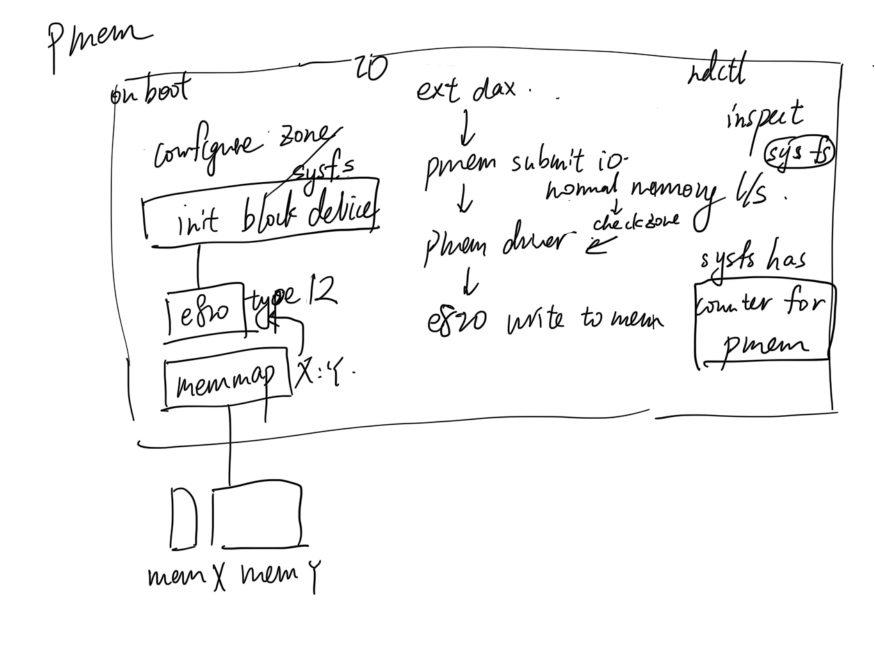
Comunicating with Jiachen, The operating system has no knowledge of a PCIe system
CXL possible boot up process


A Tech Nerd with a finance mind.
I see the nvdimm can be emulated through the kernel, so I'm wondering about the boots process.
Comunicating with Jiachen, The operating system has no knowledge of a PCIe system
最近一直在想网络SmartNIC延时的问题,发现Alex发过这篇,差不多是NSDI23的水平了。NF是用于抽象firewall/load balencer的函数,这些函数的语义会被记录在SmartNIC上。同时做一些offload的操作。这块陈昂做的很多。
传统的NIC只会做hardwired处理器操作,如TSO/LRO/checksum,用SmartNIC很自然就想到先抽象这些操作为network function,问题卷到现在演变成了谁能把serverless/ML的函数放在SmartNIC上更多,谁就顶会。
