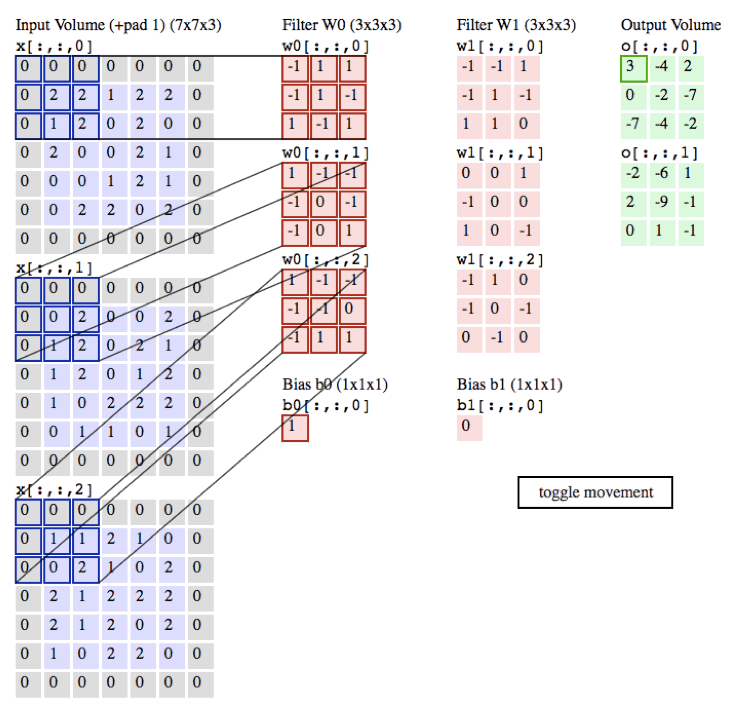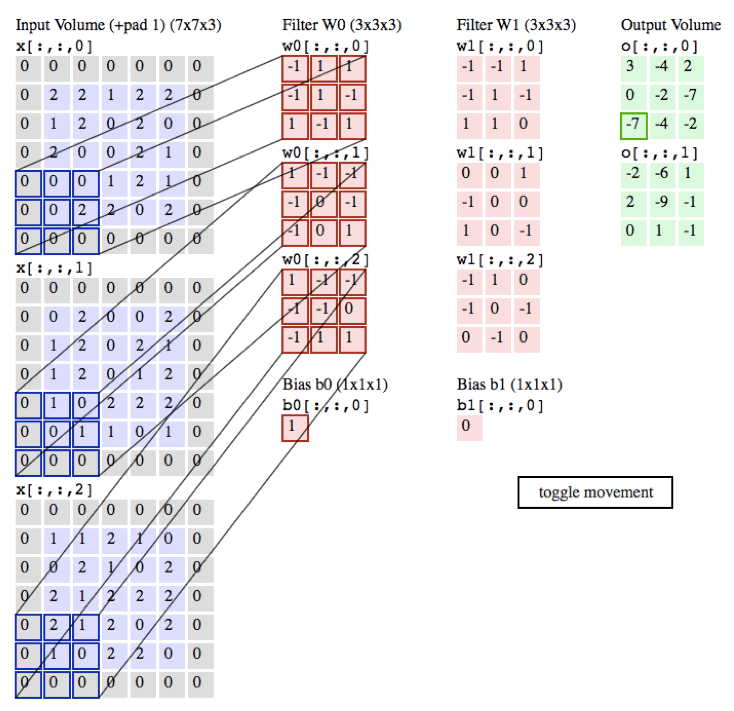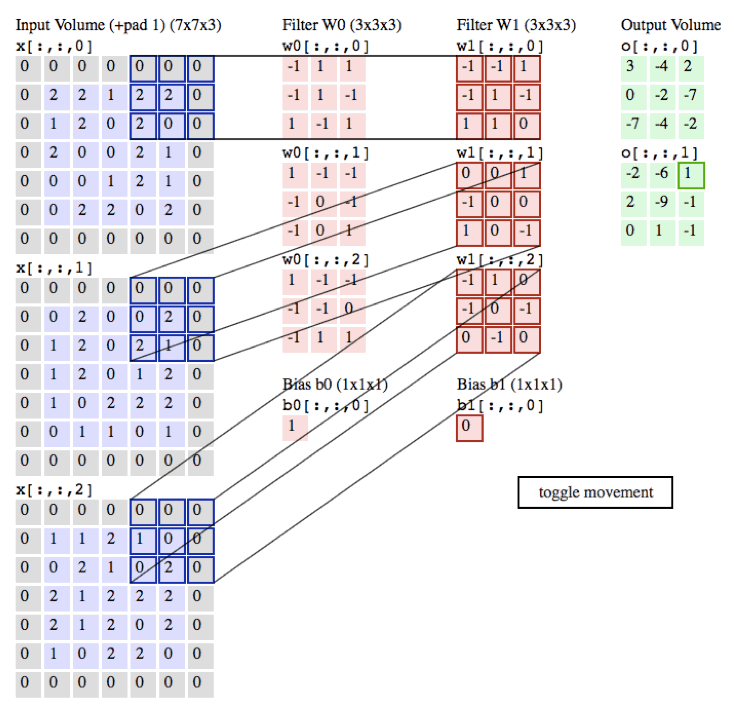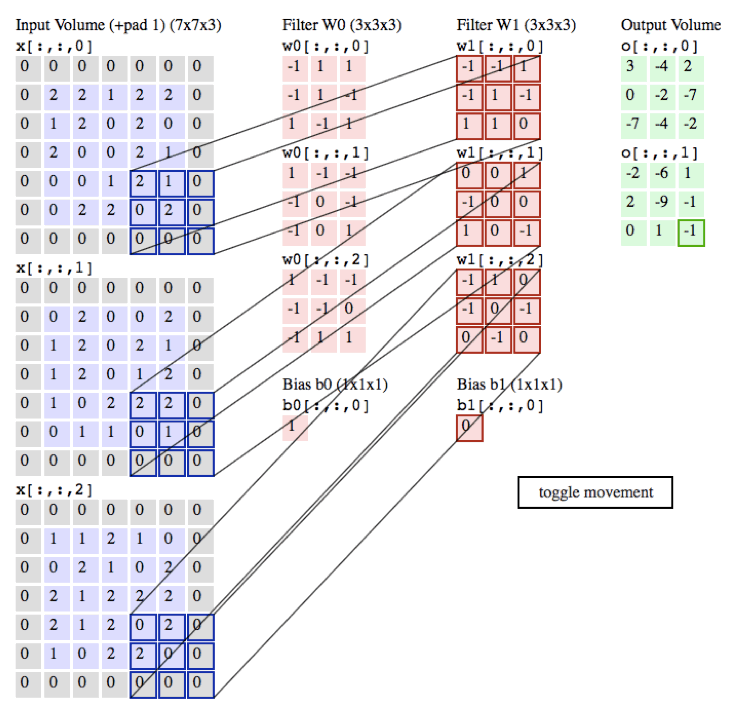
下面的程序真的是配置100分钟,运行0.01s 科科,大致就是用库3D卷积。kernel在库里面。
import tensorflow as tf
from tensorflow.python.keras import backend as K
import dropblock
import torch
class DropBlock(tf.keras.layers.Layer):
def __init__(self, keep_prob, block_size, **kwargs):
super(DropBlock, self).__init__(**kwargs)
self.keep_prob = float(keep_prob) if isinstance(keep_prob, int) else keep_prob
self.block_size = int(block_size)
def compute_output_shape(self, input_shape):
return input_shape
def build(self, input_shape):
_, self.h, self.w, self.channel = input_shape.as_list()
# pad the mask
bottom = right = (self.block_size - 1) // 2
top = left = (self.block_size - 1) - bottom
self.padding = [[0, 0], [top, bottom], [left, right], [0, 0]]
self.set_keep_prob()
super(DropBlock, self).build(input_shape)
def call(self, inputs, training=None, scale=True, **kwargs):
def drop():
mask = self._create_mask(tf.shape(inputs))
output = inputs * mask
output = tf.cond(tf.constant(scale, dtype=tf.bool) if isinstance(scale, bool) else scale,
true_fn=lambda: output * tf.to_float(tf.size(mask)) / tf.reduce_sum(mask),
false_fn=lambda: output)
return output
if training is None:
training = K.learning_phase()
output = tf.cond(tf.logical_or(tf.logical_not(training), tf.equal(self.keep_prob, 1.0)),
true_fn=lambda: inputs,
false_fn=drop)
return output
