

文章目录[隐藏]
- OSDI
ATC的容量大改是OSDI的1.5倍吧,有两个track两天的样子,ATC的工业界浓度更高一些,OSDI会选出那种新颖的方向,真的有点像奥斯卡的选奖逻辑。
OSDI
Keynote from google



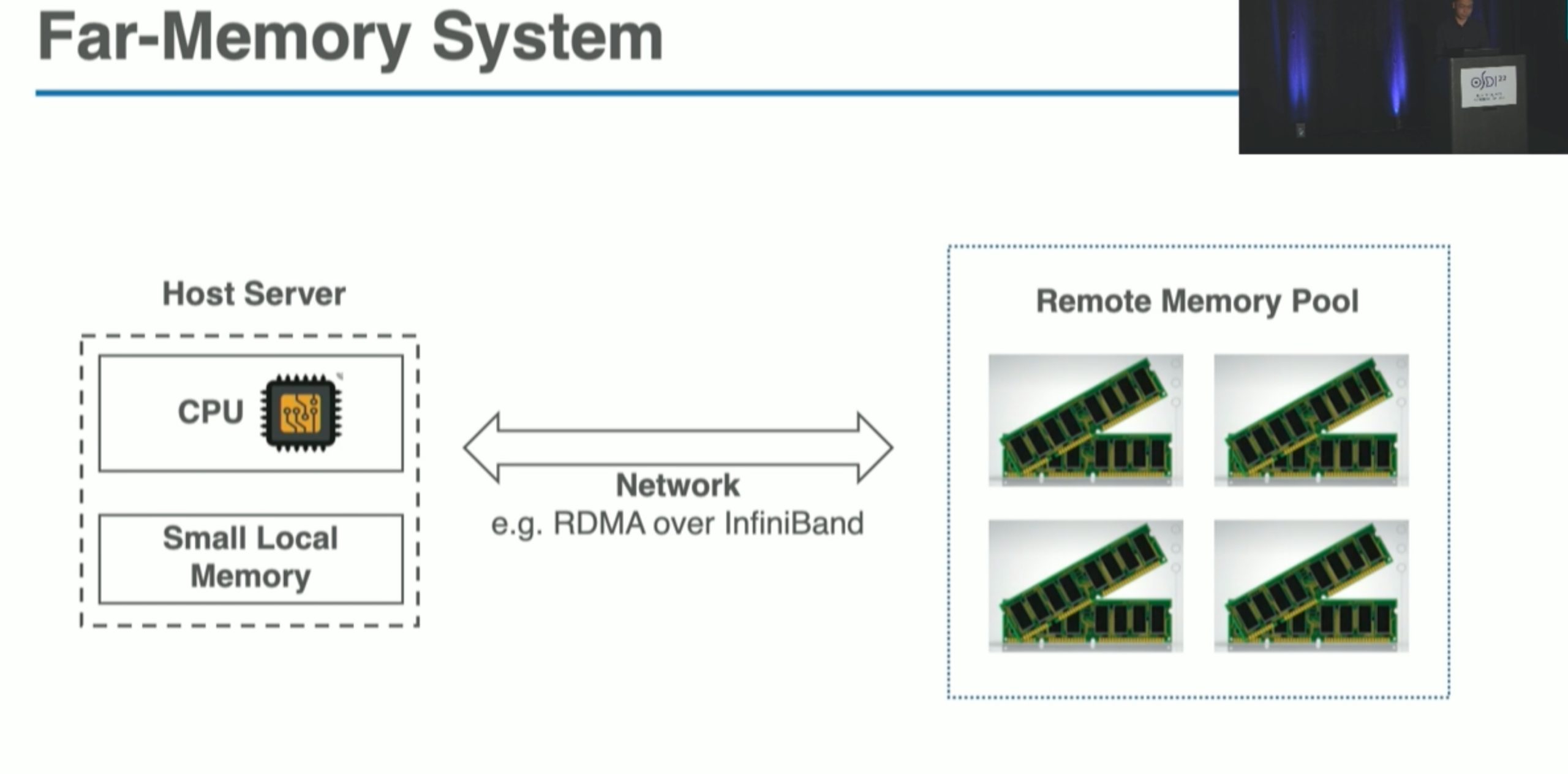
Distributed Storage and Far Memory
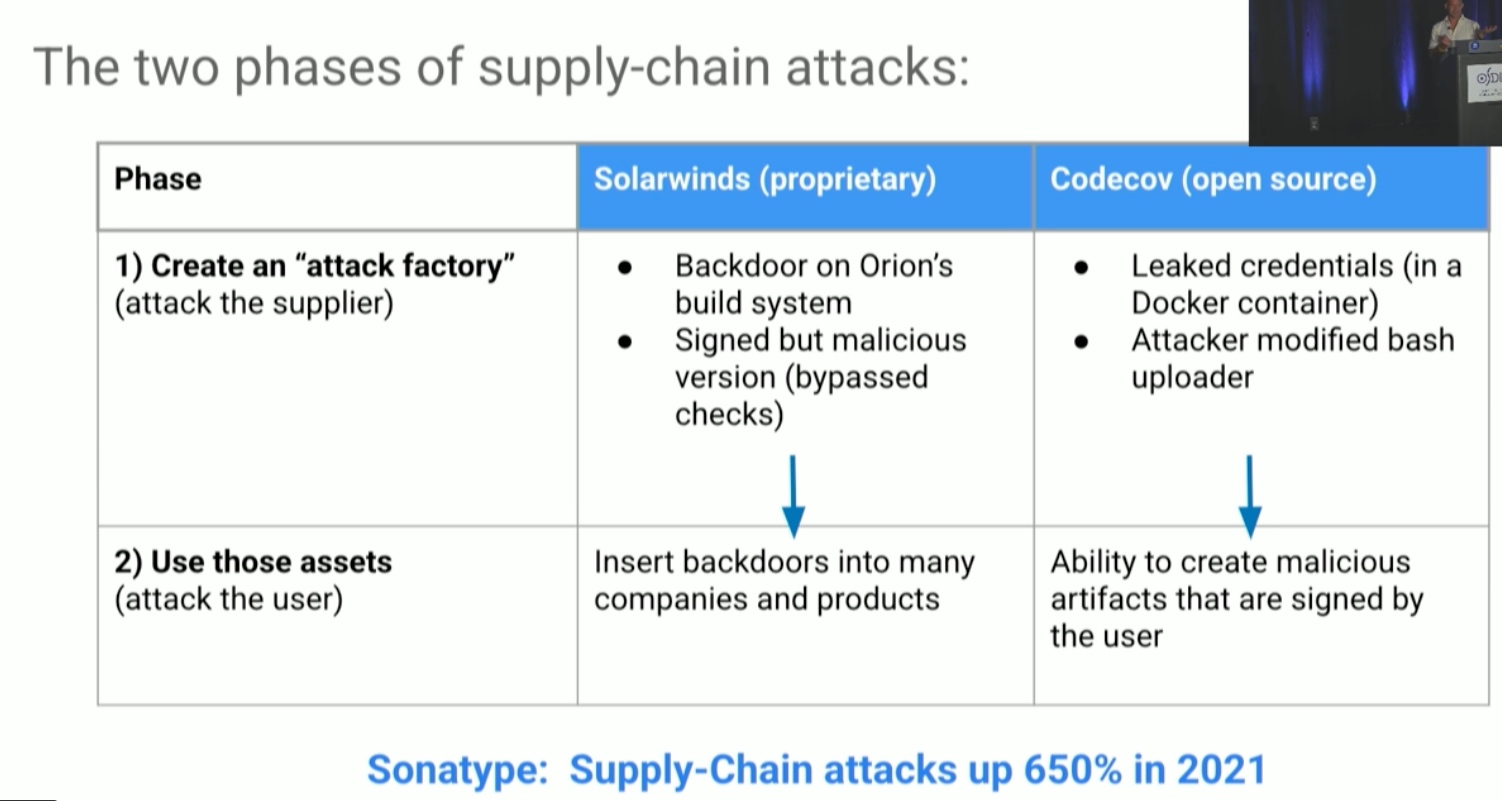
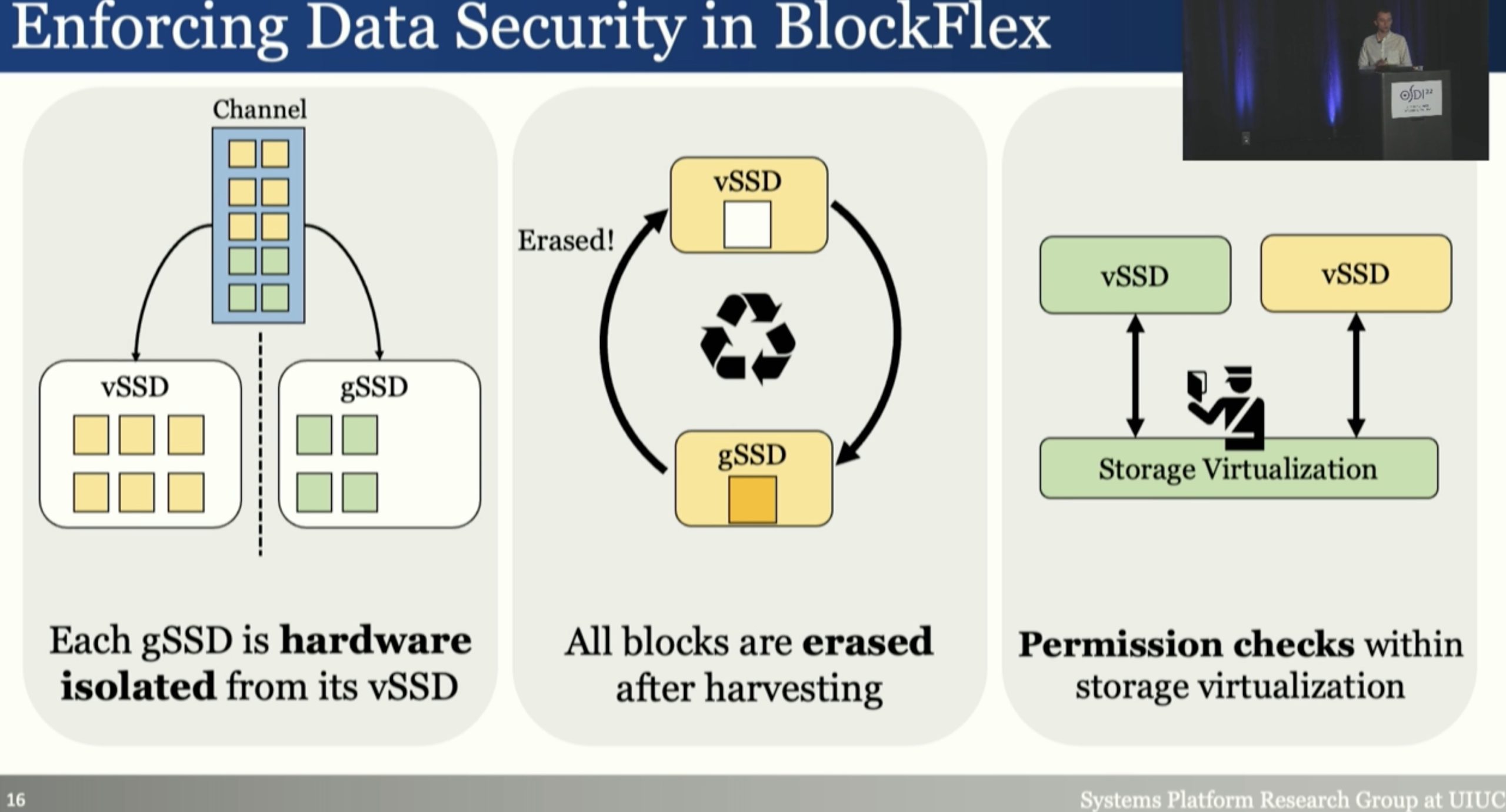
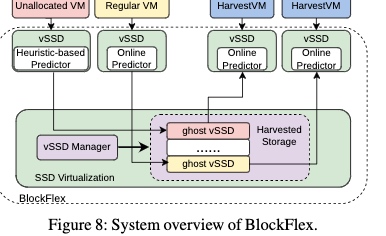
BlockFlex: Enabling Storage Harvesting with Software-Defined Flash in Modern Cloud Platforms
黄建爸爸的文章,presenter 好像之前做secure HDD也是这个老哥, a learning-based storage harvesting framework。


MemLiner: Lining up Tracing and Application for a Far-Memory-Friendly Runtime
这里可以理解为每次发现一个指向distant object 的reference 就delay 并hold 住它几次。(比如放到另一个queue)最终这些发现的reference 都要trace一遍直到没有发现 unmarked object,所以closure 是会达成的。

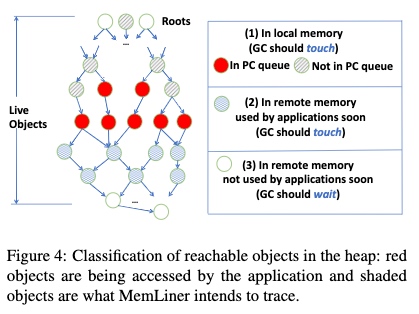
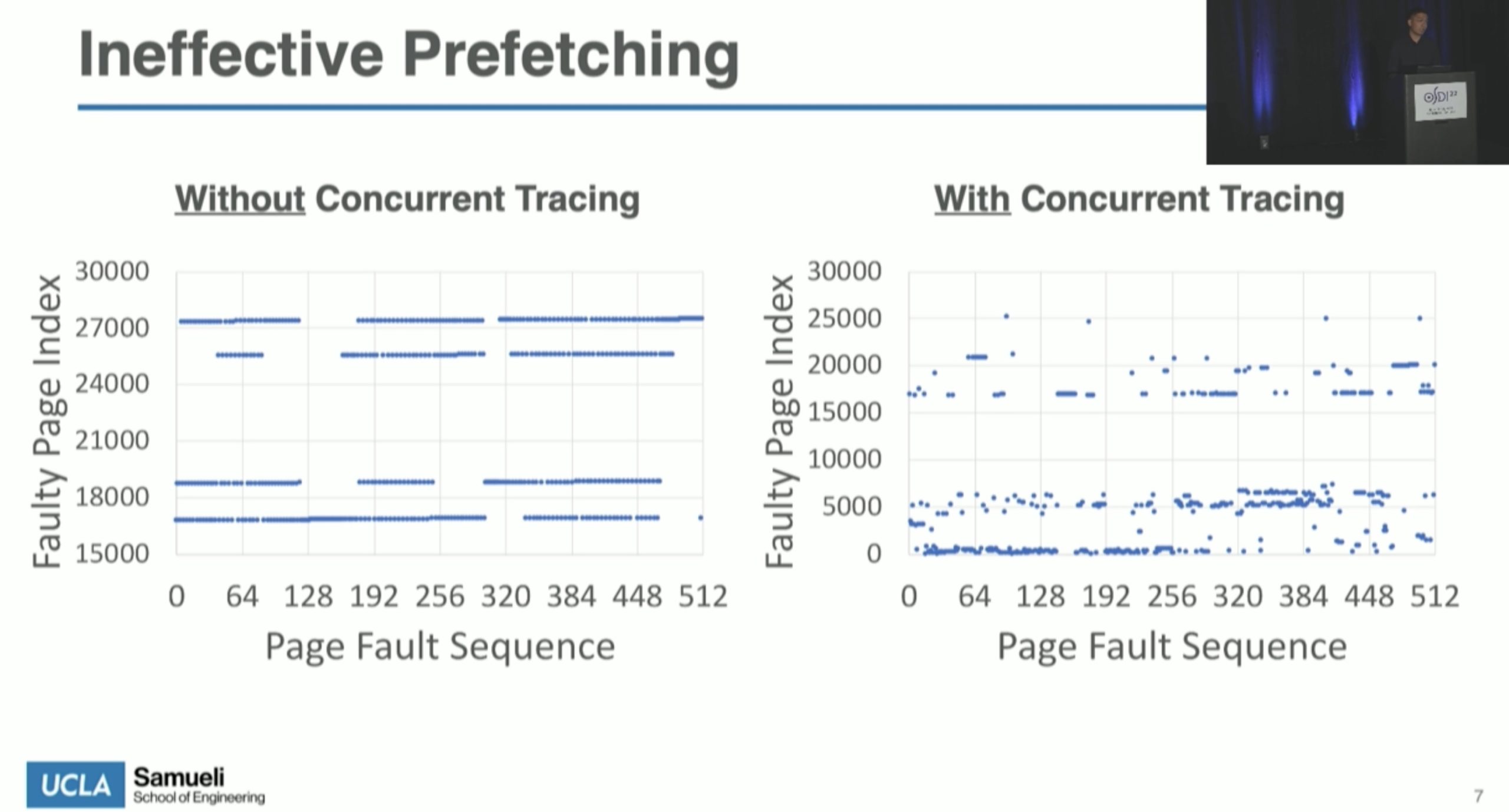

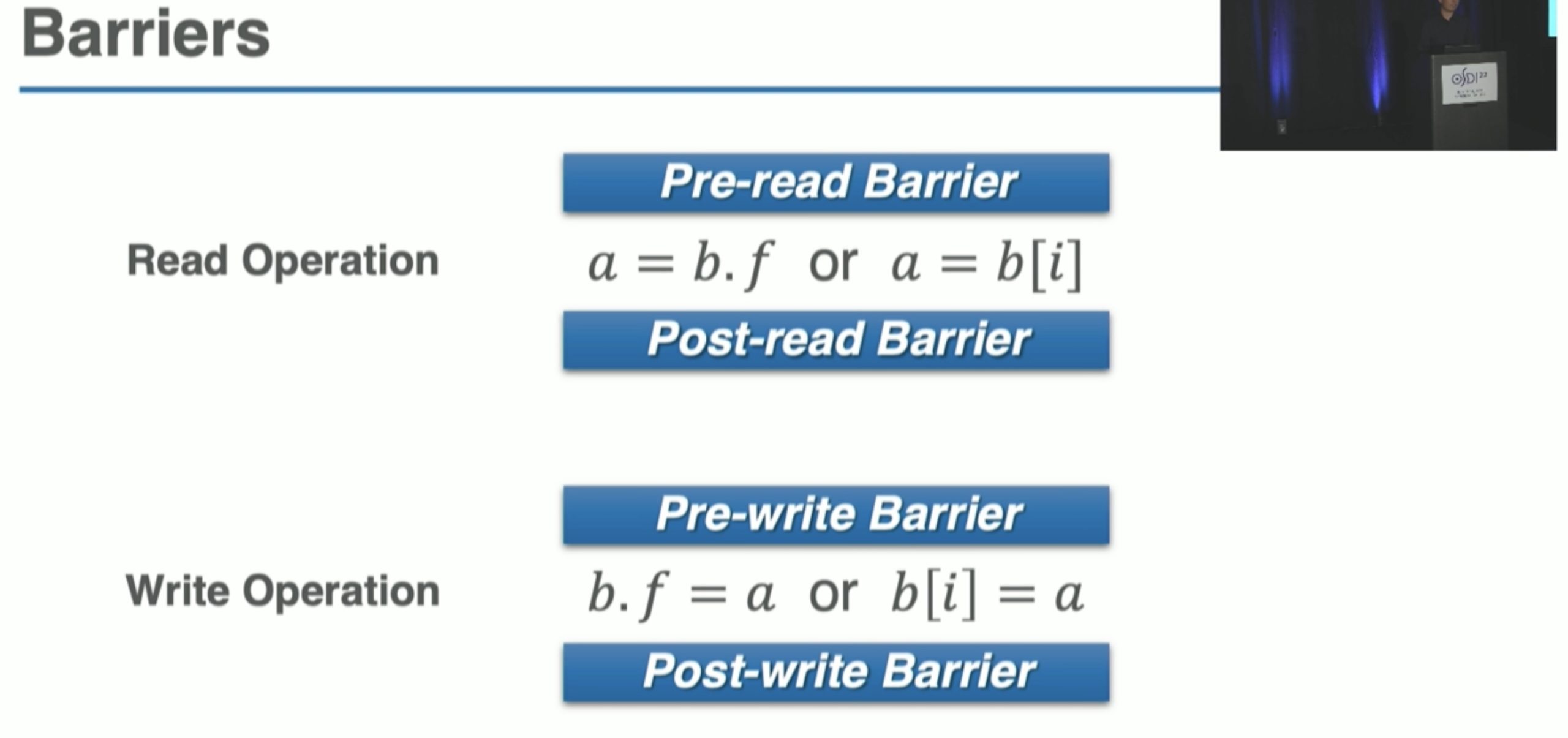
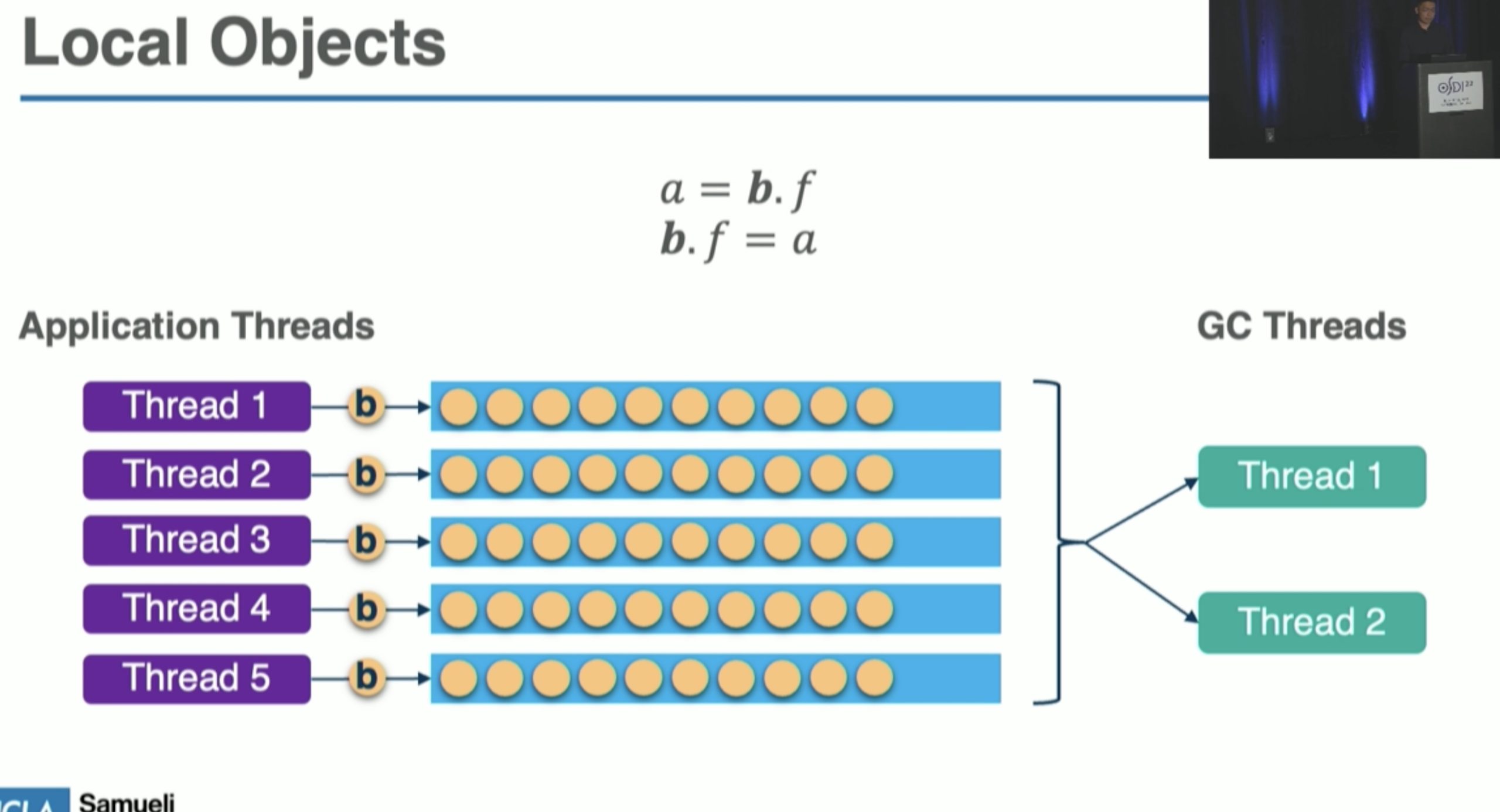

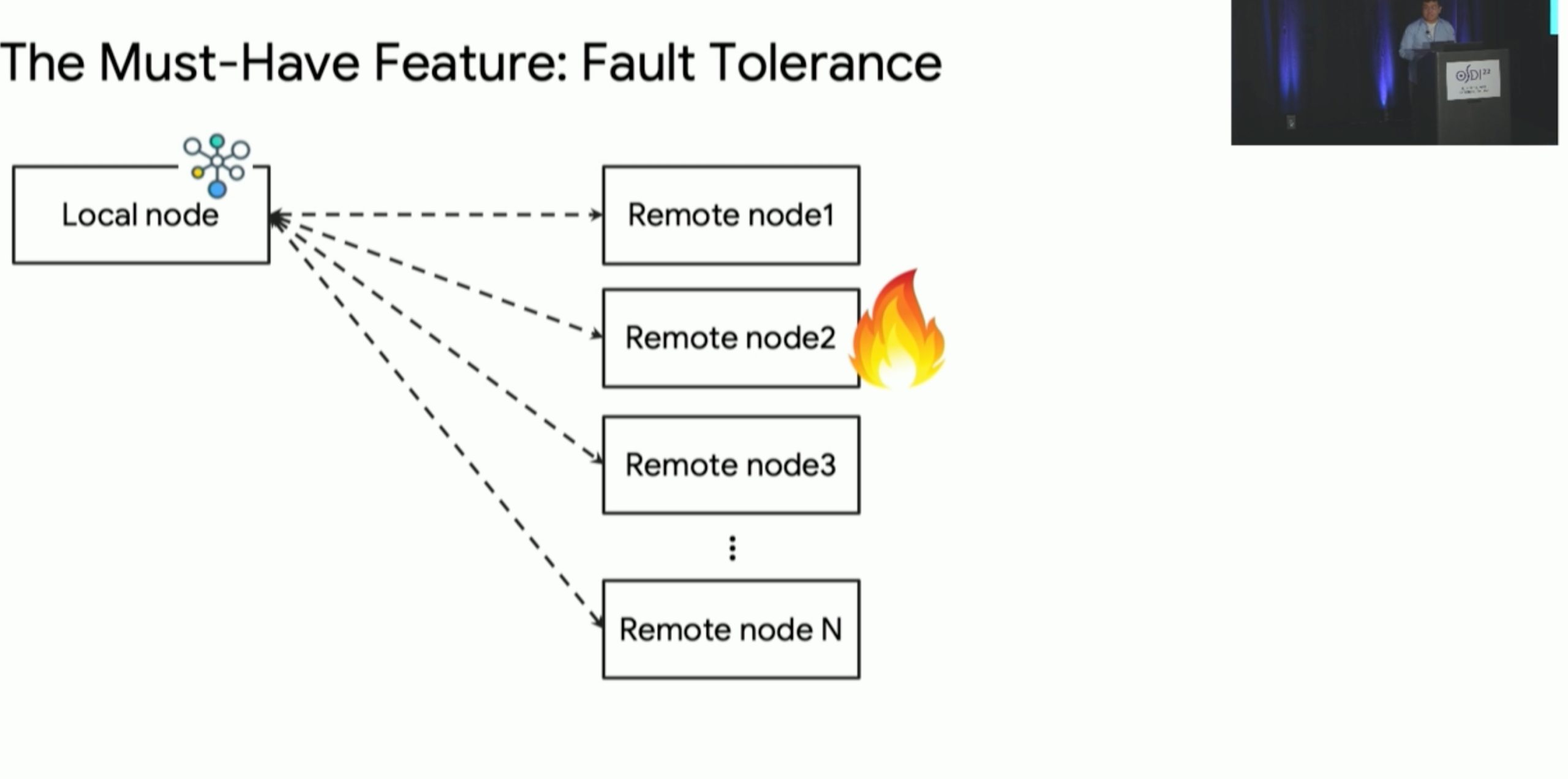
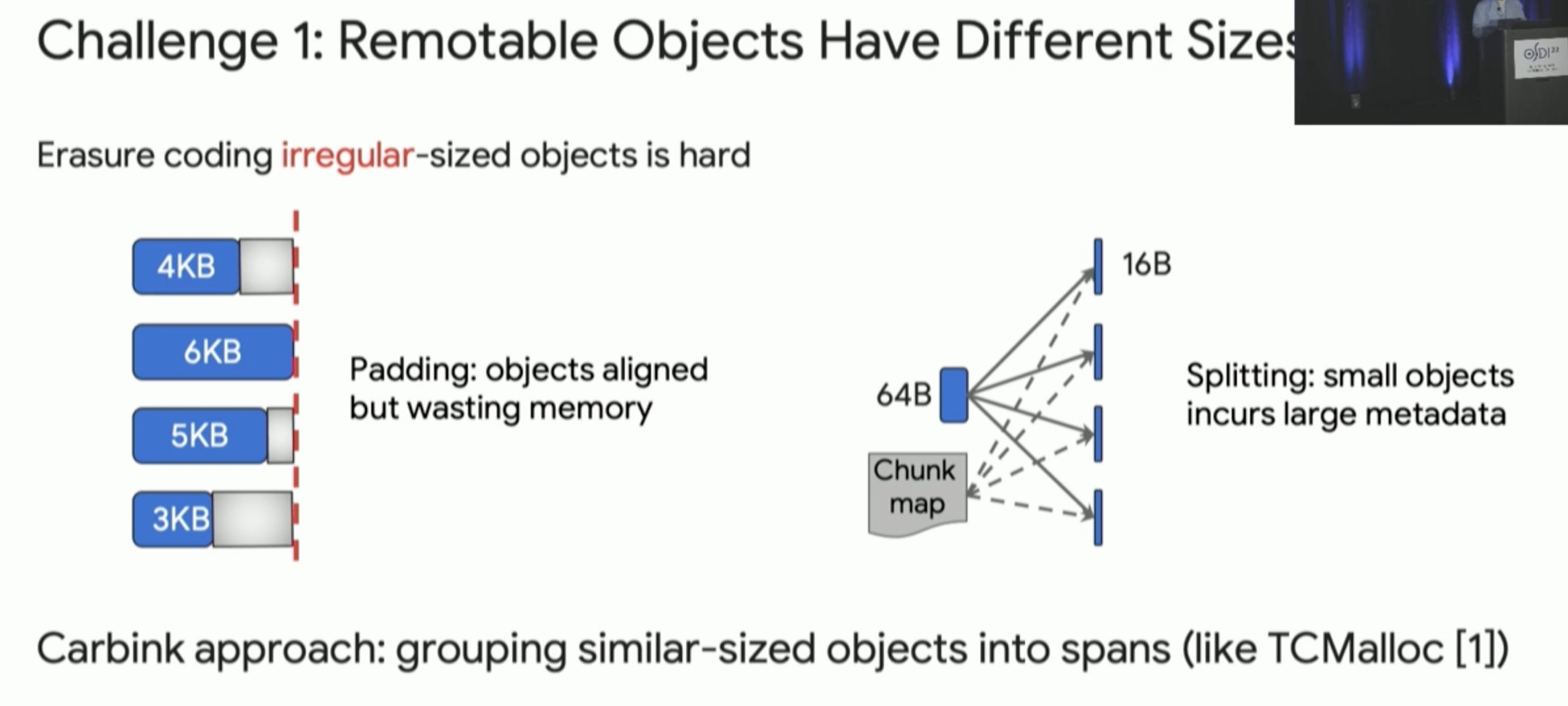
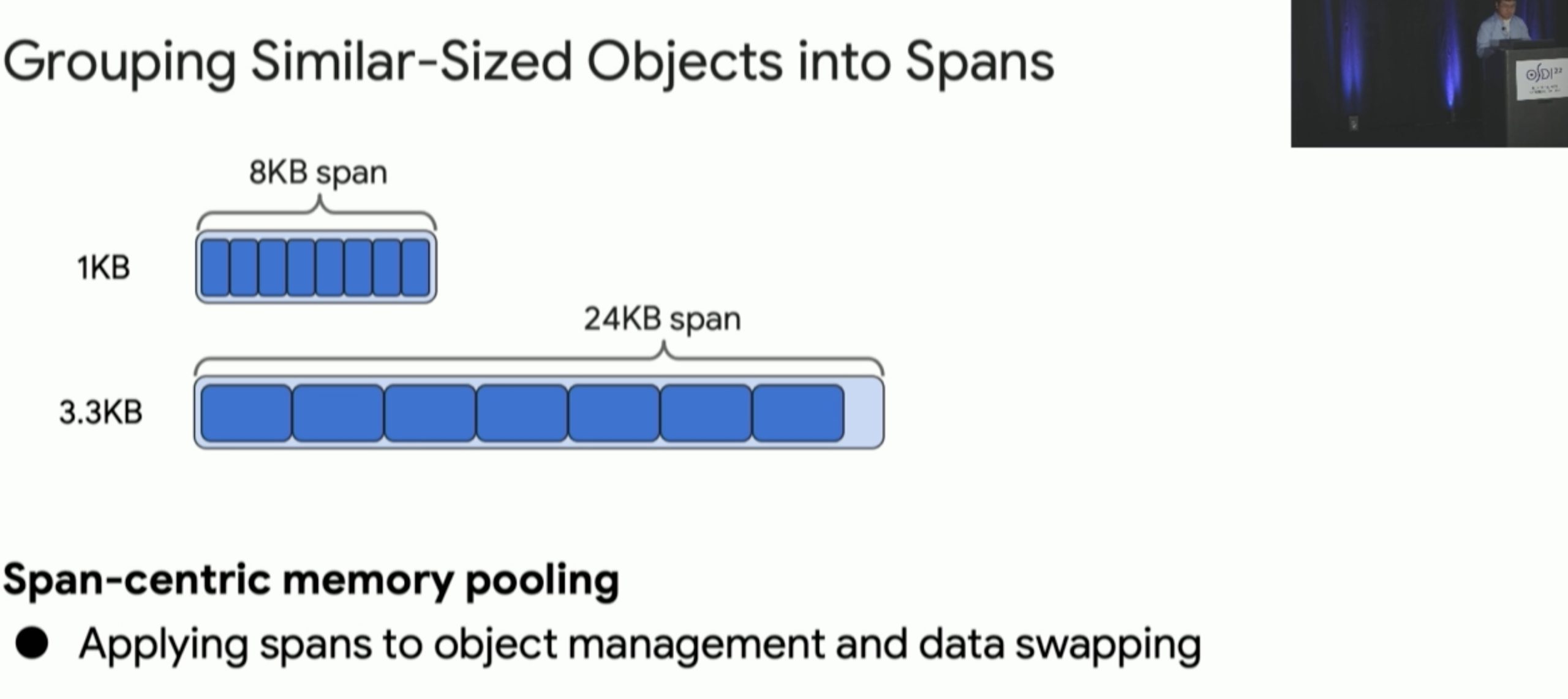
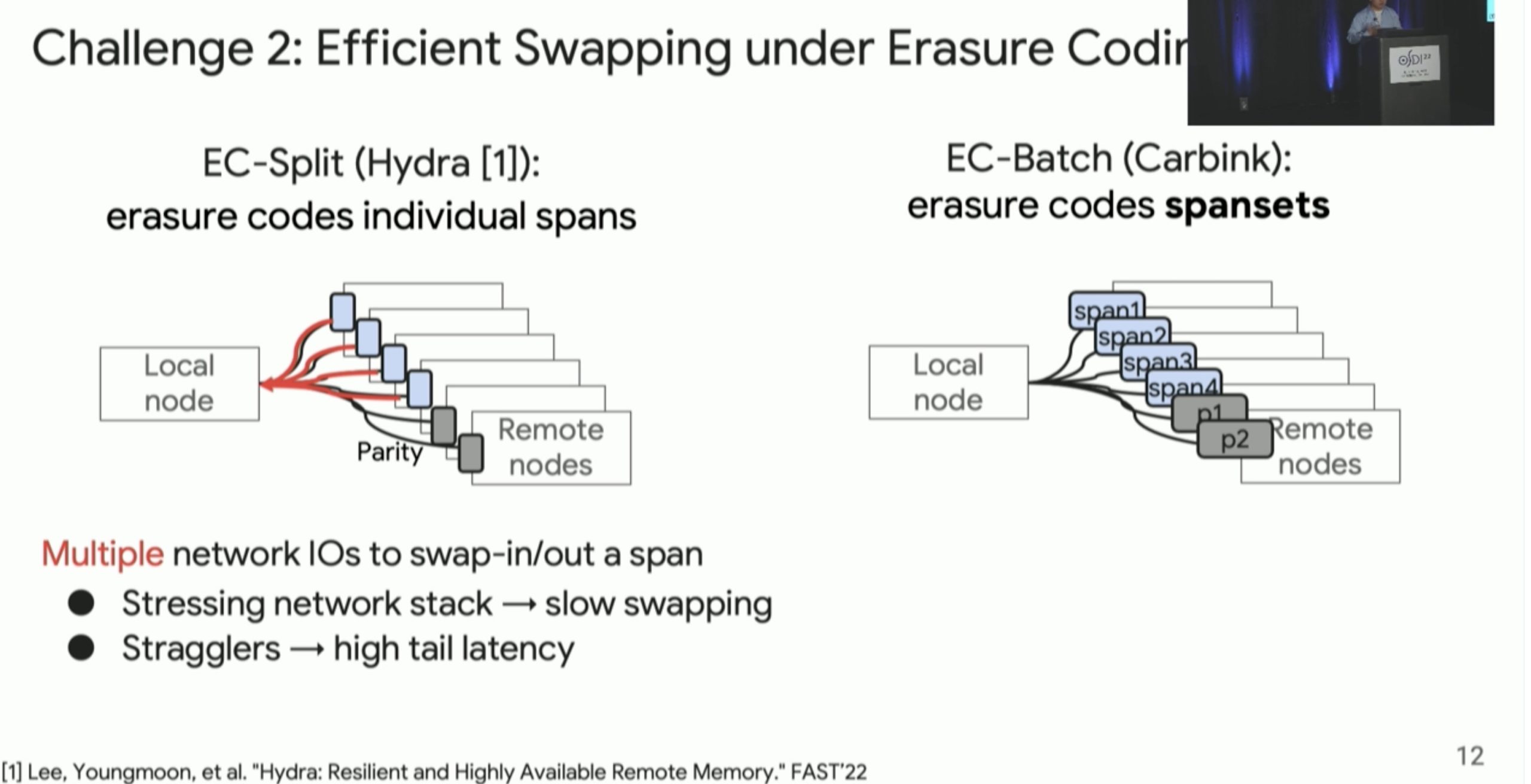
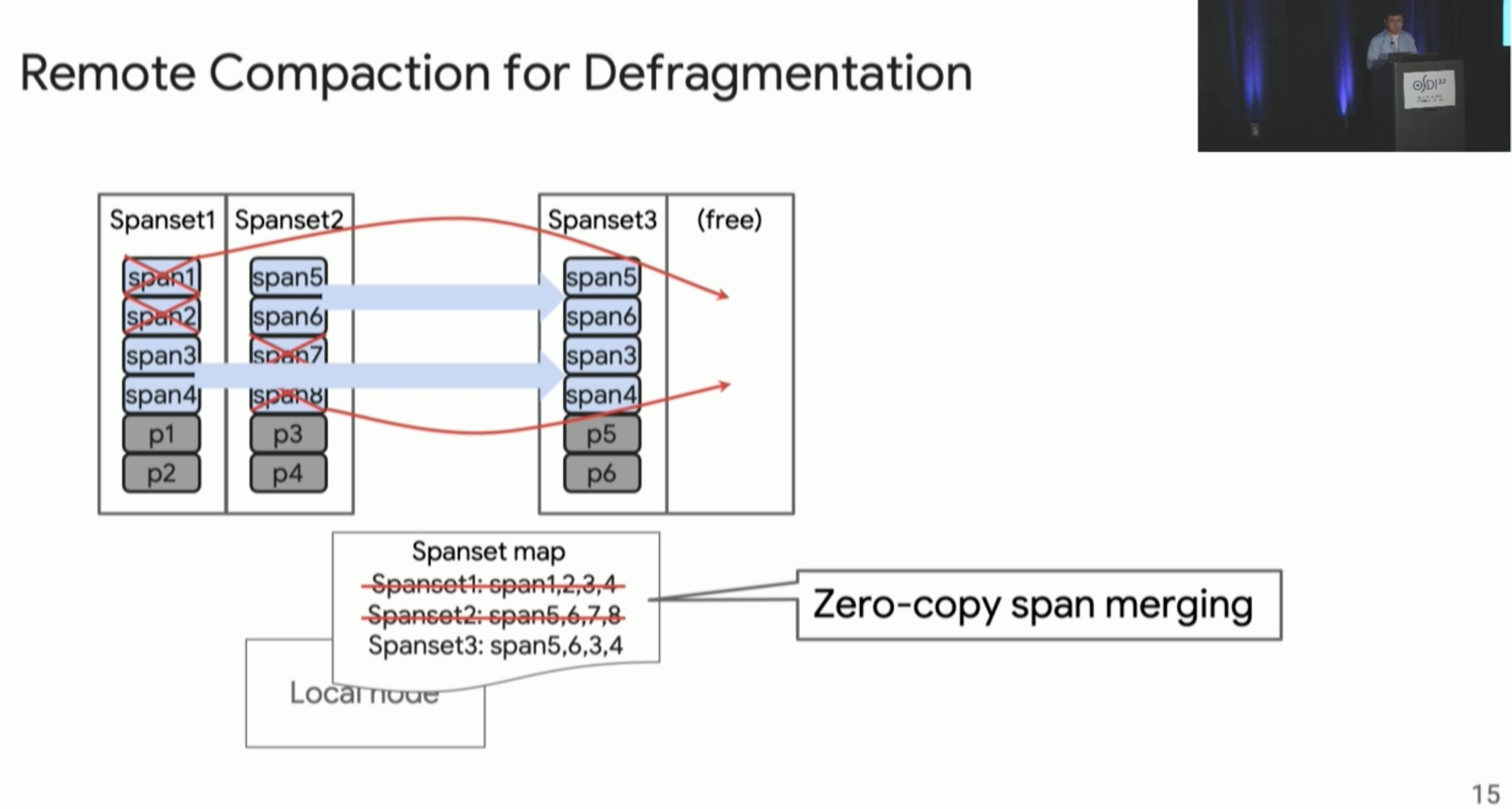
Carbink: Fault-Tolerant Far Memory
far memory 的 fault tolerence,高可用node可以raft把三个replica连起来,还有Erasure Coding的方法。这篇文章用spanset的方法监控和一些hieristics参数来保证fault tolerant。


Bugs
Metastable Failures in the Wild

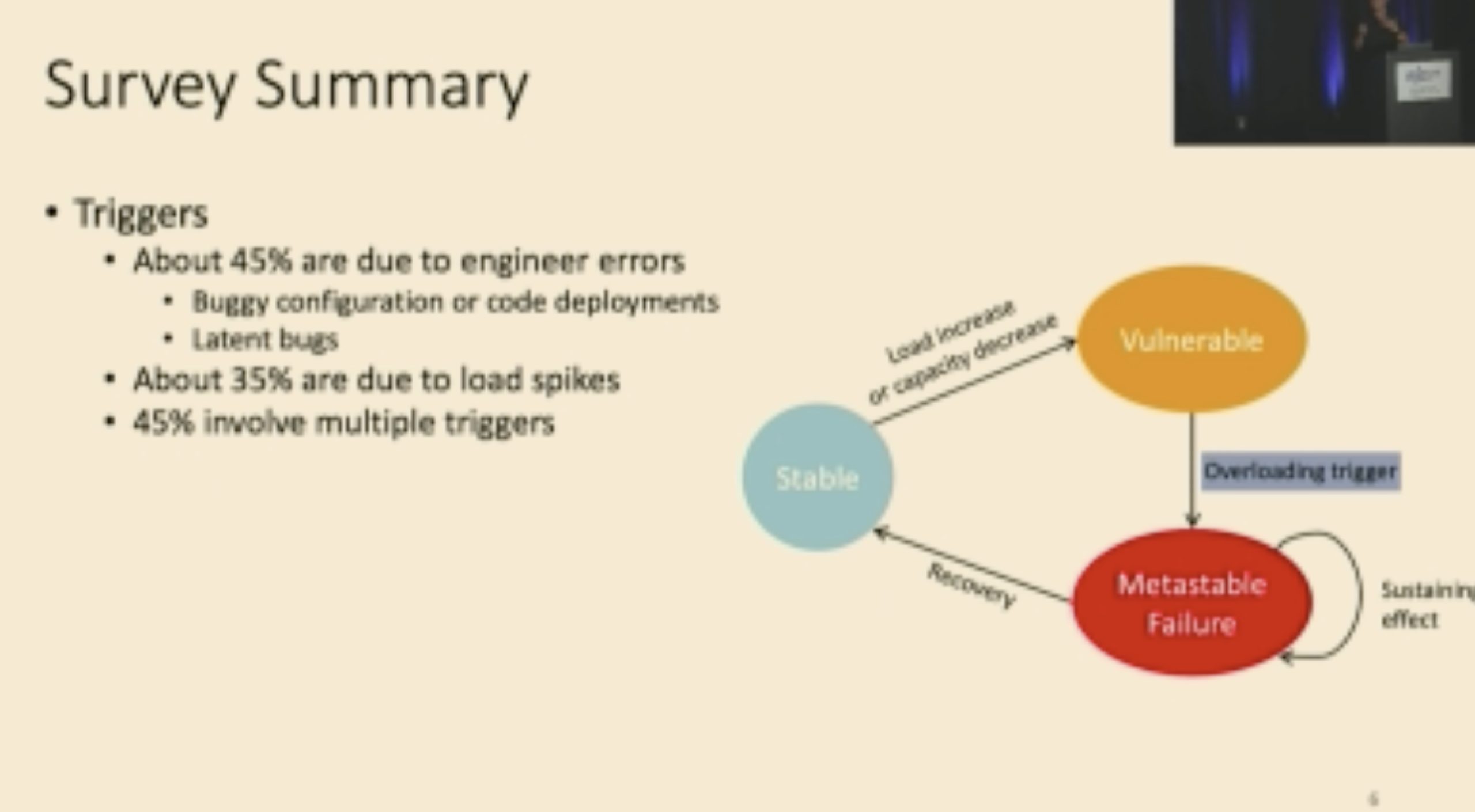
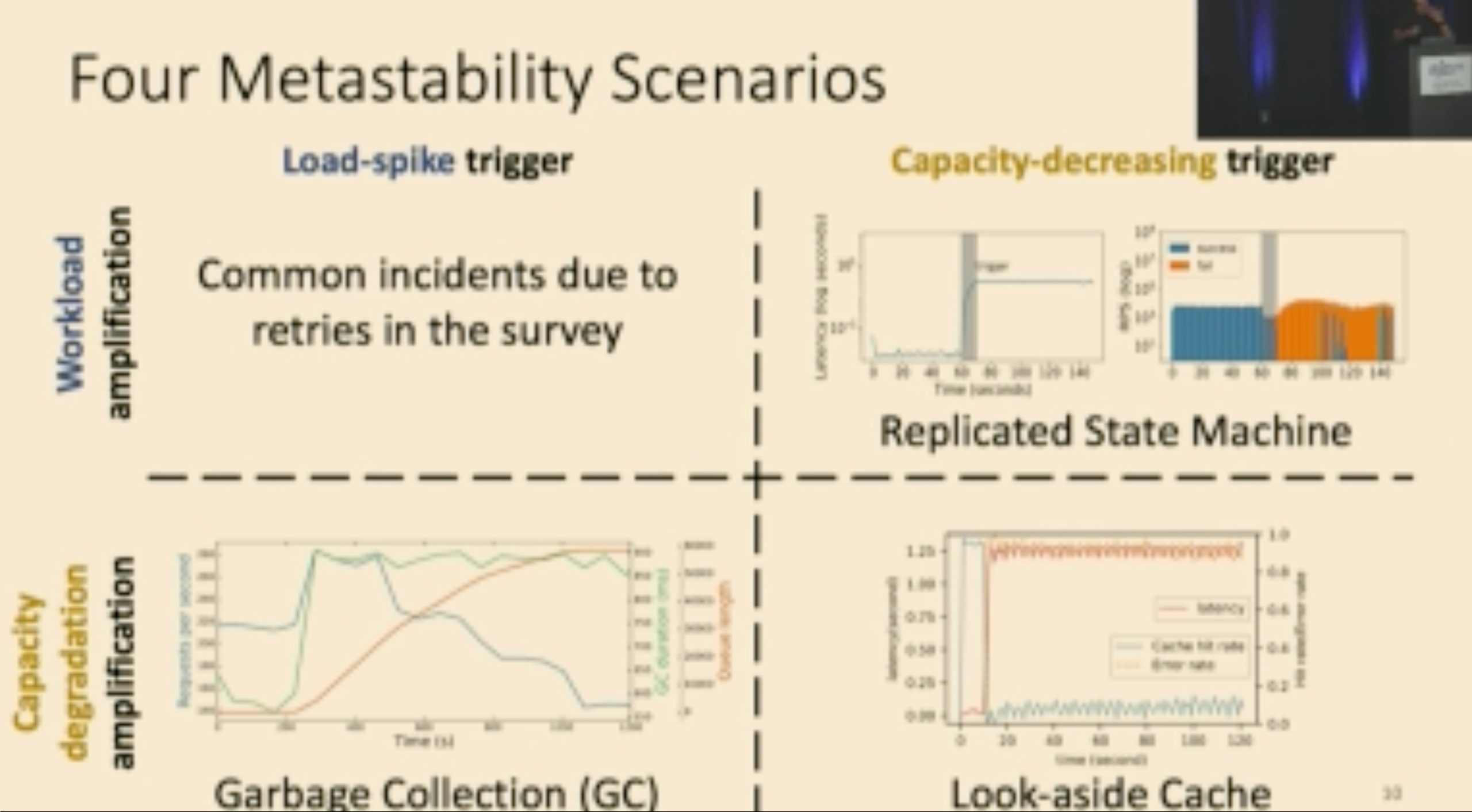
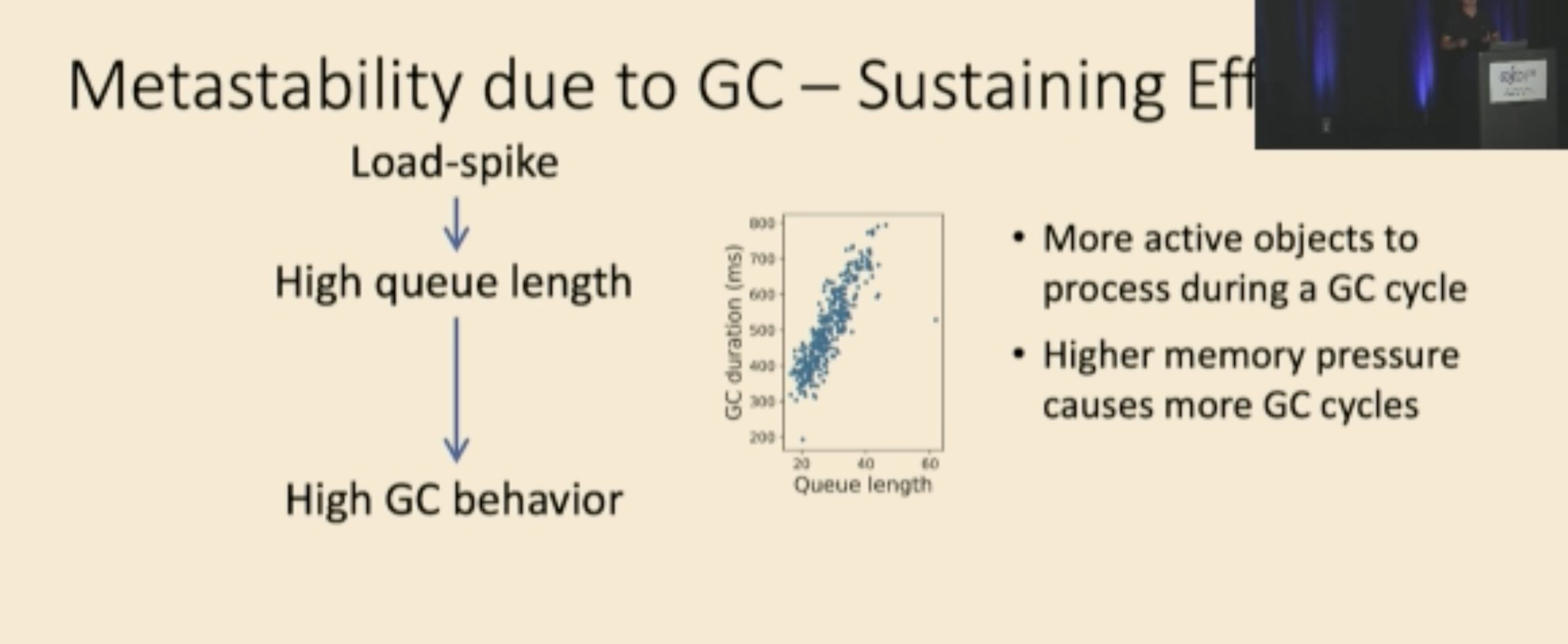
找的逻辑和profiling一样。
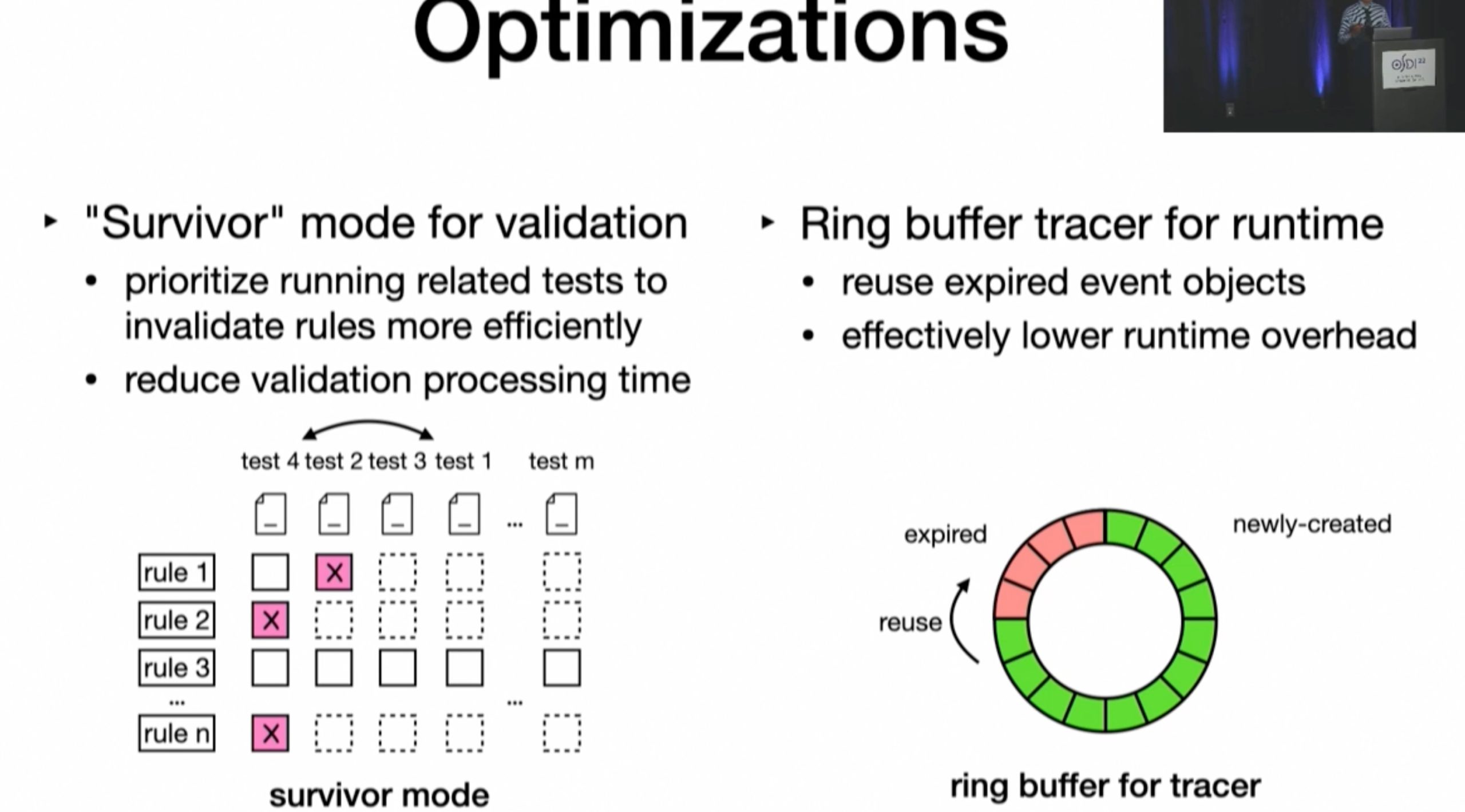
Demystifying and Checkirig Silent Semantic Violations in Large Distributed Systems