用一种SmartNIC+NIC offload pipeline的方式,把slice&splice 做的更低时延,但是这有个条件,绝大多数NF都是shallow的情况, 否则tail latency for pipeline会变得异常高.
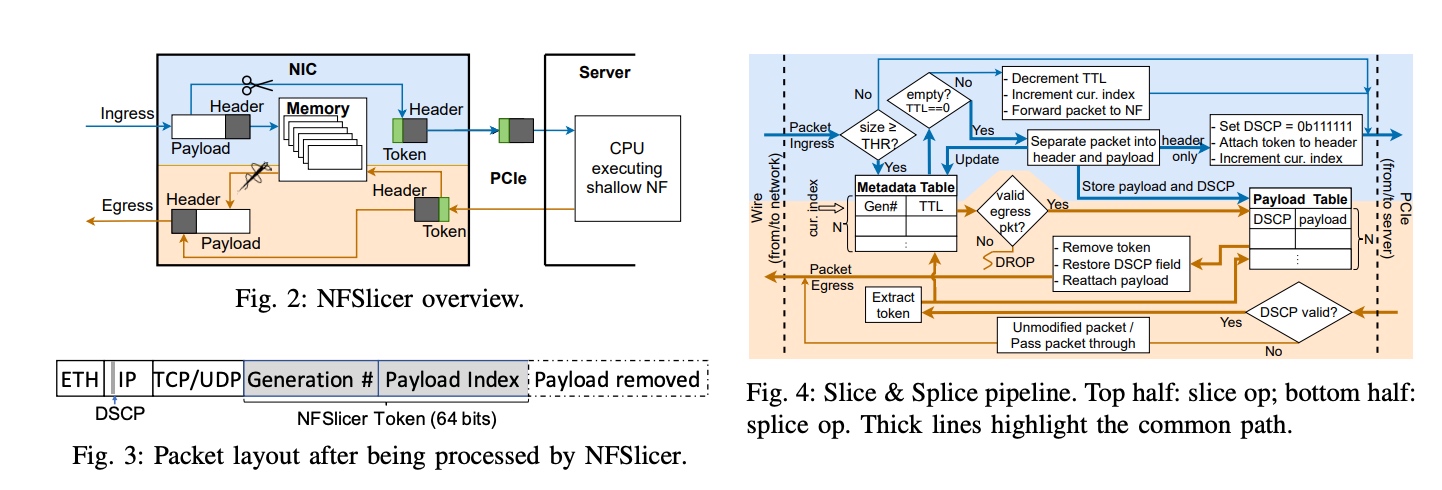
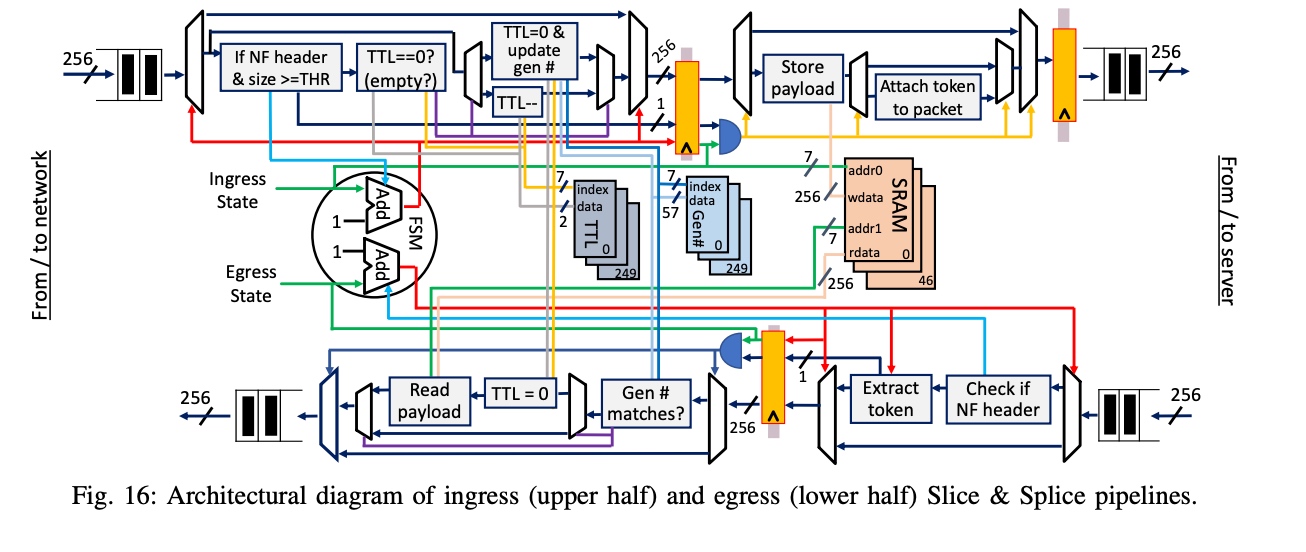
他们觉得用上了CAT+DDIO的 private caches, LLC, and memory 都还不是bottleneck, 重在以下TTL的pipeline数据通路.
FAAS对resource(CPU/Memory) disaggregation的map-reduce化?这显然是一个完全不考虑NUMA/NIC latency的考虑,就是在说dynamic memory allocation/placement大过latency的tradeoff,重点落在了怎么藏RDMA/NUMA的时延.但是为什么要套一个FAAS呢?然后就和MemTrade没啥大区别,只是多家了一套用户配置.
最近在和LemonHX一起写个跨平台下载器,想要的是个延时确定的协程调度器,然后我们就看上了字节开源的monoio,准备贡献一波Windows部分。
主要需要跨平台抽象的部分已经写好了, GAT 刚进主线, 其实感觉贡献这个更经济一点. 字节内好像也没有开始用这个, 只是做了点测试.
