文章目录[隐藏]
A short answer is no.
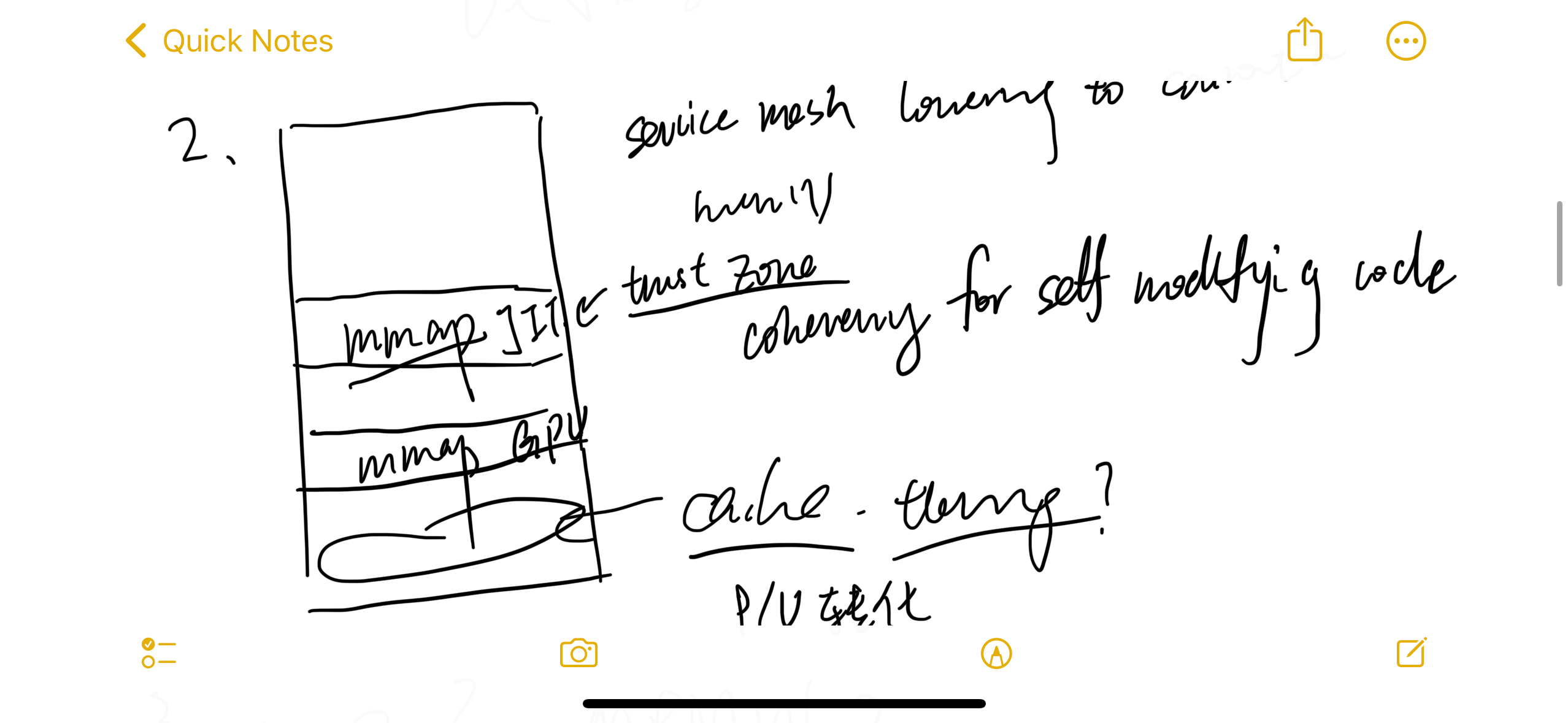
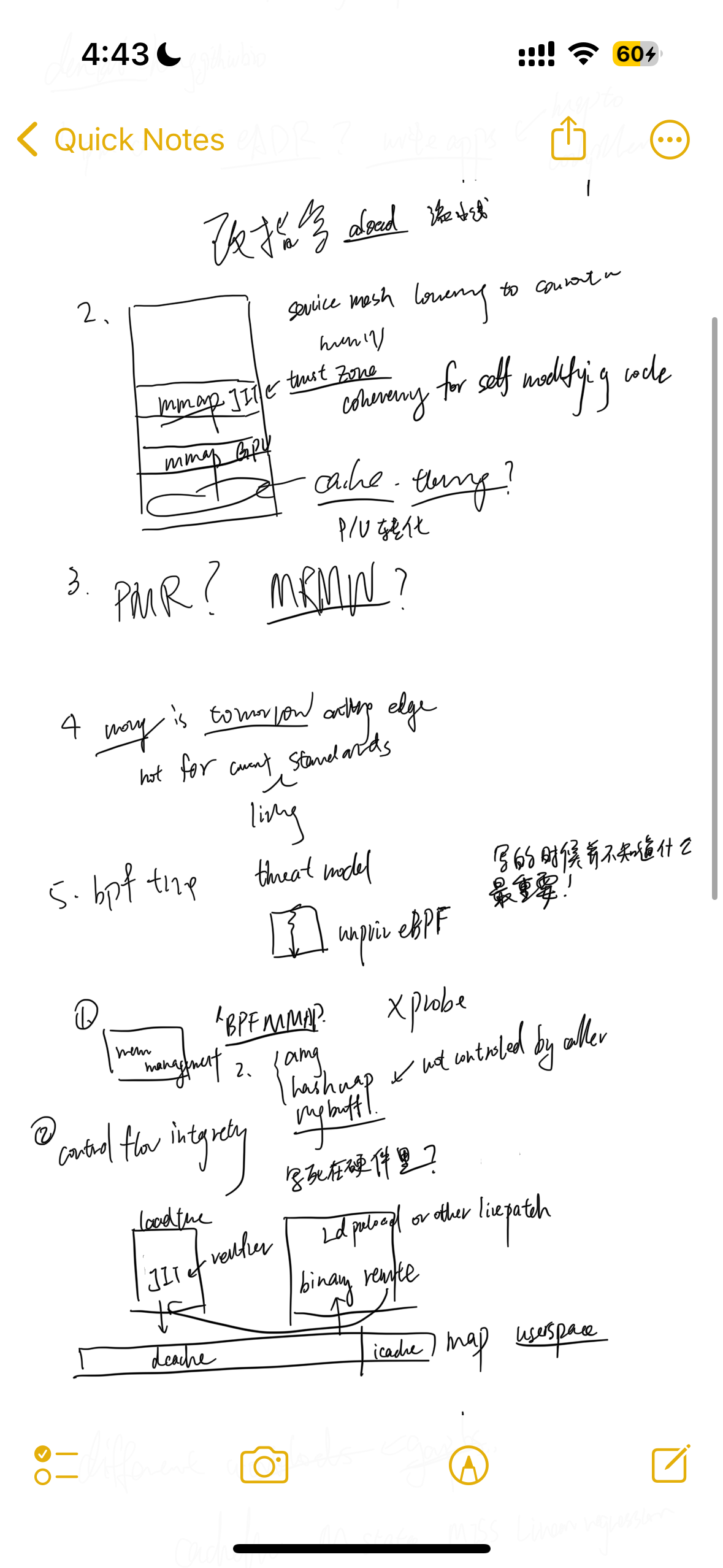
- MMAP a huge file need OS to register a virtual address to mmap the file on; once any request to the file is made, we may use page fault to load the file from disk to the private DRAM and setup the va_to_pa and buffer the file part in the DRAM, maybe use TLB to cache the next read. Every CXL device has it own mapping of memory; if you MMAP memory that was swapped onto CXL.mem devices like memory semantic SSD, the controller of SSD may decide whether to put on on-SSD DRAM or SSD and, in the backend, write through everything on physical media. CXL vendors drastically want to implement the defered allocation that lazily setup the physical memory to the virtual mmemory, which overlaps the MMAP mechenism.
- MMAP + madvise/numabind to certain CXL attached memory may cause migration efforts. Once you dirty write the pages, the transaction is currently not yet introduced in the CXL protocol. The process takes pains to implement the mechesim correctly. Instead, we can do something like TPP or CXLSwap, making everything transparent to applications. Or, we can make 3D memory and extend computability in CXL controller to decide where to put the data and maintain the transaction under the physical memory.
- MMAP is originally designed for a fast track memory together with a slower track disk like HDDs. Say you are loading graph edges from a large HDD backed pool. The frequently accessed part will be softwarely defined as a stream pool for cold/hot data management. Here MMAP can both leverage the OS page cache semantic transparently, but it's not case with more and faster endpoints. With more complexity of topology of CXL NUMA devices, we could handle fewer error at a time and serve more for the speed of main bus. Thus, we don't stop for page fault and requires those be handled in endpoints side.
Thus we still need SMDK such management layer to make jemalloc+libnuma+CXLSwap for CXL.mem. For interface with CXL.cache devices, I think defer allocation and managing everything through virtual memory would be fine. Thus we don't need programming models like CUDA; rather, we can static analysis through MLIR to do good data movement hint to every CXL controller's MMU and TLB. We could leverage CXL.cache cacheline state to treat as streaming buffer so that every possible endpoints read for and then do updates by next write.