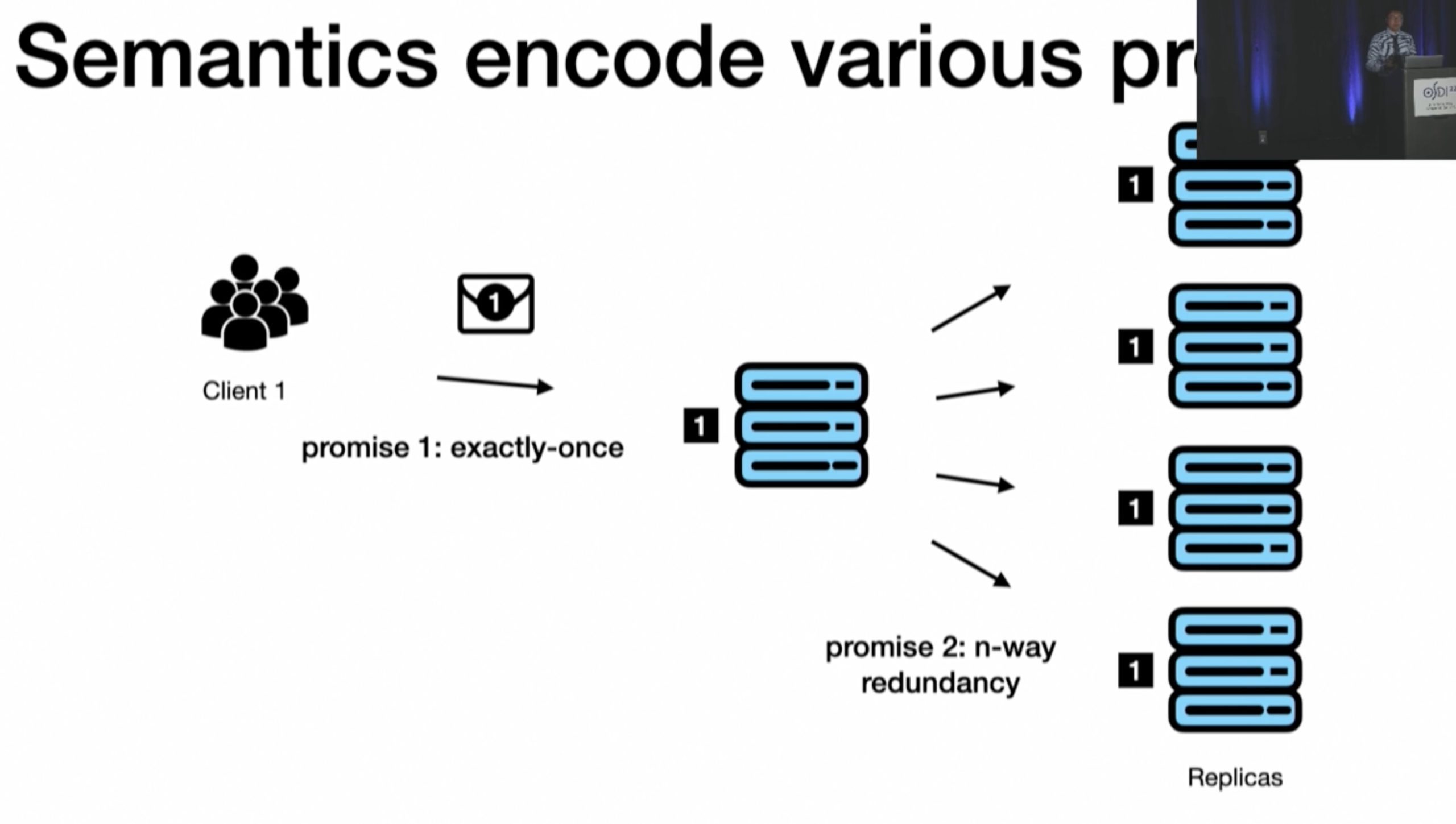

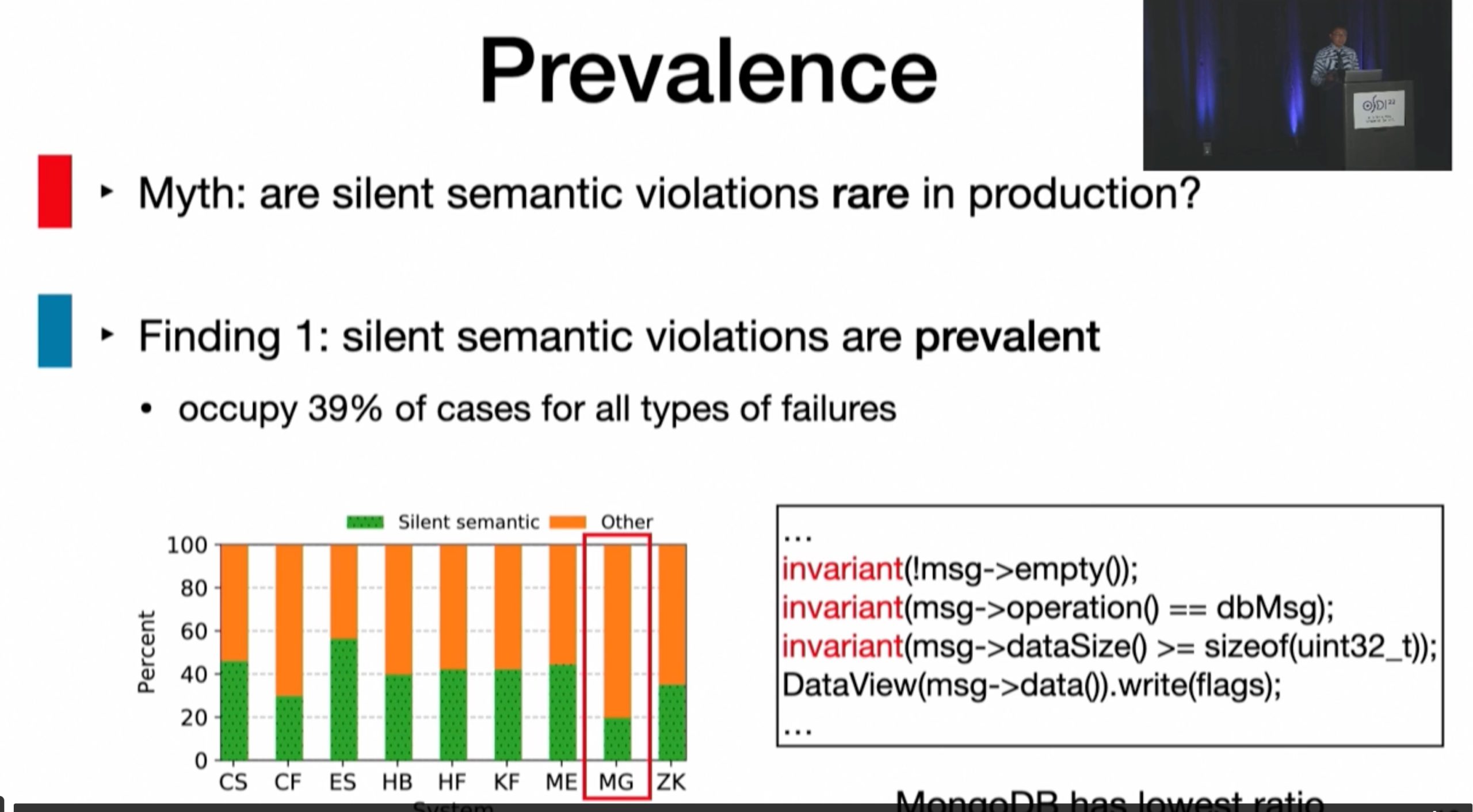

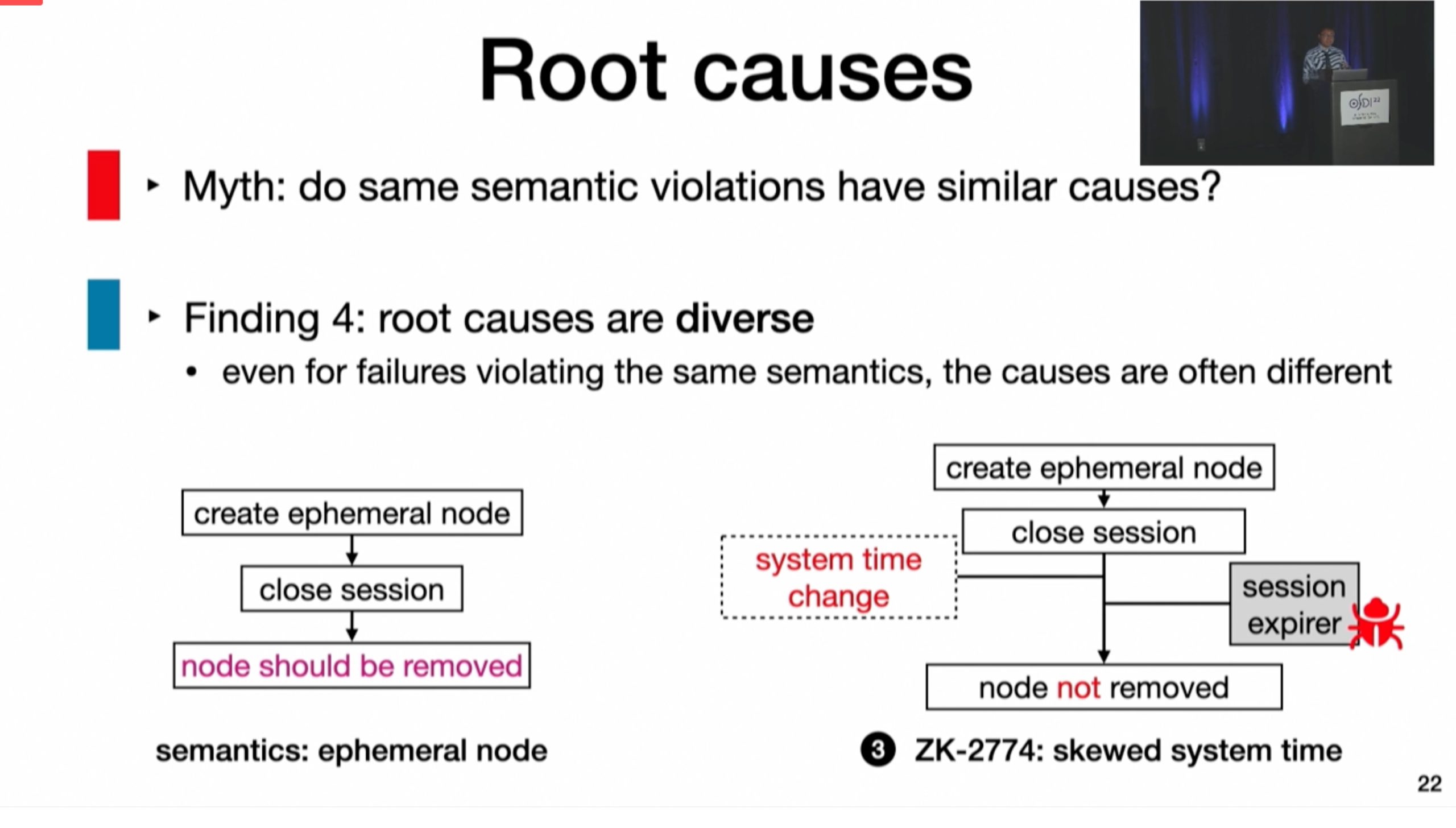

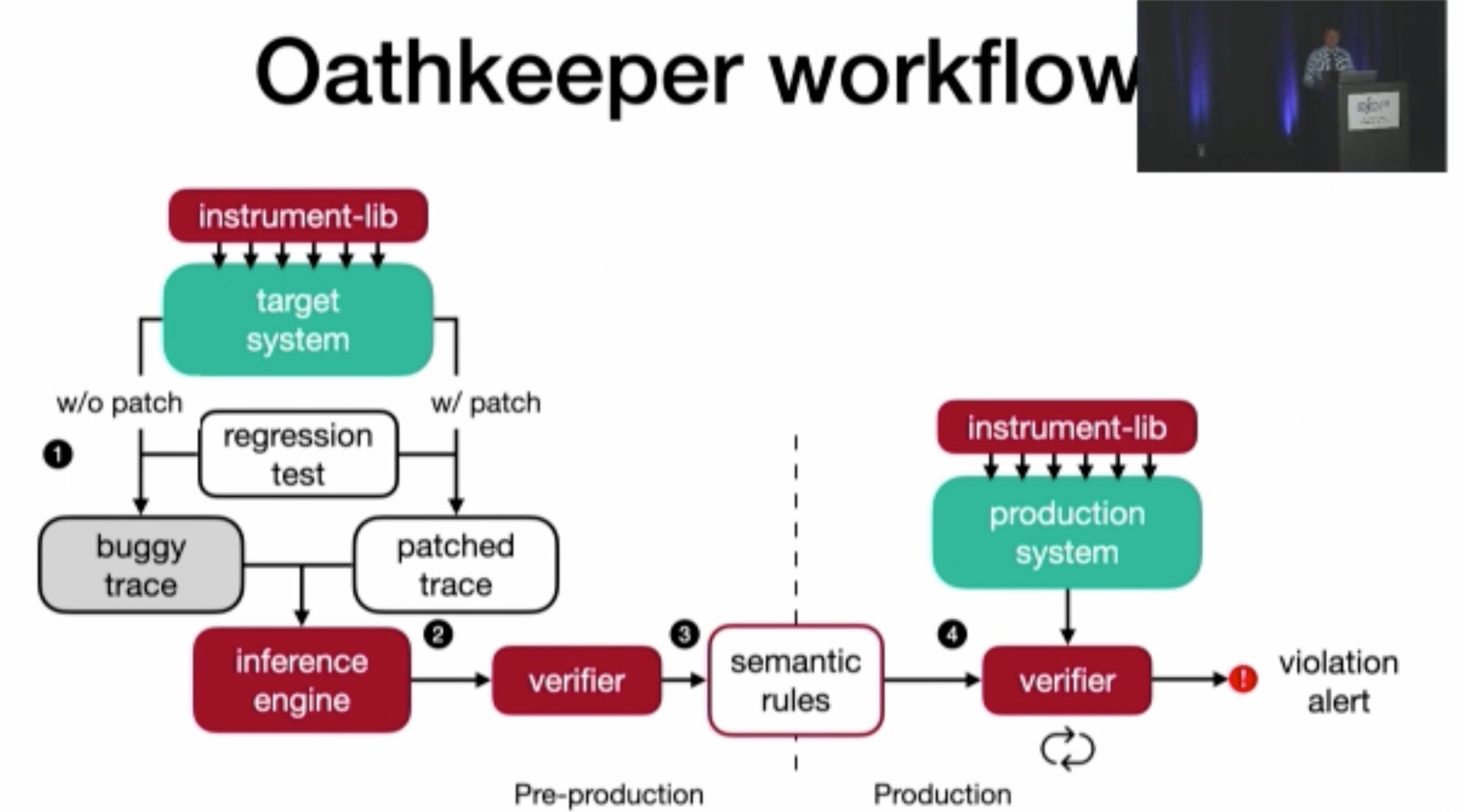

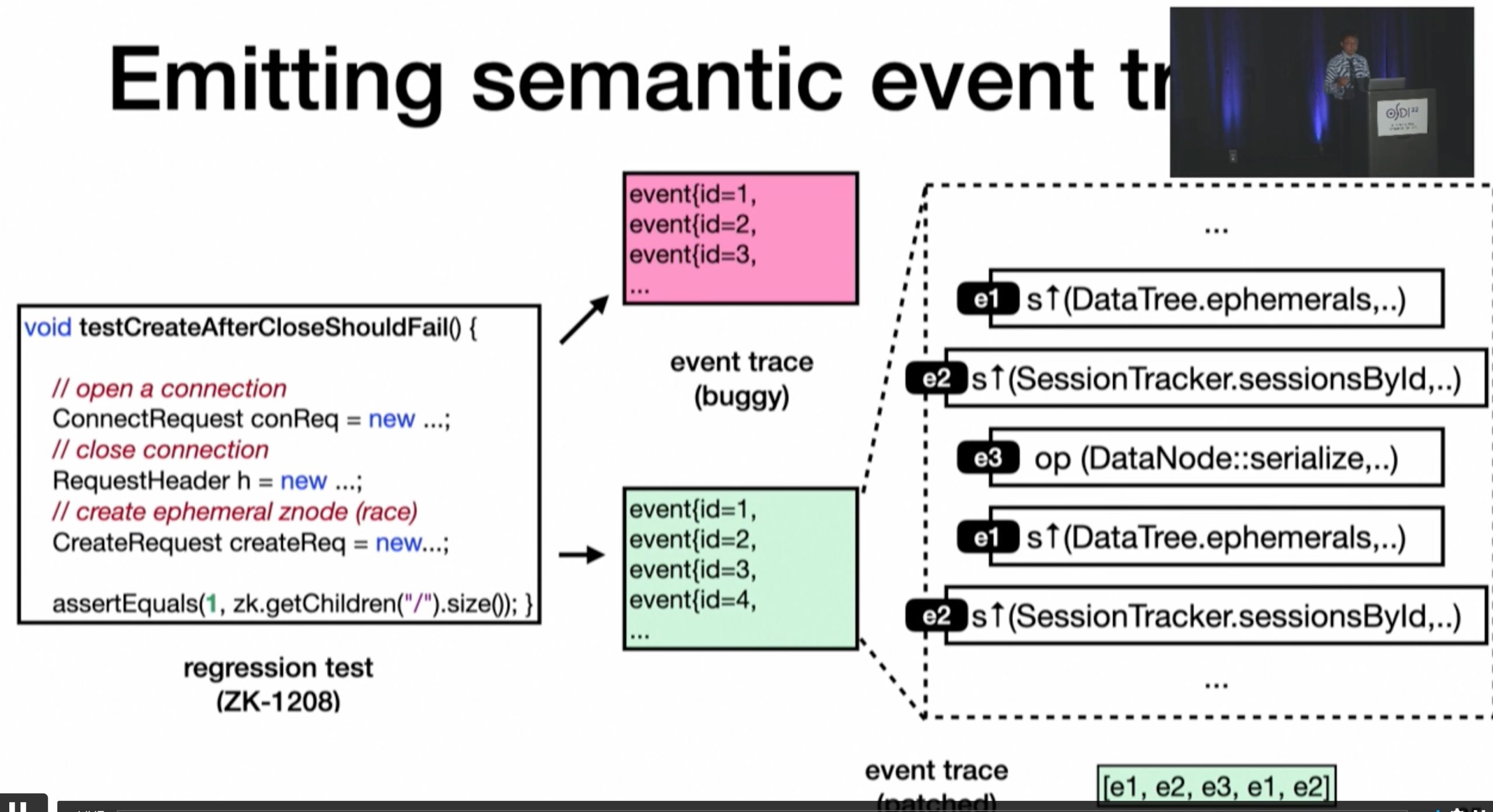

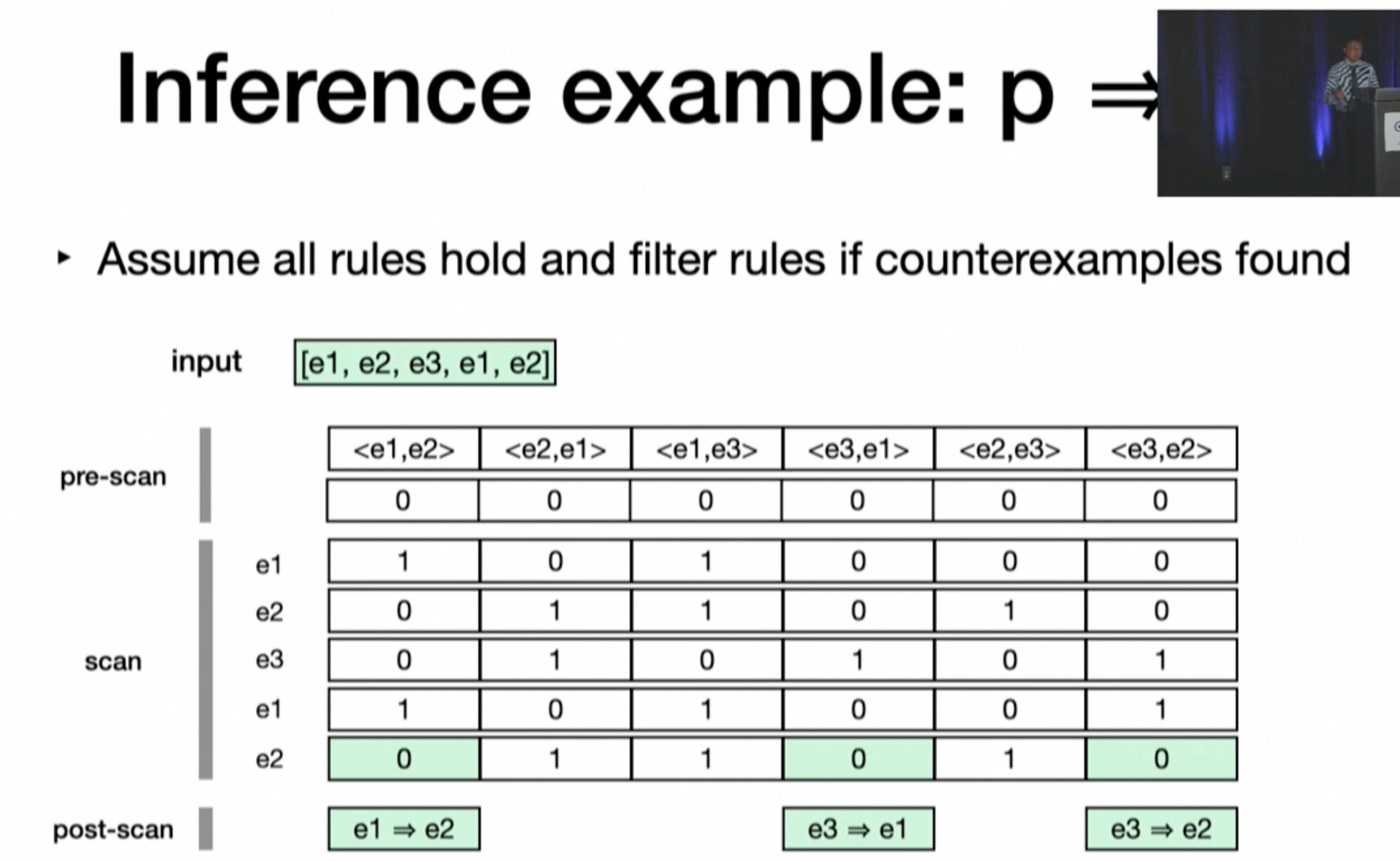
inference rule 会在post scan的时候由scan的时候给出



PM
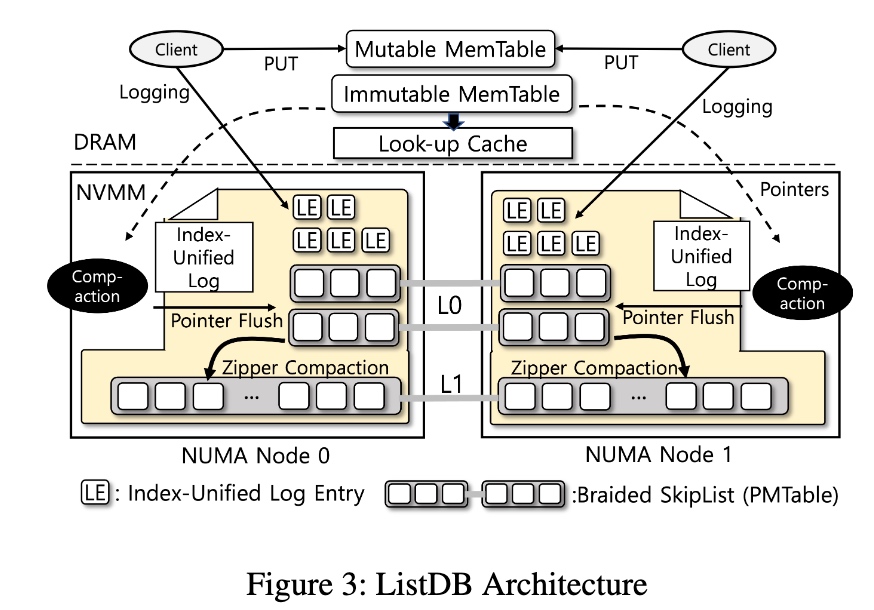
ListDB: Union of Write-Ahead Logs and Persistent SkipLists for Incremental Checkpointing on Persistent Memory
PM写index-unified log, numa aware skiplist存pointer然后写优化的zipper compaction,会在dram中放lookup cache为了减少numa开销。(cxl出来以后有external MC了会不会不用管这回事了?)
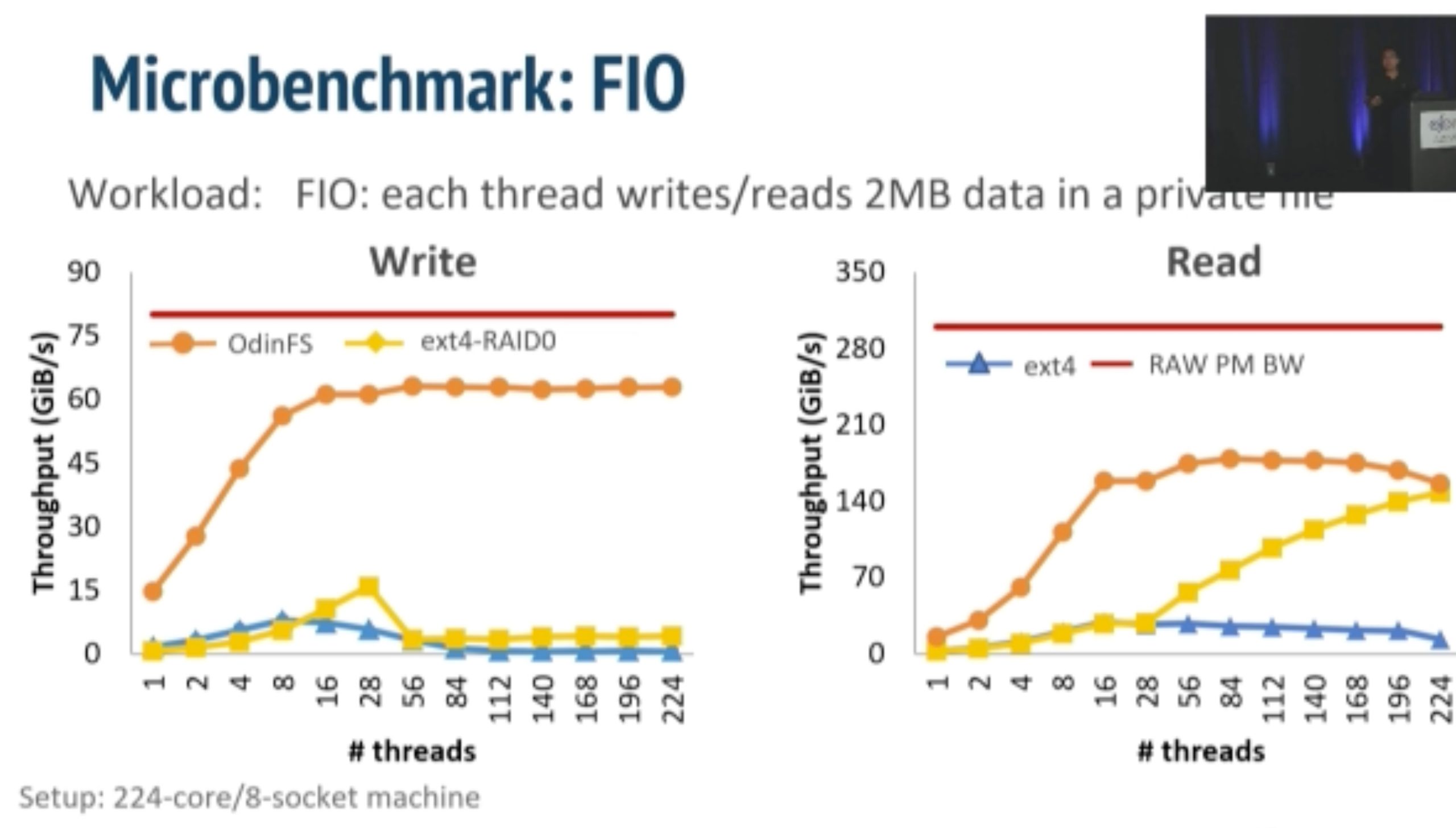
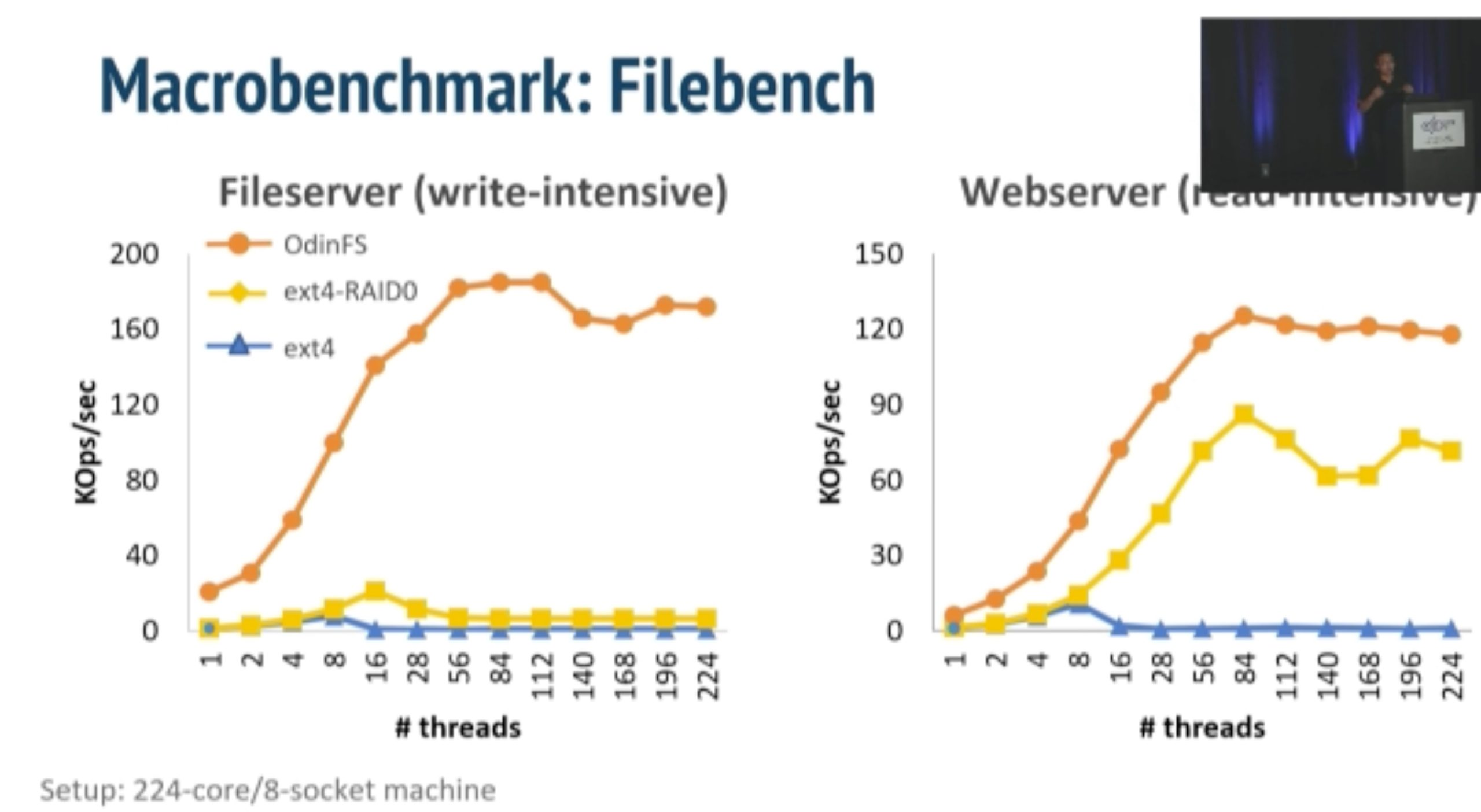
ODinFS
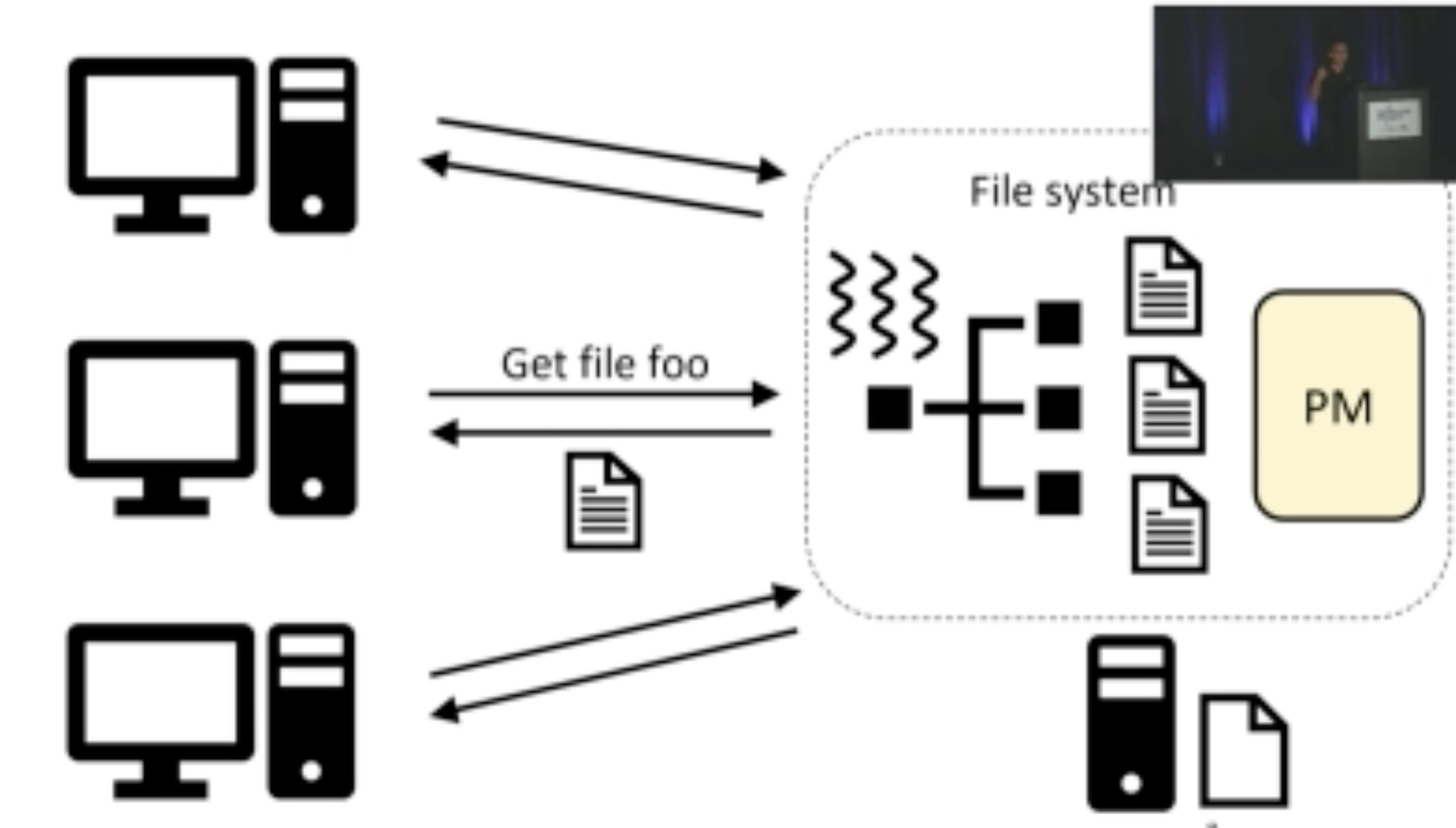
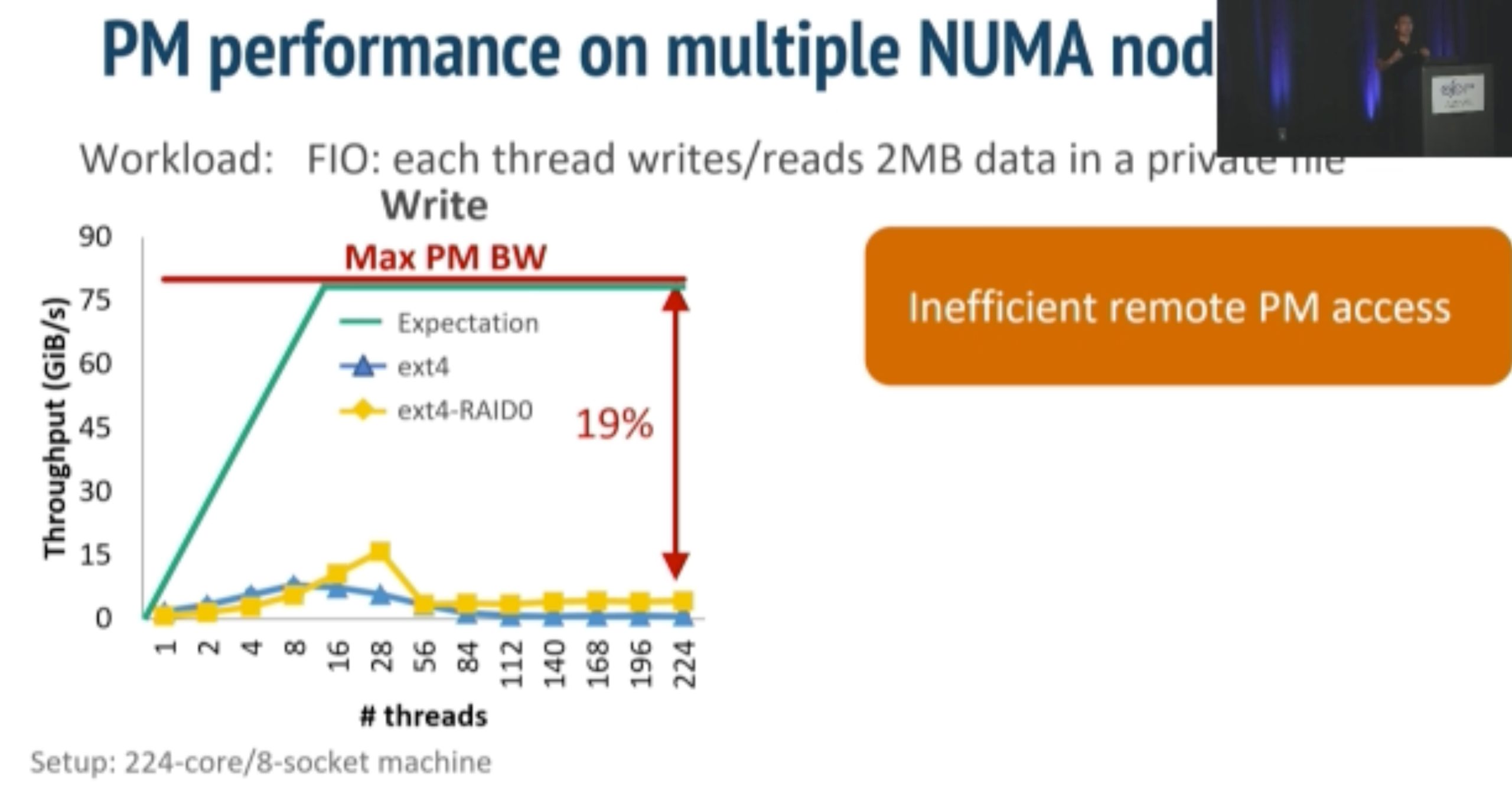
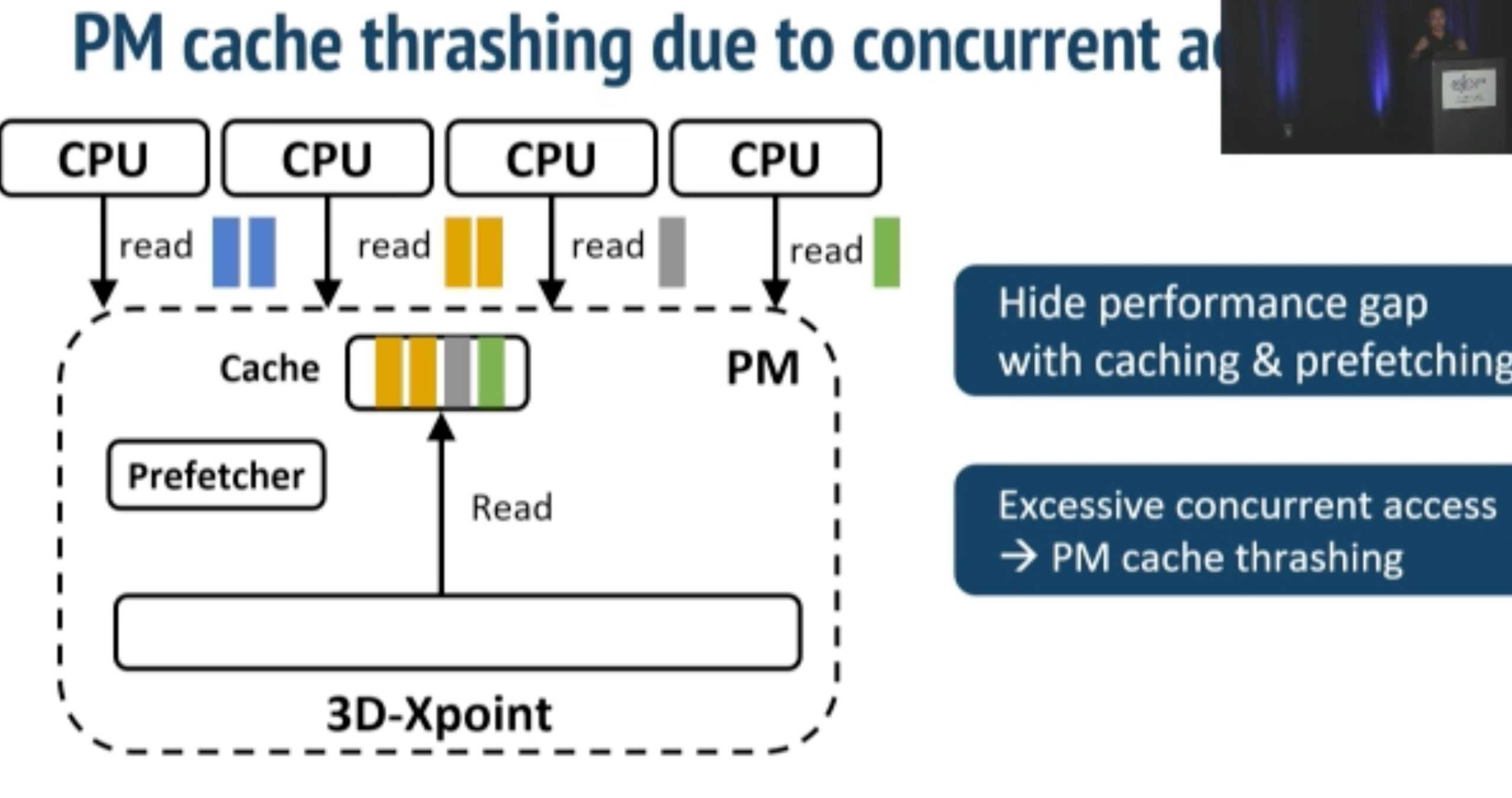
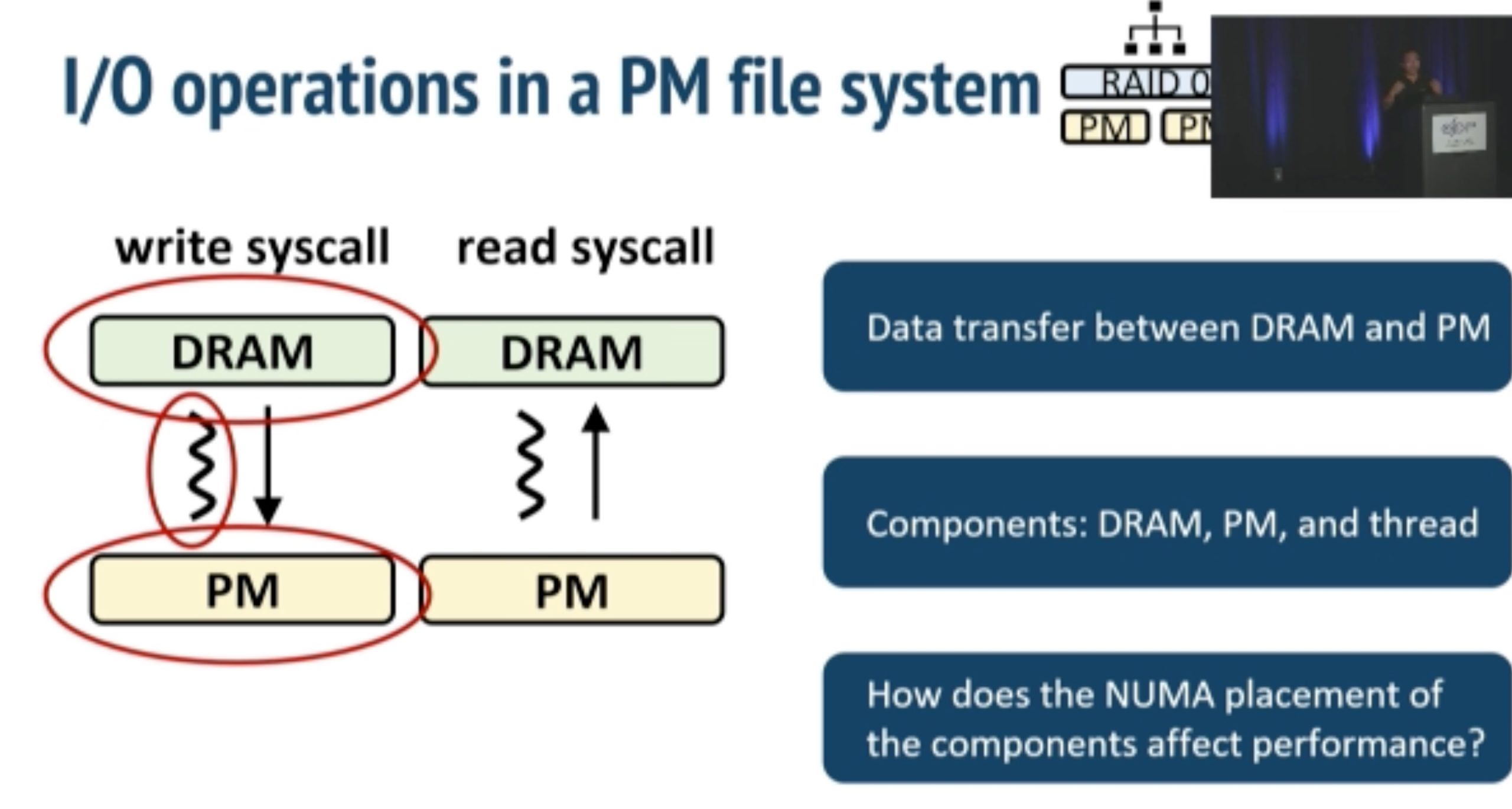
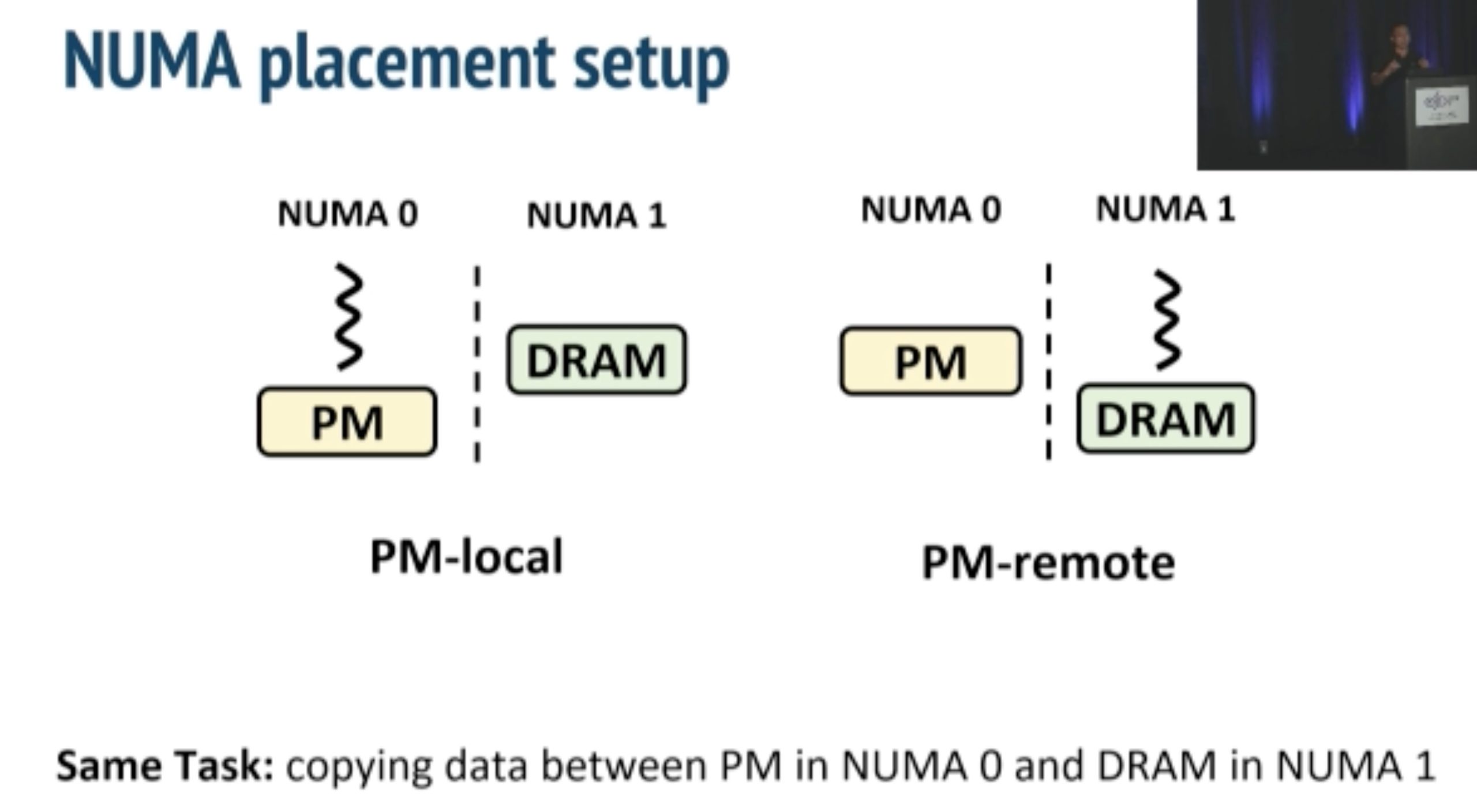
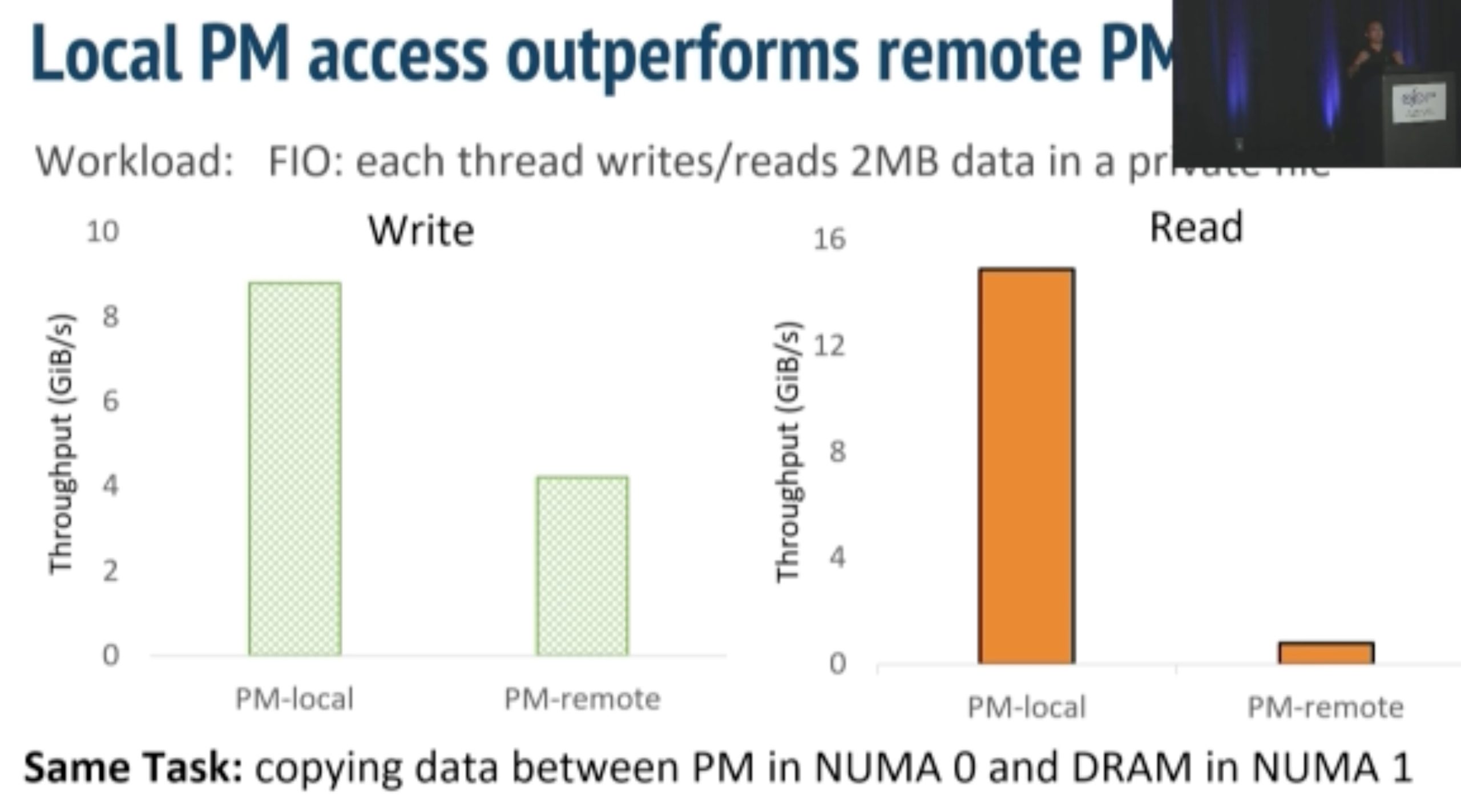
inkernel fs taking NUMA, bandwidth and thread thrashing into consideration in one device.
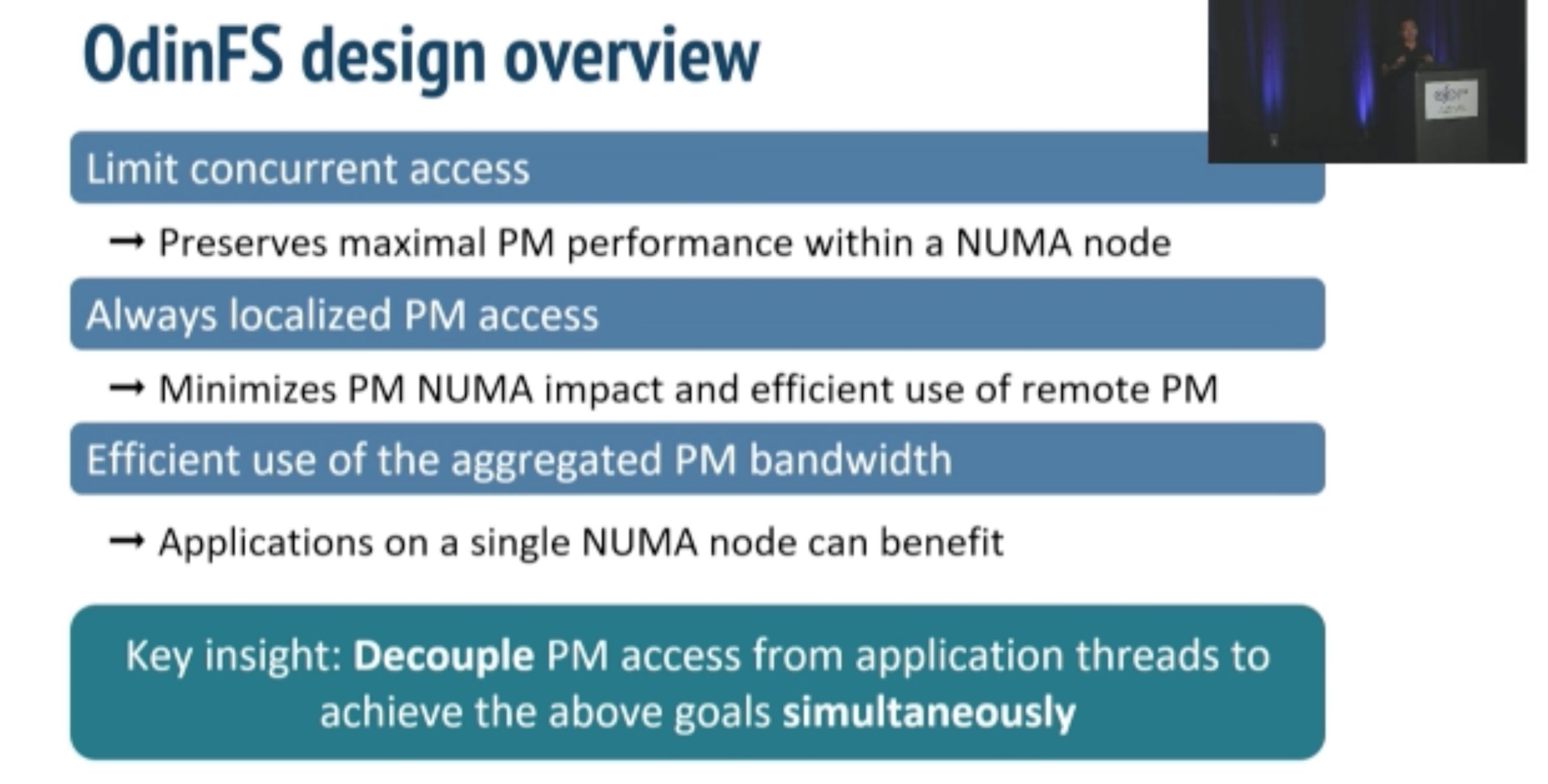
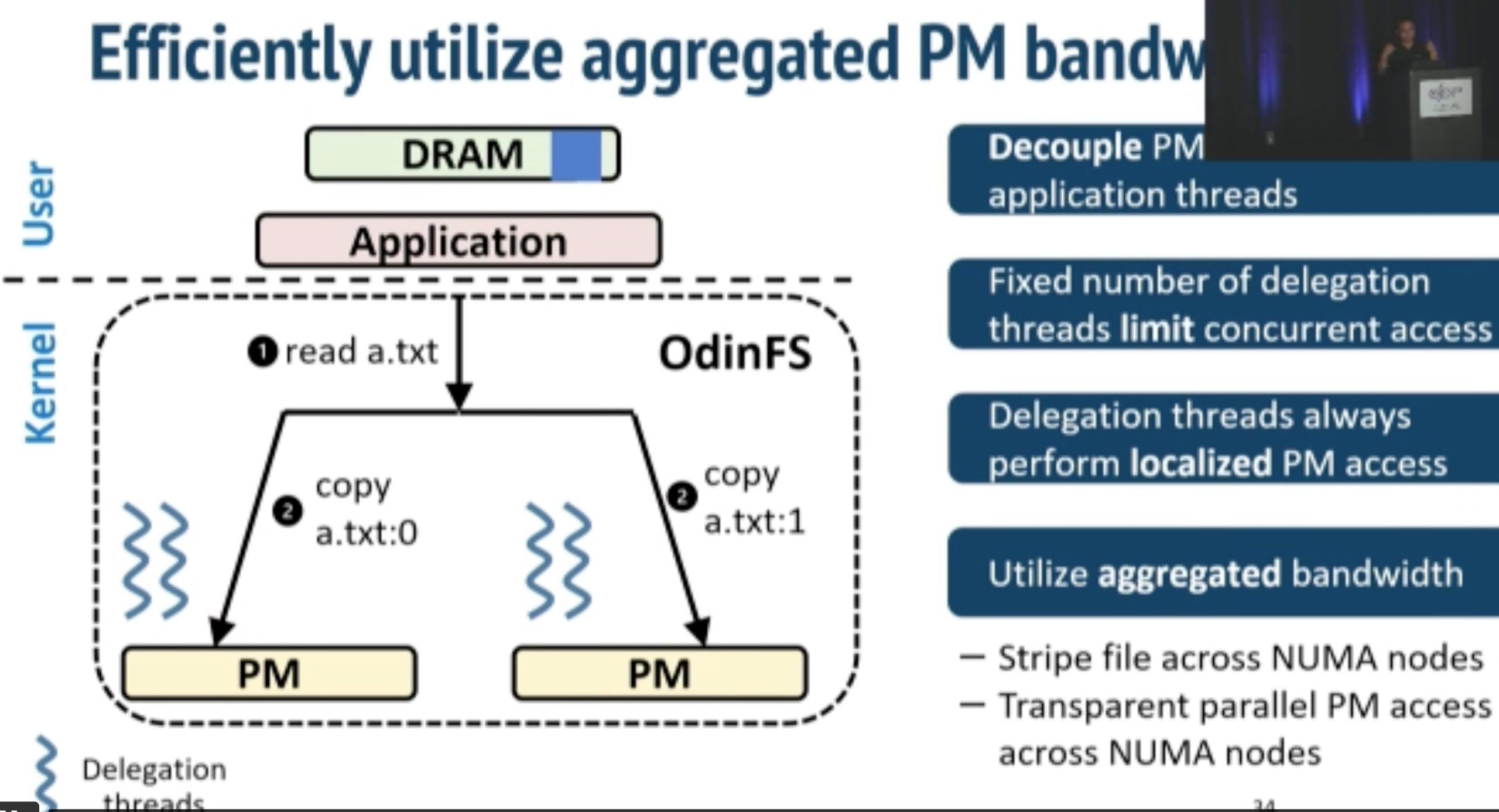
Using thread delegation as decoupled daemon in local PM access


MMAP: like NOVA MMAP propagate and then MUNMAP
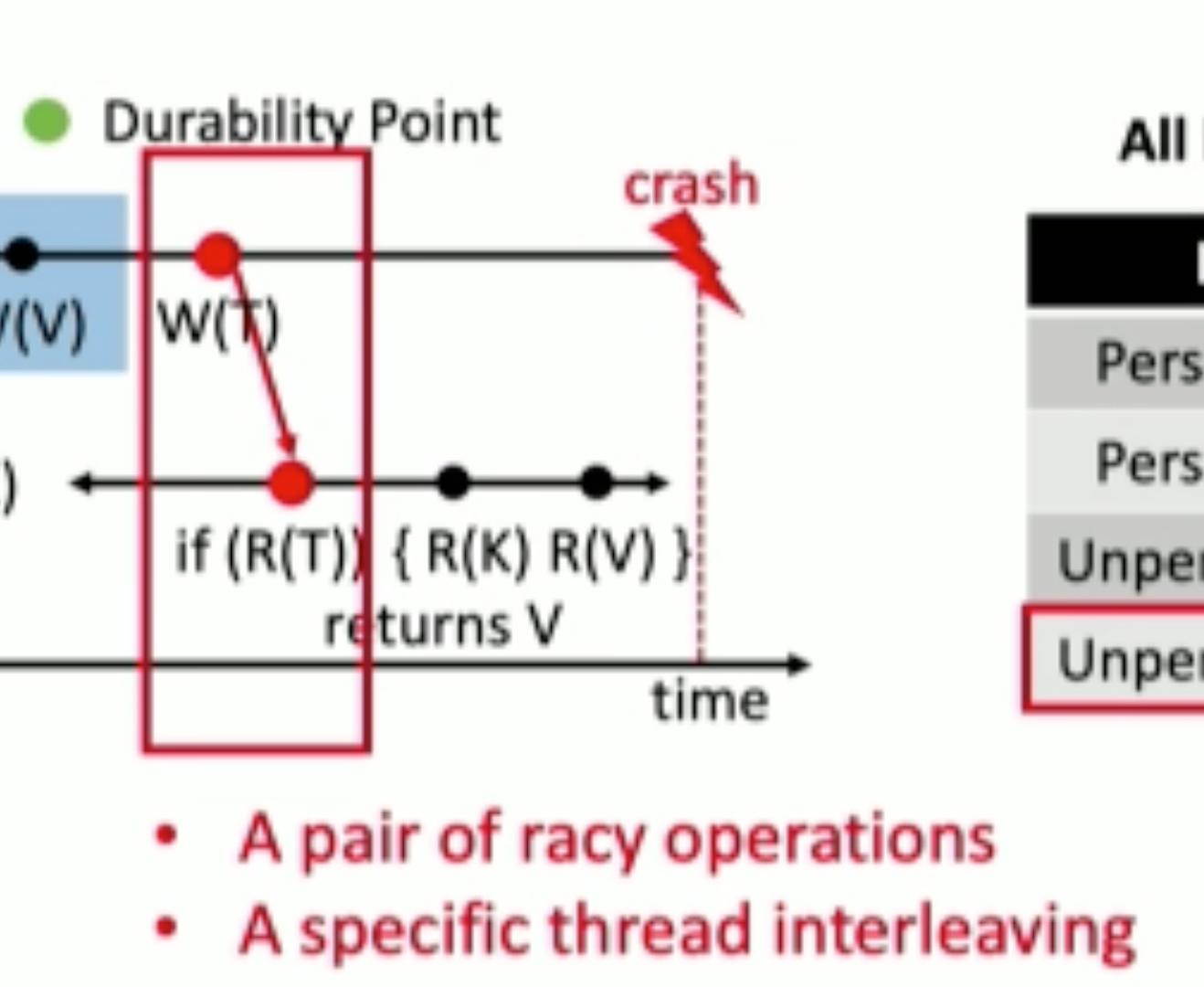
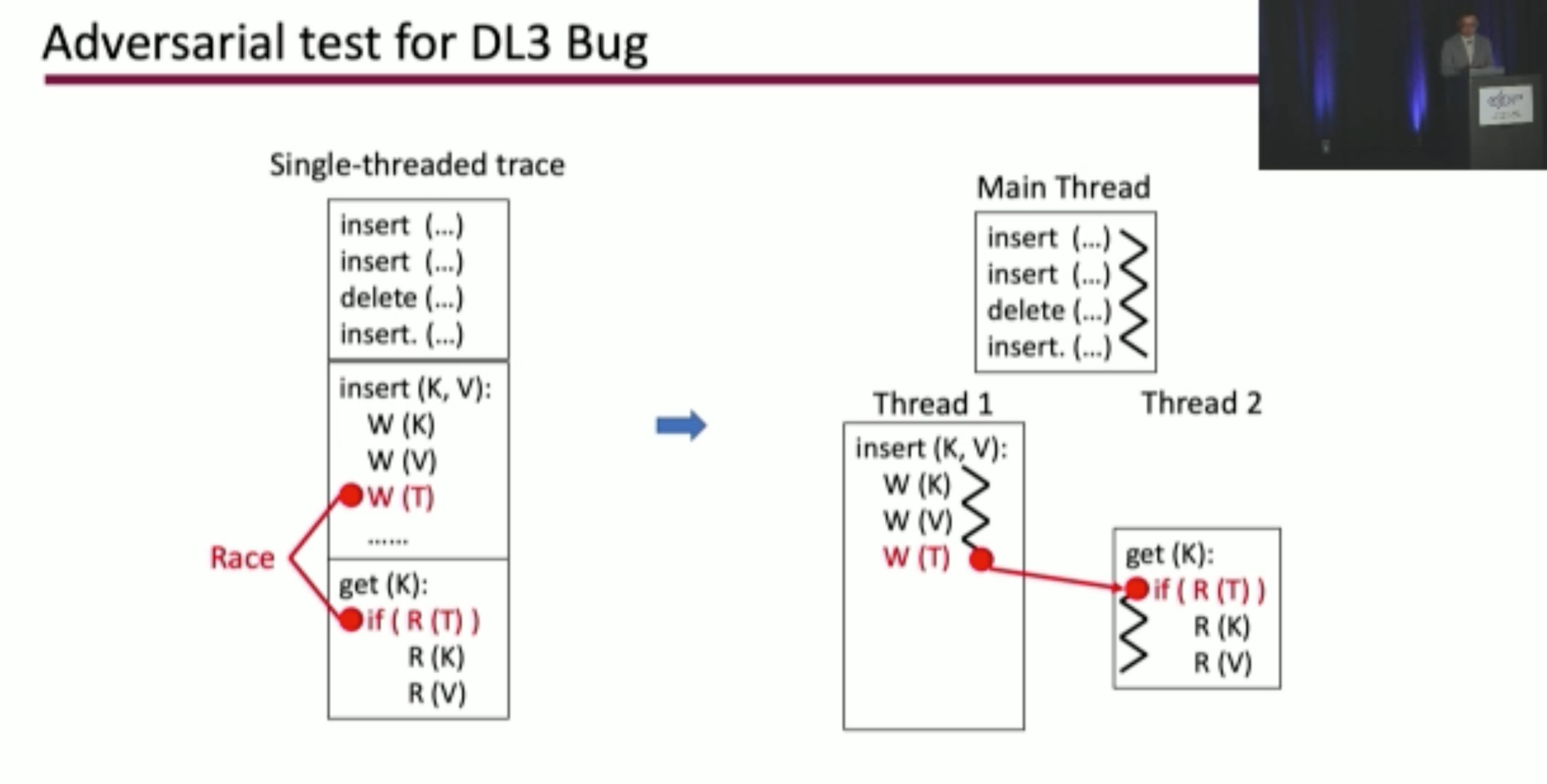
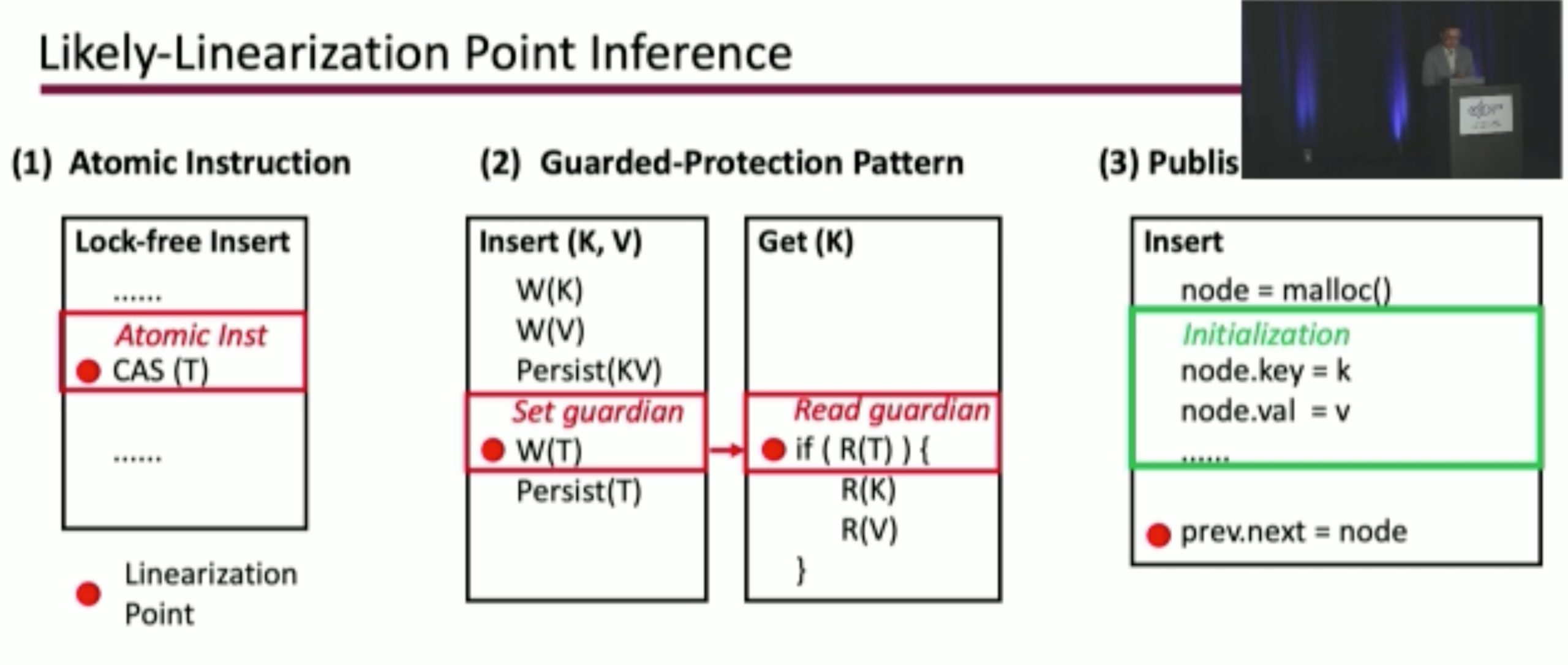
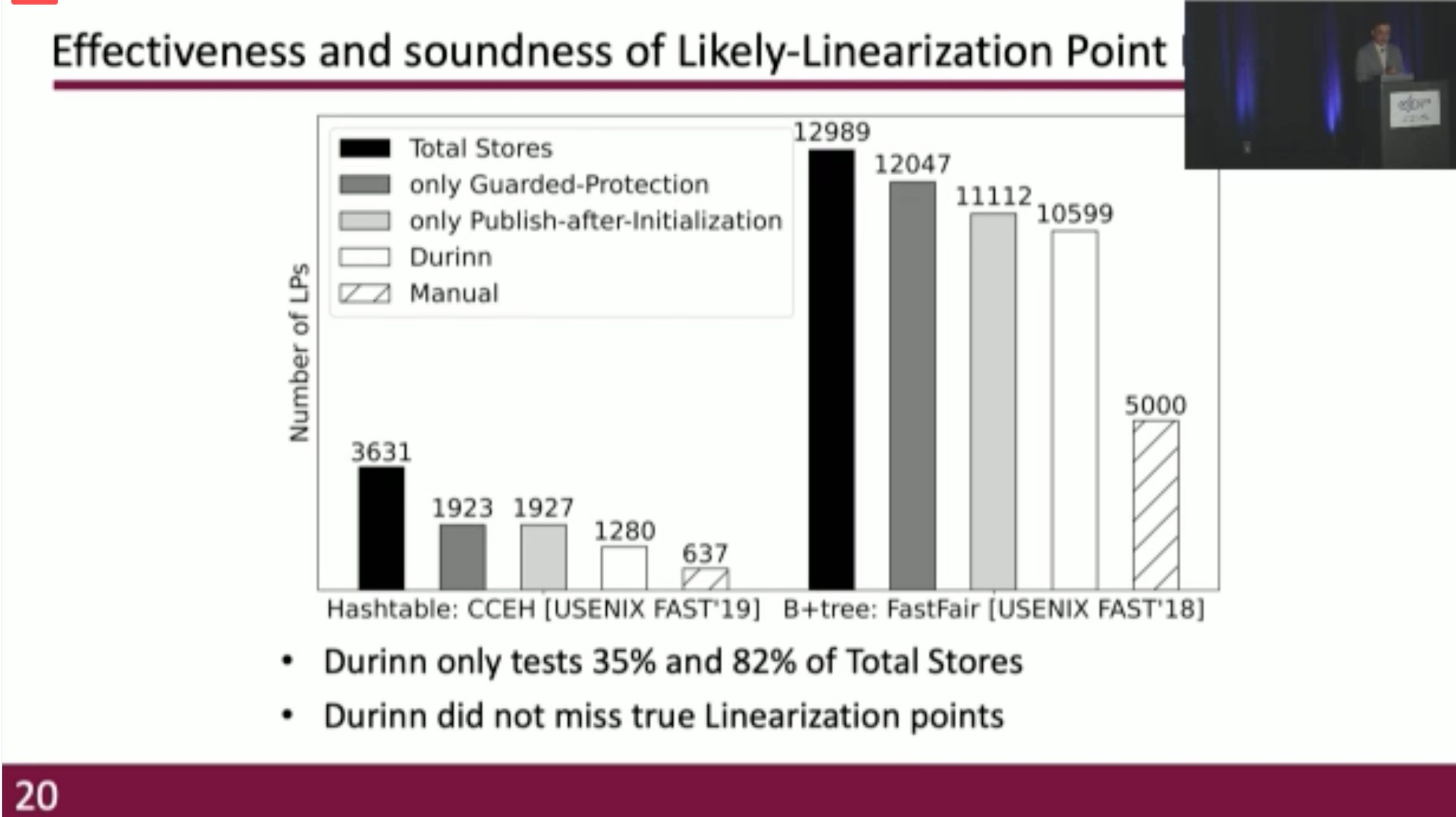
Durinn: Adversarial Memory and Thread Interleaving for Detecting Durable Linearizability Bugs