def set_keep_prob(self, keep_prob=None):
"""This method only supports Eager Execution"""
if keep_prob is not None:
self.keep_prob = keep_prob
w, h = tf.to_float(self.w), tf.to_float(self.h)
self.gamma = (1. - self.keep_prob) * (w * h) / (self.block_size ** 2) / \
((w - self.block_size + 1) * (h - self.block_size + 1))
def _create_mask(self, input_shape):
sampling_mask_shape = tf.stack([input_shape[0],
self.h - self.block_size + 1,
self.w - self.block_size + 1,
self.channel])
mask = DropBlock._bernoulli(sampling_mask_shape, self.gamma)
mask = tf.pad(mask, self.padding)
mask = tf.nn.max_pool(mask, [1, self.block_size, self.block_size, 1], [1, 1, 1, 1], 'SAME')
mask = 1 - mask
return mask
@staticmethod
def _bernoulli(shape, mean):
return tf.nn.relu(tf.sign(mean - tf.random_uniform(shape, minval=0, maxval=1, dtype=tf.float32)))
tf.enable_eager_execution()
# only support `channels_last` data format
a = tf.ones([2, 10, 10, 3])
drop_block = DropBlock(keep_prob=0.8, block_size=3)
b = drop_block(a, training=True)
print(a[0, :, :, 0])
print(b[0, :, :, 0])
配置tensorflow anaconda & vscode
直接conda install xxx就好,没有必要每一个都pip 尤其是这种conda环境,又要cuda环境gpu加速的。pytorch 注意要 ==0.4.1!
最后就是环境了(大概只有win和linux有这个需求)
手动滑稽hi
import dropblock
rather than
from dropblock import dropblock
输出结果
2018-12-16 03:07:07.196585: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
tf.Tensor(
[[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]], shape=(10, 10), dtype=float32)
tf.Tensor(
