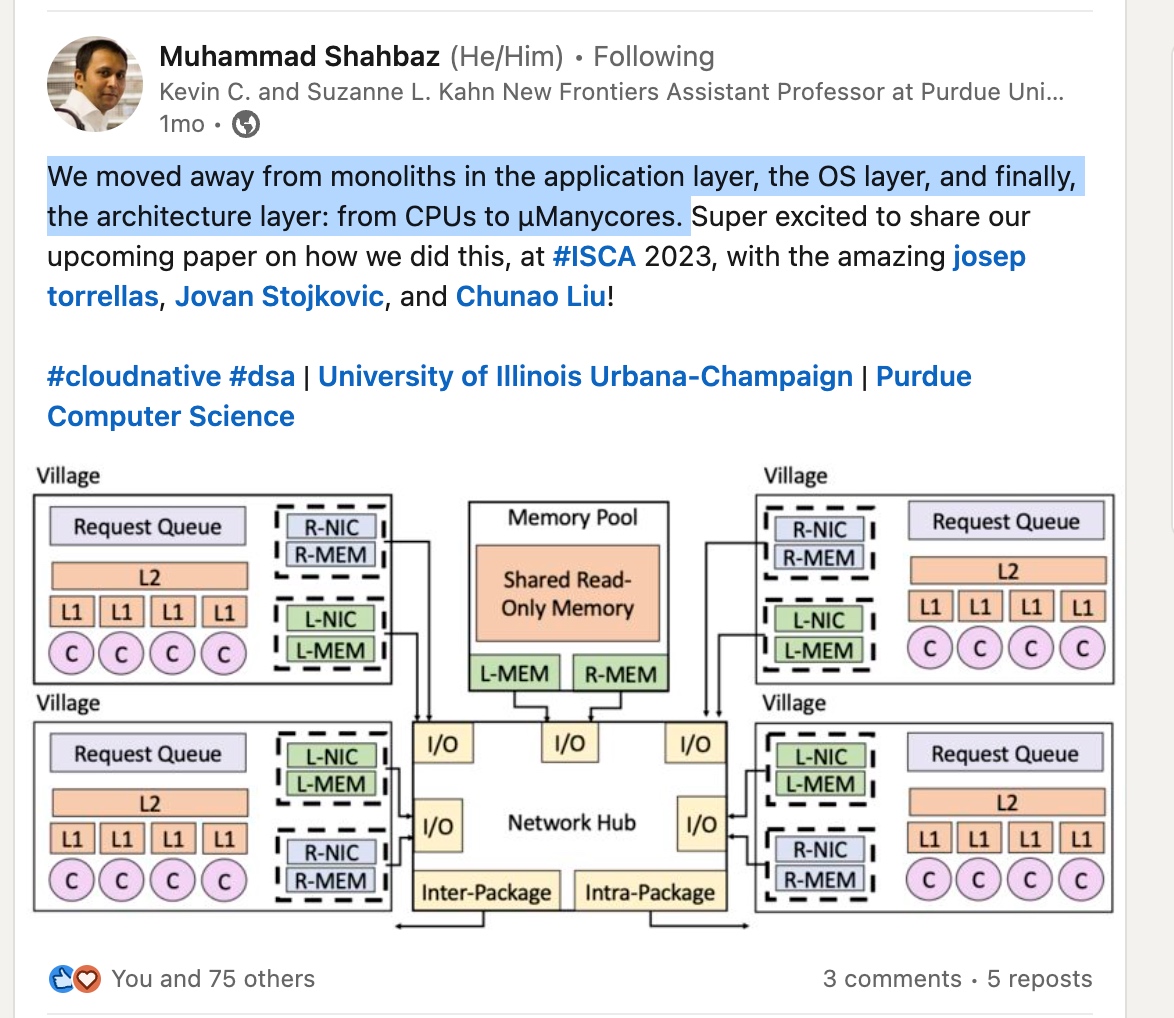
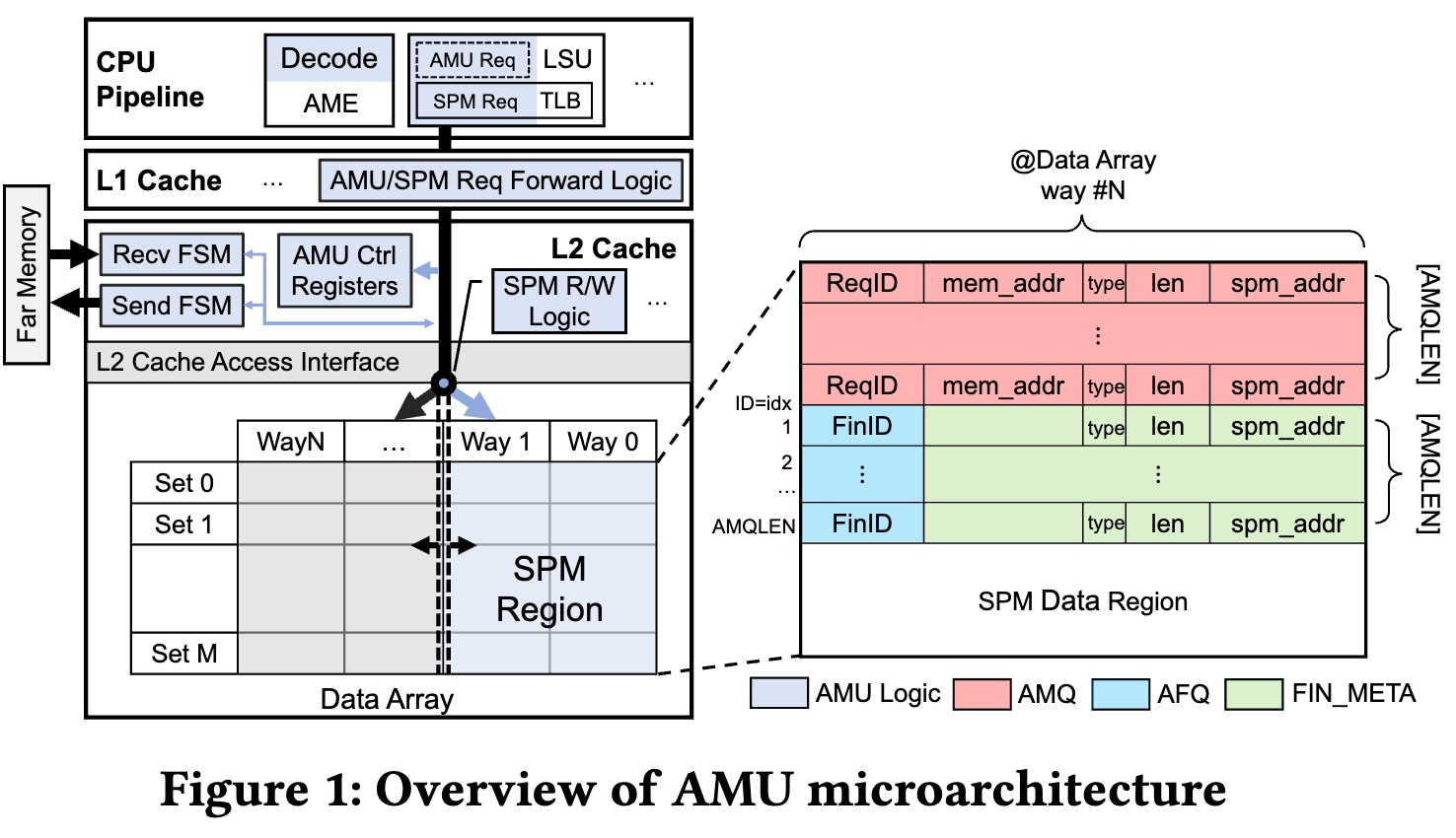
In [1], the author talked about the Asynchronous Memory Unit that the CPU and Memory controller needs to support of co-design.
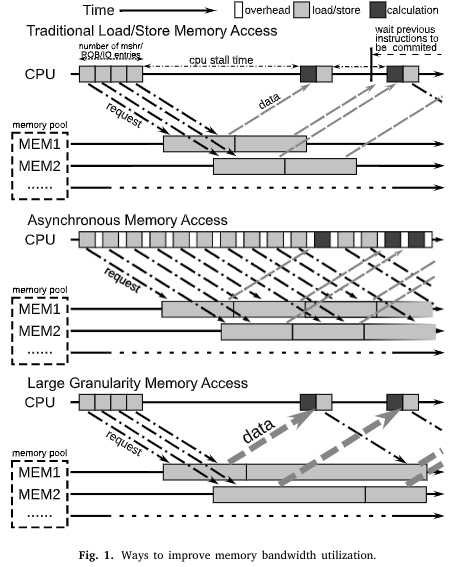
The overhead of hardware consistency checking is one reason that limits the capacity of traditional load/store queues and MSHRs. The AMU leaves the consistency issue to the software. They argue that software and hardware cooperation is the right way to exploit the memory parallelism over large latency for AMU.
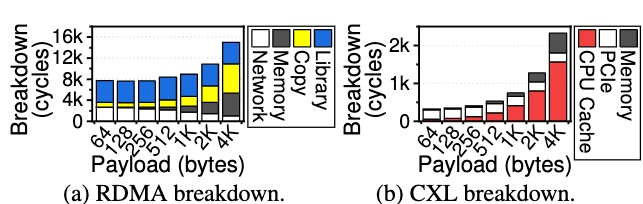
As shown in the Figure of sensitivity tests in [2], the decomposition analysis of DirectCXL shows a completely different result: no software and no data copy overhead. As the payload increases, the main component of the DirectCXL latency is the LLC (CPU Cache). This is because the Miss State Holding Register (MSHR) in the CPU LLC can handle 16 concurrent misses, so with large payload data, many memory requests (64B) are suspended on the CPU, and processing a 4KB payload takes up 67% of the total latency.
The conclusion is MHSR inside the CPU is not enough to deal with memory load in the CXL.mem world, and both the latency and the bandwidth are so diverse across the serial PCIe5 lane. Also, another possible outcome compared with RDMA SRQ approach of the controller, we think the PMU and semantics of coherency still matter and the future way of persistency according to the Huawei's approach and SRQ approaches will fall back to ld/st but with a smarter leverage in the MC that asynchronously ld/st the data.
Reference
- Asynchronous memory access unit for general purpose processors
- Direct Access, High-Performance Memory Disaggregation with DirectCXL