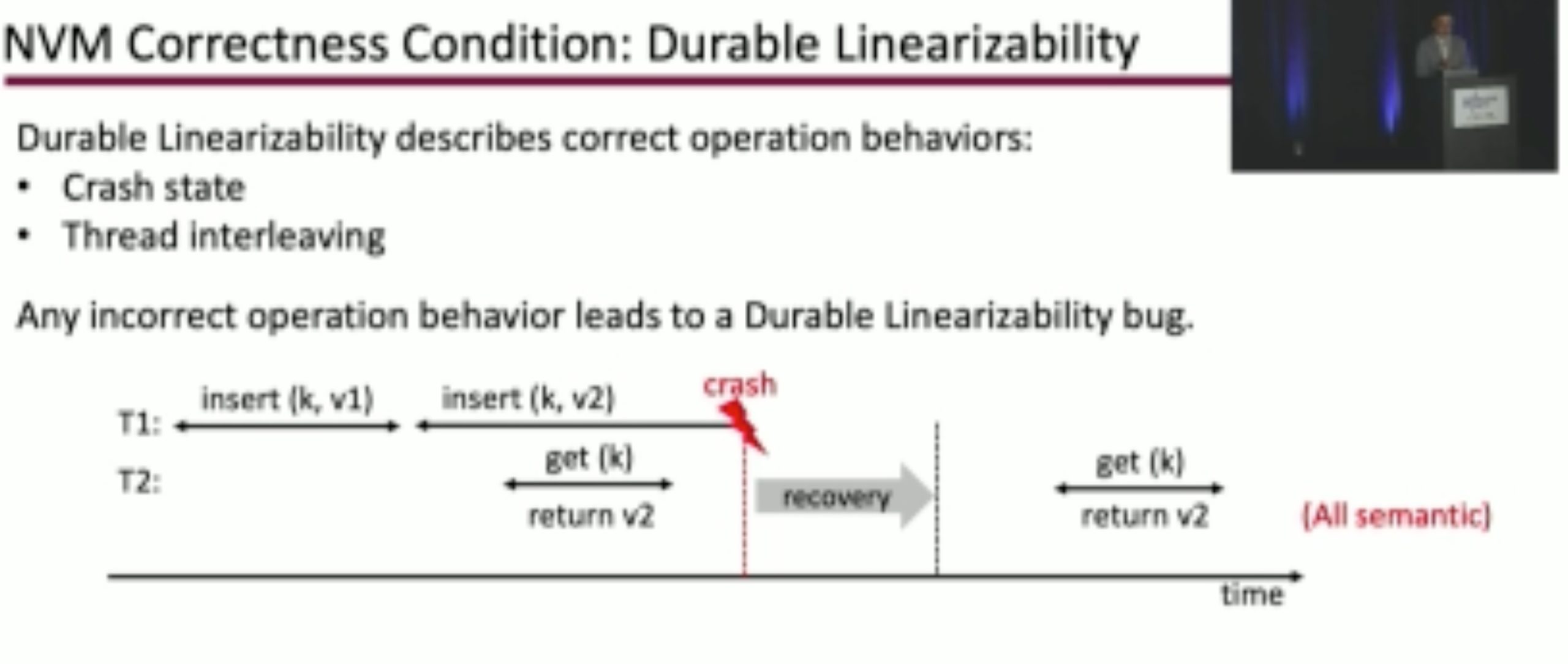
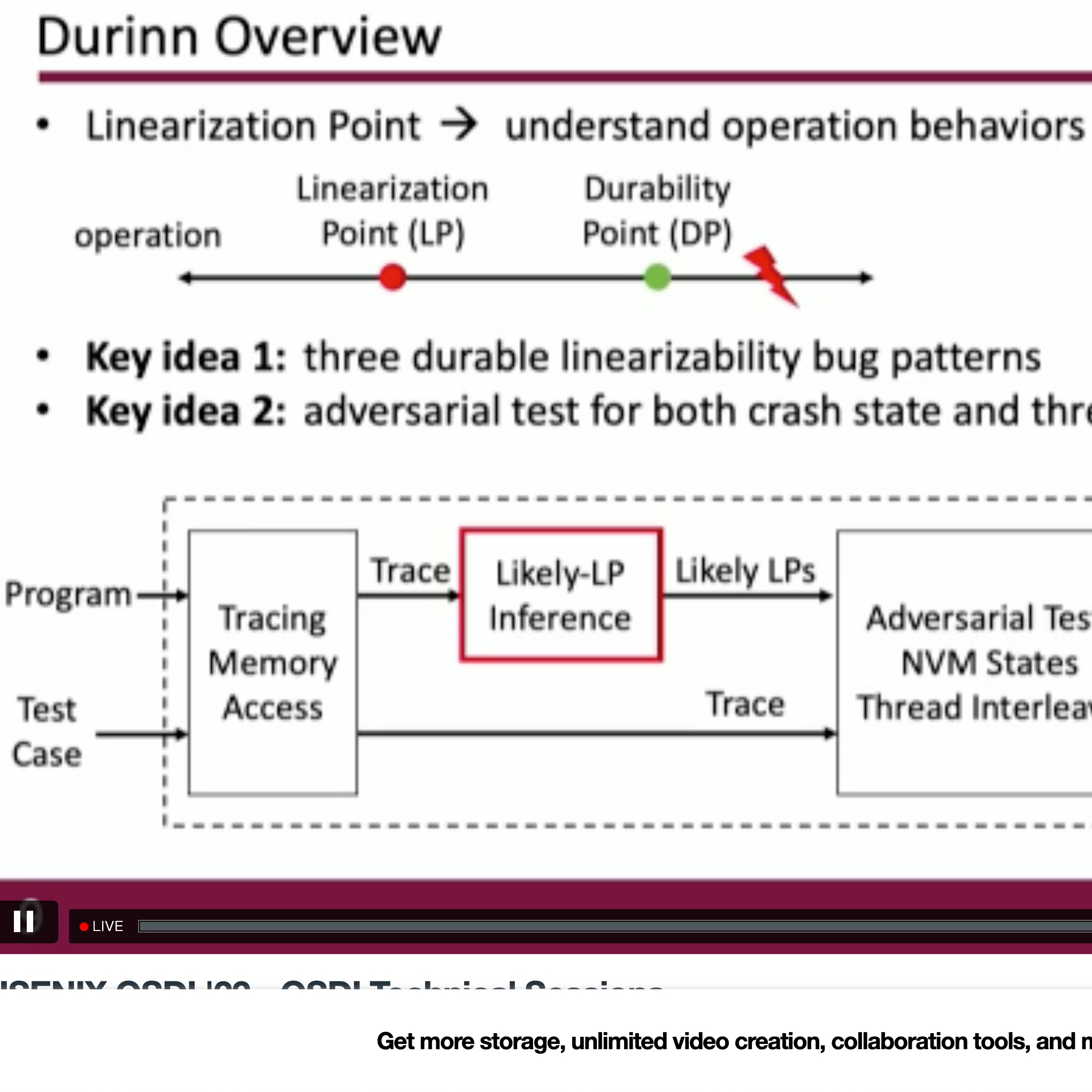
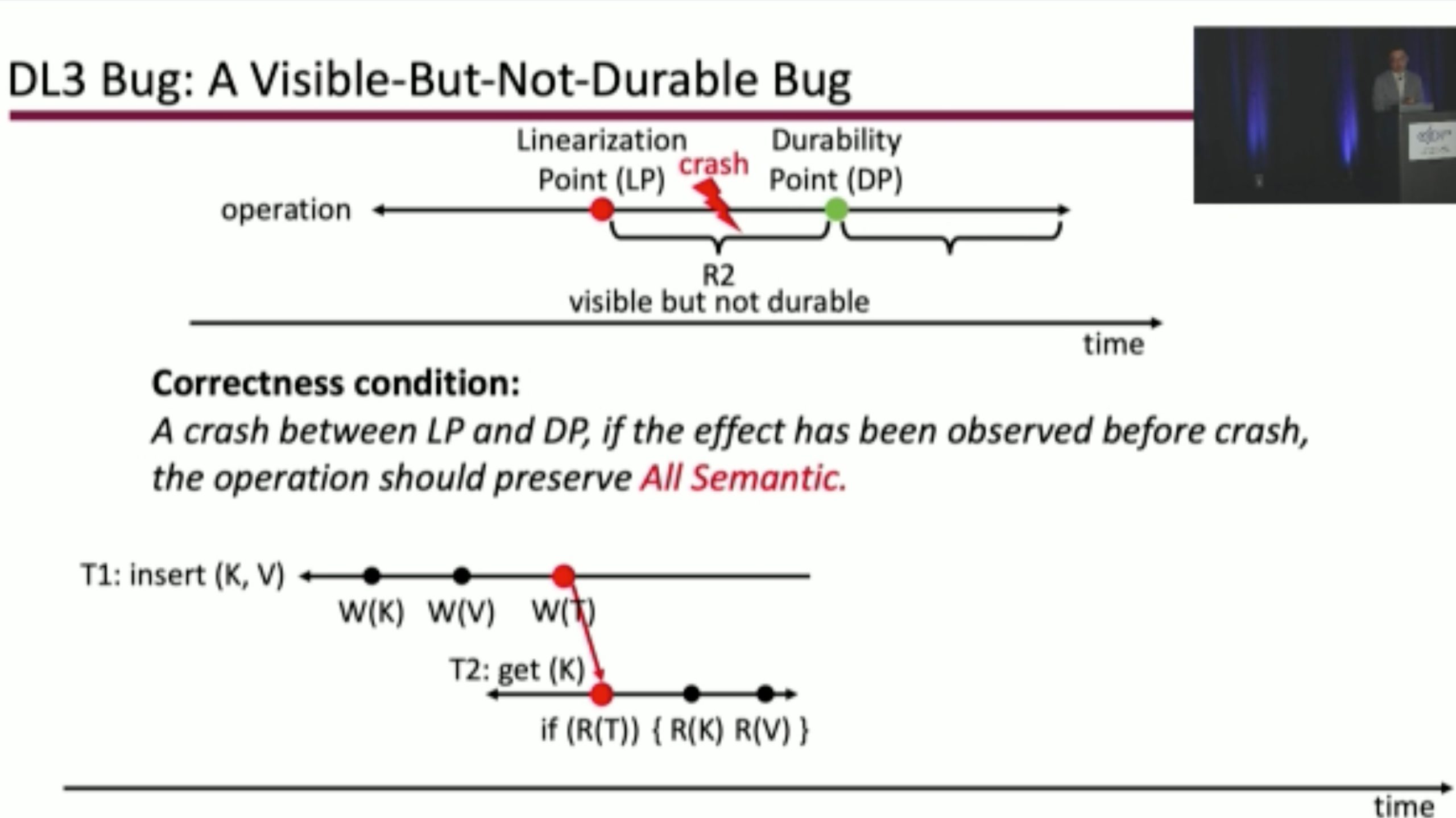
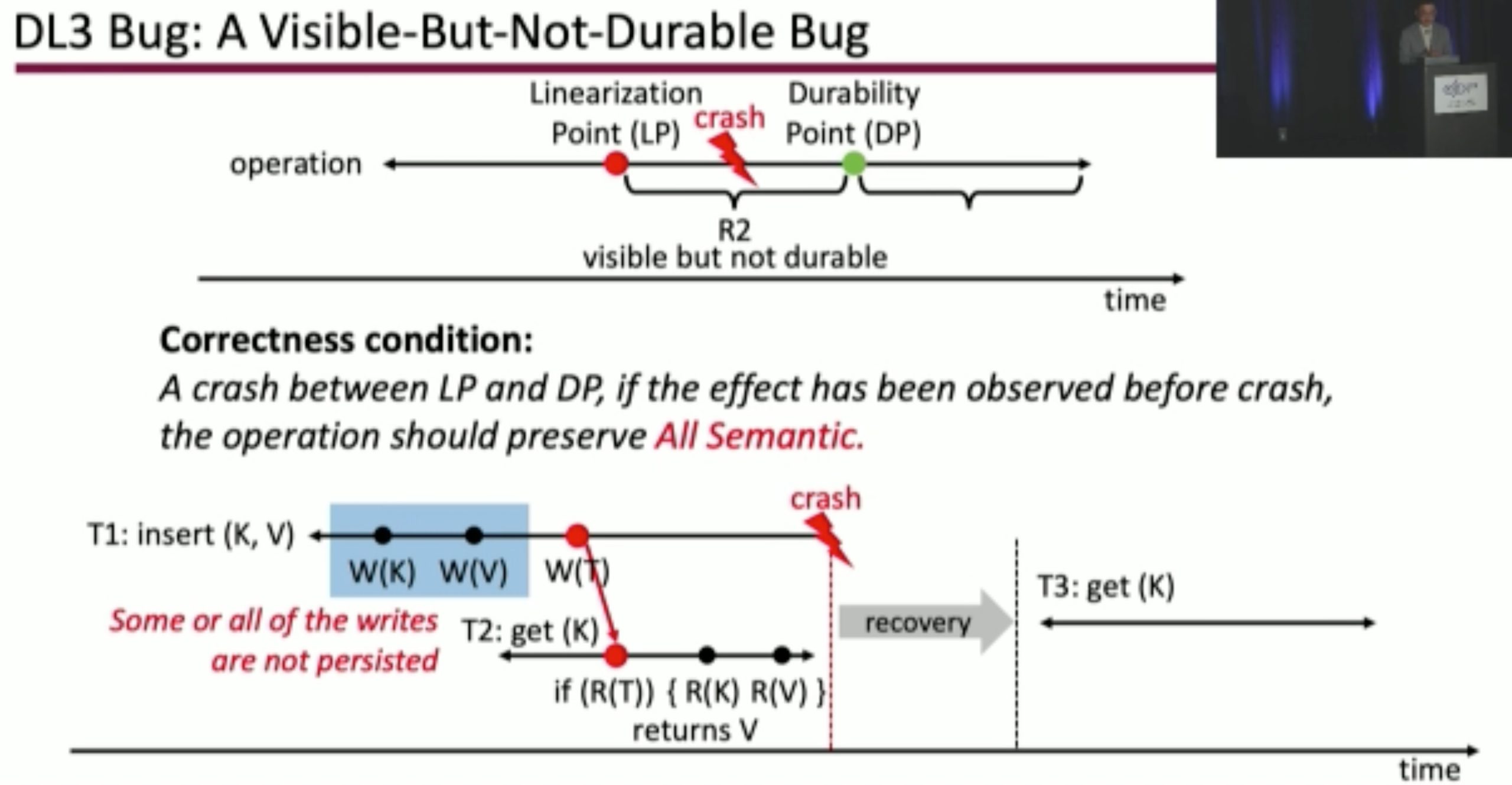
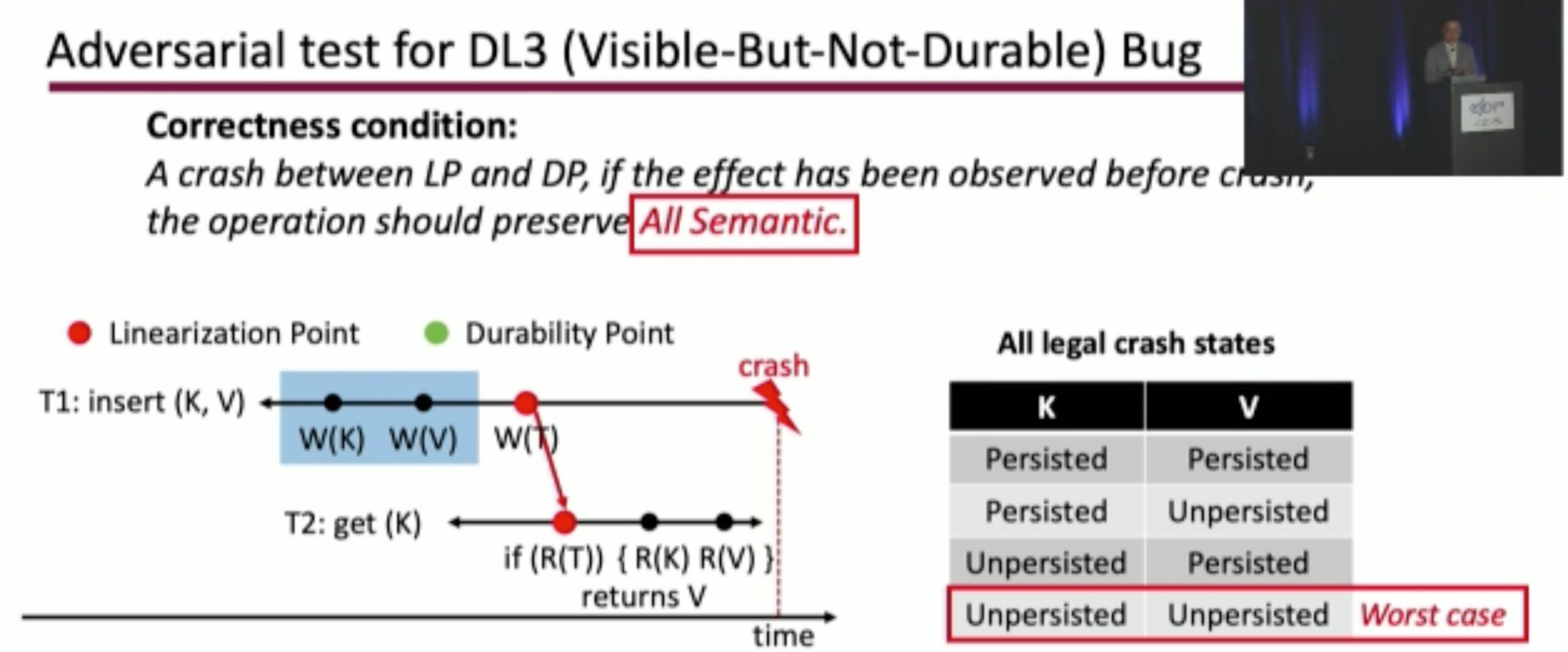
Construct the test:




Serverless
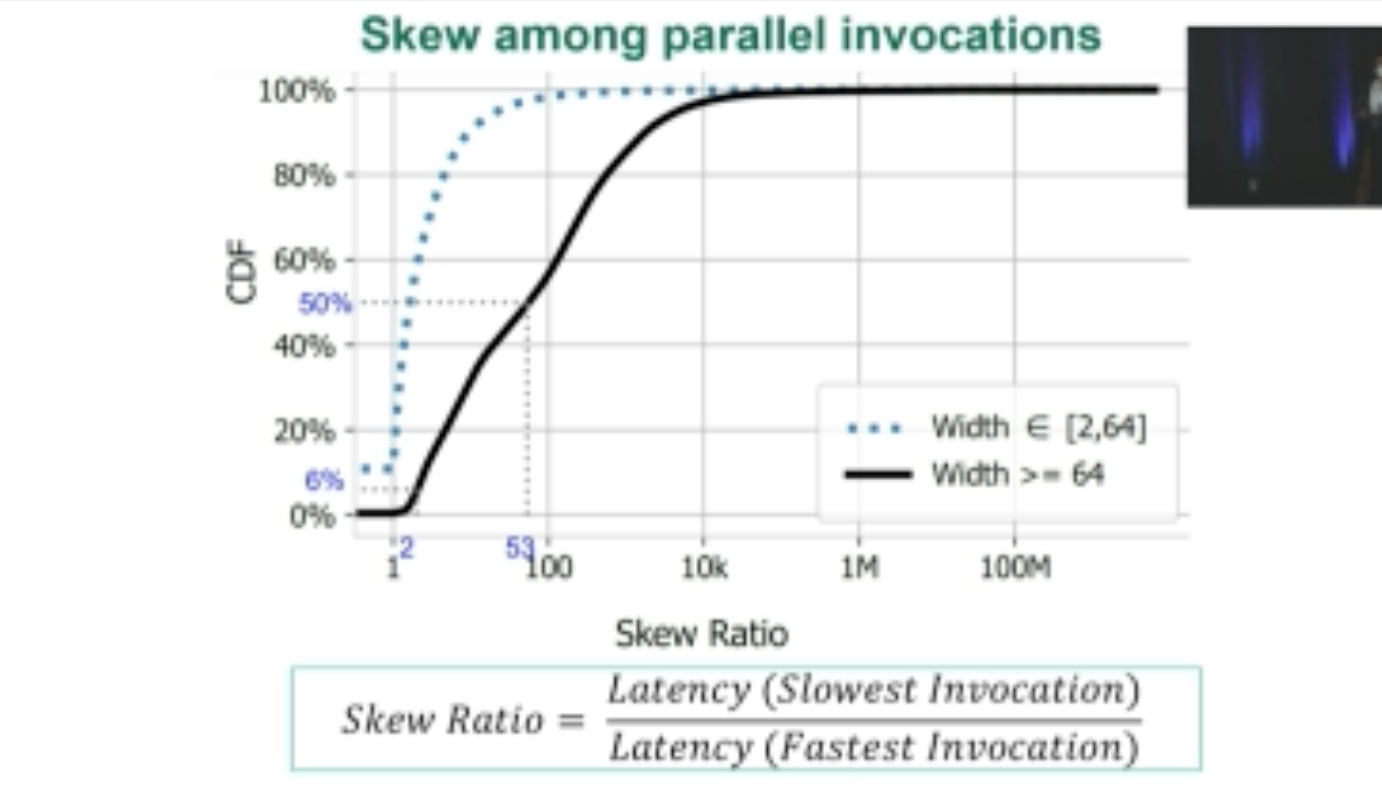
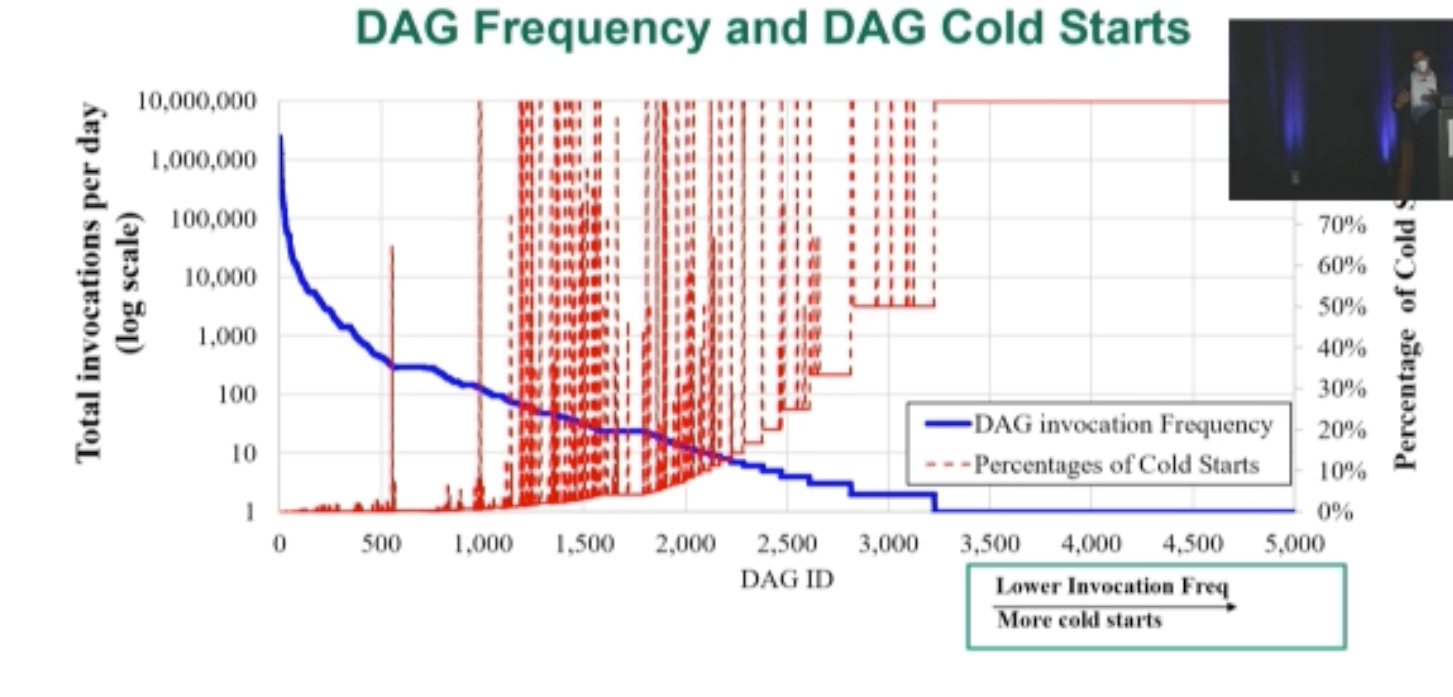
ORION: Optimized Execution Latency for Serverless DAGs

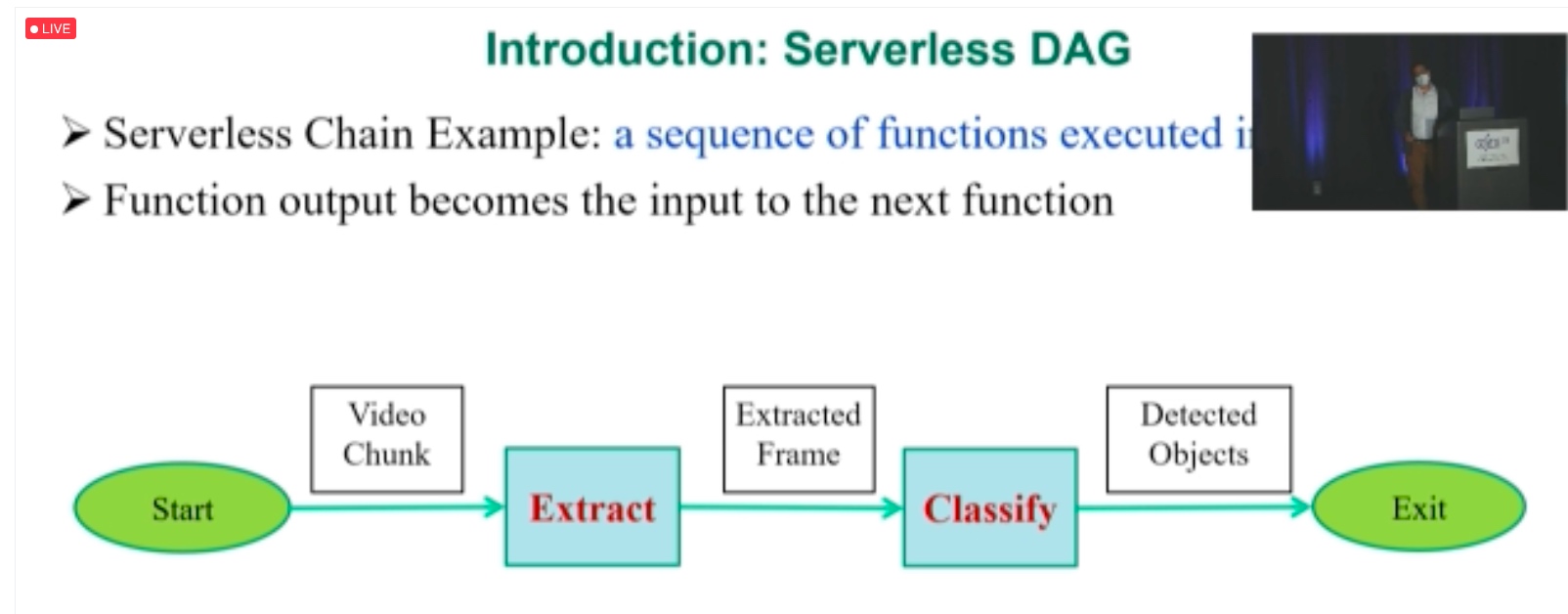
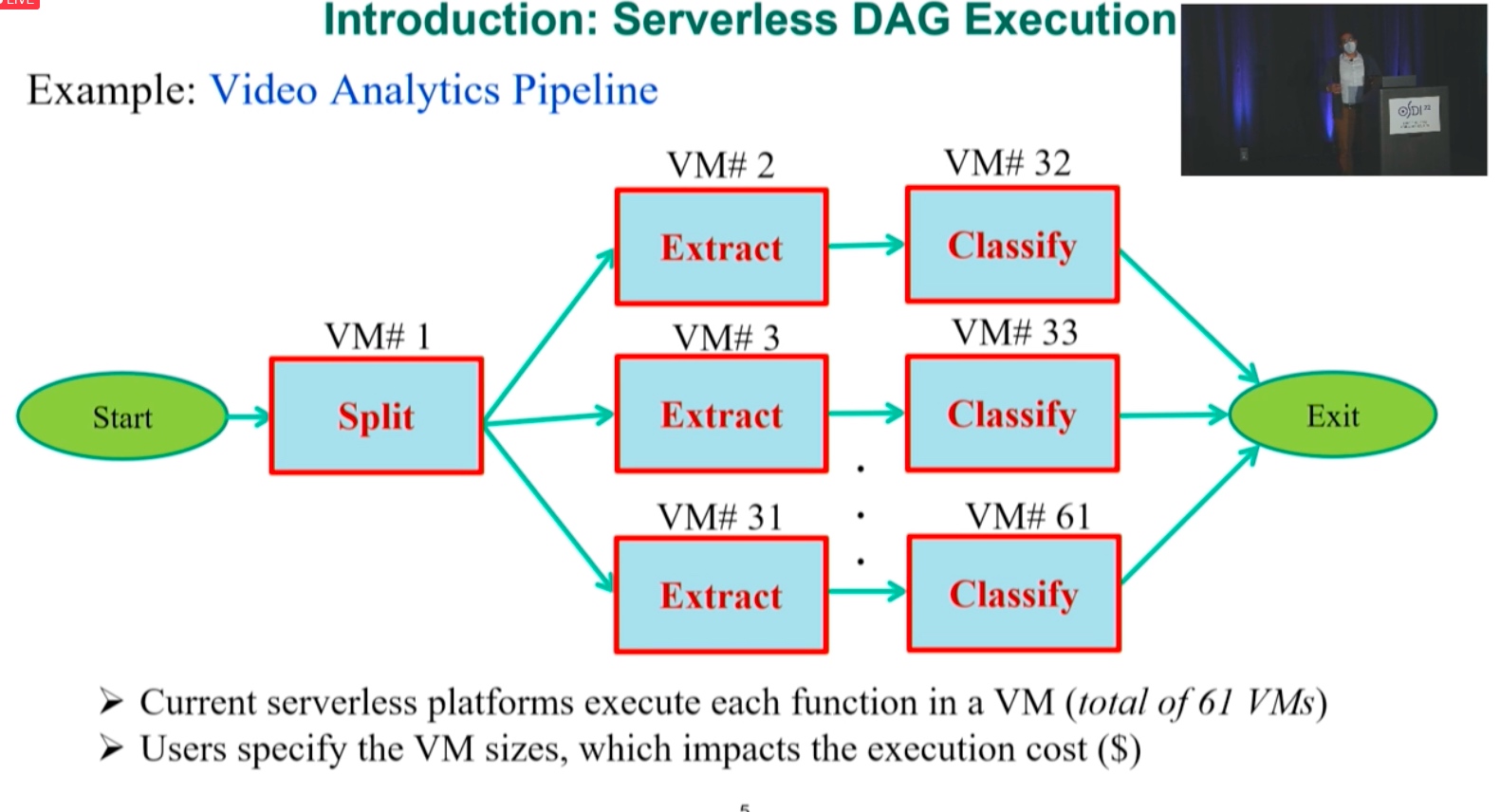
Metrics
Immortal Threaeds

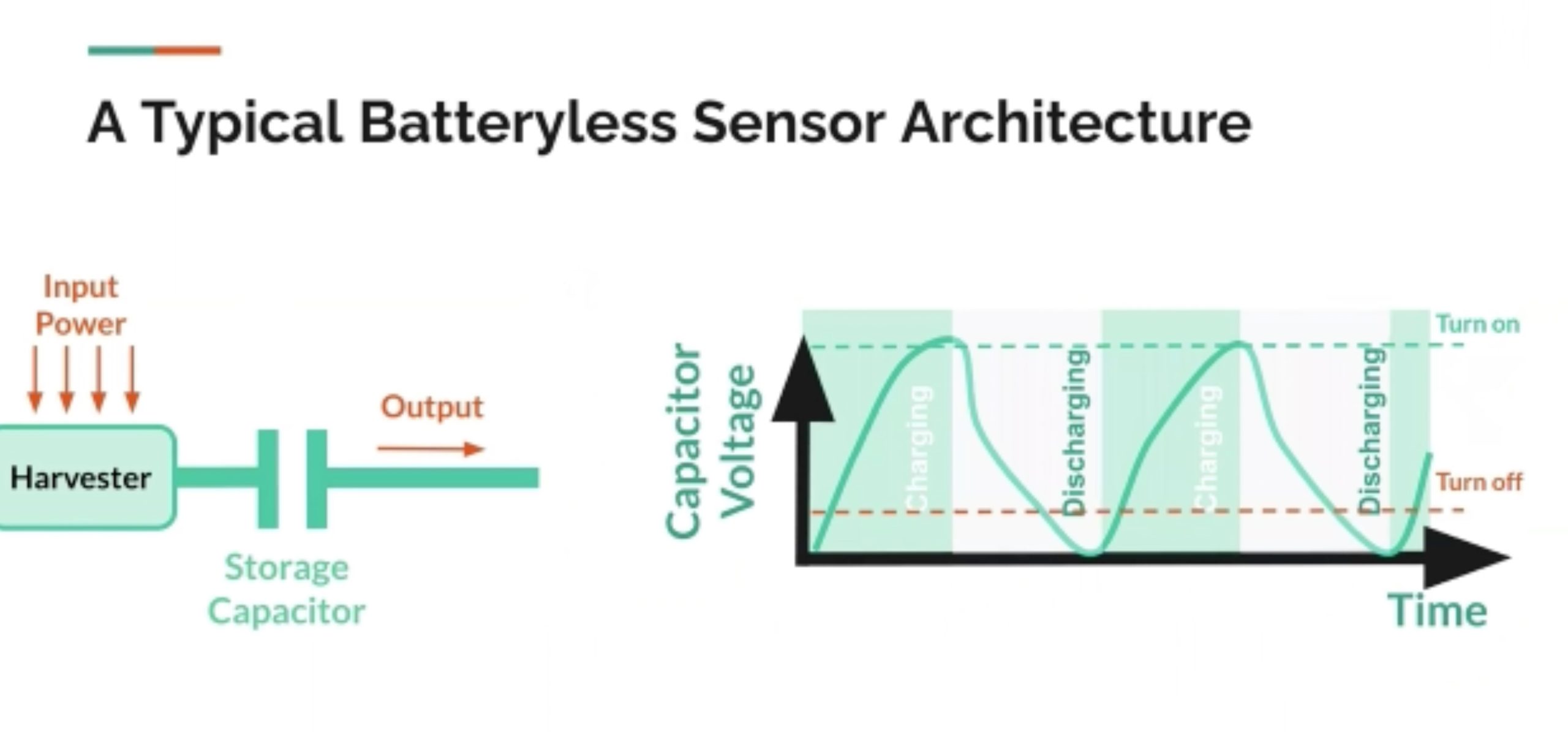
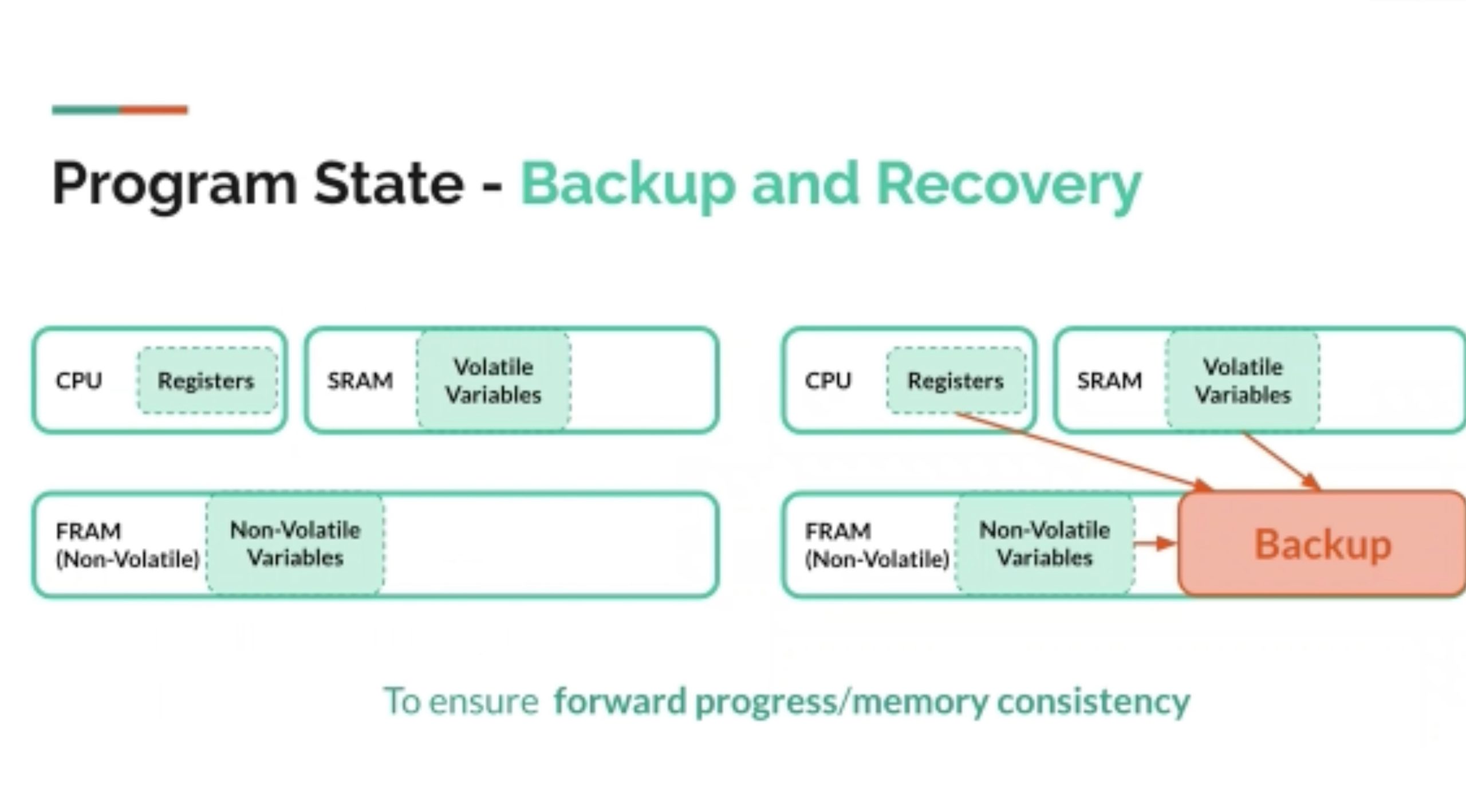
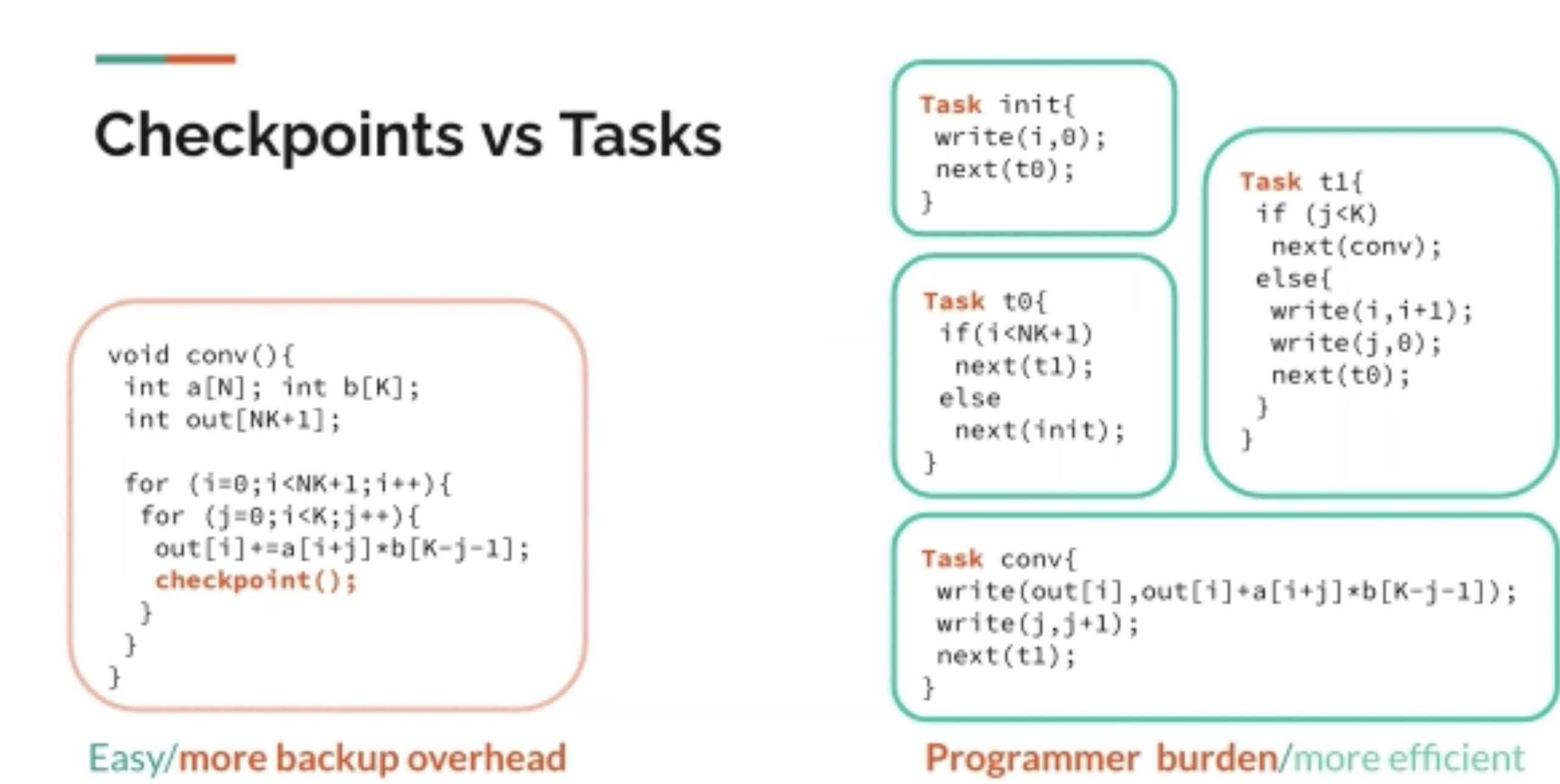
low battery下的thread存stack和一些ram state在dram上。可以把很多数据结构移植过来。
OmniTable Way

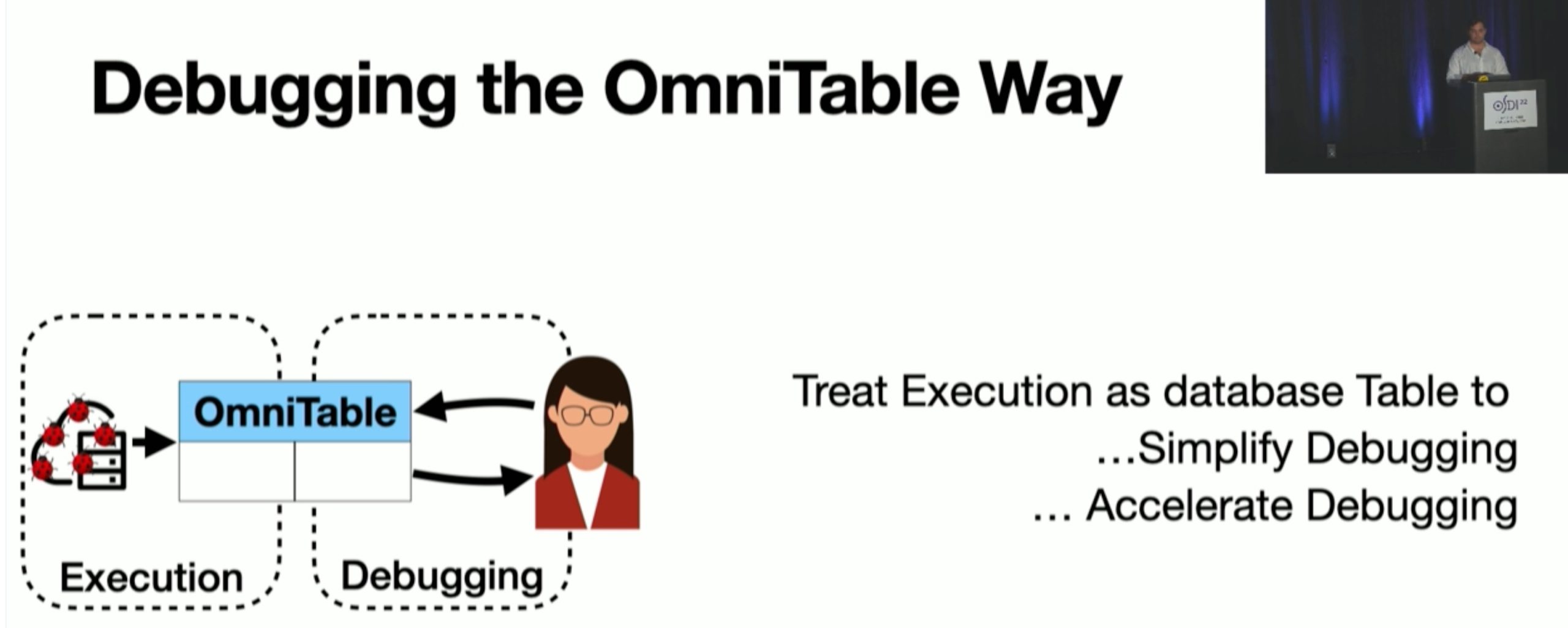
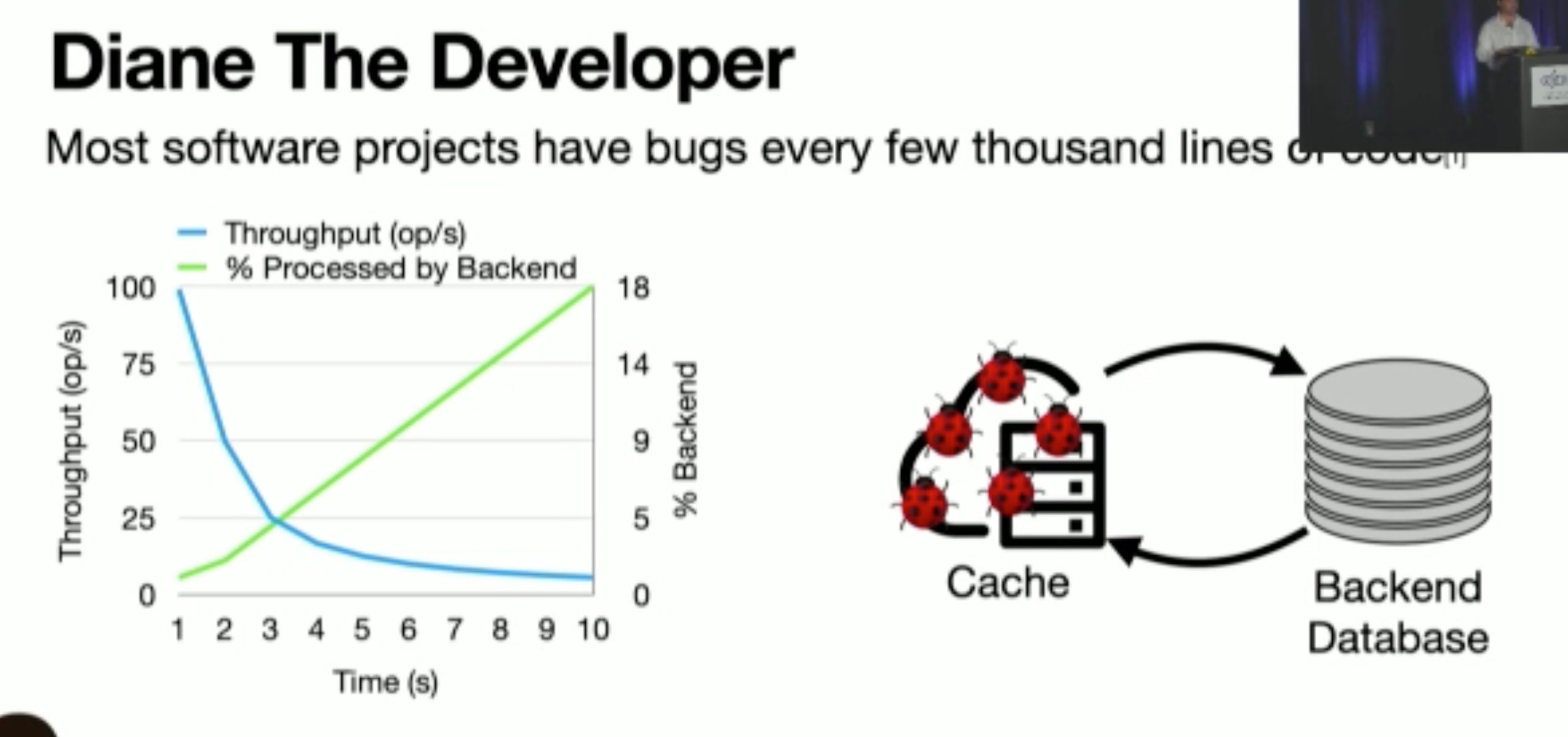
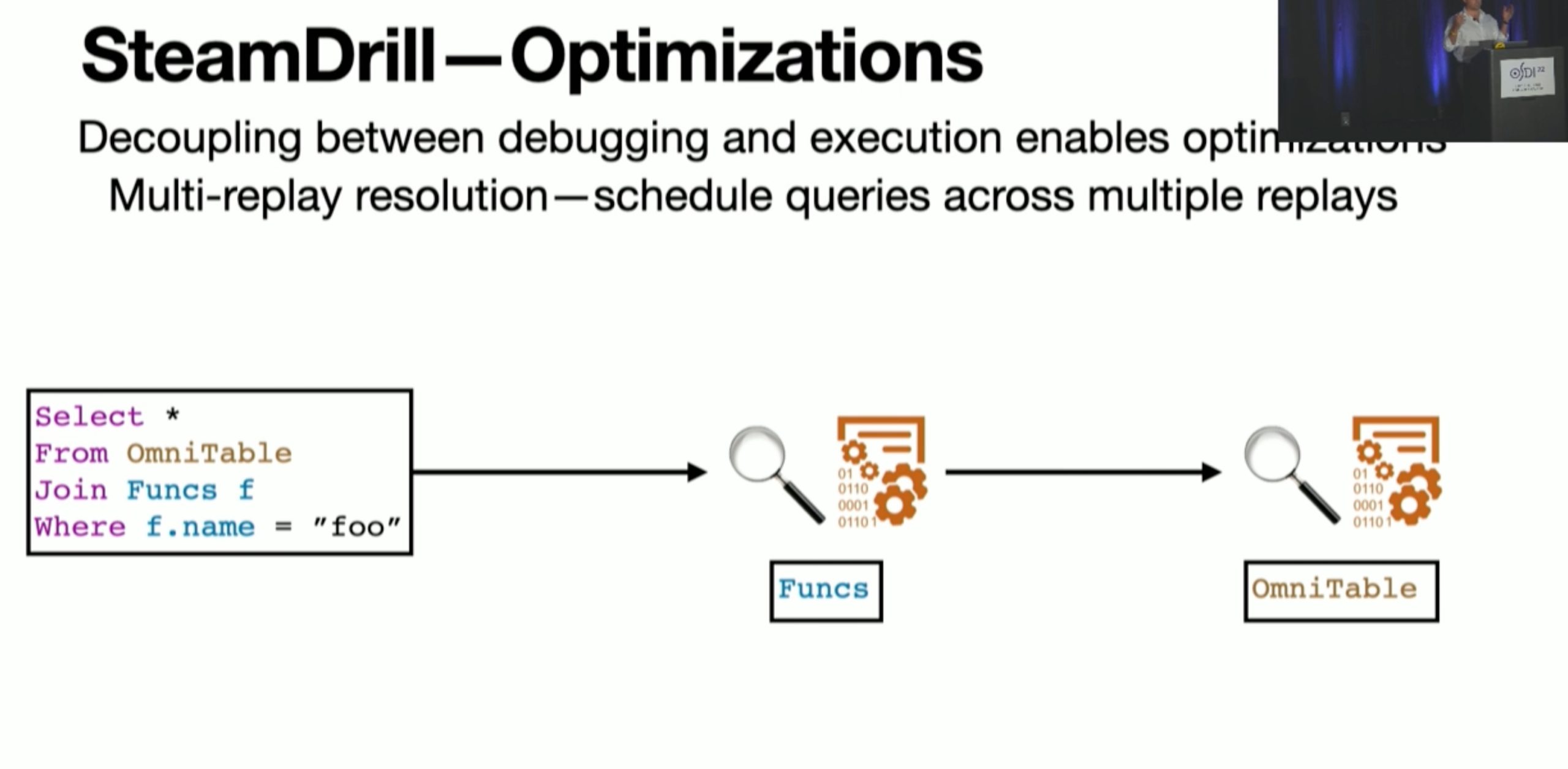
Storage
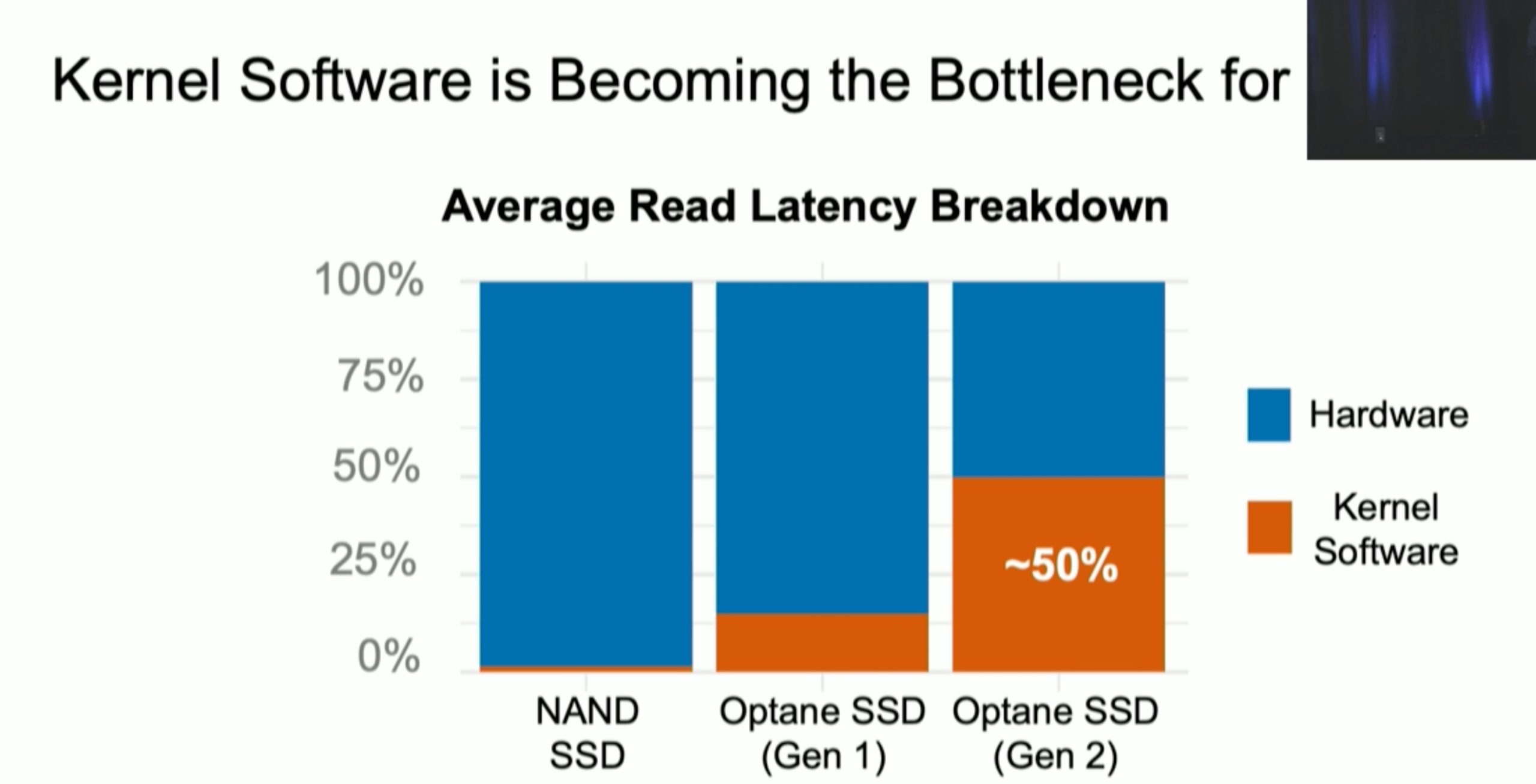
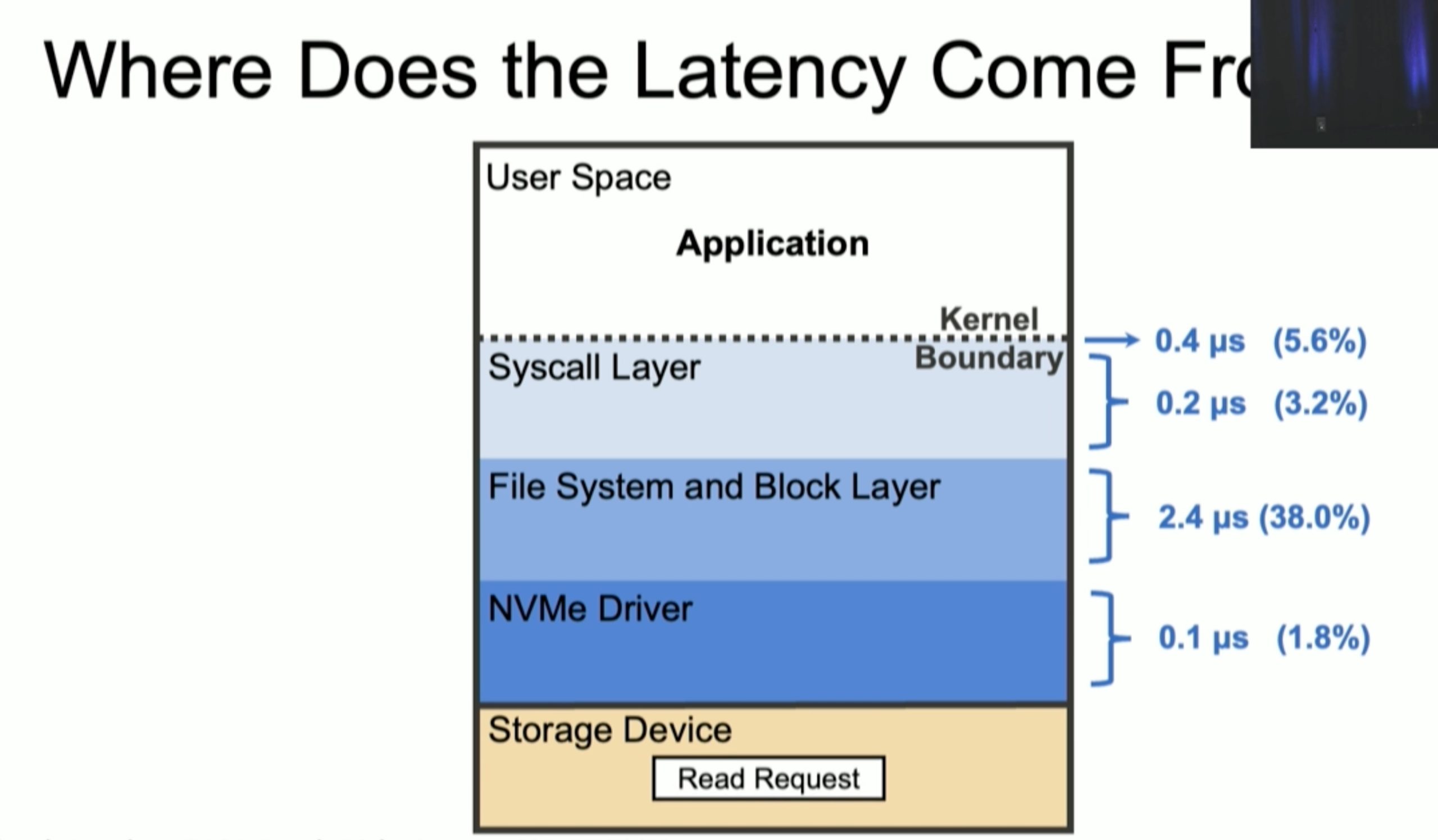
XRP: In-Kernel Storage Functions with eBPF


Tricache

Machine Learning 2
Microsecond-scale Preemption for Concurrent GPU-accelerated DNN Inferences
这篇挺厉害的,REEF改了rocm的驱动,我们知道为了低延时,我们需要一个bounded的scheduler。现有的GPU SIMT scheduler并不提供一个稳定的可控的时延。如果给我做这种事,会应用层接管scheduler,通过观察DNN的pattern,做流处理器和SM的FIFO affinity。refer to zhejia的那篇NV的microbench结果来设计这个scheduler,而REEF做的更多。REEF对实时任务使用FIFO策略,该策略是非抢占式的。使用FIFO策略使得预测一个实时任务的响应延迟变得容易。在大多数实时应用中,延迟的可预测性是很重要的。而REEF可以确保实时任务总是有一个可预测的响应时间。例如,自身的执行时间加上队列中先前任务的执行时间。如果我们允许实时任务的并发执行,这种可预测性可能会被违反。
Serverless
CAP-VM
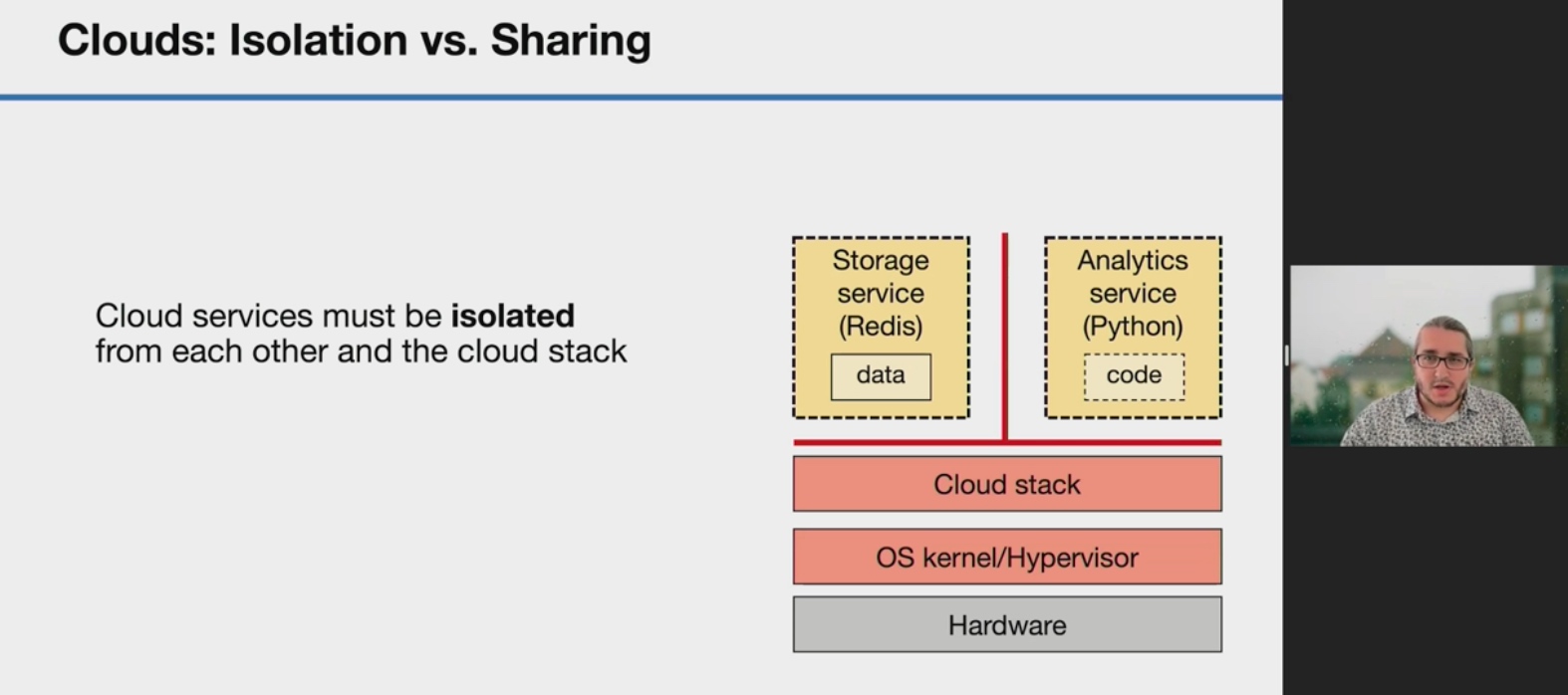
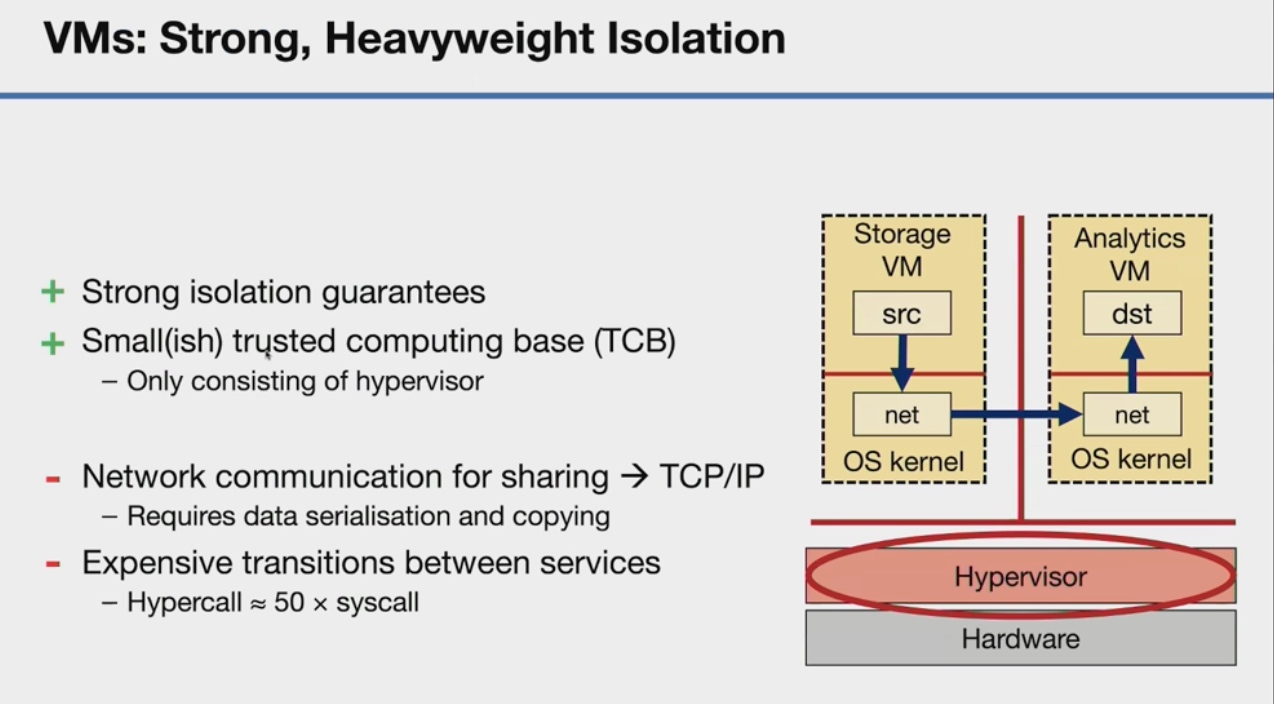

KSplit: Automating Device Driver Isolation

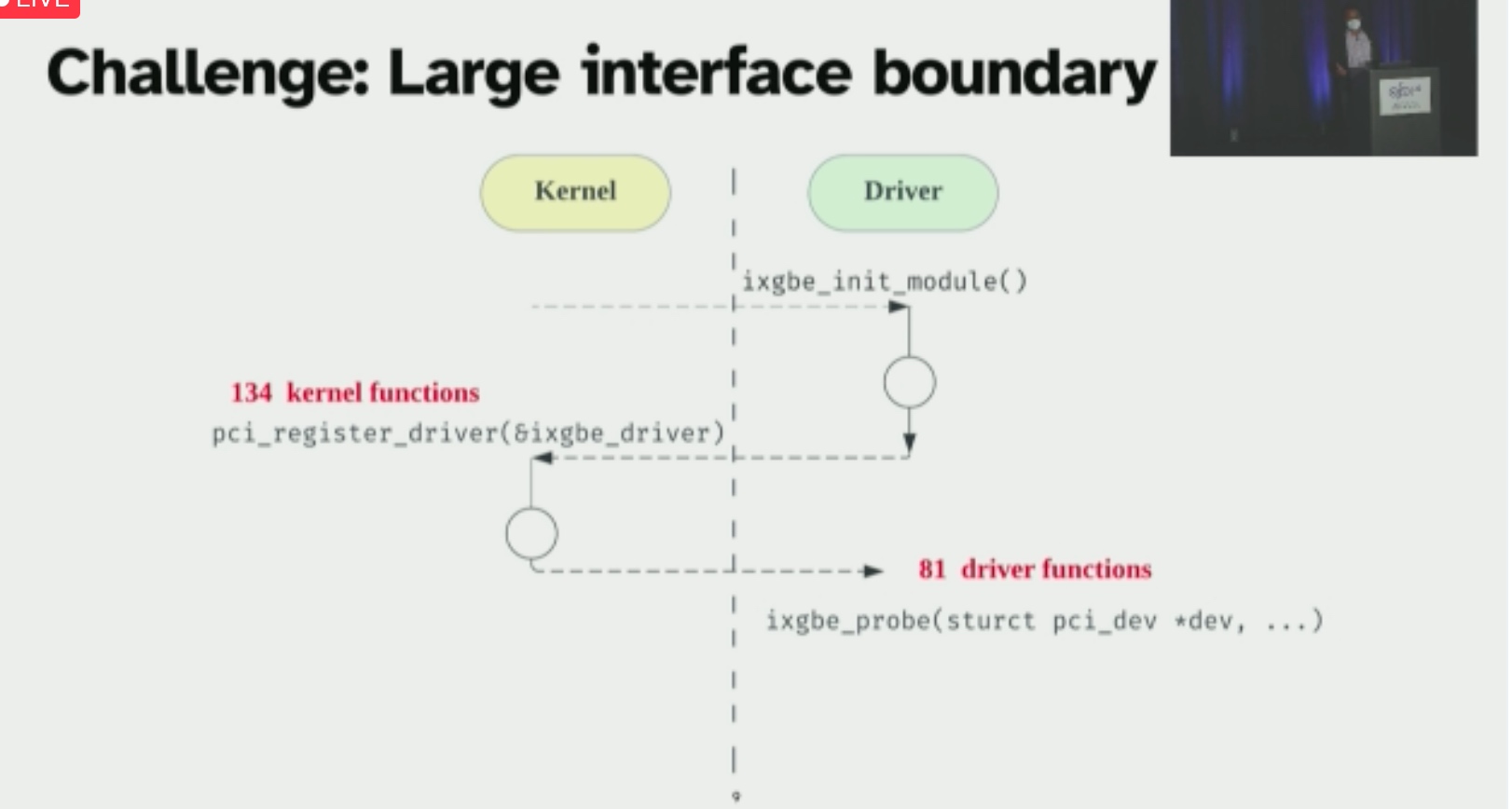
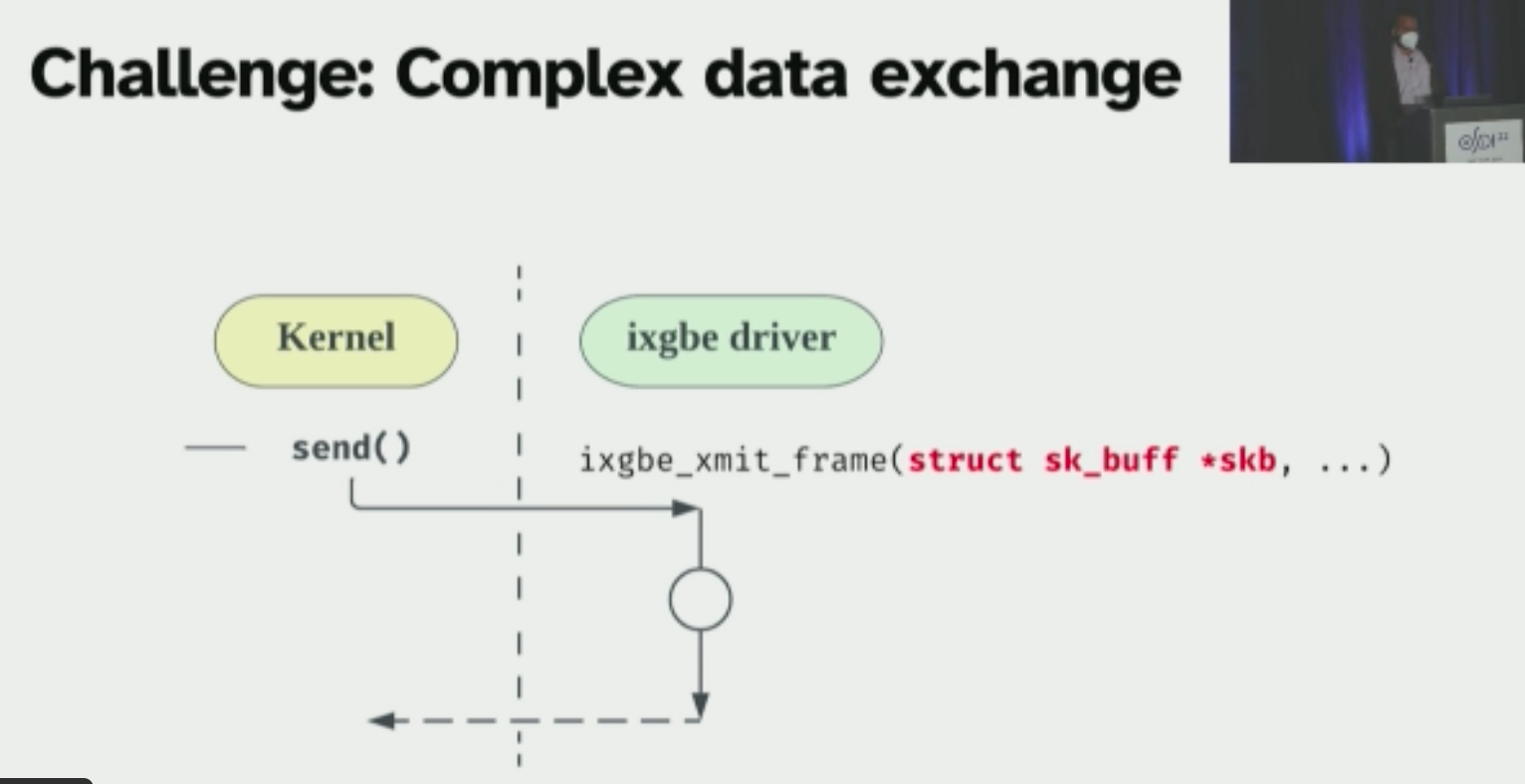
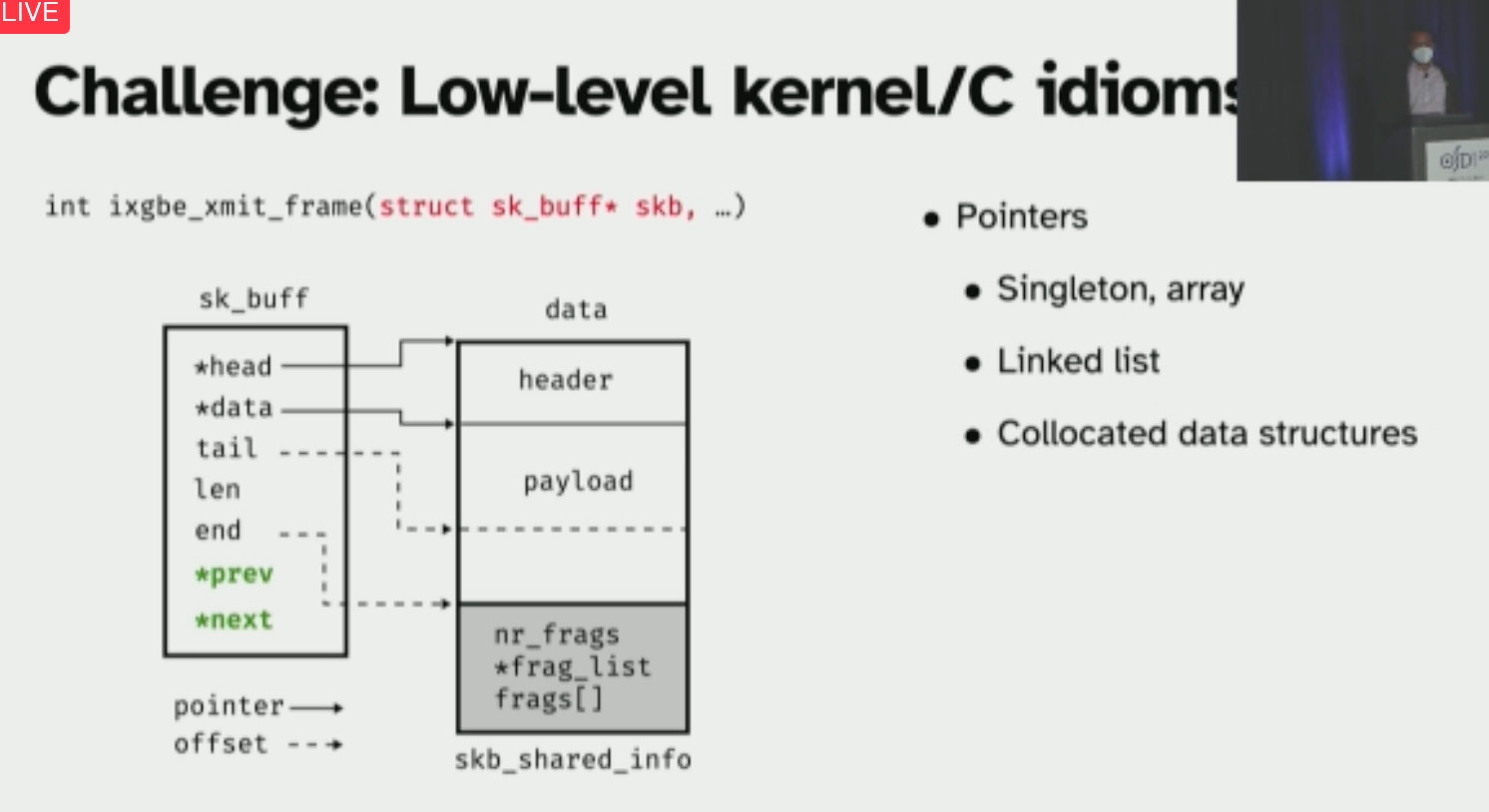