A Distributed NVM modeled OS runtime for the arrangement of NVM data structure that
Continue reading "Twizzler: a Data-Centric OS for Non-Volatile Memory"
ATC的容量大改是OSDI的1.5倍吧,有两个track两天的样子,ATC的工业界浓度更高一些,OSDI会选出那种新颖的方向,真的有点像奥斯卡的选奖逻辑。

讲的东西比较散。
Continue reading "PLDI22 Attendency"
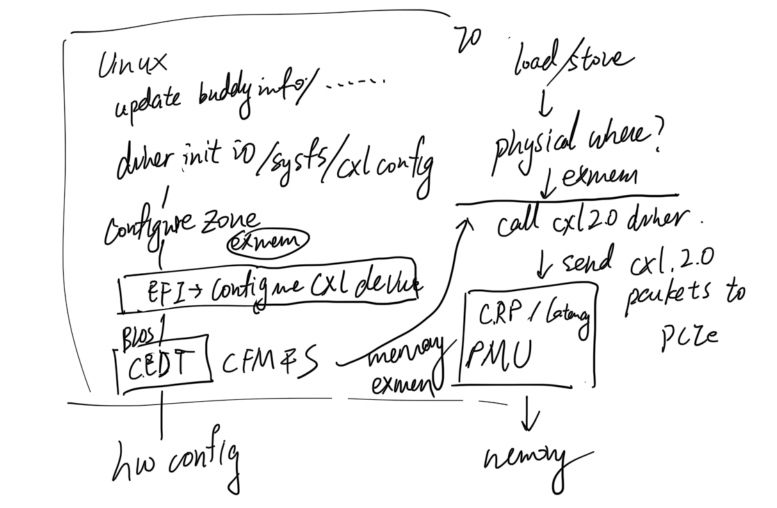
CXL disaggregation because:
Continue reading "First-generation Memory Disaggregation for Cloud Platforms @Arxiv"
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:317:9: error: no member named 'signbit' in the global namespace
using ::signbit;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:318:9: error: no member named 'fpclassify' in the global namespace
using ::fpclassify;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:319:9: error: no member named 'isfinite' in the global namespace
using ::isfinite;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:320:9: error: no member named 'isinf' in the global namespace
using ::isinf;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:321:9: error: no member named 'isnan' in the global namespace
using ::isnan;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:322:9: error: no member named 'isnormal' in the global namespace
using ::isnormal;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:323:9: error: no member named 'isgreater' in the global namespace
using ::isgreater;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:324:9: error: no member named 'isgreaterequal' in the global namespace
using ::isgreaterequal;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:325:9: error: no member named 'isless' in the global namespace
using ::isless;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:326:9: error: no member named 'islessequal' in the global namespace
using ::islessequal;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:327:9: error: no member named 'islessgreater' in the global namespace
using ::islessgreater;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:328:9: error: no member named 'isunordered' in the global namespace
using ::isunordered;
~~^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/cmath:329:9: error: no member named 'isunordered' in the global namespace
using ::isunordered;
~~^
When I was compiling LLVM recently I found this, it may be because my CommandLineTool is outdated as described in stackoverflow. And I reinstalled it with following code added.
using ::signbit _LIBCPP_USING_IF_EXISTS;
using ::fpclassify _LIBCPP_USING_IF_EXISTS;
using ::isfinite _LIBCPP_USING_IF_EXISTS;
using ::isinf _LIBCPP_USING_IF_EXISTS;
using ::isnan _LIBCPP_USING_IF_EXISTS;
using ::isnormal _LIBCPP_USING_IF_EXISTS;
using ::isgreater _LIBCPP_USING_IF_EXISTS;
using ::isgreaterequal _LIBCPP_USING_IF_EXISTS;
using ::isless _LIBCPP_USING_IF_EXISTS;
using ::islessequal _LIBCPP_USING_IF_EXISTS;
using ::islessgreater _LIBCPP_USING_IF_EXISTS;
using ::isunordered _LIBCPP_USING_IF_EXISTS;
using ::isunordered _LIBCPP_USING_IF_EXISTS;
_LIBCPP_USING_IF_EXISTS is defined as # define _LIBCPP_USING_IF_EXISTS __attribute__((using_if_exists)), simply pass if no defined in the global namespace.
Then the following code output error
using _Lim = numeric_limits<_IntT>;
add another header in
#include <limits>
Then comes to the std::isnan using bypassing no definition error in llvm/lib/Support/NativeFormatting.cpp.
error: expected unqualified-id for std::isnan(N)
just drop the std::
The full formula for riscv-rvv-llvm is located in https://github.com/victoryang00/homebrew-riscv, if anything above happens, do as the above specifies.