[[1.2631578 1.2631578 1.2631578 1.2631578 1.2631578 1.2631578 1.2631578
1.2631578 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 0. 0. 0. 1.2631578
1.2631578 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 0. 0. 0. 1.2631578
1.2631578 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 0. 0. 0. 0.
0. 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 1.2631578 1.2631578 0. 0.
0. 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 1.2631578 1.2631578 0. 0.
0. 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 1.2631578 0. 0. 0.
1.2631578 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 1.2631578 0. 0. 0.
1.2631578 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 1.2631578 0. 0. 0.
1.2631578 1.2631578 1.2631578]
[1.2631578 1.2631578 1.2631578 1.2631578 1.2631578 1.2631578 1.2631578
1.2631578 1.2631578 1.2631578]], shape=(10, 10), dtype=float32)
水题
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<deque>
using namespace std;
const int inf = 1e5 + 5;
int n, s[inf],cnt;
deque<int> q;
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i++)scanf("%d", &s[i]);
sort(s, s + n + 1);
for(int i=n;i>=1;i--)
{
if(cnt)q.push_front(s[i]),cnt^=1;
else q.push_back(s[i]),cnt^=1;
}
cnt=0;
deque<int>::iterator it;
for(it=q.begin();it!=q.end();it++)
s[++cnt]= *it ;
for(int i=2;i<=n-1;i++)
if(s[i-1]+s[i+1]<=s[i]){cout<<"NO";return 0;}
if(s[n-1]+s[1]<=s[n]){cout<<"NO";return 0;}
cout<<"YES"<<endl;
for (int i = 1; i <= n; i++)cout << s[i] << " ";
return 0;
}