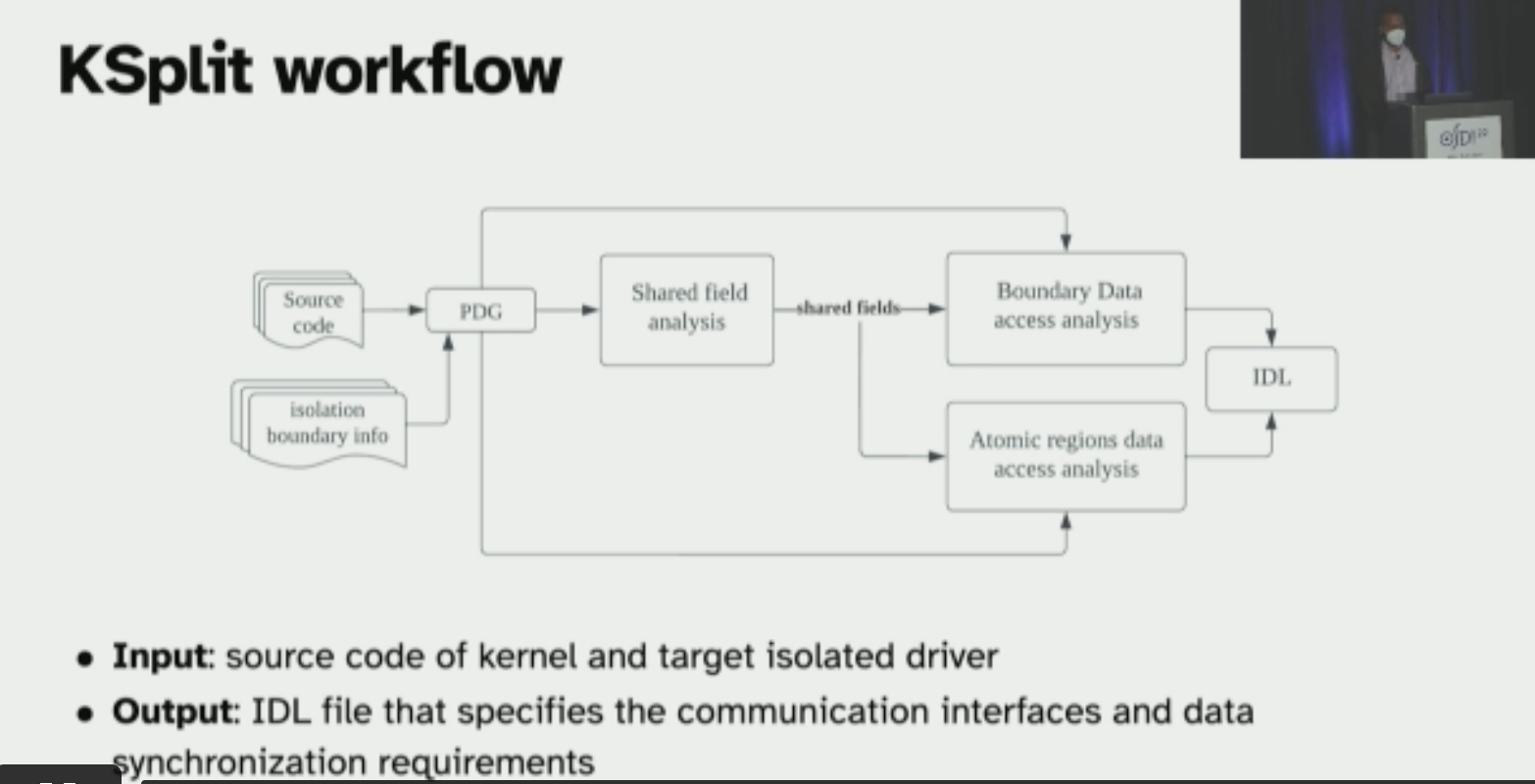
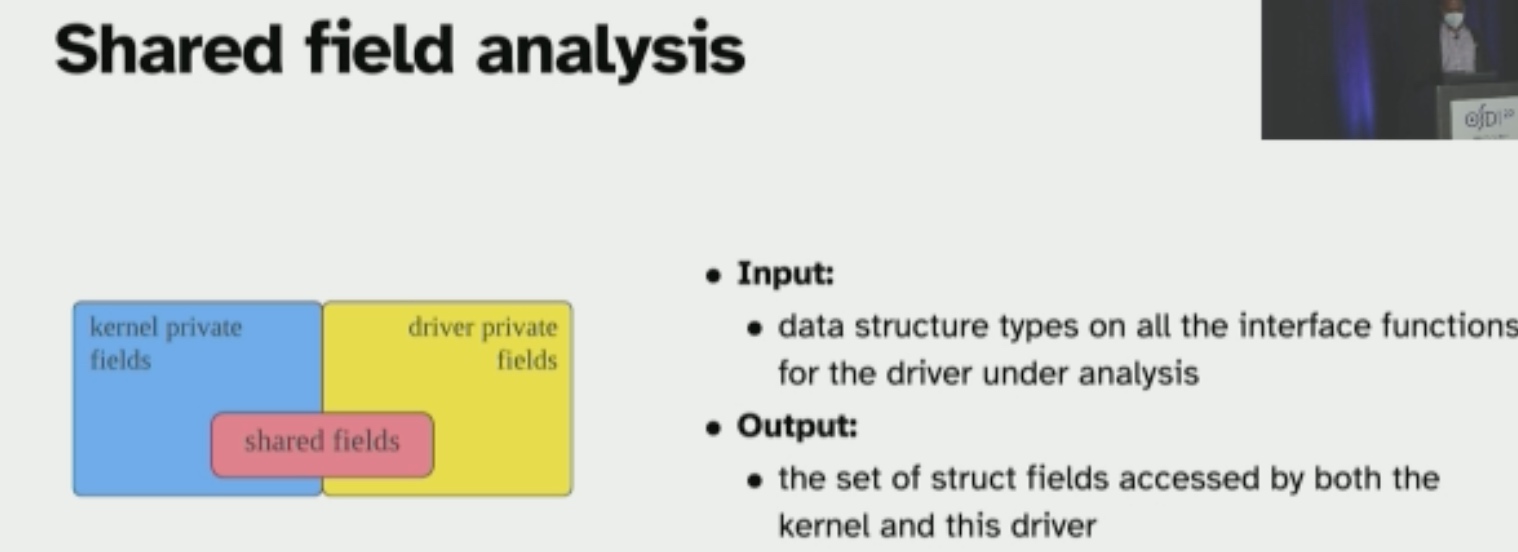
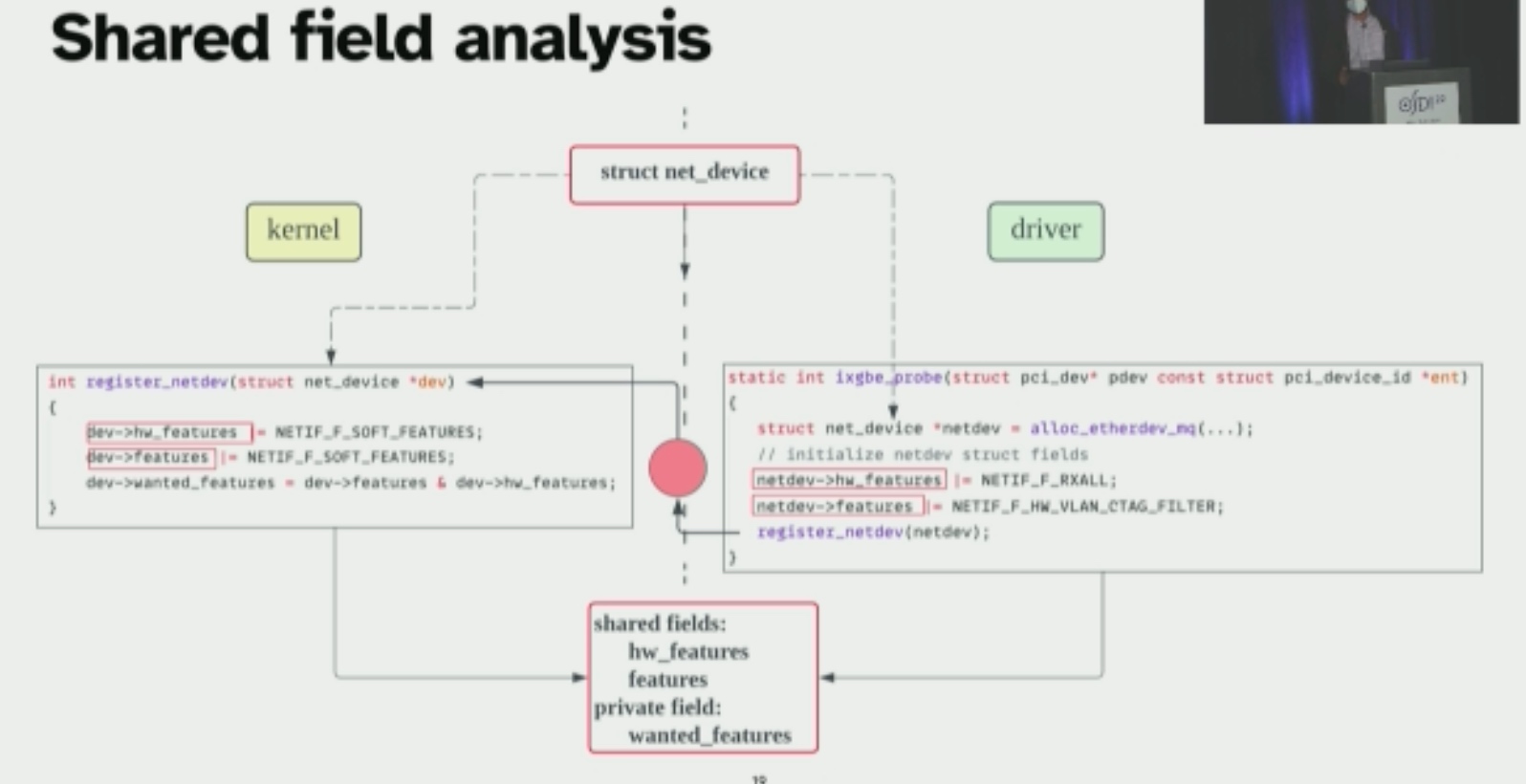
主要就是这里的shared field analysis

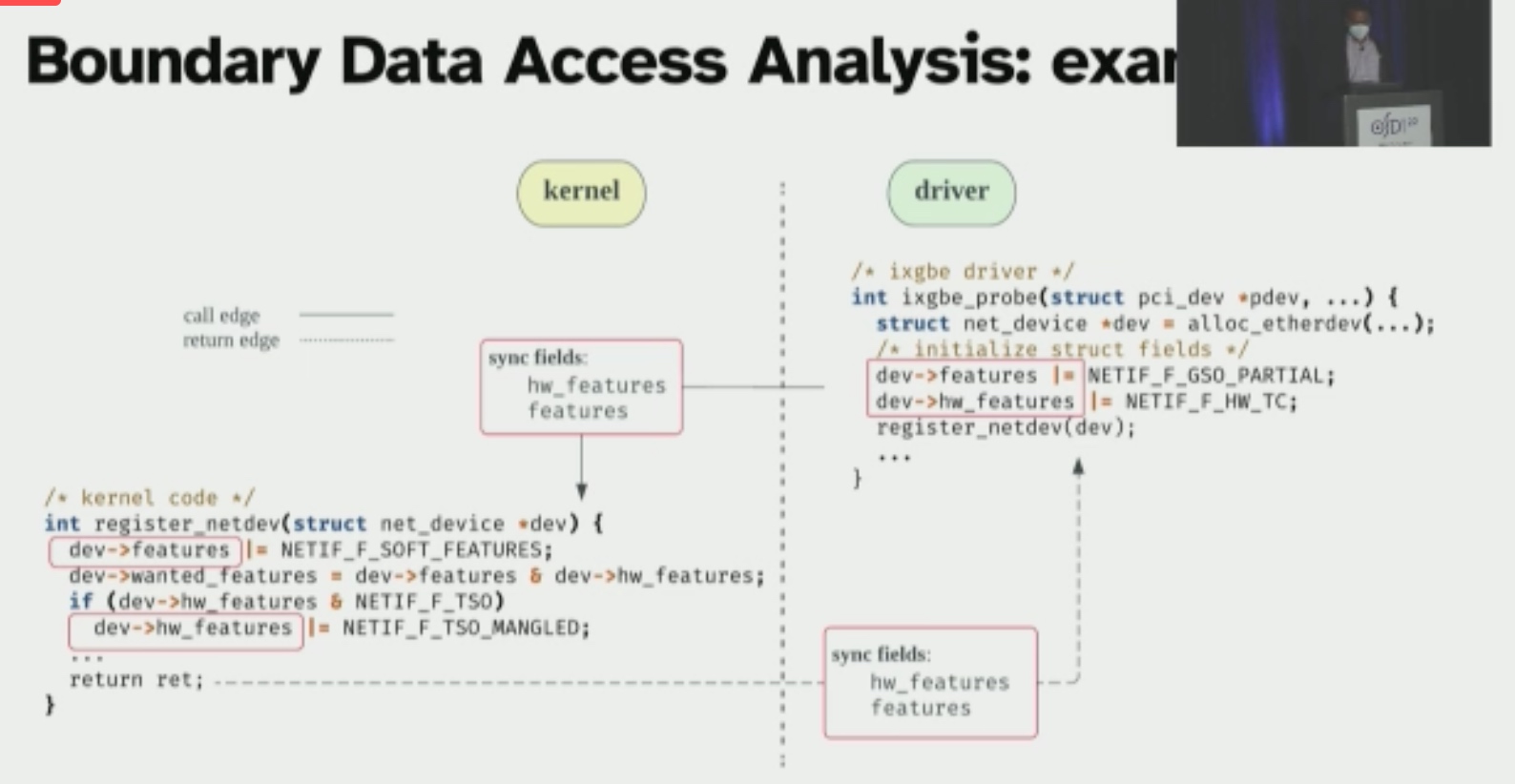
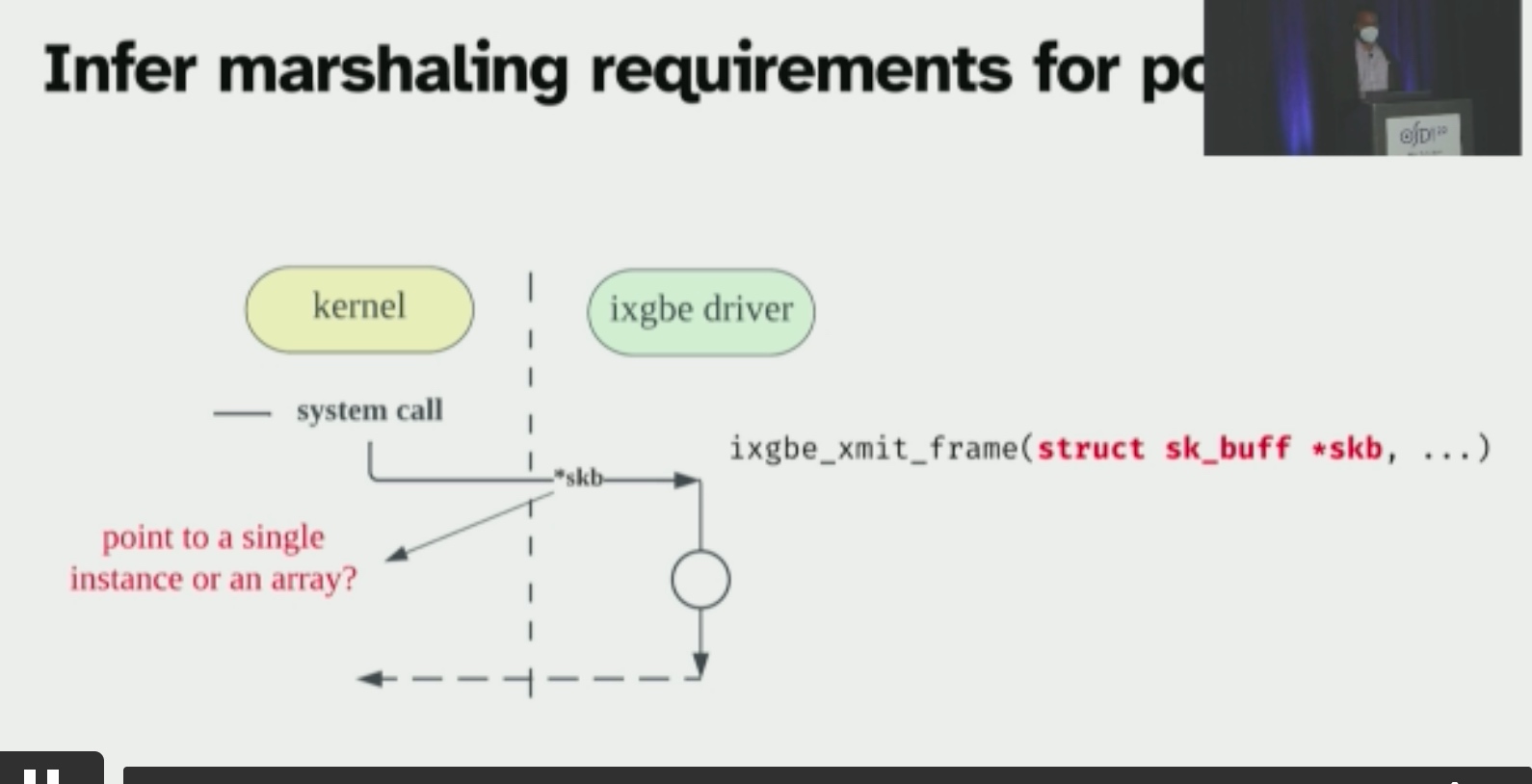
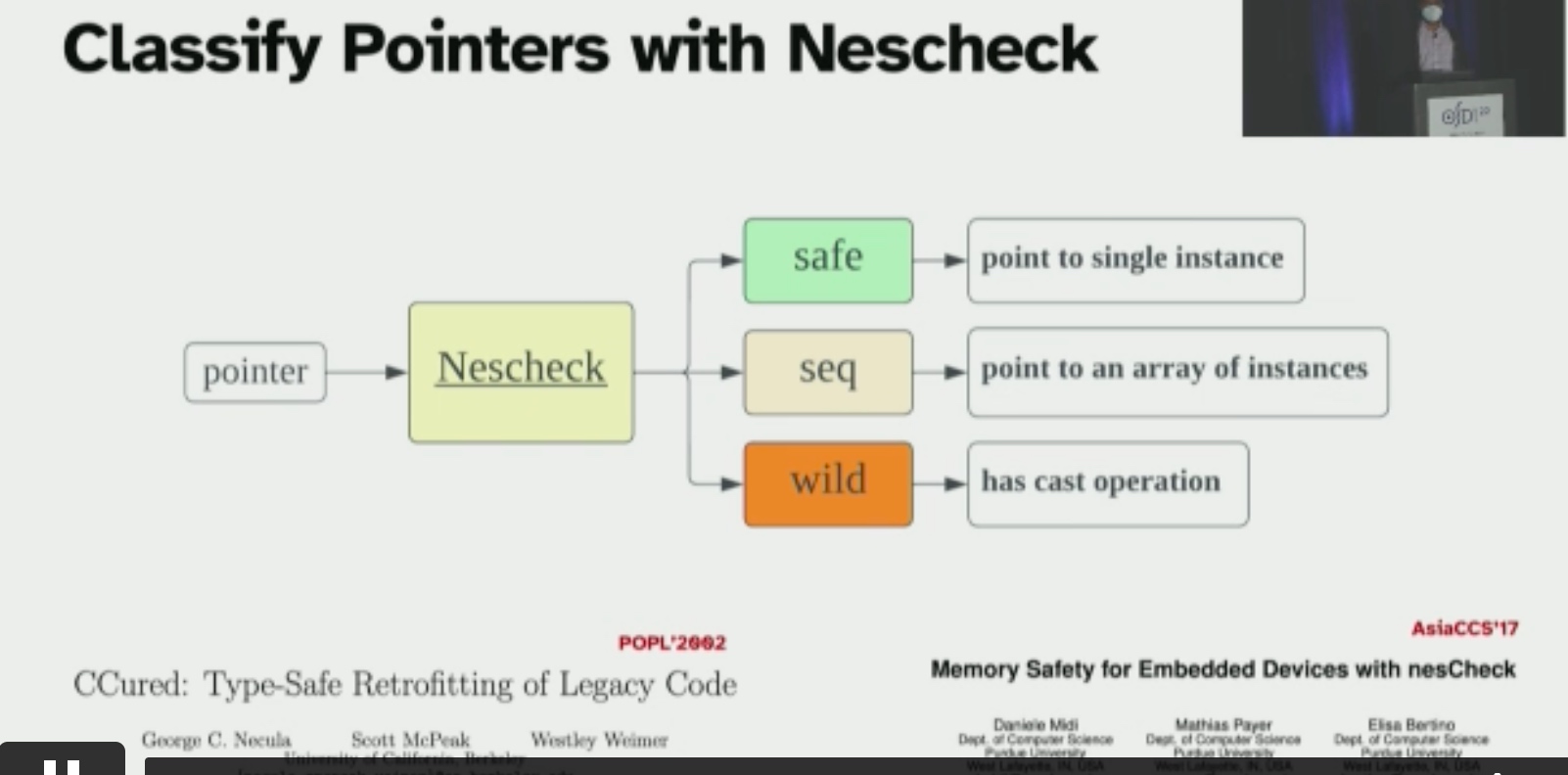

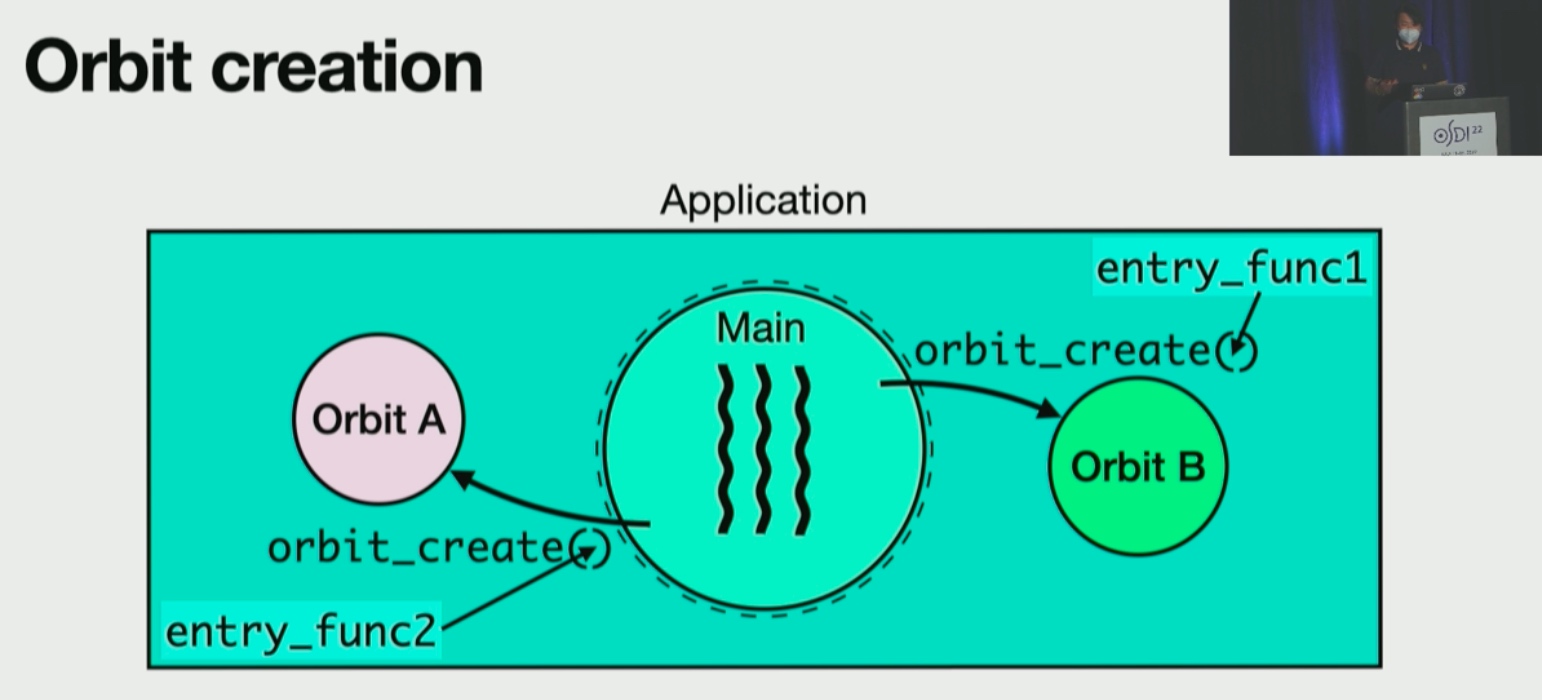
Orbit

找到subprocess的最优隔离方式。





(在kernel里delegate object seems a good technique)

确实效果很好,不知道mysql的deadlock逻辑可不可以FaaS出来。然后把内存ro map过去检查状态。
From Dynamic Loading to Extensible Transformation: An Infrastructure for Dynamic Library Transformation




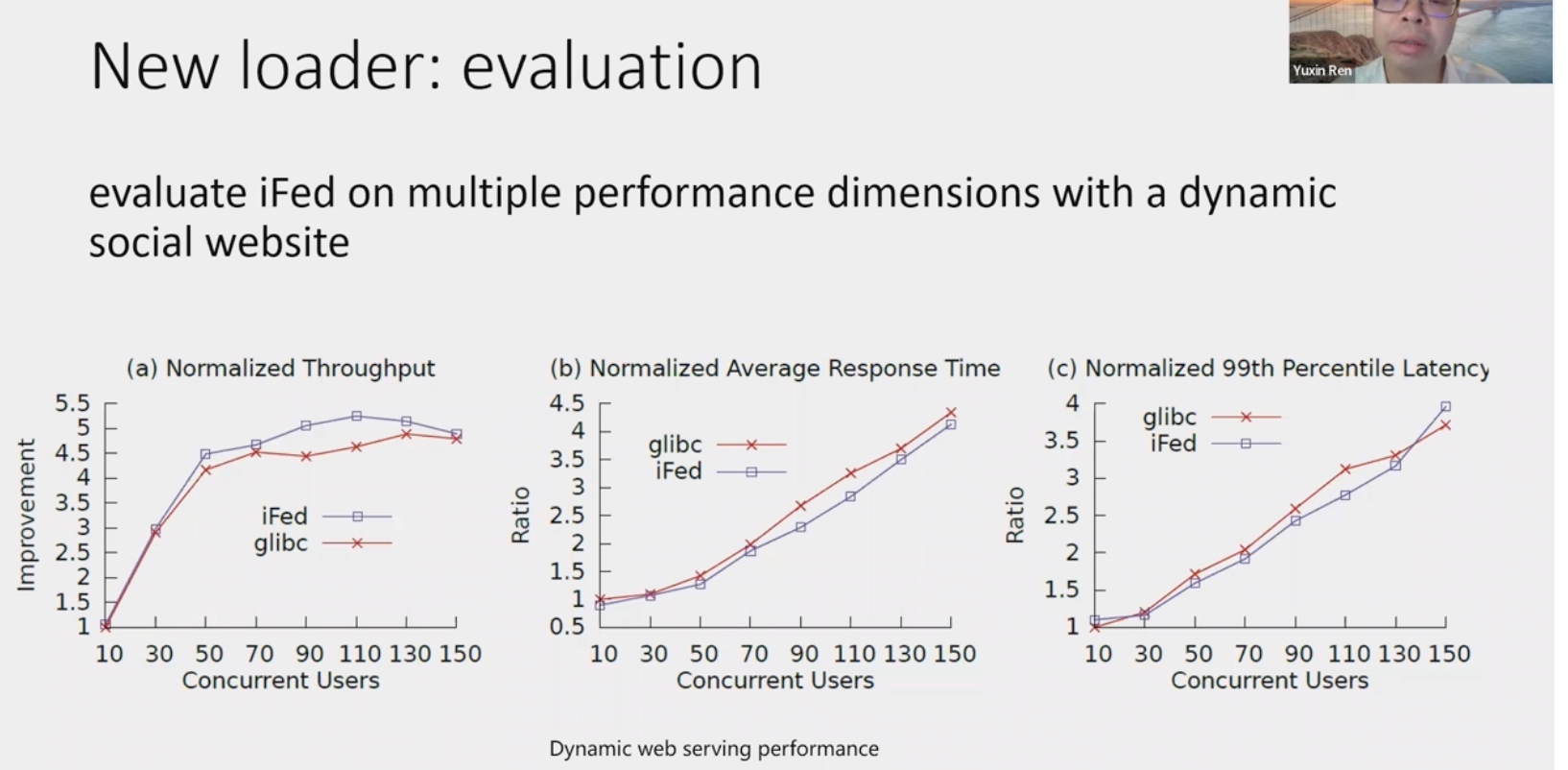

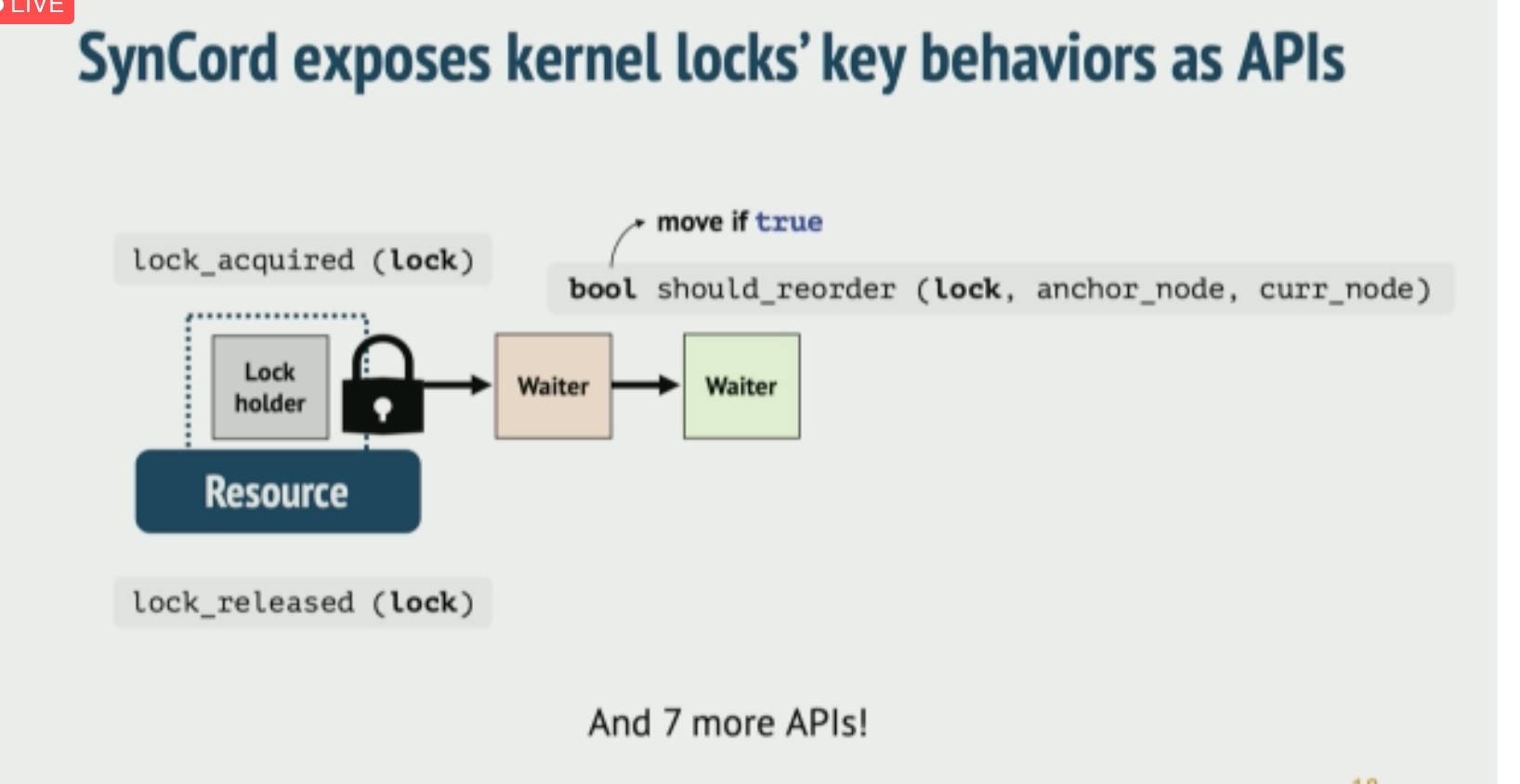
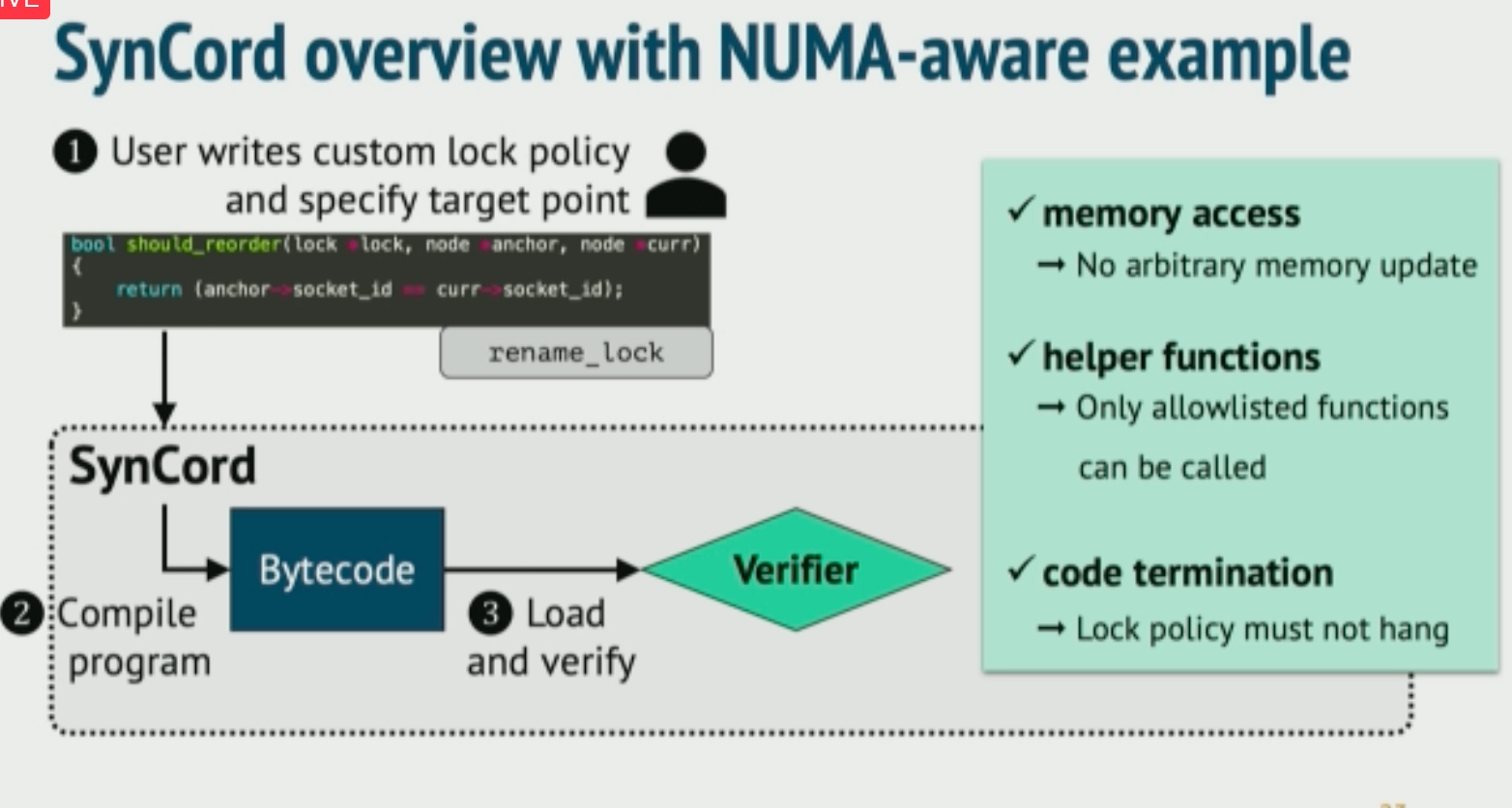
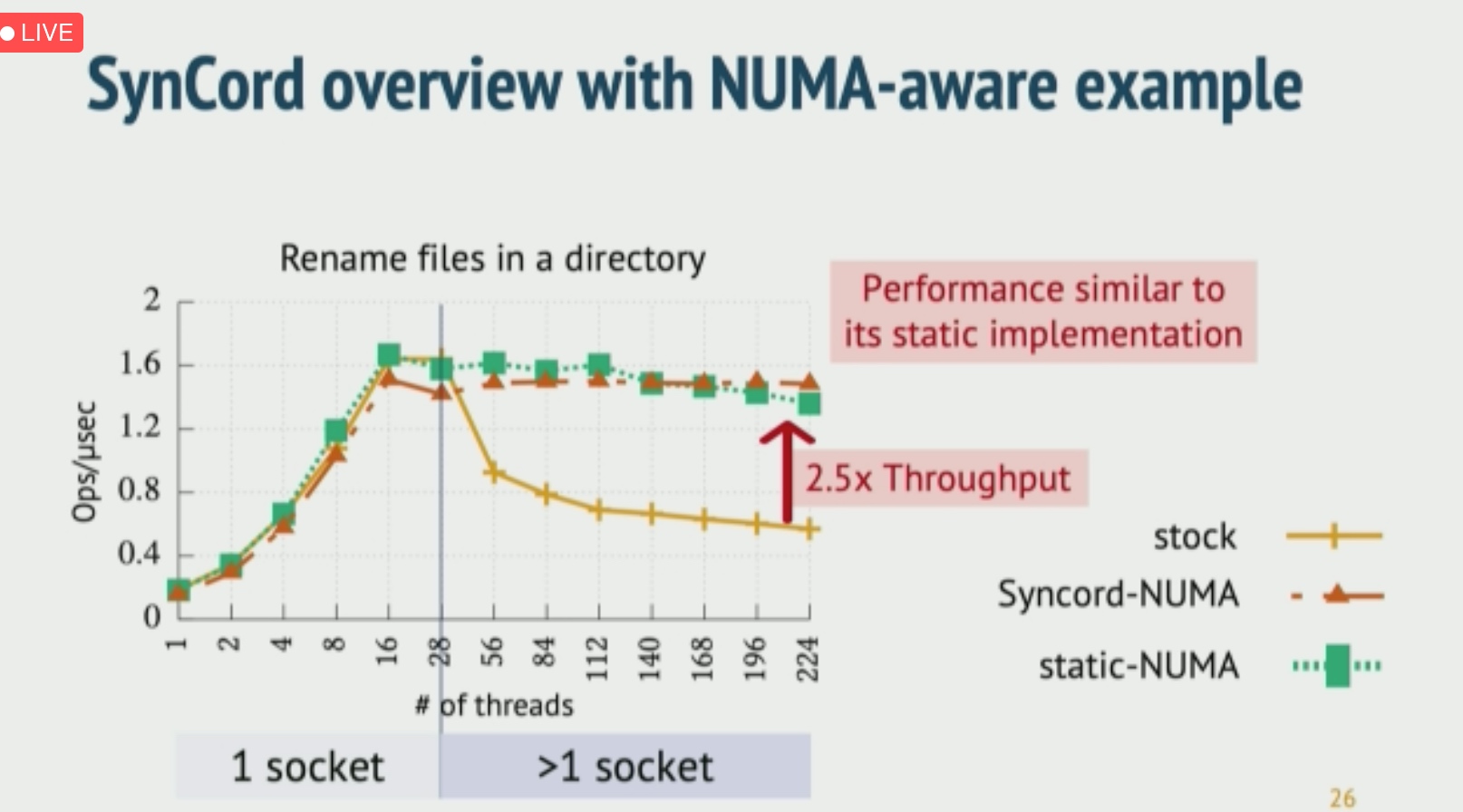
Application-Informed Kernel Synchronization Primitives
似乎是比之前libASL更屌的东西。对kernel的eBPF观测+livepatch lock heuristic
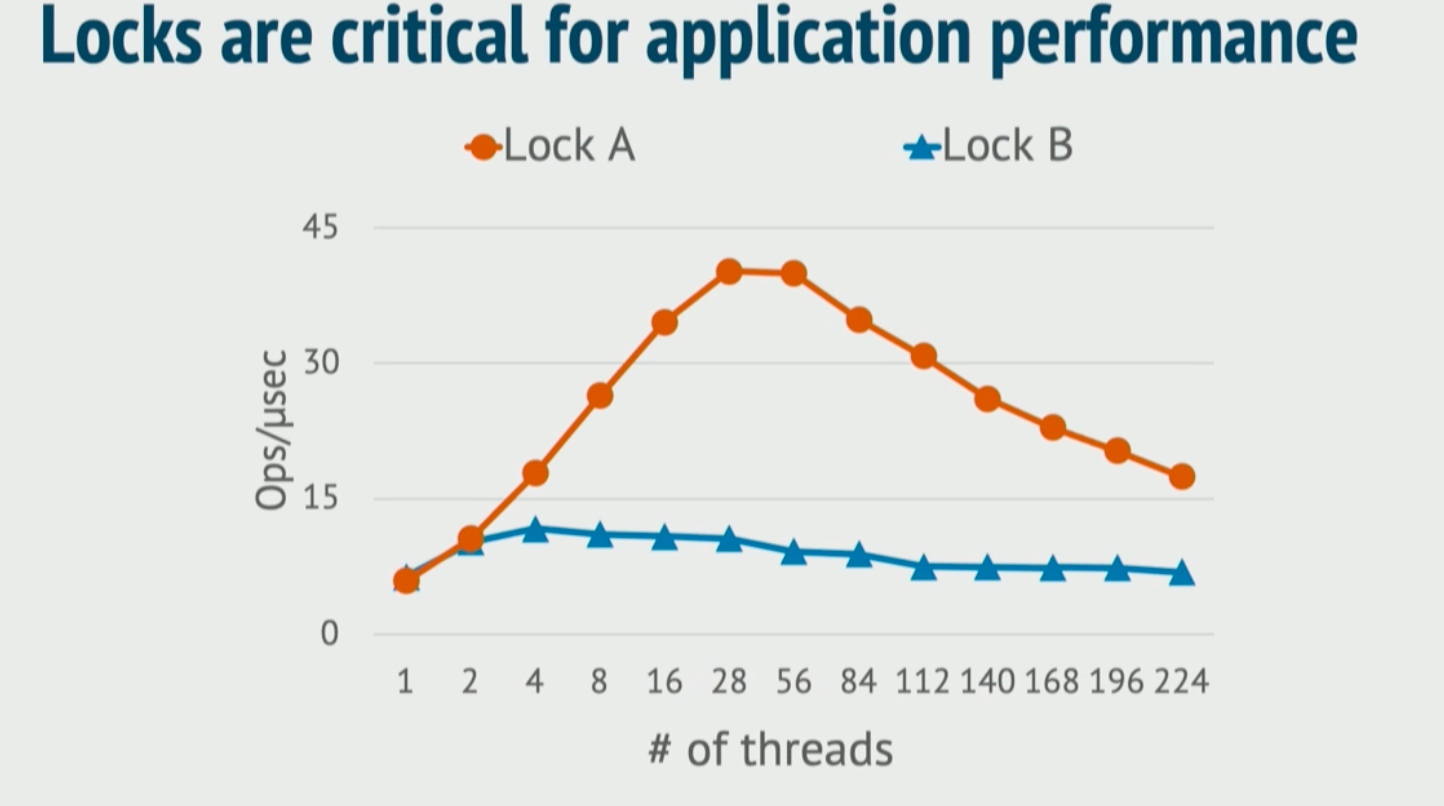
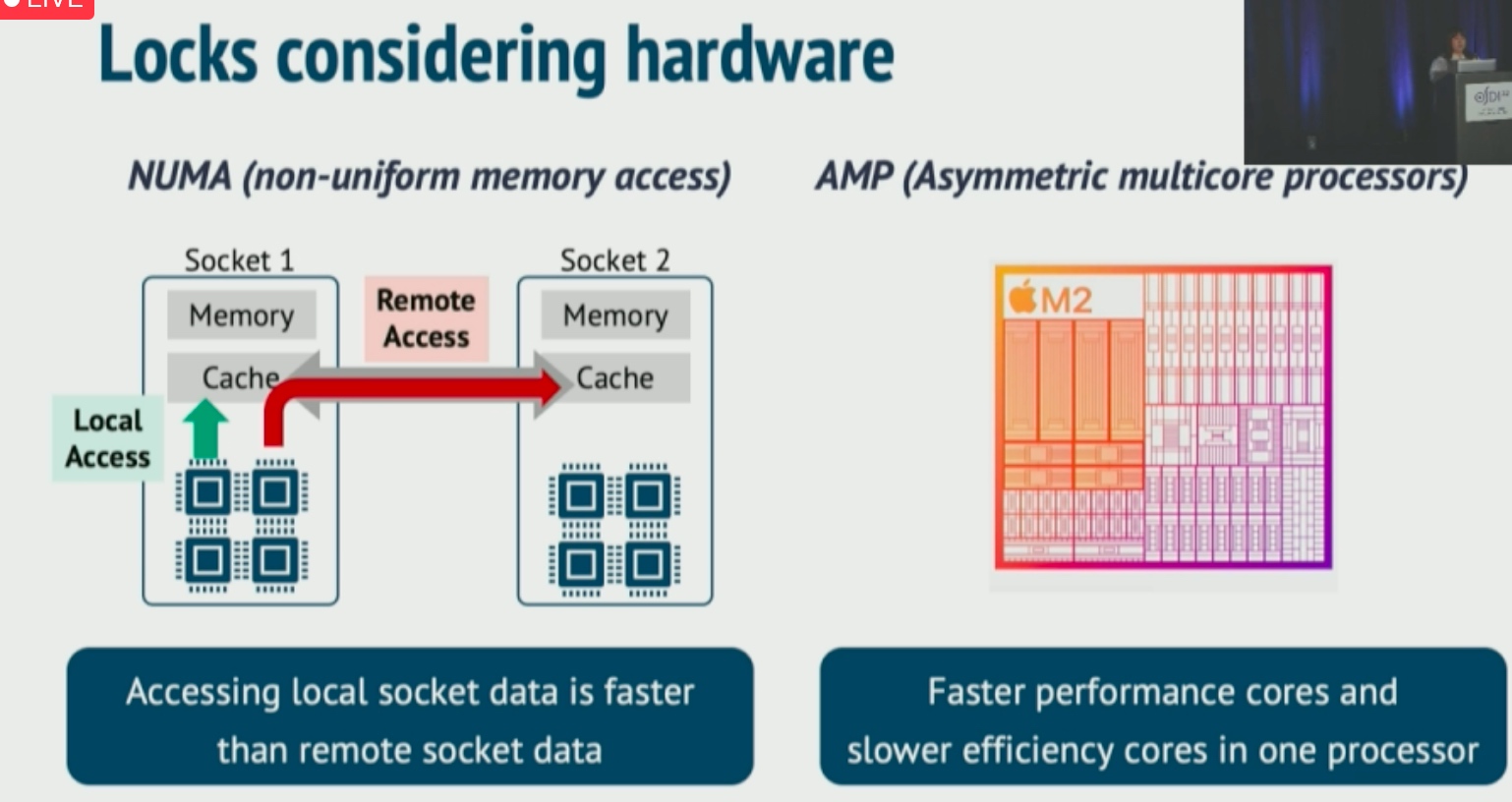
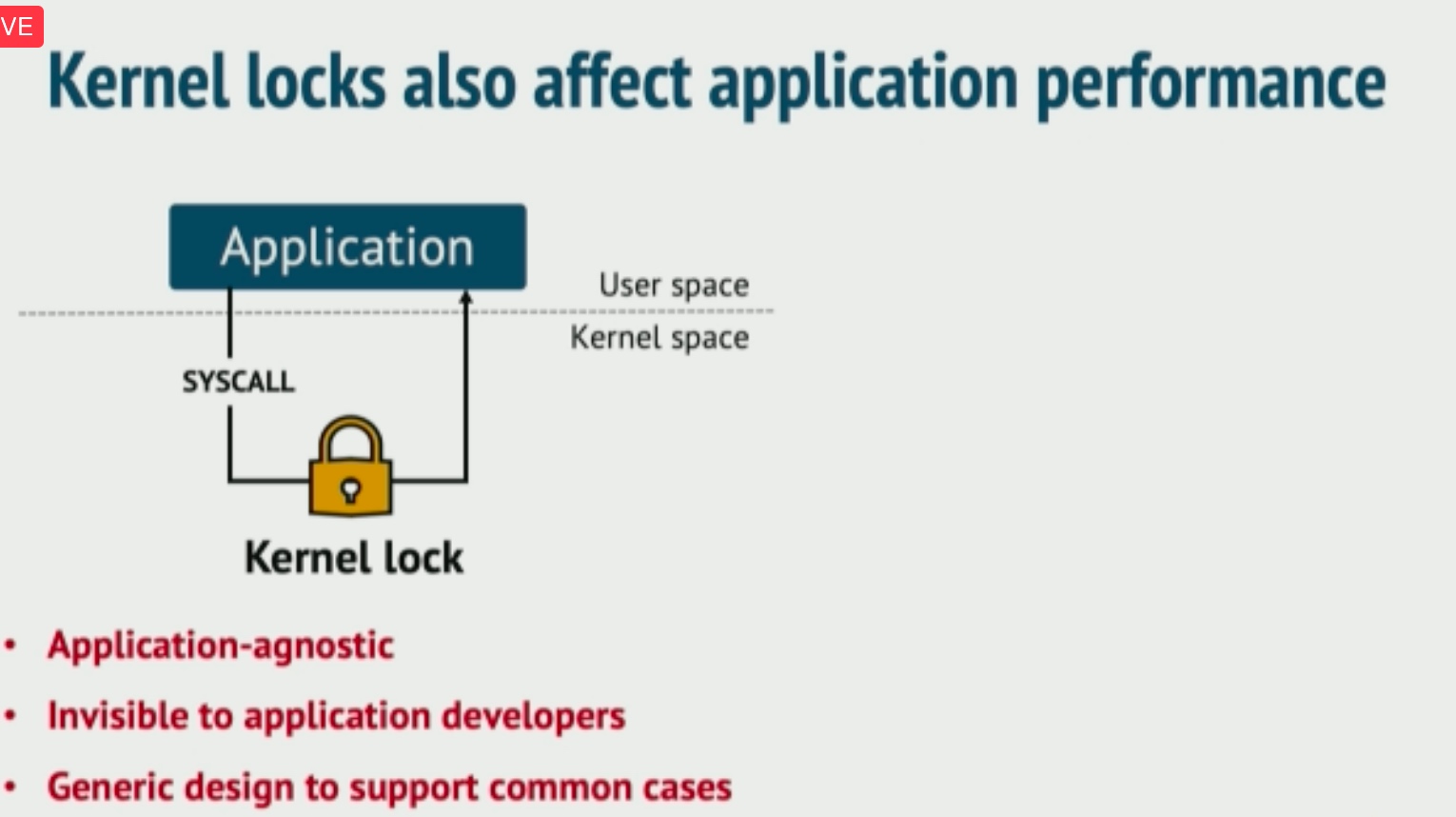
Managed Languages
UPGRADVISOR: Early Adopting Dependency Updates Using Production Traces
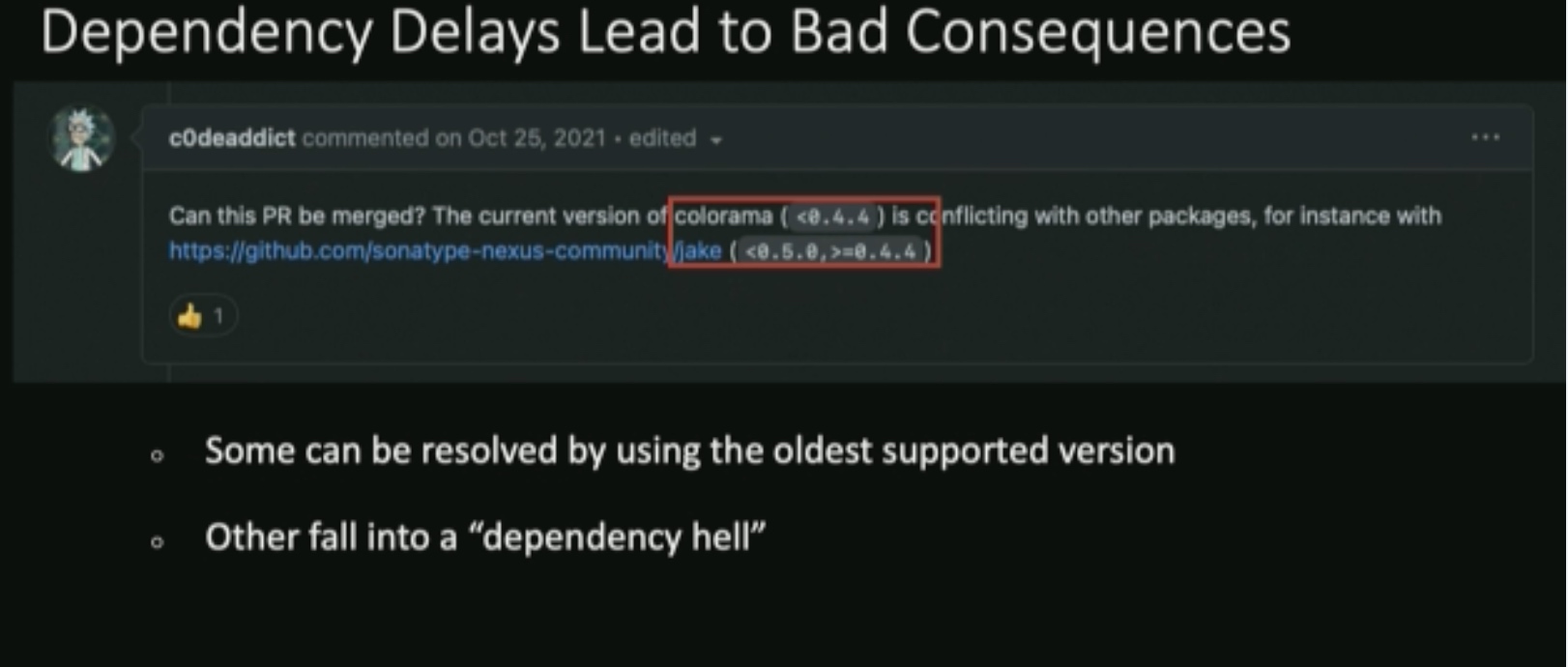
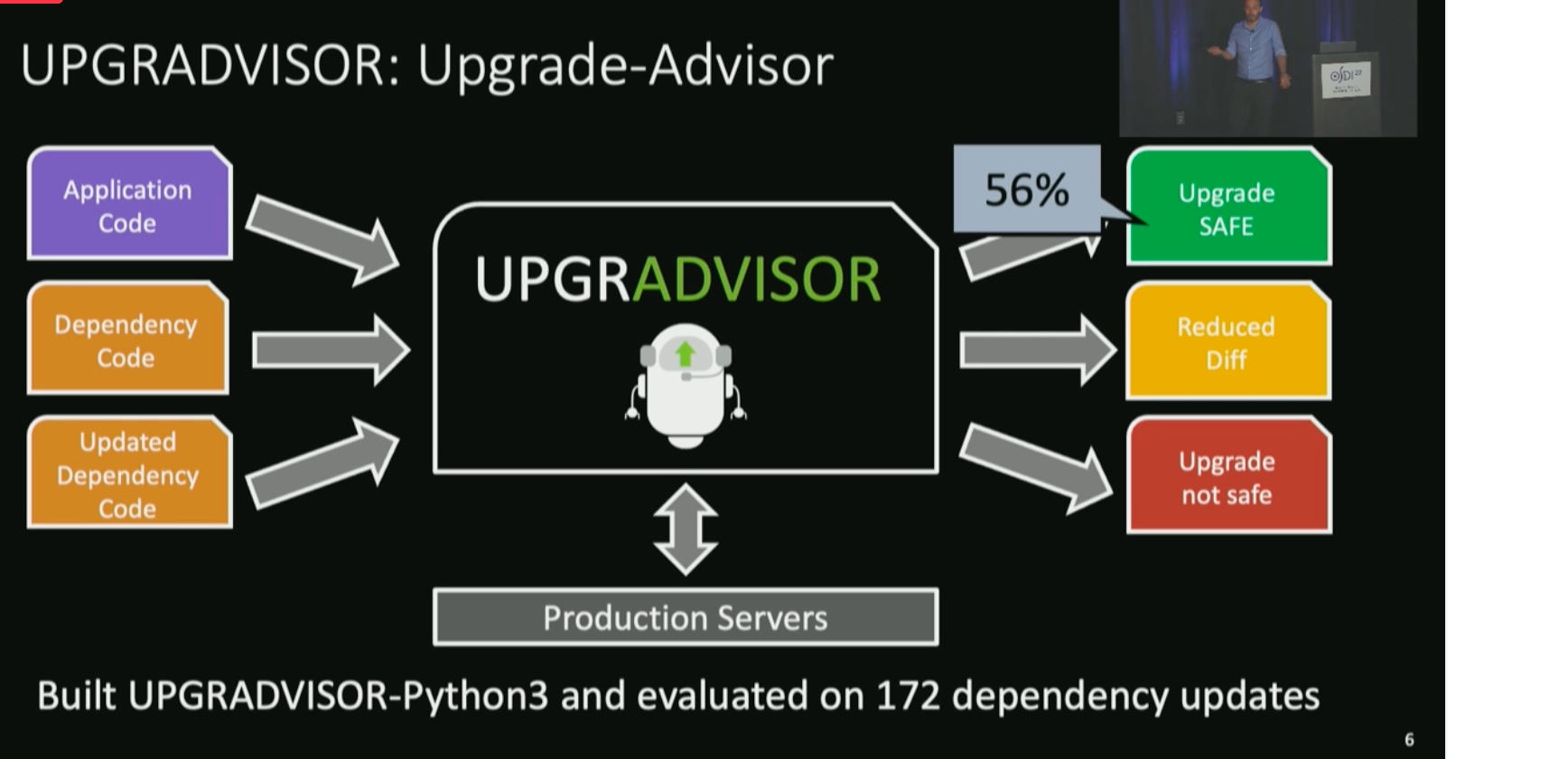


Dynamic trace the function diffs
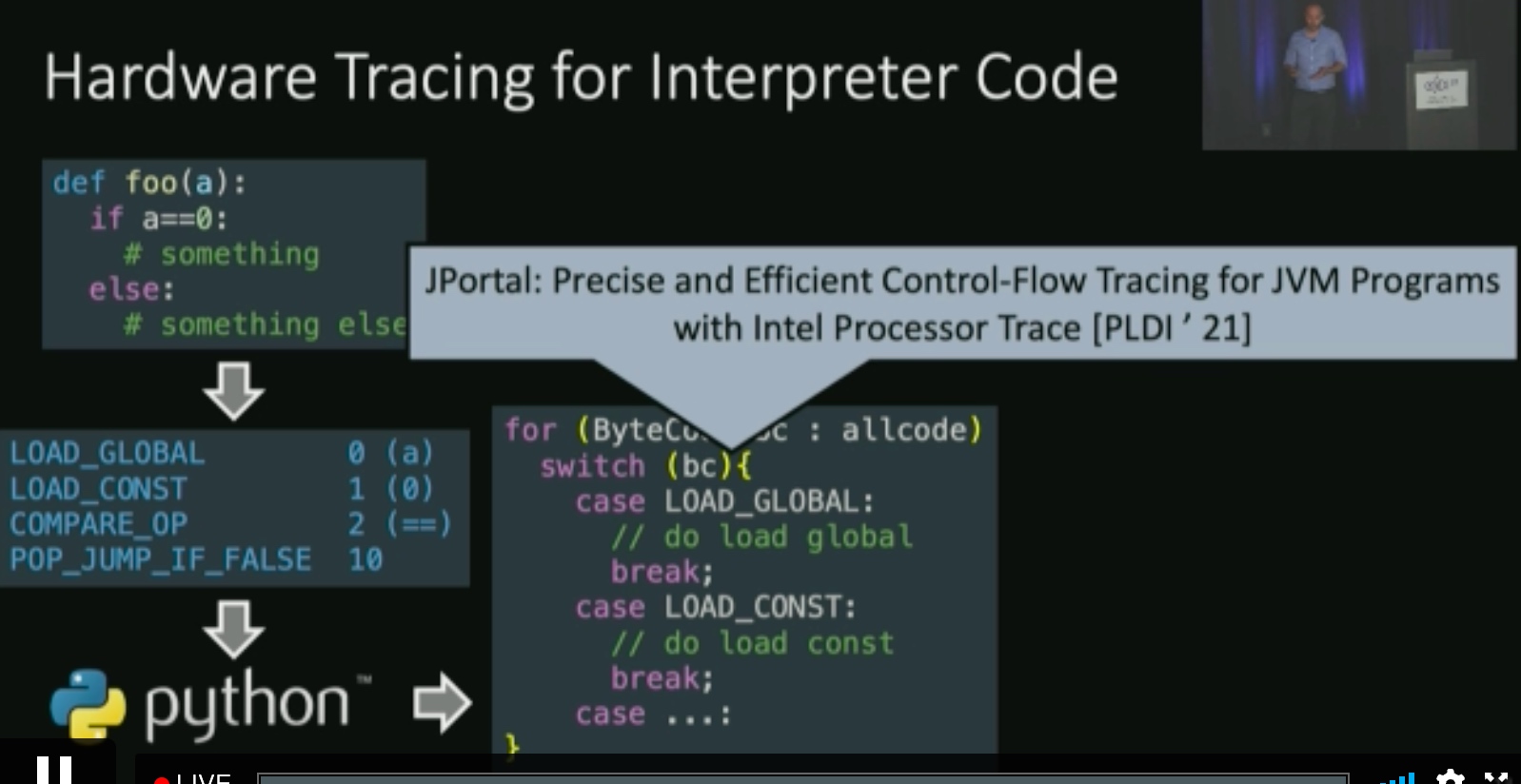
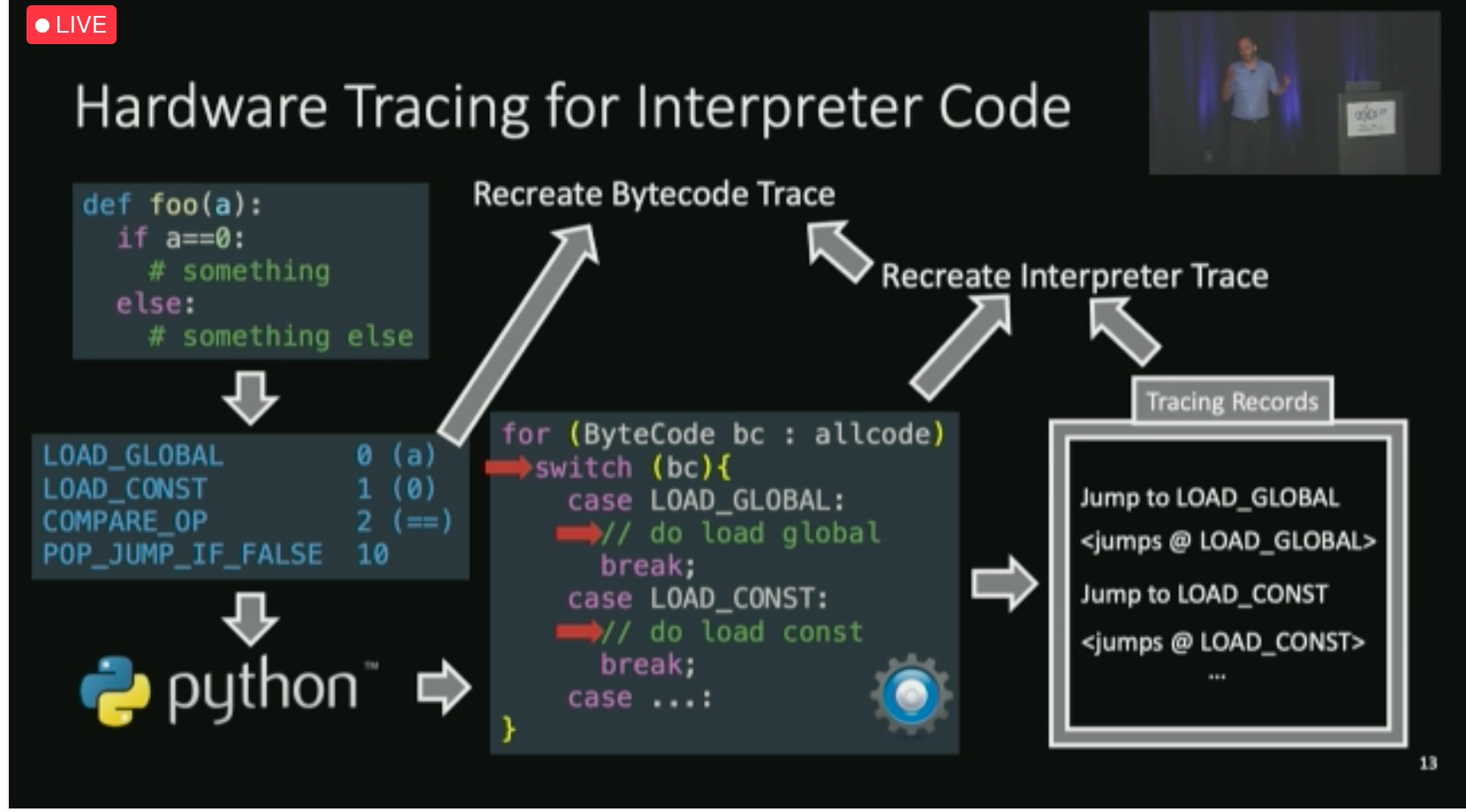

Cast bytecode jump into hardware jump
ATC
Storage 1
ZNSwap: un-Block your Swap
ZNS上的DRAM和underlying block device的swap。
Building a High-performance Fine-grained Deduplication Framework for Backup Storage with High Deduplication Ratio

Distributed System
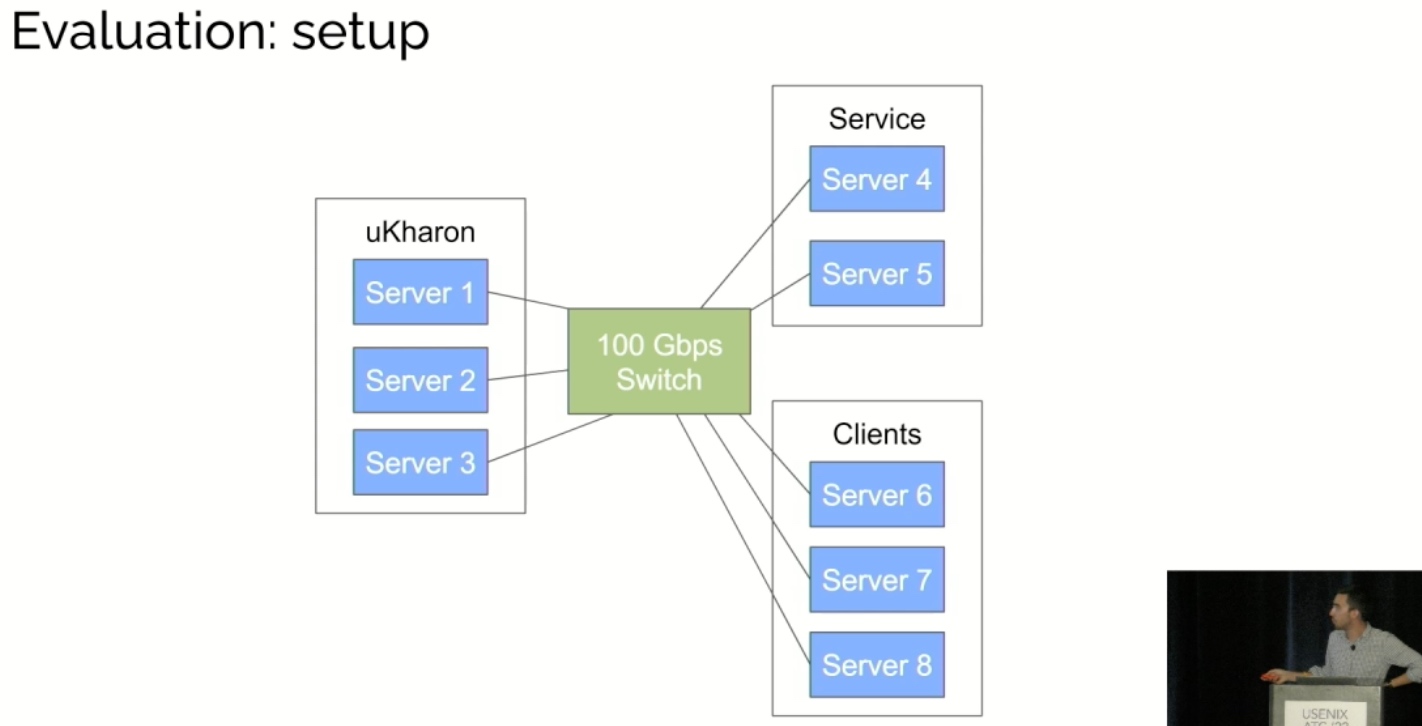
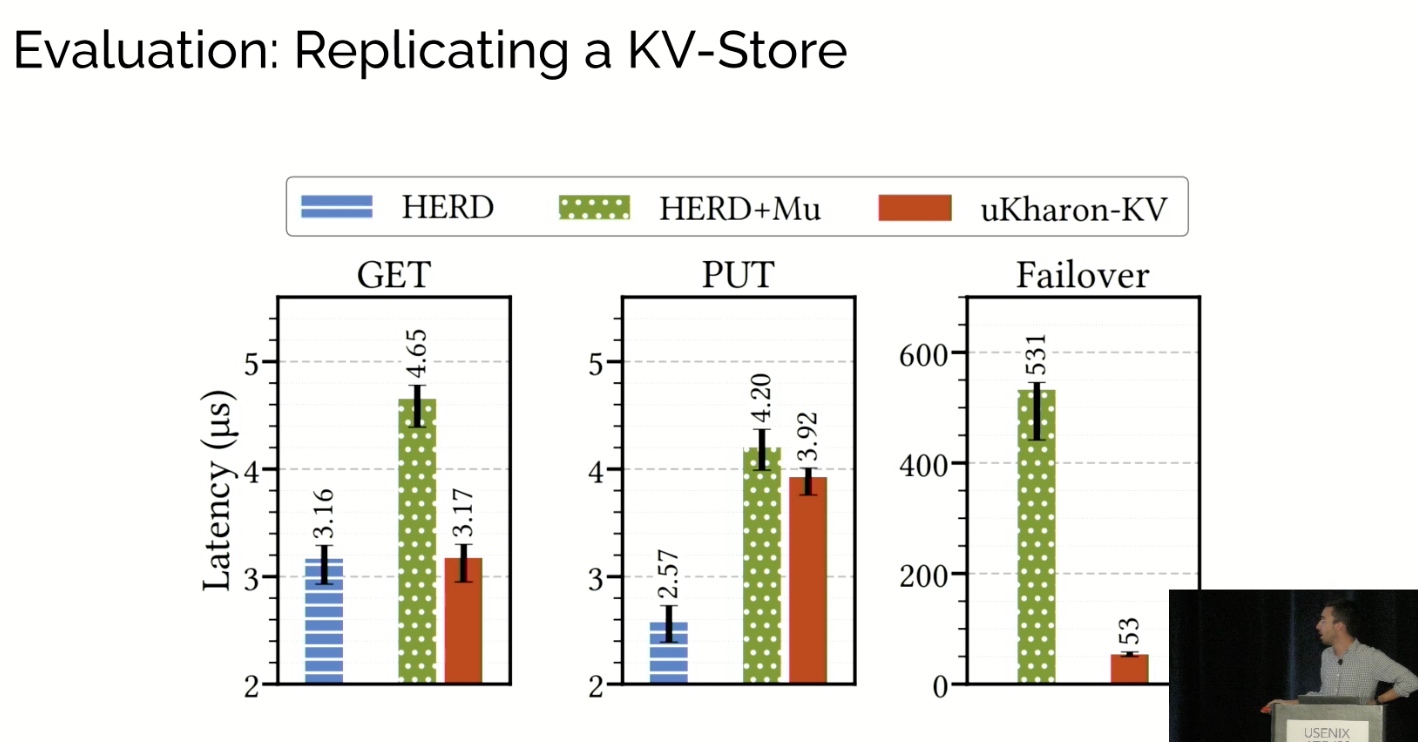
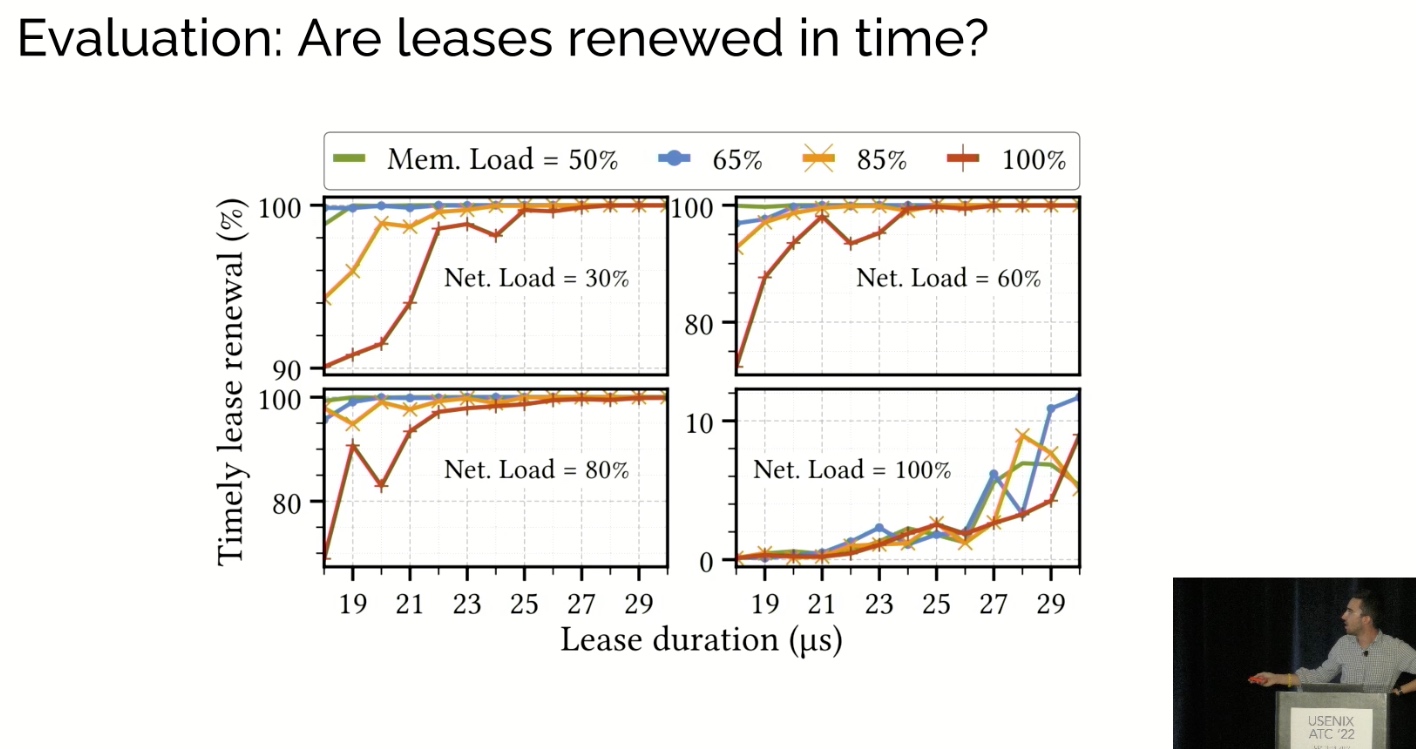
uKharon: A Membership Service for Microsecond Applications

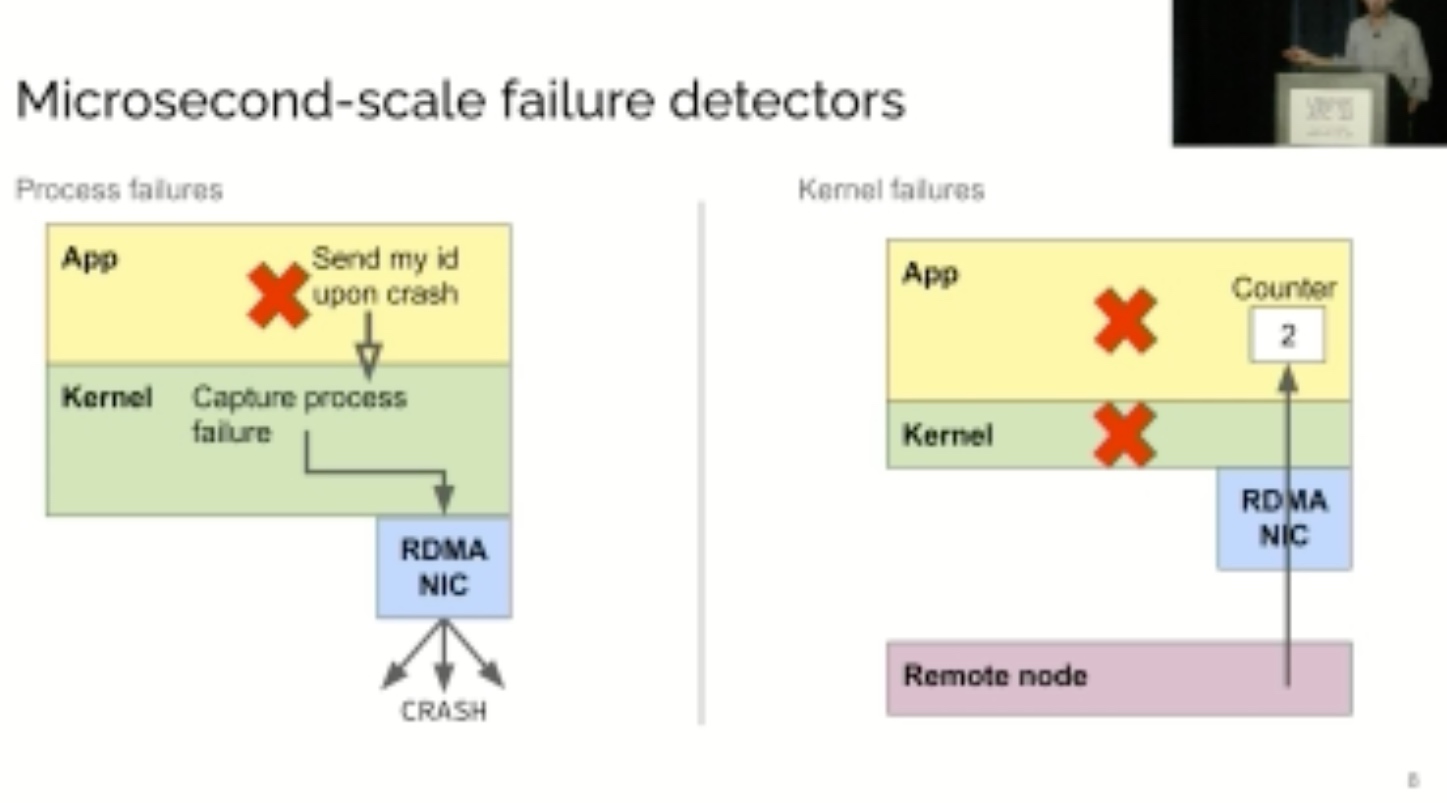


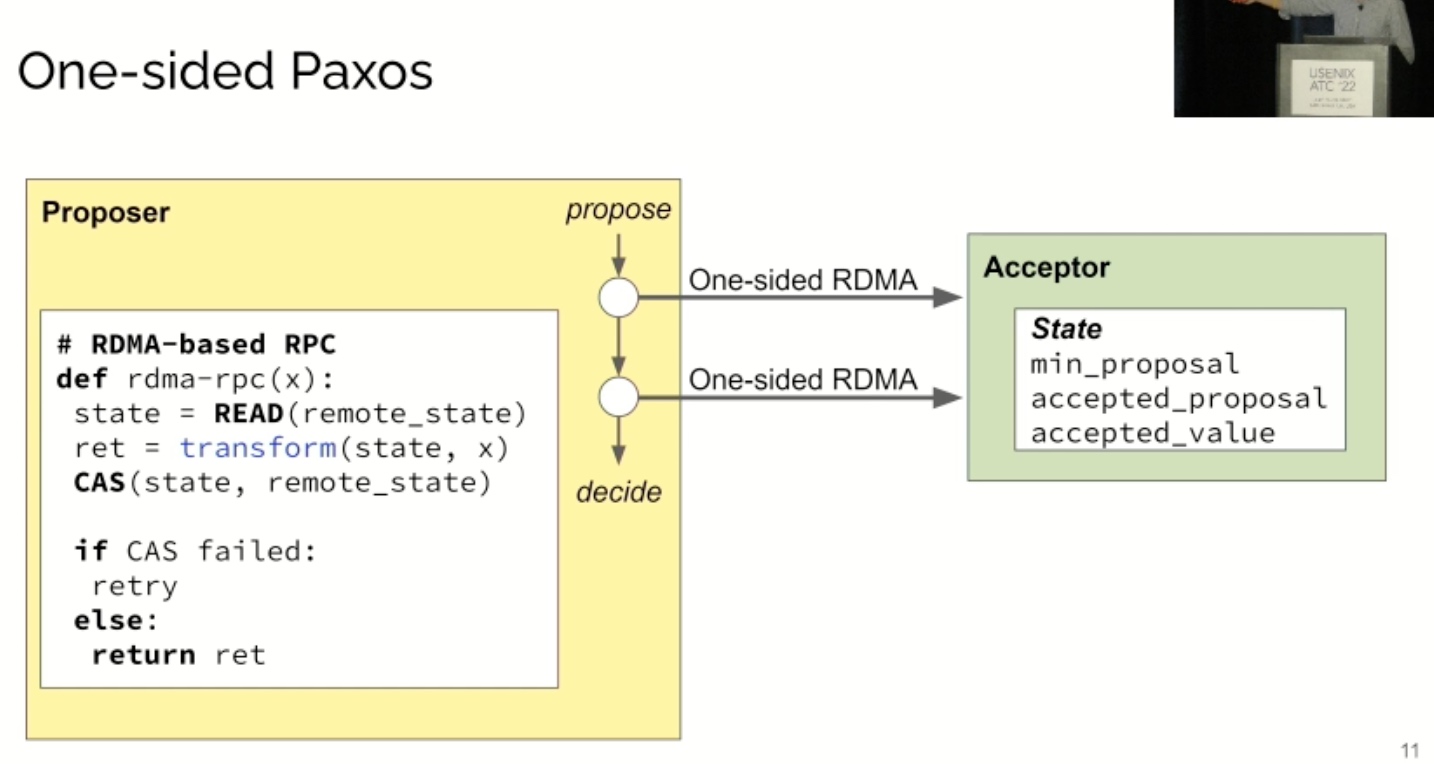
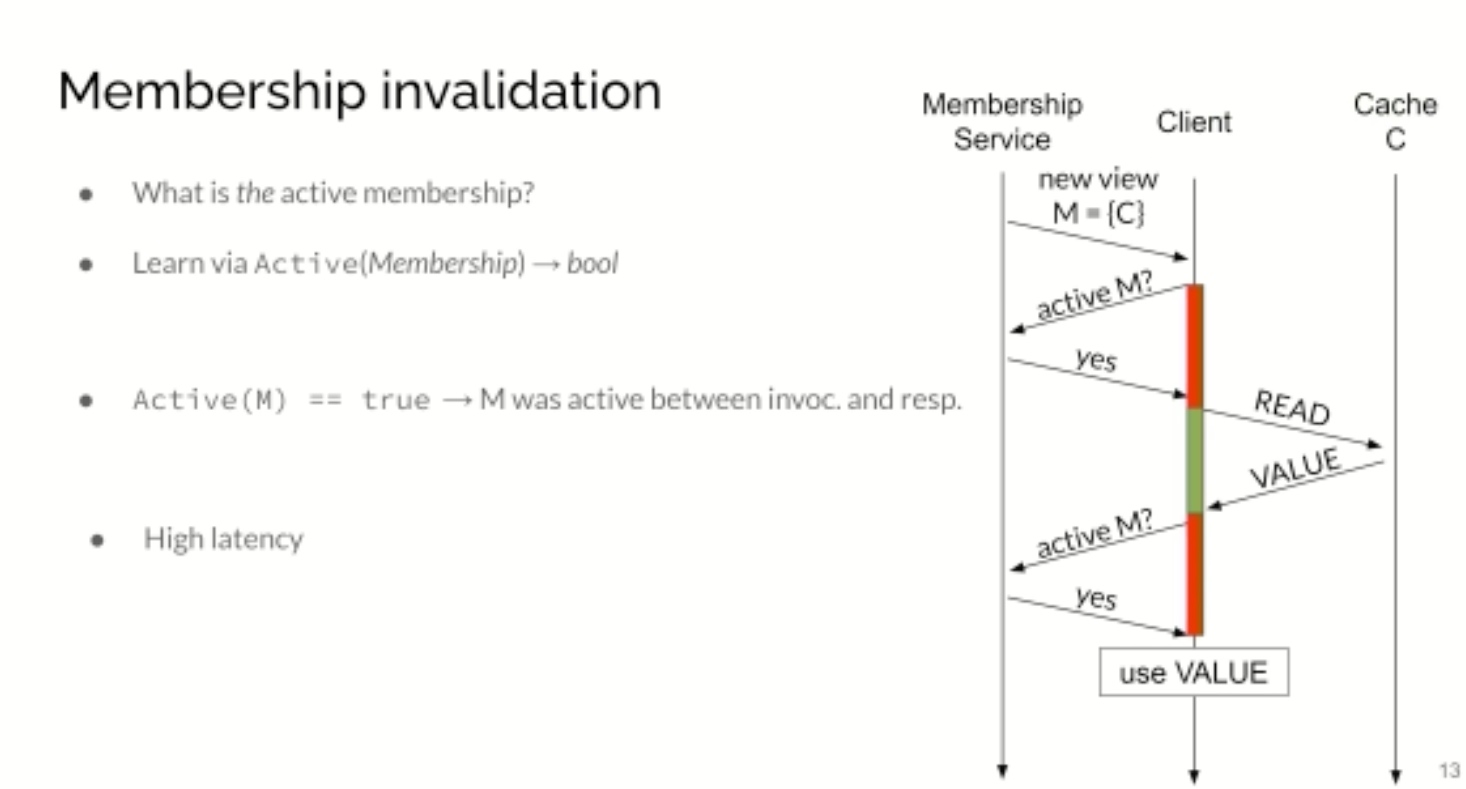
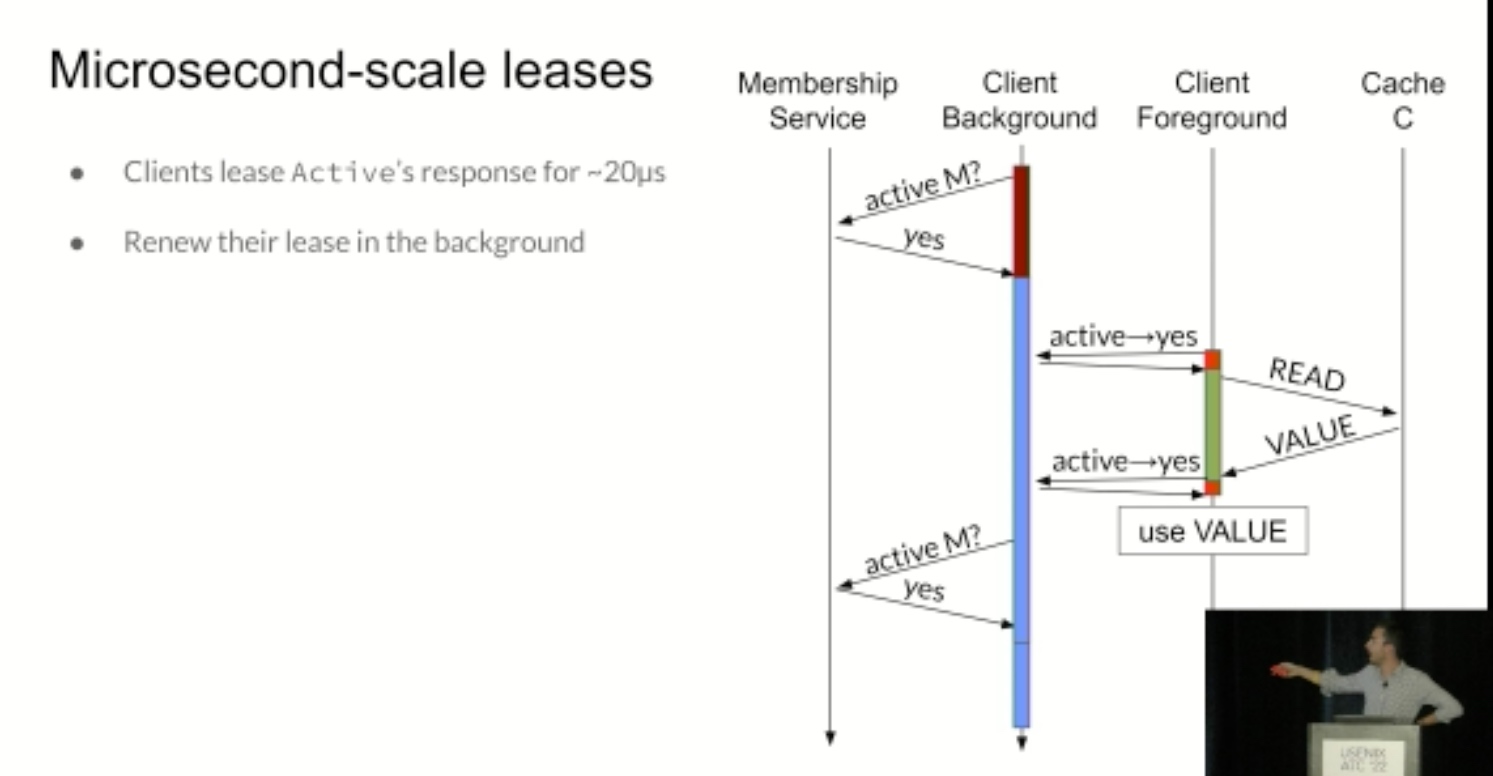
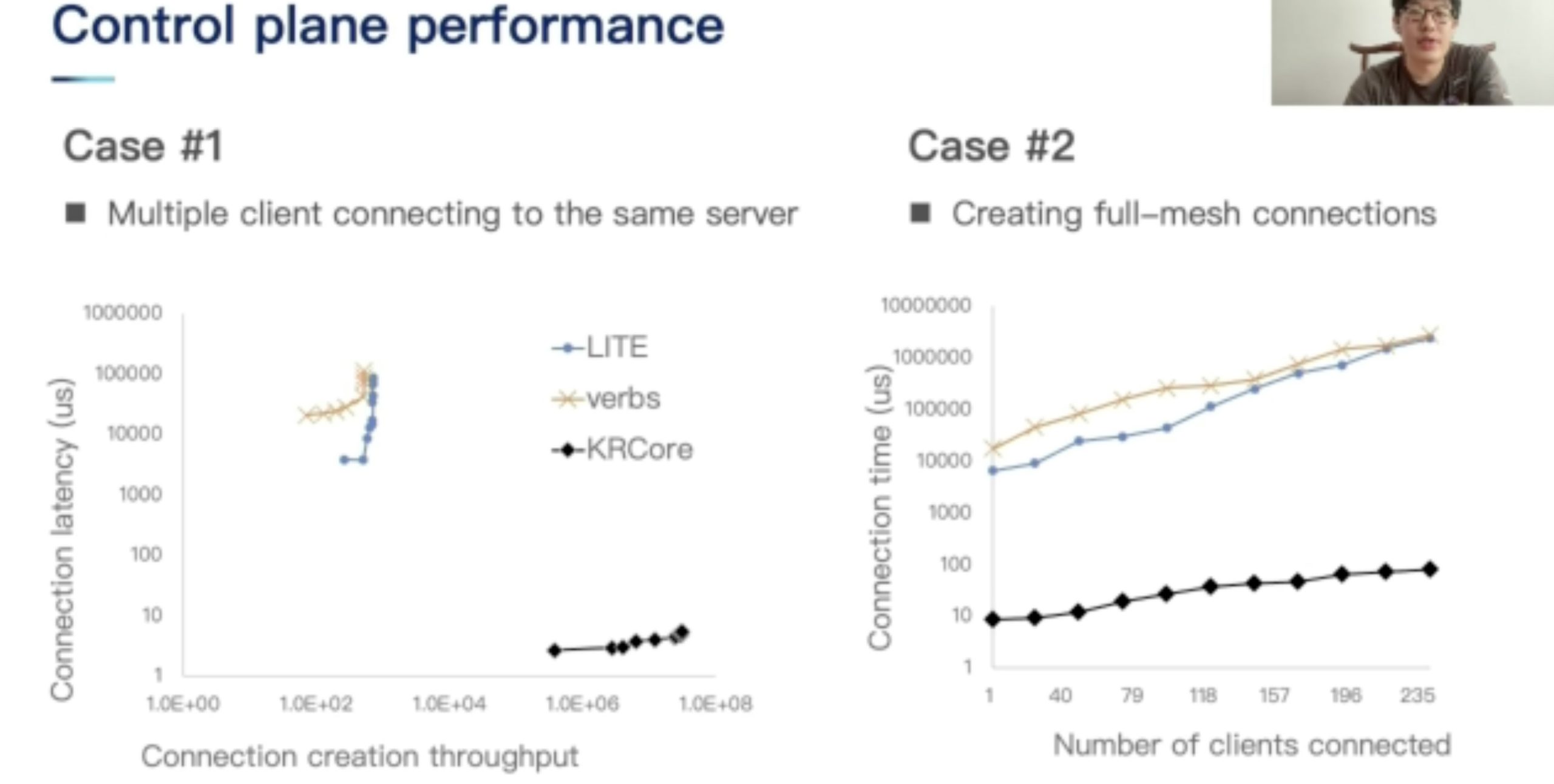
KRCore

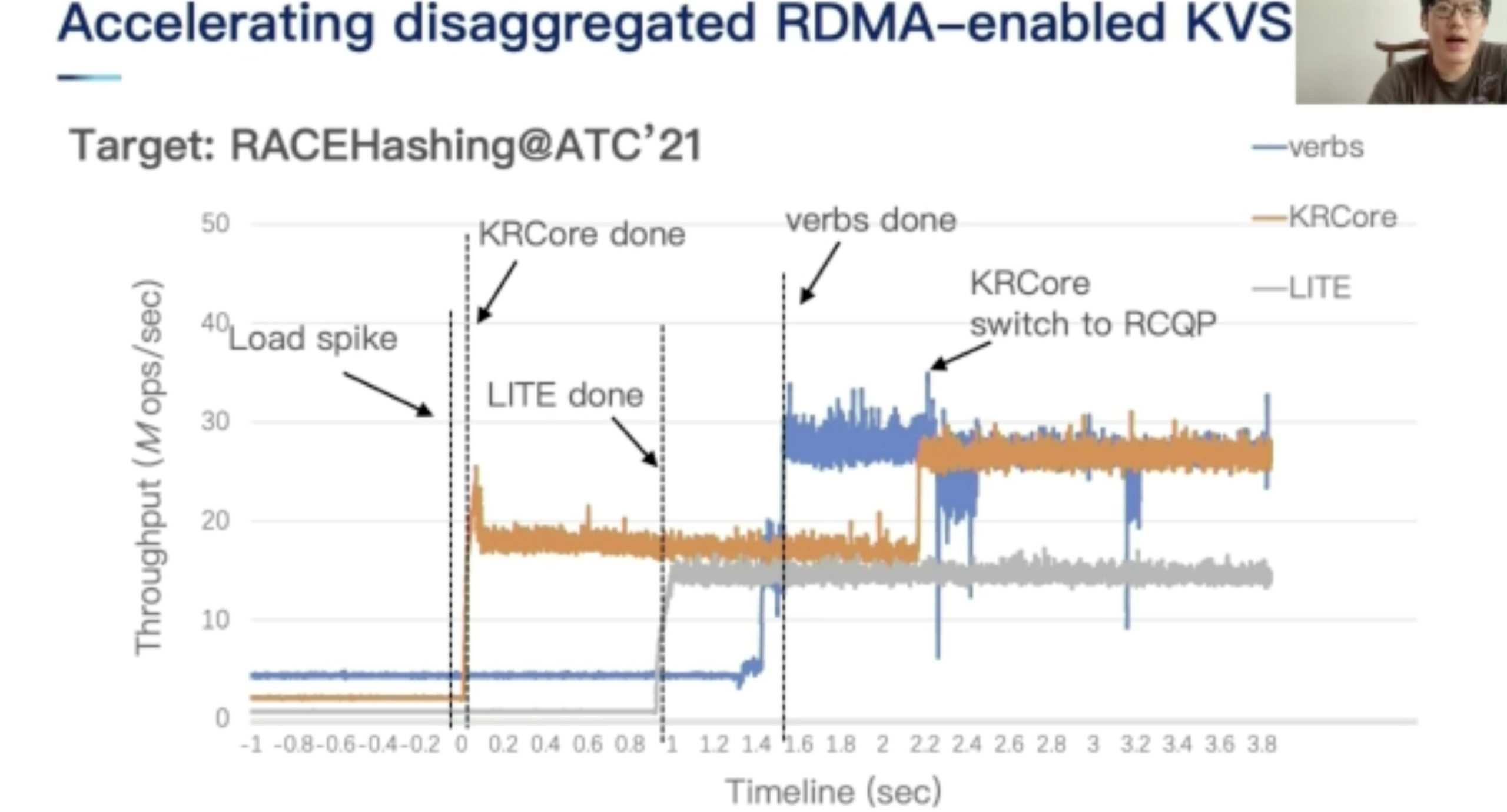

ZCOT

PrivBox


eBPF?non-intrusive linux code/ different safety model
Bugs
KSG: Augmenting Kernel Fuzzing with System Call Specification Generation

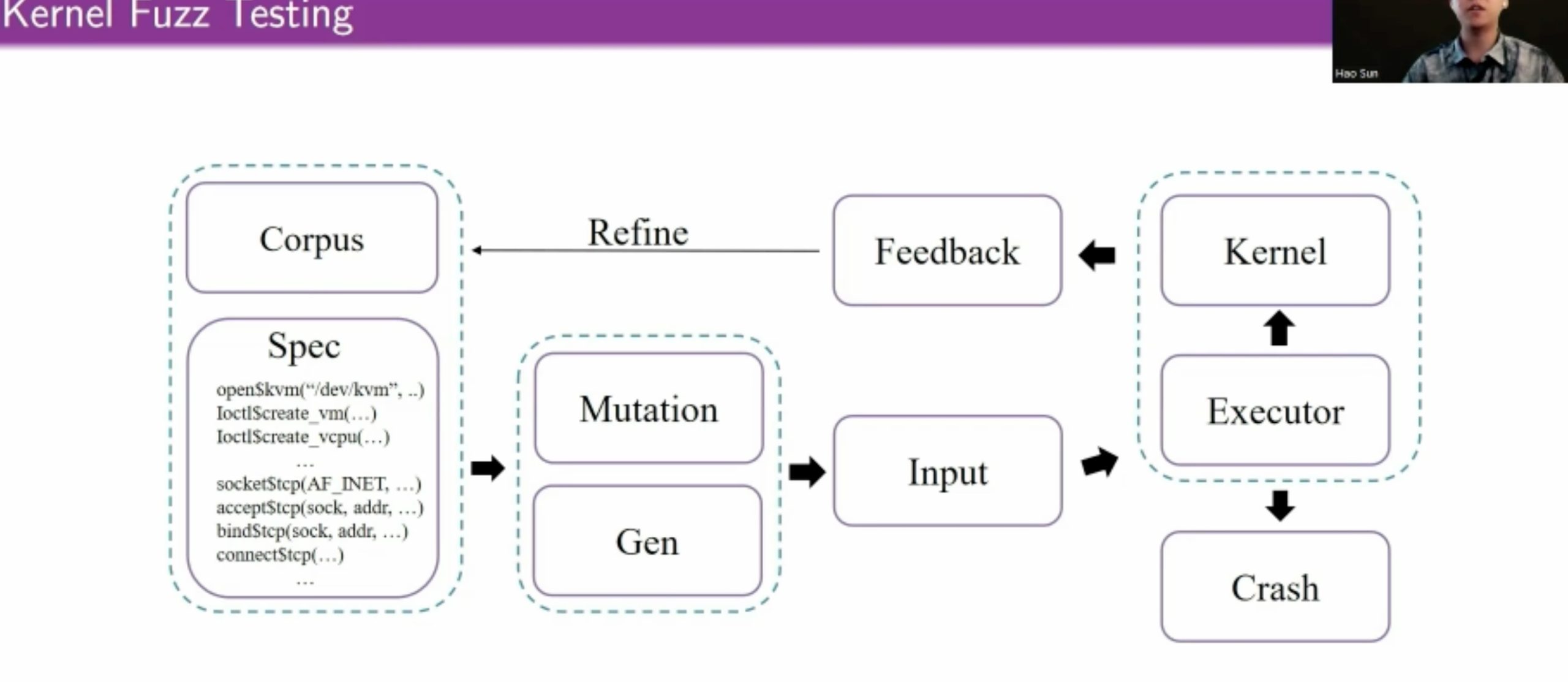



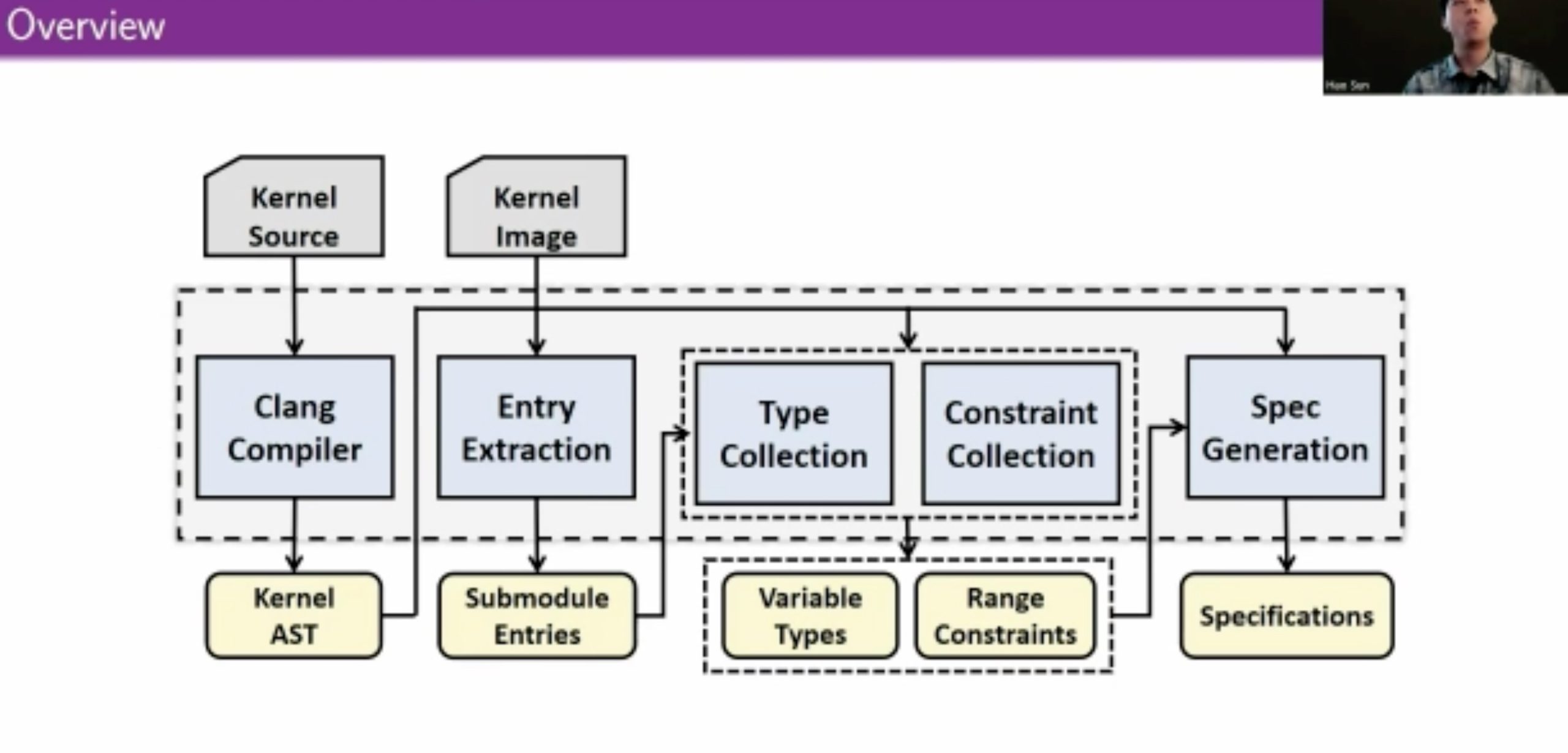
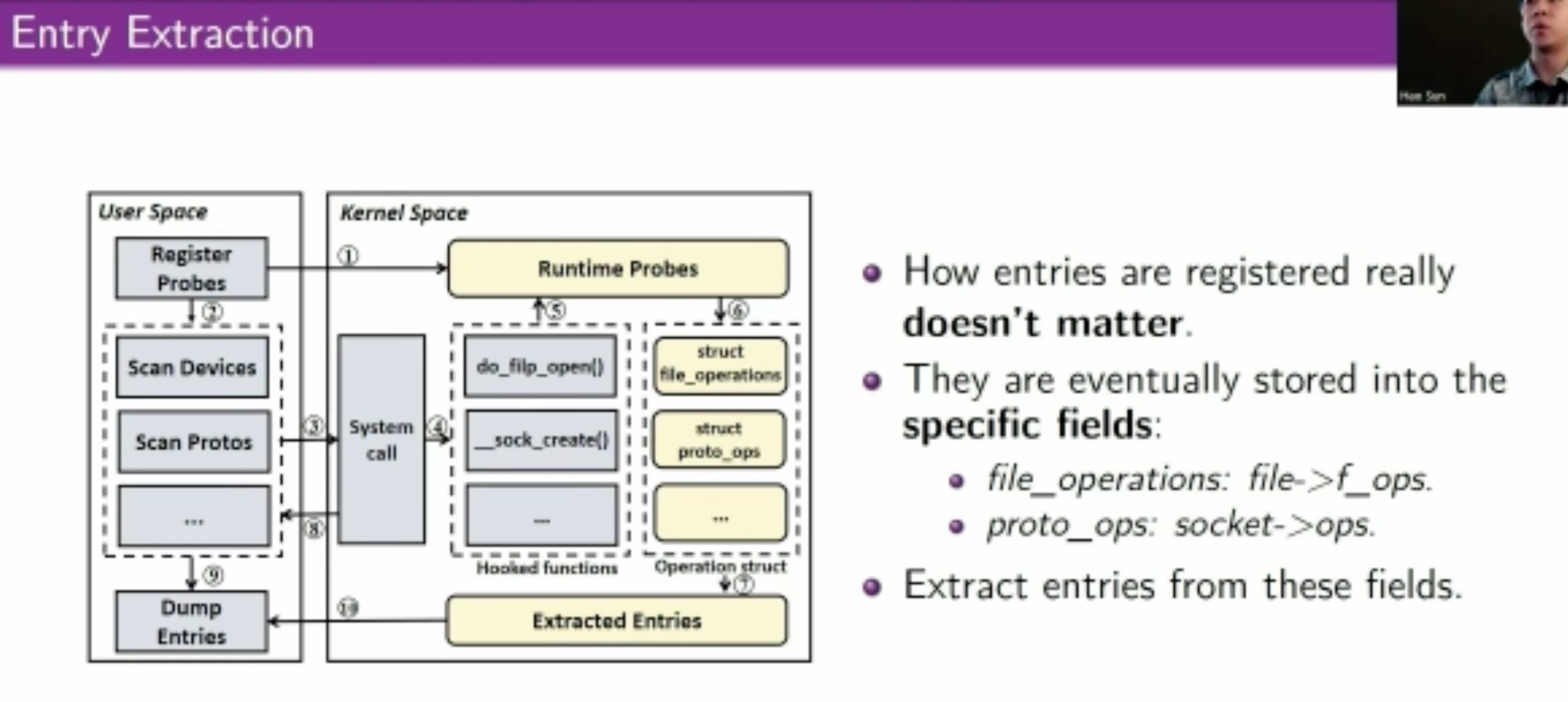
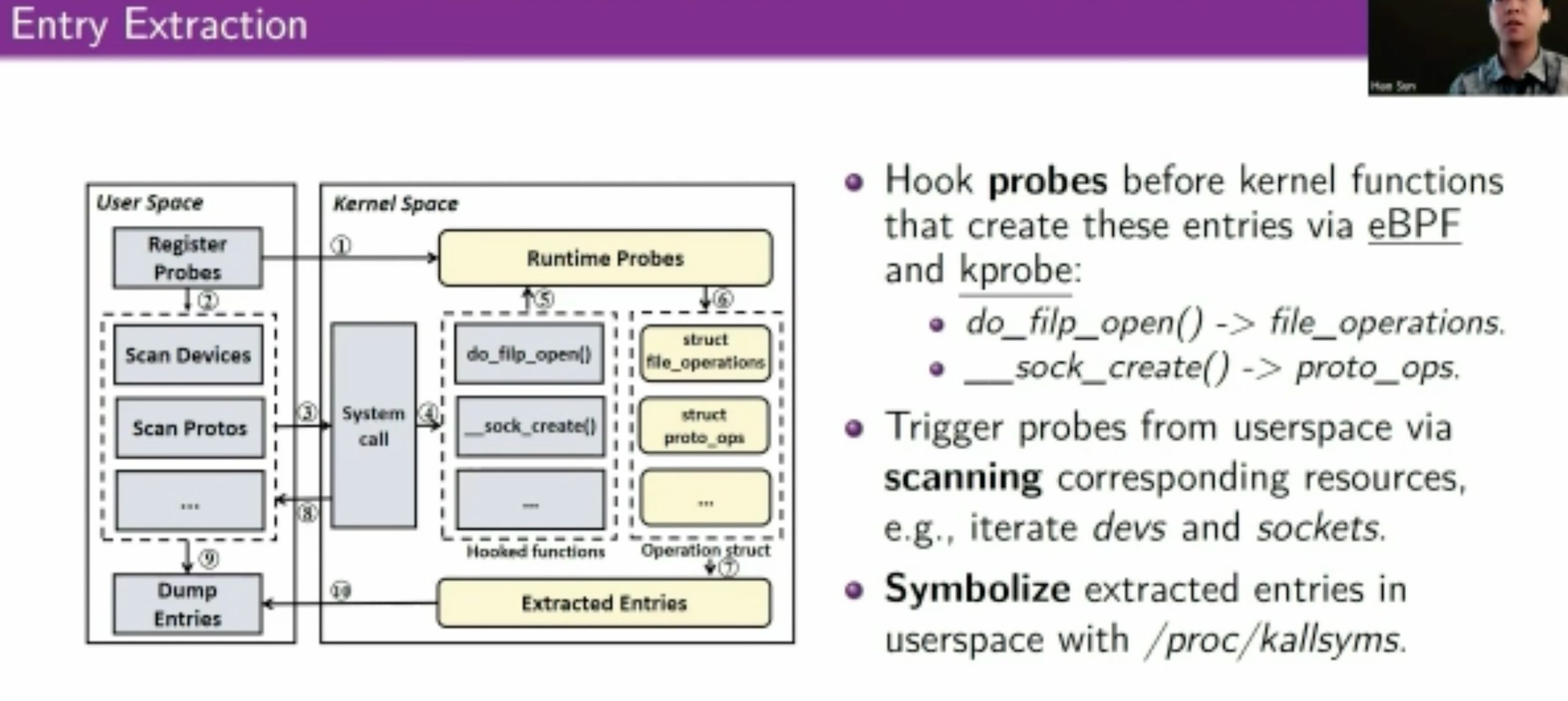

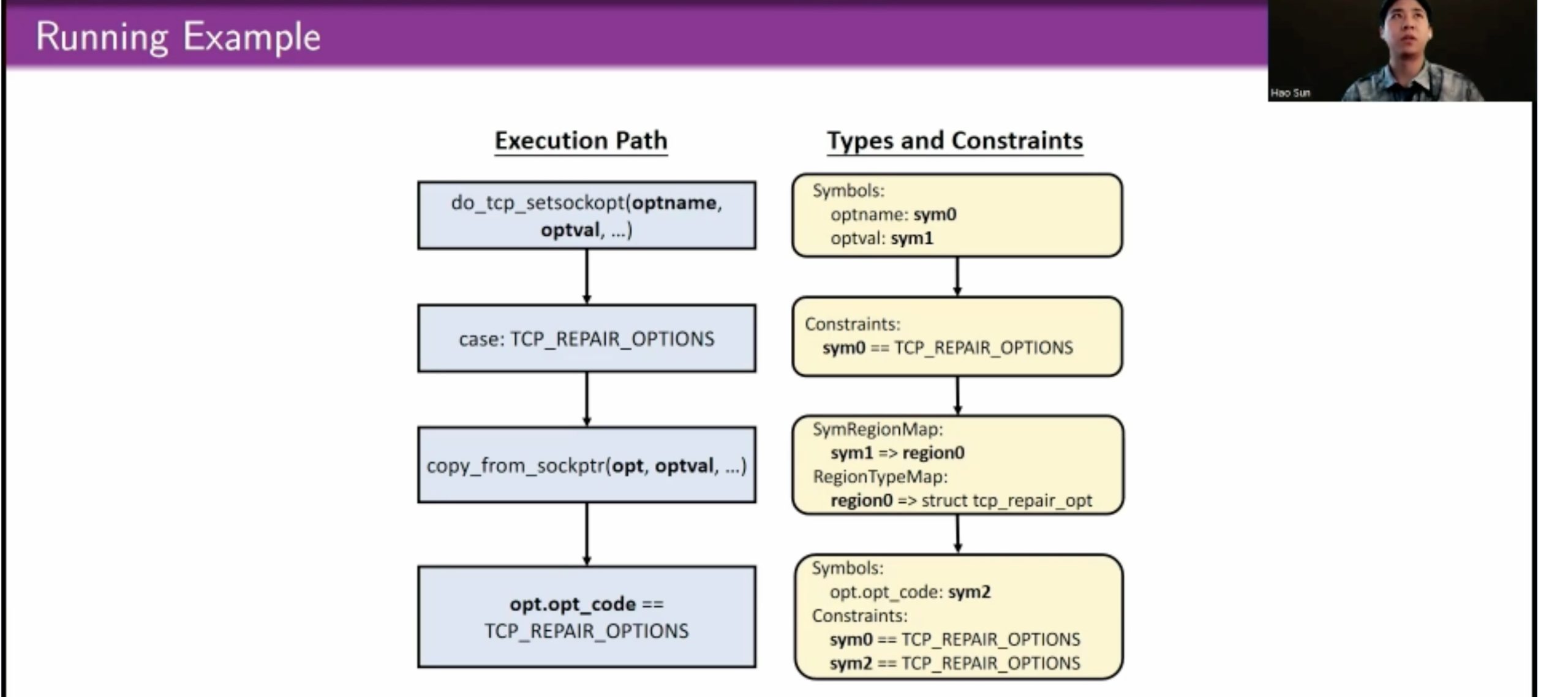

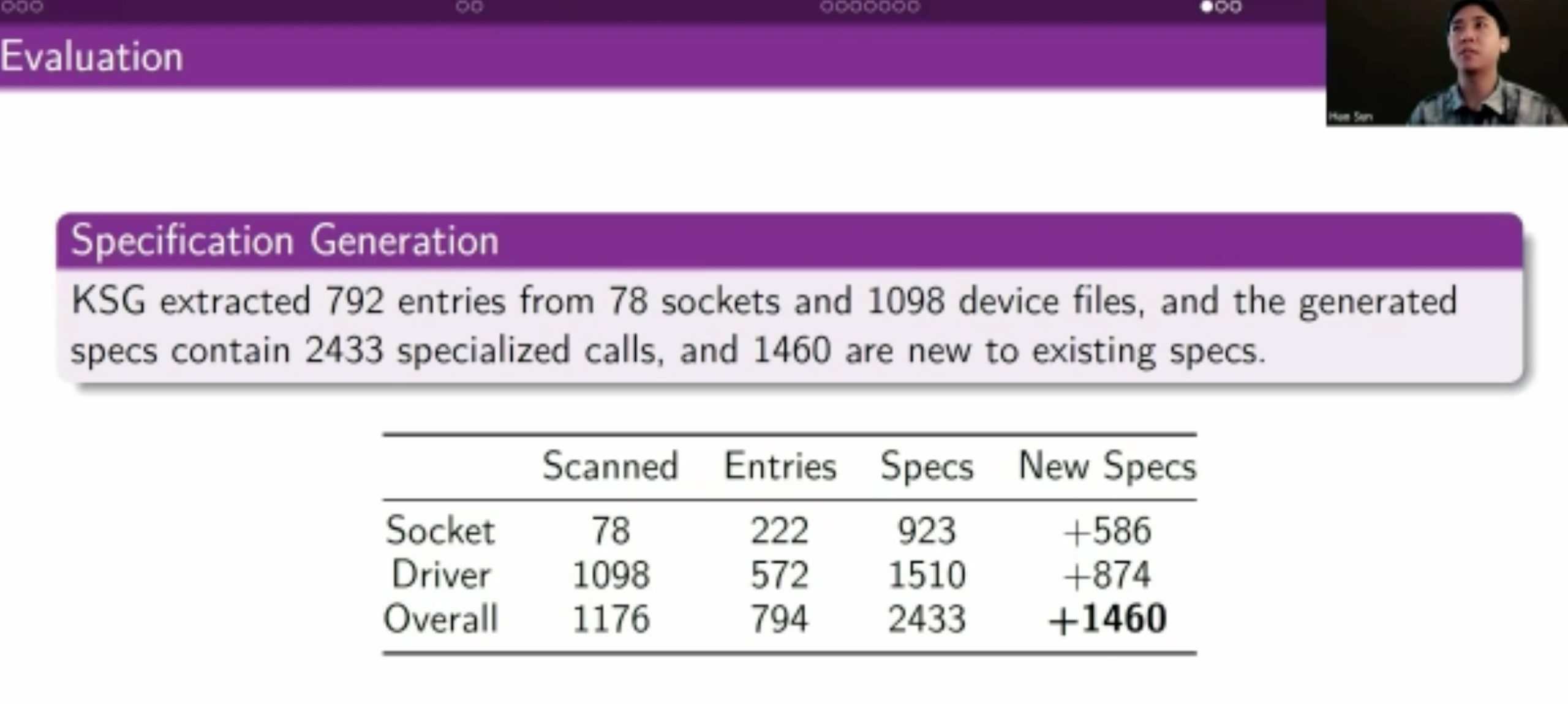
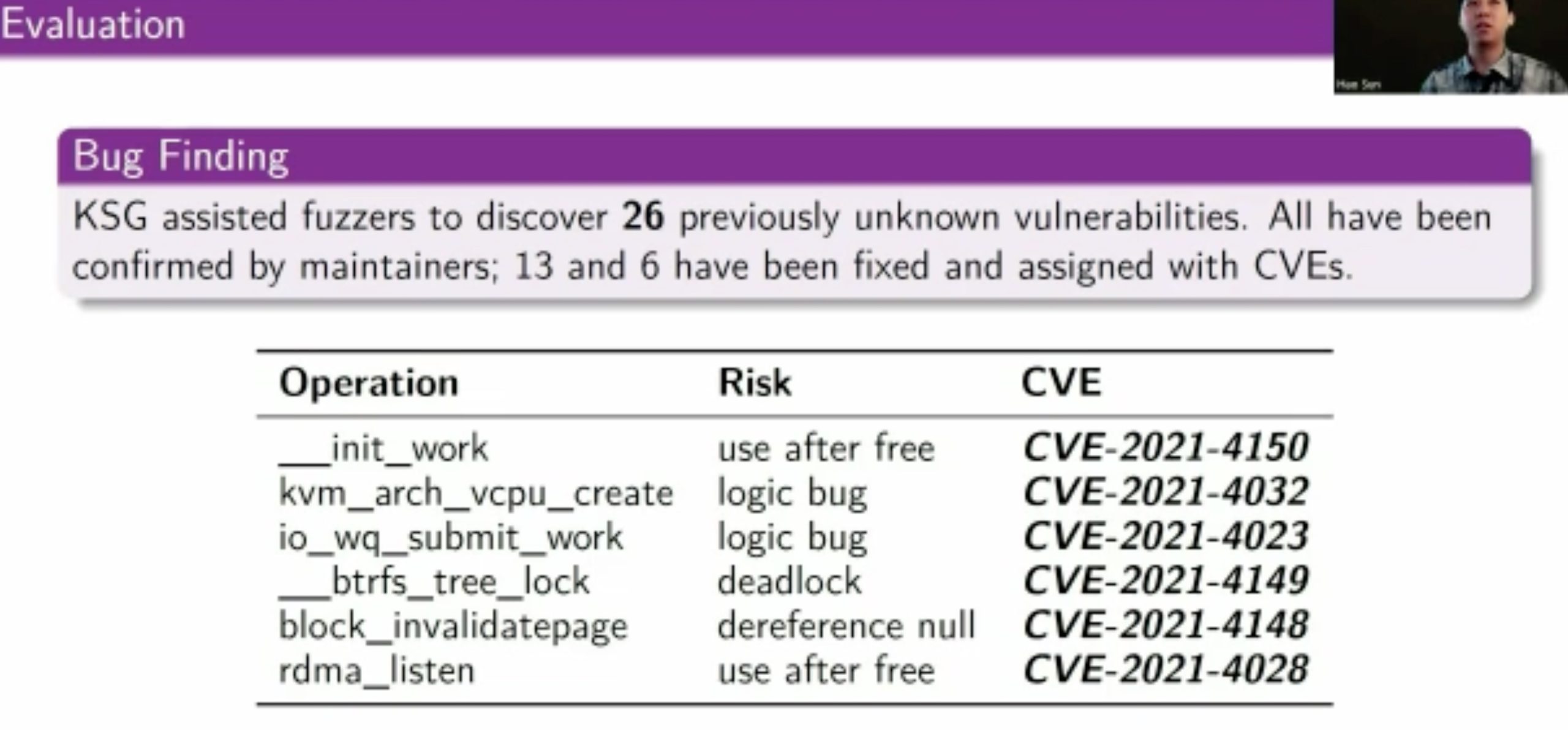
用eBPF和kprobe拿type/constraints信息喂给skywalker
coverage很难到100,因为没有硬件模拟interrupt,现有的只是syscall triggered
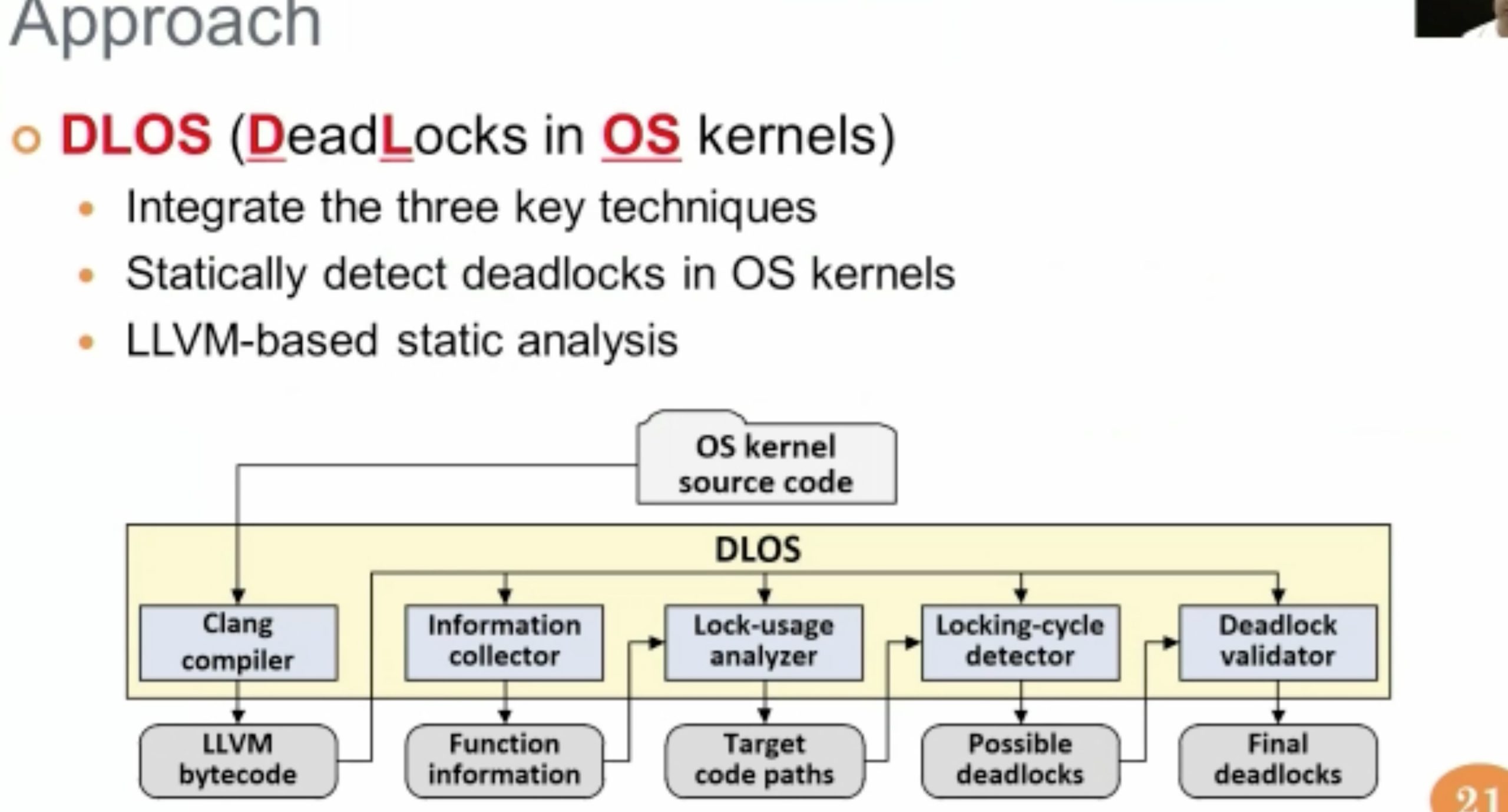
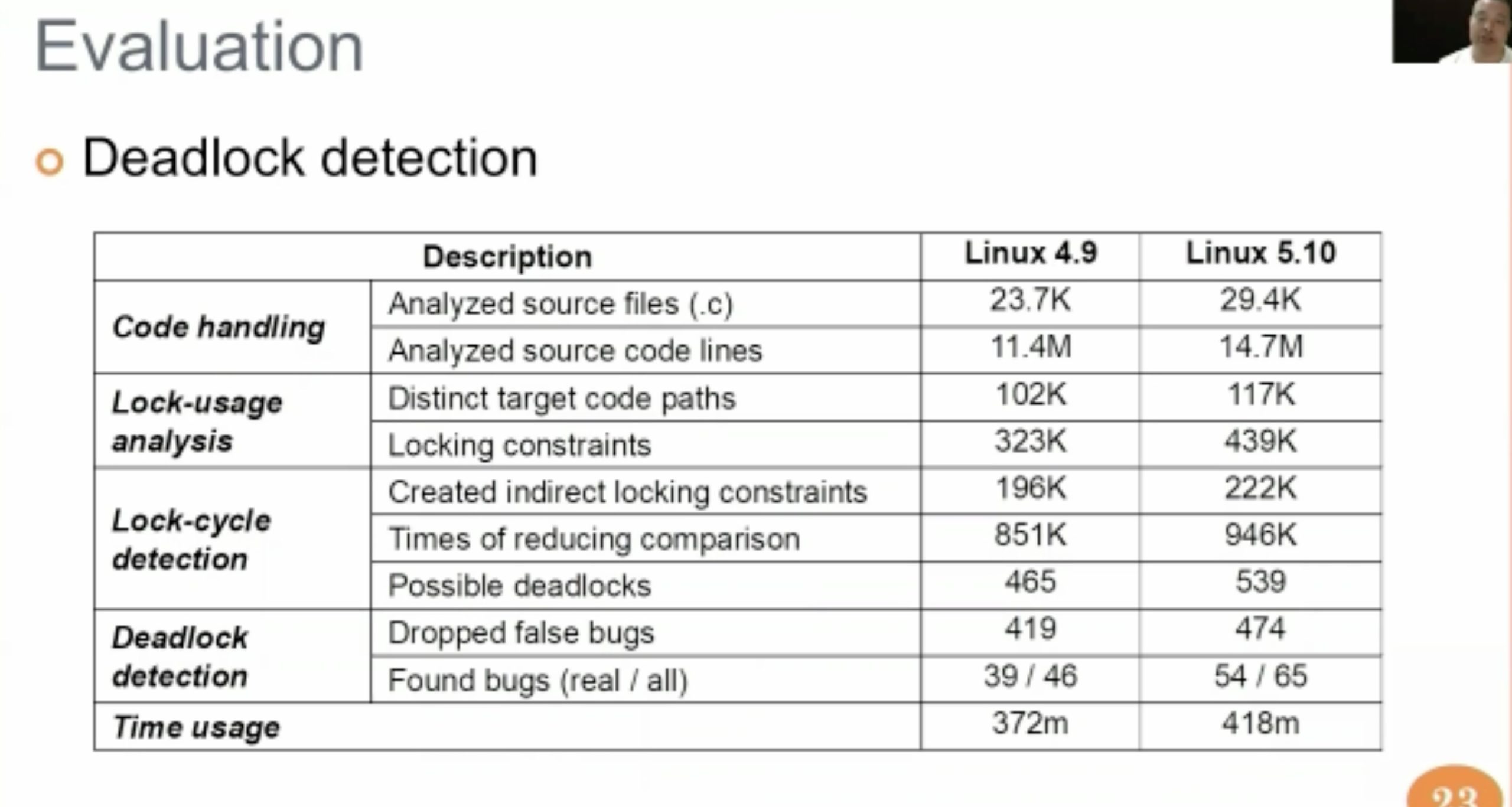
DLOS: Effective Static Detection of Deadlocks in OS Kernels


















最后还是要用z3 path verifier filter一下。


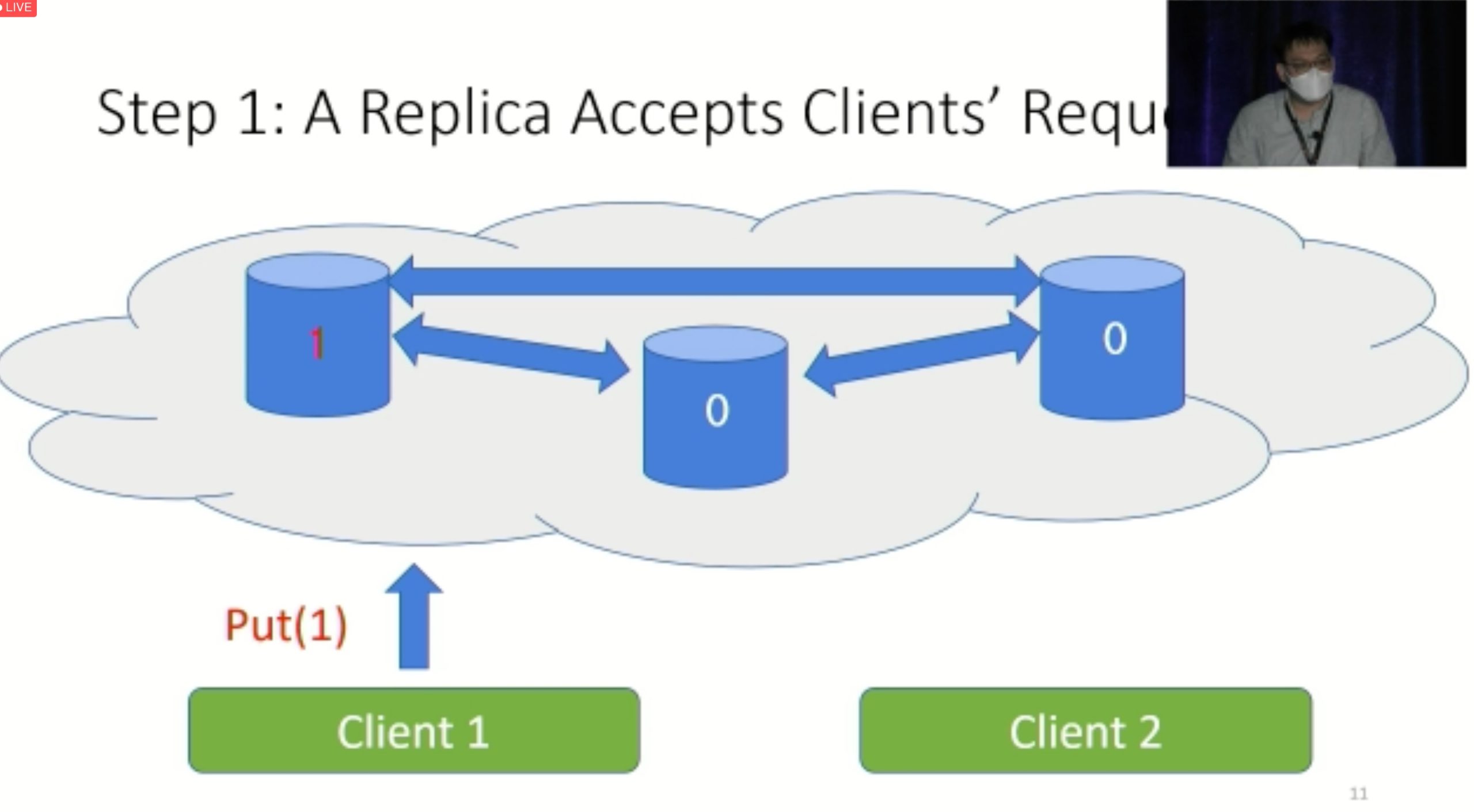
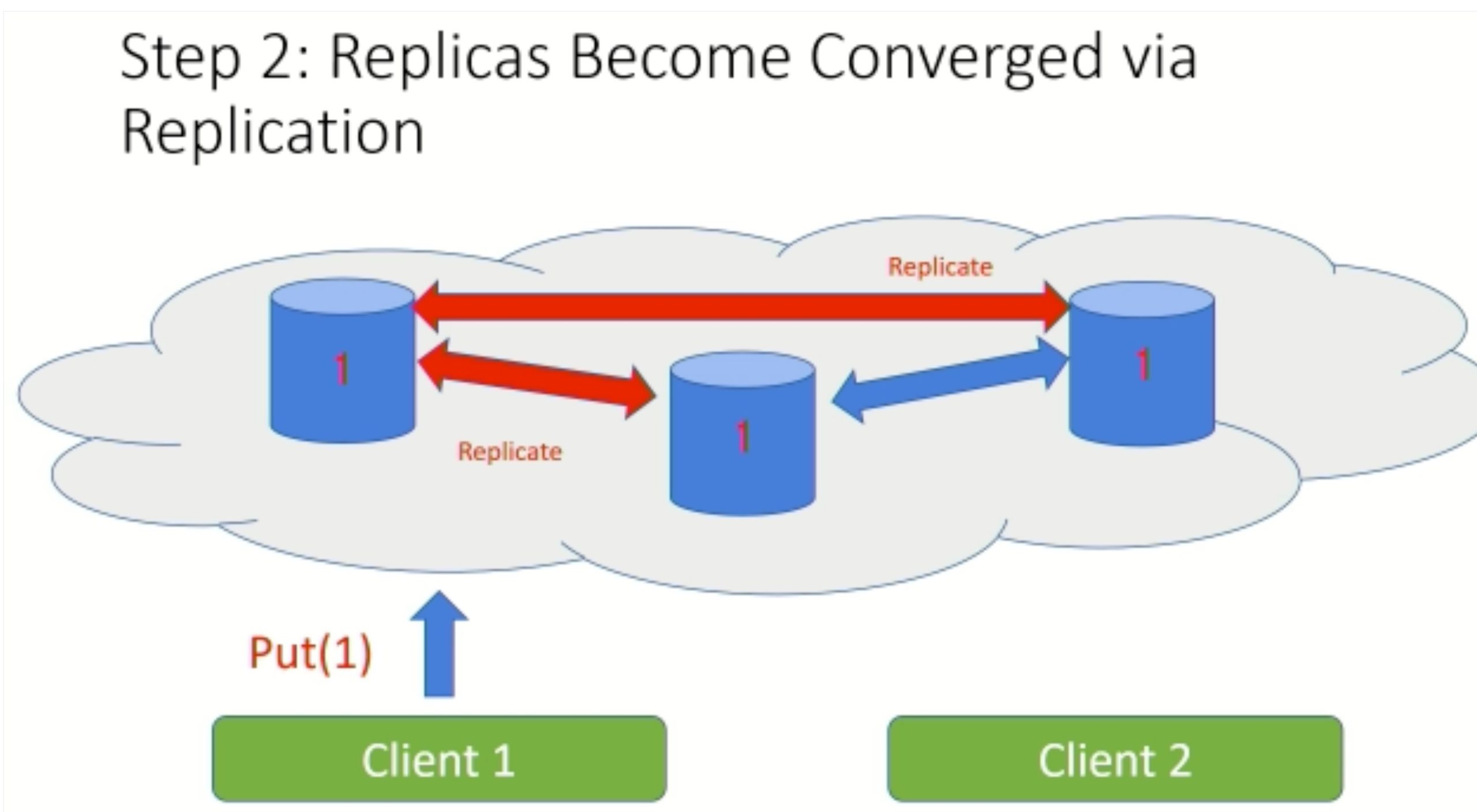
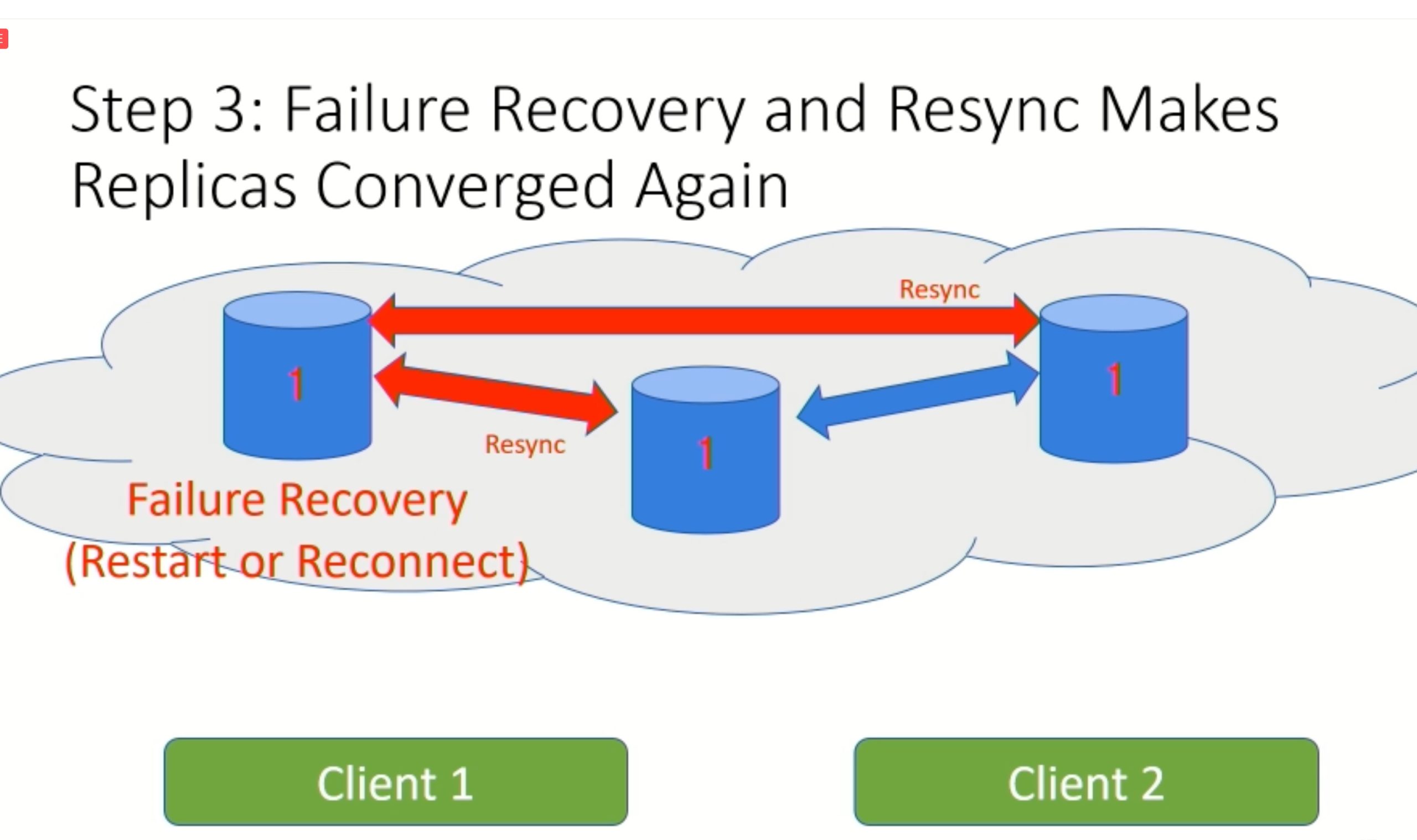
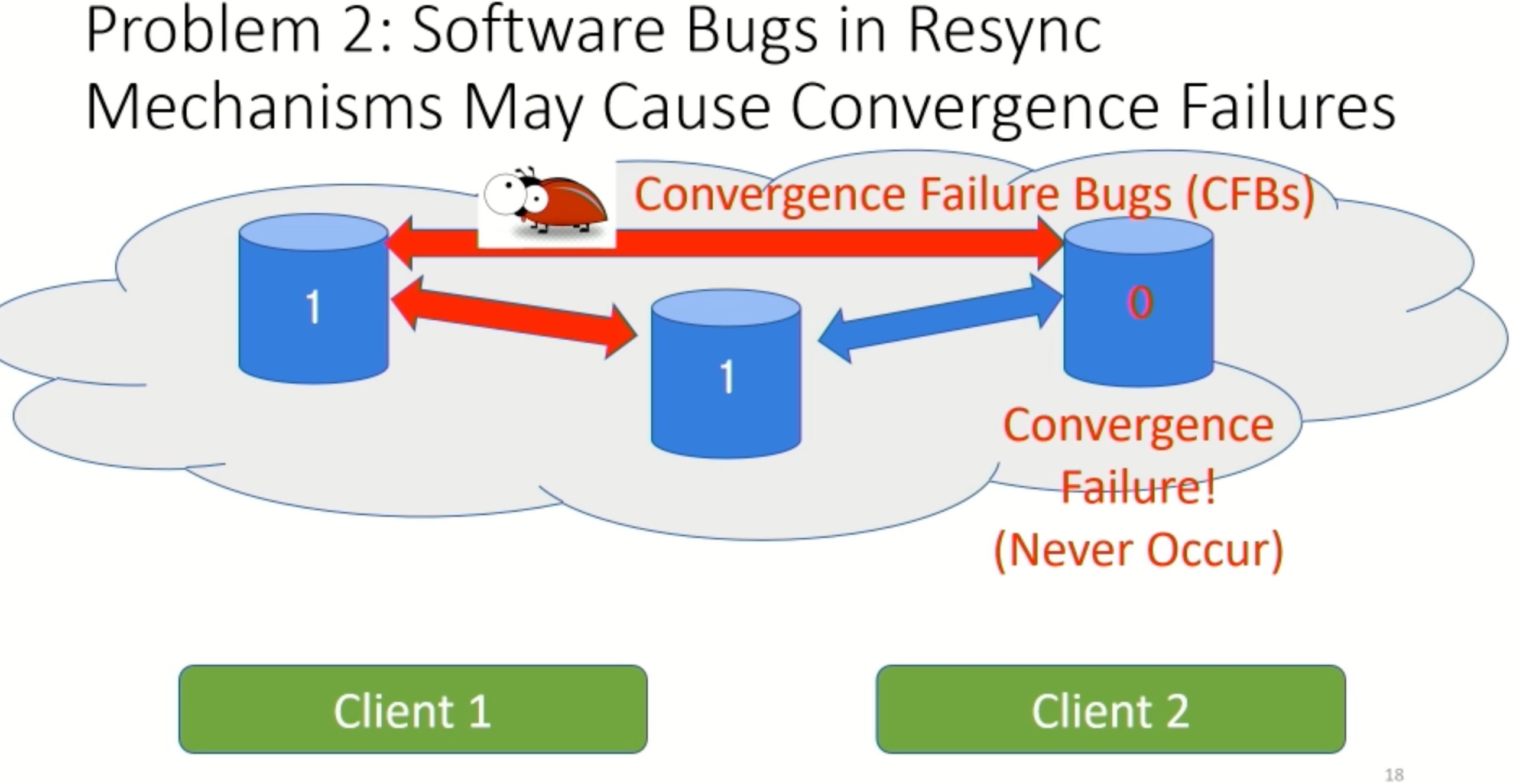
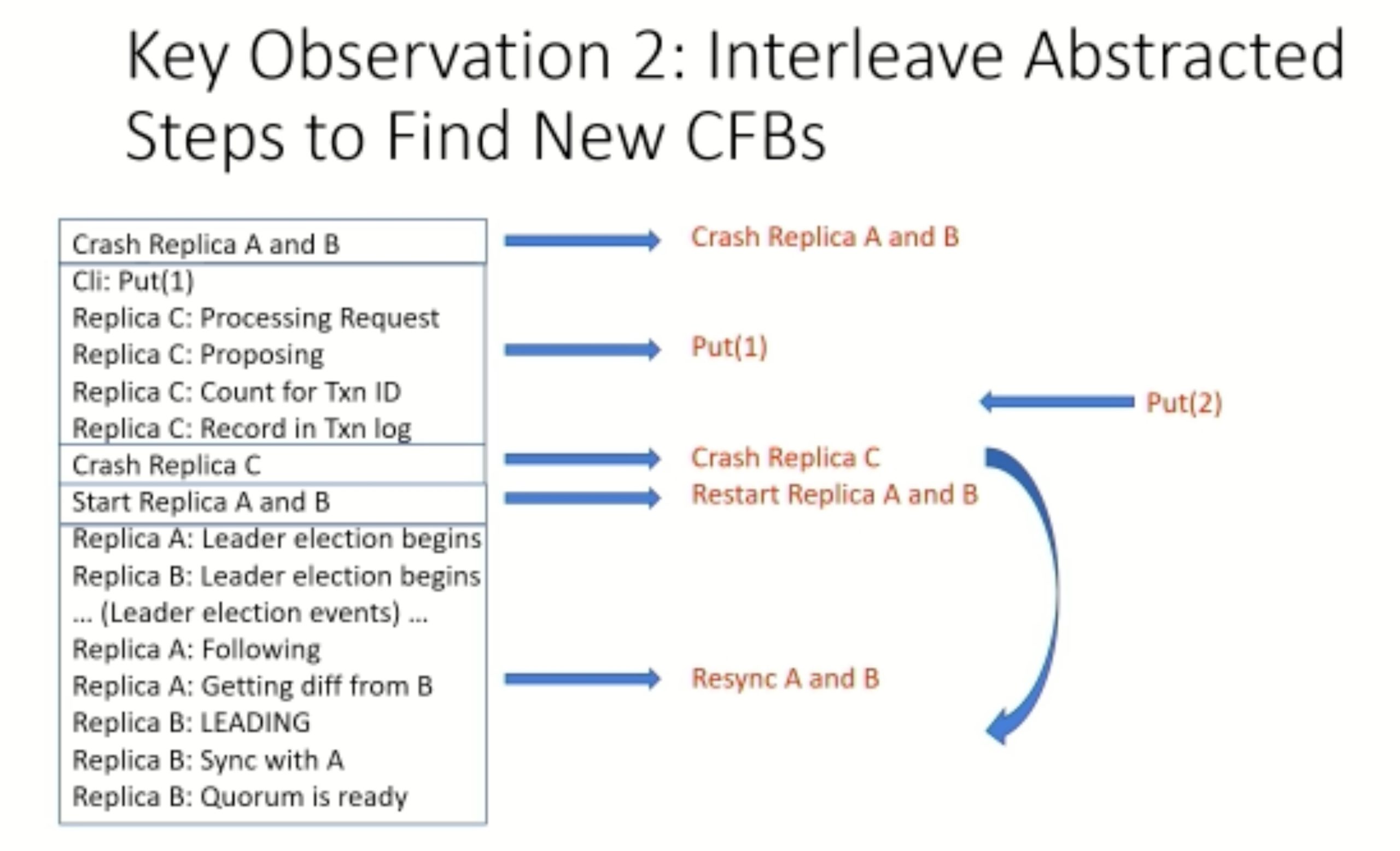
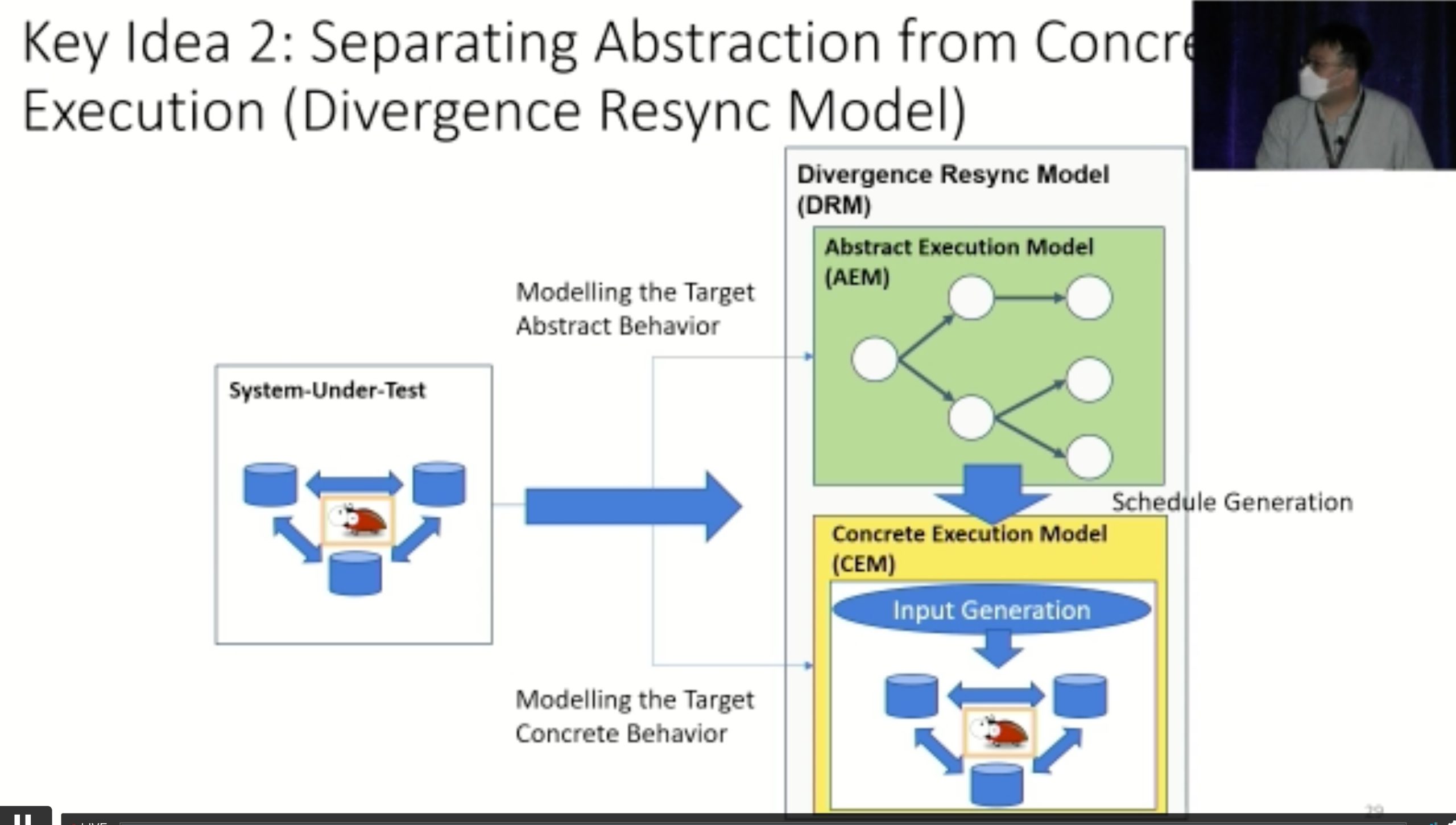
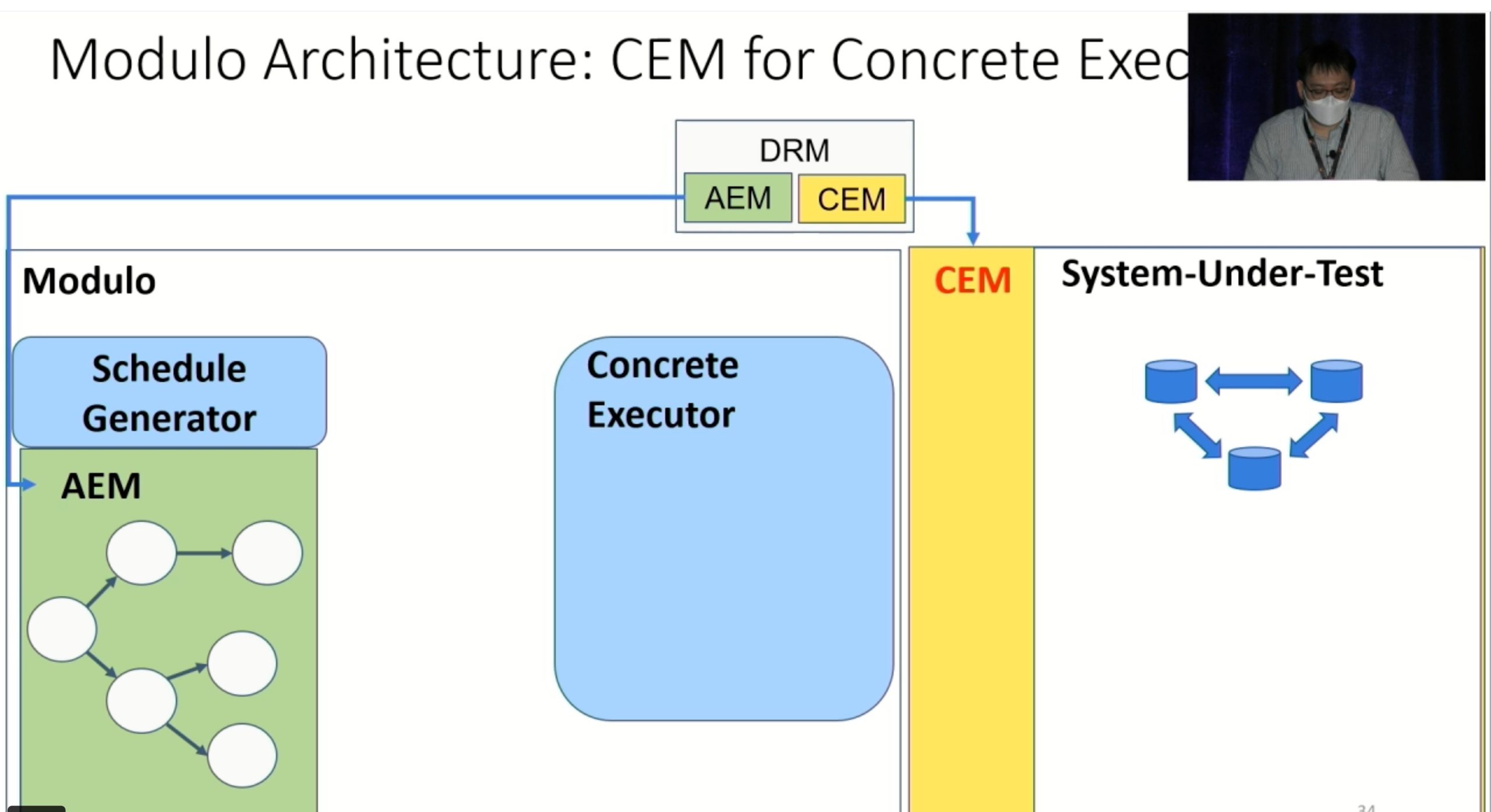
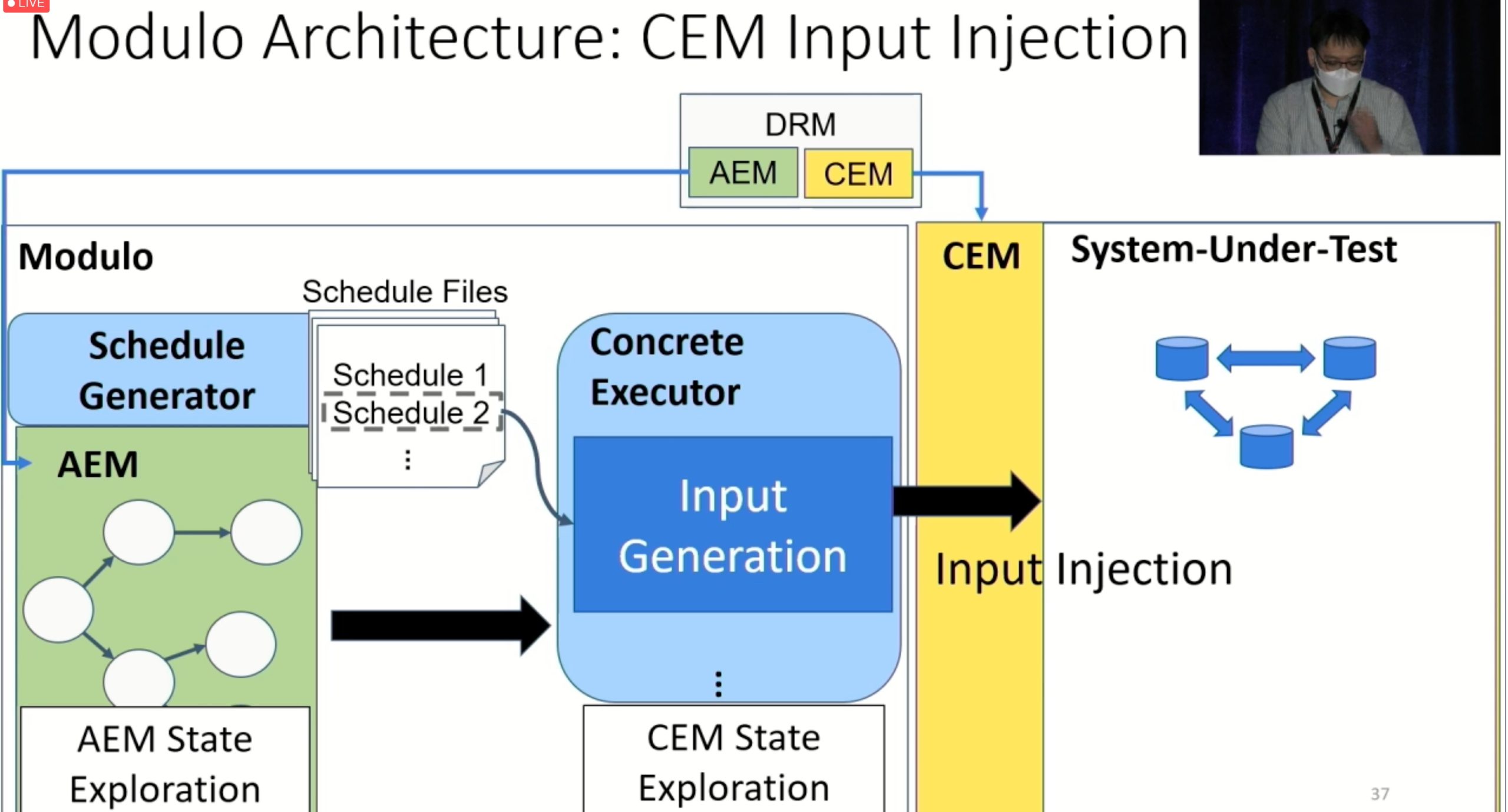
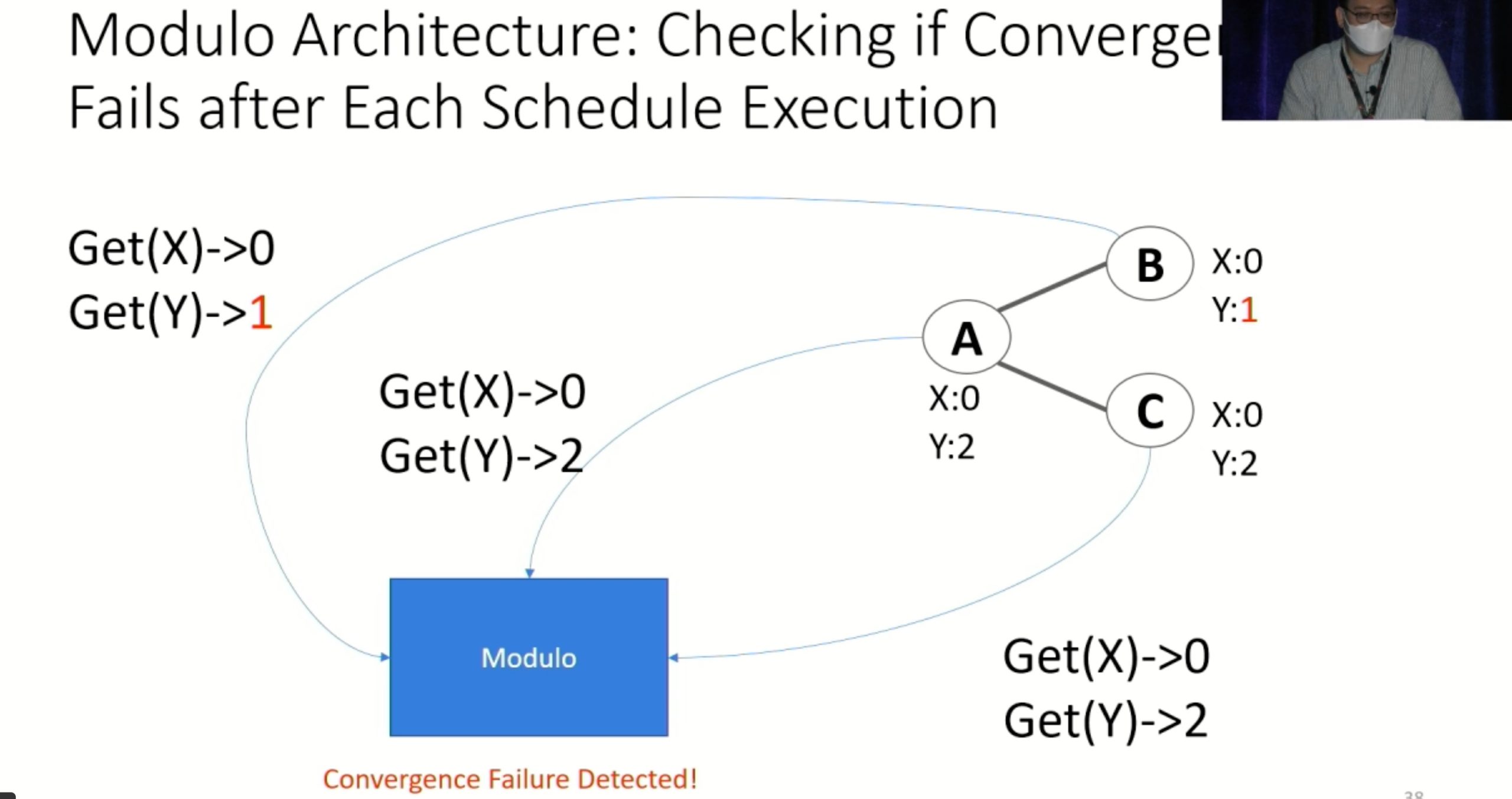
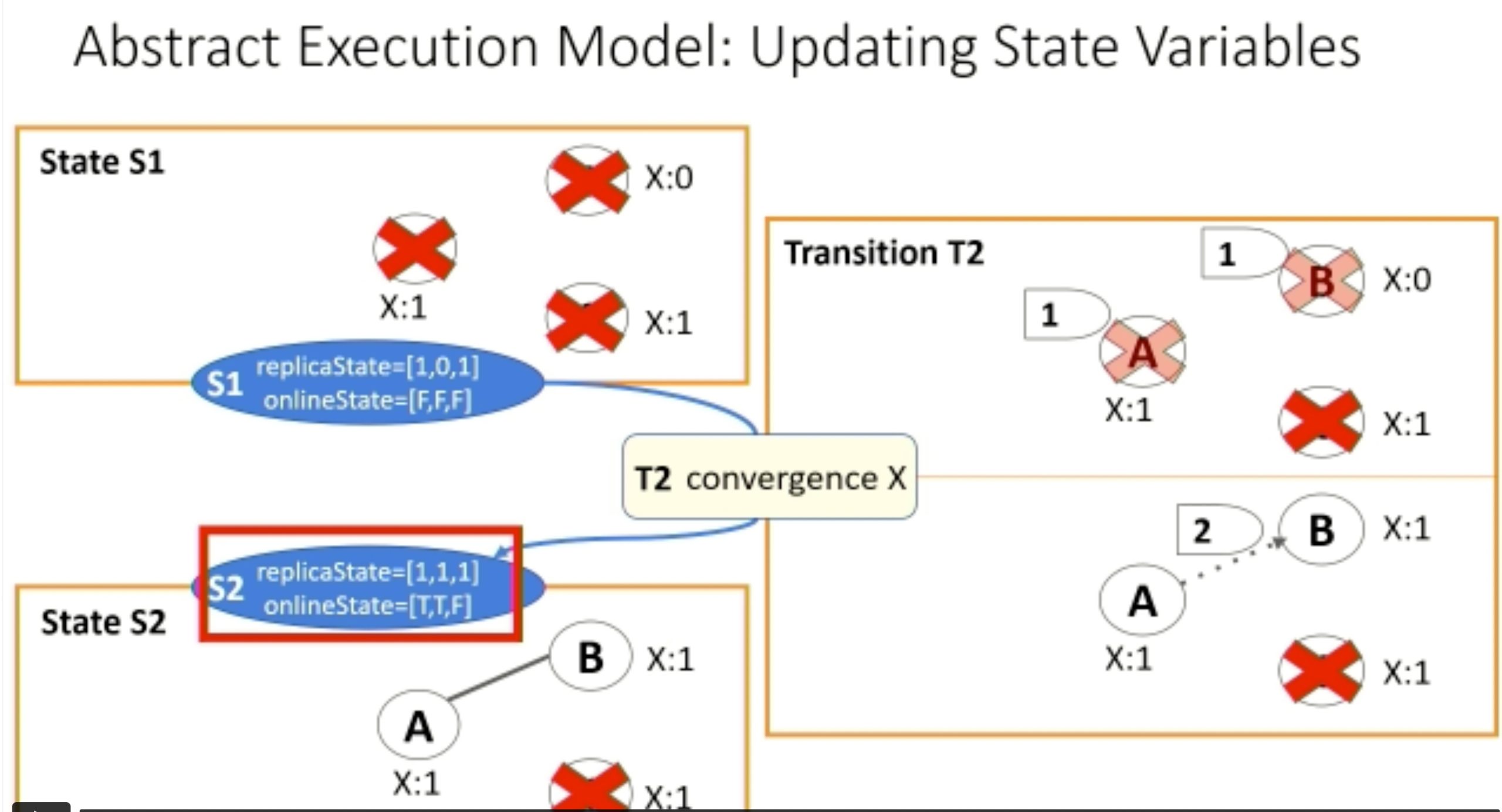
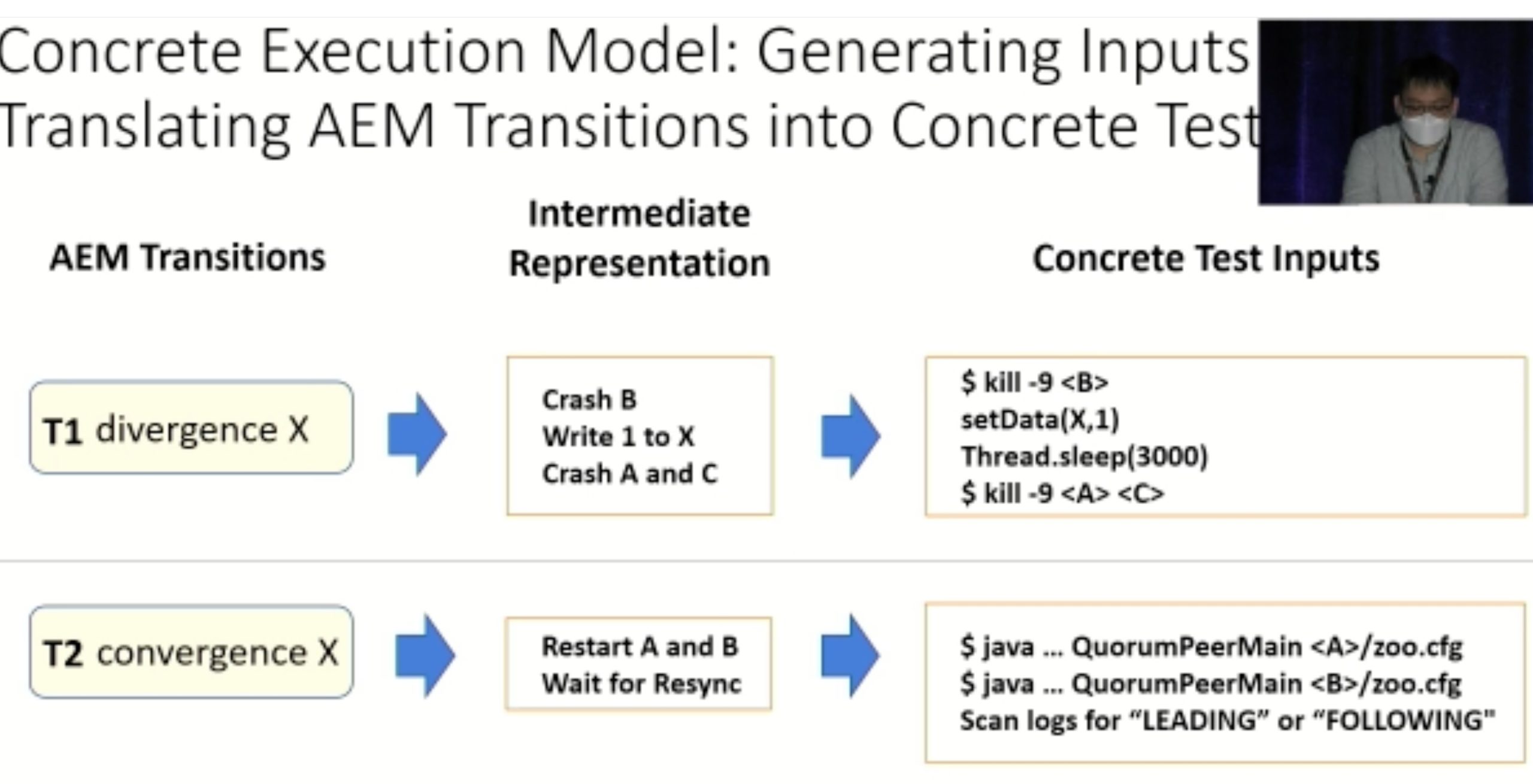
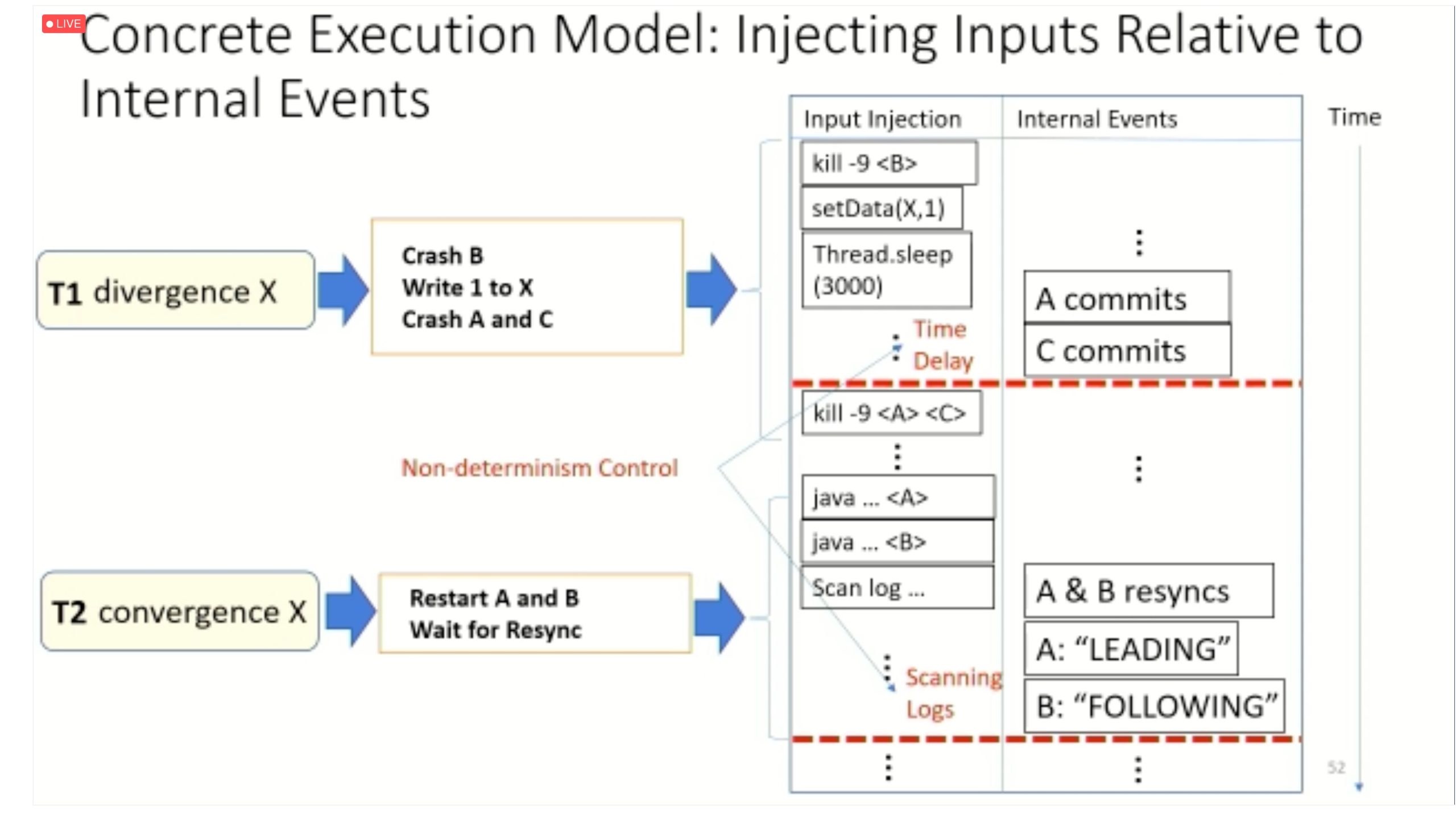
Modulo: Finding Convergence Failure Bugs in Distributed Systems with Divergence Resync Models
也是用runtime state喂path condition给solver看bug。





Disaggregated Systems
Sibylla: To Retry or Not To Retry on Deep Learning Job Failure
对DL GPU任务的disaggregation。如果failure是基于log可预测的,可以直接kill,重启。也算ML for system。
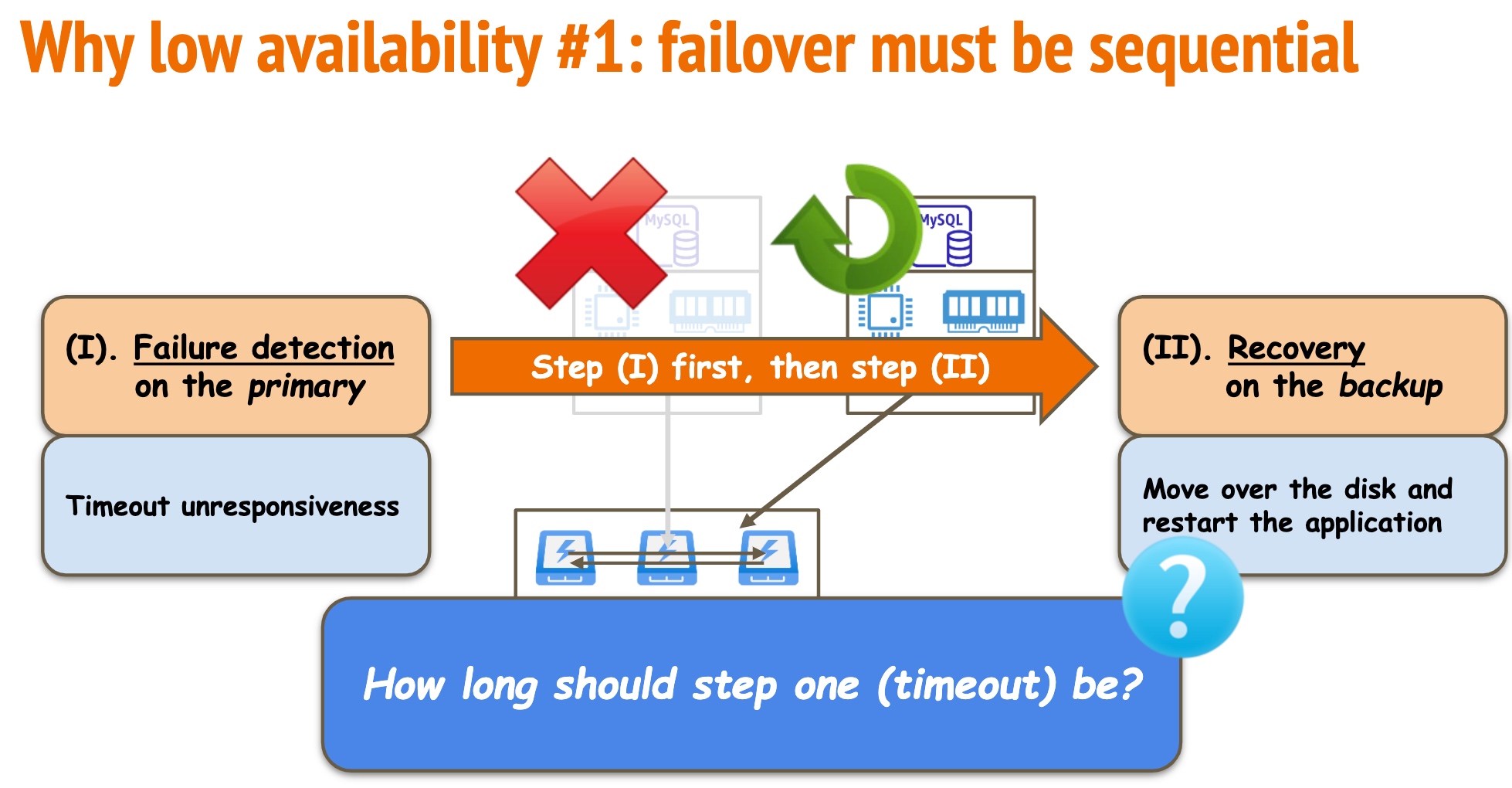
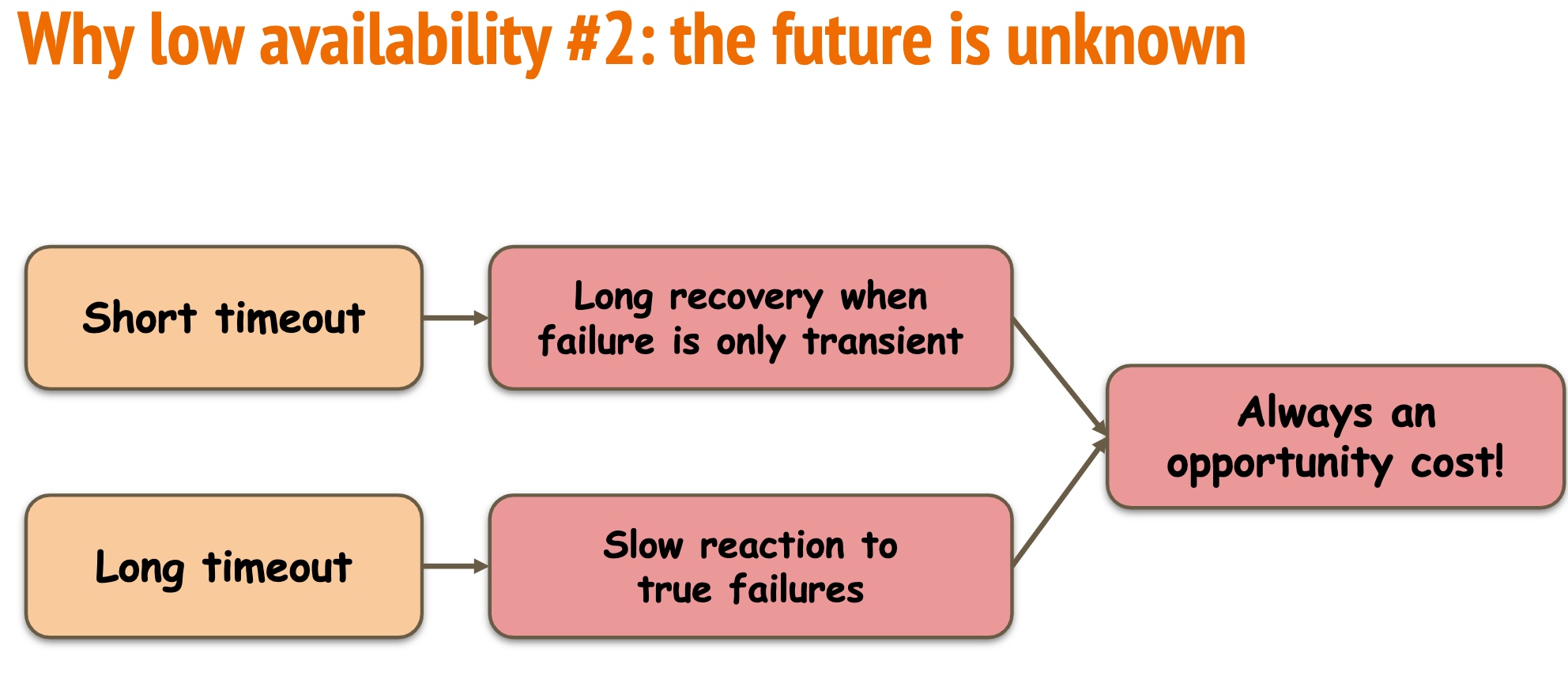
Speculative Recovery: Cheap, Highly Available Fault Tolerance with Disaggregated Storage
Direct Access, High-Performance Memory Disaggregation with DirectCXL
CXL.mem disaggregation focuses on direct access and high performance. 这篇是第一个做CXL.mem disaggregation。
- Prior work
- RDMA
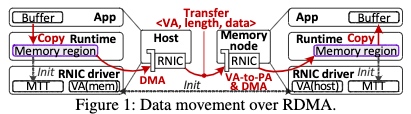 (one-sided communication w/o letting CPU aware)
(one-sided communication w/o letting CPU aware)
- require local pages sent to Memory translation Table with MR(Memory Region)
- Swap: Page-based Memory Pool: kernel
swapdlocally cached data in a finer granular manner - KVS (类似PRISM那种)Object-based Memory Pool: 基于对象的系统为主机和内存节点两方创建两个MR。各自处理缓冲数据和提交/完成的队列(SQ/CQ)。一般来说,它们采用一个KV哈希表其条目指向相应的(远程)内存对象。每当有来自一个应用程序的Put(或Get)请求时,系统就会将相应的值放到时,系统就会将相应的值放入主机的缓冲区MR中,并将该值放入缓冲区,并通过RDMA将其写入远程的MR,并通过RDMA写入远程的SQ MR。由于内存节点不断轮询SQ MR,它可以识别该请求。
- RDMA
- 通过CXL连接device&host memory弄成一个pool。
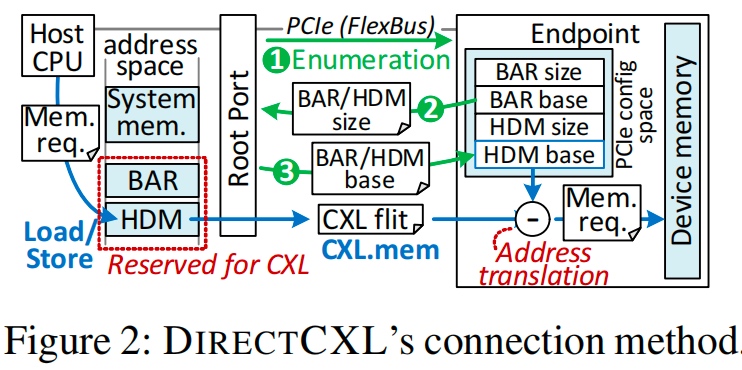
- CXL devices and controllers. CXL device 会有多个memory controller, send/recv 走PCIe Lane, device CXL controller会parse PCIe packets(PCIe flits),会做两件事
- Converts their information (address and length) to DRAM requests
- Serves them from the underlying DRAMs using the DRAM controller
- Integrating devices into system memory. for one-sided communication, root port and endpoint for more CXL devices.
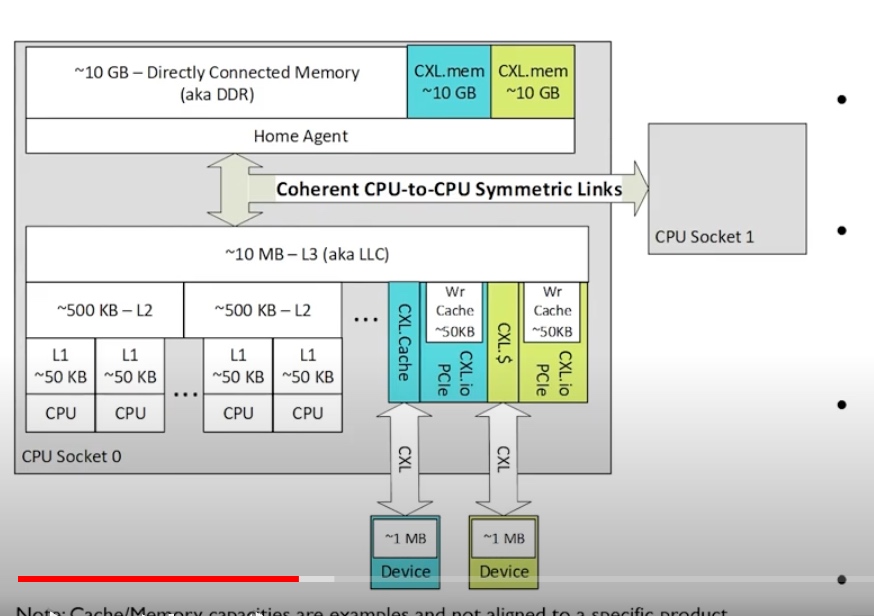 Our host-side kernel driver first enumerates CXL devices by querying the size of their base address register (BAR) and their internal memory, called host-managed device memory (HDM), through PCIe transactions. 如果CPU通过load/store指令调用HDM,request会像之前的PCIe一样先访问root complex,再翻译到CXL flits,由于mapped 地址空间不一样这,步只翻译HDM的基址到underlying DRAM。这步作者claim可以达到高性能。
Our host-side kernel driver first enumerates CXL devices by querying the size of their base address register (BAR) and their internal memory, called host-managed device memory (HDM), through PCIe transactions. 如果CPU通过load/store指令调用HDM,request会像之前的PCIe一样先访问root complex,再翻译到CXL flits,由于mapped 地址空间不一样这,步只翻译HDM的基址到underlying DRAM。这步作者claim可以达到高性能。 - CXL network switch
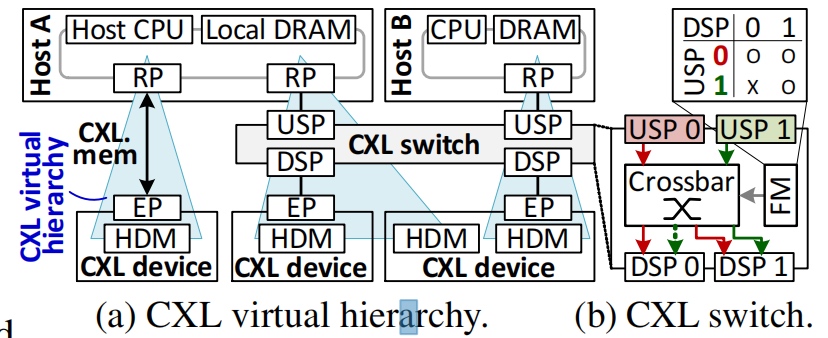
- Software runtime direct memory access to
/dev/directcxlwhich is a minimized version of PMDK(filesys for crash consistencyor DAX for 64B atomicity)
- CXL devices and controllers. CXL device 会有多个memory controller, send/recv 走PCIe Lane, device CXL controller会parse PCIe packets(PCIe flits),会做两件事
- Design 插了4个pcie,2个device(end point controller+dram host/controller都是RISC-V ISA) 1个switch with cxl flit,协议 CXL2.0 ACPI信息会集成到device tree给linux和驱动。驱动包含MMIO和cxl-reserved-area(HDM)。比较的是RDMA的memory pooling,即一个daemon接管RNIC所设计的 pre-allocated pool,类似KVS(PRISM那种)。
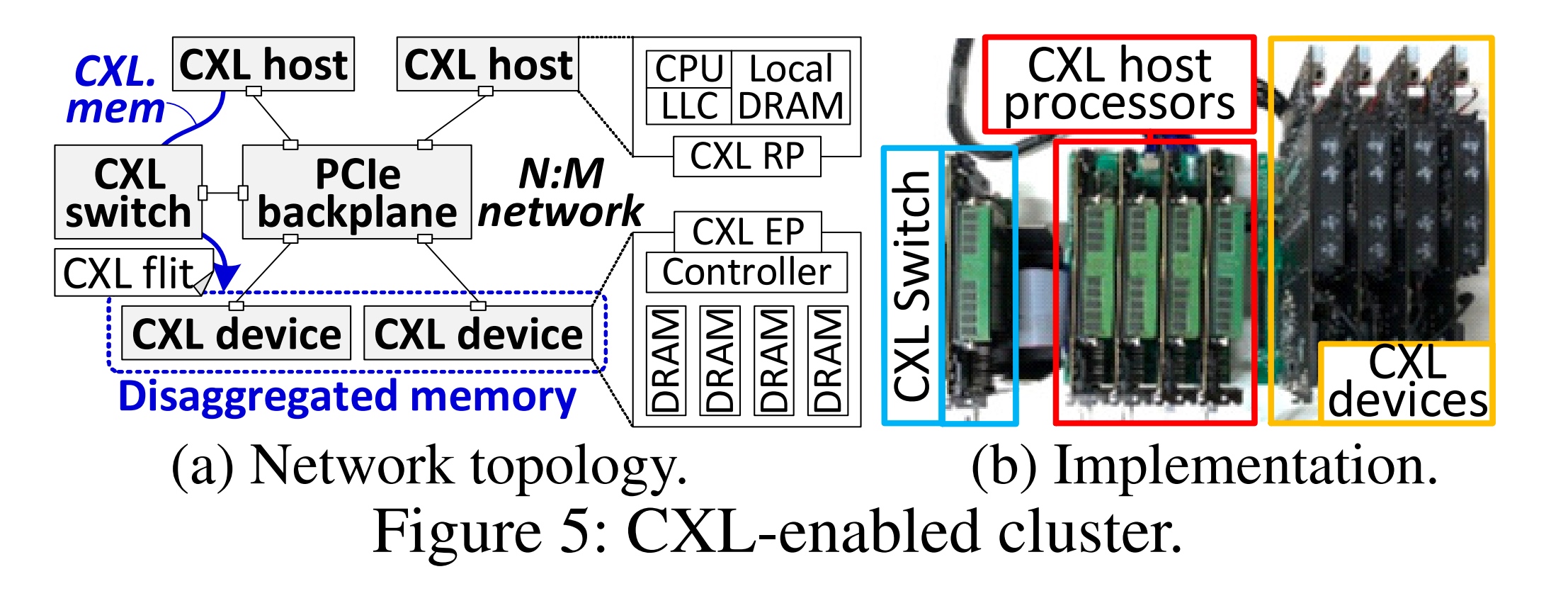
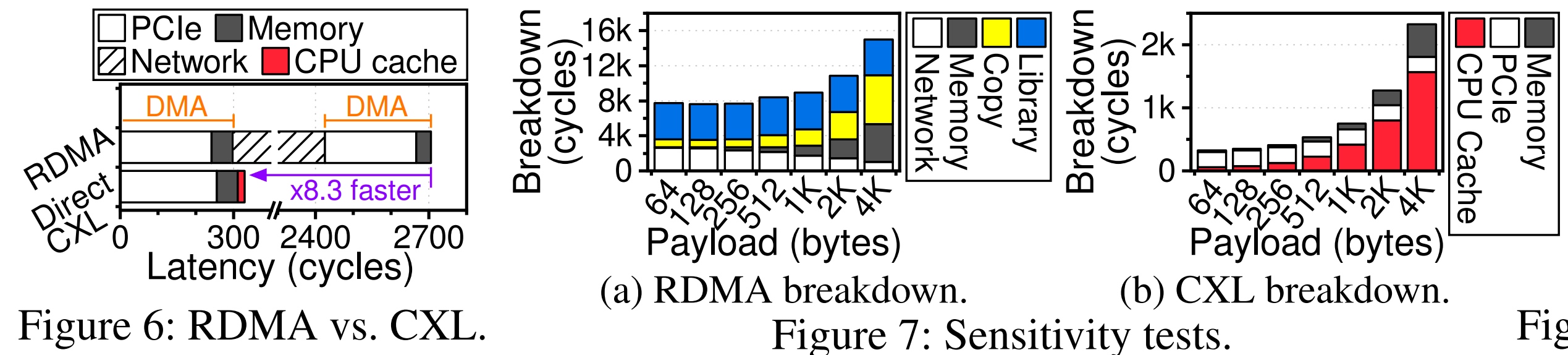
cxl是对local设备的访问,而不是经过连接CXL的NIC,感觉测试很不公平,DMA(两边PCIe+Memory Reg+网络)就要两倍CXL的时间。论文claim说这个CXL的设备在外面,可以被多个CXL swtich 访问。
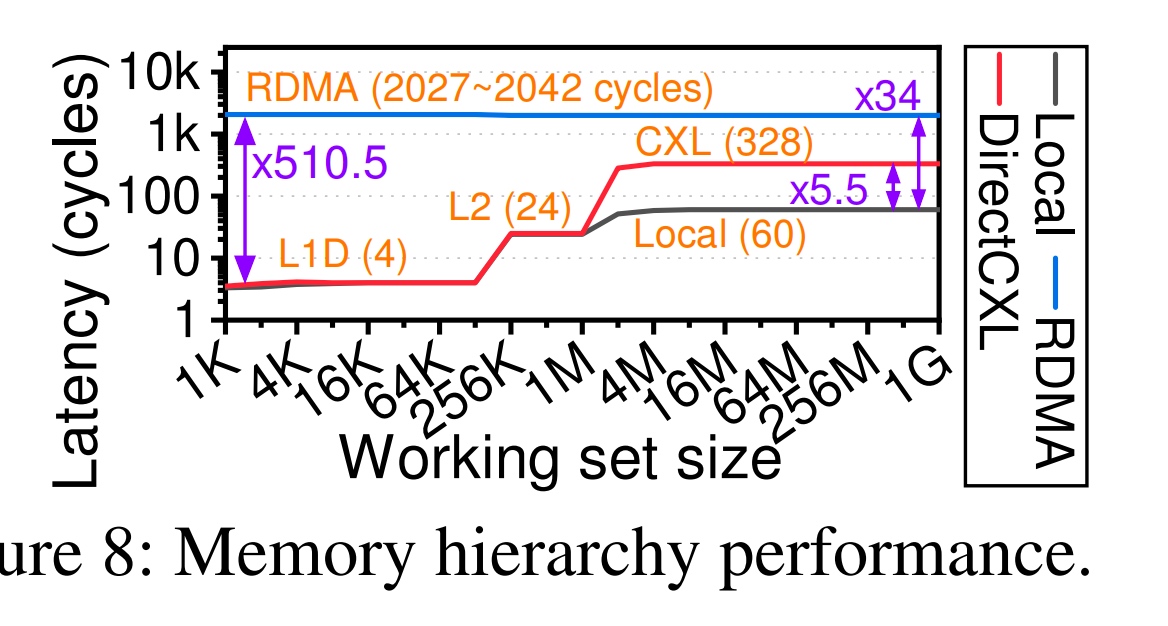
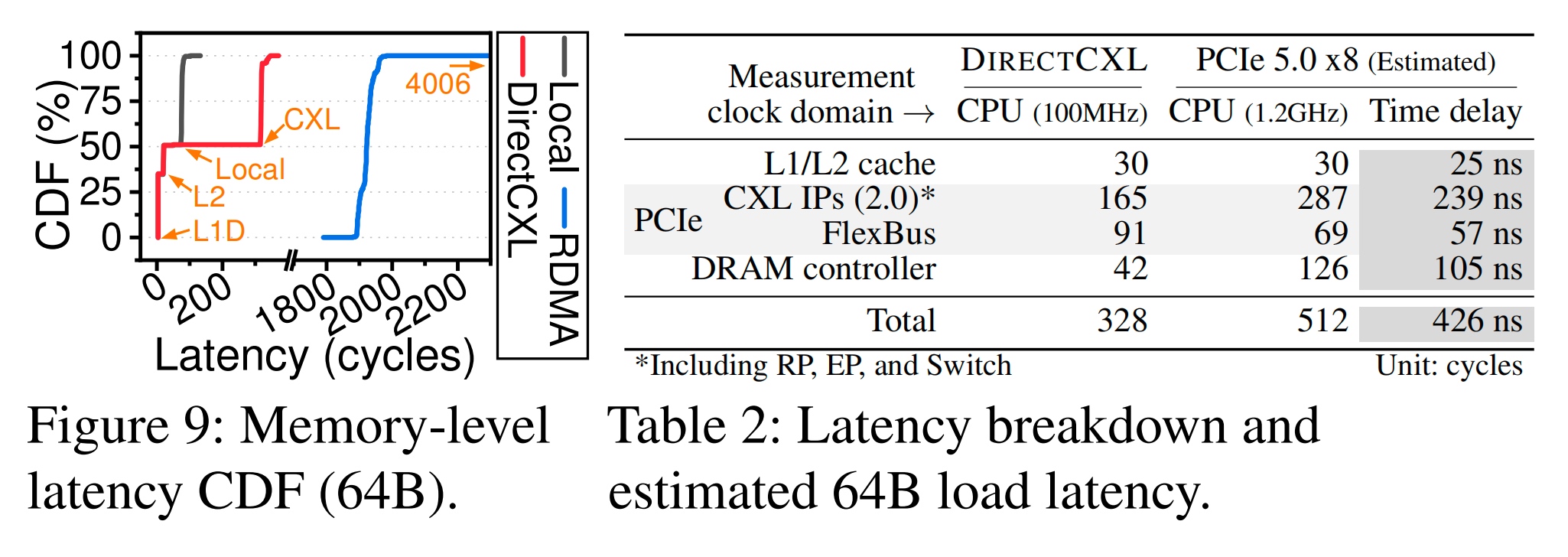
这边CXL的load latency CDF可以看到基本是两倍的时延。这边标出CPU的不同是为了测跨时序分析。
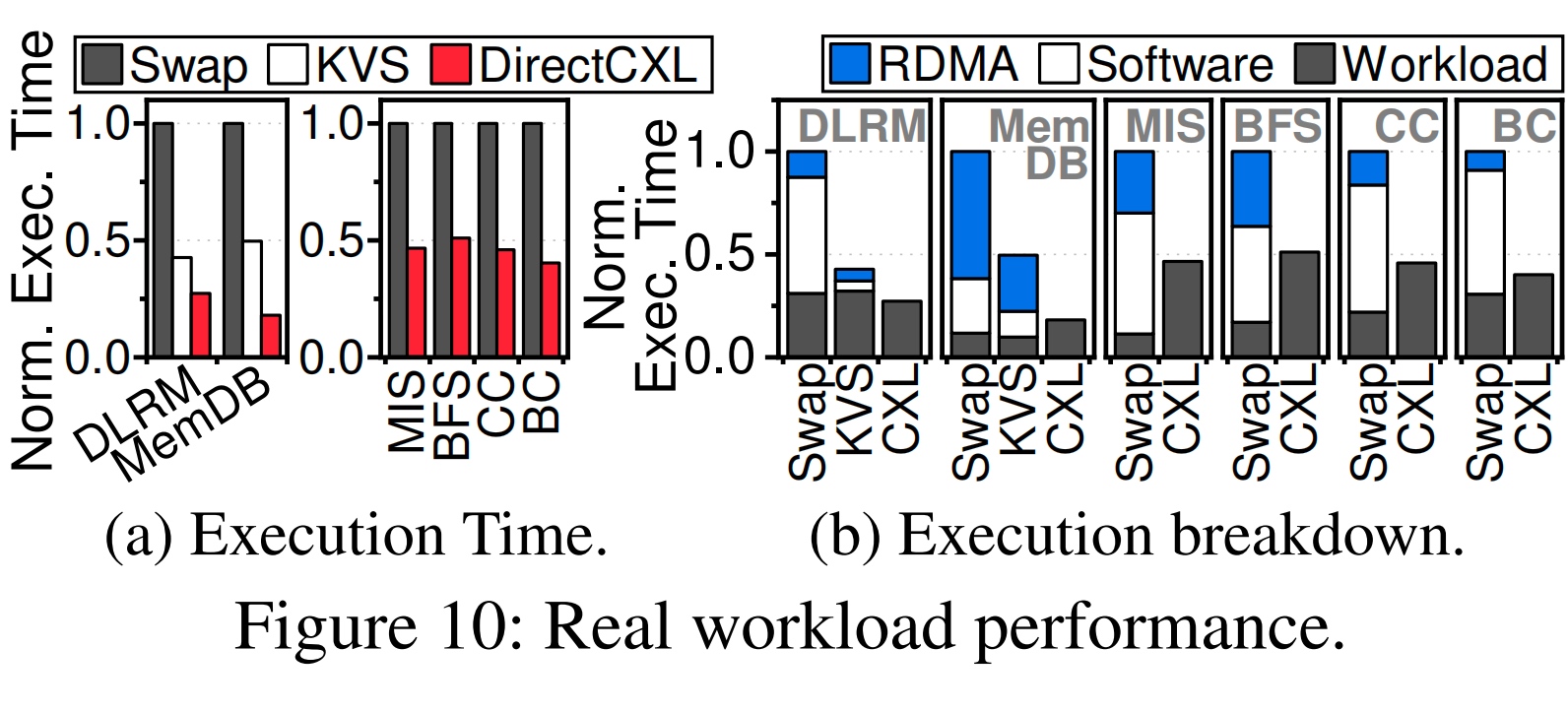
这边测了KVS和DirectCXL的差别,我觉得差距基本可以忽略,毕竟你这是对面没有负载的情况,NIC还是会灵活很多。这边就是bandwidth optimized优化。
总之这个prototype比较简易,只有memory pooling disaggregation,似乎也不支持scale到32个node。感觉能在intel机器上实现模拟器会很好,linux里面已经支持了,文章其实更好加一下现有设备的支持(不过韩国人可能拿不到intel预研)。
Security
SoftTRR


page table 1 上加了个tracer看memory access。benchmark用deviation1和6的测试来看rowhammer的robustness。
Investigating Managed Language Runtime Performance

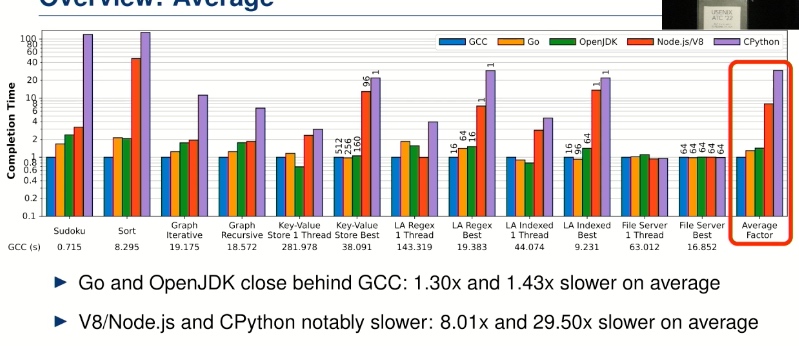


感觉GCC malloc不应该这么慢,有gc的语言应该还要慢一点。不过这种比较也算fair comparison。
NVM
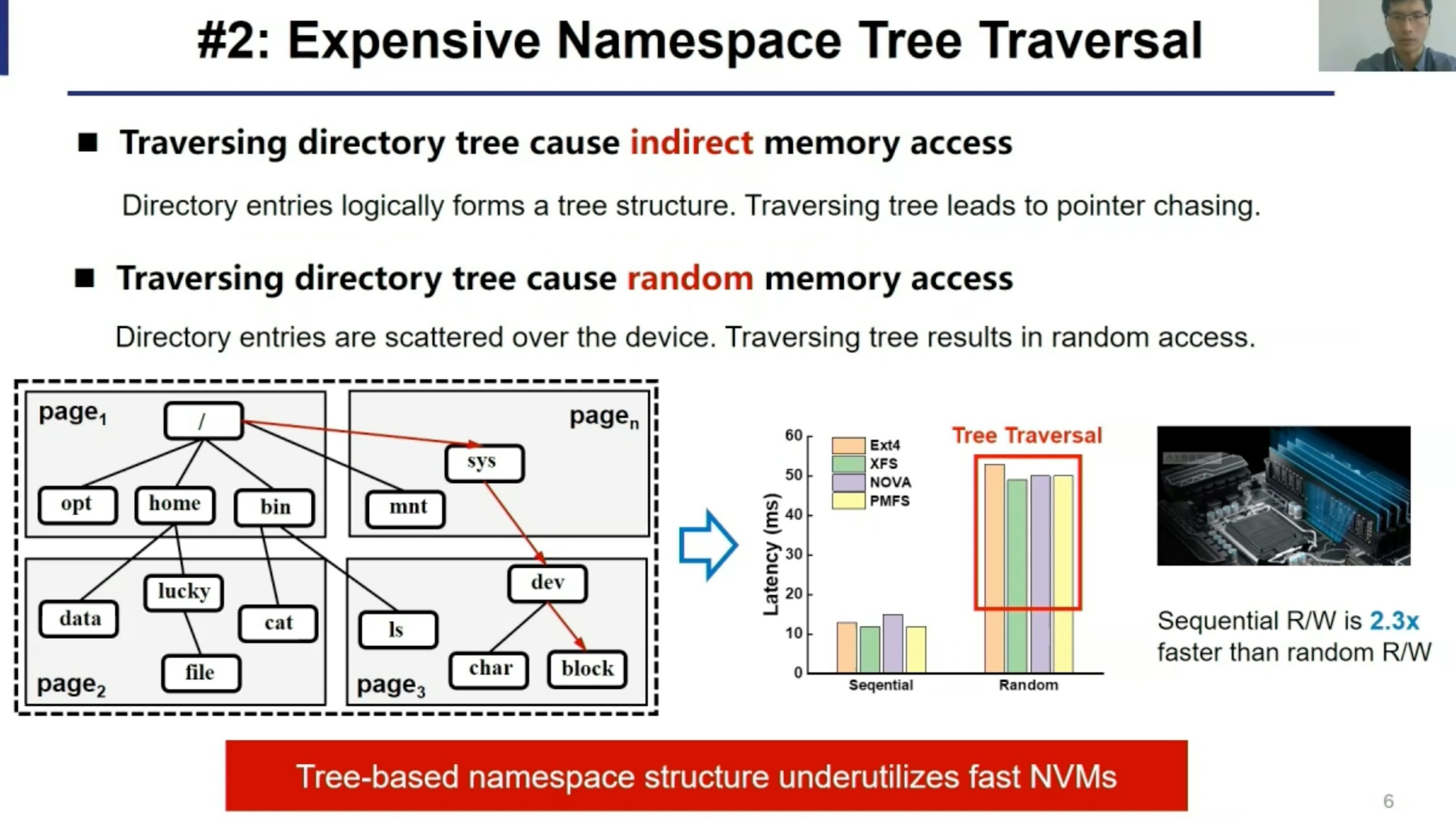
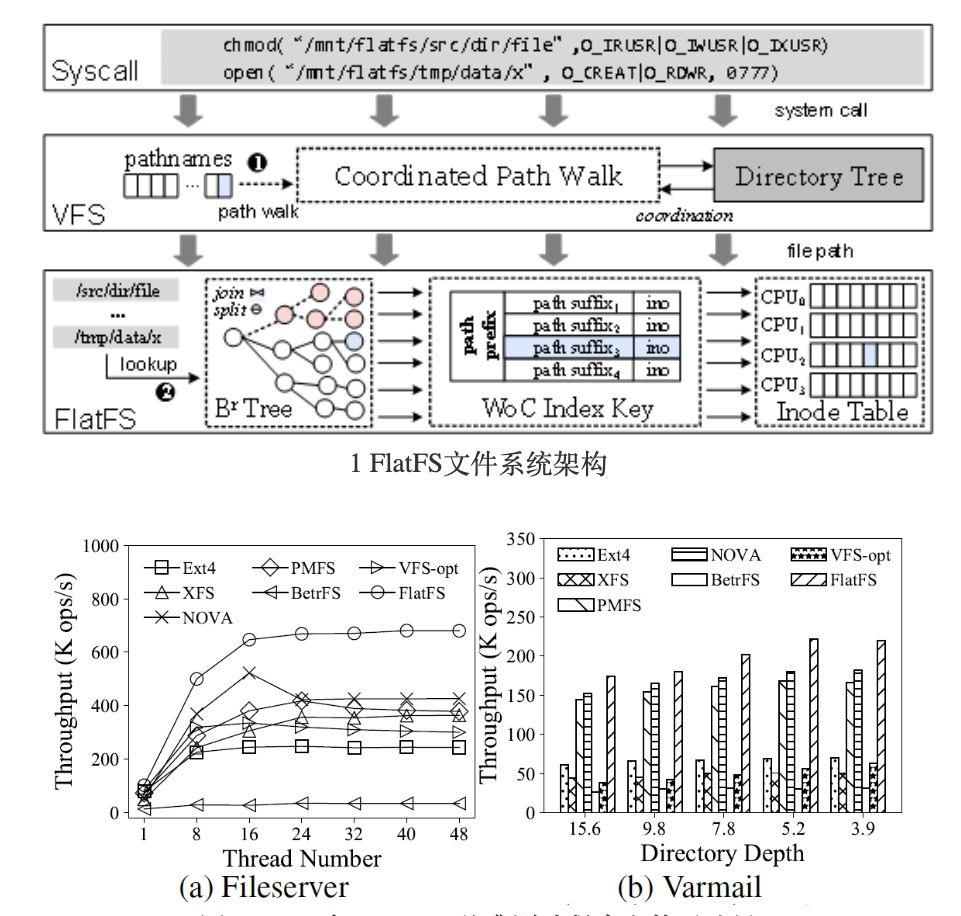
FlatFS
扁平化的命名空间架构。
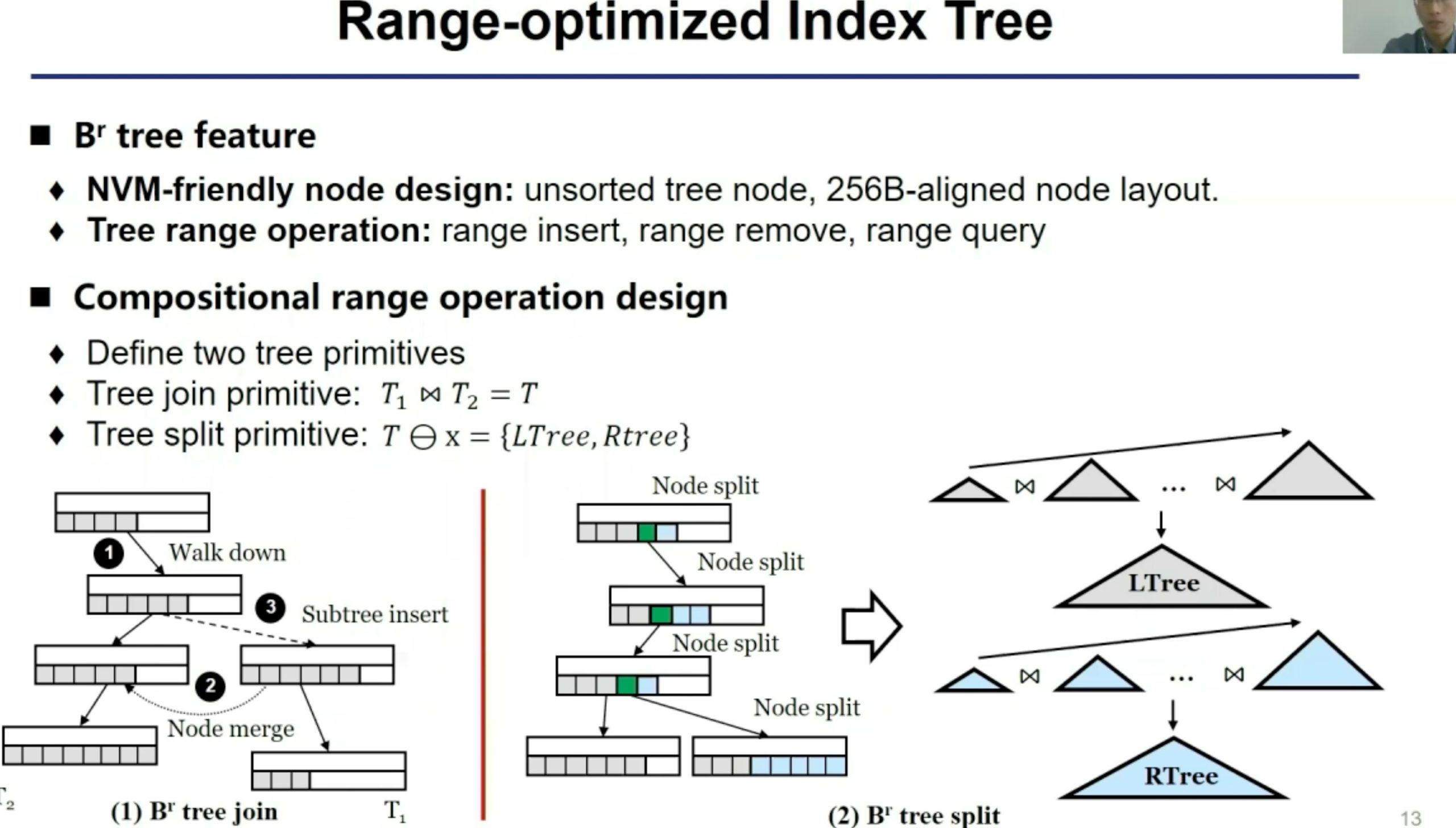
为range query 优化的index tree
Write compressed key
这篇感觉优化的点就在path walk
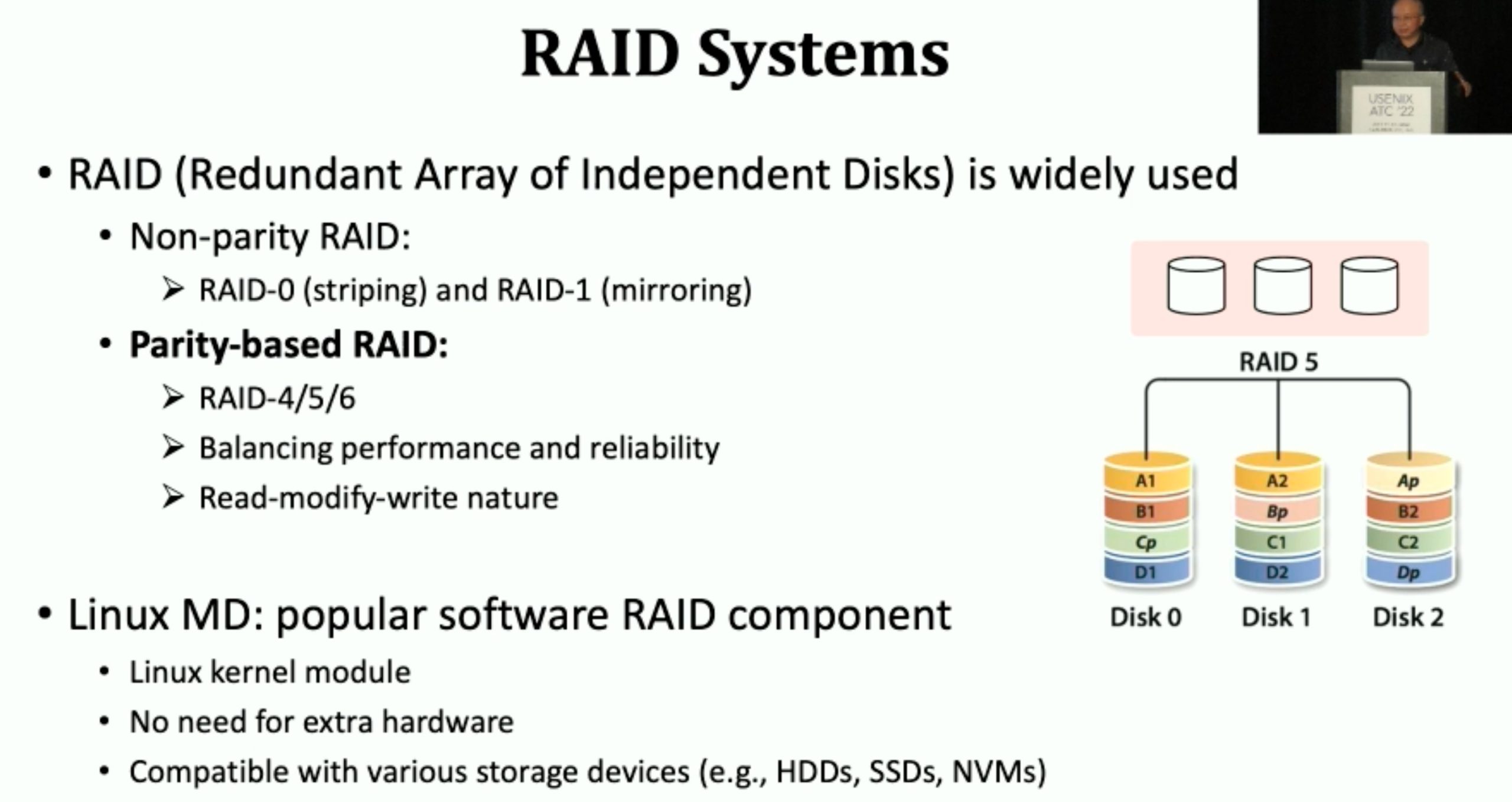
StRAID

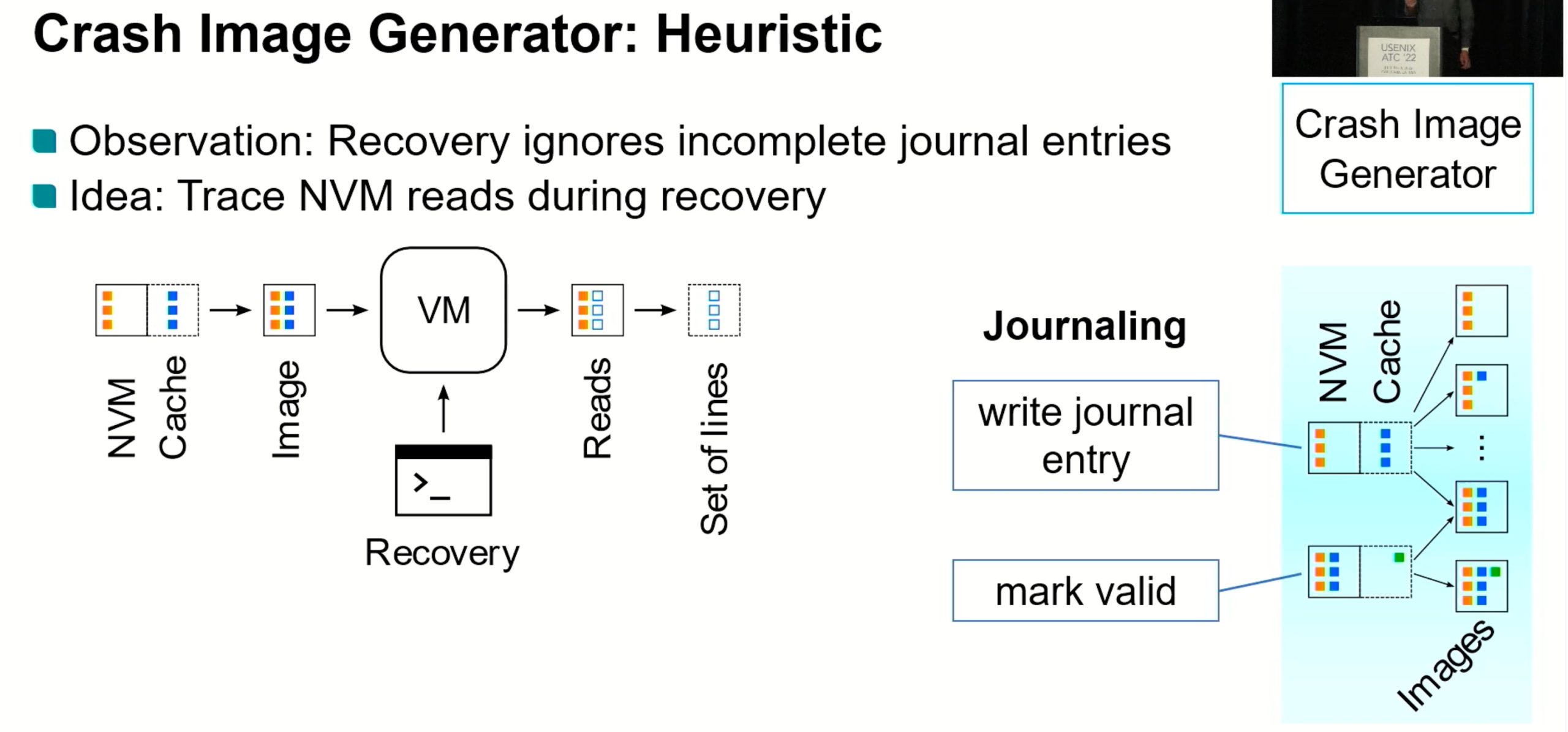
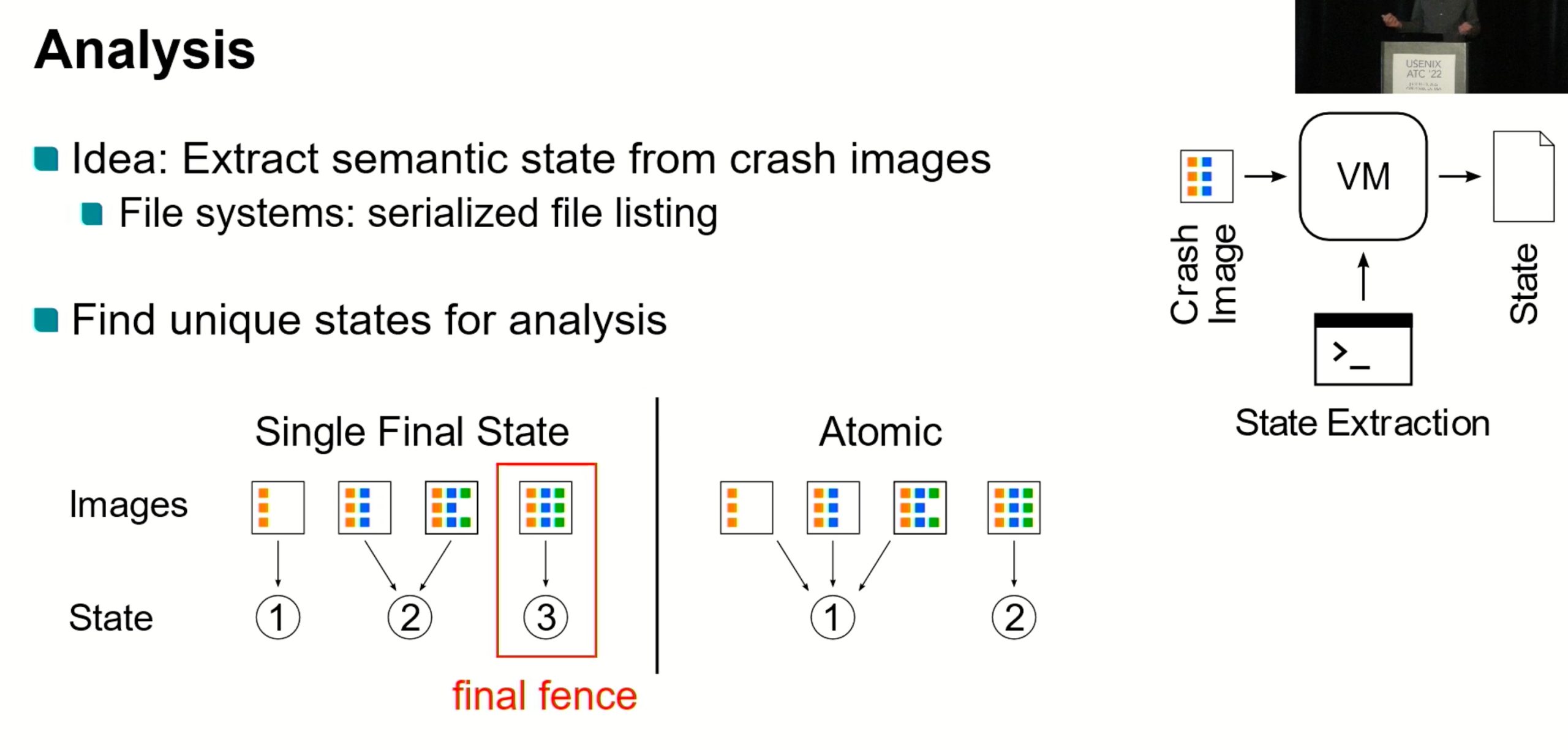
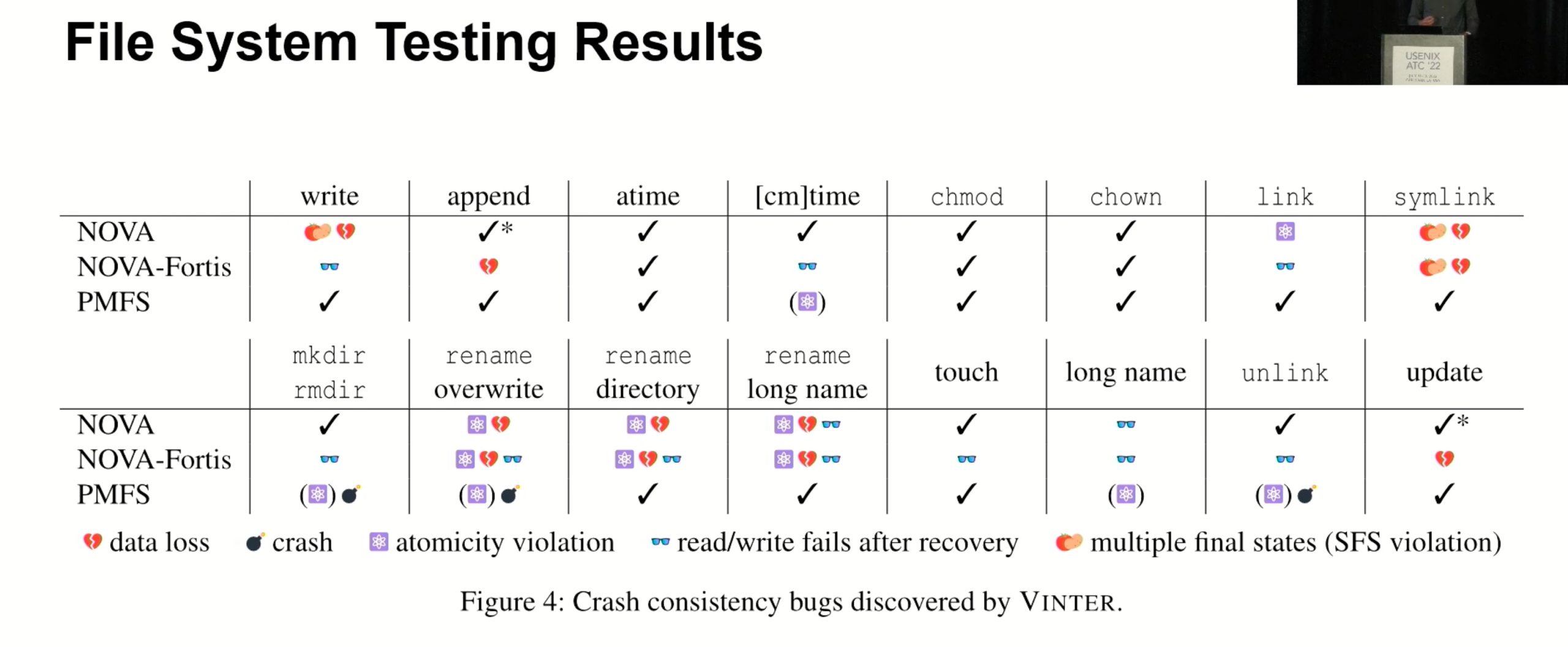
Vinter

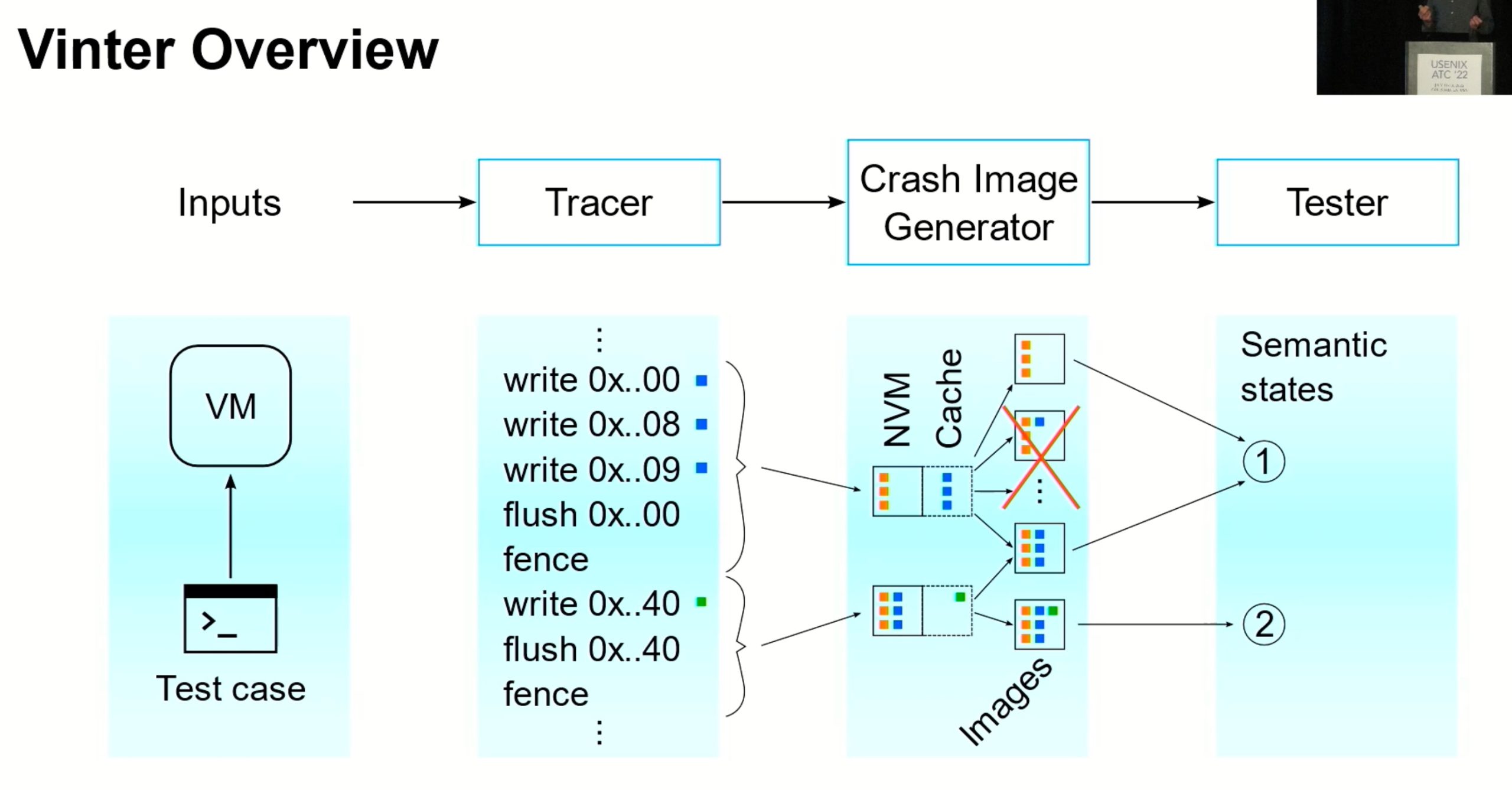
又是一个dynamic tracer,static tester。




TestCase Auto Generation? No
Only Journal Layer? No
How to capture the Crash State?
AlNiCo: SmartNIC-accelerated Contention-aware Request Scheduling for Transaction Processing
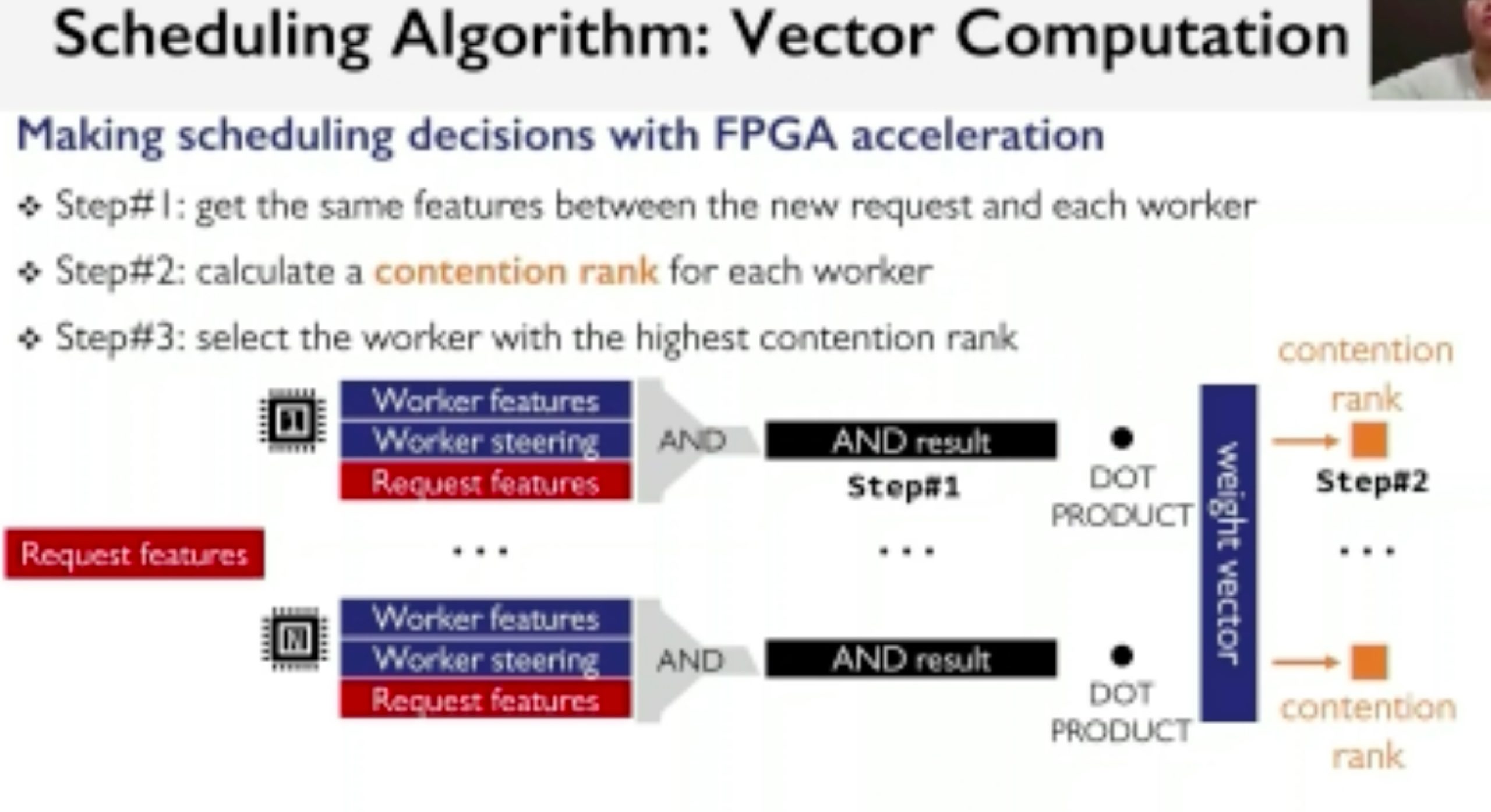
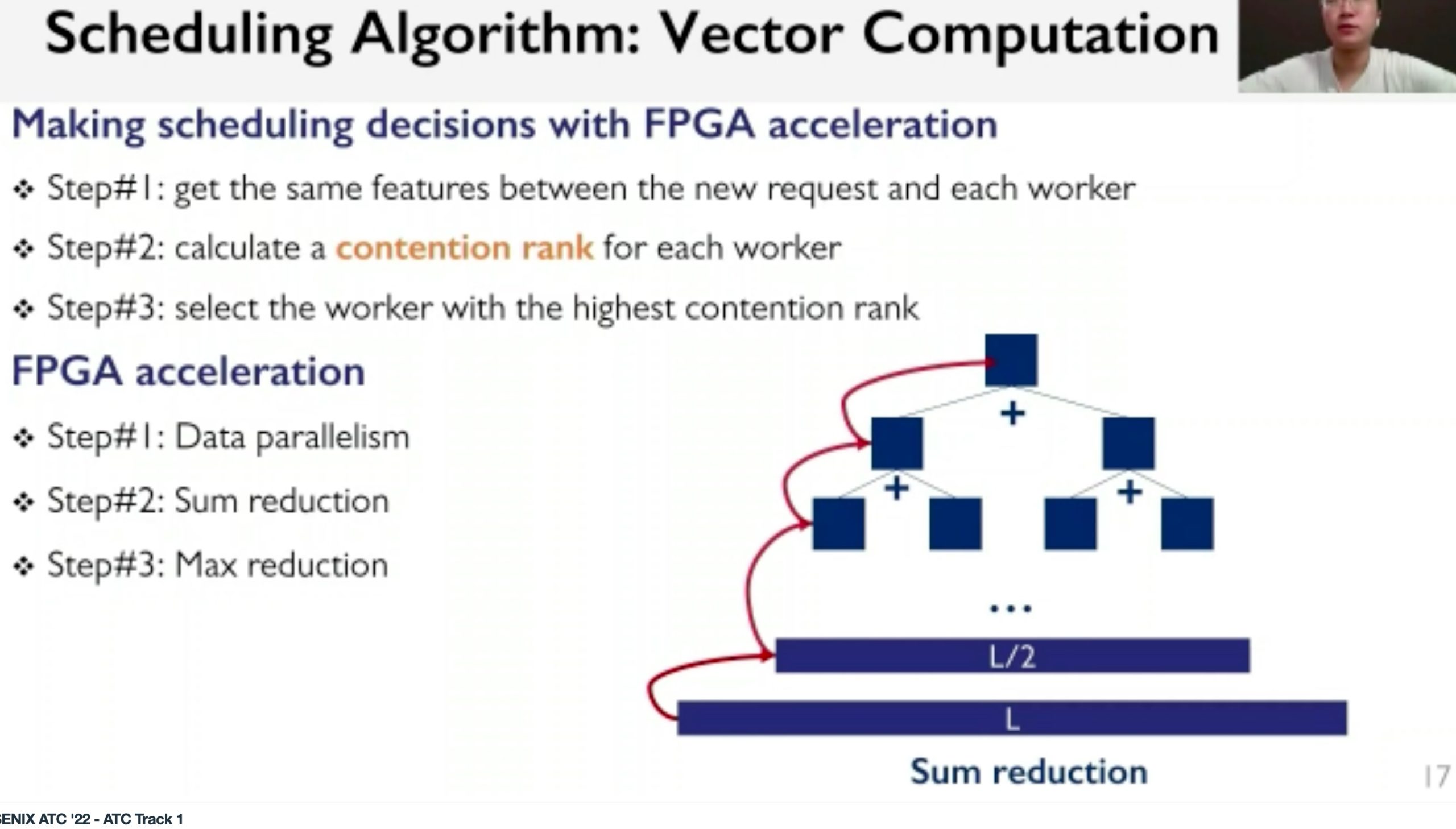

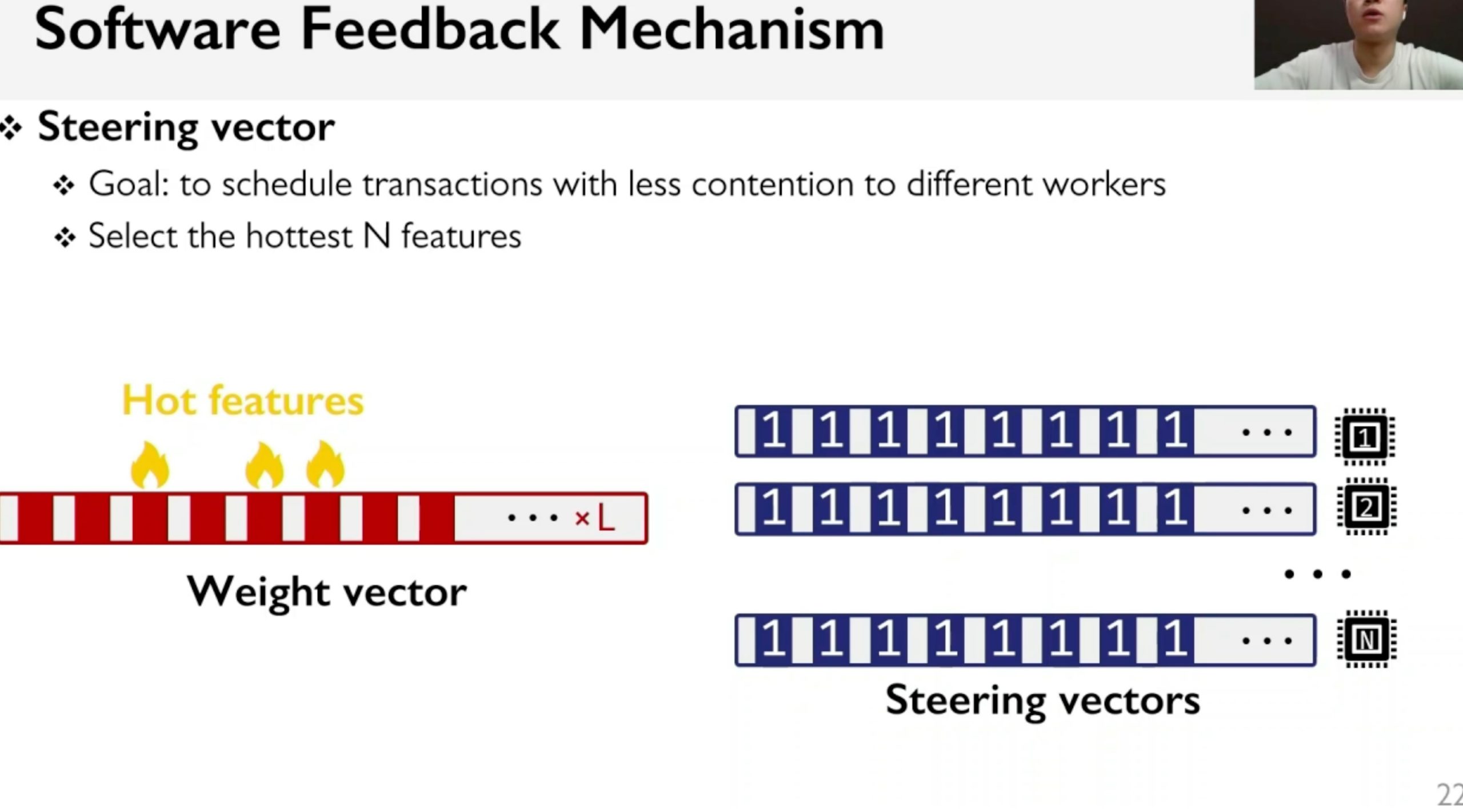
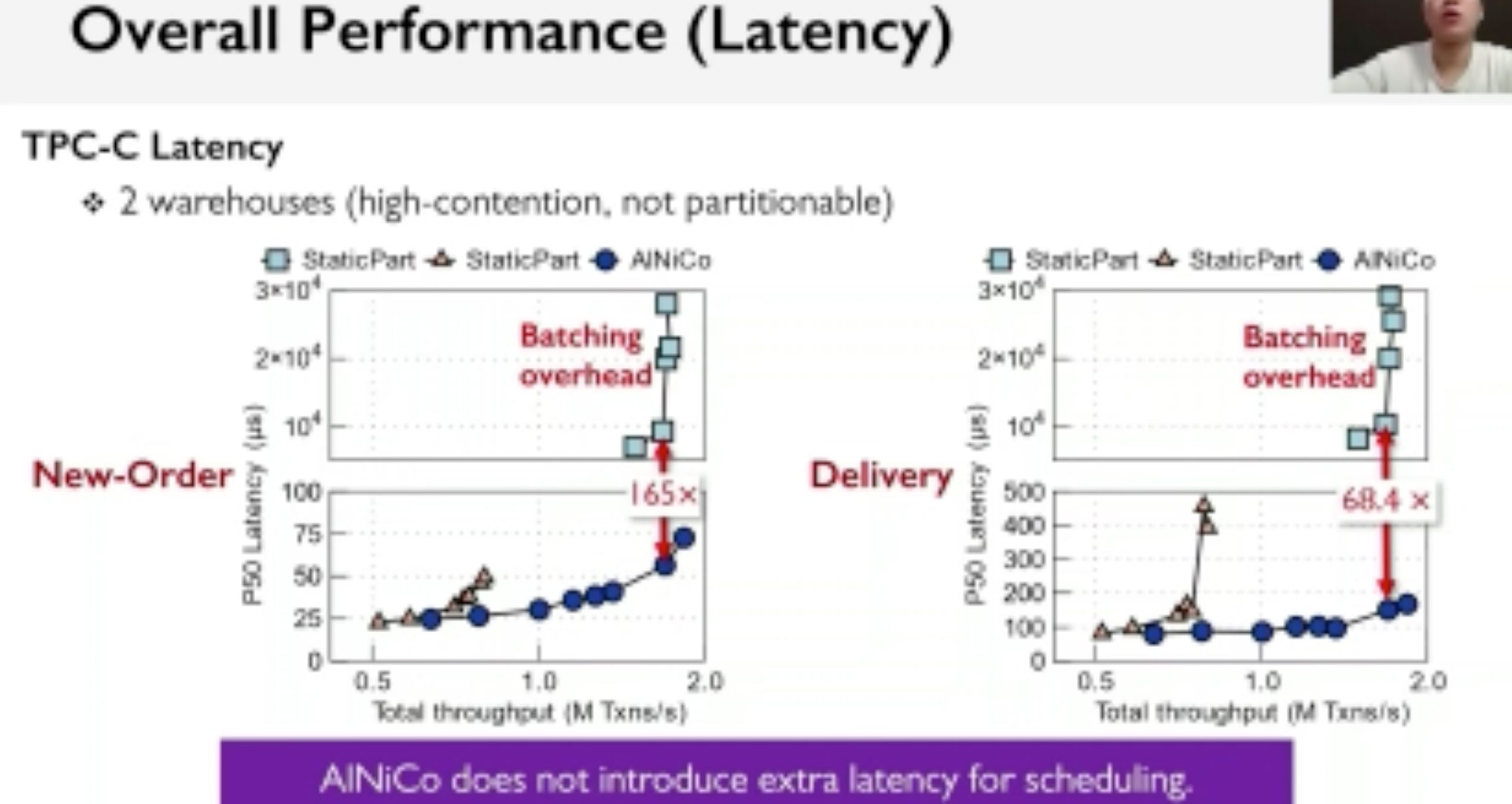
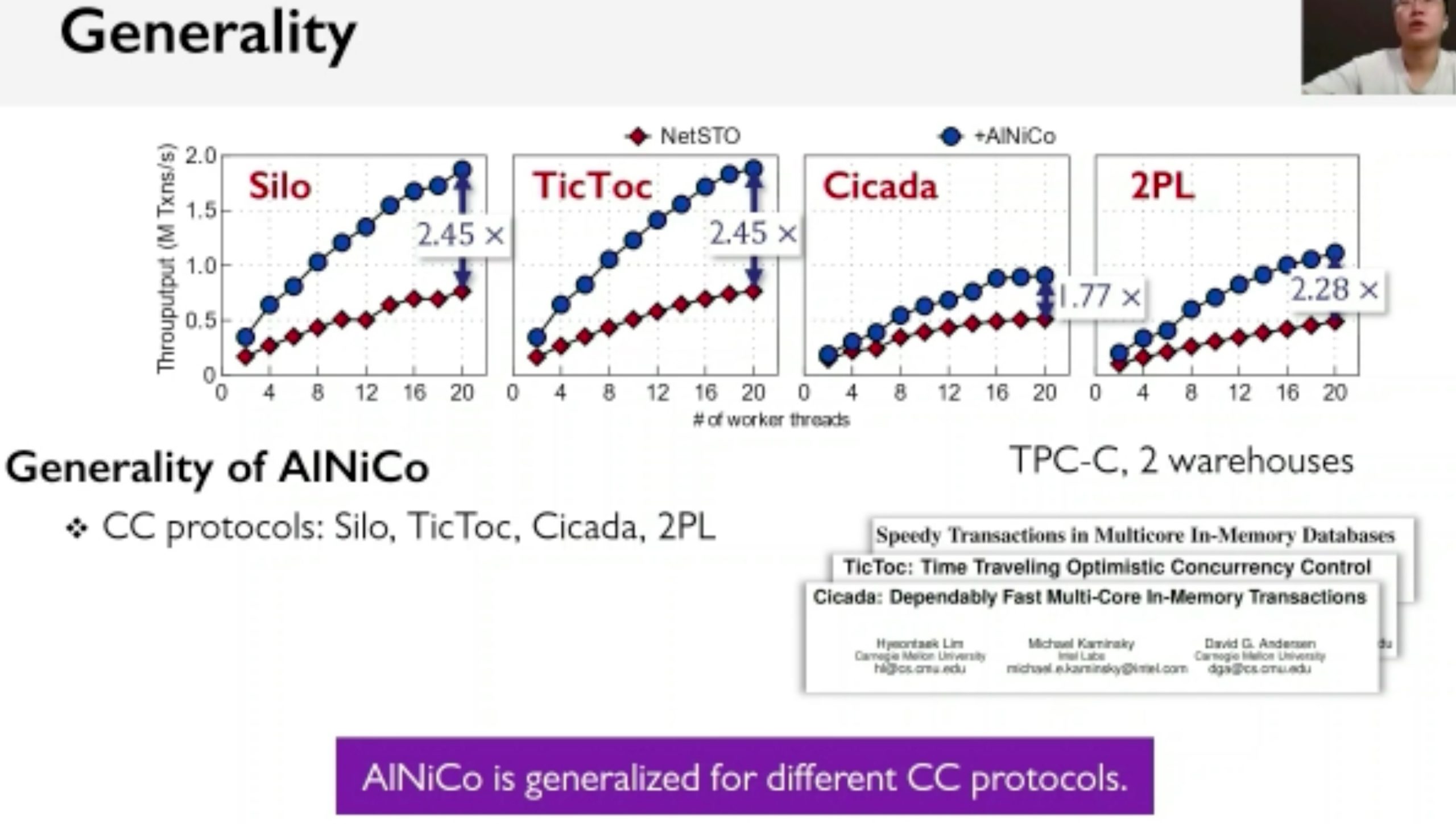
Overhead is not introduced by the SmartNIC
FPGA NIC

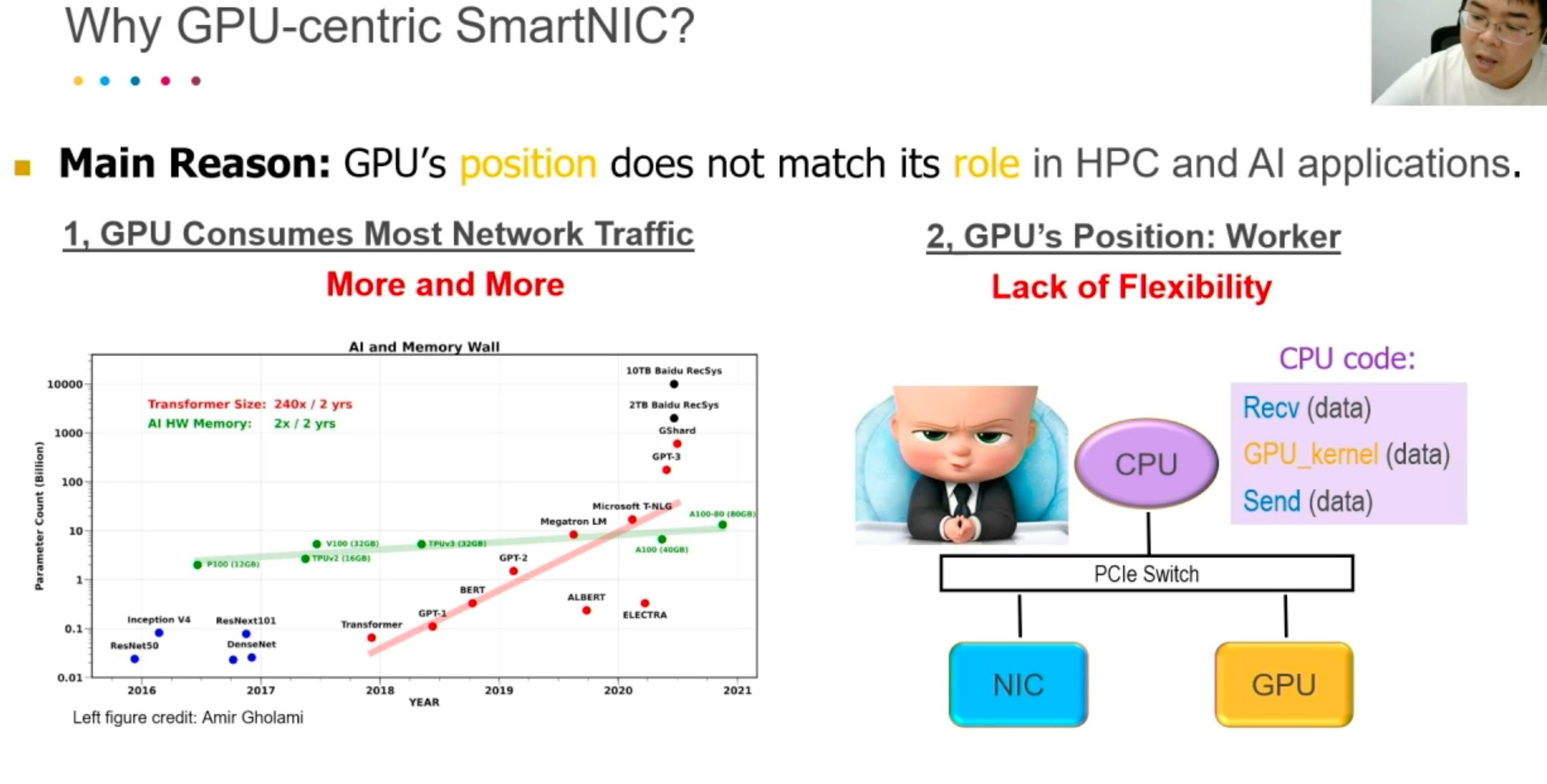

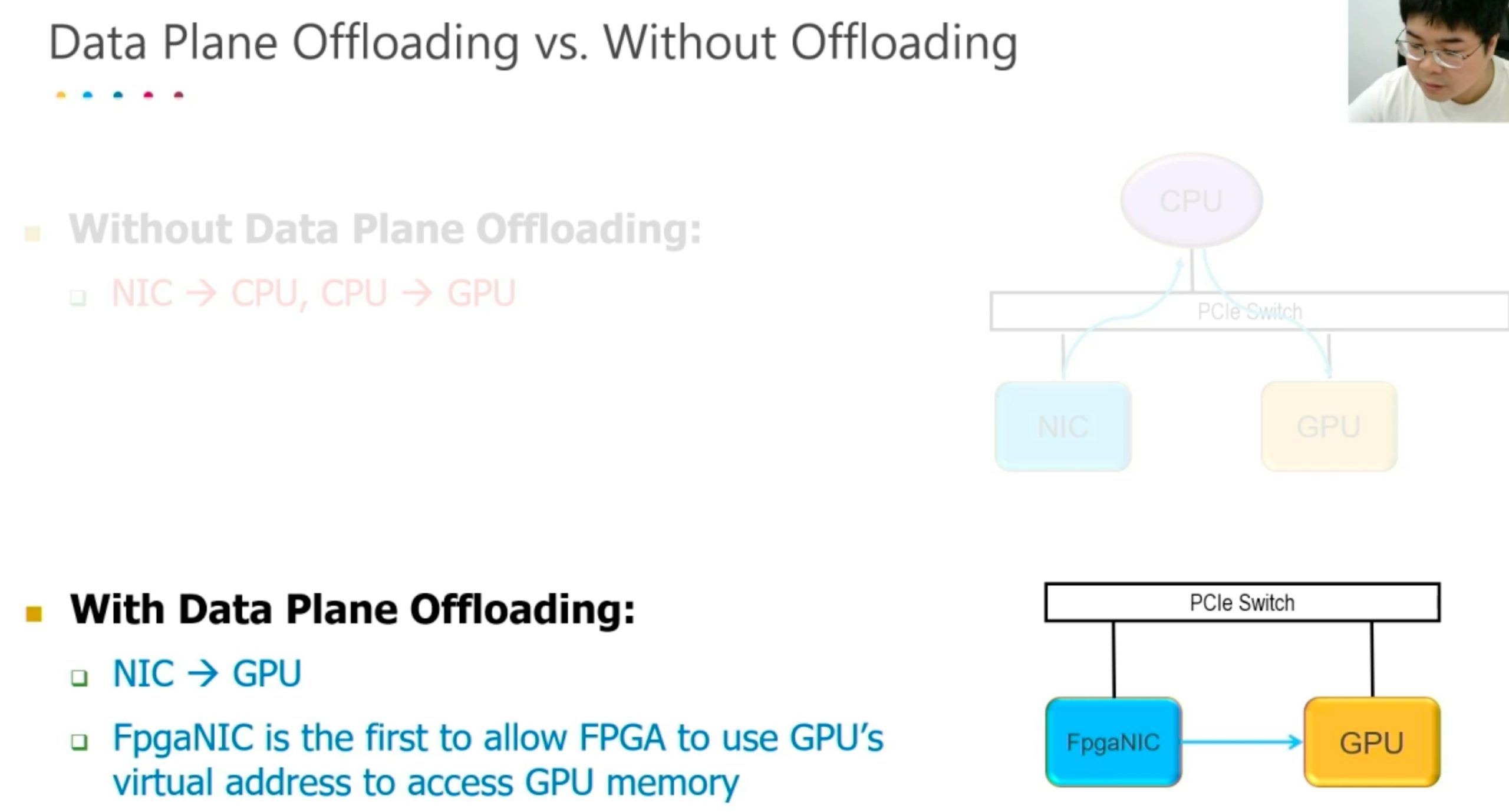
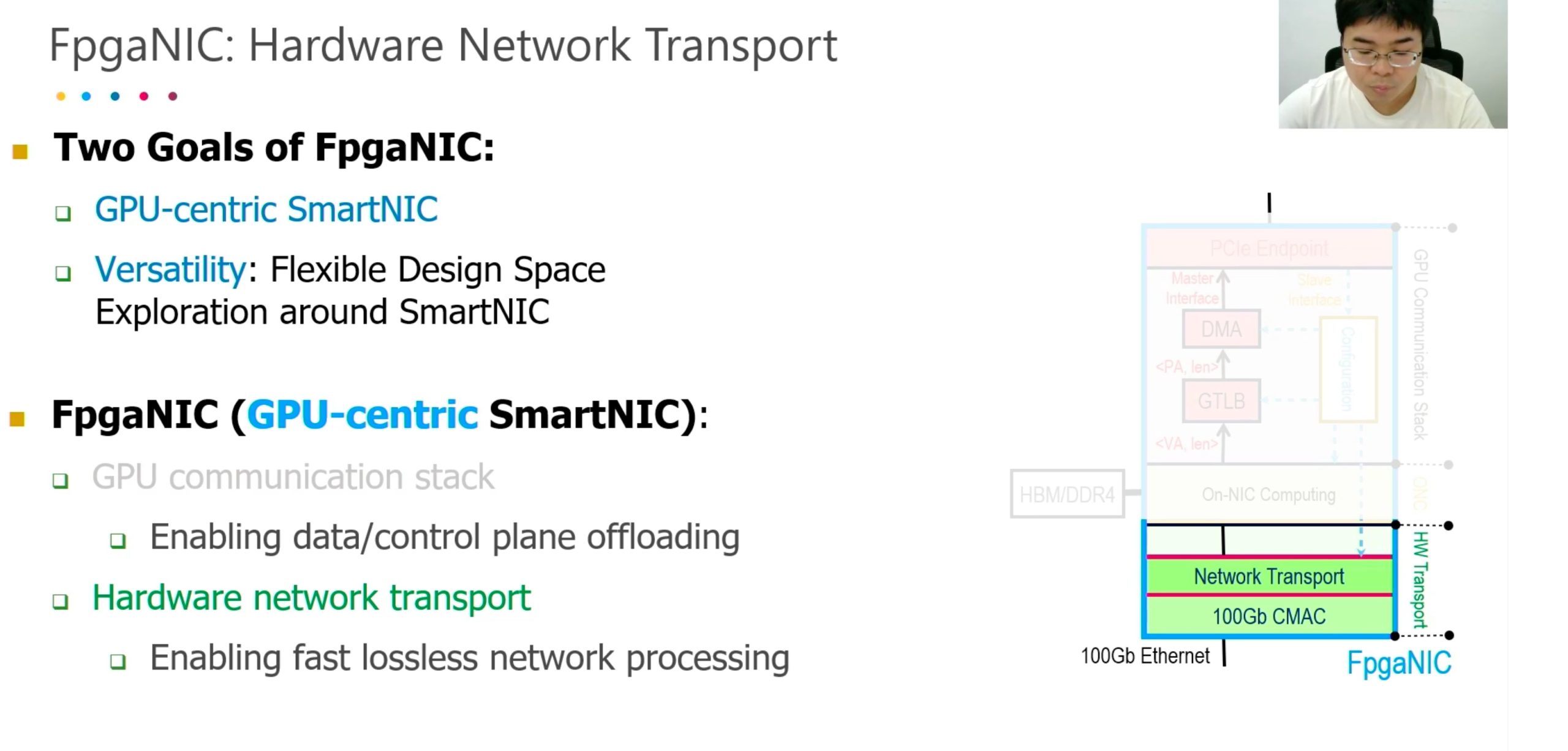
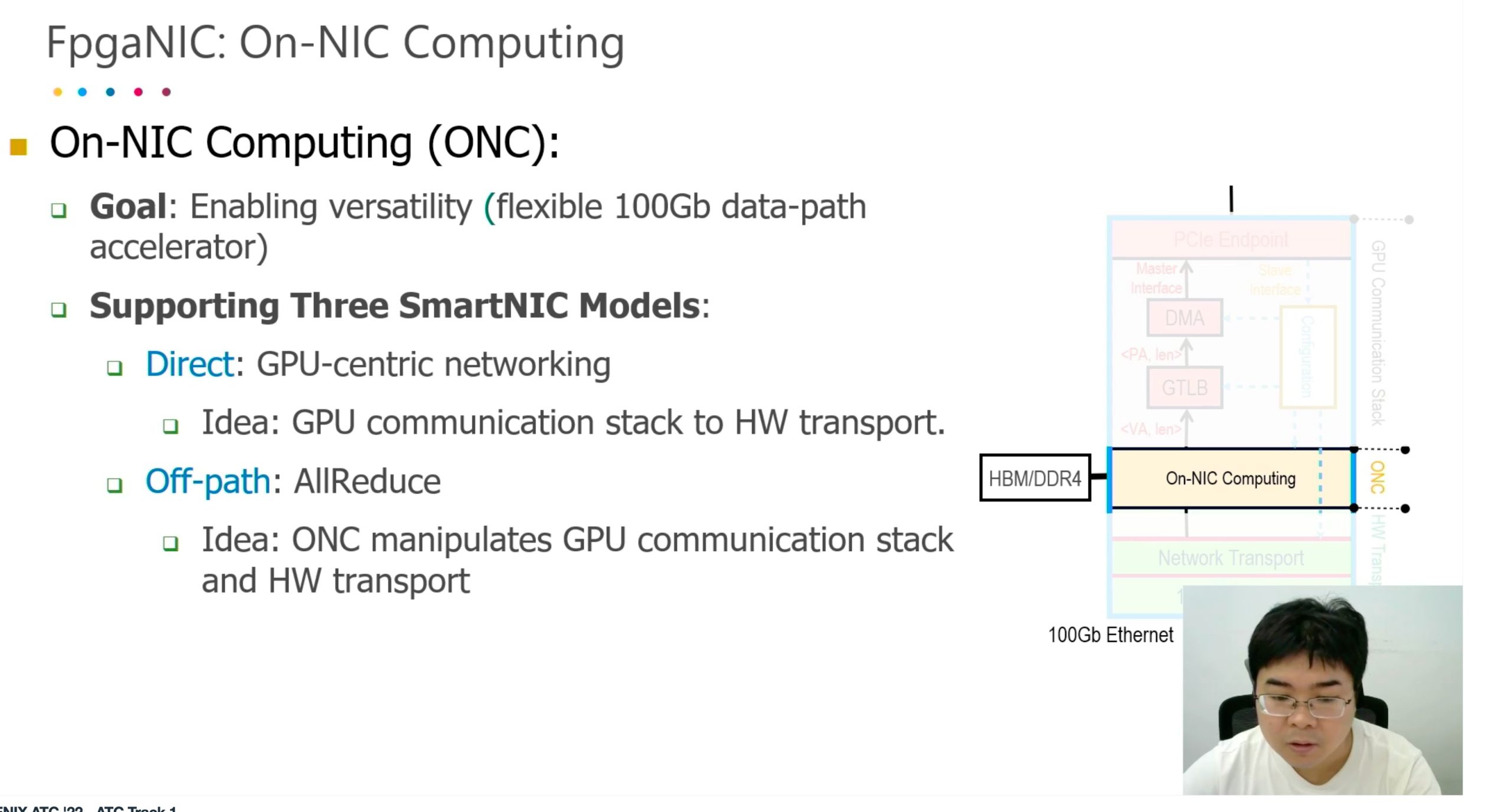
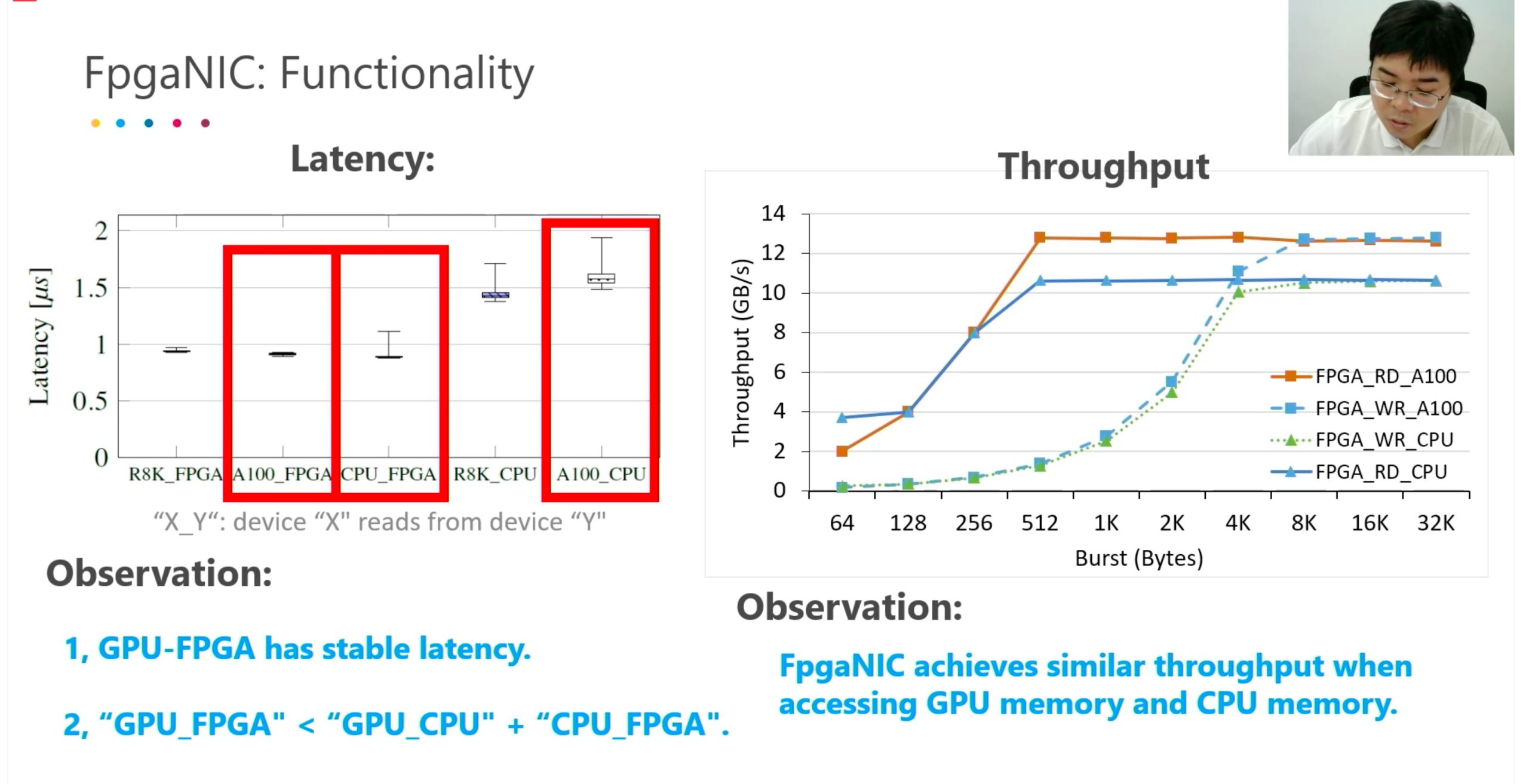
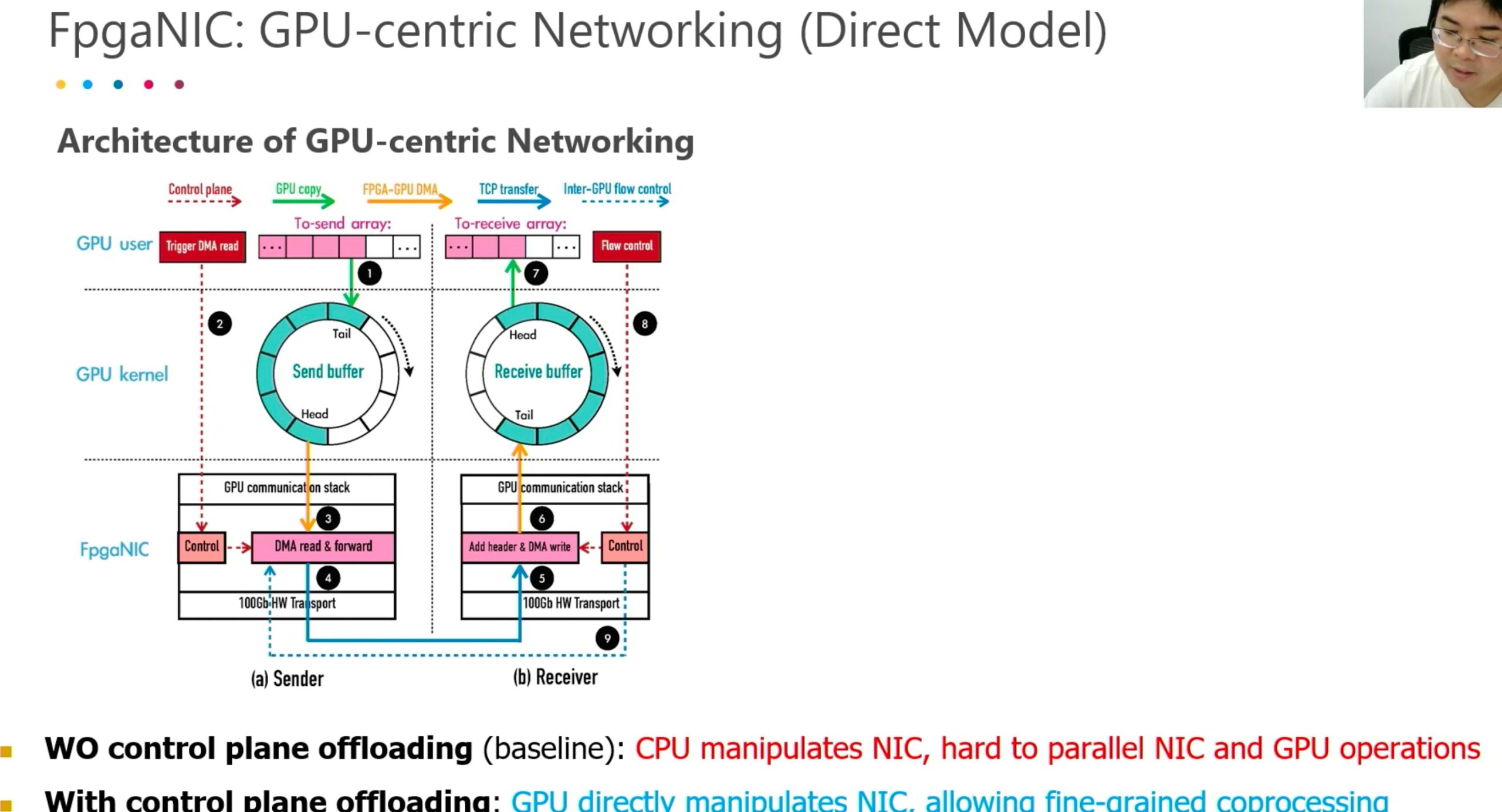
Better than arm-based SmartNIC because of the bandwidth.
Better than GPUDirect, it only mapped registers and manipulate the SmartNIC and at that time CPU become the boss, lose the parallelization.
software enabled eBPF
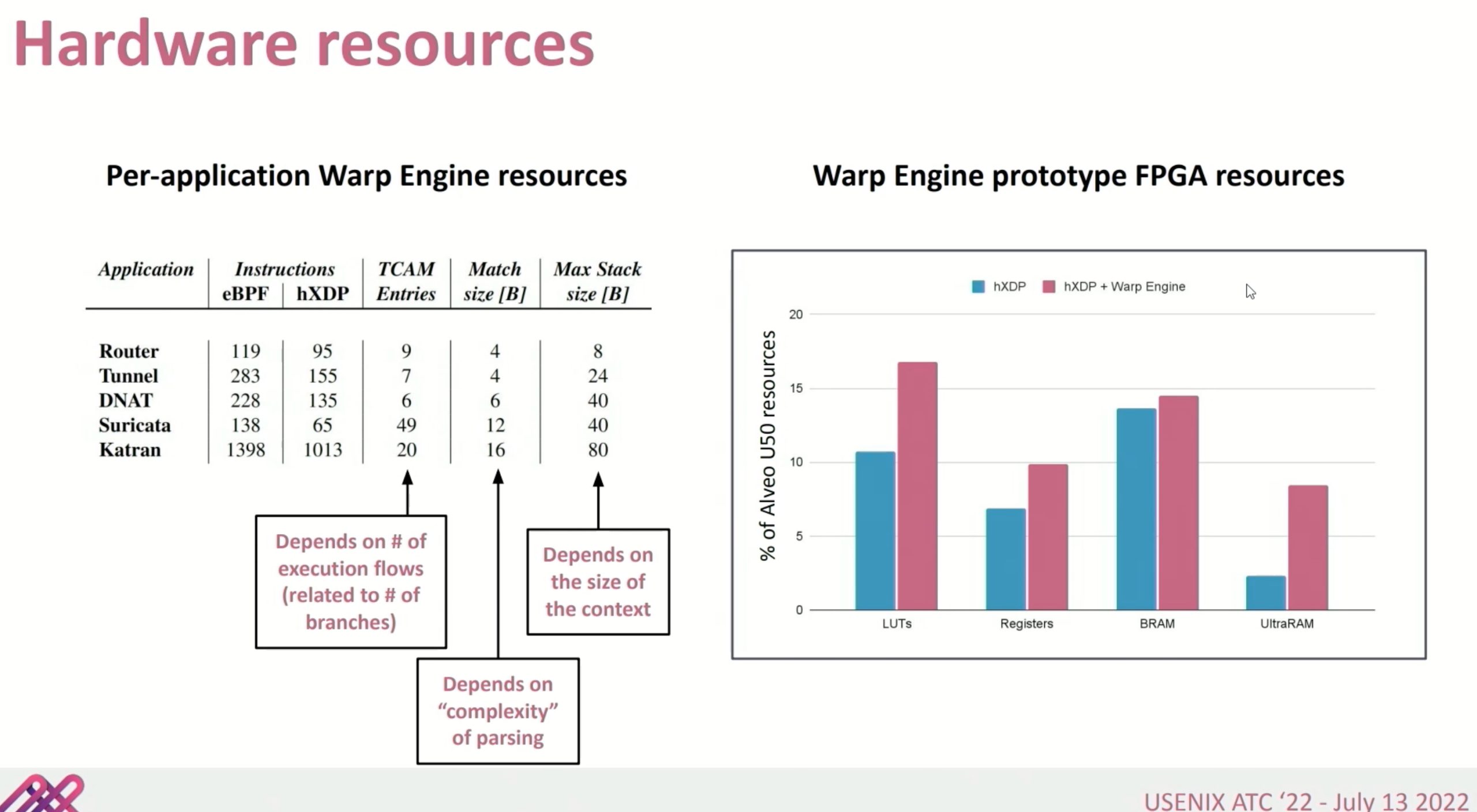
好像就是一个optimizer?减少hXDP到device memory memcpy?




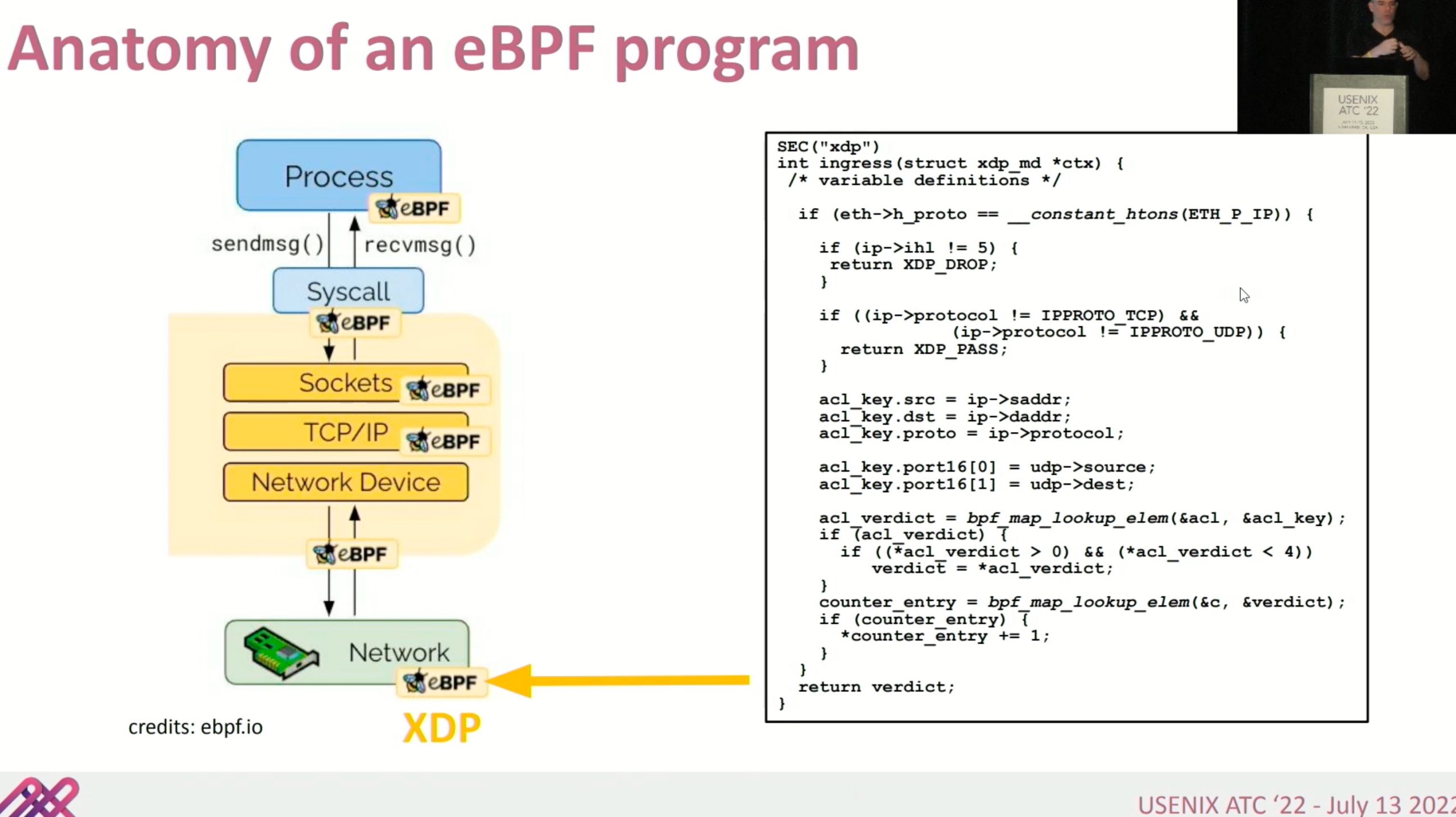
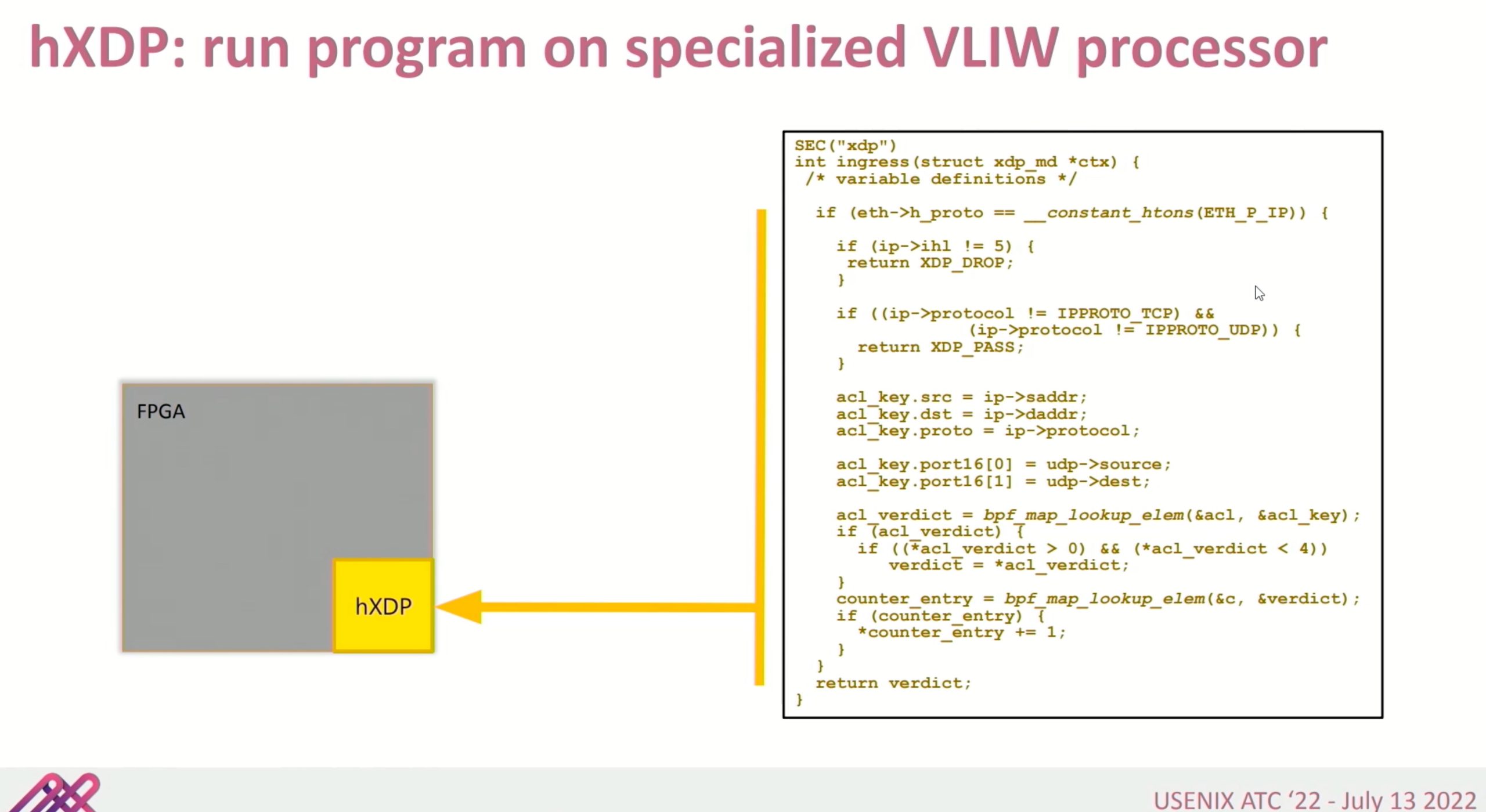
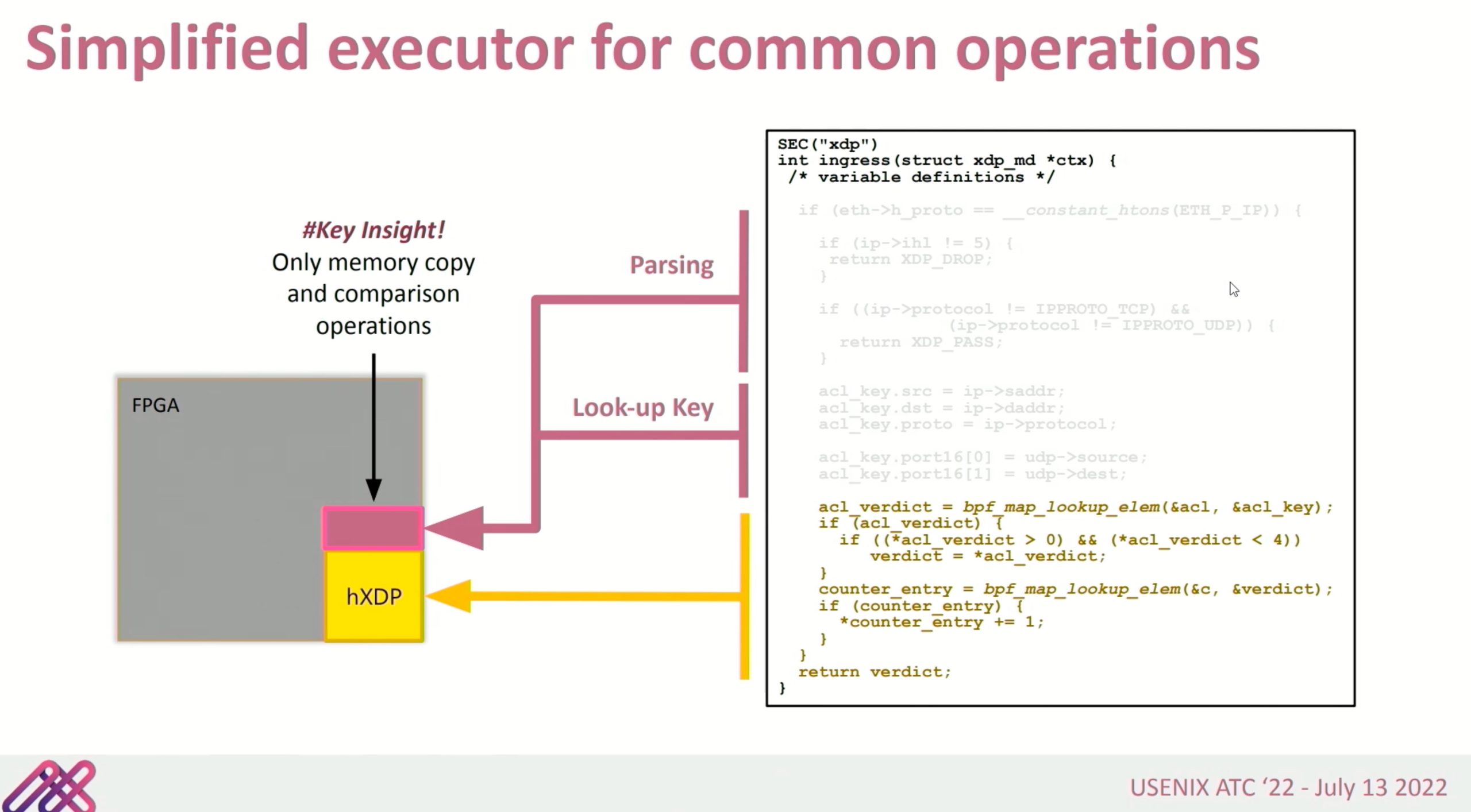
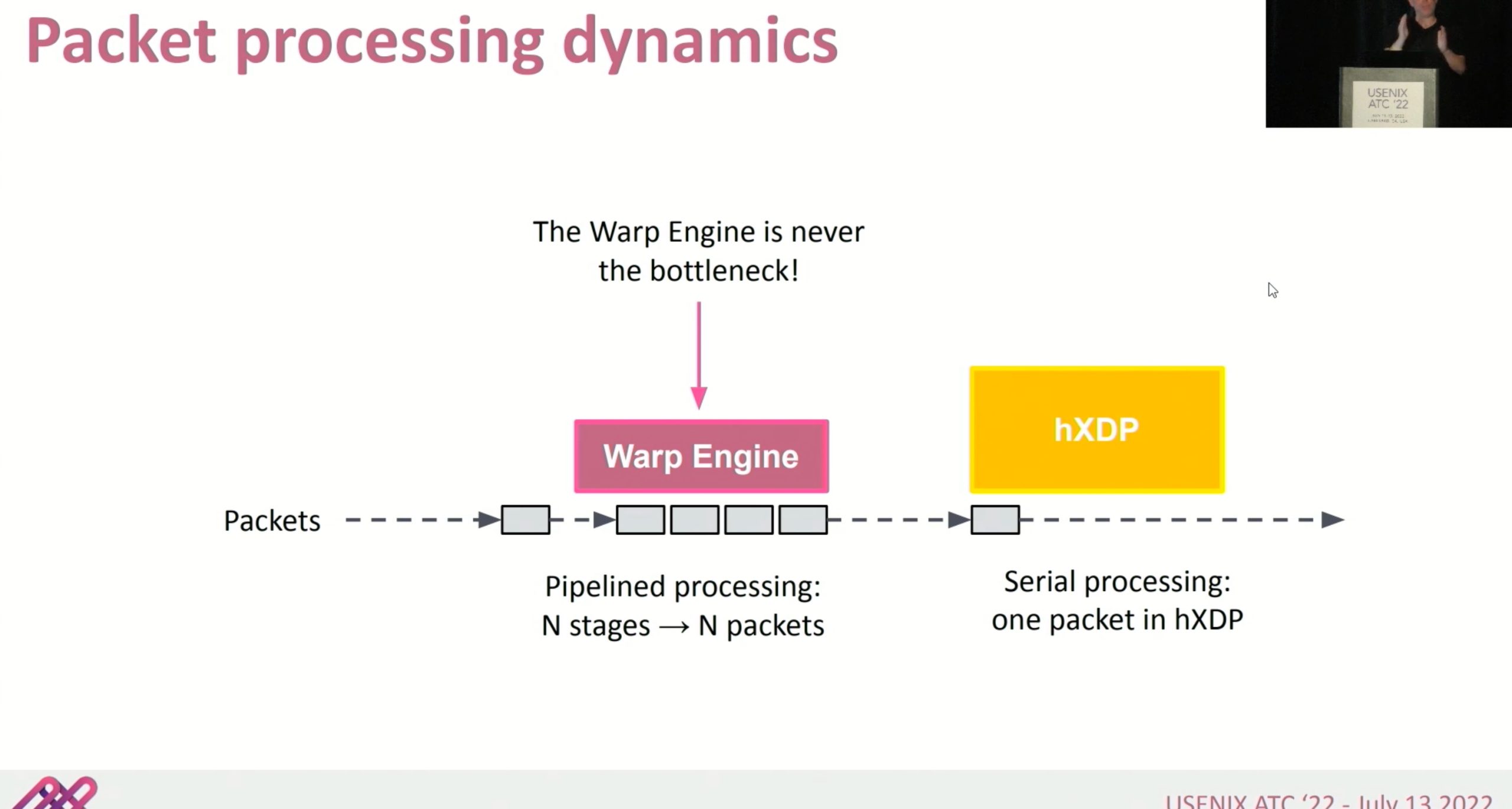
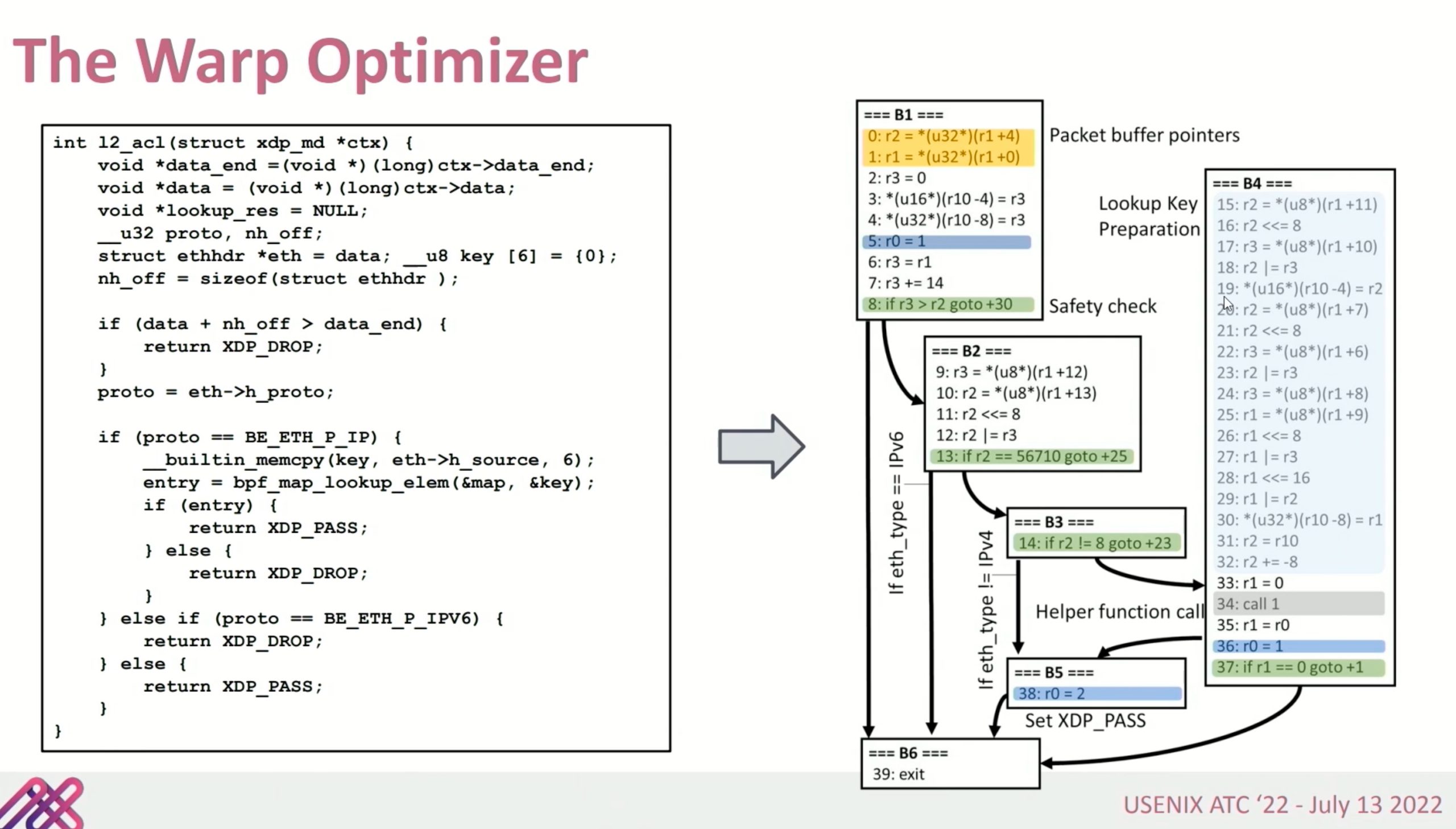
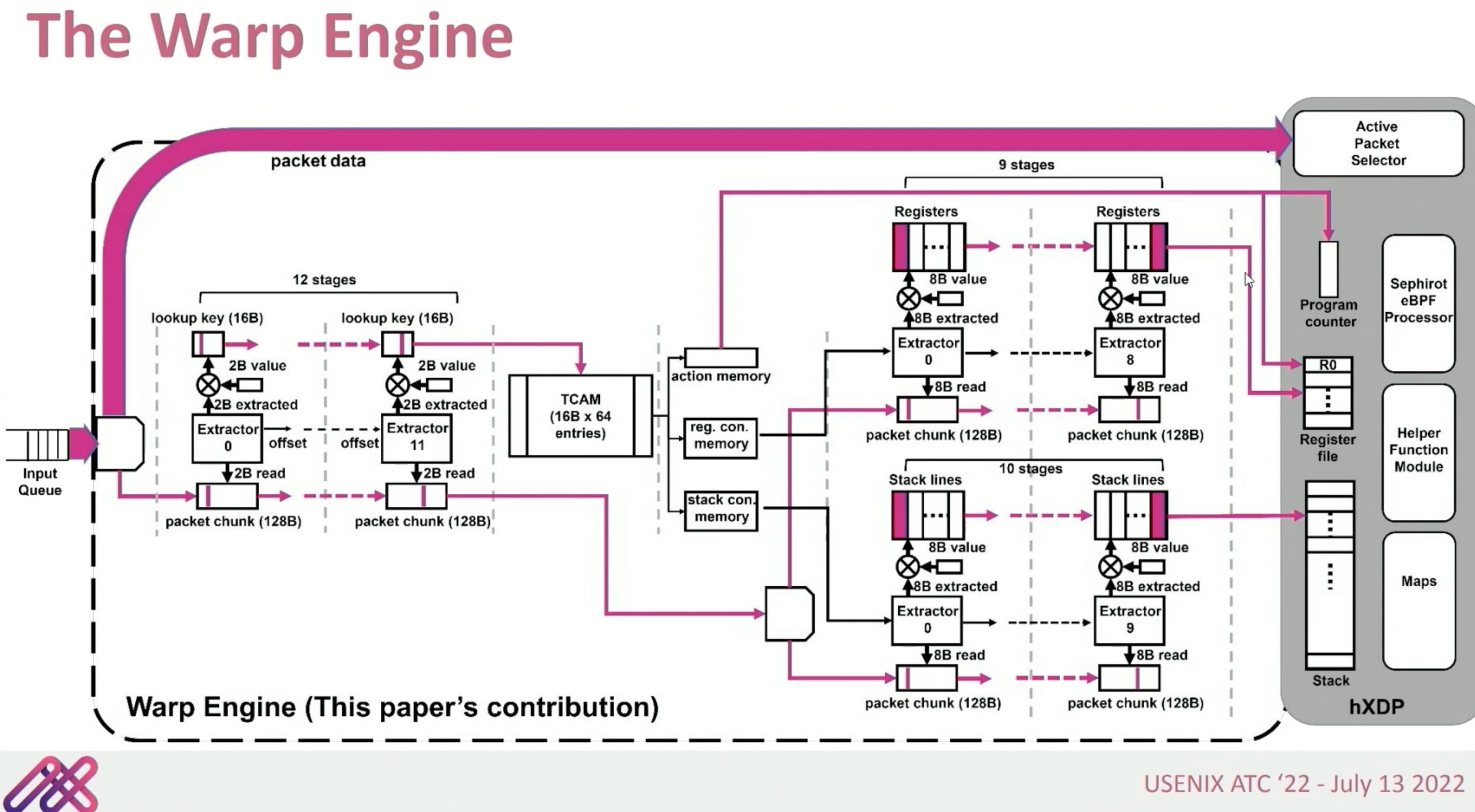
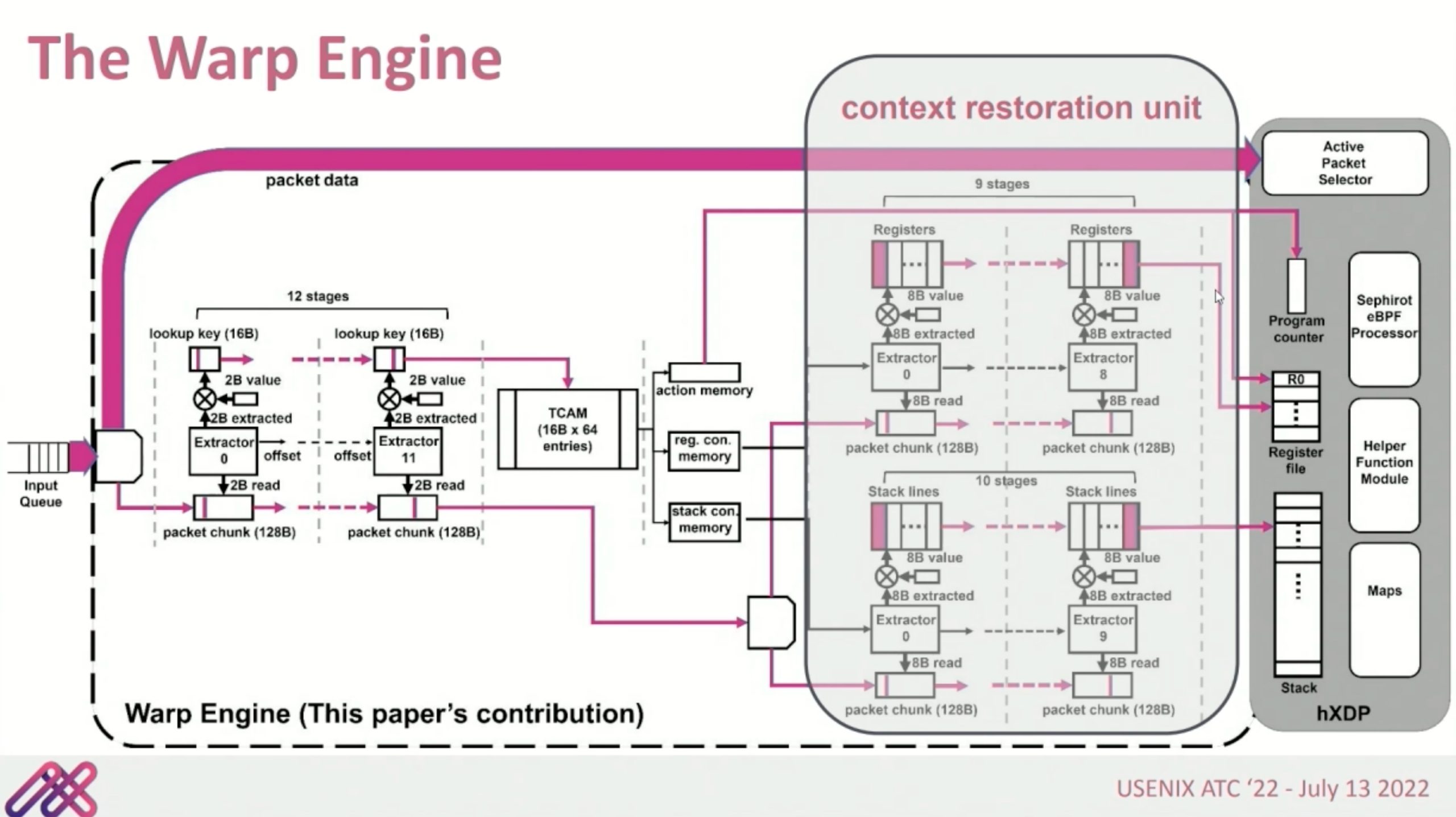
context restoration unit就是个跳转表。把程序分析成PC自动机,这里Warp Engine没有stall
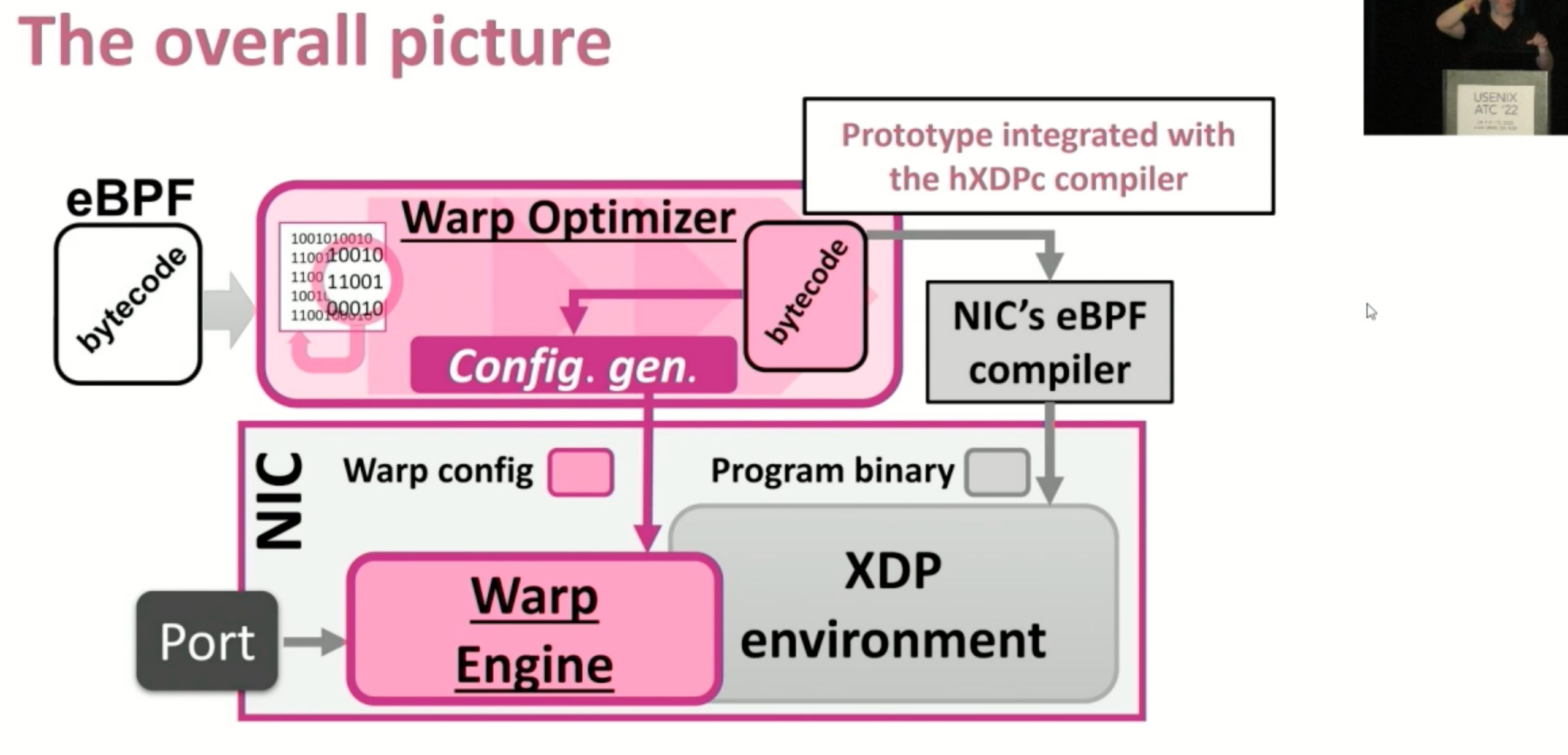
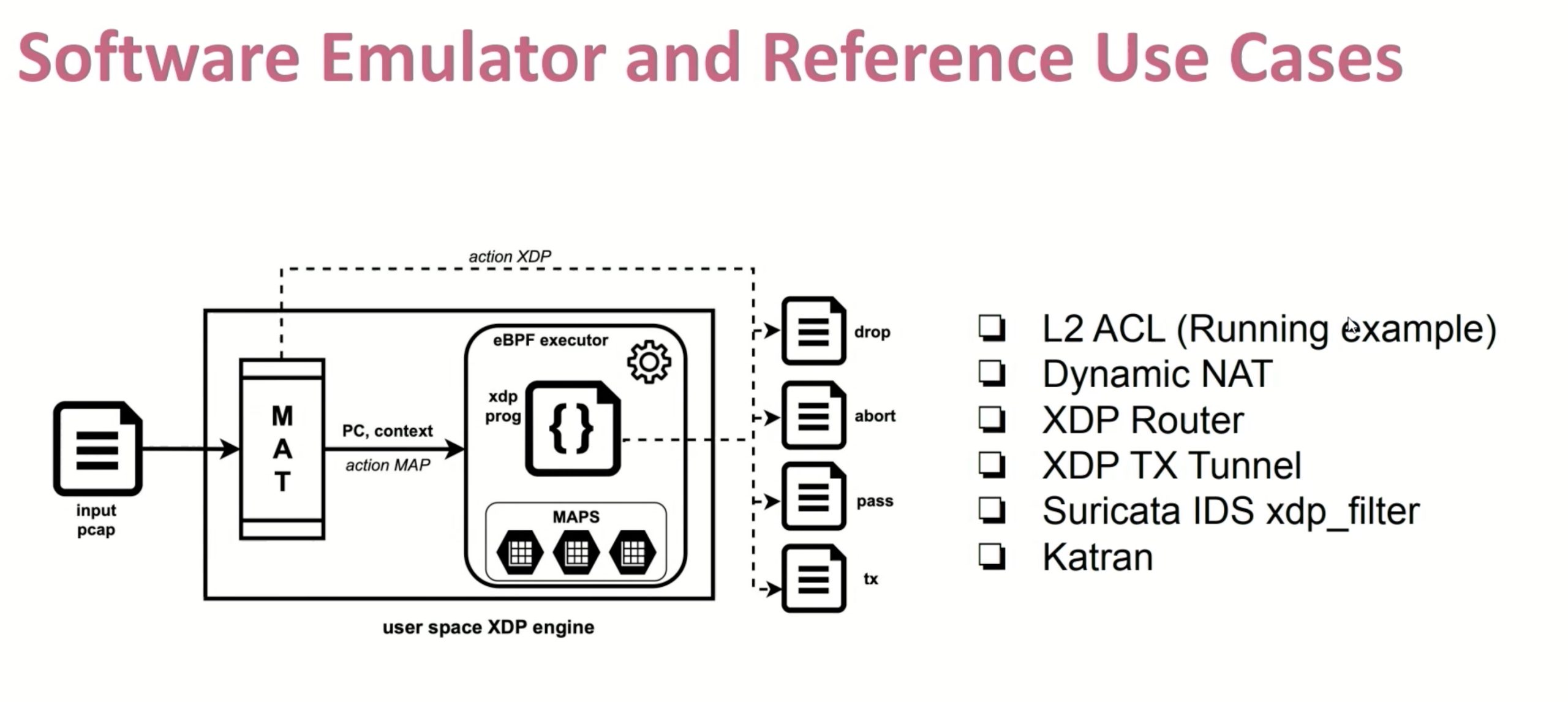
这种就是FPGA可以比CPU更好的解释执行instruction的地方。

Crash Consistency
NVMe SSD Failures in the Field: the Fail-Stop and the Fail-Slow






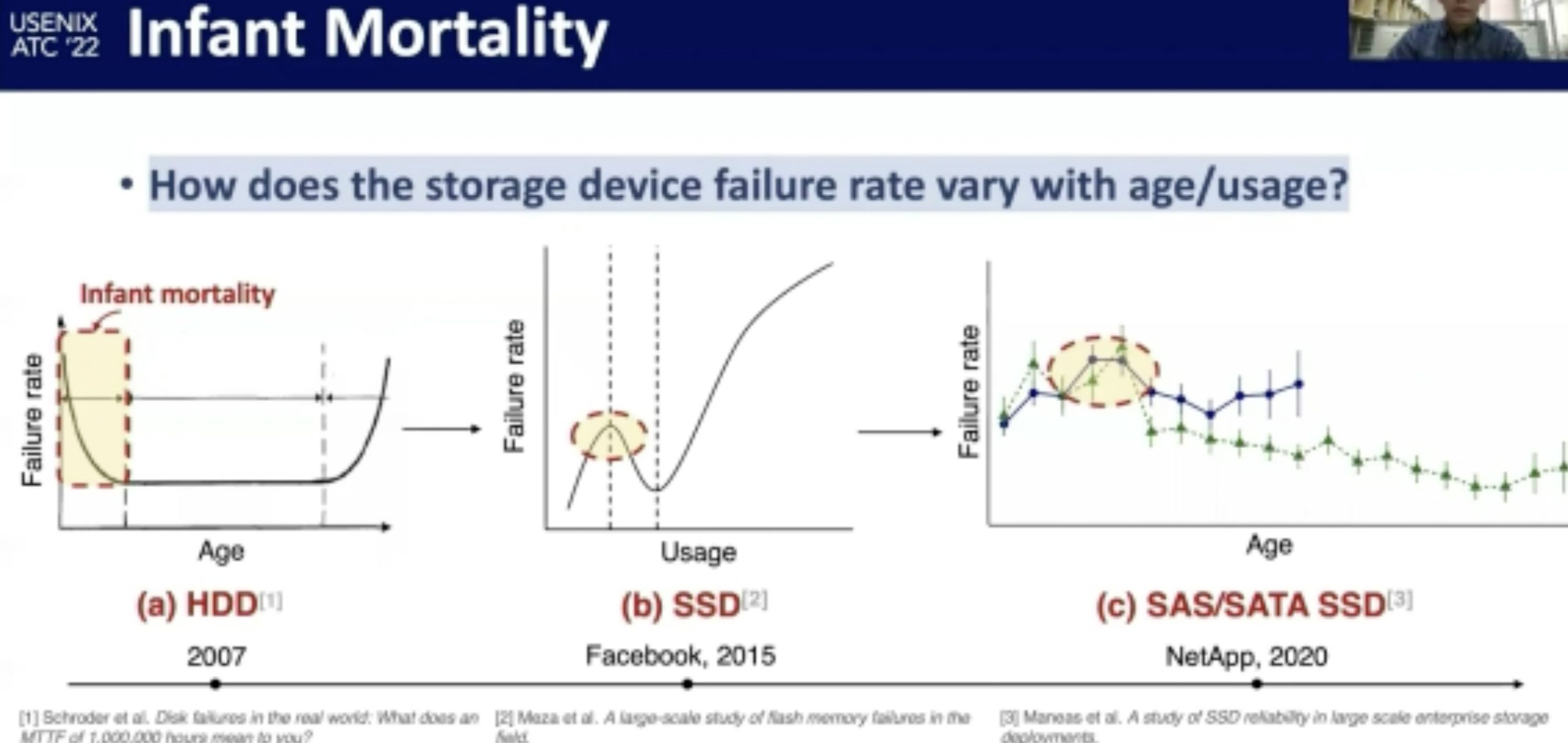
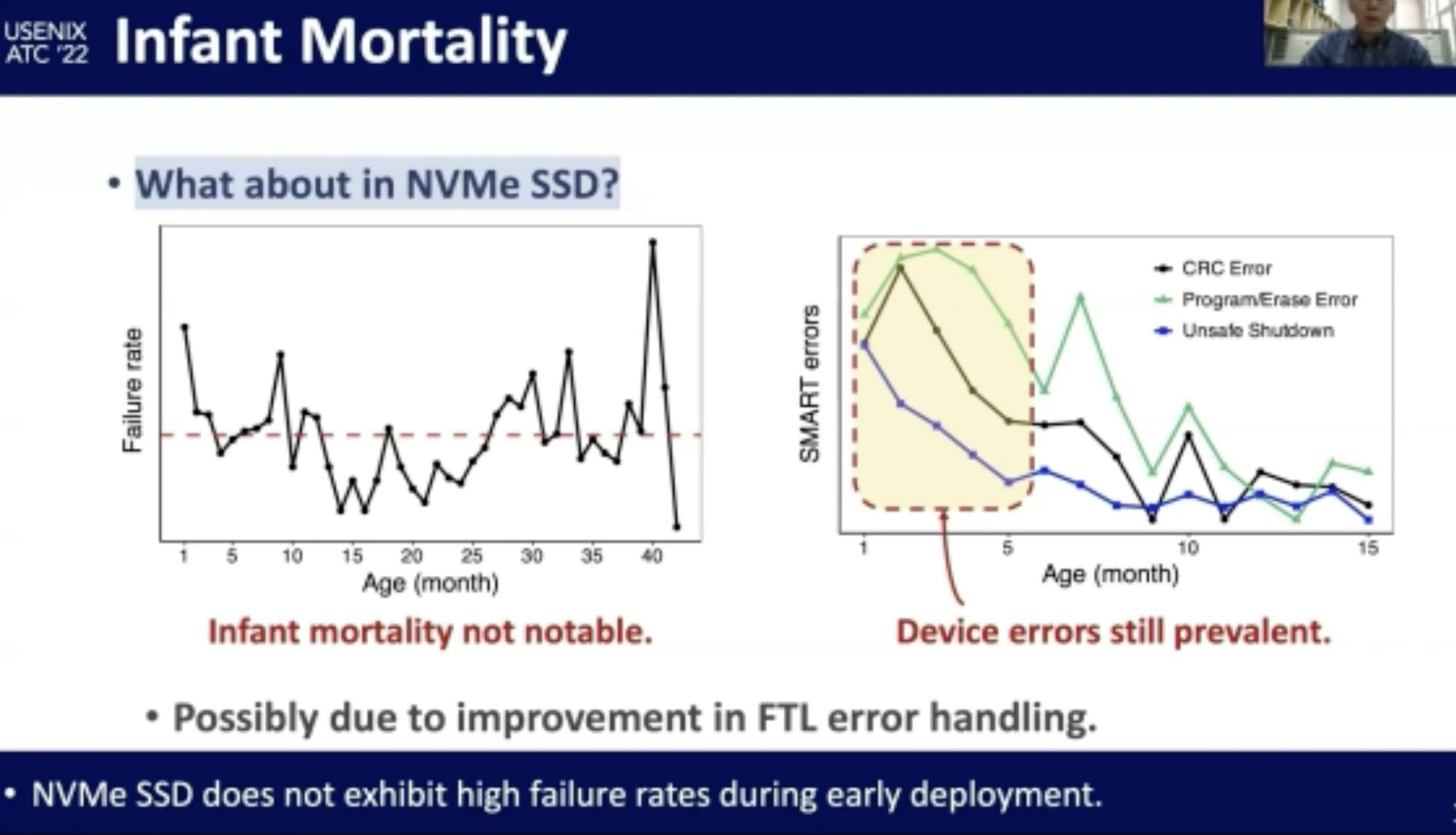
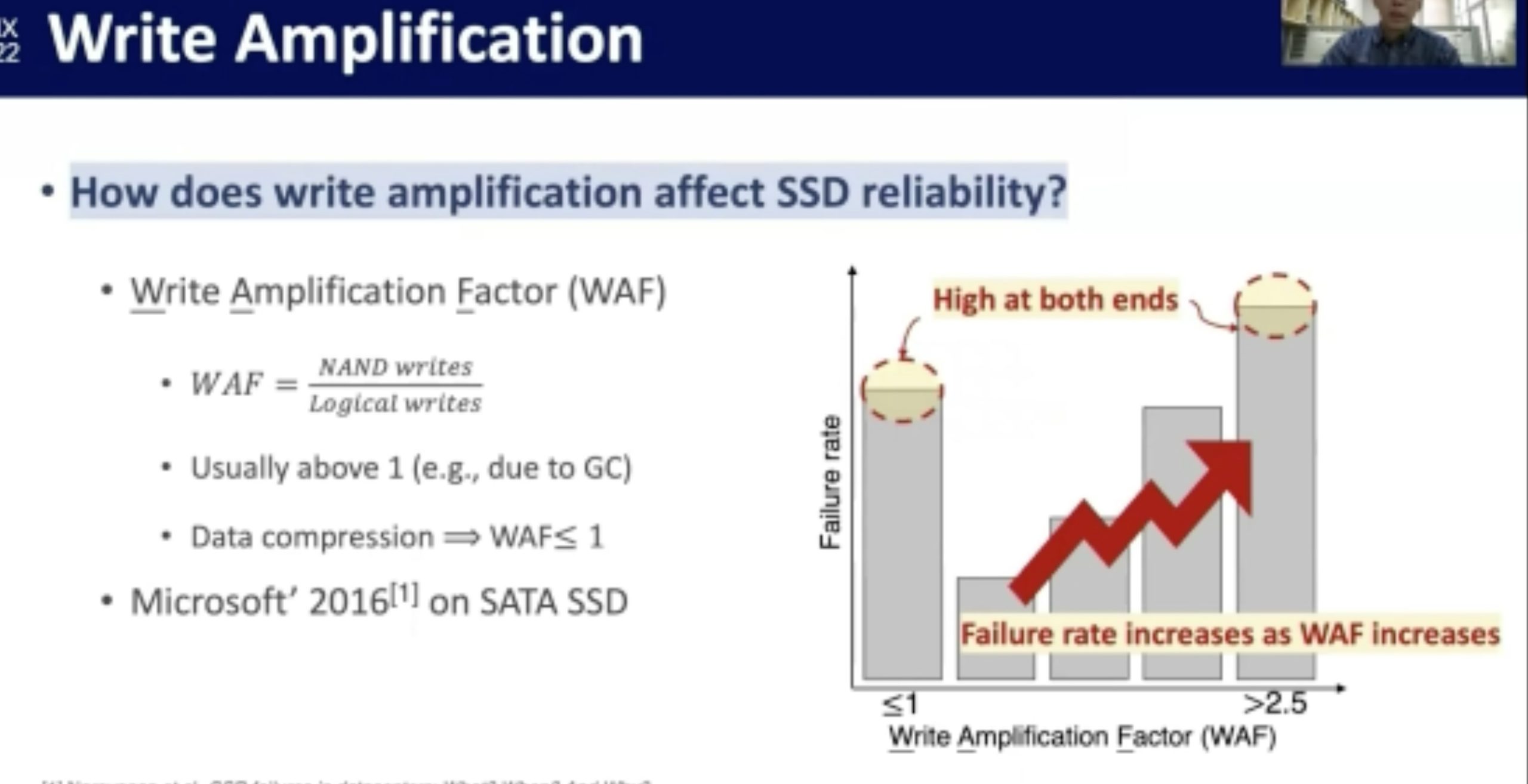
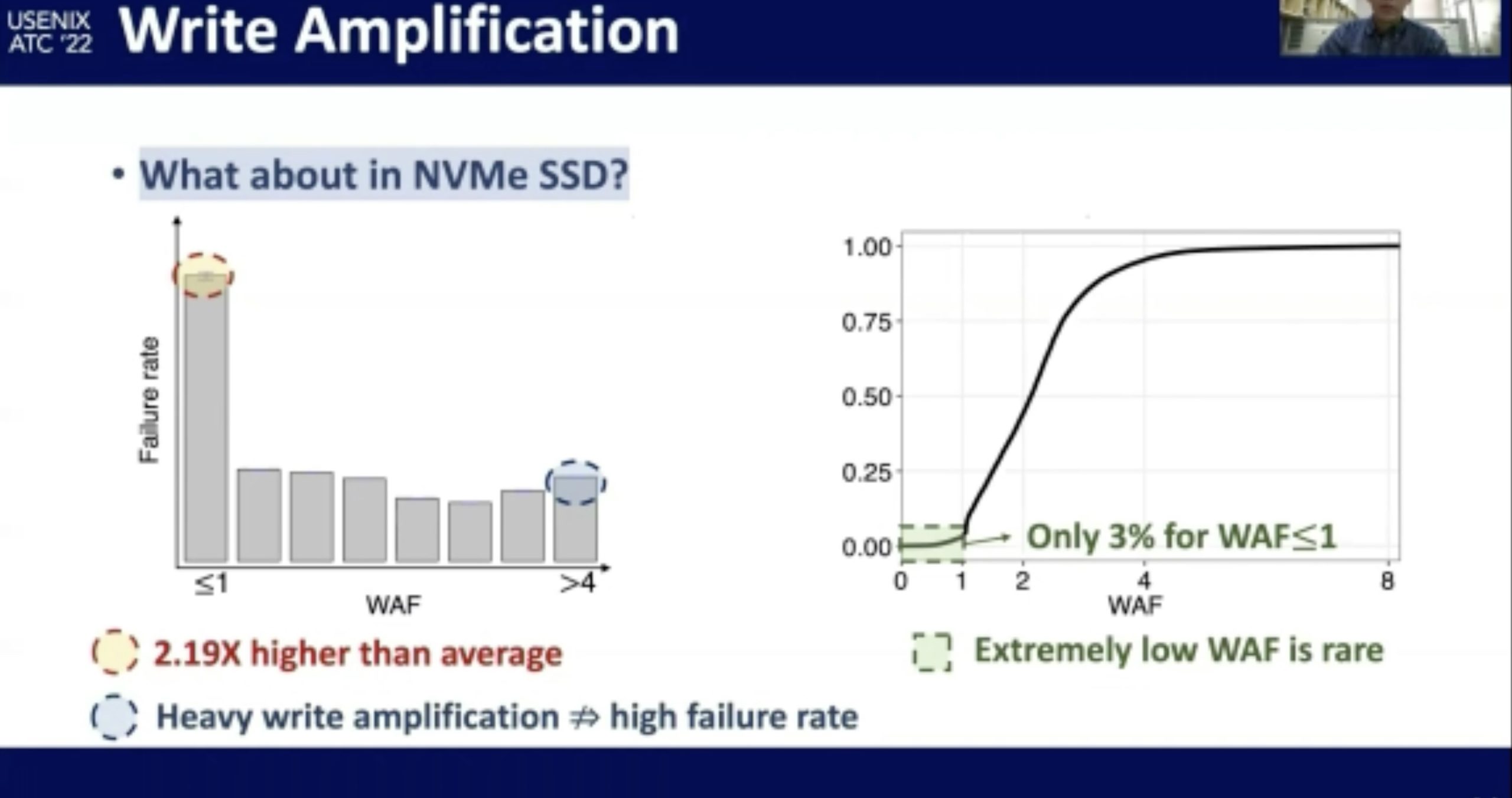

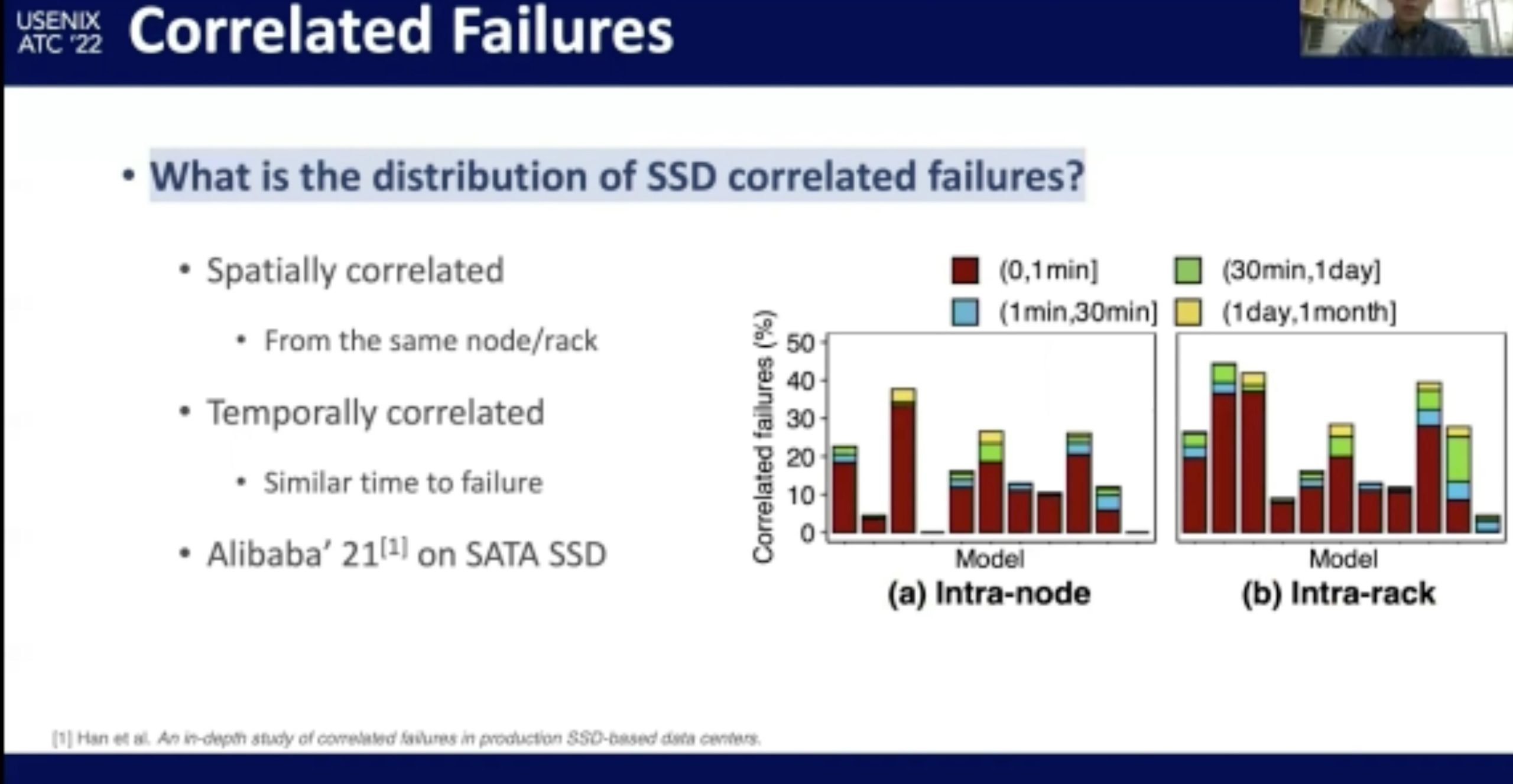

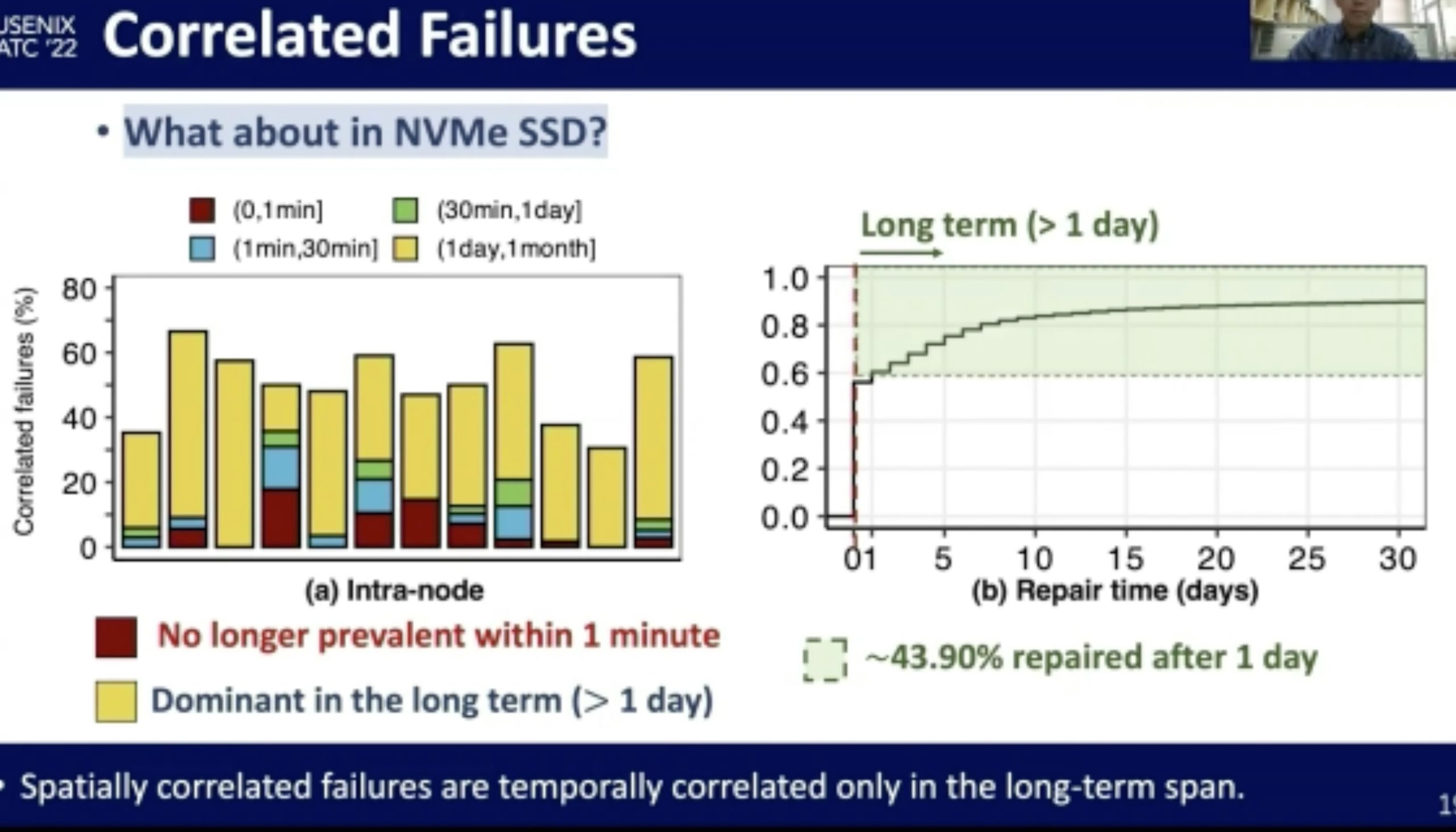
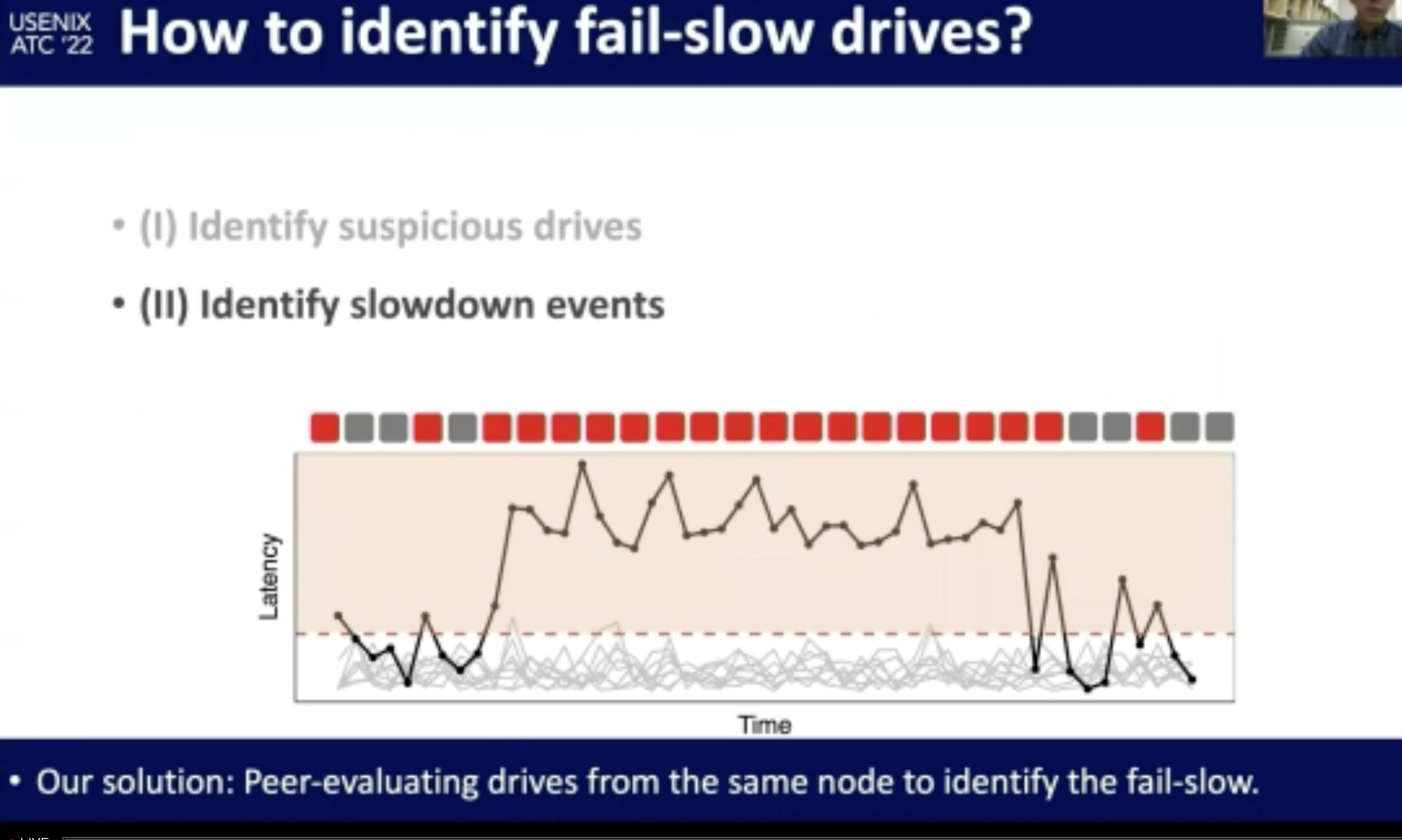
感觉在做概率论。fail-stop测的很好,fail-slow trace光测延时有啥用?还是要eBPF来知道root of cause。


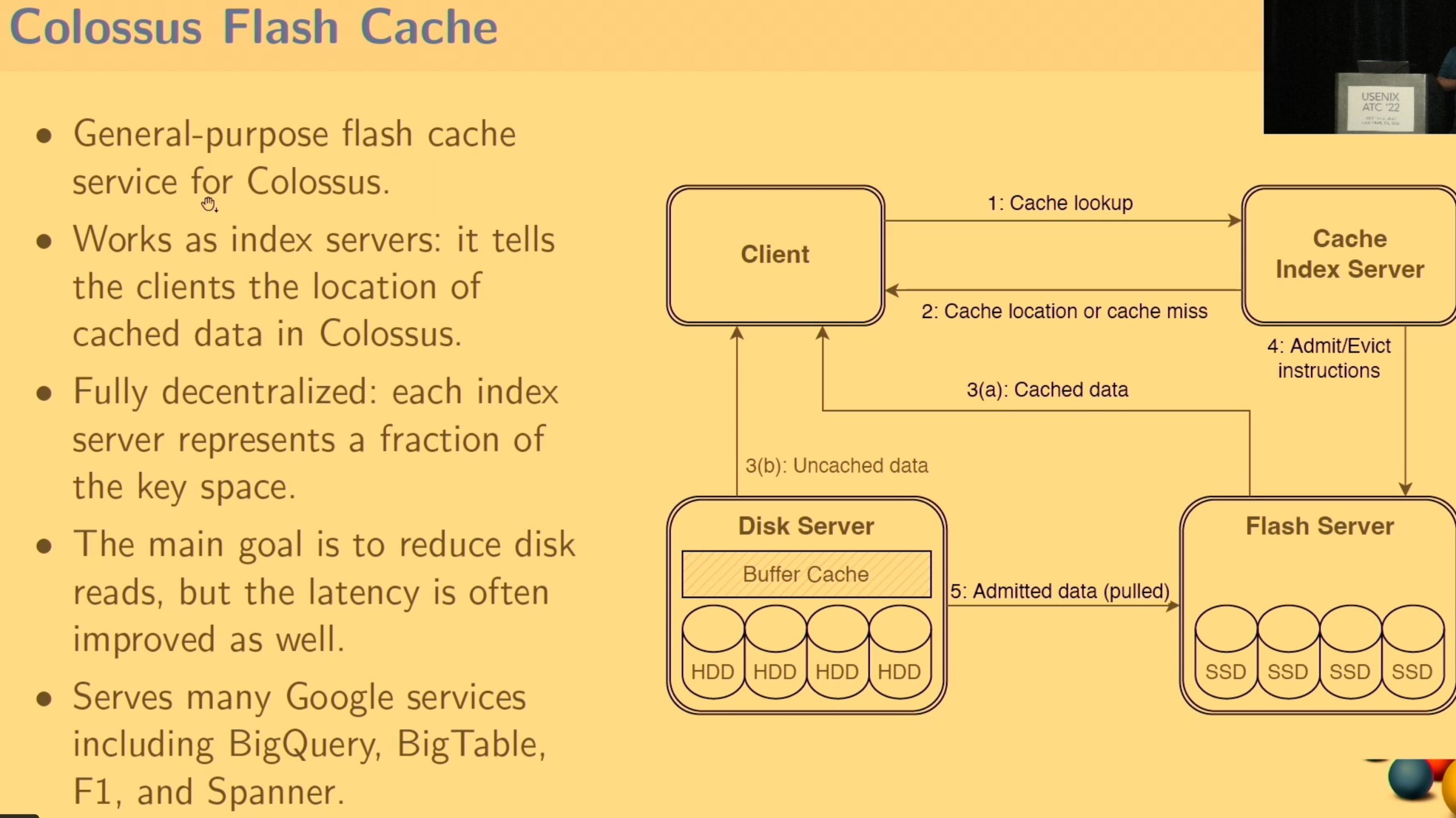
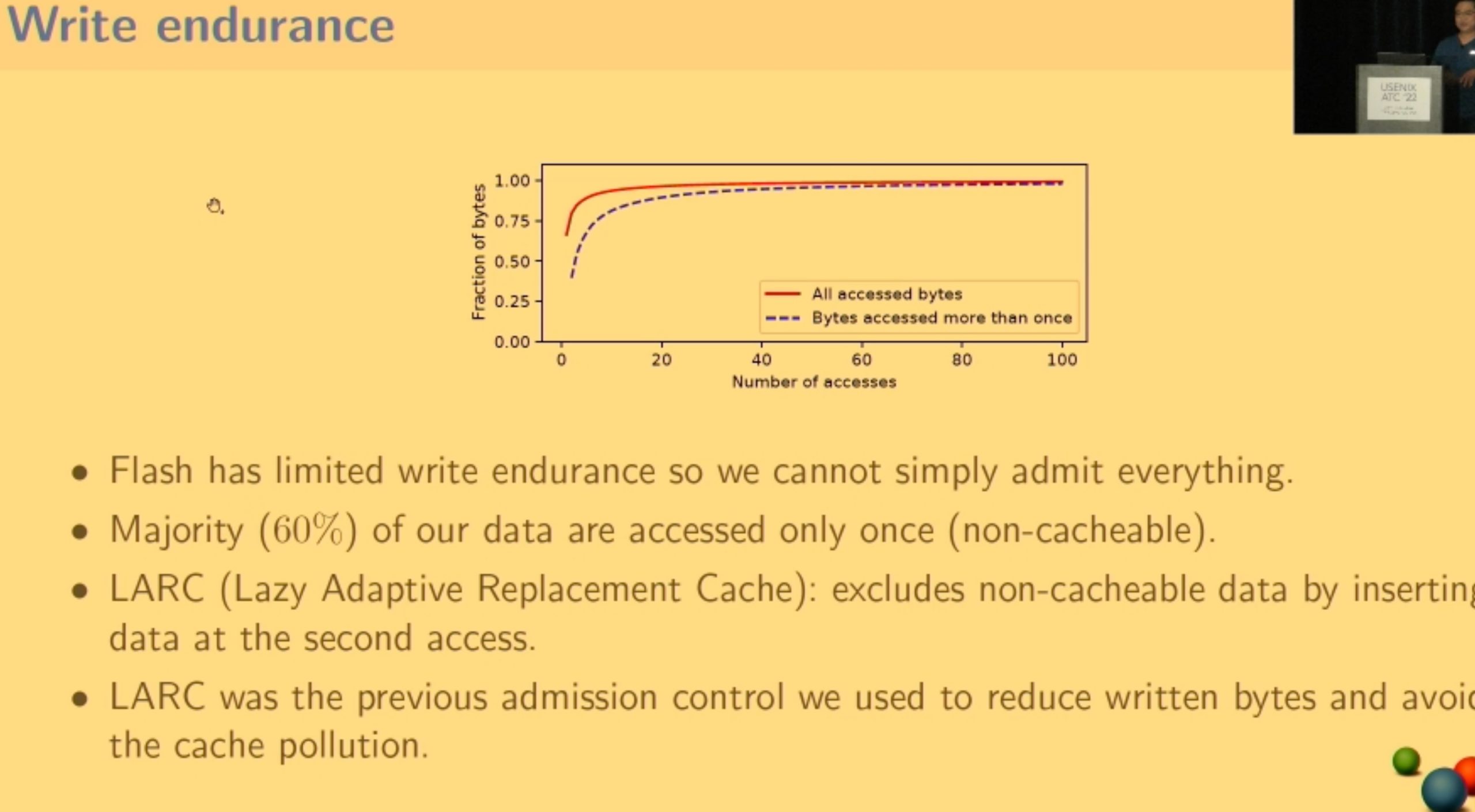
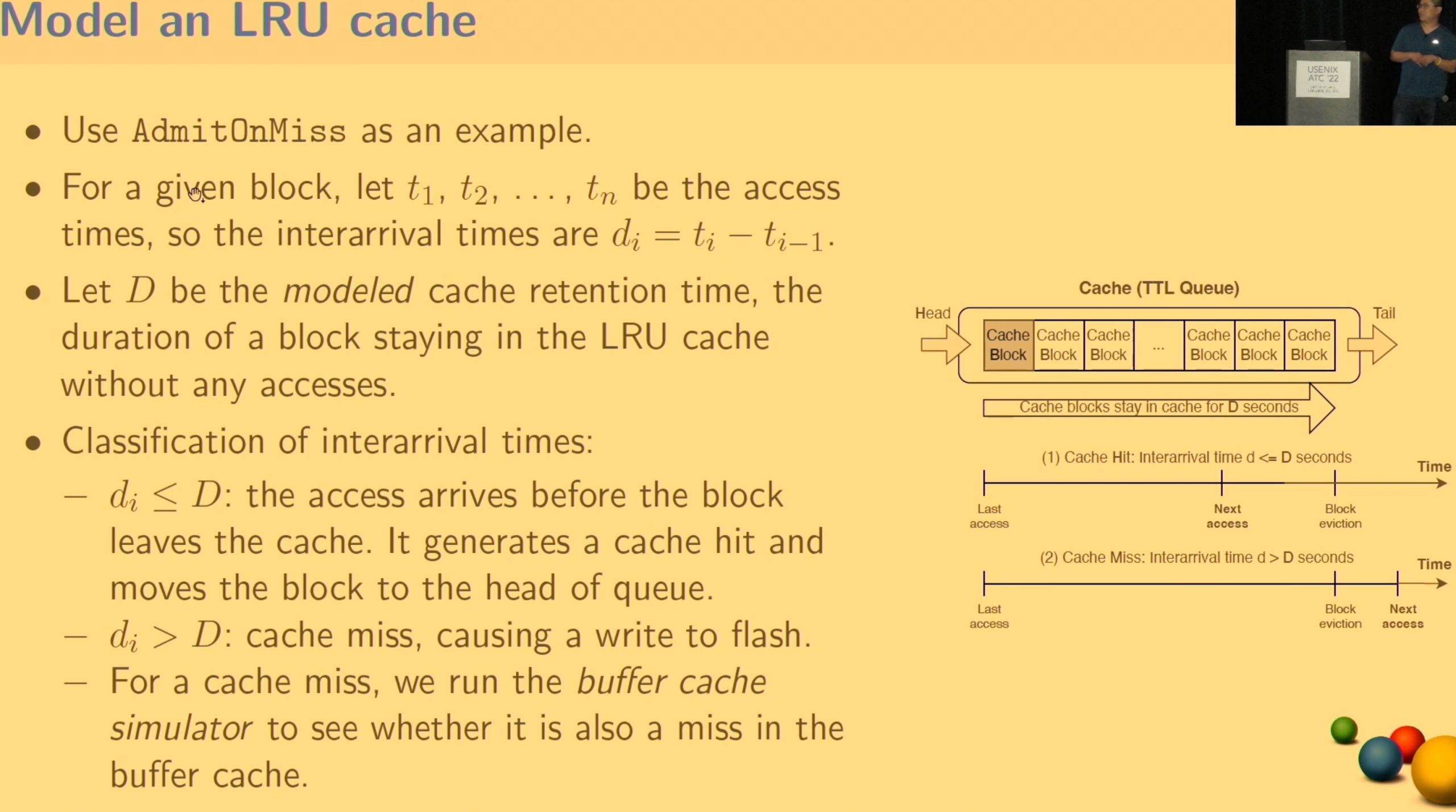
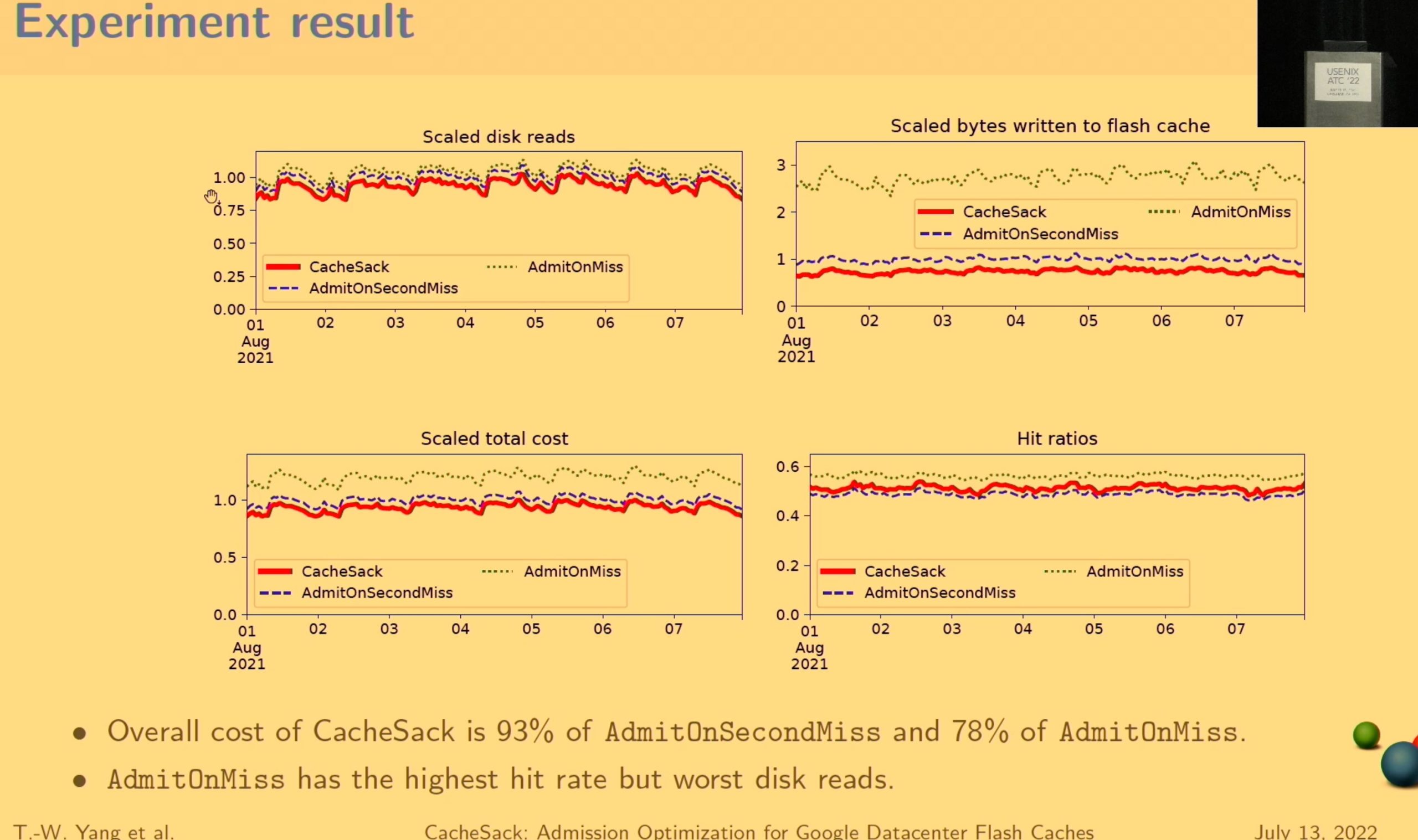
CacheSack









DynsmicDB
